

A Review on Machine/Deep Learning Techniques Applied to Building Energy Simulation, Optimization and Management



Abstract
1. Introduction
1.1. Background
1.1.1. Building Energy Optimization
- Differential evolution algorithms within multi-objective optimization models—for example, Wang et al. [24] used this method to determine optimal solutions for lifecycle costs of building retrofit planning;
- Meta-heuristic optimization algorithms—for example, Suh et al. [25] used the heuristic and meta-heuristic approach for the energy optimization of a post office building;
- Genetic algorithms—for example, Ascione et al. [26] proposed a new methodology for the multi-objective optimization of building energy performance and thermal comfort using a genetic algorithm to identify the best retrofit measures, and Hamdy et al. [27] developed a comprehensive multi-step methodology to find the cost-optimal combination of energy efficiency measures to achieve the standard of a nearly zero-energy building (nZEB);
- Particle swarm optimization algorithm—for example, Ferrara et al. [28] used this method to find the cost-optimal solution for building energy retrofit.
1.1.2. Surrogate Models: Physically Informed and Data-Driven
- Physically informed models can solve supervised learning tasks while respecting the different physics laws described, e.g., using non-linear partial differential equations; thus, the model can be trained to respect both the differential equations and the given boundary conditions. Physics-informed machine learning extracts physically relevant solutions from complex modelling problems, even partially understood and without sufficient quantity of data, through learning models informed by physically relevant predetermined information [37].
- Data-driven models are computational models that work with historical data previously collected, e.g., by monitoring, and can link inputs and outputs by identifying correlations between them. In other words, data-driven approaches include raw data from real experience and observations. These procedures have the advantage of identifying correlations between variables and can lead to the discovery of new scientific laws or forecasting without the availability of predetermined laws [38]. Statistical data-driven models include statistical assumptions concerning the generation of sample data and are the basis of data-driven models’ functioning. Therefore, they have a set of statistical assumptions with a certain property, that is the assumption that allows for the probability of any event to be calculated.
1.2. Scope and Objectives
- Energy design/retrofit optimization and prediction of energy consumption;
- Control and management of heating/cooling systems;
- Control and management of renewable energy source systems;
- Fault detection.
1.3. Significance and Relevance
- Different machine or deep learning methods can be used to pursue the same goal, e.g., decision trees/random forest and neural networks are both frequently used for consumption prediction and systems’ control;
- More than one approach can be applied to obtain a more reliable result, e.g., using both machine and deep learning methods;
- Until now, most of the studies conducted are based on the energy performance optimization of individual buildings, while building stocks are still scarcely investigated. This aspect should be addressed to provide a large-scale ecological transition;
- Furthermore, numerous studies investigated the residential sector, which covers a significant part of the world’s building stock. However, studies concerning other energy-intensive building sectors are still few and, in any case, fewer in number than those concerning the residential sector. Also, this aspect needs to be addressed.
1.4. Previous Reviews on the Topic
1.5. Rationale for this Review
1.6. Outline of this Review
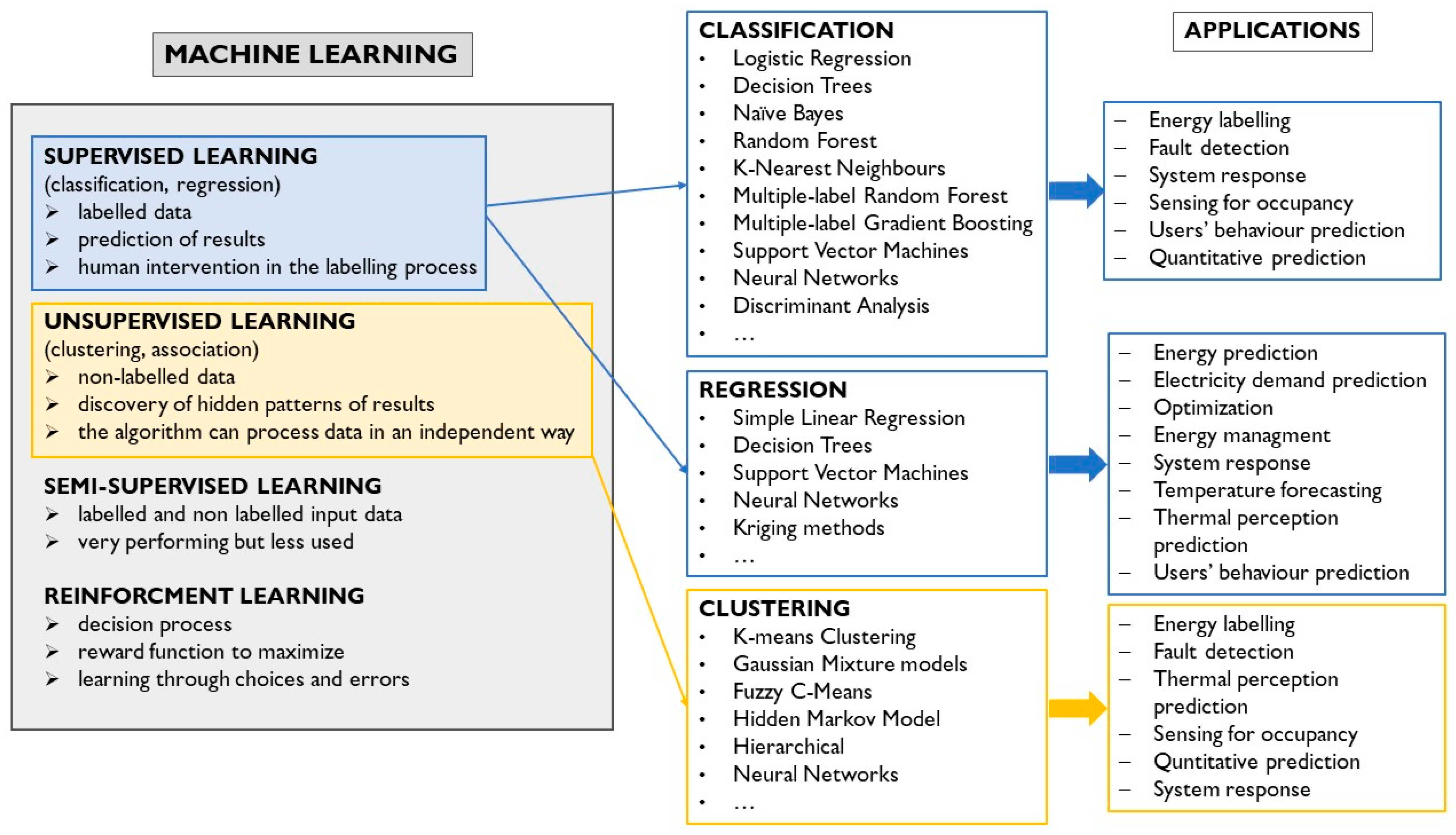
2. Machine and Deep Learning Methods
- Physically informed or data-driven (statistical);
- Supervised, unsupervised or semi-supervised.
- Variable deletion involves deleting variables with missing values. Dropping certain data can be useful when there are many missing values in a variable and the variable is of relatively minor importance;
- Average or median imputation is commonly used with non-missing observations and can be applied to a feature that contains numeric data;
- The most common value method replaces missing values with the highest value tested in a function and can be a good option for managing categorical functions.
