A Knowledge-Driven Framework for AI-Augmented Business Process Management Systems: Bridging Explainability and Agile Knowledge Sharing

 ,
,  , , and
, , and
Abstract
1. Introduction
- Be web-based and user-friendly;
- Enable the quick capture of a lesson at any time, its dissemination to potential users, and its easy and fast retrieval;
- Include a dedicated section for lessons learned and patterns;
- Create a backlog of discussions, lessons, and lessons learned to be discussed and validated (or not) during meetings and CoP;
- Incorporate advanced search techniques, leveraging keyword searches and other specialized hyperlinked relationships.
2. State of the Art
2.1. The Impact of AI on KM
2.2. Impact of AI on BPMSs
2.3. Challenges in ABPMSs
- Situation-aware Explainability: It will be required in ABPMSs where the explanation is not only context-relevant but must also be easily understood by the human user. Typical questions would relate to why a specific task is performed, what decisions it is making, and at least some conclusions about objectives in the business process. The challenge is in deriving mechanisms to elaborate on such explanations in a form that is understandable by a user as the basis for further system activities, as well as for informed decisions from such understanding.
- Autonomy Framed by Constraints: Although ABPMSs are designed to operate autonomously, this autonomy must be bounded by specific operational assumptions, goals, and environmental constraints. The systems should not only act independently but also engage in a dialogue with human users. It involves explaining their actions and providing advice for process changes or improvements. The challenge is in conceptualizing a model in which a two-way interaction is possible, keeping the system effective without compromising its accountability to the oversight of people.
- Continuous Improvement: ABPMS should present executed improvements in the business process. This will involve new skills and methods by which a system can ingest applications according to its operational capability and anticipated outcomes. The challenge will be in integrating sophisticated AI capabilities that will facilitate this learning process for adjusting system operations through feedback and changing scenarios.
- Hybrid Process Intelligence: This concept states that there is a need for an ABPMS to communicate with a human as “learning apprentices”. AI has to learn the user’s work practices rather than expect the user to modify the work. Hence, the challenge is to design systems that learn through human experiences and modify their behavior accordingly so that they work in synergy with human users in executing the processes.
- Trust and Reliability: To ensure its acceptance and efficiency, the ABPMS has to gain credibility and trustworthiness. All information regarding transparency in AI’s decision making, qualified usage of data, and exceptions in areas or types of unpredicted situations must be available to users. Making systems perform better is not the only challenge; convincing the users is also considered an important point where users should trust the decisions and actions from the system.
2.4. Emerging Trends in ABPMSs
3. Materials and Methods
3.1. Framework Description
- Process Modeling and Formalization: The first step involves defining the operational workflow through the Explainable Workflow Designer. This module allows domain experts to model business processes using a custom, user-friendly notation, abstracted from the complexity of BPMN 2.0. Thanks to a drag-and-drop interface and domain-specific semantics, non-technical users can formalize actors, data flows, and decision points. This approach not only supports initial process mapping but also facilitates subsequent automation and orchestration.
- Data Analysis and Predictive Modeling: Once the process is defined, the AI Explainability Module is applied to perform predictive analytics using AI models. The system ingests structured and unstructured data (e.g., sensor, maintenance, and production data) and applies ML techniques to forecast key operational indicators. For example, it enables the estimation of Remaining Useful Life (RUL) for mechanical components.
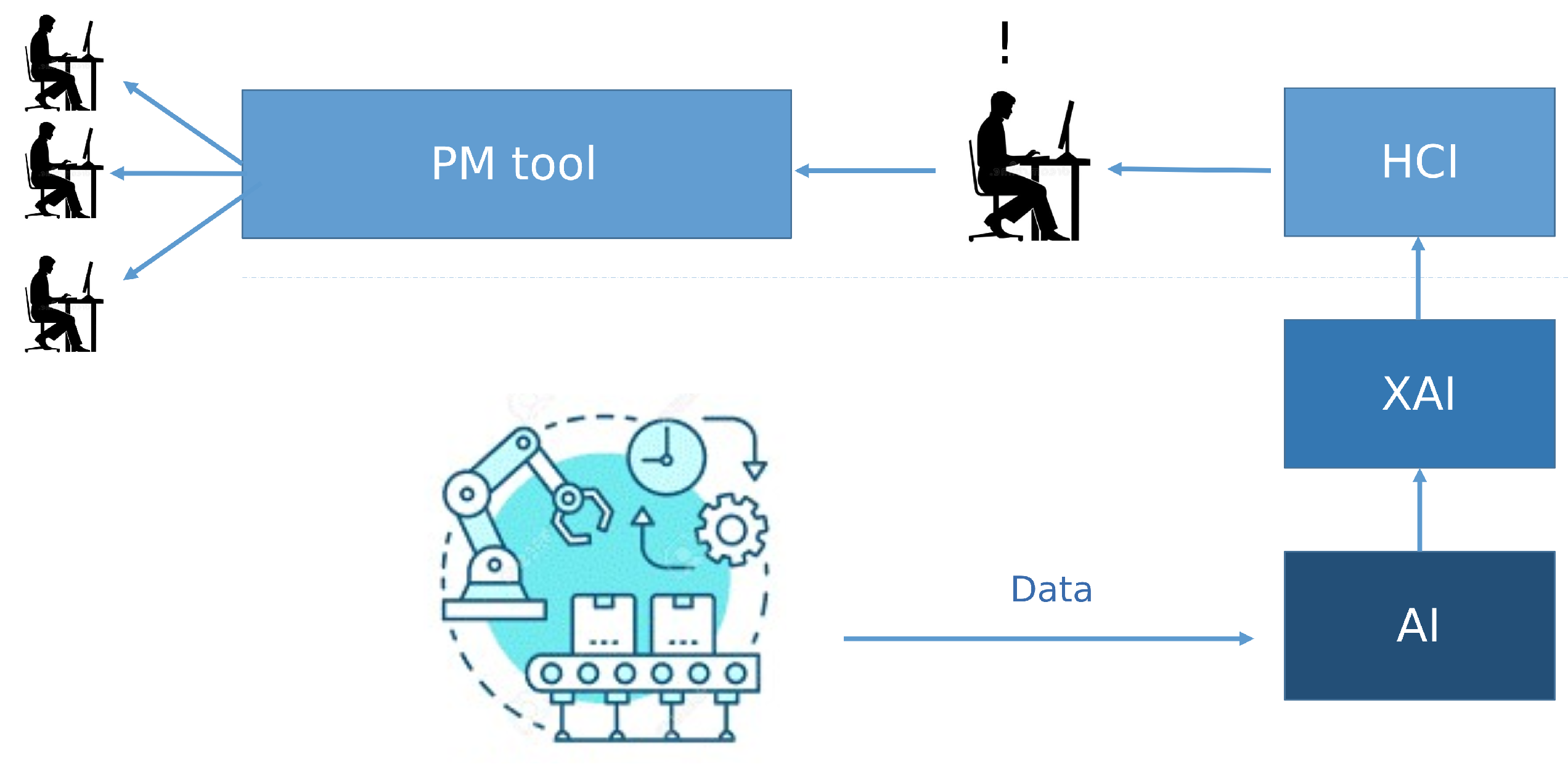
- Explainability and Human-in-the-Loop Interaction: To ensure that the AI’s outputs are transparent and actionable, XAI techniques (e.g., SHAP and LIME) are employed. These methods highlight the most influential variables driving predictions. The Innovative HCI Module then presents these insights via interactive visualizations tailored to the cognitive models of domain operators. This Human-in-the-Loop (HITL) paradigm empowers users to interpret model outputs, validate system recommendations, and retain decision-making authority.
- Knowledge Codification and Execution: The results, once validated, are formalized into a knowledge repository through the Workflow Designer. Best practices and optimization rules are stored in the Process Optimization Rules database, enabling continuous knowledge sharing and reuse. This integration of formalized process knowledge with live operational data supports real-time monitoring and adaptive decision making.
- Ethical Evaluation: The ethical XAI methodology guides organizations in assessing the ethical compliance of AI systems based on EU principles, including transparency, robustness, privacy, and social well-being. Using a structured set of indicators and visual tools (e.g., Kiviat diagrams), the framework enables quantifiable evaluation of AI behavior, ensuring responsible adoption.
- An MLP deep neural network: It is a simple neural network of the order of 100,000 parameters with “dense” connections. This model was chosen as it belongs to the family of neural networks (the currently most opaque AI algorithms), but we wanted to maintain the simplicity of the architecture to speed up training (Keras Python library).
- A Random Forest: This AI algorithm oversees the training of 200 decision trees that converge to a common decision. Unlike the neural network, Random Forest is a medium-opaque algorithm and was chosen to allow XAI techniques to obtain results more simply, to compare them with those of the neural network (Python’s Scikit-learn library).
- Local Interpretable Model-Agnostic Explanations (LIME): An XAI technique that falls into the category of explanations by simplification, where simpler surrogate models are used to simplify the complex model and draw explanations from it. In addition to it being model-agnostic, LIME was chosen due to its simplicity of implementation and common use in the scientific literature.
- SHapley Additive exPlanations (SHAP): An XAI technique that falls into the category of explanations for feature importance in which the samples are perturbed to estimate a value (called a Shap value) for each input, meaning the index of the importance that the feature has towards the output (technique used: KernelExplainer). SHAP was selected both because it falls into both macro-families of LIME (to achieve results of the same potential) and to contrast it with LIME, given the different approach to explanation.
3.2. Hardware and Software Tools
3.3. Knowledge Management System Requirements
3.3.1. Requirement ID 1: System Scope
- Initiate a discussion, allowing users to present problems and suggestions related to daily operations, aimed at solving the problem and collaboratively discussing the suggestion. The collection and cataloging of discussions can form a backlog of topics managed within the Scrum Team itself (tacit KM during the socialization step).
- Define a Lesson, allowing users to formalize an experience and discuss it collaboratively. The set of all inserted lessons can form a topic backlog accessible by all Scrum Teams during each operational activity (tacit to explicit KM during the outsourcing step).
- Define a lesson learned. This will be made possible by the functionality implemented in the system through which a lesson learned can be formalized and shared. The set of all lessons learned entered can form a backlog of topics to be evaluated in the Scrum of Scrums (SoS), consisting of the Scrum Masters, or team leaders, of the different teams.
- Formalize a pattern. The system should allow users to formalize and share a best practice. This database of inserted best practices can form a backlog of topics to be discussed in a CoP.
- Manage roles and groups; it is important to consider that a group is characterized by figures having different roles. If we want to remain in the IT sphere, we can consider, as an example, a team consisting of a developer, a tester, a team leader, a unit leader, etc.
- Track the history of each discussion, lesson, lesson learned, and best practice.
- Ensure access to the pattern archive for each user to support the propagation of explicit to tacit corporate knowledge during the internalization step.
3.3.2. Requirement ID 2—Account Management
3.3.3. Requirement ID 3—System Authentication
3.3.4. Requirement ID 4—Definition of Role in the Scrum Team
- Initiate a discussion, aimed at solving a problem and/or discuss a suggestion for improvement in a collaborative manner;
- Formalize a lesson;
- Participate in a discussion;
- Propose improvements to a discussion.
3.3.5. Requirement ID 5—Scrum Master Functionality
- Approve a discussion;
- Formalize a lesson and submit it for system validation;
- Approve a lesson in lessons learned;
- Reformulate an existing pattern to create a new lesson.
3.3.6. Requirement ID 6—Scrum Member of Scrum Meeting Functionality
3.3.7. Requirement ID 7—CoP Member Functionality
3.3.8. Requirement ID 8—Initiation and Formalization of a Discussion
- Title of the discussion;
- Discussion start date.
