Toward Reliable Models for Distinguishing Epileptic High-Frequency Oscillations (HFOs) from Non-HFO Events Using LSTM and Pre-Trained OWL-ViT Vision–Language Framework


Abstract
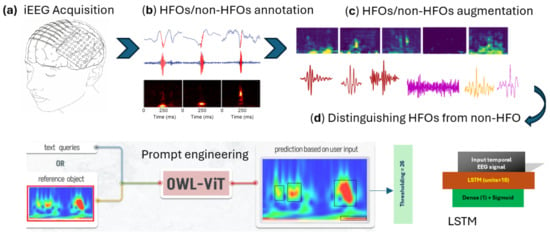
1. Introduction
- A comprehensive overview of existing automated HFO detection and classification approaches utilizing deep learning frameworks.
- The integration of classical augmentation methods with advanced GAN-based data generation techniques to produce additional realistic synthetic EEG waveforms and TF image maps.
- The introduction of a novel and advanced approach based on OWL-ViT, a large vision–language-prompted model, along with its methodologies.
- The optimization, tuning, evaluation, and comparison of different deep learning architectures implemented in this study.
2. Materials and Methods
2.1. Dataset, Visualizations, and Software Environments
2.2. Data Preprocessing
2.3. EEG Data Augmentation Using Conventional and GAN-Based Methods
2.4. Key Deep Learning Hyperparameters for Classifying HFOs
2.5. Performance Evaluation Metrics Used for Classification Tasks
3. Results
- Model Setup: We accessed and downloaded the pre-trained large OWL-ViT model on Google Colab through the Hugging Face platform, which provides convenient access to state-of-the-art large models.
- Data Input: We fed the model with image samples containing both genuine HFOs and non-HFO (artifact, background) patterns for analysis.
- Prompt Generation: We manually created 556 different text prompts by combining key words like verbs, descriptions, and target terms related to HFO context to cover many ways of describing what the model should detect.
- Prompt Evaluation: For each prompt or experiment, we ran the model to obtain the result. Our goal was to determine which prompt best helped the model to distinguish real HFOs from artifacts and give a noticeable visual distinction between the two classes.
- Selecting the Best Prompt and Threshold: Among all tested prompts, the phrase “detect the noise” produced the most clear and significant separation between HFO and non-HFO patterns. The classification decision was based on counting how many bounding boxes the model detected in each image. To find the optimal cutoff point for this count, we used ROC curve analysis, which balances sensitivity (correctly identifying HFOs) and specificity (correctly rejecting artifacts). This analysis showed that using a threshold of 26 bounding boxes gave the best performance in distinguishing between the two categories.
4. Discussion
5. Conclusions and Future Research Veins
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Adagrad | Adaptive Gradient Algorithm |
| Adam | Adaptive Moment Estimation |
| AI | Artificial Intelligence |
| AlexNet | Alex Convolutional Neural Network |
| CMOR Wavelet | Complex Morlet Wavelet |
| CNN | Convolutional Neural Network |
| CVAE | Conditional Variational Autoencoder |
| DA | Data Augmentation |
| DCGAN | Deep Convolutional Generative Adversarial Network |
| DGCNN | Deep Graph Convolutional Neural Network |
| DL | Deep Learning |
| EEG | Electroencephalography |
| ECoG | Electrocorticography |
| EMG | Electromyography |
| EZ | Epileptogenic Zone |
| FDR | False Discovery Rate |
| FIR | Finite Impulse Response Filter |
| FrSST | Fractional Synchrosqueezing Transform |
| FRs | Fast Ripples |
| GAN | Generative Adversarial Network |
