
Entropy-Based Hybrid Integration of Random Forest and Support Vector Machine for Landslide Susceptibility Analysis



Abstract
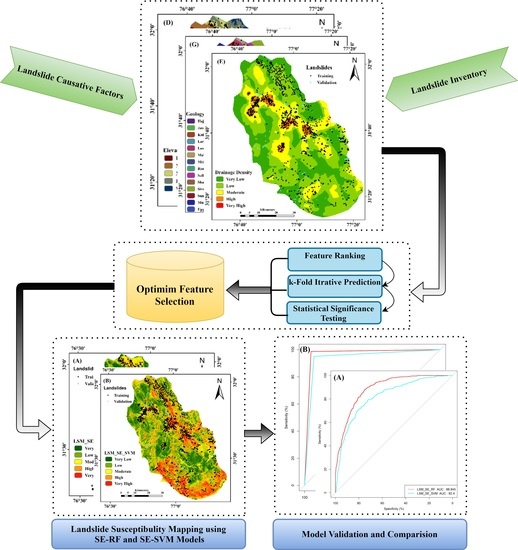
:
1. Introduction
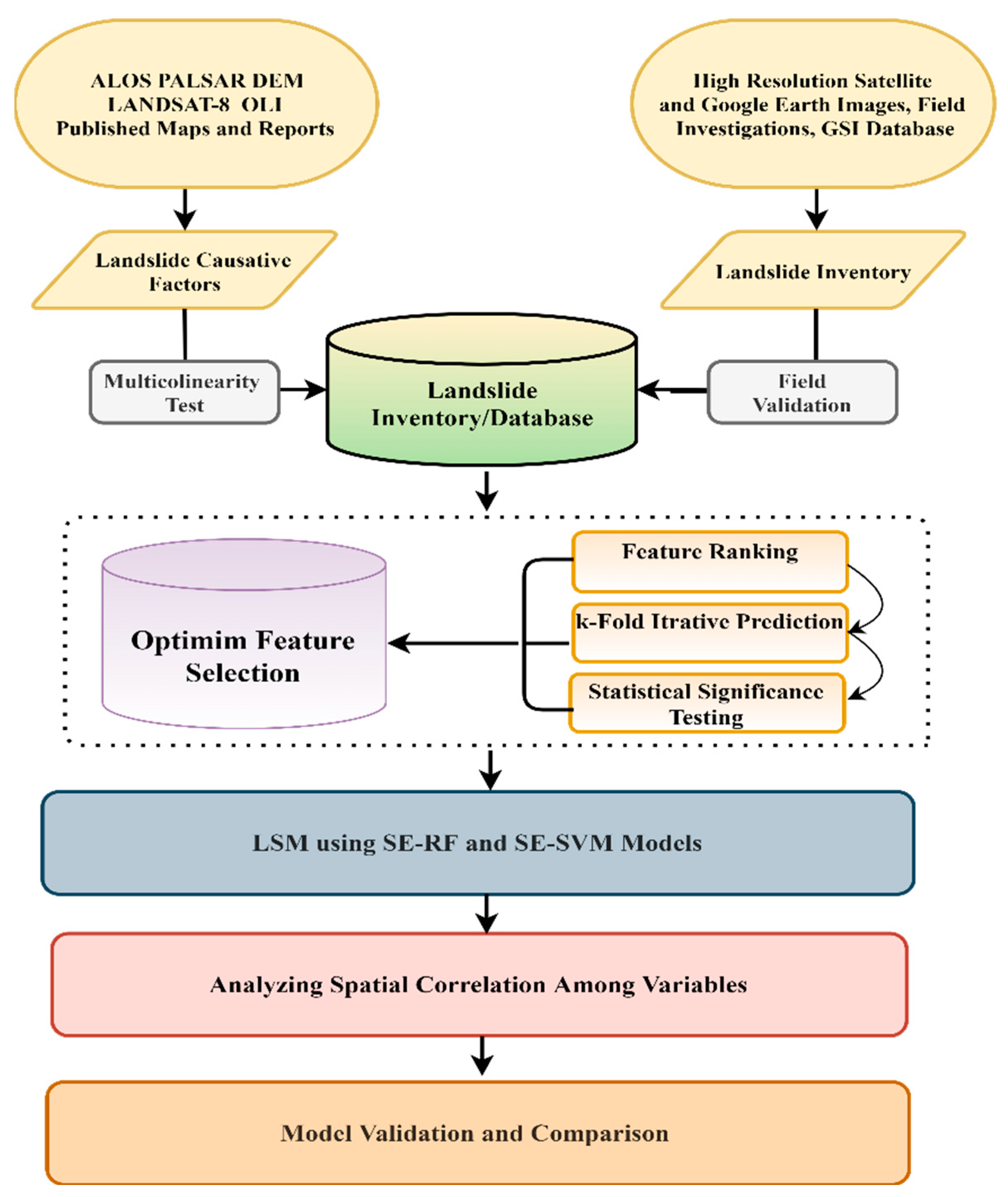
2. Materials and Methods
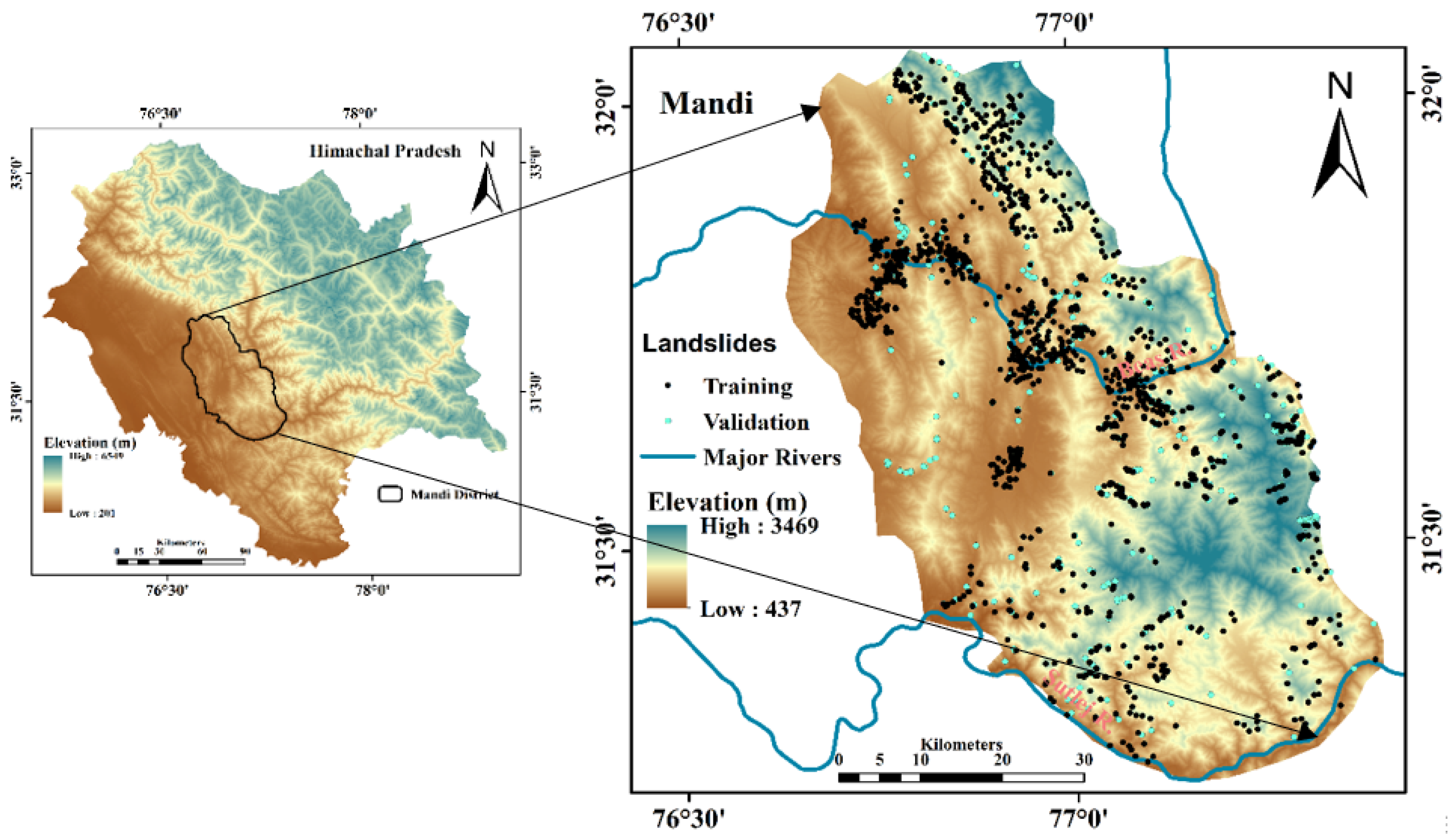
2.1. Study Area and Landslide Inventory
2.2. Landslide Causative Factors (LCF’s)
2.3. Shannon Entropy (SE) Model
2.4. Random Forest (RF) Model
