
Combining Forecasts of Time Series with Complex Seasonality Using LSTM-Based Meta-Learning †


Abstract
:1. Introduction
- A meta-learning approach based on LSTM is proposed for combining forecasts. This approach incorporates past information accumulated in the internal states, improving accuracy, especially in cases where there is a temporal relationship between base forecasts for successive time points.
- Various meta-learning variants for time series with multiple seasonal patterns are proposed, such as the use of the full training set, including base forecasts for successive time points, and the use of selected training points that reflect the seasonal structure of the data.
- Extensive experiments are conducted on 35 time series with triple seasonality using 16 base models to validate the efficacy of the proposed approach. The experimental results demonstrate the high performance of the LSTM meta-learner and its potential to combine forecasts more accurately than simple averaging and linear regression methods.
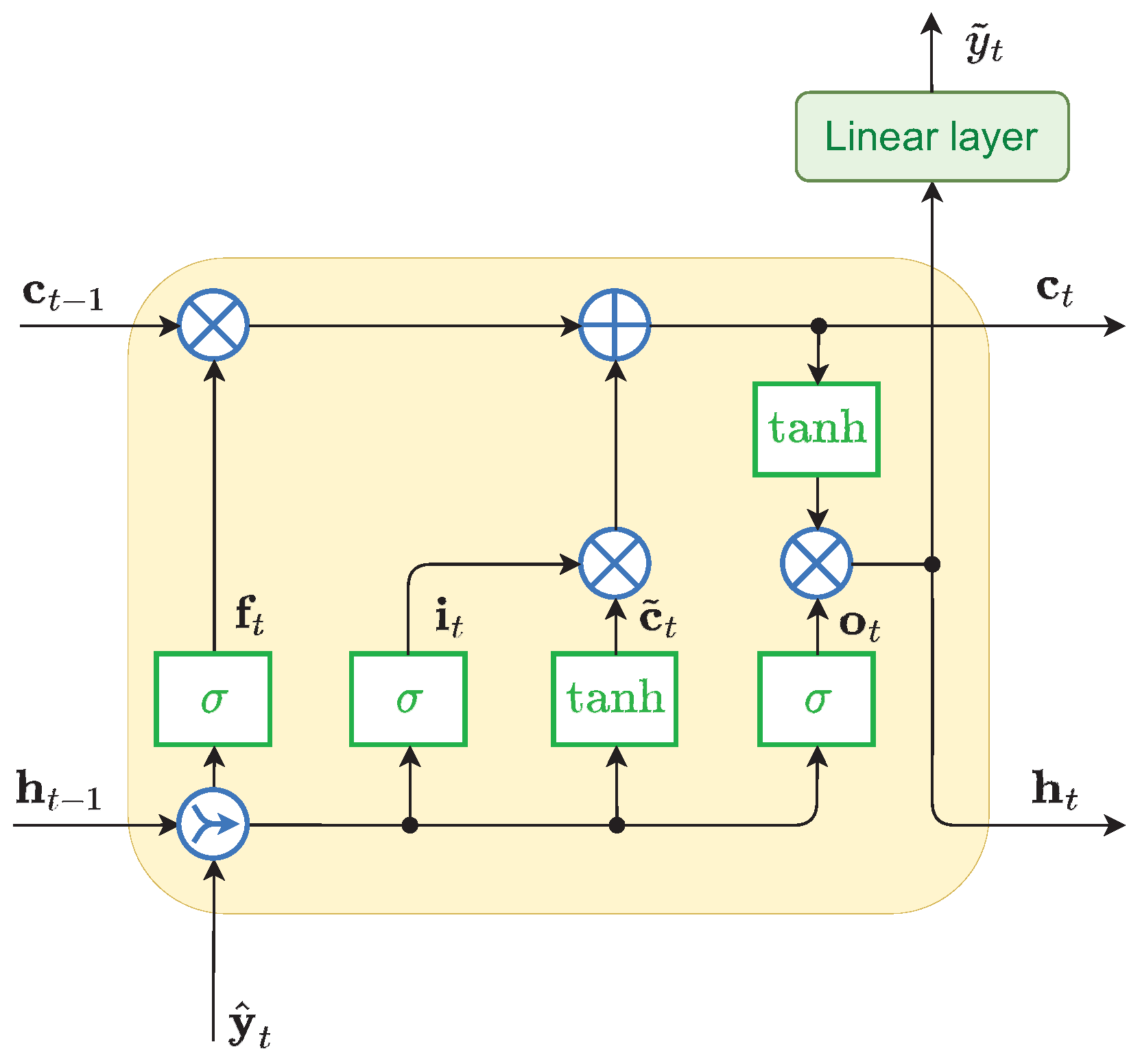
2. LSTM for Combining Forecasts
2.1. LSTM Model
2.2. Meta-Learning Variants
3. Experimental Study
3.1. Data, Forecasting Problem and Research Design
3.2. Forecasting Models
- ARIMA—auto-regressive integrated moving average model,
- ETS—exponential smoothing model,
- Prophet—modular additive regression model with nonlinear trend and seasonal components,
- N-WE—Nadaraya–Watson estimator,
- GRNN—general regression NN,
- MLP—perceptron with a single hidden layer and sigmoid nonlinearities,
- SVM—linear epsilon insensitive support vector machine (-SVM),
- LSTM—long short-term memory,
- ANFIS—adaptive neuro-fuzzy inference system,
- MTGNN—graph NN for multivariate time series forecasting,
- DeepAR—autoregressive recurrent NN model for probabilistic forecasting,
- WaveNet—autoregressive deep NN model combining causal filters with dilated convolutions,
- N-BEATS—deep NN with hierarchical doubly residual topology,
