1. Introduction
In an age of scientific and engineering advancements, the United States of America is far from the only nation with nuclear capabilities [
1]. Since the Manhattan project, the spread of basic nuclear science and technology has resulted in nuclear weapon proliferation as well as the spread of peaceful nuclear applications. Along with this spread, treaties and agreements to slow or stop testing and nuclear proliferation have also been agreed upon, such as the Treaty on the Non-Proliferation of Nuclear Weapons (NPT) and the Comprehensive Nuclear-Test-Ban Treaty (CTBT) [
2,
3]. The current method of assessing compliance with the NPT is through the International Atomic Energy Agency (IAEA) which safeguards nuclear materials and monitors activities in more than 140 countries [
4]. As the first step in guarding against diversion of materials towards nuclear weapons development, treaty verification requires gathering data about an actor’s use of nuclear technologies to give insight into potential applications.
Advanced data analysis techniques can assist in verifying whether the information collected is consistent with stated declarations. Previous research conducted by the Multi-Informatics for Nuclear Operating Scenarios (MINOS) venture explored methods of monitoring activities at nuclear reactor sites to promote nuclear treaty monitoring objectives. As an example, activities at nuclear reactors have been monitored using physical signals such as infrasound and low-frequency acoustic signals. Cárdenas et al. investigated the use of smartphones and a cloud-based architecture to detect activities near nuclear reactors such as crane operations, opening and closing of access doors, and vehicle operations in the reactor vicinity utilizing sensor networks [
5]. The research found that airlock door activity could be identified using a two-sample
t-test in conjunction with timing analysis to trigger a notification algorithm using local acoustic sensors. Members of the same group performed a subsequent study that assessed the monitoring of a nuclear reactor during full power generation utilizing a similar network of sensors for infrasound and low-frequency acoustic signals [
6]. A fundamental frequency of 21.4 Hz was found to be associated with dual-speed cooling fan operations indicative of the reactor power status and was observed up to ∼900 m from the cooling tower. Gastelum et al. performed similar studies with two data streams, open source image data and multi-modal sensing platforms for indirect physical sensing [
7]. The study looked at both data streams individually and then as one integrated analysis to assess the potential benefit of multi-modal fusion approaches. Eaton et al. used locally collected infrasound measurements to predict the operation of mechanical draft cooling towers associated with nuclear reactors which are critical for managing heat in the reactor [
8]. The approach was tested using data from the Advanced Test Reactor at Idaho National Laboratory and the High Flux Isotope Reactor at Oak Ridge National Laboratory. It was found that the developed algorithm could successfully be used to predict fan speed and active cooling capacity.
Machine Learning (ML) and Deep Learning (DL) are also being employed to characterize nuclear reactor operations. One example from Tibbets et al. exploits a data stream from the same multi-sensor network used in the present work collected in the vicinity of the High Flux Isotope Reactor (HFIR) at Oak Ridge National Laboratory [
9]. The reactor’s operational state (ON/OFF) was classified using a DL feed-forward network trained on time series sensor data. A binary classification accuracy of
was obtained. A corresponding feature importance study concluded that the magnetic field data was the most important contributing factor to the classification accuracy. Chai et al. used ML to predict a reactor’s operational state using seismic and acoustic data [
10]. The study made use of ML models such as linear regression, k-nearest neighbors, gradient boosting, and random forests with features that had been selected in both the time-domain and frequency-domain. A binary, ON/OFF, classification accuracy of 98% was achieved with a gradient boosted algorithm with fusion of both seismic and acoustic data. Going beyond the binary problem, Rao et al. used a ML model to predict the power level of a reactor given features from a data fusion technique trained on data from infrared, electromagnetic, and acoustic sensors [
11]. Their estimator achieved
or lower root mean square error utilizing a 5-fold cross validation for determination of reactor power level.
