1. Introduction
Vehicular Ad-Hoc Networks (VANETs) have drawn wide concerns since it is an effective solution to ease traffic congestion and ensure road safety. As a few form of Internet of Things (IoT) [
1,
2], VANETs is a promising technology designed to provide mature solutions for Intelligent Transport Systems (ITS). As an important component of ITS, VANETs have emerged as a promising research topic in recent years to improve traffic management efficiency, road safety, and provide entertainment service. It generally comprises an On-Board Unit (OBU) and a Road-Side Unit (RSU) used to support Vehicle-to-Vehicle (V2V) and Vehicle-to-infrastructure (V2I) communications. So that, VANETs can support safety applications that can be used to assist drivers to avoid collisions.
In V2V, vehicles communicate with other vehicles in order to exchange traffic-related information by Dedicated Short Range Communication (DSRC) standard. RSUs are the most common infrastructure in VANETs, which are deployed along the roadside. Each RSU is in charge of providing services for nearby vehicles. Therefore, based on V2I communication, these vehicles can access network quickly to download traffic data and obtain news. The typical structure of VANETs is shown in
Figure 1.
VANETs have some challenging issues that distinguish it from Mobile Ad Hoc Networks (MANETs) [
3]. The high mobility characteristic of vehicles [
4] leads to dynamic topology changes and frequent network disconnections. Thus, communication links in VANETs may have frequent outages. It is a huge challenge to construct a reliable path. Additionally, open communication environments in VANETs enhance the possibility of cyber attacks including but not limited to distributed denial-of-service [
5], jamming, and spoofing. Among many cyber attacks, the packet drop attack is the most representative. The loss of packets endangers the transmission of information and even life safety of pedestrians and drivers. Therefore, to achieve a high packet delivery ratio, designing an attack detection method is essential for VANETs [
6].
Constructing a reliable and secure routing is a huge challenge because of the inherent mobility of vehicles and packet drop attacks. The mobility characteristic results in recurrent topology deviations and intermittent connection. To this end, it is hard to construct a stable entire path between a source node and its destination. Reluctantly, some relay nodes are continually chose on the basis of current network environment. Finally, the packet is delivered hop by hop toward its destination with the help of some relay nodes.
Due to high mobility, how to choose a relay node to successfully forward packet is a challenging issue [
7]. The employed metric and strategy for selecting a relay node may affect the performance of transmitting packets. The former is applied to evaluate the link from a sender to a received node, and the latter refers to whether a relay node is chose from the candidate set opportunistically or deterministically.
As dynamic changes of topology, opportunistic routing is more appropriate for VANETs compared with deterministic routing. In opportunistic routing, a source node transmits packet toward a set of neighbor nodes instead of just one neighbor node. This transmission mechanism aids in improvement of the success rate of transmitting packet. One of nodes in this set is selected to be a relay node, and it will be responsible for forwarding the packet.
Li et al. [
8] proposed an adaptive routing protocol based on ant colony optimization. In the routing protocol, the routing problem is formulated as a constrained optimization problem. Then, an ant colony optimization algorithm is employed to solve the problem. However, the computation time of ant colony optimization increases with the number of nodes. Besides, some important network metrics like relative velocity and connectivity are not considered in route discovery. In [
9], an efficient multi-metric routing algorithm was proposed. The routing algorithm considered the connectivity and relative velocity, but it did not consider the attack issues.
Significantly, V2V communication is vulnerable to many hostile attacks due to open communication environments. As the typical attacks, Black Hole Attack (BHA) and Gray Hole Attack (GHA) disrupt the fluency of transmitting packet by dropping packet deliberately. This behavior undoubtedly increase the packet loss ratio. Therefore, to achieve a high packet delivery ratio, a method of detection these attacks need to be employed and these attackers will be prevented from routing packets.
Recently, Reinforcement Learning (RL) [
10,
11] is introduced to solve critical problems in many applications, and attack detection in VANETs is a typical application. In VANETs, some attacks can be detected by RL algorithm due to the good ability to learn dynamic environments. For example, Sherazi et al. [
12] proposed RL-based Distributed Denial of Service (DDoS) attack detection algorithm. The detection of a DDoS attack is performed by Q learning.
Motivated by these issues, a Secure and Reliable Opportunistic Routing (SROR) algorithm is proposed in this paper. In the SROR algorithm, three important network metrics, namely relative velocity, connectivity probability, and packet forwarding ratio, are taken into account, for several reasons. Firstly, in vehicular networks, relative distance depends on the relative velocity among vehicles, while the transmission delay depends on the relative distance. Therefore, considering the relative velocity may aid in reducing the delay. Secondly, the stability of routing packet is influenced by the connectivity probability of the link. So, the delay and packet delivery ratio are reduced by considering the connectivity probability. Finally, to prevent some malicious nodes from forwarding packets, the packet forwarding ratio is utilized to select a relay node. This aids in avoiding the BHA and GHA in forwarding packets.
To this end, during the selection of relay nodes, SROR algorithm takes the above-mentioned metrics into consideration. Specifically, by jointly considering relative velocity, connectivity probability, and packet forwarding ratio, the Candidate Forwarding Nodes (CFNs) are selected. Furthermore, the selection of relay node is modeled as a Markov Decision Process (MDP) [
13] and the solution of the MDP is obtained by the Deep Reinforcement Learning (DRL). In addition, to achieve a better convergence, the dynamic learning rate and exploratory factor policy are employed.
The main contributions of our work can be summarized as follows.
- (1)
We discuss the secure and reliable opportunistic routing protocol. To achieve a shorter transmission delay as well as a higher packet delivery ratio, a CFNs set is constructed based on relative velocity, connectivity probability, and packet forwarding ratio metrics.
- (2)
The selection of a relay node from CFNs set is expressed as an MDP. Then, the solution of the MDP is obtained with the help of DRL. In addition, the dynamic learning rate and exploratory factor are adopted and sensitivity of DRL to learning rate and exploratory factor are analyzed.
- (3)
An extensive performance evaluation is conducted. Compared with benchmarks, the effectiveness of SROR algorithm is evaluated by simulation.
The remainder of this paper is organized as follows. The related work are illustrated in
Section 2. Then, we formulate the network model and some important metrics in
Section 3. We illustrate the opportunistic routing and problem in
Section 4, and the selection of relay node based on DRL is illustrated in
Section 5.
Section 6 presents numerical results. Finally, a conclusion is presented in
Section 7.
