Automated Source Code Generation and Auto-Completion Using Deep Learning: Comparing and Discussing Current Language Model-Related Approaches




Abstract
:1. Introduction
[...] traditional language models limit the vocabulary to a fixed set of common words. For code, this strong assumption has been shown to have a significant negative effect on predictive performance [...]
2. Materials and Methods
2.1. Deep Neural Networks and Tokenization Models Used
2.2. Experimentation Details
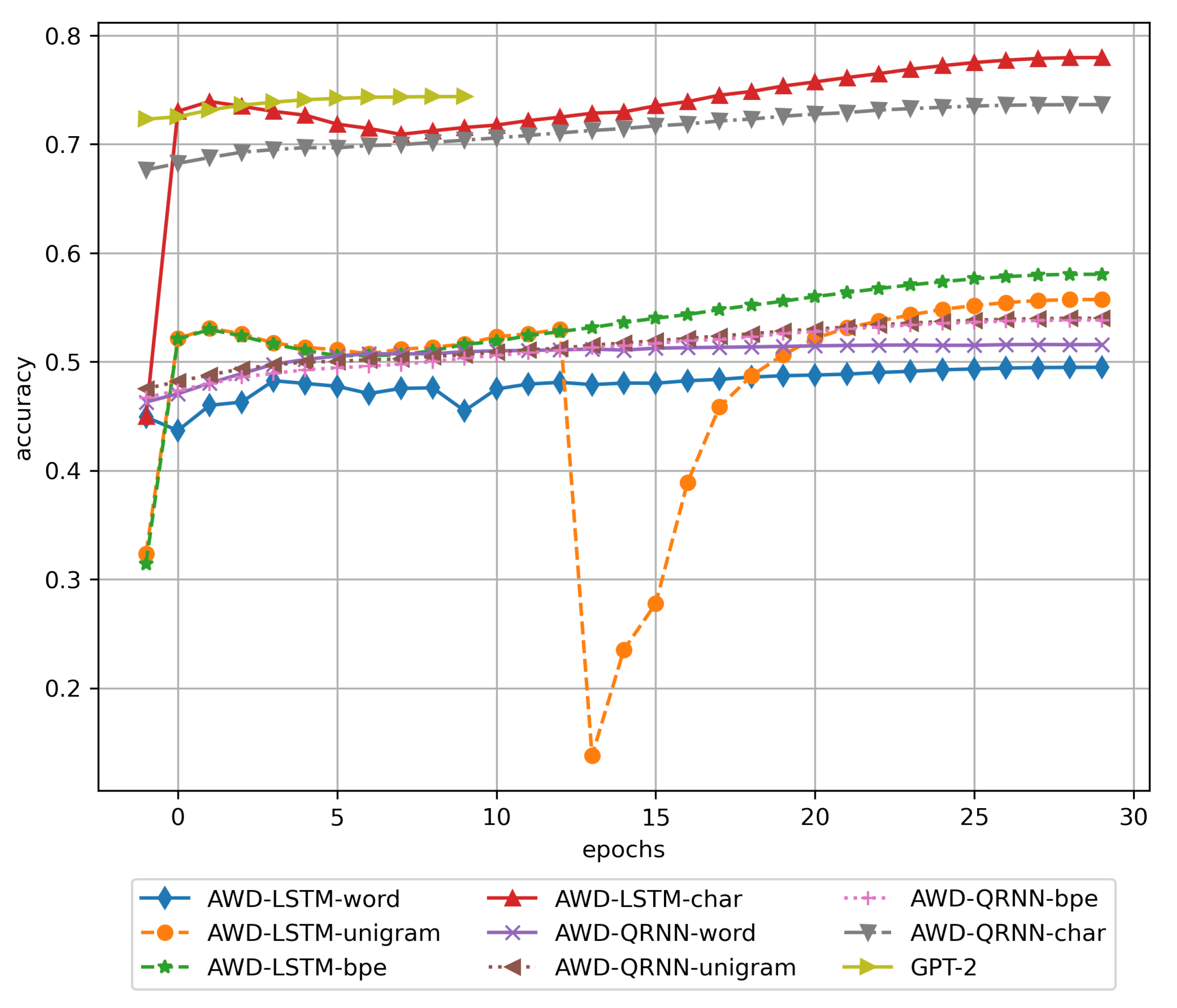
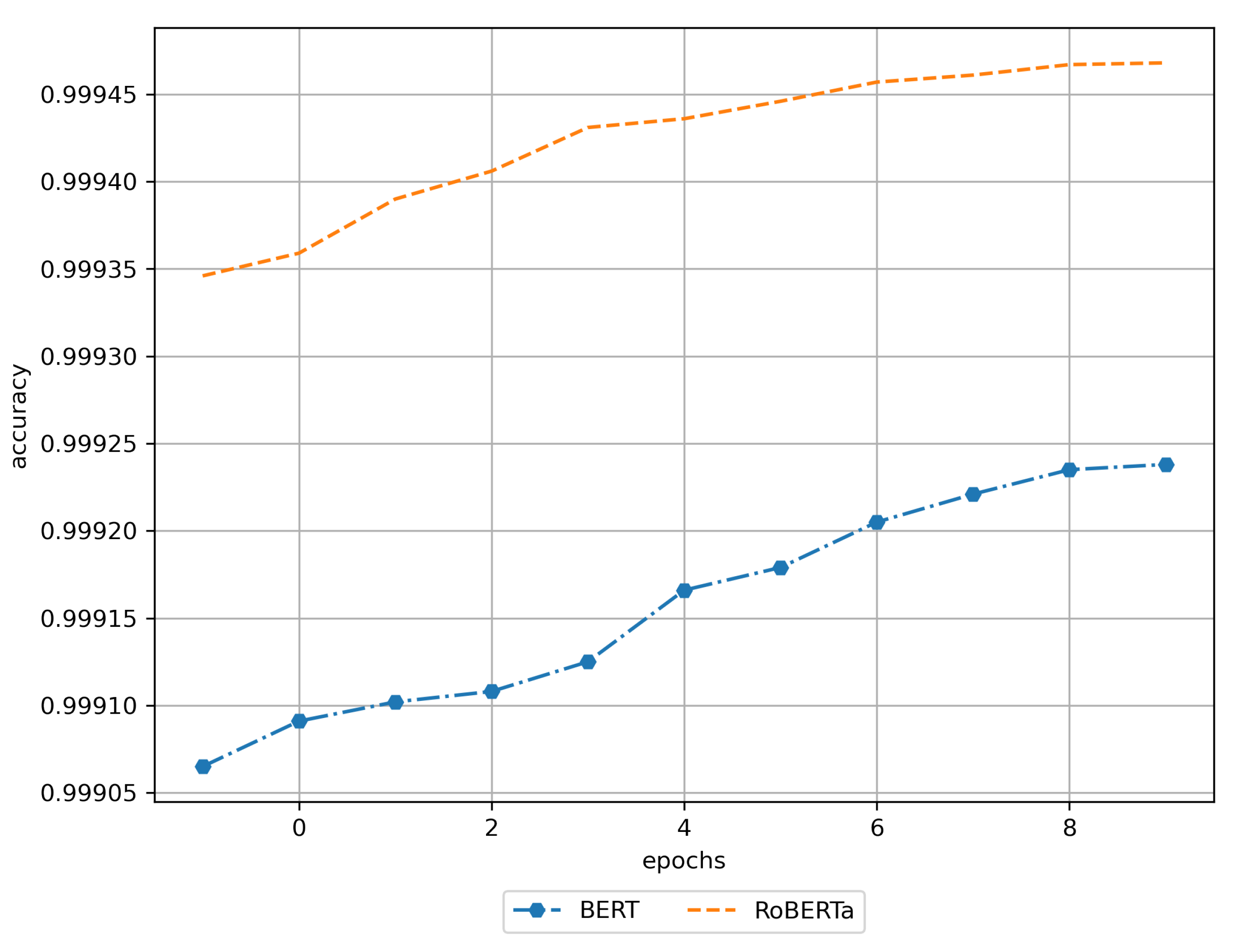
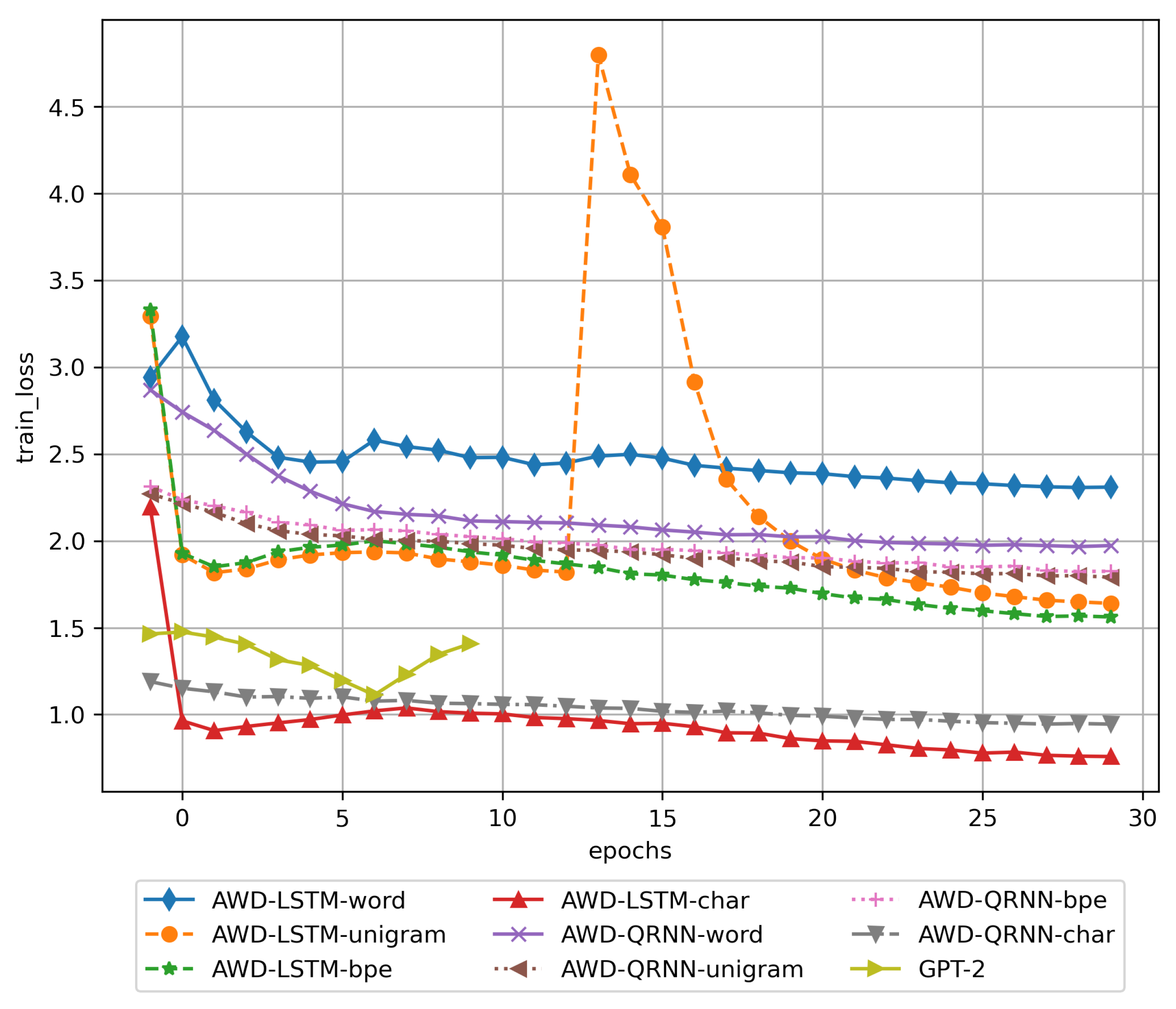
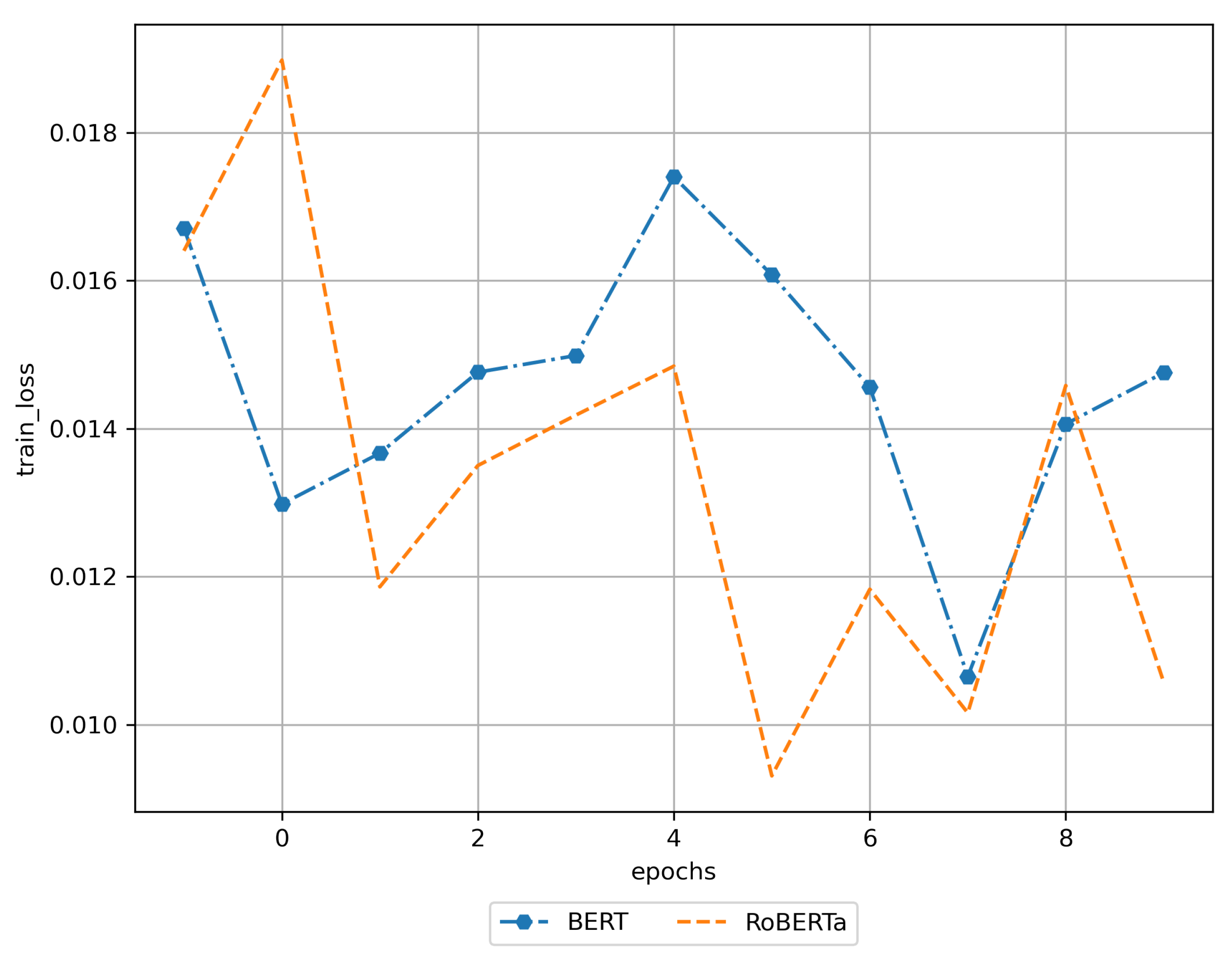
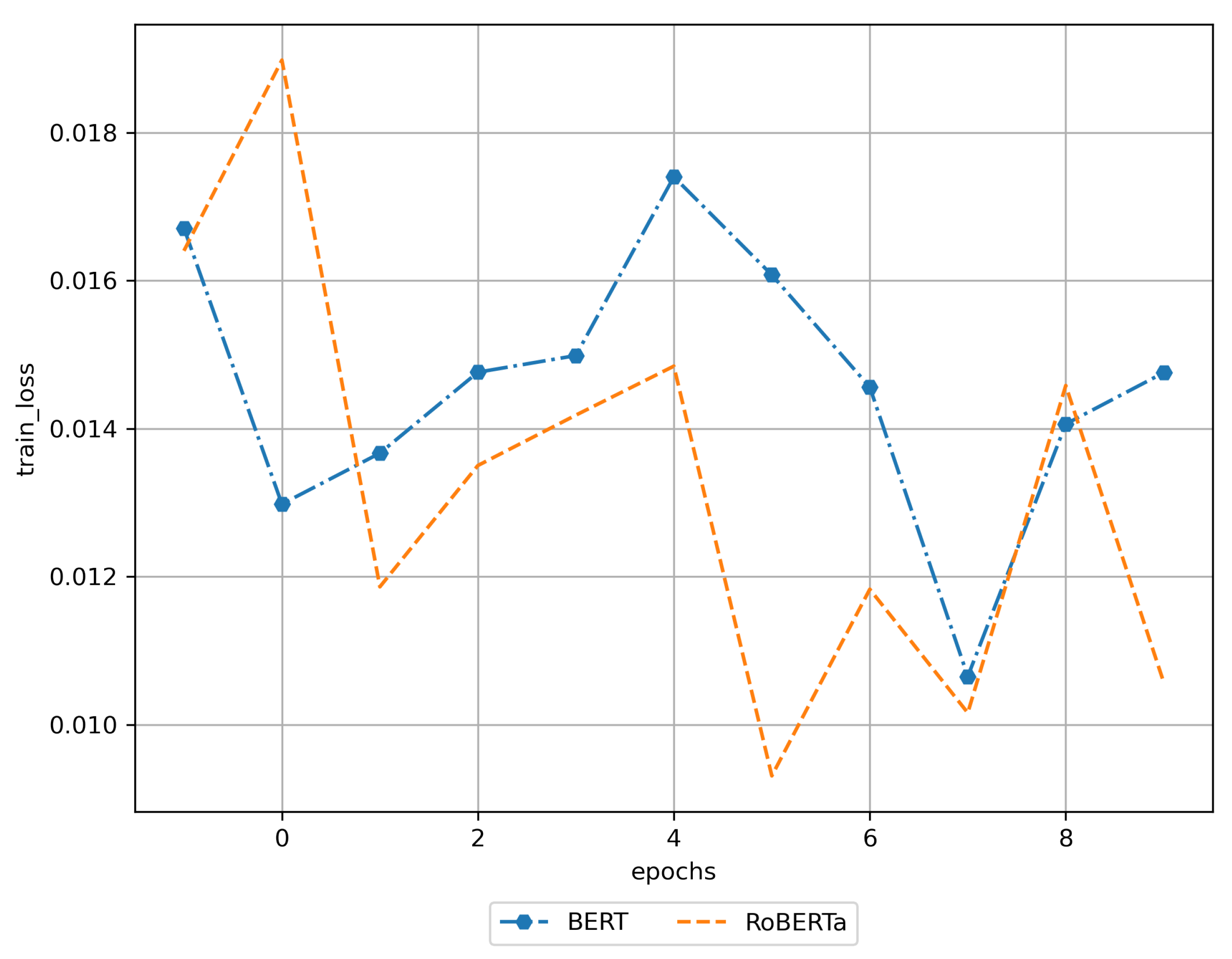
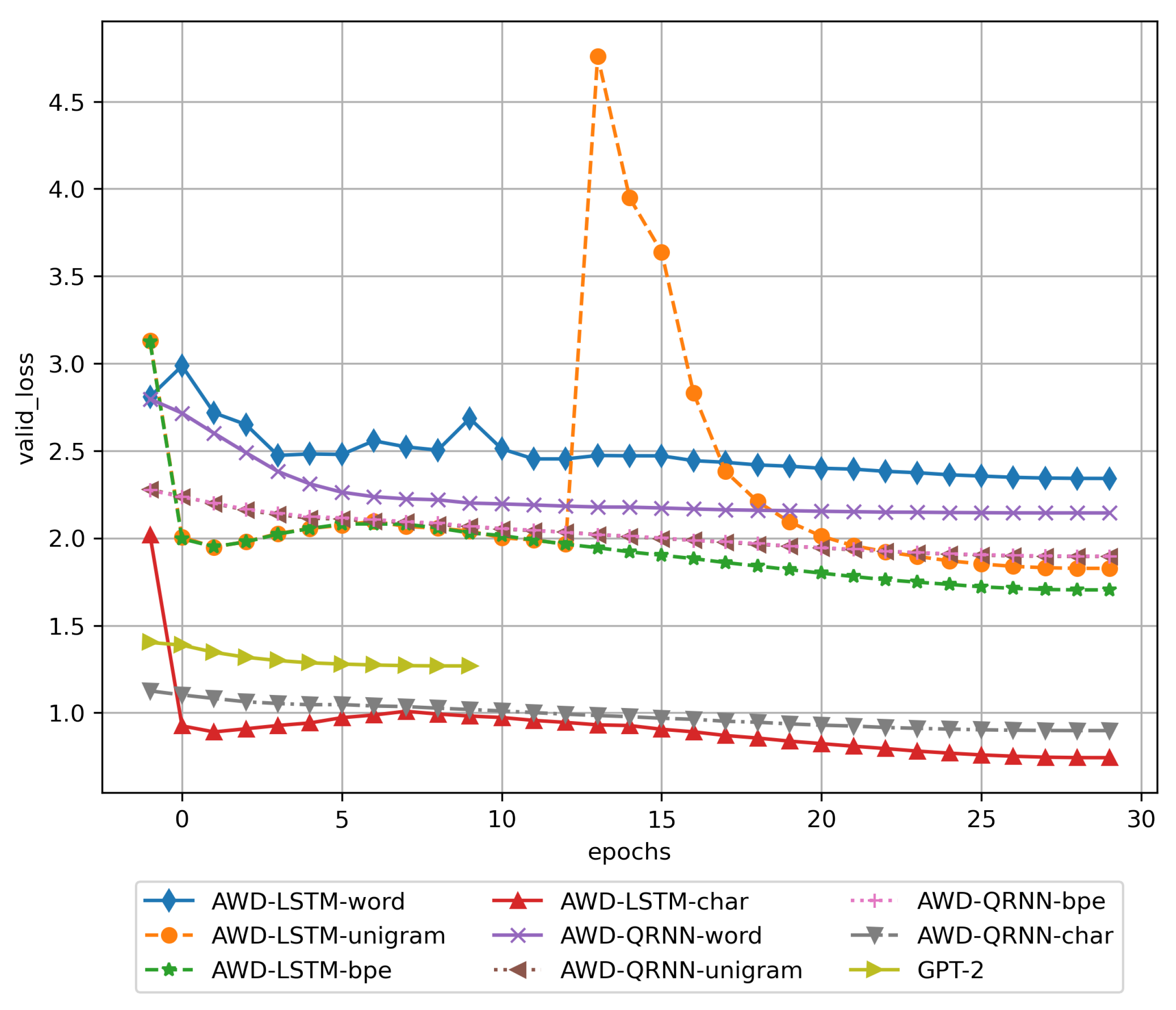
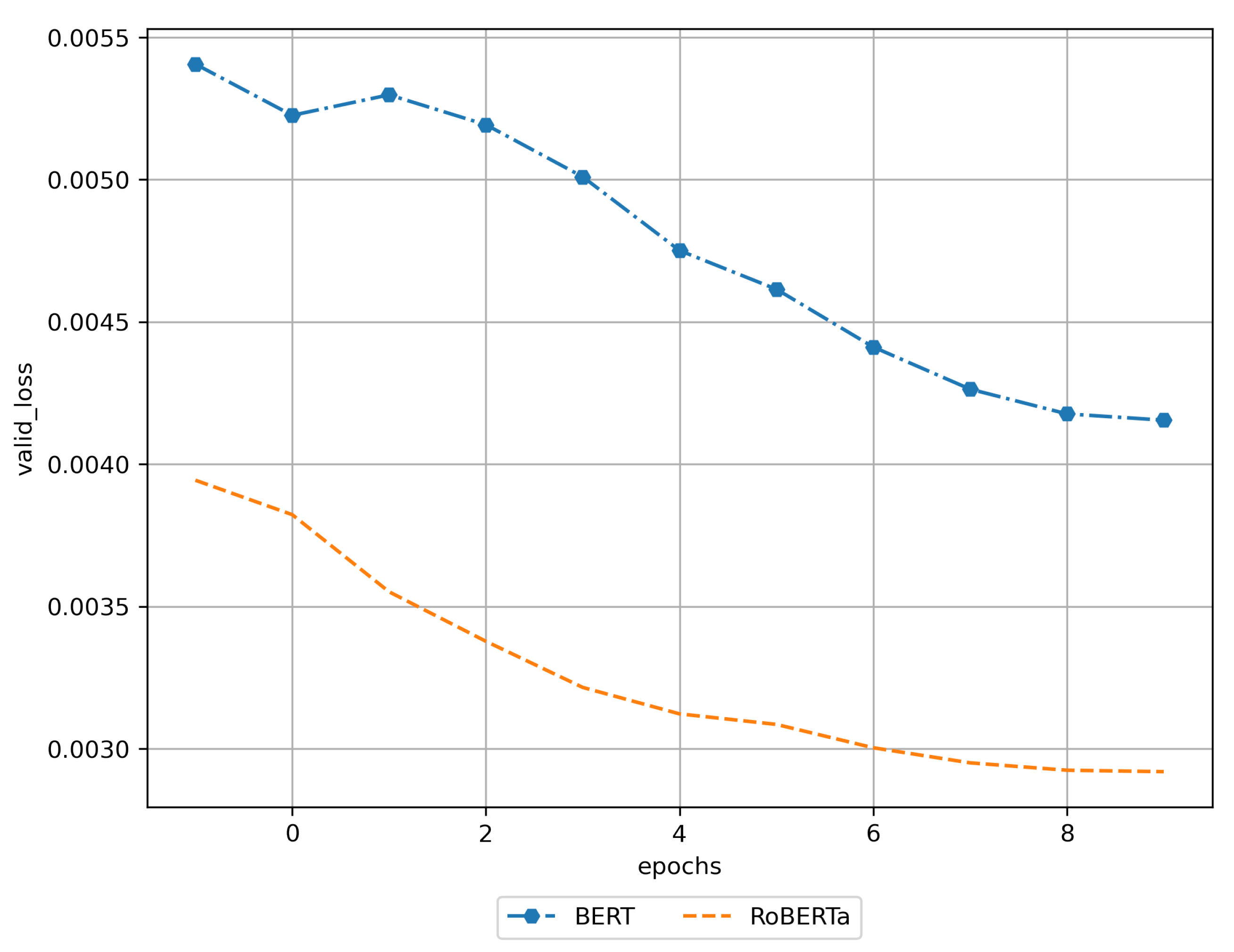
3. Results
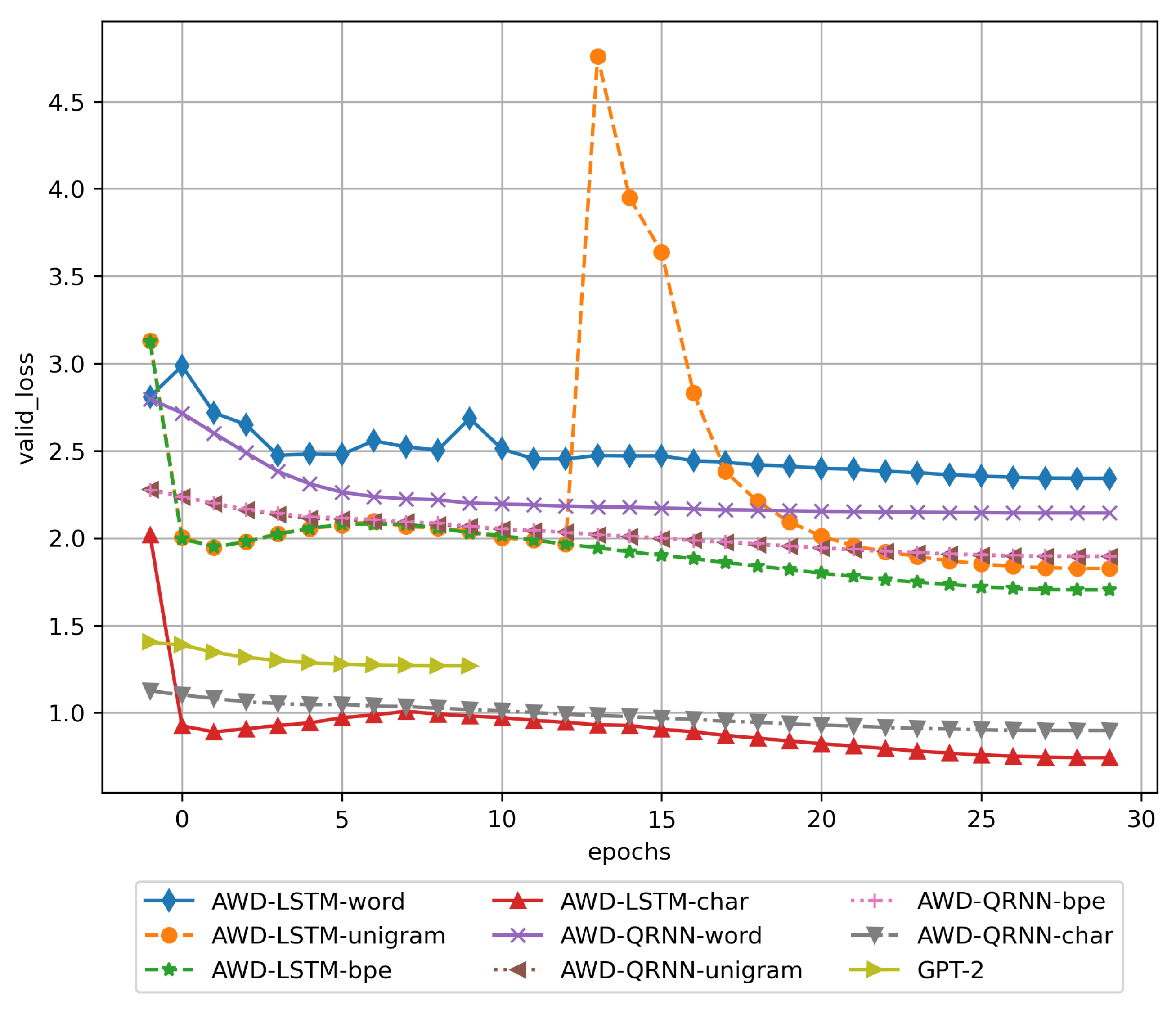
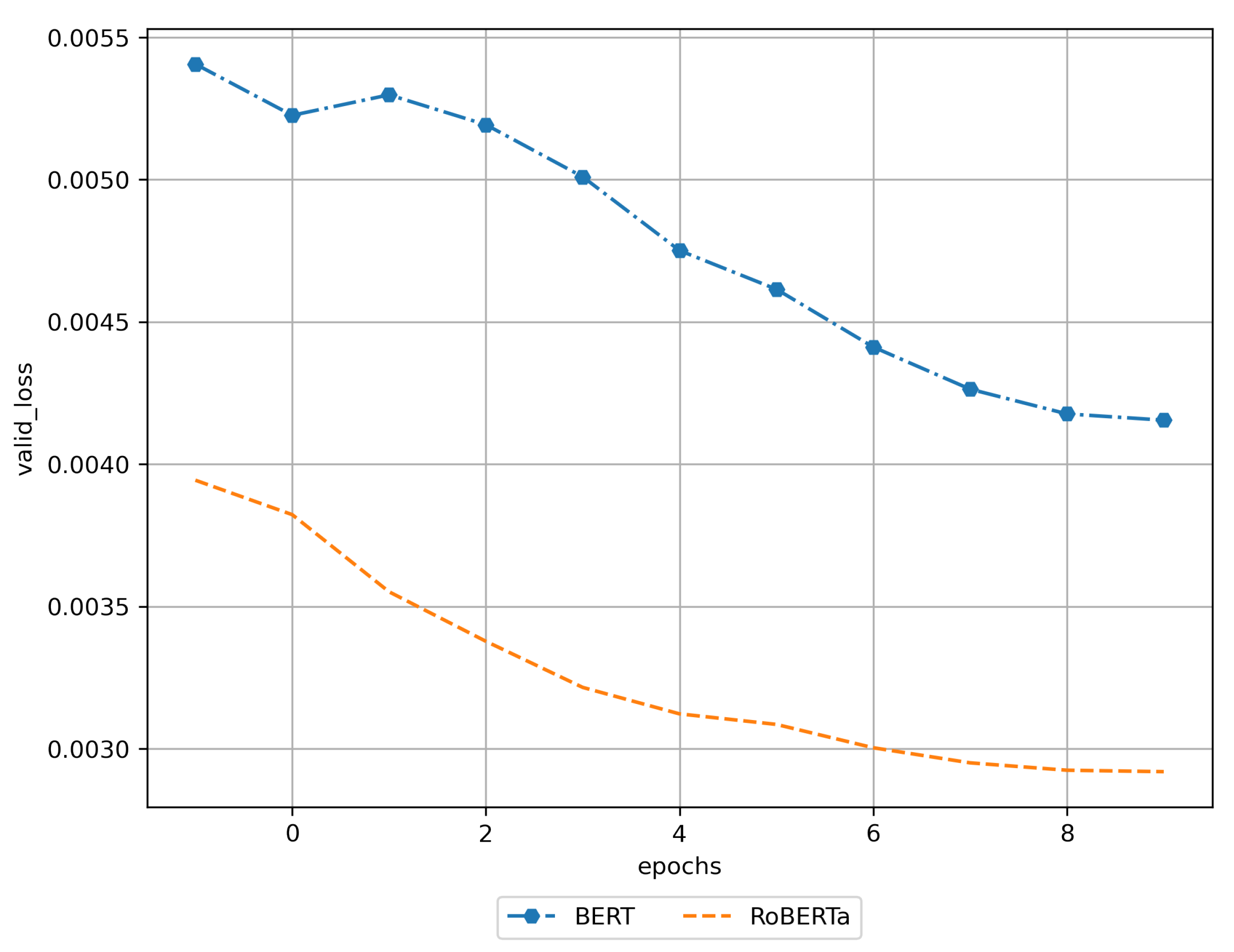
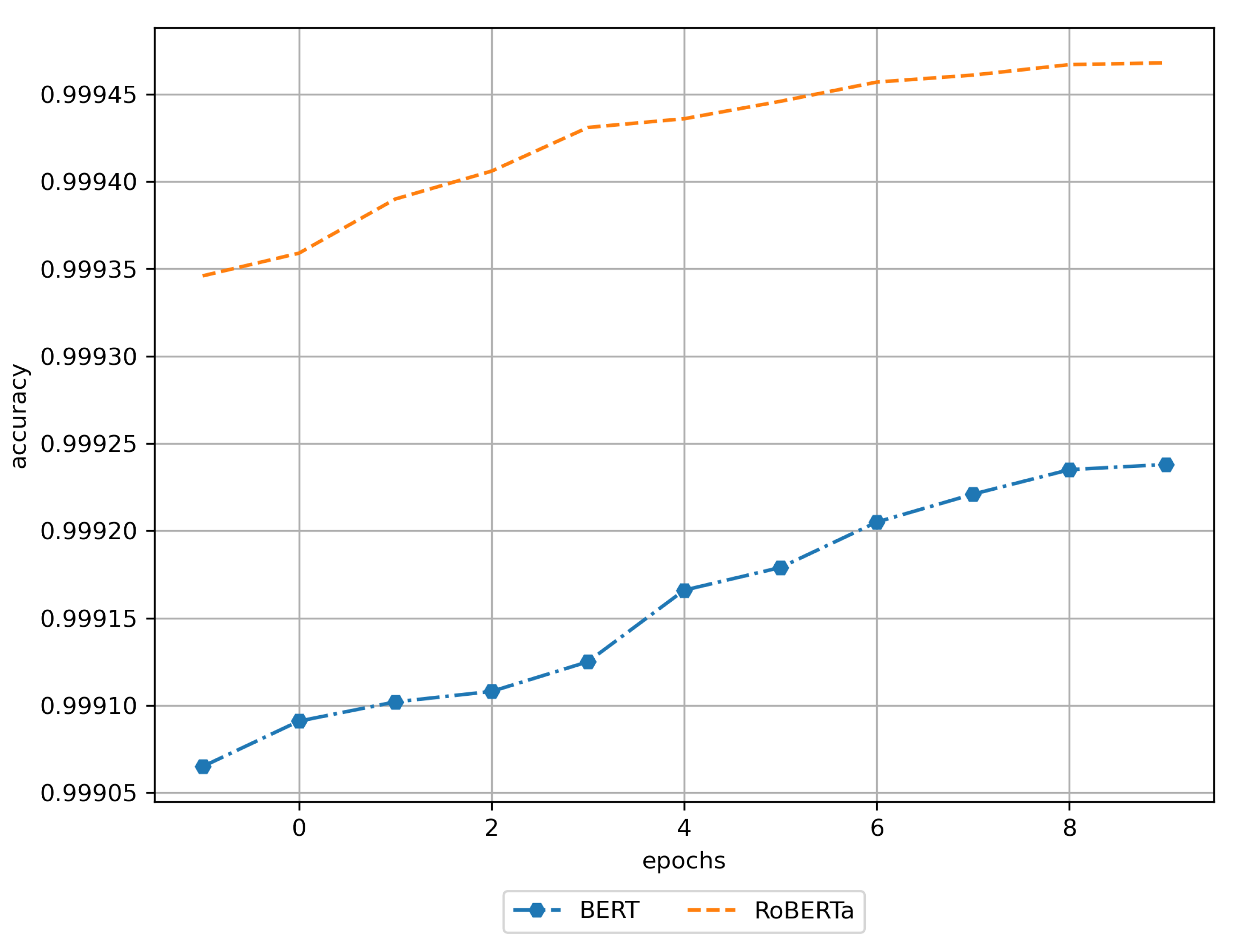
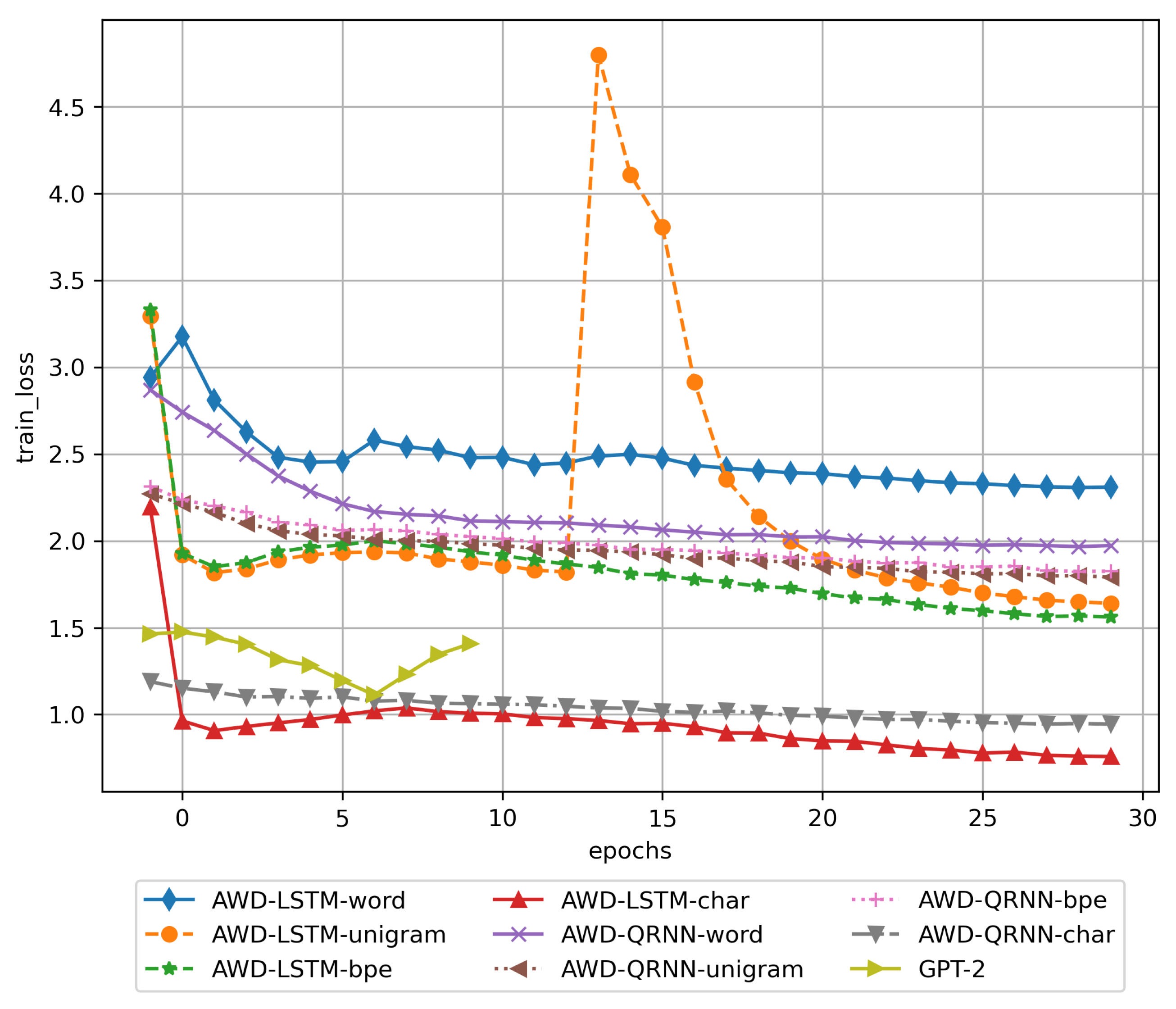
3.1. Training Results
3.2. Results of Using the Trained DNN Models
"from pandas import defaults as _rp pandas =" "from pandas import DataFrameEncoder if self" "from pandas import OrderedDict else: passed" "from pandas import sequence if type(seq1) i" "from pandas import conditional_insertion as"
"from pandas import webbrowser self.login fr"
"from pandas import __http_args or [ ’Pipeli"
"from pandas import iterations is not None p"
"from pandas import service params to servic"
"from pandas import difference if not isinst"
"from pandas import time, np\n
"
"from pandas import pandas from time.time.datetime import Date\n
with n"
"from pandas import gtk, os\n
from pandas_utils import pandas_utils\n
import pylint"
"from pandas import wcpy\n
import cpy_context as cpy_context\n
"
"from pandas import gkpy\n
"""\n
... pass\n
kwargs = cg"
[{’sequence’: ’[CLS] from pandas import [SEP] [SEP]’,
’score’: 0.9969683289527893,
’token’: 102,
’token_str’: ’[SEP]’},