2.5. Support Vector Machine (SVM) Model
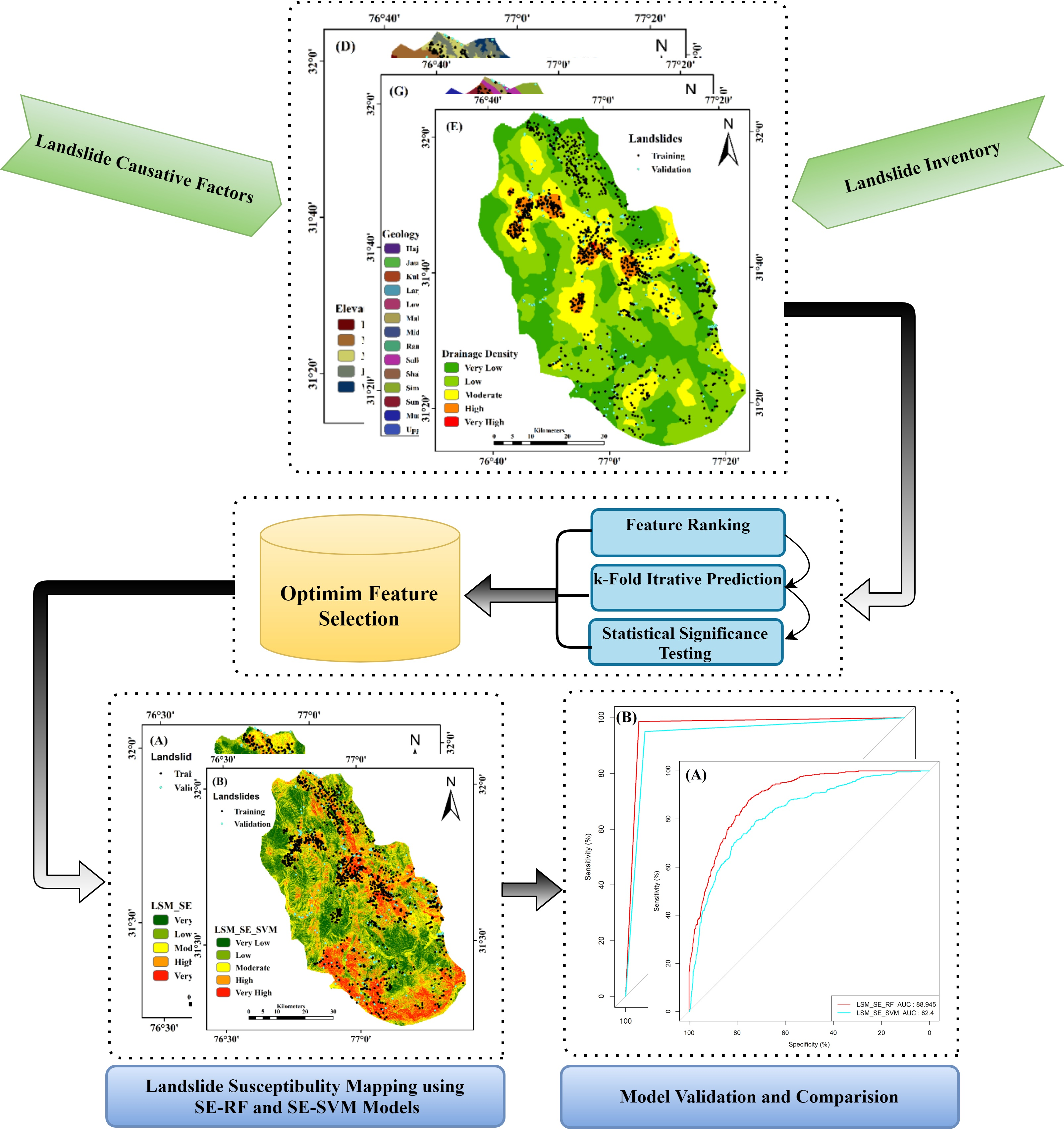
3. Results
3.1. Multicollinearity Analysis
3.2. Optimum Selection of LCF’s
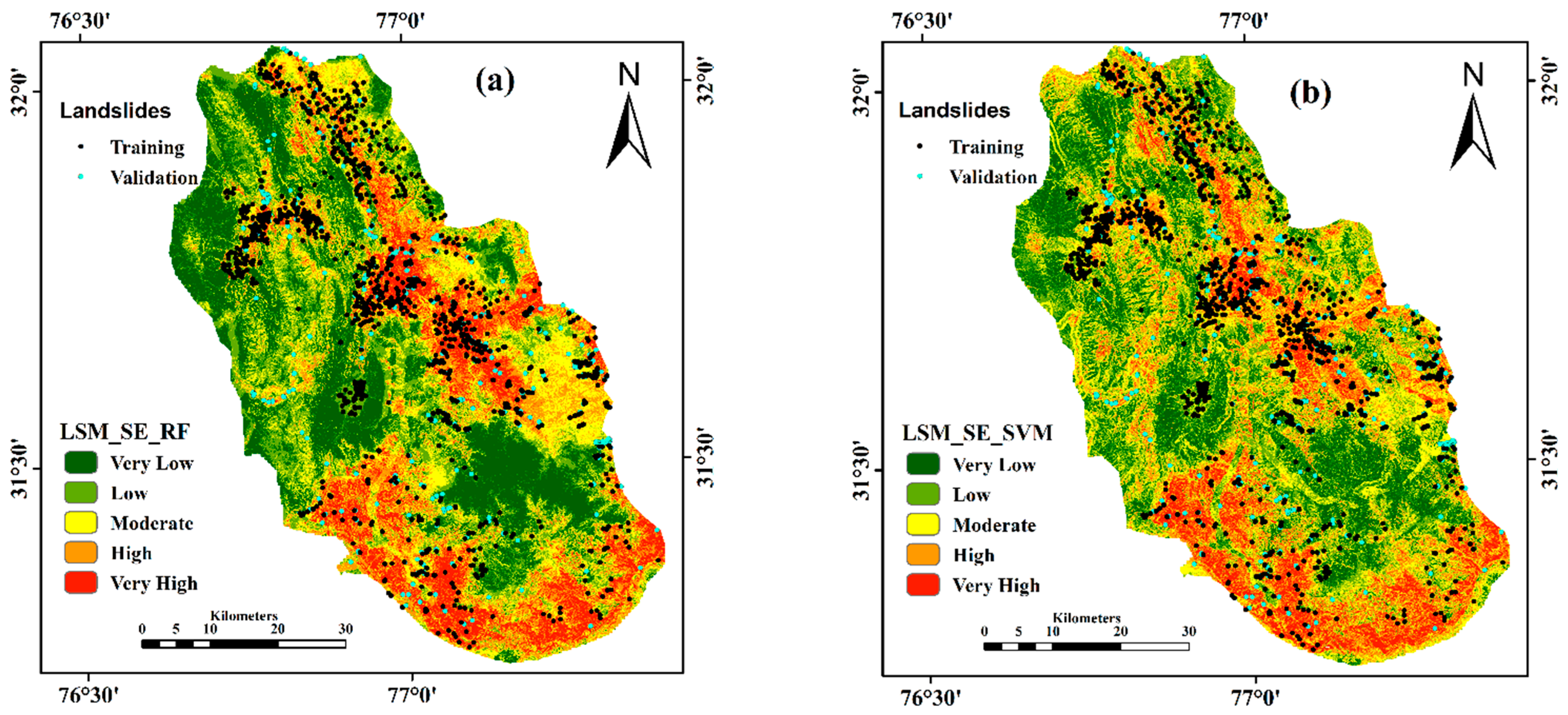
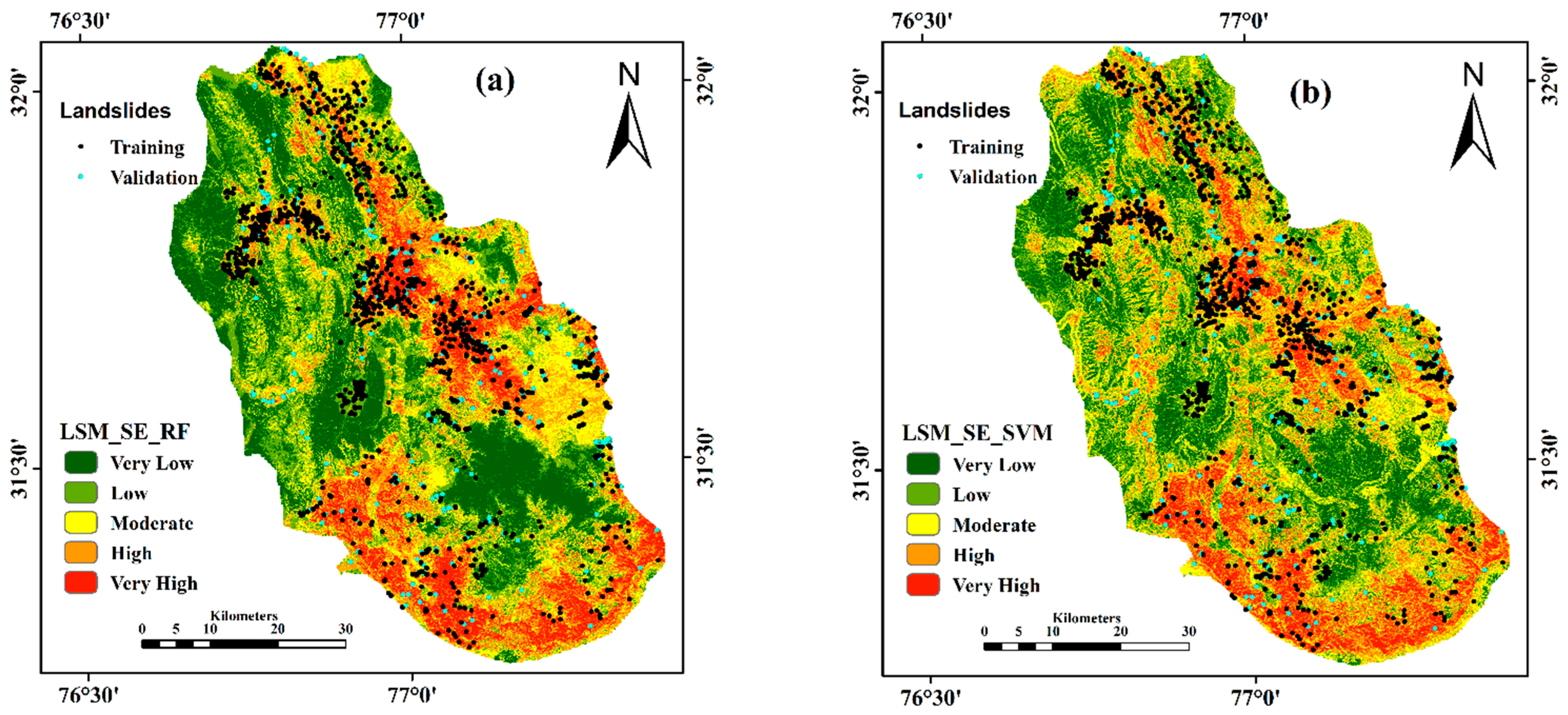
3.3. LSM Using SE-RF Model
3.4. LSM Using SE-SVM Model
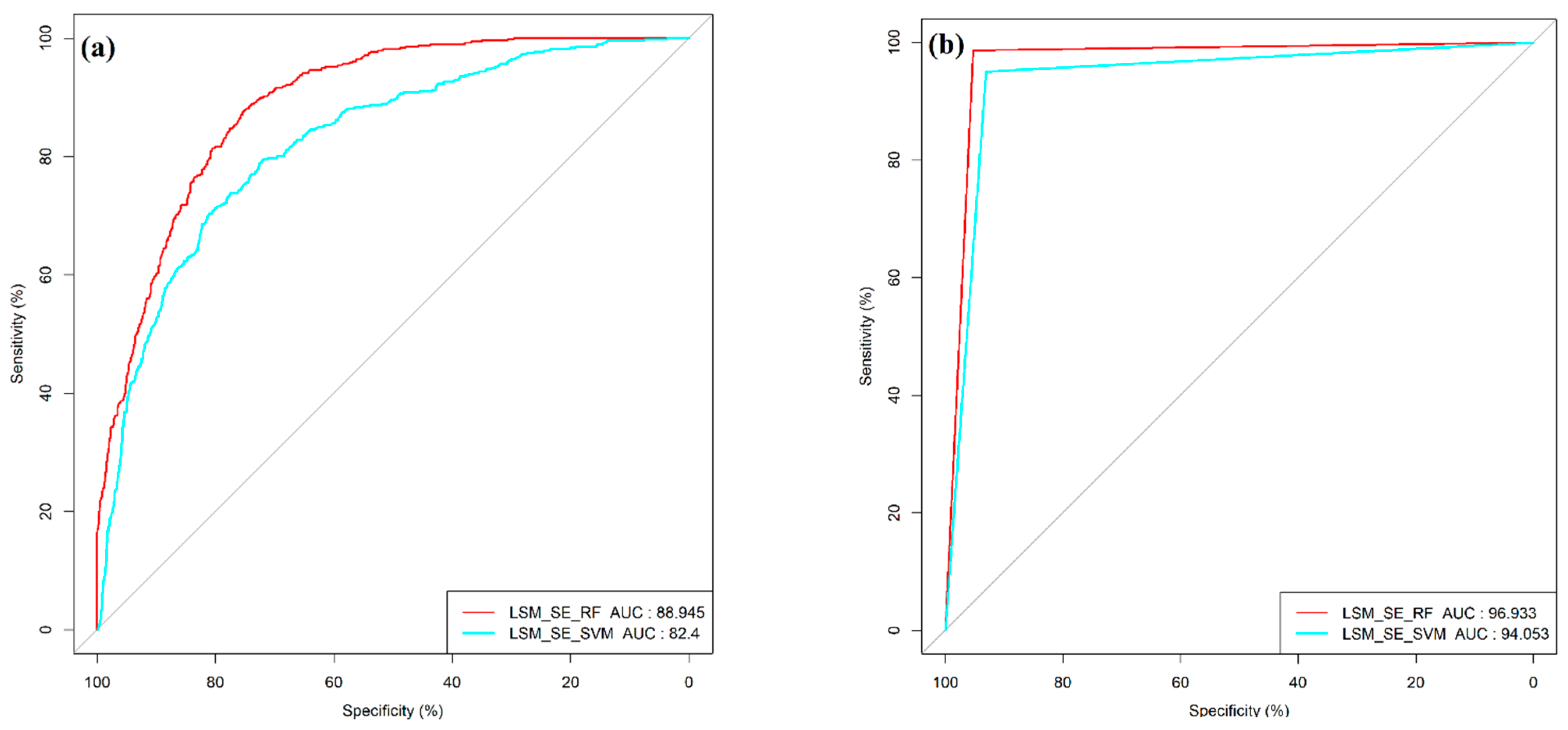
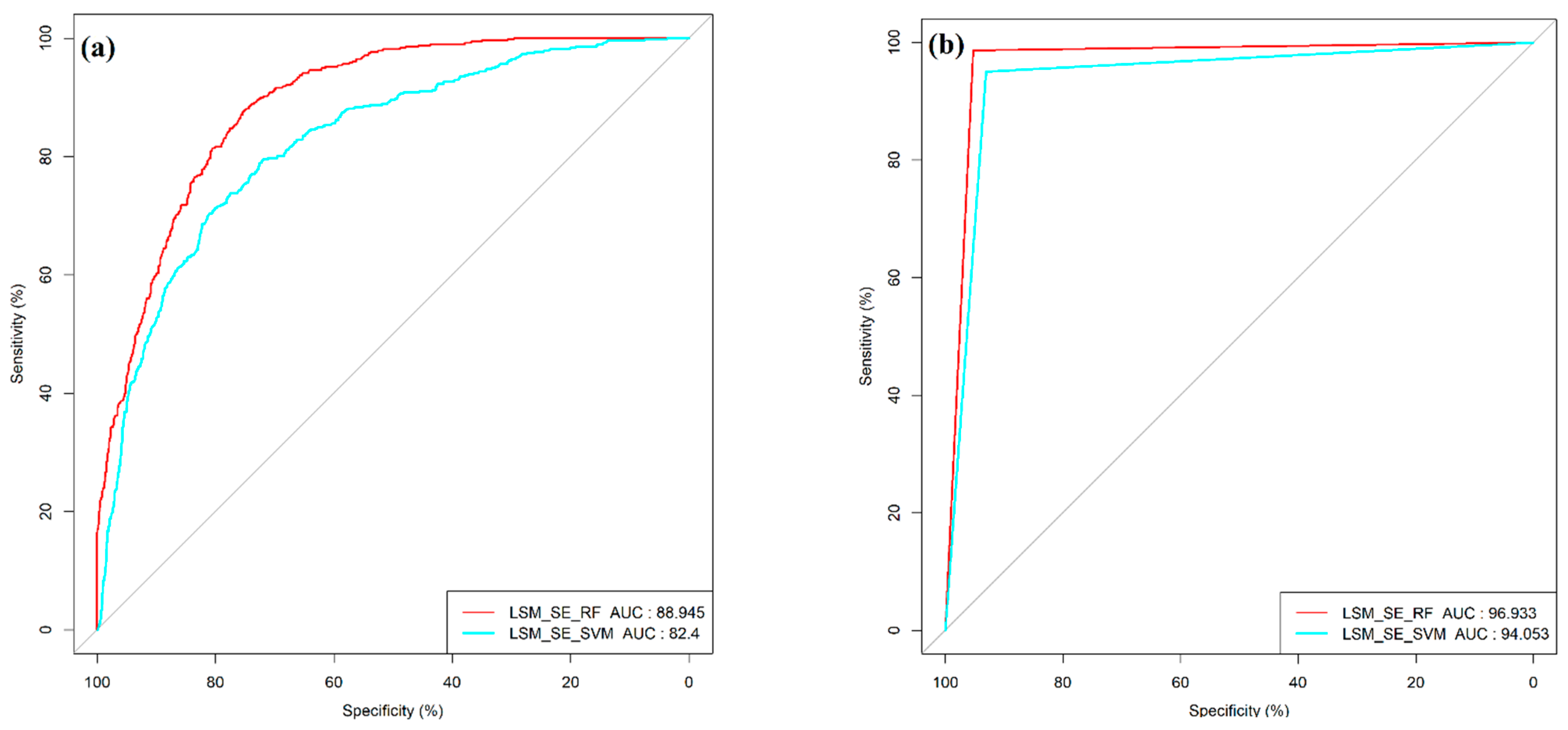
3.5. Performance and Validation of Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ali, S.A.; Parvin, F.; Vojteková, J.; Costache, R.; Linh, N.T.T.; Pham, Q.B.; Vojtek, M.; Gigović, L.; Ahmad, A.; Ghorbani, M.A. GIS-based landslide susceptibility modeling: A comparison between fuzzy multi-criteria and machine learning algorithms. Geosci. Front. 2020, 12, 857–876. [Google Scholar] [CrossRef]
- Wang, G.; Lei, X.; Chen, W.; Shahabi, H.; Shirzadi, A. Hybrid Computational Intelligence Methods for Landslide Susceptibility Mapping. Symmetry 2020, 12, 325. [Google Scholar] [CrossRef] [Green Version]
- Landslides. Available online: https://www.who.int/health-topics/landslides#tab=tab_1 (accessed on 15 September 2021).
- Revenue Department, Government of Himachal Pradesh. Memorandum of Damages Due to Flash Floods, Cloudbursts and Landslides during Monsoon Season-2020; HPSDMA: Shimla, India, 2020; pp. 14–26.