2. Related Work
To date, many researchers have made much effort to optimize the routing strategy and apply reinforcement learning. We mainly review related work of routing protocols in VANETs.
2.1. Routing Protocol for VANETs
Different from the Mobile Ad Hoc Networks (MANETs), VANETs require a more stable path to deliver the packet. A wealth of work has been performed on routing for VANETs. For the unicast routing, existing routing protocols can be roughly divided into four categories, namely location-based, topology-based, cluster-based, and opportunity-based protocol.
In the location-based routing, the location of nodes are taken into consideration in route discovery. Greedy Perimeter Stateless Routing (GPSR) is a representative of position-based routing. According to the idea of GPSR, a source node makes greedy forwarding decision based on location data of neighbors. Wang et al. [
14] proposed a location privacy-based secure routing protocol. However, this routing protocol only focuses on the privacy-preserving location. A velocity and position-based message transmission scheme is proposed in [
15]. The velocity and position information are used to alleviate rebroadcast message collision. Additionally, in [
16], authors discussed the position-based routing, and proposed FoG-oriented VANETs structure in support of location-based routing.
In the topology-based routing protocols, each vehicle needs to establish a routing tables based on the topology information. Kadadha et al. [
17] proposed a Stackelberg-game-model-based routing protocol. The relay nodes are selected by street topology. Wang et al. [
18] proposed a network connectivity-based low-latency routing protocol. They took the most representative features of vehicles into consideration during the routing discovery. A novel geographic routing is proposed in [
19]. In the routing protocol, some feasible paths to the destination are selected according to the network topology.
Based on the idea of cluster-based routing, the nodes in the network are divided into different clusters by a certain principle [
20,
21]. In [
22], a chain-branch-leaf cluster-based routing protocol is proposed and analyzed. In addition, for the sake of improving performance, vehicles with similar trajectory features are grouped in [
23]. In [
24], a connectivity prediction-based dynamic clustering model is proposed, and the proposed model is used to realize stable communications.
The opportunistic routing generally combines with the geographic routing and forms a Geographical Opportunistic Routing (GOR) protocol. In the GOR protocol, a source node trends to choose a relay node with closer to the destination. Salkuyeh et al. [
25] proposed an adaptive geographic routing to transmit video data. In the routing protocol, a number of independent path is discovered. However, multiple paths result in high complexity. In [
26], authors proposed a trajectory-based opportunistic routing. The Global Position System (GPS) information of vehicles is used to transmit data, and a relay node is selected based on the proximity to the trajectory.
2.2. Secure Routing for VANETs
The V2V communication is vulnerable to some attacks due to open communication environments in VANETs. While routing is one of the targets of attackers. A major line of work [
27,
28,
29,
30] concentrated on the security of router data. Eiza et al. [
28] proposed an ant colony optimization-based secure routing protocol. Some feasible routes are constructed by the ant colony optimization technique. Lyu et al. [
29] put forward a geographic position-based secure routing. They employed a trust model to resist black hole attack in order to choose the secure routing path. In [
27], the authors put forward an intelligent cluster-based routing protocol. In the routing protocol, an artificial neural network (ANN) model was used to detect the malicious nodes.
Trust-based solutions [
31,
32] are common methods to deal with the routing security issue. Xia et al. [
30] first studied the trust properties and put forward a novel trust inference model. Shen et al. [
33] also employed a trust model. In the trust model, the cloud is in charge of evaluating the trustworthiness of each individual. The evaluation results are used to choose the reliable relay node. Nevertheless, evaluation of trustworthiness of vehicles is very complete due to dynamic topology, and the trustworthiness of vehicles depend on many factors. Hence, it is still a challenge to objectively evaluate the behavior of vehicles by trustworthiness alone. In addition, in [
34], the authors proposed an RSU-assisted trust-based routing for VANETs. The routing provides a more reliable monitoring process for trust management in order to increase resistance to trust-based attacks.
2.3. Routing Protocol Based on RL
To cope with the dynamic environment of VANETs, RL [
35] has been widely explored in route discovery and attack detection. A decentralized routing protocol based on a multi-agent RL is put forward in [
36]. In the protocol, the problem of how vehicles learn from the environment is modeled as a multi-agent problem. A vehicle is considered as an agent, and it autonomously establishes the transmission packet path with a neighbors. In addition, a geographic routing based on Q-learning algorithm is put forward in [
37]. Each vehicle holds a Q-table, and an optimal relay node is selected by querying the Q-table. Luo et al. [
38] suggested a V2X routing protocol based on intersection. They employed a multidimensional Q-table, and the Q-table is used for selection of the most appropriate road segment to transmit the packet.
Unfortunately, Q-learning needs to maintain a Q-table. As the number of nodes increases, the Q-table is larger. To overcome this issue, a DRL-based collaborative routing protocol is put forward in [
39]. The problem of minimizing the delay is formulated as an MDP, and the solution of the MDP is solved by Deep Q-network (DQN) [
40]. Similarly, in [
41], a deep reinforcement learning is used to tackle with the network dynamics in VANETs.
In addition, RL has been widely used to detect attacks to reduce the packet loss ratio in VANETs. In [
42], an adaptive multi-agent RL algorithm is designed to detect packet drop attacks. In [
43], the malicious vehicles activity are detected by Q-learning to prevent malicious vehicles from forwarding packets. Besides, in [
44], an intelligent detection algorithm is put forward. For sake of realizing the detection of black hole attack, four network parameters are taken into consideration. In [
45], the IoT security issue is discussed and put forward a protection scheme using effective decision-making strategy of appropriate features.
2.4. Problems That Need to Be Solved
Although the above-mentioned work achieve high performance in transmitting packets, there is still much room for performance improvement.
Firstly, selecting the relay node in VANETs is a challenge task due to dynamic topology. Deep reinforcement learning algorithm has strong learning ability and can quickly capture the knowledge of dynamic environment. Therefore, the proposed SROR algorithm adopts a deep reinforcement learning to select the relay node.
Secondly, V2V communication is vulnerable to packet drop attacks due to open communication environments in VANETs. However, most of existing routing protocols have not taken the packet drop attacks into account. While these attacks reduce the success rate of transmitting packets, resulting in a large number of packet losses. For this purpose, the proposed SROR algorithm takes the packet delivery ratio into account when selecting the relay node. The facts behind this strategy are that packet drop attacks result in a low packet delivery ratio. To this end, the node is prevented from participating in routing if a node has a low packet delivery ratio. Thus, the attackers are not considered to be a relay node, and this is helpful to ensure the security of VANETs.