| GenAI | Generative Artificial Intelligence |
| HFOs | High-Frequency Oscillations |
| IEEG | Intracranial Electroencephalography |
| LDA | Linear Discriminant Analysis |
| LLMs | Large Language Models |
| LSTM | Long Short-Term Memory |
| LVMs | Large Vision Models |
| MEG | Magnetoencephalography |
| OWL-ViT | Open-World Localization Vision Transformer |
| ResNet101 | Residual Network with 101 Layers |
| RmsProp | Root Mean Square Propagation |
| RonS | Ripple on Spike |
| Rs | Ripples |
| SEEG | Stereo Electroencephalography |
| SGD | Stochastic Gradient Descent |
| SVM | Support Vector Machine |
| TF | Time–Frequency |
| TL | Transfer Learning |
| TLE | Temporal Lobe Epilepsy |
| ViT | Vision Transformer |
| VGG16 | Visual Geometry Group 16-layer Network |
References
- Zhang, Y.; Lu, Q.; Monsoor, T.; Hussain, S.A.; Qiao, J.X.; Salamon, N.; Fallah, A.; Sim, M.S.; Asano, E.; Sankar, R.; et al. Roychowdhury V and Nariai H. Refining epileptogenic high-frequency oscillations using deep learning: A reverse engineering approach. Brain Commun. 2021, 4, fcab267. [Google Scholar] [CrossRef] [PubMed]
- Noorlag, L.; van Klink, N.E.C.; Kobayashi, K.; Gotman, J.; Braun, K.P.J.; Zijlmans, M. High-frequency oscillations in scalp EEG: A systematic review of methodological choices and clinical findings. Clin. Neurophysiol. 2022, 137, 46–58. [Google Scholar] [CrossRef] [PubMed]
- Vasilica, A.M.; Litvak, V.; Cao, C.; Walker, M.; Vivekananda, U. Detection of pathological high-frequency oscillations in refractory epilepsy patients undergoing simultaneous stereo-electroencephalography and magnetoencephalography. Seizure Eur. J. Epilepsy 2023, 107, 81–90. [Google Scholar] [CrossRef]
- Chaibi, S.; Mahjoub, C.; Le Bouquin Jeannès, R.; Kachouri, A. Interactive interface for spatio-temporal mapping of epileptic human brain using characteristics of high frequency oscillations (HFOs). Biomed. Signal Process. Control 2023, 85, 105041. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, D.; Yang, X.; Xu, X.; Ren, L.; Yu, T.; Zhou, W.; Shao, X.; Yang, Z.; Wang, S.; et al. Expert consensus on clinical applications of high-frequency oscillations in epilepsy. Acta Epileptol. 2020, 2, 8. [Google Scholar] [CrossRef]
- Wong, S.M.; Arski, O.N.; Workewych, A.M.; Donner, E.; Ochi, A.; Otsubo, H.; Snead III, O.C.; Ibrahim, G.M. Detection of high-frequency oscillations in electroencephalography: A scoping review and an adaptable open-source framework. Seizure 2021, 84, 23–33. [Google Scholar] [CrossRef]
- Chander, R. Algorithms to Detect High Frequency Oscillations in Human Intracerebral EE.G. Ph.D. Thesis, Department of Biomedical Engineering McGill University Montreal, Montreal, QC, Canada, 2007. [Google Scholar]
- Chaibi, S.; Lajnef, T.; Sakka, Z.; Samet, M.; Kachouri, A. A comparison of methods for detection of high frequency oscillations (HFOs) in human intracerebral EEG recordings. Am. J. Signal Process. 2013, 3, 25–34. [Google Scholar] [CrossRef]
- Krikid, F.; Karfoul, A.; Chaibi, S.; Kachenoura, A.; Nica, A.; Kachouri, A.; Le Bouquin Jeannès, R. Classification of high frequency oscillations in intracranial EEG signals based on coupled time-frequency and image-related features. Biomed. Signal Process. Control 2022, 73, 103418. [Google Scholar] [CrossRef]
