
Optimal Partitioning of Unbalanced Datasets for BGP Anomaly Detection

 , , and
, , and 
Abstract
1. Introduction
- A novel classification method is proposed that uses optimal partitioning (OP) and the Extreme Learning Machine (ELM) for the classification and detection of anomalies in the traffic of BGP-based network environments;
- To handle the data imbalance nature of the dataset, the majority classes are targeted for optimal partitioning using the Particle Swarm Optimization technique;
- In the experiment, the Random Forest (RF), Support Vactor Machine (SVM), Artificial Neural Network (ANN), and Extreme Learning Machine (ELM) were trained and tested on the BGP traffic dataset, namely, BGP RIPE and BGP ROUTE Views;
- The results of the trained models were compared mutually, and it was determined that the OP-based ELM model provided the best results when different performance metrics were observed and experimentation was performed w.r.t. the accuracy, precision, recall, and F1-score, which acted as the proposed model to identify anomalies in BGP traffic;
- A comparison of the proposed model was also conducted with other recent state-of-the-art model approaches, and it was found to be the superior performing model.
2. Literature Review
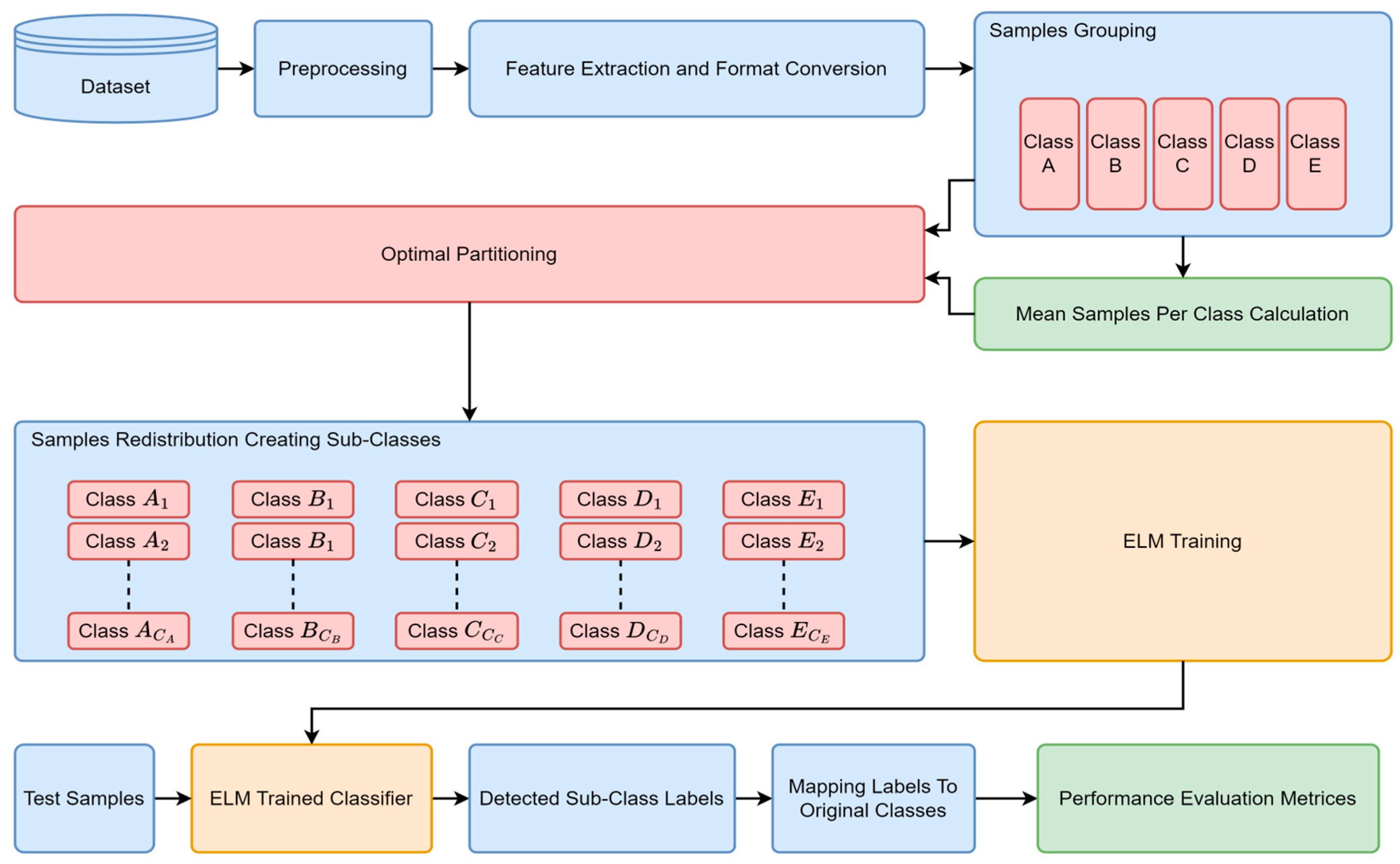
3. Proposed Approach
3.1. Optimal Partitioning (OP)
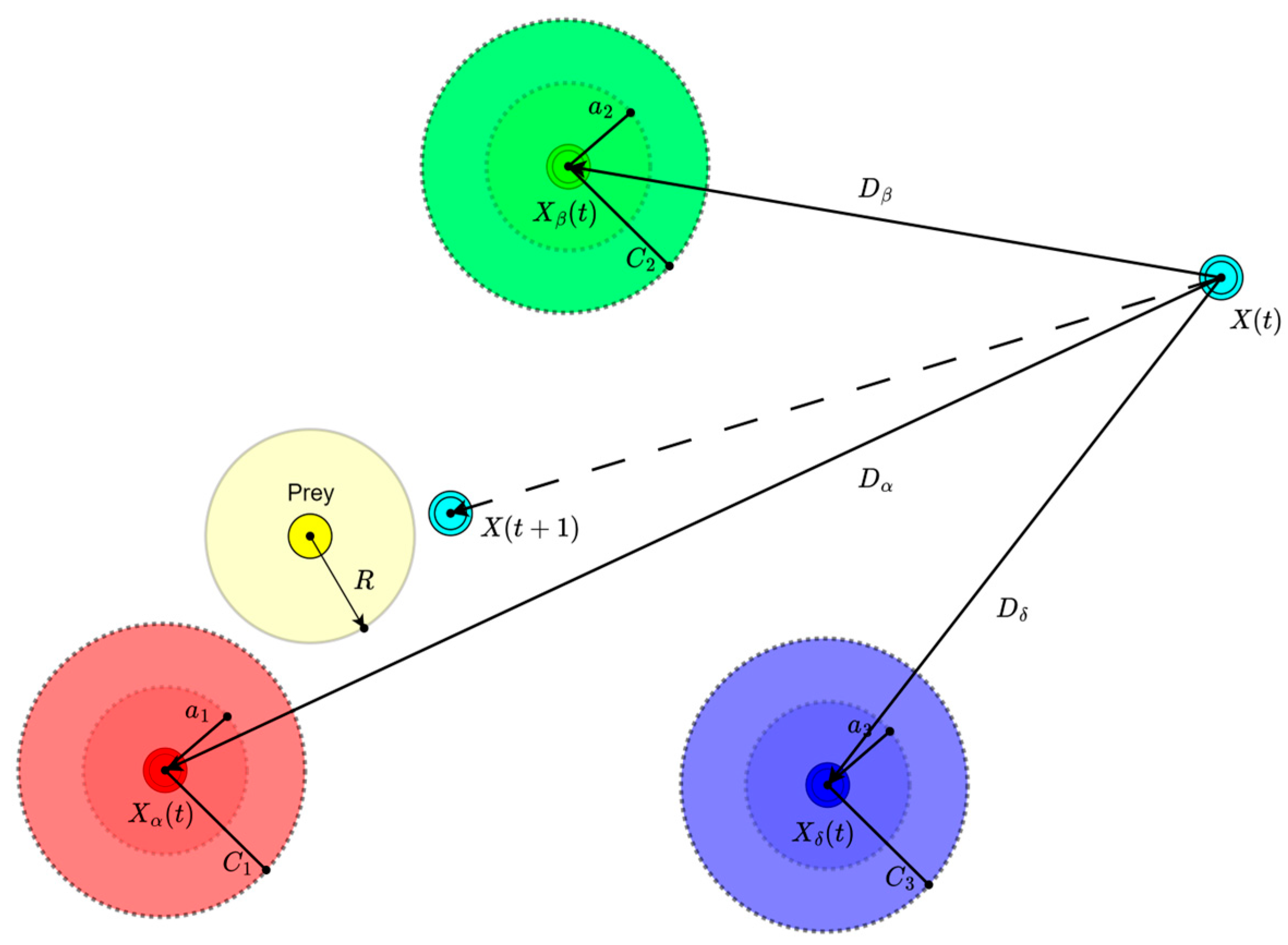
- Initialization: Generate an initial population of gray wolves (solutions). Each wolf’s position represents a potential set of centroids for the clusters.
- Fitness Evaluation: Calculate the fitness of each wolf using the Equation (2), the higher values indicate better solutions.
- Update Alpha (), Beta (), and Delta () Wolves: Identify the best three solutions based on their fitness, assigning them as the , , and wolves, representing the best (), second-best (), and third-best () solutions, respectively and are demonstrated in Figure 3.
- Hunting (Main Optimization Loop)
- Termination: repeat the optimization loop until the stopping criterion is met (e.g., maximum iterations () or minimal change in fitness);
- Result: The final positions of the alpha wolf represent the centroids of the clusters that optimally partition the data according to the given . The cluster assignments reflect the balance between minimizing the intra-class variance, maximizing the inter-class separability, and maintaining approximately equal cluster sizes, as influenced by the fitness function.
