
Texture Classification Based on Sound and Vibro-Tactile Data †


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset for Texture Classification
2.2. Proposed Solution for Texture Classification from Sound and Vibro-Tactile Data
2.3. Data Processing
2.3.1. Data Transformation
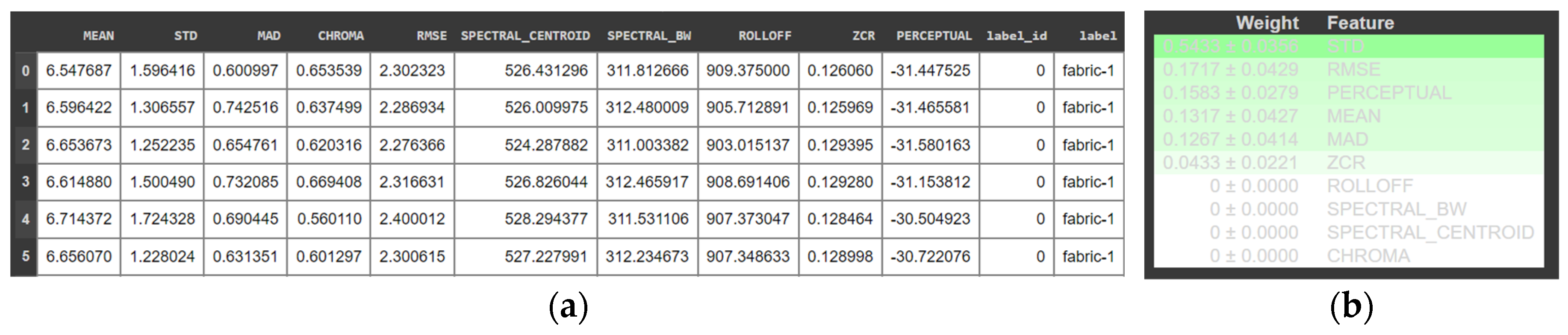
2.3.2. Feature Extraction
2.3.3. Feature Selection
2.4. Data Classification
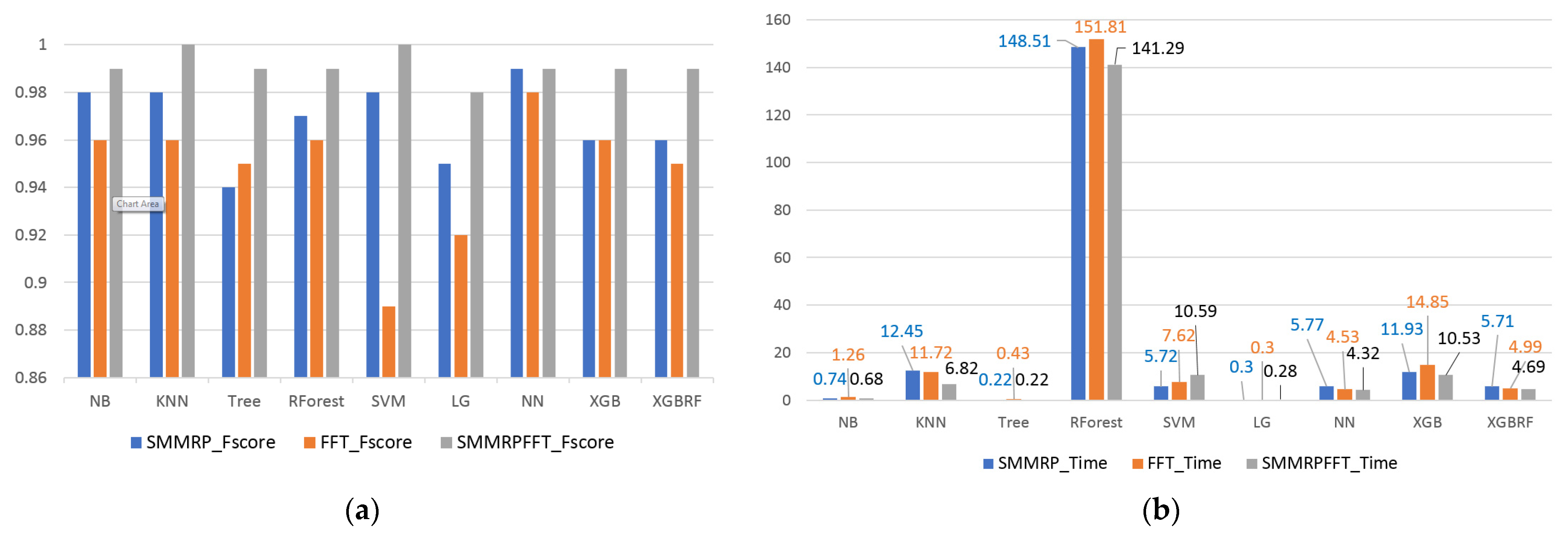
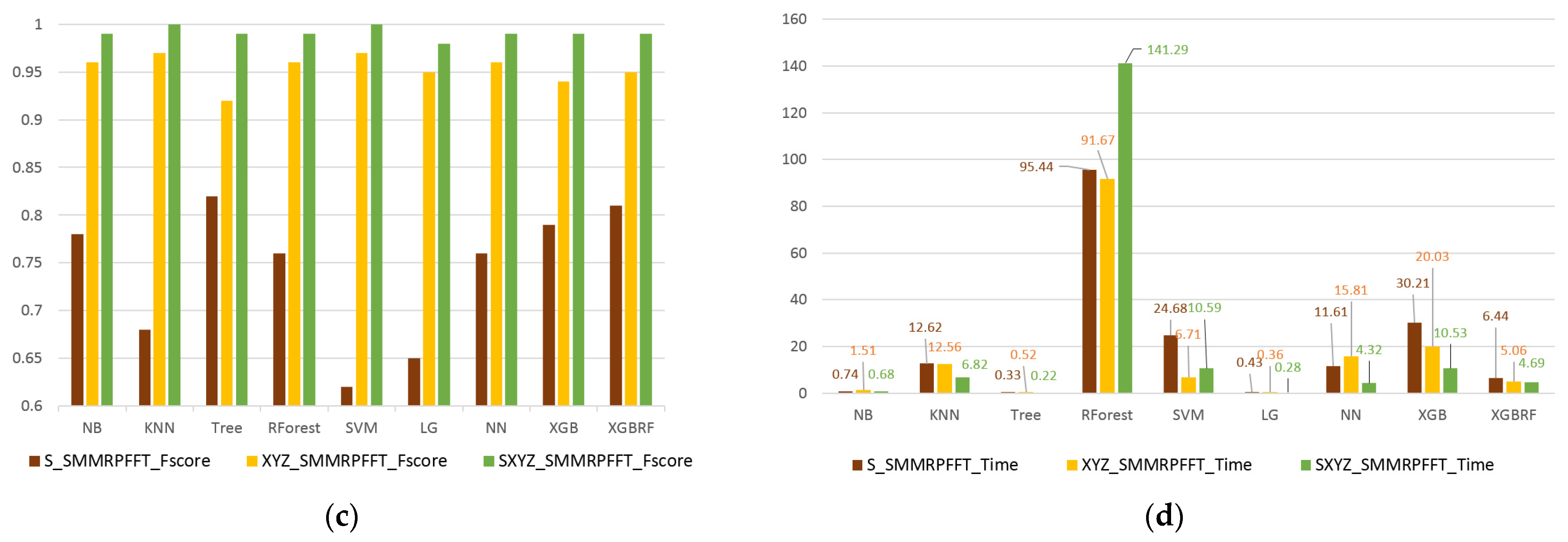
3. Results
4. Discussions and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, L.; Chen, J.; Fieguth, P.; Zhao, G.; Chellappa, R.; Pietikainen, M. From BoW to CNN: Two Decades of Texture Representation for Texture Classification. Int. J. Comput. Vis. 2019, 127, 74–109. [Google Scholar] [CrossRef]
- Luo, S.; Yuan, W.; Adelson, E.; Cohn, A.G.; Fuentes, R. Vitac: Feature sharing between vision and tactile sensing for cloth texture recognition. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Kursun, O.; Patooghy, A. An Embedded System for Collection and Real-Time Classification of a Tactile Dataset. IEEE Access 2020, 8, 97462–97473. [Google Scholar] [CrossRef]
- Oliveira, T.E.A.; Cretu, A.-M.; Petriu, E.M. A Multi-Modal Bio-Inspired Tactile Sensing Module for Surface Characterization. Sensors 2017, 17, 1187. [Google Scholar] [CrossRef] [PubMed]
- Humeau-Heurtier, A. Texture feature extraction methods: A survey. IEEE Access 2019, 7, 8975–9000. [Google Scholar] [CrossRef]