Finally, although some existing work has also applied DRL to the routing protocols, the sensitivity of DRL to learning rate and exploratory factor are not analyzed. Conversely, the proposed SROR algorithm fully analyzes the sensitivity.
Therefore, the proposed SROR algorithm addresses the performance in transmitting packet as well as defence against packet drop attacks. In addition, a DRL is employed in SROR algorithm to obtain the optimal route path as well as to prevent attackers from forwarding packets.
3. System Model and Routing-Related Metrics
The network model is presented in this section. Then, the relative velocity, packet forwarding ratio, and connectivity probability are defined. Besides, some important notations are demonstrated in
Table 1. Note that “–” represents a dimensionless quantity.
3.1. Network Model
Figure 2 depicts the considered network model, where there are
N vehicles and they are denoted by the set
. By means of an On-Board Unit (OBU) that is installed in each vehicle, each vehicle can communicate with adjacent vehicles based on the IEEE 802.11p protocol. We assume that only a small fraction of vehicles are malicious and that they may launch the BHA or GHA.
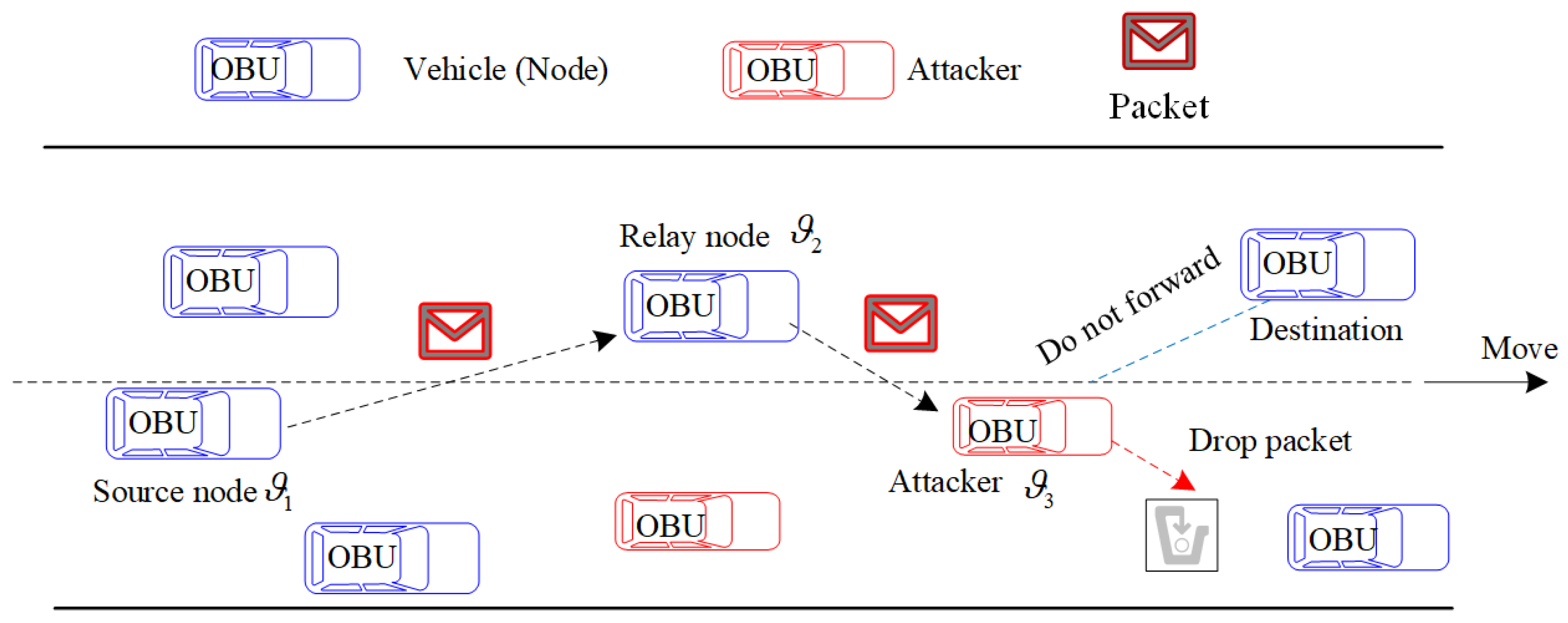
Each vehicle can be a source node, relay node, or destination. If the destination is out of the transmission range of the source node, the source node needs the help of relay node to send packet to the destination. So, multi-hop routing requires multiple relay nodes to participate in. If some relay nodes are malicious, they may launch BHA or GHA, namely deliberately drop packets, resulting in the increase of packet loss ratio, as shown in
Figure 1. For example, assume that the
is a source node, and it needs to transmit a packet toward the relay node
. The arrow represents the direction of transmitting packet. After receiving the packet from
, the attacker
should forward the packet, but instead of transmitting the packet, it drops the packet. The dotted lines without arrow indicate that the packet does not forward in
Figure 2.
Without loss of generality, assume that all vehicles have the same transmission range, which is denoted by
. Furthermore,
is commonly much larger than the length of a vehicle, similar to [
46], and thus, the length of any vehicle is not taken into consideration. The inter-vehicle distances are independent identically distributed and it is exponentially distributed random variables with mean
.
