
Quadruped Robot Locomotion Based on Deep Learning Rules †



Abstract
1. Introduction
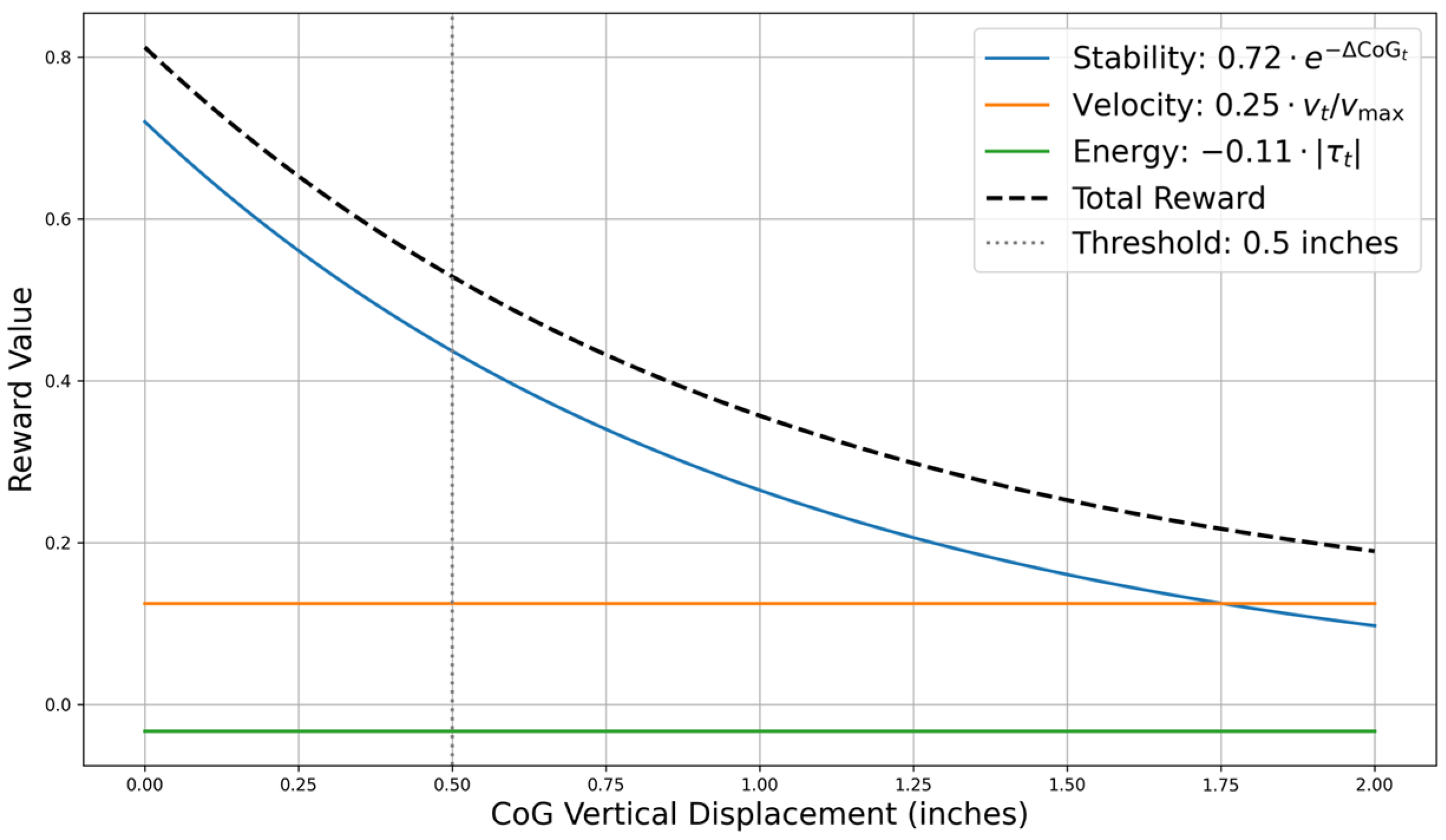
- A hybrid reward function prioritizing CoG stability, energy efficiency, and velocity, formalized as , where quantifies vertical displacement [15].
