1. Introduction
Relation extraction (RE) is a fundamental task in natural language processing (NLP) that focuses on recognizing the relationships between pairs of entities within a sentence. The goal of RE is to derive relational triples formatted as <subject, relation, object> from the text. For instance, this is demonstrated in
Table 1. Given a sentence,
, containing a pair of entities, <Jonathan Lethem, Brooklyn>, RE aims to automatically identify and extract relationships such as <Jonathan Lethem, place_of_birth, Brooklyn>. In the past decade, it has emerged as a focal point for research [
1], and this task is both critical for the construction of knowledge graphs and fundamental for various NLP applications [
2], including language inference [
3], knowledge graph [
4], and question answering systems [
5]. By predicting entity relationships, this process enhances the enrichment of the knowledge base and accelerates the development of NLP technologies in a wide range of practical applications [
6].
Early methods in the distant supervision for relation extraction (DSRE) field mainly depended on manually created features [
7,
8,
9], including part-of-speech (POS) tags, called entity recognition (NER) tags, and dependency paths. These methods employed various strategies to transform feature extraction cues, including sequences, parse trees, and syntactic information, into high-dimensional feature vectors for DSRE tasks [
10]. Although these methods achieved significant success, they rely heavily on fully supervised paradigms and demand large-scale manually annotated training corpora to achieve optimal performance. The main problem is that manual annotation is both time-consuming and expensive, making such methods less feasible for real-world applications. To resolve this limitation, Mintz et al. [
7] presented the distant supervision method, a strategy that substantially enhances corpus annotation in NLP tasks through automated generation of training datasets. This is achieved by aligning entities from knowledge graphs with corresponding mentions in the text. As proof, in
Table 1, sentences
,
, and
all contain the entity pair <Jonathan Lethem, Brooklyn>, and are automatically labeled as expressing the relationship place_of_birth through this alignment process.
Traditional feature-based methods for identifying semantic relationships between entity pairs depend on NLP tools to obtain lexical and syntactic features [
8]. Nevertheless, the limitations of human knowledge often result in errors that propagate through the extraction process [
11]. To tackle this challenge, Zeng et al. [
12] developed a deep convolutional neural network capable of automatically extracting features from datasets labeled at the sentence level. Although this method is effective, it faces challenges in scaling to large knowledge bases because of the lack of manually annotated data. To help mitigate the lack of labeled data, distant supervision was implemented to connect text with a knowledge base, enabling the automatic generation of large-scale training datasets [
9,
13]. This method introduces significant noise, as it fails to consider the contextual nuances essential for sentence-level relation extraction. This noise leads to suboptimal performance without robust noise-handling techniques. Recently, researchers have focused on enhancing the robustness of RE models to label noise. A widely used approach to reduce the effects of label noise involves integrating multi-instance learning (MIL) with attention mechanisms [
14,
15,
16]. Researchers have utilized Multiple Instance Learning (MIL) to categorize sentences that refer to the same pair of entities into ’bags’, based on the premise that at least one sentence in each bag accurately conveys the intended relationship. The relationship is subsequently applied to the whole collection, which enhances the method’s resilience to noise. By selecting sentences from these bags, models can focus on higher-quality sentences while minimizing the impact of noisy ones. Techniques such as piecewise CNN (PCNN), proposed by Zeng et al. [
17], incorporate MIL to extract perceptual features from sentences and classify them based on these features. But choosing only one sentence from a bag, as MIL does, risks losing valuable information found in other sentences within the same bag. Recent advancements [
14,
18,
19,
20,
21] have substituted the rigid selection method with sentence-level selective attention (ATT), which allocates distinct weights to each sentence in a collection, enabling the model to utilize the complete spectrum of available information. By way of example, Lin et al. [
14] assigned weights to each instance, enabling the model to utilize the rich information from all sentences while avoiding information loss. These advancements notwithstanding, sentence-level attention mechanisms continue to face certain limitations, highlighting opportunities for further refinement.
Firstly, the aforementioned methods encode each sentence independently [
20,
22,
23,
24], neglecting the relationships between sentences within the same bag. This oversight can lead to inaccurate weight assignments during bag representation calculation, as the relationships between different sentences are not considered. For example, in
Table 1, using the method proposed by Lin et al. [
14], which only considers each sentence in isolation to compute the weights for sentences
,
, and
in the bag, one might assign a low weight to
, implying that it does not express the relation place_of_birth. Conversely, if the correlations between
and
(as well as
) were taken into account, the result might differ, showing that
indeed expresses the relation—which is the true label in this case. This demonstrates that evaluating
based solely on the target relation is insufficient, as
could still be a correctly labeled sentence.
Secondly, the aforementioned methods often treat features in different dimensions with equal importance, disregarding the fact that feature relevance can vary across dimensions. By ignoring this variability, they fail to fully consider how the quality of features impacts model performance. Given the noise introduced by distant supervision and the mislabeling it causes, designing an effective DSRE neural network remains a significant challenge. Therefore, it is crucial to improve feature quality to better represent entity relationships.
