2. Background
2.1. Machine Learning Overview
Writ large, machine learning, or artificial intelligence, are sets of statistical methods typically used to describe nonlinear, physical systems, sometimes using experimental observations to guide construction. This introduction reflects much of the reasoning, and further information can be found in the textbook by Shalev-Shwartz and Ben-David [
10]. Other overviews can be found in textbooks by Russell and Norvig [
11] (which include discussions on implementation) or by Devroye et al. [
12] (with a slightly more statistical perspective). This work’s scope is limited to machine learning used for classification. Observed instances,
x, are sampled from a distribution,
, determined by domain-specific physical processes. A single instance is typically represented as a feature vector of discrete elements that could be sampled from continuous nonlinear systems. Examples include (but are not limited to) images, mathematical variables, spectra, health data, etc.
For a given , the goal of machine learning is to find a function that relates this to a label, . The set of classes, , defines the possible labels for the modeled system. The set of datapoint instances, , can take many forms depending on the input modality and the model being designed. Said another way, ML methods find a relationship between x and y such that the model, f, can approximate the relationship: . For example, the model could be trying to classify good versus bad fruit, in which case, the labels may be good banana, bad banana, good apple, or bad apple, and the instances could be observations of individual pieces of fruit (e.g., color, shape, size).
To do this, some observations must be used. Labeled instances,
L, used in "supervised" machine learning, have an associated label, and the total number of paired instances is
. If observations are present without labels, it is possible to perform "unsupervised" machine learning on this unlabeled dataset,
U, numbering
instances. The observed dataset distribution consists of both forms:
For supervised learning, this culminates in empirical risk minimization (ERM) using a loss function. The loss function is some form of penalization against misclassification of known observations:
. There may be many, even infinite, models that describe the observed system. The goal is therefore to find the optimal model that minimizes this loss function:
There are many ways to choose the model, the loss function, the method of finding
, or even the instances
used. A simple model would be a linear regression system where each feature vector,
, is connected to its label,
, by a system of weights,
. Then, the model becomes
where
b is a bias term. The loss could then be a mean square error (MSE), and ERM finds the optimal set of weights that describes all
with minimal loss:
2.2. Semi-Supervised Machine Learning
Semi-supervised machine learning encompasses ML models that use both labeled and unlabeled data. This class sits between traditional supervised and unsupervised machine learning. The development of these methods was motivated by high-cost regimes for labeling. In some fields, labeling must be carried out manually and requires domain expertise. Both methods increase the cost of this time-consuming pre-processing step. When the cost is prohibitive, but data are plentiful, SSML can be useful. For a larger overview of SSML, refer to the textbook compiled by Chappelle et al. [
13]. Semi-supervised learning relies on certain assumptions to learn a decision boundary. That is, the learned mathematical description that separates classes is in the feature space. This is necessary for connecting information about classification from labeled data to knowledge about the underlying data distribution from unlabeled data.
The cluster assumption states that if two samples, and , are close together, their labels should agree: . The notion of closeness is up to interpretation and depends on the unique data modality. If true, selected features describe the state space responsible for classification with some notion of smoothness, i.e., should exhibit the same response for some small noise, . A model cannot learn a decision boundary from a feature vector if the feature space has no correlation with class labels. This is connected to the smoothness assumption, which contends that classes of data should be clustered in a region of high density that is describable by that state space.
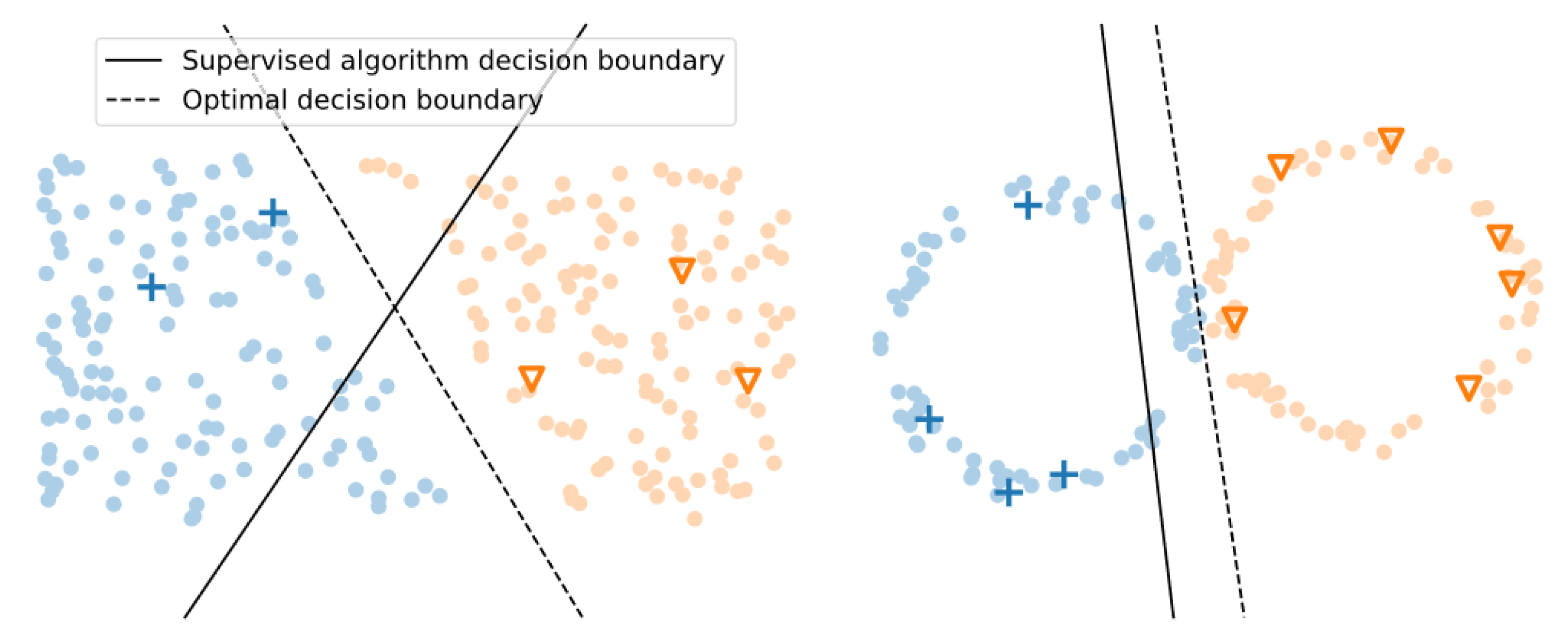
The manifold assumption maintains that higher-dimensional data lie on a lower-dimensional manifold (a topological space). Therefore, the decision boundary that separates classes in this space may also be lower dimensional and thus does not require the entire feature space to discern separation. For example, a three-dimensional dataset may have a two-dimensional representation that makes its classes separable. Both assumptions are illustrated in
Figure 1. Each assumption supports scenarios in which unlabeled data can improve a learned decision boundary with added information.
