
Survey on Comprehensive Visual Perception Technology for Future Air–Ground Intelligent Transportation Vehicles in All Scenarios †

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Both Domestic and International Research
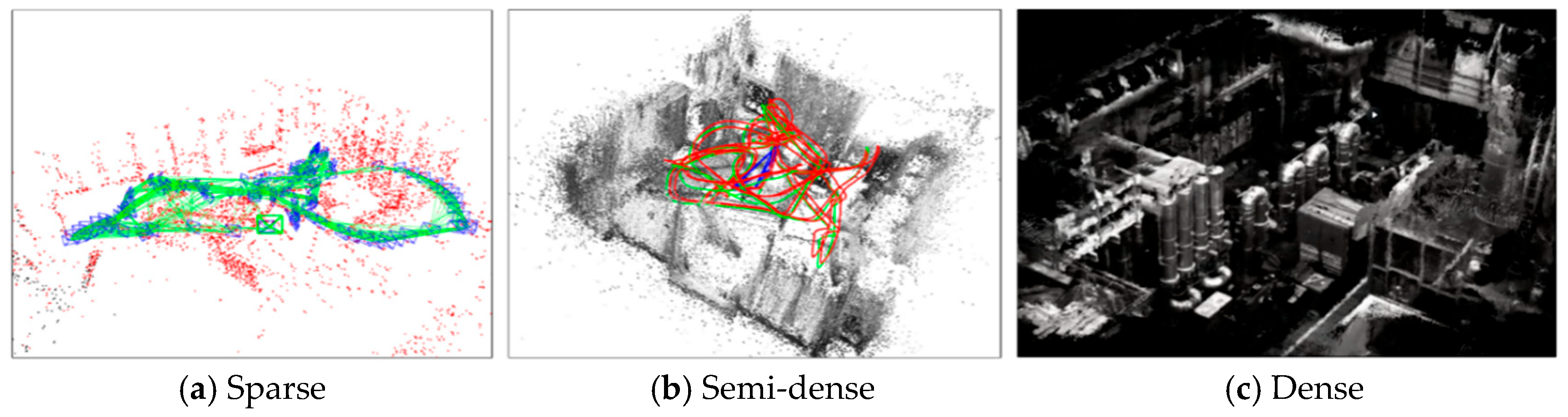
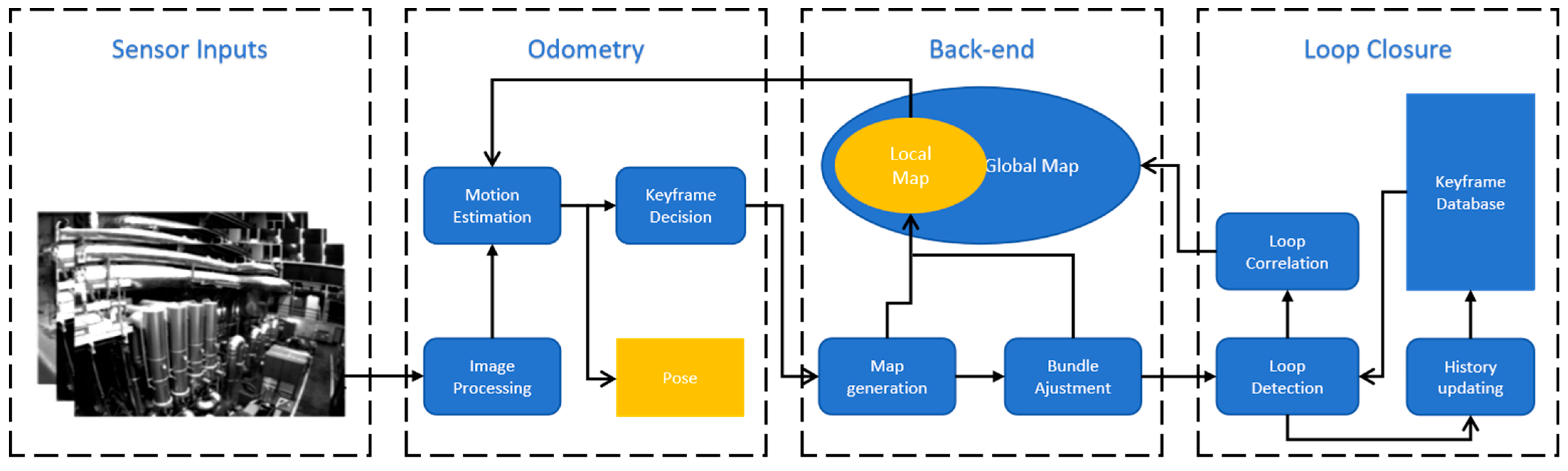
2.1. Environment Perception Algorithm Based on Visual SLAM
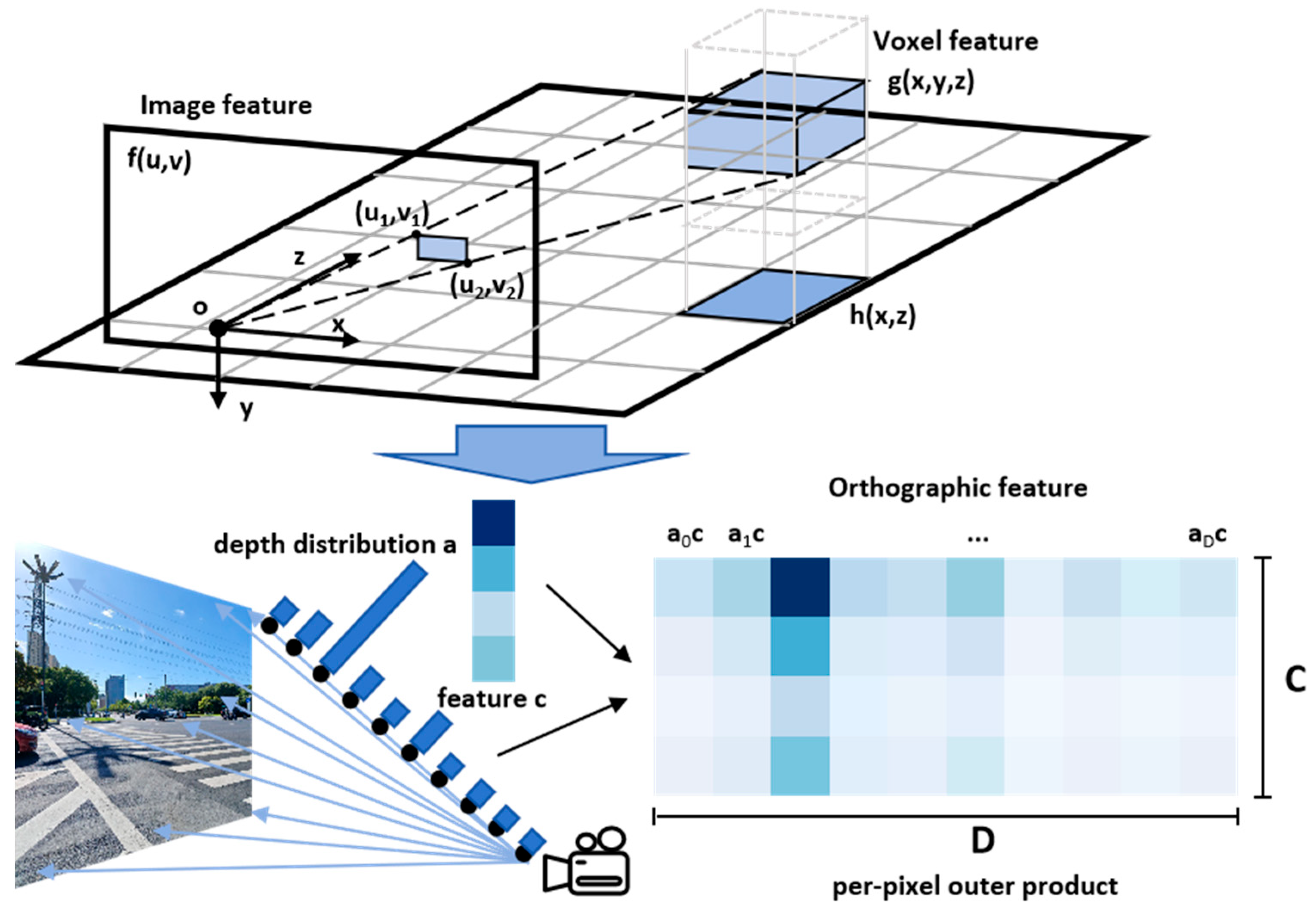
2.2. Environment Perception Algorithm Based on BEV
2.3. Environment Perception Algorithm Based on Image Enhancement
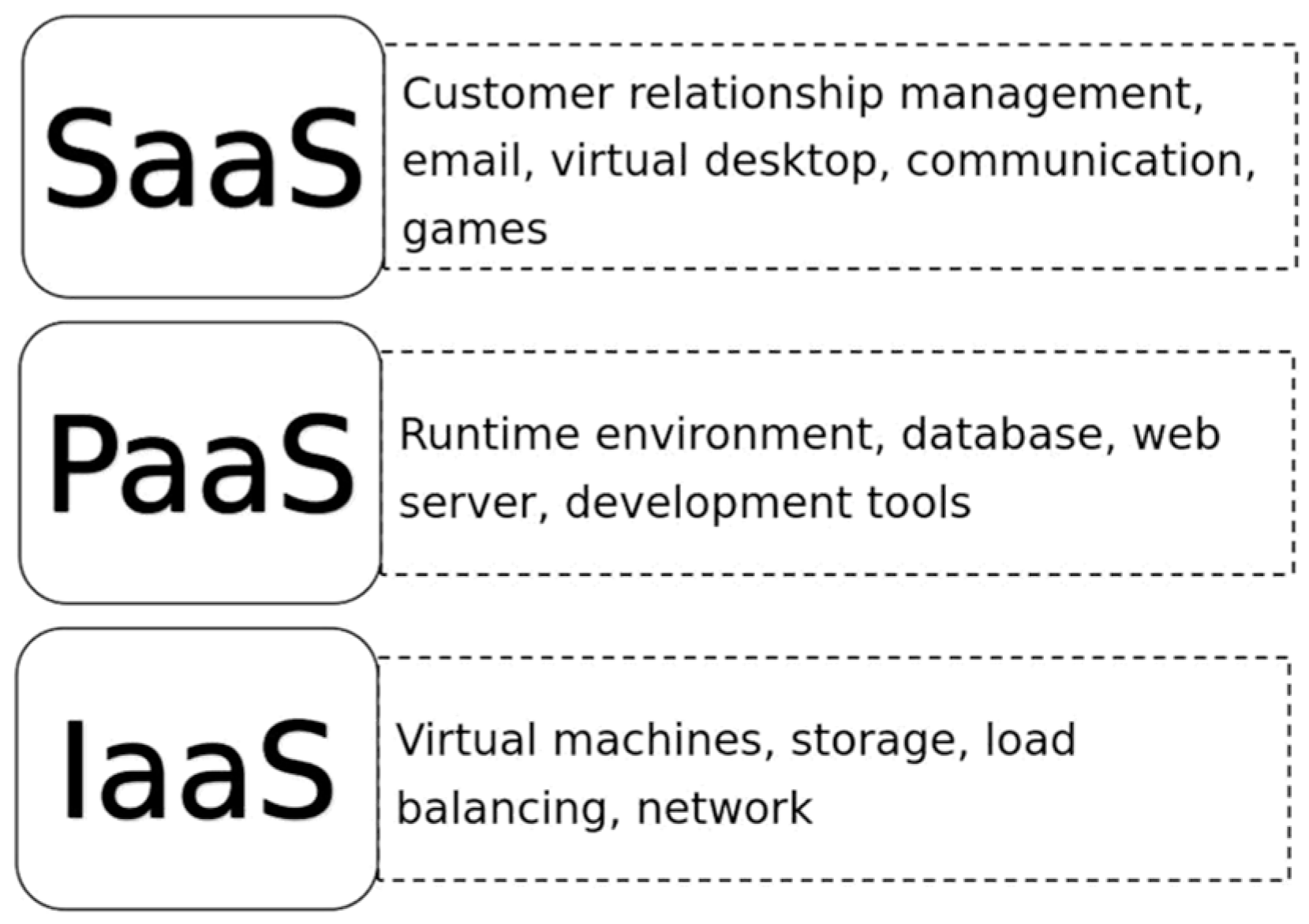
2.4. Use Cloud Computing to Optimize the Performance of Perception Algorithms
2.5. Use Edge Nodes to Rapidly Deploy Sensing Algorithms
3. Reference the Dataset
3.1. Cross-View Time (CVT) Dataset
3.2. NPS-Drones
3.3. FL-Drones
3.4. DTB70
3.5. UAV–Human Dataset
4. Comparative Analysis
4.1. Environment Perception Algorithm Based on Visual SLAM
4.2. Environment Awareness Algorithm Based on BEV
4.3. Environment Perception Algorithm Based on Image Enhancement
4.4. Use Cloud Computing to Optimize the Performance of Perception Algorithms
4.5. Rapid Deployment of Perception Algorithms Using Edge Nodes
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Demim, F.; Nemra, A.; Louadj, K. Robust SVSF-SLAM for unmanned vehicle in unknown environment. IFAC-Pap. 2016, 49, 386–394. [Google Scholar] [CrossRef]
- Ahmed, A.; Abdelkrim, N.; Mustapha, H. Smooth variable structure filter VSLAM. IFAC-Pap. 2016, 49, 205–211. [Google Scholar] [CrossRef]
- Demim, F.; Boucheloukh, A.; Nemra, A.; Louadj, K.; Hamerlain, M.; Bazoula, A.; Mehal, Z. A new adaptive smooth variable structure filter SLAM algorithm for unmanned vehicle. In Proceedings of the 2017 6th International Conference on Systems and Control (ICSC), Batna, Algeria, 7–9 May 2017; pp. 6–13. [Google Scholar]
- Demim, F.; Nemra, A.; Boucheloukh, A.; Louadj, K.; Hamerlain, M.; Bazoula, A. Robust SVSF-SLAM algorithm for unmanned vehicle in dynamic environment. In Proceedings of the 2018 International Conference on Signal, Image, Vision and Their Applications (SIVA), Guelma, Algeria, 26–27 November 2018; pp. 1–5. [Google Scholar]
- Elhaouari, K.; Allam, A.; Larbes, C. Robust IMU-Monocular-SLAM For Micro Aerial Vehicle Navigation Using Smooth Variable Structure Filter. Int. J. Comput. Digit. Syst. 2023, 14, 1063–1072. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar]
- Engel, J.; Sturm, J.; Cremers, D. Semi-dense visual odometry for a monocular camera. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1449–1456. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2016, 33, 249–265. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noel, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]
- Fu, Q.; Yu, H.; Lai, L.; Wang, J.; Peng, X.; Sun, W.; Sun, M. A robust RGB-D SLAM system with points and lines for low texture indoor environments. IEEE Sens. J. 2019, 19, 9908–9920. [Google Scholar] [CrossRef]
