In this section, we evaluate the overall performance of our proposed system by examining two primary metrics, computational and communication overhead. The experiments were conducted on a Window 11 system equipped with an Intel Core i7 processor running at 3.4 GHz, with 8 GB of random-access memory (RAM). We implemented the scheme using the Java pairing-based cryptography (JPBC) library for encryption and decryption routines. Each reported result represents an average of ten independent runs.
6.1. Computational Overhead
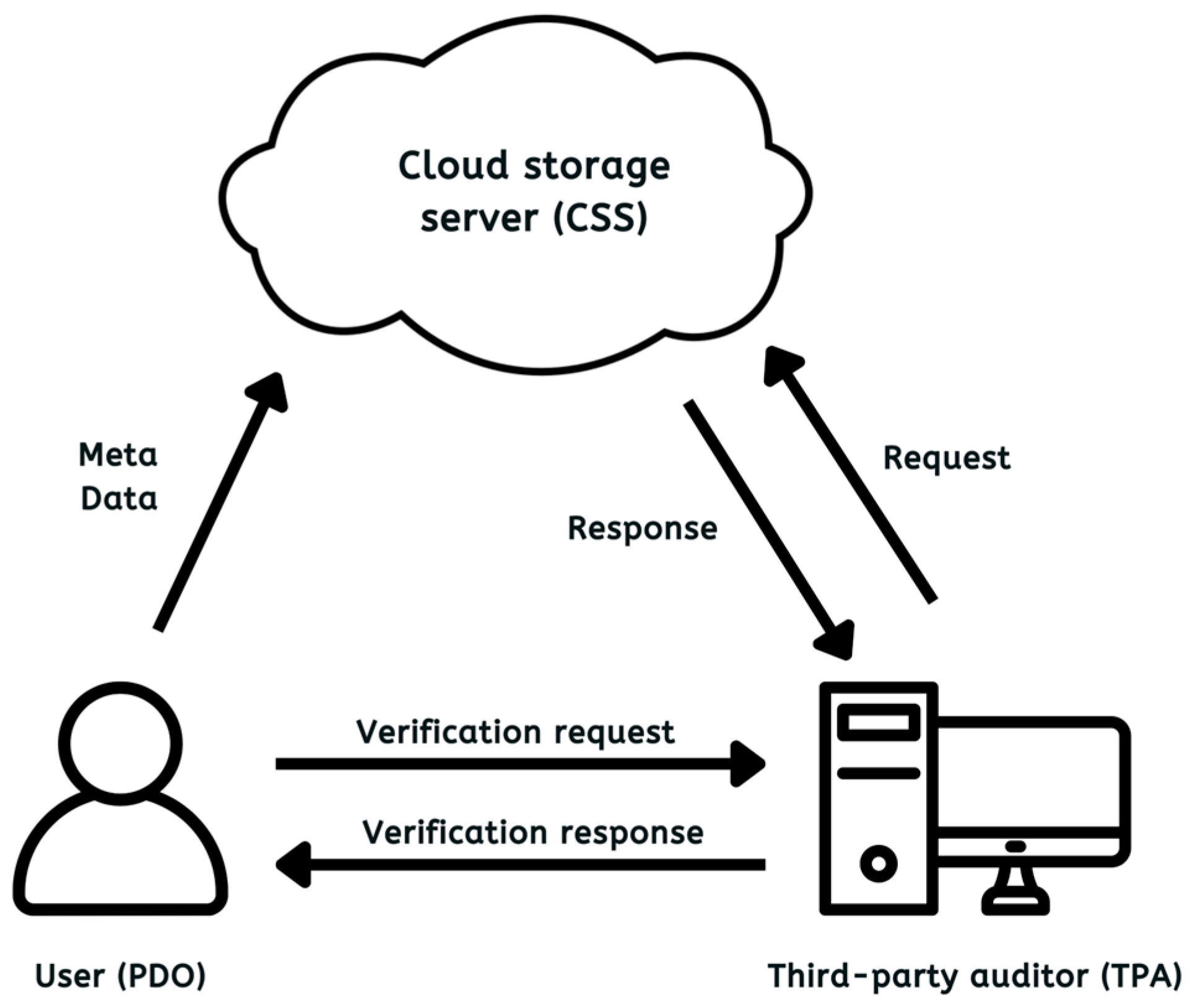
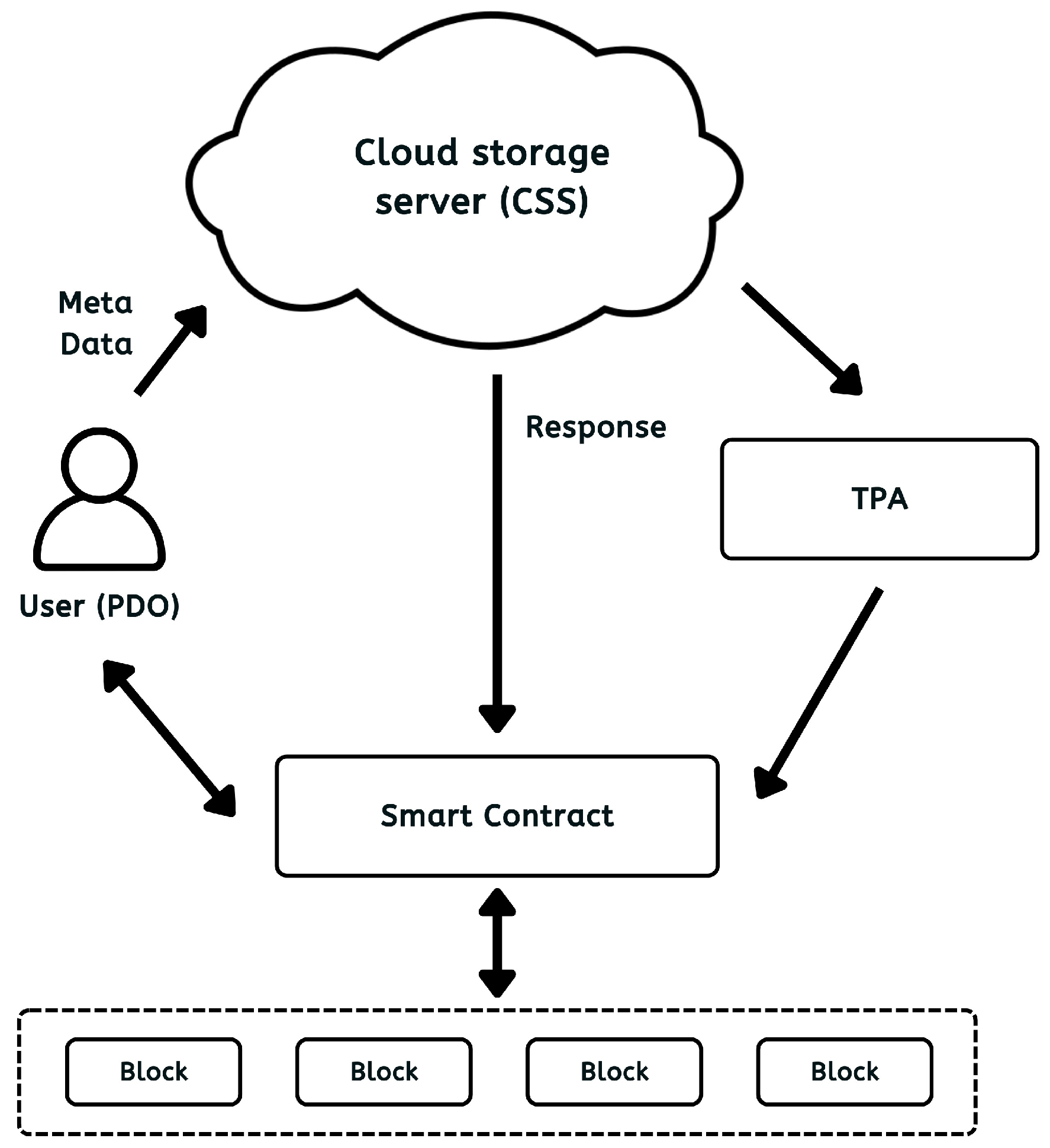
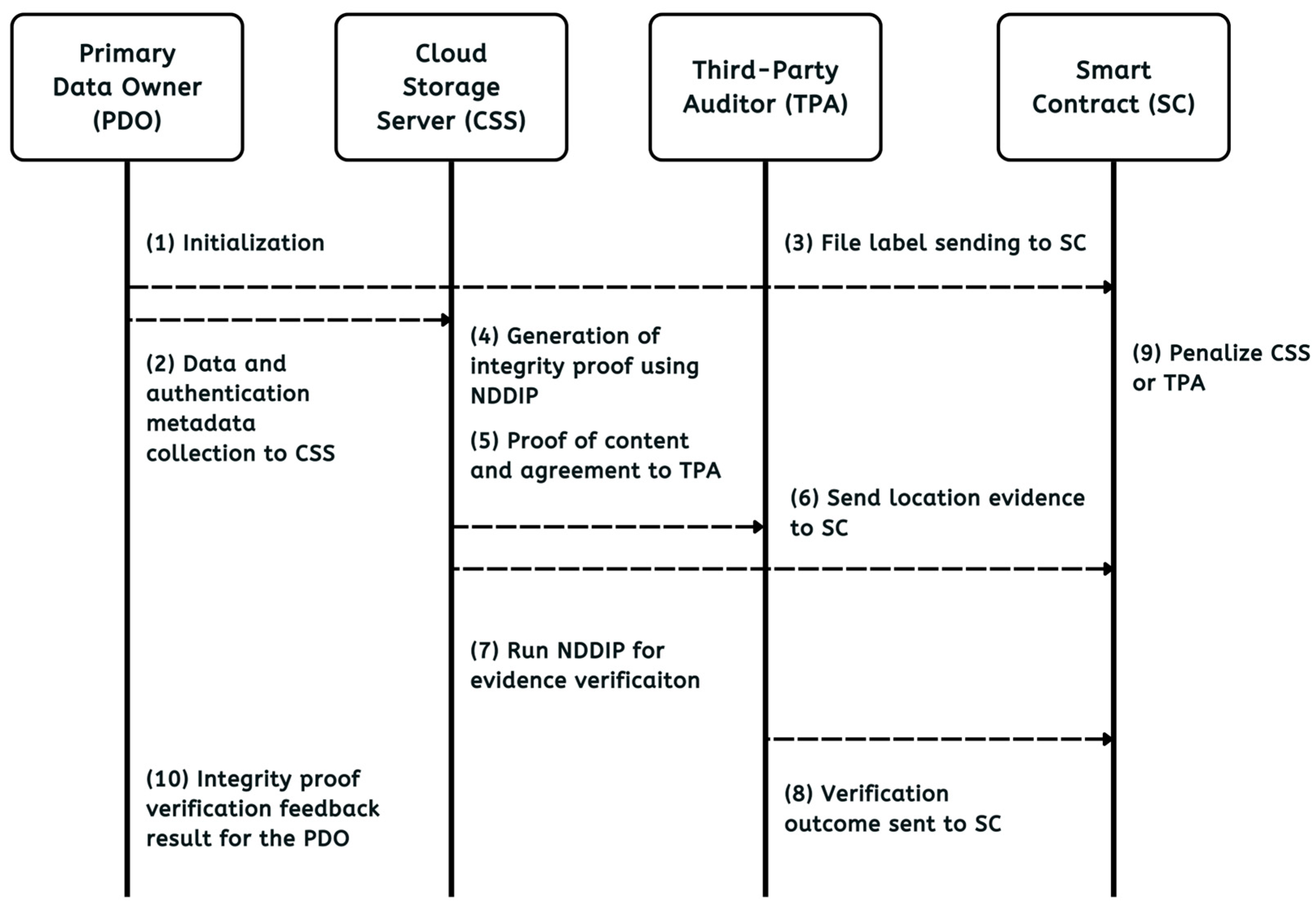
Our framework involves three core entities, namely PDO, CSS, and TPA, each contributing to the system’s computational costs at different phases. The initialization phase involves the PDO to generate authentication tags for each DB before uploading. The audit stage comprises the CSS to create cryptographic evidence in response to challenges with the TPA processing evidence for attestation. To assess how DB size affects these overheads, we performed multiple tests using file blocks of various lengths, ranging from 30 KB (kilobytes) up to 300 KB. In addition, larger files spanning 64 MB (megabytes) to 1024 MB were split into blocks from further stress testing. Throughout the audit stage, we employed a sampling strategy selecting 4.6% of the total blocks as CB [
36].