{’sequence’: ’[CLS] from pandas import [CLS] [SEP]’,
’score’: 0.0010887219104915857,
’token’: 101,
’token_str’: ’[CLS]’},
{’sequence’: ’[CLS] from pandas import. [SEP]’,
’score’: 0.0004200416151434183,
’token’: 119,
’token_str’: ’.’},
{’sequence’: ’[CLS] from pandas import ; [SEP]’,
’score’: 0.00027348980074748397,
’token’: 132,
’token_str’: ’;’},
{’sequence’: ’[CLS] from pandas import def [SEP]’,
’score’: 8.858884393703192e-05,
’token’: 19353,
’token_str’: ’def’}]
[{’sequence’: ’<s>from pandas import\n</s>’,
’score’: 0.6224209666252136,
’token’: 50118,
’token_str’: ’˙C’},
{’sequence’: ’<s>from pandas import.</s>’,
’score’: 0.22222988307476044,
’token’: 4,
’token_str’: ’.’},
{’sequence’: ’<s>from pandas import </s>’,
’score’: 0.038354743272066116,
’token’: 1437,
’token_str’: ’˙G’},
{’sequence’: ’<s>from pandas import\n\n</s>’,
’score’: 0.028566861525177956,
’token’: 50140,
’token_str’: ’˙C˙C’},
{’sequence’: ’<s>from pandas import.</s>’,
’score’: 0.021909384056925774,
’token’: 479,
’token_str’: ’˙G.’}]
4. Discussion
4.1. Discussing the Outcomes from the Resulting Models
4.2. Examining the Effect of Pre-Training and Transfer Learning
4.3. Reviewing the Textual Assessment of the Resulting LMs
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kannan, A.; Kurach, K.; Ravi, S.; Kaufmann, T.; Tomkins, A.; Miklos, B.; Corrado, G.; Lukacs, L.; Ganea, M.; Young, P.; et al. Smart reply: Automated response suggestion for email. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 955–964. [Google Scholar]
- Bryant, C.; Briscoe, T. Language model based grammatical error correction without annotated training data. In Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications, New Orleans, LA, USA, 5 June 2018; pp. 247–253. [Google Scholar]