T. Lu [
14] argues that near certainty about "some non-trivial relationship between labels and the unlabeled distribution" is required for success with SSML. Otherwise, convergence will not be guaranteed. Singh, Nowak, and Zhu [
15] take this further by quantifying the data distribution contexts in which SSML will converge faster or perform better than supervised methods (particularly when
). This is carried out within the perspective of the cluster assumption, but the definitive conclusion agrees with the above: SSML will be more effective if a relationship exists and if classes are sufficiently distinguishable. Arguably, this holds for nuclear radiation data. Spectra that come from the same radiation source should exhibit the same radiation signature/photopeak. Any variation is the result of environmental effects and detector efficiencies such as distance to source and the overall underlying background distribution. Spectra should contain the same labeling information regardless of whether they are labeled or unlabeled, excluding edge cases where the signature is barely discernible within a spectrum (such as border samples from Singh et al. [
15]).
Figure 1.
The two underlying SSML assumptions include the cluster assumption (left) and the manifold assumption (right). In each plot, pluses and triangles are labeled instances, and dots are unlabeled instances. Colors (blue and orange) represent different classes. Note how the inclusion of unlabeled data in a ML model would improve its learned decision boundary. (Image source: [
16]).
Figure 1.
The two underlying SSML assumptions include the cluster assumption (left) and the manifold assumption (right). In each plot, pluses and triangles are labeled instances, and dots are unlabeled instances. Colors (blue and orange) represent different classes. Note how the inclusion of unlabeled data in a ML model would improve its learned decision boundary. (Image source: [
16]).
3. Methods
3.1. MINOS Data
The MINOS venture at ORNL collects multi-modal data streams relevant to nuclear nonproliferation. This is accomplished using a network of nodes distributed at ORNL’s campus surrounding two points of interest: the Radiochemical Engineering Development Center (REDC) and the High-Flux Isotope Reactor (HFIR). The reactor facility, HFIR, is used for scientific experiments (e.g., neutron scattering) and isotope production. Materials generated at HFIR are loaded into shielded casks and are transferred by flat-bed truck to REDC. Once at REDC, the materials are unloaded, stored, and/or processed in, for example, hot cells.
Some of the material produced and processed at ORNL and detected by MINOS include [
9]:
Unirradiated 237Np targets used for 238Pu production;
Irradiated 237Np containing 238Pu;
Unirradiated Cm targets used for 252Cf production;
Irradiated Cm containing 252Cf;
225Ac;
Activated metals;
Spent fuel.
The ultimate goal is to develop capabilities that distinguish and differentiate between shielded radiological material that might be present at the testbed. Material transportation can occur along several routes between facilities. Nodes in MINOS are distributed across the possible routes alongside the road. These nodes collect different forms of data including atmospheric conditions (e.g., temperature and pressure), video, audio, seismo-acoustic, and radiation.
Radiation data are collected using a network of sodium iodide (NaI) detectors—each designated as a node—that are distributed along the roads between HFIR and REDC. This detector is capable of measuring gamma radiation emitted from nearby sources. Nodes are designed to take one measurement every second. This measurement is energy-dependent, binned in 1000 channels of 3 keV per bin. Energy calibration, which accounts for gain drift in detector electronics, is completed before being shared for data analysis. Materials transferred around the MINOS testbed will serve as observables for developing and testing analysis methods.
3.2. Nuclear Material Transfers
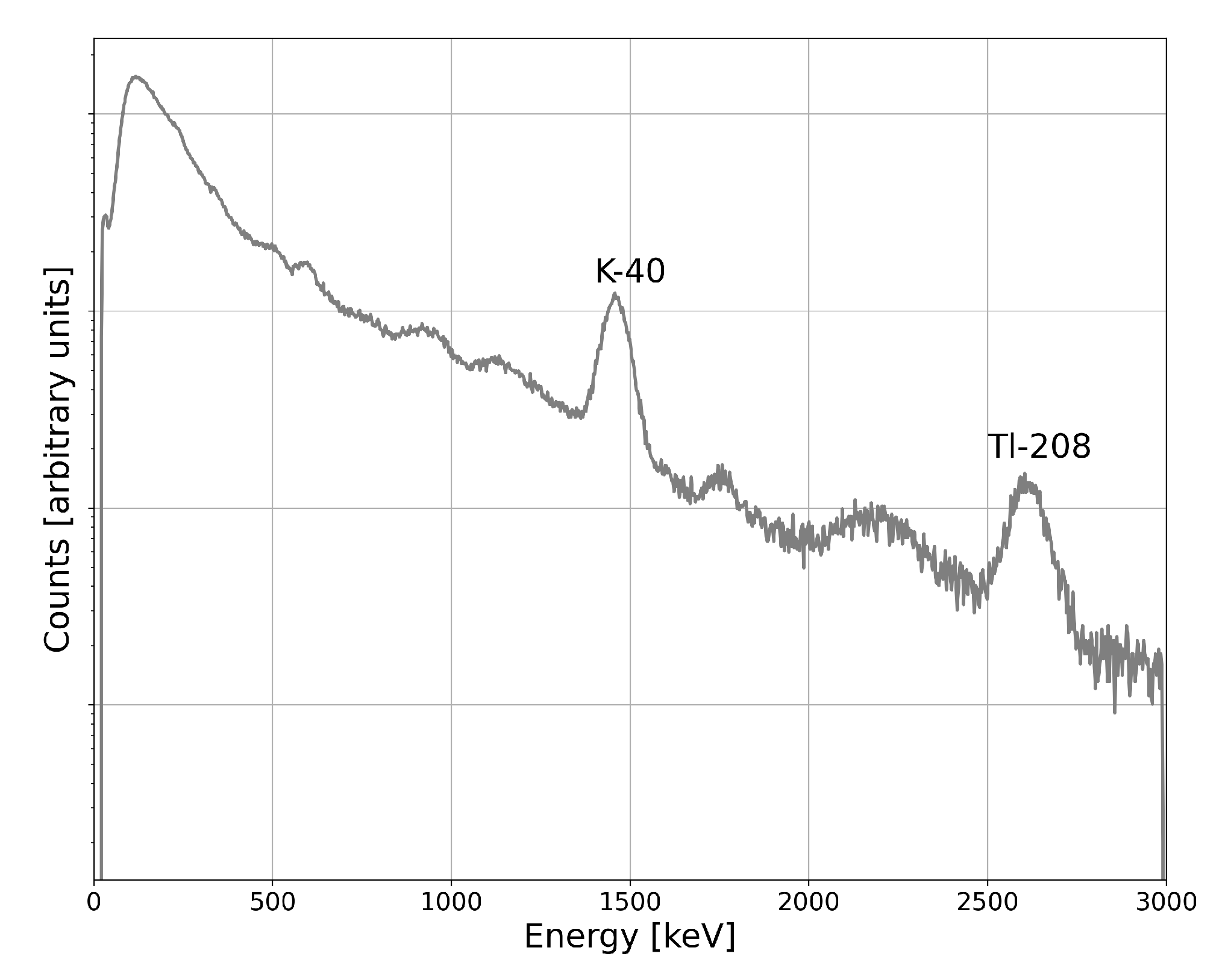
One method of detecting shielded radiological material transfers would be with radiation monitoring. An example gamma radiation spectrum can be seen in
Figure 2. Some photopeaks visible in the spectrum are the result of persistent background radiation that naturally occurs around Earth. This includes signatures related to the potassium–uranium–thorium (KUT) continuum (
40K and
208Tl, for example). Other signatures present in the spectrum must be measured and identified.