- Title identifying the proposed knowledge;
- Keywords (tags);
- Description of the proposed new knowledge.
3.3.9. Requirement ID 9—Lesson Formalization
- The name of the lesson;
- Keywords (tags);
- The areas of use of the lesson;
- The description of the lesson.
3.3.10. Requirement ID 10—Lesson Management
3.3.11. Requirement ID 11—Creation of the Lesson Learned
3.3.12. Requirement ID 12—Approval of Lesson Learned
- Title of the lesson learned;
- Keywords (tags);
- Validation date of the lesson learned (automatically compiled by the system);
- The areas of use of the lesson;
- The description of the lesson;
- The validation of Key Performance Indicators (KPIs).
3.3.13. Requirement ID 13—Managing Lesson Learned
3.3.14. Requirement ID 14—Pattern Approval
3.3.15. Requirement ID 15—Pattern Management
3.3.16. Requirement ID 16—Content Categorization
3.3.17. Requirement ID 17—Import/Export
4. Implementation
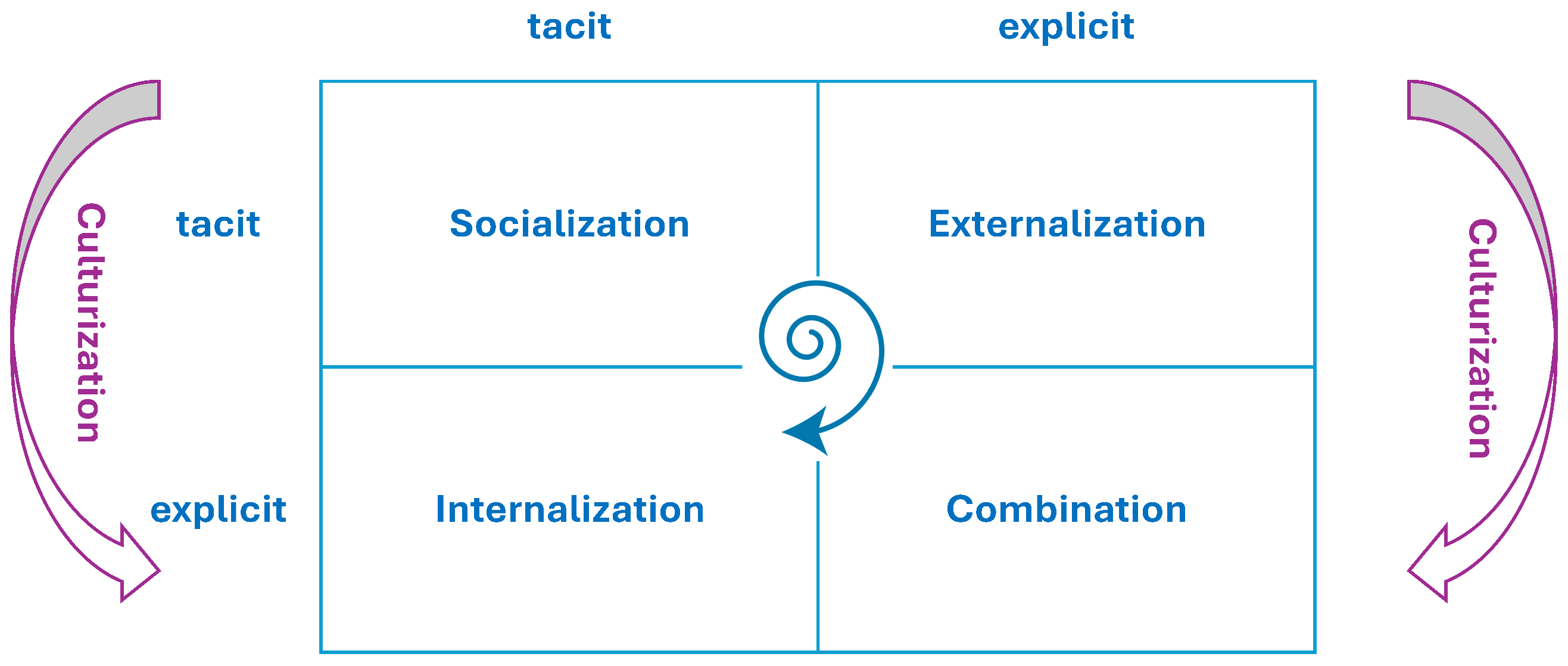
- Socialization (Tacit to Tacit): In this initial phase, tacit knowledge is shared informally among Scrum Team Members through direct interaction, collaborative work, and practical experience exchange. This occurs during Agile events such as daily stand-ups, sprint reviews, and retrospectives, where challenges, insights, and emerging solutions are openly discussed. Although no formal validation takes place at this stage, it lays the groundwork for identifying potential lessons learned.
- Externalization (Tacit to Explicit): Tacit knowledge is transformed into explicit knowledge through documentation and verbalization. This phase is reflected in Discussion Management activities, where the Scrum Team, typically under the guidance of the Scrum Master, captures knowledge in the form of documents, presentations, or textual contributions within shared repositories. While not yet validated, these contributions are systematically recorded and tracked, preparing them for future evaluation. Furthermore, the Scrum Master facilitates the documentation process and ensures that relevant knowledge is systematically discussed during retrospectives and Scrums of Scrums. This active role supports both the validation and dissemination of emerging insights across teams.
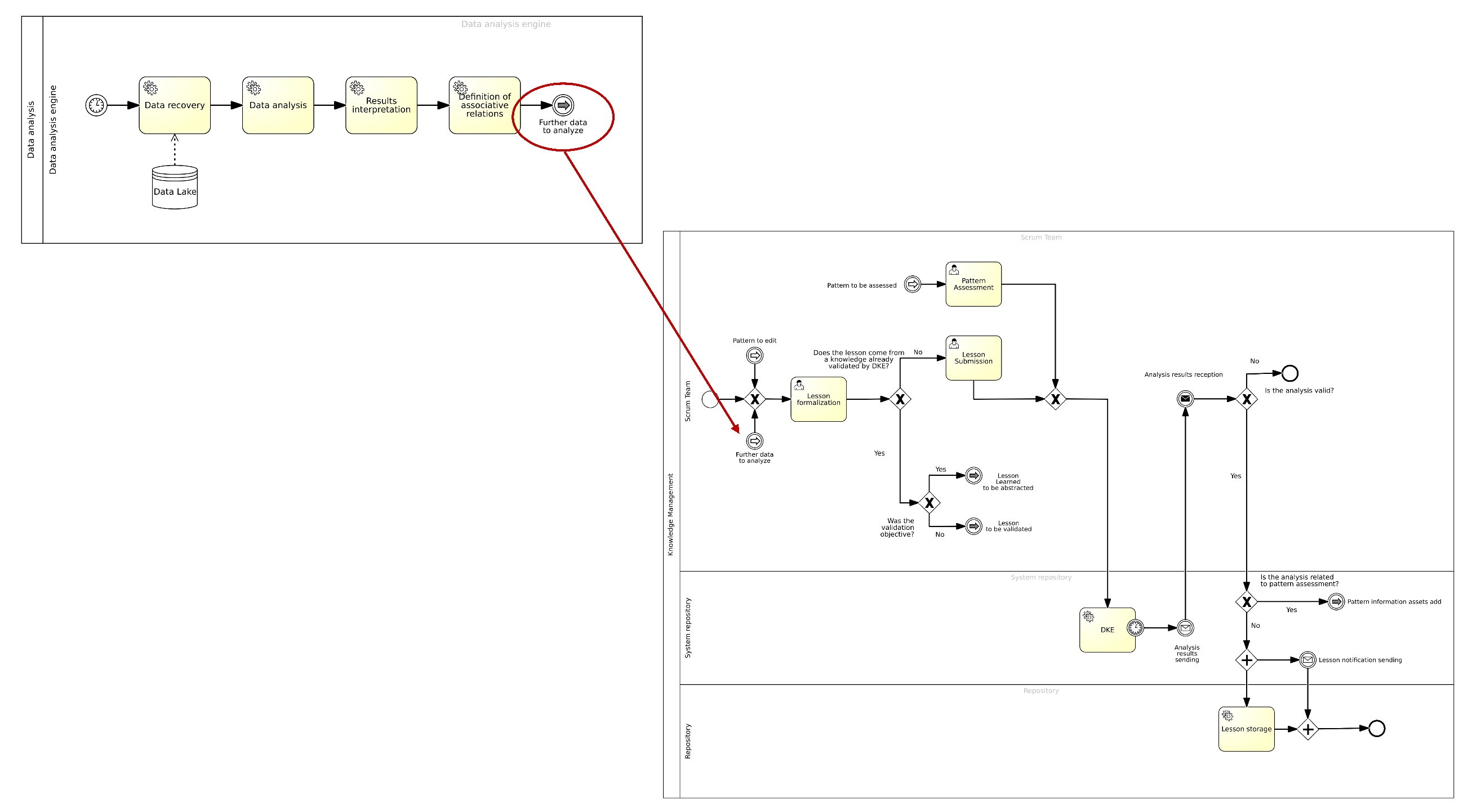
- Combination (Explicit to Explicit): During this phase, explicit knowledge is systematically aggregated, compared, and refined to generate structured insights. This stage constitutes the core of the formalization and validation process for lessons learned and the derivation of reusable patterns. Lessons are initially submitted via a standardized input form designed to ensure the consistency and completeness of the captured information. The subsequent validation process follows two parallel paths, depending on the nature of the evidence supporting the lesson. When lessons are underpinned by quantitative data, such as KPIs, they are assessed through an automated validation engine (DKE). Conversely, when lessons rely on qualitative insights, their relevance and applicability are evaluated during SoS meetings, which provide a collaborative forum for expert judgment and peer review. Once a lesson is recognized as broadly applicable across comparable contexts, it is elevated to the status of a pattern. Patterns are then forwarded to the relevant CoP, where further refinement and formal validation occur. The CoP is responsible for evaluating the generalizability, structural consistency, and overall quality of each pattern. This includes the definition of input and output parameters, identification of applicable constraints, and estimation of the expected impact, particularly concerning performance metrics such as KPIs. In addition to their validation function, CoPs play a central role in disseminating validated patterns and best practices throughout the organization. They promote reuse by organizing thematic workshops, maintaining centralized repositories, and mentoring project teams in applying the most relevant knowledge assets to their specific contexts. Overall, this phase serves as a critical component of organizational learning. It transforms individual and team-level experiences into codified, reusable knowledge assets that can inform future projects and enhance decision making across the enterprise.
- Internalization (Explicit to Tacit): Finally, explicit knowledge is internalized by individuals through concrete application in their daily activities. Teams apply the validated best practices or patterns in their operational contexts, adapting them as needed. Feedback resulting from real-world application may trigger new insights, which, if relevant, restart the SECI cycle, beginning again with socialization.