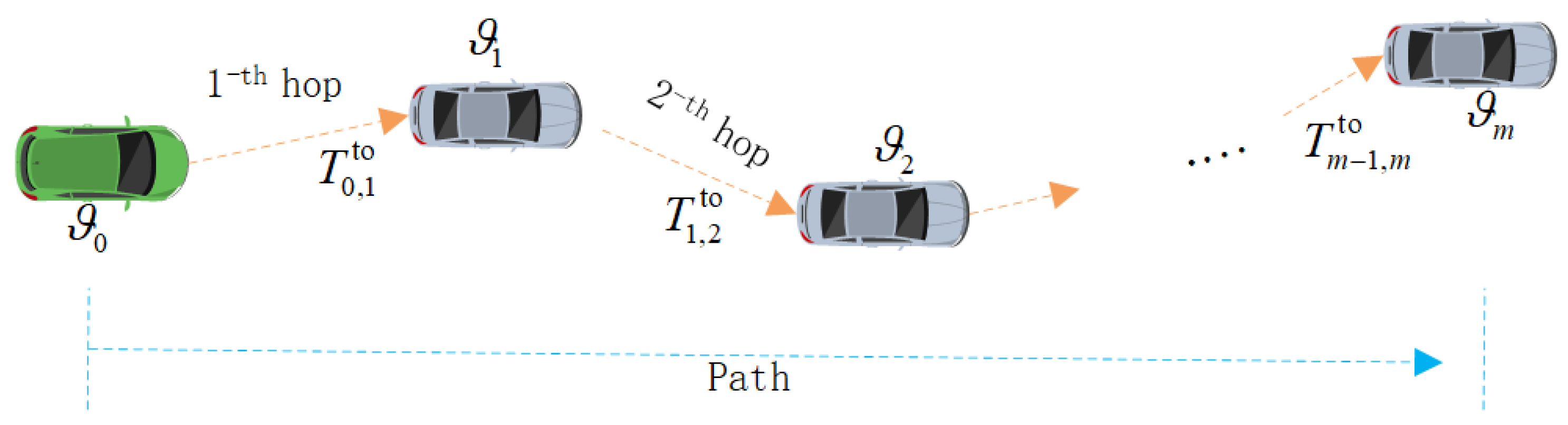
Additionally, if the distance between two vehicles is not more than , they can form a link. Let represent a link between vehicle pairs , where represents the sender and is the receiver. Moreover, each vehicle needs to maintain a neighbor set. Let denote the neighbor set of vehicle . The distance between vehicle and each vehicle in set is less than . By receiving the periodical beacon packet, the set can be updated.
Delay is a measure of the efficiency of transmitting packet. The total delay is the times that a packet is transmitted from a sender to a receiver, which included propagation delay as well as transmission delay. Let
and
represent the transmission delay and propagation delay, respectively. They can be given as [
47]:
where
represents the length of transmitted packet,
represents the transmission rate of link
,
represents the distance from
to
, and
c is the speed of light.
and
are used to calculate the end-to-end delay in
Section 6.
To this end, the end-to-end delay that a packet is transmitted through link is denoted as , satisfying . For the sender , it expects its packet to be forwarded quickly and reliably toward the next-hop node. Here, quickness means low delay and reliability means the success of forwarding the packet; that is, whether the receiver successfully received the packet within the time limit.
Additionally, the free-space path-loss model is considered as the propagation model in our work. In this model, the reception power (in dBm ) is expressed as:
where
is the transmission power in dBm,
and
are the antenna gains in the transmitter and receiver, respectively,
is the wavelength,
d is the distance between the transmitter and receiver, and
is an exponent.
3.2. Relative Velocity
As shown in Equation (
1), the end-to-end delay depends on the distance
when the length of transmitted packet and transmission rate are given. In fact, in the same VANET system, the length of packet and transmission rate of different vehicles is a little difference. Relative distance can more accurately reflect their spatial location relationship due to the mobility of vehicles, while the relative distance depends on the relative velocity. If the mobility direction of two vehicles is the same, small relative velocity can make the distance unchanged for a long time. The unchanged distance is conducive to network connectivity, and this will improve the packet delivery ratio.
As a consequence, the relative velocity is considered an important routing metric. Furthermore, it will be taken into account when the next-hop relay node is selected. For vehicle pairs
, their relative velocity is denoted by
, which can be calculated as [
9]:
where
and
represent the velocity of
and
, respectively, and
is the angle between
and
, which can be defined as:
where
and
. Furthermore,
and
represent the coordinates of
and
, respectively.
3.3. Packet Forwarding Ratio
Assume that some vehicles are attackers that intentionally drop some packets, even all packets. Furthermore, they should forward these packets. The act of intentionally dropping packets result in the increase of packet loss ratio and transmission delay. Packet Forwarding Ratio (PFR) is a metric of efficiency of forwarding packet in VANETs, which is equal to the ratio of the number of packets forwarded to the number of packets that should have been forwarded [
48]. As a result, the PFR of the vehicle
is defined as:
where
represents the total number of packets forwarded by
and
represents the number of packets that
should have forwarded. If a vehicle’s PFR is very low, this may indicate that the vehicle has a habit of dropping packets, which may be BHA or GHA.
3.4. Connectivity Probability
During the transmission, the sender hopes the selected next-hop relay node can stably connect to its nearby nodes when the next-hop relay node is out of the transmission range of the destination. That way, the next-hop relay node can probably forward the packet to its next-hop relay node when it received the packet from the sender. If the selected next-hop relay node cannot stably connect to its nearby nodes, even if it has received the packet, it may not be able to successfully deliver the packet to the destination.
Therefore, the connectivity probability should be considered when selecting the next-hop relay node. According to [
49], if vehicle intensity is less than 1000 veh/h, the inter-vehicle distance is subject to exponential function. For the vehicle pairs
, the sender
hopes the receiver
can stably connect to its nearby vehicles. The connectivity probability of the vehicle
can be defined as:
3.5. Attack Model
VANETs are vulnerable to packet drop attacks due to their dynamic topology, which is also one of the most frequent attacks on VANETs. If a node is compromised by the packet drop attack, the node will selectively drop some packets that should be forwarded. The BHA and GHA are most representative in the packet drop attack. As a result, they are taken into consideration in the proposed routing algorithm.
An attacker receives a packet and needs to forward the packet toward the next-hop node, but it actually drops the packet, and this attack behavior is a BHA. In brief, the BHA drops all the packets instead of forwarding them. On the contrary, the GHA selectively drops some packets but not all packets.
Assume that a small number of vehicles are considered to be malicious vehicles. Let represent the percentage of malicious vehicles. These malicious vehicles are acting as a BHA or GHA.
5. Deep Reinforcement Learning—Opportunistic Routing
We first discuss the problem of selecting the relay nodes in this section, and formulate this problem as an MDP. Next, the problem is solved by a DRL. The DRL model is shown in
Table 2, the learning environment of DRL model is the VANETs, and the agent is each packet that needs to be transmitted. The state of the agent is the union of the node with the holding packet and its CFNs set, and this node is the one that currently holds the packet, which is abbreviated as Node-HP. The action of the agent is to select a relay node.
The problem P1 is a sequential decision problem. To select the most suitable next-hop relay node, the problem is modeled as an MDP. Let a tuple represent the MDP, where , , and represent the state space, action space, and immediate reward, respectively. Next, we will describe the definition of each element in detail.