- Chaibi, S.; Mahjoub, C.; Ayadi, W.; Kachouri, A. Epileptic EEG patterns recognition through machine learning techniques and relevant time-frequency features. Biomed. Eng./Biomed. Tech. 2024, 69, 111–123. [Google Scholar] [CrossRef]
- Liu, J.; Sun, S.; Liu, Y.; Guo, J.; Li, H.; Gao, Y.; Sun, J.; Xiang, J. A novel MEGNet for classification of high-frequency oscillations in magnetoencephalography of epileptic patients. Complexity 2020. [CrossRef]
- Zhao, B.; Hu, W.; Zhang, C.; Wang, X.; Wang, Y.; Liu, C.; Mo, J.; Yang, X.; Sang, L.; Ma, Y.; et al. Integrated Automatic Detection, Classification and Imaging of High Frequency Oscillations with Stereo electroencephalography. Front. Neurosci. 2020, 14, 546. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Xiao, N.; Li, H.; He, L.; Li, Q.; Wu, T.; He, X.; Chen, P.; Chen, D.; Xiang, J.; et al. Transformer-based high-frequency oscillation signal detection on magnetoencephalography from epileptic patients. Front. Mol. Biosci. 2022, 9, 822810. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, J.; Liu, C.; Wu, T.; Peng, X. An efficient CADNet for classification of high-frequency oscillations in magnetoencephalography. In Proceedings of the 2022 4th International Conference on Robotics and Computer Vision (ICRCV), Wuhan, China, 25–27 September 2022; pp. 25–30. [Google Scholar] [CrossRef]
- Sadek, Z.; Hadriche, A.; Maalej, R.; Jmail, N. Multi-classification of High-Frequency Oscillations Using iEEG Signals and Deep Learning Models. J. Image Graph. 2025, 13, 52–63. [Google Scholar] [CrossRef]
- Lai, D.; Chen, Z.; Zeng, Z.; Ma, K.; Zhang, X.; Chen, W.; Zhang, H. Automated detection of high frequency oscillations in intracranial EEG using the combination of short-time energy and convolutional neural networks. IEEE Access 2019, 7, 82501–82511. [Google Scholar] [CrossRef]
- Ma, K.; Lai, D.; Chen, Z.; Zeng, Z.; Zhang, X.; Chen, W.; Zhang, H. Automatic detection of high frequency oscillations (80–500 Hz) based on convolutional neural network in human intracerebral EE.G. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 5133–5136. [Google Scholar] [CrossRef]
- Medvedev, A.V.; Agoureeva, G.I.; Murro, A.M. A long short-term memory neural network for the detection of epileptiform spikes and high-frequency oscillations. Sci. Rep. 2019, 9, 19374. [Google Scholar] [CrossRef]
- Zuo, R.; Wei, J.; Li, X.; Li, C.; Zhao, C.; Ren, Z.; Liang, Y.; Geng, X.; Jiang, C.; Yang, X.; et al. Automated Detection of High-Frequency Oscillations in Epilepsy Based on a Convolutional Neural Network. Front. Comput. Neurosci. 2019, 13, 6. [Google Scholar] [CrossRef]
- Yuki, T.; Yutaro, T.; Keiya, I.; Masaki, I.; Yumie, O. Efficient Detection of High-frequency Biomarker Signals of Epilepsy by a Transfer-learning-based Convolutional Neural Network. Adv. Biomed. Eng. 2021, 10, 158–165. [Google Scholar] [CrossRef]
- Ren, G.; Sun, Y.; Wang, D.; Ren, J.; Dai, J.; Mei, S.; Li, Y.; Wang, X.; Yang, X.; Yan, J.; et al. Identification of Epileptogenic and Non-epileptogenic High-Frequency Oscillations Using a Multi-Feature Convolutional Neural Network Model. Front. Neurol. 2021, 12, 640526. [Google Scholar] [CrossRef]
- Milon-Harnois, G.; Jrad, N.; Schang, D.; van Bogaert, P.; Chauvet, P. 1D vs 2D convolutional neural networks for scalp high frequency oscillations identification. In Proceedings of the 30th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 5–7 October 2022; p. 211. [Google Scholar] [CrossRef]
