
Optimized Ensemble Learning for Enhanced Crop Recommendations: Leveraging ML for Smarter Agricultural Decision-Making †



Abstract
1. Introduction
2. Literature Review
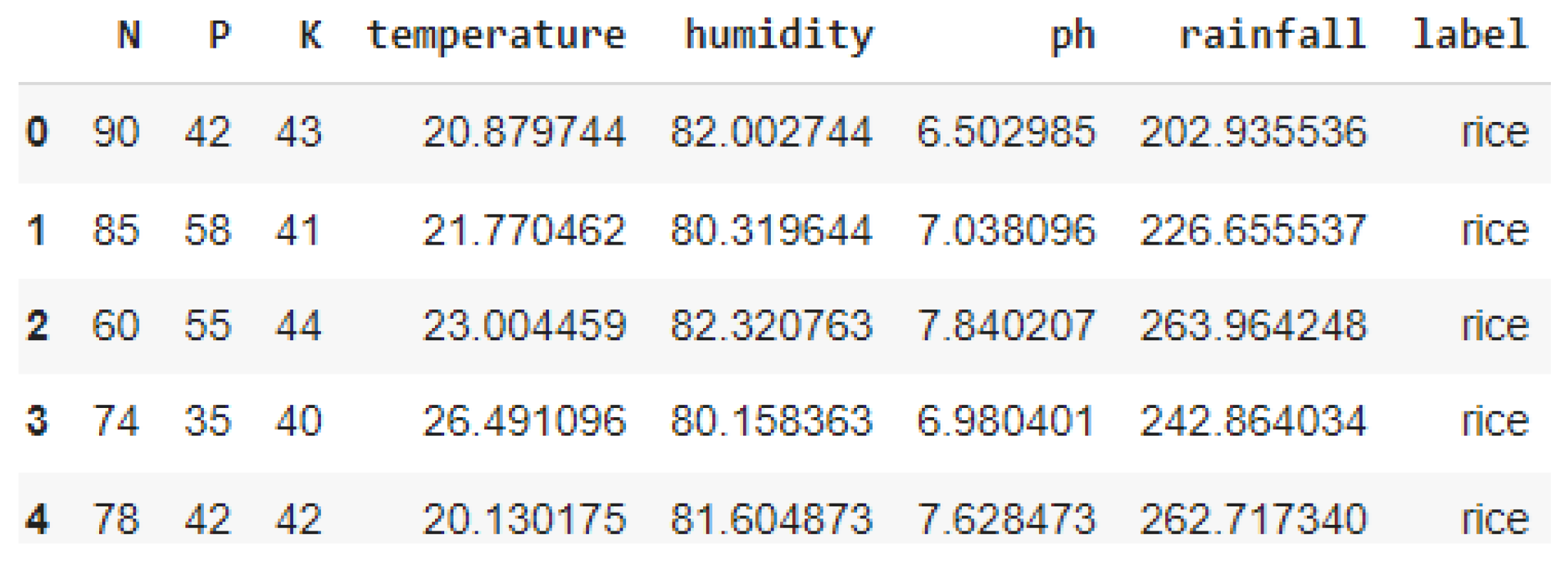
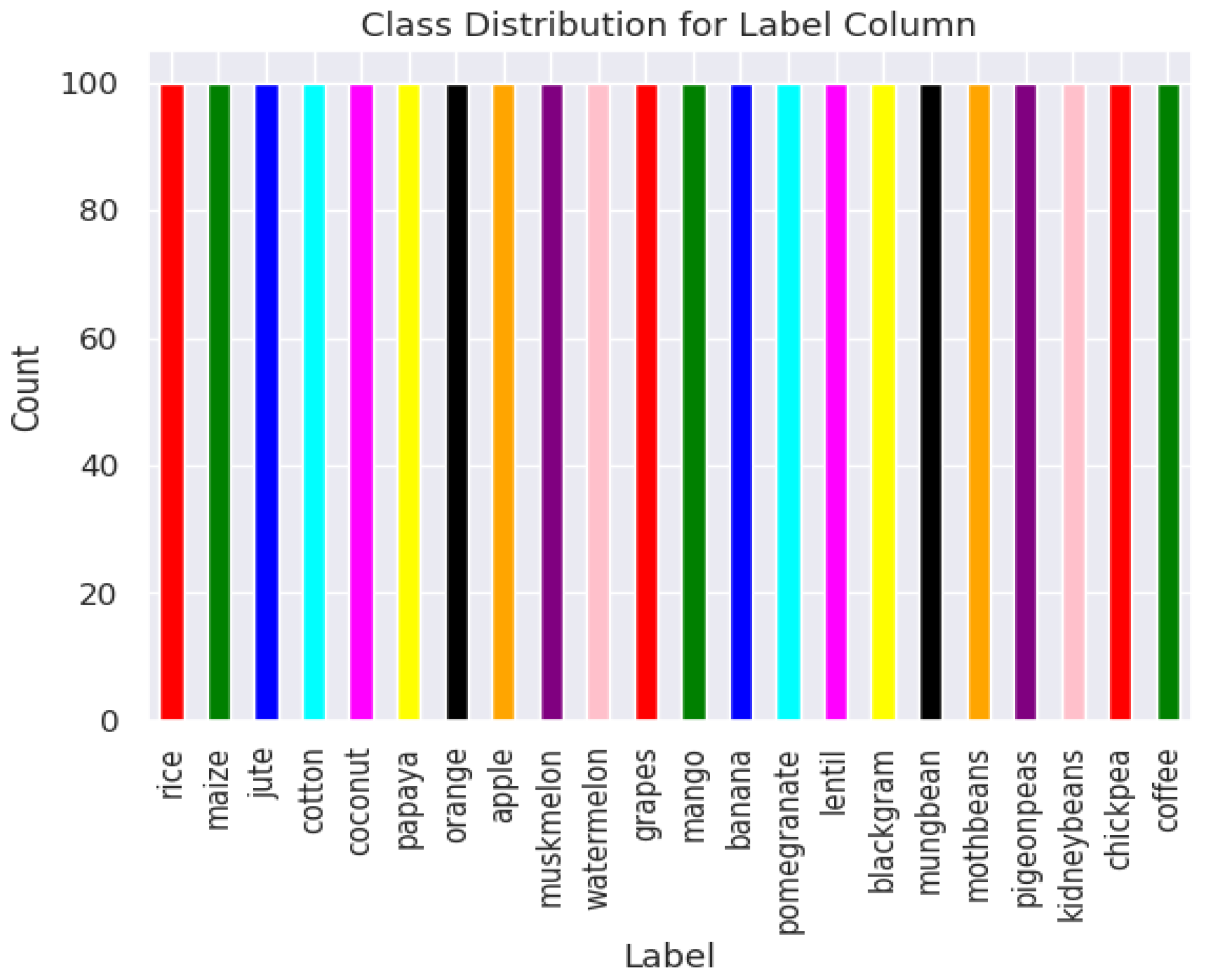
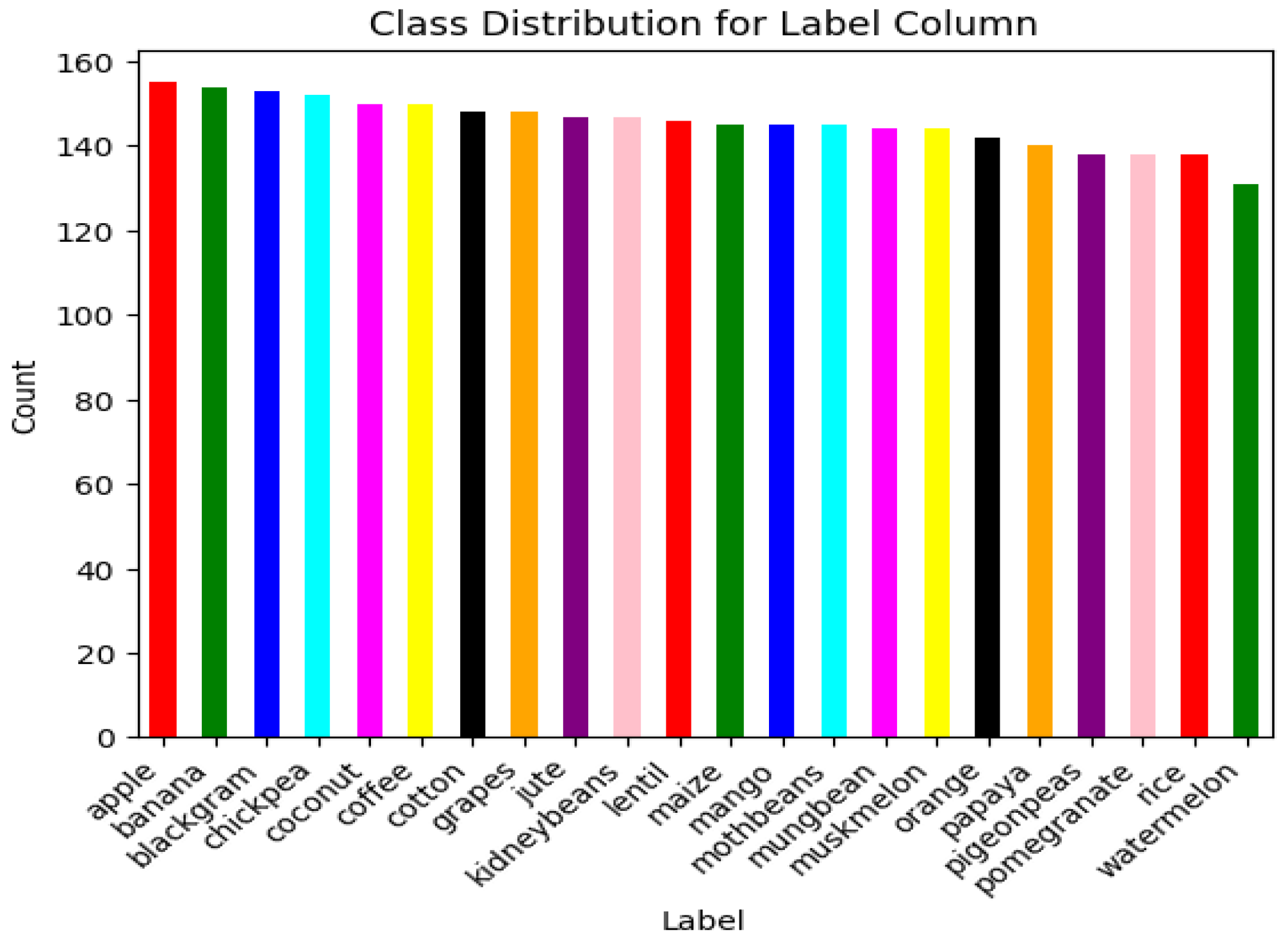
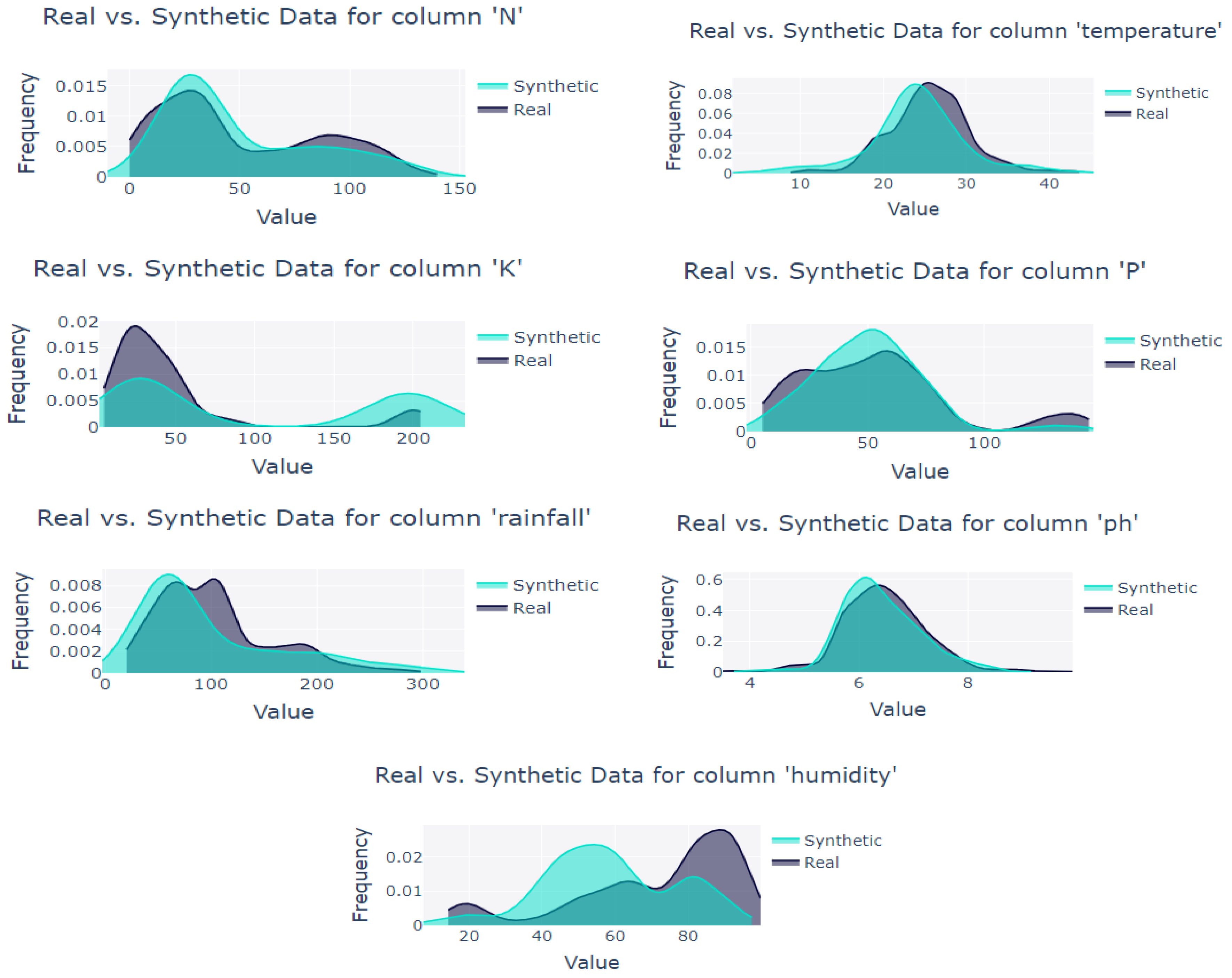
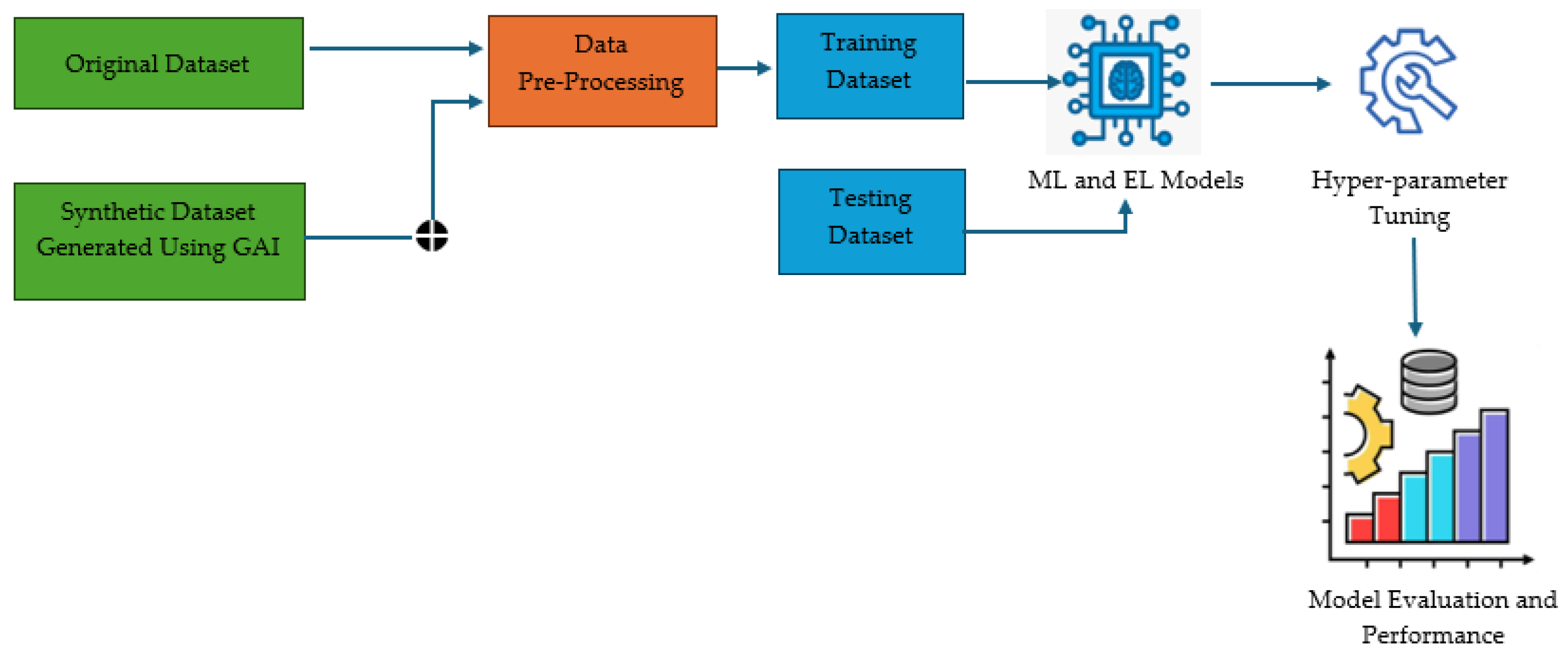
3. Data Pre-Processing
4. Methodology
5. Model Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Talaviya, T.; Shah, D.; Patel, N.; Yagnik, H.; Shah, M. Implementation of artificial intelligence in agriculture for optimisation of irrigation and application of pesticides and herbicides. Artif. Intell. Agric. 2020, 4, 58–73. [Google Scholar] [CrossRef]
- Dey, B.; Ferdous, J.; Ahmed, R. Machine learning based recommendation of agricultural and horticultural crop farming in India under the regime of NPK, soil pH and three climatic variables. Heliyon 2024, 10, e25112. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.R.; Oliullah, K.; Kabir, M.M.; Alom, M.; Mridha, M.F. Machine learning enabled IoT system for soil nutrients monitoring and crop recommendation. J. Agric. Food Res. 2023, 14, 100880. [Google Scholar] [CrossRef]
- Kiruthika, S.; Karthika, D. IOT-BASED professional crop recommendation system using a weight-based long-term memory approach. Meas. Sens. 2023, 27, 100722. [Google Scholar] [CrossRef]
- Ramzan, S.; Ghadi, Y.Y.; Aljuaid, H.; Mahmood, A.; Ali, B. An ingenious iot based crop prediction system using ML and EL. Comput. Mater. Contin. 2024, 79, 183–199. [Google Scholar] [CrossRef]
- Nikhil, U.V.; Pandiyan, A.M.; Raja, S.P.; Stamenkovic, Z. Machine Learning-Based Crop Yield Prediction in South India: Performance Analysis of Various Models. Computers 2024, 13, 137. [Google Scholar] [CrossRef]
- Jhajharia, K.; Mathur, P.; Jain, S.; Nijhawan, S. Crop Yield Prediction using Machine Learning and Deep Learning Techniques. Procedia Comput. Sci. 2023, 218, 406–417. [Google Scholar] [CrossRef]