Classification of nuclear reactor operational state is not the only use case for ML in a nuclear setting. Calivá et al. used DL to detect anomalies in nuclear reactors, such as changes in process parameters like neutron flux to gain insight into the functionality of the core [
12]. This work used simulated neutron noise in a pressurized water reactor core fed into convolutional neural networks (CNNs) and clustering algorithms such as k-means to unfold the generated signals, followed by a denoising auto-encoder to reconstruct power reactor signals with various noise levels and corruption. This process resulted in an accuracy of 95.3% for twelve classes of perturbation location sources. Another example of ML studies with nuclear reactor data is from Zhong et al. [
13]. The study used transfer learning of a convolutional neural network pre-trained on a database for fault diagnosis and accident identification, an area which has very little native data with which to work. The transfer learning technique was proposed to mitigate that problem.
The method of investigation proposed in this research is to employ ML and DL to classify whether a nuclear reactor is powered ON or OFF, based on data collected using passive persistent sensors. This study leverages the results presented by Tibbets et al. by focusing on the magnetic field data since it was found to be the most significant phenomenology contributing to the binary classification accuracy [
9]. In contrast to the previous work, a frequency domain analysis is presented.
2. Materials and Methods
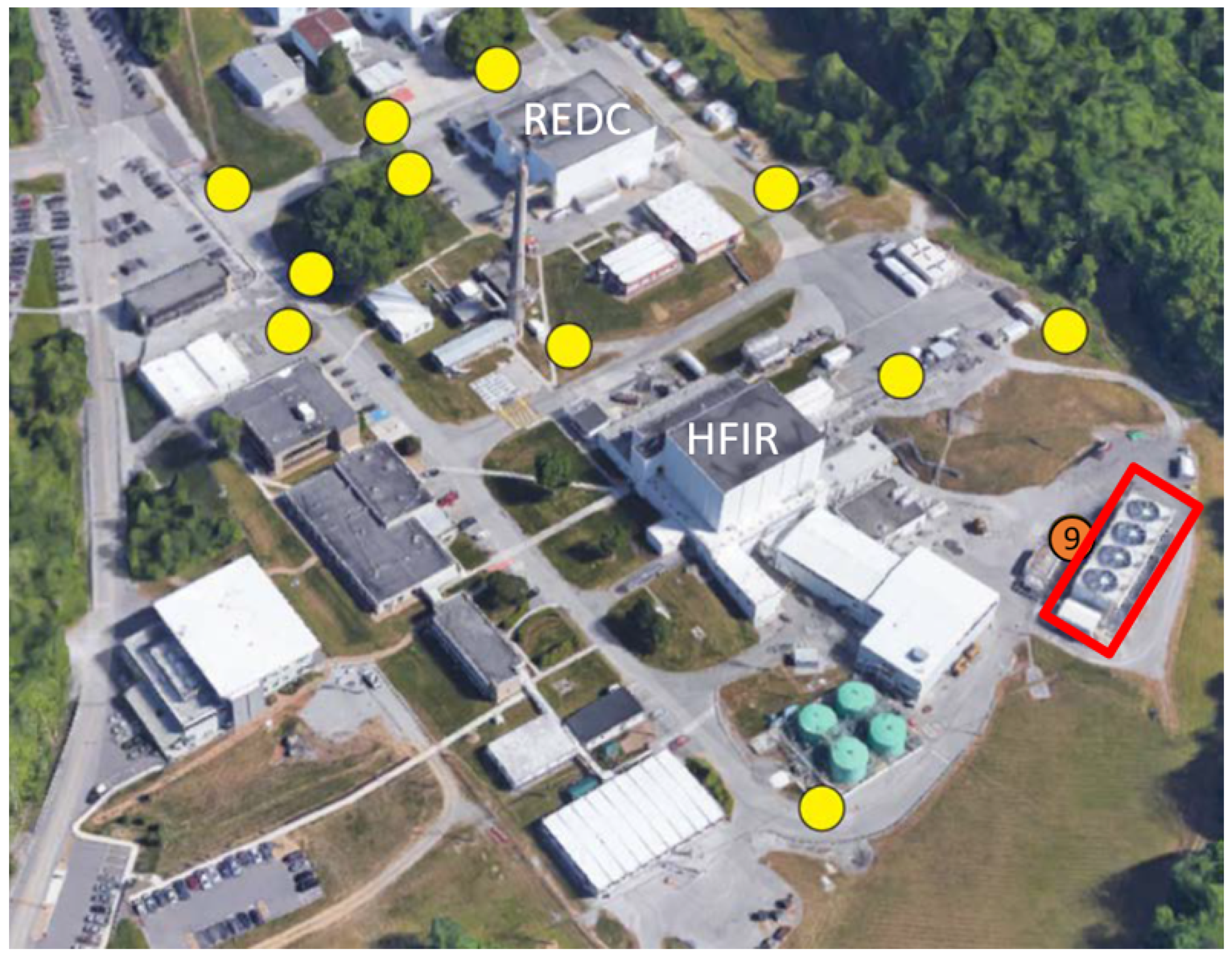
The reactor under examination is the High Flux Isotope Reactor (HFIR) at Oak Ridge National Laboratory. Twelve sensors have been placed in the area around the reactor as shown in
Figure 1. They collect information about physical phenomena such as the magnetic field in three axes
, seismic acceleration in three axes
, pressure, temperature, ambient light, color (RGB + UV) and proximity [
7].
