1. Introduction
Creating large archives or repositories is becoming easier with the availability of open data and tools to manage them. Sometimes it can be useful to integrate different data into the same repository. Textual content should be enriched with semantic tags, either provided by catalogers or extracted automatically, to be effectively usable. To achieve an efficient and effective use of these annotations (in this paper, tags, keywords, and textual annotations are intended as synonyms and therefore used interchangeably) in information retrieval, sentiment analysis, or recommendation systems, they must be general enough to represent many items, but not too many. They should be specific enough to represent some items, but not too few. Methods, models and tools are required for their cleaning, harmonization and categorization, in other words, to optimize their use. The real challenge to face, then, concerns the quality of the data and the users’ satisfaction in being able to respond to their need for information.
This paper focuses on models and tools to improve the quality of data, based on natural language processing with machine learning and deep learning approaches. The main problems with keywords are:
The use of different terms to express (more or less) the same concept, or spelling variants;
The presence of tags expressed in different languages;
The extreme specialization of the terms used;
The lack of context;
Sometimes outright misspellings.
The first two issues are frequent when integrating different datasets.
The pipeline to improve the quality of textual annotations is addressed: the first step is the automatic detection of the language in which a text is written, in our case very short. Then, the automatic detection and correction of spelling errors and the syntactic/semantic correlation between terms are dealt with. Classic preprocessing steps is performed if useful and necessary.
The following methods, models and tools are integrated into the pipeline to take full advantage of their specifics and capabilities:
- (i)
Machine learning and deep learning methods to identify both tag language and the presence of spelling errors;
- (ii)
Word embeddings models to capture the semantics of words and their context;
- (iii)
Clustering algorithms to identify/group semantically related terms;
- (iv)
Syntactic similarity methods between strings to strengthen the identification and correction of spelling errors.
In this paper, they are applied to multilanguage texts in the context of digital libraries and scientific articles produced by researchers at a research institute: the tags suffer from all the problems previously exposed. The languages processed are Italian, English, French, German, and Spanish. To avoid overfitting, due to too small datasets, the models are trained on different datasets found on the web or created ad hoc, which share some characteristics with the source dataset. We present the tools developed and the data used in the experiments, detailing the solutions adopted and the various options tested in the runs. The results obtained are presented and discussed, compared with the state of the art.
The paper is structured as follows:
Section 2 quickly outlines related works, then our approach is described in full detail.
Section 4 presents the experimentation performed, indicating the datasets used for training and evaluation, the methods implemented, with some preliminary results and a brief discussion to comment on them, including a comparison of the different approaches. Conclusions and future work complete the paper.
2. Related Works
This article deals with several aspects related to the management of annotations in multilingual archives that allow us to make the best use of tags. These tags, already defined and associated with the data, are improved by unifying them, harmonizing them, integrating methods to evaluate their syntactic or semantic similarity. In particular, we deal with three aspects: the automatic recognition of the language in which a text, or rather a string of characters, is written, the automatic identification of writing errors and the calculation of syntactic and semantic similarity.
Automatic language identification is a topic that has received a lot of attention over the years in various fields such as machine translation, speech synthesis and information retrieval, to name a few. In the text processing pipeline, language identification is one of the first activities. For example, think of Google Translate (
https://translate.google.com/ accessed on 30 January 2022) or DeepL (
https://www.deepl.com/translator accessed on 30 January 2022), which offer the possibility to automatically recognize the language of the text to be translated. A 2019 survey [
1] provides a very broad overview of the different features, methods and models used in the literature for language identification, in different domains. According to the authors, under controlled conditions, such as limiting the number of languages to a small set of Western European languages and using long, grammatical and structured text such as government documents as training data, it is possible to achieve near-perfect accuracy. The problem is still complex when dealing with very short texts, with misspelling errors or mixed language.
Regarding automatic error recognition, a variety of papers related to specific aspects of the problem can be found in the literature. Ref. [
2] deals with the specific problem of medical records in Persian, capable of identifying nonwords errors. In [
3], the authors deal with the Thai language and face the problem of handling words not present in the dictionary. The use of word embedding models, such as word2vec, GloVe or Bert, together with edit distance, is a solution adopted by [
4], in which the pretrained models proved their potential in the misspelling correction task. The literature is very extensive regarding the problem of identifying offensive texts. In 2019, one of SemEval’s tasks was the use of ensemble machine learning to detect hate speech [
5]: the paper highlighted the necessity of having more training examples, ranging from more positive to more negative. Simpler models have understandable features, while complex models obtain better results.
Artificial neural networks have been successfully applied to the understanding of text. In [
6], Goldberg surveys neural network models from the perspective of natural language processing research, in an attempt to bring natural-language researchers up to speed with the neural techniques. Different neural network methods for automatic language identification have been proposed [
7,
8,
9]. These papers agree that short texts affect the quality of the results, as well as the size of the training datasets.
In [
10], the authors provide a systematic overview of the approaches developed so far. To account for context, LSTM [
11] and sequence2sequence [
12] architectures were used for automatic error correction. The lack of resources for specific languages requires special consideration, as in [
13], for Indic languages. Ref. [
14] makes use of sequence-to-sequence (seq2seq) models for spelling correction in the Turkish language, on an artificially created misspelling dataset.
In [
15], the authors introduce a general framework of syntactic similarity measures for matching short text. Word embedding models such as word2vec [
16,
17] or BERT [
18] have greatly improved text management. The authors of [
19] proposed a learning-based approach for automatic construction of domain glossary from source code and software documentation, using word embedding models integrated with lexical similarity. The integration of word embedding models with clustering algorithms is now being studied by different research groups, mainly with classification purposes and/or in specific contexts (for example [
20,
21]), due to its ability to extract semantic and discriminative keywords.
3. Materials and Methods
The use of keywords has been identified and studied extensively in the field of information retrieval. Typically, when manually associated by catalogers/researchers, the tags are very specific, to limit the set of results to only highly relevant items. This is known as “precision”-oriented search. However, sometimes, web users are interested in the topic in a broader sense, aiming to retrieve not only specific information, but also other elements around it. In this case, we can talk about a system that operates in a “recall”-oriented way.
Our general aim is to define a pipeline able to improve the quality of tags and optimize their use in online catalogs, making the keywords associated by cataloguers more incisive, inclusive, discriminating and relevant, in a word, fit for the purpose.
