
Enhancing Efficiency and Regularization in Convolutional Neural Networks: Strategies for Optimized Dropout


Abstract
1. Introduction
2. Related Works
3. Methodology
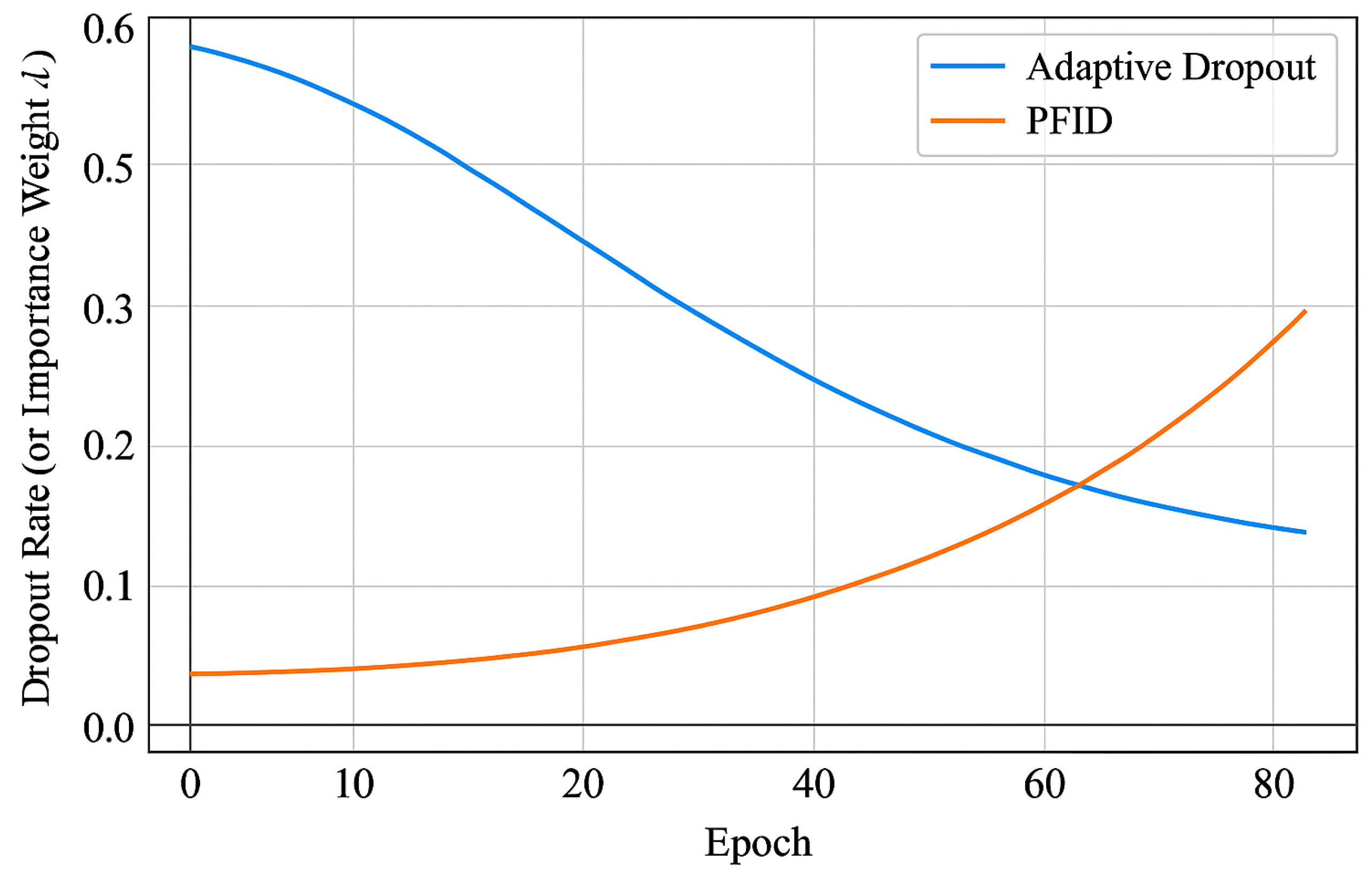
3.1. Adaptive Dropout
- : Baseline dropout rate, typically set empirically.