The magnetometers at position 9 shown by the orange circle were selected for analysis due to their proximity to the cooling fans. The duty cycle and variable speed of the cooling fans is expected to reflect the operational load of the facility. When the cooling fans operate, they use electricity. The flow of electricity produces a magnetic field. The magnetic field data was collected via 3 magnetometers positioned to collect along the x, y, and z axes at this location. The positive z-axis pointed from the cooling fans towards the HFIR, the positive y-axis pointed along the cooling fans towards the right of the image, and the positive x-axis pointed toward the sky. The data coming from the sensors is in a time-series stream, recording measurements at a rate of 16 Hz. The experiment described next creates a function which maps the signals recorded by the sensor to the facility status. The fan status is unknown.
The time frame over which data for this work was selected comes from four operational cycles of the HFIR, shown in
Table 1. Cycles 484, 485, and 486 were used to create training and testing sets, with Cycle 488 kept isolated for further testing and model verification. During each cycle, the HFIR was gradually powered up until it reached full power. The reactor was run at full power for approximately 27 days, then gradually powered down reaching its OFF state. During the OFF period, data were collected for approximately 5 days with no other systems changing. In this study, the ON class refers to the period when the reactor power is >7%, and the OFF class refers to when the reactor power is ≤7%. The 7% threshold for ON and OFF classes was based off a process by the data owners and is an inherited number. The sensitivity of this research to the threshold will be explored in the future. A class imbalance was present within the data with a greater number of measurements taken in the ON state than the OFF state. This will be accounted for in the analysis.
Data Preprocessing
The first step in preprocessing the data for input into a ML or DL model was to convert the 3-axis magnetic field data into a magnetic field magnitude via Equation (
1). That is to say that each 16th of a second, magnetic field components measured in the
,
, and
directions were converted into magnitude using Equation (
1). This step was done to decrease the dimensionality of the data, due to the total number of features resulting from the next preprocessing step.
The frequency domain may contain features indicative of a reactor’s operational state. For instance, transforming the data into the frequency domain, one can look at how often a frequency occurs within any given measurement. To use this data in the frequency domain, a Short Time Fourier Transform (STFT) was applied. Similar to a moving window of calculations, the STFT takes a range of time sampled data and converts it into a frequency spectrum with granularity dependent on the length of samples given [
14]. The amount of time series data given to the STFT must be at least one second, per the 16 Hz sampling frequency. For this paper, the time series data was split into one-minute intervals, or 960 samples. According to Nyquist’s theorem, this gives 480 sample frequencies per time window [
15]. This also equates to a bin width of 0.01667 Hz.
The real part of each of the 480 frequencies per time window was considered a feature for input into a model. After the transformation, a feature standardization was used via z-scaling to standardize each feature and decrease the influence of outliers. The method for this standardization was to take each point x, subtract the mean, , and divide by the standard deviation, . The final step of preprocessing was to split the data between a training and a testing set. The HFIR cycles 484, 485, and 486 were used as the data for models to be trained on, and cycle 488 was used as a testing set.
