
Privacy-Preserving Interpretability: An Explainable Federated Learning Model for Predictive Maintenance in Sustainable Manufacturing and Industry 4.0


Abstract
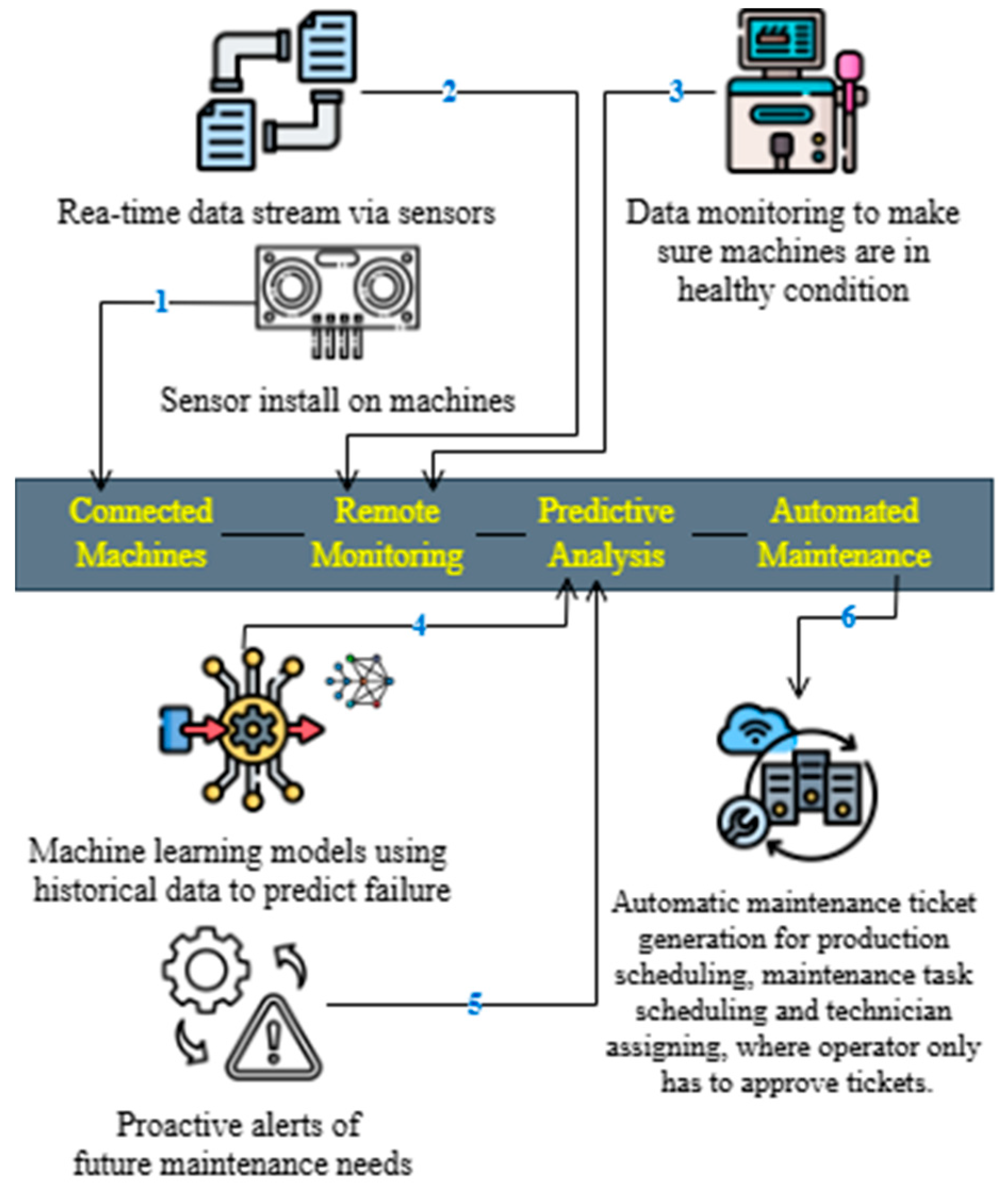
1. Introduction
2. The Literature Review
3. Limitations of Previous Research Works
3.1. A Lack of Privacy-Preserving Techniques
3.2. A Lack of Explainability and Interpretability
3.3. Limited Real-Time Processing and Scalability
4. Contributions to the Proposed Work
4.1. The Incorporation of FL for Data Privacy
