1. Introduction
Underwater acoustic communication networks (UACNs) play a critical role in marine environment monitoring, maritime rescue, and naval surveillance [
1,
2]. However, UACNs present significant challenges due to their inherent limitations, including narrow bandwidths, prolonged transmission delays, and severe multipath effects [
3,
4,
5]. These vulnerabilities make UACNs susceptible to interference, attacks, and eavesdropping on communication channels to steal sensitive information or disrupt communications by dynamically adjusting jamming power. Such attacks can deplete the energy of underwater sensor nodes and potentially trigger denial-of-service (DoS) scenarios.
Traditional anti-jamming techniques, such as frequency hopping and spread spectrum, are impractical for UACNs due to the dynamic topology of underwater networks. Consequently, power control is critical for UACNs. However, conventional power control methods struggle to adapt to the rapid variability and complexity of underwater acoustic channels as they rely on convex optimization [
6,
7]. Recently, reinforcement learning (RL) algorithms have been used to address interference using power control and relay selection technologies. In underwater relay cooperative communication networks, relay nodes are used to enhance transmission quality by forwarding signals. When channel conditions and interference models are unknown, RL algorithms optimize relay strategies to improve anti-jamming performance. For example, an RL-based anti-jamming transmission method [
8] reduces the bit error rate by optimizing transmission power. Similarly, Q-learning in multi-relay cooperative networks is used to enhance communication efficiency [
9].
Based on such results, the anti-jamming problem in UACNs was solved in this study by using a novel transmitter anti-jamming method that integrated RL with relay-assisted communication. Specifically, a transfer reinforcement learning (TRL) algorithm based on a hybrid strategy was designed to optimize transmitter actions. By leveraging prior anti-jamming data from similar scenarios, the developed approach initializes Q-values and policy distributions to mitigate the inefficiencies of traditional RL methods, which often start with zero-initialized Q-value matrices. This initialization accelerates the convergence of optimal policies, enhancing the overall anti-jamming performance.
2. System Model
We investigated a trunk-assisted anti-interference communication system for UACN, which comprises a transmitter, receiver, relay node, and a hostile jammer. The transmitter operates intermittently as transmitting information is vulnerable to disruption by nearby hostile jammers. These jammers emit interference signals to degrade the performance of information transmission. To enhance the system’s anti-interference capabilities, a relay node is introduced to forward information between the transmitter and receiver. The relay node effectively mitigates the impact of jamming, thereby improving the overall reliability and performance of the communication system.
At time k, the transmitter sends a signal to the receiver at the center frequency and bandwidth . The transmitter decides whether to trigger , where A is the set of feasible actions determined by the transmitter, to utilize the relay node for forwarding the signal. When x = 1, the transmitter activates the relay node, which forwards the signal to the receiver at a fixed transmission power and transmission cost . Otherwise, the transmitter sends the signal directly to the receiver. The transmitting power of the transmitter is selected from the range , where is the maximum allowable transmission power. The cost incurred by the transmitter per unit of transmitted power is denoted as .
3. Anti-Interference Power Control Based on Reinforcement Learning
RL enables agents to optimize actions through feedback from environmental interactions. In this study, we developed a transmitter anti-interference communication scheme, HPTR, which leverages RL-based optimization to select relay nodes and transmission power under dynamic interference and uncertain channel conditions. The proposed scheme employs a test reference least squares (TRL) algorithm based on mixed strategies. By incorporating prior knowledge from similar scenarios, the algorithm accelerates the learning process, improving efficiency and effectiveness in complex and dynamic underwater environments.
State space: The transmitter’s performance is directly influenced by the state space. At slot
k, the transmitter evaluates the previous communication performance, including the signal-to-noise ratio (SINR) of the direct link
and the bit error rate (BER) over the entire communication range
. Thus, the state space is represented as
Action space: Based on the policy distribution
and Q-value
of the current state, the transmitter selects an anti-jamming strategy
. Here, the relay triggers factor
and the transmitting power
, where
M represents the number of discrete power levels. The probability of selecting strategy
is as follows:
Reward function: The reward function is a key component of the learning process, as it directly impacts the decision-making strategy of the transmitter. Based on the selected anti-jamming strategy of the transmitter, when
, the transmitter transmits the signal to the receiver through a direct link. Otherwise, the transmitter triggers the relay node for information transmission. After receiving feedback from the receiver, the signal-to-noise ratio (
SINR) and the relay trigger factor at the destination are calculated. The reward function is expressed as
where the first term represents the effectiveness of the selected transmission strategy (either direct or relay-assisted) based on the
SINR. The second term penalizes energy consumption by weighting the transmitter’s power cost.