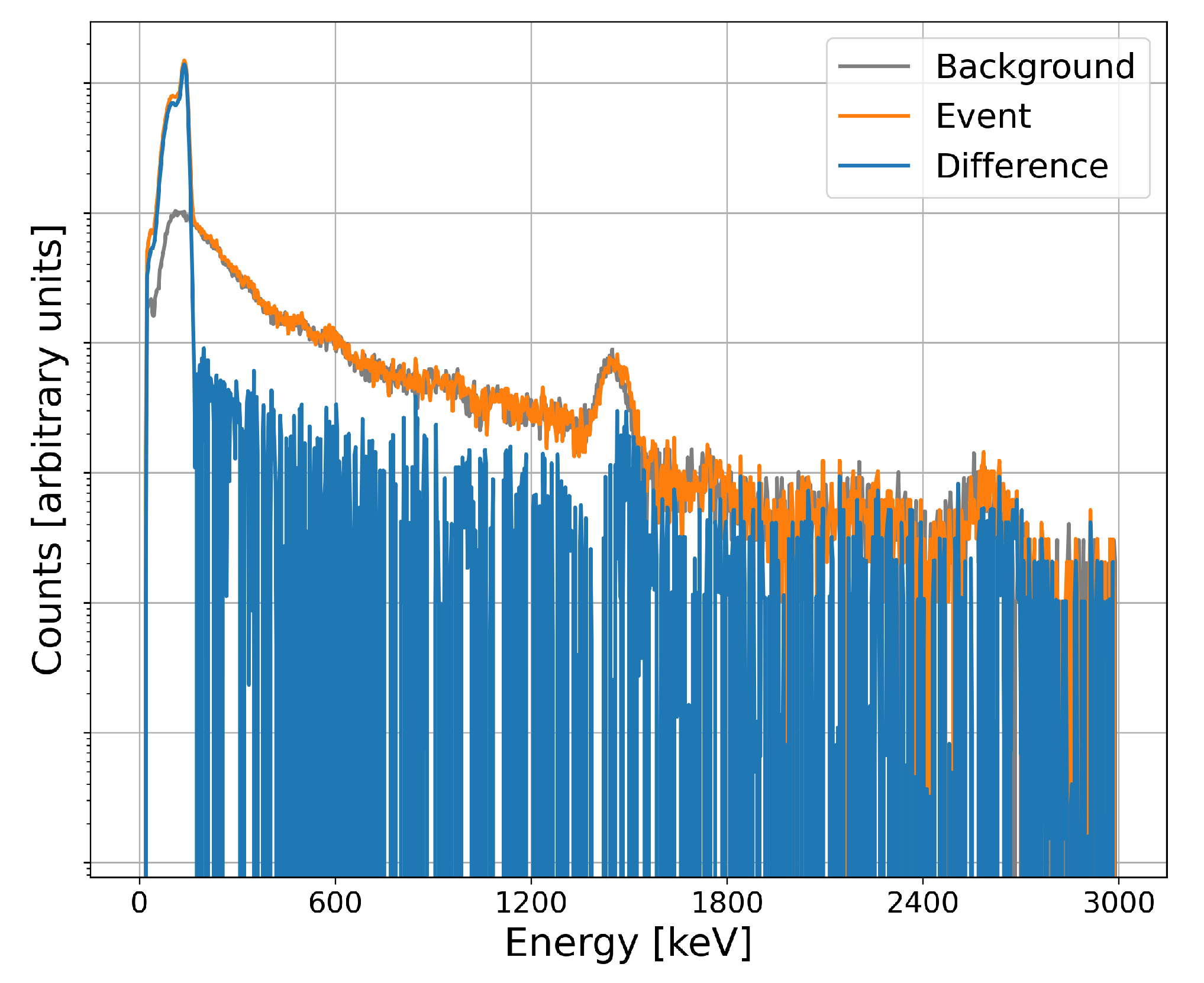
Figure 3 is a spectrum taken during a material transfer. To accentuate the portion of the spectrum that is associated with the material transferred, a portion of the background has been estimated and subtracted (blue line). Note the substantial increase in count-rate at low energies. This continuum is the result of radiation from the transferred material being downscattered by container shielding. In this case, for example, a detection model must be trained to identify this response and associate it with the appropriate radiation event type.
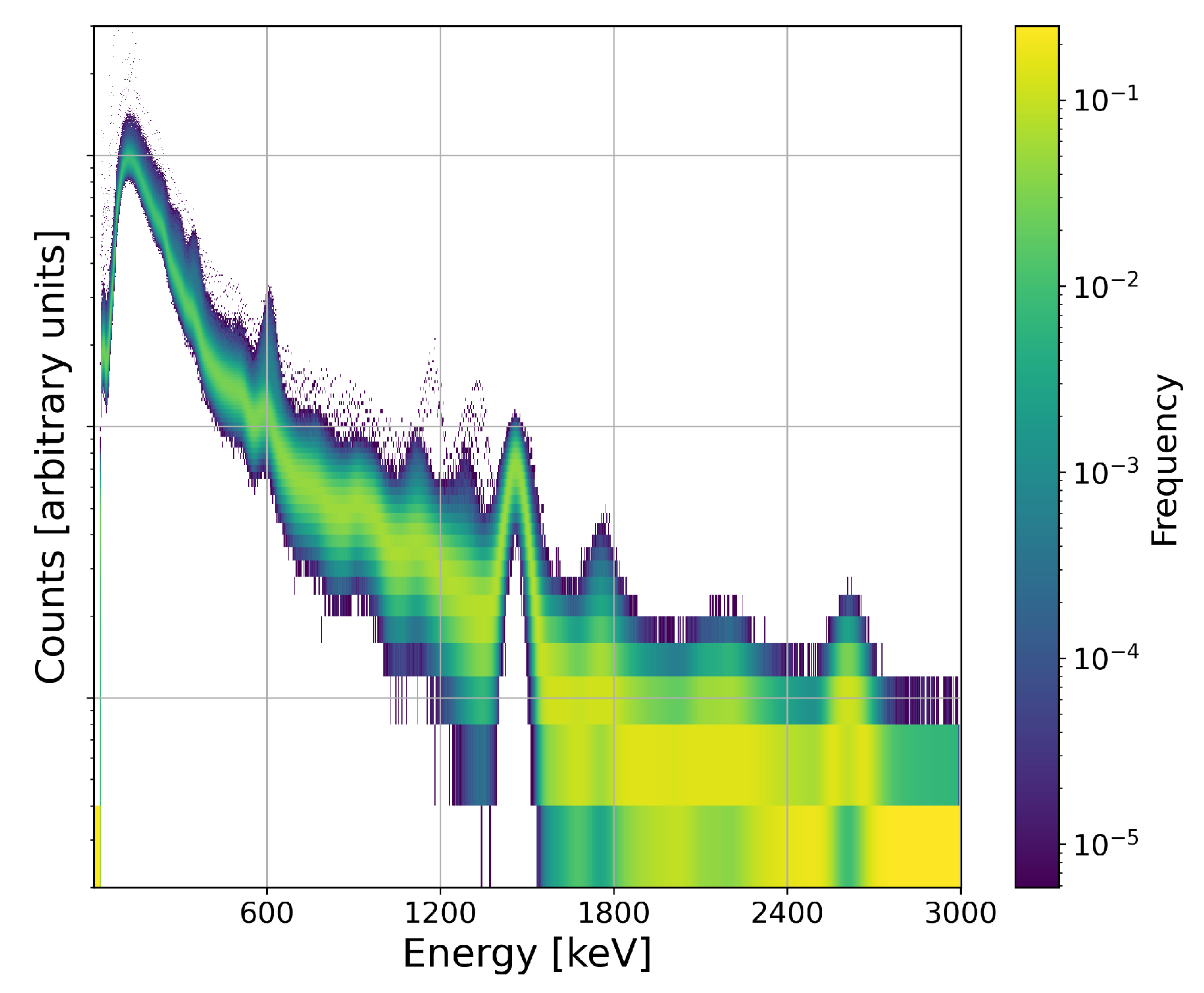
Radiation measurements are temporal, meaning they can be continuously measured and will vary statistically with time. One month of 1-minute measurements are plotted in
Figure 4. A normalized frequency histogram is plotted in each energy bin of the plot. That means that each vertical slice is a frequency of how often the measurement for that energy bin registered that magnitude of count-rate over the course of the month. The goal of this work is to identify anomalous measurements outside of the typical distribution represented in yellow and green. The low energy signatures associated with transfers are visible as small purple dots, as well as other off-normal measurements elsewhere in the energy spectrum.