4.2. Enhanced Model Interpretability with XAI
4.3. Real-Time Processing and Scalable Industrial Deployment
5. The Proposed Model
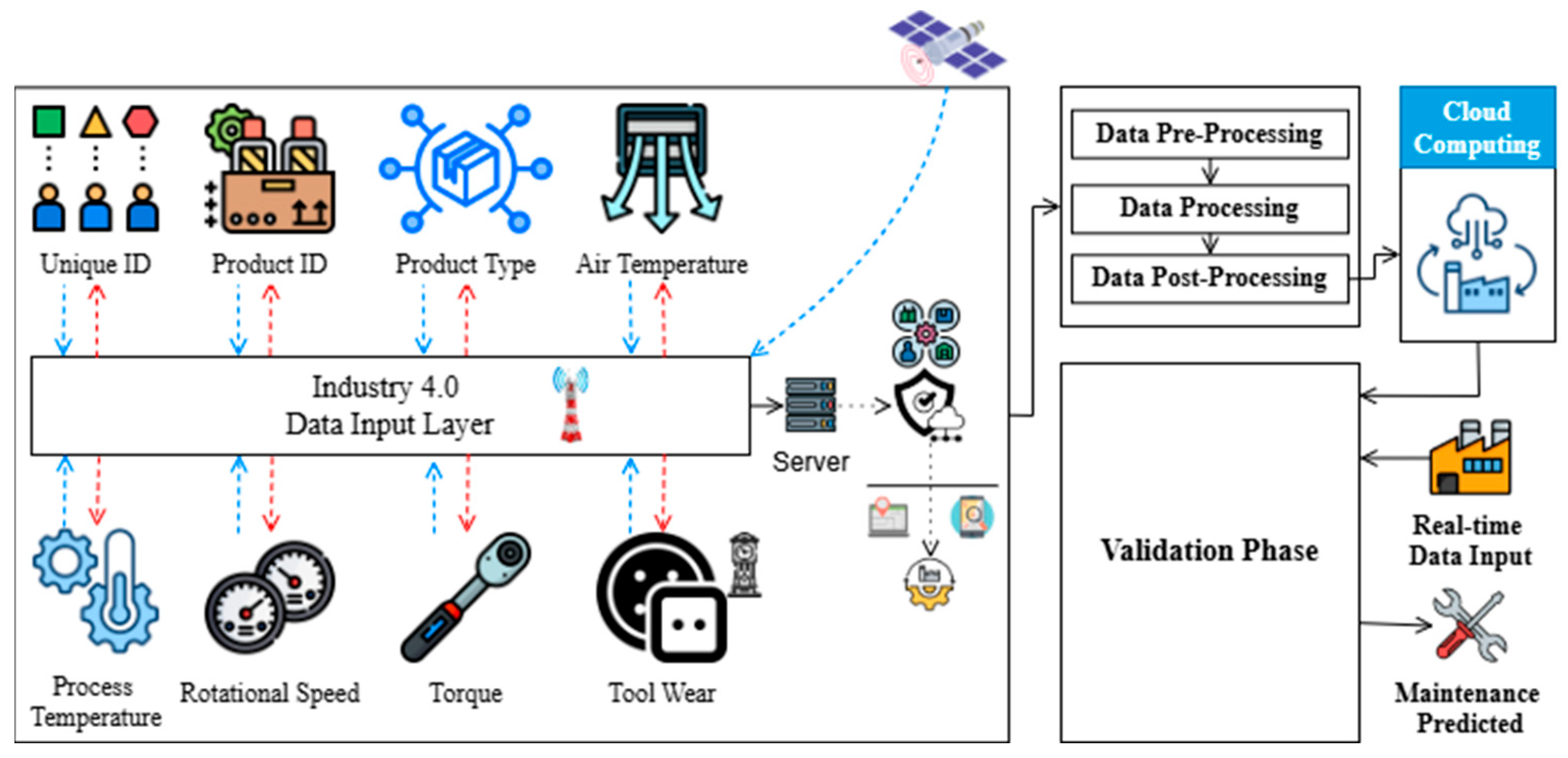
- The Input Layer: Collects real-time sensor data such as temperature, torque, rotational speed, and tool wear;
- The Preprocessing Layer: Applies feature engineering, normalization, encoding, and scaling to prepare data for training;
- The Application Layer: Trains a local PdM model for failure detection.