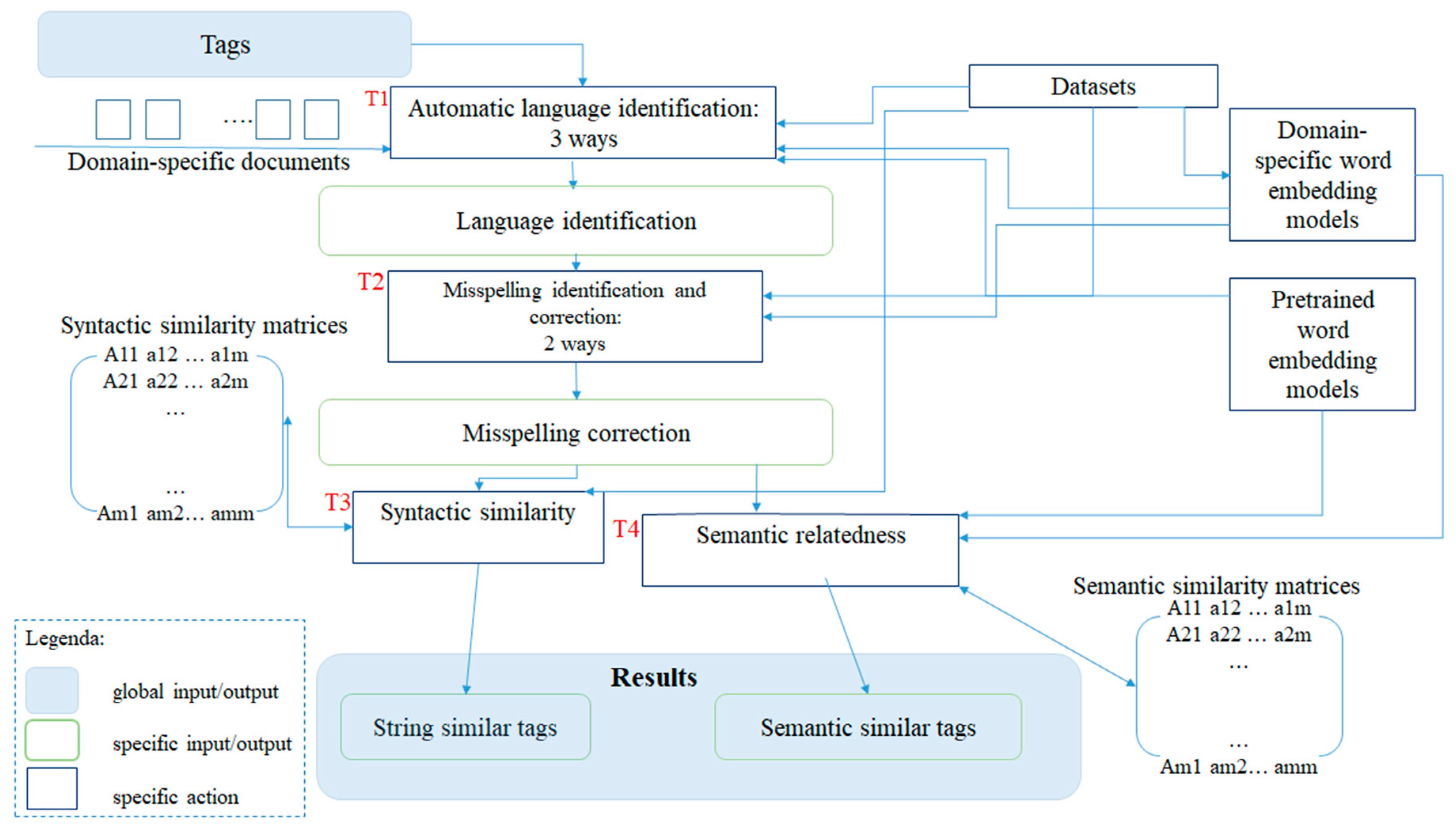
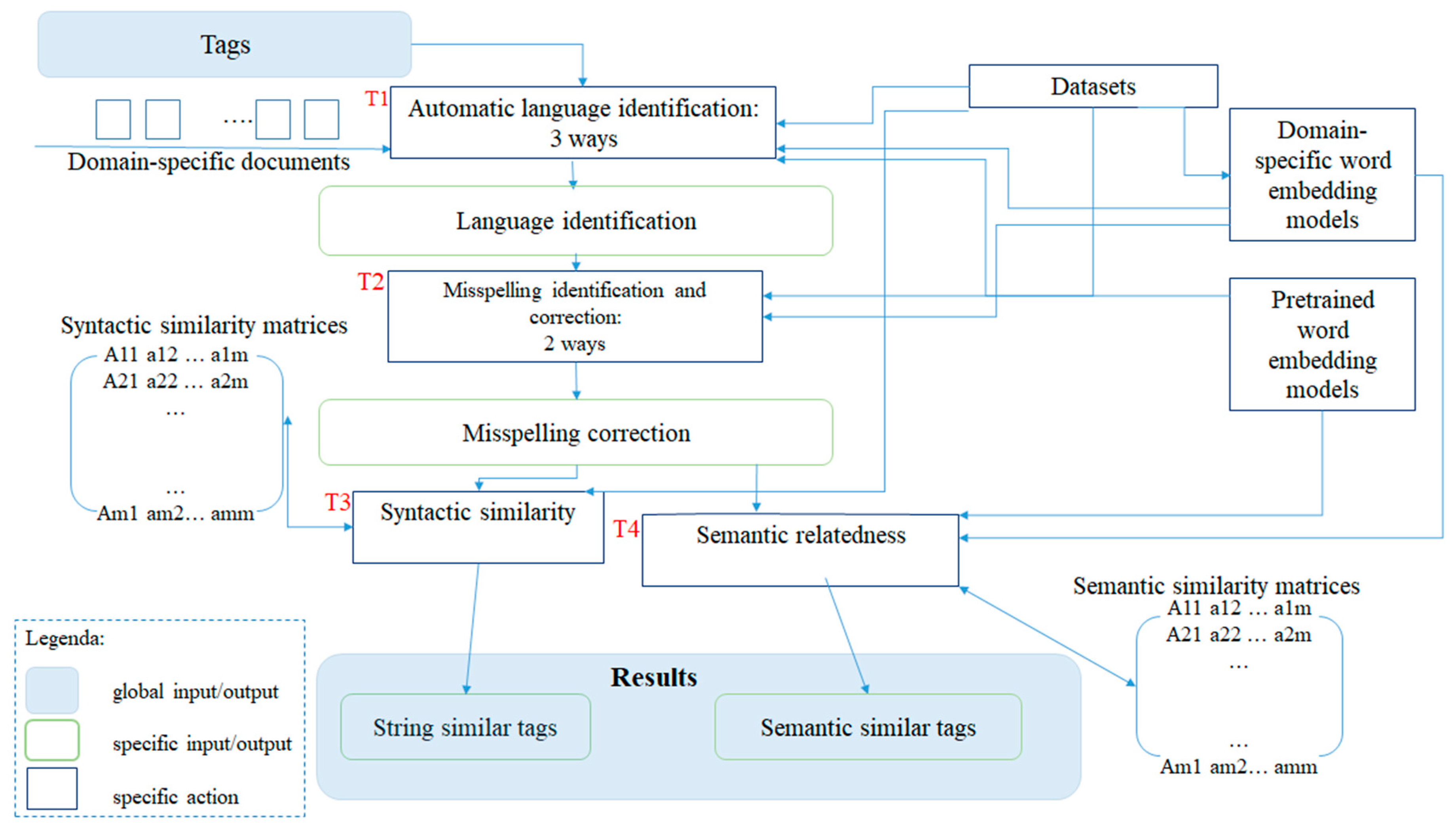
The approach presented in the paper consists of many steps (see
Figure 1), which offer different types of similarity between tags, both syntactic and semantic.
3.1. Data
The data on which we tested our approach consisted of scientific articles produced by researchers in a research institute. It contained 4000 scientific papers in Italian, English, French, German, and Spanish. The cataloguers/researchers associated 7000 different single or compound keywords with the articles. This dataset is called library.
Usually, in the natural language processing (NLP) pipeline, the first operation is pre-processing, composed of tokenization, cleaning, lemmatization, stemming, and part-of-speech tagging of the string that constitutes the input. The output of the process consists of terms, single or compound words, to be used in the following steps. In our case, the dataset was already composed only of simple terms, thus it was already tokenized and cleaned up. The preprocessing step was therefore not performed on the library dataset but was done on the training support datasets, as briefly described later.
3.2. Task 1: Automatic Language Identification
Keywords associated with collections of multilingual textual objects may be available in the same language in which the object itself is described or cataloged, or in the language of the country in which it is cataloged. For example, some Italian cataloging standards require that the metadata associated with each item be in Italian, regardless of the language of the object itself. Therefore, when we are dealing with multilingual collections, for example, books and journals of a library, or scientific production of a university or research institute, the tags can be indifferently in English, Italian, French, etc. Automatic language identification, using statistical techniques, machine learning or deep learning methods, is therefore necessary. In the following, ready-made methods are presented, tested and compared with others implemented from scratch.
3.3. Task 2: Misspelling Identification and Correction
This paper is designed for specific and specialized terms related to research activities. Tags in scientific articles can be extremely technical and fall outside of common lexicons. In addition, keywords are subject to frequent changes and updates. For these reasons, using standard methods such as presence/absence in WordNet (
https://wordnet.princeton.edu/ accessed on 30 January 2022) [
22] or lists of terms alone is not sufficient to determine the presence of spelling errors. In this paper, both statistical methods and deep-learning-based solutions are presented. Statistical methods lead to the identification of the presence of an error and suggestions for its correction, through statistical and probability functions, also related to the specific language model. The deep learning method, trained on different training sets, identifies and corrects errors in a single step. We created synthetic datasets of noisy (and correct) words by collecting highly probable spelling errors and inducing noise in the clean corpus. To obtain accurate results, training requires many epochs and large datasets.
3.4. Task 3: Syntactic Similarity
This step involves computing a similarity matrix based on the syntactic similarity of the tags. From a semantic point of view, the use of singular/plural or the use of different terms—that may appear to the nonexpert as synonyms—conveys a (slightly) different meaning; when using the search engine instead, users will greatly appreciate a system able to propose, in a clear and visible way, a syntactic clustering for terms that share a high number of letters.
Several methods of calculating similarity can be used, as those presented in [
15], e.g., Levenshtein, Damerau, Jaro, Jaro–Winkler, etc. In this paper, after a series of tests, we chose the Jaro–Winkler algorithm, which measures the difference between 2 strings, then normalizes it, with values ranging from 1 (when two strings are identical) to 0 when they are completely dissimilar. The choice of this measure is because of the ease of understanding the results and the fact that it gives results in the same range as semantic similarity, described later, and is therefore seamlessly integrable.
