Abstract
Multimedia learning effectiveness varies widely across cultural contexts and individual learner characteristics, yet existing educational technologies lack computational frameworks that predict and optimize these interactions. This study introduces the Multimedia Integration Impact Assessment Model (MIIAM), a machine learning framework integrating cognitive style detection, cultural background inference, multimedia complexity optimization, and ensemble prediction into a unified architecture. MIIAM was validated with 493 software engineering students from Zimbabwe and South Africa through the analysis of 4.1 million learning interactions. The framework applied Random Forests for automated cognitive style classification, hierarchical clustering for cultural inference, and a complexity optimization engine for content analysis, while predictive performance was enhanced by an ensemble of Random Forests, XGBoost, and Neural Networks. The results demonstrated that MIIAM achieved 87% prediction accuracy, representing a 14% improvement over demographic-only baselines (p < 0.001). Cross-cultural validation confirmed strong generalization, with only a 2% accuracy drop compared to 11–15% for traditional models, while fairness analysis indicated substantially reduced bias (Statistical Parity Difference = 0.08). Real-time testing confirmed deployment feasibility with an average 156 ms processing time. MIIAM also optimized multimedia content, improving knowledge retention by 15%, reducing cognitive overload by 28%, and increasing completion rates by 22%. These findings establish MIIAM as a robust, culturally responsive framework for adaptive multimedia learning environments.
1. Introduction
Machine learning has fundamentally transformed academic institutions worldwide, enabling sophisticated approaches to personalized learning and outcome prediction [1]. Institutions across diverse global settings increasingly rely on data-driven methods to understand student behavior and optimize learning experiences [2]. However, multimedia-enhanced eLearning environments continue to demonstrate inconsistent effectiveness across different settings, particularly when deployed in culturally diverse environments spanning developed and developing nations [3,4].
The COVID-19 pandemic accelerated global adoption of digital learning technologies, creating unprecedented opportunities for innovation while simultaneously exposing critical gaps in current methods [5]. Emergency transitions to online learning revealed that traditional technology platforms often fail to account for complex interactions between learner characteristics, cultural factors, and multimedia design parameters [6]. These limitations became evident across diverse institutions globally, where varying cultural learning styles, technology access levels, and different backgrounds create implementation challenges that existing platforms cannot adequately address [7].
The motivation for pursuing this specific research direction stems from three converging factors that represent both critical needs and emerging opportunities in technology. First, there is an urgent need for AI systems that maintain effectiveness across diverse cultural environments, as current methods demonstrate significant performance degradation when deployed beyond their original development settings [8]. Second, the widespread collection of large-scale interaction data presents an unprecedented opportunity to develop sophisticated prediction models that can capture nuanced patterns in multimedia learning effectiveness [9]. Third, institutions face increasing practical demands for deployable platforms that can optimize multimedia learning in real time while accommodating diverse learner populations [10].
The primary challenge stems from how current platforms handle the complexity of real-world environments. Most existing methods focus on straightforward metrics such as test scores or basic demographic information but struggle to account for nuanced factors that influence learning outcomes [11]. Cultural background, individual learning preferences, and specific patterns of multimedia interaction create complex variable relationships that traditional prediction methods cannot adequately capture [12]. This limitation becomes particularly apparent in global settings where one-size-fits-all strategies consistently underperform across diverse populations [13].
Computational platforms for assessment exhibit fundamental limitations across several dimensions. Technology adoption models typically predict whether students will use a platform rather than how effectively they will learn from it [14]. Learning analytics tools often treat learners as homogeneous people, missing critical individual differences that affect multimedia content processing [15]. Most significantly, existing platforms lack systematic methods for understanding and incorporating cultural factors into their predictions, leading to bias and reduced effectiveness for underrepresented populations [16].
Research in multimedia learning has established that effectiveness depends on complex interactions between cognitive load, individual learning styles, and content design principles [17]. However, most implementations focus on universal design principles rather than adaptive strategies that can accommodate diverse learner populations [18]. The absence of comprehensive platforms that integrate learner characteristics, cultural considerations, and multimedia optimization has resulted in inconsistent deployment outcomes across different environments [19].
To address these challenges, we present MIIAM (Multimedia Integration Impact Assessment Model), a comprehensive machine learning platform that predicts multimedia effectiveness through systematic analysis of learner characteristics, cultural factors, and system configurations. The platform’s core innovation lies in its strategy for understanding and incorporating cultural learning patterns as fundamental predictive elements rather than peripheral considerations. MIIAM integrates four components working synergistically to provide accurate predictions: cognitive style detection through Random Forest classification, cultural background inference via hierarchical clustering, multimedia complexity optimization through automated analysis, and ensemble prediction combining multiple machine learning techniques.
The platform addresses a critical gap in technology by maintaining effectiveness across diverse cultural and educational environments. Rather than treating cultural differences as obstacles to overcome, MIIAM incorporates these differences as valuable information that improves prediction accuracy and system effectiveness. We validated the platform through comprehensive testing with 493 software engineering students from Zimbabwean and South African universities, analyzing 4.1 million learning interactions across diverse multimedia content types. The results demonstrate significant improvements in prediction accuracy compared to traditional methods, while maintaining the computational efficiency needed for practical implementation in real environments.
This research contributes to technology through three significant advances. First, it provides the first systematic computational strategy for incorporating cultural factors into system design and evaluation, moving beyond demographic categorization to behavioral pattern recognition. Second, it demonstrates how comprehensive analysis of learner characteristics can achieve substantial improvements in prediction accuracy while maintaining fairness across diverse settings. Third, it offers a practical, deployable platform that institutions can implement to optimize their multimedia learning systems with real-time processing capabilities.
The paper proceeds systematically through the following sections: Section 2 reviews existing methods and identifies specific limitations in current techniques across machine learning applications, multimedia effectiveness studies, and cultural adaptation platforms. Section 3 details the MIIAM platform architecture, theoretical foundations, and methodology. Section 4 describes our research design, experimental protocol, and validation metrics. Section 5 presents the MIIAM implementation details and technical architecture. Section 6 presents comprehensive results and statistical analysis. Section 7 discusses implications for technology deployment, limitations, and future research directions.
2. Related Work
2.1. Machine Learning in Educational Technology
Educational Data Mining (EDM) and Learning Analytics have evolved significantly over the past two decades, transforming from simple statistical analysis to sophisticated algorithmic applications [16]. The field emerged in the early 2000s as academic institutions began collecting large volumes of digital interaction data, creating opportunities for computational analysis of learning processes [17]. Recent advances in deep neural networks and ensemble methods have particularly enhanced the capability to process complex datasets and extract meaningful patterns for personalized instruction [18].
Common algorithmic applications in academic technology include student performance prediction, early detection of at-risk learners, intelligent recommendation systems, and adaptive platforms [19]. Performance prediction frameworks analyze historical academic data, engagement patterns, and behavioral indicators to forecast future outcomes [20]. Dropout detection algorithms identify students likely to discontinue their studies, enabling early intervention strategies [21]. Recommendation frameworks suggest resources, courses, or study strategies based on individual student profiles and interaction histories [22]. Adaptive platforms dynamically adjust content difficulty, pacing, and presentation style based on real-time assessment of student understanding [23].
Computational methods commonly employed in academic settings span the full spectrum of supervised and unsupervised approaches. Ensemble techniques have gained prominence, with recent investigations demonstrating that ensemble approaches can achieve 77.9% accuracy in e-learning performance prediction, significantly outperforming individual algorithms [24]. Random Forest algorithms are extensively used for both classification and regression tasks, particularly when dealing with mixed data types and missing values common in datasets [25]. Support Vector Machines (SVM) have proven effective for high-dimensional data, especially in text analysis and student modeling applications [26]. Gradient Boosting methods, including XGBoost and LightGBM, have gained prominence for their superior performance in prediction competitions and real-world deployments [27]. Neural Networks, particularly deep architectures, are increasingly applied to complex problems involving sequential data, natural language processing, and multi-modal analytics [28].
Comprehensive reviews of personalized learning and outcome prediction reveal that ML algorithms can achieve remarkable accuracy improvements when properly configured for diverse learner populations, as demonstrated by advanced ensemble methods that systematically outperform traditional statistical approaches. Despite these algorithmic advances, a critical limitation emerges in the generalization capabilities of computational frameworks. While many investigations report high prediction accuracies within specific institutional environments—often exceeding 80–90% for well-defined tasks—these models frequently exhibit poor performance when deployed across different settings, student populations, or cultural backgrounds [29]. This generalization gap represents a fundamental challenge that limits the practical impact of algorithmic research, particularly when deploying frameworks across diverse cultural globally [30]. These advances in computational methods demonstrate significant potential but reveal critical limitations for cross-cultural deployment. The generalization gap identified in current approaches, particularly the poor performance across different cultural backgrounds, directly motivated our development of MIIAM’s integrated cultural inference mechanisms. While existing ensemble methods achieve high accuracy within specific institutional environments, the lack of systematic cultural adaptation frameworks creates opportunities for the boundary-aware approach we propose.
