
Reinforcement Learning for Collaborative Robots Pick-and-Place Applications: A Case Study †





Abstract
:1. Introduction
2. Background and Related Work
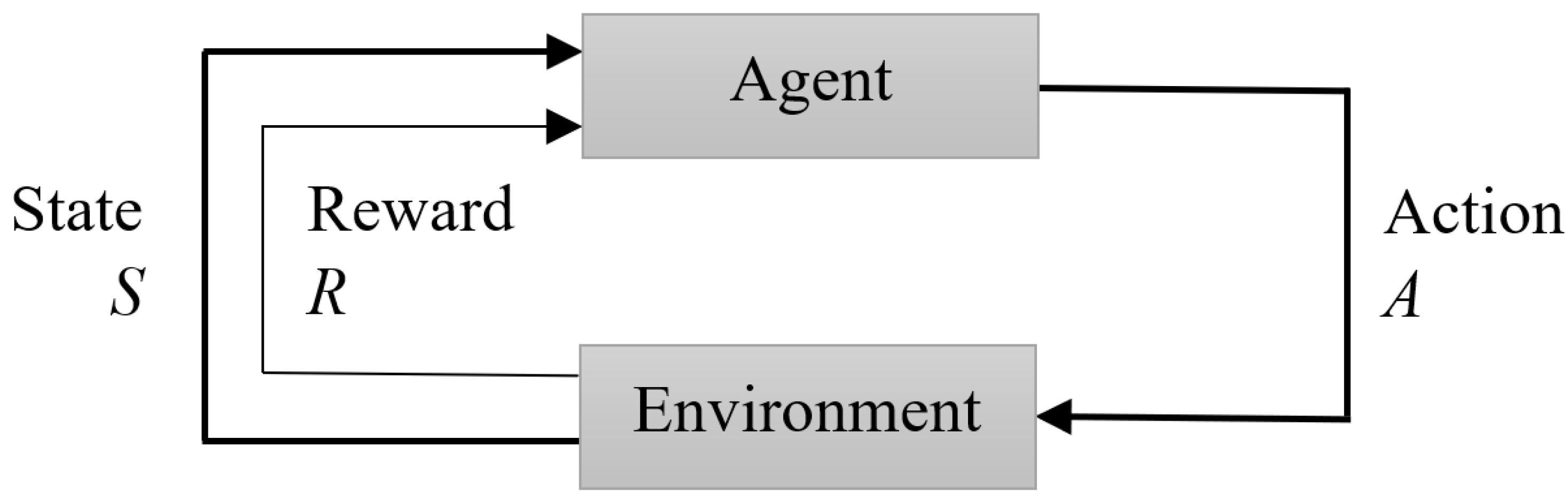
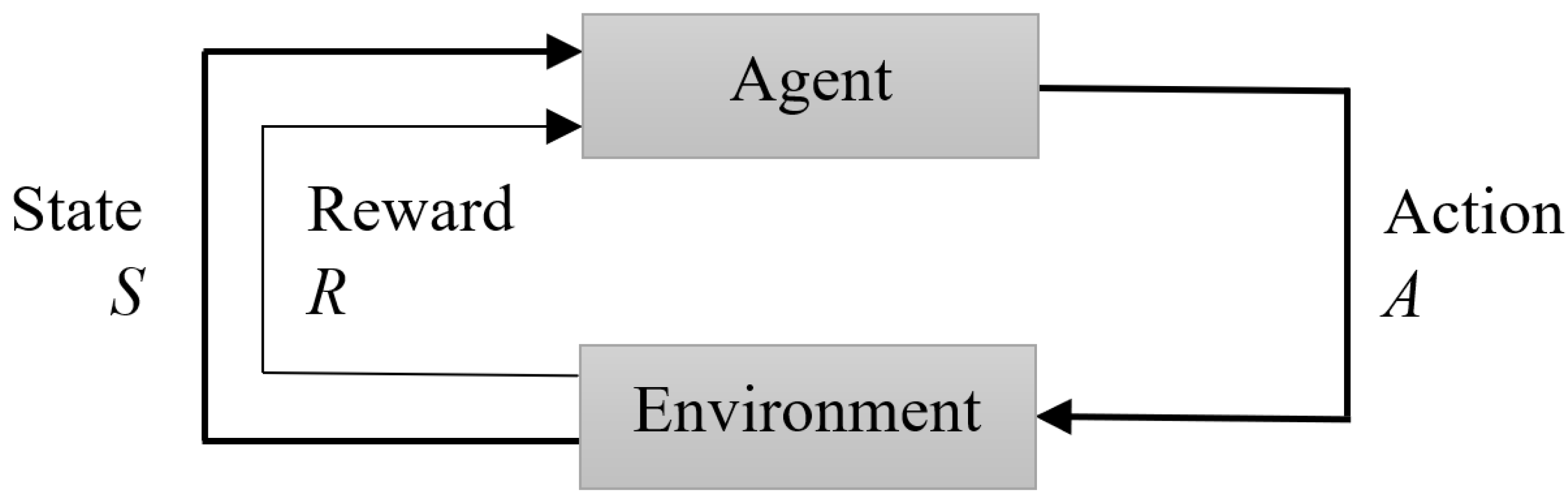
2.1. Reinforcement Learning
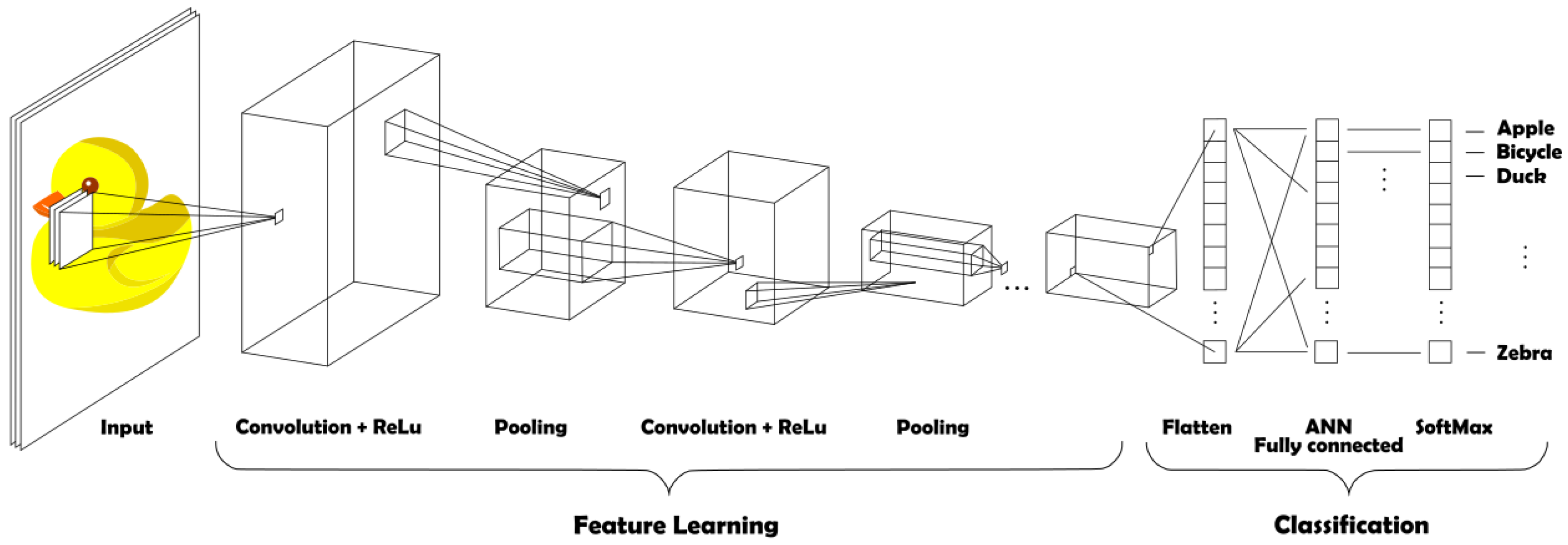
2.2. Convolutional Neural Network
2.3. Deep Reinforcement Learning
3. Problem Statement and Proposed System
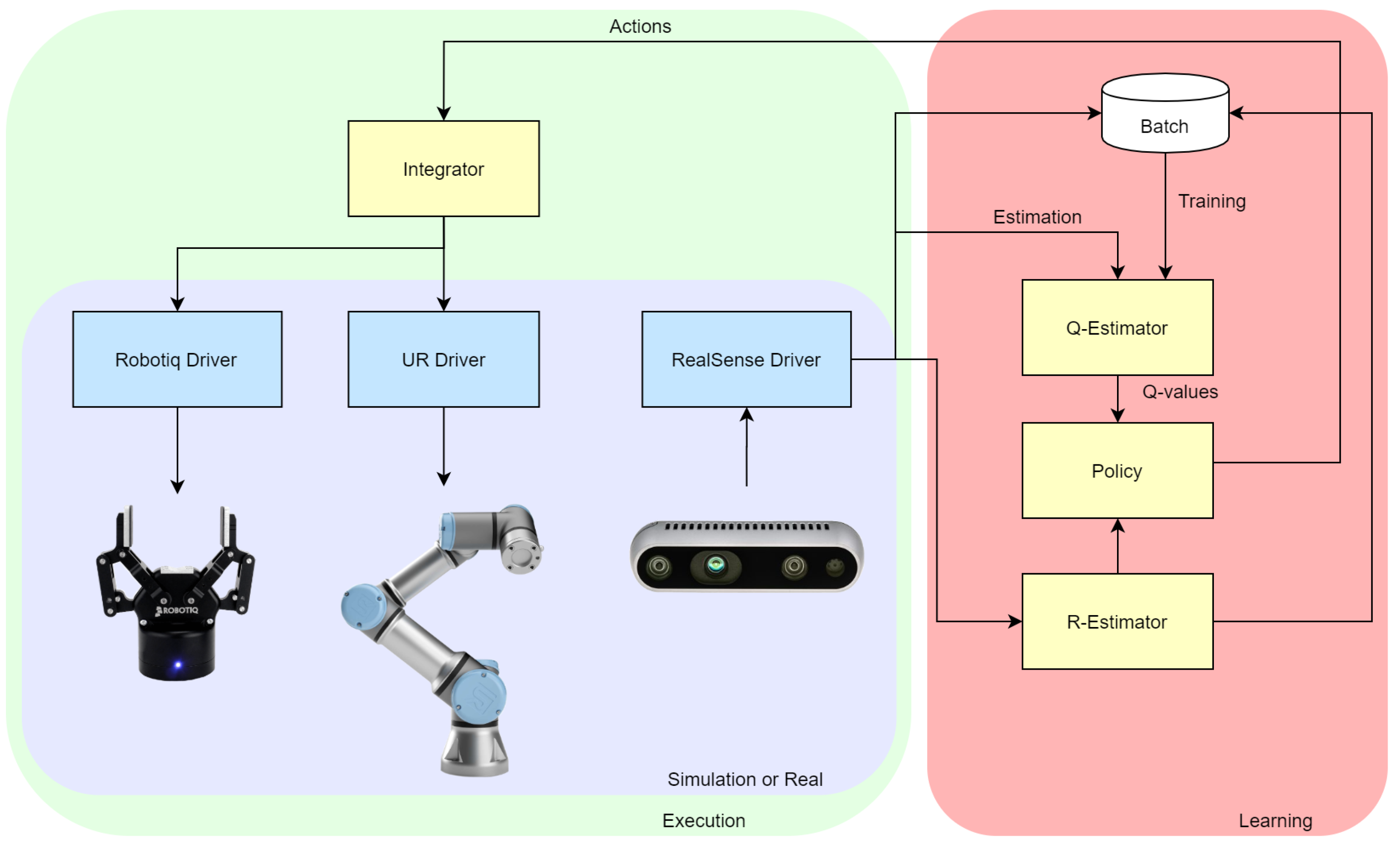
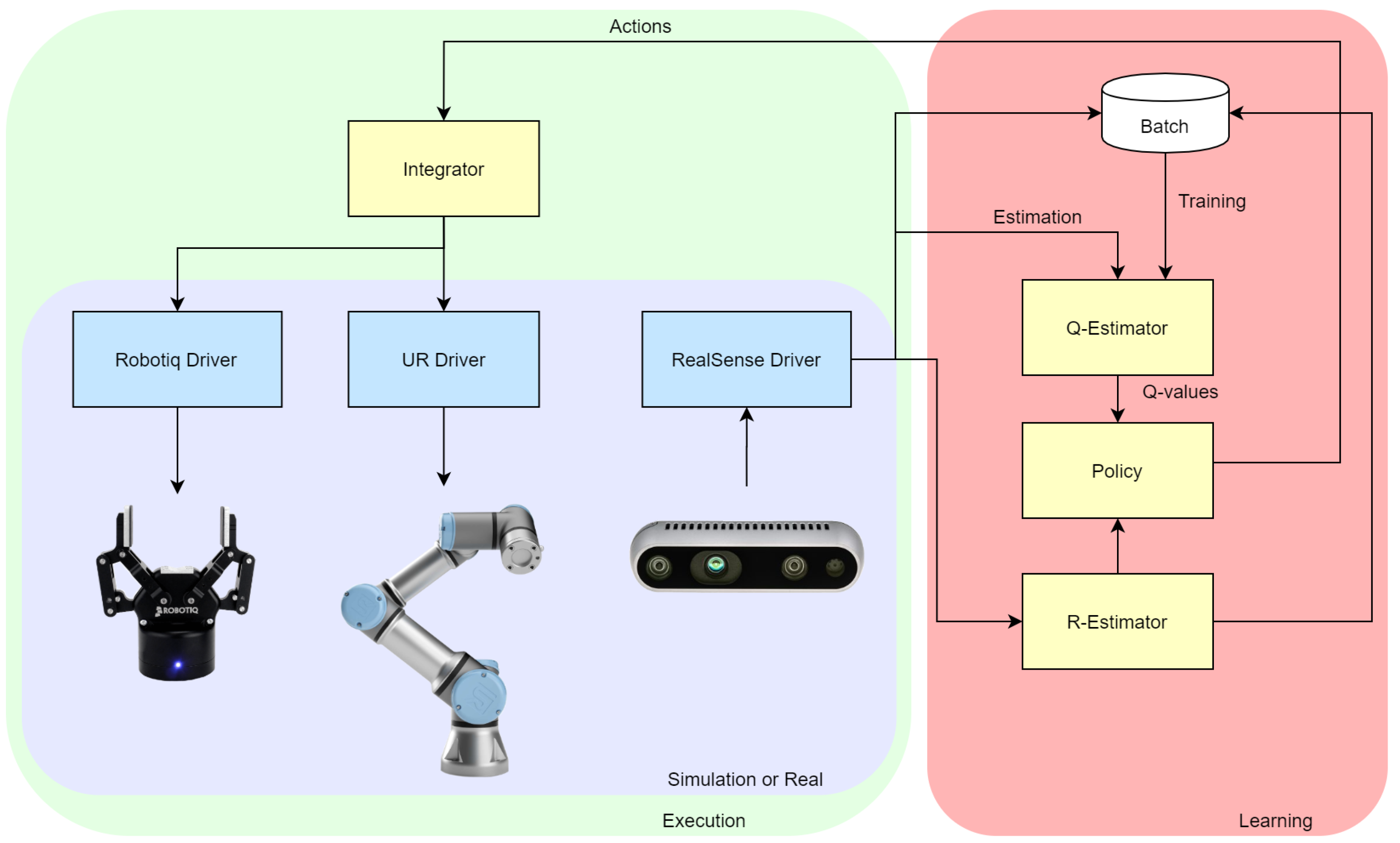
3.1. Proposed System
3.2. Simulation Setup
3.3. Experimental Setup
4. Methodology
| Algorithm 1 RL CNN Q-learning algorithm |
|
5. Results