To solve the challenges of the above challenges, we propose a network named ESI-EBF, designed to enhance sentence interaction and improve bag feature representation. The model consists of four parts: the context construction components, the feature extraction components, the group-wise enhancement components, and the classification components. To address the first challenge, we introduced the context construction components as the initial component of our design. This module transforms the sentences within a bag into a coherent context, facilitating richer interaction between sentences. The group-wise enhancement components address the second challenge by dividing the bag features into multiple groups along the feature dimension, assigning importance coefficients to the sub-features in each group to enhance significant features and diminish less important ones, thereby improving the overall bag feature representation. Based on our understanding, this is the initial research that differentiates the significance of features across various dimensions, successfully reducing the performance decline associated with low-quality features. Our experimental findings indicate that the suggested model provides enhanced bag representation and greatly enhances RE performance. The key contributions of this study are summarized in the following points:
For the part that enhances sentence interaction (ESI), we propose a context construction module that emphasizes the associations between sentences by constructing them into a unified context for joint encoding. Then, we conduct more than just simple sentence processing; we consider that the meaning of the same entity may vary across different sentences in the feature extraction module.
To enhance bag feature (EBF) quality, we introduce a group-wise enhancement module that amplifies important sub-features within each group while attenuating less significant ones.
Extensive testing on two standard DSRE datasets, NYT-10 and Wiki-20m, demonstrates that our model surpasses the state-of-the-art methods.
The remainder of this article is organized in the following manner:
Section 2 discusses previous research.
Section 3 provides a detailed description of the model we are suggesting.
Section 4 showcases the outcomes of our experiments. Lastly,
Section 5 concludes the paper.
3. The Proposed Method
In this section, we introduce a relation extraction model that integrates sentence interaction with bag-level feature enhancement. This approach adheres to the multi-instance learning framework, where a set of sentences that share the same entity pair forms a bag. The training dataset is made up of N bags, each associated with a relation
r, represented by a randomly initialized vector of size
m. For each bag, which consists of
n sentences related to the same entity pair, the goal is to develop effective bag representations
B from the input sentences. The trained model can then predict relations for unlabeled bags containing entity pairs.
Figure 1 depicts the structure of our model, which includes four main components:
The context construction module concatenates the sentences within a bag, allowing sentences containing the same entity pair to form a coherent context, facilitating richer interaction between sentences.
The feature extraction module aims to generate a bag representation. It sends the concatenated context to a BERT encoder for encoding, then splits it based on markers to obtain the embedding for each sentence. Additionally, logsumexp pooling is applied to aggregate all entity mentions to generate entity representations. Finally, the sentence embeddings and entity representations are concatenated to form the bag representation.
The group-wise enhancement module is designed to refine the quality of bag features. It partitions the bag feature into multiple semantic groups and assigns a significance coefficient to each sub-feature within these groups. This process aims to amplify the more important features while diminishing the influence of less significant ones.
The Relation Classification Module uses an MLP and a Sigmoid activation function to process the bag representation and determine the probability of it belonging to relation i.
3.1. Context Construction Module
To fully leverage the data within a bag, we concatenate the sentences to form a cohesive context, allowing for rich information exchange between the sentences within the bag. Sentences are ordered sequentially, beginning with a [CLS] tag, separated by [SEP] tokens, and padded with [PAD] tokens for consistency. Additionally, following best practices for relation extraction [
35,
36], entity mentions in each sentence are indicated by specific tokens:
and
for the first entity, and
and
for the second entity. Inspired by [
37], this process continues until (a) including an additional sentence would surpass the encoder’s maximum token capacity, or (b) every sentence in the collection has already been accounted for. An example of this construction is provided in
Table 2.
3.2. Feature Extraction Module
The sentence encoder fed the constructed context into a BERT encoder to obtain contextual embeddings,
, for each token,