- Yang, S.; Scherer, S. Direct monocular odometry using points and lines. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3871–3877. [Google Scholar]
- Gomez-Ojeda, R.; Briales, J.; Gonzalez-Jimenez, J. PL-SVO: Semi-direct monocular visual odometry by combining points and line segments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4211–4216. [Google Scholar]
- Zuo, X.; Xie, X.; Liu, Y.; Huang, G. Robust visual SLAM with point and line features. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1775–1782. [Google Scholar]
- Shu, F.; Wang, J.; Pagani, A.; Stricker, D. Structure plp-slam: Efficient sparse mapping and localization using point, line and plane for monocular, rgb-d and stereo cameras. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2105–2112. [Google Scholar]
- Zhang, Z.; Rebecq, H.; Forster, C.; Scaramuzza, D. Benefit of large field-of-view cameras for visual odometry. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 801–808. [Google Scholar]
- Huang, H.; Yeung, S.K. 360vo: Visual odometry using a single 360 camera. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5594–5600. [Google Scholar]
- Matsuki, H.; Von Stumberg, L.; Usenko, V.; Stuckler, J.; Cremers, D. Omnidirectional DSO: Direct sparse odometry with fisheye cameras. IEEE Robot. Autom. Lett. 2018, 3, 3693–3700. [Google Scholar] [CrossRef]
- Harmat, A.; Sharf, I.; Trentini, M. Parallel tracking and mapping with multiple cameras on an unmanned aerial vehicle. In Proceedings of the 5th International Conference, Intelligent Robotics and Applications, ICIRA 2012, Montreal, QC, Canada, 3–5 October 2012; Proceedings, Part I 5. Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–432. [Google Scholar]
- Kuo, J.; Muglikar, M.; Zhang, Z.; Scaramuzza, D. Redesigning SLAM for arbitrary multi-camera systems. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2116–2122. [Google Scholar]
- Derpanis, K.G. Overview of the RANSAC Algorithm. Image Rochester NY 2010, 4, 2–3. [Google Scholar]
- Tan, W.; Liu, H.; Dong, Z.; Zhang, G.; Bao, H. Robust monocular SLAM in dynamic environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, SA, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar]
- Li, S.; Lee, D. RGB-D SLAM in dynamic environments using static point weighting. IEEE Robot. Autom. Lett. 2017, 2, 2263–2270. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Yebes, J.J.; Almazan, J.; Bergasa, L.M. On combining visual SLAM and dense scene flow to increase the robustness of localization and mapping in dynamic environments. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1290–1297. [Google Scholar]
- Bescos, B.; Facil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Wang, C.C.; Thorpe, C.; Thrun, S.; Hebert, M.; Durrant-Whyte, H. Simultaneous localization, mapping and moving object tracking. Int. J. Robot. Res. 2007, 26, 889–916. [Google Scholar] [CrossRef]
