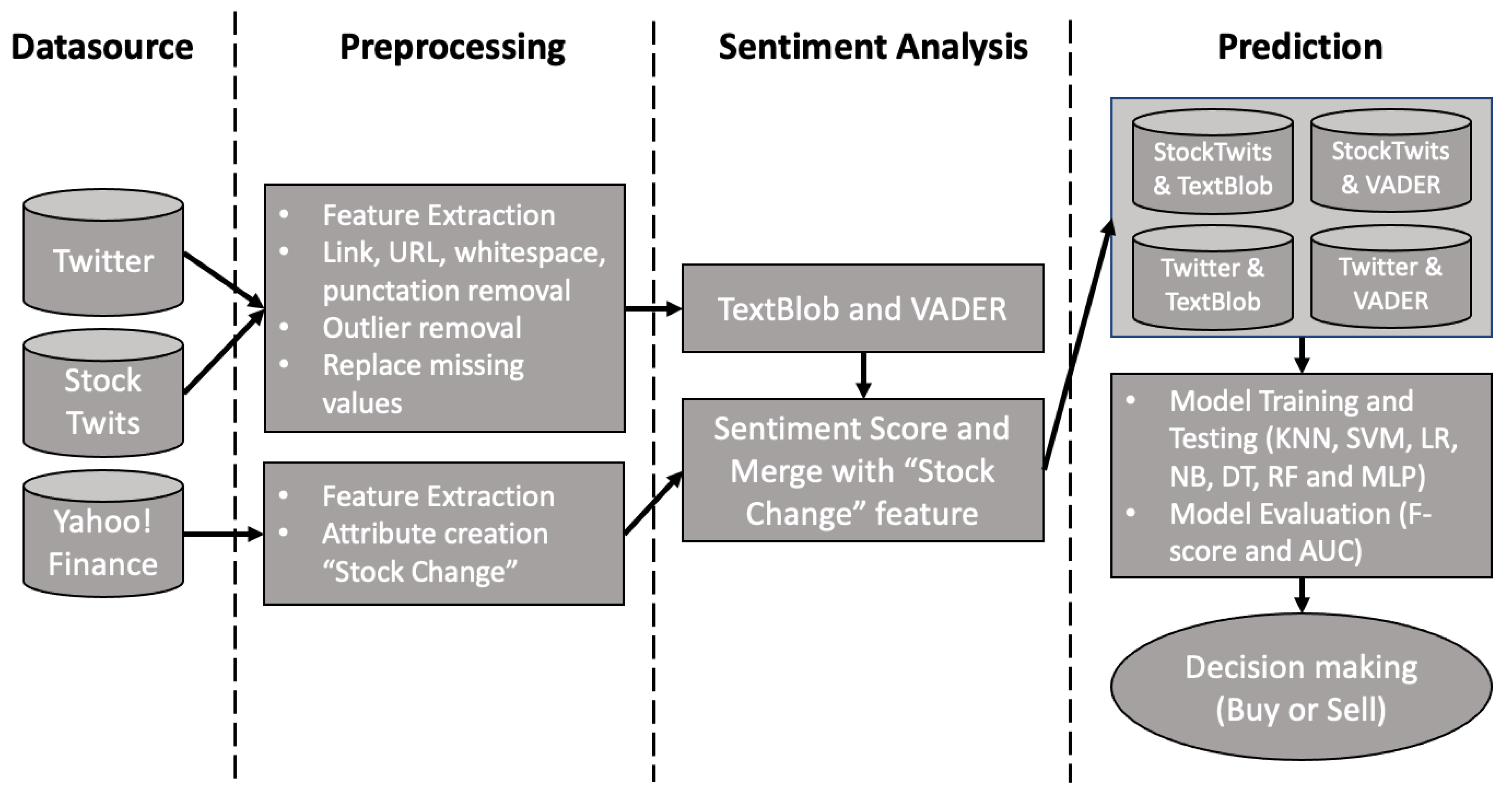
This section reviews state-of-the-art efforts to identify stock-market movements using SA on microblogging data, as well as the classification methods and performance assessment measures utilized in this work.