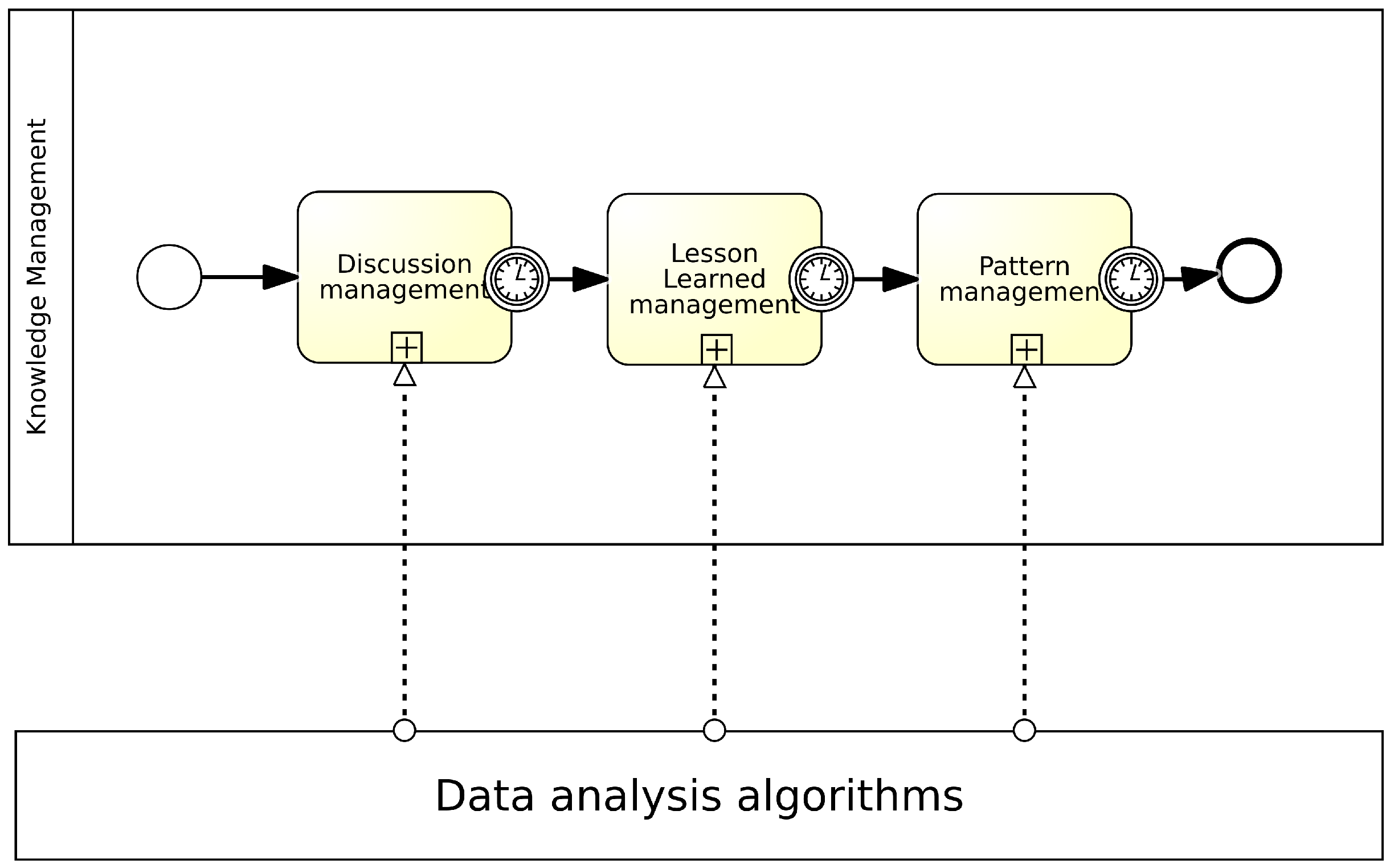
4.1. Overview of the Process
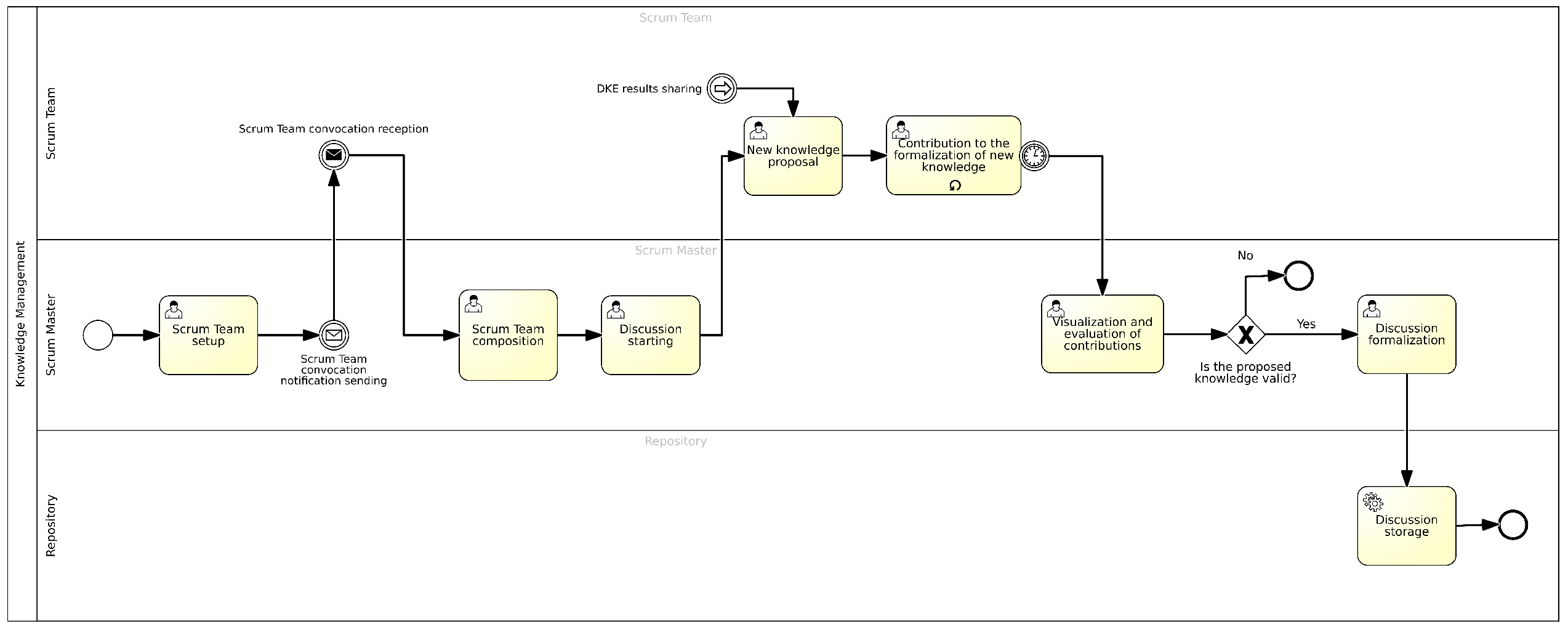
4.2. Discussion Management
- Title of the discussion;
- Description, where a summary of the defined knowledge is provided;
- Attachment, which can be a doc, ppt, or pdf file, in which the newly defined knowledge is explained, and which was the medium through which such knowledge was appropriately externalized.
- Configuring the Scrum Team: In this task, the Scrum Master proceeds to configure the Scrum Team by selecting all the key figures necessary to define the working team. Once the various members are selected, the Scrum Master sends an email (or notification) to convene the selected figures.
- Composing the Scrum Team: Once the figures constituting the potential team are identified, the Scrum Master proceeds to form the actual Scrum Team. In other words, the various team members who will participate in the process of creating and managing new knowledge are grouped.
- Starting the Discussion: Once the Team is appropriately configured and “composed”, the Scrum Master starts a discussion, during which the various team members can propose the “new knowledge” that emerged during the operational activity related to a specific sprint. In this case, a form is considered, characterized by the following fields:
- –
- Title of the discussion;
- –
- Date the discussion started;
- –
- Brief description of the discussion.
- Proposing New Knowledge: In this task, a member of the Scrum Team proposes and shares new knowledge with the team members, which can be an approach, a method with which they addressed and solved a problem, or developed a particular feature during their latest operational activities. In this task, one of the Scrum Team Members may also share the results derived from the assessment of knowledge they developed, which was previously validated by an analysis engine called the Data KPI Engine (DKE) and designed for the assessment and evaluation of data—through the selection of appropriate KPIs—to extract new knowledge;
- Contributing to the formalization of New Knowledge: the members of the Scrum Team can contribute to the formalization of the newly proposed knowledge. This activity does not end in a single task but occurs multiple times until a shared and valid proposal is reached. This task will be characterized by a limited duration within which the proposal must be improved and formalized. In this case, a text area, provided by a chat tool, will allow the various Scrum Team Members to add their comments and contributions to the formalization of the new knowledge.
- Viewing and Evaluating Contributions: In this task, the Scrum Master proceeds to view and evaluate the various contributions and the knowledge proposed during the discussion. This is a very important task because it represents the moment when the knowledge is considered valid and can then proceed to the subsequent tasks that characterize the KM process, or be definitively discarded.
- Formalizing the Discussion: In this task, the Scrum Master formalizes the discussion in a format that allows it to be archived within the BPWH:
- –
- Title of the Discussion: This field should include the title characterizing the knowledge that emerged during the discussion;
- –
- Date: It is important to insert the date on which the discussion is formalized, providing a temporal reference for the activity performed, which will also facilitate its later retrieval;
- –
- Keywords (Tags): These are the keywords that help identify and potentially facilitate the search for the proposed knowledge;
- –
- Description (Text Area): A brief description is inserted within this field to summarize the main characteristics of the validated knowledge, which will then be stored within the BPWH.
- Archiving the Discussion: In this task, once the discussion has been formalized by the Scrum Master, it will be stored in a repository, which will constitute a backlog of discussions from which new knowledge proposals can later be validated.
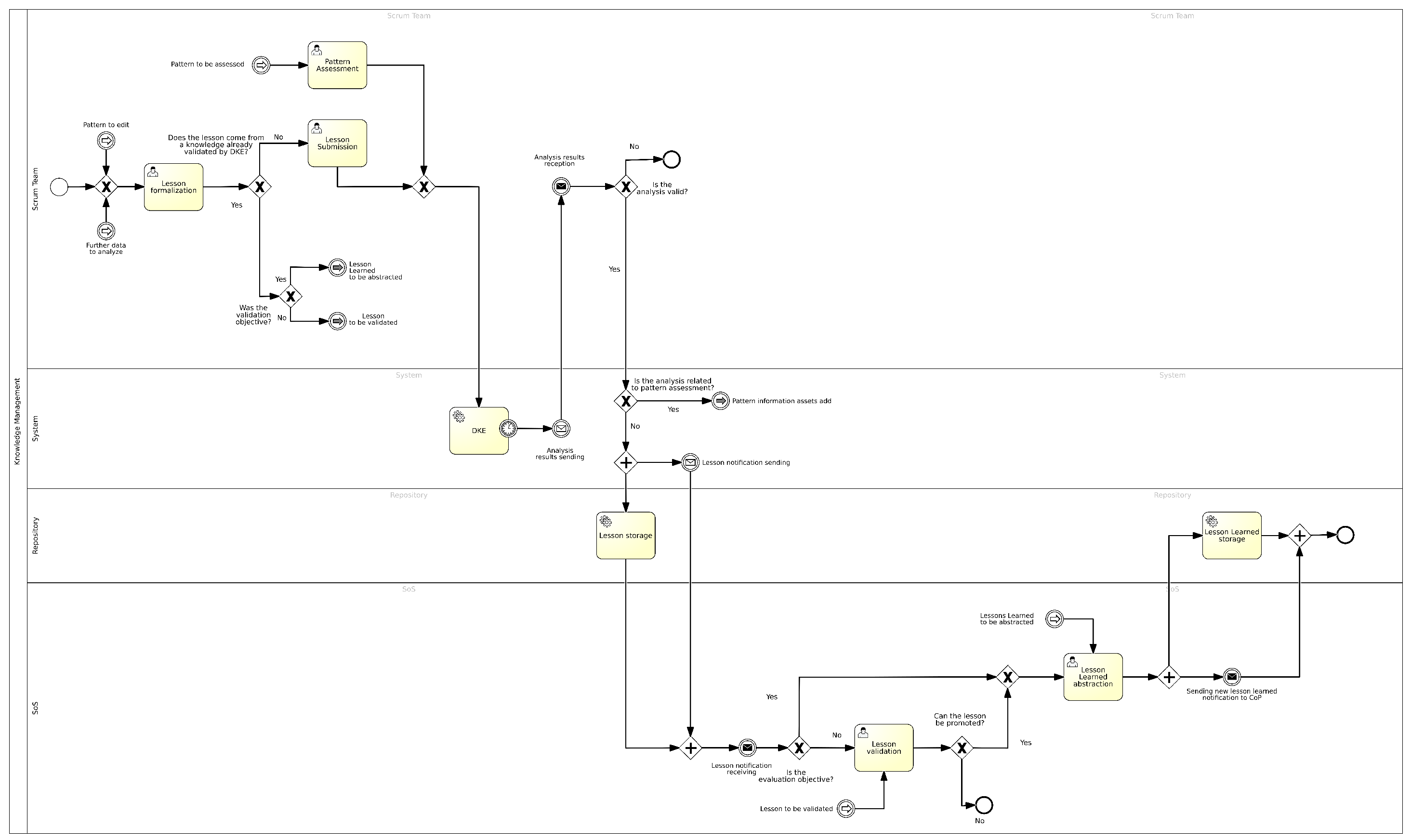
4.3. Lesson Learned Management
- Priority assigned to various defined KPIs.