4. Discussion
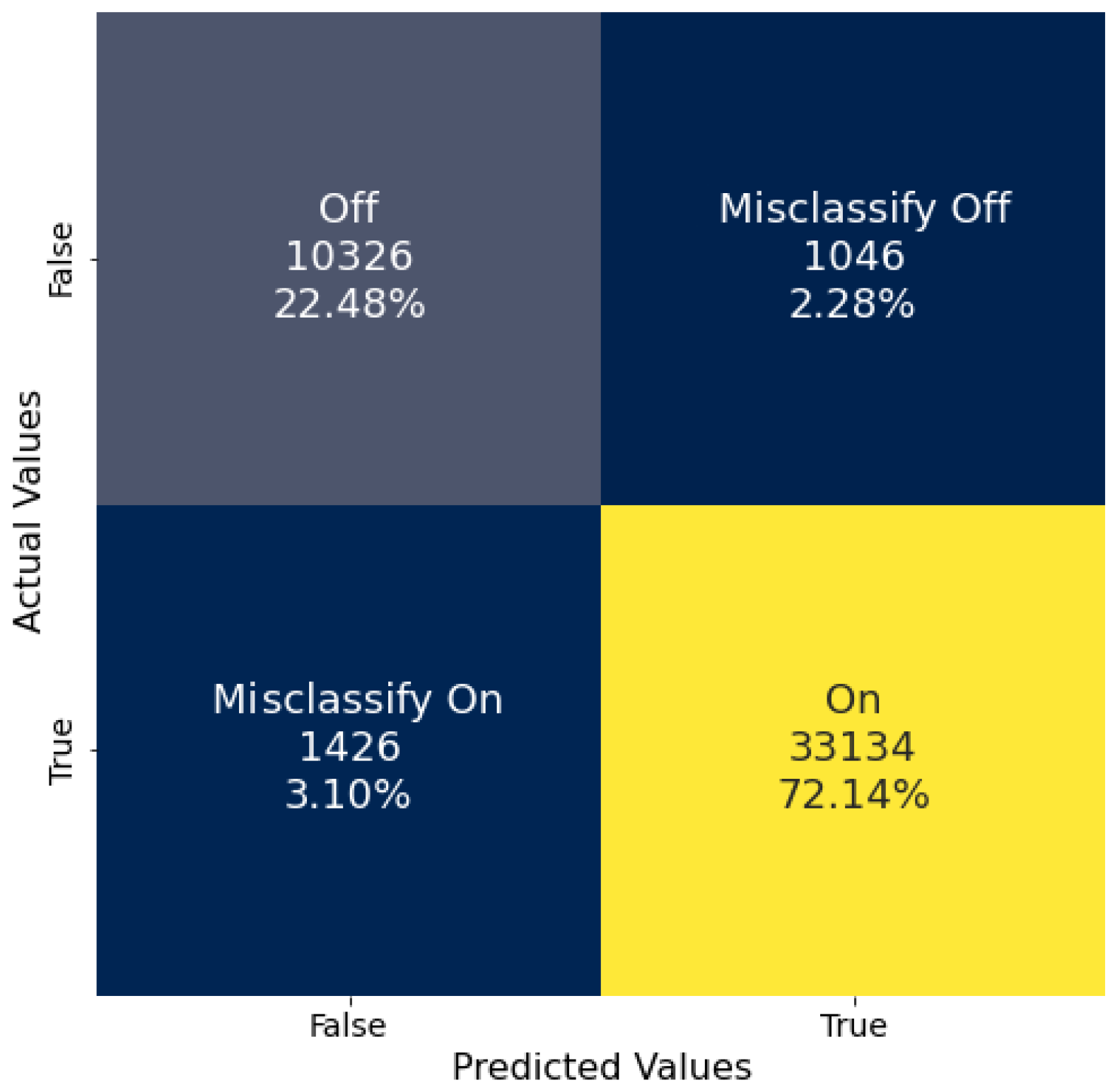
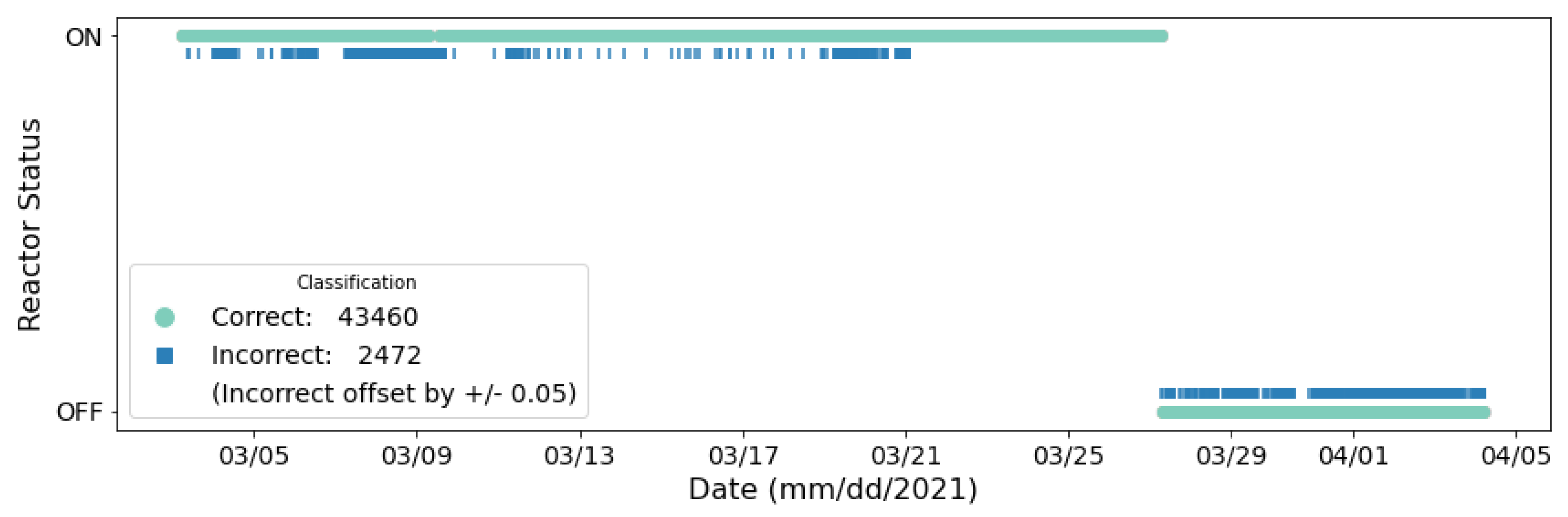
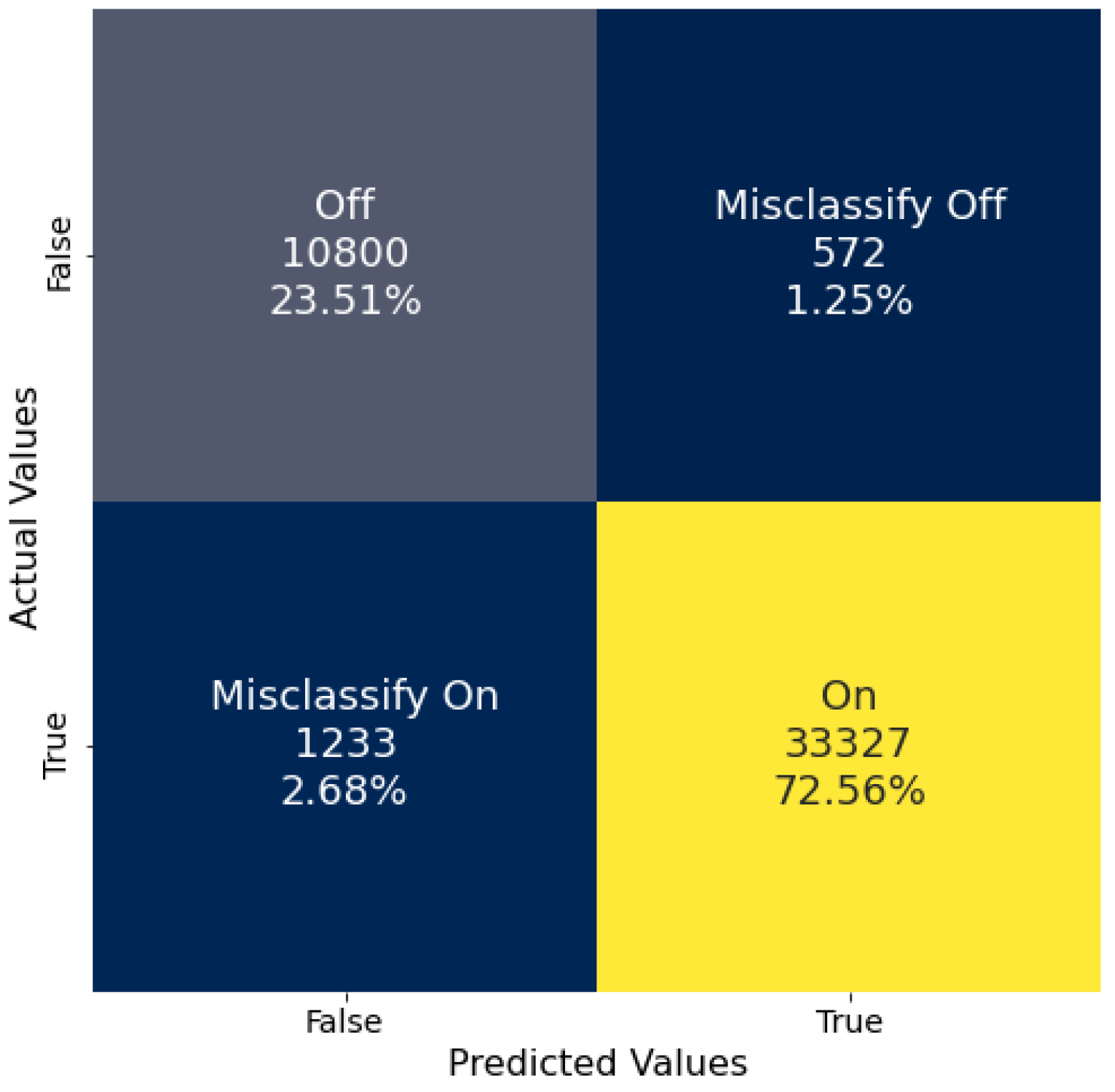
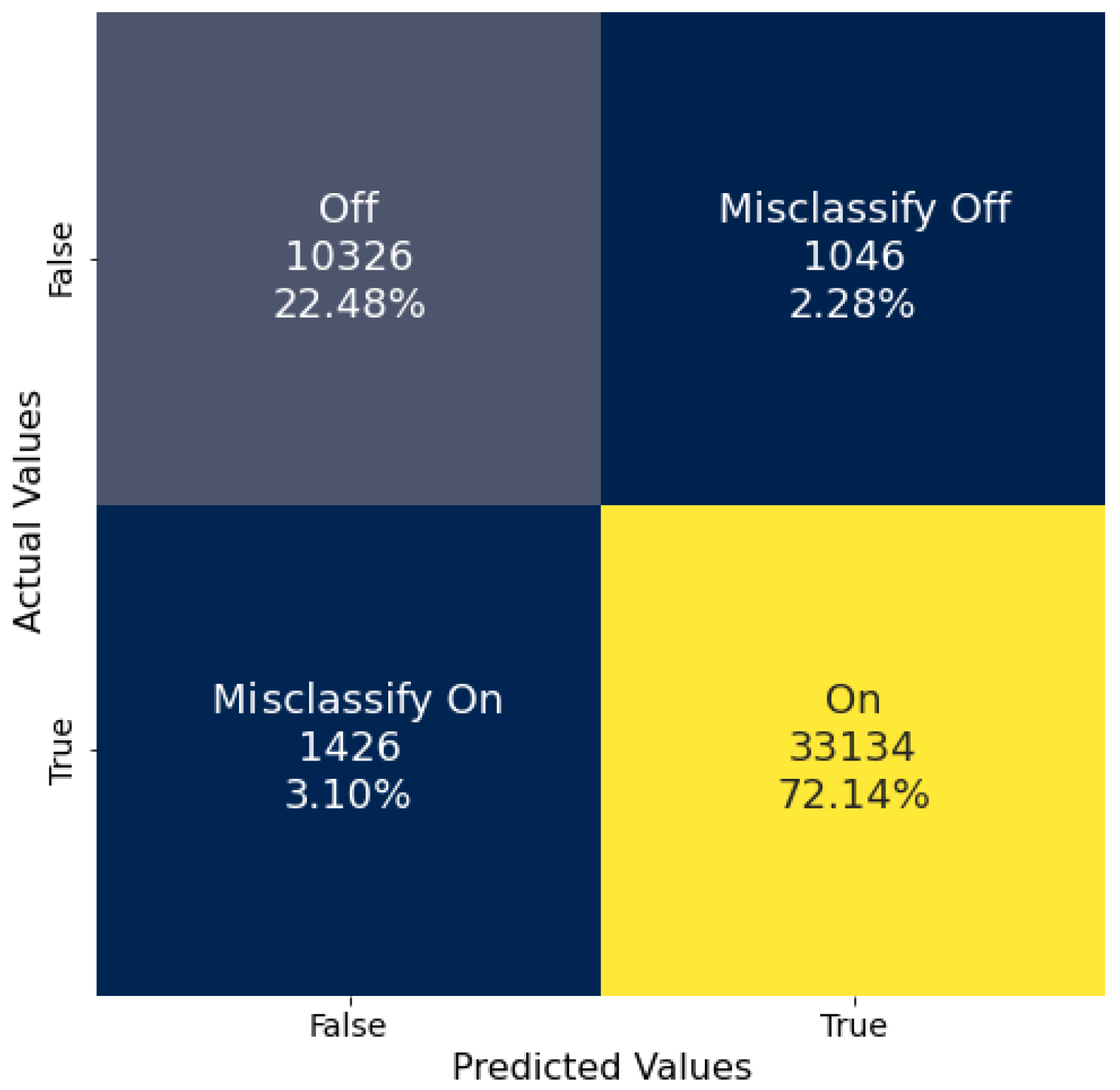
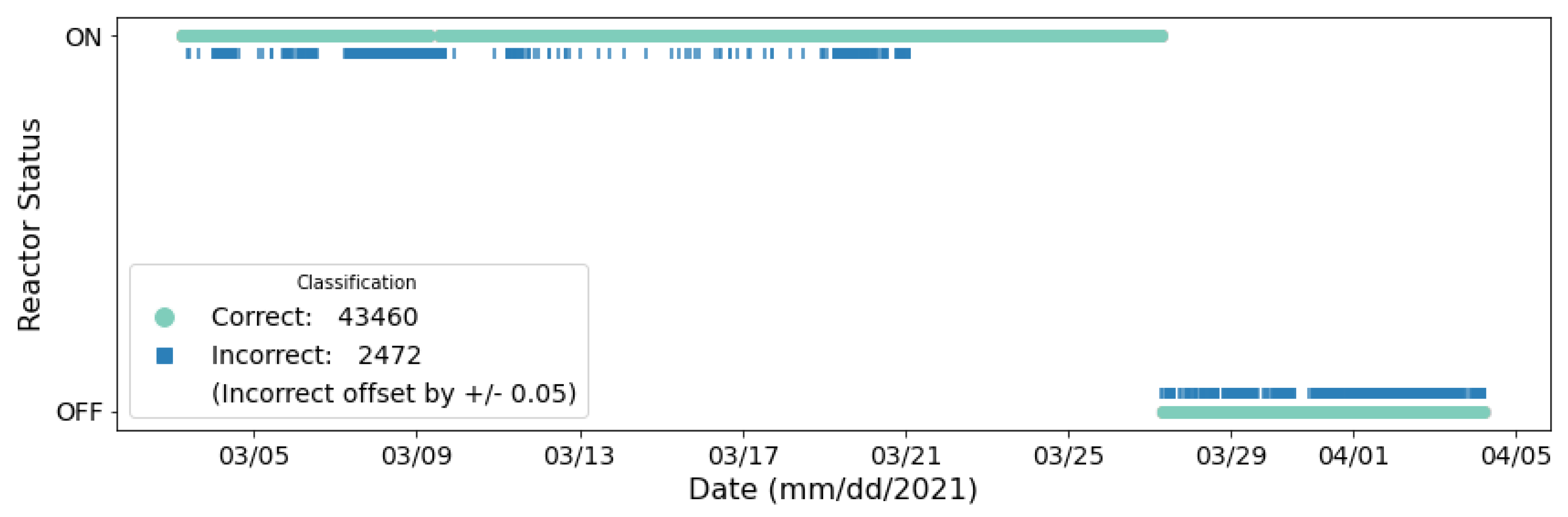
Both of the models tested in this work, a random forest and a DNN, were trained and tested on the same data to enable direct comparison of their performances. The data analyzed were collected from sensor position 9,
Figure 1, located next to the cooling fans supporting the HFIR. However, while the duty cycle and variable speed of the fans is related to the status of the reactor, the ML and DL training process used the ON/OFF status labels of the reactor not the fans. Both ML and DL models show a remarkable ability to correctly classify the HFIR operational status. The DNN (95.70%) achieved a slightly higher balanced accuracy than the RF (93.34%), suggesting that the DNN was better suited to generalize to the data as it performed slightly better with Cycle 488. The RF struggled more to generalize to the OFF class than the DNN, but differences observed in the classification of the ON class were negligible.