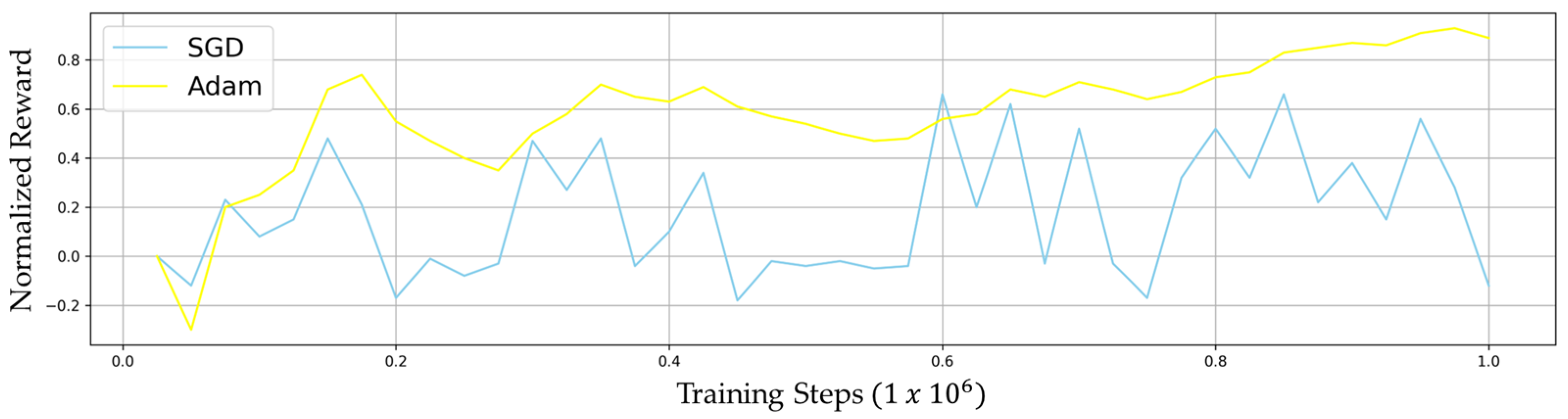
- Rigorous benchmarking of optimization methodologies (Adam vs. SGD), demonstrating Adam’s superiority in policy convergence.
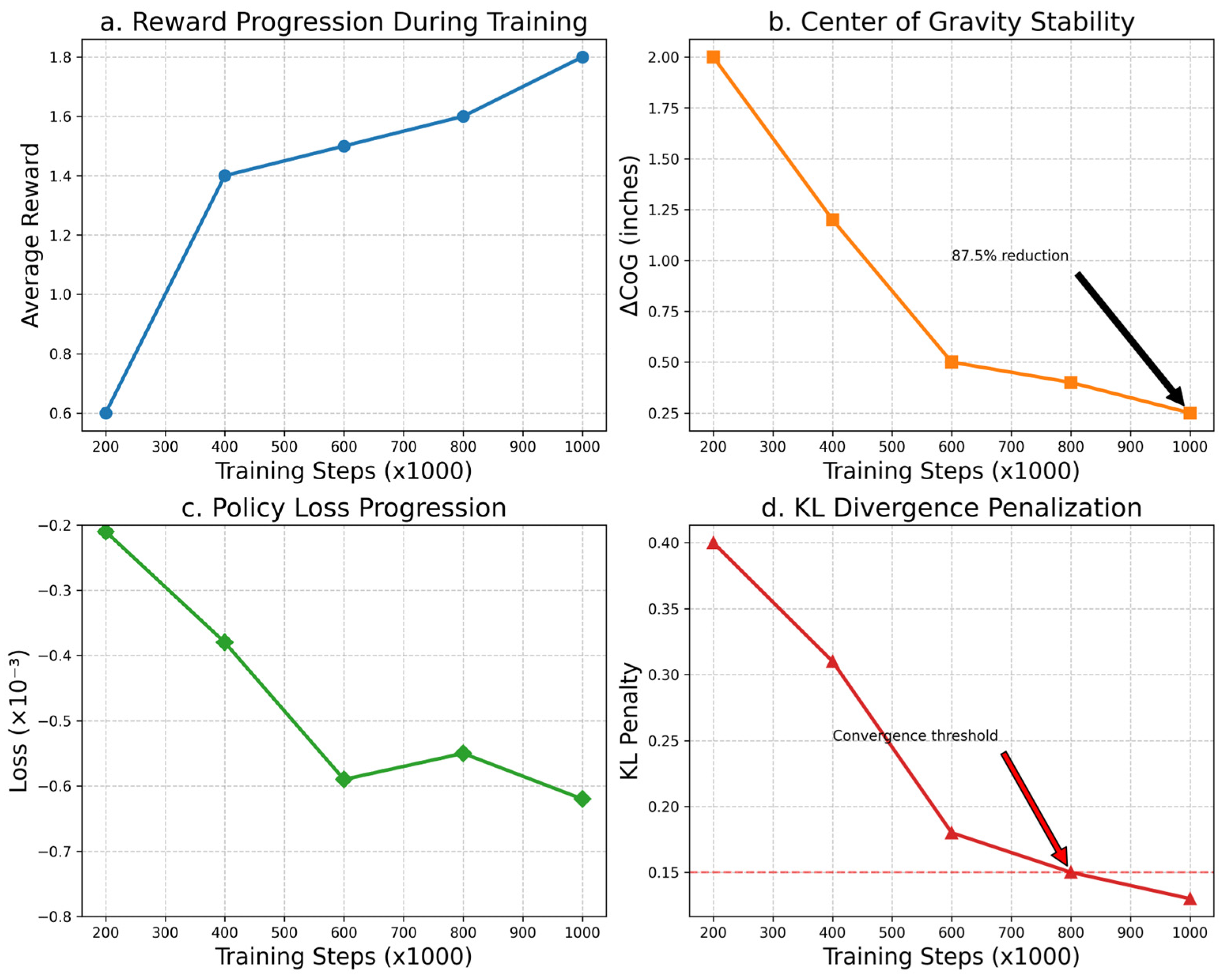
- A four-metric evaluation protocol assessing reward progression, CoG deviation, policy loss, and KL-divergence penalties over 1 M training steps.
2. Materials and Methods
2.1. PPO Framework Implementation
2.2. Reward Function Design
2.3. Artificial Neural Network Architecture
2.4. Simulation Training Pipeline
| Algorithm 1. PPO: Actor–Critic style [12] |
| 1: for iteraction = 1, 2, … do 2: for actor = 1, 2, …, N do 3: Run policy in enviromment for T timesteps 4: Compute advantage estimates 5: end for 6: Optimize surrogate L wrt θ, with K epochs and minibatch size 7: 8: end for |
2.5. Deployment Model
| Algorithm 2. runner() function |
| 1: observation = reset() 2: while (done) 3: action = agent (observations) 4: observation, reward, done, information = step(action) 5: render() |
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Raibert, M.; Blankespoor, K.; Nelson, G.; Playter, R. BigDog, the Rough-Terrain Quadruped Robot. IFAC Proc. 2008, 41, 10822–10825. [Google Scholar] [CrossRef]
- Abdulwahab, A.H.; Mazlan, A.Z.A.; Hawary, A.F.; Hadi, N.H. Quadruped Robots Mechanism, Structural Design, Energy, Gait, Stability, and Actuators: A Review Study. Int. J. Mech. Eng. Robot. Res. 2023, 12, 385–395. [Google Scholar] [CrossRef]
- Kalakrishnan, M.; Buchli, J.; Pastor, P.; Mistry, M.; Schaal, S. Fast, Robust Quadruped Locomotion Over Challenging Terrain. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, Alaska, 4–8 May 2010; pp. 2665–2670. [Google Scholar] [CrossRef]
- Di Carlo, J.; Wensing, P.M.; Katz, B.; Bledt, G.; Kim, S. Dynamic Locomotion in MIT Cheetah 3 Through Convex MPC. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning Agile and Dynamic Motor Skills for Legged Robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Kohl, N.; Stone, P. Policy Gradient Reinforcement Learning for Fast Quadrupedal Locomotion. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA’04 2004, New Orleans, LA, USA, 26 April–1 May 2004; pp. 2619–2624. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Bai, Y.; Hafner, D.; Bohez, S.; Vanhoucke, V. Sim-to-Real: Learning Agile Locomotion for Quadruped Robots. In Proceedings of the 14th Robotics: Science and Systems (RSS 2018), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar] [CrossRef]