- Kerr, E.; McGinnity, T.; Coleman, S. Material recognition using tactile sensing. Exp. Syst. Appl. 2018, 94, 94–111. [Google Scholar] [CrossRef]
- Wang, S.; Albini, A.; Maiolino, P.; Mastrogiovanni, F.; Cannata, G. Fabric Classification Using a Finger-Shaped Tactile Sensor via Robotic Sliding. Front. Neurorobot. 2022, 16, 808222. [Google Scholar] [CrossRef]
- Huang, S.; Wu, H. Texture Recognition Based on Perception Data from a Bionic Tactile Sensor. Sensors 2021, 21, 5224. [Google Scholar] [CrossRef]
- Kursun, O.; Patooghy, A. VibTac-12: Texture Dataset Collected by Tactile Sensors; IEEE Dataport: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–24. [Google Scholar]
- Korobov, M.; Lopuhin, K. ELI5 Documentation Release 0.11.0, 23 January 2021. Available online: https://readthedocs.org/projects/eli5/downloads/pdf/latest/ (accessed on 19 September 2023).
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd ed.; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NB | KNN | Tree | RForest | SVM | LG | NN | XGB | XGBRF | Average | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1s—SMMRP-PCA (5 feat.) | 0.95 | 0.94 | 0.94 | 0.95 | 0.94 | 0.91 | 0.96 | 0.97 | 0.95 | 0.95 |
| 1s—FFT-PCA (4 feat.) | 0.95 | 0.95 | 0.94 | 0.95 | 0.93 | 0.94 | 0.95 | 0.95 | 0.94 | 0.94 |
| 2s—SMMRP-PCA (5 feat.) | 0.98 | 0.99 | 0.97 | 1 | 0.98 | 0.97 | 1 | 0.98 | 0.99 | 0.984 |
