
Prediction Error-Based Action Policy Learning for Quadcopter Flight Control †


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
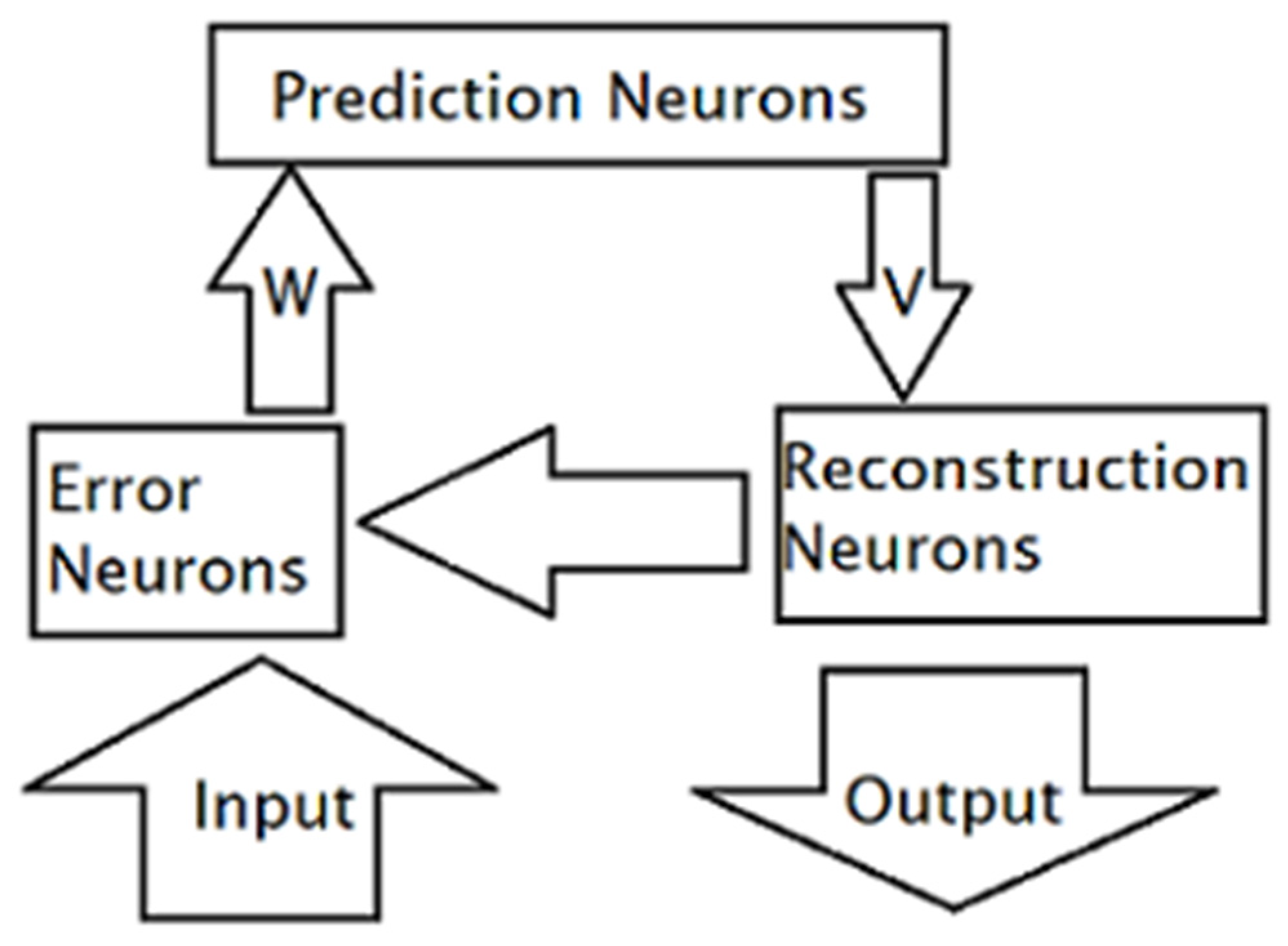
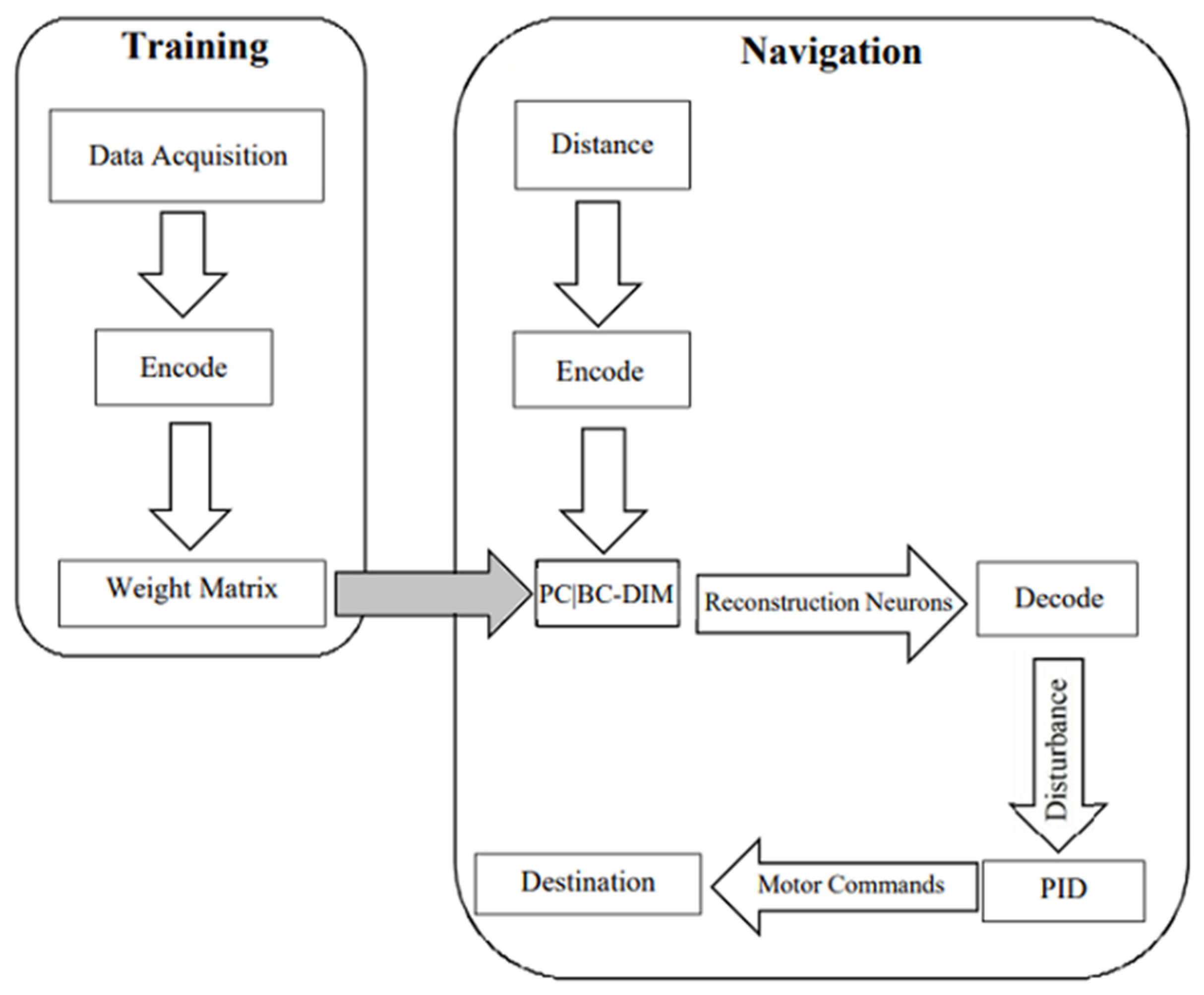
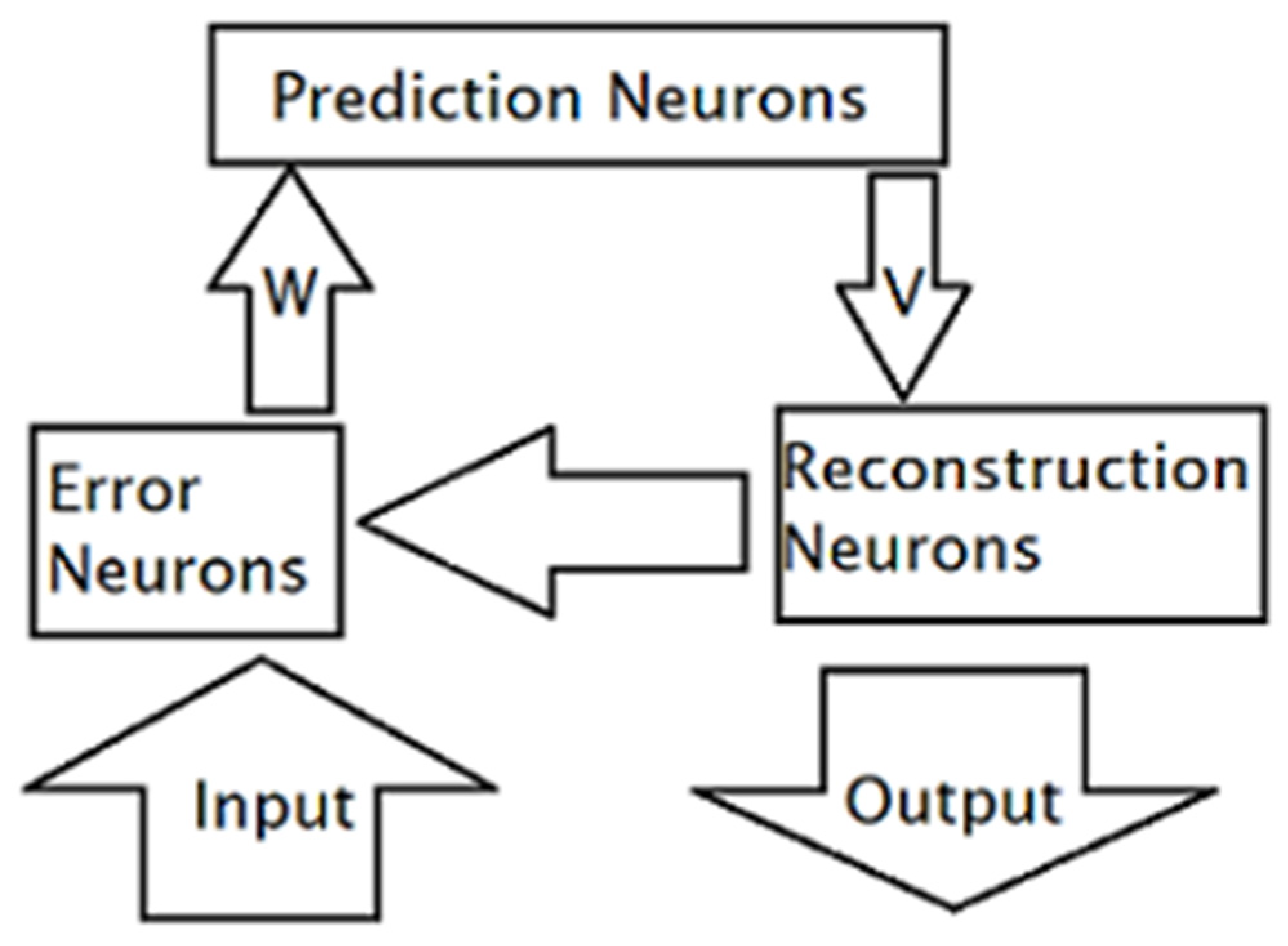
2. Methodology
2.1. Training
| Algorithm 1. Training |
|
2.2. Navigation
| Algorithm 2. Navigation |
| 1. while distance ≠ 0: 2. read GPS and gyro sensors 3. distance = goal GPS-current GPS reading 4. encode distance 5. PC/BC-DIM ← distance 6. reconstruction neurons ← PC/BC-DIM 7. disturbances ← decoded reconstruction neurons 8. PID ← disturbances |