2.1. Sentiment Analysis Applications
SA on Social Media (SM) data from various SM platforms and types [
7] has played a vital role in prediction in a variety of sectors (e.g., healthcare, financial etc.). It is the process of determining whether ideas conveyed in texts are positive or negative to the topic of discussion. Some of its advantages include analytics [
8], which may help in the advancement of marketing plans, enhancement of customer service, growth of sales income, identification of unwanted rumors for risk mitigation, and so on [
9]. Here, we will demonstrate several such prominent studies, with an emphasis on SMP utilizing data from Twitter or StockTwits.
SVM and NB algorithms were utilized to analyze public sentiment and its connection to stock market prices for the 16 most popular IT firms, such as Microsoft, Amazon, Apple, Blackberry, and others. They achieved 80.6% accuracy with NB and 79.3% accuracy with SVM on predicting sentiment utilizing seven-fold cross-validation. Furthermore, in the presence of noise in data, the prediction error for all of the tech businesses was determined to be less than 10%. Overall, the average prediction error in all cases was 1.67%, indicating an excellent performance [
10].
The association between a company’s stock-market movements and the emotion of tweet messages was investigated using SA and ML. Tweets, as well as stock opening and closing prices, were retrieved for Microsoft from the Yahoo Finance website between 31 August 2015 and 25 August 2016. Models were created with 69.01% and 71.82% accuracy using the LR and LibSVM methods, respectively. Accuracy with a big dataset was greater, and it was identified that there was a connection between stock-market movements and twitter public sentiment [
11].
The relationship between tweets and Dow Jones Industrial Average (DJIA) values was investigated by collecting Twitter data between June and December of 2009. A total of 476 million tweets were acquired from almost 17 million individuals. The timestamp and tweet text were chosen as features. The DJIA values were obtained from Yahoo Finance spanning the months June to December of 2009. The open, close, high, and low values for a specific day were chosen as features. The stock values were preprocessed by substituting missing data and calculating the average for DJIA on a particular day and the following one. In addition, instances when the data were inconsistent and making predictions was more challenging were omitted. Tweets were divided into four categories: calm, happy, alert, and kind. They used four ML algorithms to train and test the model after examining the causality relationship between both the emotions of the previous three days and the stock prices of the current day. These algorithms included Linear/Logistic Regression, SVM and Self Organizing Fuzzy (SOF) Neural Networks (NN). Six combinations were tested, using the emotion scores from the previous three days to rule out the possibility of other emotional factors being dependent on DJIA. With 75.56% accuracy, SOF NN achieved the best performance combining happy, calm, and DJIA. It was also discovered that adding any additional emotional type reduced accuracy [
12].
The relationship between Saudi tweets and the Saudi stock index was also investigated. Mubasher’s API, which is a stock analysis software, was utilized to obtain tweets. A total of 3335 tweets were retrieved for 53 days ranging from 17 March 2015 to 10 May 2015, as well as the TASI index’s closing prices. SA was carried out, utilizing ML techniques such as NB, SVM and KNN. SVM accuracy was 96.6%, while KNN accuracy was 96.45%. The results showed that as negative sentiment increased, positive sentiment and TASI index decreased, indicating a coherent correlation between sentiment and TASI index [
13].
An Apple’s stock forecast was performed, exploiting a mix of StockTwits and financial data retrieved between 2010 and 2017. SVM was used to estimate public opinion and whether or not a person would purchase or sell a stock. Three attributes were chosen for the model: date, stock price choices, and sentiment. The accuracy of the training and test models was 75.22% and 76.68%, respectively. The authors claim that the findings may be improved by expanding the volume of the data collection [
14].