5.1. State Space
At time step
t, the state of the agent is denoted by
, while the packet that needs to be transmitted is considered to be an agent. So, the state
depends on the location of the agent. If the vehicle
holds the packet, namely the agent is located in vehicle
, the current state can be defined as:
where
is the Candidate Forwarding Nodes (CFNs) set of vehicle
, satisfying
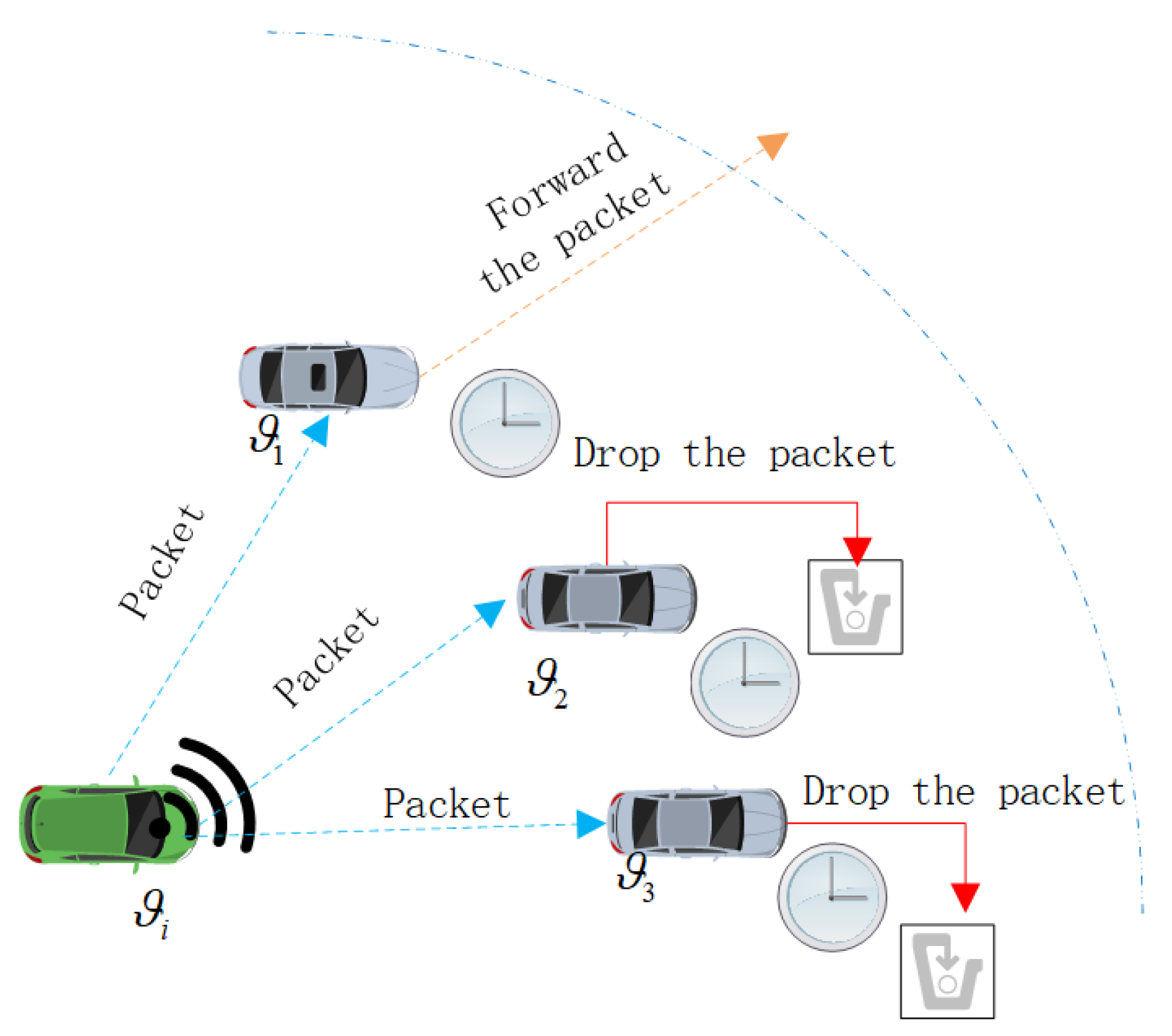
. Next, we will discuss how to construct a CFNs set. According to the idea of opportunistic routing, multiple neighbor nodes of the sender have received the packet simultaneously. To raise the utilization of the resources as well as to avoid broadcast storms, only some neighbor nodes are selected to forward the packet. The selected neighbor nodes are the CFNs, which form a CFNs set.
To construct a fast and reliable routing, a CFNs set is formed by considering the three metrics: relative velocity, packet forwarding ratio, and connectivity probability. Specifically, a sender
needs to construct a CFNs set
. If a node
meets the following three conditions [
50], the node is added to the set
.
Condition 1:
;
Condition 2:
;
Condition 3:
. To this end, the process that the
is added to the set
can be expressed as:
5.2. Action Space
The state transition depends on the selected action. Based on the definition of the state, the action refers to which node is considered to be the next-hop relay node. So, at time step
t, the action
is given by:
where
means that the vehicle
is considered to be the next-hop relay node.
5.3. Reward Function
The reward is an important part of the RL algorithm, and the influence of an action on the transmission packet is evaluated by its reward. To this end, we comprehensively consider node’s location, relative velocity, connectivity probability, and PFR when the reward function is defined. Specifically, at time step
t, the reward function is given by:
where
is the immediate reward and
represents the state at time step
. If
,
, and
, which represents the case that the packet is held by
at time step
t, the
selects
as the next-hop relay node, and the next state is
. Furthermore, we define the immediate reward
with four factors, i.e., relative velocity, connectivity probability, PFR, and an additional reward, which is given by:
where
,
, and
are all non-negative weighted factors, and
represents the additional reward, which can be defined as:
where
and
are a positive constant. If the selected action is
, the
will be a positive constant
when
is the destination. If the
is not the destination but is a neighbor node of the destination, the
will be a positive constant
; obviously,
should be greater than
.
The
just reflects the short-term rewards. For a multi-hop path, we need to have an insight into the long-term rewards so that the impact of future states on the current state is analyzed. The long-term reward is defined as:
where
is a discount factor. In the real model, the
k is set to be 5 because infinite value cannot be calculated.