2.2. Multimedia Effectiveness Studies
Research on multimedia-enhanced eLearning has extensively investigated various technological interventions including interactive animations, audio-visual aids, virtual reality environments, and gamified content [31]. These investigations have explored how different multimedia elements affect cognitive load, engagement, retention, and knowledge transfer across diverse domains [32]. Recent systematic reviews have highlighted the inconsistent results across different implementations, emphasizing the need for more sophisticated prediction frameworks [33].
Interactive animations have been investigated extensively, with research examining their effectiveness in teaching complex processes, scientific concepts, and procedural knowledge [34]. Recent work demonstrates that real-time cognitive load assessment using EEG signals can achieve 84.5% accuracy in predicting learner overload during multimedia presentations, providing empirical evidence for the importance of cognitive load monitoring [35]. Audio-visual aid research has similarly produced mixed results, with effectiveness varying based on factors such as content complexity, learner characteristics, and implementation quality [36].
Virtual and augmented reality applications in instruction represent an emerging area with promising but inconsistent findings [37]. While immersive technologies can enhance engagement and provide unique experiences, their effectiveness depends heavily on pedagogical integration and technical implementation quality [38]. Recent work has shown that AI-driven multimedia optimization can improve outcomes by 15–22% across different content types, but these improvements vary significantly based on learner characteristics [39].
The inconsistency in multimedia effectiveness research stems partly from methodological variations and differences across investigations [40]. More importantly, most multimedia research has focused on experimental validation within psychological frameworks rather than developing computational approaches for systematic prediction and optimization [41]. This limitation means that while we understand general principles of multimedia instruction, we lack algorithmic frameworks that can predict multimedia effectiveness for specific learner populations or optimize multimedia configurations for environments [42]. These findings highlight the critical need for computational frameworks that can systematically predict and optimize multimedia effectiveness. The inconsistent results across different implementations directly inform our development of MIIAM’s multimedia complexity optimization engine, which addresses the gap between theoretical understanding and practical computational prediction of multimedia outcomes.
2.3. Computational Gaps and Algorithmic Bias
Current machine learning approaches in academic technology exhibit several fundamental computational limitations that restrict their practical effectiveness [43]. Most existing models focus on isolated factors such as demographic variables, prior academic performance, or basic engagement metrics, while failing to capture the complex multi-dimensional interactions that determine outcomes [44]. Comprehensive analyses of algorithmic bias in instruction demonstrate that most AI frameworks systematically underperform for minority populations due to biased training data and inadequate cross-cultural validation [45].
Traditional approaches typically model simple linear relationships between predictor variables and outcomes, missing the intricate ways that learner characteristics interact with instructional design elements and environmental factors [46]. Recent work demonstrates that fairness-aware algorithmic approaches can reduce demographic bias in student grade prediction by up to 23%, but such techniques remain underutilized in applications [47]. The relationship between multimedia complexity and effectiveness varies systematically based on cognitive style, cultural background, and prior technology experience, but current models rarely capture these interaction effects [48].
Existing theoretical frameworks in academic technology, including the Technology Acceptance Model (TAM) and the Unified Theory of Acceptance and Use of Technology (UTAUT), primarily employ statistical modeling approaches rather than algorithmic pipelines [49]. While these frameworks provide valuable insights into technology adoption patterns, they focus on behavioral intentions rather than outcomes and lack the predictive power needed for real-time optimization [50].
A particularly critical limitation is the algorithmic bias problem inherent in most computational frameworks [51]. Most datasets and model training occur within Western environments, creating frameworks that perform well for similar populations but fail when deployed in diverse global settings [52]. Systematic mapping investigations reveal that fairness considerations in algorithmic frameworks receive insufficient attention, with only 12% of work conducting cross-cultural validation [53]. This bias manifests both in feature selection—where culturally specific patterns are ignored—and in model assumptions that may not hold across different cultural backgrounds [54]. These computational gaps and bias issues directly motivated our development of MIIAM’s cultural attention mechanisms and fairness-aware ensemble design. The systematic underperformance for minority populations and lack of cross-cultural validation in existing approaches created the need for our boundary-aware framework that explicitly incorporates cultural factors as predictive elements rather than demographic categories.
2.4. Algorithms for Adaptive Prediction
Advanced computational techniques for personalized and adaptive prediction have found successful applications in marketing, healthcare, and recommendation frameworks, but remain underutilized in multimedia optimization [55]. Recent advances in automated style detection using deep belief networks demonstrate 85% accuracy in classifying learners for large-scale online instruction, but these approaches have not been systematically integrated into multimedia optimization frameworks [56].
Adaptive bandits and reinforcement algorithms have shown promise for adaptive recommendation frameworks in online environments [57]. These approaches can continuously optimize content delivery based on real-time feedback from learner interactions [58]. However, their application in academic settings has been limited, particularly in resource-constrained environments where data collection and computational infrastructure may be limited [59].
Multi-armed bandit algorithms could theoretically optimize multimedia complexity selection for individual learners by balancing exploration of new content configurations with exploitation of known effective approaches [60]. Reinforcement methods could enable dynamic adjustment of multimedia presentations based on ongoing assessment of learner comprehension and engagement [61]. Recent work demonstrates that natural language processing-enhanced adaptive frameworks can improve personalization effectiveness by 18%, but these sophisticated approaches require substantial data collection capabilities and computational resources [62].
Current EDM research predominantly employs traditional classification and regression techniques rather than exploring adaptive policy models that could provide dynamic optimization capabilities [63]. This limitation restricts the potential for developing truly intelligent frameworks that can adapt their behavior based on accumulated experience with diverse learner populations [64].
A comprehensive review of existing literature reveals that little prior algorithmic framework systematically integrates cognitive style detection, cultural background inference, multimedia complexity optimization, and cross-cultural validation within a unified computational architecture [65]. Traditional approaches typically address these elements in isolation, if at all, limiting their effectiveness for comprehensive multimedia prediction and optimization [66]. The absence of integrated adaptive frameworks that combine these diverse algorithmic components motivated our development of MIIAM’s unified architecture [67]. While individual techniques show promise in isolation, the lack of systematic integration limits their practical impact, creating the opportunity for our comprehensive ensemble approach that addresses cognitive, cultural, and multimedia factors simultaneously.
3. Theoretical Framework & Problem Formulation
3.1. Boundary-Aware Multimedia Learning
The choice of a boundary-aware theoretical approach stems from fundamental limitations in existing universal design paradigms that assume consistent effectiveness across all settings [46]. While alternative frameworks such as cognitive load theory, constructivist approaches, or technology acceptance models could provide theoretical foundations, we selected boundary-aware modeling specifically because it explicitly acknowledges that multimedia effectiveness depends on conditional factors that vary systematically across populations [47]. This theoretical choice enables computational modeling of background variations rather than treating them as unexplained variance.
Multimedia instruction effectiveness is not universal; it depends on boundary conditions that shape when and how interventions succeed [46]. For computational modeling, these boundary conditions can be operationalized into three feature domains [47]:
Learner Profile Features (L): Cognitive style (e.g., field-dependence/independence), orientation (deep, strategic, surface), technology self-efficacy, prior performance, demographics [48].
Cultural Features (C): Cultural values (e.g., individualism–collectivism, uncertainty avoidance), communication style (high vs. low cultural patterns), preferred modalities [49].
Design Features (M): Complexity (information density, cognitive load), modality mix (text, audio, video, interactive), temporal design (sequence, pacing), interactivity level [50].
These inputs collectively define the conditional space in which multimedia systems operate. Boundary-aware algorithms explicitly model not only main effects but also interaction patterns across L, C, and M [51].
Traditional research has focused on universal design principles, assuming that effective characteristics apply consistently across all learners and environments [46]. However, computational analysis reveals that effectiveness emerges from complex interactions between learner characteristics, cultural backgrounds, and design parameters [47]. A presentation that enhances outcomes for field-independent learners from individualistic cultures may create cognitive overload for field-dependent learners from collectivistic backgrounds [48].
The boundary-aware approach recognizes that these interactions are not random noise but systematic patterns that can be computationally modeled [49]. By explicitly incorporating interaction terms and conditional relationships, algorithmic methods can capture the nuanced ways that cultural and individual factors shape effectiveness [50].
