
Research on Text Information Extraction and Analysis of Civil Transport Aircraft Accidents Based on Large Language Model †


Abstract
1. Introduction
2. Development of Research Questions
3. Methodology
3.1. Jieba Chinese Word Segmentation Technology
- Jieba segmentation employs an algorithm based on the trie tree structure. Utilizing this algorithm, Jieba efficiently performs word graph scanning. It uses the scanning to identify all possible word formations from the characters in a sentence, creating a directed acyclic graph (DAG) of these possibilities, which lays the foundation for the next step.
- The implementation of the maximum probability path in Jieba segmentation uses a dynamic programming approach. This dynamic programming method identifies the combination with the highest word frequency for optimal segmentation.
- For words not found in the built-in dictionary of Jieba segmentation, the Viterbi algorithm is employed, incorporating the hidden Markov model (HMM) used to form words from Chinese characters.
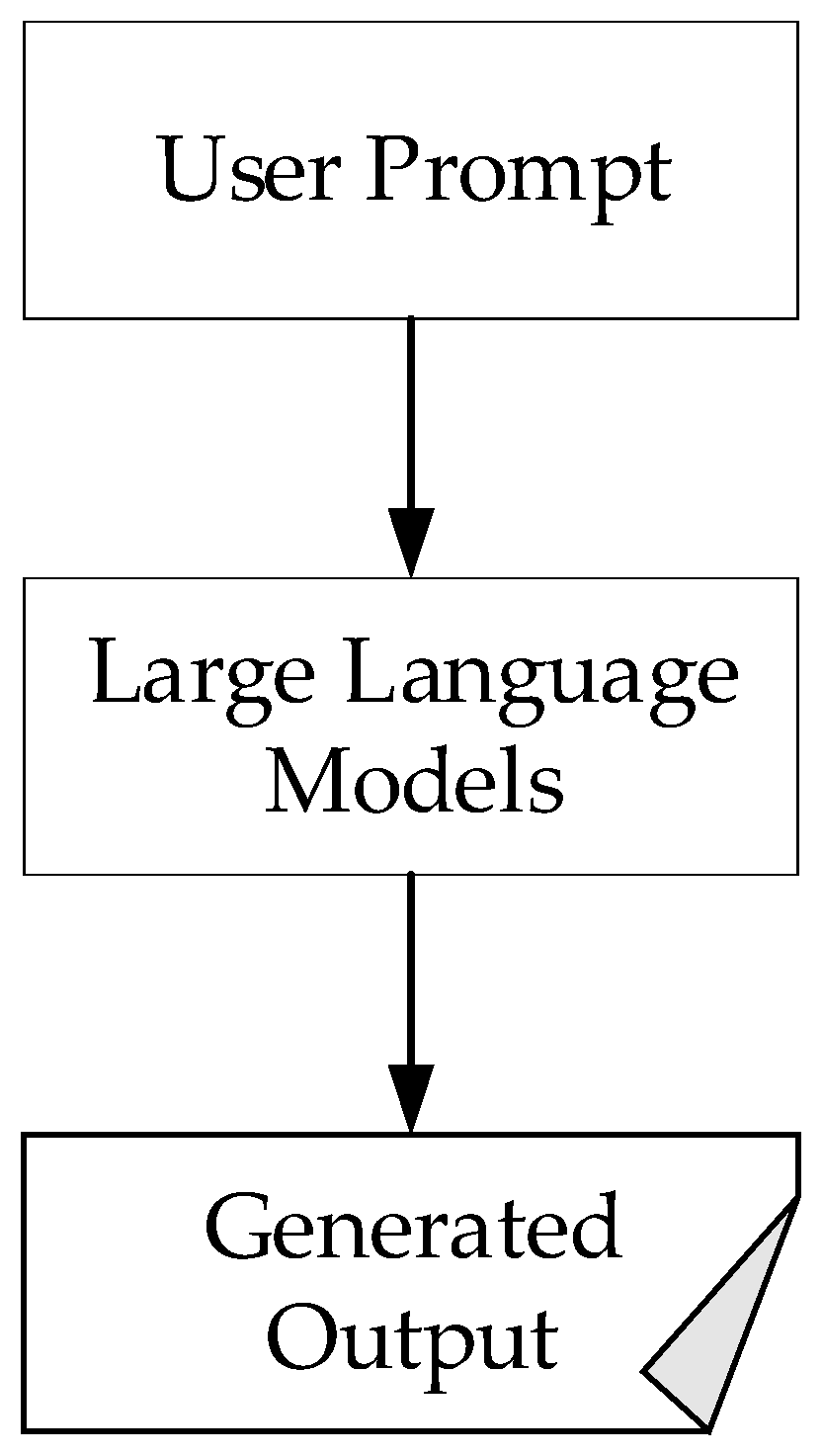
3.2. Large Models and Prompt Engineering
3.3. Term Frequency–Inverse Document Frequency (TF-IDF)
4. Results and Analysis
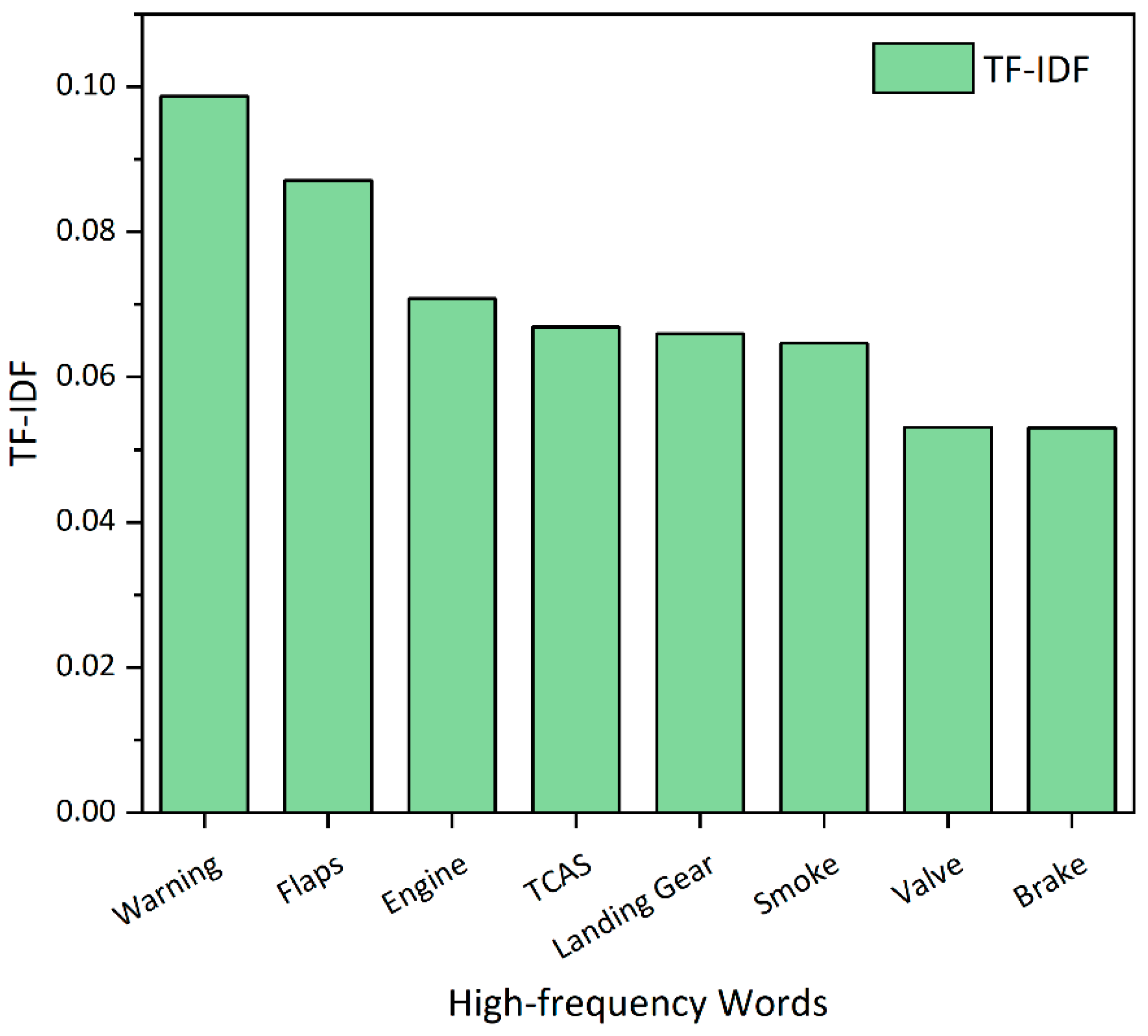
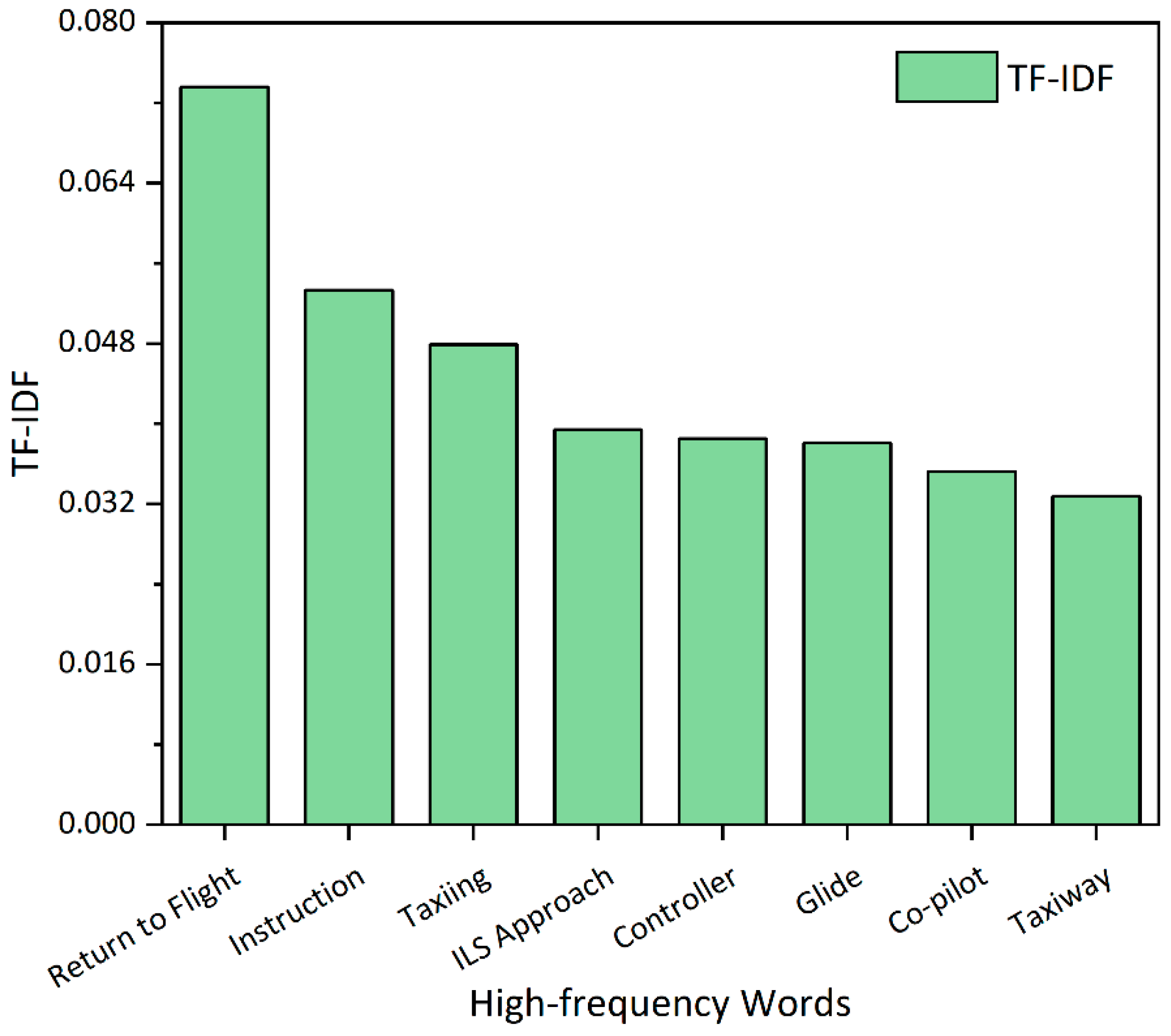
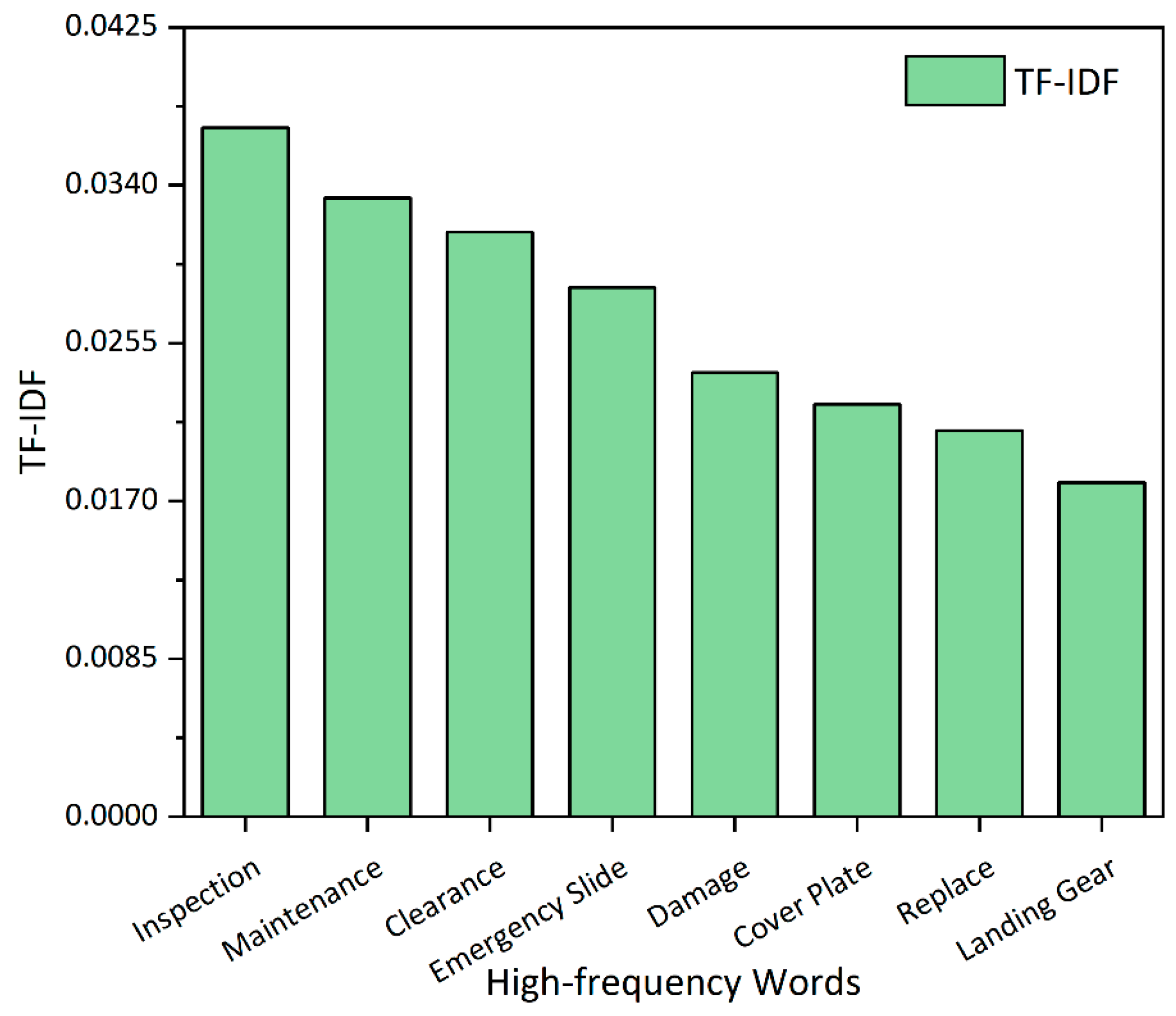
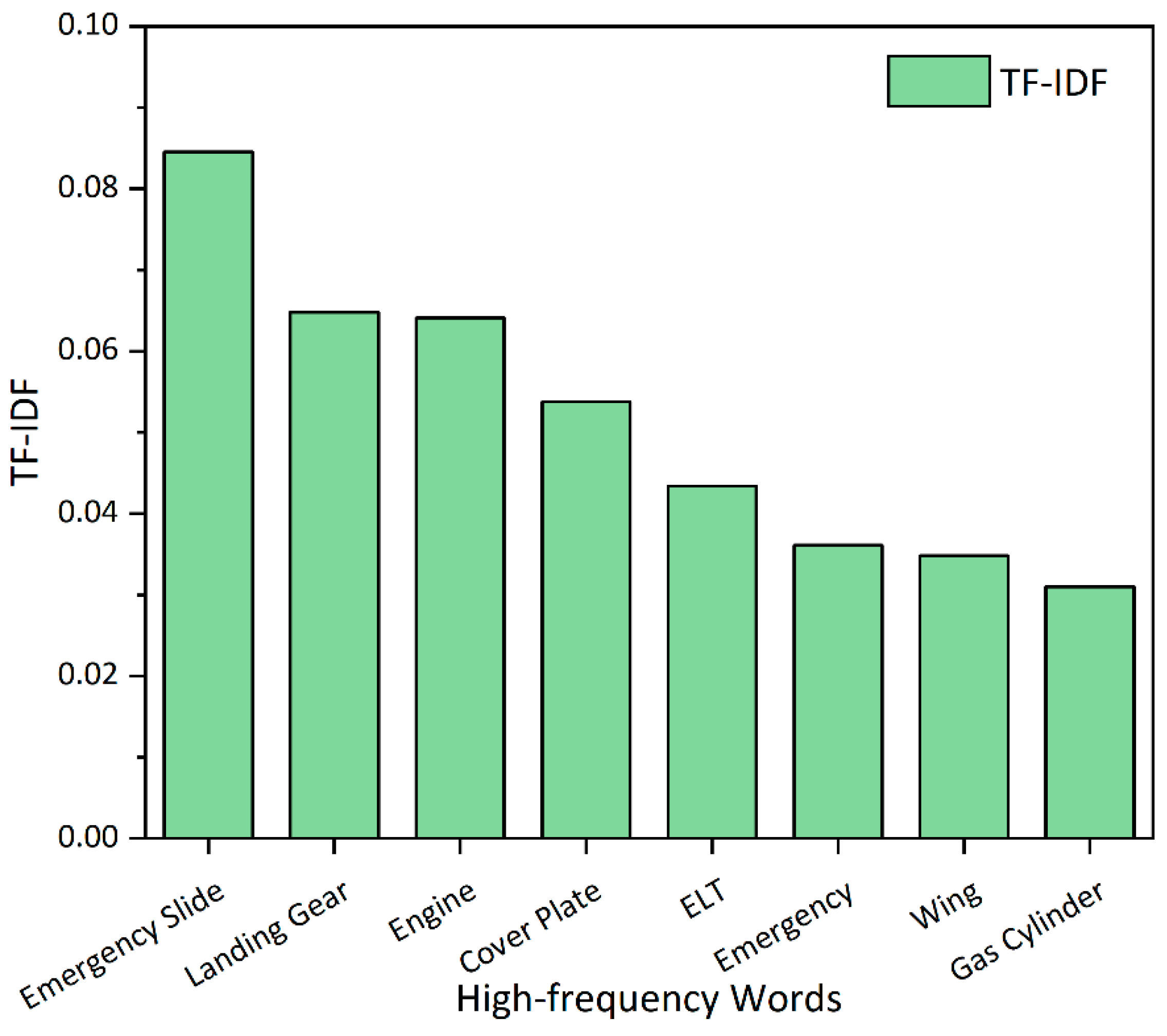
4.1. Mechanical Accidents
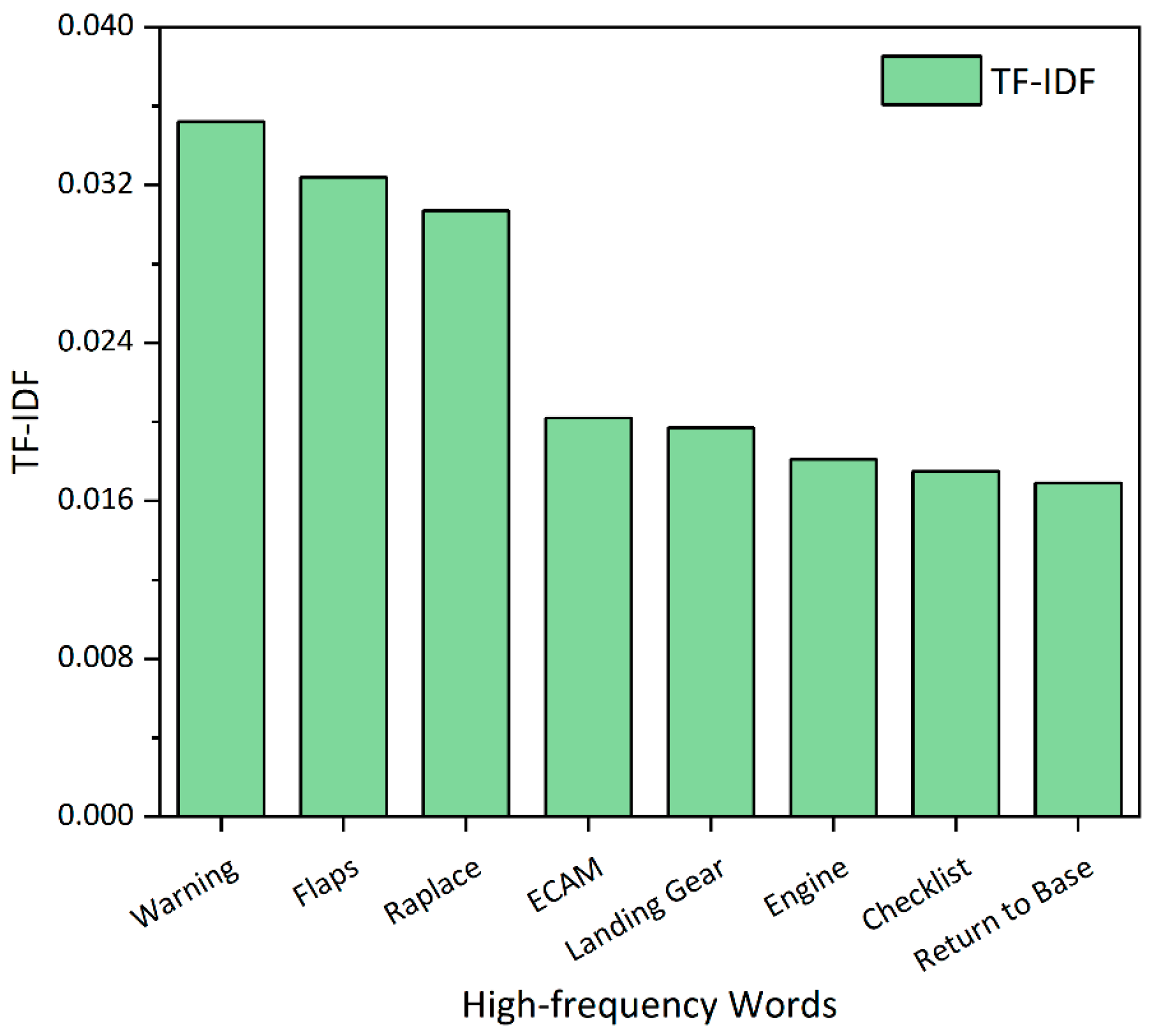
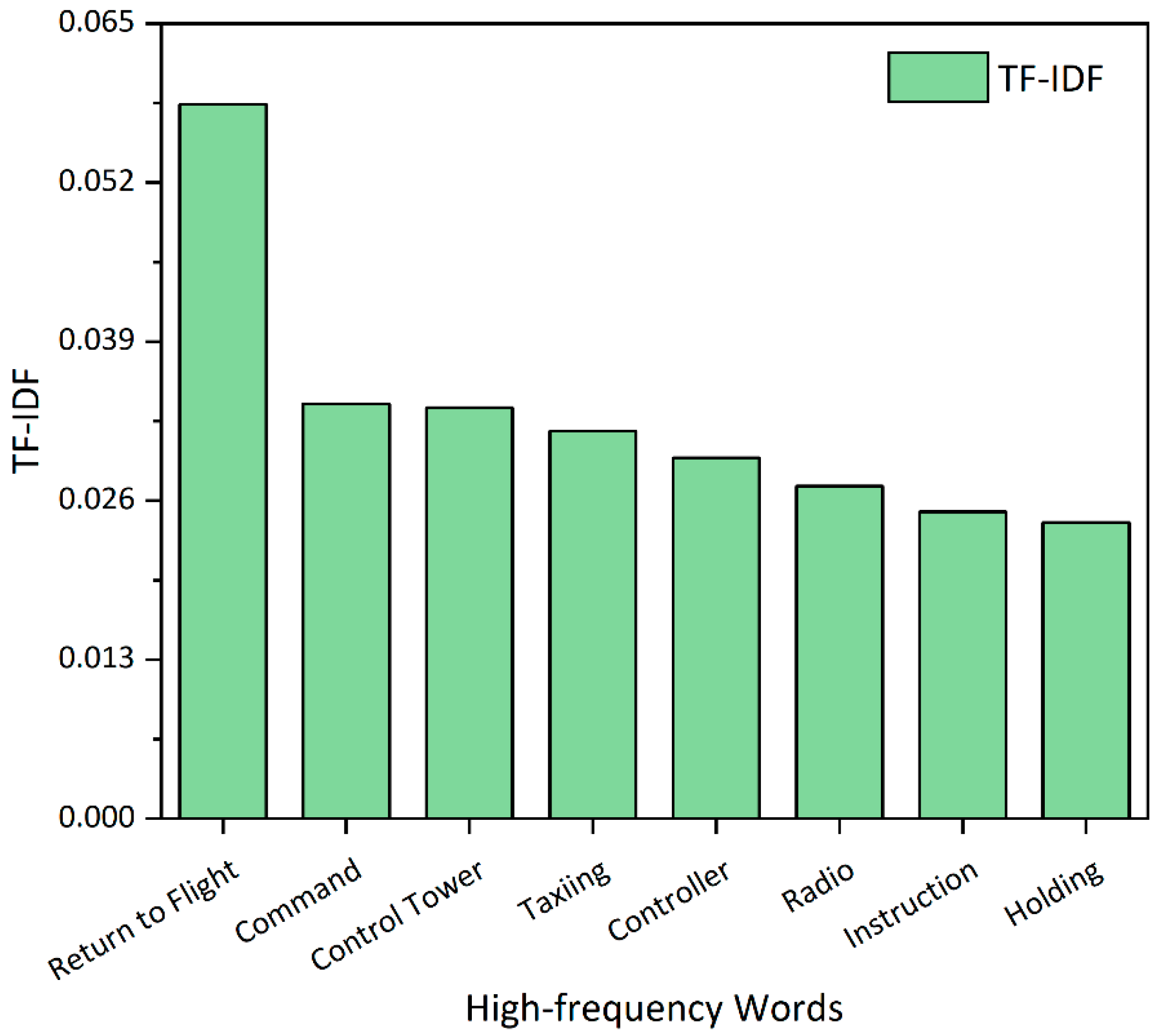
4.2. Human-Caused Accidents
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to examine the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Hu, Y. Research on the Methods of Professional Knowledge Acquisition Based on Web Information Extraction. Ph.D. Thesis, Wuhan University of Technology, Wuhan, China, 2007. [Google Scholar]