The relationship between StockTwits emotion and stock price fluctuations was investigated for five businesses, including Microsoft, Apple, General Electric, Target, and Amazon. Stock market and StockTwits data were gathered from 1 January 2019 to 30 September 2019. SA was conducted by utilizing three classifiers (LR, NB and SVM) and five featurization algorithms (bigram, LSA, trigram, bag of words and TF-IDF). This implementation was created to anticipate stock price changes for a day using both financial data and collected feelings from the preceding five days. According to the performance evaluation, accuracy varied from 62.3% to 65.6%, with Apple and Amazon exhibiting the greatest results [
15].
Another study focused on the high stock market capitalization and a distinctive SM ecosystem to investigate the link between stock price movements and SM sentiment in China [
16]. Collected data varied in terms of activity, post length, and association with stock market performance. Stock market chatroom users tended to write more but shorter blogs. Trading hours and volume were far more closely linked to activity. Multiple ML models were incorporated to identify post sentiment in chatrooms, and produced results comparable to the current state of the art. Because of the substantial connection and Granger causality between chatroom post sentiment and stock price movement, post sentiment may be utilized to enhance stock price prediction over only analyzing historical trade data. Furthermore, a trading strategy was designed based on the prediction of trading indicators. This buy-and-hold strategy was tested for seven months and yielded a 19.54% total return, versus a loss of −25.26%.
Authors in [
17] consider three distinct equities’ closing prices and daily returns to examine how SM data may predict Tehran Stock Exchange (TSE) factors. Three months of StockTwits were gathered. A lexicon-based and learning-based strategy was proposed to extract data from online discussions. Additionally, a custom sentiment lexicon was created, since existing Persian lexicons are not suitable for SA. Novel predictor models utilizing multi-regression analysis were proposed after creating and computing daily sentiment indices based on comments. The number of comments and the users’ trustworthiness were also considered in the analysis. Findings show that the predictability of TSE equities varies by their features. For estimating the daily return, it is shown that both comment volume and mood may be beneficial, and the three stocks’ trust coefficients behave differently.
Stock price prediction is a topic with both potential and obstacles. There are numerous recent stock price prediction systems, yet their accuracy is still far from sufficient. The authors of [
18] propose S_I_LSTM, a stock price prediction approach that includes numerous data sources as well as investor sentiment. First, data from different Internet sources are preprocessed. Non-traditional data sources such as stock postings and financial news are also included. Then, for non-traditional data, a Convolutional Neural Network (CNN) SA approach is applied to generate the investor sentiment index. As a last step, a Long Short-Term Memory (LSTM) network is utilized to anticipate the Shanghai A-share market. It incorporates sentiment indexes, technical indicators, and historical transaction data. With a Mean Absolute Error (MAE) value of 2.38, this approach outperforms some existing methods when compared to actual datasets from five listed businesses.
Another research study suggests a SMP system based on financial microblog sentiment from Sina Weibo [
19]. SA was performed on microblogs to anticipate stock market movements using historical data from the Shanghai Composite Index (SH000001). The system contained three modules: Microblog Filter (MF), Sentiment Analysis (SA), and Stock Prediction (SP). Financial microblog data were obtained by incorporating Latent Dirichlet Allocation (LDA). The SA module first builds a financial vocabulary, then obtains sentiment from the MF module. For predicting SH000001 price movements, the SP module presents a user-group model that adjusts the relevance of various people and blends it with previous stock data. This approach was proven to be successful, since it was tested on 6.1 million microblogs.
SA on microblogs has recently become a prominent business analytics technique investigating how this sentiment can affect SMP. In [
20], vector autoregression was performed on a data collection of four years. The dataset contained 18 million microblog messages at a daily and hourly frequency. The findings revealed that microblog sentiment affects stock returns in a statistically and economically meaningful way. Market fluctuation influenced microblog sentiment and stock returns affected negative sentiment more than positive sentiment.