The Q-function (
s,), representing the expected utility of taking action
a in state
s, is updated iteratively using the Bellman equation as follows:
where
is the next state resulting from action
a, and
V(
s′) is the value function, defined as the maximum
Q(
s,
a) across all possible actions:
In addition, the learning rate
represents the weight of current experience, while the discount factor
represents the degree of uncertainty about future utility. Based on the mixed strategy table represented by
, the probability of other actions is reduced by increasing the probability corresponding to the actions with the largest Q-value.
The proposed TRL algorithm leverages experience from large-scale UACNs in anti-jamming tasks to initialize Q-values and policy distributions for the current scenario. By transferring knowledge from similar environments, the algorithm reduces the randomness of early exploration and accelerates learning convergence. In particular,
experiments of anti-jamming UACN transmission in similar scenarios are considered before the learning process of transmitter strategy optimization begins. Each experiment lasts for time
k, during which the transmitter observes the current state, including the bit error rate, the signal-to-dry-noise ratio, and other anti-jamming transmission performances of the underwater acoustic communication network, and relays information. Then, the transmitter mix strategy is selected according to the greedy strategy. The preparation phase of the HPTR algorithm is shown in Algorithm 1.
| Algorithm 1: HPTR preparation phase |
Initialize , , , , , , , ,
For do
for do
By choice
if then
The transmitter triggers the relay with power to forward the information
else
The transmitter forwards the information directly to the receiver at power
end if
Measure the signal-to-noise ratio of current information , , ,
Acquired utility function
According to calculation
According to calculation
end for
end for
Output and |
By utilizing the initial Q-values and the mixed policy table generated by Algorithm 1, Algorithm 2 is initialized with these values to facilitate learning. In Algorithm 2, the transmitter observes the current state, which includes the
SINR of the transmitter–receiver link and the bit error rate (BER) received at the receiver from the previous time slot. Based on the observed state, the transmitter selects an action according to predefined decision rules and evaluates the utility of the chosen action. During each time slot, the Q-function and the mixed strategy table are updated using a formula for updating. Through this iterative and interactive process, the transmitter gradually learns an optimal anti-jamming strategy within the dynamic game framework of anti-jamming transmission. As a result, the proposed approach effectively enhances the anti-jamming performance of the transmission system.
| Algorithm 2: HPT algorithm |
Connect algorithm 1
Initialize , , ,
, ,
for do
By choice
if then
The transmitter triggers the relay with power to forward the information
else
The transmitter forwards the information directly to the receiver at power
end if
Measure the signal-to-noise ratio of current information , , ,
Acquired utility function
According to update
According to update
According to update
end for |
4. Simulation Results and Analysis
The performance of the HPTR learning algorithm was evaluated and analyzed through simulation experiments. In the experiment, the equipment was placed 0.5 m below the water surface. The transmitter, located at coordinates (0,0), sent signals to the receiver while selecting the appropriate transmission power. The power setting ranged from 1 to 10 W and was quantized into five discrete levels. The system operated with a center frequency of 20 kHz and a bandwidth of 2 kHz. The transmitter utilized the relay node to assist it in forwarding information. Upon receiving the trigger signal from the transmitter, the relay, positioned at (0.5,1.1), forwarded the signal to the receiver at a fixed transmission power, thereby enhancing the reliability of information delivery. The receiver, located at (1.9,0.3), decoded the received messages using a selection combination approach and evaluated BER and the signal-to-noise ratio (SNR) of the received signals to provide this feedback to the transmitter and relay. Meanwhile, an intelligent jammer at (0.5,−0.2) employed software-defined radio equipment to monitor the channel’s transmission state and estimate the quality of the transmitted signals. Using a reinforcement learning algorithm, the jammer dynamically selected its interference power, which ranged from 1 to 10 W, and was quantized into five levels to maximize its long-term discounted utility. Based on the chosen interference power, the jammer transmits interference signals targeting the receiver and relay. The transmitter power cost coefficient was set to 0.03, the interference power cost coefficient was 0.02, and the noise power was fixed at 0.1.
The anti-jamming performance of the proposed HPTR algorithm was compared with that of two benchmark algorithms commonly used in UACNs.
QPR: An anti-jamming power allocation algorithm based on Q-learning, similar to the approach described in Ref. [
10]. Among the algorithms discussed in Refs. [
10,
11,
12], the one in Ref. [
12] is the most comparable to the proposed HPTR algorithm and is thus selected for performance comparison.
PTR: A reinforcement learning algorithm based on hybrid strategies [
13]. This algorithm introduces decision randomness to create uncertainty and deceive jammers and enhance robustness against interference.
In the anti-interference attack and defense scenario of UACNs, whether the agent can quickly reach the Nash equilibrium solution is an important indicator for evaluating the convergence of the algorithm.