2.1. Machine Learning Methods
- (1)
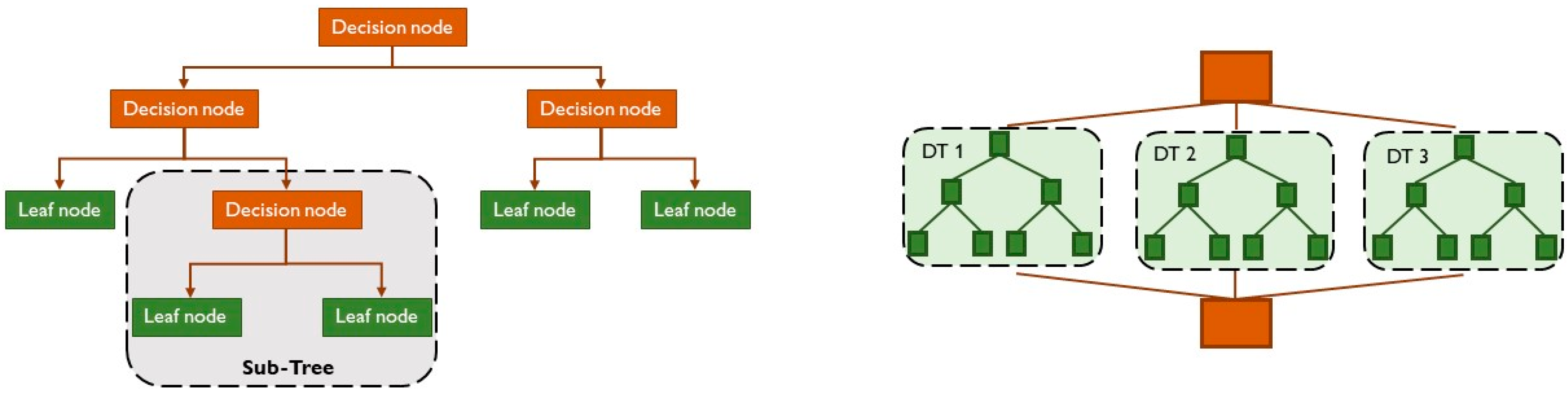
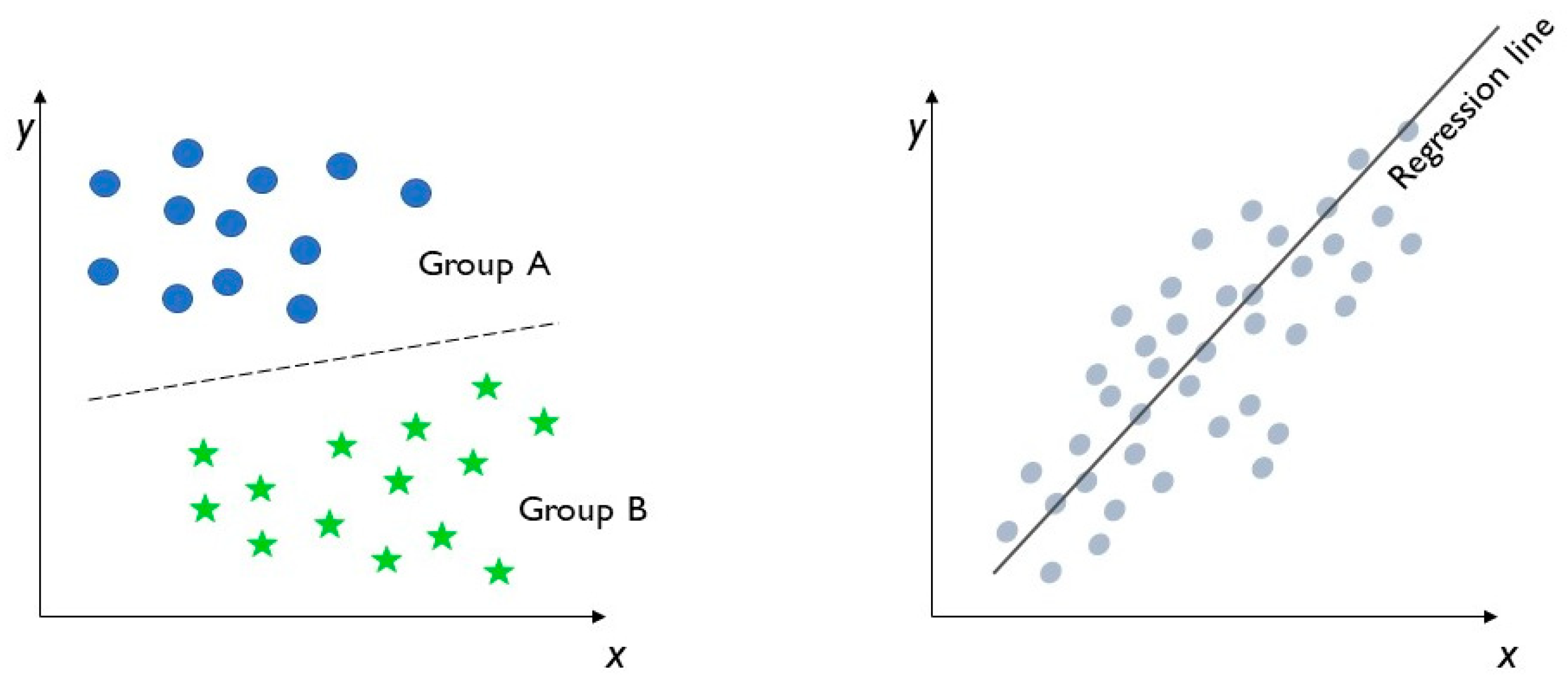
- In classification problems, the goal, based on the analysis of previously labelled training datasets, is to predict the labelling of future data classes. Labels are discrete and unordered values that can be considered to belong to a known group or a class. Thus, in this case, the output is a category. Through a supervised machine learning algorithm, it is possible to separate two classes and to associate the data, based on their values, to different categories, as in Figure 3, on the left. The inputs and outputs are both labelled, so the model can understand which features can classify an object or data.Depending on the number of class labels, it is possible to identify three types of classification: binary classification, multiple-class classification and multiple-label classification. In binary classification, the model can apply only two class labels, such as in logistic regression, decision trees and naive Bayes. In multiple-class classification, the model can apply more than two class labels, such as in random forest and naive Bayes. In multiple-label classification, the model can apply more than one class label to the same object or data, such as in multiple-label random forest and gradient boosting.
- (2)
- In regression analysis, the approach is similar to classification but the output variables are continuous values or quantities. It is generally used to predict outcomes after the identification of connections between the input- and output-labelled data. The most used regression analysis supervised learning methods are simple linear regression and decision tree regression, as in Figure 3, on the right. In simple linear regression, the model firstly identifies the relationships between the inputs and outputs; then, it can forecast a target output from an input variable. In decision tree regression models, the algorithm structure is similar to a tree, with many branches. They are frequently used both in classification and regression problems. The dataset is divided into various sub-groups to identify correlations between the independent variables. Thus, when new input data are integrated in the model, correct outcomes can be predicted with the regression analysis on the previous data.
- (3)
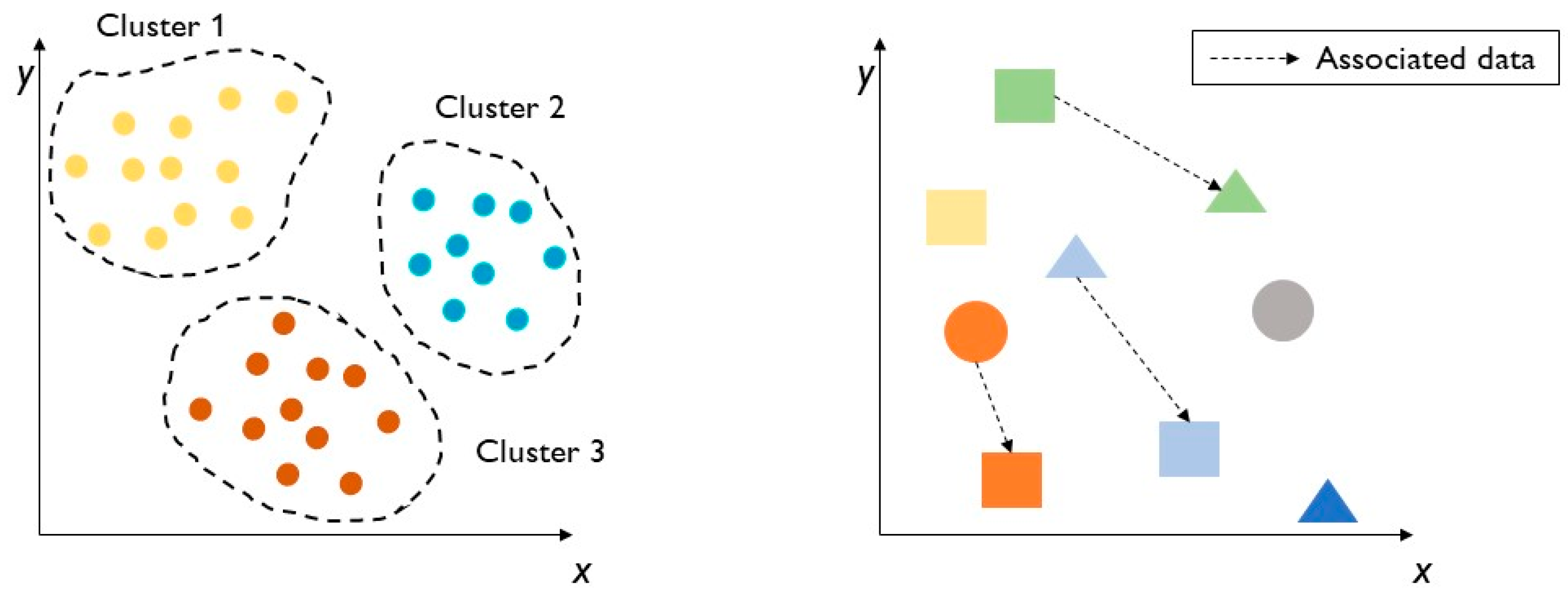
- Clustering is an exploratory technique that allows raw data to be aggregated within groups called clusters, of which there is no previous knowledge of group membership. Clustering is an excellent technique that allows the structure to be found in a collection of unlabelled data, as in Figure 4, on the left. The main aim is to put an object in a precise cluster depending on its characteristics and to ensure that the cluster to which it belongs is dissimilar to other clusters [44]. The total number of clusters has been previously defined by data scientists, and it is the only human intervention in the clustering process. Irregularities can be found in the data located outside of the clusters, i.e., such data do not belong to the main clusters. The most commonly used clustering unsupervised identification methods are k-means clustering and Gaussian mixture models. In k-means clustering, k is the number of clusters, which are defined by the distance from the centre of each group. It is a useful method to identify external data, overlapping parts in two or more clusters, and data that belong only to one cluster. Gaussian mixture models are based on the probability that a precise datum or object belongs to a cluster.