Another study presented a microblogging data model that estimates stock market returns, volatility, and trade volume [
21]. Indicators from microblogs (a large Twitter dataset) and survey indices (AAII and II, USMC and Sentix) were used to aggregate these indicators in daily resolution. A Kalman Filter (KF) was used to merge microblog and survey sources. Findings showed that Twitter sentiment and tweeting volume were useful for projecting S&P 500 returns. Additionally, Twitter and KF sentiment indicators helped forecast survey sentiment indicators. Thus, it is concluded that microblogging data may be used to anticipate stock market activity and provide a viable alternative to traditional survey solutions.
Time-series analysis is a prominent tool for predicting stock prices. However, relying solely on stock index series results in poor forecasting performance. As a supplement, SA on online textual data of the stock market may provide a lot of relevant information, which can act as an extra indicator. A novel technique is proposed for integrating such indicators and stock index time-series [
22]. A text processing approach was suggested to produce a weighted sentiment time-series. The data were crawled from financial micro-blogs from prominent Chinese websites. Each microblog was segmented and preprocessed, and the sentiment values were determined on a daily basis. The proposed time-series model with weighted sentiment series was validated by predicting the future value of the Shanghai Composite Index (SSECI).
The authors of [
23] investigated a possible association between the Chinese stock market and Chinese microblogs. At first, C-POMS (Chinese Profile of Mood States) was proposed for SA on microblog data. Then, the Granger causality test validated the existence of association between C-POMS and stock prices. Utilizing different prediction models for SMP showed that Support Vector Machine (SVM) outperforms Probabilistic Neural Networks (PNN) in terms of accuracy. Adding a dimension of C-POMS to the input data improved accuracy to 66.66%. Utilizing two dimensions to the input data resulted in 71.42% accuracy, which is nearly 20% greater than just using historical data.
2.2. Classification Algorithms
Classification algorithms are predictive computations that recognize, comprehend, and categorize data [
24,
25]. A list of such methods utilized in this work is compiled here.
K-nearest Neighbors (KNN) is a lazy and non-parametric algorithm. It computes the distance employing the most popular distance function, the Euclidean distance
d, which determines the difference or similarity (or else the shortest distance) between two instances/points
and
, according to (
1).
For a particular value of
K, the method will determine the K-Nearest Neighbors of the data point and then assign the class to the data point based on the class with the most data points among the K-Neighbors [
26]. Following the calculation of the distance, the input
x is allocated to the class with the highest probability according to (
2).
Support Vector Machine (SVM) is a classification method that solves binary problems by searching for an optimal hyperplane in high-dimensional space, isolating the points with the greatest margin. If two categories of points are differentiated, then there is a hyperplane that splits them. The purpose of this classification is to calculate a decent separating hyperplane between two outcomes. This is achieved by locating the hyperplane that optimizes the margin in between categories or classes [
27]. In more detail, given training vectors
,
i = 1, …,
n, in two classes, and a vector
, the main goal is to find
and
such that the prediction given by
is correct for most of the samples. The SVM solves the problem (
3):
Therefore, the aim is to minimize , while applying a penalty when a sample is not correctly classified. Preferably, the value would be ≥1 for all of the samples indicating a perfect prediction. Nonetheless, problems are not always perfectly separable with a hyperplane allowing some samples to be at a distance from their ideal margin boundaries.
Logistic Regression (LR) is classification technique estimating the likelihood that an observation belongs to one of two classes (1 or 0). LR employs a complicated function (sigmoid), which transfers predicted values to their corresponding distributions of likelihoods. The logistic function is a sigmoid function given by (
4) and pushes the values from (−n, n) to (0, 1) [
28].
Naive Bayes (NB) is a classification technique that may be used for binary and multi-class classification. NB techniques are a type of supervised learning algorithms that use Bayes’ theorem with the ‘naive’ assumption of conditional independence between every pair of features given a class variable
y and a dependent feature vector from
to
, as stated in (
5). When compared to numerical variables, NB performs well with categorical input data. It is helpful for anticipating data and creating predictions based on past findings [
29].
