
Highly Discriminative Driver Distraction Detection Method Based on Swin Transformer




Abstract
1. Introduction
- Due to the powerful image feature learning ability of Swin Transformer, it is introduced to extract more representative features from the input images in this paper.
- A novel highly discriminative feature learning strategy based on SC loss and center vector shift process is proposed in this paper.
- To evaluate the effectiveness of the proposed driver distraction detection method, extensive experiments have been conducted on the famous public driver distraction detection datasets (AUC-DDD and State-Farm) in this paper.
2. Related Works
2.1. Driver Distraction Detection Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Description | Methods |
|---|---|---|
| [20] | Develop a real-time driver cognitive distraction approach according to drivers’ eye movements and their driving performance | SVM |
| [21] | Propose a data-driven method based on the decision tree classifier | Decision tree |
| [22] | Develop a driver distraction detection method by combining the dynamic Bayesian network (DBN) and supervised clustering | DBN |
| [25] | Propose a CNN model that outperforms VGG16, ResNet50, and logistic regression | CNN |
| [26] | Develop a convolutional neural network (CNN)-based technique with the integration of a channel attention (CA) mechanism | CNN |
| [2] | Propose a novel lightweight model called multi-stream deep fusion network | CNN |
2.2. Research Related to Swin Transformer
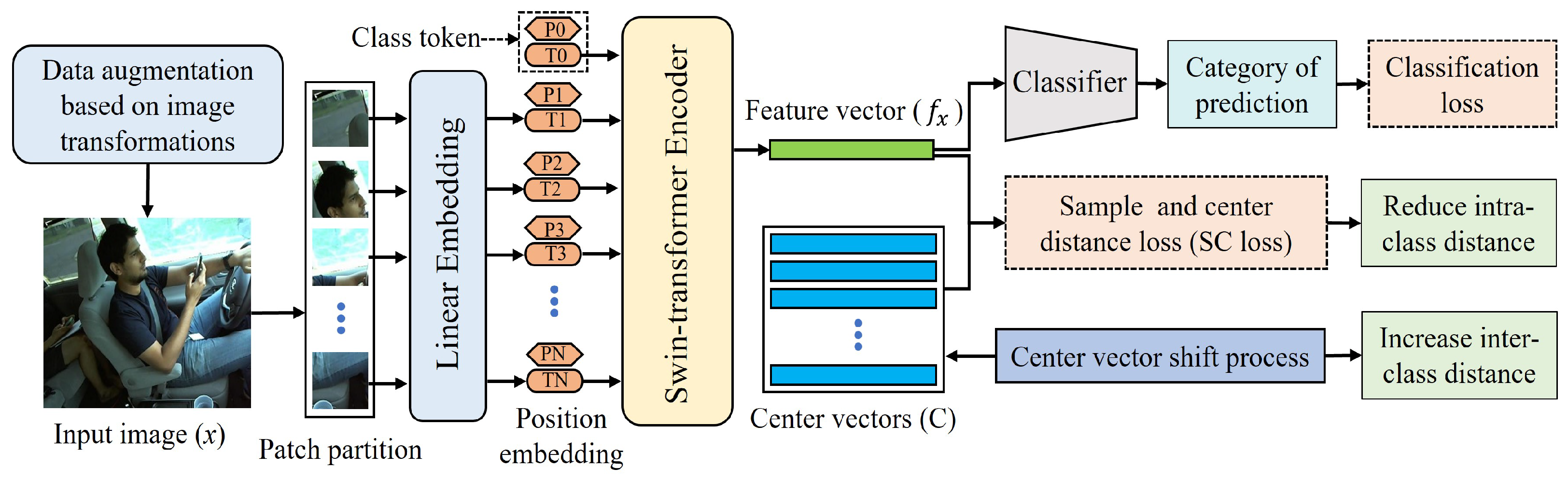
3. Methodology
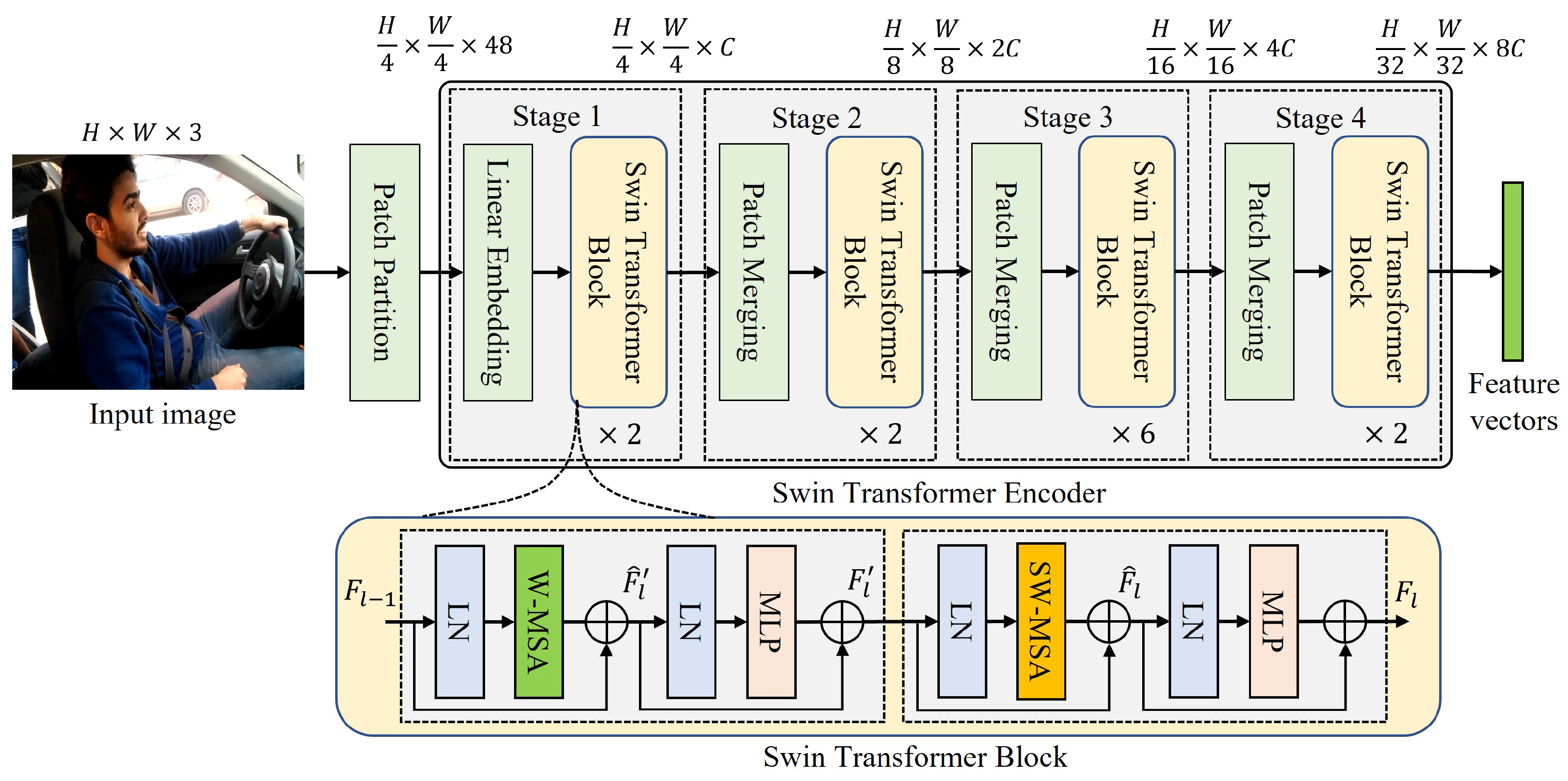
3.1. Feature Extraction through Swin Transformer
- (1)
- Hierarchical feature maps
- (2)
- Shifted window attention
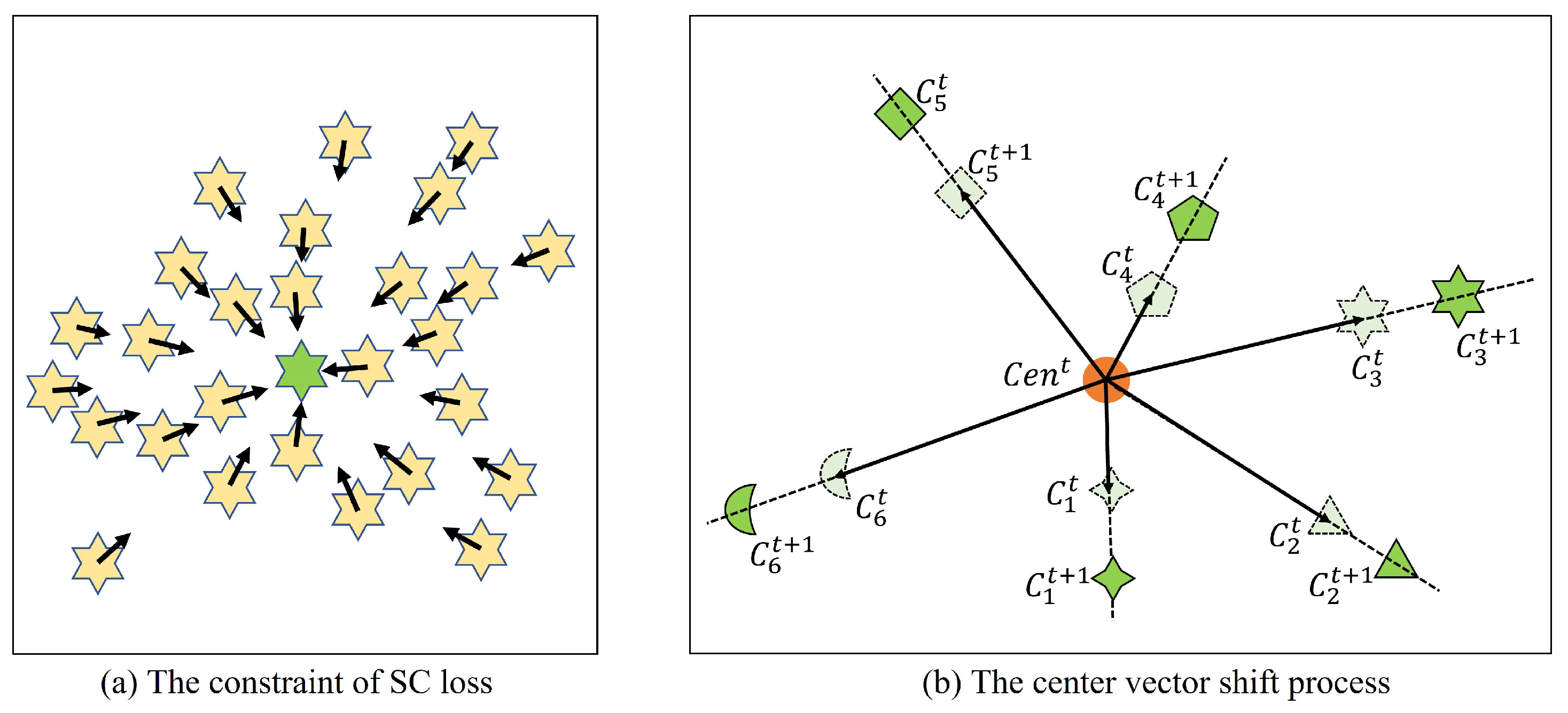
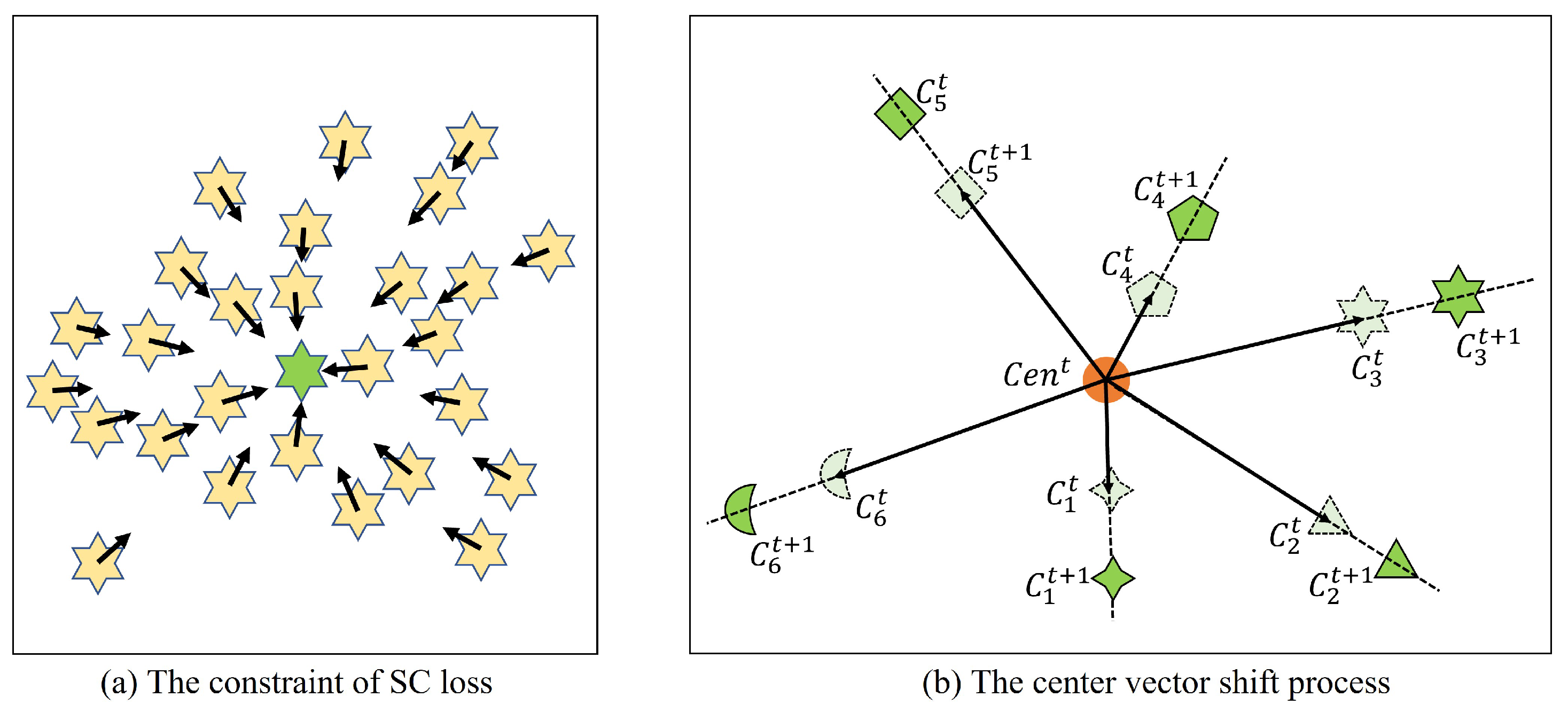
3.2. Highly Discriminative Feature Learning Strategy
- (1)
- Center vector initialization process.