3.3. Radiation Events
A transfer event occurs when a vehicle or source moves past a detector and thereby exhibits a response in that node. Material recently generated in HFIR will typically have high activity, which is why shielding is necessary for the safety of individuals handling the material. This shielding means that the signature’s characteristic photopeak will not be observed by the detector. Instead, emitted gammas are scattered by the shielding material before reaching the detector. The NaI response will appear as a low-energy, downscattered continuum without the expected photopeak. If a background spectrum can be measured or approximated, this continuum should appear above the characteristic background. This is time dependent, and count rates will rapidly rise as the transportation vehicle approaches and fall as it drives past the detecting node.
Other radiation events can appear to be anomalous if they exhibit similar rapidity in count-rate change and must be accounted for in detection algorithms. For example, HFIR produces a large flux of neutrons when it is active. These neutrons can be captured by argon naturally in the air at a non-negligible rate. This produces 41Ar, which is radioactive, undergoing decay to stable 41K while emitting gamma radiation with a photopeak energy of 1294 keV. Another example occurs when it rains, which can "washout" radioactive 222Rn with a half-life of approximately 3.8 days and is a result of the decay of 238U. This weather pattern will exhibit elevated gamma radiation sourced from the radioactive daughters in this decay chain.
These unique environmental conditions will each contribute to the background radiation distribution with different intensities at different times. Exact characterization of the background spectrum is impossible without full knowledge of these conditions. Even a fully constructed background distribution for one measurement may not be transferable to a second measurement with different diurnal or seasonal variations. Here, an estimation of background is used if it is reasonable for a given time and state of a measurement.
3.4. Hypothesis Testing
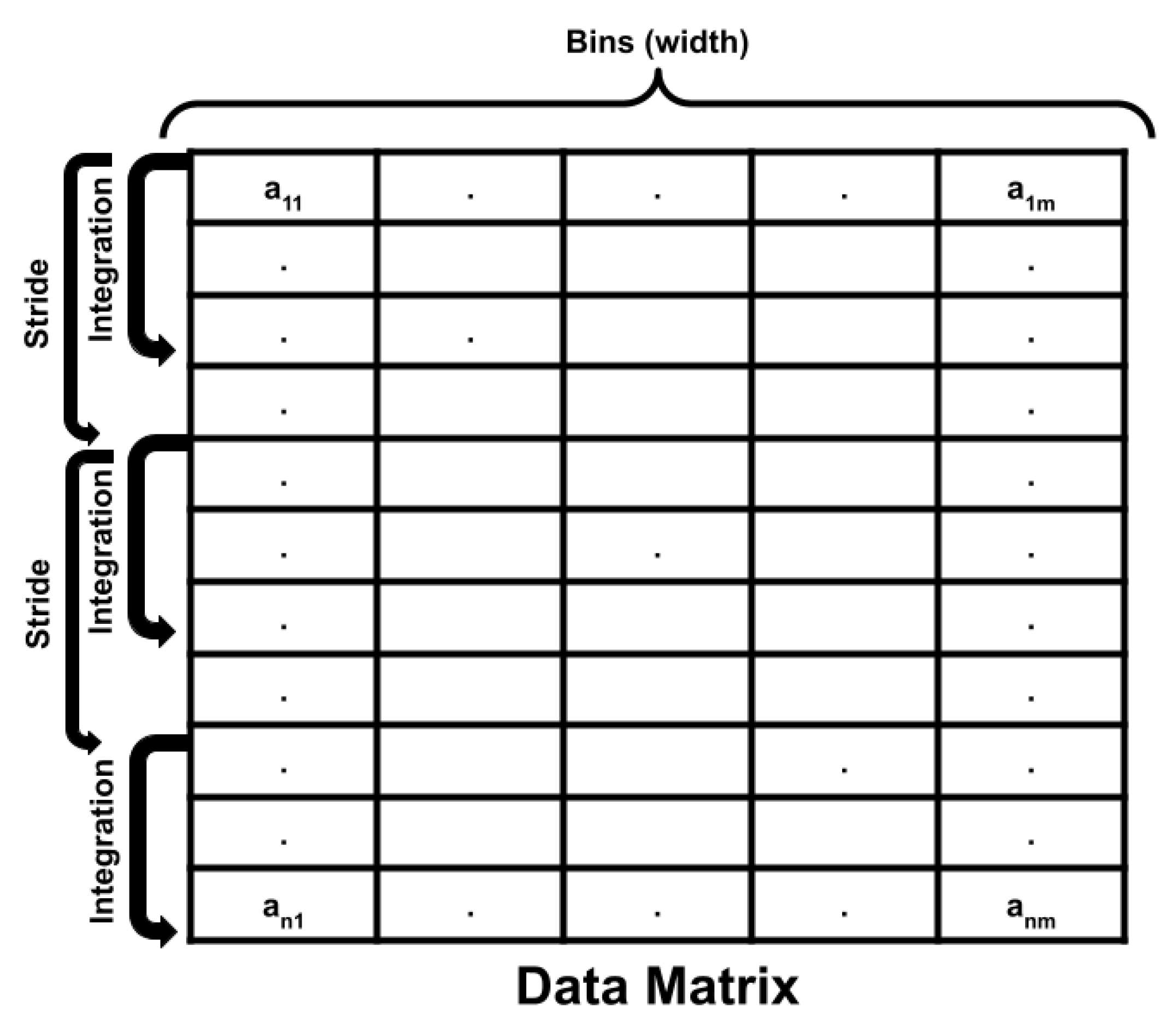
First, a model is constructed to identify anomalous measurements from the temporally continuous radiation data stream. This model ingests energy-independent count rates for each minute of measurement. That is, the one-second, 1000-bin measurements are integrated for all energies and every second in a one-minute window. This results in a "gross" count rate that is a raw measure of the number of gamma emissions counted by the NaI detector in that period. All of this data pre-processing occurs in RadClass—the software suite developed for this analysis—as shown in
Figure 5.
