
An Open Source and Reproducible Implementation of LSTM and GRU Networks for Time Series Forecasting †


Abstract
:1. Introduction
2. Method
2.1. Recurrent Neural Networks
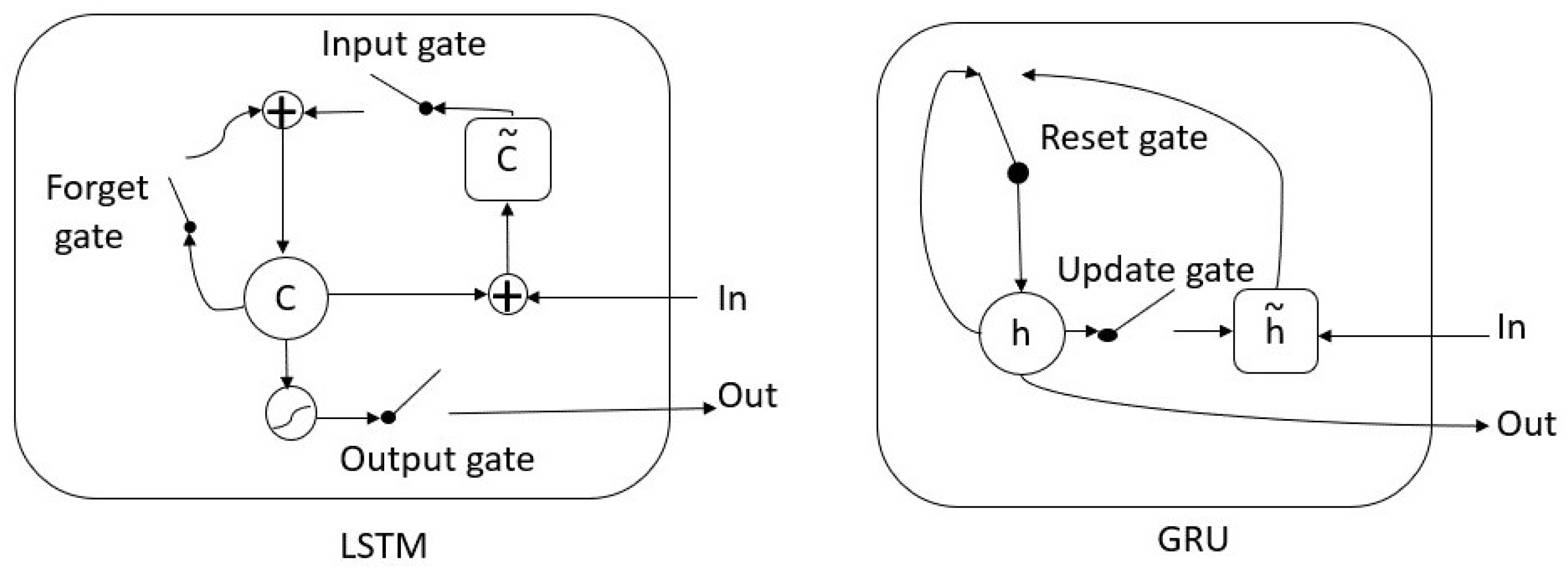
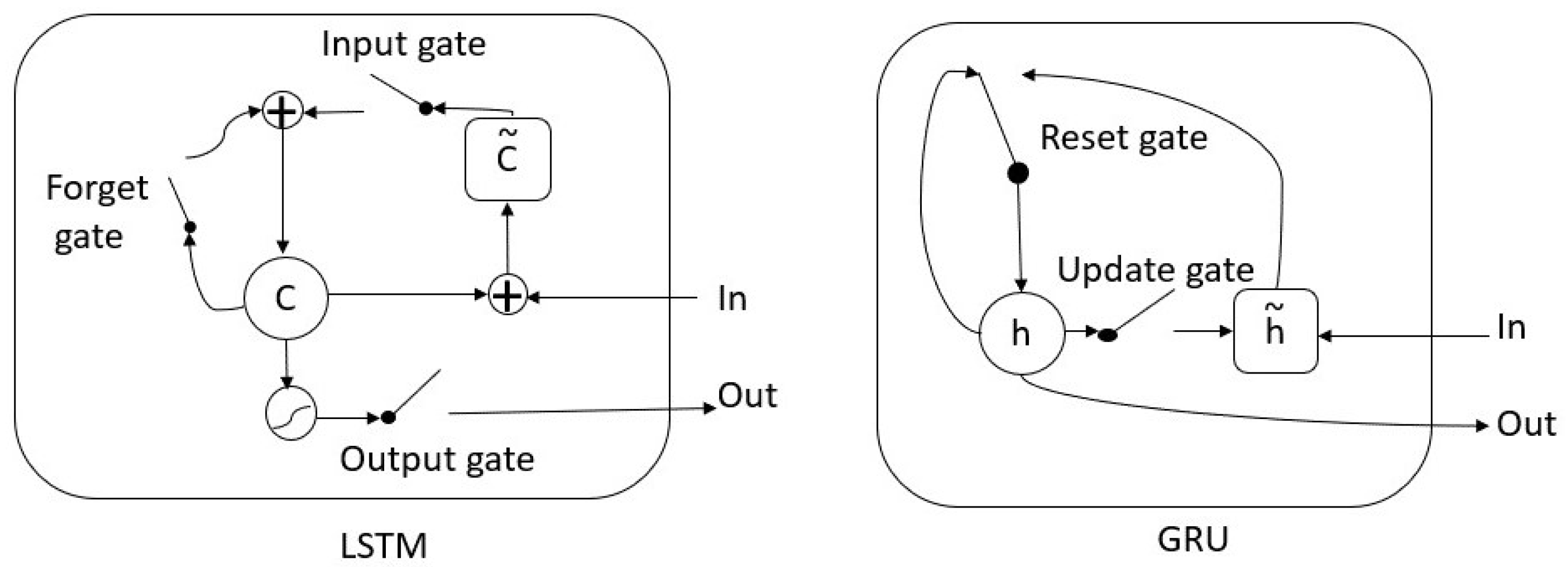