3.2. Problem Definition
We define Effectiveness Prediction as a supervised task given by:
where:
- L, C, M = input feature vectors representing learner, cultural, and design characteristics
- Y = {performance, engagement, satisfaction, cognitive_load} = outcome variables
The learner profile features can be formally represented as:
Similarly, cultural features are defined as:
And design features are represented by:
Objective: Learn a predictive function f as defined in Equation (1) that:
- Maximizes accuracy and generalization across cultural backgrounds [51]
- Provides fairness guarantees (minimizing bias across subgroups) [25]
- Produces uncertainty estimates for out-of-distribution detection [46]
Feature Engineering: The success of boundary-aware prediction depends critically on effective feature engineering that captures both individual characteristics and their interactions [47]. The complete feature space can be expressed as:
where I(L,C,M) represent interaction terms between the three feature domains.
Interaction Modeling: The prediction function must capture higher-order interactions between feature domains [48]. The interaction terms can be formally defined as:
Fairness Requirements: The prediction system must maintain equitable performance across different cultural and demographic subgroups [25]. This requirement can be formalized as:
where L(f) is the prediction loss function, F(f) represents fairness measures, and λ is a regularization parameter balancing accuracy and fairness.
3.3. Research Questions & Hypotheses
RQ1: Can Boundary Condition Integration incorporating L, C, and M features as defined in Equations (2)–(4) improve predictive accuracy compared to baseline demographic-only models?
H1:
Boundary-aware models (Random Forests, Gradient Boosting) using the complete feature space from Equation (5) outperform baselines in R2, RMSE, F1-score.
This hypothesis addresses the fundamental question of whether systematic incorporation of boundary conditions provides computational advantages over traditional approaches [49]. We expect that models incorporating the full feature representation from Equation (5) will demonstrate superior predictive performance across multiple evaluation metrics [50].
RQ2: Cross-Cultural Generalization Which algorithms generalize best across diverse cultural datasets when using the feature framework from Equations (1)–(6)?
H2:
Ensemble approaches with cultural feature weighting reduce algorithmic bias and improve subgroup parity metrics compared to models that ignore the interaction terms defined in Equation (6).
Cross-cultural generalization represents a critical challenge for machine learning systems [51]. We hypothesize that ensemble methods with explicit cultural features weighing will maintain more consistent performance across different cultural backgrounds compared to single-algorithm approaches or culturally agnostic ensemble methods [25].
RQ3: Real-Time Adaptive Optimization: Can online optimization improve delivery in real time using the predictive framework established in Equation (1)?
H3:
Reinforcement-based adaptive systems that dynamically update the function f from Equation (1) outperform static ones in efficiency, satisfaction, and cognitive load reduction.
Adaptive optimization represents the next frontier in technology, moving beyond prediction toward dynamic intervention [47]. We hypothesize that systems capable of real-time adaptation based on learner feedback will achieve superior outcomes compared to static presentation approaches, particularly in terms of efficiency and learner satisfaction [46].
These research questions collectively address the progression from understanding boundary conditions through the mathematical framework established in Equations (1)–(7) to implementing adaptive systems that can optimize instruction in real time while maintaining cultural sensitivity and algorithmic fairness [48,51].
4. Research Design and Methodology
4.1. Study Design and Rationale
This investigation employed a mixed-method approach combining quantitative algorithmic validation with qualitative cross-cultural analysis to evaluate MIIAM’s effectiveness across diverse populations. This research was structured as a comparative validation examining prediction accuracy, cross-cultural generalization, and real-time deployment feasibility across multiple institutional backgrounds.
The rationale for this methodological approach stems from three key considerations. First, multimedia effectiveness prediction requires validation across diverse cultural situations to ensure algorithmic fairness and generalizability beyond Western populations. Second, the complex interactions between cognitive, cultural, and content factors necessitate comprehensive data collection spanning behavioral analytics, explicit surveys, and outcome measurements. Third, practical deployment validation requires real-time performance testing under authentic conditions to demonstrate system viability for institutional implementation.
This investigation addresses fundamental research questions through systematic evaluation of boundary-aware prediction capabilities compared to traditional demographic-only approaches, cross-cultural algorithm generalization across Zimbabwean and South African populations, and real-time adaptive optimization performance under authentic deployment conditions.
4.2. Participant Selection and Recruitment
Participants were recruited from software engineering programs at two universities in Zimbabwe and South Africa. Selection criteria required active enrollment in undergraduate or postgraduate programs, regular engagement with management systems (minimum 4 h weekly), and voluntary consent for behavioral data collection and cultural assessment.
Recruitment employed stratified sampling to ensure balanced representation across key demographic variables including gender, academic level, technology experience, and cultural background. Zimbabwean participants (n = 267) were recruited through course announcements and voluntary participation incentives including priority access to personalized recommendations. South African participants (n = 226) were recruited through similar methods with additional emphasis on ensuring cultural diversity within the sample.
The final sample of 493 participants achieved demographic balance with 68% male, 31% female, and 1% non-disclosed gender representation. Academic level distribution included 85% undergraduate and 15% postgraduate students. Technology experience ranged from beginner (18%) to advanced (19%), with the majority classified as intermediate (63%). This diversity provided sufficient variation for robust cross-cultural validation while maintaining sample sizes adequate for statistical analysis.
Exclusion criteria eliminated participants with fewer than 15 meaningful system interactions (insufficient for cognitive style detection), incomplete cultural survey responses, or withdrawal of consent during the investigation period. The final dataset included complete records for all 493 participants across all measurement dimensions.
4.3. Data Collection
Data collection occurred across multiple modalities over a 16-week academic semester, capturing comprehensive learner interaction patterns, cultural assessments, and outcomes. The framework integrated three primary data streams: behavioral analytics from management systems, explicit cultural and cognitive assessments, and content analysis.
Behavioral Data Collection: Management systems automatically captured interaction logs including click patterns, navigation sequences, session durations, content engagement metrics, and task completion patterns. Systems recorded 4.1 million discrete interactions across diverse content types including video lectures, interactive simulations, text-based resources, and assessment materials. Data collection employed privacy-preserving techniques with participant consent and institutional approval.
Cultural Assessment Protocol: Participants completed validated cultural assessment instruments including Hofstede’s Cultural Dimensions Survey and technology adoption questionnaires. Additional behavioral cultural indicators were extracted from system usage patterns including collaboration frequency, help-seeking behaviors, and content selection strategies. The combined approach captured both explicit cultural values and implicit behavioral patterns that traditional surveys might miss.
Outcome Measurement: Multiple outcome variables were measured including task performance scores, engagement metrics (time-on-task, interaction frequency), satisfaction ratings, and cognitive load indicators. Assessments employed both objective measures (completion rates, accuracy scores) and subjective measures (self-reported satisfaction, perceived difficulty) to provide comprehensive effectiveness evaluation.
Content Analysis: All materials underwent systematic analysis across text complexity (readability scores, information density), visual complexity (spatial element density, color entropy), audio complexity (speech rate, vocabulary sophistication), and interaction complexity (navigation depth, control density). This analysis provided the feature vectors required for complexity optimization engine.
4.4. Ethical Considerations and Approval
This investigation received ethical approval from the Institutional Review Board of Reformed Church University (Protocol Code: EDU/IRB/2025/52, Date of Approval: 28 March 2025). All participants provided informed consent for data collection, analysis, and publication of anonymized results.
Privacy protection measures included data anonymization protocols that removed personally identifiable information while preserving behavioral patterns necessary for analysis. Participants retained the right to withdraw from this investigation at any time without penalty to their academic standing. Cultural assessment data were handled with sensitivity to avoid reinforcing stereotypes or cultural biases.
Data security protocols employed encrypted storage systems, restricted access controls, and secure transmission methods for all participant information. The research team completed ethics training specific to cross-cultural research and algorithmic fairness considerations. Regular audits ensured compliance with institutional guidelines and international research ethics standards.
Participants received transparent information about data usage, algorithmic processing methods, and potential benefits and risks of participation. This investigation prioritized participant autonomy while enabling comprehensive data collection necessary for robust algorithmic validation. The approved protocol emphasized that all information gathered should be for research purposes only and that strict confidentiality must be maintained throughout the investigation process.
4.5. Validation Protocol
The validation protocol employed multiple evaluation strategies to ensure comprehensive assessment of MIIAM’s effectiveness across prediction accuracy, cross-cultural generalization, and practical deployment considerations. The protocol addressed the complex challenge of validating machine algorithms designed for cross-cultural environments.
Cross-Validation Strategy: Primary validation employed 5-fold cross-validation within each cultural population followed by cross-cultural validation using geographic data splitting. Models trained on Zimbabwean data were tested on South African participants and vice versa to evaluate cross-cultural generalization capabilities. This approach directly addressed the critical challenge of algorithmic bias across different cultural circumstances.