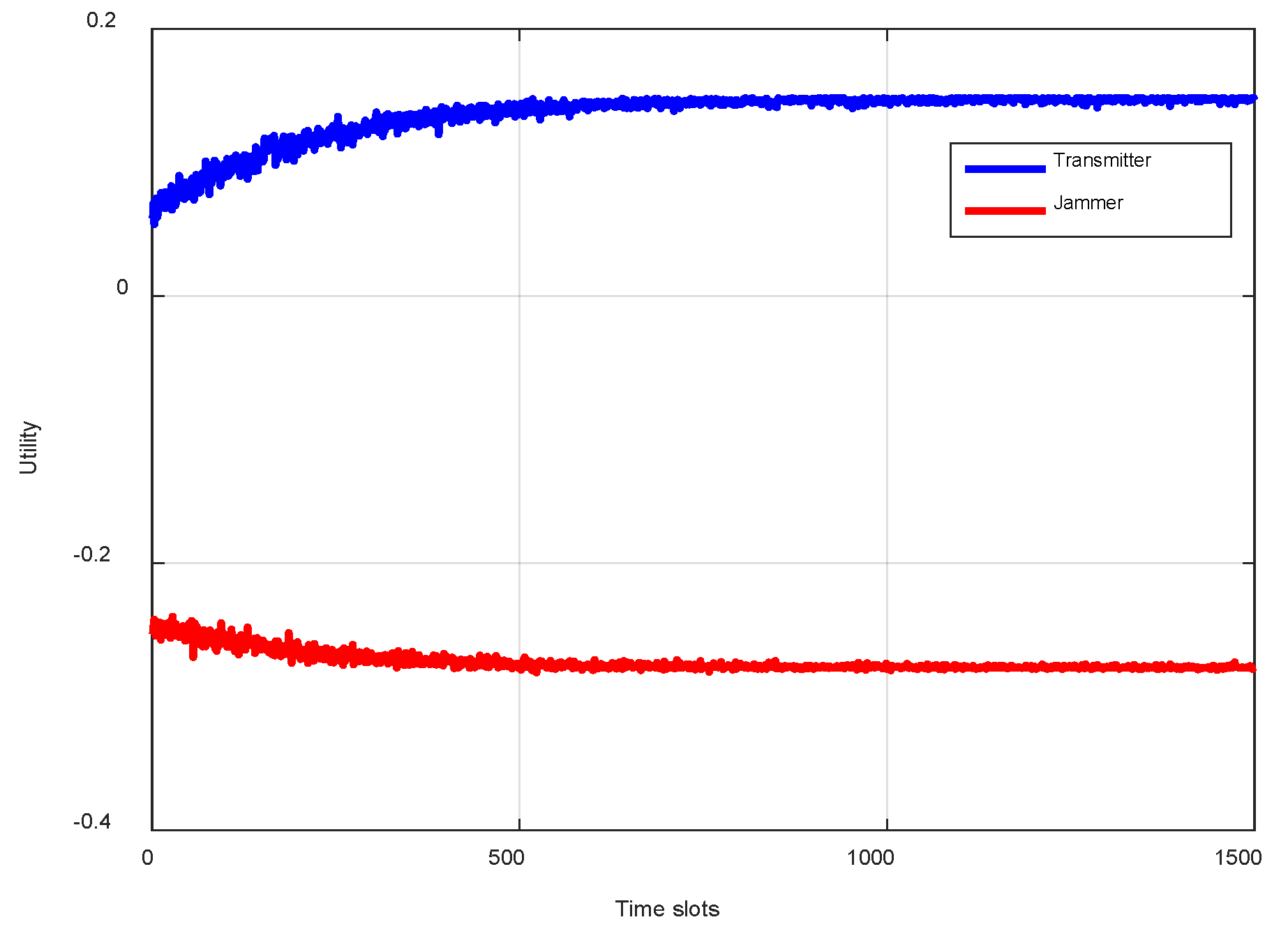
Figure 1 shows the convergence of the HPTR algorithm in terms of utility. The results show that both the transmitter and the jammer can converge quickly, where the utility of the transmitter gradually increases over time, while the utility of the jammer gradually decreases over time, which verifies the effectiveness of the proposed model.
Figure 2 illustrates the convergence of the HPTR algorithm in terms of utility. The transmitter and the jammer converged quickly, and the transmitter’s utility increased over time, while the jammer’s utility decreased. The results validated the effectiveness of the proposed scheme model.