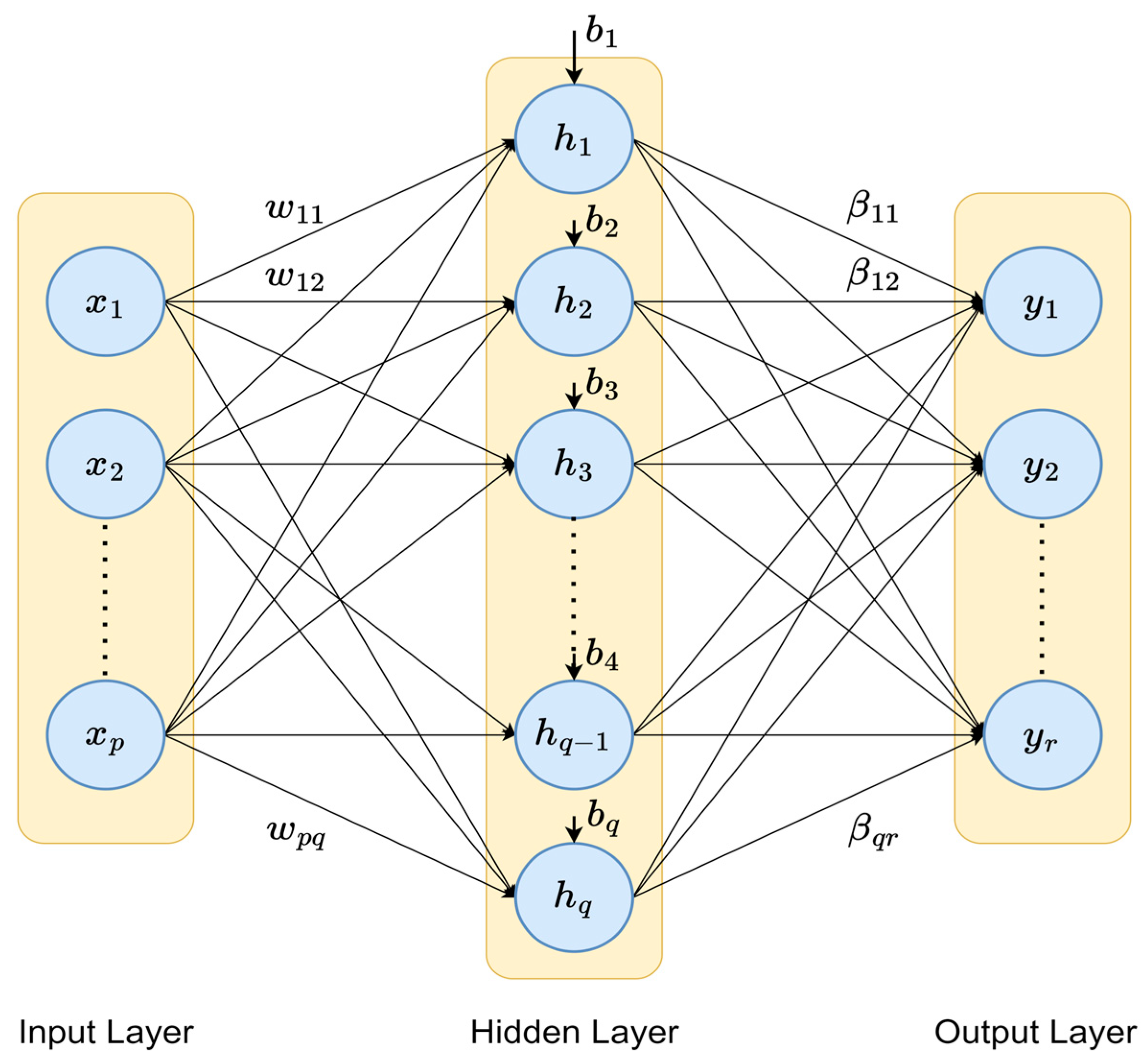
3.2. Extreme Learning Machine
3.3. ELM Functionality Explanation
3.4. Experimental Dataset Details
3.5. Feature Analysis
3.6. Proposed Methodology
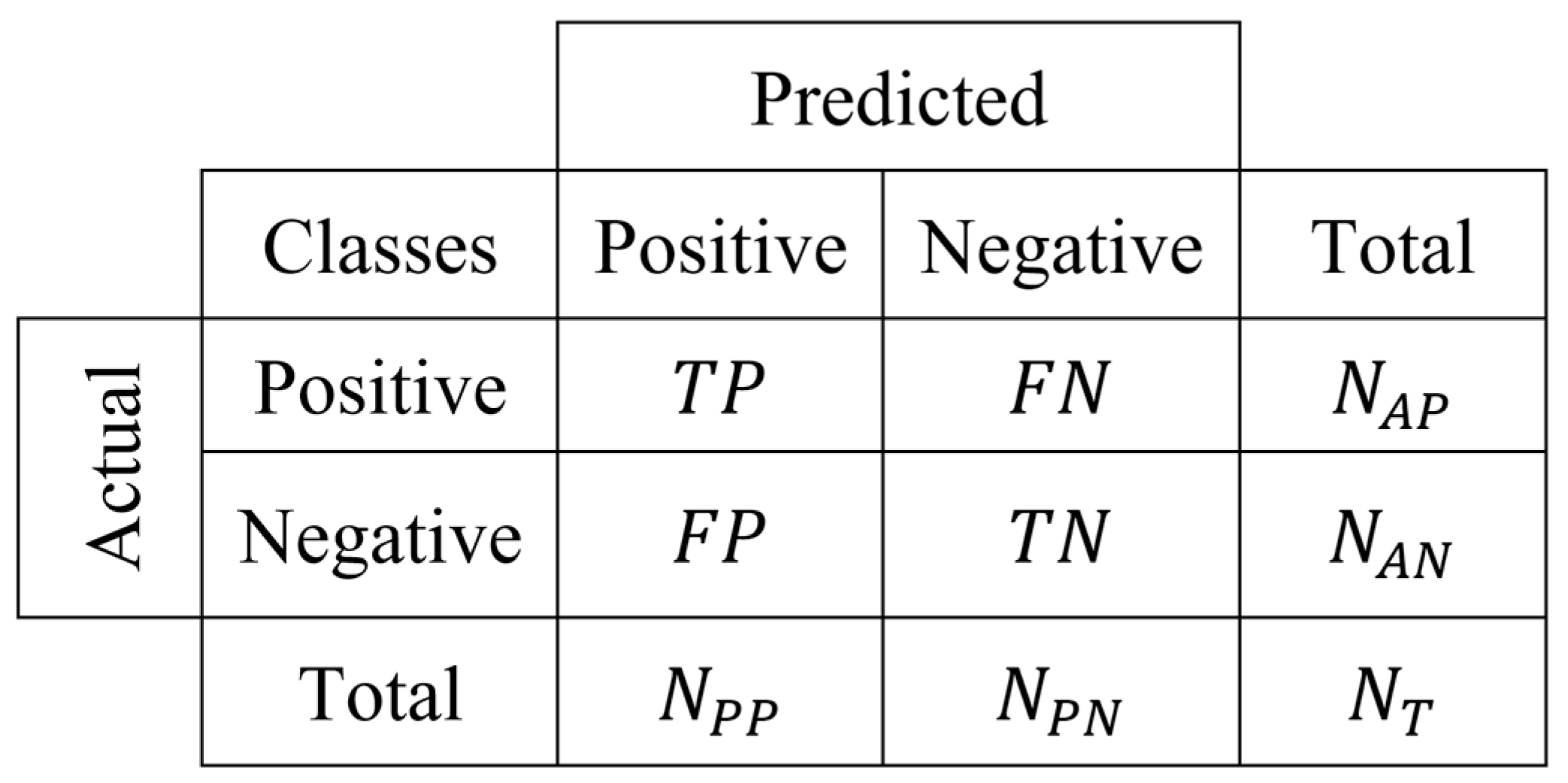
4. Performance Evaluation Metrics
5. Results Analysis
5.1. Overall Accuracy and Performance
5.2. Computational Efficiency Analysis
5.3. Comparison with Other Recent Approaches
5.4. Observations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Meaning |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| AP | Affinity Propagation |
| AS | Autonomous System |
| BSS | Between-Cluster Sum of Squares |
| BGP | Border Gateway Protocol |
| BCNET | British Columbia Network |
| DE | Differential Evolution |
| DDoS | Distributed Denial of Service |
| ELM | Extreme Learning Machine |
| EGP | Exterior Gateway Protocol |
| FN | False Negative |
| FP | False Positive |
| GWO | Gray Wolf Optimization |
| IGP | Interior Gateway Protocol |
| IoT | Internet of Things |
| ML | Machine Learning |
| NLRI | Network Layer Reachability Information |
| OP | Optimal Partitioning |
| OP-ELM | Optimal Partitioning Extreme Learning Machine |
| PSO | Particle Swarm Optimization |
| ReLU | Rectified Linear Unit |
| RF | Random Forest |
| RIPE | Réseaux IP Européens |
| SLFN | Single-Layer Feedforward Network |
| SMOTE | Synthetic Minority Oversampling Technique |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True Positive |
| W-ELM | Weighted Extreme Learning Machine |
| WOA | Whale Optimization Algorithm |
| WSS | Within-Cluster Sum of Squares |
References
- Gao, L.; Rexford, J. Stable Internet routing without global coordination. IEEEACM Trans. Netw. 2001, 9, 681–692. [Google Scholar] [CrossRef]
- Aceto, G.; Botta, A.; Marchetta, P.; Persico, V.; Pescapé, A. A comprehensive survey on internet outages. J. Netw. Comput. Appl. 2018, 113, 36–63. [Google Scholar] [CrossRef]
- Butler, K.; Farley, T.R.; McDaniel, P.; Rexford, J. A Survey of BGP Security Issues and Solutions. Proc. IEEE 2010, 98, 100–122. [Google Scholar] [CrossRef]
- Mitseva, A.; Panchenko, A.; Engel, T. The state of affairs in BGP security: A survey of attacks and defenses. Comput. Commun. 2018, 124, 45–60. [Google Scholar] [CrossRef]
- Bakkali, S.; Benaboud, H.; Ben Mamoun, M. Security problems in BGP: An overview. In Proceedings of the 2013 National Security Days (JNS3), Rabat, Morocco, 26–27 April 2013; Volume 2013, pp. 1–5. [Google Scholar]
- Verma, R.D.; Samaddar, S.G.; Samaddar, A.B. Securing BGP by Handling Dynamic Network Behavior and Unbalanced Datasets. Int. J. Comput. Netw. Commun. 2021, 13, 41–52. [Google Scholar] [CrossRef]
- Al-Rousan, N.M.; Trajković, L. Machine learning models for classification of BGP anomalies. In Proceedings of the 2012 IEEE 13th International Conference on High Performance Switching and Routing, Belgrade, Serbia, 24–27 June 2012; Volume 2012, pp. 103–108. [Google Scholar]
