1. Introduction
The accurate forecasting of short-term water demand is crucial for the efficient monitoring and operation of Water Distribution Networks (WDNs). This process provides essential support for managing the system’s components, including pump settings and valve manipulation, during both normal and crisis situations. There already exists a substantial corpus of research pertaining to short-, medium-, and long-term water demand prediction [
1,
2,
3]. Two technical challenges need to be overcome to predict residential water demand: choosing (1) the right data and features and (2) the most appropriate modeling technique for high prediction accuracy [
4]. The outcomes of the research underscore the absence of a universally effective method applicable to all circumstances for predicting water demand patterns accurately. Additionally, a multitude of factors, such as population size, presence of industries, socio-economic factors (e.g., income), and the deployment of water-saving measures (e.g., rainwater tanks) [
5], contribute to the complexity of urban water demand prediction.
This manuscript presents an approach to short-term water demand forecasting as part of the Battle of Water Demand Forecasting (BWDF), for which the whole problem description is provided in [
6]. The paper is structured as follows: firstly, a presentation of the method is given, followed by the exposition of the main results pertaining to all the DMAs for a specific forecasted week. Lastly, conclusions are drawn, and future research to improve the proposed method is outlined.
2. Materials and Methods
The challenge presented in the BWDF entails forecasting water demand for an actual case study located in the north-east of Italy. This case study comprises ten DMAs, each showing variations in size (quantified by the number of supplied customers) and average water demand.
The data supplied for the BWDF includes the historical net-inflow time series, spanning from 1 January 2021 to 31 March 2023, at an hourly frequency for each DMA. Additionally, weather data for the same period, along with a calendar detailing national holidays, is provided. The time series data for the water demand forecast is provided at four intervals, aligning with the requirement for forecasting across four evaluation weeks (from W1 to W4).
The paper’s methodology comprises two distinct steps: (1) a pre-processing analysis to evaluate data quality and completeness, and (2) the implementation of a robust machine-learning algorithm, XGBoost, for water demand forecasting. XGBoost was chosen because it is particularly effective at handling large data sets with many features. Moreover, XGBoost has been shown to outperform other popular machine learning algorithms, such as neural networks [
7].
2.1. Data Pre-Processing
The objective of the data pre-processing step is to detect and mitigate outliers, identify data gaps, and perform imputation based on trend analysis, including temporal patterns such as hourly variations, day-of-week effects, and seasonal fluctuations.
Data pre-processing consists of two steps. Firstly, missing values are imputed. If µh,d,s,i and σh,d,s,i are the empirical mean and standard deviation of all data with the same hour of the day h, day of the week d, and season s in DMA I, respectively, then, if for a certain time t with a certain combination of hour h, day d, and season s, the consumption data are missing, the consumption is taken to be µh,d,s,i.
Secondly, outliers are detected and taken out using the Z-score approach; if for a datapoint (t,x) in DMA i where the time t has a certain combination of hour h, day d, and season s, and the rescaled variable |x-µh,d,s,i|/σh,d,s,i is larger than 3, the datapoint (t,x) is replaced with (t,µh,d,s,i).
2.2. Forecast Model
In developing the XGBoost model, two distinct functions are used to generate foundational features, such as the day of the month and hour, alongside a separate function dedicated to creating lagged and rolling mean features. These functions are applied to both the training and testing datasets independently to avoid unintentionally transferring information from the test set to the training set.
In contrast to the traditional 70/30 test/train set split, in this research, 10-fold cross-validation is employed to ensure a comprehensive evaluation over extended time intervals. This approach effectively minimizes the risk of seasonal bias, enhancing the model’s predictive accuracy across different seasons. Monitoring the mean squared error (MSE) across the cross-validation folds has provided valuable insights into the model’s progressive improvement.
For feature selection, the “hyperopt” library of Python is used, which implements a Bayesian optimization technique for hyperparameter tuning. This process is customized to identify the most significant features for each DMA, focusing on minimizing the mean absolute error (MAE). Following hyperparameter tuning, features with an importance score exceeding 10, based on the “gain” importance type, are incorporated into the model. These features, along with the basic features generated by the initial function (e.g., special days such as national and school holidays, local event days, hour of the day, etc.), form the final set of predictors for the XGBoost model. Weather data were intentionally not included in the model because inaccurate weather forecasting quality may introduce additional error in the water demand prediction.
To assess the model’s performance, a range of estimators is used, including MAE (24 h) representing the MAE of the initial 24 h, MAE (144 h) signifying the MAE of the subsequent 144 h, and MaxAE (24 h) denoting the maximum absolute error of the first 24 h. Each metric adheres to the indicators outlined in the BWDF guidelines [
6].
3. Results
Since real measurements are available only for W1, the performance of the model is showcased in this paper exclusively for that week.