3.5. Task 4: Semantic Relatedness
Catalogers/researchers who associate tags with their items may choose terms that are similar to others while making use of different words. This may be due to the need to differentiate concepts, to the different background of the catalogers/researchers who use distinct languages and jargon, or to the fact that data come from different archives. While it is correct not to replace or suggest changes to tags, it is fundamental that the search engine can retrieve all items that are semantically related.
The semantic relatedness of terms is based on both the term itself and the context in which this term is used. Here, we present a method to compute semantic correlation based on word embedding. Particular attention has been paid to compound tags, which are not present in the compound form in the word embedding model, but as individual components. In this case, a new vector is computed as the average of the composing vectors.
In this work, we are interested in the semantic correlation between tags, in a broad sense. As a result, we did not investigate the type of correlation, e.g., synonyms, antonyms, etc. (see also [
23]), being interested in all without the need of distinction, using the cosine between the vectors representing the tags as a similarity measure.
3.6. The Use of library Tags
This section describes how
Figure 1 is applied to the keywords used in the experimentation. The tags in the
library dataset are the input to the pipeline specifically defined to deal with them. These tags are used without further processing and first undergo task 1 (T1), i.e., language identification, using previously trained ad hoc models. The output of this task is the association of the language to each tag. For the training of the models, we used large multilingual datasets, such as Wikipedia or papers from scientific journals scraped from Scopus or ArXiv. In this case, individual words, obtained by tokenizing sentences and removing stopwords, were annotated with the language and were the input for training.
Task 2 (T2) led to the identification and correction of misspellings. Again, models were trained on different datasets. library tags were used only in the evaluation phase. Two steps were performed on the data: (i) if there were errors in the source data, the correct version of the tag was manually associated; (ii) the tags were artificially modified applying misspelling algorithms. The output of T2 were error-free tags.
At this point, the tags, definitely correct and accompanied by the language, were associated with similar terms, syntactically or semantically. For the latter activity, the language is crucial to translate the tags into vectors and create the similarity matrix. For syntactic similarity, which is based only on the characters present in each term, knowing its language is less important and could even be a limitation in the search for similar terms, in the presence of multilingual archives. The results of T3 and T4 were a list of tags, syntactically or semantically related.
In
Section 4 the different steps are described and commented on, highlighting the results obtained.
4. Our Approach: Results and Discussions
Each task was trained and evaluated on separate datasets. The library dataset, composed of single or compound keywords, did not require any preprocessing. The tags, exactly as entered by the catalogers/researchers were used. On the other datasets, used for training or evaluation and described below, several preprocessing steps were performed: (1) tokenization, identification of tokens, i.e., words, and (2) removal of stopwords.
4.1. Datasets and Models
The experiments conducted aimed at defining methods and models to improve the quality of the textual keywords within the library dataset. It was necessary to identify the best features able to provide the ML and ANN models with the information to identify the language and possible spelling errors. In addition to the word itself, as a unicum (word unigram feature), several attempts were made to consider subsets of the word itself. In this paper, we report character n-grams, i.e., sets of n successive characters, with n = 3. This is a similar approach to a bag-of-words model, except that we are using characters and not words.
For each feature, the m most frequent elements (word unigram or character trigrams) were extracted, with m = 400, 800 and 1200. The constraints led to the actual extraction of features used for training and subsequent validation of the results (see Table 2, column features extracted).
These “objects”—data, models and algorithms—were used in the creation of the datasets, in the training and testing of the models and in the validation of the results on the data we were interested in:
- -
- -
ArXiv dataset: set of all papers in the ArXiv repository [
24] (about 1,700,000 papers). This dataset ensures the presence of specialized scientific terms that might be excluded from a standard vocabulary;
- -
Papers5: papers harvested from Scopus databases in the languages considered. Only title, language and keywords, if any, were collected:
papers: it contains titles as a single string, consisting of multiple words;
papers_1gram: each word, excluding stopwords, was evaluated individually;
- -
Keywords taken from the catalog of the library of interest;
- -
Pretrained word embedding models: here, we used pretrained Wikipedia models using word2vec model (w2v_wiki);
- -
Word embedding model trained on ArXiv dataset, available only for the English language (w2v_arXiv).
4.1.1. Language Identification
The starting dataset is the Wikipedia datasets in the different languages considered, in this case, Italian, English, French, Spanish and German. Two experiments were conducted:
wikitxt: For each language, all words (in the title and abstract) in the annotated dataset for that language were kept, except for stopwords. This implies that the same word could appear annotated in multiple languages. For each language, 100,000 records were used, divided into training/test sets. From the training set, 386,228, 231,816, 229,483, 369,906 and 151,173 single words were extracted in English, Italian, French, Spanish and German, respectively. They were 65,714, 51,779, 45,178, 70,541, 44,121 when taken once. The total number of char trigrams extracted were 24,609 for English, 22,194 for Italian, 20,892 for French, 29,487 for Spanish and 23,017 for German.
wiki_nooov: From the wikitxt dataset, the terms overlapping in different languages and those not present in the pretrained models of word2vec were eliminated. Using the same parameters as for wikitxt, we obtained 14,584, 38,932, 30,465, 39,769, 47,853 single words, and 9622, 25,737, 19,994, 26,202, 31,555 words taken once in English, Italian, French, Spanish and German, respectively. The total char trigrams extracted were 4508 for English, 3033 for Italian, 5231 for French, 4827 for Spanish and 7318 for German.
The machine learning and artificial neural network models were then trained on the Wikipedia datasets split into training/test sets and validated both on the training set and test set and on a set of data taken from the library we were working on.
4.1.2. Misspelling Identification and Correction
Datasets were artificially created, adding misspellings. We used two starting datasets and two misspelling algorithms. For the starting datasets, we extracted single terms as in the following: from the ArXiv dataset for English and from Wikipedia (the same used above) for the other languages: this dataset is called general; from Papers_1gram terms.
The two misspelling algorithms mimicked the most frequent errors that are introduced when writing:
- -
Simple changes to a word, such as a deletion (removing a letter), a transposition (swapping two adjacent letters), a substitution (changing one letter for another), or an insertion (adding a letter). This algorithm is called
edit1 and is based on the correction algorithm of Peter Norvig (
http://norvig.com/spell-correct.html accessed on 30 January 2022).
- -
Replacement of a letter with another nearby on the keyboard or deletion of a letter. Small variations on the set of possible characters that were replaced gave rise to:
Nearby (the one used in the tests reported here) replaces one letter with another nearby on the keyboard;
Nearby_complete: one letter is replaced with zero, one or two nearby letters.
We applied the two misspelling algorithms to the General, papers_1gram and library (used for evaluation purpose only) datasets, obtaining circa 200,000 artificially misspelled words for each language. The same word was used several times to obtain large corpora.
4.2. Task 1: Automatic Language Identification
The need to identify the language of a tag arises from the fact that algorithms, methods, and models for misspelling identification and syntactic and semantic relatedness computation are language-dependent.
Experimentations of different methods for language identification were carried out on wiki_nooov and wikitxt, consisting of many thousands of individual terms, annotated with the language they belong to, using three different approaches:
- (1)
Off-the-shelf standard packages;
- (2)
Machine learning approach;
- (3)
Deep learning approach.
4.2.1. Off-the-Shelf Standard Packages
On the Internet, there are many sites for the translation of texts from one language to another, such as Google Translate (
http://translate.google.com accessed on 30 January 2022) or DeepL (
https://www.deepl.com/translator accessed on 30 January 2022), which make use of neural networks, very large datasets and the help of users to improve or correct the translation. There are several sites like Booking (
https://www.booking.com/index.it.html accessed on 30 January 2022) or even Amazon, which offer automatically translated reviews and comments.
In
Table 1, the accuracy of the off-the-shelf methods tested are reported, and the ensemble—in grey—is obtained as the majority of votes [
25]. Results are reported for both
Wikipedia and
Papers/Papers_1gram datasets. The methods were applied as is, without fine-tuning or retraining on the specific data used, which could have brought further improvement. It can be seen that the voting mechanism improves the accuracy of the results. FastText, the package based on Facebook’s text management tools, achieves the best results for all corpora.
4.2.2. Machine Learning Approach
For language identification, we implemented two machine learning classification methods (logistic regression and multinomial naïve Bayes classifier), using those features that better characterize our data. Each term of the training/validation set was then “vectorized” using unigram or character trigram features, with Python standard feature extraction methods.