- Krikid, F.; Karfoul, A.; Chaibi, S.; Kachenoura, A.; Nica, A.; Kachouri, A.; Le Bouquin Jeannès, R. Multi-classification of high frequency oscillations in intracranial EEG signals based on CNN and data augmentation. Signal Image Video Process. 2023, 18, 1099–1109. [Google Scholar] [CrossRef]
- Broti, N.M.; Sawada, M.; Takayama, Y.; Iwasaki, M.; Ono, Y. Detection of high-frequency biomarker signals of epilepsy by combined deep-learning feature selection and linear discrimination analysis. In Proceedings of the 37th Annual Conference of the Japanese Society for Artificial Intelligence 2023, Kumamoto, Japan, 6–9 June 2023. Paper 1L5-OS-18b-03. [Google Scholar]
- Gharebaghi, F.; Sardouie, S.H. HFO detection from iEEG signals in epilepsy using time-trained graphs and deep graph convolutional neural network. In Proceedings of the 2024 32nd International Conference on Electrical Engineering (ICEE) 2024, Tehran, Iran, 14–16 May 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Chen, W.; Kang, T.; Heyat, M.B.B.; Fatima, J.E.; Xu, Y.; Lai, D. Unsupervised detection of high-frequency oscillations in intracranial electroencephalogram: Promoting a valuable automated diagnostic tool for epilepsy. Front. Neurol. 2025, 16, 1455613. [Google Scholar] [CrossRef]
- Bénar, C.G.; Chauvière, L.; Bartolomei, F.; Wendling, F. Pitfalls of high pass filtering for detecting epileptic oscillations: A technical note on “false” ripples. Clin. Neurophysiol. 2010, 121, 301–310. [Google Scholar] [CrossRef] [PubMed]
- Park, C.J.; Hong, S.B. High Frequency Oscillations in Epilepsy: Detection Methods and Considerations in Clinical Application. J. Epilepsy Res. 2019, 9, 1–13. [Google Scholar] [CrossRef]
- Gliske, S.V.; Qin, Z.; Lau, K.; Alvarado-Rojas, C.; Salami, P.; Zelman, R.; Stacey, W.C. Distinguishing false and true positive detections of high frequency oscillations. J. Neural Eng. 2020, 17, 056005. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; You, J.; Kumar, U.; Weiss, S.A.; Bragin, A.; Engel, J., Jr.; Papadelis, C.; Li, L. An approach for reliably identifying high-frequency oscillations and reducing false-positive detections. Epilepsia Open 2022, 7, 674–686. [Google Scholar] [CrossRef]
- Chaibi, S.; Mahjoub, C.; Kachouri, A. EEG-based cognitive fatigue recognition using relevant multi-domain features and machine learning. Adv. Neural Eng. Brain-Comput. Interfaces 2025, 327–344. [Google Scholar] [CrossRef]
- Zhang, K.; Xu, G.; Han, Z.; Ma, K.; Zheng, X.; Chen, L.; Duan, N.; Zhang, S. Data Augmentation for Motor Imagery Signal Classification Based on a Hybrid Neural Network. Sensors 2020, 20, 4485. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Xiao, C.; Westover, M.B.; Sun, J. Self-Supervised Electroencephalogram Representation Learning for Automatic Sleep Staging: Model Development and Evaluation Study. JMIR AI 2023, 2, e46769. [Google Scholar] [CrossRef]
- Du, X.; Wang, X.; Zhu, L.; Ding, X.; Lv, Y.; Qiu, S.; Liu, Q. Electroencephalographic Signal Data Augmentation Based on Improved Generative Adversarial Network. Brain Sci. 2024, 14, 367. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. IEEE Trans. Knowl. Data Eng. 2023, 35, 3313–3332. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar] [CrossRef]
- Cooper, A.; Kato, K.; Shih, C.-H.; Yamane, H.; Vinken, K.; Takemoto, K.; Sunagawa, T.; Yeh, H.-W.; Yamanaka, J.; Mason, I.; et al. Rethinking VLMs and LLMs for image classification. Sci. Rep. 2025, 15, 19692. [Google Scholar] [CrossRef] [PubMed]