5.4. Selection of Relay Node
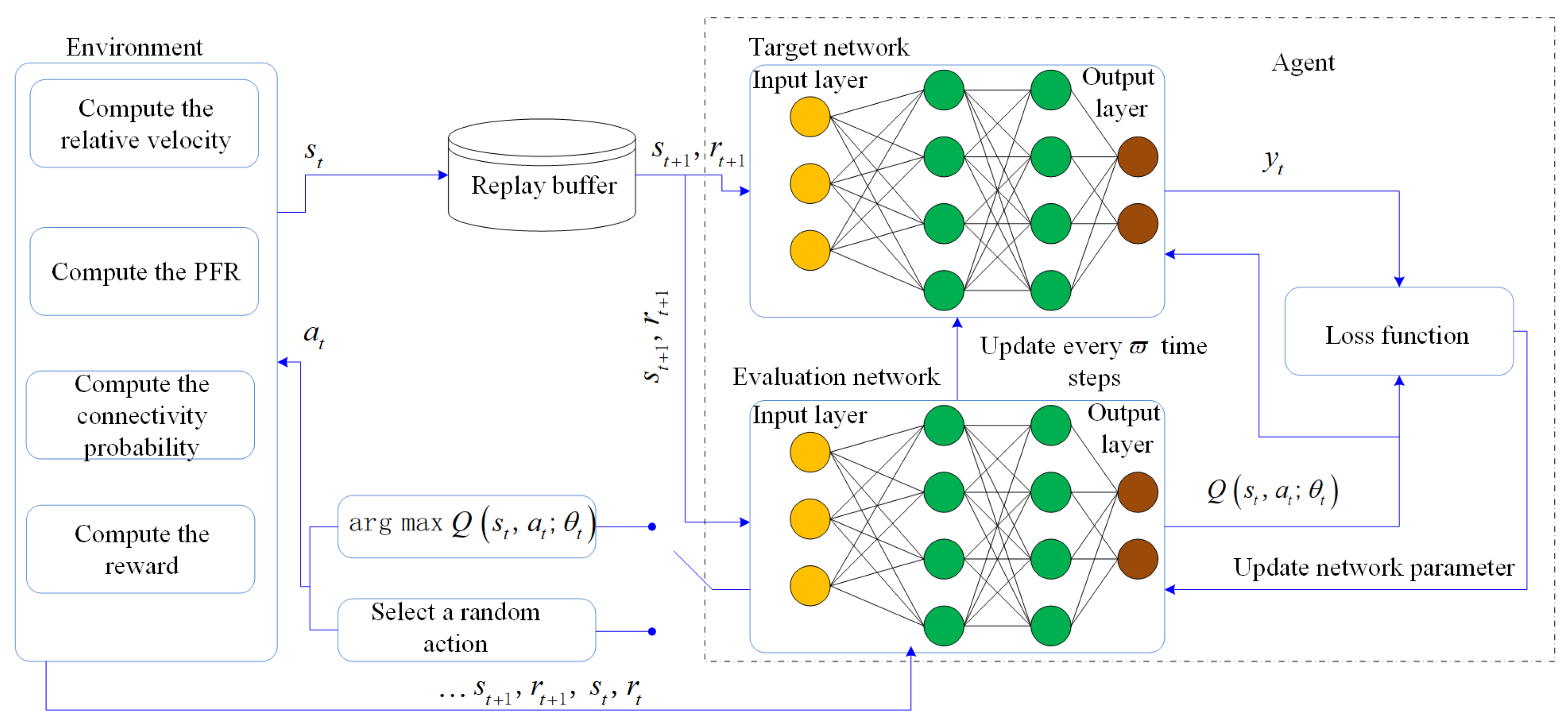
The DRL that is employed in the SROR algorithm consists of an evaluation network and a target network, and their structure is same. Therefore, a DRL-based method is designed to find the relay node.
Figure 5 depicts the overall SROR framework. The pseudo code of the SROR is illustrated in Algorithm 1. Next, we analyze the computational complexity of the Algorithm 1. For the SROR, computational complexity of each time slot is denoted by
. Here, the
and
represent the size of the action space and state space, respectively. The
N is the number of vehicles. Considering the total number of episodes and the number of time slots in each episode, the total computational complexity of Algorithm 1 is denoted by
, where
and
represent the total number of episodes and the number of time slots in each episode, respectively.
| Algorithm 1: SROR |
![Vehicles 06 00084 i001]() |
Specifically, a current state
is generated randomly by the environment at time step
t, and the state
is inputted into the DRL. Then, an action
is selected according to a
-greedy policy. Finally,
Q value of the action
is evaluated by the evaluation network:
where
represents the expectation operation and
represents the network parameter of evaluation network.
Then, the state
is transferred to the state
. The quadruples
are stored into a replay buffer. To revisit the (17),
is a prediction value, and it is evaluated by the evaluation network. Correspondingly, the target value is denoted by
, which is evaluated by the target network. The
is given by:
where
is the target network parameter and
represents the action with the greatest
Q value in evaluation network.
In addition, the target network parameter
is copied from the evaluation network parameter
every
time steps due to the same network structure. Upon computation of the target value
, a loss function [
51] is established by the evaluation network:
Subsequently, the gradient of
can be given by:
According to a stochastic gradient descent [
52], the parameter
is updated, which is given by:
where
represents the learning rate (LR).