- Minimum percentage of success related to the result obtained and visualized through a RADAR chart; this value defines the acceptable percentage of result achievable within a specific time frame.
- Time duration of the analysis to be carried out.
- Threshold for evaluating the assigned priorities in case of subjective evaluation by the DKE.
- Lesson Formalization: In this task, the Scrum Master or the designated Scrum Team Member retrieves a previously formalized discussion and proceeds to complete the dedicated form; the fields to be completed are the following:
- –
- Lesson title;
- –
- Tags;
- –
- Scope of use;
- –
- Lesson description;
- –
- Attachments (if any).
- Lesson Submission: In this task, through a dedicated interface, the dataset to be used for lesson validation and the KPIs to be achieved within a specific time frame are defined. Specifically, the fields to populate are the following:
- –
- Priority assigned to each KPI;
- –
- Analysis duration;
- –
- Threshold;
- –
- Minimum success percentage.
- DKE: In this task, the DKE proceeds with the validation of the submitted lesson; in the event of a positive outcome, it is stored in the appropriate repository, and a notification is sent both to the Scrum Team that formalized the lesson and to the SoS meeting so that they can proceed with further validation and its promotion to the rank of lesson learned;
- Lesson Validation: In this task, various SoS members review the results of the analysis carried out by the DKE on the proposed lesson.This task can also be triggered by a system notification following knowledge that has previously been subjectively validated and formalized by the Scrum Team and is now ready for evaluation by the SoS meeting.
- Lesson Learned Abstraction: Once the actual validity of the results of the received lesson is confirmed, the SoS members approve the lesson and promote it to the rank of lesson learned. The fields populated are the following:
- –
- Lesson Learned Title: a text field to enter the title characterizing the lesson learned;
- –
- Tags: a text field to enter a series of keywords to identify the lesson learned and potentially facilitate its search by other members of the organization;
- –
- Scope of Use: a field indicating the main scopes of use of the lesson learned;
- –
- Lesson Learned Description: a field dedicated to a description of the lesson learned and its main features and functionalities;
- –
- Achieved KPIs: the main KPIs obtained from the lesson learned;
- –
- Used Services: definition of the main technological services used;
- –
- Attachments (if any): PDF, PPT, or DOC files to attach to the form containing additional information related to the structure and features of the lesson learned.
- Sending a notification to the CoP members so that they can proceed with further evaluation and validation of the lesson learned to the rank of best practice pattern;
- Archiving the newly approved lesson learned within the BPWH.