- Raja, S.P.; Sawicka, B.; Stamenkovic, Z.; Mariammal, G. Crop Prediction Based on Characteristics of the Agricultural Environment Using Various Feature Selection Techniques and Classifiers. IEEE Access 2022, 10, 23625–23641. [Google Scholar] [CrossRef]
- Sharma, K.; Kumar, D. ML- and IoT-Based Crop Prediction System. In Innovations in Electrical and Electronic Engineering; Shaw, R.N., Siano, P., Makhilef, S., Ghosh, A., Shimi, S.L., Eds.; ICEEE 2023, Lecture Notes in Electrical Engineering; Springer: Singapore, 2024; Volume 1109. [Google Scholar] [CrossRef]
- Parween, S.; Pal, A.; Snigdh, I.; Kumar, V. An IoT and Machine Learning-Based Crop Prediction System for Precision Agriculture. In Emerging Technologies for Smart Cities; Bora, P.K., Nandi, S., Laskar, S., Eds.; Lecture Notes in Electrical Engineering; Springer: Singapore, 2021; Volume 765. [Google Scholar] [CrossRef]
- Bakthavatchalam, K.; Karthik, B.; Thiruvengadam, V.; Muthal, S.; Jose, D.; Kotecha, K.; Varadarajan, V. IoT Framework for Measurement and Precision Agriculture: Predicting the Crop Using Machine Learning Algorithms. Technologies 2022, 10, 13. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular Data Using Conditional GAN. Available online: https://github.com/DAI-Lab/CTGAN (accessed on 19 September 2024).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Gunasekaran, H.; Gladys, A.; Kanmani, D.; Macedo, R.; Wilfred Blessing, N.R. Brain Stroke Prediction Using Stacked Ensemble Model. J. Kejuruter. 2024, 36, 1759–1768. [Google Scholar] [CrossRef] [PubMed]
- Gunasekaran, H.; Deepa Kanmani, S.; Ebenezer, S.; Blessing, W.; Ramalakshmi, K. Detection of Lung and Colon Cancer using Average and Weighted Average Ensemble Models. EAI Endorsed Trans. Pervasive Health Tech. 2024, 10. [Google Scholar] [CrossRef]
- Elbasi, E.; Zaki, C.; Topcu, A.E.; Abdelbaki, W.; Zreikat, A.I.; Cina, E.; Shdefat, A.; Saker, L. Crop Prediction Model Using Machine Learning Algorithms. Appl. Sci. 2023, 13, 9288. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ‘19), Anchorage, AK, USA, 1–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2623–2631. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kaggle Dataset | Kaggle + Synthetic Dataset | |
|---|---|---|
| No. of rows | 2200 | 3200 |
| No. of samples per class | 100 | 161 |
| No. of classes for target variable | 22 | 22 |
| Model | Base Estimator | No. of Estimator | Meta-Classifier |
|---|---|---|---|
| Bagging | Random Forest | 100 | Nil |
| Boosting | Gradient | 100 | Nil |
| Voting | ExtraTreesClassifier, RandomForestClassifier, XGBClassifier, Decision Tree Classifier | Voting Method: hard | |
| Stacking | ExtraTreesClassifier, RandomForestClassifier, XGBClassifier, Decision Tree Classifier | LinearRegression |
| Method | Kaggle—Data Set | Synthetic Dataset | ||||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | Accuracy | Precision | Recall | |
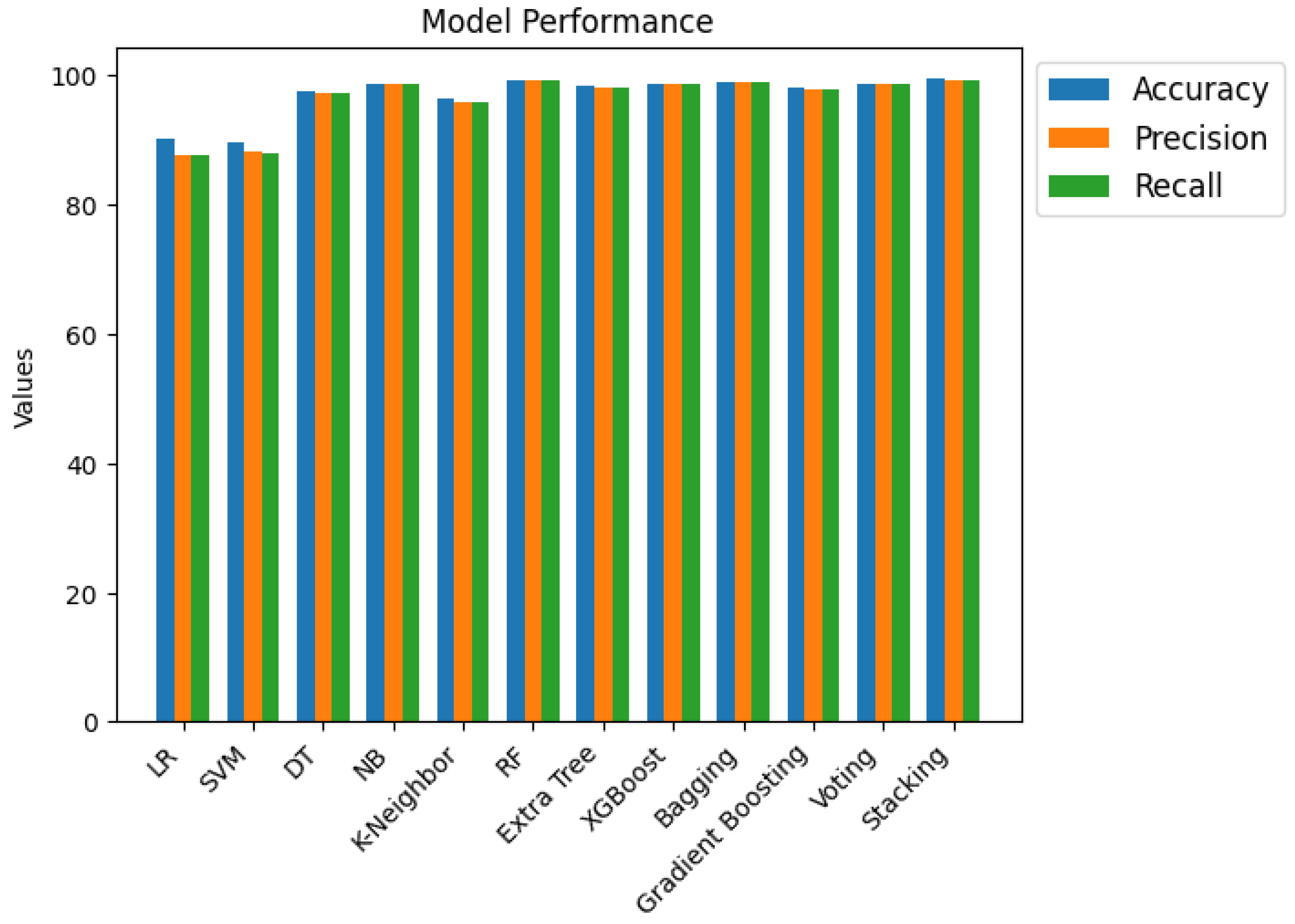
| LR | 90.20 | 87.5 | 87.621 | 55.85 | 55.54 | 57.42 |
| SVM | 89.74 | 88.18 | 87.83 | 46.26 | 46.10 | 45.31 |
| DT | 97.44 | 97.27 | 97.27 | 69.95 | 69.75 | 70.19 |
| NB | 98.70 | 98.64 | 98.63 | 57.68 | 57.49 | 58.25 |
| K-Neighbor | 96.40 | 95.91 | 95.90 | 70.38 | 70.29 | 71.55 |