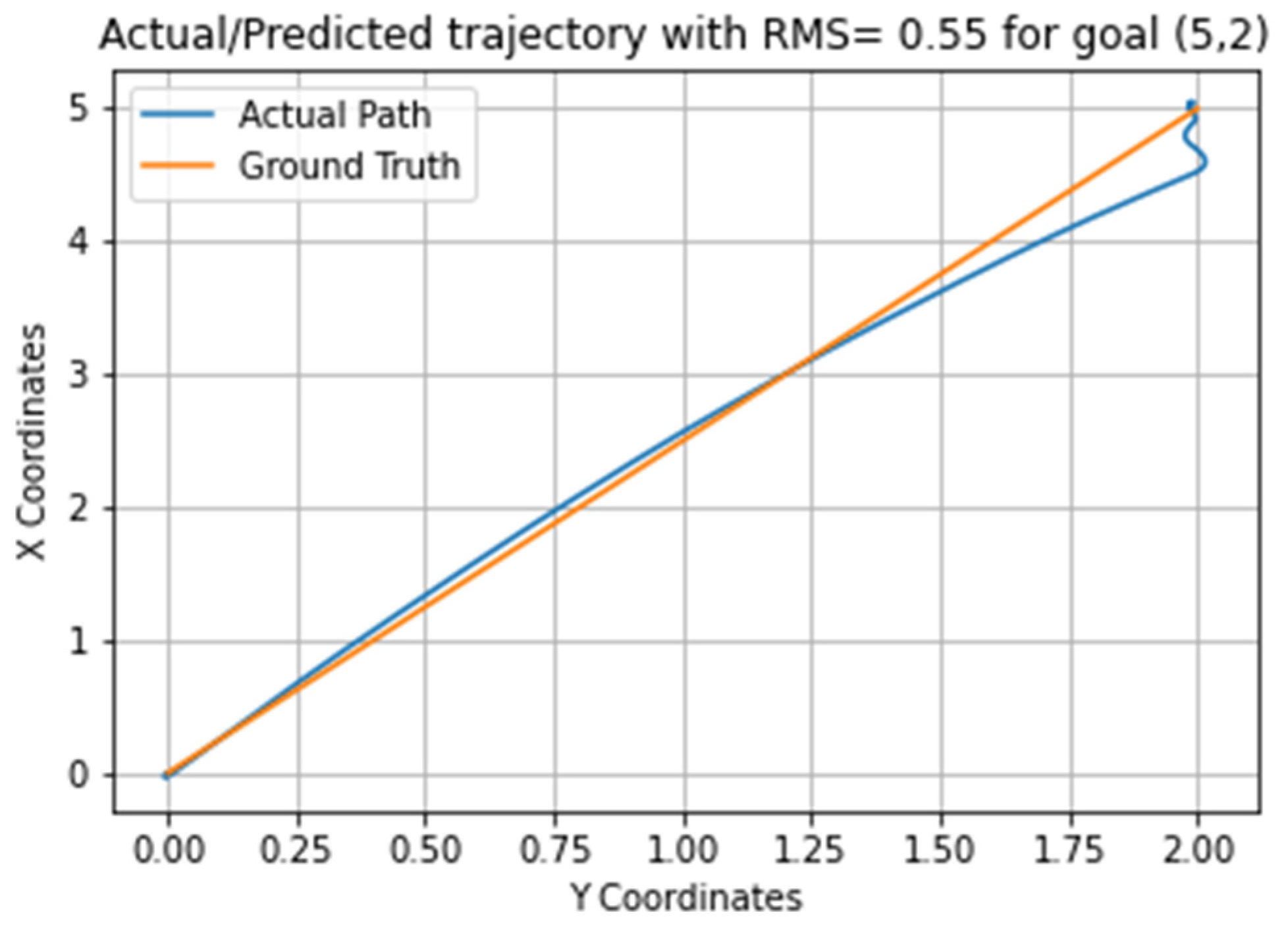
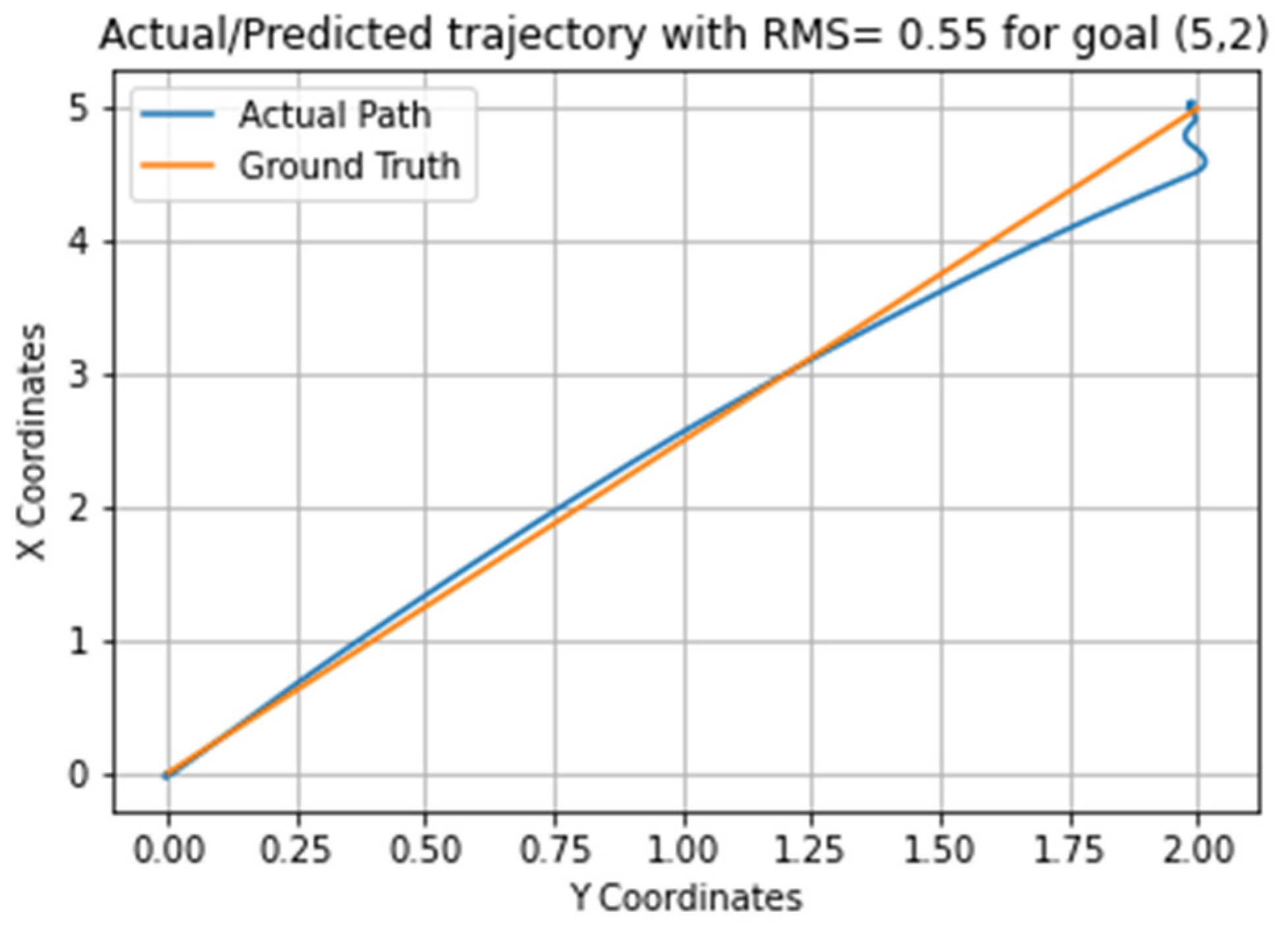
3. Results
4. Conclusions
Conflicts of Interest
References
- Maleki, K.N.; Ashenayi, K.; Hook, L.R.; Fuller, J.G.; Hutchins, N. A reliable system design for nondeterministic adaptive controllers in small UAV autopilots. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–5. [Google Scholar]
- Greatwood, C.; Richards, A.G. Reinforcement learning and model predictive control for robust embedded quadrotor guidance and control. Auton. Robot. 