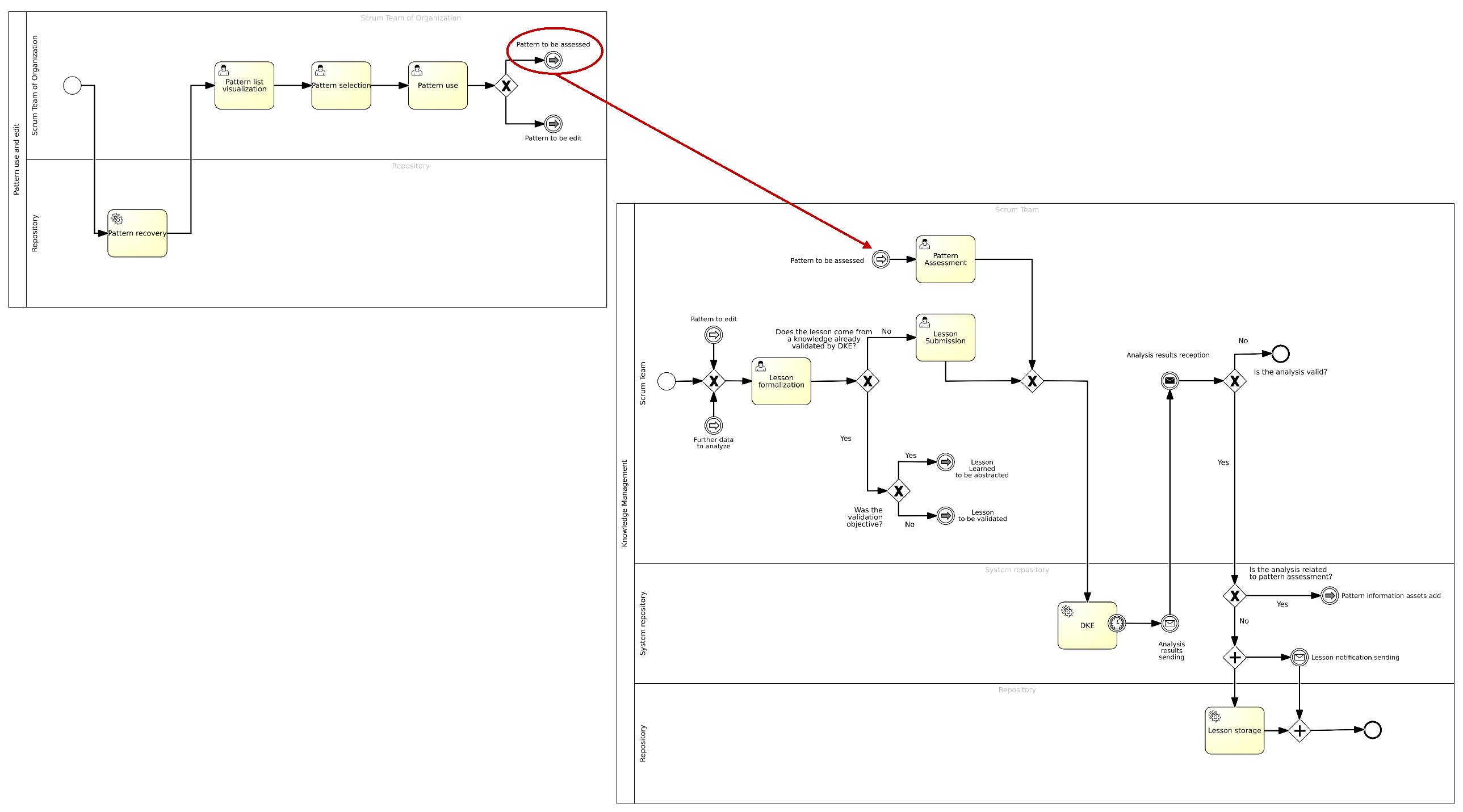
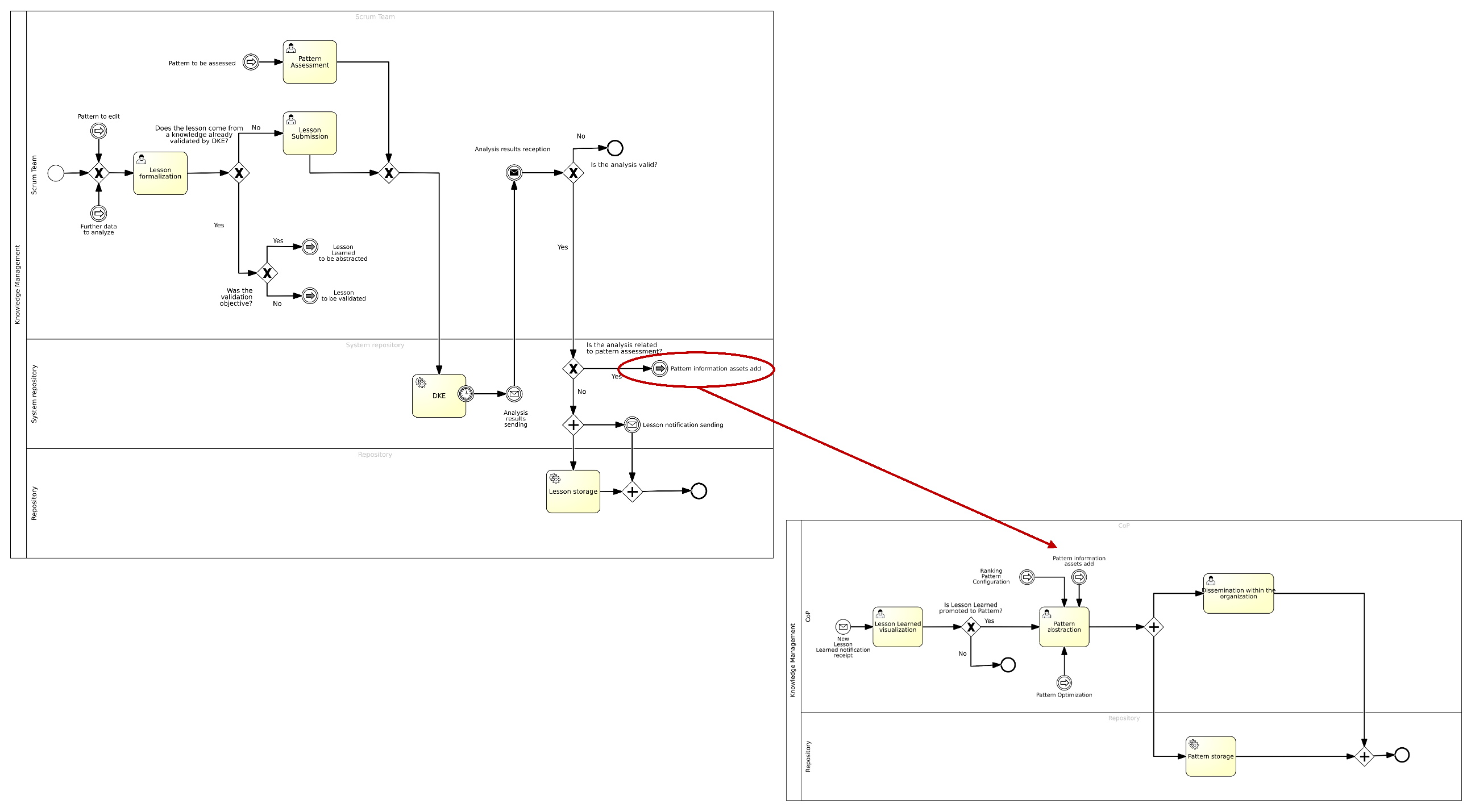
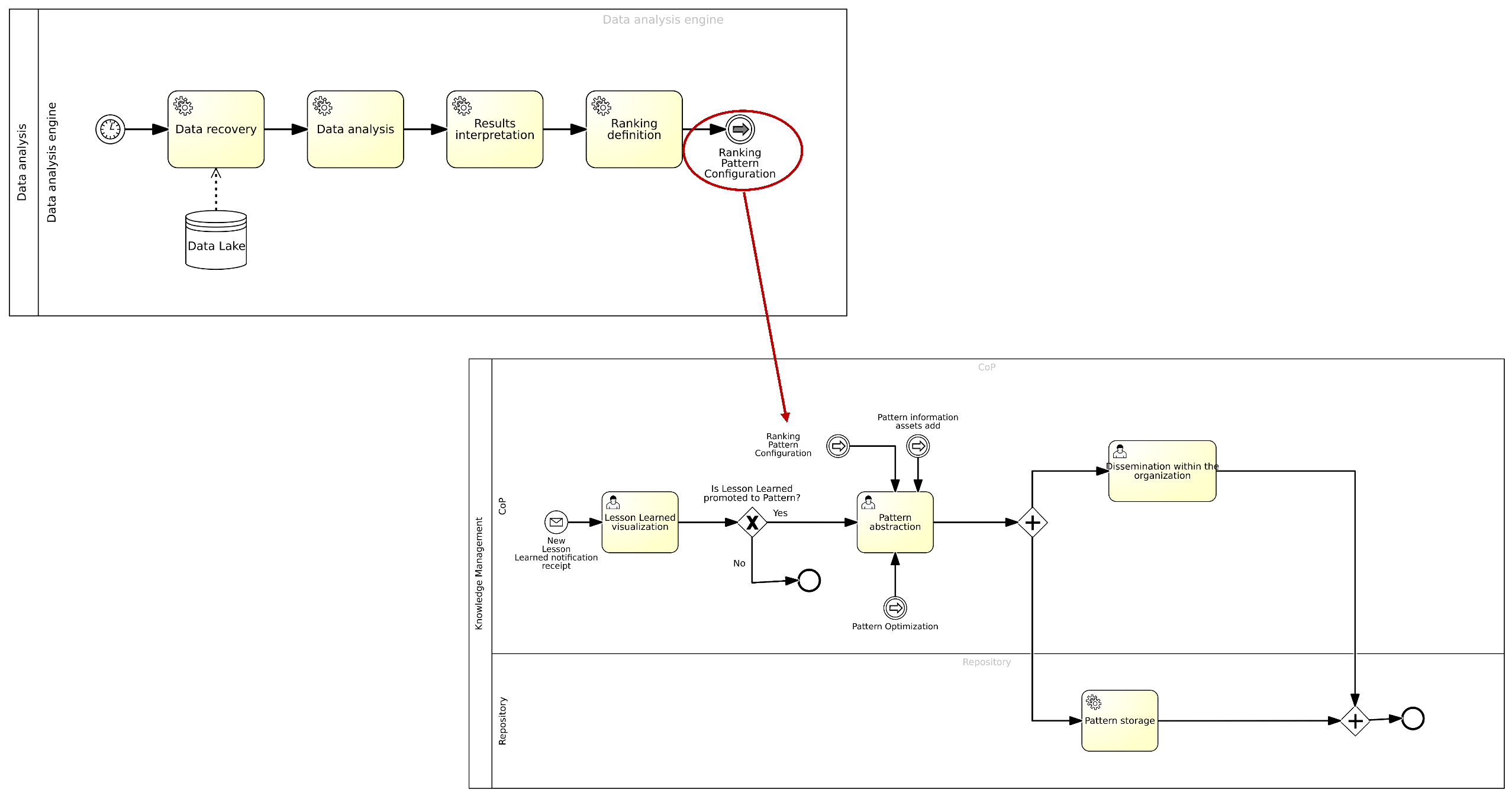
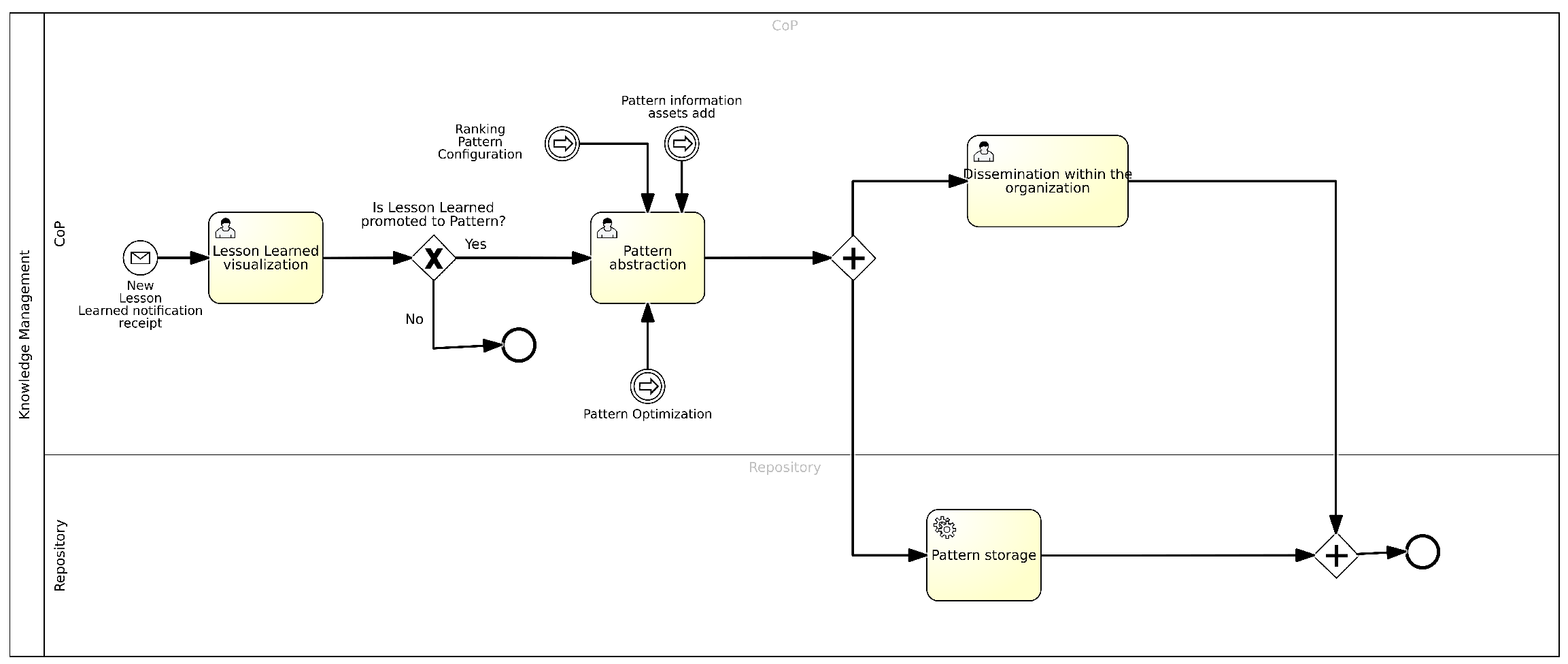
4.4. Pattern Management
- Input parameters, including the name, type, and acceptable range;
- Output parameters, including the name, type, and acceptable range;
- Functions for calculating output parameters based on the input parameters;
- Constraints to monitor: defined about the input and output parameters and/or the data provided by the services used;
- Interfaces exposed to external applications.
- Viewing the Lesson Learned. In this task, members of the CoP view the validated lesson learned flagged by the SoS and evaluate whether what has been proposed can be considered a pattern to be utilized across the organization.
- Abstracting the Pattern. In this task, members of the CoP decide that the lesson learned in question is reusable in various contexts and fields. Therefore, it is regarded as a pattern within the organization. Following this decision, a form is filled out where the following information is entered:
- Pattern Title: a text field where the title that characterizes the pattern is inserted;
- Tags: a text field to insert a series of keywords to identify the pattern and facilitate its search by other organization members;
- Usage Domains: a field indicating the main domains where the pattern can be applied;
- Pattern Description: a field dedicated to describing the pattern and its main characteristics and functionalities;
- KPIs: the main KPIs obtained by the pattern;
- Services Used: definition of the main services used by the pattern;
- Input Parameters: definition of acceptable parameters (name, type, and acceptable range);
- Output Parameters: definition of acceptable parameters (name, type, and acceptable range);
- Constraints: definition of constraints to monitor, based on input and output parameters and/or data provided by the services used;
- Attachments: PDF, PPT, or DOC files to be attached to the form, containing additional information about the pattern’s structure and characteristics.
Once the form is completed, the new knowledge is saved within the BPWH and subsequently disseminated throughout the organization.During this task, members of the CoP may discuss additional informative contributions, releases, or optimizations derived from the ML algorithms that characterize the data analytics component. - Dissemination within the organization. The pattern, newly approved to the rank of best practice, is disseminated throughout the organization to ensure that various members of the Scrum Teams can use it during their coding activities.
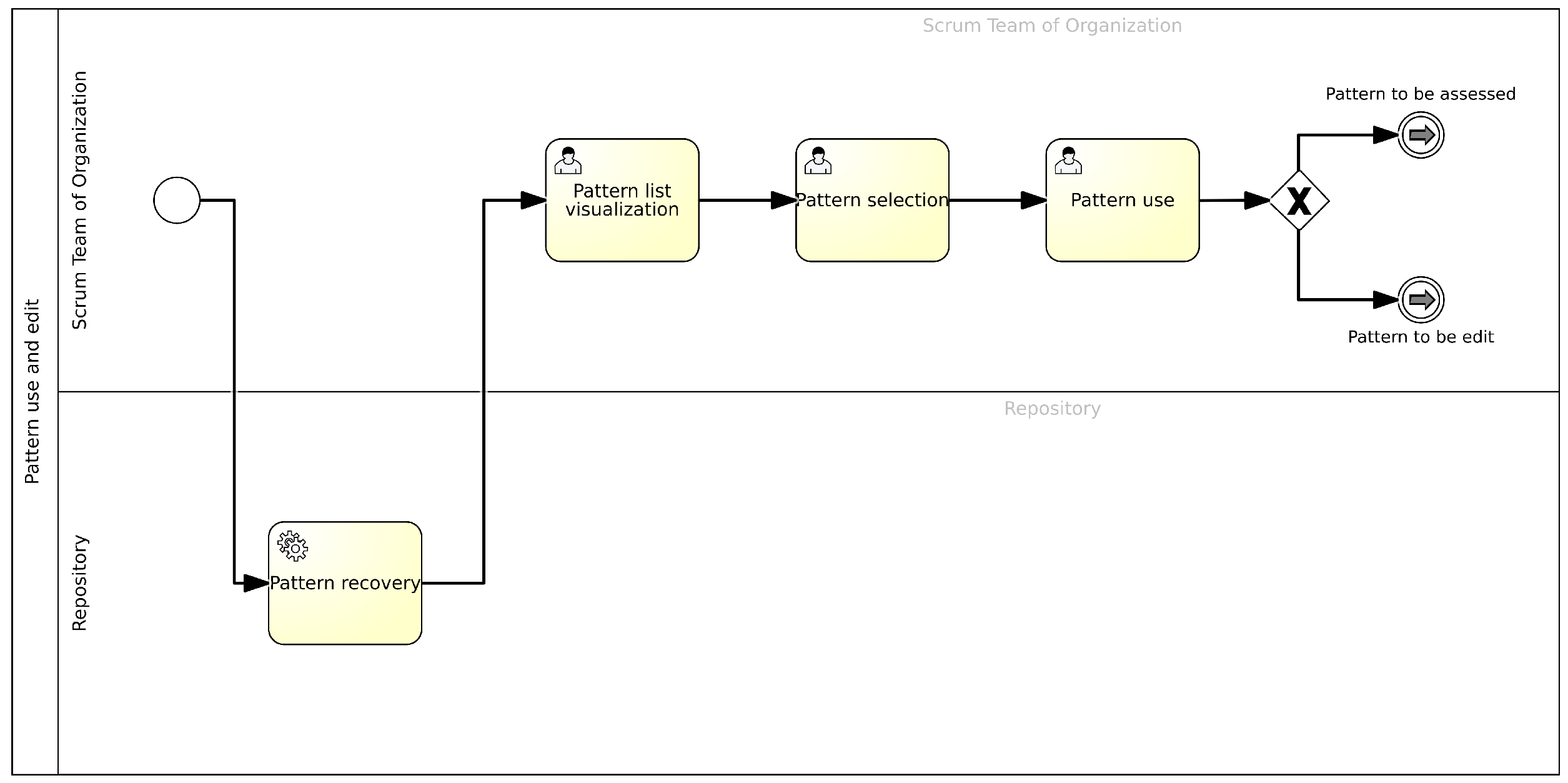
4.5. Patter Usage and Editing
- Viewing the pattern list: In this task, the Scrum Team Member views the list of patterns present in the BPWH; this also allows them to view the different properties and characteristics of the various patterns present.