- Allahdadi, A.; Morla, R.; Prior, R. A Framework for BGP Abnormal Events Detection 2017. arXiv 2017, arXiv:1708.03453. [Google Scholar]
- Brzezinski, D.; Minku, L.L.; Pewinski, T.; Stefanowski, J.; Szumaczuk, A. The impact of data difficulty factors on classification of imbalanced and concept drifting data streams. Knowl. Inf. Syst. 2021, 63, 1429–1469. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Kumar, R.; Tripathi, S.; Agrawal, R. Handling dynamic network behavior and unbalanced datasets for WSN anomaly detection. J. Ambient. Intell. Humaniz. Comput. 2022, 14, 10039–10052. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- de Urbina Cazenave, I.O.; Köşlük, E.; Ganiz, M.C. An Anomaly Detection Framework for BGP. In Proceedings of the 2011 International Symposium on Innovations in Intelligent Systems and Applications, Istanbul, Turkey, 15–18 June 2011; Volume 2011, pp. 107–111. [Google Scholar]
- Moriano, P.; Hill, R.; Camp, L.J. Using bursty announcements for detecting BGP routing anomalies. Comput. Netw. 2021, 188, 107835. [Google Scholar] [CrossRef]
- Lutu, A.; Bagnulo, M.; Pelsser, C.; Maennel, O.; Cid-Sueiro, J. The BGP Visibility Toolkit: Detecting Anomalous Internet Routing Behavior. IEEEACM Trans. Netw. 2016, 24, 1237–1250. [Google Scholar] [CrossRef]
- Zhang, J.; Rexford, J.; Feigenbaum, J. Learning-based anomaly detection in BGP updates. In Proceedings of the 2005 ACM SIGCOMM Workshop on Mining Network Data, Philadelphia, PA, USA, 26 August 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 219–220. [Google Scholar]
- Zhang, K.; Yen, A.; Zhao, X.; Massey, D.; Wu, S.F.; Zhang, L. On Detection of Anomalous Routing Dynamics in BGP. In Proceedings of the Networking 2004, Athens, Greece, 9–14 May 2004; Mitrou, N., Kontovasilis, K., Rouskas, G.N., Iliadis, I., Merakos, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 259–270. [Google Scholar]
- Kruegel, C.; Mutz, D.; Robertson, W.; Valeur, F. Topology-Based Detection of Anomalous BGP Messages. In Proceedings of the Recent Advances in Intrusion Detection, Pittsburgh, PA, USA, 8–10 September 2003; Vigna, G., Kruegel, C., Jonsson, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 17–35. [Google Scholar]
- Bhagat, A.; Kshirsagar, N.; Khodke, P.; Dongre, K.; Ali, S. Penalty Parameter Selection for Hierarchical Data Stream Clustering. Procedia Comput. Sci. 2016, 79, 24–31. [Google Scholar] [CrossRef]
- Altamimi, M.; Albayrak, Z.; Çakmak, M.; Özalp, A.N. BGP Anomaly Detection Using Association Rule Mining Algorithm. Avrupa Bilim Teknol. Derg. 2022, 134–139. [Google Scholar] [CrossRef]
- Zhu, P.; Liu, X.; Yang, M.; Xu, M. Rule-Based Anomaly Detection of Inter-domain Routing System. In Proceedings of the Advanced Parallel Processing Technologies, Hong Kong, China, 27–28 October 2005; Cao, J., Nejdl, W., Xu, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 417–426. [Google Scholar]