- LGBM—Light Gradient-Boosting Machine,
- XGB—eXtreme Gradient-Boosting algorithm,
- cES-adRNN—contextually enhanced hybrid and hierarchical model combining ETS and dilated RNN with attention mechanism.
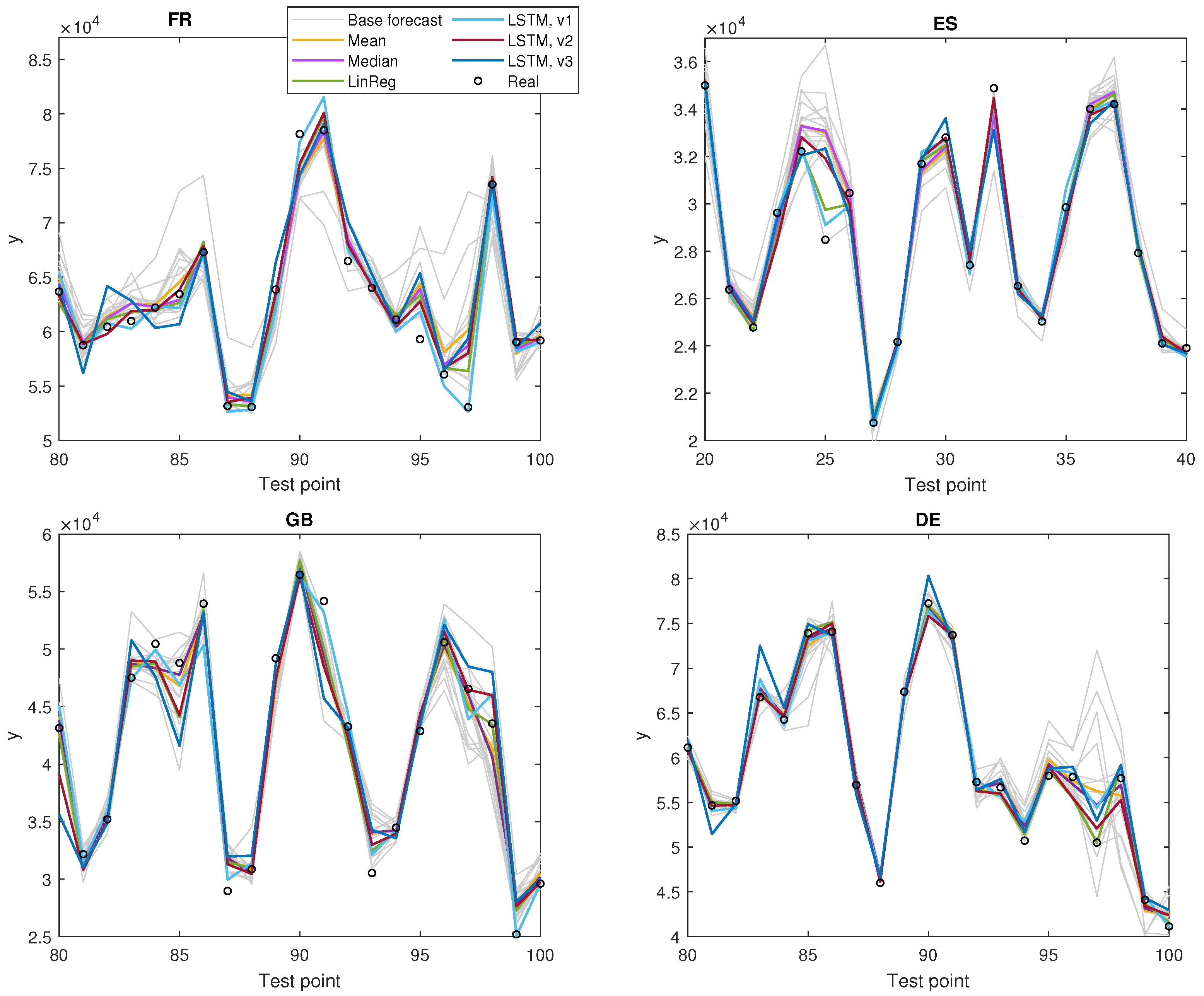
3.3. Results and Discussion
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANFIS | Adaptive Neuro-Fuzzy Inference System |
| ARIMA | Auto-Regressive Integrated Moving Average |
| cES-adRNN | contextually enhanced hybrid and hierarchical model combining ETS and dilated |
| RNN with attention mechanism | |
| DE | Germany |
| DeepAR | Auto-Regressive Deep recurrent NN model for probabilistic forecasting |
| ES | Spain |
| ETS | Exponential Smoothing |
| FR | France |
| GB | Great Britain |
| GRNN | General Regression Neural Network |
| LinReg | Linear Regression |
| LGBM | Light Gradient-Boosting Machine |
| LSTM | Long Short-Term Memory Neural Network |
| MAPE | Mean Absolute Percentage Error |
| MdAPE | Median of Absolute Percentage Error |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| MPE | Mean Percentage Error |
| MSE | Mean Square Error |
| MTGNN | Graph Neural Network for Multivariate Time series forecasting |
| N-BEATS | deep NN with hierarchical doubly residual topology |
| N-WE | Nadaraya–-Watson Estimator |
| NN | Neural Network |
| PE | Percentage Error |
| PL | Poland |
| RNN | Recurrent Neural Network |
| StdPE | Standard Deviation of Percentage Error |
| SVM | Support Vector Machine |
| STLF | Short-Term Load Forecasting |
| WaveNet | Auto-Regressive deep NN model combining causal filters with dilated convolutions |
| XGB | eXtreme Gradient Boosting |
References
- Clements, M.; Hendry, D. Forecasting Economic Time Series; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Wang, X.; Hyndman, R.; Li, F.; Kang, Y. Forecast combinations: An over 50-year review. Int. J. Forecast. 2022; in press. [Google Scholar] [CrossRef]