| RF | 99.16 | 99.09 | 99.09 | 75.66 | 74.33 | 74.50 |
| Extra Tree | 98.36 | 98.18 | 98.19 | 75.41 | 74.33 | 74.46 |
| XGBoost | 98.71 | 98.64 | 98.63 | 73.64 | 72.64 | 72.76 |
| Bagging | 98.95 | 98.86 | 98.86 | 73.52 | 72.92 | 72.95 |
| Gradient Boosting | 98.10 | 97.73 | 97.74 | 72.27 | 70.38 | 70.60 |
| Voting | 98.68 | 98.64 | 98.63 | 73.94 | 72.78 | 72.85 |
| Stacking | 99.36 | 99.32 | 99.32 | 74.75 | 73.77 | 73.87 |
| Reference | Model | Dataset | Accuracy |
|---|---|---|---|
| Elbasi et al. (2023) [13] | Bayes net algorithm | Kaggle dataset with feature selection | 99.59% |
| S.P. Raja et al. (2022) [9] | Bagging | Kaggle with MRFE feature selection | 97.29% |
| Biplob et al. (2024) [3] | XGBoost | Kaggle dataset | 99.09% |
| Ramzan et al. (2023) [6] | KNN | Kaggle dataset | 97.81% |
| Kiruthika et al. (2023) [5] | IDCSO-WLSTM | Kaggle dataset | 92.68% |
| Bakthavatchalam et al. (2022) [12] | MLP | Kaggle dataset | 98% |