- Ghosh, S.; Kristensson, P.O. Neural networks for text correction and completion in keyboard decoding. arXiv 2017, arXiv:1709.06429. [Google Scholar]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A survey of machine learning for big code and naturalness. ACM Comput. Surv. (CSUR) 2018, 51, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Le, T.H.M.; Babar, M.A. Deep Learning for Source Code Modeling and Generation: Models, Applications and Challenges. ACM Comput. Surv. (CSUR) 2020, 53, 1–38. [Google Scholar]
- Nguyen, A.T.; Nguyen, T.N. Graph-based statistical language model for code. In Proceedings of the 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Florence, Italy, 24 May 2015; Volume 1, pp. 858–868. [Google Scholar]
- Bielik, P.; Raychev, V.; Vechev, M. PHOG: Probabilistic model for code. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2933–2942. [Google Scholar]
- Cruz-Benito, J.; Faro, I.; Martín-Fernández, F.; Therón, R.; García-Peñalvo, F.J. A Deep-Learning-based proposal to aid users in Quantum Computing programming. In International Conference on Learning and Collaboration Technologies; Springer: Berlin, Germany, 2018; pp. 421–430. [Google Scholar]
- Oda, Y.; Fudaba, H.; Neubig, G.; Hata, H.; Sakti, S.; Toda, T.; Nakamura, S. Learning to generate pseudo-code from source code using statistical machine translation (t). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 574–584. [Google Scholar]
- Tiwang, R.; Oladunni, T.; Xu, W. A Deep Learning Model for Source Code Generation. In Proceedings of the 2019 SoutheastCon, Huntsville, AL, USA, 11–14 April 2019; pp. 1–7. [Google Scholar]
- Fedus, W.; Goodfellow, I.; Dai, A.M. MaskGAN: Better Text Generation via Filling in the _______. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Nguyen, A.T.; Nguyen, T.T.; Nguyen, T.N. Lexical statistical machine translation for language migration. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering, Saint Petersburg, Russia, 18 August 2013; pp. 651–654. [Google Scholar]
- Roziere, B.; Lachaux, M.A.; Chanussot, L.; Lample, G. Unsupervised Translation of Programming Languages. Adv. Neural Inf. Process. Syst. 2020, 33. [Google Scholar]