- Selecting a pattern: In this task, the Scrum Team Member selects the pattern they consider most appropriate for their needs from the list returned by the BPWH.
- Using the pattern: In this task, the user, a member of the Scrum Team, proceeds to use the pattern by leveraging its available functionalities.
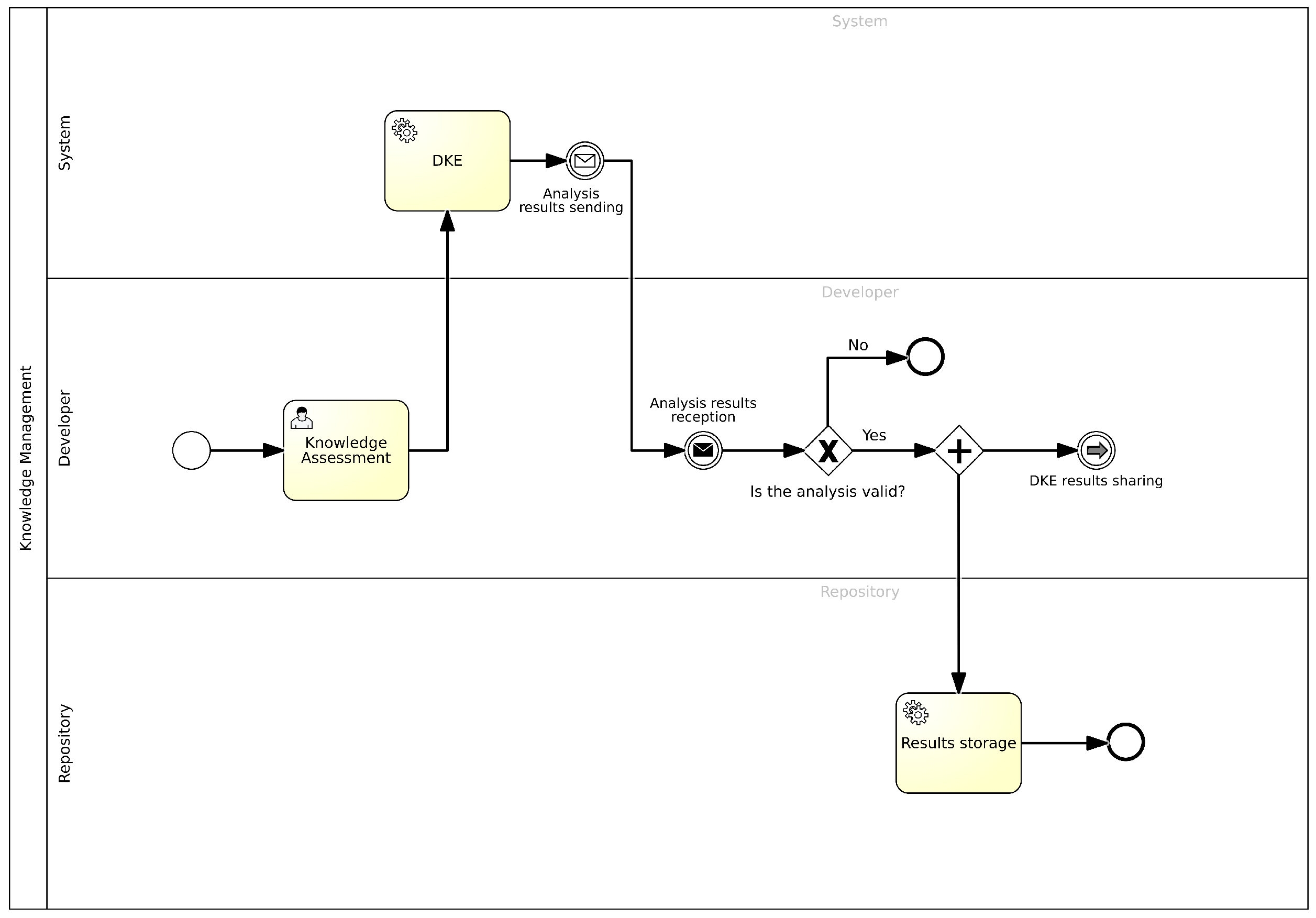
4.6. Knowledge Assessment Management
- KPIs, i.e., performance indicators and the potential quality level that can be achieved from the knowledge being analyzed.
- Data to be analyzed to obtain these KPIs.
- Prioritization of the various defined KPIs.
- Minimum success percentage related to the result obtained and displayed by the resulting RADAR chart; this value helps define the acceptable result percentage achievable within a specific time frame.
- Duration of the analysis to be carried out.
- Thresholds through which the priorities assigned can be evaluated in the case of a subjective assessment by the DKE.
- Knowledge Assessment: In this task, the user, once the data collection and processing have been completed, defines all the information necessary to start the knowledge analysis. Through a specific form, the following information is entered:
- –
- Data;
- –
- KPIs;
- –
- Priority assigned to each KPI;
- –
- Duration of the analysis;
- –
- Threshold;
- –
- Minimum success percentage;
- –
- Brief description of the knowledge to be tested.
- DKE: In this task, the DKE will proceed with the validation of the submitted knowledge. If the outcome is positive, the knowledge will be stored in the appropriate repository.
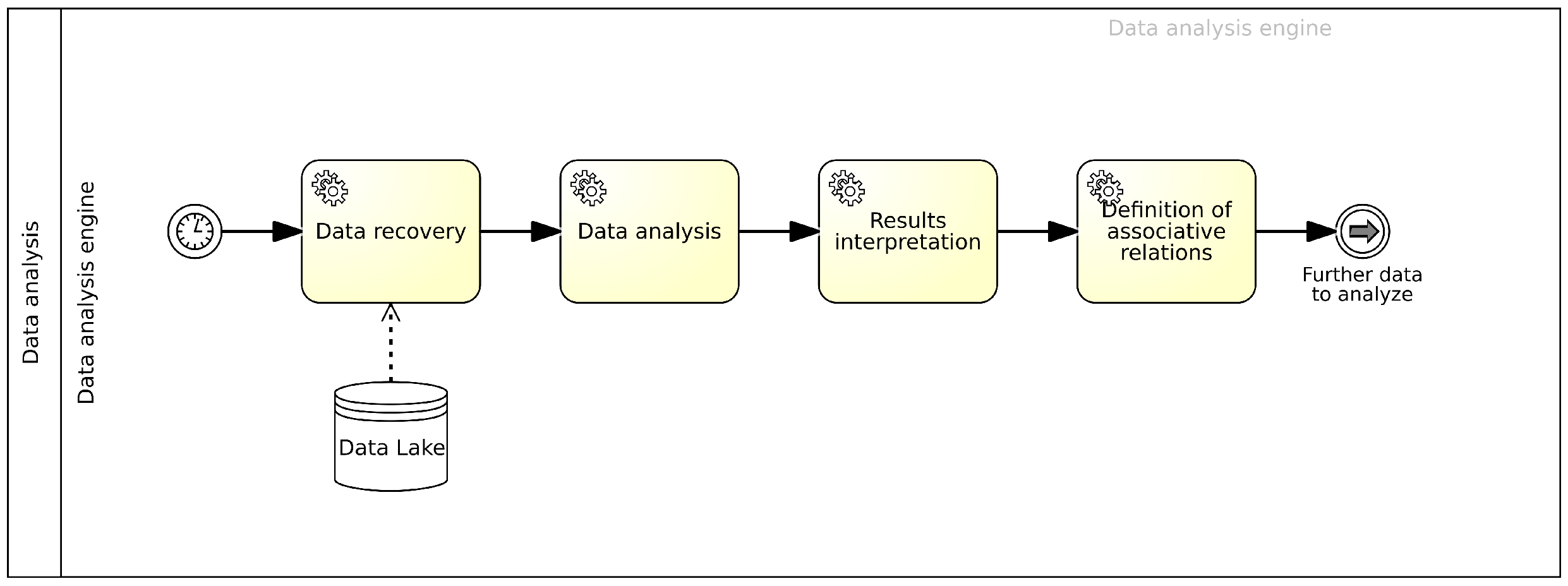
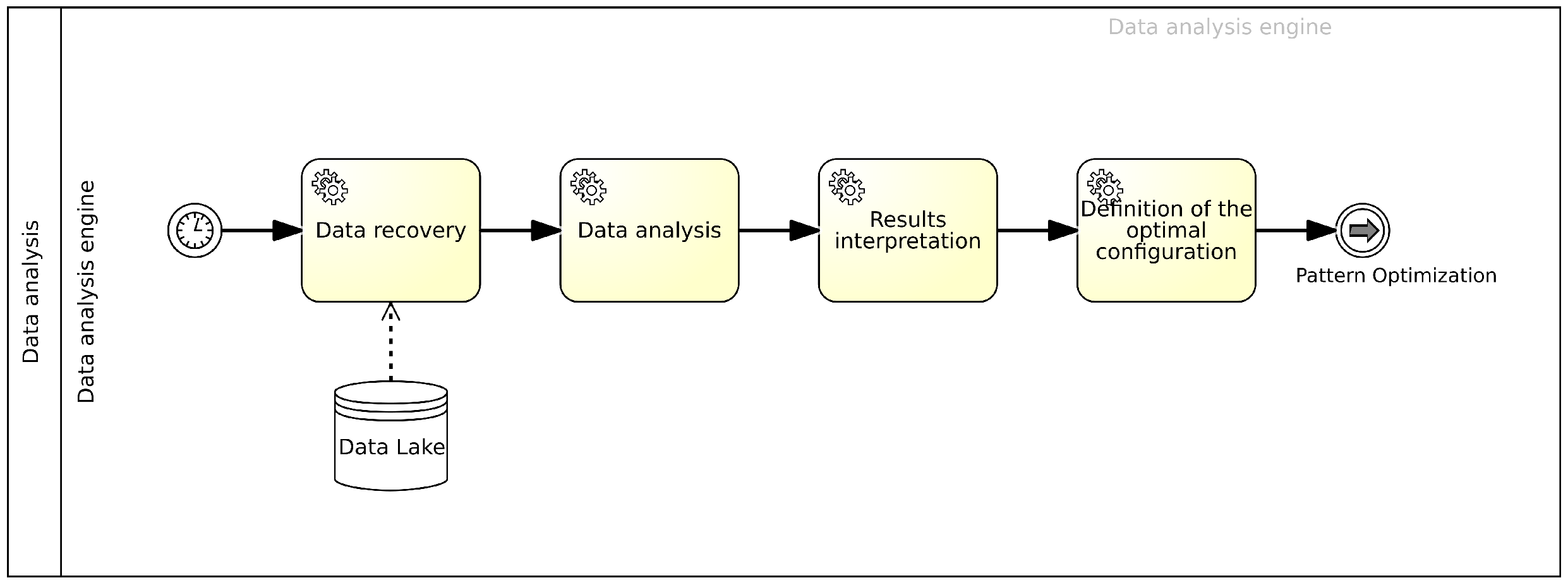
4.7. Data Analysis Engine
- Best configuration;
- Association rule management;
- Machine Learning.