- Rossi, B. Forecasting in the presence of instabilities: How we know whether models predict well and how to improve them. J. Econ. Lit. 2021, 59, 1135–1190. [Google Scholar] [CrossRef]
- Blanc, S.; Setzer, T. When to choose the simple average in forecast combination. J. Bus. Res. 2016, 69, 3951–3962. [Google Scholar] [CrossRef]
- Genre, V.; Kenny, G.; Meyler, A.; Timmermann, A. Combining expert forecasts: Can anything beat the simple average? Int. J. Forecast. 2013, 29, 108–121. [Google Scholar] [CrossRef]
- Jose, V.; Winkler, R. Simple robust averages of forecasts: Some empirical results. Int. J. Forecast. 2008, 24, 163–169. [Google Scholar] [CrossRef]
- Pawlikowski, M.; Chorowska, A. Weighted ensemble of statistical models. Int. J. Forecast. 2020, 36, 93–97. [Google Scholar] [CrossRef]
- Poncela, P.; Rodriguez, J.; Sanchez-Mangas, R.; Senra, E. Forecast combination through dimension reduction techniques. Int. J. Forecast. 2011, 27, 224–237. [Google Scholar] [CrossRef]
- Kolassa, S. Combining exponential smoothing forecasts using Akaike weights. Int. J. Forecast. 2011, 27, 238–251. [Google Scholar] [CrossRef]
- Babikir, A.; Mwambi, H. Evaluating the combined forecasts of the dynamic factor model and the artificial neural network model using linear and nonlinear combining methods. Empir. Econ. 2016, 51, 1541–1556. [Google Scholar] [CrossRef]
- Zhao, S.; Feng, Y. For2For: Learning to forecast from forecasts. arXiv 2020, arXiv:2001.04601. [Google Scholar]
- Gastinger, J.; Nicolas, S.; Stepić, D.; Schmidt, M.; Schülke, A. A study on ensemble learning for time series forecasting and the need for meta-learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Smyl, S.; Dudek, G.; Pełka, P. Contextually enhanced ES-dRNN with dynamic attention for short-term load forecasting. arXiv 2022, arXiv:2212.09030. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAPE | MdAPE | MSE | MPE | StdPE | |
|---|---|---|---|---|---|
| ARIMA | 2.86 | 1.82 | 777,012 | 0.0556 | 4.60 |
| ETS | 2.83 | 1.79 | 710,773 | 0.1639 | 4.64 |