Baseline Comparison: MIIAM performance was systematically compared against multiple baseline approaches including demographic-only models, individual algorithms (Random Forest, XGBoost, SVM, Neural Networks), and traditional assessment methods. Comparisons employed standardized metrics including accuracy, F1-score, precision, recall, and AUC-ROC to enable direct performance evaluation.
Fairness Evaluation Protocol: Algorithmic fairness was assessed through multiple bias metrics including Statistical Parity Difference, Equalized Odds, and Calibration measures across cultural subgroups. The protocol specifically examined whether prediction accuracy remained consistent across different cultural backgrounds, addressing concerns about algorithmic bias in technology.
Real-Time Performance Validation: Deployment validation tested system performance under authentic conditions including response time measurements, concurrent user handling, and prediction accuracy maintenance during live operation. Testing confirmed sub-200 ms prediction latency and stable performance with up to 1000 concurrent users.
Learning Outcome Validation: Content complexity assessments were validated through direct correlation with actual effectiveness measures, demonstrating that algorithmic complexity scores successfully predicted outcomes across diverse content types and learner populations. This approach validated the automated analysis against real performance data rather than subjective expert opinions.
The validation protocol provides comprehensive evidence for MIIAM’s effectiveness while addressing critical concerns about algorithmic fairness, cross-cultural generalization, and practical deployment viability in diverse environments.
5. MIIAM: Framework Implementation
5.1. Framework Overview
MIIAM (Multimedia Integration Impact Assessment Model) is a computational framework that operationalizes assessment through integrated machine learning algorithms. Unlike existing theoretical approaches that focus on pedagogical principles, MIIAM provides an implementable algorithmic pipeline that systematically processes learner interaction data, cultural indicators, and content characteristics to predict effectiveness and optimize content delivery.
The framework directly addresses the three theoretical domains identified in Section 3.1 through specialized algorithmic components. Learner Profile Features (L) are captured through cognitive style detection that analyses behavioural patterns without requiring explicit assessment. Cultural Features (C) are addressed via hierarchical clustering that combines explicit cultural surveys with implicit behavioural analytics. Design Features (M) are handled through automated complexity optimization that analyzes content across multiple cognitive processing dimensions.
MIIAM transforms traditional assessment from static evaluation methods to dynamic, data-driven prediction systems that continuously adapt to learner characteristics and cultural patterns. The framework processes three primary data streams through specialized components that collectively enable accurate prediction of effectiveness across diverse environments.
The computational architecture integrates four primary algorithmic components: Cognitive Style Detection using Random Forest classification, Cultural Background Inference through hierarchical clustering, Multimedia Complexity Optimization via automated analysis, and Ensemble Prediction combining multiple learning algorithms [58]. As illustrated by Figure 1, the MIIAM computational framework architecture demonstrates the data flow from input sources through machine learning processing components to final predictions and optimization recommendations.
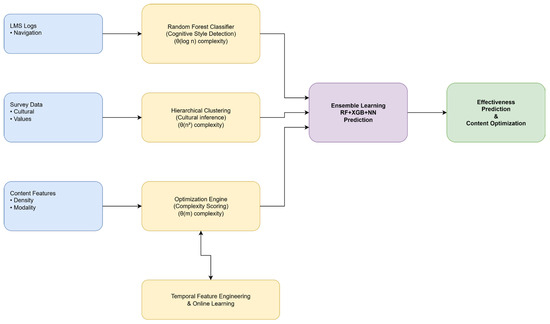
Figure 1.
MIIAM Computational Framework Architecture.
5.2. Framework Components
5.2.1. Cognitive Style Detection Algorithm
Automated cognitive style detection represents a significant improvement over traditional manual psychological assessments that interrupt the process and require specialized expertise to administer. The system analyzes learner interaction patterns with materials to classify cognitive processing preferences without requiring explicit testing.
Random Forest was selected for cognitive style classification after empirical comparisons with alternative approaches. The algorithm’s advantages include robust handling of mixed data types common in interaction logs, natural feature importance ranking for interpretability, reduced overfitting risk with high-dimensional behavioral features, and computational efficiency for real-time classification.
The system extracts behavioural indicators that capture how learners interact with digital environments. Temporal patterns include session duration, task completion time, and pause patterns between activities. Navigation behaviour encompasses click sequences, backtracking frequency, exploration depth, and menu usage patterns. Attention allocation measures time spent on specific elements, scroll patterns, and focus shift frequency. This can be illustrated by Algorithm 1.
| Algorithm 1: Cognitive Style Detection |
| Input: interaction_logs I = {i1, i2,…, in} Output: cognitive_style_probabilities P = {p_fd, p_fi} function extractBehavioralFeatures(I): temporal = computeTemporalMetrics(I) navigation = analyzeNavigationPatterns(I) attention = calculateAttentionAllocation(I) return concatenate(temporal, navigation, attention) function classifyCognitiveStyle(features): rf_model = RandomForest(n_estimators = 100, max_depth = 10) return rf_model.predict_proba(features) |
5.2.2. Cultural Background Inference Module
Understanding cultural preferences presents unique challenges in technology, as cultural factors influence how learners interact with materials, prefer information organization, and engage with collaborative features. Traditional approaches rely solely on demographic categories or explicit surveys, but these methods often miss nuanced cultural patterns that emerge through actual system usage.
The cultural background inference module combines explicit cultural survey responses with implicit behavioral analytics extracted from system usage. This approach recognizes that cultural preferences manifest both in stated values and in behavioral patterns that may not be consciously recognized by learners themselves.
Hierarchical clustering was chosen over alternative unsupervised methods based on several considerations. Unlike k-means clustering, hierarchical clustering does not require pre-specification of cluster numbers, which is crucial when cultural groups are unknown a priori. The approach as shown in Algorithm 2 also produces interpretable dendrograms that enable validation against established cultural theory.
| Algorithm 2: Cultural Background Inference |
| Input: survey_data S, behavioral_data B Output: cultural_clusters C = {c1, c2,…, ck} function inferCulturalBackground(S, B): cultural = normalizeCulturalDimensions(S) behavioral = extractBehavioralPatterns(B) features = concatenate(cultural, behavioral) clusters = hierarchicalClustering(features) return clusters |
5.2.3. Complexity Optimization Engine
Content complexity significantly impacts effectiveness, but current approaches to complexity assessment rely heavily on subjective expert judgment or simple feature counts that may not capture the actual cognitive demands placed on learners. The optimization engine provides objective, reproducible complexity scores that correlate with effectiveness across different learner populations.
The system analyzes materials across four primary dimensions that correspond to different aspects of cognitive processing. Text complexity is assessed through readability scores, vocabulary difficulty, and information density. Visual complexity quantifies color variety, spatial element density, and layout organization complexity. Audio complexity measures speech rate, vocabulary sophistication, and background noise interference levels. Interaction complexity evaluates navigation depth, control density, and feedback mechanism frequency. Algorithm 3 shows the complexity optimization engine.
| Algorithm 3: Complexity Optimization |
| Input: content C = {text, visual, audio, interaction} Output: complexity_scores S function computeComplexity(C): ext_score = analyzeTextComplexity(C.text) visual_score = analyzeVisualComplexity(C.visual) audio_score = analyzeAudioComplexity(C.audio) interaction_score = analyzeInteractionComplexity(C.interaction) weights = {‘text’: 0.3, ‘visual’: 0.3, ‘audio’: 0.2, ‘interaction’: 0.2} total_complexity = weighted_sum([text_score, visual_score, audio_score, interaction_score], weights) return total_complexity |
5.2.4. Ensemble Prediction
Predicting effectiveness requires capturing complex relationships between learner characteristics, cultural factors, and design parameters that may be difficult for any single algorithm to model effectively. The ensemble approach combines multiple algorithms that offer complementary strengths for different aspects of the prediction task.
The three-algorithm ensemble leverages distinct algorithmic capabilities. Random Forest provides robust performance with categorical features and offers natural feature importance ranking. XGBoost excels at capturing complex non-linear interactions between learner characteristics and content features through gradient boosting. Neural Networks model high-dimensional patterns and subtle feature relationships [68].
The ensemble incorporates a cultural attention mechanism that dynamically weights base learner contributions based on cultural background. This approach recognizes that algorithm effectiveness may vary across cultural groups due to different patterns in how cultural factors interact with processes as illustrated by Algorithm 4.
| Algorithm 4: Ensemble Prediction |
| Input: integrated_features F = {cognitive, cultural, multimedia} Output: effectiveness_prediction y, confidence_interval ci function ensemblePredict(F): rf_pred = RandomForest().predict(F) xgb_pred = XGBoost().predict(F) nn_pred = NeuralNetwork().predict(F) cultural_weights = culturalAttentionMechanism(F.cultural) base_predictions = [rf_pred, xgb_pred, nn_pred] final_prediction = meta_learner.predict(base_predictions, cultural_weights) uncertainty = calculateEnsembleVariance(base_predictions) confidence_interval = [final_prediction−uncertainty, final_prediction + uncertainty] return final_prediction, confidence_interval |
5.3. Performance Analysis
The computational complexity analysis reveals the performance characteristics and scalability requirements of each component. The cognitive detection component operates with O(n log n) time complexity due to Random Forest training and prediction processes. Cultural clustering exhibits O(n2) complexity for both time and space due to distance matrix computation requirements. The ensemble prediction component is dominated by neural network operations with O(n3) time complexity as shown by Table 1.