4.7.1. Best Configuration
4.7.2. Association Rule Management
4.7.3. Machine Learning
5. Results and Discussion
- Lead Time, i.e., the time required to complete operational activities about the knowledge patterns obtained and formalized through the framework.
- Service Level Agreement (SLA), understood as the framework’s ability to ensure high service levels by leveraging the newly acquired knowledge.
- Error Rate, meaning the rate of errors resulting from applying the newly formalized knowledge.
- Mean Time To Detection (MTTD) and Mean Time to Repair (MTTR), which refer to the average time needed to identify errors during operations and to resolve them using the acquired knowledge.
6. Limitations
7. Future Research
- Automation of knowledge capture: AI agents embedded in the system could automatically collect and organize knowledge artifacts, minimizing manual effort and allowing seamless knowledge sharing without disrupting sprint workflows.
- Incremental and contextual integration: The framework could be extended to support incremental knowledge updates that align with the iterative nature of the Agile methodology, enabling continuous documentation of decisions and lessons learned throughout the sprint.
- Toolchain compatibility: The system architecture could be designed for seamless integration with Agile tools already in use by teams, such as Jira, Trello, or Confluence, facilitating easy access to the reuse of knowledge within daily workflows.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABPMS | AI-Augmented Business Process Management System |
| AI | Artificial Intelligence |
| BPMS | Business Process Management System |
| BPM | Business Process Management |
| BPWH | Best Practice Warehouse |
| CPA | Cognitive Process Automation |
| CoP | Community of Practice |
| DKE | Data KPI Engine |
| GANs | Generative Adversarial Networks |
| GenAI | Generative Artificial Intelligence |
| HCI | Human–Computer Interaction |
| KM | Knowledge Management |
| RUL | Remaining Useful Life |
| UCD | User-Centered Design |
| HITL | Human-in-the-Loop |
| BPE | Business Process Engine |
| MiSB | Middleware Service Bus |
| KPIs | Key Performance Indicators |
| LIME | Local Interpretable Model-Agnostic Explanations |
| SHAP | SHapley Additive exPlanations |
| LL | Lesson Learned |
| LPMs | Large Process Models |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| PM | Process Mining |
| RPA | Robotic Process Automation |
| SCM | Supply Chain Management |
| SECI | Socialization, Externalization, Combination, Internalization |
| SoS | Scrum of Scrums |
| XAI | Explainable Artificial Intelligence |
| MRO | Maintenance, Repair, and Overhaul |
| SLA | Service-Level Agreement |
| MTTD | Mean Time To Detection |
| MTTR | Mean Time to Repair |
| APDEX | Application Performance Index |
Appendix A
Appendix A.1. Detailed Architecture of the Proposed Framework
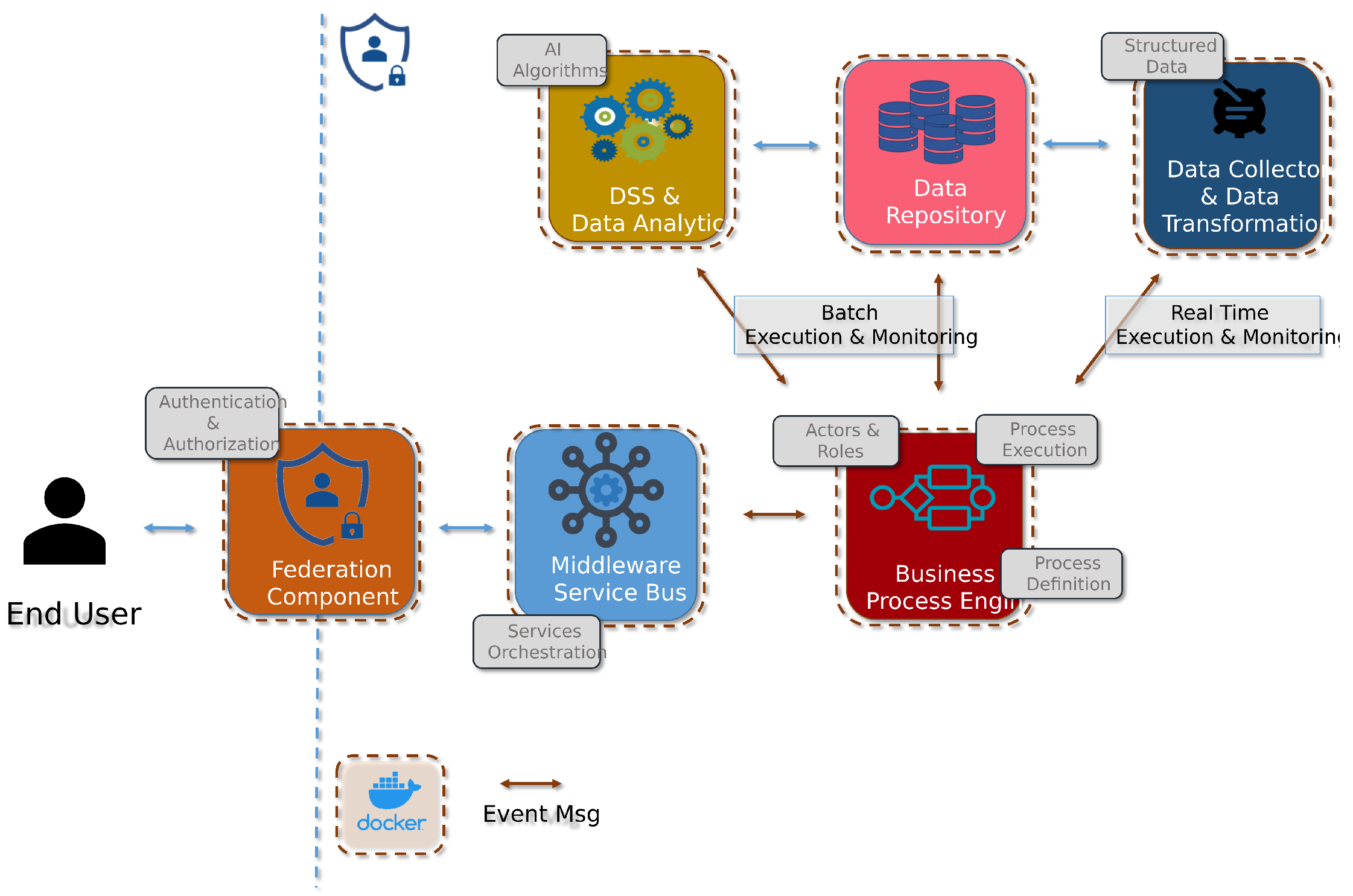
Appendix A.2. Connections Between Knowledge Management Processes



References
- Dumas, M.; Fournier, F.; Limonad, L.; Marrella, A.; Montali, M.; Rehse, J.R.; Accorsi, R.; Calvanese, D.; De Giacomo, G.; Fahland, D.; et al. AI-augmented business process management systems: A research manifesto. ACM Trans. Manag. Inf. Syst. 2023, 14, 1–19. [Google Scholar] [CrossRef]
- Yakyma, A. Knowledge Flow in Scaled Agile Delivery Model. 2011. Available online: http://www.yakyma.com/2011/07/knowledge-flow-in-scaled-agile-delivery.html (accessed on 20 February 2025).