- Huang, J.; Yang, S.; Zhao, Z.; Lai, Y.K.; Hu, S.M. Clusterslam: A slam backend for simultaneous rigid body clustering and motion estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5875–5884. [Google Scholar]
- Huang, J.; Yang, S.; Mu, T.J.; Hu, S.M. ClusterVO: Clustering moving instances and estimating visual odometry for self and surroundings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2168–2177. [Google Scholar]
- Bescos, B.; Campos, C.; Tardos, J.D.; Neira, J. DynaSLAM II: Tightly-coupled multi-object tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Zhang, J.; Henein, M.; Mahony, R.; Ila, V. VDO-SLAM: A visual dynamic object-aware SLAM system. arXiv 2020, arXiv:2005.11052. [Google Scholar]
- Kim, Y.; Kum, D. Deep learning based vehicle position and orientation estimation via inverse perspective mapping image. In Proceedings of the IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; pp. 317–323. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Palazzi, A.; Borghi, G.; Abati, D.; Calderara, S.; Cucchiara, R. Learning to Map Vehicles into Bird’s Eye View. In Proceedings of Image Analysis and Processing-ICIAP; Battiato, S., Gallo, G., Schettini, R., Stanco, F., Eds.; Springer: Cham, Switzerland, 2017; Volume 10484, pp. 233–243. [Google Scholar]
- Zhu, M.; Zhang, S.; Zhong, Y.E. Monocular 3d vehicle detection using uncalibrated traffic cameras through homography. In Proceedings of the IROS, Prague, Czech Republic, 21 September–1 October 2021; pp. 3814–3821. [Google Scholar]
- Reiher, L.; Lampe, B.; Eckstein, L. A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird’s eye view. In Proceedings of the ITSC, Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Hou, Y.; Zheng, L.; Gould, S. Multiview detection with feature perspective transformation. In Proceedings of the ECCV; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer Nature: Glasgow, UK, 2020; Volume 12352, pp. 1–18. [Google Scholar]
- Garnett, N.; Cohen, R.; Pe’er, T.E. 3d-lanenet: End-to-end 3d multiple lane detection. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2921–2930. [Google Scholar]
- Gu, J.; Wu, B.; Fan, L.; Huang, J.; Cao, S.; Xiang, Z.; Hua, X. Homography loss for monocular 3d object detection. In Proceedings of the CoRR, New Orleans, LN, USA, 19–24 June 2022; pp. 1080–1089. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.E. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Zhu, X.; Yin, Z.; Shi, J.E. Generative adversarial frontal view to bird view synthesis. In Proceedings of the 3DV, Verona, Italy, 5–8 September 2018; pp. 454–463. [Google Scholar]
- Jiongjiong, G. Cloud Computing Architecture Technology and Practice; Tsinghua University Press: Beijing, China, 2014. [Google Scholar]