, which can be indicated as
where
represents the length of the
n-th sentence. By encoding the concatenated sentences with BERT, we transform sentences that were originally processed independently into a cohesive context, allowing for comprehensive information exchange among them. To obtain the encoding for each individual sentence, we split the contextual embeddings based on the marker
positions. The embedding for the
i-th sentence after splitting is denoted as
, reflecting the information exchange with other sentences in the bag. A weighted average is subsequently used on these embeddings to derive the sentence representation
, denoted as:
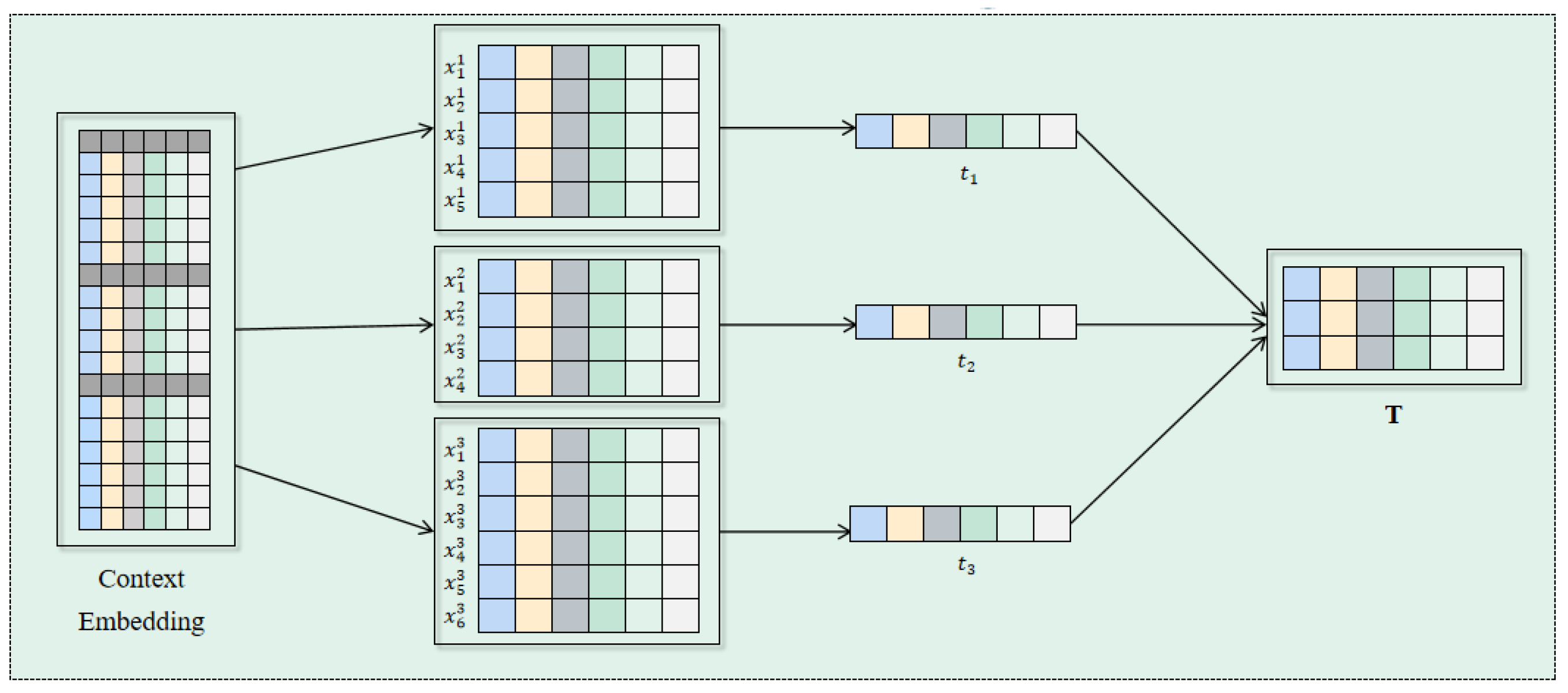
Once all the sentences are averaged, the resulting sentence embeddings are combined to create a comprehensive joint sentence representation, T. This process is depicted in
Figure 2.
Entity enhancement is utilized to gather worldwide entity information within a specific context. We represent the head entity in each sentence using the “
” token positioned before the entity. To capture its overall contextual information, we aggregate the head entity representations from all sentences using logsumexp pooling [
38], as shown below:
A similar approach is applied to the tail entity
; we represent it using the “
” token preceding the tail entity in each sentence:
This pooling accumulates information from references in context. Experimental results show that, compared with average pooling, this method has better performance.
Joint mapping combines the sentence and entity embeddings to produce a richly informative bag-level embedding, , where n is the number of sentence in the context, L represents n+2, and m denotes the dimensionality of the word embeddings.
3.3. Group-Wise Enhancement Module
This module aims to enhance important features and suppress less relevant ones at the bag level, improving the quality of bag features to facilitate classification. The overall process is shown in
Figure 3. We first divide the joint bag mapping,
B, obtained from the previous module into
p groups along the feature dimension. Then, we can achieve the bag group feature mapping,
, where p represents the number of groups. Let us examine how the process works for a given group in detail.
For a given group, its corresponding feature mapping is denoted as
, where
, and the sub-feature vector
, where
is a feature in sub-feature
f. We presume that each group contains a representative semantic feature during the network learning process. We obtain a representation that approximates the global semantic feature of the group learning representation
by averaging the features within the group:
Next, using this semantic vector, we use a simple dot product operation to generate an importance coefficient
c for each sub-feature, representing the resemblance between the semantic feature
and each sub-feature vector
. Specifically, the formula is defined as follows:
To avoid bias in the coefficients across different samples, we apply normalization to
within the feature space:
Here,
(for example,
) is a constant included to ensure numerical stability,
is the mean of all correlation coefficient data in the current group, and
is its standard deviation. To ensure that the normalization within the network accurately reflects the identity transformation, we incorporate two parameters,
and
, for each coefficient
. These parameters adjust the scaling and shifting of the normalized value. As a result, a new importance coefficient
is produced through the sigmoid function
:
Finally, the generated normalized importance coefficients are used to scale, enhancing the important features while weakening the less significant ones, resulting in an enhanced sub-feature vector
:
In this way, after all the features have been enhanced, a more optimal feature group, , is formed. Once the features in all groups have been enhanced, we can obtain the group-wise feature mapping . Thus, we obtain an improved mapping of the features of the joint bag .
3.4. Relation Classification Module
In this final module, the enhanced bag representation, , obtained from the group-wise enhancement module is used to perform relation classification. The purpose of this module is to translate the enhanced features into a probability distribution regarding the potential relationships, enabling us to forecast the most probable relationship for each entity pair within the bag.
First, we assign a weight to each row of the bag
(where each row represents the embedding of a sentence), thus minimizing the effect of irrelevant sentences in the collection [
39], as shown below:
Here,
k is an index for the relation, taking values from 1 to
h, and
represents the attention weight that connects the
k-th relation to the
i-th sentence in the bag
B. For the uniform representation, where
is the head entity
and
is the tail entity
,
can be further defined as
where
represents the degree of correspondence between the
i-th sentence and the
k-th relation in the bag, which is specifically computed using the dot product of the vectors to assess the extent of their correspondence as follows:
where
represents the k-th row of the relation embedding matrix
.