- Zamini, M.; Hasheminejad, S.M.H. A comprehensive survey of anomaly detection in banking, wireless sensor networks, social networks, and healthcare. Intell. Decis. Technol. 2019, 13, 229–270. [Google Scholar] [CrossRef]
- Karimi, M.; Jahanshahi, A.; Mazloumi, A.; Sabzi, H.Z. Border Gateway Protocol Anomaly Detection Using Neural Network. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 6092–6094. [Google Scholar]
- Latif, H.; Paillissé, J.; Yang, J.; Cabellos-Aparicio, A.; Barlet-Ros, P. Unveiling the potential of graph neural networks for BGP anomaly detection. In Proceedings of the 1st International Workshop on Graph Neural Networking, Rome, Italy, 9 December 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 7–12. [Google Scholar]
- Xu, M.; Li, X. BGP Anomaly Detection Based on Automatic Feature Extraction by Neural Network. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 46–50. [Google Scholar]
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Kecman, V. Support Vector Machines—An Introduction. In Support Vector Machines: Theory and Applications; Wang, L., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–47. ISBN 978-3-540-32384-6. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; ISBN 978-0-387-77242-4. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Kumar, B.; Vyas, O.P.; Vyas, R. A comprehensive review on the variants of support vector machines. Mod. Phys. Lett. B 2019, 33, 1950303. [Google Scholar] [CrossRef]
- Singla, M.; Shukla, K.K. Robust statistics-based support vector machine and its variants: A survey. Neural Comput. Appl. 2020, 32, 11173–11194. [Google Scholar] [CrossRef]
- Karamizadeh, S.; Abdullah, S.M.; Halimi, M.; Shayan, J.; javad Rajabi, M. Advantage and drawback of support vector machine functionality. In Proceedings of the 2014 International Conference on Computer, Communications, and Control Technology (I4CT), Langkawi, Malaysia, 2–4 September 2014; pp. 63–65. [Google Scholar]
- Abdiansah, A.; Wardoyo, R. Time Complexity Analysis of Support Vector Machines (SVM) in LibSVM. Int. J. Comput. Appl. 2015, 128, 28–34. [Google Scholar] [CrossRef]
- Chapelle, O. Training a Support Vector Machine in the Primal. Neural Comput. 2007, 19, 1155–1178. [Google Scholar] [CrossRef]
- Wang, J.; Lu, S.; Wang, S.-H.; Zhang, Y.-D. A review on extreme learning machine. Multimed. Tools Appl. 2021, 81, 41611–41660. [Google Scholar] [CrossRef]
- Huang, G.-B.; Ding, X.; Zhou, H. Optimization method based extreme learning machine for classification. Neurocomputing 2010, 74, 155–163. [Google Scholar] [CrossRef]
- Li, M.-B.; Huang, G.-B.; Saratchandran, P.; Sundararajan, N. Channel Equalization Using Complex Extreme Learning Machine with RBF Kernels. In Proceedings of the Advances in Neural Networks—ISNN 2006, Chengdu, China, 28 May–1 June 2006; Wang, J., Yi, Z., Zurada, J.M., Lu, B.-L., Yin, H., Eds.; Springer: Berlin/Heidelberg, Germany; pp. 114–119. [Google Scholar]
- Müller, K.-R.; Mika, S.; Tsuda, K.; Schölkopf, K. An Introduction to Kernel-Based Learning Algorithms. In Handbook of Neural Network Signal Processing; CRC Press: Boca Raton, FL, USA, 2002; ISBN 978-1-315-22041-3. [Google Scholar]
