
Rényi Transfer Entropy Estimators for Financial Time Series †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Rényi Transfer Entropy
2.1. Rényi Entropy
2.2. Shannon’s and Rényi’s Transfer Entropies
3. Financial Data Processing and Rényi Entropy Estimation
Rényi’s Entropy Estimation
- Relative accuracy for small datasets;
- Applicability for high-dimensional data;
- Combining the set estimators provides statistics for estimation.
4. Model Setup: Coupled GARCH Processes
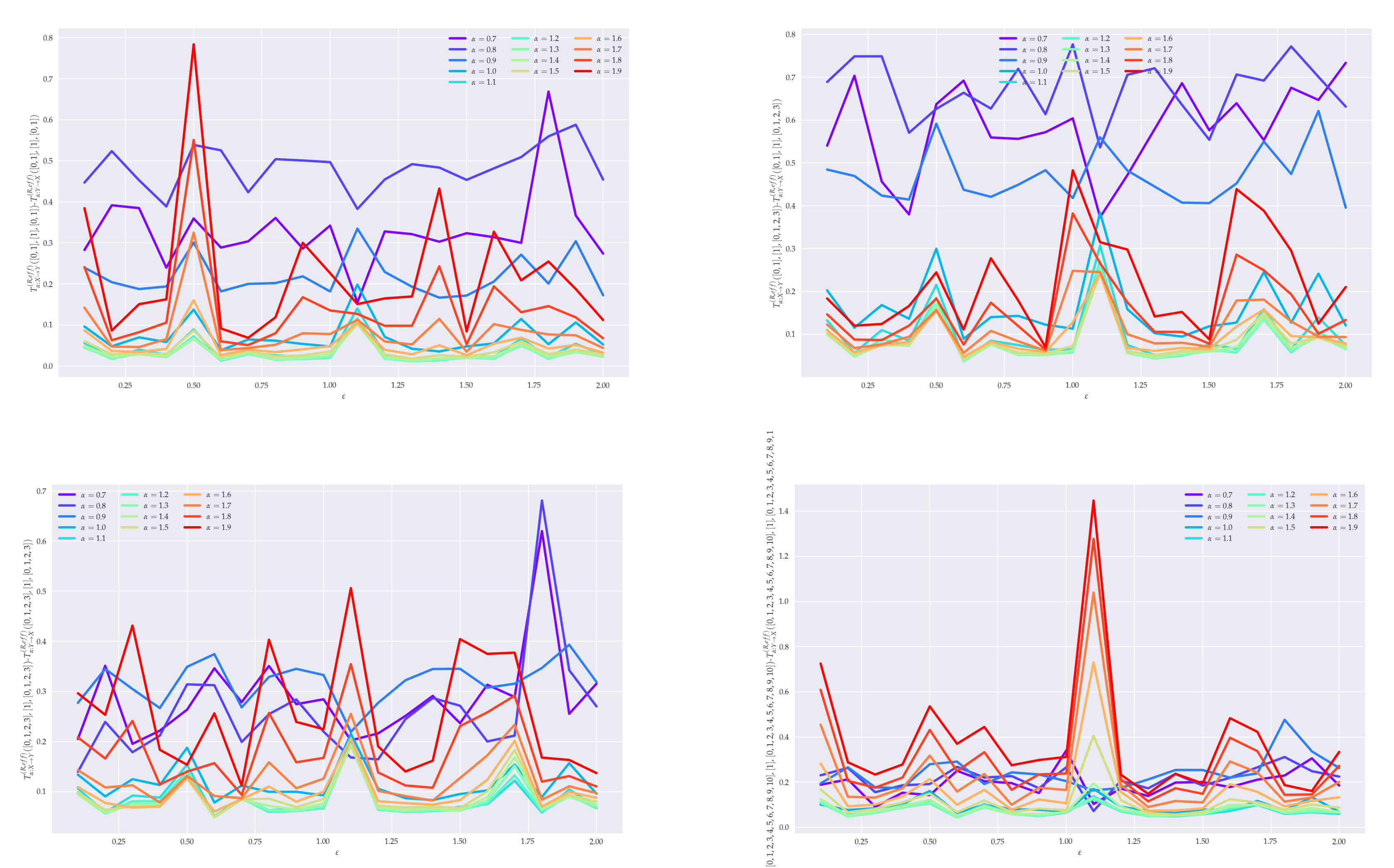
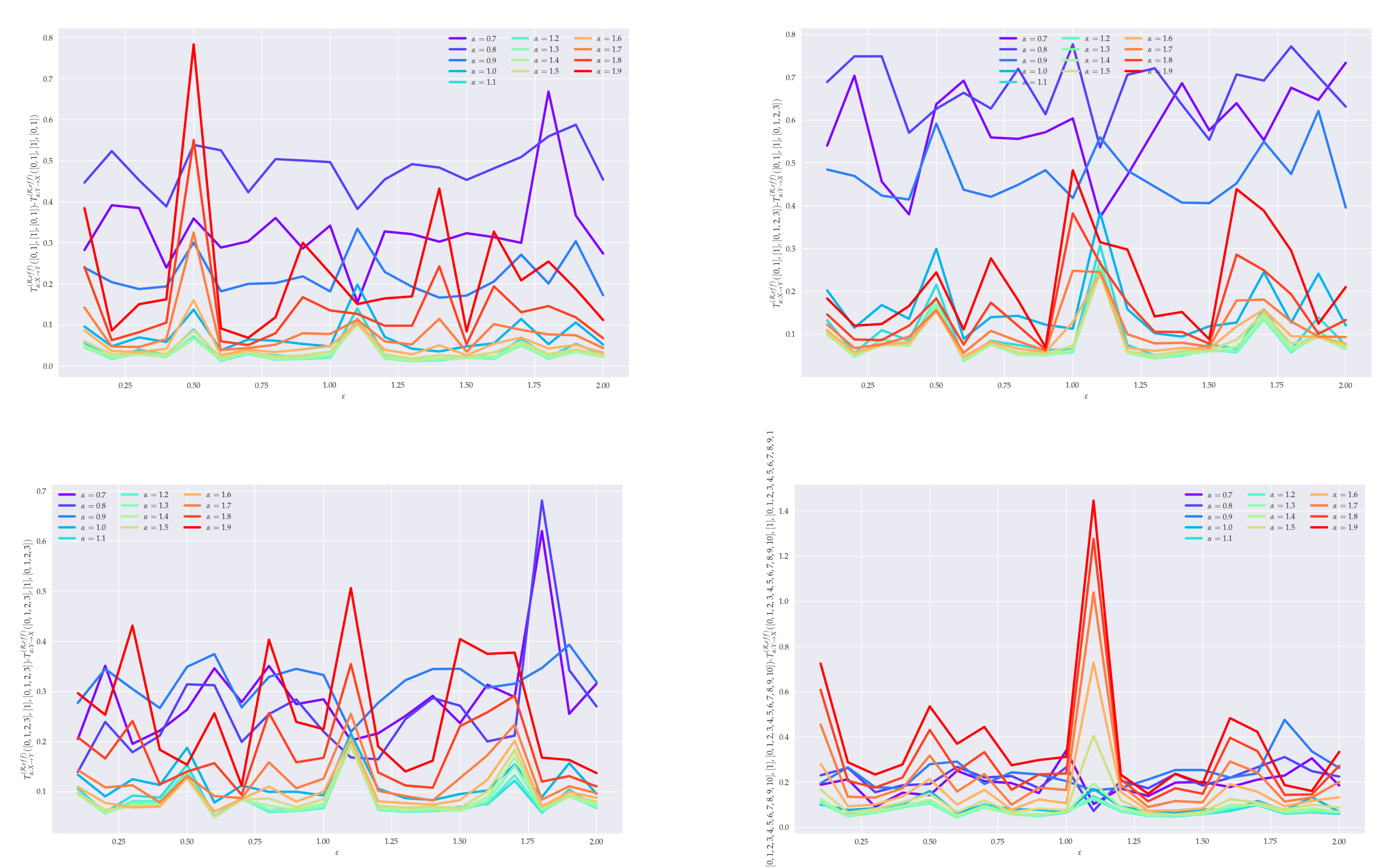
5. Analysis of Effective RTE for Coupled GARCH() Processes
6. Conclusions
6.1. Summary
6.2. Perspectives and Generalizations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger Causality and Transfer Entropy Are Equivalent for Gaussian Variables. Phys. Rev. Lett. 2009, 103, 238701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lungerella, M.; Ishigoro, K.; Kuniyoshi, Y.; Otsu, N. Methods for quantifying the causal structure of bivariate time series. Prog. Neurobiol. 2007, 77, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Jizba, P.; Kleinert, H.; Shefaat, M. Rényi’s information transfer between financial time series. Physica A 2012, 391, 2971–2989. [Google Scholar] [CrossRef] [Green Version]