A method of hypothesis testing is employed that was originally used in counting statistics [
17]. Given two measurements,
and
(in this case, one-minute gross count-rates), taken at times
and
, respectively, it is expected that they are each sampled from some statistical distribution. In the case of radiation counting statistics,
where
and
are the expected values of the Poisson distribution. If the magnitudes of
and
are approximately equivalent, then they likely come from the same distribution. For example, if that distribution is the background, then they can both confidently be labeled as coming from the background. However, if their magnitudes are appreciably different, then they should be labeled as anomalous, i.e., from different statistical distributions:
This anomalous behavior could be from a nuclear material transfer or from any other kind of radiation event off-normal for the defined background distribution. Anomalies depend on the rate of change between
and
to be recognized as having sufficiently varying magnitudes. The expected values,
and
, are typically not measurable without enough unbiased samples. Suppose
is true, then a mathematical translation can be made:
Therefore, comparing one measurement,
, with the sum of both measurements,
n, behaves like a binomial distribution
If is true, then the binomial test above will fail to some significance level. This binomial test can be completed using MINOS data and identifies anomalous measurements in a temporal dataset. Each consecutive pair of measurements is tested, a p value is computed, and the null hypothesis is either accepted or rejected to some significance level. For a specified significance level, certain amounts of deviation are tolerated beyond which the null hypothesis is rejected, and an anomaly is identified. This significance level threshold acts as a hyperparameter and must be set via optimization using a ground-truth reference.
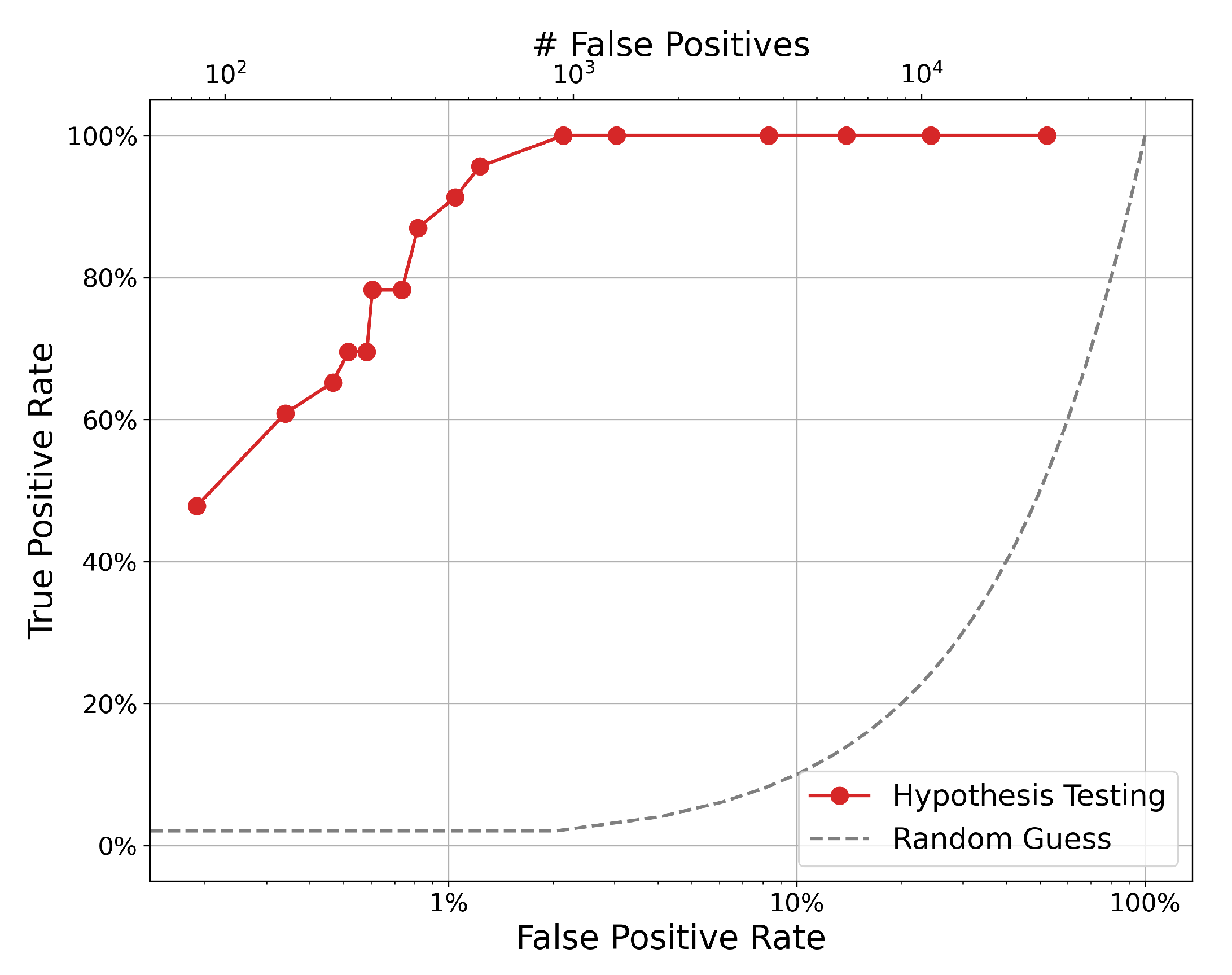
Using one node, one month of data (approximately 43,200 measurements) and ground truth for transfers, a receiver operating characteristic (ROC) curve can be generated (see
Figure 6). Here, a positive is defined as a prediction of a transfer event, and a negative is a prediction of some other anomalous event. First, the number of correct positive classifications can be expressed as the true positive rate:
. The rate of positive misclassifications can be expressed as the false positive rate:
. True positives are defined here as an anomalous measurement taken within 20 min of the timestamp for the event in ground truth or, absent a specific ground-truth timestamp, one anomalous measurement in a given day with a recorded transfer. This accounts for transportation and detector efficiencies that delay nuclear material transfers from being registered in a detector response for some time after the event may be recorded in ground truth.
Note that the ROC curve sweeps over several values for significance level. An ideal significance level is one that maximizes true positives while minimizing false positives. However, true positives (i.e., material transfers) are rare in the dataset compared to the measurement frequency. This leads to an imbalance in the number of true positives and true negatives. That is, a percentage increase in the is a larger increase in magnitude of false positives than a comparable percentage increase in the .
For example, the tenth point (a significance level of ) registers 22 out of 23 true positives () with a of only 1.2%. In gross terms, this false-positive rate corresponds to 540 one-minute false-positive measurements. The next significance level of captures the last true positive at the cost of an additional 397 false positives (, ). This imbalance must be considered in choosing a strict value for training and testing the models below.
The p value used for the analysis below is , which is the strictest value tested with a true positive rate of only about 40% but is also the smallest false positive rate tested. Future experiments can loosen this restriction by using a larger significance level that increases the number of true positives and false positives and thereby furthers the need for event discrimination. The overall magnitude of false positives is very large in part because of noisy ground-truth labeling. A small significance level is chosen to avoid confounding the machine learning models tested below with a large number of false positives, especially since the ground truth will not be used moving forward. This further emphasizes the need to carefully discriminate between SNM transfers and other anomalous measurements in any downstream analyses.