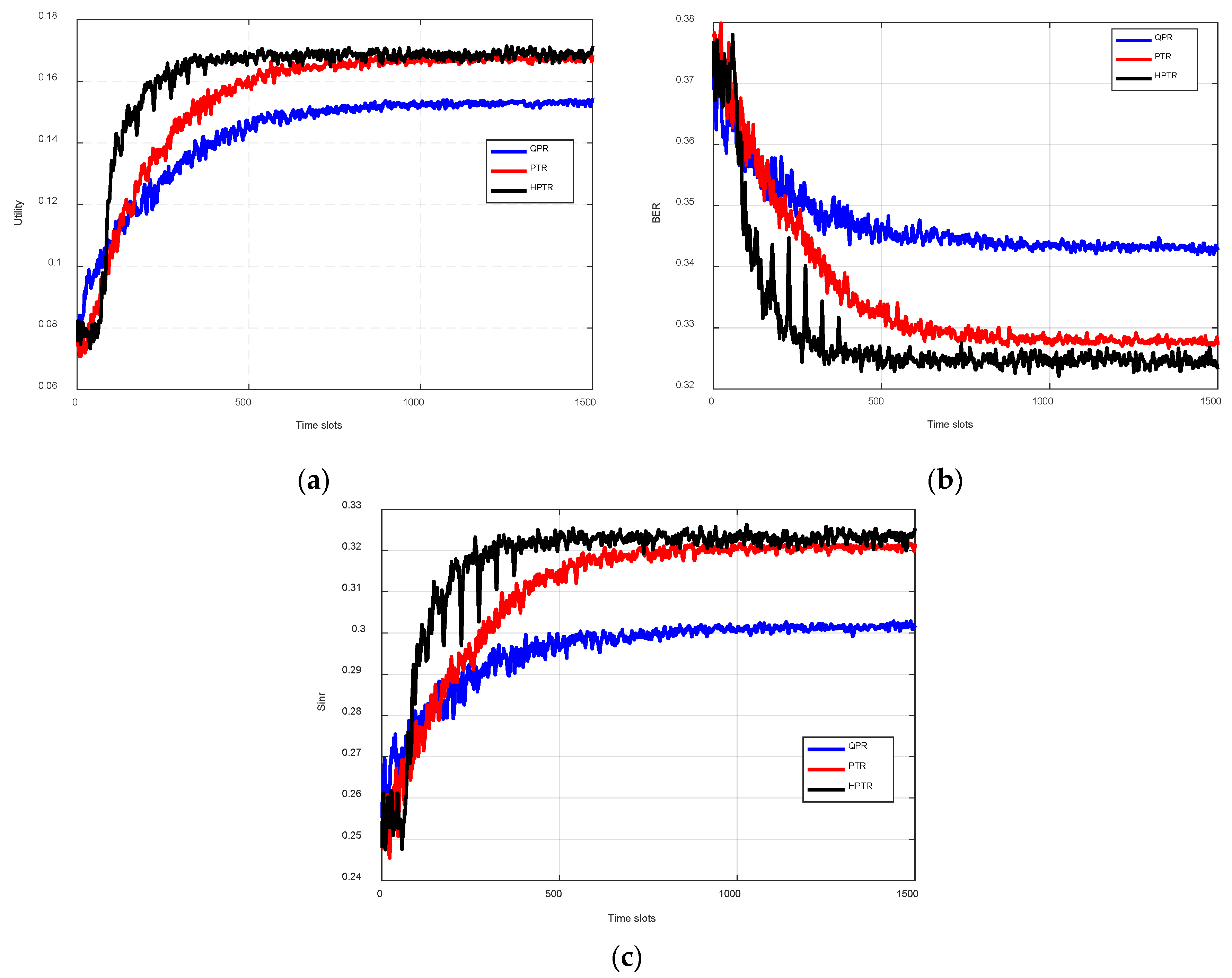
As shown in
Figure 3, the
SINR and transmitter utility of the proposed scheme were improved over time, while the message BER decreased. Specifically, from the initial stage to 1000 time slots, the message error rate of HPTR was reduced from 0.63 to 0.60, the
SINR increased from 0.24 to 0.275 (increased by 14.5%), and the transmitter utility was increased by 125%. In comparison to QPR, the proposed scheme exhibited a higher
SINR, improved transmitter utility, and a lower BER. For instance, at 1000 time slots, the HPTR scheme improved the transmitter utility by 12.5% and the SNR by 3.77% and reduced the bit error rate by 1.6%, compared with those of QPR. This improvement is attributed to the transfer learning technology employed by HPTR, which leverages anti-jamming experiences from similar UACNs. In the initial phase of transmitter strategy optimization, HPTR mitigates the inefficiencies of blind random exploration by incorporating additional experience. Furthermore, the hybrid strategy-based reinforcement learning algorithm optimizes the transmitter’s strategy to confuse the jammer, preventing it from executing precise attacks, thereby enhancing anti-jamming communication performance. Compared with PTR, the proposed HPTR method requires approximately 500 times more slots to converge to the optimal policy. The policy is then used until the network state or attack strategy changes for faster convergence due to the anti-jamming experience accumulated by HPTR via transfer learning.



{kind=link}
{kind=link}
{kind=link}