- (4)
- Association is the process of understanding how certain data features connect with other features. This association between variables can be mapped, as happens in e-commerce, where some products are recommended because they are similar to others that the customer wants to buy. An association scheme is reported in Figure 4, on the right.
- Decision trees and random forest;
- Naive Bayes;
- Support vector machines (SVMs);
- Kriging method;
- Artificial neural networks (ANNs).
2.1.1. Decision Trees and Random Forest
2.1.2. Naive Bayes
- Naive Bayes categorical classification, where data have a discrete distribution;
- Naive Bayes binary classification, where data assume values of 0 or 1;
- Naive Bayes integer and float classification, where a naive Gaussian classifier is used [59].
2.1.3. Support Vector Machines (SVMs)
2.1.4. Kriging Method
- Ordinary Kriging, to be applied where the average of the residuals is constant, i.e., the trend is constant, throughout the studied domain;
- Simple Kriging, to be applied in the case in which the average of residuals is constant and known;
- Universal Kriging, to be applied when the average of residuals is not constant and the law of autocorrelation presents a trend, and is useful in forecasting random variables with spatially correlated errors;
- Co-Kriging, to be applied when the estimate of the main variable is not based only on values of the examined variable but also considers other auxiliary variables, correlated with the target variable.
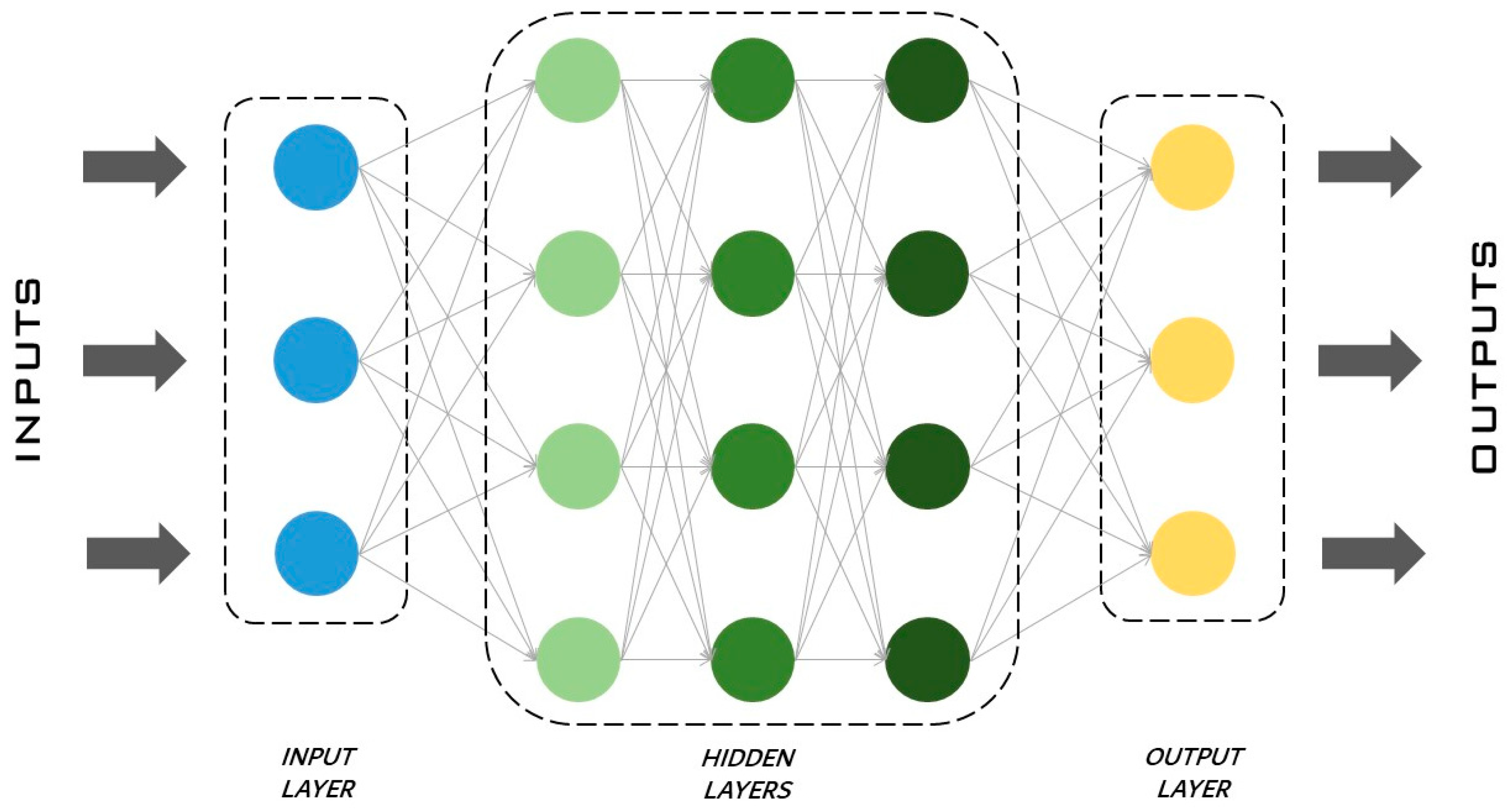
2.1.5. Artificial Neural Networks (ANNs)
- Feedforward neural networks, where data travel in a unique direction, from the input to output layers;
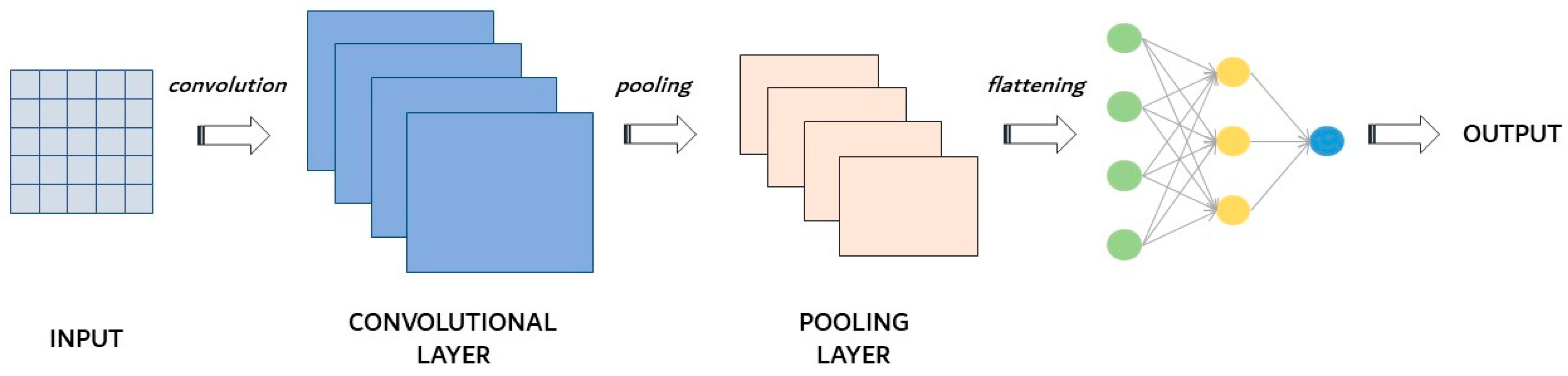
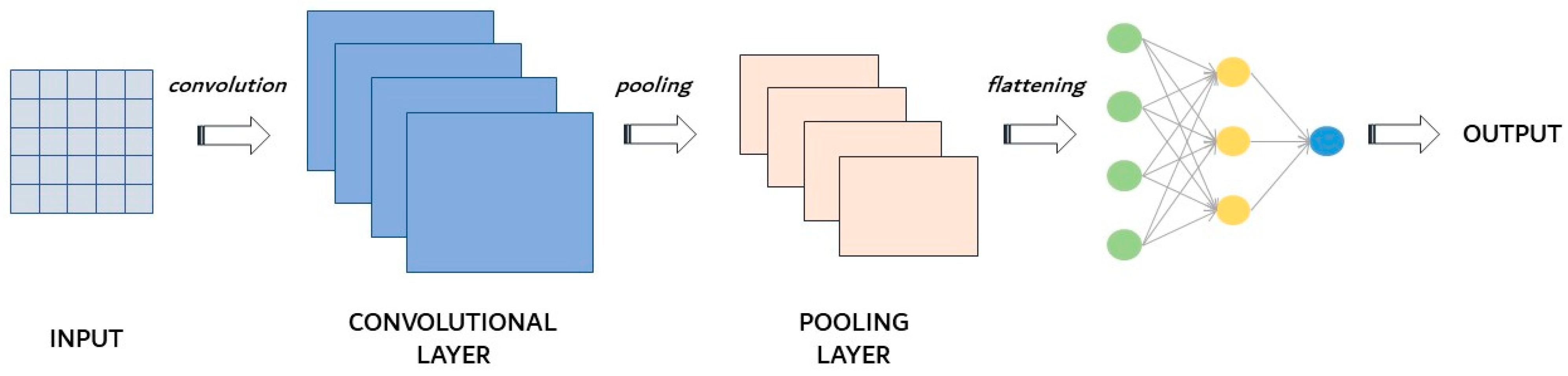
- Convolutional neural networks, where the connection between units has different weights that influence the final outcome in different ways, where the results of each convolutional layer are obtained as the output to the next layer, and where in the convolutional layer, features are extracted from the input dataset. Convolutional neural networks are explained in detail in Section 2.2.1;
- Modular neural networks, where different neural networks work separately, thus without interaction, in order to achieve a unique final result;
- Radial basis function neural network, a real-valued function whose value depends exclusively on the distance from the argument of the function and a fixed point of the domain;
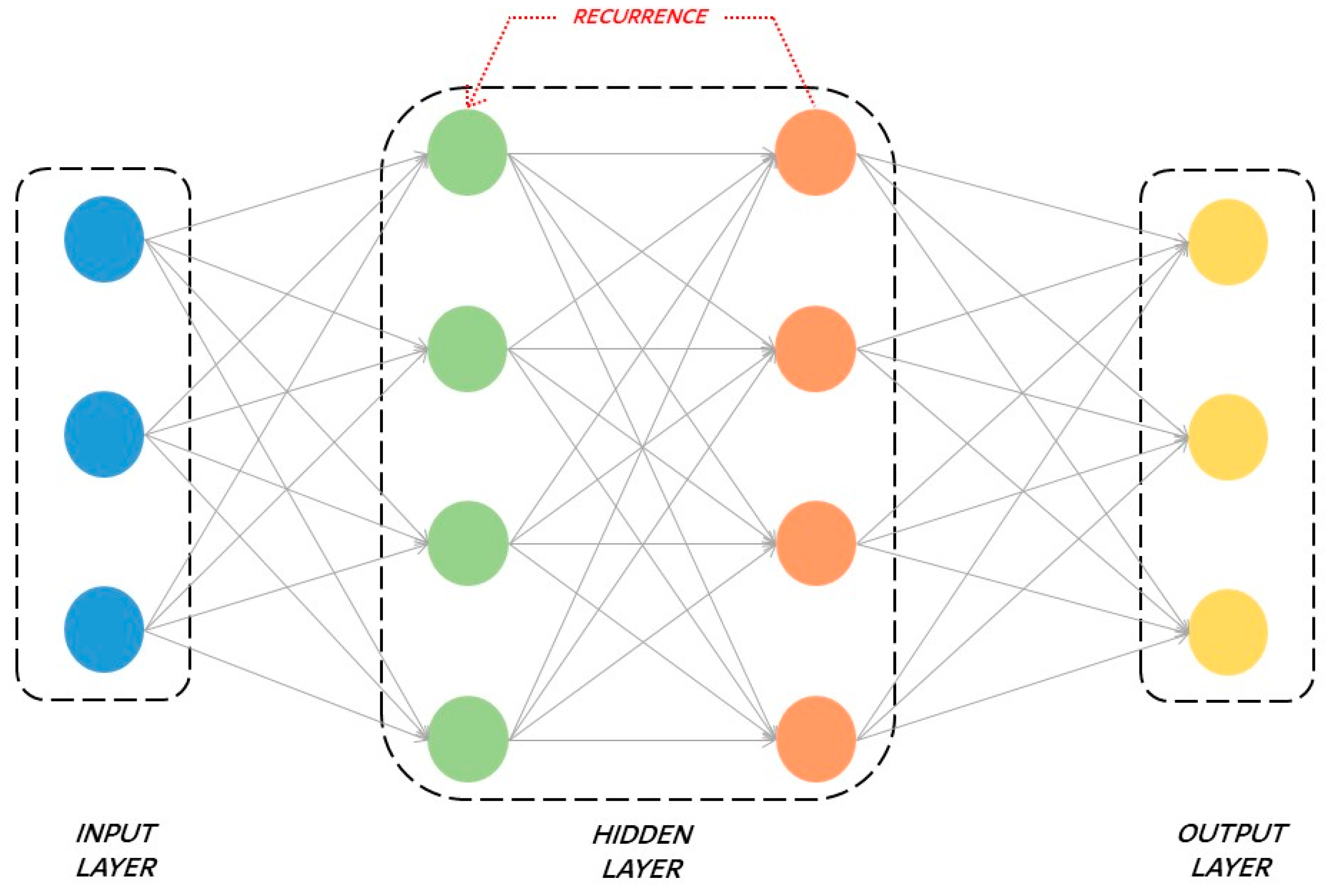
- Recurrent neural networks, where the output of a single layer comes back to the input layer in order to improve itself and then is transmitted to the output layer. Recurrent neural networks are explained in detail in Section 2.2.2.
2.2. Deep Learning Methods
- The rectified linear activation function, also called “ReLU”, is the most commonly used activation function in DL methods for its simplicity. It returns 0 if it receives a negative input, while for a positive value, it returns that value back (see Equation (5)). In various cases, this function performs very well when taking into account non-linearities in the dataset:
- The sigmoid activation function, also known for its peculiar S-curve, is a real, monotonic, differentiable and bounded function in which the independent variable is always a real number. Its constraints are two horizontal asymptotes for the x variable tending to infinity. It has a non-negative derivate at every point and only one inflection point. An example of the sigmoid function is the arctangent function in Equation (6):
- The hyperbolic tangent activation function, like the sigmoid function, has an S-shape and assumes real values as inputs. Its output varies between −1 and +1. When using this function for hidden layers, it is good practice to scale the input data to the range from −1 to +1 before training. Its expression is reported in Equation (7).
2.2.1. Convolutional Neural Networks (CNNs)
2.2.2. Recursive Neural Networks (RNNs)
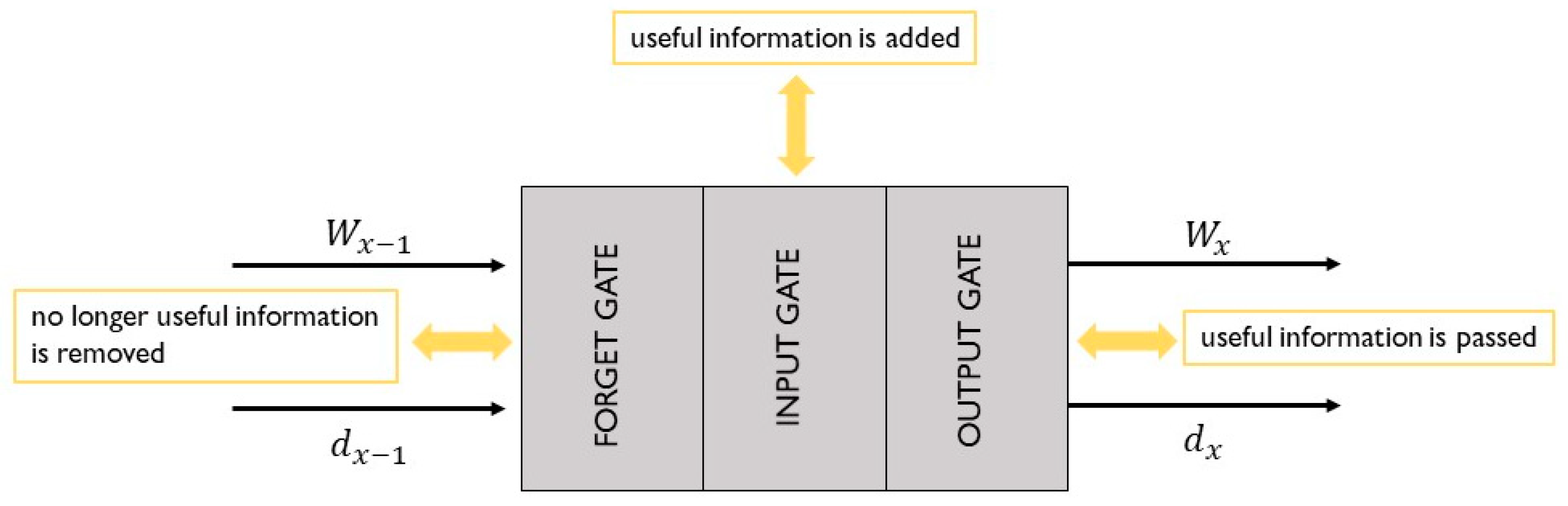
Long Short-Term Memory
Gated Recurrent Units
