
Complex Scene Occluded Object Detection with Fusion of Mixed Local Channel Attention and Multi-Detection Layer Anchor-Free Optimization


Abstract
1. Introduction
2. Related Work
2.1. YOLOv8
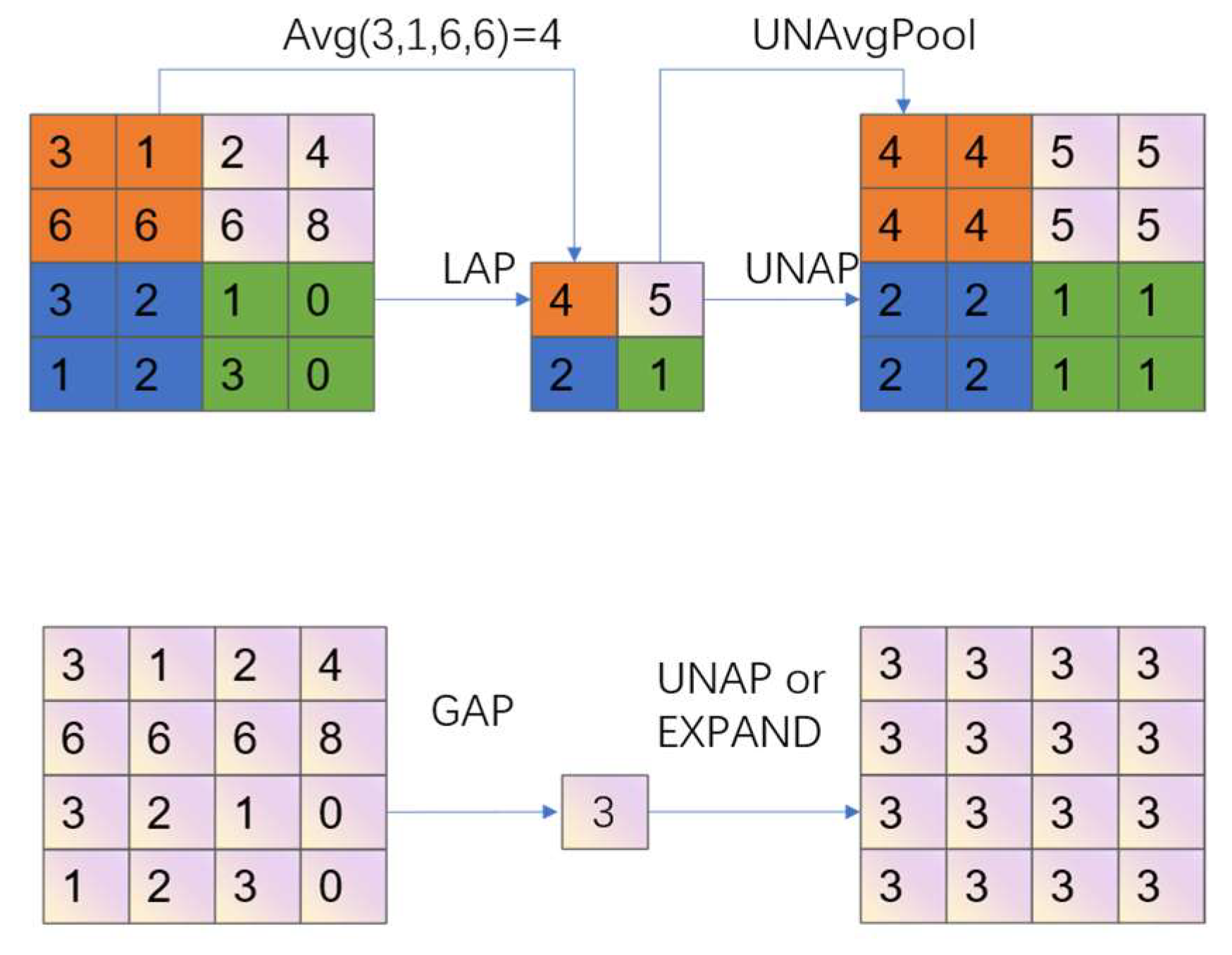
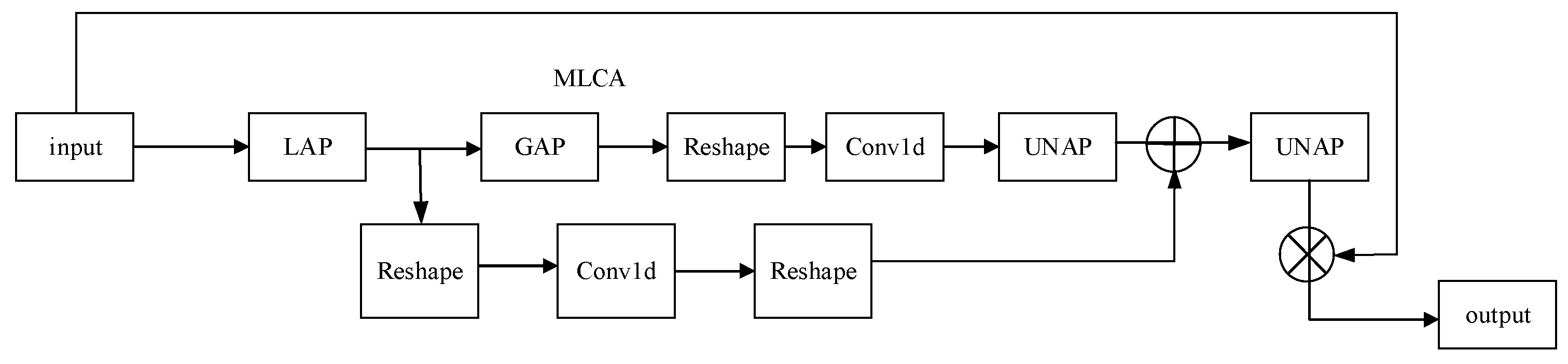
2.2. Mixed Local Channel Attention
2.3. Gaussian Penalty Function Soft Non-Maximum Suppression
2.4. Dataset/Experimental Environment and Evaluation Metrics
3. Model Building
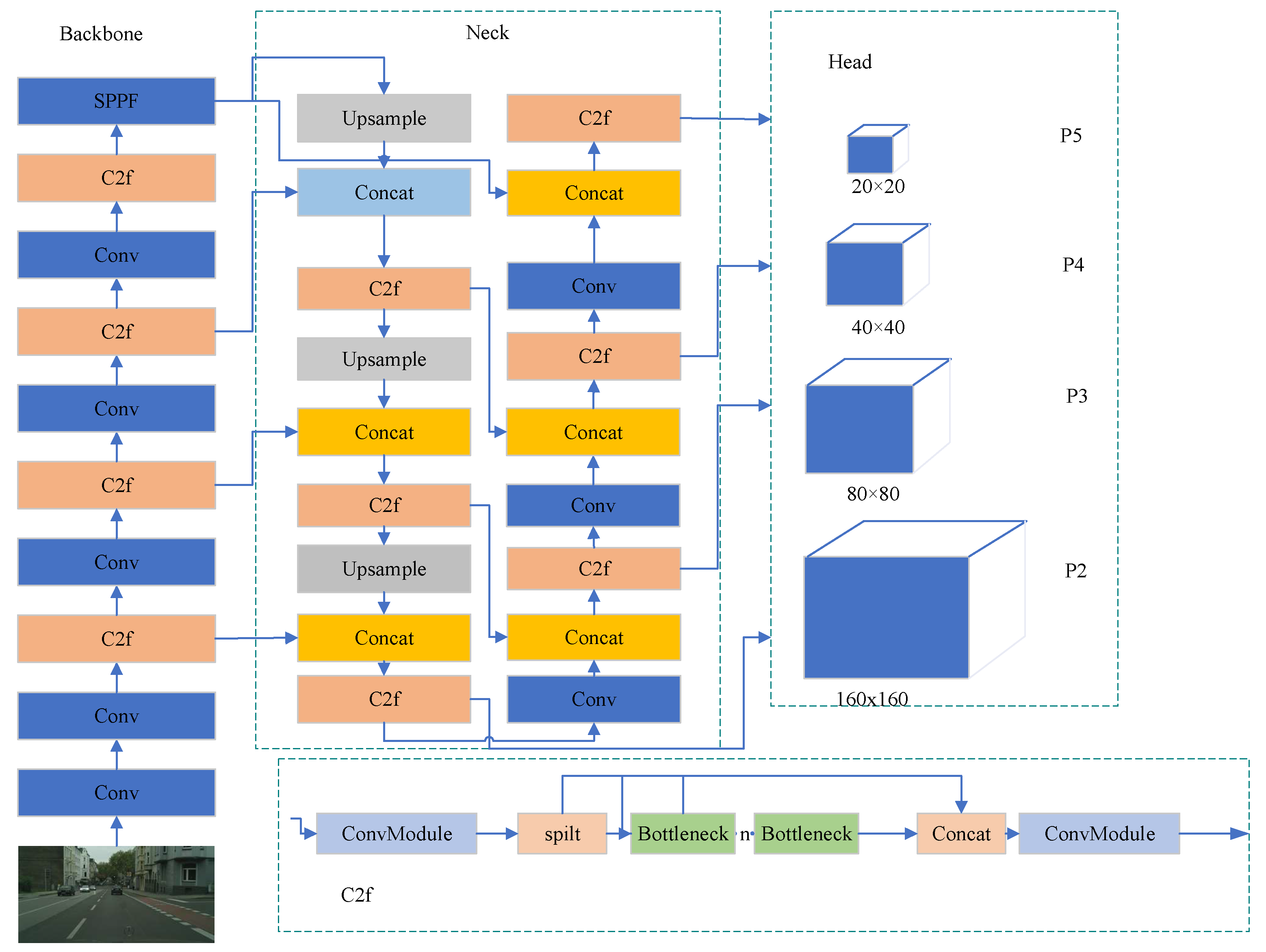
3.1. Adding a Small Target Detection Head and Sampling Layer
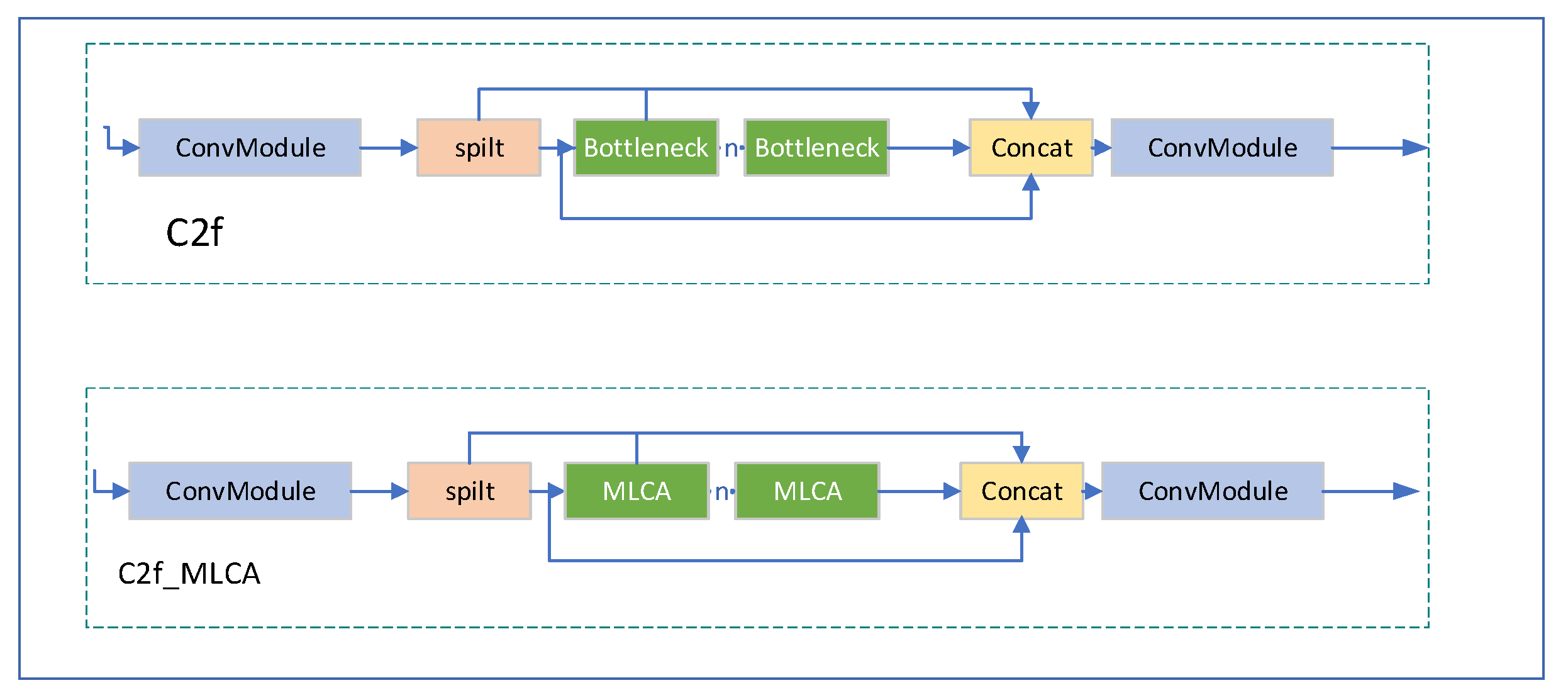
3.2. Fusing Mixed Local Channel Attention
3.3. Gaussian Penalty Function for Optimizing Soft-NMS Occluded Object Candidate Boxes
4. Experimental Results and Analysis
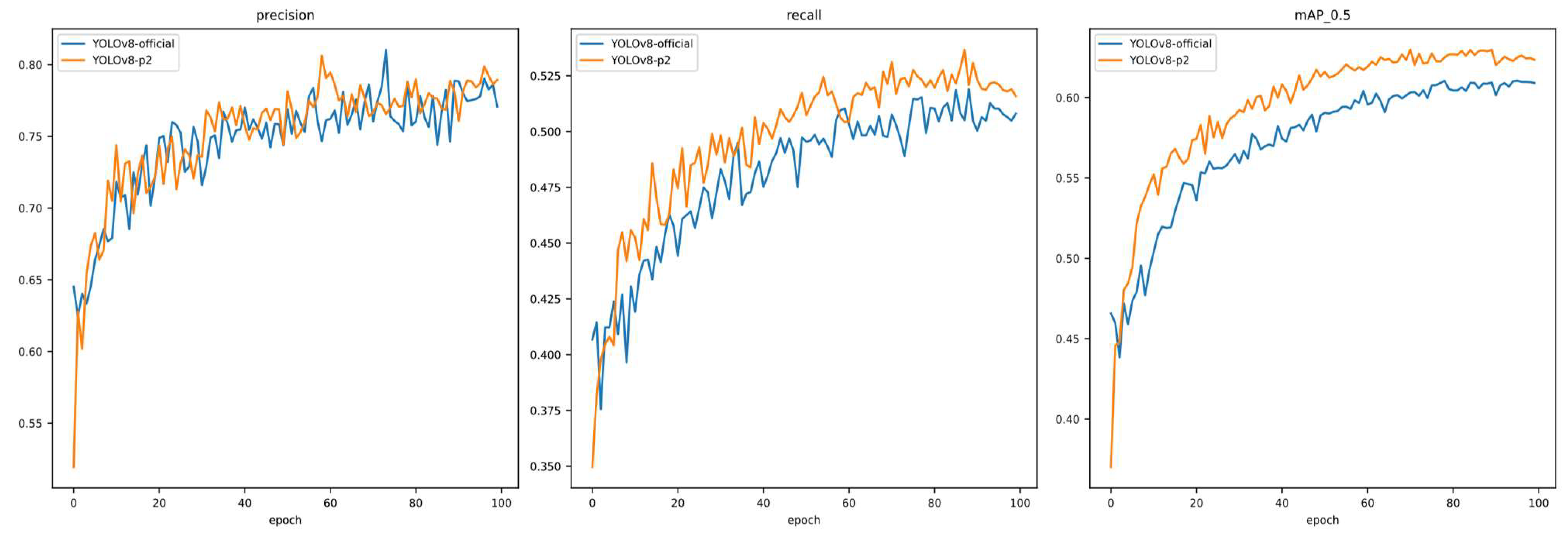
4.1. Ablation Experiments
4.2. Model Testing
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pei, Z.; Zhang, Y.; Yang, T.; Zhang, X.; Yang, Y.-H. A novel multi-object detection method in complex scene using synthetic aperture imaging. Pattern Recognit. 2012, 45, 1637–1658. [Google Scholar] [CrossRef]