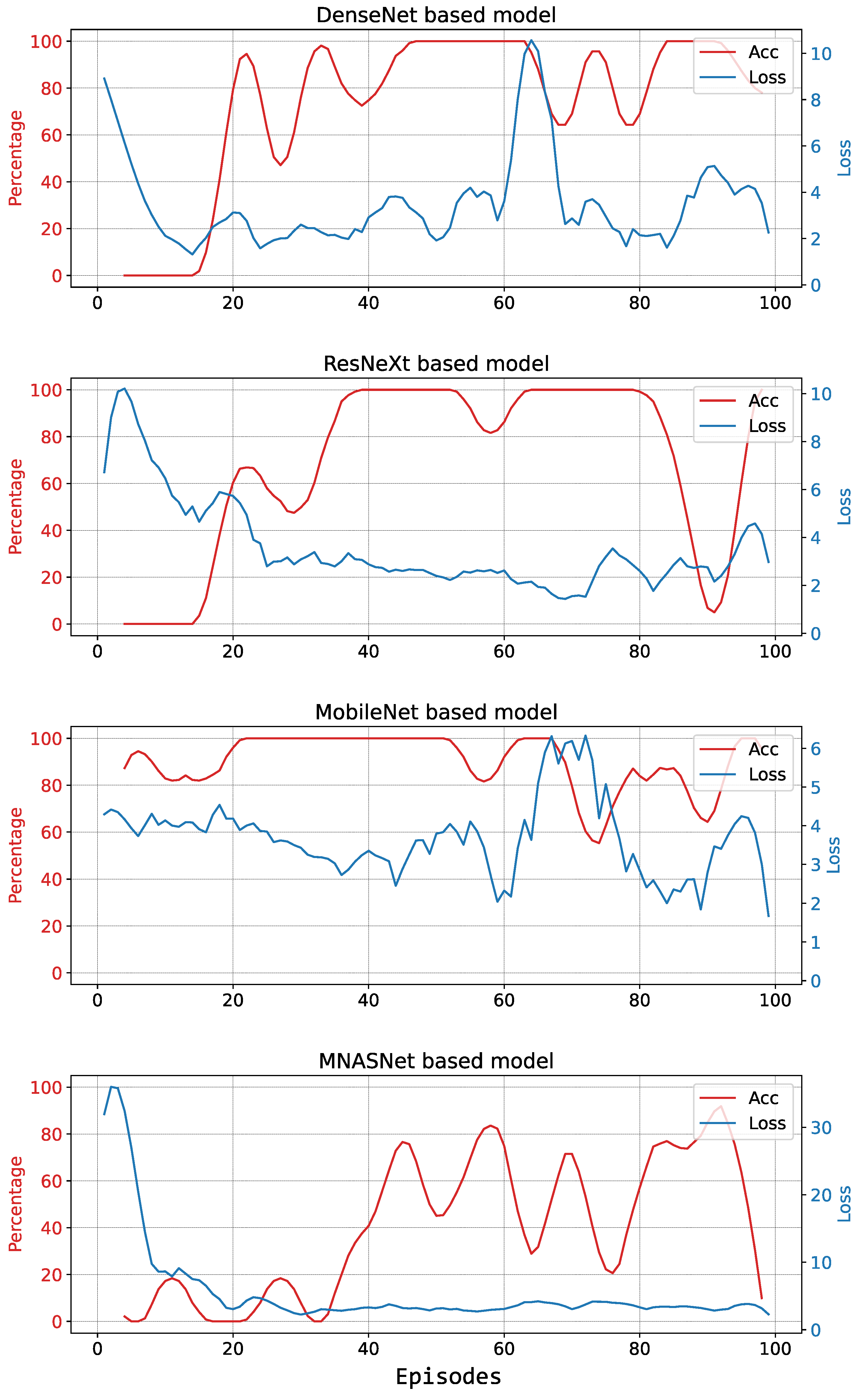
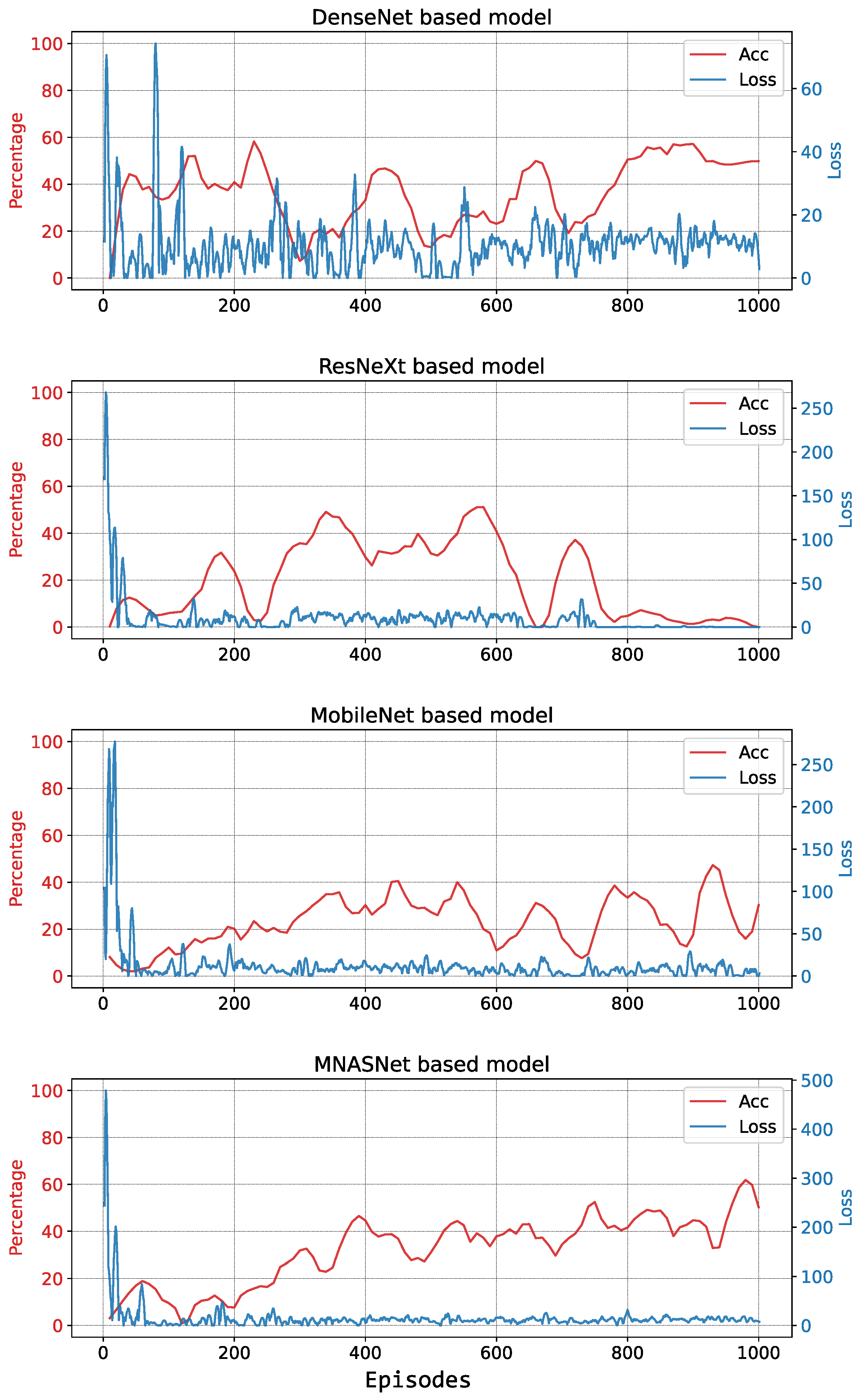
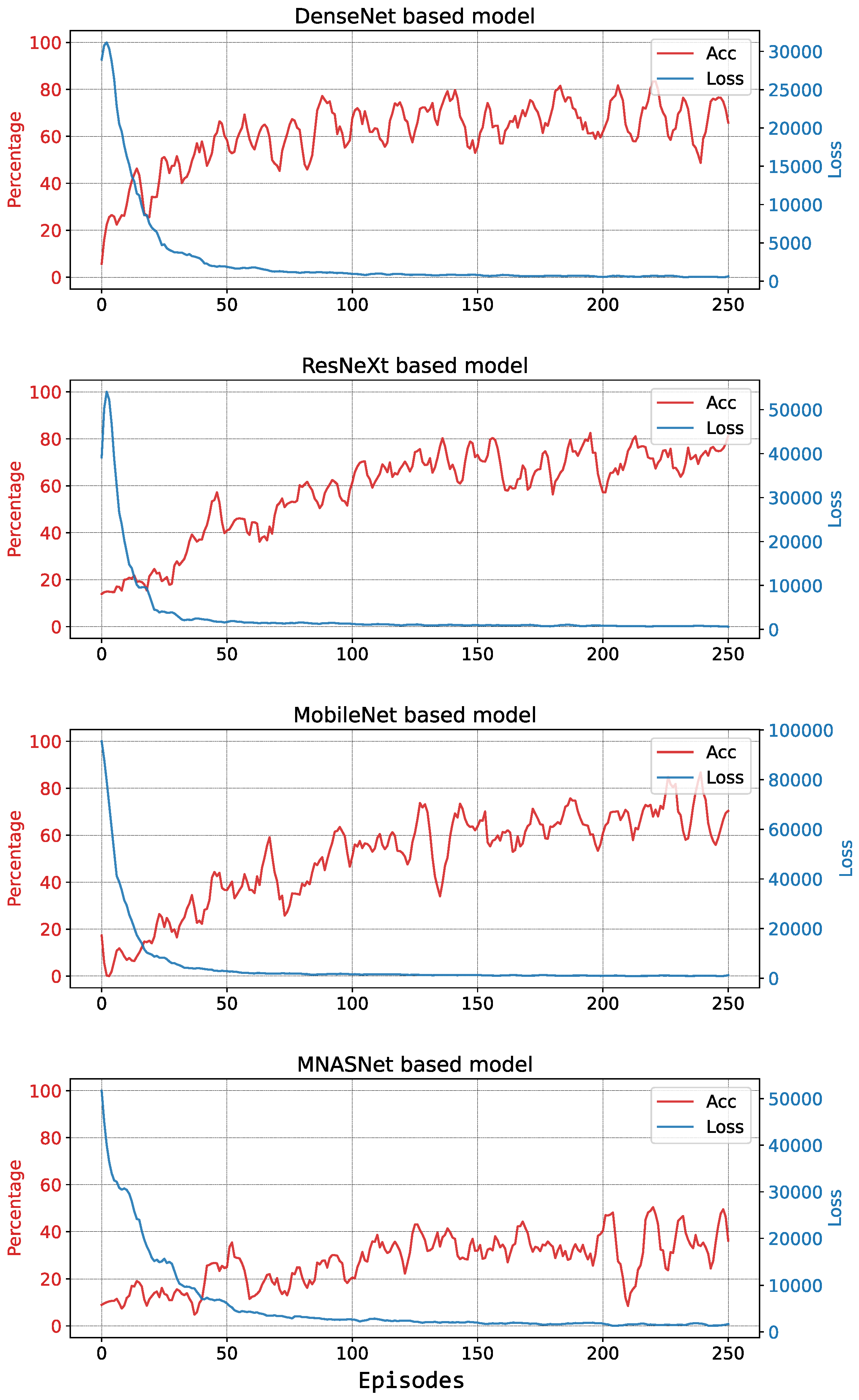
5.1. Simulations
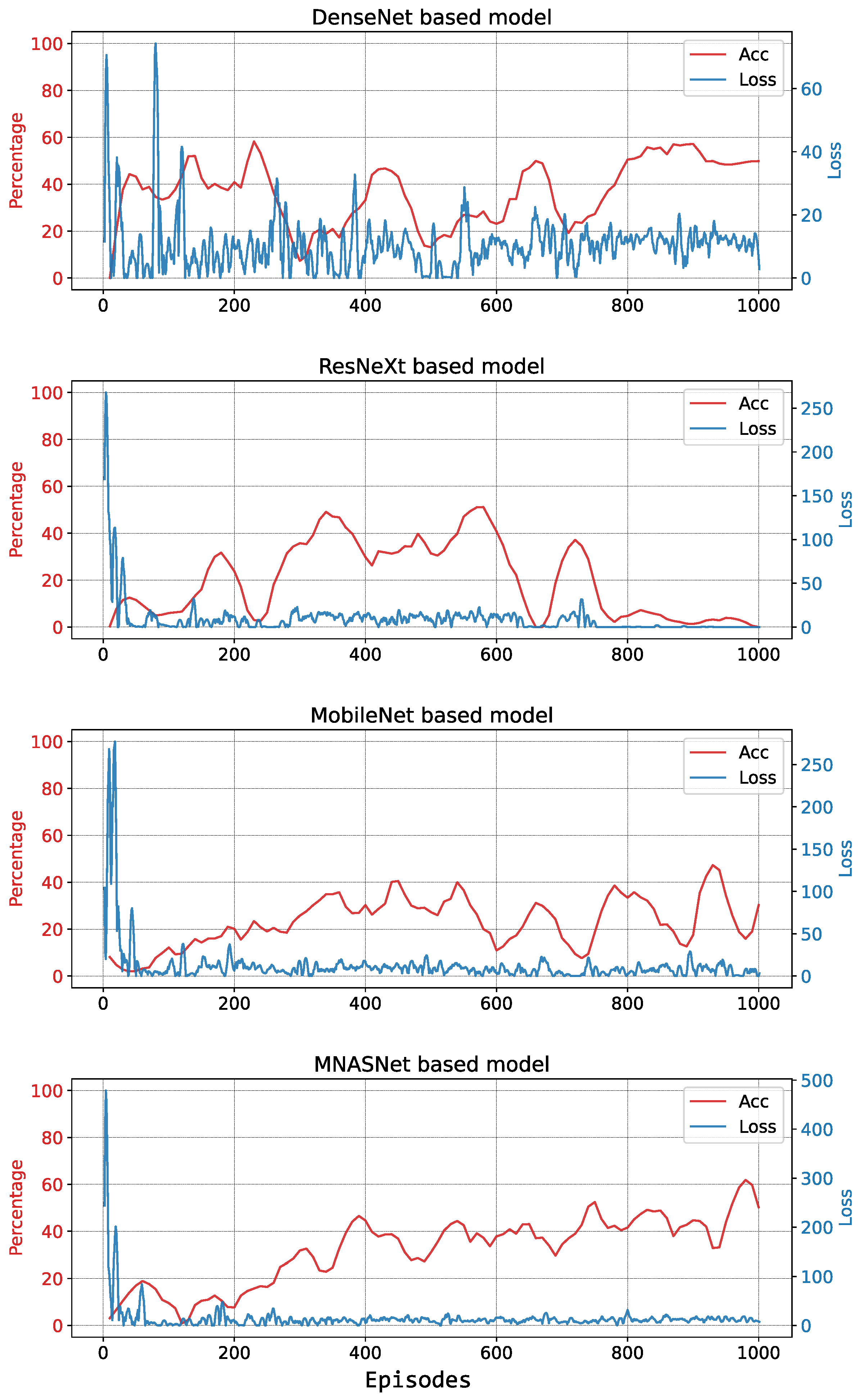
5.1.1. First Training Session
5.1.2. Second Training Session
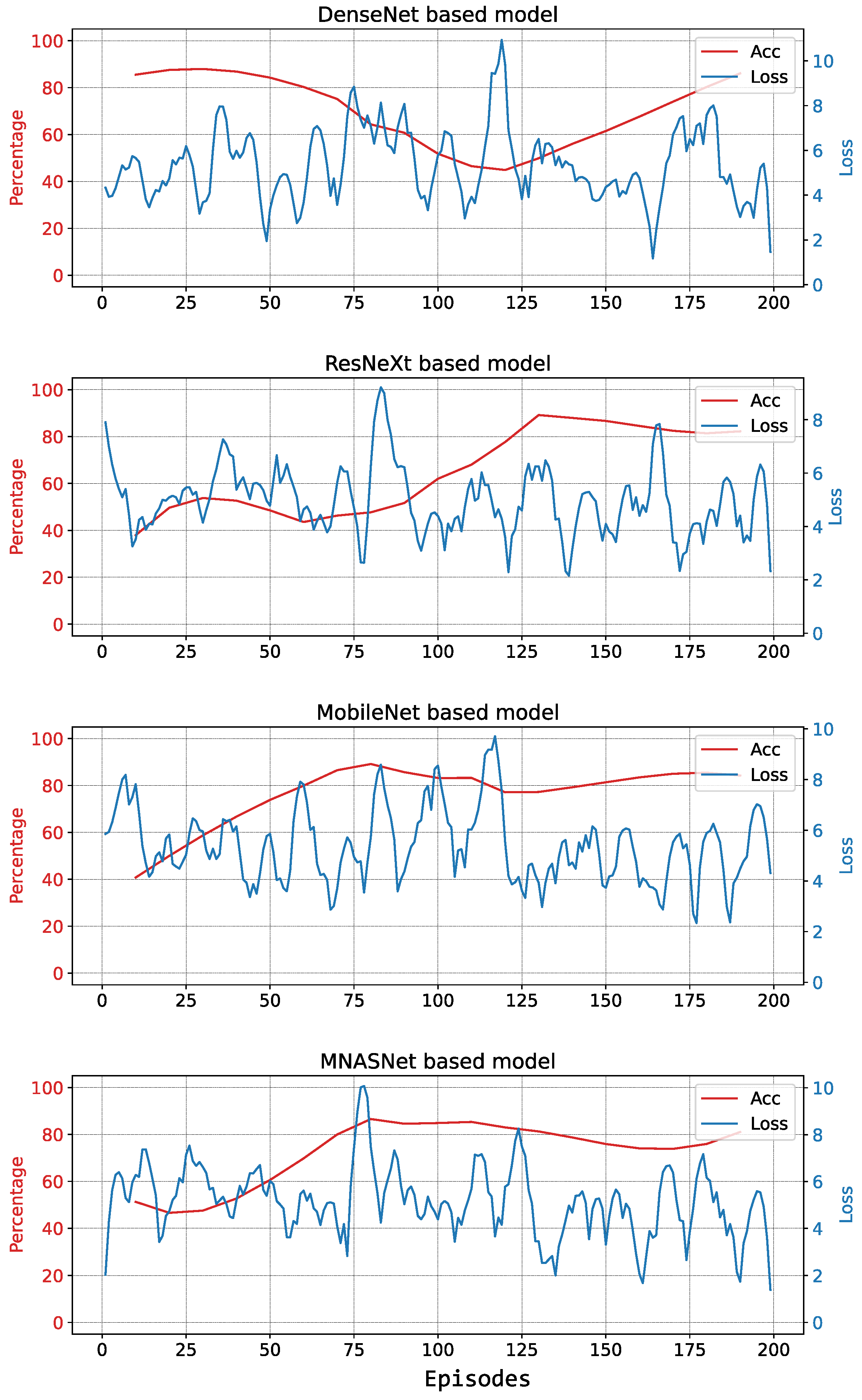
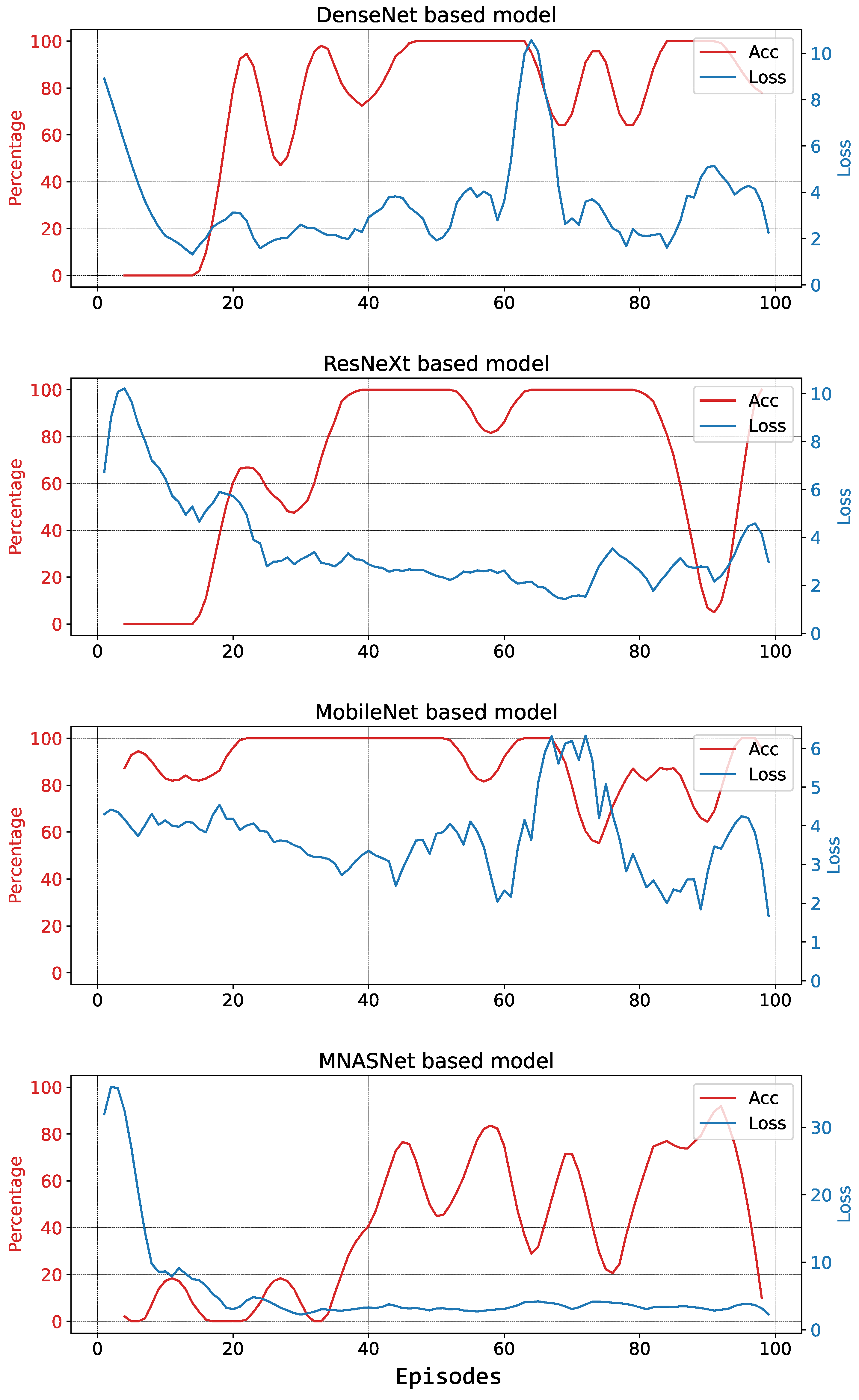
5.2. Experiments
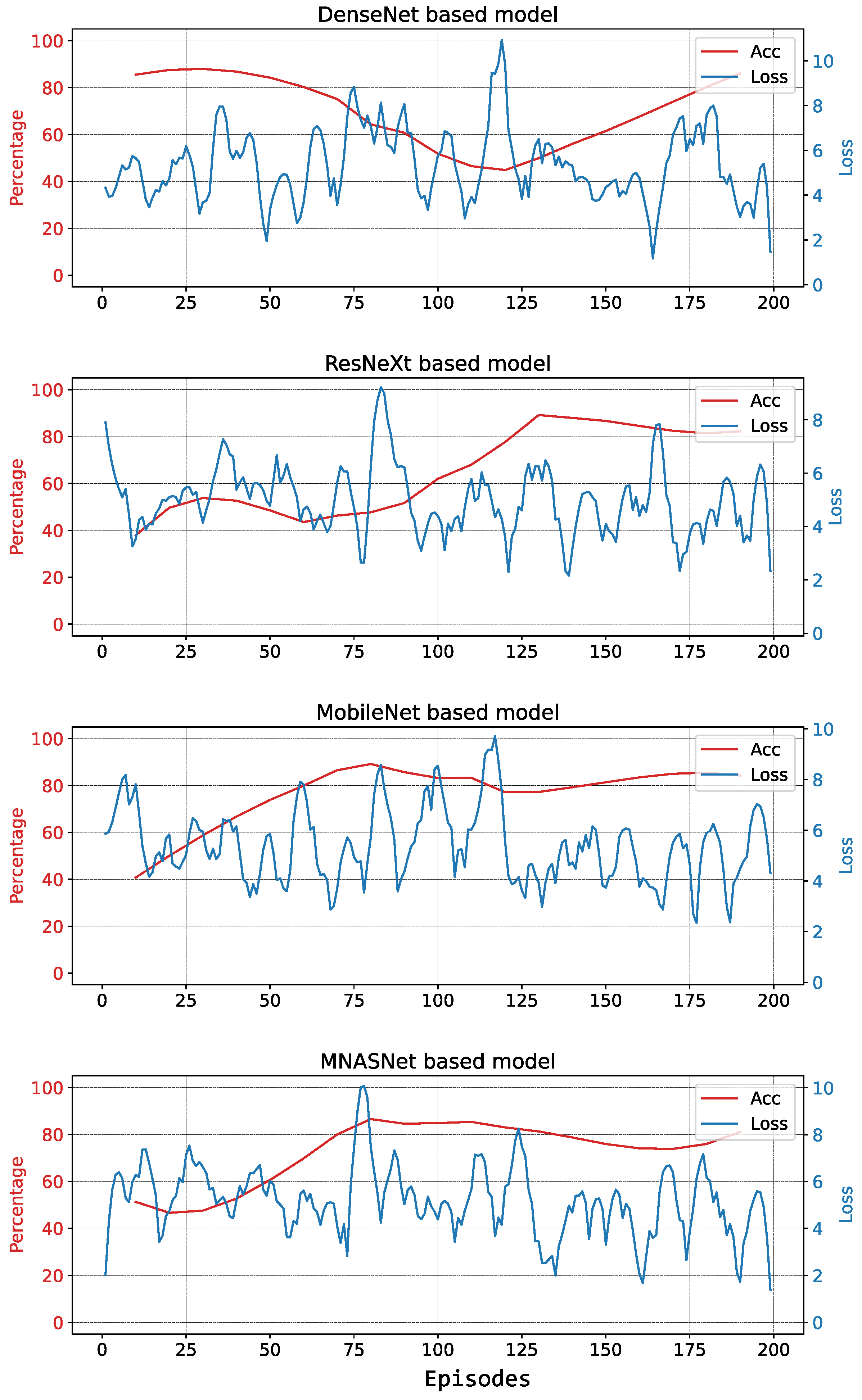
5.2.1. First Testing Session
5.2.2. Second Testing Session
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| Cobot | Collaborative Robot |
| CPU | Central Processing Unit |
| DCNN | Deep Convolutional Neural Network |
| DRL | Deep Reinforcement Learning |