- Hairong, Z.; Jing, G. Cloud Computing Technology and Application. In Proceedings of the Inner Mongolia Communication; No. 1–2; Inner Mongolia Branch of China Unicom, Black Mountain Branch of China Unicom: Beijing, China, 2014; pp. 106–110. [Google Scholar]
- Luo, J.-Z.; Jia-Hui, J.; Song, A.-B.; Dong, F. Cloud computing: Architecture and key technologies. J. Commun. 2011, 32, 3–21. [Google Scholar]
- Buyya, R.; Yeo, C.S.; Venugopal, S.; Broberg, J.; Brandic, I. Cloud Computing and Emerging IT Platforms: Vision, Hype, and Reality for Delivering Computing as the 5th Utility. Future Gener. Comput. Syst. 2009, 25, 599–616. [Google Scholar] [CrossRef]
- Yu, H.; Jun, Z.; Wenxin, H. Ant colony optimization resource allocation algorithm based on cloud computing environment. J. East China Norm. Univ. 2010, 2010, 127–134. [Google Scholar]
- Zimmerman, J.B.; Pizer, S.M.; Staab, E.V.; Perry, J.R.; McCartney, W.; Brenton, B.C. An evaluation of the effectiveness of adaptive histogram equalization for contrast enhancement. IEEE Trans. Med. Imaging 1988, 7, 304–312. [Google Scholar] [CrossRef]
- Wang, Q.; Ward, R.K. Fast image/video contrast enhancement based on weighted thresholded histogram equalization. IEEE Trans. Consum. Electron. 2007, 53, 757–764. [Google Scholar] [CrossRef]
- Yang, S.; Oh, J.H.; Park, Y. Contrast enhancement using histogram equalization with bin underflow and bin overflow. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. 881–884. [Google Scholar]
- Kim, Y.T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar]
- Wan, Y.; Chen, Q.; Zhang, B.M. Image enhancement based on equal area dualistic sub-image histogram equalization method. IEEE Trans. Consum. Electron. 1999, 45, 68–75. [Google Scholar]
- Chen, S.; Ramli, A. Minimum mean brightness error bi-histogram equalization in contrast enhancement. IEEE Trans. Consum. Electron. 2003, 49, 1310–1319. [Google Scholar] [CrossRef]
- Kim, W.K.; You, J.M.; Jeong, J. Contrast enhancement using histogram equalization based on logarithmic mapping. Opt. Eng. 2012, 51, 067002. [Google Scholar] [CrossRef]
- Celik, T. Spatial entropy-based global and local image contrast enhancement. IEEE Trans. Image Process. 2014, 23, 5298–5308. [Google Scholar] [CrossRef]
- Lin, N. Wavelet transform and image processing. Hefei: Univ. Sci. Technol. China Press 2010, 6, 151–152. [Google Scholar]
- Ding, X. Research on Image Enhancement Based on Wavelet Transform. Master’s Thesis, Anhui University, Hefei, China, 2010. [Google Scholar]
- Demirel, H.; Anbarjafari, G. Image resolution enhancement by using discrete and stationary wavelet decomposition. IEEE Trans. Image Process. 2011, 20, 1458–1460. [Google Scholar] [CrossRef] [PubMed]
- Demirel, H.; Anbarjafari, G. Discrete wavelet transform based satellite image resolution enhancement. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1997–2004. [Google Scholar] [CrossRef]