- Proksch, S.; Lerch, J.; Mezini, M. Intelligent code completion with Bayesian networks. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2015, 25, 1–31. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; Lyu, M.R.; King, I. Code completion with neural attention and pointer networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Melbourne, Australia, 19–25 August 2017; pp. 4159–4165. [Google Scholar]
- Donahue, C.; Lee, M.; Liang, P. Enabling Language Models to Fill in the Blanks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2492–2501. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Bird, C.; Sutton, C. Suggesting accurate method and class names. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Bergamo, Italy, 30 August–4 September 2015; pp. 38–49. [Google Scholar]
- Karampatsis, R.M.; Sutton, C. Maybe deep neural networks are the best choice for modeling source code. arXiv 2019, arXiv:1903.05734. [Google Scholar]
- Karampatsis, R.M.; Babii, H.; Robbes, R.; Sutton, C.; Janes, A. Big Code != Big Vocabulary: Open-Vocabulary Models for Source Code. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, New York, NY, USA, 24 June–16 July 2020; pp. 1073–1085. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-Aware Neural Language Models. In Proceedings of the AAAI’16: Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Menlo Park, CA, USA, 2016; pp. 2741–2749. [Google Scholar]
- Karpathy, A. The unreasonable effectiveness of recurrent neural networks. Andrej Karpathy Blog 2016, 21, 23. [Google Scholar]
- Merity, S.; Keskar, N.S.; Socher, R. Regularizing and Optimizing LSTM Language Models. In Proceedings of the International Conference on Learning Representations, 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bradbury, J.; Merity, S.; Xiong, C.; Socher, R. Quasi-recurrent neural networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Wang, D.; Gong, C.; Liu, Q. Improving Neural Language Modeling via Adversarial Training. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Long Beach, CA, USA, 2019; Volume 97, pp. 6555–6565. [Google Scholar]