- Mukherjea, S.; Subramaniam, L.V.; Chanda, G.; Sankararaman, S.; Kothari, R.; Batra, V.; Bhardwaj, D.; Srivastava, B. Enhancing a biomedical information extraction system with dictionary mining and context disambiguation. IBM J. Res. Dev. 2004, 48, 693–701. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Choi, M.; Kim, H. Social relation extraction from texts using a support-vector-machine-based dependency trigram kernel. Inf. Process. Manag. 2013, 49, 303–311. [Google Scholar] [CrossRef]
- Somprasertsri, G.; Lalitrojwong, P. A maximum entropy model for product feature extraction in online customer reviews. In Proceedings of the 2008 IEEE Conference on Cybernetics and Intelligent Systems, Chengdu, China, 21–24 September 2008; IEEE: New York, NY, USA, 2008; pp. 575–580. [Google Scholar]
- Yu, X.; Zhang, J. Medical risk information extraction based on Hidden Markov Model. In Proceedings of the 2016 2nd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 14–17 October 2016; IEEE: New York, NY, USA, 2016; pp. 778–782. [Google Scholar]
- Liu, K.; El-Gohary, N. Ontology-based semi-supervised conditional random fields for automated information extraction from bridge inspection reports. Autom. Constr. 2017, 81, 313–327. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.F.; Bin Alam, S.; Hassan, M.; Rozbu, M.R.; Ishtiak, T.; Rafa, N.; Mofijur, M.; Ali, A.B.M.S.; Gandomi, A.H. Deep learning modelling techniques: Current progress, applications, advantages, and challenges. Artif. Intell. Rev. 2023, 56, 13521–13617. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, Q.Q.; Yan, R.; Liu, J. A survey on deep learning-based open-domain dialogue systems. Chin. J. Comput. 2019, 42, 1439–1466. [Google Scholar]