Next, the score
for classifying bag
into relation
k is determined using
and the relation embedding
as follows:
where
is a bias. Next, we apply a softmax activation function to transform the score vector into probability values:
where
indicates the likelihood that the bag is associated with a particular relation
k. This allows the model to predict the likelihood of the bag being associated with each relation in the label space.
To enhance the model’s performance, we use the negative log-likelihood as the objective function, which is defined in the following way:
where N refers to the total number of bags in a batch,
represents the label for a bag
, and
represents the set of parameters for the model. During the model training, we utilize mini-batch stochastic gradient descent (SGD) to reduce the loss function
.
4. Experiment
In this section, we present several experiments to demonstrate the effectiveness of our suggested method. We begin by detailing the datasets and the experimental framework. Next, we explore various versions of the method (which can serve as ablation experiments) and compare the ESI-EBF against seven competing DSRE methods. We also conduct an ablation study to evaluate the impact of each component. Furthermore, we examine how the number of feature groups affects performance. Lastly, we present a case study to demonstrate the effectiveness of our proposed method.
4.1. Datasets
We assessed the model by using the NYT [
8] and Wiki-20m [
37] datasets in our experiments. The details are described in
Table 3.
The
NYT dataset was initially introduced by Riedel et al. [
8]. The New York Times employs data from 2005 to 2006 for training purposes and uses data from 2007 for testing. In NYT, sentences are organized into bags, and the labels are determined based on whether they contain specific entity pairs, which are automatically created through distant supervision. NYT is the most popular dataset in DSRE, and is widely used for evaluating relation extraction models. Both the training and testing splits are supervised from a distance, ensuring consistency in the dataset’s automatic labeling process. Additionally, the NYT dataset exemplifies the primary purpose of DSRE, which is to reduce the cost of labeling. Therefore, given its widespread adoption and reliability, we chose this dataset for experimental validation. The dataset includes over 52 relation types, with “1” indicating N/A, and is divided into training and testing sets. The dataset details are as follows: (1) The training set consists of 522,611 sentences, 281,270 entity pairs, and 18,252 triples. (2) The test set includes 172,448 sentences, 96,678 entity pairs, and 1950 triples.
The
Wiki-20m dataset was constructed by integrating Wikipedia articles [
40], leveraging them as the corpus to ensure high-quality annotations and fewer noisy labels compared to automatically labeled datasets like NYT. Wiki-20m is a newly launched dataset created for training DSRE models and assessing their performance using a manually annotated test set. In this dataset, sentences (instances) are grouped into bags based on entity pairs, with labels derived from the relationships between the entities. The primary purpose of Wiki-20m is to provide a benchmark for evaluating relation extraction models under a more realistic and less noisy setting. The dataset comprises 30 different types of relationships, excluding “N/A”. The particulars of the dataset are outlined as follows: (1) The training dataset includes 6,987,222 sentences, 304,870 entity pairs, and 157,740 triples. (2) The testing dataset includes 137,986 sentences, 74,390 pairs of entities, and 56,000 triples.
4.2. Experimental Setup
Evaluation metrics. In line with earlier techniques, each DSRE method was assessed using held-out testing, where precision and recall are determined by comparing the predictions against the relational facts in the dataset. For our experiments, we utilized the Precision–Recall (PR) curve for visual analysis, the Area Under the ROC Curve (AUC) for numerical evaluation, and Precision@N (P@N) to assess the accuracy of the top-N outcomes [
21,
39,
41]. For Precision@N, we employed the P@N metrics for the top 100, 200, and 300 results for these datasets. In comparison, Wiki-20m is a dataset annotated by humans, so it provides better performance for DSRE models because of its excellence labels. To facilitate a more precise evaluation, we utilized P@N metrics for the top 30,000, 40,000, and 50,000 results from the Wiki-20m dataset.
Parameter Settings. In our experiment, the word vector dimension was 300. The specific parameter configurations are presented in
Table 4. To optimize hyperparameters, we conducted a grid search using learning rates of
and
, batch sizes of 8, 16, and 32, and feature group sizes of 10, 20, and 30, ultimately choosing the configuration that yielded the best performance for each dataset. For the baseline methods used for comparison, we adopted the parameter configurations that achieved the best performance according to the original studies.
Comparative Experiments. We carried out two types of comparative experiments. The first involved comparing three different versions of our proposed method (refer to
Section 4.3), which served as an ablation study. The second set compared our proposed method with state-of-the-art approaches using two different datasets (see
Section 4.4). Alongside these comparative experiments, we also conducted ablation studies (see
Section 4.5). Lastly, we analyzed the impact of varying sizes of different feature groups.
4.3. Different Versions of the Proposed Method
Because our suggested framework can be applied in various manners, we will present three different versions of the proposed method. (1) ESI + EBF: This is the original approach we came up with, which constructs the sentences in a bag into a coherent context for encoding, enhances the information interaction between the sentences (ESI), and the features of the bag are grouped to enhance the features (EBF) separately. (2) PCNN + EBF: The method of feature extraction is replaced by a piecewise CNN encoder (Zeng et al. [
12]). (3) ESI + ATT: The variations in bag-level features are not taken into account, with ATT being the attention technique introduced by Lin et al. [
14]. Furthermore, we included PCNN + ATT as part of the baseline models. The evaluation of these four approaches on the NYT dataset acted as an ablation study.