- Gong, C.; He, D.; Tan, X.; Qin, T.; Wang, L.; Liu, T.Y. Frage: Frequency-agnostic word representation. Adv. Neural Inf. Process. Syst. 2018, 31, 1334–1345. [Google Scholar]
- Takase, S.; Suzuki, J.; Nagata, M. Direct Output Connection for a High-Rank Language Model. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4599–4609. [Google Scholar]
- Yang, Z.; Dai, Z.; Salakhutdinov, R.; Cohen, W.W. Breaking the Softmax Bottleneck: A High-Rank RNN Language Model. In Proceedings of the International Conference on Learning Representations, 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Krause, B.; Kahembwe, E.; Murray, I.; Renals, S. Dynamic Evaluation of Neural Sequence Models. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: Stockholmsmässan, Stockholm Sweden, 2018; Volume 80, pp. 2766–2775. [Google Scholar]
- Rae, J.W.; Potapenko, A.; Jayakumar, S.M.; Hillier, C.; Lillicrap, T.P. Compressive Transformers for Long-Range Sequence Modelling. In Proceedings of the International Conference on Learning Representations, 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Baevski, A.; Auli, M. Adaptive Input Representations for Neural Language Modeling. In Proceedings of the International Conference on Learning Representations, 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Merity, S.; Keskar, N.S.; Socher, R. An analysis of neural language modeling at multiple scales. arXiv 2018, arXiv:1803.08240. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar]