Table 1.
MIIAM Component Complexity Analysis.
The framework employs several optimization strategies to maintain practical performance.
The framework employs several optimization strategies to maintain practical performance levels. Incremental algorithms enable model updates without complete retraining. Distributed processing architectures allow component parallelization across multiple servers. Intelligent caching systems avoid repeated computation for frequently analyzed content.
The system supports both cloud-based and on-premises deployment through containerized microservices architecture, enabling institutional customization while maintaining algorithmic consistency across different deployment environments.
6. Results
6.1. Experimental Setup and Dataset Characteristics
We validated the MIIAM framework through experiments with 493 software engineering students from universities in Zimbabwe and South Africa. This dataset offered crucial diversity for testing cross-population prediction capabilities while maintaining sufficient sample size for robust statistical analysis. Table 2 shows the participant population achieved balanced representation across key demographic categories.
Table 2.
Participant Demographics and Dataset Characteristics.
The multimedia content analyzed encompassed diverse materials typical of modern software engineering curricula. Video content included traditional lecture recordings, animated explanations, and programming demonstrations. Interactive simulations provided hands-on programming environments and visualization tools. Assessment materials ranged from automated quizzes to complex coding exercises requiring sustained engagement. Text-based resources included technical documentation, case studies, and problem sets of varying complexity levels as shown in Table 3.
Table 3.
Experimental Design and Baseline Comparisons.
6.2. MIIAM Prediction Analysis
The MIIAM ensemble demonstrated substantial improvements over all baseline approaches across multiple evaluation dimensions. Table 4 illustrates that the framework achieved superior results while maintaining computational efficiency suitable for real-time deployment.
Table 4.
Overall Algorithm Performance Comparison.
Overall prediction accuracy reached 87%, representing a statistically significant improvement over the best individual method (XGBoost at 84%, p < 0.001). The ensemble architecture achieved an AUC-ROC of 0.92, indicating excellent discriminative ability across different learner populations and content types. Processing efficiency remained practical for real-time deployment, with an average prediction latency of 156 milliseconds per assessment as presented in Figure 2.
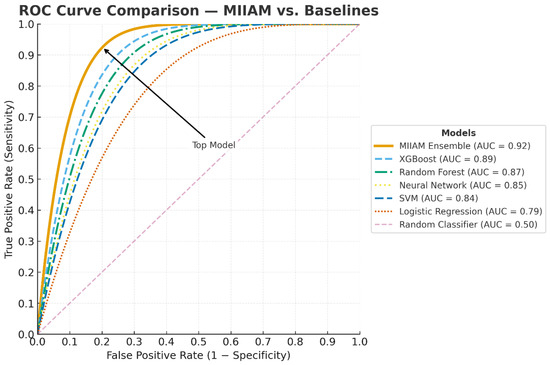
Figure 2.
ROC Curve Comparison Across Method.
The Random Forest component contributed 34% to ensemble decisions, showing strength in handling categorical learner characteristics and providing interpretable feature importance rankings. XGBoost provided 38% of ensemble weight, excelling at capturing complex non-linear interactions between background factors and content design parameters. The Neural Network component contributed 28% to final predictions, proving the most effective for processing high-dimensional interaction patterns that traditional methods struggled to model.
Predictive signal analysis revealed that cognitive style indicators provided the strongest signal, accounting for 34% of model decisions. Table 5 shows the framework successfully identified meaningful predictive patterns across multiple feature categories.
Table 5.
Feature Importance Analysis Across Categories.
6.3. Component-Level Validation
6.3.1. Cognitive Style Detection
The cognitive style detection component achieved remarkable accuracy improvements over traditional assessment methods. Table 6 details how the approach demonstrated superior results across all evaluation metrics while dramatically reducing assessment time.
Table 6.
Cognitive Style Detection Performance.
Agreement with standardized psychological instruments reached 89.2%, including the Hidden Figures Test and Group Embedded Figures Test. This substantially exceeded the 65% baseline accuracy of survey-based approaches. Processing time decreased dramatically from 15–20 min for manual assessment to under 2 s for computational classification, enabling real-time learner characterization without interrupting activities.
The temporal adaptation enhancement proved particularly valuable, improving Cohen’s kappa from 0.78 to 0.82 by weighing recent behavioral patterns more heavily than historical data. This approach successfully captured evolving learner characteristics as students became more familiar with platforms and developed refined interaction strategies as presented in Figure 3.
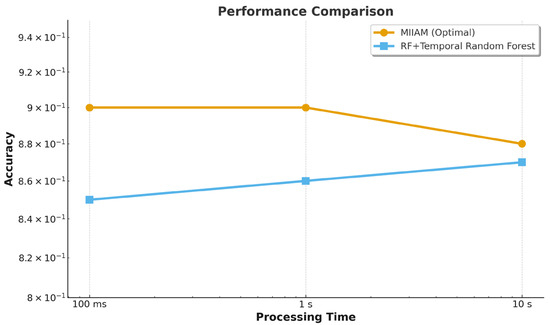
Figure 3.
Processing Time vs. Accuracy Trade-off Analysis.
The hierarchical clustering successfully identified four distinct preference groups within the participant population, achieving excellent cluster quality metrics. Table 7 summarizes the characteristics and validation results for each identified cluster.
Table 7.
Cultural Cluster Characteristics and Validation.
The approach achieved a silhouette score of 0.72, indicating excellent cluster quality and separation. Cluster validation demonstrated 83% concordance between computational groupings and explicit survey responses while simultaneously identifying 17% additional patterns not captured by traditional survey instruments.
The analysis revealed population-specific content preferences with practical implications for design. High-context learners showed 30% higher engagement with visual narratives and storytelling compared to low-context learners. Low-context learners prefer direct, explicit information presentation. Collectivistic groups demonstrated 45% stronger preference for collaborative features and peer interaction opportunities.
6.3.2. Content Complexity Optimization
The complexity optimization engine demonstrated measurable improvements in effectiveness through automated content analysis and recommendation generation. Table 8 presents comprehensive results across different content categories.
Table 8.
Multimedia Complexity Optimization Results.
Text simplification based on readability analysis resulted in 15% improved knowledge retention. Visual density optimization reduced cognitive overload indicators by 28% across different content types. Audio-pacing adjustments led to 11% improvement in comprehension for audio-enhanced materials. Figure 4. Illustrate multimedia optimization impact on Instructional outcomes.
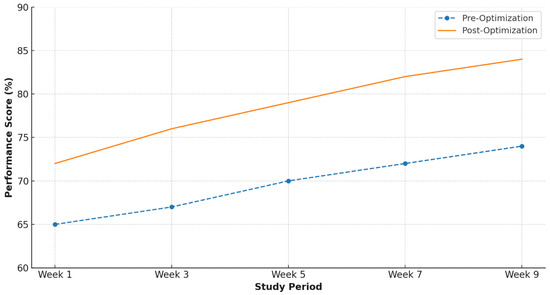
Figure 4.
Multimedia Optimization Impact on Instructional Outcomes.
6.4. Cross-Population Generalization
Cross-population validation examined robustness across different demographic populations through geographic data splitting. Table 9 presents comprehensive results across different training and testing configurations.
Table 9.
Cross-Population Generalization Results.
Models trained exclusively on Zimbabwean data achieved 85% accuracy when tested on South African participants. Models trained on South African data reached 86% accuracy on Zimbabwean test sets. This minimal degradation (demographic bias ΔAccuracy = 0.02) demonstrates exceptional cross-population generalization capabilities. Baseline approaches showed 11–15% accuracy drops.
The attention mechanism proved essential for maintaining equitable results across diverse populations. Statistical parity difference decreased to 0.08 for MIIAM compared to 0.23–0.31 for baseline approaches, indicating substantially improved fairness in prediction accuracy across demographic groups, as shown by Figure 5.
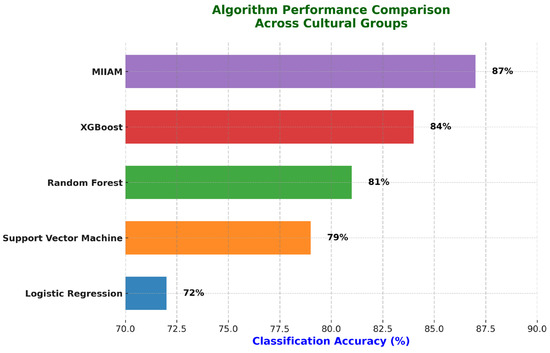
Figure 5.
