1. Introduction
The study of the damage caused over time and stress on a mechanical part allows for prediction of the failure of this part [
1,
2]. For this, it is necessary, on the one hand, to have reliable data and, on the other hand, to have a model that is faithful to reality. Such models are used to generate some scenarios using the solution of partial derivative equations (PDEs). Their input is often composed of different variables in the form of a time series denoted by
X, and their output
may be multidimensional and depend on space and time. The use of such models consists of solving complicated PDEs, and each generated scenario corresponds in the machine learning paradigm to an inference for a new input
X, and, therefore, to the computation of
. The more complex that these models are, and the closer they are to reality, the more expensive they are in terms of computing time and power. In practice, these calculations can take days or weeks.
Consider a set with a distribution similar to that of the time series X lying in a separable metric space . To each observation, we apply a deterministic smooth function. This function, , is expensive and complex and may be seen as a black box. Moreover, we have a large sample of size with the same distribution as X. We do not know the values . The goal is to find a subsample of a size smaller than in such a way that the distribution of is close to that of .
At first sight, this is a classic sampling problem. We can use sampling techniques identical to those used in surveys as well as unsupervised [
3] or supervised techniques [
4,
5,
6]. Some recent algorithms were proposed in [
7] to solve this problem for the general case of variable
X that lies in any metric space. We are interested, in this paper, in adapting such algorithms for the case in which
X is a time series. We explore, in this paper, two possible adaptations; the first consists of encoding the time series
X by independent features, and the second using appropriate distances between time series and adjusting the sampling algorithms to use such distances.
This manuscript is organized as follows. In
Section 2, we fix some notations that will be used throughout the manuscript, and we specify the framework of the problem to be solved. In
Section 3, we describe the algorithms used in [
7] to solve the problem. In
Section 4, we suggest alternative adaptations for these algorithms for their application to time series.
Section 5 gives an industrial application of these approaches. In
Section 6, some concluding remarks are provided.
2. The Problem Setting
Let
as a set of
time series following the same distribution
as
X, and
as a second set of time series of size
coming from the same distribution
. Let
as a deterministic function that is very complicated and hard to compute. The unknown distribution of
will be denoted by
F. Moreover, we dispose of
of the images of the first sample
denoted
. The images of
by
f are not available.
From this information, we want to determine a subsample of size in such a way that the empirical distribution of will be close to the distribution of .
Several approaches are possible for this problem in a general setting in which X is a random variable in a separable metric space.
If
stands for the empirical distribution of
and
for that of a subset
, and the function
f is regular, we look for a subset
such that a:
is minimal among all possible subsets. Here,
d is a distance metrizing weak convergence, similar to the Prokhorov distance. In the next section, we will describe some algorithms proposed in [
7] to solve this problem and that we aim to adapt to the time series.
3. Sampling Algorithms
We describe briefly some existing algorithms designed to solve our problem in a general context where
X is a random variable that lies in any metric space. A more detailed description of these approaches may be found in [
7].
Let and be two independent samples with that come from the same distribution of X.
Among the following algorithms, some make use of , and others do not.
3.1. Extended Nearest Neighbors Approach
This algorithm does not make use of . The selected subset is simply the set of the nearest extended neighbors of in . Consider the nearest neighbors of in , , their ordered distances and their indices.
Suppose that two elements of , called and , have identical nearest neighbors, , with respective distances and , and suppose that if , then will be the nearest neighbor of , while for we will have to take its second nearest neighbor, and so on. This approach is based on the idea that if the elements of are close to those of , then the images of by f should be close to those of .
3.2. A Partition-Based Algorithm
For this algorithm, a partition of the set into L clusters of size m is built s.t. Denote the clusters by , their complements by and the empirical cdf of Y in . Denote by the cluster which minimizes , and the subset fulfilling which is a subset of . is defined as the set of the nearest neighbors of from . The partition used in this algorithm may be any random partition, or any partition obtained from a clustering algorithm similar to k-means.