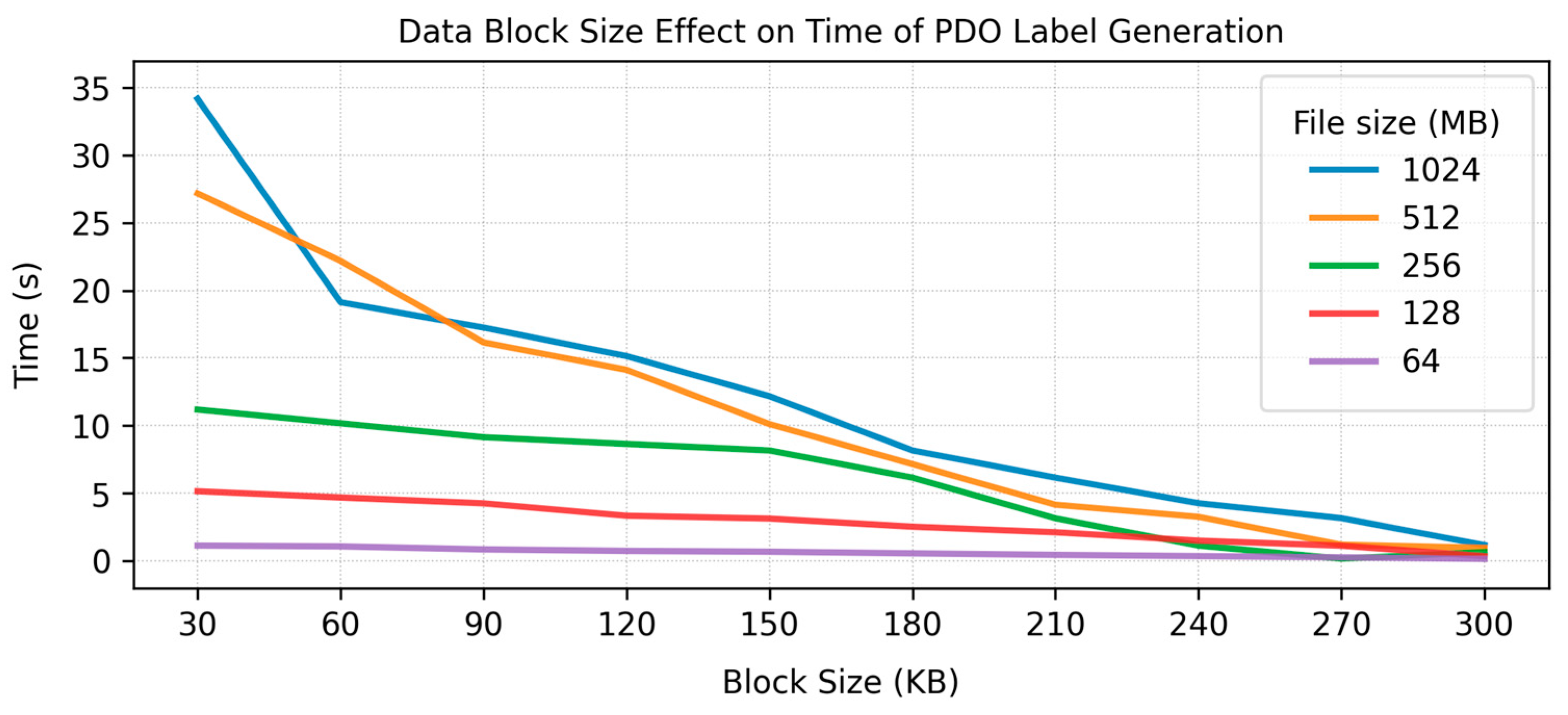
Table A1 and
Figure 6 illustrate how DB size influences the time required by the PDO to produce authentication metadata. At the onset, as the block size grows from smaller values (30 KB) to moderate-sized values (240 KB), the time spent on generating tags tends to drop. This situation occurs because larger blocks reduce the total number of blocks that need tagging. However, once the DB size passes a certain threshold, each individual tag operation grows more expensive. The total time begins to level off rather than continuing to decrease. In simple words, tag generation stabilizes once the size of the block and the number of segments within it reach an equilibrium in computational costs.
