
Improving Facial Expression Recognition with a Focal Transformer and Partial Feature Masking Augmentation †



Abstract
1. Introduction
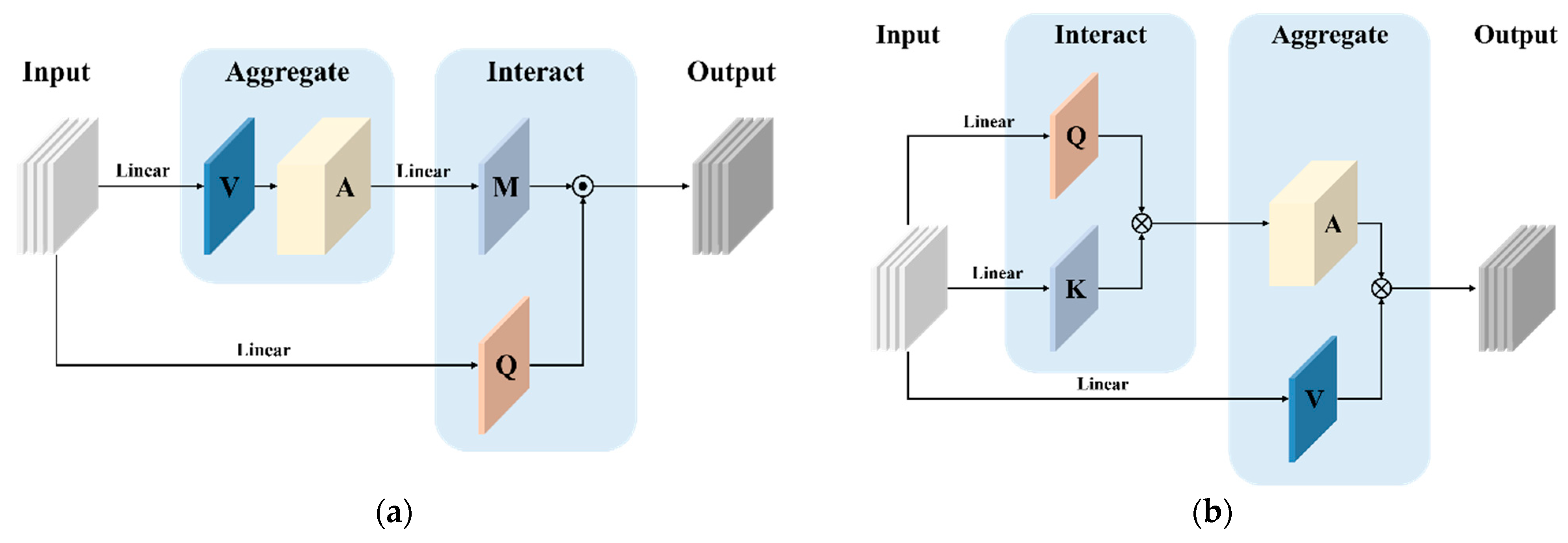
2. Method
2.1. Partial Feature Masking
2.2. Focal Vision Transformer
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, T.-Y.; Chan, H.-T.; Hsia, C.-H.; Lai, C.-F. Facial skincare products recommendation with computer vision technologies. Electronics 2022, 11, 143. [Google Scholar] [CrossRef]
- Hsia, C.-H.; Chiang, J.-S.; Lin, C.-Y. A fast face detection method for illumination variant condition. Sci. Iran. 2015, 22, 2081–2091. [Google Scholar]
- Huang, Q.; Huang, C.; Wang, X.; Jiang, F. Facial expression recognition with grid-wise attention and visual transformer. Inf. Sci. 2021, 580, 35–54. [Google Scholar] [CrossRef]
- Zou, R.; Song, C.; Zhang, Z. The Devil is in the details: Window-based attention for image compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17492–17501. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying convolution and attention for all data sizes. In Proceedings of the Neural Information Processing Systems, Virtual, 6–14 December 2021; pp. 3965–3977. [Google Scholar]
- Nan, Y.; Ju, J.; Hua, Q.; Zhang, H.; Wang, B. A-MobileNet: An approach of facial expression recognition. Alex. Eng. J. 2022, 61, 4435–4444. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, J.; Li, C.; Dai, X.; Gao, J. Focal modulation networks. In Proceedings of the Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 4203–4217. [Google Scholar]
- Zhang, W.-L.; Jia, R.-S.; Wang, H.; Che, C.-Y.; Sun, H.-M. A self-supervised learning network for student engagement recognition from facial expressions. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 12399–12410. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar]
- Liao, J.; Lin, Y.; Ma, T.; He, S.; Liu, X.; He, G. Facial expression recognition methods in the wild based on fusion feature of attention mechanism and LBP. Sensors 2023, 23, 4204. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
| Methods | RHF | RR | RE | PFM | Accuracy |
|---|---|---|---|---|---|
| This paper | 87.68% | ||||
| ✓ | ✓ | 88.89% | |||
| ✓ | ✓ | ✓ | 88.75% | ||
| ✓ | ✓ | ✓ | 89.08% |
| Methods | PFM | Patch Size | Accuracy |
|---|---|---|---|
| This paper | w/o | N/A | 88.89% |
| w/ | 4 | 88.40% | |
| 8 | 88.79% | ||
| 16 | 89.08% | ||
| 32 | 88.82% |
| Methods | PFM | Accuracy | ||
|---|---|---|---|---|
| This paper | w/o | N/A | N/A | 88.89% |
| w/ | 0.02 | 0.25 | 89.08% | |
| 0.25 | 0.50 | 88.95% | ||
| 0.50 | 0.75 | 88.69% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ke, L.-Y.; Liao, C.-Y.; Hsia, C.-H. Improving Facial Expression Recognition with a Focal Transformer and Partial Feature Masking Augmentation. Eng. Proc. 2025, 92, 70. https://doi.org/10.3390/engproc2025092070
Ke L-Y, Liao C-Y, Hsia C-H. Improving Facial Expression Recognition with a Focal Transformer and Partial Feature Masking Augmentation. Engineering Proceedings. 2025; 92(1):70. https://doi.org/10.3390/engproc2025092070
Chicago/Turabian StyleKe, Liang-Ying, Chia-Yu Liao, and Chih-Hsien Hsia. 2025. "Improving Facial Expression Recognition with a Focal Transformer and Partial Feature Masking Augmentation" Engineering Proceedings 92, no. 1: 70. https://doi.org/10.3390/engproc2025092070
APA StyleKe, L.-Y., Liao, C.-Y., & Hsia, C.-H. (2025). Improving Facial Expression Recognition with a Focal Transformer and Partial Feature Masking Augmentation. Engineering Proceedings, 92(1), 70. https://doi.org/10.3390/engproc2025092070