6. Simulation Results
7. Conclusions
8. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goel, R.; Gupta, P. Robotics and Industry 4.0. A Roadmap to Industry 4.0: Smart Production, Sharp Business, and Sustainable Development; Springer Nature: Berlin/Heidelberg, Germany, 2020; pp. 157–169. [Google Scholar]
- Zalte, S.; Deshmukh, S.; Patil, P.; Patil, M.; Kamat, R.K. Industry 4.0: Design Principles, Technologies, and Applications. In Handbook of Research on Technical, Privacy, and Security Challenges in a Modern World; IGI Global: Hershey, PA, USA, 2022; pp. 25–45. [Google Scholar]
- Sun, Y.; Jung, H. Machine Learning (ML) Modeling, IoT, and Optimizing Organizational Operations through Integrated Strategies: The Role of Technology and Human Resource Management. Sustainability 2024, 16, 6751. [Google Scholar] [CrossRef]
- Kumar, P.; Chinthamu, N.; Misra, S.; Shiva, J. Smart Decision-Making in Industry 4.0: Bayesian Meta-Learning and Machine Learning Approaches for Multimodal Tasks. In Proceedings of the 3rd International Conference on Optimization Techniques in the Field of Engineering (ICOFE-2024), Tiruchengode, India, 22–23 October 2024. [Google Scholar] [CrossRef]
- Mohanty, A.; Mohapatra, A.G.; Mohanty, S.K.; Mahalik, N.P.; Anand, J. Leveraging Digital Twins for Optimal Automation and Smart Decision-Making in Industry 4.0: Revolutionizing Automation and Efficiency. In Handbook of Industrial and Business Applications with Digital Twins; CRC Press: Boca Raton, FL, USA, 2024; pp. 221–242. [Google Scholar]
- Rosunee, S.; Unmar, R. Predictive Maintenance for Industry 4.0. In Intelligent and Sustainable Engineering Systems for Industry 4.0 and Beyond; CRC Press: Boca Raton, FL, USA, 2025; pp. 117–127. [Google Scholar]
- Sarje, S.H.; Kumbhalkar, M.A.; Washimkar, D.N.; Kulkarni, R.H.; Jaybhaye, M.D.; Al Doori, W.H. Current Scenario of Maintenance 4.0 and Opportunities for Sustainability-Driven Maintenance. Adv. Sustain. Sci. Eng. Technol. 2025, 7, 0250102. [Google Scholar] [CrossRef]
- Babaeimorad, S.; Fattahi, P.; Fazlollahtabar, H.; Shafiee, M. An integrated optimization of production and preventive maintenance scheduling in industry 4.0. Facta Univ. Ser. Mech. Eng. 2024, 22, 711–720. [Google Scholar] [CrossRef]
- Çınar, Z.M.; Abdussalam Nuhu, A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine learning in predictive maintenance towards sustainable smart manufacturing in industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Hoffmann, M.A.; Lasch, R. Unlocking the Potential of Predictive Maintenance for Intelligent Manufacturing: A Case Study On Potentials, Barriers, and Critical Success Factors. Schmalenbach J. Bus. Res. 2025, 77, 27–55. [Google Scholar] [CrossRef]
- Gupta, K.; Kaur, P. Application of Predictive Maintenance in Manufacturing with the Utilization of AI and IoT Tools. Authorea Preprints. 2024. Available online: https://www.techrxiv.org/users/870921/articles/1251882-application-of-predictive-maintenance-in-manufacturing-with-the-utilization-of-ai-and-iot-tools (accessed on 2 January 2025).