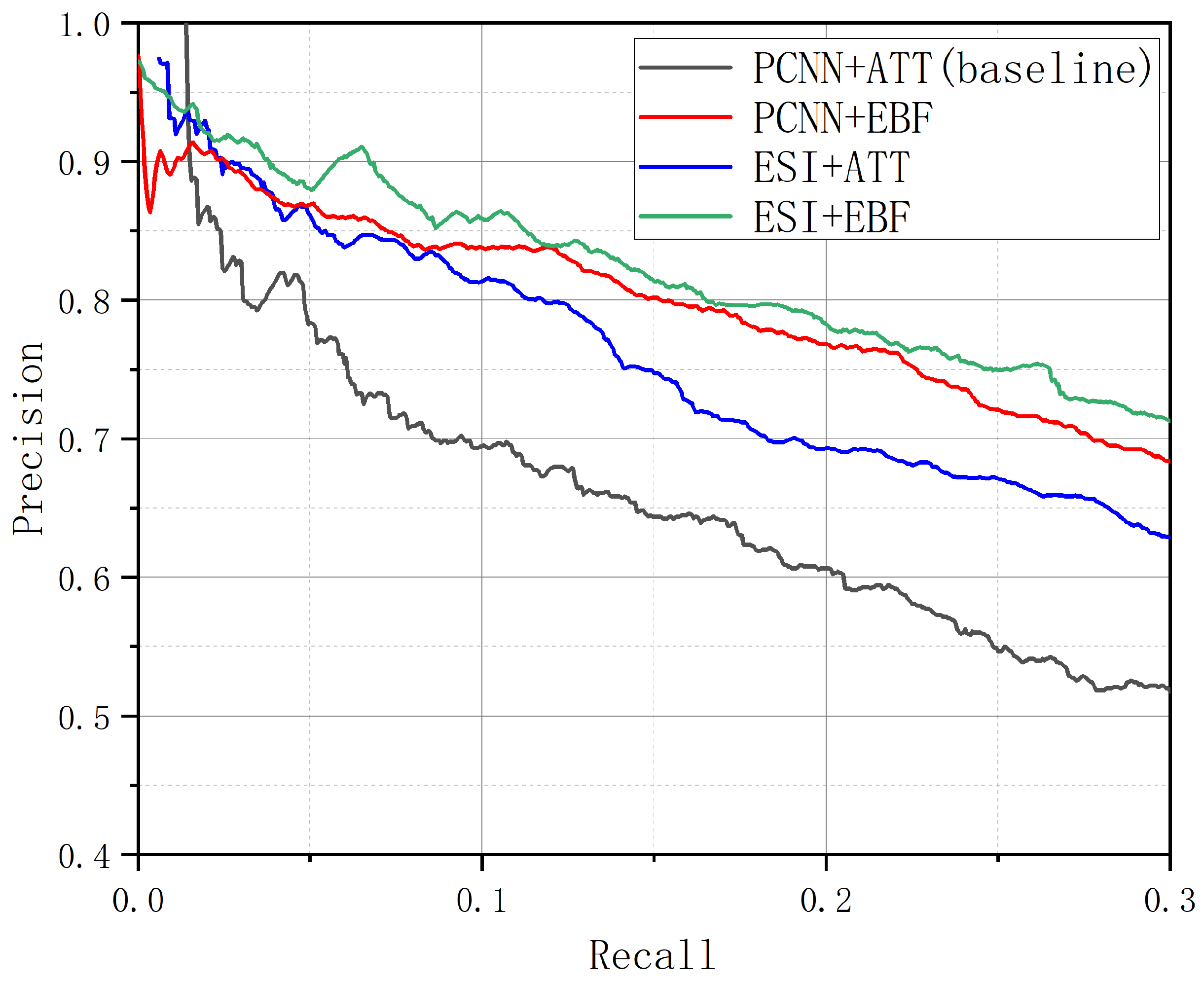
The experimental findings are presented in
Figure 4 and
Table 5. Our observations are as follows: (1) Regardless of the sentence encoders employed, our EBF outperforms ATT. This indicates the importance of taking bag feature quality into account. EBF evaluates feature importance from the perspective of sentence feature dimensions, ensuring that an unimportant sentence does not lead to the suppression of all its features. Even though some sentences may be noisy, certain feature dimensions within those noisy sentences could still play a crucial role. (2) In both sentence encoder modes, the models that utilize EBF perform better than those that do not include EBF. This further illustrates the importance of features in the different dimensions. (3) From an encoding standpoint, models that incorporate ESI perform better than those that do not. This indicates that it is important to take into account the relationships between sentences within the collection. However, a model with only the ESI module performs worse than only the EBF module, highlighting the importance of considering feature significance from the perspective of feature dimensions. (4) ESI + EBF reaches the highest AUC of 0.440, which is an improvement of 5.8% over PCNN + ATT.
4.4. Comparison with Previous Work
We compared our advanced ESI-EBF model with eight state-of-the-art models on the NYT dataset and five top models on the Wiki-20m dataset. A brief overview of the models being compared is provided below:
PCNN + ATT [
34] PCNN + ATT uses a selective attention mechanism to reduce the influence of noisy sentences, serving as a strong baseline for RE models.
PCNN+RL [
19] introduces a reinforcement learning (RL) framework designed to handle false positives by optimizing instance selection.