2019, 43, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Kahn, G.; Levine, S.; Abbeel, P. Learning deep control policies for autonomous aerial vehicles with mpc-guided policy search. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 528–535. [Google Scholar]
- Zemalache, K.M.; Maaref, H. Controlling a drone: Comparison between a based model method and a fuzzy inference system. Appl. Soft Comput. 2009, 9, 553–562. [Google Scholar] [CrossRef] [Green Version]
- Koch, W.; Mancuso, R.; West, R.; Bestavros, A. Reinforcement learning for UAV attitude control. ACM Trans. Cyber-Phys. Syst. 2019, 3, 22. [Google Scholar] [CrossRef] [Green Version]
- Spratling, M.W. A neural implementation of Bayesian inference based on predictive coding. Connect. Sci. 2016, 28, 346–383. [Google Scholar] [CrossRef] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khanzada, J.S.; Muhammad, W.; Irshad, M.J. Prediction Error-Based Action Policy Learning for Quadcopter Flight Control. Eng. Proc. 2021, 12, 47. https://doi.org/10.3390/engproc2021012047
Khanzada JS, Muhammad W, Irshad MJ. Prediction Error-Based Action Policy Learning for Quadcopter Flight Control. Engineering Proceedings. 2021; 12(1):47. https://doi.org/10.3390/engproc2021012047
Chicago/Turabian StyleKhanzada, Jamal Shams, Wasif Muhammad, and Muhammad Jehanzeb Irshad. 2021. "Prediction Error-Based Action Policy Learning for Quadcopter Flight Control" Engineering Proceedings 12, no. 1: 47. https://doi.org/10.3390/engproc2021012047
APA StyleKhanzada, J. S., Muhammad, W., & Irshad, M. J. (2021). Prediction Error-Based Action Policy Learning for Quadcopter Flight Control. Engineering Proceedings, 12(1), 47. https://doi.org/10.3390/engproc2021012047