- : Adaptation intensity hyperparameter, which determines the extent of dropout rate modulation.
- : Normalized depth of the layer within the CNN architecture.
- : Normalized progression of training epochs.
- , : Scaling exponents that control sensitivity to layer depth and training phase, respectively.
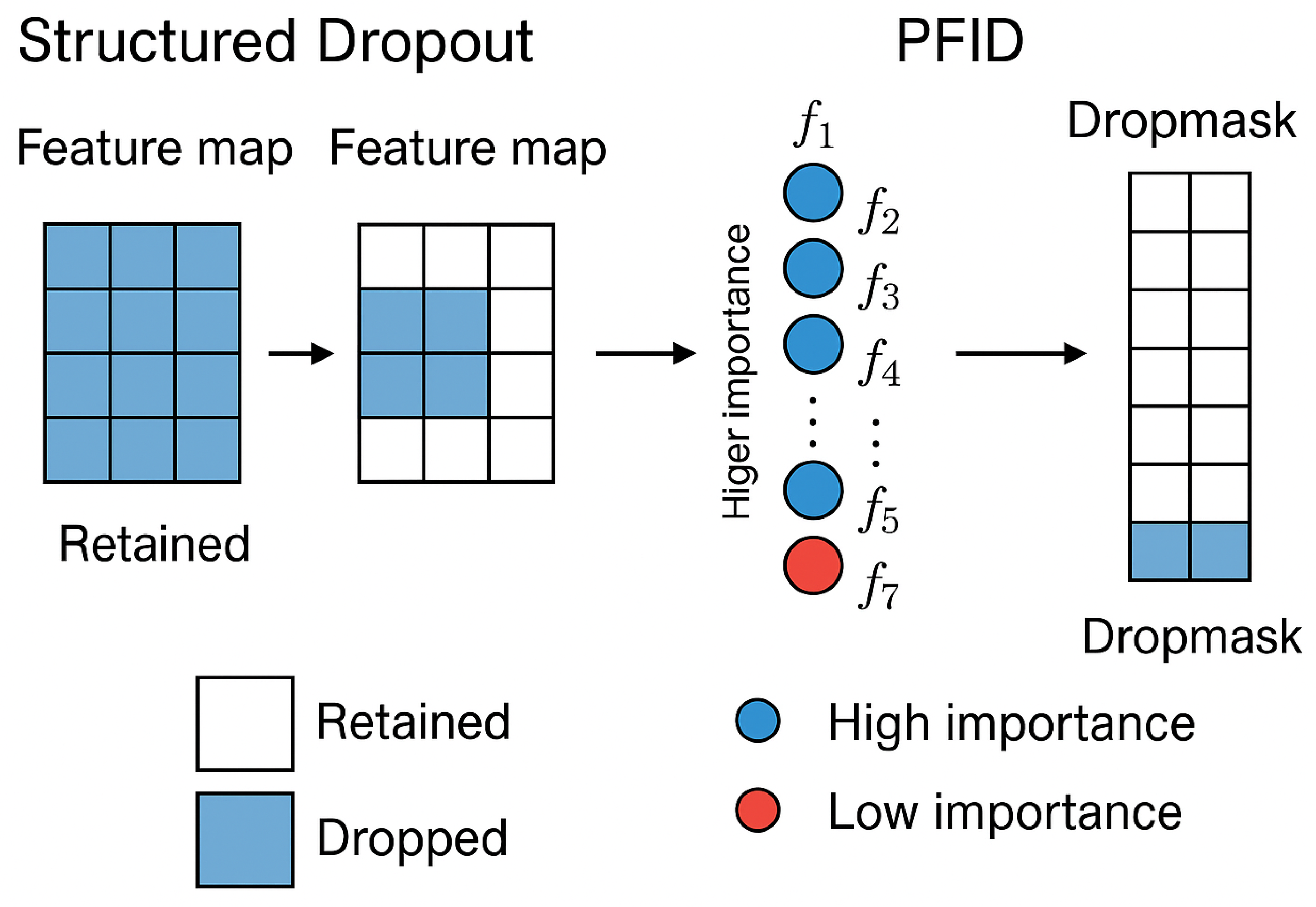
3.2. Structured Dropout
- Neuron topology and connectivity patterns;
- Filter size and arrangement of convolutional layers;
- Spatial dependencies and correlations across feature maps.