- Rasamoelina, A.D.; Adjailia, F.; Sinčák, P. A Review of Activation Function for Artificial Neural Network. In Proceedings of the 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herl’any, Slovakia, 23–25 January 2020; pp. 281–286. [Google Scholar]
- Baksalary, O.M.; Trenkler, G. The Moore–Penrose inverse: A hundred years on a frontline of physics research. Eur. Phys. J. H 2021, 46, 9. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Gupta, A.; Tatbul, N.; Marcus, R.; Zhou, S.; Lee, I.; Gottschlich, J. Class-Weighted Evaluation Metrics for Imbalanced Data Classification. arXiv 2020, arXiv:2010.05995. [Google Scholar]
- Zhao, H.; Wang, Y.; Duan, J.; Huang, C.; Cao, D.; Tong, Y.; Zhang, Q. Multivariate Time-Series Anomaly Detection via Graph Attention Network. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020. [Google Scholar]
- Tayeh, T.; Aburakhia, S.; Myers, R.; Shami, A. An attention-based ConvLSTM autoencoder with dynamic thresholding for unsupervised anomaly detection in multivariate time series. Mach. Learn. Knowl. Extr. 2022, 4, 350–370. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Wang, J.; Pan, Z. Unsupervised deep anomaly detection for multi-sensor time-series signals. IEEE Trans. Knowl. Data Eng. 2021, 35, 2118–2132. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Date | Total Samples |
|---|---|---|---|
| Slammer | Anomaly | January 2003 | 7200 |
| Nimda | Anomaly | September 2001 | 8609 |
| Code Red I | Anomaly | July 2001 | 7200 |
| WannaCrypt | Anomaly | May 2017 | 11,520 |
| Moscow Blackout | Anomaly | May 2005 | 7200 |
| Normal-BCNET | Regular | -- | 1440 |
| Normal-RIPE | Regular | -- | 7196 |
| Anomaly Names | Class Labels | Dataset Class Instances |
|---|---|---|
| Normal | A | 2000 |
| Slammer | B | 400 |
| Nimda | C | 200 |
| Code Red I | D | 600 |
| WannaCrypt | E | 1000 |
| Moscow Blackout | F | 1000 |
| Feature | Definition | Type | Category |
|---|---|---|---|
| 1 | Number of announcements | Continuous | Volume |
| 2 | Number of withdrawals | Continuous | Volume |
| 3 | Number of announced NLRI prefixes | Continuous | Volume |
| 4 | Number of withdrawn NLRI prefixes | Continuous | Volume |
| 5 | Average AS-PATH length | Categorical | AS-path |
| 6 | Maximum AS-PATH length | Categorical | AS-path |
| 7 | Average unique AS-PATH length | Continuous | AS-path |
| 8 | Number of duplicate announcements | Continuous | Volume |
| 9 | Number of duplicate withdrawals | Continuous | Volume |
| 10 | Number of implicit withdrawals | Continuous | Volume |
| 11 | Average edit distance | Categorical | AS-path |
| 12 | Maximum edit distance | Categorical | AS-path |
| 13 | Inter-arrival time | Continuous | Volume |
| 14–24 | Maximum edit distance = , where | Binary | AS-path |
| 25–33 | Maximum AS_PATH length = , where | Binary | AS-path |
| 34 | Number of IGP packets | Continuous | Volume |