| 2s—FFT-PCA (4 feat.) | 0.99 | 0.96 | 0.98 | 0.99 | 0.96 | 0.96 | 1 | 0.99 | 0.99 | 0.980 |
| Material | Correct Predictions (%) | Wrong Predictions—Material Type, Algorithm (%) |
|---|---|---|
| fabric-1 | 100 | |
| aluminium_film | 100 | |
| fabric-2 | 90 | moquette-1, XGB (5%), toy-tire-rubber, NN (5%) |
| fabric-3 | 100 | |
| moquette-1 | 77 | fabric-2, NN, LG, SVM (16%), fabric-4, NN (7%) |
| moquette-2 | 100 | |
| fabric-4 | 100 | |
| sticky fabric-5 | 100 | |
| sticky-fabric | 100 | |
| sparkle-paper-1 | 95 | sparkle_paper-2, LG (5%) |
| sparkle-paper-2 | 92 | sparkle_paper-1, Tree (8%) |
| toy-tire-rubber | 55 | fabric-1, LG, SVM, RForest, Tree, kNN, NB (44%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Najib, M.; Cretu, A.-M. Texture Classification Based on Sound and Vibro-Tactile Data. Eng. Proc. 2023, 58, 5. https://doi.org/10.3390/ecsa-10-16082
Najib M, Cretu A-M. Texture Classification Based on Sound and Vibro-Tactile Data. Engineering Proceedings. 2023; 58(1):5. https://doi.org/10.3390/ecsa-10-16082
Chicago/Turabian StyleNajib, Mustapha, and Ana-Maria Cretu. 2023. "Texture Classification Based on Sound and Vibro-Tactile Data" Engineering Proceedings 58, no. 1: 5. https://doi.org/10.3390/ecsa-10-16082
APA StyleNajib, M., & Cretu, A.-M. (2023). Texture Classification Based on Sound and Vibro-Tactile Data. Engineering Proceedings, 58(1), 5. https://doi.org/10.3390/ecsa-10-16082