- is the activation of feature i,
- denotes its variance over a batch,
- is the Pearson correlation with neighboring features,
- represents the norm of the corresponding convolutional kernel,
- are hyperparameters controlling the weighting of each term,
- is a normalization function ensuring .
3.2.1. The Pattern Function
- : An indicator function that returns 1 if a randomly drawn number is less than the dropout rate r, injecting stochasticity into the mask generation.
- ⊙: The Hadamard (element-wise) product, which fuses the random and structural masks to produce the final dropout mask.
- : A structural function that evaluates the topological features of the layer to generate a binary vector that respects spatial coherence.
3.2.2. Spatially Aware Dropout
- L: The structural configuration of the layer, including spatial layout and filter arrangements.
- F: The spatial feature matrix representing activations or feature responses within the layer.
- : A function that generates a binary importance mask based on spatial prominence and correlations.
- ⊙: Element-wise (Hadamard) product, used to combine probabilistic dropout with spatially informed selection.
3.3. Contextual Dropout
- : A normalized measure of dataset complexity, such as label entropy or feature diversity.
- : A scalar representing training progression, typically normalized between 0 and 1 (e.g., current epoch over total epochs).
- : The initial baseline dropout rate, empirically determined based on network architecture.
- : A real-time performance metric, such as validation accuracy or loss, capturing the model’s current learning state.
- : A scaling function controlling the dropout intensity relative to dataset complexity, with tunable parameters .
- : A time-dependent decay function adjusting dropout based on training progress, governed by .
- : A modulation function that reduces the dropout rate as the model performance improves, with parameters .
Contextual Function
- is the initial (baseline) dropout rate, which serves as a starting point for adjustments.
- : A scaling function that adjusts the dropout rate based on the dataset’s complexity, such as the number of classes, input dimensionality, and intra-class variance. The parameter set controls the sensitivity of this function to complexity changes.
- : A time-based decay or scaling function that modulates dropout over the course of training. This is often designed to reduce regularization as the model converges. The parameter set defines the temporal decay behavior.
- : A performance-aware modulation function that adapts the dropout rate in response to real-time validation metrics (e.g., accuracy, loss). If performance plateaus or declines, dropout can increase to counter overfitting. defines the threshold and rate of adjustment.
3.4. Probabilistic Feature Importance Dropout (PFID)
- : Adjusted dropout rate for feature i
- : Baseline dropout rate (manually set or cross-validated)
- : Epoch-sensitive importance weight (learned or adaptively adjusted)
- : Feature importance score (calculated using Equation (14))
- : Initial importance scaling factor
- : Rate of increase in importance weight
- : Current training epoch
- : Total number of training epochs
- : Exponent controlling sensitivity over time (typically tuned via validation)
- N: Number of features in the layer
- : Importance of feature i
4. Algorithm for Optimized Dropout
| Algorithm 1 Optimized Dropout for CNNs |
|
| Algorithm 2 Probabilistic Feature Importance Dropout (PFID) |
|
4.1. Implementation Results
4.1.1. Comparative Analysis
4.1.2. Statistical Testing
4.2. Comparative Analysis and Distinctive Efficacy
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; LeCun, Y.; Fergus, R. Regularization of Neural Networks using DropConnect. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1058–1066. [Google Scholar]