3.3. A Histogram-Based Approach
The idea in this algorithm is to use the empirical distribution of the sample
. First,
is obtained by a stratified sampling from
where the stratas are obtained using the bins of the histogram built on
.
is then taken to be the set of the nearest neighbors of
from
. The empirical distribution of
is close to that of
,
, and the
distributions are expected to be close if
f is smooth. Two alternatives to this algorithm have been proposed in [
7], replacing the stratified sampling to get
with either the support points approach [
3] or the D-optimality [
4].
4. Adaptation of Algorithms to Time Series
We suppose that the time series available in both samples
and
have different lengths. In this section, we will show how the algorithms presented in
Section 3 may be adjusted to be used when
X is a time series. For this purpose, two approaches are considered, encoding and choosing appropriate distances for time series. For the first approach, each time series in the data is embedded in a vectorial metric space through feature extraction; features may be used arbitrarily or obtained from an autoregressive linear model applied to each time series.
4.1. Encoding
We experiment with two types of encodings.
Simple statistical feature extraction
The p statistical characteristics are computed for each time series. These include the minimum, maximum, sum, number of times a threshold is crossed, length of zero periods, and so on. These engineering features depend on the dataset at hand and its characteristics.
Using linear autoregressive (AR) models
A linear autoregressive model is adjusted to each time series with a maximum order . Once the optimal orders are obtained for all time series in any sample, we fix the final desired order as . Finally, each time series is represented by its p estimated coefficients.
4.2. Using Appropriate Distance
Most of the algorithms described in
Section 3 are based on neighborhood and, thus, distances. Here, we suggest replacing the Euclidean distance used in the general framework with dynamic time warping (DTW).
DTW allows for comparison of two time series by measuring their similarity, even if they have different lengths [
8,
9].
Consider the two time series
and
with
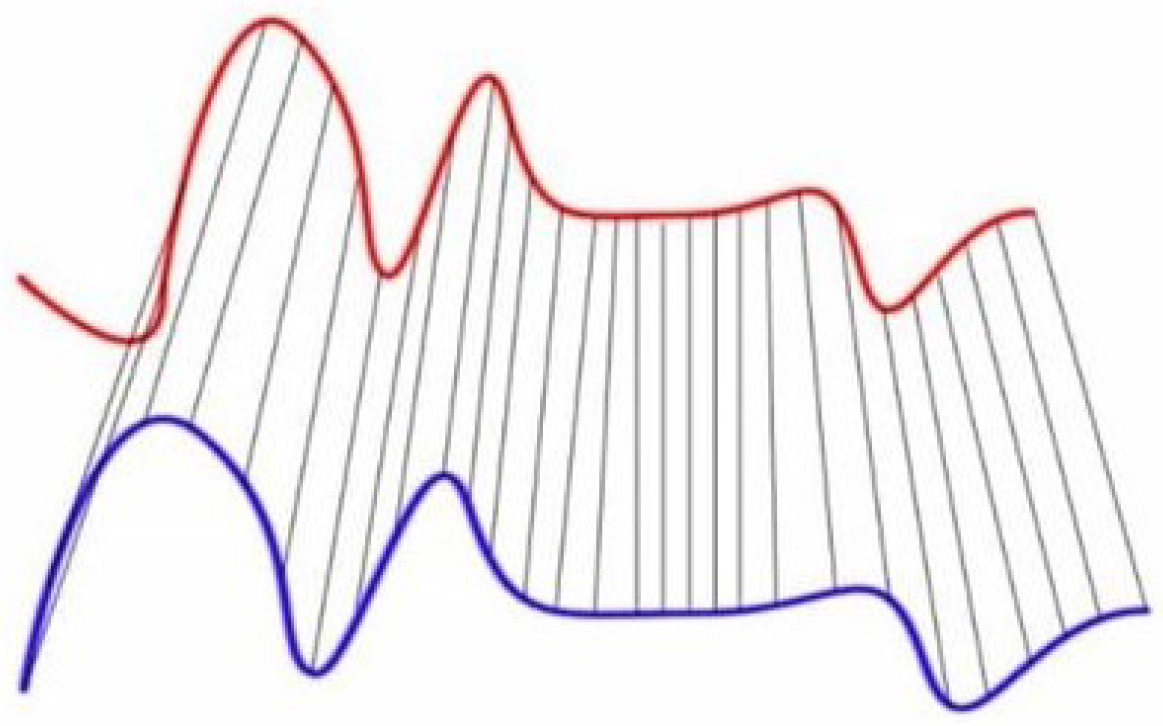
, which lie in the same dimensional space. The goal of DTW is to find the optimal temporal alignment between
A and
B; each point from
A is associated with at least one point from
B (and reciprocally), as shown in
Figure 1. The optimal alignment, corresponding to the DTW distance between
A and
B, is the one giving the minimum total length between the couples of aligned points. This may be computed by resolving a linear programming problem.