- Li, P.; Mao, K. Knowledge-oriented convolutional neural network for causal relation extraction from natural language texts. Expert Syst. Appl. 2019, 115, 512–523. [Google Scholar] [CrossRef]
- Gupta, S.; Pawar, S.; Ramrakhiyani, N.; Palshikar, G.K.; Varma, V. Semi-supervised recurrent neural network for adverse drug reaction mention extraction. BMC Bioinform. 2018, 19, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Yang, X.; Yang, C.; Guo, X.; Zhang, X.; Wu, C. Dependency-based long short term memory network for drug-drug interaction extraction. BMC Bioinform. 2017, 18, 99–109. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint 2018, arXiv:1810.04805. [Google Scholar]
- Dagdelen, J.; Dunn, A.; Lee, S.; Walker, N.; Rosen, A.S.; Ceder, G.; Persson, K.A.; Jain, A. Structured information extraction from scientific text with large language models. Nat. Commun. 2024, 15, 1418. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Xiao, Z.; Li, X.; Zhang, Q.; Chan, E.W.; Wong, I.C. Research Data Collaboration Task Force. Large Language Model in Medical Information Extraction from Titles and Abstracts with Prompt Engineering Strategies: A Comparative Study of GPT-3.5 and GPT-4. medRxiv 2024. [Google Scholar] [CrossRef]
- Giray, L. Prompt engineering with ChatGPT: A guide for academic writers. Ann. Biomed. Eng. 2023, 51, 2629–2633. [Google Scholar] [CrossRef] [PubMed]
- Xing, B.; Gen, R.; Ji, D. E-commerce shopping system based on Jieba segmentation search and SSM framework. Inf. Comput. (Theor. Ed.) 2018, 7, 104–105, 108. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, X.; Yu, Y. ChatGLM-6B Fine-Tuning for Cultural and Creative Products Advertising Words. In