- In the update gate, the long-term connection is recognized. It takes the past information and passes it to the other state. Equation (9) reports the value of the update gate outcome:
- In the reset gate, the decision regarding the quantity of past information to discard takes place and short-term relations are identified. Equation (10) reports the value of the reset gate outcome:
3. Applications to Building Energy Issues
3.1. Energy Design/Retrofit Optimization and Energy Consumption Prediction
3.2. Control and Management of Heating/Cooling Systems
3.3. Control and Management of Renewable Energy Source Systems
3.4. Fault Detection
4. Final Outline
- Application—(1) energy design and/or retrofit optimization, (2) control and management of heating/cooling systems, (3) control and management of renewable energy source systems or (4) fault detection;
- Machine or deep learning method used;
- Physically informed or data-driven model.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Application | ML | DL | ML or DL Technique | Data-Driven (D) or Physically Informed (P) |
|---|---|---|---|---|---|
| Fan et al., (2019) [97] | 1—energy design/optimization | X | RNNs, LSTM, GRUs | D | |
| Xu et al., (2019) [98] | 1 | X | ANNs | D | |
| Pham et al., (2020) [99] | 1 | X | Random forest | D | |
| Zhou et al., (2019) [100] | 1 | X | ANNs, SVMs | D | |
| Liu et al., (2021) [101] | 1 | X | Random forest, ANNs, SVMs | P | |
| Ramos et al., (2022) [102] | 1 | X | ANNs, decision tree | D | |
| Yilmaz et al., (2023) [103] | 1 | X | Naive Bayes, SVMs, random forest | D | |
| Thrampoulidis et al., (2023) [104] | 1 | X | ANNs | P | |
| Xue et al., (2019) [107] | 2—management of energy systems | X | X | LSTM, SVMs, random forest | D |
| Luo et al., (2020) [108] | 2 | X | Genetic algorithm, DNNs | D | |
| Moustakidis et al., (2019) [110] | 2 | X | LSTM | D | |
| Lu et al., (2019) [115] | 2 | X | SVMs, random forest | D | |
| Wei et al., (2020) [111] | 2 | X | CNNs | P | |
| Tien et al., (2021) [112] | 2 | X | CNNs | P | |
| Sha et al., (2021) [114] | 2 | X | X | SVMs, RNNs, CNNs, LSTM | D |
| Somu et al., (2021) [116] | 2 | X | CNNs, LSTM | P | |
| Savadkoohi et al., (2023) [109] | 2 | X | Neural networks | D | |
| Lu et al., (2023) [113] | 2 | X | X | LSTM, CNNs, GRUs, SVMs | D |
| Nabavi et al., (2021) [119] | 3—renewable energy systems | X | LSTM | D | |
| Rana et al., (2022) [120] | 3 | X | X | LSTM, CNNs, random forest | D |
| Mostafa et al., (2022) [121] | 3 | X | X | Random forest, decision trees, CNNs | P |
| Balakumar et al., (2023) [122] | 3 | X | LSTM, GRUs | D | |
| Mirjalili et al., (2023) [123] | 3 | X | X | SVMs, DNNs | P |
| Shahnazari et al., (2019) [127] | 4—fault detection | X | RNNs | P | |
| Taheri et al., (2021) [128] | 4 | X | X | DNNs, random forest | D |
| Ciaburro et al., (2023) [129] | 4 | X | CNNs | P | |
| Copiaco et al., (2023) [130] | 4 | X | X | SVMs, CNNs | p |
| Mustafa et al., (2023) [131] | 4 | X | CNNs, LSTM | P | |
| Albayati et al., (2023) [132] | 4 | X | SVMs | D |
5. Conclusions
Funding
Conflicts of Interest
Nomenclature
| AI | Artificial intelligence |
| ANNs | Artificial neural networks |
| CNNs | Convolutional neural networks |
| DL | Deep learning |
| GRUs | Gated recurrent units |
| LSTM | Long short-term memory |
| ML | Machine learning |
| RNNs | Recursive neural networks |
| SVMs | Support vector machines |
References
- Rocha, P.; Kaut, M.; Siddiqui, A.S. Energy-efficient building retrofits: An assessment of regulatory proposals under uncertainty. Energy 2016, 101, 278–287. [Google Scholar] [CrossRef]
- Khatib, H. IEA world energy outlook 2011—A comment. Energy Policy 2012, 48, 737–743. [Google Scholar] [CrossRef]
- Kottek, M.; Grieser, J.; Beck, C.; Rudolf, B.; Rubel, F. World map of the Köppen-Geiger climate classification updated. Meteorol. Z. 2006, 15, 259–263. [Google Scholar] [CrossRef] [PubMed]
- Lorusso, A.; Maraziti, F. Heating system projects using the degree-days method in livestock buildings. J. Agric. Eng. Res. 1998, 71, 285–290. [Google Scholar] [CrossRef]