For a long time series, the DTW may be very complex to compute. The computation may be simplified using fast versions of the underlying optimization algorithm or by sampling the time series using arbitrary frequencies.
5. Real Dataset Application
We apply now the proposed approach to a time series dataset concerning real customers provided by RENAULT ( the French car industry). All experiments were run using the R software [
11] together with packages [
12,
13].
5.1. Driving Behavior Dataset
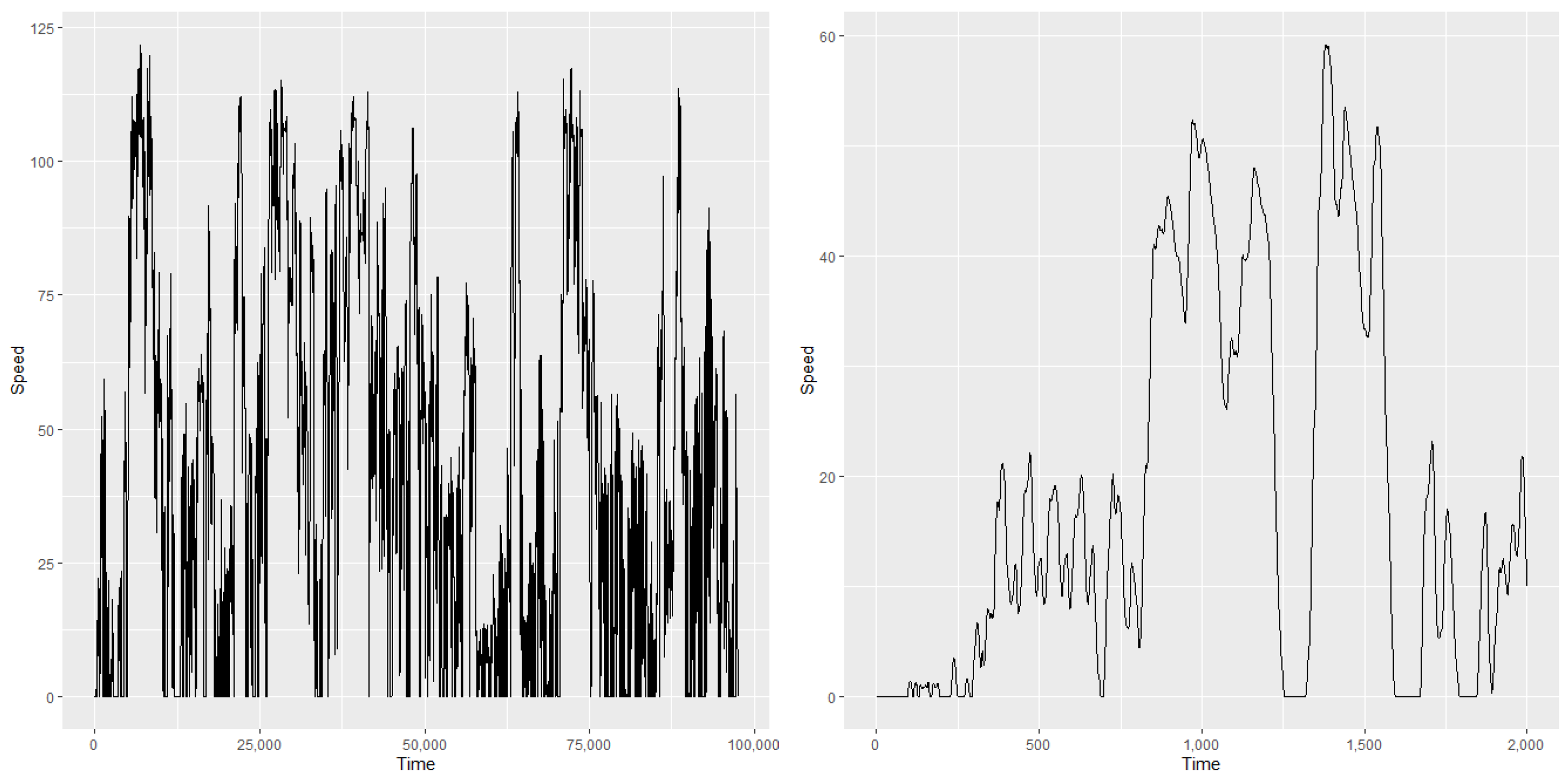
The variable
X in our dataset is the time series of driver’s speed. A large number of time series are available sampled at 5 Hz with a recording duration varying from a few days to a few weeks. Sampling at 5 Hz represents 86,400 points per day. This means that the time series studied are very large and different. An example of such time series is provided in
Figure 2. We have used a selected sample of 691 customers.
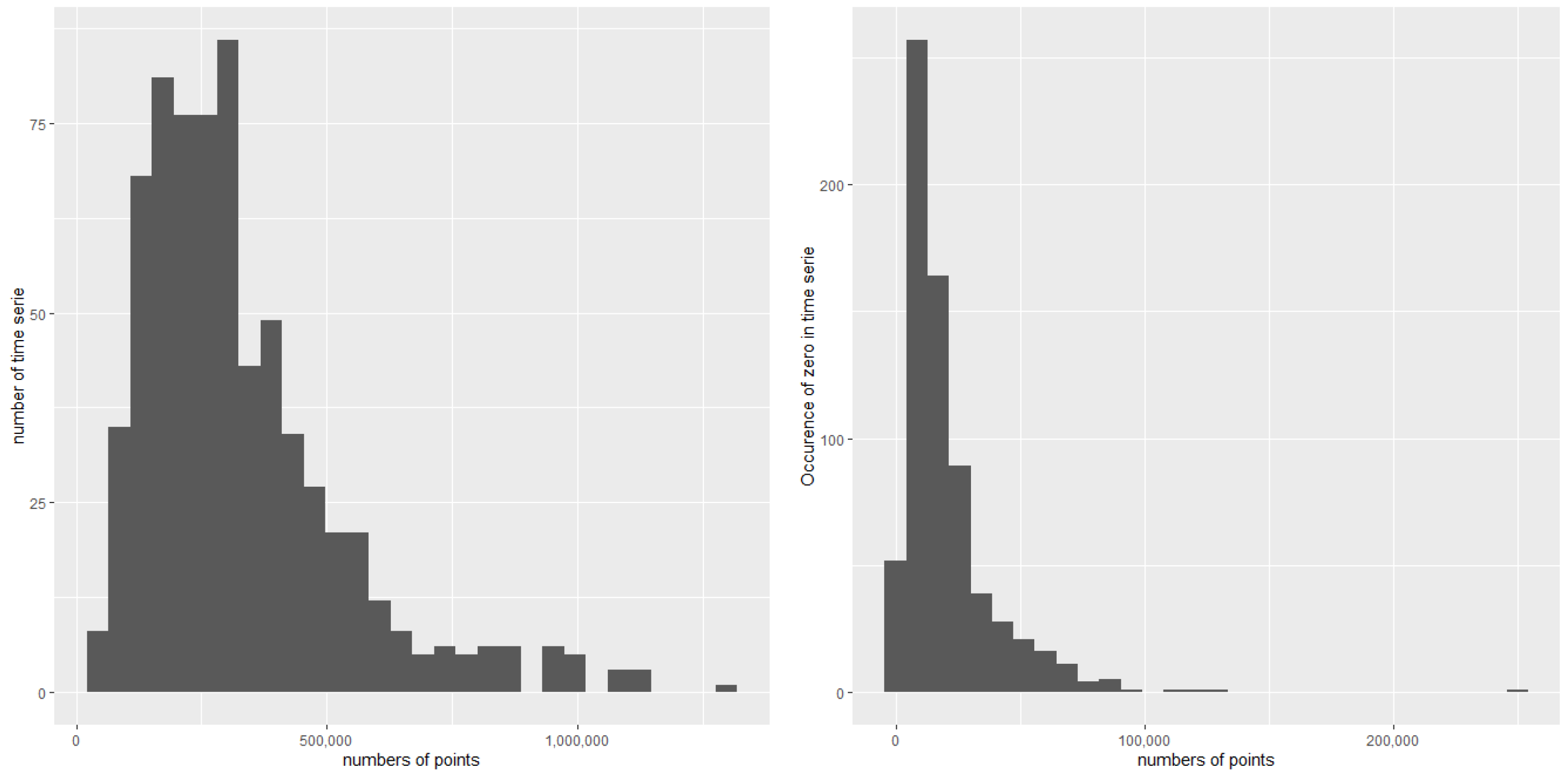