- Eisenschlos, J.; Ruder, S.; Czapla, P.; Kadras, M.; Gugger, S.; Howard, J. MultiFiT: Efficient Multi-lingual Language Model Fine-tuning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 5702–5707. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT (1), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Mikolov, T.; Deoras, A.; Kombrink, S.; Burget, L.; Černockỳ, J. Empirical evaluation and combination of advanced language modeling techniques. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Merity, S.; Xiong, C.; Bradbury, J.; Socher, R. Pointer sentinel mixture models. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Chelba, C.; Mikolov, T.; Schuster, M.; Ge, Q.; Brants, T.; Koehn, P.; Robinson, T. One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Wang, A.; Cho, K. BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model. In Proceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation (NAACL HLT 2019), 2019, Minneapolis, MN, USA, 6 June 2019; pp. 30–36. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Bostrom, K.; Durrett, G. Byte Pair Encoding is Suboptimal for Language Model Pretraining. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Association for Computational Linguistics, Online. 16–20 November 2020; pp. 4617–4624. [Google Scholar]
- Schuster, M.; Nakajima, K. Japanese and korean voice search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5149–5152. [Google Scholar]
- Husain, H.; Wu, H.H.; Gazit, T.; Allamanis, M.; Brockschmidt, M. Codesearchnet challenge: Evaluating the state of semantic code search. arXiv 2019, arXiv:1909.09436. [Google Scholar]
- Howard, J.; Gugger, S. Fastai: A layered API for deep learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 66–71. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Hugging Face’s Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Association for Computational Linguistics, Online. 16–20 November 2020; pp. 38–45. [Google Scholar]
- Ruder, S.; Peters, M.E.; Swayamdipta, S.; Wolf, T. Transfer learning in natural language processing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Tutorials, Minneapolis, MN, USA, 2 June 2019; pp. 15–18. [Google Scholar]