- Łoza, A.; Bull, D.R.; Hill, P.R.; Achim, A.M. Automatic contrast enhancement of low-light images based on local statistics of wavelet coefficients. Digit. Signal Process. 2013, 23, 1856–1866. [Google Scholar]
- Cho, D.; Bui, T.D. Fast image enhancement in compressed wavelet domain. Signal Process. 2014, 98, 295–307. [Google Scholar] [CrossRef]
- Nasri, M.; Pour, H.N. Image denoising in the wavelet domain using a new adaptive thresholding function. Neurocomputing 2009, 72, 1012–1025. [Google Scholar] [CrossRef]
- Chang, S.; Yu, B.; Vetterli, M. Adaptive wavelet thresholding for image denoising and compression. IEEE Trans. Image Process. 2000, 9, 1532–1546. [Google Scholar] [CrossRef] [PubMed]
- Bhandari, A.K.; Kumar, A.; Singh, G.K. Improved knee transfer function and gamma correction based method for contrast and bringtness enhancement of satellite image. Int. J. Electron. Commun. 2015, 69, 579–589. [Google Scholar] [CrossRef]
- Se, E.K.; Jong, J.J.; Il, K.E. Image contrast enhancement using entropy scaling in wavelet domain. Signal Process. 2016, 127, 1–11. [Google Scholar]
- Demirel, H.; Ozcinar, C.; Anbarjafari, G. Satellite image contrast enhancement using discrete wavelet transform and singular value decomposition. IEEE Geosci. Remote Sens. Lett. 2010, 7, 333–337. [Google Scholar] [CrossRef]
- Bhutada, G.G.; Anand, R.S.; Saxena, S.C. Edge preserved image enhancement using adaptive fusion of miages denoised by wavelet and cruvelet transform. Digit. Signal Process. 2011, 21, 118–130. [Google Scholar] [CrossRef]
- Bhat, P.; Zitnick, C.L.; Cohen, M.; Curless, B. Gradient Shop: A gradient-domain optimization framework for image and video filtering. ACM Trans. Graph. 2010, 29, 1–14. [Google Scholar] [CrossRef]
- Bhat, P.; Curless, B.; Cohen, M.; Zitnick, C.L. Fourier analysis of the 2D screened poisson equation for gradient domain problems. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 114–128. [Google Scholar]
- Kong, P. Research on Image Denoising and Enhancement Based on Partial Differential Equations. Master’s Thesis, Nanjing University of Science and Technology: Nanjing, China, 2012. [Google Scholar]
- Wang, S. Research on Image Enhancement Technology Based on Partial Differential Equations. Master’s Thesis, Changchun University of Science and Technology, Changchun, China, 2012. [Google Scholar]
- Chao, W. Research on Image Processing Techniques Based on Variational Problems and Partial Differential Equations. Ph.D. Thesis, University of Science and Technology of China, Hefei, China, 2007. [Google Scholar]
- Chan, T.F.; Shen, J.H. Image Processing and Analysis; Chen, W.B.; Cheng, J., Translators; Science Press: Beijing, China, 2011. [Google Scholar]