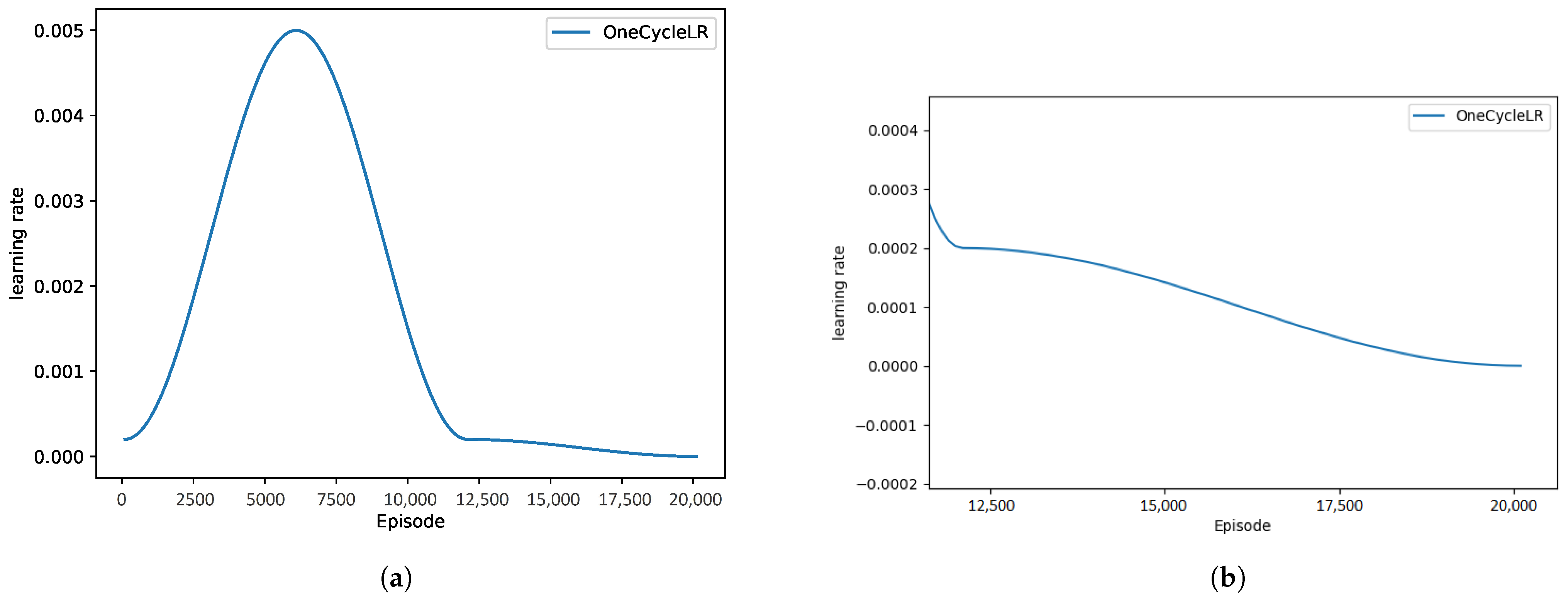
To obtain the better convergence performance, we employ a dynamic LR rather than a fixed LR. The learning rate can be adjusted using the learning rate attenuation strategy when using the Adam optimizer. Fixed attenuation, exponential attenuation, and cosine attenuation are common attenuation strategies. Our methodology adopts the OneCycleLR strategy. This strategy can ensure a large learning rate at the beginning of training, and after a certain amount of training, the learning rate gradually decreases. At the later stage of training, the learning rate decays slowly.
Specially, the OneCycleLR policy is introduced in the proposed SROR. In the OneCycleLR policy, the LR changes after every batch. The maximum LR and the percentage of the cycle are the important parameters for the OneCycleLR policy, the former being the upper learning rate boundary in the cycle, and the latter being the percentage of the cycle spent in increasing the LR. The default value of is 0.3.
To get a better idea of how the learning rate varies,
Figure 6 shows the curve of the learning rate using the OneCycleLR policy, where the total number of episodes is 20,000,
, and
. As shown in
Figure 6, in a cycle (
× 20,000 = 6000), the learning rate first increases to maximum learning rate
when the number of episodes increases from 1 to 6000. Then, the learning rate decays from the maximum learning rate to initial learning rate when the number of episodes increases from 6001 to 12,000. Finally, the learning rate decay to the minimum value
by cosine when the number of episodes increases from 12,001 to 20,000, as shown in
Figure 6b. In the OneCycleLR policy, the LR is growing faster in the early stages of training. This is conducive to improving the speed of model convergence. On the contrary, the LR slowly decays in the later stages of training. This aid in avoiding over-fitting as well as improving the ability of generalization.