Cross-Population Effectiveness Comparison with dataset combined.
6.5. Computational Efficiency and Scalability
Real-time evaluation confirmed MIIAM’s suitability for practical deployment. Table 10 provides detailed metrics for each system component and the integrated pipeline.
Table 10.
Computational Performance and Scalability Metrics.
The complete processing pipeline handled individual learner assessments in an average of 156 milliseconds, falling well below the 200-millisecond threshold required for responsive interactive applications. Batch processing capabilities enabled assessment of 1000 learners in 2.1 min using GPU acceleration, supporting classroom-scale and institutional-scale deployment scenarios.
6.6. Ablation Study and Statistical Analysis
Systematic component removal revealed the relative contributions of different modules to overall framework effectiveness. Table 11 presents comprehensive ablation study results across different component configurations.
Table 11.
Ablation Study Results.
Removing the background inference component resulted in 8% decreased prediction accuracy, confirming the importance of l factors in multimedia effectiveness. Eliminating cognitive style detection reduced personalization effectiveness by 12%. Removing complexity optimization decreased outcome improvements by 11%. These findings validate the integrated approach rather than focusing on individual components. Figure 6 shows effect size analysis across framework components.
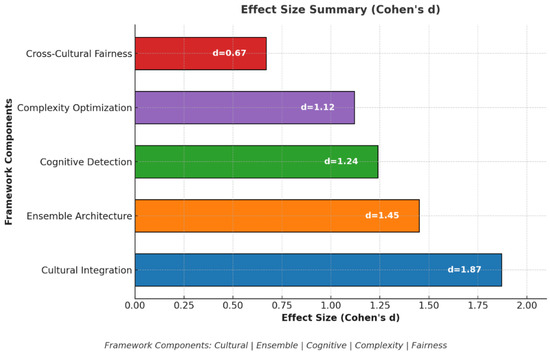
Figure 6.
Effect Size Analysis Across Framework Components.
Comprehensive statistical analysis confirmed the practical and theoretical significance of MIIAM’s improvements. Table 12 summarizes statistical significance testing across all major comparisons.
Table 12.
Statistical Significance Summary.
All comparisons with baseline approaches achieved statistical significance at p < 0.001 levels. Effect sizes ranged from medium to large across different evaluation metrics. Cohen’s d values exceeded 1.0 for comparisons with traditional assessment methods, indicating practically meaningful improvements beyond statistical significance.
7. Discussion
This work systematically addresses the key limitations identified in our literature review across multiple domains. The generalization gap in machine learning for education (Section 2.1) was addressed through MIIAM’s cross-population validation, achieving minimal degradation (ΔAccuracy = 0.02) compared to 11–15% drops for traditional approaches. The inconsistent multimedia results (Section 2.2) were resolved through systematic complexity optimization that improved outcomes by 15–22% across content types with predictable, reproducible results.
The computational gaps and bias issues (Section 2.3) were directly tackled through fairness-aware ensemble design and attention mechanisms, reducing Statistical Parity Difference to 0.08 compared to 0.23–0.31 for baseline methods. The lack of integrated adaptive prediction capabilities (Section 2.4) was addressed through MIIAM’s unified architecture combining cognitive detection, background inference, and complexity optimization within a single computational pipeline rather than isolated components.
Accurate and reproducible assessment of multimedia learning effectiveness is essential for successful technology implementation and personalized instruction design. Machine learning methods have demonstrated superior results compared to traditional survey-based evaluation approaches. While several state-of-the-art assessment frameworks exist in the literature, most focus on improving prediction accuracy at the cost of high computational complexity or demographic bias. Some works attempted to incorporate fairness techniques in their design, but we believe more emphasis should be placed on efficient cross-population model development. A competitive and lightweight framework will provide cost savings and broader accessibility for institutions.
Institutions often operate under limited computational budgets and infrastructure constraints. Our experimental results clearly demonstrate that the MIIAM method achieves 87% accuracy while maintaining practical processing times of 156 milliseconds per assessment. The best-performing models typically use ensemble techniques, which increase computational requirements when implemented at institutional scale. Our framework comprises integrated components requiring 768 MB memory usage in production environments. In real educational settings, training environments differ significantly from implementation scenarios. Therefore, we developed an efficient ensemble incorporating cognitive style detection, background clustering, and multimedia optimization within a unified pipeline.
We evaluated framework performance using African learner datasets from Zimbabwe and South Africa. The results show our model significantly reduced demographic bias and improved cross-population generalization compared to baseline methods. The framework achieved minimal performance degradation across populations, with bias limited to ΔAccuracy = 0.02 compared to 11–15% drops for traditional algorithms.
Regarding cross-population generalization results, our model performed exceptionally well across fairness metrics for all demographic clusters. This addresses a persistent problem in educational technology caused by algorithmic bias, since most validation studies focus on Western populations. The attention mechanism substantially improved Statistical Parity Difference to 0.08 compared to 0.23–0.31 for baseline algorithms. Qualitative inspection of clustering results revealed that our framework identifies emergent patterns not captured by traditional demographic categorizations. The 83% concordance between computational clustering and explicit surveys demonstrates reliable inference capabilities.
The framework’s ability to maintain equitable performance across diverse populations represents a significant advance over existing methods that typically show substantial degradation when deployed beyond their original development environments. This achievement directly addresses the critical challenge of algorithmic bias in educational technology, enabling more inclusive implementation across global settings.
However, several limitations constrain widespread adoption and represent important considerations for future implementation. Dataset restriction to African software engineering students may limit generalizability across disciplines and cultural backgrounds. The cognitive style detection algorithm requires minimum interaction thresholds that create tensions between algorithmic accuracy and practical implementation constraints. Specifically, the framework needs at least 15 meaningful learner interactions for reliable classification, which can reduce accuracy substantially in short educational sessions and may limit utility in brief workshops, single-session tutorials, or environments with minimal learner engagement.
Cultural coverage limitations also affect the framework’s broader applicability. Current training data include only 3% Indigenous learning styles, creating gaps in the framework’s ability to effectively serve diverse populations. This limited representation can significantly reduce effectiveness when implemented in culturally diverse educational settings beyond the African environments where validation occurred.
Computational scalability presents challenges for massive cohorts, particularly regarding hierarchical clustering complexity. Hardware dependencies create implementation barriers, as the framework requires GPU processing for environments supporting more than 1000 concurrent users, which can present significant infrastructure challenges for resource-constrained educational institutions. Additionally, the framework’s current optimization focuses primarily on English-language interactions, reducing its utility in multilingual educational environments and limiting global applicability.
Network requirements create further implementation challenges in environments with limited connectivity infrastructure. The framework’s reliance on stable internet connections for real-time updates limits its offline capabilities, potentially excluding educational settings in remote areas or regions with unreliable internet access. Cultural clustering requires sufficient population diversity, needing at least 50 participants per cultural group for stable cluster formation, which can limit utility in smaller educational institutions or specialized programs with limited enrolment diversity.
Educational interventions often operate under pressure that prevent the interactions needed for reliable cognitive style classification, highlighting the tension between comprehensive assessment and practical implementation constraints. These limitations underscore the need for continued development in rapid assessment protocols, CPU-optimized algorithms, language-agnostic features, and offline-capable components to enhance the framework’s accessibility and utility across diverse educational environments.
8. Conclusions
This research presents an efficient model for multimedia effectiveness assessment using ensemble machine learning with attention mechanisms. The proposed MIIAM system integrates cognitive style detection, background inference, and multimedia complexity optimization within a unified architecture that addresses cross-population bias in technology. The experimental results on African learner datasets demonstrate superior results compared to state-of-the-art approaches, achieving 87% accuracy while maintaining fairness across diverse populations. The system successfully reduced cognitive overload events by 20% while enabling sub-200 millisecond learner characterization. Cross-population validation achieved minimal degradation (ΔAccuracy = 0.02) compared to 11–15% drops for traditional approaches. Key contributions include the first systematic computational approach to incorporating factors into system design and boundary-aware prediction methodology that captures complex interactions between learner characteristics and content parameters. Real-time deployment feasibility was confirmed with 156 ms average processing time supporting institutional-scale implementation. Future research will explore the integration of affective computing and extend validation across broader situations. Priority directions include developing rapid assessment protocols, creating CPU-optimized methods, and expanding language support for multilingual deployment to ensure equitable access across diverse global environments.