Figure 2 shows the comparison in the overlapping of the character trigram features for the different number of most frequent elements (400 and 1200), extracted from
wiki_nooov and
wikitxt, respectively. French and German are the languages where there is the least overlap, while Spanish, Italian and English share more character trigrams. This allows us to hypothesize that French and German give better results in terms of precision, while the other languages are more recall-oriented. Given the model of dataset construction,
wikitxt has a higher number of overlaps, since the same word can belong to different classes. In
wiki_nooov, words that belong to more than one language were removed.
Tests were done with a different maximum number of features extracted, to confirm the intuitive idea that more data lead to greater accuracy.
Table 2 reports results from the logistic regression and naïve Bayes classifiers trained on datasets using character trigrams with n top results (we have not reported the results for individual words here because they are not valid enough to compare). In the table, train indicates the subset of
wiki_nooov or
wikitxt used to train and evaluate the data, while test was used for evaluation only.
It can be seen that the results obtained with the trained model on Wikitxt are worse than those obtained using cleaner data.
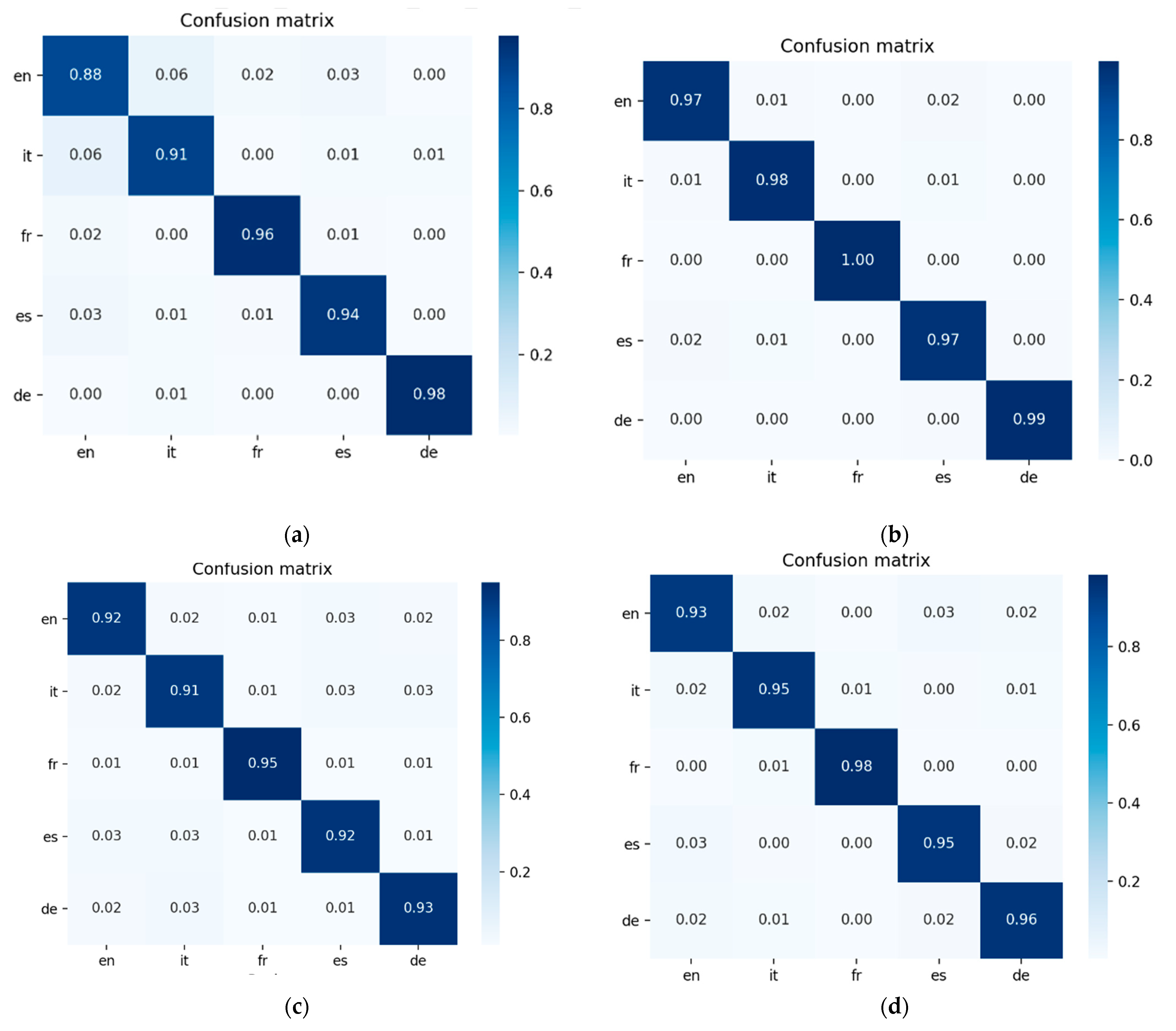
Table 3 and
Table 4 show the recall, precisions and F1 values for term classification in the different languages, on the different datasets on which they were trained and validated, and on
Papers and
Papers_1 gram. The average is also shown, and the weighted average computed on the numerosity of the different classes. Data for the 1200 features are shown.
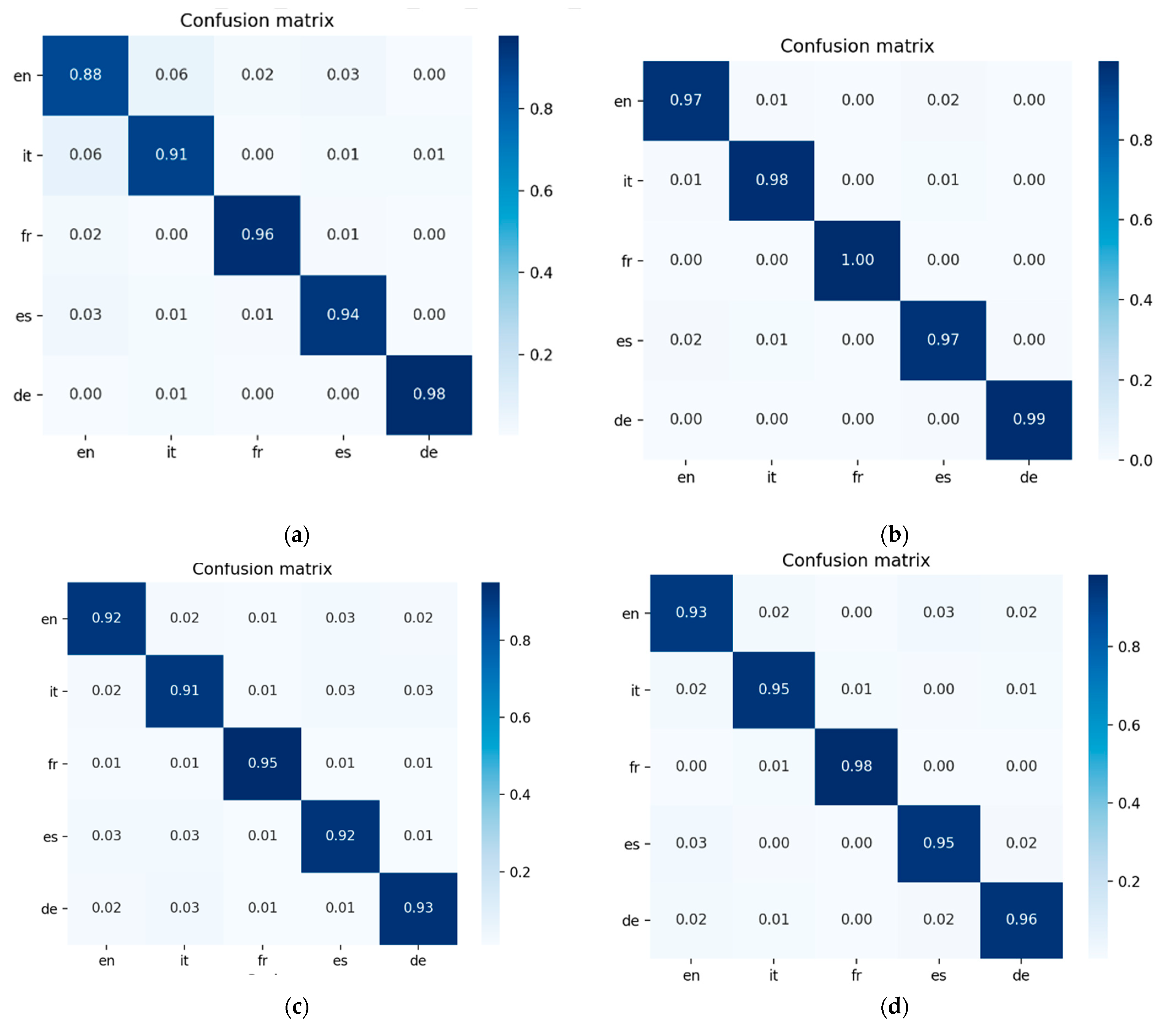
The values of the evaluation measures are consistent with the reported confusion matrices for the same values. The values for the
wiki_nooov dataset, which shows very few overlaps for the extracted trigrams, are very high in the evaluation measures. In
Table 4 for the training data, using logistic regression, the recall values are very high compared to the precision values, for all languages except German.