- Boudraa, A.O.; Salzenstein, F. Teager–Kaiser energy methods for signal and image analysis. Digit. Signal Process. 2018, 78, 338–375. [Google Scholar] [CrossRef]
- Moca, V.V.; Bârzan, H.; Nagy-Dăbâcan, A.; Mihali, A.; Mureșan, R.C. Time-frequency super-resolution with superlets. Nat. Commun. 2021, 12, 337. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Ramli, D.A. Fractional synchrosqueezing transform for enhanced multicomponent signal separation. Sci. Rep. 2024, 14, 18082. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, L.; Xiao, P.; Xu, L.; Li, Z. Enhancing time-frequency resolution via deep-learning framework. IET Signal Process. 2023, 17, e12210. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors Year of Publication | Deep Learning Method Nature of Dataset Size of Gold Standard | Models’ Efficiency | Encountered Pitfalls | Significance of Results |
|---|---|---|---|---|
| Lai D et al., 2019 [16] | CNN-2D Intracranial EEG data Five patients 14,998 real HFOs | Sensitivity = 88.16% Rs Sensitivity = 93.37% FRs | FDR = 12.58% for Rs FDR = 8.1% for FRs A relatively small dataset was collected in this work, which still poses challenges to the generalizability of the model. | The proposed model allows fast analysis of large amounts of test data with higher accuracy. |
| Ma K et al., 2019 [17] | CNN-2D Intracranial EEG data Three epileptic patients 9200 real HFOs | Precision = 94.19% Recall = 89.37% F1-score = 91.71% | Limitations include a small patient’s dataset, risk of overfitting, and the need for more clinical data and cross-validation to improve the CNN’s performance and generalizability. | The proposed HFO detector would be more efficient and useful in the diagnosis of epilepsy. |
| Medvedev A.V et al., 2019 [18] | LSTM Intracranial EEG 12 patients 2000 events (R, RonS) | Accuracy and specificity for each class exceeding 90% | - | The proposed model can significantly accelerate the analysis of iEEG data and increase their diagnostic value, which may improve surgical outcomes. |
| Zuo R et al., 2019 [19] | CNN-2D Intracranial EEG 19 participants 49,340 Rs and 19,734 FRs | Sensitivity: 77.04% for Rs and 83.23% for FRs Specificity: 72.27% for Rs and 79.36% for FRs | It lacked cross-channel information and was unable to capture the main characteristics of HFOs, such as duration, amplitude, and energy. | This detector may be used to assist clinicians in locating epileptogenic zones. |
| Liu J et al., 2020 [11] | MEGNET MEG 20 epileptic patients 50 Rs and 50 FRs | Accuracy, precision, recall, and F1-score: 94%, 95%, 94%, and 94% | The gold-standard dataset is small, with only 100 samples used. There is a lack of external validation. Only single-modality data (i.e., MEG) was utilized. Multimodal data (e.g., concurrent EEG recordings) are needed for improved performance. | The proposed method is robust and outperforms the compared models. |
| Zhao B et al., 2020 [12] | ResNet101 SEEG 20 patients 38,447 R events 26,454 FR events | Accuracies on the validation dataset were above 95% | Performance validation on a larger cohort of data from a multicenter is needed. This algorithm is computationally expensive. | This detector can provide robust HFO analysis results, revealing EZ identification. |