Table 1 shows the results obtained for all the DMAs in the forecasting of W1, summarized in terms of various performance indicators. Analysis of the results table reveals that the features that are chosen exhibit high R
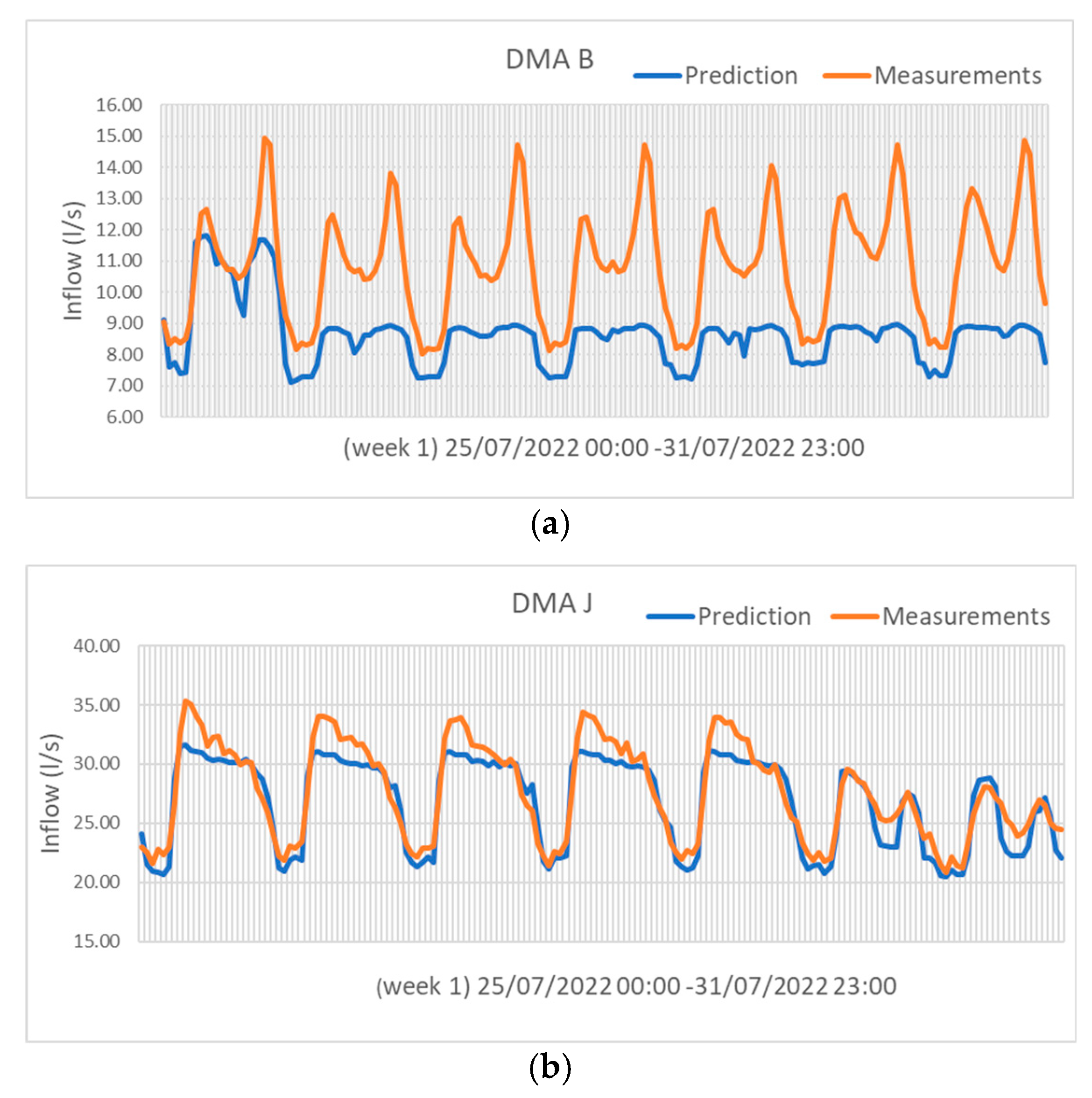
2 values for several DMAs, such as A, D, E, G, H, I, and J, indicating that these features effectively capture a substantial portion of the signal variance. Regarding the mean absolute percentage error (MAPE) scores, DMA J and E demonstrate the best performance, while DMA B and C perform less favorably. Notably, DMA E exhibits the highest MaxAE, whereas DMA F demonstrates the lowest.
Figure 1 shows that the model performs better for the commercial/industrial DMA J compared to the residential DMA B, a trend observed across all DMAs. In general, the model is successful in capturing the seasonality of the time series, but it tends to underperform in predicting peak demands.
4. Conclusions
This paper introduces a two-step methodology for short-term water demand forecasting, emphasizing the importance of tailored approaches in addressing the complex dynamics of urban water demand. Tailored features are optimally selected to enhance prediction accuracy across ten distinct DMAs in the north-east of Italy. The results, showcased for the first prediction week, W1, reveal promising performance metrics, with notable variations observed among different DMAs. These findings underscore the efficacy of the proposed methodology while providing valuable insights for future refinement and application. Moving forward, efforts will focus on further enhancing the model’s performance through the exploration of a combination of diverse learning algorithms and the potential incorporation of additional features such as high-quality predictions of weather data. Building upon the robustness and generalized approach explained in the paper, the model can be reused for various applications beyond the initial scope, allowing us to deploy the enhanced method within the ongoing development of the Digital Twin of the WDN in the province of North Brabant (The Netherlands), facilitating the monitoring and decision-making processes in day-to-day system operations.



{kind=link}