Intra–Inter Bag [
39] utilizes intra-bag methods to reduce noise within individual sentences, while inter-bag attention is applied to address noise at the bag level.
C2SA [
21] enhances relation extraction by applying a contextualized attention mechanism that considers all potential relations, assigning higher importance to higher-quality entity pairs.
SeG [
34] uses an Self-Attention Enhanced Selective Gate to overcome problems occurring in selective attention, which is caused by one-sentence bags.
CIL [
24] is a strategy for relation extraction that enhances the model’s ability to perceive subtle differences during training through a contrastive learning framework, thereby improving overall relation extraction performance.
HiCLRE [
41] employs a multi-layer structure to extract features and model associations at both the instance level and the concept level, thus enhancing the accuracy and robustness of relation extraction.
PARE [
37] provides a simple and powerful baseline for both monolingual and multilingual DSRE.
FAN [
42] employs adversarial training to consolidate false negative cases into a common feature space and apply pseudo labels, using a PCNN combined with a transformer layer as its encoder.
Performance Measured by the PR Curve. The PR curve comparison for eight models on the NYT dataset is presented in
Figure 5. Since the authors of PCNN + ATT and PCNN + RL only plotted the first 2000 points of their PR curves, we also limited our plot to the first 2000 points to ensure a fair comparison. The following conclusions can be obtained: (1) Our proposed ESI-EBF model demonstrates superior performance compared to the other models, validating the effectiveness of incorporating sentence-level interactions and accounting for feature-level distinctions. (2) Our model demonstrates more stable performance. Our approach demonstrates minor fluctuations at lower recall rates, but maintains overall strong performance. When the recall rate exceeds 0.09, our model consistently performs the best.
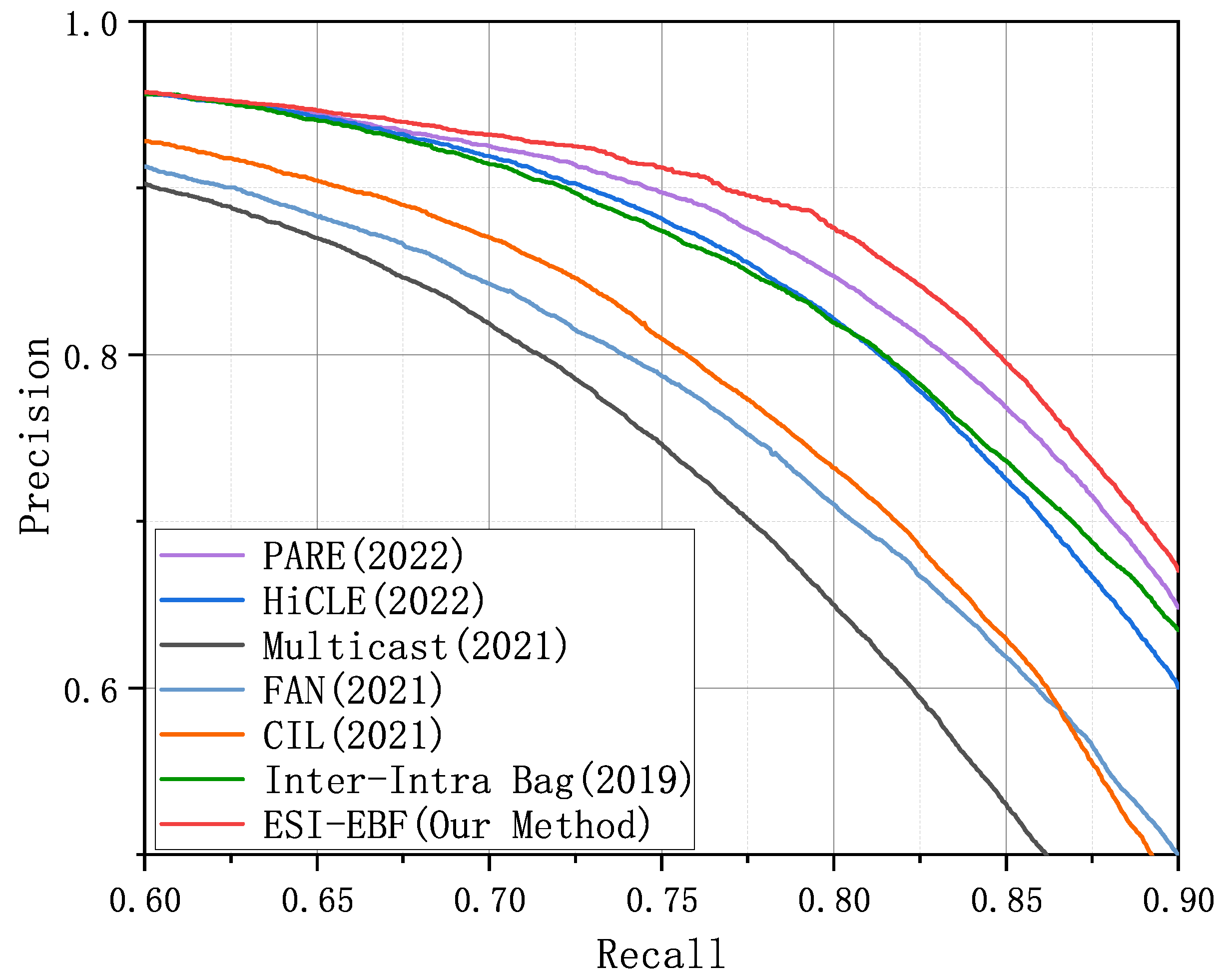
The outcomes of evaluating five models on the Wiki-20m dataset are presented in
Figure 6. The following is evident: (1) Our model outperformed all other models in the comparison. (2) With manually annotated labels, Wiki-20m contains far fewer mislabeled instances. Despite its significantly larger size compared to NYT, all models demonstrate strong performance on this dataset, with our method achieving superior results.