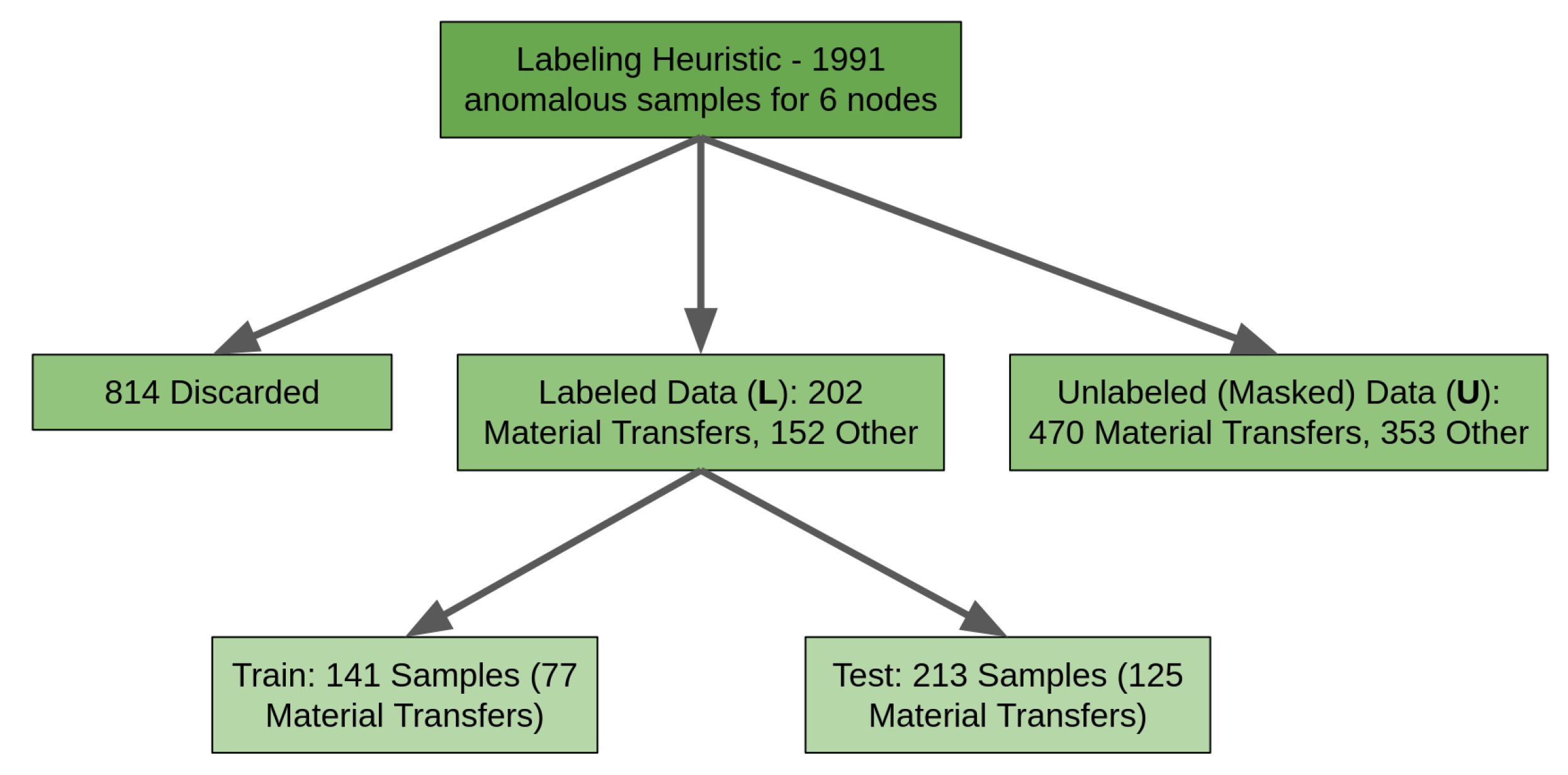
3.5. Labeling Heuristic
In evaluating the predictive accuracy of the machine learning models described below, three data subsets must be created: labeled training data, unlabeled training data, and labeled testing data. First, five months of energy-independent (gross count-rate) data from six different MINOS nodes are passed through the hypothesis-testing algorithm with a temporal integration time of one-minute. This provides a collection of spectra for timestamps at which the gross count rate was deemed anomalous (i.e., the null hypothesis was rejected). For this and all downstream tasks, the background is removed from the anomalous spectrum by estimation. It is assumed that for each event, a spectrum taken 20 min prior would constitute a typical background distribution absent any radiation events. This is subtracted from the event spectrum, resulting in a feature vector that notionally consists of only energy-dependent counts associated with the anomalous event (called the difference spectrum, illustrated in
Figure 3).
Rather than using the ground truth to apply labels to the data, a labeling heuristic applies an automated "guess" that serves as a noisy label (i.e., with nonzero labeling error) for each sample. That guess could be a material transfer, 41Ar event, Radon washout, or other anomalous behavior. The labeling heuristic uses Scikit-learn’s find_peaks method to estimate the most prominent peaks in each spectrum. If one of those peaks appears within an energy range where signatures resulting from shielded radiological material transfers would be expected, and that peak is sufficiently prominent, the labeling heuristic assigns a material transfer guess to that sample. If not, a different label may apply. If none of the peaks are prominent enough to make a definitive guess, the spectrum is not labeled, and the sample is removed from the collection of anomalies.
In this way, the labeling heuristic applies a noisy label prediction to samples without relying on ground-truth information. This heuristic itself is not a sufficient model for discriminating between SNM transfers and other anomalous events because its accuracy is limited by an intrinsic error rate related to noisy labeling. The labeling heuristic is still better than random guessing because it applies limited domain knowledge related to expected behavior from material transfers and the detector response from MINOS. Therefore, these labels can appropriately be used for training and testing machine learning models because the uncertainty associated with noisy labeling is propagated to each model and is thus invariant when comparing models to each other. Any uncertainty associated with the labeling heuristic will be propagated to each model trained and tested on the resulting labels. Therefore, MINOS data can be used to train and compare ML models, avoiding reliance on ground truth for preparing training data.
The labels are organized for binary classification: material transfer or "other" anomalous measurement. The labeled corpus is then randomly split into small subsets that approximately maintain the binary class population ratio. The remaining majority are passed (as unlabeled data) with their label masked from any models or evaluation techniques. This simulates the real-world behavior of costly labeling in which it may be difficult to label a large amount of data, but a smaller amount is still feasible. Labeling these unlabeled data was not necessary (since the label was not stored) but it ensured that the labeled and unlabeled subsets had similar distributions of classes. The heuristic is summarized in
Figure 7.
5. Results
Hyperparameter optimization was implemented using the
Hyperopt [
22] software package. This method uses Bayesian inference to explore the hyperparameter state space and to find the model parameters that maximize classification accuracy. Hyperparameters are chosen in a direction of expected accuracy increase. The loss function for optimization is the error rate, which
Hyperopt attempts to minimize. Different hyperparameters are chosen over 100 tuning epochs. The resulting performance ranges are shown in
Table 1. Local minima are possible for more complex models, but convergence typically occurs well before 100 tuning epochs.
The following metrics for binary classification—relating correctly classified instances, true positives (
) and true negatives (
), to misclassifications, false positives (
) and negatives (
)—are used in evaluating a model’s performance:
Balanced accuracy (balanced for different class populations) will be used as a concise measure for comparing models. Several feature vector normalization options were also tested to maximize accuracy. Label propagation benefited from input features that were not normalized, since it measures distances between samples. Therefore, any notional distance exhibited by data samples would be affected by normalization, reducing label propagation’s performance. Shadow significantly benefited from normalization against the distribution’s mean and standard deviation, since the neural network’s loss function is sensitive to large feature magnitudes. K-fold cross-validation was studied on logistic regression and co-training to ensure that there was no accuracy biasing because of random train–test splits. No appreciable difference was noted from different random splits.