4.2.3. Deep Learning Approach
There are several different deep learning approaches to language identification, such as reported in [
1]. Here, we used a simple RNN, using the same two features used in the ML approach: character n-grams and single words. The neural network model was constituted by three layers fully connected that classified each input word as belonging to a language class. The first layers were composed of 500 or 250 nodes, with ReLu activation function, while the last one, which associated each word to a class (i.e., a language), was composed of five nodes with a SoftMax activation function.
Table 5 reports the results of the training/test set on different datasets. The training phase was conducted with 10 epochs using an Adam optimizer and loss categorical cross-entropy function. The choice of the architecture of the ANN was made both based on the literature [
1,
7], and on the basis of other experiments carried out [
26].
The first step was to transform the data into vectors, according to the features selected. Then, a feature matrix was created, based on the occurrences of each character trigram/word in the dataset. In the training phase, for all the cases tested there was no or little overlap on the features in the various languages (see
Figure 2). This resulted in the model being able to discriminate between languages very well.
Table 5 reports the results, in terms of loss/accuracy, obtained applying the model comparing the two features, and a different number of features. The greater the number of features extracted, the better the results obtained. As n increases, the number of features extracted from the data increases, resulting in greater accuracy in the results. Results with 10 epochs are shown here. 50 epochs were tested, but the accuracy of the results did not change, while the computation time increased significantly. The results obtained using trigrams are better than those obtained on words. Results on unigram terms are not reported here.
4.2.4. Discussion
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 report the results in terms of accuracy of both the off-the-shelf methods and the models implemented and trained from scratch. In bold are the best results for each model/dataset.
Here are some considerations:
Results on the dataset where there were overlaps (wikitxt) were worse than those with the cleanest data (wiki_nooov) with all methods.
The papers_1gram dataset consists of single words: it achieved very low precision with all methods. On the contrary, the papers dataset, made up of strings with more words, obtained better results. In all tests, the methods generalized quite well on the Papers dataset, while on Papers_1 gram they did not perform as well. This is the only case where the off-the-shelf packages achieved results comparable with the ML/ANN methods.
More data lead to better results: this was valid for the size of the training set, for the length of the string to be evaluated and for the number of features to be extracted.
In cases of nonbinary classification, such as this one, if the training data for a class are less numerous than the others, the results for that class are worse in terms of precision, while the effects on the other classes are worse in terms of recall. Generally, the general accuracy worsening was not very pronounced.
Models based on an ANN, with the different hidden levels and the many parameters used in training, are able to outperform other methods in the task of language identification: ANN methods in the same tests achieved better results than ML and off-the-shelf methods.
4.3. Task 2: Misspelling Identification and Correction
Due to the specific scope of the experiment, identifying misspelled words was a particularly difficult task due to: (i) different languages; (ii) a lack of context; (iii) very specialized scientific terms; (iv) the presence of proper nouns/project names.
4.3.1. Statistical Approach
At the stage of identifying spelling errors, several strategies were identified to be integrated, since individually none proved sufficient in the specific case. All these strategies indicated clues about the correctness of the tags:
Presence of the tag in the word embedding model adopted. The word embedding models, both the pretrained ones and the ones trained on the ArXiv repository, produced for each word, single or compound, a vector that allowed us to compare it with those of other words to obtain semantic similarities, usage contexts, etc. An indicator of whether the term was spelled correctly/had spelling errors was whether the term was identified in the model or classified oov (out of vocabulary) in the word embedding models. To minimize the probability that a correct but infrequent term, because it belonged to a specific context or was newly introduced, was classified as oov, we used both pretrained (w2v_wiki) and specifically trained word embedding (w2v_arxiv). The last model was only for the English language.
Presence of “as-is” tags (both compound and as single components) in the ArXiv/Wikipedia datasets. The presence of the term in the dataset offered us the possibility of identifying the presence/absence of possible misspellings. It also helped us compute the probability that that word appears in the chosen/identified language, thus providing indications that were proper to the language model. This information was then used to calculate the probability of a specific correction, in the ascertained presence of an error.
Presence of “as-is” tags in the first results of Google.
Once the presence of misspellings was detected with a certain degree of confidence, the second step of the approach was to apply statistical and/or machine learning methods to assess the probability of replacing one term with another. It also used the first results of a Google search or the “do you mean” function to propose a correction: it proposed several tools for automatic correction as follows:
Automatic correction of the error, due to, e.g., the inversion of two characters, to the substitution of two close characters on the keyboard;
Google search first n results, with n = 1;
Split terms proved to be pasted (lack of space).
A voting system (ensemble) was defined, which associated to each term (suggestion of correction) a degree of confidence; the ensemble was evaluated based on a voting mechanism determined by the overlapping/equality of the proposed solution and eventually by the probability of the correction.
Table 6 reports the results for each step of the automatic correction tools and the final ensemble (in grey) accuracy values. Due to the method used to introduce errors, the EDIT1 misspelling algorithm yielded better results than those
nearby. We report only the results of the EDIT1 algorithm, better than those of NEARBY, which are more comparable with those (even better) obtained by the artificial neural network.
4.3.2. Deep Learning Approach
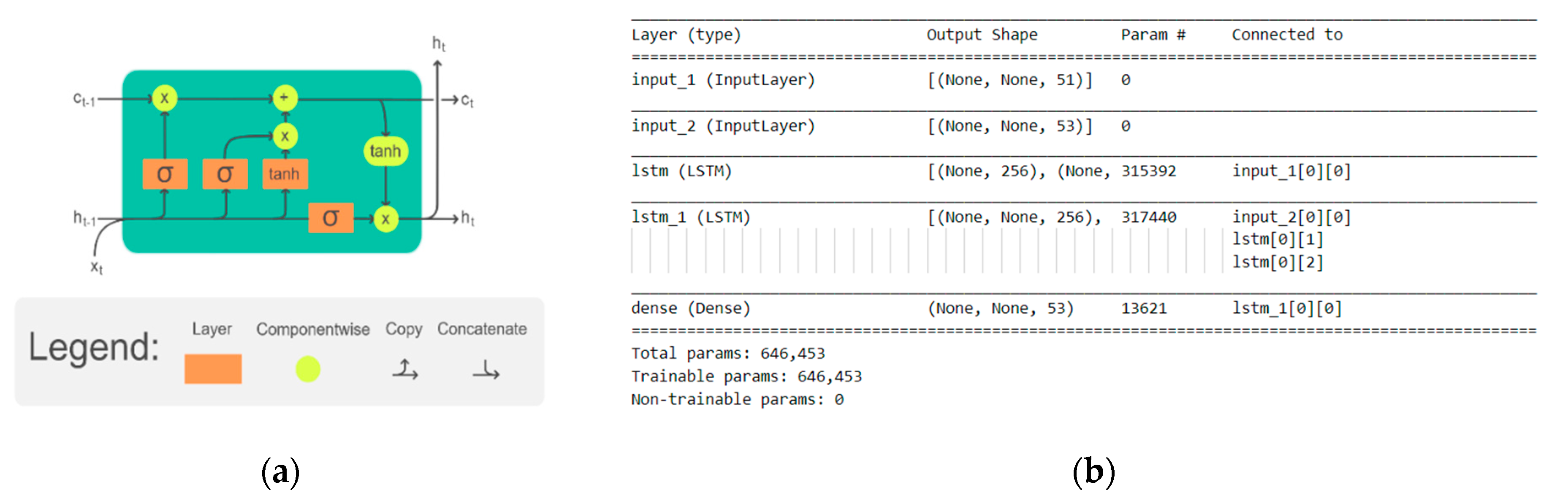
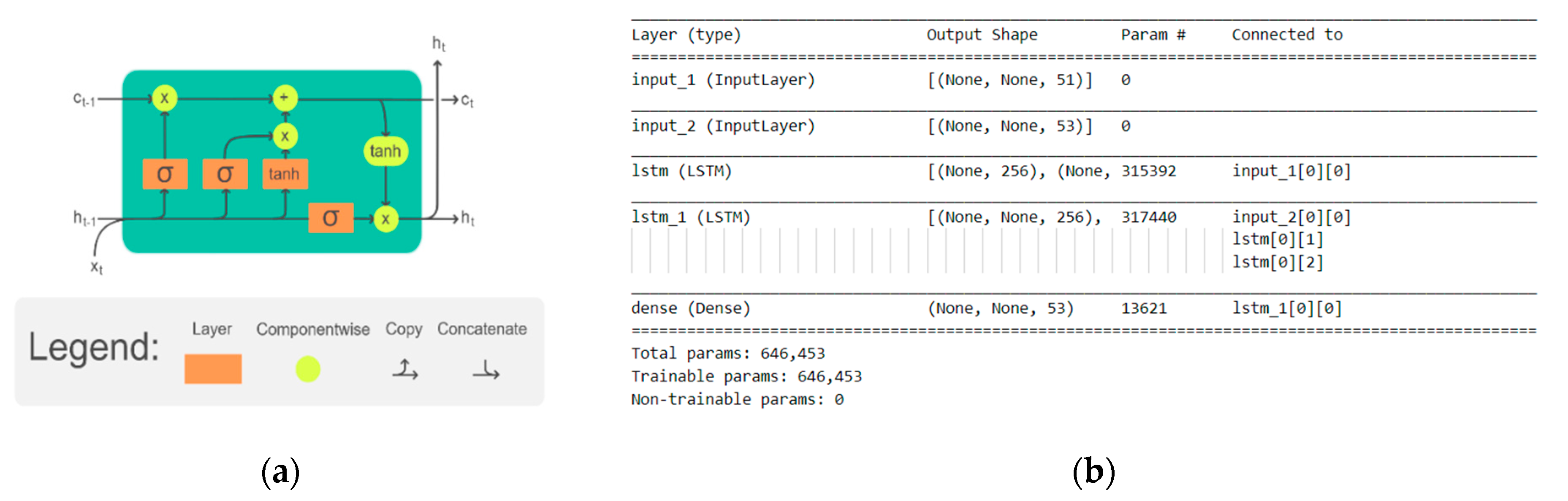
The basic idea is to use an artificial neural network designed to transform an input into an output, adapted to natural language, thus capable of remembering the various states of the input. Recurrent neural networks, such as the long short-term memory, or LSTM, network, are specifically designed to support sequences of input data. In
Figure 3a, the LSTM cell is represented.