- Kim, J.H.; Kim, J.H.; Jung, S.W.; Noh, C.K.; Ko, S.J. Novel contrast enhancement scheme for infrared image using detail-preserving stretching. Opt. Eng. 2011, 50, 077002. [Google Scholar] [CrossRef]
- Xizhen, H.; Jian, Z. Enhancing image texture and contrast with Partial Differential Equation. Opt. Precis. Eng. 2012, 20, 1382–1388. [Google Scholar]
- Land, E. The Retinex. Am. Sci. 1964, 52, 247–264. [Google Scholar]
- Land, E.; Mccann, J. Ligntness and Retinex theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Gonzales, A.M.; Grigoryan, A.M. Fast Retinex for color image enhancement: Methods and algorithms. SPIE 2015, 9411, 129–140. [Google Scholar]
- Shen, C.T.; Hwang, W.L. Color image enhancement using Retinex with robust envelope. In Proceedings of the 16th IEEE International Conference on Image Process, Cairo, Egypt, 7–10 November 2009; pp. 3141–3144. [Google Scholar]
- Wharton, E.; Panetta, K.; Agaian, S. Human visual system-based image enhancement and logarithmic contrast measure. IEEE Trans. Syst. Man Cybern. Part B-Cybern. 2008, 38, 174–188. [Google Scholar]
- Jobson, D.; Rahman, Z.; Woodell, G. A multiscale Retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Zhao, H.; Xiao, C.; Yu, J.; Bai, L. Retinex nighttime color image enhancement under Markov random field model. Opt. Precis. Eng. 2014, 22, 1048–1055. [Google Scholar] [CrossRef]
- Fu, X.; Lin, Q.; Guo, W.; Huang, Y.; Zeng, D.; Ding, X. A novel Retinex algorithm based on alternation direction optimization. In Proceedings of the Sixth International Symposium on Precision Mechanical Measurements, Guiyang, China, 8–12 August 2013; pp. 761–766. [Google Scholar]
- Chang, H.B.; Ng, M.K.; Wang, W.; Zeng, T. Retinex image enhancement via a learned dictionary. Opt. Eng. 2015, 54, 013107. [Google Scholar] [CrossRef]
- Shi, W.; Pallis, G.; Xu, Z. Edge Computing [Scanning the Issue]. Proc. IEEE 2019, 107, 1474–1481. [Google Scholar] [CrossRef]
- Saidi, K.; Bardou, D. Task scheduling and VM placement to resource allocation in cloud computing: Challenges and opportunities. Clust. Comput. 2023, 26, 3069–3087. [Google Scholar] [CrossRef]
- Alkhanak, E.N.; Lee, S.P. A hyper-heuristic cost optimization approach for scientific workflow scheduling in cloud computing. Futur. Gener. Comput. Syst. 2018, 86, 480–506. [Google Scholar] [CrossRef]
- Gupta, I.; Kaswan, A.; Jana, P.K. A flower pollination algorithm based task scheduling in cloud computing. In Proceedings of the Computational Intelligence, Communications, and Business Analytics: First International Conference, CICBA 2017, Kolkata, India, 24–25 March 2017; Revised Selected Papers, Part II. Springer: Singapore, 2017; pp. 97–107. [Google Scholar]
- Mandal, R.; Mondal, M.K.; Banerjee, S.; Srivastava, G.; Alnumay, W.; Ghosh, U.; Biswas, U. MECPVMS: An SLA aware energy-efficient virtual machine selection policy for green cloud computing. Clust. Comput. 2023, 26, 651–665. [Google Scholar] [CrossRef]