- Chronopoulou, A.; Baziotis, C.; Potamianos, A. An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 2089–2095. [Google Scholar]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-strength Natural Language Processing in Python. Zenodo 2020. [Google Scholar] [CrossRef]
- Czapla, P.; Howard, J.; Kardas, M. Universal language model fine-tuning with subword tokenization for polish. arXiv 2018, arXiv:1810.10222. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Smith, L.N.; Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications. International Society for Optics and Photonics, Baltimore, MD, USA, 15–17 April 2019; Volume 11006, p. 1100612. [Google Scholar]
- Cruz-Benito, J.; Vishwakarma, S. cbjuan/tokenizers-neural-nets-2020- paper: v1.0. Zenodo 2020. [Google Scholar] [CrossRef]
- Cruz-Benito, J.; Vishwakarma, S. NN models produced by cbjuan/tokenizers-neural-nets-2020-paper: v1.0. Zenodo 2020. [Google Scholar] [CrossRef]
- Raychev, V.; Bielik, P.; Vechev, M. Probabilistic model for code with decision trees. ACM SIGPLAN Not. 2016, 51, 731–747. [Google Scholar] [CrossRef]
- Celikyilmaz, A.; Clark, E.; Gao, J. Evaluation of Text Generation: A Survey. arXiv 2020, arXiv:2006.14799. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Post, M. A Call for Clarity in Reporting BLEU Scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, Belgium, Brussels, 31 October–1 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 186–191. [Google Scholar] [CrossRef] [Green Version]
- Weston, J.; Bordes, A.; Chopra, S.; Rush, A.M.; van Merriënboer, B.; Joulin, A.; Mikolov, T. Towards ai-complete question answering: A set of prerequisite toy tasks. arXiv 2015, arXiv:1502.05698. [Google Scholar]
- Ribeiro, M.T.; Wu, T.; Guestrin, C.; Singh, S. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online. 5–10 July 2020; pp. 4902–4912. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DNN Architecture | Epochs | Accuracy | Train Loss | Validation Loss | Pre-Trained? |