Decision Tree (DT) is a classification method that uses decision rules to predict the class of the target variable. For the purpose of creating a tree, the ‘divide and conquer’ strategy can be used. The parameter utilized for the root node is chosen because it has a high
p-value, and then the tree is partitioned into sub trees. The sub trees are further divided, employing the same technique until they get to the leaf node. Decision rules can be derived only after the tree has been created [
30]. In more detail, given some training vectors
,
i = 1, …,
l and a label vector
, a decision tree recursively partitions the feature space in a way that the samples with the same labels or similar target values belong to the same group.
Let the data at node
m be represented by
with
samples. For each candidate split
that consists of a feature
j and threshold
, partition the data into
and
subsets (
6):
The quality of a candidate split of node
m is then calculated, utilizing an impurity function
for classification problems (
7).
Then, select the respected parameters that minimize the impurity (
8):
Finally, recurse for subsets and until the point that the maximum depth allowed, or .
Random Forest (RF) is an ensemble learning approach comprising numerous arbitrary generated DTs. Random Forest seeks the greatest feature from an arbitrary feature subset, with the goal of using it as a criterion for dividing the nodes. RF solves the problem of over-fitting and delivers higher accuracy predictions than regular DTs [
31].
The Multilayer Perceptron (MLP) is a deep artificial NN and supervised learning approach. MLP is made up of numerous layers of input nodes connected by a directed graph that connects the input and output layers. The signal is fed into the input layer, and the prediction is made by the output layer. The purpose is to estimate the best relationship between the input and output layers [
32]. Given a set of training examples
where
and
, a one-hidden layer one-hidden neuron MLP learns the function
where
and
are model parameters.
represent the weights of the input layer and hidden layer, respectively, while
show the bias added to the hidden layer and the output layer, respectively.
is the activation function, set by default as the hyperbolic tan according to (
9).
For binary classification, passes through the logistic function to retrieve output values between zero and one. A threshold is set to 0.5, assigning samples of outputs larger or equal 0.5 to the positive class, and the remainder to the negative class.