| DQN | Deep Q-Network |
| GG-CNN | Generative Grasping Convolutional Neural Network |
| GPU | Graphics Processing Unit |
| MDP | Markov Decision Process |
| ML | Machine Learning |
| RCNN | Region-Based Convolutional Neural Network |
| ResNet | Residual Neural Network |
| RGBD | Red, Green, Blue, Depth |
| RL | Reinforcement Learning |
| ROS | Robot Operating System |
| TCP | Tool Center Point |
References
- Siciliano, B.; Khatib, O. Springer Handbook of Robotics; Springer International Publishing: Berlin, Germany, 2016; pp. 1–2227. [Google Scholar] [CrossRef]
- ISO/TS 15066; Robots and Robotic Devices-Collaborative Robots. Standard, International Organization for Standardization: Geneva, Switzerland, 2016.
- Gomes, J.F.S.; Leta, F.R. Applications of computer vision techniques in the agriculture and food industry: A review. Eur. Food Res. Technol. 2012, 235, 989–1000. [Google Scholar] [CrossRef]
- Arakeri, M.P.; Lakshmana. Computer Vision Based Fruit Grading System for Quality Evaluation of Tomato in Agriculture industry. In Procedia Computer Science; Elsevier B.V.: Hoboken, NJ, USA, 2016; Volume 79, pp. 426–433. [Google Scholar] [CrossRef] [Green Version]
- Bhutta, M.U.M.; Aslam, S.; Yun, P.; Jiao, J.; Liu, M. Smart-Inspect: Micro Scale Localization and Classification of Smartphone Glass Defects for Industrial Automation. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021. [Google Scholar] [CrossRef]
- Saxena, A.; Driemeyer, J.; Kearns, J.; Ng, A.Y. Robotic grasping of novel objects. In Advances in Neural Information Processing Systems; IEEE: New York, NY, USA, 2007; pp. 1209–1216. [Google Scholar] [CrossRef] [Green Version]
- Torras, C. Computer Vision: Theory and Industrial Applications; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar] [CrossRef]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 769–776. [Google Scholar] [CrossRef] [Green Version]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Shafii, N.; Kasaei, S.H.; Lopes, L.S. Learning to grasp familiar objects using object view recognition and template matching. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 2895–2900. [Google Scholar] [CrossRef]
- Miljković, Z.; Mitić, M.; Lazarević, M.; Babić, B. Neural network Reinforcement Learning for visual control of robot manipulators. Expert Syst. Appl. 2013, 40, 1721–1736. [Google Scholar] [CrossRef]
- Gomes, N.M.; Martins, F.N.; Lima, J.; Wörtche, H. Deep Reinforcement Learning Applied to a Robotic Pick-and-Place Application. In Optimization, Learning Algorithms and Applications; Pereira, A.I., Fernandes, F.P., Coelho, J.P., Teixeira, J.P., Pacheco, M.F., Alves, P., Lopes, R.P., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 251–265. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018; p. 552. [Google Scholar]
- Saha, S. A Comprehensive Guide to Convolutional Neural Networks-Towards Data Science. 2018. Available online: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53 (accessed on 20 June 2020).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Radosavovic, I.; Gkioxari, G.; Dollár, P.; He, K. Detectron. 2018. Available online: https://github.com/facebookresearch/detectron (accessed on 20 June 2020).