- Leonenko, N.; Pronzato, L.; Savani, V. A class of Rényi information estimators for multidimensional densities. Ann. Stat. 2008, 36, 2153–2182. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. Proc. Fourth Berkeley Symp. on Math. Statist. Prob. 1961, 1, 547–561. [Google Scholar]
- Rényi, A. Selected Papers of Alfred Rényi; Akademia Kiado: Budapest, Hungary, 1976; Volume 2. [Google Scholar]
- Jizba, P.; Arimitsu, T. World According to Rényi: Thermodynamics of Multifractal Systems. Ann. Phys. 2004, 312, 17–57. [Google Scholar] [CrossRef]
- Beck, C.; Schlögl, F. Thermodynamics of Chaotic Systems; Cambridge Nonlinear Science Series (Book 4); Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Paluš, M.; Hlaváčkovxax-Schindler, K.; Vejmelka, M.; Bhattacharya, J. Causality detection based on information-theoretic approaches in time series analysis. Phys. Rep. 2007, 441, 1–46. [Google Scholar]
- Marschinski, R.; Kantz, H. Analysing the Information Flow Between Financial Time Series. Eur. Phys. J. B 2002, 30, 275–281. [Google Scholar] [CrossRef]
- Samuelson, P.A. Rational Theory of Warrant Pricing. Ind. Manag. Rev. 1965, 6, 13–31. [Google Scholar]
- Keylock, C.J. Constrained surrogate time series with preservation of the mean and variance structure. Phys. Rev. E 2006, 73, 036707. [Google Scholar] [CrossRef] [PubMed]