- Narendrababu Reddy, G.; Phani Kumar, S. Multi objective task scheduling algorithm for cloud computing using whale optimization technique. In Proceedings of the Smart and Innovative Trends in Next Generation Computing Technologies: 3rd International Conference, NGCT 2017, Dehradun, India, 30–31 October 2017; Revised Selected Papers, Part I 3. Springer: Singapore; pp. 286–297. [Google Scholar]
- Rimal, B.P.; Maier, M. Workflow scheduling in multi-tenant cloud computing environments. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 290–304. [Google Scholar] [CrossRef]
- Zhang, L.; Li, K.; Li, C.; Li, K. Bi-objective workflow scheduling of the energy consumption and reliability in heterogeneous computing systems. Inf. Sci. 2017, 379, 241–256. [Google Scholar] [CrossRef]
- Nabi, S.; Ahmad, M.; Ibrahim, M.; Hamam, H. ADPSO: Adaptive PSO-based task scheduling approach for cloud computing. Sensors 2022, 22, 920. [Google Scholar] [CrossRef] [PubMed]
- Abed-Alguni, B.H.; Alawad, N.A. Distributed grey wolf optimizer for scheduling of workflow applications in cloud environments. Appl. Soft Comput. 2021, 102, 107113. [Google Scholar] [CrossRef]
- Deng, Y.; Chen, Z.; Yao, X.; Hassan, S.; Ibrahim, A.M. Parallel offloading in green and sustainable mobile edge computing for delay-constrained IoT system. IEEE Trans. Veh. Technol. 2019, 68, 12202–12214. [Google Scholar] [CrossRef]
- Li, M.; Cheng, N.; Gao, J.; Wang, Y.; Zhao, L.; Shen, X. Energy-efficient UAV-assisted mobile edge computing: Resource allocation and trajectory optimization. IEEE Trans. Veh. Technol. 2020, 69, 3424–3438. [Google Scholar] [CrossRef]
- Guo, F.; Zhang, H.; Ji, H.; Li, X.; Leung, V.C. An efficient computation offloading management scheme in the densely deployed small cell networks with mobile edge computing. IEEE/ACM Trans. Netw. 2018, 26, 2651–2664. [Google Scholar] [CrossRef]
- Xu, X.; Liu, Q.; Luo, Y.; Peng, K.; Zhang, X.; Meng, S.; Qi, L. A computation offloading method over big data for IoT-enabled cloud-edge computing. Futur. Gener. Comput. Syst. 2019, 95, 522–533. [Google Scholar] [CrossRef]
- Huang, L.; Feng, X.; Feng, A.; Huang, Y.; Qian, L.P. Distributed deep learning-based offloading for mobile edge computing networks. Mob. Netw. Appl. 2018, 27, 1123–1130. [Google Scholar] [CrossRef]
- Min, M.; Xiao, L.; Chen, Y.; Cheng, P.; Wu, D.; Zhuang, W. Learning-based computation offloading for IoT devices with energy harvesting. IEEE Trans. Veh. Technol. 2019, 68, 1930–1941. [Google Scholar] [CrossRef]
- Liu, X.; Yu, J.; Wang, J.; Gao, Y. Resource allocation with edge computing in IoT networks via machine learning. IEEE Internet Things J. 2020, 7, 3415–3426. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Zhan, W.; Ni, Q.; Georgalas, N. Computation offloading in multi-access edge computing using a deep sequential model based on reinforcement learning. IEEE Commun. Mag. 2019, 57, 64–69. [Google Scholar] [CrossRef]