The network chosen was sequence2sequence, widely used for machine translation purposes. This network, also called NN encoder–decoder, consists of two recurrent neural networks (RNN) that act as an encoder and a decoder pair. This architecture allows the model both to support variable-length input sequences and to predict or output variable-length output sequences. An encoder LSTM model reads the input sequence step-by-step. After reading in the entire input sequence, the hidden state or output of this model represents an internal learned representation of the entire input sequence as a fixed-length vector. This vector is then provided as an input to the decoder model that interprets it as each step in the output sequence is generated.
The two networks were trained jointly to maximize the conditional probability of the target sequence given a source sequence. Additionally, hidden units were inserted to improve both the memory capacity and the ease of training. The model was based on the character unigram feature. The number of input/out tokens varies from a minimum of 33/29 to a maximum of 61/53, respectively. The different number of characters in the input/output depends both on the language and on the error-introduction algorithm chosen. The lower bound was that of the English dataset, which has no accented letters, while the upper bound was that of the mixed dataset.
Figure 3b represents the sequence2sequence neural network implemented using two LSTM layers.
4.3.3. Discussion
Table 7 shows the loss and accuracy of the network on the augmented data broken down by the languages of the experiment and a dataset that takes and mixes data in the different languages. The model was trained on two different datasets,
general and
papers: the table reports both the accuracy/loss obtained on the datasets used in the training, split in train/test and on the
library dataset, for which these experiments were carried out. The model generalized quite well for Italian and mixed data, maintaining high accuracy, but losing a few points when using the ANN trained on the other dataset. This is because the
library dataset is mostly composed of Italian tags.