Similarly, when observing the CSS’s time to generate proof data, the performance is influenced by both the size and the number of segments included in each block. As larger blocks are used, the total segment count within those blocks and the consequent components in the integrity proof rise [
37]. This leads to an overall increase in the time required for evidence generation, as demonstrated in
Table A2 and
Figure 7. The pattern stems from two competing factors. First, increasing the block size means that each contains more data segments. Thus, more cryptographic elements must be processed. Secondly, fewer total blocks are needed for the same dataset when those blocks are larger. The net effect is that while the per-block overhead climbs, the overall quantity to be processed decreases. As a result, the measured CSS generation time, although trending upward, remains manageable within practical bounds versus the block complexity. Therefore, the evidence-generation phase does not become a serious bottleneck in actual deployments.
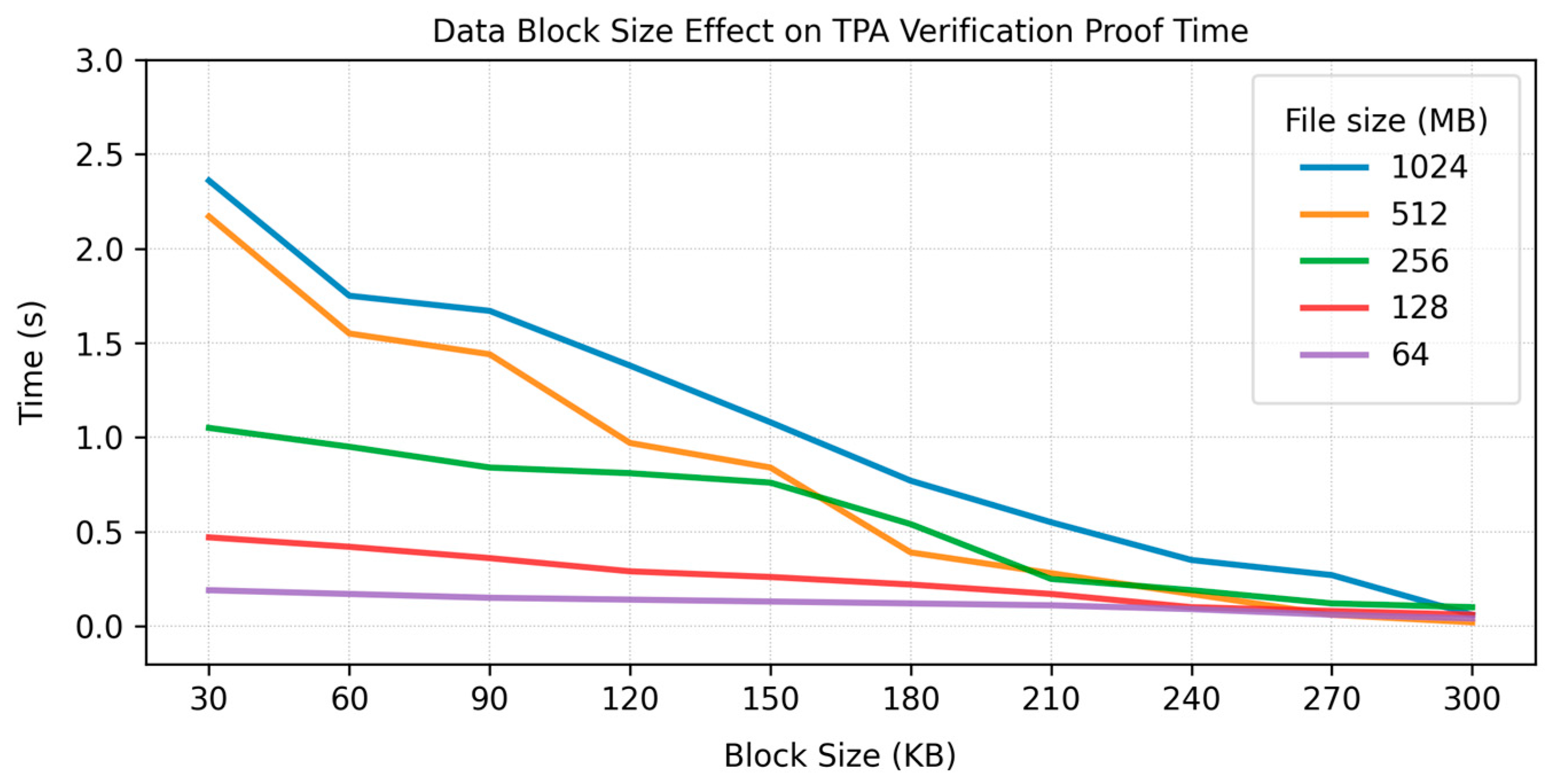
As shown in
Table A3 and
Figure 8, the time required for the TPA to verify the integrity evidence inclines to decrease as the size of each DB increases. An important reason for this behavior is that fewer total blocks exist in larger block configurations, so the number of CSs goes down. To make this clearer, we can model the TPA’s overhead in terms of Equation (34):
where
is the challenged blocks in a given audit;
is the segments within each block;
is the computational cost per block for certain multiplication, hashing, or message authentication procedures;
represents the encryption cost per label verification step; and
represents any additional pairing operation costs needed to finalize the proof check. Under most parameter settings,
decreases more sharply with larger block sizes than
increases. Consequently, the term
sees a notable reduction, while
gradually rises. It does not offset the savings gained from having fewer blocks in entirety. Thus, the net effect is that TPA verification time generally goes down for bigger blocks until extremely large blocks could potentially start increasing
to a point that can limit these gains. Based also on the graph, for smaller blocks (e.g., 30 KB),
can be relatively large, ensuing higher values for the
term, an initial high time for small blocks. It is also observed that when block size grows (150 to 300 KB), the TPA verification times drop to under 1 s in most cases. This is because fewer challenge blocks (CBs) are needed, which makes
and