- de Llano-Paz, F.; Fernandez, P.M.; Soares, I. Addressing 2030 EU policy framework for energy and climate: Cost, risk and energy security issues. Energy 2016, 115, 1347–1360. [Google Scholar] [CrossRef]
- EU COM 112. A Roadmap for moving to a competitive low carbon economy in 2050. In Communication from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of the Regions n. 112; European Commission: Brussels, Belgium, 2012.
- EU Commission and Parliament, Directive 2010/31/EU of the EuropeanParliament and of the Council of 19 May 2010 on the energy performance ofbuildings (EPBD Recast). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32010L0031 (accessed on 8 January 2024).
- EU Commission, Commission Delegated Regulation (EU) No 244/2012 of 16 January 2012 Supplementing Directive 2010/31/EU of the EuropeanParliament and of the Council on the Energy Performance of Buildings. Available online: https://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=OJ:L:2012:081:0018:0036:en:PDF (accessed on 8 January 2024).
- D.M. (Interministerial Decree) 26 Giugno 2015. Available online: http://www.sviluppoeconomico.gov.it/index.php/it/normativa/decreti-interministeriali/2032966-decreto-interministeriale-26-giugno-2015-applicazione-delle-metodologie-di-calcolo-delle-prestazioni-energetiche-e-definizione-delle-prescrizioni-e-dei-requisiti-minimi-degli-edifici#page_top (accessed on 1 September 2020). (In Italian)
- Cho, H.I.; Cabrera, D.; Patel, M.K. Estimation of energy savings potential through hydraulic balancing of heating systems in buildings. J. Build. Eng. 2020, 28, 101030. [Google Scholar] [CrossRef]
- Nguyen, A.T.; Reiter, S.; Rigo, P. A review on simulation-based optimization methods applied to building performance analysis. Appl. Energy 2014, 113, 1043–1058. [Google Scholar] [CrossRef]
- Aruta, G.; Ascione, F.; Bianco, N.; Mauro, G.M. Sustainability and energy communities: Assessing the potential of building energy retrofit and renewables to lead the local energy transition. Energy 2023, 282, 128377. [Google Scholar] [CrossRef]
- Diakaki, C.; Grigoroudis, E.; Kabelis, N.; Kolokotsa, D.; Kalaitzakis, K.; Stavrakakis, G. A multi-objective decision model for the improvement of energy efficiency in buildings. Energy 2010, 35, 5483–5496. [Google Scholar] [CrossRef]
- Lizana, J.; Molina-Huelva, M.; Chacartegui, R. Multi-criteria assessment for the effective decision management in residential energy retrofitting. Energy Build. 2016, 129, 284–307. [Google Scholar] [CrossRef]
- Fesanghary, M.; Asadi, S.; Geem, Z.W. Design of low-emission and energy-efficient residential buildings using a multi-objective optimization algorithm. Build. Environ. 2012, 49, 245–250. [Google Scholar] [CrossRef]
- Kerdan, I.G.; Raslan, R.; Ruyssevelt, P. An exergy-based multi-objective optimisation model for energy retrofit strategies in non-domestic buildings. Energy 2016, 117, 506–522. [Google Scholar] [CrossRef]
- Harmathy, N.; Magyar, Z.; Folić, R. Multi-criterion optimization of building envelope in the function of indoor illumination quality towards overall energy performance improvement. Energy 2016, 114, 302–317. [Google Scholar] [CrossRef]
- Magnier, L.; Haghighat, F. Multiobjective optimization of building design using TRNSYS simulations, genetic algorithm, and Artificial Neural Network. Build. Environ. 2010, 45, 739–746. [Google Scholar] [CrossRef]
- Li, X.; Malkawi, A. Multi-objective optimization for thermal mass model predictive control in small and medium size commercial buildings under summer weather conditions. Energy 2016, 112, 1194–1206. [Google Scholar] [CrossRef]
- US Department of Energy. Energy Efficiency and Renewable Energy Office, Building Technology Program (2013), EnergyPlus (8.4). Available online: https://energyplus.net/ (accessed on 5 November 2020).
- TRNSYS®, Transient System Simulation Program; University of Wisconsin: Madison, WI, USA, 2000.
- ESP-r. Available online: http://www.esru.strath.ac.uk/Programs/ESP-r.htm (accessed on 5 November 2020).
- IDA-ICE, IDA Indoor Climate and Energy. Available online: http://www.equa.se/ice/intro.html (accessed on 5 November 2020).