2.2. Long Short-Term Memory
2.3. Gated Recurrent Unit
2.4. Data Preparation
2.5. Networks’ Architecture and Training
- A layer with 128 units,
- A dense layer with size equal to the number of steps ahead for prediction,
2.6. Evaluation
3. Experiments
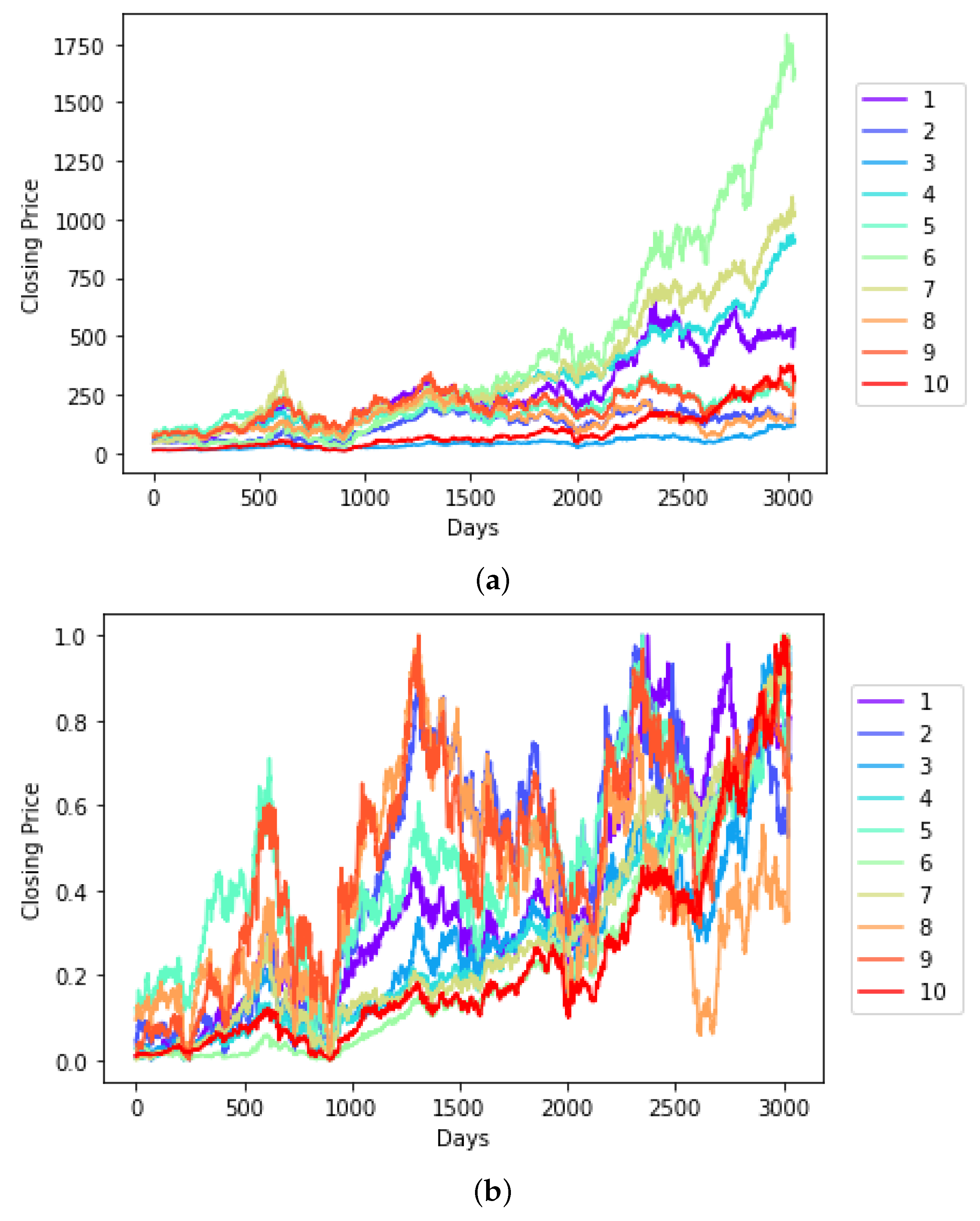
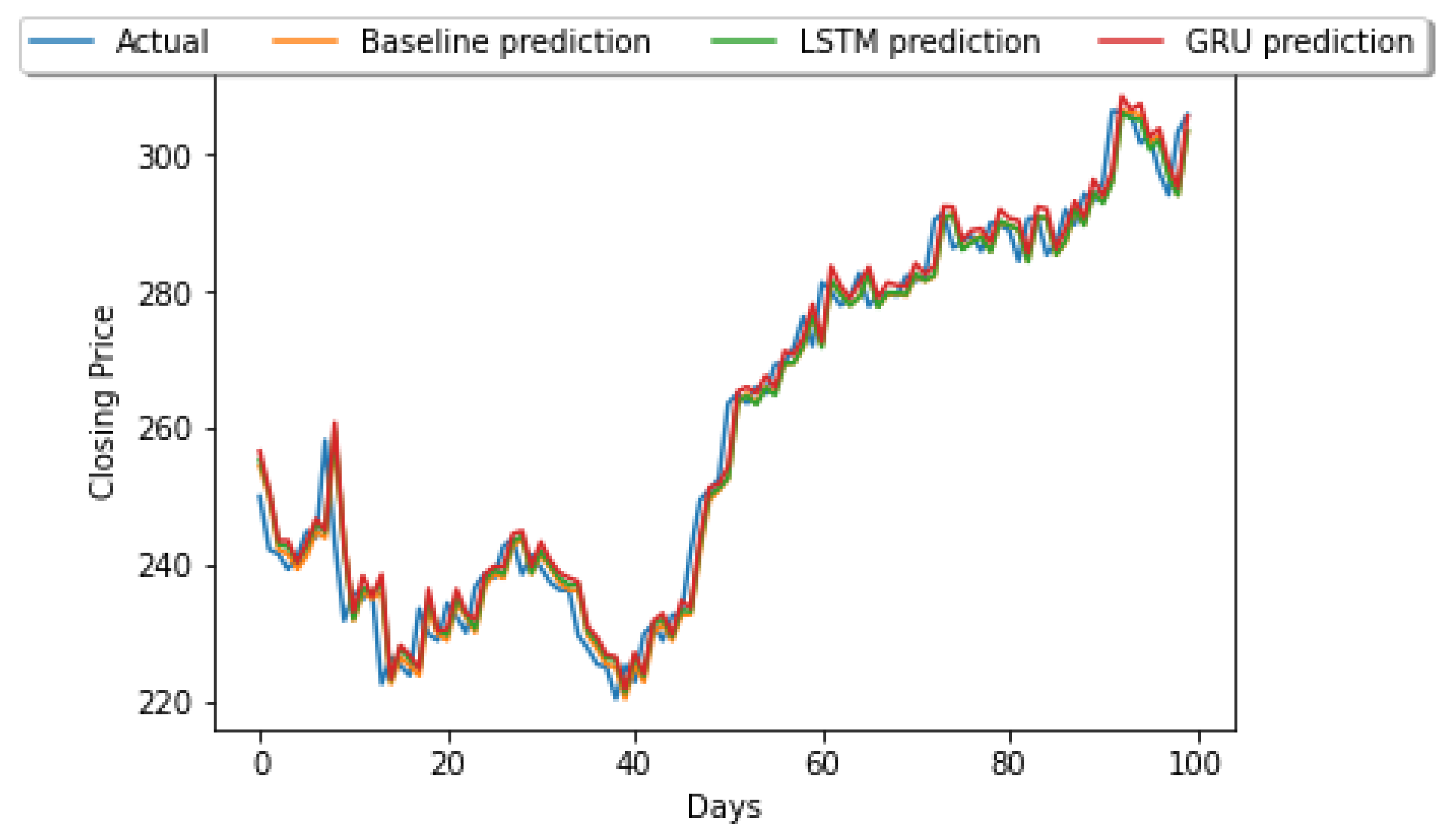
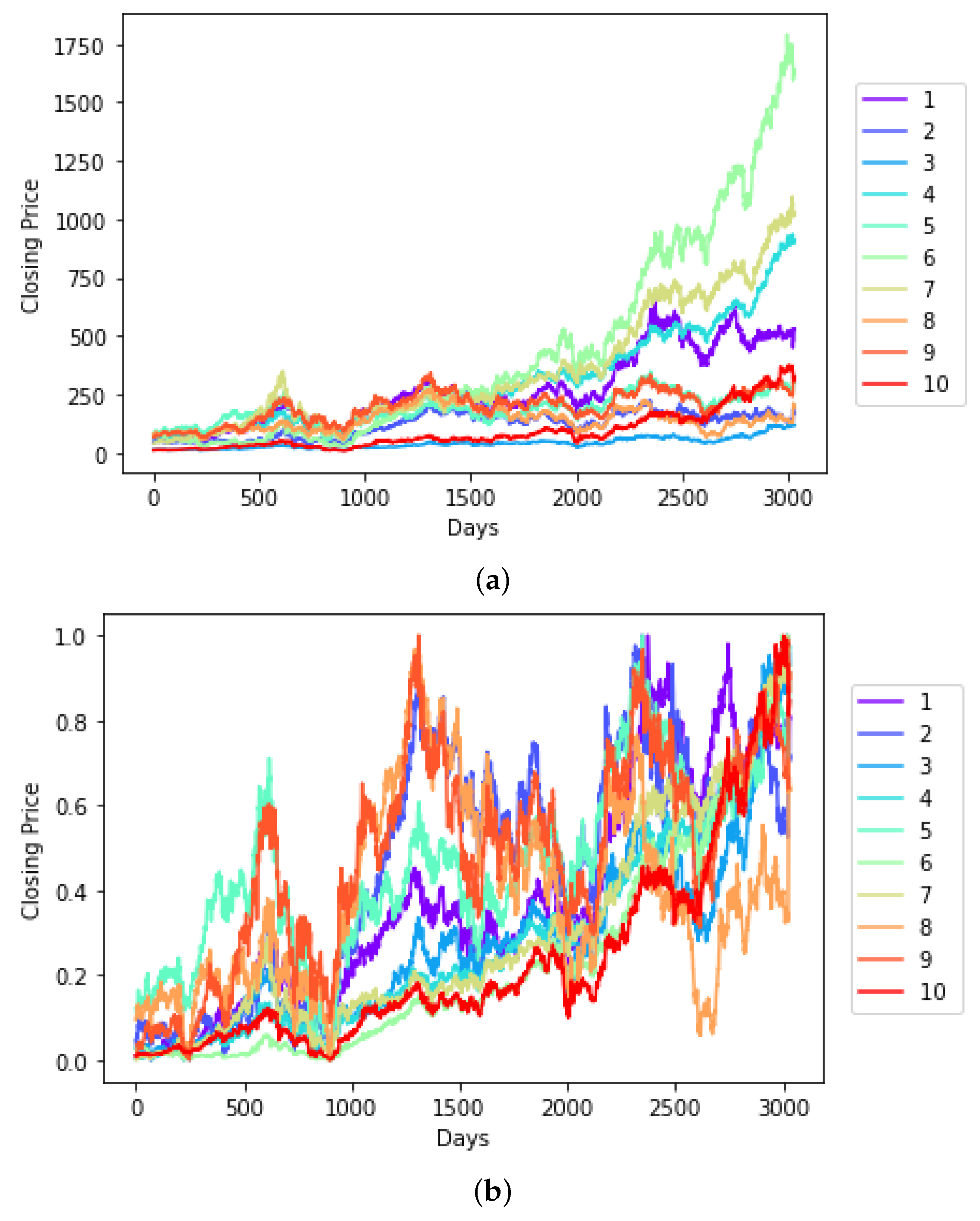
3.1. The S&P BSE BANKEX Dataset
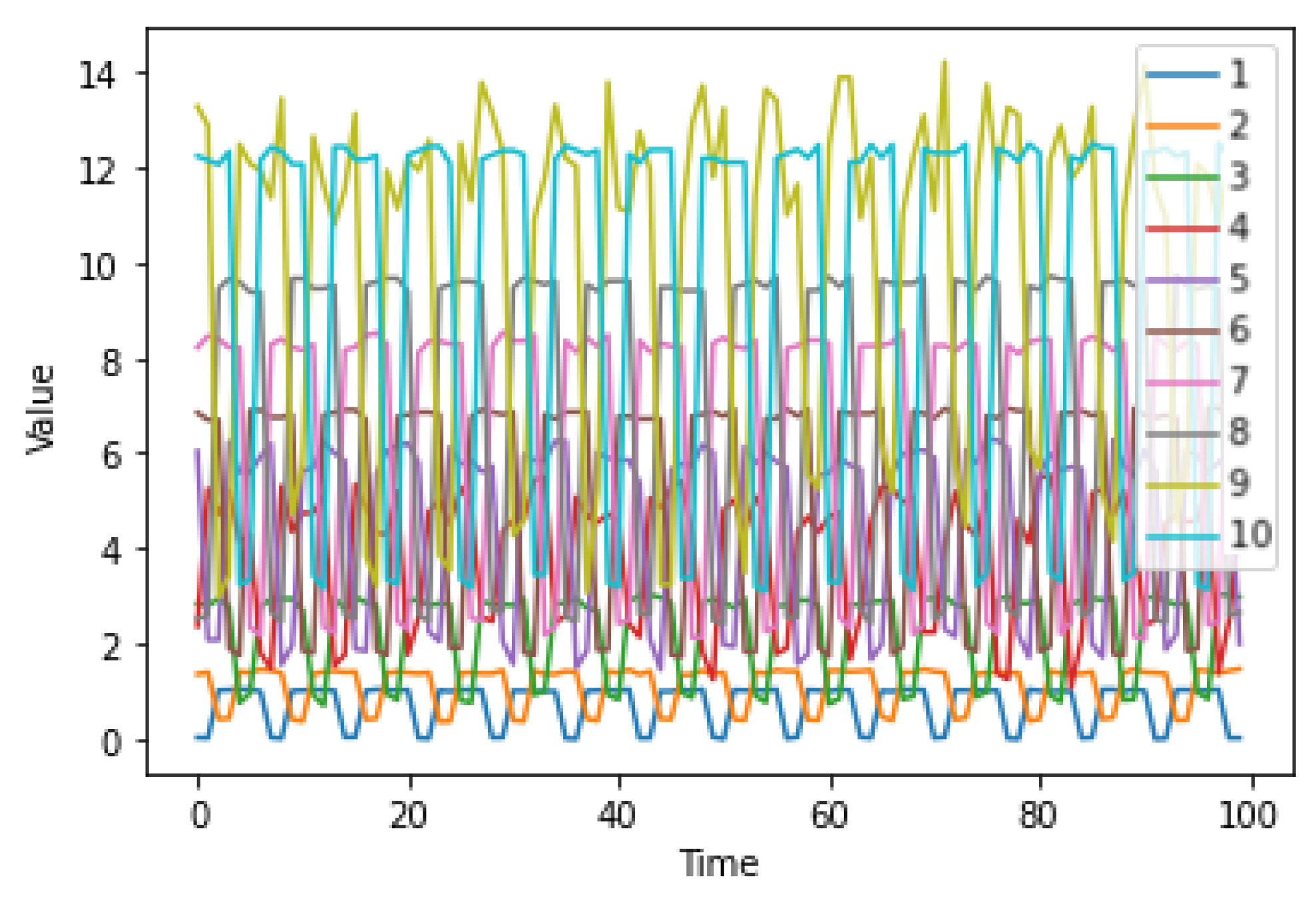