converge to smaller values. A variation in overall file size is also noted, with 1024 KB, 512 KB, 256 KB, 128 KB, and 64 KB constituting different total file magnitudes. Each line shows a downward slope. The differences among these curves reflect how large files involve more blocks but also benefit more from consolidation when scaled up. In a practical setting, moderately sized blocks appear to strike an optimal balance between overhead reduction and data granularity. This outcome guarantees that verifying proof remains efficient while maintaining sufficient data segmentation for reliability and security.
Article [
36] developed a TPA-based verification method composed of two phases, an initialization and audit stage. In order to highlight the performance gains, we compare both overheads against the selected benchmark. Notably, the work supports both global and sampling authentication with the same adoption of a fixed 4.6% probability of challenged blocks.
Table 1 provides a theoretical cost comparison between the methods and the mechanism described. In the table,
is the total number of DBs,
is the challenged blocks, and
denotes segments within each block. The parameters
,
, and
reflect the cost of multiplication, exponentiation, and bilinear pairing operations.
For the existing PDO generation method [
36] of
, each block requires
multiplications plus
exponentiations for tag creating, multiplied by the
total blocks. We proposed a strategy of
, where the PDO treats each block as having
segments plus an additional factor to handle a “frame” or label aggregator. Per block, we need
multiplications. The
term parallels the existing technique to reflect two exponentiations per block. Although this slightly increases the cost for blocks due to segment handling, it lays the groundwork for more efficient auditing in later phases.
Each challenge for the CSP generation evidence of
in the reference need to aggregate partial proofs requiring multiple processes. The term
indicates that the CSP multiplies intermediate proof elements an additional
times, while
indicates exponentiations correlated with the CB. Our method
factor is in
because each CB can be subdivided into segments that contribute to evidence calculation. The final multiplier is thus
; it embodies the cost of aggregation of segment tags from each of the CB.
is needed for consistent exponentiation for each segment set. While the numeric front of
appears larger (due to
in practice, having total blocks can (optimized segment size) mitigate the impact. The random sampling fixed value makes sure that
remains a fraction of
.