- (2)
- The constraint of SC loss.
- (3)
- Center vector shift process.
4. Experimental Datasets and Experiment Setup
4.1. Experimental Datasets
- (1)
- AUC-DDD dataset
- (2)
- State-Farm dataset
4.2. Data Augmentation Based on Image Transformation
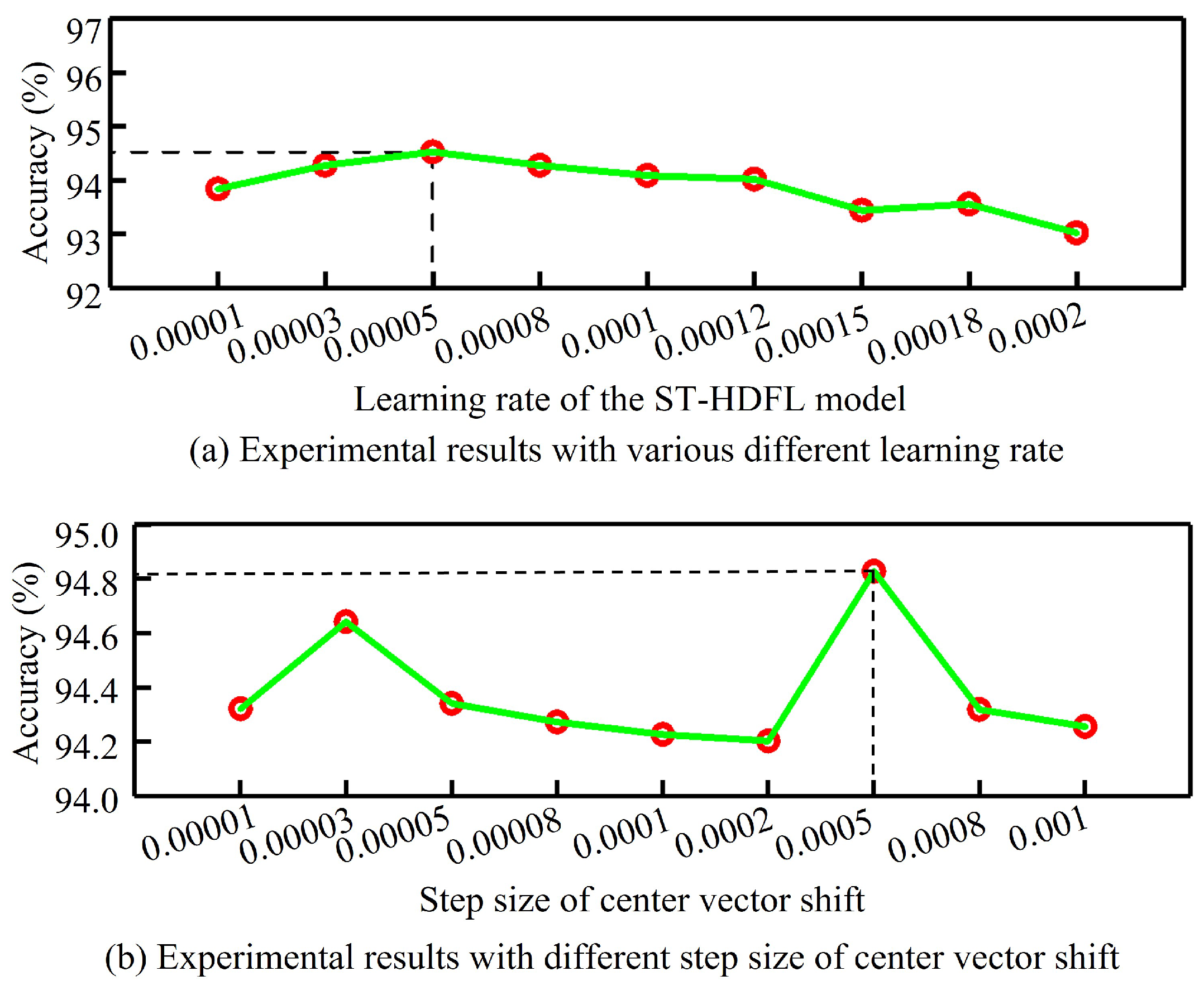
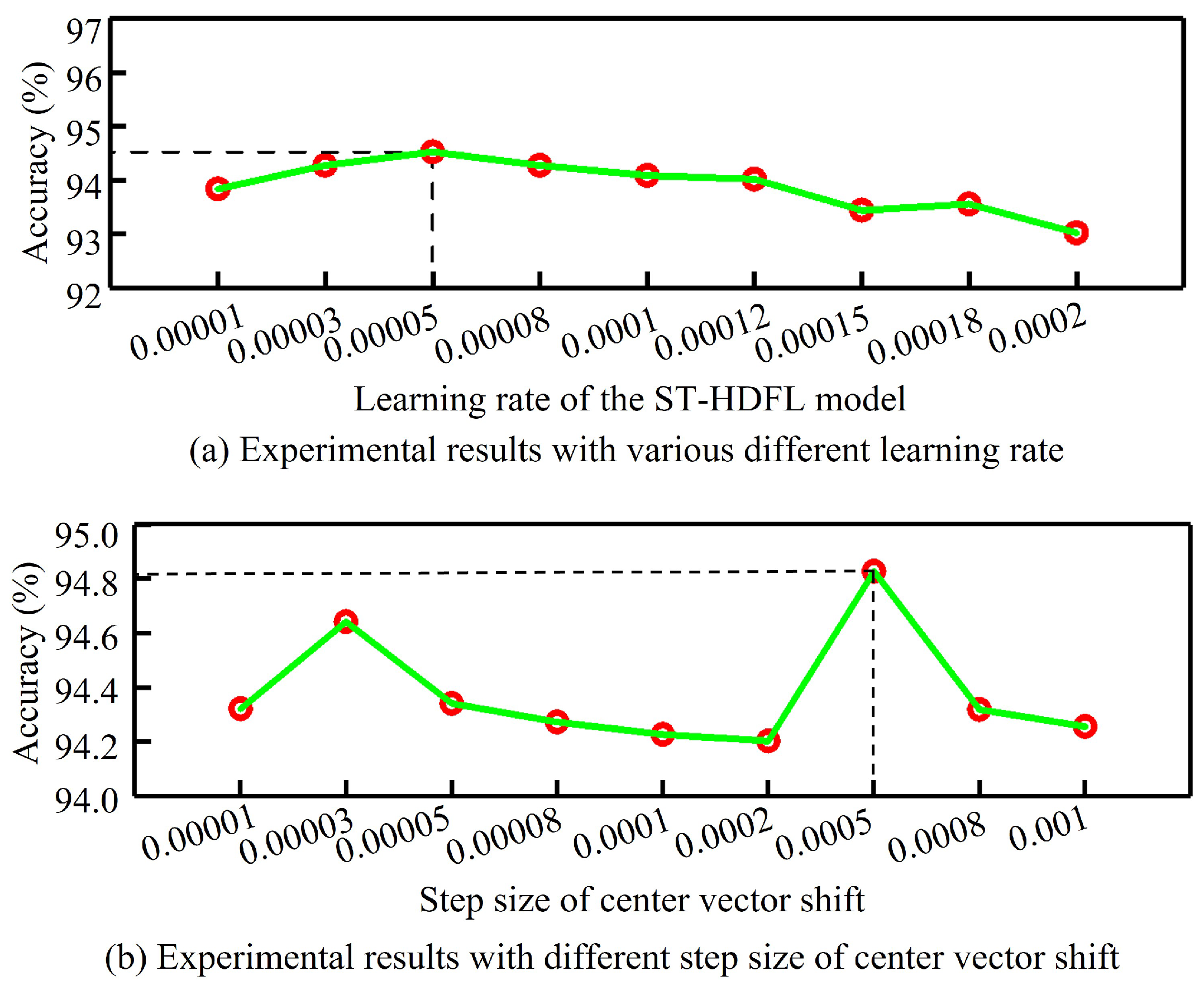
4.3. Implementation Details
5. Experimental Results
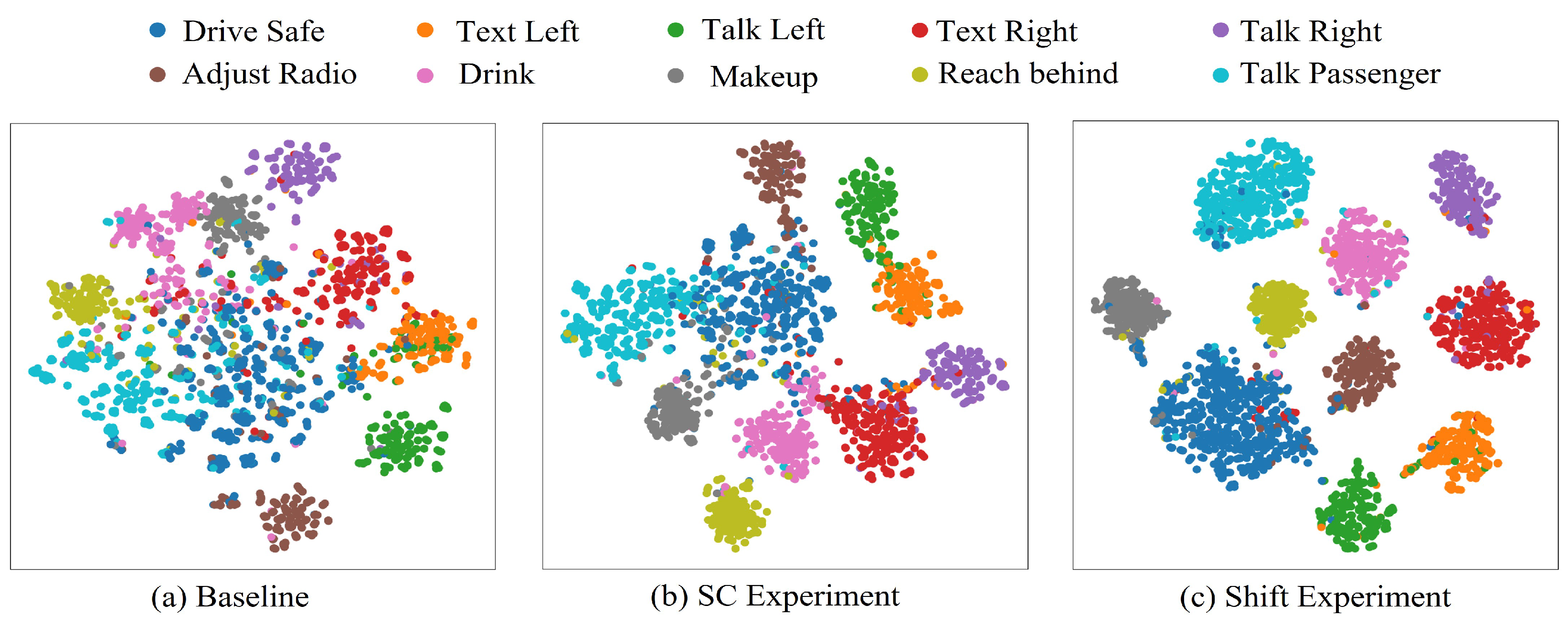
5.1. Evaluation of the Highly Discriminative Feature Learning Strategy
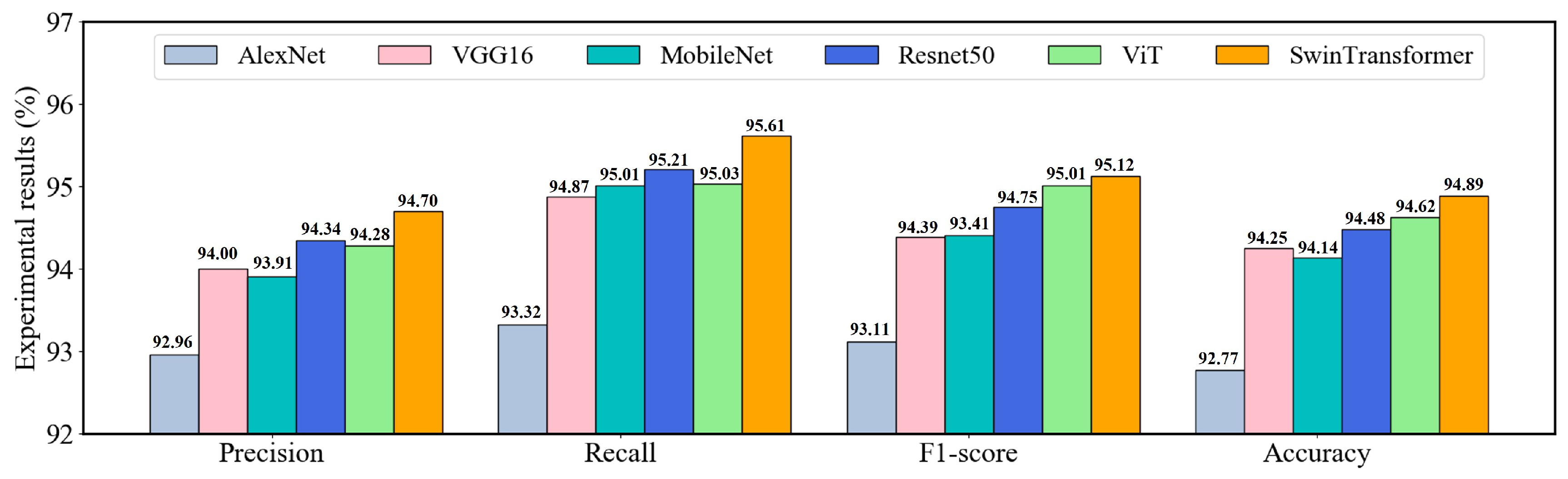
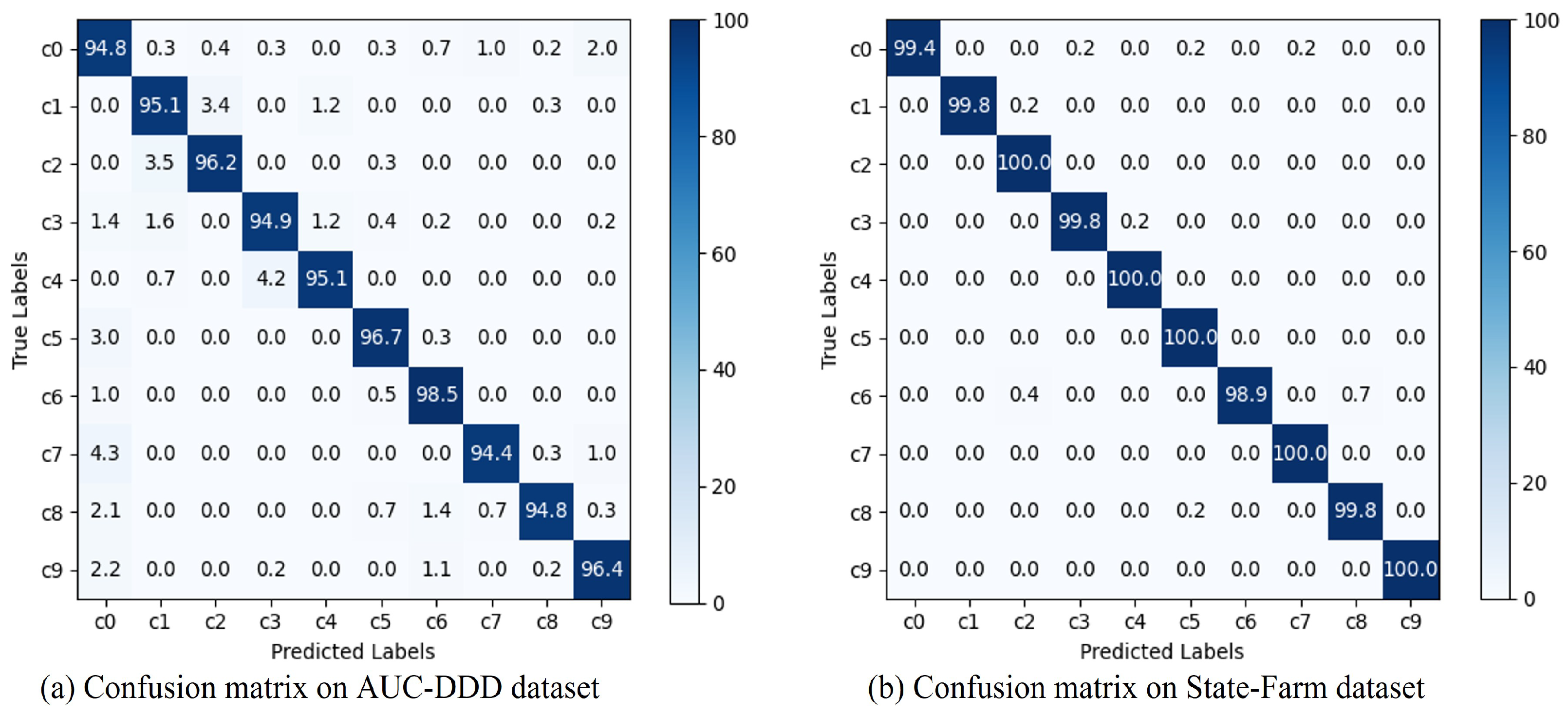
5.2. Comparison Experiments on the Public Datasets
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Chai, W.; Venkatachalapathy, A.; Tan, K.L.; Haghighat, A.; Velipasalar, S.; Adu-Gyamfi, Y.; Sharma, A. A survey on driver behavior analysis from in-vehicle cameras. IEEE Trans. Intell. Transp. Syst. 2021, 23, 10186–10209. [Google Scholar] [CrossRef]
- Hu, Z.; Xing, Y.; Gu, W.; Cao, D.; Lv, C. Driver anomaly quantification for intelligent vehicles: A contrastive learning approach with representation clustering. IEEE Trans. Intell. Veh. 2022, 8, 37–47. [Google Scholar] [CrossRef]