| Prophet | 3.83 | 2.53 | 1,641,288 | −0.5195 | 6.24 |
| N-WE | 2.12 | 1.34 | 357,253 | 0.0048 | 3.47 |
| GRNN | 2.10 | 1.36 | 372,446 | 0.0098 | 3.42 |
| MLP | 2.55 | 1.66 | 488,826 | 0.2390 | 3.93 |
| SVM | 2.16 | 1.33 | 356,393 | 0.0293 | 3.55 |
| LSTM | 2.37 | 1.54 | 477,008 | 0.0385 | 3.68 |
| ANFIS | 3.08 | 1.65 | 801,710 | −0.0575 | 5.59 |
| MTGNN | 2.54 | 1.71 | 434,405 | 0.0952 | 3.87 |
| DeepAR | 2.93 | 2.00 | 891,663 | −0.3321 | 4.62 |
| WaveNet | 2.47 | 1.69 | 523,273 | −0.8804 | 3.77 |
| N-BEATS | 2.14 | 1.34 | 430,732 | −0.0060 | 3.57 |
| LGBM | 2.43 | 1.70 | 409,062 | 0.0528 | 3.55 |
| XGB | 2.32 | 1.61 | 376,376 | 0.0529 | 3.37 |
| cES-adRNN | 1.70 | 1.10 | 224,265 | −0.1860 | 2.57 |
| Variant | MAPE | MdAPE | MSE | MPE | StdPE | |
|---|---|---|---|---|---|---|
| Mean | - | 1.91 | 1.23 | 316,943 | −0.0775 | 3.11 |
| Median | - | 1.82 | 1.13 | 287,284 | −0.0682 | 3.05 |
| LinReg | - | 1.63 | 1.11 | 213,428 | 0.0131 | 2.38 |
| LSTM | v1, | 1.55 | 1.09 | 139,667 | 0.0247 | 2.26 |
| LSTM | v2, global | 1.95 | 1.34 | 270,266 | −0.1046 | 2.89 |
| LSTM | v3, global | 2.97 | 1.84 | 726,108 | −0.3628 | 4.84 |
| LinReg | 48 | 13 | 27 |
| LSTM v1 | 447 | 192 | 244 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dudek, G. Combining Forecasts of Time Series with Complex Seasonality Using LSTM-Based Meta-Learning. Eng. Proc. 2023, 39, 53. https://doi.org/10.3390/engproc2023039053
Dudek G. Combining Forecasts of Time Series with Complex Seasonality Using LSTM-Based Meta-Learning. Engineering Proceedings. 2023; 39(1):53. https://doi.org/10.3390/engproc2023039053
Chicago/Turabian StyleDudek, Grzegorz. 2023. "Combining Forecasts of Time Series with Complex Seasonality Using LSTM-Based Meta-Learning" Engineering Proceedings 39, no. 1: 53. https://doi.org/10.3390/engproc2023039053
APA StyleDudek, G. (2023). Combining Forecasts of Time Series with Complex Seasonality Using LSTM-Based Meta-Learning. Engineering Proceedings, 39(1), 53. https://doi.org/10.3390/engproc2023039053