- Rayarao, S.R. Advanced Predictive Maintenance Strategies: Insights from the AI4I 2020 Dataset. Authorea Preprints. 2024. [Google Scholar]
- Karwa, R.R.; Bamnote, G.R.; Dhumale, Y.A.; Deshmukh, P.P.; Meshram, R.A.; Iqbal, S.M. Predictive Maintenance: Machine Learning Approaches for Enhanced Equipment Reliability. In Proceedings of the 2024 2nd DMIHER International Conference on Artificial Intelligence in Healthcare, Education and Industry (IDICAIEI), Wardha, India, 29–30 November 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar]
- Stark, J. Barriers to Successful Implementation of PDM. In Product Lifecycle Management (Volume 2) The Devil Is in the Details; Springer International Publishing: Cham, Switzerland, 2015; pp. 371–386. [Google Scholar]
- Alabadi, M.; Habbal, A. Next-generation predictive maintenance: Leveraging blockchain and dynamic deep learning in a domain-independent system. PeerJ Comput. Sci. 2023, 9, e1712. [Google Scholar] [CrossRef]
- Rustambekov, I.; Saidakhmedovich, G.S.; Abduvaliyev, B.; Kan, E.; Abdukhakimov, I.; Yakubova, M.; Karimov, D. Predictive Maintenance of Smart Grid Components Based on Real-Time Data Analysis. In Proceedings of the 2024 6th International Conference on Control Systems, Mathematical Modeling, Automation and Energy Efficiency (SUMMA), Lipetsk, Russia, 13–15 November 2024; IEEE: New York, NY, USA, 2024; pp. 949–952. [Google Scholar]
- Kalaiselvi, K.; Niranjana, K.; Prithivirajan, V.; Kumar, K.S.; Syambabu, V.; Sathiya, B. Machine Learning for Predictive Maintenance in Industrial Equipment: Challenges and Application. In Proceedings of the 2024 4th Asian Conference on Innovation in Technology (ASIANCON), Pimari Chinchwad, India, 23–25 August 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar]
- Ghelani, D. Harnessing machine learning for predictive maintenance in energy infrastructure: A review of challenges and solutions. Int. J. Sci. Res. Arch. 2024, 12, 1138–1156. [Google Scholar] [CrossRef]
- Srinivas, M.; Sucharitha, G.; Matta, A. (Eds.) Machine Learning Algorithms and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Nasarian, E.; Alizadehsani, R.; Acharya, U.R.; Tsui, K.L. Designing interpretable ML system to enhance trust in healthcare: A systematic review to propose a responsible clinician-AI-collaboration framework. Inf. Fusion 2024, 108, 102412. [Google Scholar] [CrossRef]
- Belghachi, M. A review on explainable artificial intelligence methods, applications, and challenges. Indones. J. Electr. Eng. Inform. (IJEEI) 2023, 11, 1007–1024. [Google Scholar] [CrossRef]
- Cakir, M.; Guvenc, M.A.; Mistikoglu, S. The experimental application of popular machine learning algorithms on predictive maintenance and the design of IIoT-based condition monitoring system. Comput. Ind. Eng. 2021, 151, 106948. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Ayvaz, S.; Alpay, K. Predictive maintenance system for production lines in manufacturing: A machine learning approach using IoT data in real-time. Expert Syst. Appl. 2021, 173, 114598. [Google Scholar] [CrossRef]
- Moosavi, S.; Farajzadeh-Zanjani, M.; Razavi-Far, R.; Palade, V.; Saif, M. Explainable AI in manufacturing and industrial cyber–physical systems: A survey. Electronics 2024, 13, 3497. [Google Scholar] [CrossRef]
- Kumar, V.; Yadav, V.; Singh, A.P. Demystifying Predictive Maintenance: Achieving Transparency through Explainable AI. In Proceedings of the 2024 1st International Conference on Advanced Computing and Emerging Technologies (ACET), Ghaziabad, India, 23–24 August 2024; IEEE: New York, NY, USA, 2024; pp. 1–7. [Google Scholar]