- Zhang, K.; Zhu, Y.; Leng, S.; He, Y.; Maharjan, S.; Zhang, Y. Deep learning empowered task offloading for mobile edge computing in urban informatics. IEEE Internet Things J. 2019, 6, 7635–76471. [Google Scholar] [CrossRef]
- Yu, S.; Wang, X.; Langar, R. Computation offloading for mobile edge computing: A deep learning approach. In Proceedings of the 2017 IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017; pp. 1–6. [Google Scholar]
- Konečný, J.; McMahan, B.; Ramage, D. Federated optimization: Distributed optimization beyond the datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Liu, K.-H.; Hsu, Y.-H.; Lin, W.-N.; Liao, W. Fine-grained offloading for multi-access edge computing with actor-critic federated learning. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Pan, C.; Wang, Z.; Liao, H.; Zhou, Z.; Wang, X.; Tariq, M.; Al-Otaibi, S. Asynchronous federated deep reinforcement learning-based URLLC-aware computation offloading in space-assisted vehicular networks. IEEE Trans. Intell. Transp. Syst. 2022, 24, 7377–7389. [Google Scholar] [CrossRef]
- Qu, G.; Wu, H.; Cui, N. Joint blockchain and federated learning-based offloading in harsh edge computing environments. In Proceedings of the International Workshop on Big Data in Emergent Distributed Environments, Virtual Event, China, 20 June 2021; pp. 1–6. [Google Scholar]
- Zhang, L.; Jiang, Y.; Zheng, F.-C.; Bennis, M.; You, X. Computation offloading and resource allocation in F-RANS: A federated deep reinforcement learning approach. In Proceedings of the 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, South Korea, 20 May 2022; pp. 97–102. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, G.; Chen, F.; Yang, S.; Zhou, F.; Xu, B. Survey on Comprehensive Visual Perception Technology for Future Air–Ground Intelligent Transportation Vehicles in All Scenarios. Eng. Proc. 2024, 80, 50. https://doi.org/10.3390/engproc2024080050
Ren G, Chen F, Yang S, Zhou F, Xu B. Survey on Comprehensive Visual Perception Technology for Future Air–Ground Intelligent Transportation Vehicles in All Scenarios. Engineering Proceedings. 2024; 80(1):50. https://doi.org/10.3390/engproc2024080050
Chicago/Turabian StyleRen, Guixin, Fei Chen, Shichun Yang, Fan Zhou, and Bin Xu. 2024. "Survey on Comprehensive Visual Perception Technology for Future Air–Ground Intelligent Transportation Vehicles in All Scenarios" Engineering Proceedings 80, no. 1: 50. https://doi.org/10.3390/engproc2024080050
APA StyleRen, G., Chen, F., Yang, S., Zhou, F., & Xu, B. (2024). Survey on Comprehensive Visual Perception Technology for Future Air–Ground Intelligent Transportation Vehicles in All Scenarios. Engineering Proceedings, 80(1), 50. https://doi.org/10.3390/engproc2024080050