The current procedure uses pairing, P, to check the correctness of each block’s integrity proof, and
precedes an initial pairing for global signature, plus
of additional coupling for CB. A single
correspond to a final check. Our proposal differentiates by integrating further multiplications
to handle the extended label structure. The count
connotes that each CB has
sub-checks, plus an overall aggregator and a final exponent for signature verification. Only two pairings,
, are needed in the designs, one for the global verification step and one for the secondary signature. This is less than
in large datasets. Since the pairing operations are often the bottlenecks, reducing them down to
is a substantial improvement for scenarios where
is significant. We derived our method by analyzing the extra sub-block segmentation and partial-tag aggregations introduced in our RBMHT. Concretely, each block is subdivided into
segments, so the label-generation cost grows to
, and the CSP’s proof-assembly must account for each CB’s segments, giving
. For TPA verification, we decomposed repeated pairings down to a constant
, but must perform exponentiations to handle each segment’s partial evidence; thus,
. To demonstrate the calculations for parameters at 64 MB, we split the file into
= 64 blocks,
= 3 (4.6% or 5% of 64), and
= 2 (proposed method only). Time operations clocked in at
= 0.0038 s,
= 0.0059 s,
= 0.0090 s and
= 0.0012 s,
= 0.0023 s, and
= 0.0030 s, respectively. According to the three phases, the existing method and our method results in
= 0.9984 s,
= 0.0367 s, and
= 0.0533 s, with sum of 1.0884 s or 1.10 s and
= 0.5248,
= 0.0165 s, and
= 0.0258 s with sum of 0.5671 s or 0.60 s, respectively.
Table A4 and
Figure 9 show the experimental results.
In terms of performance trends, our method exhibits consistent factor improvement across all tested file sizes with 1.83 (64 MB, from 1.10/0.60), 1.44 (128 MB), 1.28 (256 MB), 1.20 (512 MB), and 1.06 (1024 MB). When we say the ratio is 1.83, it means that the existing technique takes 1.83 times as long. In other words, if our method needs 0.60 s, then the existing method requires 1.10 s, almost twice as slow. The degree of ratio is larger for smaller files, and it gradually shrinks for bigger files until it belongs 1.06 times faster at 1024 MB. It can be attributed to reduced pairing operations and efficient exponentiation handling. As file size increases from 64 MB to 1024 MB, both show a growth in total time, but our solution scales more gracefully because it limits the linear expansion of cost-intensive bilinear pairings. For mid-range file sizes (128 MB to 512 MB), exponentiation and multiplication dominate total runtime, but our technique’s segmentation strategy prevents theses operations from escalating sharply. A key reason for the performance gap is the relegation of pairing to a nearly constant overhead, whereas the old method applies it more frequently. This causes faster growth in total computational cost. The technical optimization allows us to outperform its counterpart by up to 40% for smaller file sizes and still maintain a competitive edge for 1024 MB, as seen by a near parallel but lower curve in the graph.
6.2. Communication Overhead
The overhead of communication measures the quantity of data exchanged among the CSS, TPA, and SC during integrity checks [
38]. In an audit process, the TPA sends dispute information to the CSS. It then replies with certificates, and the TPA returns attestation results to the SC. Our proposed mechanism minimizes these transmissions through an efficient proof generation by omitting TPA-to-CSS challenge messages. Thus, diminishing the number and size of network packets. Below, we detail how each step contributes to the overall overhead and compare our method’s performance against the chosen similar benchmark.
Table 2 contrasts these communication steps for the two approaches. We list their complexity as
, where n is the total DB,
is the audit’s challenged blocks, and
is partial evidence used to prove correctness, requiring logarithmic-size proofs relative to the total and challenged block ratios. For these derivations, we followed the standard practice in [
38] of labeling each message exchange with
. We replaced the baseline’s
challenge transmissions with zero or near-zero overhead by localizing challenge generation (no TPA to CSS roundtrips), introducing a
factor for the size of partial proofs that reference only refuted blocks within a bigger dataset.
For article [
36], the
infers that each block challenge is explicitly transmitted to the CSs, while our procedure (0 overhead) is to allow the TPA to derive the challenge locally and does not need to repeatedly inform the CSS. This design substantially cut back roundtrip communications. The
returns a single proof while
is a compressed structure. As
shrinks relative to
, the overhead for returning these partial proofs are grown only logarithmically rather than linearly. In the current method, when a TPA returns content, a 0 overhead is established, interpreted as negligible or a fused step. Our
is for a final acknowledgment that the TPA’s assessments are complete. This include a small extra message to inform a SC.