- Zhao, X.; Chen, W. Optimization of Computational Intelligence Models for Landslide Susceptibility Evaluation. Remote Sens. 2020, 12, 2180. [Google Scholar] [CrossRef]
- Nohani, E.; Moharrami, M.; Sharafi, S.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Lee, S.; Melesse, A.M. Landslide Susceptibility Mapping Using Different GIS-Based Bivariate Models. Water 2019, 11, 1402. [Google Scholar] [CrossRef] [Green Version]
- Nayak, J.; Westen, C.V.; Das, I.C.; Nayak, J. Landslide Risk Assessment along a Major Road Corridor Based on Historical Landslide Inventory and Traffic Analysis; University of Twente Faculty of Geo-Information and Earth Observation (ITC): Enschede, The Netherlands, 2010; p. 104. [Google Scholar]
- Reichenbach, P.; Rossi, M.; Malamud, B.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Jankowski, P.; Blaschke, T. A GIS based spatially-explicit sensitivity and uncertainty analysis approach for multi-criteria decision analysis. Comput. Geosci. 2013, 64, 81–95. [Google Scholar] [CrossRef] [Green Version]
- Saha, A.; Saha, S. Comparing the efficiency of weight of evidence, support vector machine and their ensemble approaches in landslide susceptibility modelling: A study on Kurseong region of Darjeeling Himalaya, India. Remote Sens. Appl. Soc. Environ. 2020, 19, 100323. [Google Scholar] [CrossRef]
- Arabameri, A.; Karimi-Sangchini, E.; Pal, S.; Saha, A.; Chowdhuri, I.; Lee, S.; Bui, D.T. Novel Credal Decision Tree-Based Ensemble Approaches for Predicting the Landslide Susceptibility. Remote Sens. 2020, 12, 3389. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Panahi, M.; Kornejady, A.; Wang, J.; Xie, X.; Cao, S. Spatial prediction of landslide susceptibility using an adaptive neuro-fuzzy inference system combined with frequency ratio, generalized additive model, and support vector machine techniques. Geomorphology 2017, 297, 69–85. [Google Scholar] [CrossRef]
- Shahabi, H.; Khezri, S.; Bin Ahmad, B.; Hashim, M. RETRACTED: Landslide susceptibility mapping at central Zab basin, Iran: A comparison between analytical hierarchy process, frequency ratio and logistic regression models. CATENA 2014, 115, 55–70. [Google Scholar] [CrossRef]
- Galli, M.; Ardizzone, F.; Cardinali, M.; Guzzetti, F.; Reichenbach, P. Comparing landslide inventory maps. Geomorphology 2008, 94, 268–289. [Google Scholar] [CrossRef]
- Ngadisih; Bhandary, N.P.; Yatabe, R.; Dahal, R.K. Logistic regression and artificial neural network models for mapping of regional-scale landslide susceptibility in volcanic mountains of West Java (Indonesia). AIP 2016, 1730, 60001. [Google Scholar] [CrossRef]
- Sharma, R.K.; Mehta, B.S. Macro-zonation of landslide susceptibility in Garamaura-Swarghat-Gambhar section of national highway 21, Bilaspur District, Himachal Pradesh (India). Nat. Hazards 2011, 60, 671–688. [Google Scholar] [CrossRef]
- Banshtu, R.S.; Prakash, C. Application of Remote Sensing and GIS Techniques in Landslide Hazard Zonation of Hilly Terrain; Springer: Cham, Switzerland, 2014; pp. 313–317. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.-J.; Jung, H.-S.; Lee, S. Landslide Susceptibility Mapping Using Naïve Bayes and Bayesian Network Models in Umyeonsan, Korea. Geocarto Int. 2019, 35, 1665–1679. [Google Scholar] [CrossRef]
- Bui, D.T.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Bin Ahmad, B.; Panahi, M.; Hong, H.; et al. Landslide Detection and Susceptibility Mapping by AIRSAR Data Using Support Vector Machine and Index of Entropy Models in Cameron Highlands, Malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef] [Green Version]
- Alvioli, M.; Mondini, A.; Fiorucci, F.; Cardinali, M.; Marchesini, I. Automatic Landslide Mapping from Satellite Imagery with a Topography-Driven Thresholding Algorithm. PeerJ Prepr. 2018, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Nagarajan, R.; Mukherjee, A.; Roy, A.; Khire, M.V. Technical note Temporal remote sensing data and GIS application in landslide hazard zonation of part of Western ghat, India. Int. J. Remote Sens. 1998, 19, 573–585. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Spatial prediction of landslide hazards in Hoa Binh province (Vietnam): A comparative assessment of the efficacy of evidential belief functions and fuzzy logic models. CATENA 2012, 96, 28–40. [Google Scholar] [CrossRef]
- Shahri, A.A.; Spross, J.; Johansson, F.; Larsson, S. Landslide susceptibility hazard map in southwest Sweden using artificial neural network. CATENA 2019, 183, 104225. [Google Scholar] [CrossRef]
- Frangov, G.; Petkova, V.; Stoyanov, V.; Kadiyski, M.; Kostov, V.; Papaliangas, T. Landslide Risk Assessment and Mitigation Along a Road in Sw Bulgaria. Fresenius Environ. Bull. 2017, 26, 244–253. [Google Scholar]
- Pradhan, B.; Abokharima, M.H.; Jebur, M.N.; Tehrany, M.S. Land subsidence susceptibility mapping at Kinta Valley (Malaysia) using the evidential belief function model in GIS. Nat. Hazards 2014, 73, 1019–1042. [Google Scholar] [CrossRef]
- Mandal, S.; Mondal, S. Statistical Approaches for Landslide Susceptibility Assessment and Prediction; Springer International Publishing: Cham, Switzerland, 2019; Available online: https://doi.org/10.1007/978-3-319-93897-4 (accessed on 25 September 2020).
- Ozdemir, A.; Altural, T. A comparative study of frequency ratio, weights of evidence and logistic regression methods for landslide susceptibility mapping: Sultan Mountains, SW Turkey. J. Asian Earth Sci. 2013, 64, 180–197. [Google Scholar] [CrossRef]
- Zare, M.; Jouri, M.H.; Salarian, T.; Askarizadeh, D. Comparing of Bivariate Statistic, AHP and Combination Methods to Predict the Landslide Hazard in Northern Aspect of Alborz Mt (Iran). Int. J. Agric. Crop Sci. 2014, 7, 543–554. [Google Scholar]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Duan, Z.; Li, S.; Zhu, A.-X. GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. CATENA 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Devkota, K.C.; Regmi, A.D.; Pourghasemi, H.R.; Yoshida, K.; Pradhan, B.; Ryu, I.C.; Dhital, M.R.; Althuwaynee, O.F. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat. Hazards 2012, 65, 135–165. [Google Scholar] [CrossRef]
- Liu, W.; Song, Z. Review of studies on the resilience of urban critical infrastructure networks. Reliab. Eng. Syst. Saf. 2019, 193, 106617. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Remote Sensing Data Derived Parameters and its Use in Landslide Susceptibility Assessment Using Shannon’s Entropy and GIS. Appl. Mech. Mater. 2012, 225, 486–491. [Google Scholar] [CrossRef]