- Wang, B.; Xia, X.; Zhang, J. A multi-objective optimization model for the life-cycle cost analysis and retrofitting planning of buildings. Energy Build. 2014, 77, 227–235. [Google Scholar] [CrossRef]
- Suh, W.J.; Park, C.S.; Kim, D.W. Heuristic vs. meta-heuristic optimization for energy performance of a post office building. In Proceedings of the 12th Conference of International Building Performance Simulation Association, Sydney, Australia, 14–16 November 2011; IBPSA: Sydney, Australia, 2011; pp. 704–711. [Google Scholar]
- Ascione, F.; Bianco, N.; De Stasio, C.; Mauro, G.M.; Vanoli, G.P. A new methodology for cost-optimal analysis by means of the multi-objective optimization of building energy performance. Energy Build. 2015, 88, 78–90. [Google Scholar] [CrossRef]
- Hamdy, M.; Hasan, A.; Siren, K. A multi-stage optimization method for cost-optimal and nearly-zero-energy building solutions in line with the EPBD-recast 2010. Energy Build. 2013, 56, 189–203. [Google Scholar] [CrossRef]
- Ferrara, M.; Fabrizio, E.; Virgone, J.; Filippi, M. A simulation-based optimization method for cost-optimal analysis of nearly Zero Energy Buildings. Energy Build. 2014, 84, 442–457. [Google Scholar] [CrossRef]
- Albertin, R.; Prada, A.; Gasparella, A. A novel efficient multi-objective optimization algorithm for expensive building simulation models. Energy Build. 2023, 297, 113433. [Google Scholar] [CrossRef]
- Seçkiner, S.U.; Koç, A. Agent-based simulation and simulation optimization approaches to energy planning under different scenarios: A hospital application case. Comput. Ind. Eng. 2022, 169, 108163. [Google Scholar] [CrossRef]
- Delgarm, N.; Sajadi, B.; Kowsary, F.; Delgarm, S. Multi-objective optimization of the building energy performance: A simulation-based approach by means of particle swarm optimization (PSO). Appl. Energy 2016, 170, 293–303. [Google Scholar] [CrossRef]
- Hamdy, M.; Hasan, A.; Siren, K. Applying a multi-objective optimization approach for design of low-emission cost-effective dwellings. Build. Environ. 2011, 46, 109–123. [Google Scholar] [CrossRef]
- Ascione, F.; Bianco, N.; De Stasio, C.; Mauro, G.M.; Vanoli, G.P. CASA, cost-optimal analysis by multi-objective optimisation and artificial neural networks: A new framework for the robust assessment of cost-optimal energy retrofit, feasible for any building. Energy Build. 2017, 146, 200–219. [Google Scholar] [CrossRef]
- Corgnati, S.P.; Fabrizio, E.; Filippi, M.; Monetti, V. Reference buildings for cost optimal analysis: Method of definition and application. Appl. Energy 2013, 102, 983–993. [Google Scholar] [CrossRef]
- Ashrafian, T.; Yilmaz, A.Z.; Corgnati, S.P.; Moazzen, N. Methodology to define cost-optimal level of architectural measures for energy efficient retrofits of existing detached residential buildings in Turkey. Energy Build. 2016, 120, 58–77. [Google Scholar] [CrossRef]
- Ascione, F.; Cheche, N.; De Masi, R.F.; Minichiello, F.; Vanoli, G.P. Design the refurbishment of historic buildings with the cost-optimal methodology: The case study of a XV century Italian building. Energy Build. 2015, 99, 162–176. [Google Scholar] [CrossRef]
- Pateras, J.; Rana, P.; Ghosh, P. A Taxonomic Survey of Physics-Informed Machine Learning. Appl. Sci. 2023, 13, 6892. [Google Scholar] [CrossRef]
- Montáns, F.J.; Chinesta, F.; Gómez-Bombarelli, R.; Kutz, J.N. Data-driven modeling and learning in science and engineering. Comptes Rendus Mécanique 2019, 347, 845–855. [Google Scholar] [CrossRef]
- Wei, W.; Ramalho, O.; Malingre, L.; Sivanantham, S.; Little, J.C.; Mandin, C. Machine learning and statistical models for predicting indoor air quality. Indoor Air 2019, 29, 704–726. [Google Scholar] [CrossRef] [PubMed]
- Swan, L.G.; Ugursal, V.I. Modeling of end-use energy consumption in the residential sector: A review of modeling techniques. Renew. Sustain. Energy Rev. 2009, 13, 1819–1835. [Google Scholar] [CrossRef]
- Langevin, J.; Reyna, J.L.; Ebrahimigharehbaghi, S.; Sandberg, N.; Fennell, P.; Nägeli, C.; Laverge, J.; Delghust, M.; Mata, É.; Van Hove, M.; et al. Developing a common approach for classifying building stock energy models. Renew. Sustain. Energy Rev. 2020, 133, 110276. [Google Scholar] [CrossRef]
- Bourdeau, M.; Qiangzhai, X.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Mousavi, S.; Marroquín, M.G.V.; Hajiaghaei-Keshteli, M.; Smith, N.R. Data-driven prediction and optimization toward net-zero and positive-energy buildings: A systematic review. Build. Environ. 2023, 242, 110578. [Google Scholar] [CrossRef]
- Fathi, S.; Srinivasan, R.; Fenner, A.; Fathi, S. Machine learning applications in urban building energy performance forecasting: A systematic review. Renew. Sustain. Energy Rev. 2020, 133, 110287. [Google Scholar] [CrossRef]
- Tien, P.W.; Wei, S.; Darkwa, J.; Wood, C.; Calautit, J.K. Machine learning and deep learning methods for enhancing building energy efficiency and indoor environmental quality—A review. Energy AI 2022, 10, 100198. [Google Scholar] [CrossRef]
- Pan, Y.; Zhu, M.; Lv, Y.; Yang, Y.; Liang, Y.; Yin, R.; Yang, Y.; Jia, X.; Wang, X.; Zeng, F.; et al. Building energy simulation and its application for building performance optimization: A review of methods, tools, and case studies. Adv. Appl. Energy 2023, 10, 100135. [Google Scholar] [CrossRef]
- PK, F.A. What is artificial intelligence? In Learning Outcomes of Classroom Research; L’ Ordine Nuovo Publication: Turin, Italy, 1984; p. 65. [Google Scholar]
- Boeschoten, S.; Catal, C.; Tekinerdogan, B.; Lommen, A.; Blokland, M. The automation of the development of classification models and improvement of model quality using feature engineering techniques. Expert Syst. Appl. 2023, 213, 118912. [Google Scholar] [CrossRef]
- Nasteski, V. An overview of the supervised machine learning methods. Horizons. B 2017, 4, 51–62. [Google Scholar] [CrossRef]
- Geysen, D.; De Somer, O.; Johansson, C.; Brage, J.; Vanhoudt, D. Operational thermal load forecasting in district heating networks using machine learning and expert advice. Energy Build. 2018, 162, 144–153. [Google Scholar] [CrossRef]
- Somvanshi, M.; Chavan, P.; Tambade, S.; Shinde, S.V. A review of machine learning techniques using decision tree and support vector machine. In Proceedings of the 2016 International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 12–13 August 2016; pp. 1–7. [Google Scholar]
- Ryu, S.H.; Moon, H.J. Development of an occupancy prediction model using indoor environmental data based on machine learning techniques. Build. Environ. 2016, 107, 1–9. [Google Scholar] [CrossRef]
- Daniya, T.; Geetha, M.; Kumar, K.S. Classification and regression trees with gini index. Adv. Math. Sci. J. 2020, 9, 8237–8247. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M.J. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Chou, J.S.; Bui, D.K. Modeling heating and cooling loads by artificial intelligence for energy-efficient building design. Energy Build. 2014, 82, 437–446. [Google Scholar] [CrossRef]
- Sapnken, F.E.; Hamed, M.M.; Soldo, B.; Tamba, J.G. Modeling energy-efficient building loads using machine-learning algorithms for the design phase. Energy Build. 2023, 283, 112807. [Google Scholar] [CrossRef]
- Cai, W.; Wei, R.; Xu, L.; Ding, X. A method for modelling greenhouse temperature using gradient boost decision tree. Inf. Process. Agric. 2022, 9, 343–354. [Google Scholar] [CrossRef]
- Chen, Y.T.; Piedad, E., Jr.; Kuo, C.C. Energy consumption load forecasting using a level-based random forest classifier. Symmetry 2019, 11, 956. [Google Scholar] [CrossRef]
- Vishwakarma, M.; Kesswani, N. A new two-phase intrusion detection system with Naïve Bayes machine learning for data classification and elliptic envelop method for anomaly detection. Decis. Anal. J. 2023, 7, 100233. [Google Scholar] [CrossRef]
- Bassamzadeh, N.; Ghanem, R. Multiscale stochastic prediction of electricity demand in smart grids using Bayesian networks. Appl. Energy 2017, 193, 369–380. [Google Scholar] [CrossRef]
- Hosamo, H.H.; Nielsen, H.K.; Kraniotis, D.; Svennevig, P.R.; Svidt, K. Improving building occupant comfort through a digital twin approach: A Bayesian network model and predictive maintenance method. Energy Build. 2023, 288, 112992. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Dong, B.; Cao, C.; Lee, S.E. Applying support vector machines to predict building energy consumption in tropical region. Energy Build. 2005, 37, 545–553. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Reynolds, J.; Rezgui, Y. Predictive modelling for solar thermal energy systems: A comparison of support vector regression, random forest, extra trees and regression trees. J. Clean. Prod. 2018, 203, 810–821. [Google Scholar] [CrossRef]
- Kapp, S.; Choi, J.K.; Hong, T. Predicting industrial building energy consumption with statistical and machine-learning models informed by physical system parameters. Renew. Sustain. Energy Rev. 2023, 172, 113045. [Google Scholar] [CrossRef]
- Kim, J.B.; Kim, S.E.; Aman, J.A. An urban building energy simulation method integrating parametric BIM and machine learning. In Proceedings of the Human-Centric, 27th International Conference of the Association for Computer-Aided Architectural Design Research in Asia (CAADRIA), Sydney, Australia, 28 September 2021–26 January 2022; pp. 18–24. [Google Scholar]
- Krige, D.G. A Statistical Approach to Some Mine Valuation and Allied Problems on the Witwatersrand: By DG Krige. Ph.D. Thesis, University of the Witwatersrand, Johannesburg, South Africa, 1951. [Google Scholar]
- Matheron, G. The selectivity of the distributions and “the second principle of geostatistics”. In Geostatistics for Natural Resources Characterization. Part 1; Springer: Dordrecht, The Netherlands, 1984; pp. 421–433. [Google Scholar] [CrossRef]
- Martin, J.D.; Simpson, T.W. Use of kriging models to approximate deterministic computer models. AIAA J. 2005, 43, 853–863. [Google Scholar] [CrossRef]
- Cressie, N. Statistics for Spatial Data; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Kleijnen, J.P. Kriging metamodeling in simulation: A review. Eur. J. Oper. Res. 2009, 192, 707–716. [Google Scholar] [CrossRef]
- Eguía, P.; Granada, E.; Alonso, J.M.; Arce, E.; Saavedra, A. Weather datasets generated using kriging techniques to calibrate building thermal simulations with TRNSYS. J. Build. Eng. 2016, 7, 78–91. [Google Scholar] [CrossRef]
- Hopfe, C.J.; Emmerich, M.T.; Marijt, R.; Hensen, J. Robust multi-criteria design optimisation in building design. Proc. Build. Simul. Optim. 2012, 118–125. Available online: https://publications.ibpsa.org/conference/paper/?id=bso2012_1A3 (accessed on 8 January 2024).