- Vollert, S.; Atzmueller, M.; Theissler, A. Interpretable Machine Learning: A brief survey from the predictive maintenance perspective. In Proceedings of the 26th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Västerås, Sweden, 7–10 September 2021; IEEE: New York, NY, USA, 2021; pp. 01–08. [Google Scholar]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Boobalan, P.; Ramu, S.P.; Pham, Q.V.; Dev, K.; Pandya, S.; Maddikunta, P.K.R.; Gadekallu, T.R.; Huynh-The, T. Fusion of federated learning and industrial Internet of Things: A survey. Comput. Netw. 2022, 212, 109048. [Google Scholar] [CrossRef]
- Farahani, B.; Monsefi, A.K. Smart and collaborative industrial IoT: A federated learning and data space approach. Digit. Commun. Netw. 2023, 9, 436–447. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.; Wang, S.; Sun, X.; Di Cairano-Gilfedder, C.; Titmus, S.; Syntetos, A.A. Predictive maintenance using cox proportional hazard deep learning. Adv. Eng. Inform. 2020, 44, 101054. [Google Scholar] [CrossRef]
- Cheng, J.C.; Chen, W.; Chen, K.; Wang, Q. Data-driven predictive maintenance planning framework for MEP components based on BIM and IoT using machine learning algorithms. Autom. Constr. 2020, 112, 103087. [Google Scholar] [CrossRef]
- Gohel, H.A.; Upadhyay, H.; Lagos, L.; Cooper, K.; Sanzetenea, A. Predictive maintenance architecture development for nuclear infrastructure using machine learning. Nucl. Eng. Technol. 2020, 52, 1436–1442. [Google Scholar] [CrossRef]
- Zenisek, J.; Holzinger, F.; Affenzeller, M. Machine learning-based concept drift detection for predictive maintenance. Comput. Ind. Eng. 2019, 137, 106031. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, Q.; Yu, Q.; Li, Z.; Liu, Y.; Lo, S.K.; Chen, S.; Xu, X.; Zhu, L. Blockchain-based federated learning for device failure detection in industrial IoT. IEEE Internet Things J. 2020, 8, 5926–5937. [Google Scholar] [CrossRef]
- Oladapo, K.A.; Adedeji, F.; Nzenwata, U.J.; Quoc, B.P.; Dada, A. Fuzzified case-based reasoning blockchain framework for predictive maintenance in industry 4.0. In Data Analytics and Computational Intelligence: Novel Models, Algorithms and Applications; Springer Nature: Cham, Switzerland, 2023; pp. 269–297. [Google Scholar]
- Kaul, K.; Singh, P.; Jain, D.; Johri, P.; Pandey, A.K. Monitoring and controlling energy consumption using IOT-based predictive maintenance. In Proceedings of the 2021 10th International Conference on System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 10–11 December 2021; IEEE: New York, NY, USA, 2021; pp. 587–594. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Biswal, S.; Sabareesh, G.R. Design and development of a wind turbine test rig for condition monitoring studies. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015; IEEE: New York, NY, USA, 2015; pp. 891–896. [Google Scholar]
- Xiang, S.; Huang, D.; Li, X. A generalized predictive framework for data-driven prognostics and diagnostics using machine logs. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju Island, Republic of Korea, 28–31 October 2018; IEEE: New York, NY, USA, 2018; pp. 0695–0700. [Google Scholar]
- Huuhtanen, T.; Jung, A. Predictive maintenance of photovoltaic panels via deep learning. In Proceedings of the 2018 IEEE Data Science Workshop (DSW), Lausanne, Switzerland, 4–6 June 2018; IEEE: New York, NY, USA, 2018; pp. 66–70. [Google Scholar]
- Available online: https://www.kaggle.com/code/atom1991/predictive-maintenance-for-industrial-devices/input (accessed on 2 January 2025).