| Proposed | Stacking ensemble with Optuna optimization | Kaggle dataset | 99.43% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gunasekaran, H.; Kanmani, D.; Krishnamoorthi, R. Optimized Ensemble Learning for Enhanced Crop Recommendations: Leveraging ML for Smarter Agricultural Decision-Making. Eng. Proc. 2024, 82, 95. https://doi.org/10.3390/ecsa-11-20366
Gunasekaran H, Kanmani D, Krishnamoorthi R. Optimized Ensemble Learning for Enhanced Crop Recommendations: Leveraging ML for Smarter Agricultural Decision-Making. Engineering Proceedings. 2024; 82(1):95. https://doi.org/10.3390/ecsa-11-20366
Chicago/Turabian StyleGunasekaran, Hemalatha, Deepa Kanmani, and Ramalakshmi Krishnamoorthi. 2024. "Optimized Ensemble Learning for Enhanced Crop Recommendations: Leveraging ML for Smarter Agricultural Decision-Making" Engineering Proceedings 82, no. 1: 95. https://doi.org/10.3390/ecsa-11-20366
APA StyleGunasekaran, H., Kanmani, D., & Krishnamoorthi, R. (2024). Optimized Ensemble Learning for Enhanced Crop Recommendations: Leveraging ML for Smarter Agricultural Decision-Making. Engineering Proceedings, 82(1), 95. https://doi.org/10.3390/ecsa-11-20366