| 35 | Number of EGP packets | Continuous | Volume |
| 36 | Number of incomplete packets | Continuous | Volume |
| 37 | Packet size (B) | Continuous | Volume |
| Class Name | Accuracy (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forest | SVM | ANN | Weighted ELM | Proposed Method | |||||||
| -- | SMOTE | Tomek | -- | SMOTE | Tomek | -- | SMOTE | Tomek | |||
| A | 98.12 | 98.45 | 98.24 | 96.51 | 97.17 | 96.82 | 97.53 | 97.27 | 97.22 | 98.11 | 98.81 |
| B | 89.85 | 91.18 | 90.55 | 87.07 | 88.21 | 87.51 | 89.22 | 88.71 | 88.51 | 90.14 | 91.98 |
| C | 84.91 | 85.93 | 85.56 | 82.23 | 83.26 | 82.58 | 84.03 | 83.52 | 83.06 | 85.21 | 87.75 |
| D | 92.03 | 93.19 | 92.51 | 88.95 | 89.97 | 89.52 | 91.51 | 91.09 | 90.51 | 93.18 | 94.02 |
| E | 94.85 | 95.91 | 95.57 | 92.18 | 93.06 | 92.51 | 94.01 | 93.56 | 93.21 | 94.52 | 96.12 |
| F | 93.48 | 94.35 | 93.88 | 91.22 | 92.24 | 91.57 | 93.48 | 93.10 | 92.51 | 93.51 | 95.67 |
| Class Name | Precision (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forest | SVM | ANN | Weighted ELM | Proposed Method | |||||||
| -- | SMOTE | Tomek | -- | SMOTE | Tomek | -- | SMOTE | Tomek | |||
| A | 97.02 | 97.56 | 97.29 | 96.10 | 96.53 | 96.48 | 96.12 | 96.51 | 96.27 | 97.77 | 98.27 |
| B | 88.12 | 89.10 | 88.58 | 85.08 | 86.18 | 85.39 | 87.23 | 88.04 | 87.54 | 89.48 | 90.81 |
| C | 83.91 | 85.07 | 84.64 | 80.78 | 82.23 | 81.42 | 82.43 | 83.93 | 82.62 | 85.56 | 87.04 |
| D | 91.02 | 91.89 | 91.56 | 88.05 | 89.31 | 88.47 | 90.02 | 91.74 | 90.35 | 92.45 | 93.14 |
| E | 94.22 | 94.35 | 94.51 | 91.07 | 91.76 | 91.51 | 92.30 | 93.45 | 92.60 | 93.88 | 95.22 |
| F | 91.78 | 93.12 | 92.54 | 88.78 | 90.05 | 89.56 | 91.02 | 92.76 | 91.10 | 93.41 | 94.10 |
| Class Name | Recall (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forest | SVM | ANN | Weighted ELM | Proposed Method | |||||||
| -- | SMOTE | Tomek | -- | SMOTE | Tomek | -- | SMOTE | Tomek | |||
| A | 97.96 | 98.52 | 98.28 | 96.61 | 96.59 | 96.30 | 97.00 | 97.51 | 97.25 | 91.98 | 98.62 |
| B | 85.07 | 87.85 | 85.51 | 83.51 | 84.07 | 83.50 | 84.00 | 85.45 | 84.53 | 87.57 | 89.34 |
| C | 80.20 | 81.26 | 80.55 | 78.18 | 79.12 | 78.50 | 79.00 | 80.71 | 79.53 | 82.53 | 85.65 |
| D | 87.87 | 89.17 | 88.48 | 86.62 | 87.65 | 86.50 | 87.00 | 88.75 | 87.57 | 90.05 | 91.62 |
| E | 93.11 | 93.22 | 93.62 | 90.56 | 91.66 | 90.50 | 91.00 | 92.67 | 91.53 | 93.57 | 94.11 |
| F | 90.75 | 92.03 | 91.50 | 88.15 | 89.83 | 88.50 | 90.00 | 91.81 | 90.51 | 92.15 | 93.43 |
| Class Name | F1-Score (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forest | SVM | ANN | Weighted ELM | Proposed Method | |||||||
| -- | SMOTE | Tomek | -- | SMOTE | Tomek | -- | SMOTE | Tomek | |||
| A | 97.48 | 98.03 | 97.78 | 96.35 | 96.55 | 96.38 | 96.55 | 97.00 | 96.75 | 94.78 | 98.44 |
| B | 86.56 | 88.47 | 87.01 | 84.28 | 85.11 | 84.43 | 85.58 | 86.72 | 86.00 | 88.51 | 90.06 |
| C | 82.01 | 83.12 | 82.54 | 79.45 | 80.64 | 79.93 | 80.67 | 82.28 | 81.04 | 84.01 | 86.33 |