- Kovačić, M.; Mutavdžija, M.; Buntak, K.; Pus, I. Using artificial intelligence for creating and managing organizational knowledge. Teh. Vjesn. 2022, 29, 1413–1418. [Google Scholar]
- Psarommatis, F.; Kiritsis, D. A hybrid Decision Support System for automating decision making in the event of defects in the era of Zero Defect Manufacturing. J. Ind. Inf. Integr. 2021, 26, 100263. [Google Scholar] [CrossRef]
- Enholm, I.M.; Papagiannidis, E.; Mikalef, P.; Krogstie, J. Artificial intelligence and business value: A literature review. Inf. Syst. Front. 2022, 24, 1709–1734. [Google Scholar] [CrossRef]
- Taherdoost, H.; Madanchian, M. Artificial intelligence and knowledge management: Impacts, benefits, and implementation. Computers 2023, 12, 72. [Google Scholar] [CrossRef]
- Jarrahi, M.H.; Askay, D.; Eshraghi, A.; Smith, P. Artificial intelligence and knowledge management: A partnership between human and AI. Bus. Horizons 2023, 66, 87–99. [Google Scholar] [CrossRef]
- Alavi, M.; Leidner, D.; Mousavi, R. Knowledge Management Perspective of Generative Artificial Intelligence (GenAI). J. Assoc. Inf. Syst. 2024, 25, 1–12. [Google Scholar] [CrossRef]
- Thakuri, S.; Bon, M.; Cavus, N.; Sancar, N. Artificial Intelligence on Knowledge Management Systems for Businesses: A Systematic Literature Review. TEM J. 2024, 13, 2146–2155. [Google Scholar] [CrossRef]
- Linder, A.; Anand, L.; Falk, B.; Schmitt, R. Technical complaint feedback to ramp-up. Procedia CIRP 2016, 51, 99–104. [Google Scholar] [CrossRef]
- Chen, E. Empowering artificial intelligence for knowledge management augmentation. Issues Inf. Syst. 2024, 25, 409–416. [Google Scholar]
- Casciani, A.; Bernardi, M.L.; Cimitile, M.; Marrella, A. Conversational Systems for AI-Augmented Business Process Management. In Research Challenges in Information Sciences; Springer: Cham, Switzerland, 2024; pp. 183–200. [Google Scholar]
- Kokala, A. Business Process Management: The Synergy of Intelligent Automation and AI-Driven Workflows. Int. Res. J. Mod. Eng. Technol. Sci. 2024, 6, 12. [Google Scholar]
- Zebec, A.; Indihar Štemberger, M. Creating AI business value through BPM capabilities. Bus. Process Manag. J. 2024, 30, 1–26. [Google Scholar] [CrossRef]
- Helo, P.; Hao, Y. Artificial intelligence in operations management and supply chain management: An exploratory case study. Prod. Plan. Control 2022, 33, 1573–1590. [Google Scholar] [CrossRef]
- Aggarwal, S. Guidelines for the Use of AI in BPM Systems: A Guide to Follow to USE AI in BPM Systems. Master’s Thesis, Universidade NOVA de Lisboa, Lisbon, Portugal, 2021. [Google Scholar]
- Rosemann, M.; Brocke, J.V.; Van Looy, A.; Santoro, F. Business process management in the age of AI–three essential drifts. Inf. Syst. e-Bus. Manag. 2024, 22, 415–429. [Google Scholar] [CrossRef]
- Szelągowski, M.; Lupeikiene, A.; Berniak-Woźny, J. Drivers and evolution paths of BPMS: State-of-the-art and future research directions. Informatica 2022, 33, 399–420. [Google Scholar] [CrossRef]
- Schaschek, M.; Gwinner, F.; Neis, N.; Tomitza, C.; Zeiß, C.; Winkelmann, A. Managing next generation BP-x initiatives. Inf. Syst. e-Bus. Manag. 2024, 22, 457–500. [Google Scholar] [CrossRef]
- Wang, L.; Liu, Z.; Liu, A.; Tao, F. Artificial intelligence in product lifecycle management. Int. J. Adv. Manuf. Technol. 2021, 114, 771–796. [Google Scholar] [CrossRef]
- Kampik, T.; Warmuth, C.; Rebmann, A.; Agam, R.; Egger, L.N.; Gerber, A.; Hoffart, J.; Kolk, J.; Herzig, P.; Decker, G.; et al. Large Process Models: A Vision for Business Process Management in the Age of Generative AI. KI-Künstl. Intell. 2024, 1–15. [Google Scholar] [CrossRef]
- De Nicola, A.; Formica, A.; Mele, I.; Missikoff, M.; Taglino, F. A comparative study of LLMs and NLP approaches for supporting business process analysis. Enterp. Inf. Syst. 2024, 18, 2415578. [Google Scholar] [CrossRef]
- Fahland, D.; Fournier, F.; Limonad, L.; Skarbovsky, I.; Swevels, A.J. How well can large language models explain business processes? arXiv 2024, arXiv:2401.12846. [Google Scholar]
- Olatunji, A.O. Machine Learning in Business Process Optimization: A Framework for Efficiency and Decision-Making. J. Basic Appl. Res. Int. 2025, 31, 18–28. [Google Scholar] [CrossRef]
- Chapela-Campa, D.; Dumas, M. From process mining to augmented process execution. Softw. Syst. Model. 2023, 22, 1977–1986. [Google Scholar] [CrossRef]
- Gabryelczyk, R.; Sipior, J.C.; Biernikowicz, A. Motivations to adopt BPM in view of digital transformation. Inf. Syst. Manag. 2024, 41, 340–356. [Google Scholar] [CrossRef]
- Salvadorinho, J.; Teixeira, L. Organizational knowledge in the I4. 0 using BPMN: A case study. Procedia Comput. Sci. 2021, 181, 981–988. [Google Scholar] [CrossRef]
- Abbasi, M.; Nishat, R.I.; Bond, C.; Graham-Knight, J.B.; Lasserre, P.; Lucet, Y.; Najjaran, H. A Review of AI and Machine Learning Contribution in Predictive Business Process Management (Process Enhancement and Process Improvement Approaches). arXiv 2024, arXiv:2407.11043. [Google Scholar]
- Nonaka, I.; Takeuchi, H. The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Beck, K.; Jeffries, R.; Highsmith, J.; Grenning, J.; Martin, R.; Schwaber, K.; Cunningham, W.; Sutherland, J.; Mellor, S.; Thomas, D. Manifesto per lo Sviluppo Agile di Software. 2001. Available online: https://agilemanifesto.org/iso/it/manifesto.html (accessed on 10 April 2025).
- Carroll, J.M. Human Computer Interaction (HCI). Encyclopedia of Human-Computer Interaction; The Interaction Design Foundation: Aarhus, Denmark, 2009. [Google Scholar]
- da Costa Brito, L.; Quaresma, M. User-Centered Design in Agile Methodologies. Ergodesign HCI 2009, 7, 126–137. [Google Scholar] [CrossRef]
- Nielsen, J. Ten Usability Heuristics. 2005. Available online: https://pdfs.semanticscholar.org/5f03/b251093aee730ab9772db2e1a8a7eb8522cb.pdf (accessed on 6 May 2025).
- Easa, N.F.; Fincham, R. The application of the socialisation, externalisation, combination and internalisation model in cross-cultural contexts: Theoretical analysis. Knowl. Process Manag. 2012, 19, 103–109. [Google Scholar] [CrossRef]
- European Commission. European Commission White Paper on Artificial Intelligence—A European Approach to Excellence and Trust. Available online: https://commission.europa.eu/publications/white-paper-artificial-intelligence-european-approach-excellence-and-trust_en (accessed on 13 March 2025).
- Europea Commission. Gruppo di Esperti ad alto Livello Sull’intelligenza Artificiale. Orientamenti etici per un’IA Affidabile. Available online: https://digital-strategy.ec.europa.eu/it/library/ethics-guidelines-trustworthy-ai (accessed on 5 May 2025).
- Maged, A.; Kassem, G. Self-Adaptive ERP: Embedding NLP into Petri-Net creation and Model Matching. In Proceedings of the 2024 International Conference on Computer and Applications (ICCA), Cairo, Egypt, 17–19 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Miller, R.; Whelan, H.; Chrubasik, M.; Whittaker, D.; Duncan, P.; Gregório, J. A Framework for Current and New Data Quality Dimensions: An Overview. Data 2024, 9, 151. [Google Scholar] [CrossRef]
- Gualo, F.; Rodríguez, M.; Verdugo, J.; Caballero, I.; Piattini, M. Data quality certification using ISO/IEC 25012: Industrial experiences. J. Syst. Softw. 2021, 176, 110938. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scrum Framework Nomenclature | Definition |
|---|---|
| Scrum Team | Set of several roles such as Scrum Master, CoP Member, etc. … |
| Scrum Master | Team Leader |
| CoP Member | Unit Leader |
| ID | Requirement Title | Description |
|---|---|---|
| 1 | System Scope | Collection, storage, and visualization of information throughout the lifecycle. Support for discussions, lessons learned, and patterns. Traceability and management of roles and groups. Centralized access to patterns. |
| 2 | Account Management | Management of accounts with different roles based on the user’s position within the group. |
| 3 | System Authentication | Authentication through a basic authentication mechanism, respecting corporate security policies. |
| 4 | Definition of Role in the Scrum Team | Functions for Scrum Team Members: initiating discussions, formalizing lessons, participating in discussions, and proposing improvements. |
| 5 | Scrum Master Functionality | In addition to the functions of the Scrum Team Member: approving discussions, formalizing lessons, approving lessons learned, and reformulating patterns. |
| 6 | Scrum Member of Scrum Meeting Functionality | Scrum Master can take over additional functionality to participate in SoS meetings. |
| 7 | CoP Member Functionality | Participation in the validation of lessons learned in patterns and best practices. Functions inherited from the Scrum Master. |
| 8 | Initiation and formalization of a discussion | Initiation of discussions by the Scrum Master. Formalization of new knowledge through title, keywords, and description. |
| 9 | Lesson formalization | Formalization by a user or requested by the team leader. Entry of name, keywords, areas of use, and description. Automatic linking to related discussions. |
| 10 | Lesson Management | Repository for formalized lessons, visible and editable by all users. |
| 11 | Creation of the Lesson Learned | Creation from an existing formalized lesson or pattern. Insertion of related information, inherited from the source Lesson. |
| 12 | Approval of Lesson Learned | Validation by the SoS. Input of KPIs and other details required for validation. |
| 13 | Managing Lesson Learned | Repository for lessons learned, visible and improvable by all users. |
| 14 | Pattern Approval | Validation of best practice by the CoP. Additional information and specific constraints are required. |
| 15 | Pattern Management | Classification of content by ID, type, and subject. Advanced search using metadata. |
| 16 | Content Categorization | Classification by type (discussion, lesson, lesson learned, pattern), theme, and unique ID. Search based on tags, scope of use, and date of creation. |
| 17 | Import/Export | Lesson, lesson learned, and pattern import and export functionality. |
| Term | Definition |
|---|---|
| Discussion | Externalization of new knowledge that emerges during an operational activity |
| Lesson | Potentially valuable experience, not necessarily applied and/or validated by others, still in the process of being formalized |
| Lesson Learned | Guideline, advice, a checklist that identifies what was right or wrong in a particular event |
| Best Practice | Practice that in a systematic and documented way allows for the achievement of excellent results |
| Pattern | Model that, through quantitative data, has allowed us to demonstrate that its use reduces time, work, and costs, as well as increases quality and satisfaction of the end customer, or that it at least affects some of these requirements |
| Criteria | AI-Augmented BPMS (Dumas et al.) [1] | Self-Adaptive ERP (Maged & Kassem) [37] | Large Process Models (Kampik et al.) [21] | The Proposed Framework |
|---|---|---|---|---|
| Lifecycle Phases | Perception, reason, enact, adapt, explain, improve | Adaptation of ERP processes through AI and NLP | LLM-based contextual recommendations | Perception, validation, formalization, adaptation, dissemination |
| Knowledge Management Focus | Limited, no detailed mechanisms for validation and dissemination | Lacks socio-organizational integration, focuses mainly on technology | Data-driven, lacks structured knowledge sharing | Strong focus with iterative cycles and structured roles |
| Organizational Structure | Not explicitly defined | No defined roles for knowledge integration | No role definition for knowledge processes | Defined roles: Scrum Masters, Communities of Practice (CoPs) |
| Socio-Technical Integration | Mainly technical, organizational learning is implicit | Predominantly technological, no community involvement | Focused on AI, lacks socio-organizational perspective | Socio-technical balance: integrates organizational learning and collaboration |
| Validation Mechanism | Implicit, not role-specific | None, relies on system adaptation | AI-driven, lacks formal validation of lessons learned | Clear mechanisms for validation through CoPs and structured roles |
| Dissemination of Knowledge | Not clearly addressed | No structured dissemination | Limited to LLM recommendations | Explicitly defined, CoPs and Scrum Masters manage sharing |
| Learning from Experience | Implied but not explicit | Lacks focus on organizational learning | Data-driven, no structured learning cycle | Central to the framework, learning cycles drive process adaptation |
| Process Adaptation Cycle | Adaptive but lacks socio-technical context | Technology-driven without social learning | Contextual but lacks structured feedback loops | Iterative cycle driven by validated feedback and structured roles |
| Target Environment | Generic BPM systems | ERP Systems | Software-supported BPM | Complex and dynamic organizational contexts |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martino, D.; Perlangeli, C.; Grottoli, B.; La Rosa, L.; Pacella, M. A Knowledge-Driven Framework for AI-Augmented Business Process Management Systems: Bridging Explainability and Agile Knowledge Sharing. AI 2025, 6, 110. https://doi.org/10.3390/ai6060110
Martino D, Perlangeli C, Grottoli B, La Rosa L, Pacella M. A Knowledge-Driven Framework for AI-Augmented Business Process Management Systems: Bridging Explainability and Agile Knowledge Sharing. AI. 2025; 6(6):110. https://doi.org/10.3390/ai6060110
Chicago/Turabian StyleMartino, Danilo, Cosimo Perlangeli, Barbara Grottoli, Luisa La Rosa, and Massimo Pacella. 2025. "A Knowledge-Driven Framework for AI-Augmented Business Process Management Systems: Bridging Explainability and Agile Knowledge Sharing" AI 6, no. 6: 110. https://doi.org/10.3390/ai6060110
APA StyleMartino, D., Perlangeli, C., Grottoli, B., La Rosa, L., & Pacella, M. (2025). A Knowledge-Driven Framework for AI-Augmented Business Process Management Systems: Bridging Explainability and Agile Knowledge Sharing. AI, 6(6), 110. https://doi.org/10.3390/ai6060110