- Dobrushin, R.L. A simplified method of experimentally evaluating the entropy of a stationary sequence. Teor. Veroyatnostei Primen. 1958, 3, 462–464. [Google Scholar] [CrossRef]
- Vašíček, O. A test for normality based on sample entropy. J. Roy. Statist. Soc Ser. B Methodol. 1976, 38, 54–59. [Google Scholar]
- Kantz, H.; Schreiber, T. Nonlinear Time Series Analysis; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Engle, R.F. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized Autoregressive Conditional Heteroskedasticity. J. Econom. 1986, 31, 7–327. [Google Scholar] [CrossRef] [Green Version]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jizba, P.; Lavička, H.; Tabachová, Z. Rényi Transfer Entropy Estimators for Financial Time Series . Eng. Proc. 2021, 5, 33. https://doi.org/10.3390/engproc2021005033
Jizba P, Lavička H, Tabachová Z. Rényi Transfer Entropy Estimators for Financial Time Series . Engineering Proceedings. 2021; 5(1):33. https://doi.org/10.3390/engproc2021005033
Chicago/Turabian StyleJizba, Petr, Hynek Lavička, and Zlata Tabachová. 2021. "Rényi Transfer Entropy Estimators for Financial Time Series " Engineering Proceedings 5, no. 1: 33. https://doi.org/10.3390/engproc2021005033
APA StyleJizba, P., Lavička, H., & Tabachová, Z. (2021). Rényi Transfer Entropy Estimators for Financial Time Series . Engineering Proceedings, 5(1), 33. https://doi.org/10.3390/engproc2021005033