- Milaghardan, A.H.; Abbaspour, R.A.; Khalesian, M. Evaluation of the effects of uncertainty on the predictions of landslide occurrences using the Shannon entropy theory and Dempster–Shafer theory. Nat. Hazards 2019, 100, 49–67. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Aryal, J.; Shahabi, H.; Safarrad, T. Fuzzy Shannon Entropy: A Hybrid GIS-Based Landslide Susceptibility Mapping Method. Entropy 2016, 18, 343. [Google Scholar] [CrossRef]
- Roy, J.; Saha, S.; Arabameri, A.; Blaschke, T.; Bui, D.T. A Novel Ensemble Approach for Landslide Susceptibility Mapping (LSM) in Darjeeling and Kalimpong Districts, West Bengal, India. Remote Sens. 2019, 11, 2866. [Google Scholar] [CrossRef] [Green Version]
- Yusof, N.M.; Pradhan, B.; Shafri, H.Z.M.; Jebur, M.N.; Yusoff, Z.M. Spatial landslide hazard assessment along the Jelapang Corridor of the North-South Expressway in Malaysia using high resolution airborne LiDAR data. Arab. J. Geosci. 2015, 8, 9789–9800. [Google Scholar] [CrossRef]
- Pradhan, A.M.S.; Kim, Y.-T. Spatial data analysis and application of evidential belief functions to shallow landslide susceptibility mapping at Mt. Umyeon, Seoul, Korea. Bull. Int. Assoc. Eng. Geol. 2016, 76, 1263–1279. [Google Scholar] [CrossRef]
- Budimir, M.E.A.; Atkinson, P.M.; Lewis, H.G. A systematic review of landslide probability mapping using logistic regression. Landslides 2015, 12, 419–436. [Google Scholar] [CrossRef] [Green Version]
- Yousefi, S.; Pourghasemi, H.R.; Emami, S.N.; Pouyan, S.; Eskandari, S.; Tiefenbacher, J.P. A machine learning framework for multi-hazards modeling and mapping in a mountainous area. Sci. Rep. 2020, 10, 1–14. [Google Scholar] [CrossRef]
- Saha, S.; Paul, G.C.; Pradhan, B.; Maulud, K.N.A.; Alamri, A.M. Integrating multilayer perceptron neural nets with hybrid ensemble classifiers for deforestation probability assessment in Eastern India. Geomat. Nat. Hazards Risk 2020, 12, 29–62. [Google Scholar] [CrossRef]
- Chang, K.-T.; Merghadi, A.; Yunus, A.P.; Pham, B.T.; Dou, J. Evaluating scale effects of topographic variables in landslide susceptibility models using GIS-based machine learning techniques. Sci. Rep. 2019, 9, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Sahin, E.K.; Colkesen, I.; Acmali, S.S.; Akgun, A.; Aydinoglu, A.C. Developing comprehensive geocomputation tools for landslide susceptibility mapping: LSM tool pack. Comput. Geosci. 2020, 144, 104592. [Google Scholar] [CrossRef]
- Dou, J.; Bui, D.T.; Yunus, A.P.; Jia, K.; Song, X.; Revhaug, I.; Xia, H.; Zhu, Z. Optimization of Causative Factors for Landslide Susceptibility Evaluation Using Remote Sensing and GIS Data in Parts of Niigata, Japan. PLoS ONE 2015, 10, e0133262. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Liu, J.; Zhu, A.-X. Modeling landslide susceptibility using LogitBoost alternating decision trees and forest by penalizing attributes with the bagging ensemble. Sci. Total Environ. 2020, 718, 137231. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M.B. Rotation forest fuzzy rule-based classifier ensemble for spatial prediction of landslides using GIS. Nat. Hazards 2016, 83, 97–127. [Google Scholar] [CrossRef]
- Duch, W.; Wieczorek, T.; Biesiada, J.; Blachnik, M. Comparison of feature ranking methods based on information entropy. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 1415–1419. [Google Scholar] [CrossRef]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M.; et al. Hybrid Machine Learning Approaches for Landslide Susceptibility Modeling. Forests 2019, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Model. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2020, 12, 639–655. [Google Scholar] [CrossRef]
- Polykretis, C.; Chalkias, C. Comparison and evaluation of landslide susceptibility maps obtained from weight of evidence, logistic regression, and artificial neural network models. Nat. Hazards 2018, 93, 249–274. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Khosravi, K.; Yang, Y.; Pham, B.T. Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan. Sci. Total Environ. 2019, 662, 332–346. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Xie, X.; Peng, J.; Wang, J.; Duan, Z.; Hong, H. GIS-based landslide susceptibility modelling: A comparative assessment of kernel logistic regression, Naïve-Bayes tree, and alternating decision tree models. Geomat. Nat. Hazards Risk 2017, 8, 950–973. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Zhao, L. Review on landslide susceptibility mapping using support vector machines. CATENA 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth-Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naïve Bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Chen, W. Landslide Susceptibility Evaluation Using Hybrid Integration of Evidential Belief Function and Machine Learning Techniques. Water 2019, 12, 113. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Chen, W. GIS-based landslide susceptibility assessment using optimized hybrid machine learning methods. CATENA 2020, 196, 104833. [Google Scholar] [CrossRef]
- Survey, C.G.; Paper, C.; John, C.; California, W.; Survey, G.; Ca, S.; Calif, B.S.; Survey, G. Landslide Inventory Maps of Highway Corridors in California. In Proceedings of the 3rd North American Symposium on Landslides, Roanoke, VA, USA, 4–8 June 2017; pp. 529–540. [Google Scholar]
- Varnes, D.J. Landslide Hazard Zonation A Review of Principles and Practice, Natural Hazards; UNESCO: Paris, France, 1984; Available online: https://www.scirp.org/(S(351jmbntvnsjt1aadkposzje))/reference/ReferencesPapers.aspx?ReferenceID=1768332 (accessed on 6 August 2021).
- Fell, R. Landslide risk assessment and acceptable risk. Can. Geotech. J. 1994, 31, 261–272. [Google Scholar] [CrossRef]
- Arca, D.; Citiroglu, H.K.; Tasoglu, I.K. A comparison of GIS-based landslide susceptibility assessment of the Satuk village (Yenice, NW Turkey) by frequency ratio and multi-criteria decision methods. Environ. Earth Sci. 2019, 78, 81. [Google Scholar] [CrossRef]
- Jiménez-Perálvarez, J.D.; Irigaray, C.; El Hamdouni, R.; Chacón, J. Landslide-susceptibility mapping in a semi-arid mountain environment: An example from the southern slopes of Sierra Nevada (Granada, Spain). Bull. Int. Assoc. Eng. Geol. 2010, 70, 265–277. [Google Scholar] [CrossRef]
- Chen, W.; Fan, L.; Li, C.; Pham, B.T. Spatial Prediction of Landslides Using Hybrid Integration of Artificial Intelligence Algorithms with Frequency Ratio and Index of Entropy in Nanzheng County, China. Appl. Sci. 2019, 10, 29. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, B. Remote sensing and GIS-based landslide hazard analysis and cross-validation using multivariate logistic regression model on three test areas in Malaysia. Adv. Space Res. 2010, 45, 1244–1256. [Google Scholar] [CrossRef]