- Tresidder, E.; Zhang, Y.; Forrester, A.I. Acceleration of building design optimisation through the use of kriging surrogate models. Proc. Build. Simul. Optim. 2012, 2012, 1–8. [Google Scholar]
- Almutairi, K.; Aungkulanon, P.; Algarni, S.; Alqahtani, T.; Keshuov, S.A. Solar irradiance and efficient use of energy: Residential construction toward net-zero energy building. Sustain. Energy Technol. Assess. 2022, 53, 102550. [Google Scholar] [CrossRef]
- Küçüktopcu, E.; Cemek, B.; Simsek, H. Application of Spatial Analysis to Determine the Effect of Insulation Thickness on Energy Efficiency and Cost Savings for Cold Storage. Processes 2022, 10, 2393. [Google Scholar] [CrossRef]
- Naji, S.; Keivani, A.; Shamshirband, S.; Alengaram, U.J.; Jumaat, M.Z.; Mansor, Z.; Lee, M. Estimating building energy consumption using extreme learning machine method. Energy 2016, 97, 506–516. [Google Scholar] [CrossRef]
- Uzair, M.; Jamil, N. Effects of hidden layers on the efficiency of neural networks. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020; pp. 1–6. [Google Scholar]
- Li, Y.F.; Ng, S.H.; Xie, M.; Goh, T.N. A systematic comparison of metamodeling techniques for simulation optimization in decision support systems. Appl. Soft Comput. 2010, 10, 1257–1273. [Google Scholar] [CrossRef]
- Ascione, F.; Bianco, N.; De Stasio, C.; Mauro, G.M.; Vanoli, G.P. Artificial neural networks to predict energy performance and retrofit scenarios for any member of a building category: A novel approach. Energy 2017, 118, 999–1017. [Google Scholar] [CrossRef]
- Fanger, P.O. Thermal comfort. Analysis and applications in environmental engineering. In Thermal Comfort. Analysis and Applications in Environmental Engineering; McGraw Hill: New York, NY, USA, 1970. [Google Scholar]
- Asadi, E.; Da Silva, M.G.; Antunes, C.H.; Dias, L.; Glicksman, L. Multi-objective optimization for building retrofit: A model using genetic algorithm and artificial neural network and an application. Energy Build. 2014, 81, 444–456. [Google Scholar] [CrossRef]
- Melo, A.P.; Cóstola, D.; Lamberts, R.; Hensen, J.L.M. Development of surrogate models using artificial neural network for building shell energy labelling. Energy Policy 2014, 69, 457–466. [Google Scholar] [CrossRef]
- Pérez-Gomariz, M.; López-Gómez, A.; Cerdán-Cartagena, F. Artificial neural networks as artificial intelligence technique for energy saving in refrigeration systems—A review. Clean Technol. 2023, 5, 116–136. [Google Scholar] [CrossRef]
- Chen, X.; Cao, B.; Pouramini, S. Energy cost and consumption reduction of an office building by Chaotic Satin Bowerbird Optimization Algorithm with model predictive control and artificial neural network: A case study. Energy 2023, 270, 126874. [Google Scholar] [CrossRef]
- Zhang, H.; Feng, H.; Hewage, K.; Arashpour, M. Artificial neural network for predicting building energy performance: A surrogate energy retrofits decision support framework. Buildings 2022, 12, 829. [Google Scholar] [CrossRef]
- Singaravel, S.; Suykens, J.; Geyer, P. Deep-learning neural-network architectures and methods: Using component-based models in building-design energy prediction. Adv. Eng. Inform. 2018, 38, 81–90. [Google Scholar] [CrossRef]
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 2019, 198, 111799. [Google Scholar] [CrossRef]
- Amarasinghe, K.; Marino, D.L.; Manic, M. Deep neural networks for energy load forecasting. In Proceedings of the 2017 IEEE 26th International Symposium on Industrial Electronics (ISIE), Edinburgh, UK, 19–21 June 2017; pp. 1483–1488. [Google Scholar]
- Khan, Z.A.; Hussain, T.; Haq, I.U.; Ullah, F.U.M.; Baik, S.W. Towards efficient and effective renewable energy prediction via deep learning. Energy Rep. 2022, 8, 10230–10243. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Jebli, I.; Belouadha, F.Z.; Kabbaj, M.I.; Tilioua, A. Deep learning based models for solar energy prediction. Advances in Science. Technol. Eng. Syst. J. 2021, 6, 349–355. [Google Scholar]
- Karijadi, I.; Chou, S.Y. A hybrid RF-LSTM based on CEEMDAN for improving the accuracy of building energy consumption prediction. Energy Build. 2022, 259, 111908. [Google Scholar] [CrossRef]
- Peng, L.; Wang, L.; Xia, D.; Gao, Q. Effective energy consumption forecasting using empirical wavelet transform and long short-term memory. Energy 2022, 238, 121756. [Google Scholar] [CrossRef]
- Abid, F.; Alam, M.; Alamri, F.S.; Siddique, I. Multi-directional gated recurrent unit and convolutional neural network for load and energy forecasting: A novel hybridization. AIMS Math. 2023, 8, 19993–20017. [Google Scholar] [CrossRef]
- Jiao, Y.; Tan, Z.; Zhang, D.; Zheng, Q.P. Short-term building energy consumption prediction strategy based on modal decomposition and reconstruction algorithm. Energy Build. 2023, 290, 113074. [Google Scholar] [CrossRef]
- Fan, C.; Wang, J.; Gang, W.; Li, S. Assessment of deep recurrent neural network-based strategies for short-term building energy predictions. Appl. Energy 2019, 236, 700–710. [Google Scholar] [CrossRef]
- Xu, X.; Wang, W.; Hong, T.; Chen, J. Incorporating machine learning with building network analysis to predict multi-building energy use. Energy Build. 2019, 186, 80–97. [Google Scholar] [CrossRef]
- Pham, A.D.; Ngo, N.T.; Truong, T.T.H.; Huynh, N.T.; Truong, N.S. Predicting energy consumption in multiple buildings using machine learning for improving energy efficiency and sustainability. J. Clean. Prod. 2020, 260, 121082. [Google Scholar] [CrossRef]
- Zhou, Y.; Zheng, S. Machine-learning based hybrid demand-side controller for high-rise office buildings with high energy flexibilities. Appl. Energy 2020, 262, 114416. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.; Zhang, L.; Feng, Z. Enhancing building energy efficiency using a random forest model: A hybrid prediction approach. Energy Rep. 2021, 7, 5003–5012. [Google Scholar] [CrossRef]
- Ramos, D.; Faria, P.; Morais, A.; Vale, Z. Using decision tree to select forecasting algorithms in distinct electricity consumption context of an office building. Energy Rep. 2022, 8, 417–422. [Google Scholar] [CrossRef]
- Yılmaz, D.; Tanyer, A.M.; Toker, İ.D. A data-driven energy performance gap prediction model using machine learning. Renew. Sustain. Energy Rev. 2023, 181, 113318. [Google Scholar] [CrossRef]
- Thrampoulidis, E.; Hug, G.; Orehounig, K. Approximating optimal building retrofit solutions for large-scale retrofit analysis. Appl. Energy 2023, 333, 120566. [Google Scholar] [CrossRef]
- Sajjadi, S.; Shamshirband, S.; Alizamir, M.; Yee, L.; Mansor, Z.; Manaf, A.A.; Altameem, T.A.; Mostafaeipour, A. Extreme learning machine for prediction of heat load in district heating systems. Energy Build. 2016, 122, 222–227. [Google Scholar] [CrossRef]
- Saloux, E.; Candanedo, J.A. Forecasting district heating demand using machine learning algorithms. Energy Procedia 2018, 149, 59–68. [Google Scholar] [CrossRef]
- Xue, G.; Pan, Y.; Lin, T.; Song, J.; Qi, C.; Wang, Z. District heating load prediction algorithm based on feature fusion LSTM model. Energies 2019, 12, 2122. [Google Scholar] [CrossRef]
- Luo, X.J.; Oyedele, L.O.; Ajayi, A.O.; Akinade, O.O.; Owolabi, H.A.; Ahmed, A. Feature extraction and genetic algorithm enhanced adaptive deep neural network for energy consumption prediction in buildings. Renenable Sustain. Energy Rev. 2020, 131, 109980. [Google Scholar] [CrossRef]
- Savadkoohi, M.; Macarulla, M.; Casals, M. Facilitating the implementation of neural network-based predictive control to optimize building heating operation. Energy 2023, 263, 125703. [Google Scholar] [CrossRef]