The MLP loss function for classification is the Average Cross-Entropy, which in binary case is calculated according to (
10).
In a gradient descent, the gradient
of the loss concerning the weights is calculated and subtracted from
W according to (
11), where
k is the iteration step and
stands as the learning rate with a greater value from zero. The algorithm terminates when the maximum number of iterations is reached, or when the gain in loss is less than a particular, very small threshold.






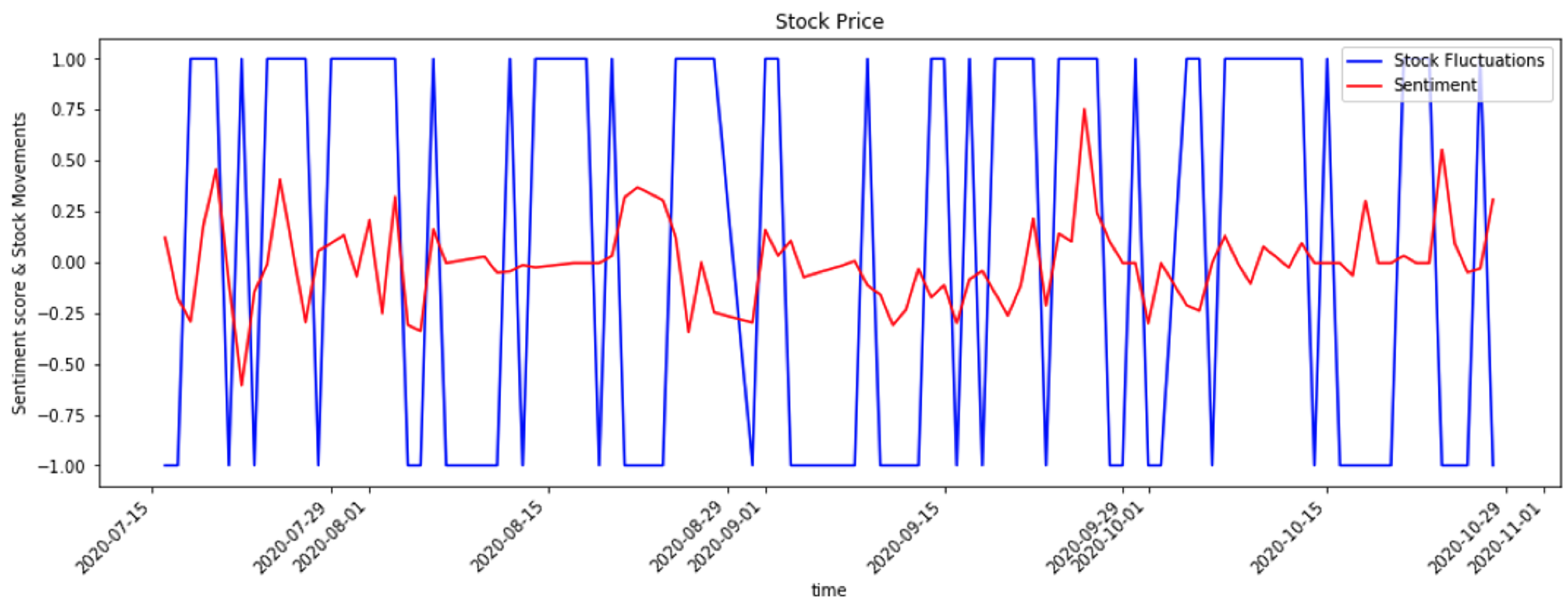
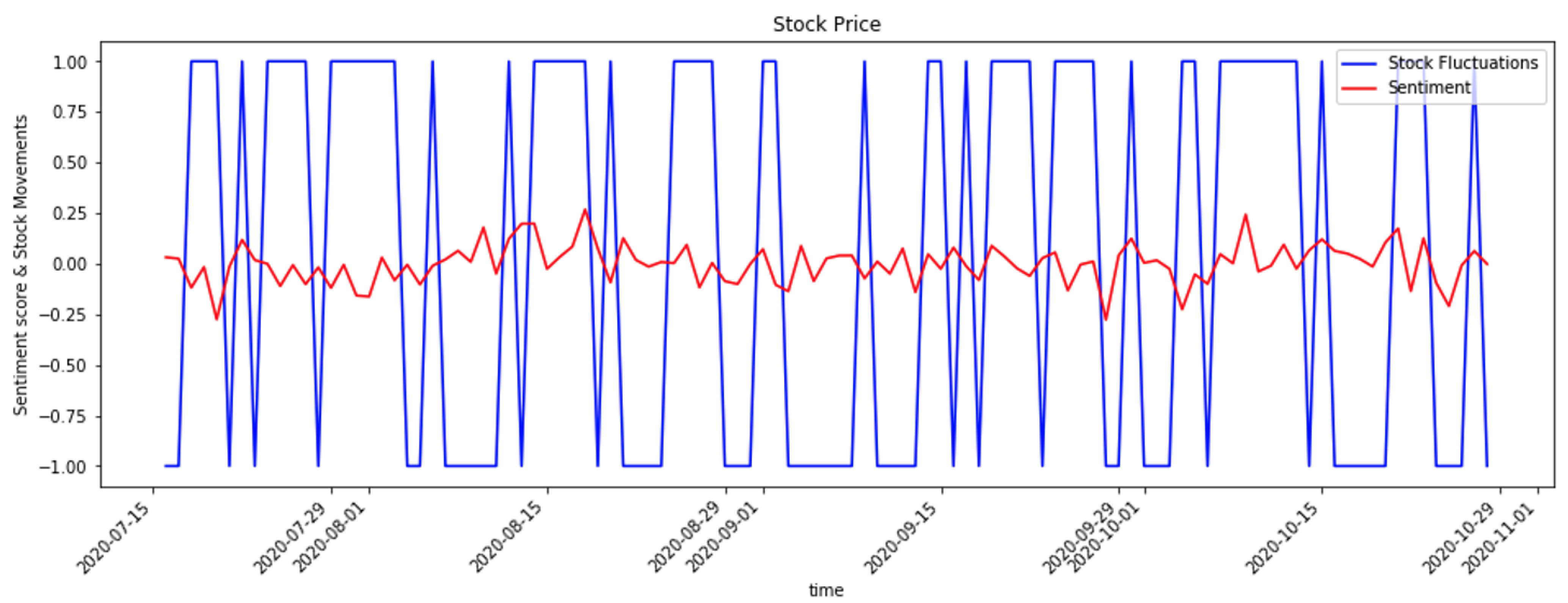
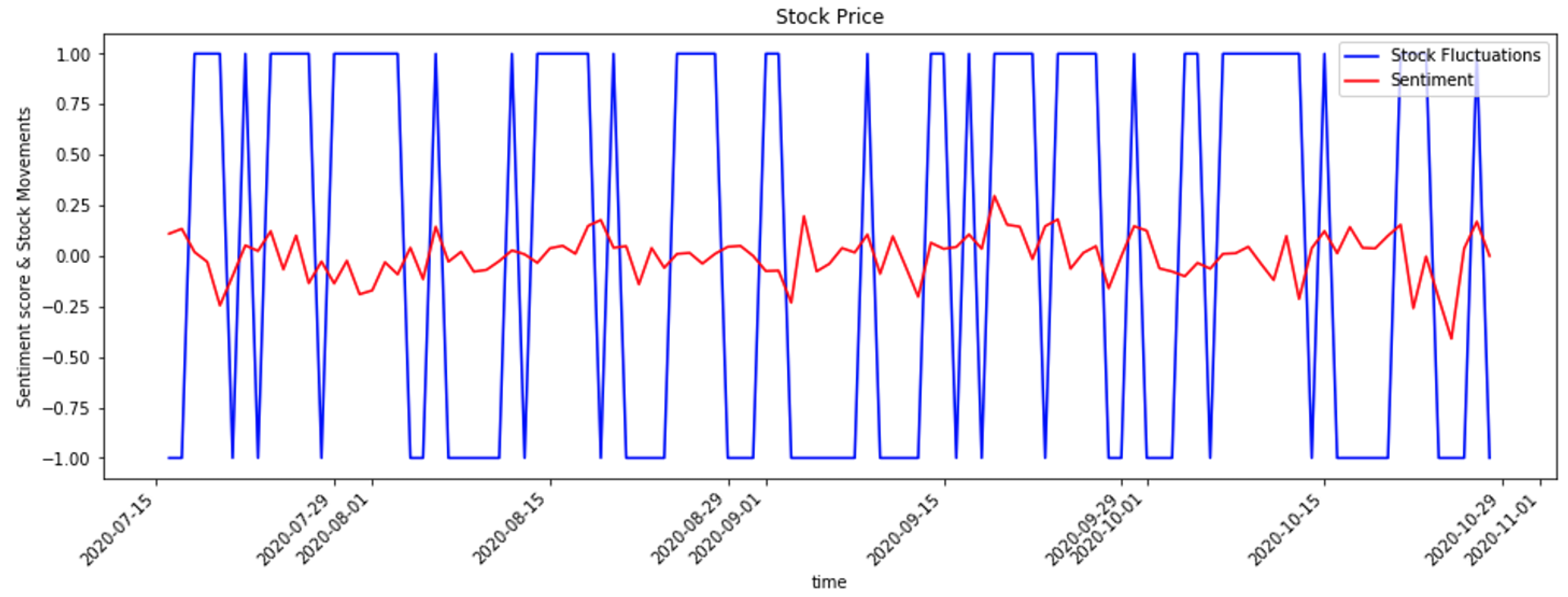


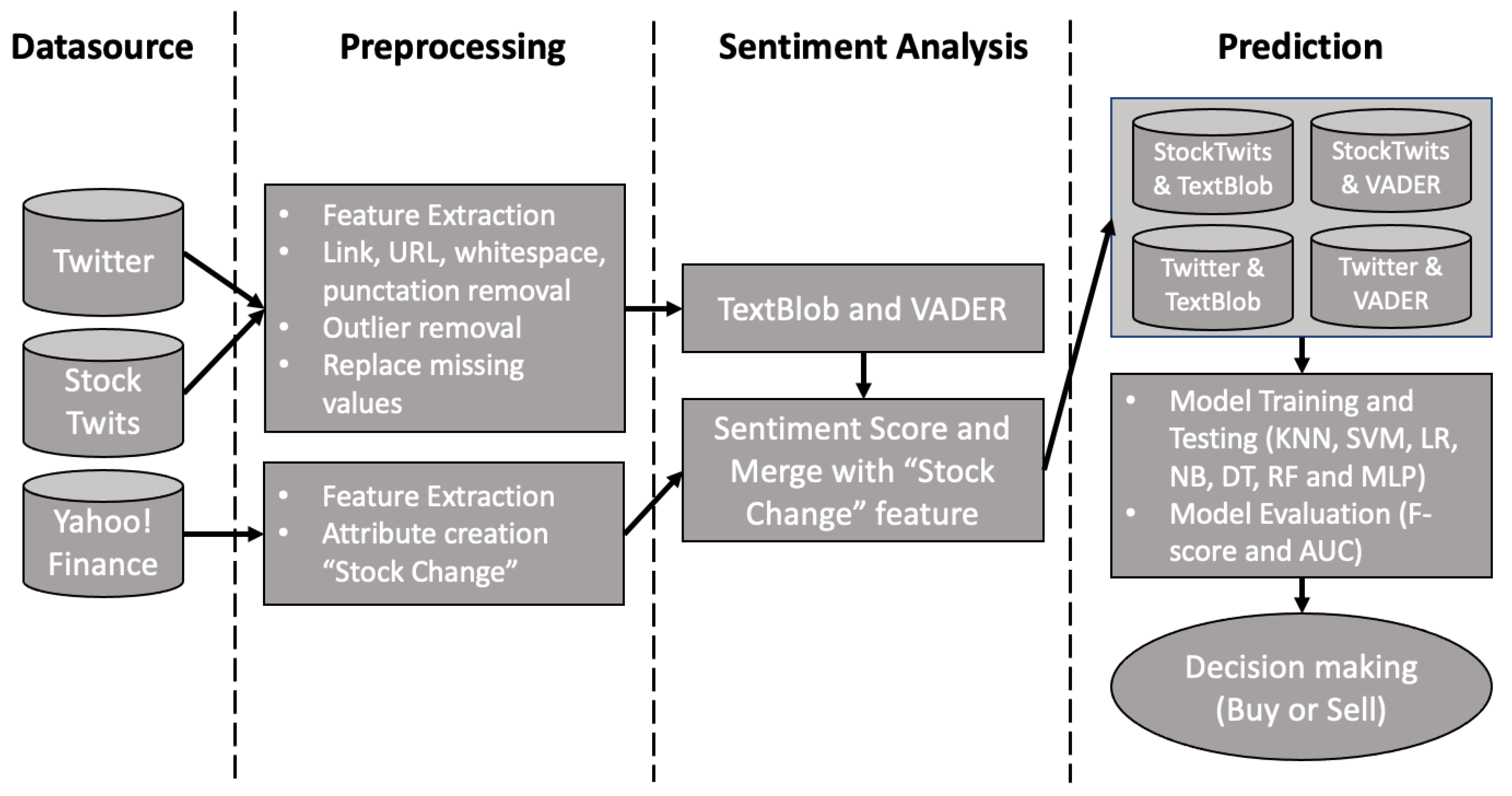{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}