- Tan, M.; Ni, G.; Liu, X.; Zhang, S.; Wu, X.; Wang, Y.; Zeng, R. Bidirectional posture-appearance interaction network for driver behavior recognition. IEEE Trans. Intell. Transp. Syst. 2021, 23, 13242–13254. [Google Scholar] [CrossRef]
- Kashevnik, A.; Shchedrin, R.; Kaiser, C.; Stocker, A. Driver distraction detection methods: A literature review and framework. IEEE Access 2021, 9, 60063–60076. [Google Scholar] [CrossRef]
- Alemdar, K.D.; Kayacı Çodur, M.; Codur, M.Y.; Uysal, F. Environmental Effects of Driver Distraction at Traffic Lights: Mobile Phone Use. Sustainability 2023, 15, 15056. [Google Scholar] [CrossRef]
- Meiring, G.A.M.; Myburgh, H.C. A review of intelligent driving style analysis systems and related artificial intelligence algorithms. Sensors 2015, 15, 30653–30682. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, B.; He, J.; Lian, J. Recognition of driving postures by contourlet transform and random forests. IET Intell. Transp. Syst. 2012, 6, 161–168. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, N.; Wang, F.; He, Y. Visual recognition of driver hand-held cell phone use based on hidden CRF. In Proceedings of the 2011 IEEE International Conference on Vehicular Electronics and Safety, Beijing, China, 10–12 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 248–251. [Google Scholar]