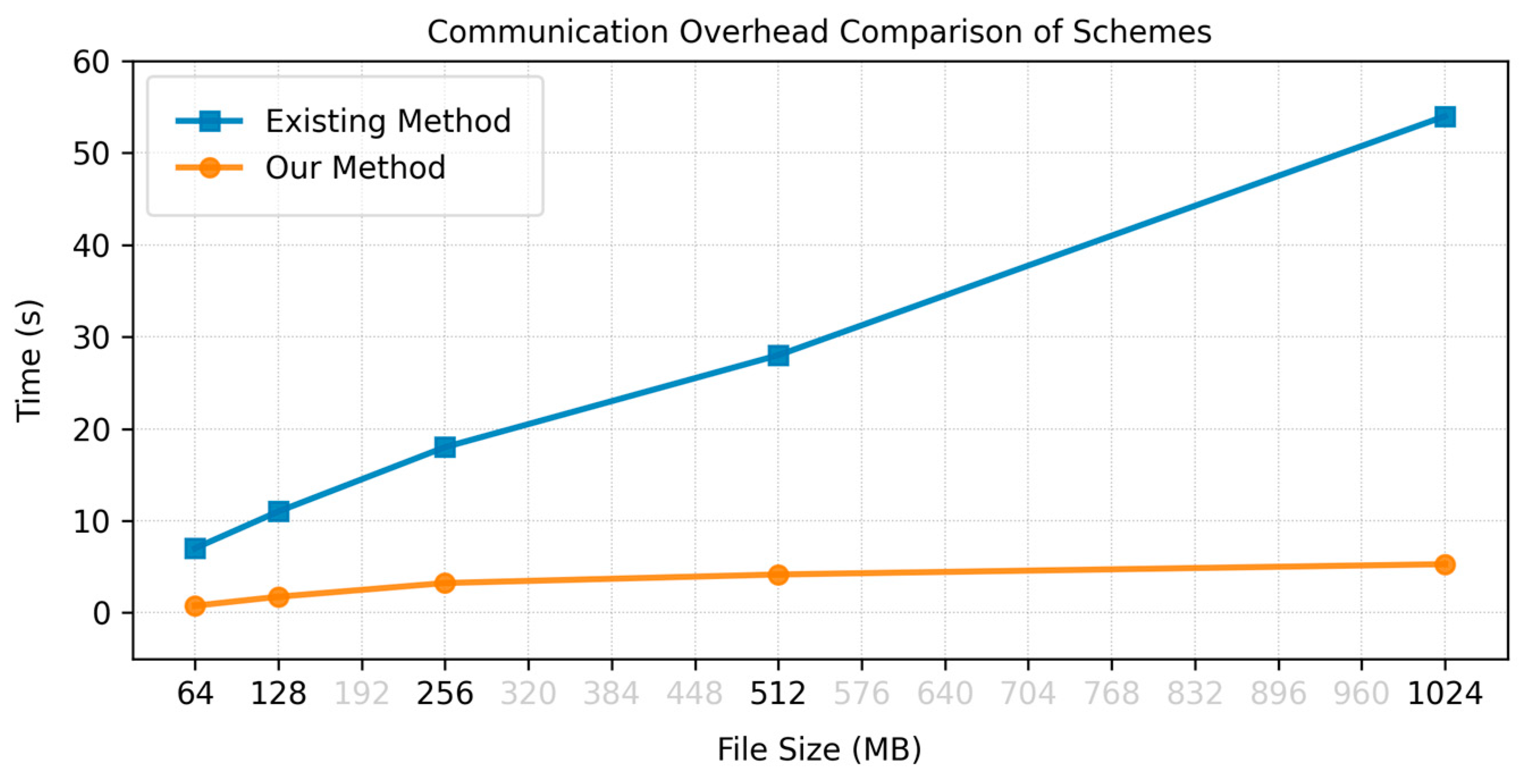
Table A5 and
Figure 10 displays the actual simulation for file sizes ranging from 64 MB to 1024 MB. We observed that the existing method’s overheads grows considerably from 7 units at 64 MB to 54 units at 1024 MB while our proposal remains comparatively low. It only climbs from 0.75 to 5.27. The discrepancy arises mainly because it requires the TPA to send requests
and do not compress the proofs effectively, whereas we eliminated the back-and-forth concept and used logarithmic-sized certificates.
Both removing repeated, unnecessary communications and compressing proofs greatly streamline data exchange [
38]. We achieved a lower mean latency of 86.22%, especially for large datasets, where
, improving scalability in cloud audits where frequent hold-up results in extensive network traffic.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}