- Moustakidis, S.; Meintanis, I.; Karkanias, N.; Halikias, G.; Saoutieff, E.; Gasnier, P.; Ojer-Aranguren, J.; Anagnostis, A.; Marciniak, B.; Rodot, I.; et al. Innovative technologies for district heating and cooling: InDeal Project. Proceedings 2019, 5, 1. [Google Scholar]
- Wei, S.; Tien, P.W.; Calautit, J.K.; Wu, Y.; Boukhanouf, R. Vision-based detection and prediction of equipment heat gains in commercial office buildings using a deep learning method. Appl. Energy 2020, 277, 115506. [Google Scholar] [CrossRef]
- Tien, P.W.; Wei, S.; Calautit, J.K.; Darkwa, J.; Wood, C. Occupancy heat gain detection and prediction using deep learning approach for reducing building energy demand. J. Sustain. Dev. Energy Water Environ. Syst. 2021, 9, 1–31. [Google Scholar] [CrossRef]
- Lu, C.; Gu, J.; Lu, W. An improved attention-based deep learning approach for robust cooling load prediction: Public building cases under diverse occupancy schedules. Sustain. Cities Soc. 2023, 96, 104679. [Google Scholar] [CrossRef]
- Sha, H.; Moujahed, M.; Qi, D. Machine learning-based cooling load prediction and optimal control for mechanical ventilative cooling in high-rise buildings. Energy Build. 2021, 242, 110980. [Google Scholar] [CrossRef]
- Lu, S.; Wang, W.; Lin, C.; Hameen, E.C. Data-driven simulation of a thermal comfort-based temperature set-point control with ASHRAE RP884. Build. Environ. 2019, 156, 137–146. [Google Scholar] [CrossRef]
- Somu, N.; Sriram, A.; Kowli, A.; Ramamritham, K. A hybrid deep transfer learning strategy for thermal comfort prediction in buildings. Build. Environ. 2021, 204, 108133. [Google Scholar] [CrossRef]
- Yaïci, W.; Entchev, E. Performance prediction of a solar thermal energy system using artificial neural networks. Appl. Therm. Eng. 2014, 73, 1348–1359. [Google Scholar] [CrossRef]
- Mocanu, E.; Nguyen, P.H.; Gibescu, M.; Kling, W.L. Deep learning for estimating building energy consumption. Sustain. Energy Grids Netw. 2016, 6, 91–99. [Google Scholar] [CrossRef]
- Nabavi, S.A.; Motlagh, N.H.; Zaidan, M.A.; Aslani, A.; Zakeri, B. Deep learning in energy modeling: Application in smart buildings with distributed energy generation. IEEE Access 2021, 9, 125439–125461. [Google Scholar] [CrossRef]
- Rana, M.; Sethuvenkatraman, S.; Heidari, R.; Hands, S. Solar thermal generation forecast via deep learning and application to buildings cooling system control. Renew. Energy 2022, 196, 694–706. [Google Scholar] [CrossRef]
- Mostafa, N.; Ramadan, H.S.M.; Elfarouk, O. Renewable energy management in smart grids by using big data analytics and machine learning. Mach. Learn. Appl. 2022, 9, 100363. [Google Scholar] [CrossRef]
- Balakumar, P.; Vinopraba, T.; Chandrasekaran, K. Deep learning based real time Demand Side Management controller for smart building integrated with renewable energy and Energy Storage System. J. Energy Storage 2023, 58, 106412. [Google Scholar] [CrossRef]
- Mirjalili, M.A.; Aslani, A.; Zahedi, R.; Soleimani, M. A comparative study of machine learning and deep learning methods for energy balance prediction in a hybrid building-renewable energy system. Sustain. Energy Res. 2023, 10, 8. [Google Scholar] [CrossRef]
- Nelson, W.; Culp, C. Machine Learning Methods for Automated Fault Detection and Diagnostics in Building Systems—A Review. Energies 2022, 15, 5534. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, T.; Zhang, X.; Zhang, C. Artificial intelligence-based fault detection and diagnosis methods for building energy systems: Advantages, challenges and the future. Renew. Sustain. Energy Rev. 2019, 109, 85–101. [Google Scholar] [CrossRef]
- Liang, J.; Du, R. Model-based fault detection and diagnosis of HVAC systems using support vector machine method. Int. J. Refrig. 2007, 30, 1104–1114. [Google Scholar] [CrossRef]
- Shahnazari, H.; Mhaskar, P.; House, J.M.; Salsbury, T.I. Modeling and fault diagnosis design for HVAC systems using recurrent neural networks. Comput. Chem. Eng. 2019, 126, 189–203. [Google Scholar] [CrossRef]
- Taheri, S.; Ahmadi, A.; Mohammadi-Ivatloo, B.; Asadi, S. Fault detection diagnostic for HVAC systems via deep learning algorithms. Energy Build. 2021, 250, 111275. [Google Scholar] [CrossRef]
- Ciaburro, G.; Padmanabhan, S.; Maleh, Y.; Puyana-Romero, V. Fan Fault Diagnosis Using Acoustic Emission and Deep Learning Methods. Informatics 2023, 10, 24. [Google Scholar] [CrossRef]
- Copiaco, A.; Himeur, Y.; Amira, A.; Mansoor, W.; Fadli, F.; Atalla, S.; Sohail, S.S. An innovative deep anomaly detection of building energy consumption using energy time-series images. Eng. Appl. Artif. Intell. 2023, 119, 105775. [Google Scholar] [CrossRef]
- Mustafa, Z.; Awad, A.S.; Azzouz, M.; Azab, A. Fault identification for photovoltaic systems using a multi-output deep learning approach. Expert Syst. Appl. 2023, 211, 118551. [Google Scholar] [CrossRef]
- Albayati, M.G.; Faraj, J.; Thompson, A.; Patil, P.; Gorthala, R.; Rajasekaran, S. Semi-supervised machine learning for fault detection and diagnosis of a rooftop unit. Big Data Min. Anal. 2023, 6, 170–184. [Google Scholar] [CrossRef]




| Technique | ML | DL | Characterization | Applications |
|---|---|---|---|---|
| Decision trees | X | Can handle heterogeneous data; simple to use; overfitting problems | Prediction and control | |
| Random forest | X | Accurate; less overfitting problems; computationally expensive | Prediction, control and fault detection | |
| Naive Bayes | X | Simple to use; limited applicability | Control | |
| SVMs | X | Can handle high-dimensional and non-linear data; computationally expensive; careful choice of the hyperparameters | Prediction, control and fault detection | |
| ANNs | X | X | Can handle big dataset and non-linear data correlations; can solve complex problems; require large training dataset | Prediction and control |
| CNNs | X | Can learn features automatically; useful for image classification and recognition; require large training dataset; computationally expensive | Prediction, control and fault detection | |
| RNNs | X | Can handle sequential data and learn long-term dependencies; overfitting and vanishing gradient problems | Prediction, control and fault detection | |
| LSTM | X | Can learn long-term dependencies; possible vanishing gradient problems | Prediction, control and fault detection | |
| GRUs | X | Fast training; can handle high-dimensional data; no vanishing gradient problems | Prediction and control |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villano, F.; Mauro, G.M.; Pedace, A. A Review on Machine/Deep Learning Techniques Applied to Building Energy Simulation, Optimization and Management. Thermo 2024, 4, 100-139. https://doi.org/10.3390/thermo4010008
Villano F, Mauro GM, Pedace A. A Review on Machine/Deep Learning Techniques Applied to Building Energy Simulation, Optimization and Management. Thermo. 2024; 4(1):100-139. https://doi.org/10.3390/thermo4010008
Chicago/Turabian StyleVillano, Francesca, Gerardo Maria Mauro, and Alessia Pedace. 2024. "A Review on Machine/Deep Learning Techniques Applied to Building Energy Simulation, Optimization and Management" Thermo 4, no. 1: 100-139. https://doi.org/10.3390/thermo4010008
APA StyleVillano, F., Mauro, G. M., & Pedace, A. (2024). A Review on Machine/Deep Learning Techniques Applied to Building Energy Simulation, Optimization and Management. Thermo, 4(1), 100-139. https://doi.org/10.3390/thermo4010008