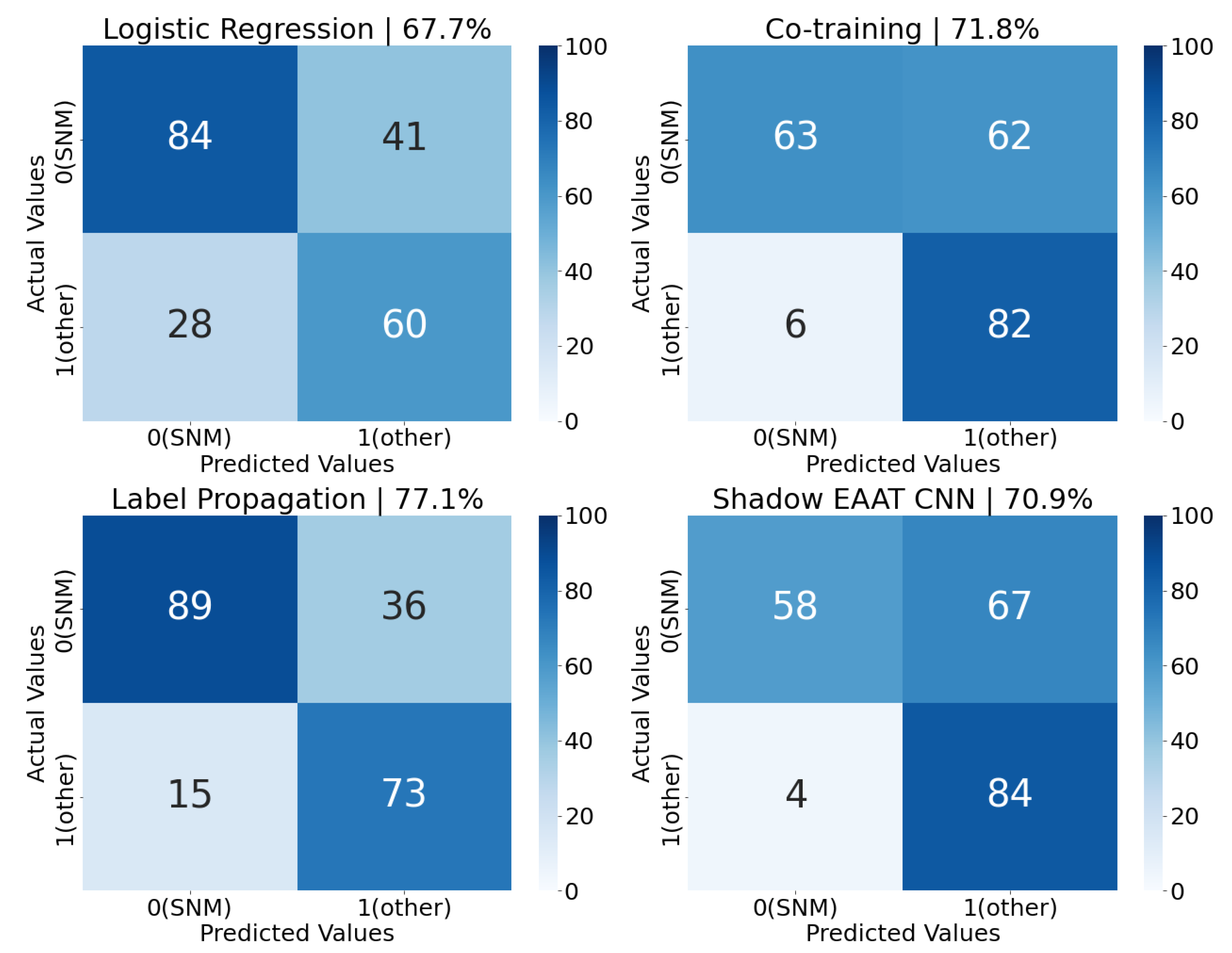
Confusion matrices for each model’s best balanced accuracy score (from
Table 1) can be seen in
Figure 11. The models, in order of increasing maximum balanced accuracy achieved, are: logistic regression,
Shadow, co-training, and label propagation. None of the models tested predicted more false positives than false negatives, leading each to have a higher precision than recall. Co-training and
Shadow, despite having comparable balanced accuracy scores, have exceptionally low recall (and very high precision) due to numerous false negatives, and only a handful of false positives. False positives are arguably less impactful than false negatives (i.e., recall is more important than precision) since detecting all instances of SNM transfers is the desired objective. In practice, the level of tolerance for false positives and false negatives is influenced by the needs of an end-user. A policy could be designed that weights these factors in model optimization or guides the deployment choice from a selection of trained models.
Several possible explanations exist for each model’s accuracy. Logistic regression performs the worst of all four methods, suggesting that it is not generalizable to the test dataset. That is, this model has relatively simple complexity but is still capable of learning a decision boundary within the limited labeled training dataset. A more complex supervised model, such as a multilayer perceptron (MLP), could possibly generalize, but these methods are typically data hungry. This illustrates the challenge of using supervised models in this regime because a large, labeled data corpus is required to achieve high performance, but collecting such a dataset is costly (perhaps infeasible).
Co-training achieves a higher balanced accuracy because it utilizes previously unused unlabeled data. However, the increase in accuracy is likely limited by the structure of the data algorithm used. The authors of this method state that the two sets of labeled data, and , must exhibit conditional independence. That is, , i.e., each subset contains predictive information for the classification but not for its counterpart. This is enforced so that each model learns different information to share. If and do not exhibit conditional independence, convergence to a higher accuracy is not guaranteed.
The data passed here are not necessarily conditionally independent. Only radiation data are used, and the measurements of all nodes are combined into one corpus. Two measurements from the same detector, and even for the same event, could be present in the training data for both models, breaking independence. Any increase in performance from training could be the result of information passed between models that is from different detectors and events. Co-training’s accuracy could be increased by enforcing conditional independence and by carefully separating detectors between models. A more powerful implementation would utilize data fusion, a natural extension of MINOS. For example, one model could be trained on seismo-acoustic data, and one model could be trained on radiation measurements, both of which are coincident on SNM transfers but conditionally independent of each other.
Label propagation achieves the highest recall among the four models used (with the largest number of true positives classified). This is likely because label propagation is the only model to consider the geometric or distance relationship between data points, thus indicating that pattern information could be embedded in the data manifold. A manifold pattern also suggests some feature importance, or low-dimensional representation, which leads to eventual classifications. This agrees with physical intuition that radiation signatures are energy-dependent and should be unique between transfers of shielded radiological material and other types of radiation events.