- Ba, J.; Frey, B. Adaptive Dropout for Training Deep Neural Networks. Adv. Neural Inf. Process. Syst. 2013, 26, 3084–3092. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient Object Localization Using Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? Adv. Neural Inf. Process. Syst. 2018, 31, 2488–2498. [Google Scholar]
- Ghayoumi, M.; Bansal, A.K. Multimodal Architecture for Emotion in Robots Using Deep Learning. In Proceedings of the 2016 Future Technologies Conference, San Francisco, CA, USA, 6–7 December 2016. [Google Scholar]
- Ghayoumi, M.; Bansal, A.K. Emotion in Robots Using Convolutional Neural Networks. In Proceedings of the International Conference on Social Robotics, Kansas City, MO, USA, 1–3 November 2016; pp. 285–295. [Google Scholar]
- Ghayoumi, M. A Quick Review of Deep Learning in Facial Expression. J. Commun. Comput. 2017, 14, 34–38. [Google Scholar]
- Ghayoumi, M.; Bansal, A.K. Unifying Geometric Features and Facial Action Units for Improved Performance of Facial Expression Analysis. New Dev. Circuits Syst. Signal Process. Commun. Comput. 2015, 8, 259–266. [Google Scholar]
- Ghayoumi, M. A Review of Multimodal Biometric Systems: Fusion Methods and Their Applications. In Proceedings of the IEEE/ACIS International Conference on Computer and Information Science (ICIS), Las Vegas, NV, USA, 28 June–1 July 2015. [Google Scholar]
- Ghayoumi, M.; Ghazinour, K. Early Alzheimer’s Detection Using Bidirectional LSTM and Attention Mechanisms in Eye Tracking. In Proceedings of the World Congress in Computer Science, Computer Engineering & Applied Computing, Las Vegas, NV, USA, 22–25 July 2024. [Google Scholar]
- Ghayoumi, M. Mathematical Foundations for Deep Learning; CRC Press: Boca Raton, FL, USA, 2025. [Google Scholar]
- Ghayoumi, M. Generative Adversarial Networks in Practice; CRC Press: Boca Raton, FL, USA, 2023. [Google Scholar]
- Ghayoumi, M. Deep Learning in Practice; Chapman and Hall/CRC: Boca Raton, FL, USA, 2022. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the Importance of Initialization and Momentum in Deep Learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Sasaki, Y. The Truth of the F-Measure; Technical Report; School of Computer Science, University of Manchester: Manchester, UK, 2007. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Metric | CIFAR-10 | MNIST | Fashion MNIST | PFID Enhanced |
|---|---|---|---|---|
| Traditional Accuracy (%) | 67.45 | 99.12 | 90.17 | – |
| Optimized Accuracy (%) | 67.64 | 99.14 | 90.14 | – |
| PFID Accuracy (%) | 97.00 | 99.99 | 98.50 | Best accuracy |
| Traditional Loss | 0.95 | 0.03 | 0.28 | – |
| Optimized Loss | 0.92 | 0.028 | 0.27 | – |
| PFID Loss | 0.30 | 0.005 | 0.12 | Lowest loss |
| Traditional Training Time (s) | 750 | 610 | 630 | – |
| Optimized Training Time (s) | 740 | 600 | 620 | – |
| PFID Training Time (s) | 500 | 480 | 490 | Fastest training |
| Metric | Traditional | Optimized | PFID |
|---|---|---|---|
| Accuracy (%) | 67.45 | 67.64 | 97.20 |
| Precision (%) | 65.00 | 65.50 | 96.50 |
| Recall (%) | 64.00 | 64.50 | 96.00 |
| F1-Score | 0.645 | 0.650 | 0.965 |
| Training Time (s) | 750 | 740 | 500 |
| Validation Loss | 0.95 | 0.92 | 0.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghayoumi, M. Enhancing Efficiency and Regularization in Convolutional Neural Networks: Strategies for Optimized Dropout. AI 2025, 6, 111. https://doi.org/10.3390/ai6060111
Ghayoumi M. Enhancing Efficiency and Regularization in Convolutional Neural Networks: Strategies for Optimized Dropout. AI. 2025; 6(6):111. https://doi.org/10.3390/ai6060111
Chicago/Turabian StyleGhayoumi, Mehdi. 2025. "Enhancing Efficiency and Regularization in Convolutional Neural Networks: Strategies for Optimized Dropout" AI 6, no. 6: 111. https://doi.org/10.3390/ai6060111
APA StyleGhayoumi, M. (2025). Enhancing Efficiency and Regularization in Convolutional Neural Networks: Strategies for Optimized Dropout. AI, 6(6), 111. https://doi.org/10.3390/ai6060111