Performance Measured by the AUC. In our experiments, AUC was chosen as the evaluation metric because it provides a clearer distinction in performance between our proposed ESI-EBF model and the competing methods.
Table 6 and
Table 7 offer a detailed comparison of ESI-EBF with other approaches, presenting the Top-N P@N(s), Mean P@N, and AUC results for the NYT and Wiki-20m datasets, respectively. Similarly, our proposed ESI-EBF model consistently outperforms all other models across both datasets, demonstrating improvements of 1.1% in average P@N and 0.9% in AUC according to
Table 6, and 1.0% in average P@N and 1.4% in AUC as seen in
Table 7.
4.5. Examination and Evaluation of Ablation Studies
As these two modules are essential parts, they cannot be eliminated for ablation studies. Instead, we initially substituted them with various existing methods for comparison purposes. Afterward, we selected the best-performing alternatives for in-depth comparative experiments.
To determine the performance of ESI, we compared it with LSTM, CNN, and BERT-based relation extractors using the NYT dataset, as NYT is the most commonly utilized benchmark in DSRE. As shown in
Table 8, ESI + ATT consistently outperforms other neural network architectures. Furthermore, we compared EBF with alternative approaches that utilize the same sentence encoder for sentence- or bag-level representations. The results in
Table 8 indicate that EBF also achieves superior performance over other models.
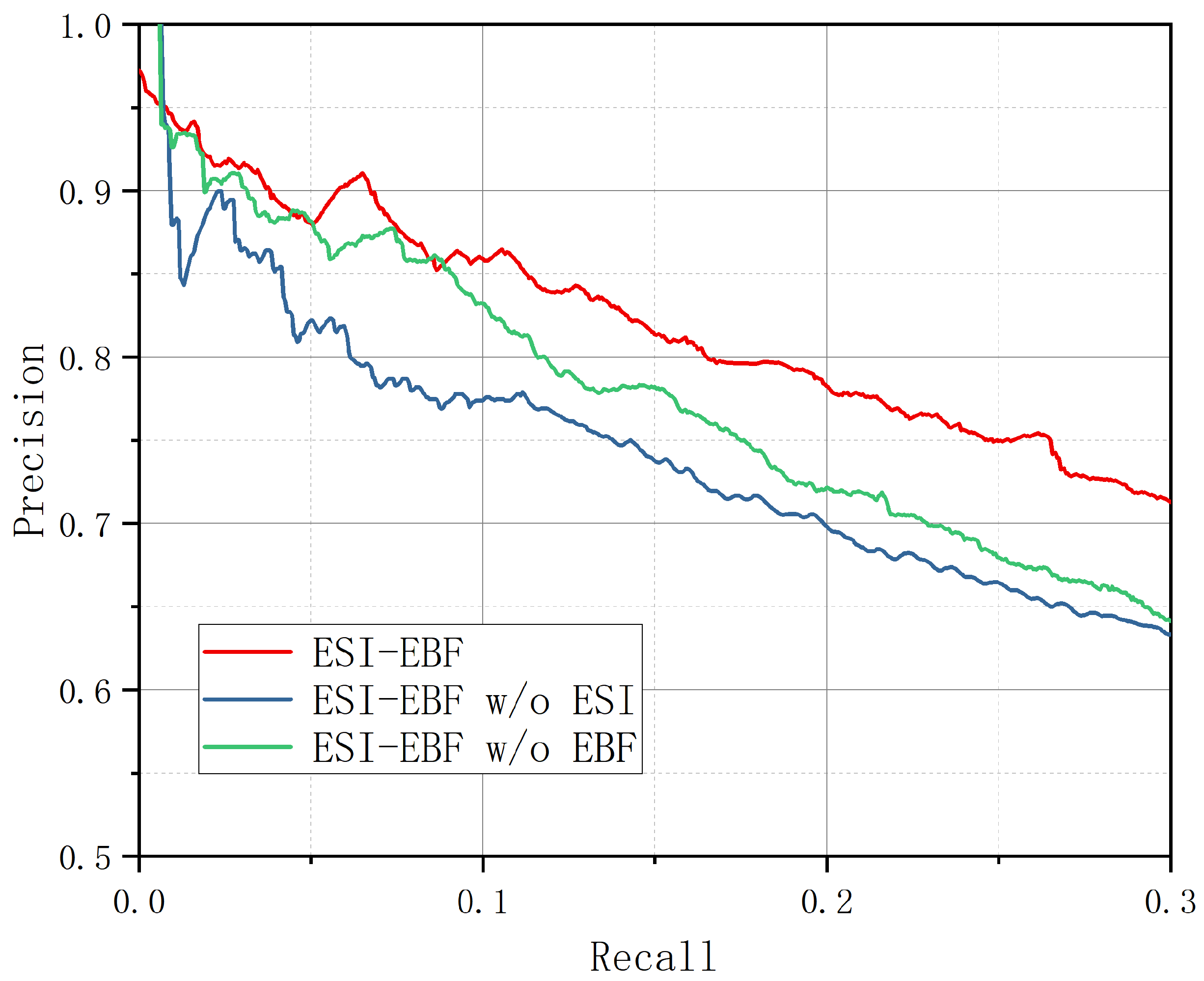
To further validate the effectiveness of ESI-EBF, we compared it with two ablation variants. In particular, we swapped out ESI for BERT to create ESI-EBF without ESI, and we replaced EBF with ATT_RA + BAG_ATT to develop ESI-EBF without EBF. As shown in
Figure 7, the accuracy curve of ESI-EBF surpasses those of the ablation models, indicating that each module contributes to performance improvement.