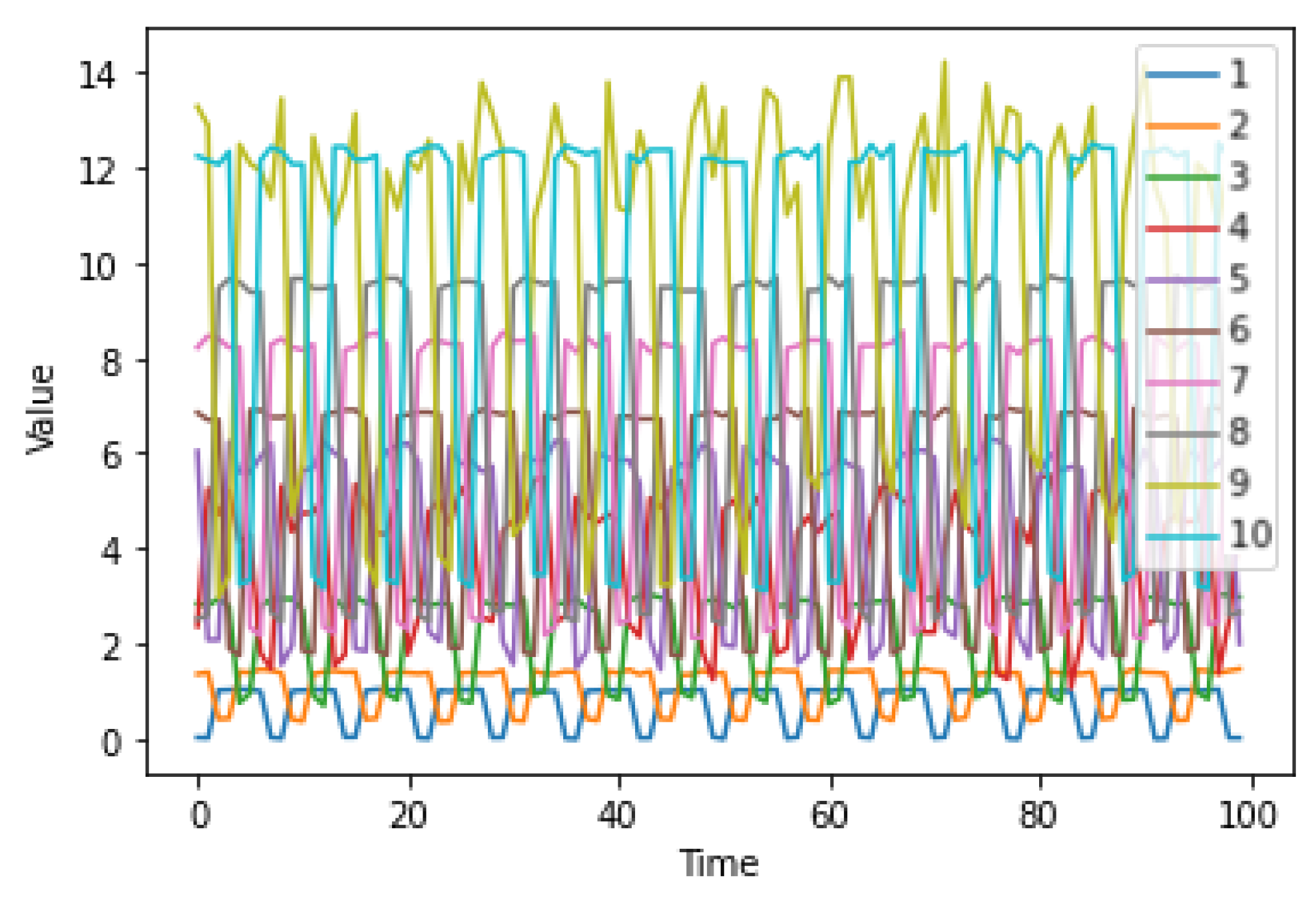
3.2. The Activities Dataset
3.3. Datasets Preparation and Partition
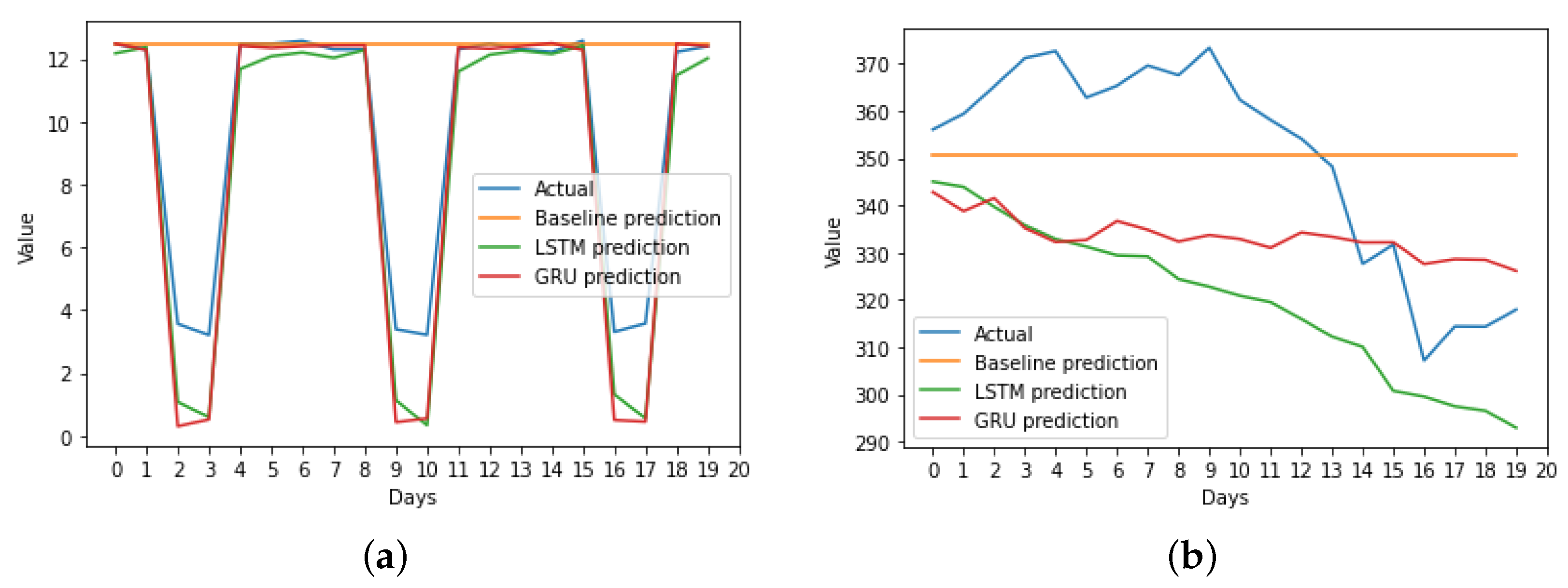
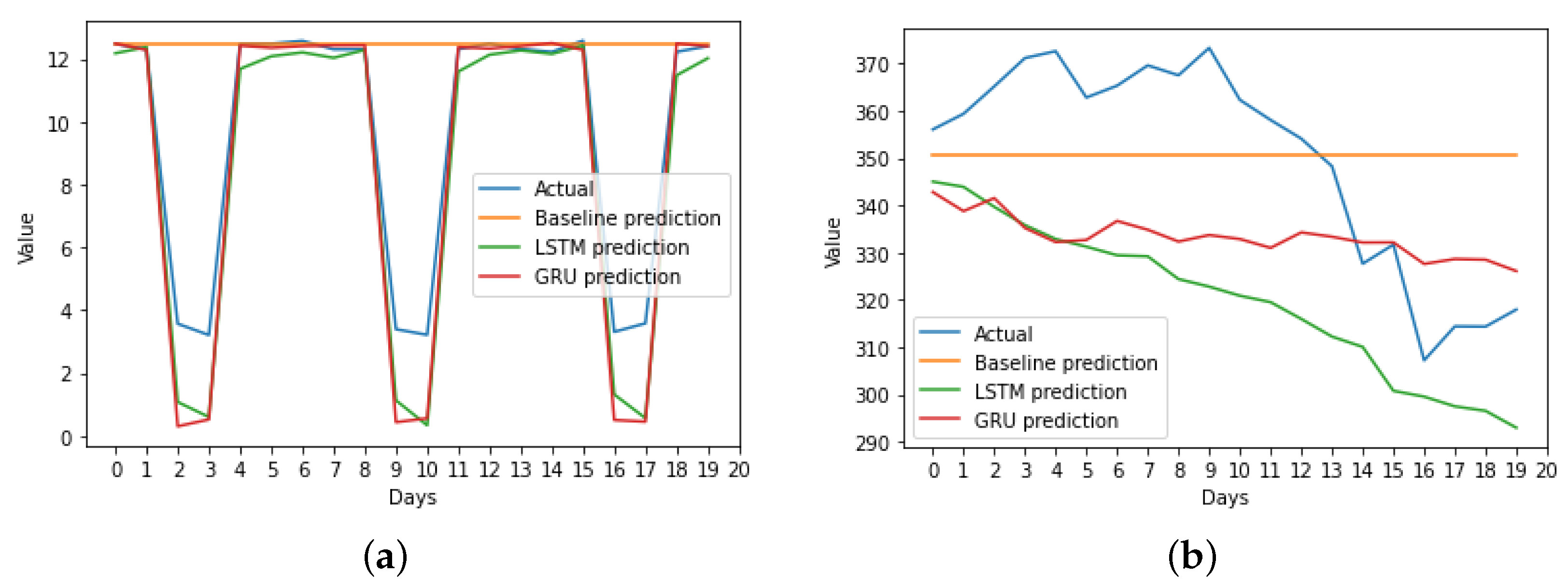
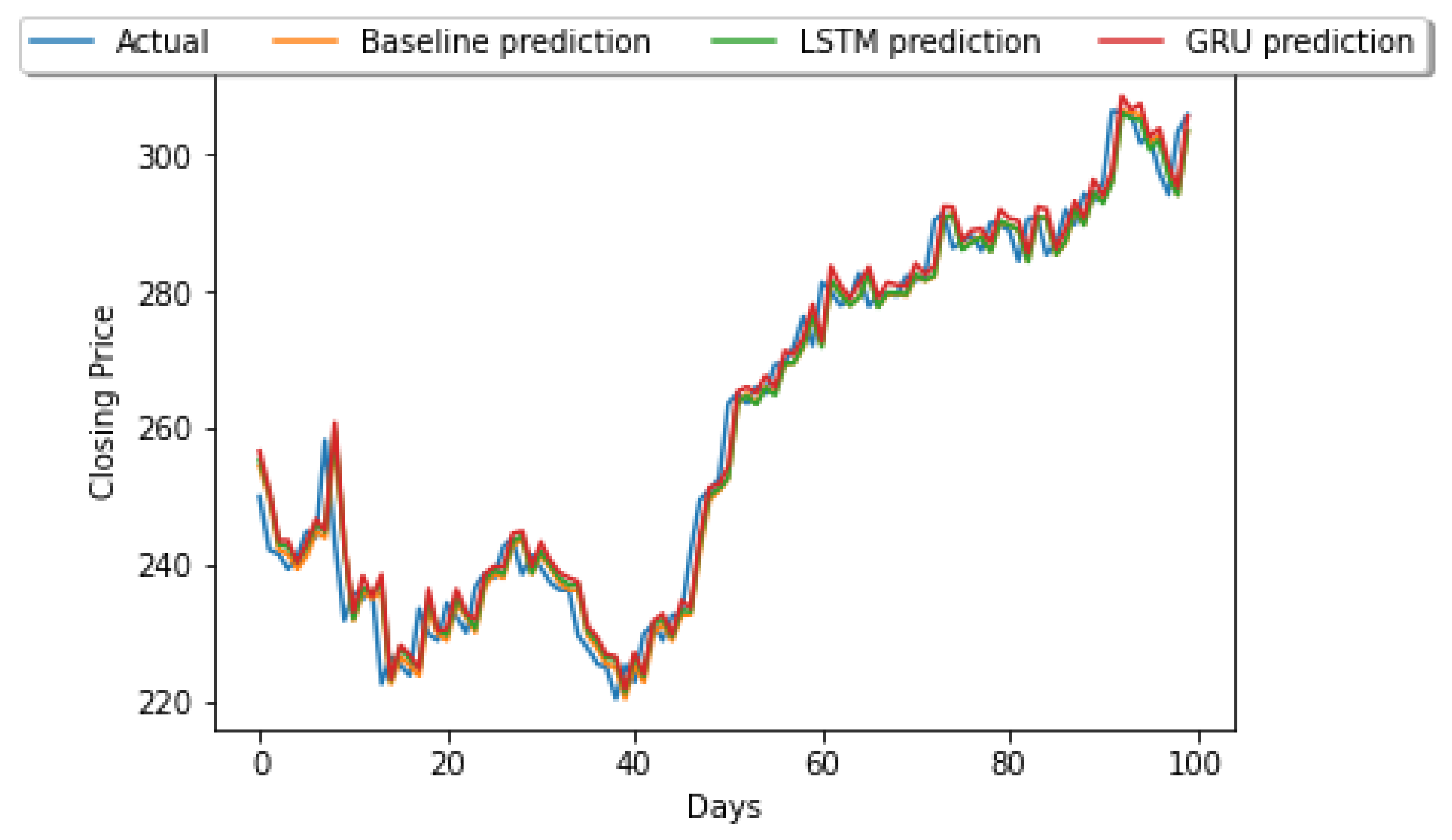
3.4. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A comparison of ARIMA and LSTM in forecasting time series. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar]
- Box, G.; Jenkins, G. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Balaji, A.J.; Ram, D.H.; Nair, B.B. Applicability of deep learning models for stock price forecasting an empirical study on BANKEX data. Procedia Comput. Sci. 2018, 143, 947–953. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, J.J.; Wang, J.Z.; Zhang, Z.G.; Guo, S.P. Stock index forecasting based on a hybrid model. Omega 2012, 40, 758–766. [Google Scholar] [CrossRef]
- Yahoo. Yahoo! Finance’s API. 2022. Available online: https://pypi.org/project/yfinance/ (accessed on 20 January 2022).