By analyzing the results of both misspelling algorithms, we can see that the datasets obtained by applying EDIT1 obtain almost the same results, compared to the nearby datasets.
Comparing the results, we can see that the artificial neural networks outperform the ML voting mechanism on all tests.
4.4. Task3: Syntactic Similarity
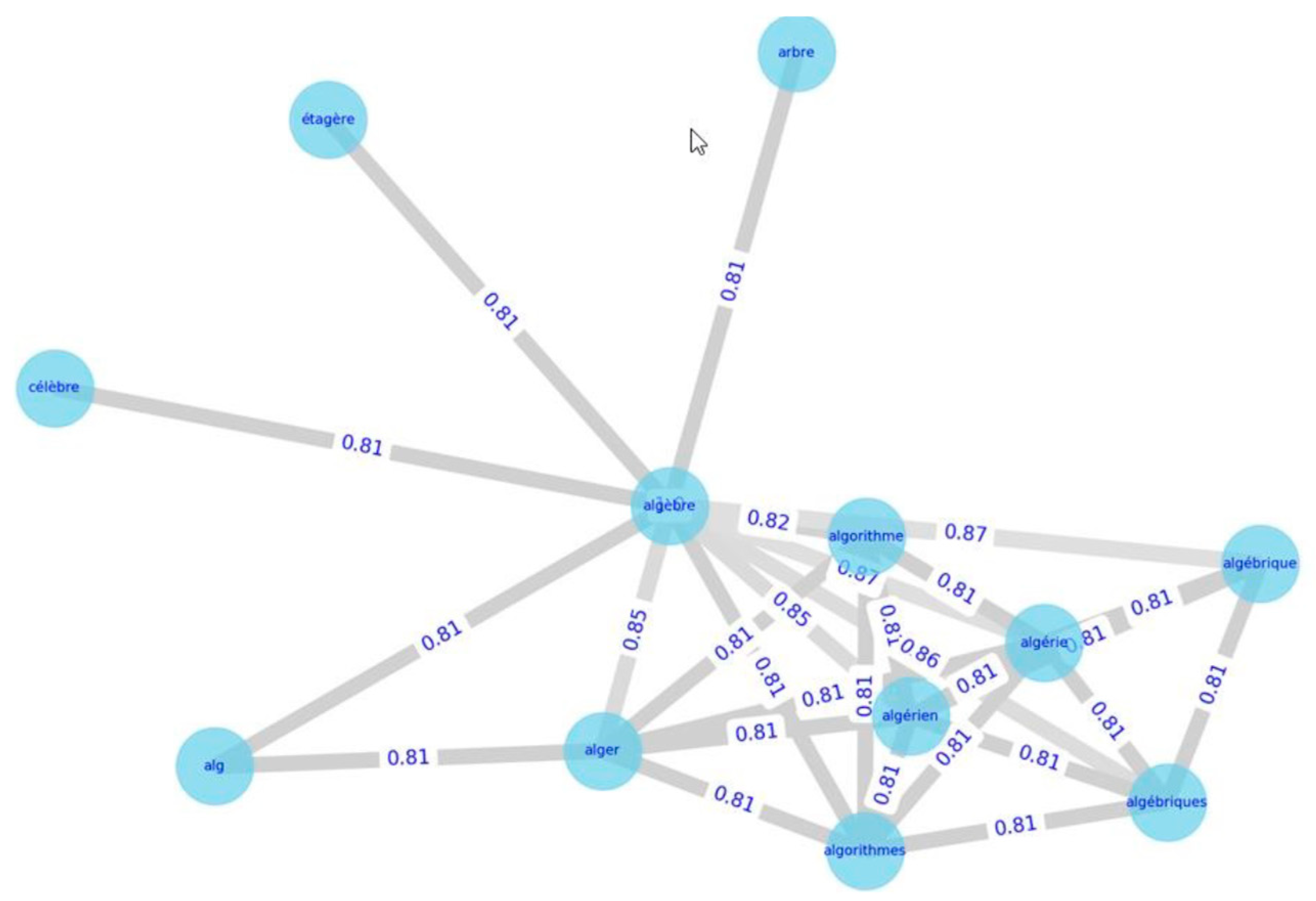
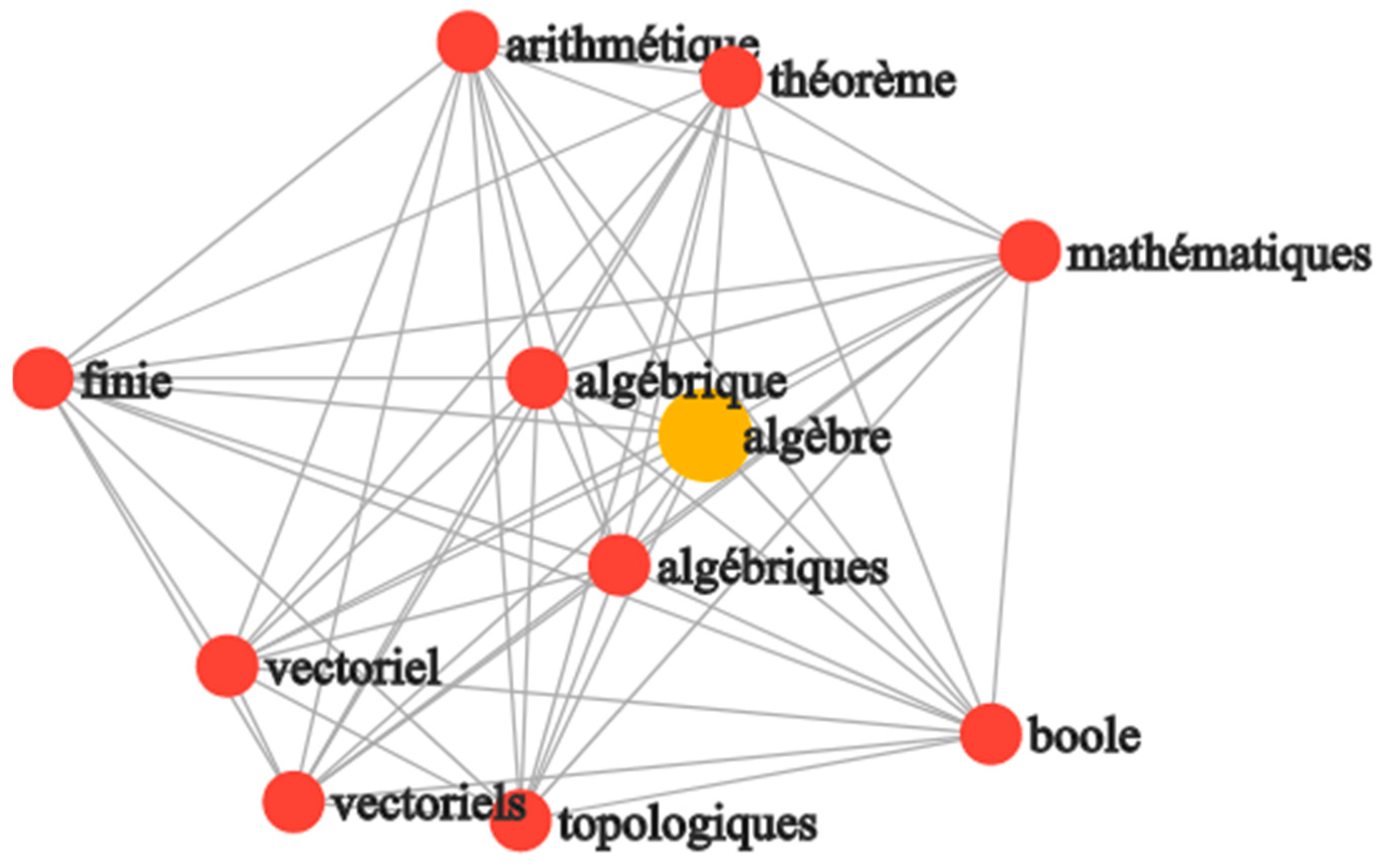
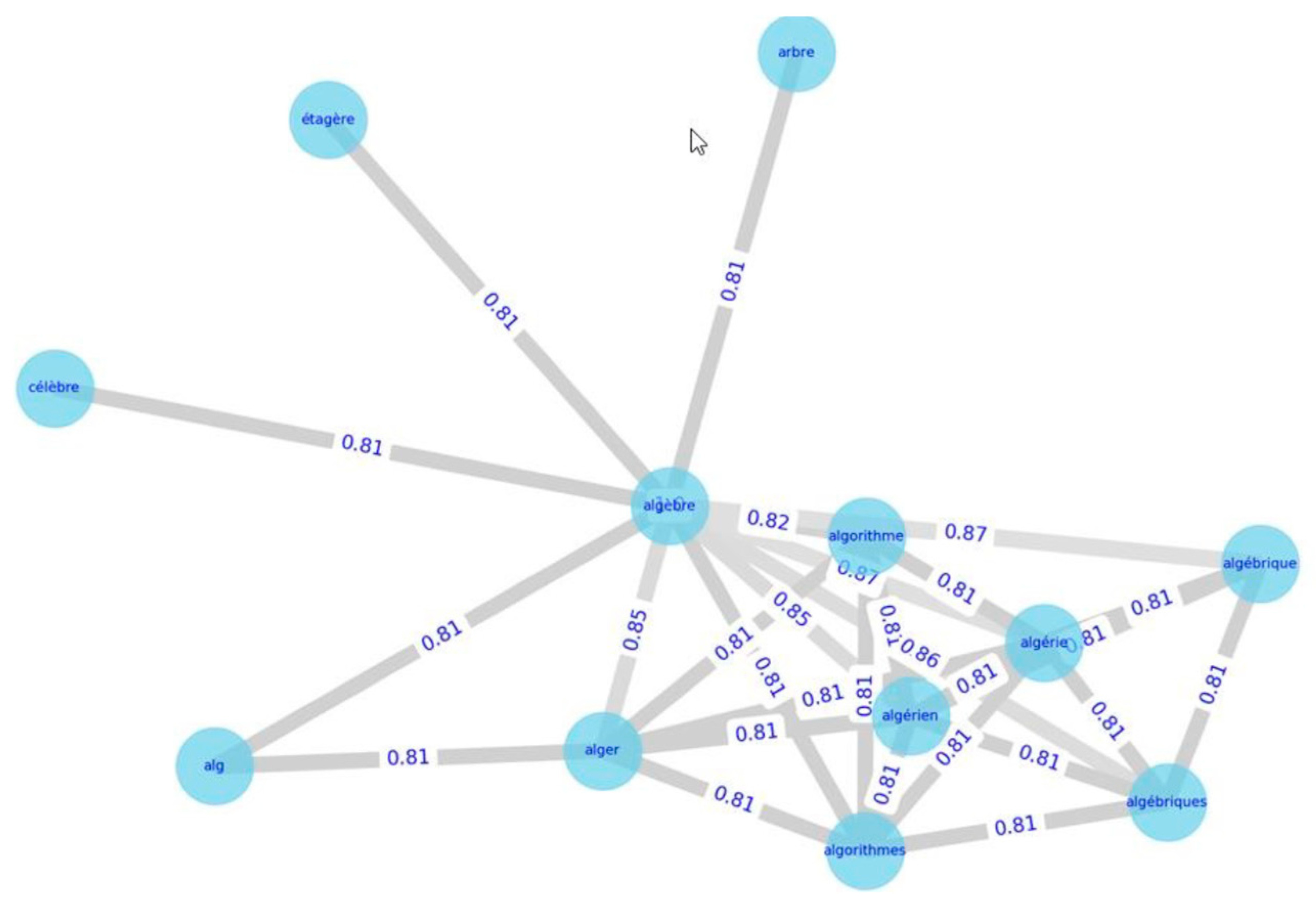
The syntactic similarity between the two terms implies that these terms share many characters in common. When two strings have a very high similarity, it means that they are virtually identical; it can be the same singular/plural tag or the presence of one more letter or one less or a substituted letter. In this case, strings with a similarity greater than 0.84 were considered related and stored in a syntactic similarity matrix. To calculate syntactic similarity, we used the Jaro–Winkler algorithm (using the Jellyfish Python package), creating a correlation matrix with a minimum similarity value. For example, a French web user interested in “algèbre” should also be suggested “algébrique”, and “algebriques”, all with similarity values greater than 0.86. The algorithm also proposes syntactically but non semantically related terms such as “alger” and “algorithme”.
Figure 4 shows the syntactic similarity graph for “algèbre”.
4.5. Task 4: Semantic Relatedness
The semantic similarity was used here to overcome the problem of synonyms: for example, catalogers/researchers can use the same concept using different terms, or data from different sources can address the same topic from different perspectives. Moreover, the suggestion of tags to web users allows them to continue their exploration according to content-based browsing.
The first step was the computation of the similarity matrix to the terms (and their vectors) of the tags. In a second phase, the cosine similarity as a criterion of similarity was applied to the similarity matrices and/or directly to word2vec models. The similarity matrix was based on the vectors from the word2vec model. Currently, each language is processed individually. The example uses the word2vec pretrained model for French.