- Choubey, V.M.; Mukherjee, P.K.; Bajwa, B.J.S.; Walia, V. Geological and tectonic influence on water–soil–radon relationship in Mandi–Manali area, Himachal Himalaya. Environ. Earth Sci. 2006, 52, 1163–1171. [Google Scholar] [CrossRef]
- Baum, R.L.; Godt, J. Early warning of rainfall-induced shallow landslides and debris flows in the USA. Landslides 2009, 7, 259–272. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y. GIS-based evaluation of landslide susceptibility using hybrid computational intelligence models. CATENA 2020, 195, 104777. [Google Scholar] [CrossRef]
- Lee, S.; Talib, J.A. Probabilistic landslide susceptibility and factor effect analysis. Environ. Earth Sci. 2005, 47, 982–990. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. CATENA 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Liu, L.-L.; Yang, C.; Wang, X.-M. Landslide Susceptibility Assessment Using Feature Selection-Based Machine Learning Models. Geomech. Eng. 2020, 25, 1–16. [Google Scholar]
- Laborda, J.; Ryoo, S. Feature Selection in a Credit Scoring Model. Mathematics 2021, 9, 746. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Micheletti, N.; Foresti, L.; Robert, S.; Leuenberger, M.; Pedrazzini, A.; Jaboyedoff, M.; Kanevski, M. Machine Learning Feature Selection Methods for Landslide Susceptibility Mapping. Math. Geol. 2013, 46, 33–57. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2019, 17, 641–658. [Google Scholar] [CrossRef]
- Cigdem, O.; Demirel, H. Performance analysis of different classification algorithms using different feature selection methods on Parkinson’s disease detection. J. Neurosci. Methods 2018, 309, 81–90. [Google Scholar] [CrossRef]
- Zhang, T.; Han, L.; Chen, W.; Shahabi, H. Hybrid Integration Approach of Entropy with Logistic Regression and Support Vector Machine for Landslide Susceptibility Modeling. Entropy 2018, 20, 884. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Sahana, M.; Chen, C.-W.; Zhu, Z.; Wang, W.; Pham, B.T. Evaluating GIS-Based Multiple Statistical Models and Data Mining for Earthquake and Rainfall-Induced Landslide Susceptibility Using the LiDAR DEM. Remote Sens. 2019, 11, 638. [Google Scholar] [CrossRef] [Green Version]
- Pourghasemi, H.R.; Kerle, N. Random forests and evidential belief function-based landslide susceptibility assessment in Western Mazandaran Province, Iran. Environ. Earth Sci. 2016, 75, 1–17. [Google Scholar] [CrossRef]
- Arabameri, A.; Saha, S.; Roy, J.; Chen, W.; Blaschke, T.; Bui, D.T. Landslide Susceptibility Evaluation and Management Using Different Machine Learning Methods in The Gallicash River Watershed, Iran. Remote Sens. 2020, 12, 475. [Google Scholar] [CrossRef] [Green Version]
- Arabameri, A.; Pradhan, B.; Rezaei, K.; Lee, C.-W. Assessment of Landslide Susceptibility Using Statistical- and Artificial Intelligence-based FR–RF Integrated Model and Multiresolution DEMs. Remote Sens. 2019, 11, 999. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Data Purpose | Data Source | Scale/Resolution |
|---|---|---|---|
| District Administration Mandi, Himachal Pradesh | Administrative boundary of Mandi | https://hpmandi.nic.in/map-of-district/ (accessed on 20 September 2020) | 1:50,000 |
| H.P. Disaster Revenue Reports (2015–2019), Google Earth, GSI-BHUKOSH, Handheld GPS | Landslide inventory | https://hpsdma.nic.in/ https://bhukosh.gsi.gov.in/ (accessed on 25 September 2020 | 1:50,000 |
| ALOS-PALSAR DEM | Slope, curvature, aspect, elevation, drainage density, and TWI | https://search.asf.alaska.edu (accessed on 12 October 2020) | 12.5 m |
| Landsat-8 OLI | NDVI and lineaments | http://earthexplored.usgs.gov (accessed on 7 October 2020) | 30 m |
| Geological Survey of India (GSI), BHUKOSH | Geology and lithology | https://bhukosh.gsi.gov.in/ (accessed on 17 July 2020) | 1:50,000 |
| Ministry of Road Transport and Highways (MoRTH) | Major roads of Mandi district | https://morth.nic.in/ (accessed on 22 July 2020) | 1:50,000 |
| National Bureau of Soil Survey and Land Use Planning (ICAR-NBSS and LUP) | Soil-Type, depth, and drainage of Mandi District | https://www.nbsslup.in/ (accessed on 19 July 2020) | 1:50,000 |
| Model | Collinearity Statistics | |
|---|---|---|
| Tolerance | VIF | |
| Slope | 0.798 | 3.658 |
| Aspect | 0.557 | 2.784 |
| Curvature | 0.217 | 5.633 |
| Elevation | 0.451 | 2.741 |
| Drainage Density | 0.751 | 5.214 |
| Lineament Density | 366 | 7.212 |
| Geology | 0.421 | 1.322 |
| NDVI | 0.257 | 6.369 |
| Soil | 0.785 | 4.321 |
| Roads | 0.741 | 2.357 |
| TWI | 0.679 | 4.212 |
| Information Gain | Chi-Squared | ||
|---|---|---|---|
| TWI | 0.301 | Distance to Roads | 0.579 |
| Drainage Density | 0.247 | TWI | 0.447 |
| Distance to Roads | 0.158 | Slope Gradient | 0.438 |
| NDVI | 0.147 | Drainage Density | 0.301 |
| Plan Curvature | 0.121 | Soil | 0.295 |
| Slope Gradient | 0.123 | Geology | 0.278 |
| Geology | 0.097 | Elevation | 0.199 |
| Elevation | 0.082 | Slope Aspect | 0.154 |
| Slope Aspect | 0.065 | NDVI | 0.125 |
| Soil | 0.047 | Plan Curvature | 0.081 |
| Lineament Density | 0.031 | Lineament Density | 0.065 |
| SPI | 0.020 | LULC | 0.042 |
| Lithology | 0.012 | Lithology | 0.015 |
| LULC | 0.010 | SPI | 0.008 |
| Feature Ranking Methods | Case No. | Statistical Tests | Model and Subset Size | Features in the Optimum Subset |
|---|---|---|---|---|
| Information Gain | Case-1 | One Sample T-Test | Model-12 | Slope; Aspect; Curvature; Elevation; Drainage Density; Lithology; NDVI; LULC; Soil; SPI; TWI Distance to Roads |
| Case-2 | Wilcoxon Signed-Rank Test | Model-11 | Slope; Aspect; Curvature; Elevation; Drainage Density; Geology; NDVI; Lineament Density; SPI; TWI; Distance from Roads | |
| Chi-Squared | Case-3 | One Sample T-Test | Model-9 | Slope; Curvature; Drainage Density; Geology; LULC; Soil; Lineament Density; SPI; Distance to Roads |
| Case-4 | Wilcoxon Signed-Rank Test | Model-11 | Slope; Aspect; Curvature; Elevation; Drainage Density; Geology; NDVI; Soil; Lineament Density; TWI; Distance from Roads |
| Class Pixels | Percent of Pixels | Landslide Pixels | Percent of Pixels | Frequency Ratio | Shanon Entropy | ||
|---|---|---|---|---|---|---|---|
| FR Values | Pij | Wj | |||||
| Landslide Causative Factors | |||||||
| Slope Gradient (Degree) | |||||||
| Flat (<15°) | 435,014 | 0.102 | 9 | 0.008 | 0.079 | 0.016 | 0.093 |