7. Conclusions, Limitations, and Future Directions
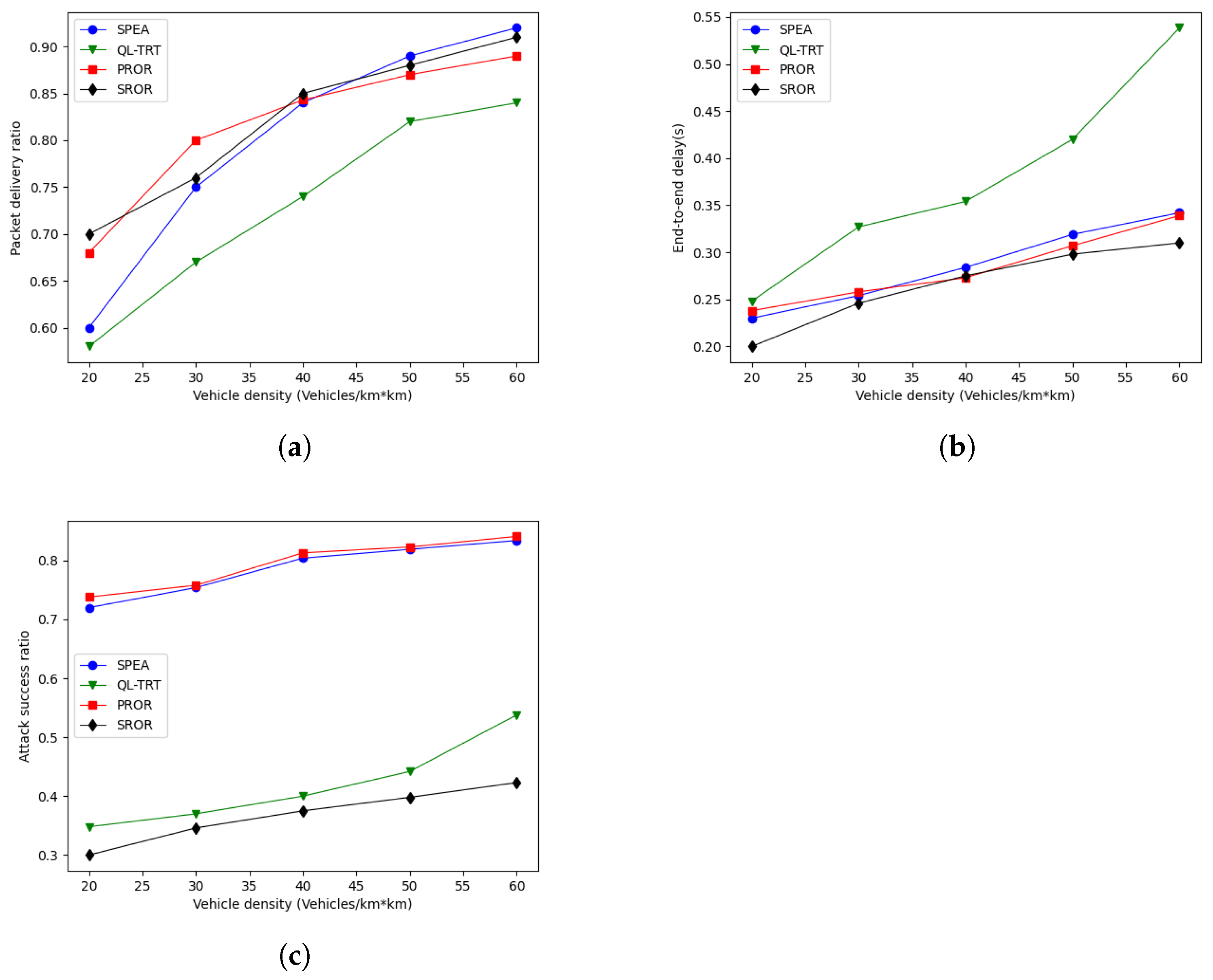
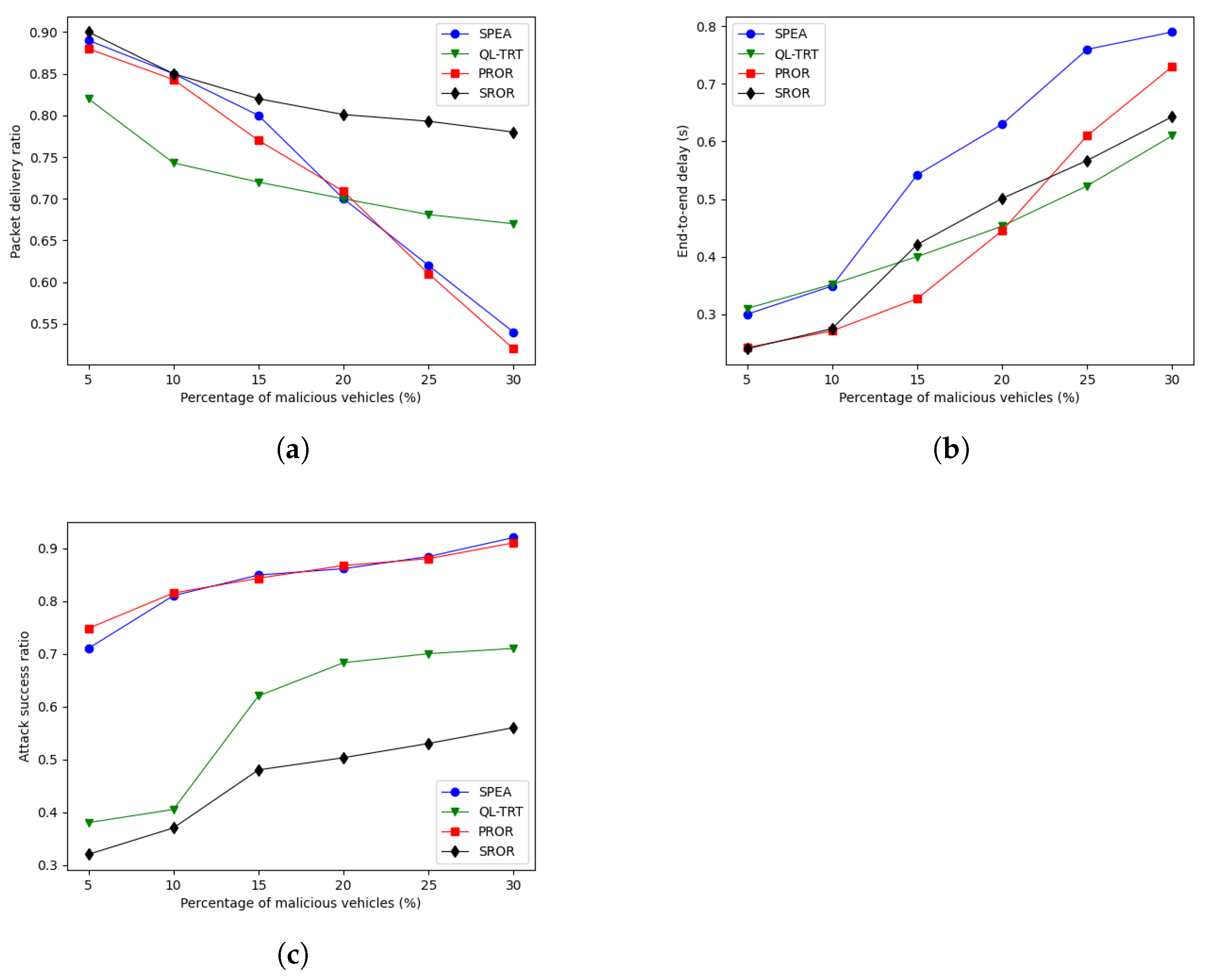
In this paper, a secure and reliable opportunistic routing named SROR is proposed for selecting a stable route path. The proposed methodology was embraced to address issues regrading selection of relay node and attackers. These attackers often lead to packet drops due to their malicious activities. By employing three important network metrics, some candidate forwarding nodes are selected. The aim of the proposed SROR algorithm is to select relay nodes from the candidate forwarding nodes. In addition, the dynamic exploratory factor and OneCycleLR policy are adopted to improve the reward and achieve a better convergence. Compared with benchmarks, simulation experiments show that the SROR algorithm achieves better routing performance. When the percentage of malicious vehicles ranges from 5% to 30% and the vehicle density is fixed 40, the SROR algorithm improves the average PDR by 12% and lowers the ASR by about 26% compared with QL-TRT, displaying the best overall performance among the SPEA, PROR, and QL-TRT protocols. The comparative analysis illustrated the efficiency of the proposed SROR algorithm.
Although the effectiveness of the SROR algorithm was verified, it has some limitations. The main limitations of our research are as follows: (1) this study was confined to identifying BHA and GHA attacks in the routing protocol; (2) this study verified the effectiveness of the SROR algorithm by simulation, and the real-world validation is not discussed.
Therefore, in future work, we plan to consider multiple different types of attacks simultaneously in the routing protocol. Additionally, the proposed SROR algorithm will be refined to apply to the real vehicular network, and the performance is further analyzed.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}