- Alpaydin, E. Introduction to Machine Learning; The MIT Press: Cambridge, MA, USA; London, UK, 2014. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 2022. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Entity | Symbol |
|---|---|---|
| 1 | Axis Bank | AXISBANK.BO |
| 2 | Bank of Baroda | BANKBARODA.BO |
| 3 | Federal Bank | FEDERALBNK.BO |
| 4 | HDFC Bank | HDFCBANK.BO |
| 5 | ICICI Bank | ICICIBANK.BO |
| 6 | Indus Ind Bank | INDUSINDBK.BO |
| 7 | Kotak Mahindra | KOTAKBANK.BO |
| 8 | PNB | PNB.BO |
| 9 | SBI | SBIN.BO |
| 10 | Yes Bank | YESBANK.BO |
| RMSE | DA | |||||
|---|---|---|---|---|---|---|
| LSTM | GRU | Baseline | LSTM | GRU | Baseline | |
| Mean | 0.2949 | 0.1268 | 0.3730 | 0.6360 | 0.6236 | 0.4212 |
| SD | 0.0941 | 0.0425 | 0.0534 | 0.0455 | 0.0377 | 0.0403 |
| RMSE | DA | |||||
|---|---|---|---|---|---|---|
| LSTM | GRU | Baseline | LSTM | GRU | Baseline | |
| Mean | 0.1267 | 0.2048 | 0.4551 | 0.6419 | 0.6261 | 0.4805 |
| SD | 0.0435 | 0.0683 | 0.0678 | 0.0331 | 0.0255 | 0.0413 |
| RMSE | DA | |||||
|---|---|---|---|---|---|---|
| LSTM | GRU | Baseline | LSTM | GRU | Baseline | |
| Mean | 0.0163 | 0.0163 | 0.0161 | 0.4884 | 0.4860 | 0.4880 |
| SD | 0.0052 | 0.0056 | 0.0056 | 0.0398 | 0.0385 | 0.0432 |
| RMSE | DA | |||||
|---|---|---|---|---|---|---|
| LSTM | GRU | Baseline | LSTM | GRU | Baseline | |
| Mean | 0.0543 | 0.0501 | 0.0427 | 0.5004 | 0.5004 | 0.4969 |
| SD | 0.0093 | 0.0064 | 0.0113 | 0.0071 | 0.0087 | 0.0076 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Velarde, G.; Brañez, P.; Bueno, A.; Heredia, R.; Lopez-Ledezma, M. An Open Source and Reproducible Implementation of LSTM and GRU Networks for Time Series Forecasting. Eng. Proc. 2022, 18, 30. https://doi.org/10.3390/engproc2022018030
Velarde G, Brañez P, Bueno A, Heredia R, Lopez-Ledezma M. An Open Source and Reproducible Implementation of LSTM and GRU Networks for Time Series Forecasting. Engineering Proceedings. 2022; 18(1):30. https://doi.org/10.3390/engproc2022018030
Chicago/Turabian StyleVelarde, Gissel, Pedro Brañez, Alejandro Bueno, Rodrigo Heredia, and Mateo Lopez-Ledezma. 2022. "An Open Source and Reproducible Implementation of LSTM and GRU Networks for Time Series Forecasting" Engineering Proceedings 18, no. 1: 30. https://doi.org/10.3390/engproc2022018030
APA StyleVelarde, G., Brañez, P., Bueno, A., Heredia, R., & Lopez-Ledezma, M. (2022). An Open Source and Reproducible Implementation of LSTM and GRU Networks for Time Series Forecasting. Engineering Proceedings, 18(1), 30. https://doi.org/10.3390/engproc2022018030