As these time series are speed traces of real customers, they vary from 0 to 150 km/h in our sample. Long and short stays at zero may be observed in these time series, corresponding to either night periods or shorter periods that correspond to car pauses, such as those for red lights. The lengths of the time series in our sample vary from 25,000 points to several million.
Figure 3 shows the distribution of the time series lengths and the distribution of the zero values among the time series.
In addition, for the 691 customers, a complex numerical model f was run in order to estimate the maximum soot released from each customer’s vehicle. This model requires as input x the speed data time series together with many other characteristics of the vehicle. The maximum soot is the output of interest. As this model requires very long time computations (several hours for each customer depending on its parametrization), the objective is to select from among a dataset not used with the model, such as a sample of customers, for which the model would issue a similar distribution for the maximum soot to that already modeled for the customers.
5.2. Results
In this section, we provide the results of the algorithms proposed in
Section 3: the extended nearest neighbors, the partition-based algorithm, the histogram-based approach and both variants using the support point and D-optimality.
To test these algorithms, the sample was randomly split into two parts with
having 100 customers, and
having the other 591. Each algorithm was run 100 times, and, from each run, the obtained optimal subsample
was compared to
using the Kolmogorov–Smirnov (KS) two samples test between
and
, as the output of the model is known for all the samples in our dataset.
Table 1 gives the average values of the KS statistics and the
p-values over the 100 runs. We can observe that, depending on the encoding used, the algorithms do not react in the same way. We can see that the histogram-based algorithm provides the same results for the AR coefficients and feature extraction, though it is less efficient with the DTW. For the partition-based algorithms, the DTW performs much better than the two encoding approaches. While for the nearest neighbors and the support point, we get very close results for both encodings. Finally, for the D-optimality, we can see that the DTW and AR features provide the same results, which are better than those for feature extraction.