| Moderate (15–25°) | 948,259 | 0.222 | 85 | 0.076 | 0.341 | 0.069 | |
| Moderately Steep (25–35°) | 1,374,272 | 0.322 | 304 | 0.271 | 0.842 | 0.170 | |
| Steep (35–45°) | 1,047,813 | 0.245 | 490 | 0.437 | 1.780 | 0.359 | |
| Very Steep (>45°) | 466,470 | 0.109 | 234 | 0.209 | 1.910 | 0.386 | |
| Plan Curvature | |||||||
| Convex (−45–−25) | 94,610 | 0.022 | 55 | 0.049 | 2.213 | 0.299 | 0.033 |
| Slight Convex (−25–−5) | 711,548 | 0.167 | 407 | 0.363 | 2.178 | 0.294 | |
| Flat (−5–5) | 1,953,189 | 0.457 | 254 | 0.226 | 0.495 | 0.093 | |
| Slight Concave (5–25) | 1,346,104 | 0.315 | 233 | 0.208 | 0.659 | 0.089 | |
| Concave (25–50) | 166,377 | 0.039 | 73 | 0.065 | 1.671 | 0.225 | |
| Slope Aspect | |||||||
| Flat | 33,660 | 0.008 | 4 | 0.004 | 0.452 | 0.054 | 0.013 |
| North | 484,657 | 0.113 | 126 | 0.112 | 0.990 | 0.119 | |
| Northeast | 515,422 | 0.121 | 115 | 0.102 | 0.849 | 0.102 | |
| East | 497,821 | 0.117 | 81 | 0.072 | 0.619 | 0.074 | |
| Southeast | 503,993 | 0.118 | 108 | 0.096 | 0.816 | 0.098 | |
| South | 545,067 | 0.128 | 175 | 0.156 | 1.222 | 0.147 | |
| Southwest | 647,098 | 0.151 | 238 | 0.212 | 1.400 | 0.168 | |
| West | 546,964 | 0.128 | 195 | 0.174 | 1.357 | 0.163 | |
| Northwest | 497,146 | 0.116 | 80 | 0.071 | 0.613 | 0.074 | |
| Elevation (m) | |||||||
| Low (400–1000) | 995,824 | 0.233 | 212 | 0.189 | 0.811 | 0.188 | 0.066 |
| Moderate (1000–1500) | 1,624,309 | 0.380 | 266 | 0.237 | 0.623 | 0.144 | |
| Moderately High (1500–2000) | 1,028,156 | 0.241 | 539 | 0.480 | 1.996 | 0.462 | |
| High (2000–2500) | 537,465 | 0.126 | 101 | 0.090 | 0.715 | 0.166 | |
| Very High (2500–3500) | 86,074 | 0.020 | 4 | 0.004 | 0.177 | 0.041 | |
| Drainage Density | |||||||
| Very Low (0–0.6) | 1,299,831 | 0.305 | 150 | 0.134 | 0.439 | 0.017 | 0.269 |
| Low (0.6–1.2) | 1,908,487 | 0.448 | 229 | 0.204 | 0.456 | 0.018 | |
| Moderate (1.2–1.8) | 877,782 | 0.206 | 337 | 0.300 | 1.459 | 0.058 | |
| High (1.8–2.4) | 179,820 | 0.042 | 393 | 0.350 | 8.307 | 0.321 | |
| Very High (2.4–3.0) | 5908 | 0.001 | 23 | 0.020 | 14.797 | 0.586 | |
| Lineament Density | |||||||
| Very Low (−0.1–0.3) | 585,993 | 0.138 | 67 | 0.060 | 0.434 | 0.081 | 0.048 |
| Low (0.3–0.6) | 1,093,925 | 0.257 | 113 | 0.101 | 0.392 | 0.073 | |
| Moderate (0.6–0.9) | 1,109,204 | 0.260 | 329 | 0.293 | 1.126 | 0.211 | |
| High (0.9–1.2) | 1,085,918 | 0.255 | 407 | 0.363 | 1.423 | 0.266 | |
| Very High (1.2–1.6) | 396,788 | 0.093 | 206 | 0.184 | 1.971 | 0.369 | |
| Geology | |||||||
| Larji Group | 17,112 | 0.004 | 6 | 0.005 | 1.335 | 0.115 | 0.060 |
| Shali Group | 480,871 | 0.113 | 99 | 0.088 | 0.784 | 0.068 | |
| Jaunsar Group | 90,819 | 0.021 | 6 | 0.005 | 0.252 | 0.022 | |
| Middle Siwalik Group | 77,936 | 0.018 | 37 | 0.033 | 1.808 | 0.156 | |
| Salkhala Group | 1,020,010 | 0.239 | 326 | 0.291 | 1.217 | 0.105 | |
| Hajaribagh Granite and Pegmatite | 481,719 | 0.113 | 77 | 0.069 | 0.609 | 0.052 | |
| Dharmasala Group, Dagshai and Kasauli Formations | 761,109 | 0.178 | 186 | 0.070 | 1.679 | 0.145 | |
| Upper Siwalik Group | 258,408 | 0.060 | 4 | 0.004 | 0.059 | 0.005 | |
| Rampur Group | 2779 | 0.001 | 0 | 0.000 | 0.000 | 0.000 | |
| Lower Siwalik Group | 61,338 | 0.014 | 3 | 0.003 | 0.186 | 0.016 | |
| Sundernagar Formation | 100,192 | 0.023 | 33 | 0.119 | 0.650 | 0.056 | |
| Malani Volcanic Suite | 15,813 | 0.004 | 1 | 0.007 | 0.112 | 0.010 | |
| Simlipal Ultramafics | 368,975 | 0.086 | 144 | 0.128 | 1.486 | 0.128 | |
| Kulu Formation | 534,747 | 0.125 | 200 | 0.178 | 1.424 | 0.123 | |
| NDVI | |||||||
| Waterbodies (−0.15–0.015) | 16,242 | 0.004 | 33 | 0.029 | 7.736 | 0.574 | 0.121 |
| Urban (0.015–0.14) | 492,012 | 0.115 | 286 | 0.255 | 2.213 | 0.164 | |
| Barren Land (0.14–0.18) | 470,706 | 0.110 | 152 | 0.135 | 1.230 | 0.091 | |
| Shrubs and Grassland (0.18–0.27) | 1,933,318 | 0.453 | 399 | 0.356 | 0.786 | 0.058 | |
| Sparse Vegetation (0.27–0.36) | 1,204,917 | 0.282 | 219.000 | 0.195 | 0.692 | 0.051 | |
| Dense Vegetation (0.36–0.74) | 154,633 | 0.036 | 33 | 0.029 | 0.813 | 0.060 | |
| Soil | |||||||
| Lesser Himalayan Soils of Side/Reposed Slopes | 2,736,453 | 0.641 | 899 | 0.801 | 1.251 | 0.289 | 0.075 |
| Lesser Himalayan Soils of Fluvial Valleys | 280,750 | 0.066 | 124 | 0.111 | 1.682 | 0.389 | |
| Siwaliks Soils of Side/Reposed Slopes | 1,083,902 | 0.254 | 79 | 0.070 | 0.278 | 0.064 | |
| Siwaliks Soils of Fluvial Valleys | 62,713 | 0.015 | 16 | 0.014 | 0.971 | 0.225 | |
| Lesser Himalayas Soils of Summits and Ridge Tops | 108,010 | 0.025 | 4 | 0.004 | 0.141 | 0.033 | |
| TWI | |||||||
| Very Low (0.00–4.00) | 3,192,586 | 0.747 | 349 | 0.311 | 0.416 | 0.004 | 0.140 |
| Low (4.00–10.00) | 1,031,330 | 0.241 | 436 | 0.389 | 1.610 | 0.014 | |
| Moderate (10.00–16.00) | 37,036 | 0.009 | 208 | 0.185 | 21.383 | 0.182 | |
| High (16.00–22.00) | 9038 | 0.002 | 105 | 0.094 | 44.232 | 0.377 | |
| Very High (22.00–28.00) | 1838 | 0.000 | 24 | 0.021 | 49.715 | 0.424 | |
| Distance from Road (m) | |||||||
| 0–100 | 240,721 | 0.056 | 406 | 0.362 | 6.421 | 0.359 | 0.082 |
| 100–200 | 196,740 | 0.046 | 297 | 0.265 | 5.747 | 0.321 | |
| 200–300 | 172,030 | 0.040 | 111 | 0.099 | 2.456 | 0.137 | |
| 300–400 | 156,805 | 0.037 | 80 | 0.071 | 1.942 | 0.109 | |
| 400–500 | 145,918 | 0.034 | 43 | 0.038 | 1.122 | 0.063 | |
| >500 | 3,359,614 | 0.787 | 185 | 0.165 | 0.210 | 0.012 | |
| Model | Accuracy | AUC Prediction | AUC Validation | MAE | RMSE | Precision | Recall |
|---|---|---|---|---|---|---|---|
| SE-RF | 0.8963 | 88.94 | 96.93 | 0.1354 | 0.2956 | 0.9589 | 0.8144 |
| SE-SVM | 0.8541 | 82.40 | 94.05 | 0.1747 | 0.3479 | 0.9314 | 0.7902 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, A.; Prakash, C.; Manivasagam, V.S. Entropy-Based Hybrid Integration of Random Forest and Support Vector Machine for Landslide Susceptibility Analysis. Geomatics 2021, 1, 399-416. https://doi.org/10.3390/geomatics1040023
Sharma A, Prakash C, Manivasagam VS. Entropy-Based Hybrid Integration of Random Forest and Support Vector Machine for Landslide Susceptibility Analysis. Geomatics. 2021; 1(4):399-416. https://doi.org/10.3390/geomatics1040023
Chicago/Turabian StyleSharma, Amol, Chander Prakash, and V. S. Manivasagam. 2021. "Entropy-Based Hybrid Integration of Random Forest and Support Vector Machine for Landslide Susceptibility Analysis" Geomatics 1, no. 4: 399-416. https://doi.org/10.3390/geomatics1040023
APA StyleSharma, A., Prakash, C., & Manivasagam, V. S. (2021). Entropy-Based Hybrid Integration of Random Forest and Support Vector Machine for Landslide Susceptibility Analysis. Geomatics, 1(4), 399-416. https://doi.org/10.3390/geomatics1040023