- Paolanti, M.; Romeo, L.; Felicetti, A.; Mancini, A.; Frontoni, E.; Loncarski, J. Machine learning approach for predictive maintenance in industry 4.0. In Proceedings of the 2018 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Oulu, Finland, 2–4 July 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Durbhaka, G.K.; Selvaraj, B. Predictive maintenance for wind turbine diagnostics using vibration signal analysis based on a collaborative recommendation approach. In Proceedings of the 2016 International Conference on Advances in Computing, Communications, and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; IEEE: New York, NY, USA, 2016; pp. 1839–1842. [Google Scholar]
- Karlsson, L. Predictive Maintenance for RM12 with Machine Learning. 2020. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1437847&dswid=-5590 (accessed on 2 January 2025).
- Liu, J.; Cheng, H.; Liu, Q.; Wang, H.; Bu, J. Research on the damage diagnosis model algorithm of cable-stayed bridges based on data mining. Sustainability 2023, 15, 2347. [Google Scholar] [CrossRef]
- Li, J.; Zhu, D.; Li, C. Comparative analysis of BPNN, SVR, LSTM, Random Forest, and LSTM-SVR for conditional simulation of non-Gaussian measured fluctuating wind pressures. Mech. Syst. Signal Process. 2022, 178, 109285. [Google Scholar] [CrossRef]
- Ahn, J.; Lee, Y.; Kim, N.; Park, C.; Jeong, J. Federated learning for predictive maintenance and anomaly detection using time series data distribution shifts in manufacturing processes. Sensors 2023, 23, 7331. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Model(s) Used | Objective | Preprocessing Technique | Predictive Model | Privacy-Preserving (FL) | Interpretability (XAI) | Scalability | Regulatory Compliance | Real-Time PdM Capability | Strengths | Limitations |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Chen et al. [31] | CoxPHDL, Autoencoder, LSTM | Address data censoring and sparsity in maintenance analyses | Feature extraction; structured representation | CoxPHM, LSTM | 🞬 | 🞬 | Moderate | 🞬 | 🞬 | An improved RMSE and MCC, optimized reliability | Lacks explainability and privacy preservation; real-time limitations. |
| Cheng et al. [32] | BIM, IoT, ANN, SVM | PdM for facility management | Data integration from FM, IoT, and BIM | ANN, SVM | 🞬 | 🞬 | High | 🞬 | ☑ | Effective BIM-IoT integration for PdM | Lacks privacy and interpretability; real-time adaptability issues. |
| [33] | LR, SVM | PdM for nuclear infrastructure | Parameter optimization; anomaly detection | LR, SVM | 🞬 | 🞬 | Moderate | 🞬 | 🞬 | ML-driven PdM for high-risk environments | Needs improved scalability; lacks privacy and interpretability; real-time limitations. |
| Zenisek et al. [34] | RF | Detect concept drift in continuous data streams | Data screening; anomaly detection | RF | 🞬 | 🞬 | Moderate | 🞬 | 🞬 | Early fault detection reduces costs | Requires high-quality data, lacks privacy and interpretability, and real-time challenges. |
| [35,36,37] | FL, Blockchain, IIoT | Enhance PdM in Industry 4.0 | Secure distributed training; anomaly detection | Various ML models | ☑ | 🞬 | High | ☑ | ☑ | Strong data privacy, integrity, and real-time monitoring | Lacks interpretability, computational efficiency, and real-world deployment challenges. |
| [38] | LIME, SHAP, Grad-CAM, Attention Mechanisms | Classification of interpretability techniques | Model-agnostic explainability; feature attribution | Applied to various ML models | 🞬 | ☑ | High | ☑ | ☑ | Enhances model transparency and trust in AI decisions | Lacks privacy and complexity in integrating XAI for real-time industrial use. |