- Zhu, W.; Guo, X.; Owaki, D.; Kutsuzawa, K.; Hayashibe, M. A Survey of Sim-to-Real Transfer Techniques Applied to RL for Bioinspired Robots. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 3444–3459. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; An, D. Reinforcement learning and neural network-based artificial intelligence control algorithm for self-balancing quadruped robot. J. Mech. Sci. Technol. 2021, 35, 307–322. [Google Scholar] [CrossRef]
- Cherubini, A.; Giannone, F.; Iocchi, L.; Nardi, D.; Palamara, P. Policy Gradient Learning for Quadruped Soccer Robots. Robot. Auton. Syst. 2010, 58, 872–878. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Kobayashi, T.; Sugino, T. Reinforcement learning for quadrupedal locomotion with design of continual–hierarchical cur-riculum. Eng. Appl. Artif. Intell. 2020, 95, 103869. [Google Scholar] [CrossRef]
- Fan, Y.; Pei, Z.; Wang, C.; Li, M.; Tang, Z.; Liu, Q. A Review of Quadruped Robots: Structure, Control, and Autonomous Motion. Adv. Intell. Syst. 2024, 6, 2300783. [Google Scholar] [CrossRef]
- Liu, M.; Xu, F.; Jia, K.; Yang, Q.; Tang, C. A Stable Walking Strategy of Quadruped Robot Based on Foot Trajectory Planning. In Proceedings of the 2016 3rd International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 8–10 July 2016; pp. 799–803. [Google Scholar] [CrossRef]
- Coumans, E.; Bai, Y. PyBullet Physics Engine. GitHub Repository, 2016–2021. Available online: https://github.com/bulletphysics/bullet3 (accessed on 10 January 2025).
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar] [CrossRef]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv 2016. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the Difficulty of Training Recurrent Neural Networks. Int. Conf. Mach. Learn. 2013, 28, 1310–1318. [Google Scholar]