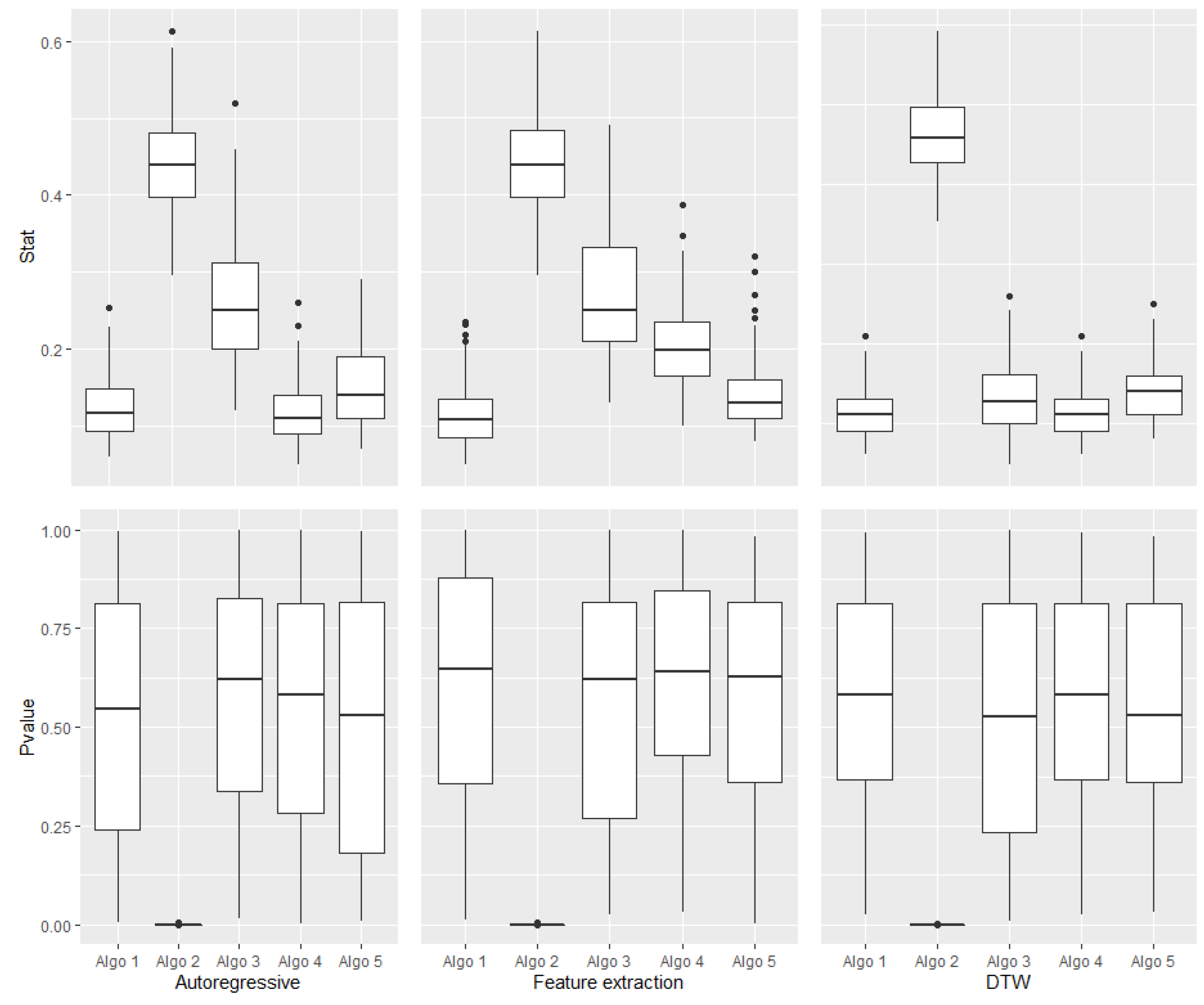
Figure 4 shows the distribution of the
p-values and the KS statistics over the 100 runs for all algorithms, the two encodings and DTW.
We can see that the deviation of the computed statistics are different for the three approaches: the AR, feature extraction and DTW. We can see that, for all algorithms, the AR encoding results are more unstable than those of the two other approaches.




{kind=link}
{kind=link}
{kind=link}
{kind=link}