Proceedings of the 2023 International Conference on Culture-Oriented Science and Technology (CoST), Xi’an, China, 11–14 October 2023; IEEE: New York, NY, USA, 2023; pp. 291–295. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Accident | Prompts |
|---|---|
| Human-Caused Accidents | What specific human errors or operational mistakes occurred in this accident? Please answer in 40 words or less, or state if unknown. |
| Which aircraft components related to maintenance were involved in failures or needed replacements in this accident? Please answer in 40 words or less, or state if unknown. | |
| Mechanical Accidents | Please identify which systems, structures, or mechanical components failed in this accident. Answer in 20 words or less. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Su, T.; Chen, X. Research on Text Information Extraction and Analysis of Civil Transport Aircraft Accidents Based on Large Language Model. Eng. Proc. 2024, 80, 4. https://doi.org/10.3390/engproc2024080004
Yang J, Su T, Chen X. Research on Text Information Extraction and Analysis of Civil Transport Aircraft Accidents Based on Large Language Model. Engineering Proceedings. 2024; 80(1):4. https://doi.org/10.3390/engproc2024080004
Chicago/Turabian StyleYang, Jianzhong, Tao Su, and Xiyuan Chen. 2024. "Research on Text Information Extraction and Analysis of Civil Transport Aircraft Accidents Based on Large Language Model" Engineering Proceedings 80, no. 1: 4. https://doi.org/10.3390/engproc2024080004
APA StyleYang, J., Su, T., & Chen, X. (2024). Research on Text Information Extraction and Analysis of Civil Transport Aircraft Accidents Based on Large Language Model. Engineering Proceedings, 80(1), 4. https://doi.org/10.3390/engproc2024080004