- Bledt, G.; Powell, M.J.; Katz, B.; Di Carlo, J.; Wensing, P.M.; Kim, S. MIT Cheetah 3: Design and Control of a Robust, Dynamic Quadruped Robot. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2245–2252. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value | Description |
|---|---|---|
| Learning rate | 0.003 | Adam optimizer [19] |
| Discount factor | 0.985 | Reward horizon |
| GAE parameter | 0.95 | Bias–variance tradeoff [18] |
| Clipping range | 0.2 | Policy update constraint [12] |
| Minibatch size | 64 | Samples per update |
| Entropy coefficient | 0.01 | Exploration encouragement |
| Parameter | Range | Distribution |
|---|---|---|
| Joint friction | ±15% nominal | Uniform |
| Link masses | ±10% nominal | Gaussian |
| Ground friction | μ ∈ [0.4, 1.2] | Log-uniform |
| IMU noise | σ = 0.05 rad/s | Gaussian |
| Optimizer | Learning Rate | Convergence Steps | |
|---|---|---|---|
| SGD | 0.01 | 0.41 | >800 K |
| Adam | 0.0003 | 0.13 | 400 k |
| Steps | Reward Obtained | Average Height Variation (Inches) | Policy Loss Function | KL Penalty Adjustment |
|---|---|---|---|---|
| 200 K | 0.6 | 2.00 | −2.1 × 10−4 | 0.40 |
| 400 K | 1.40 | 1.20 | −3.8 × 10−4 | 0.31 |
| 600 K | 1.80 | 0.50 | −6.9 × 10−4 | 0.18 |
| 800 K | 1.60 | 0.40 | −5.5 × 10−4 | 0.15 |
| 1 M | 1.80 | 0.25 | −6.2 × 10−4 | 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Escudero-Villa, P.; Machado-Merino, G.D.; Paredes-Fierro, J. Quadruped Robot Locomotion Based on Deep Learning Rules. Eng. Proc. 2025, 87, 100. https://doi.org/10.3390/engproc2025087100
Escudero-Villa P, Machado-Merino GD, Paredes-Fierro J. Quadruped Robot Locomotion Based on Deep Learning Rules. Engineering Proceedings. 2025; 87(1):100. https://doi.org/10.3390/engproc2025087100
Chicago/Turabian StyleEscudero-Villa, Pedro, Gustavo Danilo Machado-Merino, and Jenny Paredes-Fierro. 2025. "Quadruped Robot Locomotion Based on Deep Learning Rules" Engineering Proceedings 87, no. 1: 100. https://doi.org/10.3390/engproc2025087100
APA StyleEscudero-Villa, P., Machado-Merino, G. D., & Paredes-Fierro, J. (2025). Quadruped Robot Locomotion Based on Deep Learning Rules. Engineering Proceedings, 87(1), 100. https://doi.org/10.3390/engproc2025087100