- Ruan, J.; Cui, H.; Huang, Y.; Li, T.; Wu, C.; Zhang, K. A review of occluded objects detection in real complex scenarios for autonomous driving. Green Energy Intell. Transp. 2023, 2, 100092. [Google Scholar] [CrossRef]
- Bonin-Font, F.; Ortiz, A.; Oliver, G. Visual navigation for mobile robots: A survey. J. Intell. Robot. Syst. 2008, 53, 263–296. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Preece, J.; Rogers, Y.; Sharp, H.; Benyon, D.; Holland, S.; Carey, T. Human-Computer Interaction; Addison-Wesley Longman Ltd.: Albany, NY, USA, 1994. [Google Scholar]
- Finogeev, A.; Finogeev, A.; Fionova, L.; Lyapin, A.; Lychagin, K.A. Intelligent monitoring system for smart road environment. J. Ind. Inf. Integr. 2019, 15, 15–20. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Chu, X.; Zheng, A.; Zhang, X.; Sun, J. Detection in crowded scenes: One proposal, multiple predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 12214–12223. [Google Scholar]
- Shao, X.; Wang, Q.; Yang, W.; Chen, Y.; Xie, Y.; Shen, Y.; Wang, Z. Multi-scale feature pyramid network: A heavily occluded pedestrian detection network based on ResNet. Sensors 2021, 21, 1820. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Wang, J.; Hu, L.; Liu, B.; Zhao, H. Research on Occluded Object Detection by Improved RetinaNet. J. Comput. Eng. Appl. 2022, 58, p209. [Google Scholar]
- Luo, Z.; Fang, Z.; Zheng, S.; Wang, Y.; Fu, Y. NMS-loss: Learning with non-maximum suppression for crowded pedestrian detection. In Proceedings of the 2021 International Conference on Multimedia Retrieval, New York, NY, USA, 21–24 August 2021; pp. 481–485. [Google Scholar] [CrossRef]
- Huang, X.; Ge, Z.; Jie, Z.; Yoshie, O. Nms by representative region: Towards crowded pedestrian detection by proposal pairing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 10750–10759. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20 June 2019; pp. 840–849. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Posner, M.I.; Boies, S.J. Components of attention. Psychol. Rev. 1971, 78, 391. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 11534–11542. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 25 June 2021; pp. 13713–13722. [Google Scholar]
- Wan, D.; Lu, R.; Shen, S.; Xu, T.; Lang, X.; Ren, Z. Mixed local channel attention for object detection. Eng. Appl. Artif. Intell. 2023, 123, 106442. [Google Scholar] [CrossRef]
- Blaschko, M.B.; Kannala, J.; Rahtu, E. Non maximal suppression in cascaded ranking models. In Image Analysis, Proceedings of the 18th Scandinavian Conference, SCIA 2013, Espoo, Finland, 17–20 June 2013; Proceedings 18; Springer: Berlin/Heidelberg, Germany, 2013; pp. 408–419. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 1440–1448. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | FPS | map@0.5 | GFLOPs |
|---|---|---|---|
| YOLOv8-official | 243 | 0.609 | 8.2 |
| YOLOv8-p2 | 192 | 0.629 | 12.4 |
| YOLOv8-Soft | 133 | 0.658 | 8.2 |
| YOLOv8-mlca-neck | 232 | 0.618 | 8.2 |
| Ours | 128 | 0.676 | 12.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Q.; Mu, J. Complex Scene Occluded Object Detection with Fusion of Mixed Local Channel Attention and Multi-Detection Layer Anchor-Free Optimization. Automation 2024, 5, 176-189. https://doi.org/10.3390/automation5020011
Su Q, Mu J. Complex Scene Occluded Object Detection with Fusion of Mixed Local Channel Attention and Multi-Detection Layer Anchor-Free Optimization. Automation. 2024; 5(2):176-189. https://doi.org/10.3390/automation5020011
Chicago/Turabian StyleSu, Qinghua, and Jianhong Mu. 2024. "Complex Scene Occluded Object Detection with Fusion of Mixed Local Channel Attention and Multi-Detection Layer Anchor-Free Optimization" Automation 5, no. 2: 176-189. https://doi.org/10.3390/automation5020011
APA StyleSu, Q., & Mu, J. (2024). Complex Scene Occluded Object Detection with Fusion of Mixed Local Channel Attention and Multi-Detection Layer Anchor-Free Optimization. Automation, 5(2), 176-189. https://doi.org/10.3390/automation5020011