- Redmon, J.; Farhadi, A. YOLO: Real-Time Object Detection. 2018. Available online: https://pjreddie.com/darknet/yolo (accessed on 20 June 2020).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Luo, C.; He, X.; Zhan, J.; Wang, L.; Gao, W.; Dai, J. Comparison and benchmarking of ai models and frameworks on mobile devices. arXiv 2020, arXiv:2005.05085. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2815–2823. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Zanuttigh, P.; Mutto, C.D.; Minto, L.; Marin, G.; Dominio, F.; Cortelazzo, G.M. Time-of-Flight and Structured Light Depth Cameras: Technology and Applications; Springer International Publishing: Berlin, Germany, 2016; pp. 1–355. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Leitner, J.; Milford, M.; Upcroft, B.; Corke, P. Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control. arXiv 2015, arXiv:1511.03791. [Google Scholar]
- Rahman, M.M.; Rashid, S.M.H.; Hossain, M.M. Implementation of Q learning and deep Q network for controlling a self balancing robot model. Robot. Biomim. 2018, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hase, H.; Azampour, M.F.; Tirindelli, M.; Paschali, M.; Simson, W.; Fatemizadeh, E.; Navab, N. Ultrasound-Guided Robotic Navigation with Deep Reinforcement Learning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25 October 2020–24 January 2021. [Google Scholar]
- Joshi, S.; Kumra, S.; Sahin, F. Robotic grasping using deep reinforcement learning. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1461–1466. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Gomes, N.M. Natanaelmgomes/drl_ros: ROS Package with Webots Simulation Environment, Layer of Control and a Deep Reinforcement Learning Algorithm Using Convolutional Neural Network. Available online: https://github.com/natanaelmgomes/drl_ros (accessed on 22 January 2021).
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Models and Pre-Trained Weights. 2022. Available online: https://pytorch.org/vision/stable/models.html (accessed on 3 January 2022).
- Webots. Commercial Mobile Robot Simulation Misc. Available online: http://www.cyberbotics.com (accessed on 18 August 2020).
- Ayala, A.; Cruz, F.; Campos, D.; Rubio, R.; Fernandes, B.; Dazeley, R. A comparison of humanoid robot simulators: A quantitative approach. In Proceedings of the 2020 Joint IEEE 10th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Valparaiso, Chile, 7–11 September 2020; pp. 1–6. [Google Scholar]
- Open Robotics. Robot Operating System. Available online: http://wiki.ros.org/melodic (accessed on 18 August 2020).
- Universal Robots. Universal_Robots_ROS_Driver. Available online: https://github.com/UniversalRobots/Universal_Robots_ROS_Driver (accessed on 5 August 2020).
- Ros-Industrial/Robotiq: Robotiq Packages. Available online: http://wiki.ros.org/robotiq (accessed on 19 October 2020).
- Intel(R) RealSense(TM) ROS Wrapper for D400 Series, SR300 Camera and T265 Tracking Module: IntelRealSense/realsense-ros. 2019. Available online: https://github.com/IntelRealSense/realsense-ros (accessed on 3 January 2022).
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. Technical Report. arXiv 2017, arXiv:1709.10087. [Google Scholar] [CrossRef]
- Hawkins, K.P. Analytic Inverse Kinematics for the Universal Robots UR-5/UR-10 Arms; Technical Report; Georgia Institute of Technology: Atlanta, GA, USA, 2013. [Google Scholar]
- Universal Robots-Parameters for Calculations of Kinematics and Dynamics. Available online: https://www.universal-robots.com/articles/ur/application-installation/dh-parameters-for-calculations-of-kinematics-and-dynamics/ (accessed on 31 December 2020).
- Universal Robots. Universal Robots e-Series User Manual-US Version 5.7. 2020. Available online: https://www.universal-robots.com/download/manuals-e-series/user/ur5e/57/user-manual-ur5e-e-series-sw-57-english-us-en-us/ (accessed on 5 August 2020).
- Robotiq Inc. Manual Robotiq 2F-85 & 2F-140 for e-Series Universal Robots, Robotiq Inc.: Québec, QC, Canada, 7 November 2018.
- SmoothL1Loss - PyTorch 1.7.0 Documentation. Available online: https://pytorch.org/docs/stable/generated/torch.nn.SmoothL1Loss.html (accessed on 15 January 2021).
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings. International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Brys, T.; Harutyunyan, A.; Suay, H.B.; Chernova, S.; Taylor, M.E.; Nowé, A. Reinforcement learning from demonstration through shaping. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3352–3358. [Google Scholar]
- De Bruin, T.; Kober, J.; Tuyls, K.; Babuška, R. Experience selection in deep reinforcement learning for control. J. Mach. Learn. Res. 2018, 19, 1–56. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Symbol | Value |
|---|---|---|
| CNN Learning rate | 1 × 10−3 | |
| CNN Weight decay | 8 × 10−4 | |
| RL Learning rate | 0.7 | |
| RL Discount factor | 0.90 | |
| RL Initial exploration factor | 0.90 | |
| RL Final exploration factor | 5 × 10−2 | |
| RL Exploration factor decay | 200 |
| CNN Model | Forward Time [s] | Backward Time [s] |
|---|---|---|
| DenseNet | 0.408 ± 0.113 | 0.676 ± 0.193 |
| ResNext | 0.366 ± 0.097 | 0.760 ± 0.173 |
| MobileNet | 0.141 ± 0.036 | 0.217 ± 0.053 |
| MNASNet | 0.156 ± 0.044 | 0.257 ± 0.074 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomes, N.M.; Martins, F.N.; Lima, J.; Wörtche, H. Reinforcement Learning for Collaborative Robots Pick-and-Place Applications: A Case Study. Automation 2022, 3, 223-241. https://doi.org/10.3390/automation3010011
Gomes NM, Martins FN, Lima J, Wörtche H. Reinforcement Learning for Collaborative Robots Pick-and-Place Applications: A Case Study. Automation. 2022; 3(1):223-241. https://doi.org/10.3390/automation3010011
Chicago/Turabian StyleGomes, Natanael Magno, Felipe Nascimento Martins, José Lima, and Heinrich Wörtche. 2022. "Reinforcement Learning for Collaborative Robots Pick-and-Place Applications: A Case Study" Automation 3, no. 1: 223-241. https://doi.org/10.3390/automation3010011
APA StyleGomes, N. M., Martins, F. N., Lima, J., & Wörtche, H. (2022). Reinforcement Learning for Collaborative Robots Pick-and-Place Applications: A Case Study. Automation, 3(1), 223-241. https://doi.org/10.3390/automation3010011