| Yuki T et al., 2021 [20] | Transfer learning with AlexNet CNN ECoG data Two patients 1809 real HFOs | The accuracy and F1-measure were greater than 91% and 73%, respectively | FDR = 19.0 ± 4.42%. A larger number of patients is required to enhance the generality and feasibility of the model. There were limitations regarding the age of the patients. | The results suggest that the proposed method may provide an accurate, automatic, and personalized HFO classification. |
| Zhang Y et al., 2021 [1] | CNN-2D Intracranial EEG data 19 patients 10151 real HFOs | Accuracy = 96.3%, F1-score = 96.8% using artifact detection model | It is of interest to include more patients and EEG data to train and improve the model. All the data were collected from the same institution. | This framework reliably replicated the HFO classification tasks typically performed by human experts. |
| Ren G et al., 2021 [21] | CNN-2D Intracranial EEG data 19 patients 7000 epochs of Rs and 2000 epochs of FRs | Accuracy: 80.89 ± 1.43% and 77.85 ± 1.61% for Rs and FRs | There was a limitation in the number of patients. In addition, same patients were used for training, validation, and testing. Due to the small number of events, the performance of the model was not good enough. | The proposed method is an effective deep learning model that can be used to distinguish EZ and non-EZ HFOs. |
| Milon-Harnois G et al., 2022 [22] | CNN-1D and CNN-2D Scalp EEG Three epileptic patients 2591 visually labeled HFOs | Precision, sensitivity, specificity, and F1-score: 85.7%, 84.9%, 85.7%, and 85.3% for CNN-2D 87.5%, 91.4%, 86.9%, and 89.4% for CNN-1D | - | Experimental results show that CNN-1D is more effective compared to CNN-2D. The proposed DL models reached competitive performance levels. |
| Guo J et al., 2022 [13] | Transformer 1D MEG data 20 clinical patients 101 HFO samples | Accuracy of 0.9615, precision of 1.000, sensitivity of 0.9286, specificity of 1.000, and F-score of 0.963 | A small cohort of epilepsy patients, from which 101 samples from 20 patients were collected. Internal validation was conducted on a set of data from one institution. | The proposed framework outperforms the state-of-the-art HFO classifiers. |
| Zhang M et al., 2022 [14] | CNN-2D+ Transformer 2D MEG data 20 epileptic patients 50 Ripples and 50 FRs | Accuracy, precision, recall, and F1-score of the optimized model reached 0.97, 0.98, 0.97, and 0.97 | - | The results demonstrate that this model outperforms other compared methods. |
| Krikid F et al., 2023 [23] | CNN-2D with Data augmentation Intracranial EEG Five patients 710 Rs and 418 FRs | Sensitivity, specificity, accuracy, and F1-score, are, respectively, 0.861, 0.964, 0.978, and 0.905 | - | The proposed approach yields superior results. |
| Broti NM et al., 2023 [24] | VGG19 + LDA ECoG data 2 patients 1809 real HFOs | Accuracy of 87% | - | This method may aid clinical research by reducing the need for large annotations and accurate HFO detection. |
| Gharebaghi F et al., 2024 [25] | DGCNN iEEG 20 patients | Sensitivity of 90.7%, specificity of 93.3%, and an AUC of 0.96 | - | The proposed approach automatically learns discriminative features across patients. |
| Sadek Z et al., 2025 [15] | GoogLeNet + SVM iEEG 21 patients 3220 trials of HFOs | Accuracy: 94.07% | This study was limited by increased data dimensionality from HFO-to-image conversion. A relatively small dataset was used, which affected the model generalization. | This model hold promise for classifying epileptic biomarkers and may improve seizure prediction. |