| D | 89.41 | 90.50 | 89.99 | 87.32 | 88.47 | 87.47 | 88.48 | 90.22 | 88.93 | 91.23 | 92.37 |
| E | 93.66 | 93.78 | 94.06 | 90.81 | 91.70 | 91.00 | 91.64 | 93.05 | 92.06 | 93.72 | 94.66 |
| F | 91.26 | 92.57 | 92.01 | 88.46 | 89.93 | 89.02 | 90.50 | 92.28 | 90.80 | 92.77 | 93.76 |
| Measure | Classifier | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forest | SVM | ANN | Weighted ELM | Proposed Method | |||||||
| -- | SMOTE | Tomek | -- | SMOTE | Tomek | -- | SMOTE | Tomek | |||
| Accuracy (%) | 92.52 | 92.67 | 92.81 | 89.32 | 89.71 | 89.66 | 91.22 | 92.05 | 91.51 | 91.56 | 94.13 |
| Precision (%) | 91.03 | 91.96 | 91.25 | 87.04 | 88.13 | 87.51 | 90.71 | 91.15 | 90.27 | 90.15 | 93.22 |
| Recall (%) | 88.12 | 90.01 | 89.10 | 84.87 | 86.08 | 85.40 | 88.34 | 89.45 | 88.41 | 88.55 | 90.87 |
| F1-Score (%) | 89.55 | 90.97 | 90.16 | 85.94 | 87.09 | 86.44 | 89.50 | 90.29 | 89.33 | 89.34 | 92.03 |
| Measure | Classifier | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forest | SVM | ANN | Weighted ELM | Proposed Method | |||||||
| -- | SMOTE | Tomek | -- | SMOTE | Tomek | -- | SMOTE | Tomek | |||
| Accuracy (%) | 92.47 | 93.67 | 92.86 | 89.37 | 90.07 | 89.62 | 91.21 | 91.89 | 91.85 | 90.52 | 94.52 |
| Precision (%) | 93.52 | 93.91 | 93.59 | 89.07 | 90.21 | 89.15 | 91.15 | 92.05 | 91.75 | 91.43 | 95.18 |
| Recall (%) | 92.17 | 93.08 | 92.45 | 88.10 | 88.74 | 88.45 | 89.28 | 89.78 | 89.41 | 90.84 | 94.48 |
| F1-Score (%) | 92.06 | 93.18 | 92.35 | 87.92 | 88.41 | 88.53 | 90.51 | 90.98 | 90.45 | 91.56 | 94.67 |
| Classifier | Training Time (in sec.) | Detection Time (in sec.) |
|---|---|---|
| Random Forest | 4.36 | 0.0271 |
| RF + SMOTE | 5.12 | 0.0284 |
| RF + Tomek | 4.95 | 0.0279 |
| SVM | 40.52 | 0.1216 |
| SVM + SMOTE | 45.78 | 0.1302 |
| SVM + Tomek | 42.15 | 0.1258 |
| ANN | 24.81 | 0.0654 |
| ANN + SMOTE | 28.12 | 0.072 |
| ANN + Tomek | 26.75 | 0.0695 |
| W-ELM | 3.34 | 0.0057 |
| Proposed Method | 10.27 | 0.0055 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verma, R.D.; Keserwani, P.K.; Jain, V.K.; Govil, M.C.; Maduranga, M.W.P.; Tilwari, V. Optimal Partitioning of Unbalanced Datasets for BGP Anomaly Detection. Telecom 2025, 6, 25. https://doi.org/10.3390/telecom6020025
Verma RD, Keserwani PK, Jain VK, Govil MC, Maduranga MWP, Tilwari V. Optimal Partitioning of Unbalanced Datasets for BGP Anomaly Detection. Telecom. 2025; 6(2):25. https://doi.org/10.3390/telecom6020025
Chicago/Turabian StyleVerma, Rahul Deo, Pankaj Kumar Keserwani, Vinesh Kumar Jain, Mahesh Chandra Govil, M. W. P. Maduranga, and Valmik Tilwari. 2025. "Optimal Partitioning of Unbalanced Datasets for BGP Anomaly Detection" Telecom 6, no. 2: 25. https://doi.org/10.3390/telecom6020025
APA StyleVerma, R. D., Keserwani, P. K., Jain, V. K., Govil, M. C., Maduranga, M. W. P., & Tilwari, V. (2025). Optimal Partitioning of Unbalanced Datasets for BGP Anomaly Detection. Telecom, 6(2), 25. https://doi.org/10.3390/telecom6020025