| Biswal and Sabareesh [39] | ANN | Condition monitoring of wind turbines | Vibration data acquisition; feature extraction | ANN | 🞬 | 🞬 | Low | 🞬 | 🞬 | A high classification accuracy (92.6%) for fault detection | Lacks privacy and interpretability; limited scalability for diverse environments; real-time challenges. |
| Xiang et al. [40] | SVM, RF, GBM | Diagnostics and prognostics for PdM | Data labeling; supervised learning | GBMs outperformed the others | 🞬 | 🞬 | Moderate | 🞬 | 🞬 | Over 80% accuracy in diagnostics and strong model optimization | Requires accurate data labeling, lacks privacy snd interpretability; real-world validation needed; real-time adaptability issues. |
| Huuhtanen and Jung [41] | CNN | PdM for PV panels | Electrical power curve estimation | CNN | 🞬 | 🞬 | Moderate | 🞬 | 🞬 | Accurate prediction of the power curve, better than interpolation | Scalability and real-world deployment challenges; lacks privacy and interpretability; real-time limitations. |
| Proposed XFL model | FL, XAI (SHAP, LIME), AI-driven PdM | Privacy-preserving and explainable PdM | Secure data aggregation; model interpretability | FL with AI-based PdM | ☑ | ☑ | High | ☑ | ☑ | Ensures privacy, enhances interpretability, and is scalable and real-time | Computational complexity requires robust infrastructure for deployment. |
| Sr. No. | Features | Description |
|---|---|---|
| 1 | UDI | int64 |
| 2 | Product ID | object |
| 3 | Type | object |
| 4 | Air temperature [K] | float64 |
| 5 | Process temperature [K] | float64 |
| 6 | Rotational speed [rpm] | int64 |
| 7 | Torque [Nm] | float64 |
| 8 | Tool wear [min] | Int64 |
| 9 | Target | int64 |
| 10 | Failure type | object |
| Step | Process |
|---|---|
| 1 | Start |
| 2 | Data Collection: Gather real-time sensor data, (e.g., temperature, torque, speed, tool wear). |
| 3 | Preprocessing: ☑ Data loading and inspection ☑ Exploratory data analysis ☑ Feature engineering ☑ Feature selection ☑ Categorical variable encoding ☑ Feature scaling |
| 4 | Split Data: Partition the dataset into the training set (Tr) and the testing set (Te). |
| 5 | Model Training: Initialize ML models for PdM. |
| 6 | Iterative Training: Optimize the learning rate , retrain until convergence . |
| 7 | Validation: Evaluate the model with the accuracy . If , retrain the model. |
| 8 | Store Trained Model: Save the optimized model on the local server. |
| 9 | Global Model Sync (If Required): Send to the global system for aggregation. |
| 10 | Real-Time Prediction: Import data from the cloud, generate failure predictions , and trigger maintenance alerts. |
| 11 | Stop |
| Steps | Processes |
|---|---|
| 1. Global Model Initialization | ✔ Initializes the global model and sets the performance threshold . The threshold is selected based on the validation accuracy to ensure only high-performing global models are deployed. |
| 2. Local Model Training and Aggregation | ✔ Receives trained models from local industries trained on the dataset . ✔ Evaluates each local model using the validation dataset . ✔ Selects the best-performing model based on evaluation: |
| 3. Convergence Check and Retraining | ✔ Checks convergence: If , the model is deployed. ✔ If not converged, requests additional training with hyperparameter tuning. |