Table 9 shows that ESI-EBF consistently surpasses both ablation variants in various Top-N configurations and average P@N scores. In contrast, the ablation models show variable performance across P@N values. Specifically, ESI-EBF without EBF has the lowest performance, indicating that EBF is essential for improving the overall effectiveness of the model. This is because EBF captures feature correlations across different dimensions while considering feature quality, preventing all dimensions from being treated equally.
Although ATT_RA + BAG_ATT also evaluates sentence-level features, it weakens sentence representations as a whole rather than adjusting feature importance at different dimensions. In contrast, EBF selectively suppresses irrelevant features while emphasizing essential ones. Even if a sentence is less informative overall, certain feature dimensions within it might still be valuable. By preserving these important feature dimensions, EBF avoids the loss of critical information caused by disregarding entire sentences.
4.6. The Influence of the Bag Feature Group-Wise Size
By applying group-wise enhancement to the features at the bag level, the capabilities of the bag are enhanced, allowing the model to better capture essential patterns in relation extraction. However, determining the optimal number of groups is crucial for achieving the best performance.
In this section, we examine the impact of the number of feature groups on the model’s performance.
Figure 8 illustrates that the model performs better with an increasing number of groups. This improvement occurs because having more groups allows for more detailed feature differentiation, enabling the model to concentrate on distinct aspects of the data. The performance peaks when the number of groups reaches 20, suggesting that this setting provides the best balance between feature refinement and noise reduction. Beyond this point, further increasing the number of groups leads to a decline in performance, likely due to excessive fragmentation of features, which introduces noise and reduces the model’s ability to generalize effectively. In summary, if there are too few group sizes, the model’s ability to improve is restricted because it cannot take full advantage of the interactions between features. Conversely, setting the group size too large disrupts meaningful patterns and adds unnecessary complexity.
Therefore, in practical applications, selecting an appropriate number of groups is essential to maximizing performance while minimizing noise, ensuring a more robust and effective relation extraction model.
4.7. A Case Study
To further demonstrate the performance of our proposed method, we conducted a case study comparing the ESI-EBF model with PCNN + ATT [
14] and Intra–Inter Bag [
39].
Table 8 presents several sample cases selected from the NYT-10 dataset, consisting of two bags. Each bag is accompanied by its respective label and a collection of sentences that are included within the bag. Additionally, “True?” indicates whether the entity pair in the corresponding sentence aligns with the label of the bag. A “No” indicates that the sentence’s label does not align with the bag’s label, implying that the sentence can be viewed as irrelevant or extraneous within the bag. Conversely, a “Yes” signifies alignment. Furthermore, the table includes experimental results for the three models, featuring sentence weights and predictions (i.e., the anticipated label of the bag). The designation “NA” signifies a specific label indicating no relation.
For the input bag
, both ESI-EBF and Intra–Inter Bag correctly predict the relation. On the other hand, PCNN + ATT mistakenly assigns an “NA” label to the bag. For the input bag
, only ESI-EBF makes the correct prediction. As shown in
Table 10, for all noise sentences that are consistent with the bag’s label, PCNN + ATT assigns significantly higher weights to these sentences compared to the other two methods, while our proposed method assigns much lower weights. This demonstrates that fully leveraging the information exchange between sentences proves beneficial for the task. Therefore, it is evident that our model enhances the performance of relation extraction.
5. Conclusions
This paper proposes a distantly supervised network based on sentence interaction enhancement and bag feature enhancement, which facilitates communication between sentences to mitigate the noise problem. Simultaneously, it strengthens useful bag features while suppressing less relevant ones, thereby improving the overall quality of bag representations.
For sentence representation, we first concatenated all sentences within a bag to construct a shared context and encoded them as a whole. Then, we split the encoded representation based on specific markers to obtain individual sentence embeddings. Additionally, we applied logsumexp pooling to aggregate all entity mentions, generating more robust entity representations. The sentence embeddings and entity representations were combined to create the final bag representation. At the bag level, we enhanced the feature representations by organizing bag features across various dimensions. This grouping mechanism selectively enhances critical features while attenuating those of lesser importance, allowing the model to focus on the most informative aspects of the data.
To assess the performance of ESI-EBF, we carried out extensive experiments using two popular DSRE benchmark datasets: NYT and Wiki-20m. The results indicate that ESI-EBF surpasses current leading methods, with a 0.9% enhancement in AUC for the NYT dataset and a 1.4% rise for the Wiki-20m dataset. These findings highlight the potential of ESI-EBF to contribute to future advancements in knowledge graph construction, information extraction, and various natural language processing applications.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}