|---|---|---|---|---|---|
| AWD-LSTM word | 31 | 0.494893 | 2.308937 | 2.341698 | Yes |
| AWD-LSTM unigram | 31 | 0.557226 | 1.639875 | 1.826841 | Yes |
| AWD-LSTM BPE | 31 | 0.580373 | 1.561393 | 1.703536 | Yes |
| AWD-LSTM char | 31 | 0.779633 | 0.757956 | 0.742808 | Yes |
| AWD-QRNN word | 31 | 0.515747 | 1.972508 | 2.144126 | No |
| AWD-QRNN unigram | 31 | 0.539951 | 1.790150 | 1.894901 | No |
| AWD-QRNN BPE | 31 | 0.538290 | 1.824709 | 1.896698 | No |
| AWD-QRNN char | 31 | 0.736358 | 0.944526 | 0.897850 | No |
| GPT-2 | 11 | 0.743738 | 1.407818 | 1.268246 | Yes |
| BERT | 11 | 0.999238 | 0.014755 | 0.004155 | Yes |
| RoBERTa | 11 | 0.999468 | 0.010569 | 0.002920 | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cruz-Benito, J.; Vishwakarma, S.; Martin-Fernandez, F.; Faro, I. Automated Source Code Generation and Auto-Completion Using Deep Learning: Comparing and Discussing Current Language Model-Related Approaches. AI 2021, 2, 1-16. https://doi.org/10.3390/ai2010001
Cruz-Benito J, Vishwakarma S, Martin-Fernandez F, Faro I. Automated Source Code Generation and Auto-Completion Using Deep Learning: Comparing and Discussing Current Language Model-Related Approaches. AI. 2021; 2(1):1-16. https://doi.org/10.3390/ai2010001
Chicago/Turabian StyleCruz-Benito, Juan, Sanjay Vishwakarma, Francisco Martin-Fernandez, and Ismael Faro. 2021. "Automated Source Code Generation and Auto-Completion Using Deep Learning: Comparing and Discussing Current Language Model-Related Approaches" AI 2, no. 1: 1-16. https://doi.org/10.3390/ai2010001
APA StyleCruz-Benito, J., Vishwakarma, S., Martin-Fernandez, F., & Faro, I. (2021). Automated Source Code Generation and Auto-Completion Using Deep Learning: Comparing and Discussing Current Language Model-Related Approaches. AI, 2(1), 1-16. https://doi.org/10.3390/ai2010001