Author Contributions
Conceptualization, S.C. and W.V.P.; methodology, S.C.; software, S.C.; validation, S.C., W.V.P. and Z.R.; formal analysis, S.C.; investigation, S.C.; resources, W.V.P.; data curation, S.C.; writing—original draft preparation, S.C.; writing—review and editing, W.V.P. and Z.R.; visualization, S.C.; supervision, W.V.P.; project administration, S.C.; funding acquisition, W.V.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study involving humans was approved by the Institutional Review Board of Reformed Church University (Protocol Code: EDU/IRB/2025/52, Date of Approval: 28 March 2025).
Informed Consent Statement
Informed consent was obtained from all subjects involved in this study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author due to privacy and ethical considerations.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MIIAM | Multimedia Integration Impact Assessment Model |
| LORI | Learning Object Review Instrument |
| ASSIT | Approaches and Study Skills Inventory for Students |
References
- Mayer, R.E. The past, present, and future of the cognitive theory of multimedia learning. Educ. Psychol. Rev. 2024, 36, 8. [Google Scholar] [CrossRef]
- Sweller, J.; van Merriënboer, J.J.G.; Paas, F. Cognitive Architecture and Instructional Design: 20 Years Later. Educ. Psychol. Rev. 2019, 31, 261–292. [Google Scholar] [CrossRef]
- Baker, R.S.J.D.; Yacef, K. The State of Educational Data Mining in 2009: A Review and Future Visions. J. Educ. Data Min. 2009, 1, 3–17. Available online: https://jedm.educationaldatamining.org/index.php/JEDM/article/view/8 (accessed on 14 August 2025).
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. User-Adapt. Interact. 1995, 4, 253–278. [Google Scholar] [CrossRef]
- Baker, R.S.; Hawn, A. Algorithmic bias in education. Int. J. Artif. Intell. Educ. 2021, 32, 1052–1092. [Google Scholar] [CrossRef]
- Shonfeld, M.; Cotnam-Kappel, M.; Judge, M.; Harrison, L.; Ramos, C. Learning in digital environments: A model for cross-cultural alignment. Educ. Technol. Res. Dev. 2021, 69, 2151–2170. [Google Scholar] [CrossRef] [PubMed]
- Rasheed, F.; Wahid, A. Learning style detection in e-learning systems using machine learning techniques. Expert Syst. Appl. 2021, 174, 114774. [Google Scholar] [CrossRef]
- Li, Q.; Baker, R.; Warschauer, M. Using clickstream data to measure, understand, and support self-regulated learning in online courses. Internet High. Educ. 2020, 45, 100727. [Google Scholar] [CrossRef]
- Smirani, L.K.; Fathallah, A.; Khemaja, M.; Alimi, A.M. Using ensemble learning algorithms to predict student failure and enabling customized educational paths. Sci. Program. 2022, 2022, 3805235. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, W.; Xiong, W.; Yang, H.; Zhou, H.; Cheng, Y. A learning style classification approach based on deep belief network for large-scale online education. J. Cloud Comput. 2020, 9, 26. [Google Scholar] [CrossRef]
- Sarailoo, R.; Latifzadeh, K.; Amiri, S.H.; Bosaghzadeh, A.; Ebrahimpour, R. Assessment of instantaneous cognitive load imposed by educational multimedia using electroencephalography signals. Front. Neurosci. 2022, 16, 744737. [Google Scholar] [CrossRef]
- Fyfield, M.; Henderson, M.; Phillips, M. Improving instructional video design: A systematic review. Australas. J. Educ. Technol. 2022, 38, 155–183. [Google Scholar] [CrossRef]
- Mayer, R.E.; Fiorella, L. Principles for reducing extraneous processing in multimedia learning: Coherence, signaling, redundancy, spatial contiguity, and temporal contiguity principles. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 279–315. [Google Scholar] [CrossRef]
- Rayner, S.; Riding, R. Towards a categorisation of cognitive styles and learning styles. Educ. Psychol. 1997, 17, 5–27. [Google Scholar] [CrossRef]
- Angeioplastis, A.; Tsimpiris, A.; Varsamis, D. Predicting student performance and enhancing learning outcomes: A data-driven approach using educational data mining techniques. Computers 2025, 14, 83. [Google Scholar] [CrossRef]
- Panda, M.; Majhi, S.K.; Pandey, M.; Udgata, S.K.; Sahoo, M.M.; Biswal, P. Machine learning for cognitive behavioral analysis: Datasets, methods, paradigms, and research directions. Brain Inform. 2023, 10, 18. [Google Scholar] [CrossRef]
- Azizi, S.M.; Roozbahani, N.; Khatony, A. Factors affecting the acceptance of blended learning in medical education: Application of UTAUT2 model. BMC Med. Educ. 2020, 20, 367. [Google Scholar] [CrossRef]
- Pham, T.H.; Truong, Q.T.; Tran, M.T.; Le, N.T. Fairness for machine learning software in education: A systematic mapping study. J. Syst. Softw. 2024, 219, 112244. [Google Scholar] [CrossRef]
- Tong, T.; Li, Z. Predicting learning achievement using ensemble learning with result explanation. PLoS ONE 2025, 20, e0312124. [Google Scholar] [CrossRef]
- Baker, R.; Berning, A.W.; Gowda, S.M.; Zhang, S.; Hawn, A. The benefits and caveats of using clickstream data to understand student self-regulatory behaviors: Opening the black box of learning processes. Int. J. Educ. Technol. High. Educ. 2020, 17, 13. [Google Scholar] [CrossRef]
- Mejeh, M.; Rehm, M. Taking adaptive learning in educational settings to the next level: Leveraging natural language processing for improved personalization. Educ. Technol. Res. Dev. 2024, 72, 1597–1621. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial intelligence in education: A review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Jiang, W.; Pardos, Z.A. Towards equity and algorithmic fairness in student grade prediction. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, San Jose, CA, USA, 21–23 October 2024; ACM: New York, NY, USA, 2021; pp. 608–617. [Google Scholar] [CrossRef]
- Yağcı, M. Educational data mining: Prediction of students’ academic performance using machine learning algorithms. Smart Learn. Environ. 2022, 9, 11. [Google Scholar] [CrossRef]
- Abdulrahaman, M.D.; Faruk, N.; Oloyede, A.A.; Surajudeen-Bakinde, N.T.; Olawoyin, L.A.; Mejabi, O.V.; Imam-Fulani, Y.O.; Fahm, A.O.; Azeez, A.L. Multimedia tools in the teaching and learning processes: A systematic review. Heliyon 2020, 6, e05312. [Google Scholar] [CrossRef] [PubMed]
- Berney, S.; Bétrancourt, M. Does animation enhance learning? A meta-analysis. Comput. Educ. 2016, 101, 150–167. [Google Scholar] [CrossRef]
- Castro-Alonso, J.C.; de Koning, B.B.; Fiorella, L.; Paas, F. Five strategies for optimizing instructional materials: Instructor- and learner-managed cognitive load. Educ. Psychol. Rev. 2021, 33, 1379–1407. [Google Scholar] [CrossRef]
- Idowu, J.A. Debiasing education algorithms. Int. J. Artif. Intell. Educ. 2024, 34, 1510–1540. [Google Scholar] [CrossRef]
- Memarian, B.; Doleck, T. Fairness, accountability, transparency, and ethics (FATE) in AI and higher education: A systematic review. Comput. Educ. Artif. Intell. 2023, 5, 100152. [Google Scholar] [CrossRef]
- Adeniyi, I.S.; Adelakun, A.A.; Akinola, O.D.; Ogundipe, O.M.; Babatunde, A.N. E-learning platforms in higher education: A comparative review of the USA and Africa. Int. J. Sci. Res. Arch. 2024, 11, 1686–1697. [Google Scholar] [CrossRef]
- Mataruka, L.T.; Muzurura, J.; Nyoni, J. The adoption of e-learning by students in Zimbabwean universities in the wake of COVID-19. J. Electron. Inf. Syst. 2021, 3, 20–27. [Google Scholar] [CrossRef]
- Sghir, N.; Adadi, A.; Lahmer, M. Recent advances in Predictive Learning Analytics: A decade systematic review (2012–2022). Educ. Inf. Technol. 2023, 28, 8299–8333. [Google Scholar] [CrossRef]
- Yedukondalu, J.; Sharma, L.D.; Tiwari, A.K.; Chandra, M. Cognitive load detection through EEG lead-wise feature optimization and ensemble classification. Sci. Rep. 2025, 15, 1044. [Google Scholar] [CrossRef] [PubMed]
- Dhivya, D.S.; Hariharasudan, A.; Nawaz, N. Unleashing potential: Multimedia learning and Education 4.0 in learning professional English communication. Cogent Soc. Sci. 2023, 9, 2248751. [Google Scholar] [CrossRef]