| 4. XAI Integration | ✔ Applies SHAP and LIME for interpretability. ✔ Computes the SHAP values for feature importance: ✔ Trains a LIME surrogate model for interpretable local predictions. |
| 5. Global Model Deployment and Prediction | ✔ Deploys the final model . ✔ Uses new sensor data to predict failure probability: ✔ If , triggers automated maintenance. |
| 6. Storage and Completion | ✔ Securely stores validated predictions in cloud storage. ✔ Terminates the process. |
| Confusion Matrix | ||||||||
|---|---|---|---|---|---|---|---|---|
| K Neighbors Classifier | Gradient Boosting Classifier | Bagging Classifier | Hist Gradient Boosting Classifier | |||||
| Train (8000) | Test (2000) | Train (8000) | Test (2000) | Train (8000) | Test (2000) | Train (8000) | Test (2000) | |
| True Positive (TP) | 7698 | 1928 | 7711 | 1929 | 7720 | 1925 | 7721 | 1924 |
| True Negative (TN) | 100 | 18 | 161 | 34 | 254 | 33 | 270 | 34 |
| False Positive (FP) | 24 | 11 | 11 | 10 | 2 | 14 | 1 | 15 |
| False Negative (FN) | 178 | 43 | 117 | 27 | 24 | 28 | 8 | 27 |
| Performance Metrics | ||||||||
|---|---|---|---|---|---|---|---|---|
| K Neighbors Classifier | Gradient Boosting Classifier | Bagging Classifier | Hist Gradient Boosting Classifier | |||||
| Train | Test | Train | Test | Train | Test | Train | Test | |
| Accuracy | 97.48 | 97.3 | 98.4 | 98.15 | 99.68 | 97.9 | 99.89 | 97.9 |
| Sensitivity (TPR) | 97.74 | 97.82 | 98.51 | 98.62 | 99.69 | 98.57 | 99.9 | 98.62 |
| Specificity (TNR) | 80.65 | 62.07 | 93.6 | 77.27 | 99.22 | 70.21 | 99.63 | 69.39 |
| Miss rate (FNR) | 2.52 | 2.7 | 1.6 | 1;85 | 0.32 | 2.1 | 0.11 | 2.1 |
| Positive Predictive Value (PPV) | 99.69 | 99.43 | 99.86 | 99.48 | 99.97 | 99.28 | 99.99 | 99.23 |
| Negative Predictive Value (NPV) | 35.97 | 29.51 | 57.91 | 55.74 | 91.37 | 54.1 | 97.12 | 55.74 |
| References | Model | Accuracy (%) | Miss-Rate (%) |
|---|---|---|---|
| Biswal et al., 2015 [39] | ANN | 92.6 | 7.4 |
| Paolanti et al., 2018 [43] | RF | 95 | 5 |
| Xiang et al., 2018 [40] | SVM, RF, GBM | 80 | 20 |
| Durbhaka et al., 2016 [44] | SVM, K-means, KNN, Euclidean distance, and CRA | 93 | 7 |
| Karlsson et al., 2020 [45] | LR | 87 | 13 |
| Liu et al., 2023 [46] | LR | 67.71 | 32.29 |
| Li et al., 2022 [47] | LSTM | 79.30 | 20.7 |
| Ahn et al., 2023 [48] | FL + 1DCNN-BiLSTM | 97.2 | 2.8 |
| The proposed XFL model for PdM | FL + XAI | 98.15 | 1.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshkeili, H.M.H.A.; Almheiri, S.J.; Khan, M.A. Privacy-Preserving Interpretability: An Explainable Federated Learning Model for Predictive Maintenance in Sustainable Manufacturing and Industry 4.0. AI 2025, 6, 117. https://doi.org/10.3390/ai6060117
Alshkeili HMHA, Almheiri SJ, Khan MA. Privacy-Preserving Interpretability: An Explainable Federated Learning Model for Predictive Maintenance in Sustainable Manufacturing and Industry 4.0. AI. 2025; 6(6):117. https://doi.org/10.3390/ai6060117
Chicago/Turabian StyleAlshkeili, Hamad Mohamed Hamdan Alzari, Saif Jasim Almheiri, and Muhammad Adnan Khan. 2025. "Privacy-Preserving Interpretability: An Explainable Federated Learning Model for Predictive Maintenance in Sustainable Manufacturing and Industry 4.0" AI 6, no. 6: 117. https://doi.org/10.3390/ai6060117
APA StyleAlshkeili, H. M. H. A., Almheiri, S. J., & Khan, M. A. (2025). Privacy-Preserving Interpretability: An Explainable Federated Learning Model for Predictive Maintenance in Sustainable Manufacturing and Industry 4.0. AI, 6(6), 117. https://doi.org/10.3390/ai6060117