In real use cases, further analysis of the expected small number of incorrectly-classified time segments could provide additional illumination to existing model biases present in these prototypes and lead to opportunities for performance improvement through model redesign. Future exploration using statistical techniques (e.g., training the models with different bootstrapped samples of the data) could be used to characterize the uncertainty present in the model’s performance characterization.
The overall high classification accuracy obtained suggests that ML shows promise for application to signals collected from unattended remote sensors to verify declared activities involving nuclear reactors. This conclusion is consistent with results published previously [
9,
10,
11]. However, the current study reveals that when converted to frequency space, the signal detected by the 3-axis magnetometers placed near the HFIR cooling fans can be used to classify the reactor operational state more accurately than the time series data [
9]. Additionally, a comparable balanced classification accuracy was obtained in this study to that reported by Chai et al. [
10]. This indicates that a judiciously placed magnetic field sensor can provide a similar level of declarations verification as does data fusion applied to a single seismo-acoustic station.
The operational cycle of a nuclear reactor used for commercial power production is expected to be dramatically different from that of a nuclear reactor used for plutonium production. This study demonstrates the viability of an important new technique for nuclear treaty monitoring because high fidelity classification tools can be used to independently verify declared operations. Independent verification of declared activities via multiple phenomenologies strengthens monitoring robustness making illicit proliferation activities more difficult to mask.
5. Summary, Conclusions, and Outlook