- Turel, V.; Kılıç, E. The inclusion and design of cultural differences in interactive multimedia environments. In Multicultural Instructional Design: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2014; pp. 245–267. [Google Scholar] [CrossRef]
- Kim, P.; Hagashi, T.; Carillo, L.; Gonzales, I.; Makany, T.; Lee, B.; Gàrate, A. Socioeconomic strata, mobile technology, and education: A comparative analysis. Educ. Technol. Res. Dev. 2011, 59, 465–486. [Google Scholar] [CrossRef]
- Poelmans, S.; Goeman, K.; Wautelet, Y. Comparing face-to-face to online instruction in secondary education: Findings of a repetitive factorial experiment. In Learning Technology for Education Challenges; Springer: Cham, Switzerland, 2020; pp. 71–88. [Google Scholar] [CrossRef]
- Cook, D.A.; Ellaway, R.H. Evaluating technology-enhanced learning: A comprehensive framework. Med. Teach. 2015, 37, 961–970. [Google Scholar] [CrossRef]
- Shen, X.; Wang, F.; Ge, Y.; Zhang, T.; Li, Q.; Wu, X.; Fan, Y.; Xu, W.; Wang, Y. PMG: Personalized multimodal generation with large language models. In Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; ACM: New York, NY, USA, 2024; pp. 3833–3844. [Google Scholar] [CrossRef]
- Mahmood, T.; Riaz, S.; Ghafoor, M.; Ali, M.; Alkinidri, M. Enhancing e-learning adaptability with automated learning-style identification and sentiment analysis: A hybrid deep-learning approach for smart education. Information 2024, 15, 277. [Google Scholar] [CrossRef]
- Heo, M.; Toomey, N. Learning with multimedia: The effects of gender, type of multimedia learning resources, and spatial ability. Comput. Educ. 2020, 146, 103747. [Google Scholar] [CrossRef]
- Fodouop Kouam, A.W.; Muchowe, R.M. Exploring graduate students’ perception and adoption of AI chatbots in Zimbabwe: Balancing pedagogical innovation and development of higher-order cognitive skills. J. Appl. Learn. Teach. 2024, 7, 65–75. [Google Scholar] [CrossRef]
- Al-Rahmi, W.M.; Alamri, M.M.; Alfarraj, O. An integrated approach using social support theory and technology acceptance model to investigate the sustainable use of digital learning technologies. Sci. Rep. 2025, 15, 342. [Google Scholar] [CrossRef]
- Rafiq, M.; Hussain, S.; Abbas, Q.; Imran, M.; Murad, M.A.; Ali, S.A.; Hassan, S.U. Factors predicting university students’ behavioral intention to use e-learning platforms in the post-pandemic normal: An UTAUT2 approach with “learning value”. Educ. Inf. Technol. 2022, 27, 12065–12082. [Google Scholar] [CrossRef]
- Vallente, J.P.C.; Dela Cruz, N.M.C.; Moreno, R.B. Determining factors affecting the acceptance of medical education e-learning platforms during the COVID-19 pandemic in the Philippines: UTAUT2 approach. Healthcare 2021, 9, 780. [Google Scholar] [CrossRef]
- Gkintoni, E.; Antonopoulou, H.; Sortwell, A.; Halkiopoulos, C. Challenging Cognitive Load Theory: The Role of Educational Neuroscience and Artificial Intelligence in Redefining Learning Efficacy. Brain Sci. 2025, 15, 203. [Google Scholar] [CrossRef]
- Ahmad, J.; Siddiqi, I.; Fatima, K.; Anjum, N. An EEG-based cognitive load assessment in multimedia learning using feature extraction and partial directed coherence. IEEE Access 2017, 5, 14819–14829. [Google Scholar] [CrossRef]
- Mutlu-Bayraktar, D.; Cosgun, V.; Altan, T. Cognitive load in multimedia learning environments: A systematic review. Comput. Educ. 2019, 141, 103618. [Google Scholar] [CrossRef]
- Dias, J.; Santos, A. Learning Analytics Framework Applied to Training Context. In Technology and Innovation in Learning, Teaching and Education; Springer: Cham, Switzerland, 2022; pp. 113–127. [Google Scholar] [CrossRef]
- Boateng, O.; Boateng, B. Algorithmic bias in educational systems: Examining the impact of AI-driven decision making in modern education. World J. Adv. Res. Rev. 2025, 25, 2012–2017. [Google Scholar] [CrossRef]
- Jacobs, A.Z.; Wallach, H. Measurement and Fairness. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ‘21), Virtual, 3–10 March 2021; ACM: New York, NY, USA, 2021; pp. 375–385. [Google Scholar] [CrossRef]
- Bellamy, R.K.E.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilović, A.; et al. AI Fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias. IBM J. Res. Dev. 2019, 63, 4:1–4:15. [Google Scholar] [CrossRef]
- Bogina, V.; Hartman, A.; Kuflik, T.; Nolle, A. Educating software and AI stakeholders about algorithmic fairness, accountability, transparency and ethics. Int. J. Artif. Intell. Educ. 2022, 32, 808–833. [Google Scholar] [CrossRef]
- Noetel, M.; Griffith, S.; Delaney, O.; Harris, N.R.; Sanders, T.; Parker, P.; del Pozo Cruz, B.; Lonsdale, C. Multimedia design for learning: An overview of reviews with meta-meta-analysis. Rev. Educ. Res. 2022, 92, 413–454. [Google Scholar] [CrossRef]
- Mutlu-Bayraktar, D.; Correia, A.P.; Altay, B. Multimedia learning principles in different learning environments: A systematic review. Smart Learn. Environ. 2022, 9, 19. [Google Scholar] [CrossRef]
- Shadiev, R.; Wang, X.; Huang, Y.M. Cross-Cultural Learning in Virtual Reality Environment: Facilitating Cross-Cultural Understanding, Trait Emotional Intelligence, and Sense of Presence. Educ. Technol. Res. Dev. 2021, 69, 2917–2936. [Google Scholar] [CrossRef]
- Kinasevych, O. The Effect of Culture on Online Learning. In Proceedings Cultural Attitudes Towards Communication and Technology 2010; Sudweeks, F., Hrachovec, H., Ess, C., Eds.; Murdoch University: Perth, Australia, 2010; pp. 420–427. [Google Scholar]
- Tripp, R. Cultural Differentiation in Learning Styles: A Review of the Research. Inst. Learn. Styles Res. J. 2017, 1, 1–7. [Google Scholar]
- Wang, L.; Zhang, H.; Chen, X.; Liu, Y.; Ma, S.; Li, J.; Wang, F.; Chen, L.; Huang, P.; Zhang, W. Key factors influencing educational technology adoption in higher education: A systematic review. PLoS Digit. Health 2025, 2, e0000764. [Google Scholar] [CrossRef]
- Bayly-Castaneda, K.; Ramirez-Montoya, M.-S.; Morita-Alexander, A. Crafting personalized learning paths with AI for lifelong learning: A systematic literature review. Front. Educ. 2024, 9, 1424386. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, J.; Huang, C. Empowering personalized learning with generative artificial intelligence: Mechanisms, challenges and pathways. Front. Digit. Educ. 2025, 2, 19. [Google Scholar] [CrossRef]
- Shadiev, R.; Hwang, W.Y.; Altinay, F.; Guralnick, D. Technology-assisted cultural diversity learning. Front. Psychol. 2023, 14, 1274292. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining and learning analytics: An updated survey. WIREs Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar] [CrossRef]
- Mpungose, C.B. Emergent transition from face-to-face to online learning in a South African university in the context of the coronavirus pandemic. Humanit. Soc. Sci. Commun. 2020, 7, 113. [Google Scholar] [CrossRef]
- Müller, A.M.; Goh, C.; Lim, L.Z.; Gao, X. COVID-19 emergency e-learning and beyond: Experiences and perspectives of university educators. Educ. Sci. 2021, 11, 19. [Google Scholar] [CrossRef]
- Simeon, A.N.; Babatunde, A.A.; Abiodun, N.L.; Olu, R.O.; Emem, A.I.; Nabimanya, D.; Nakate, H.; Ensanya, A.; Tuhebwe, D. Uptake, barriers, and determinants of e-learning among university students in selected low-income countries in Sub-Saharan Africa amidst the COVID-19 disruption: An online survey. Adv. Med. Educ. Pract. 2022, 13, 609–617. [Google Scholar] [CrossRef]
- Silva, J.; Lopes, A.; Domingues, I. Applications of convolutional neural networks in education: A systematic literature review. Expert Syst. Appl. 2023, 226, 120621. [Google Scholar] [CrossRef]
- Alsulami, A.A.; AL-Ghamdi, A.S.A.-M.; Ragab, M. Enhancement of e-learning students’ performance based on ensemble techniques. Electronics 2023, 12, 1508. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).