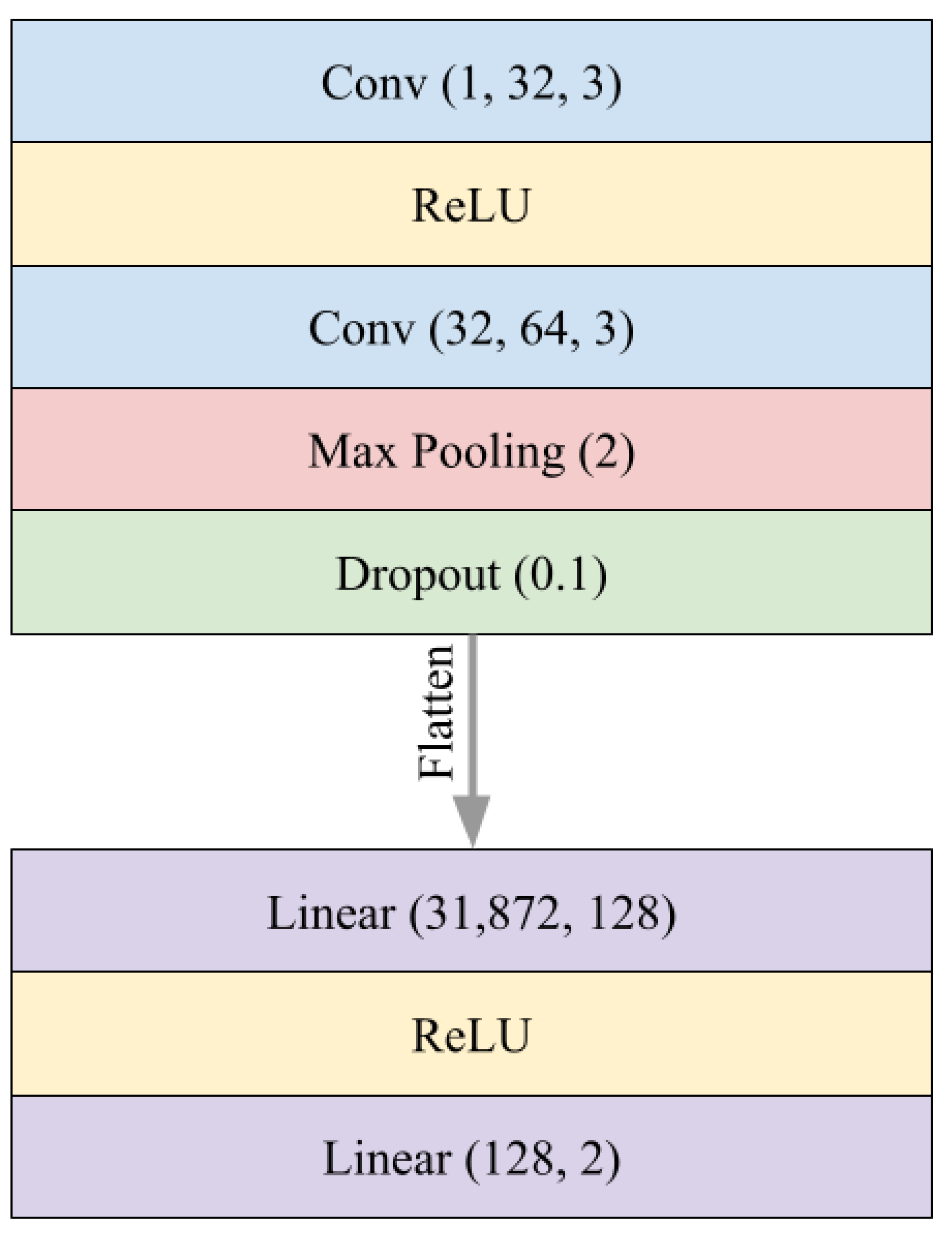
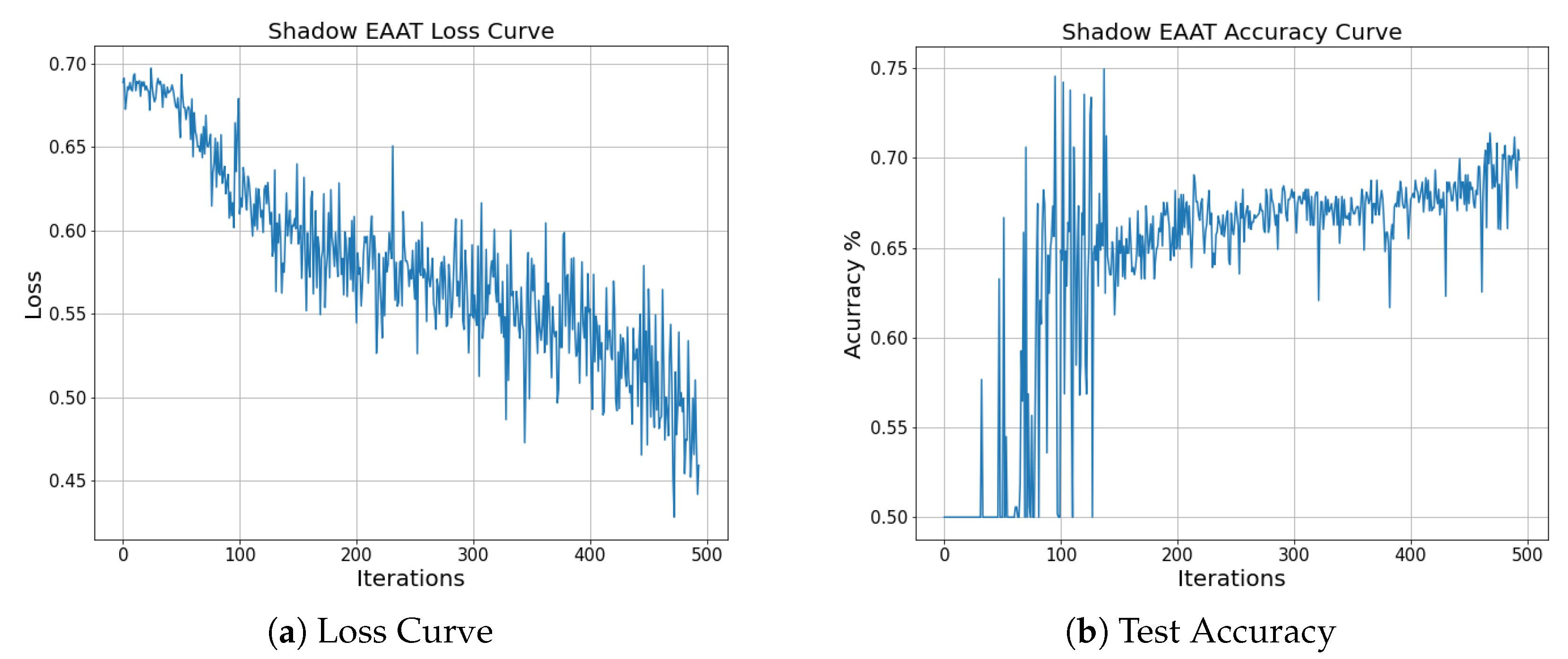
Finally, Shadow’s performance was surprisingly the lowest among the semi-supervised models. Shadow’s CNN has many hyperparameters that can be further optimized, including the architecture of the network itself. The MNIST structure used here might not lend itself to spectral data. Rather, a network architecture such as those used for frequency/audio data could be used. The loss function may be too difficult to minimize for high-variance data such as radiation spectra. Training indicated that Shadow can optimize to many local minima in its state space. Different loss functions could be applied, including different semi-supervised functions, that may train with more stability or converge to an optimal decision boundary. Overall, a CNN still requires significant amounts of data to train an accurate classifier. Despite the inclusion of unlabeled data, more labeled (and unlabeled) data could be required to find an effective decision boundary.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}