| Chen W et al., 2025 [26] | CVAE autoencoder + K-means iEEG 5 patients 1611 HFOs | Accuracy of 93.02%, sensitivity of 94.48%, specificity of 92.06% | There was limited patient diversity (age and clinical symptoms). Small dataset size: larger and more varied data are needed. | It offers a promising clinical tool to support surgical planning and improve outcomes in epilepsy patients. The method shows promise for aiding surgical planning in epilepsy. |
| Hyperparameter | Optimizer | Loss Function | Batch Size | Number of Epochs in Early Stopping | Learning Rate | Cross-Validation | Patience Used in Early Stopping | |
|---|---|---|---|---|---|---|---|---|
| Method | ||||||||
| CNN-1D | RmsProp | Binary Cross-Entropy | 20 | 130 | 0.0003 | 15 | ||
| LSTM | 15 | 57 | 0.003 | 10 | ||||
| Transformer 1D | 40 | 55 | 0.0003 | 20 | ||||
| CNN-2D | 12 | 135 | 0.0004 | 10-K-Folders | 25 | |||
| CNN-2D-LSTM | 20 | 140 | 0.0004 | 15 | ||||
| VGG16 | 15 | 89 | 0.0002 | 15 | ||||
| ResNet101 | 30 | 25 | 0.0005 | 4 | ||||
| AlexNet | 50 | 34 | 0.000001 | 5 | ||||
| Transformer ViT-2D | 10 | 65 | 0.0004 | 15 | ||||
| OWL-ViT method | - | - | - | - | - | - | - | |
| Performance Metric | FDR | Accuracy | Recall | Specificity | NPV | Precision | F1-Score | AUC | Overall Metric | |
| Method | ||||||||||
| Time-series DL Networks | CNN-1D | 9.84 | 91.94 | 94.16 | 89.72 | 93.89 | 90.15 | 92.11 | 92.0 | 79.26 |
| LSTM | 1.63 | 99.16 | 100 | 98.33 | 100 | 98.36 | 99.17 | 99.0 | 86.54 | |
| Transformer-1D | 12.54 | 90.50 | 95.04 | 85.77 | 94.31 | 87.45 | 91.08 | 90.0 | 77.70 | |
| Time–Frequency DL Networks | CNN-2D | 3.12 | 96.8 | 96.87 | 96.72 | 96.72 | 96.87 | 96.87 | 97.0 | 84.34 |
| CNN-2D-LSTM | 4.26 | 90.77 | 85.23 | 96.25 | 86.84 | 95.73 | 90.17 | 91.0 | 78.96 | |
| VGG16 | 6.81 | 93.30 | 94.61 | 91.74 | 93.45 | 93.18 | 93.89 | 93.0 | 80.79 | |
| ResNet101 | 4.76 | 93.30 | 92.30 | 94.49 | 91.15 | 95.73 | 90.17 | 91.0 | 80.42 | |
| AlexNet | 1.61 | 96.8 | 95.31 | 98.36 | 95.23 | 98.38 | 96.82 | 97.0 | 84.53 | |
| Transformer-2D | 3.01 | 98.10 | 99.22 | 97.01 | 99.23 | 96.98 | 98.09 | 98.0 | 85.45 | |
| Prompted OWL-ViT | 1.25 | 99.07 | 99.41 | 98.74 | 99.15 | 99.40 | 99.08 | 97.00 | 86.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaibi, S.; Kachouri, A. Toward Reliable Models for Distinguishing Epileptic High-Frequency Oscillations (HFOs) from Non-HFO Events Using LSTM and Pre-Trained OWL-ViT Vision–Language Framework. AI 2025, 6, 230. https://doi.org/10.3390/ai6090230
Chaibi S, Kachouri A. Toward Reliable Models for Distinguishing Epileptic High-Frequency Oscillations (HFOs) from Non-HFO Events Using LSTM and Pre-Trained OWL-ViT Vision–Language Framework. AI. 2025; 6(9):230. https://doi.org/10.3390/ai6090230
Chicago/Turabian StyleChaibi, Sahbi, and Abdennaceur Kachouri. 2025. "Toward Reliable Models for Distinguishing Epileptic High-Frequency Oscillations (HFOs) from Non-HFO Events Using LSTM and Pre-Trained OWL-ViT Vision–Language Framework" AI 6, no. 9: 230. https://doi.org/10.3390/ai6090230
APA StyleChaibi, S., & Kachouri, A. (2025). Toward Reliable Models for Distinguishing Epileptic High-Frequency Oscillations (HFOs) from Non-HFO Events Using LSTM and Pre-Trained OWL-ViT Vision–Language Framework. AI, 6(9), 230. https://doi.org/10.3390/ai6090230