With the increasing simplicity of nuclear proliferation as science and technology advance, the opportunity arises for treaty verification to grow and develop. Treaty verification plays an important role in slowing the proliferation of nuclear weapons because it acts as a deterrent force. The analysis methodology presented in this paper relies on the availability of passive persistent sensing exterior to a nuclear reactor. This modality of data collection is ideal for nuclear treaty monitoring because it requires no access to the interior of a facility yet provides continuous observation. This study provides a first look at the feasibility of applying machine learning and deep learning techniques to magnetic field sensor data transformed to the frequency domain to verify the declared operational state of a nuclear reactor. The high level of classification accuracy achieved in this study for both ML and DL approaches demonstrates a proof of principle success in applying advanced data analytical techniques to remote sensor data collected exterior to a nuclear reactor.
Future work will examine the transferability of the tuned models to alternate reactors and sites with no additional model changes or training. This will require labeled data be available for those alternate locations so that the generalizability of the trained models can be quantified. Quantification of generalizability will inform the user of existing limitations associated with each trained model.
Other considerations for future studies include utilizing training data that covers a complete calendar year to account for greater variability in the background temperature against which the reactor and cooling fans must operate. This has the potential to produce a more robust model. Additional studies should examine the sensitivity of the classification method to the reactor power ON/OFF threshold value of set by the data owners. Finally, while binary classification provides a foundation, information is available for intermediate power levels between the ON and OFF states. The ability to utilize ML and DL to classify the power levels of this reactor should be investigated.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}