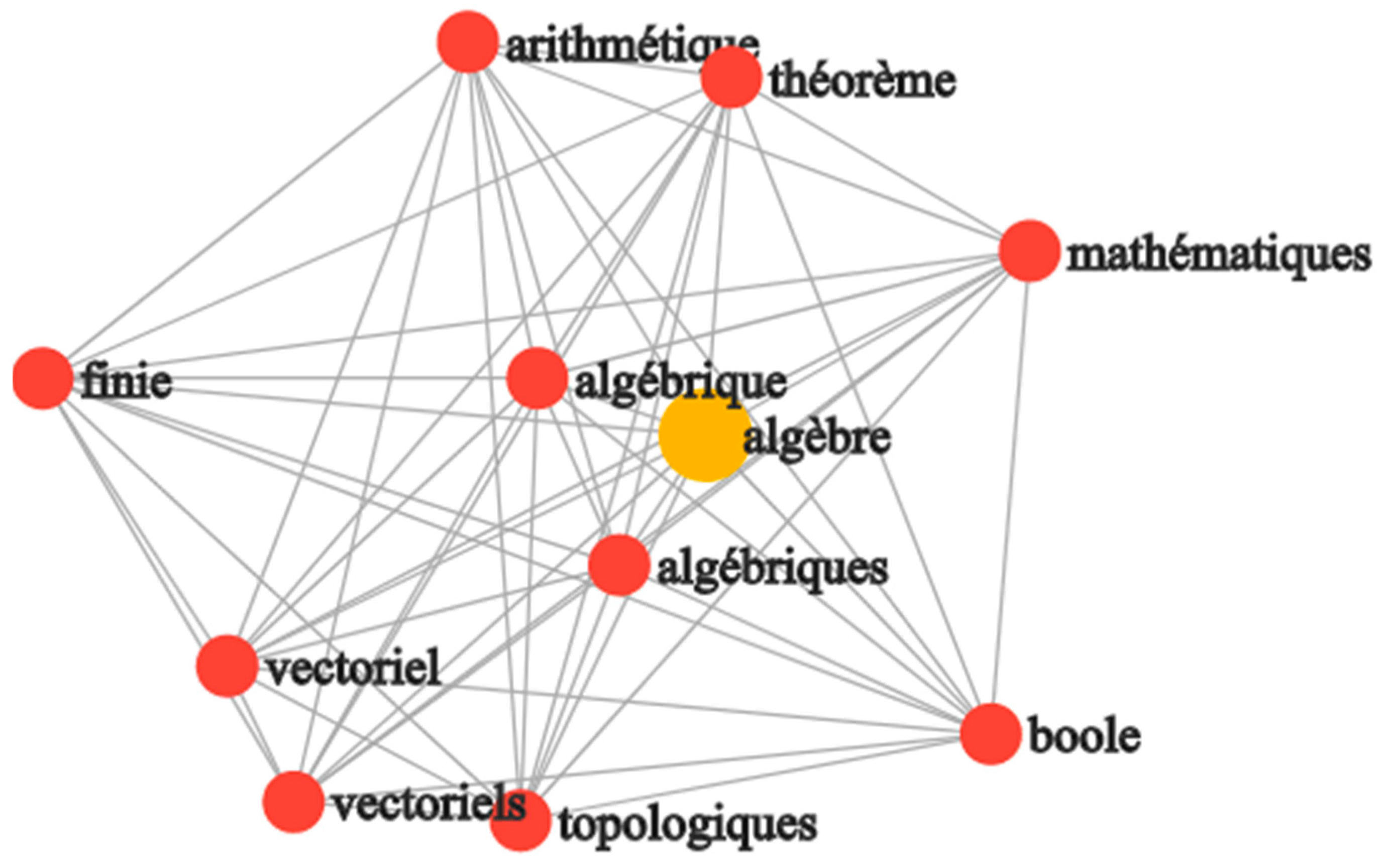
For cosine similarity, similarity values of 0.5, 0.6, 0.7, 0.75, 0.8, 0.85 and 0.90 were tested. In the end, 0.75 was chosen as a reasonable trade-off between a too low number of similar tags and the retrieval of elements that were not too closely related.
Figure 5 shows the tags most similar to “algèbre”using the pretrained model for French.
5. Discussion
Language identification works well on long strings of standard terms, i.e., frequent terms in that language. The problems encountered in the experimentation were due both to the presence of extremely specialized terms related to innovative research activities and the use of single or short words. In addition, the training on the set of clean terms, i.e., without overlapping, allowed us to obtain better results. ANN methods outperformed the others, and it can be said that off-the-shelf packages obtained results comparable to machine learning methods.
Misspelling correction is a very useful tool because it improves not only the quality of the data but also the overall evaluation of the system. In our case, we were interested in the ability to correct highly specialized data. Typically, word correction tools are language-dependent because words simply written in another language could be considered errors. We experimented with both monolingual and mixed data. In general, we can say that ANN performed much better than statistical methods. ANN results were always very good on the data they were trained on. Models trained on the general dataset generalized better. While there was no significant difference for ANN models across languages, statistical methods performed best in English.
Regarding syntactic similarity, the creation of the similarity matrix using the Jaro–Winkler algorithm allowed us to overcome singular/plural problems as well as different spellings of the same tag, possibly also in different languages. For example, in British English color is spelled “colour”, in American English it is spelled “color”, in Italian “colore”, while in French it is “couleur”. Moreover, in French, Spanish, German, Italian, etc., words are spelled with accents: you do not have to worry about how you spell them anymore, because the system will be able to retrieve the different spellings. On the other hand, it can be difficult to set the degree of similarity to find similar tags without introducing terms that are of no help in the search.
Semantic similarity is something we intuitively need to group similar terms within the scope of the specific application. Semantic similarity also allows us to overcome the problems of different spellings and the presence/absence of accents, with the condition that the words are present in the vocabulary of the word embedding model used, i.e., they are not oov. Thus, it could be the case for extremely specific oov terms or not being able to identify similar terms. Unlike syntactic similarity, which can be used on tags in different languages, semantic similarity requires a vectorization of the terms, which is language-dependent.
The experimental setup was implemented in Python 3.7, using standard packages like Numpy, Matplotlib, Pandas and other more specific ones for the processing of textual data such as NLTK, Treetagger, Gensim, Scikit-learn, Pytorch, Tensorflow, Keras, together with some experimental packages in GitHub.
6. Conclusions and Future Work
In this paper, we presented some tools useful to handle the problems of textual annotations in digital libraries, or more generally in archives that rely heavily on the use of keywords in searching and browsing. These tools were designed both for catalogers/researchers who find themselves managing data from a variety of sources and for those who require data cleaning based on the language in which it is written. These tools will be integrated into web catalogs to enhance traditional ways of searching and browsing data on the web and offer a multimodal search and visualization tools. Language detection and typos detection and correction were addressed with both machine learning and deep learning techniques. To train and validate the models, several datasets were used/created/scraped, both in a single language (Italian/English/French/German and Spanish) and in mixed languages. The mixed datasets were the basis for the language detection models. They were also used in Task 2, to train the deep learning model. In addition, datasets were artificially constructed for automatic error correction based on two different error models. Syntactic and semantic similarity rely on edit distance among tags, the use of word embedding methods and similarity measures.
We plan to include these tools both at the cataloging stage, to help catalogers detect errors early, and to facilitate the use of legacy library archives in the presence of dirty data. Researchers, students and scholars often use keywords to search for items of interest. The presence of errors could penalize them greatly.
This work is still in progress. Preliminary results have been discussed with catalogers to evaluate them, both qualitatively and quantitatively. They have been very positively received. For the tags organization, analyzing the results, according to our experience and sensibility, we can say that actually proposing a search engine based on clusters can be of great value for a web user, integrating it with other more standard methods.
Some problems have already emerged in both language identification and automatic error detection because, especially when tags refer to very specific instances such as ongoing project titles, it is impossible to automatically determine whether the tag is correct or not.
Another problem, intrinsic to the data we work on, is to deal with short strings that have no context: in fact, the models we have presented do not generalize well on the papers_1 gram dataset. We intend to address the problem in a combined way: on the one hand using other data, if any, to help create a context, or integrating/annotating them from the web, and on the other hand, improving the training/testing datasets.
Another issue concerns semantic similarity between different language tags. We need to further investigate how to train models whose terms are aligned, how to define datasets for this purpose, and how to fully exploit the results in the search phase.
Moreover, we intend to work on:
Extending the managed languages to additional Western languages and considering the inclusion of language extensions to languages that use different alphabets, such as Chinese (simplified), Japanese, Russian, etc.
Integrating syntactic and similarity relatedness in a unique similarity measure;
Considering not only syntactic errors, but also semantic ones. This will require considering the context in which the keywords are used. If available, the title and an abstract will also be used.
In addition, we intend to experiment with an evolution of word embedding models, using Bert [
18], Elmo, etc., which are able to identify and manage homonyms.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}