- Feng, S.; Yan, X.; Sun, H.; Feng, Y.; Liu, H.X. Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment. Nat. Commun. 2021, 12, 748. [Google Scholar] [CrossRef]
- Yang, H.; Wu, J.; Hu, Z.; Lv, C. Real-Time Driver Cognitive Workload Recognition: Attention-Enabled Learning with Multimodal Information Fusion. IEEE Trans. Ind. Electron. 2023, 71, 4999–5009. [Google Scholar] [CrossRef]
- Yang, H.; Liu, H.; Hu, Z.; Nguyen, A.-T.; Guerra, T.-M.; Lv, C. Quantitative Identification of Driver Distraction: A Weakly Supervised Contrastive Learning Approach. IIEEE Trans. Intell. Transp. Syst. 2023; early access. [Google Scholar] [CrossRef]
- He, X.; Wu, J.; Huang, Z.; Hu, Z.; Wang, J.; Sangiovanni-Vincentelli, A.; Lv, C. Fear-Neuro-Inspired Reinforcement Learning for Safe Autonomous Driving. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 267–279. [Google Scholar] [CrossRef]
- Mase, J.M.; Chapman, P.; Figueredo, G.P.; Torres, M.T. A hybrid deep learning approach for driver distraction detection. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 21–23 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Yang, L.; Song, Y.; Ma, K.; Xie, L. Motor imagery EEG decoding method based on a discriminative feature learning strategy. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 368–379. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Yang, H.; Hu, B.-B.; Wang, Y.; Lv, C. A Robust Driver Emotion Recognition Method Based on High-Purity Feature Separation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15092–15104. [Google Scholar] [CrossRef]
- Yang, L.; Song, Y.; Ma, K.; Su, E.; Xie, L. A novel motor imagery EEG decoding method based on feature separation. J. Neural Eng. 2021, 18, 036022. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in Remote Sensing: A Survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Chen, T.; Mo, L. Swin-fusion: Swin-transformer with feature fusion for human action recognition. Neural Process. Lett. 2023, 55, 11109–11130. [Google Scholar] [CrossRef]
- Xiao, H.; Li, L.; Liu, Q.; Zhu, X.; Zhang, Q. Transformers in medical image segmentation: A review. Biomed. Signal Process. Control 2023, 84, 104791. [Google Scholar] [CrossRef]
- Liang, Y.; Reyes, M.L.; Lee, J.D. Real-time detection of driver cognitive distraction using support vector machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 340–350. [Google Scholar] [CrossRef]
- Zhang, Y.; Owechko, Y.; Zhang, J. Driver cognitive workload estimation: A data-driven perspective. In Proceedings of the 7th International IEEE Conference on Intelligent Transportation Systems (IEEE Cat. No. 04TH8749), Washington, WA, USA, 3–6 October 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 642–647. [Google Scholar]
- Liang, Y.; Lee, J.D.; Reyes, M.L. Nonintrusive detection of driver cognitive distraction in real time using Bayesian networks. Transp. Res. Board 2007, 2018, 1–8. [Google Scholar] [CrossRef]
- Yang, L.; Tian, Y.; Song, Y.; Yang, N.; Ma, K.; Xie, L. A novel feature separation model exchange-GAN for facial expression recognition. Knowl.-Based Syst. 2020, 204, 106217. [Google Scholar] [CrossRef]
- Guo, Z.; You, L.; Liu, S.; He, J.; Zuo, B. ICMFed: An Incremental and Cost-Efficient Mechanism of Federated Meta-Learning for Driver Distraction Detection. Mathematics 2023, 11, 1867. [Google Scholar] [CrossRef]
- Dhiman, A.; Varshney, A.; Hasani, F.; Verma, B. A Comparative Study on Distracted Driver Detection Using CNN and ML Algorithms. In Proceedings of the International Conference on Data Science and Applications, London, UK, 25–26 November 2023; Lecture Notes in Networks and Systems. Saraswat, M., Chowdhury, C., Kumar Mandal, C., Gandomi, A.H., Eds.; Springer: Singapore, 2023; Volume 552. [Google Scholar]
- Khan, T.; Choi, G.; Lee, S. EFFNet-CA: An efficient driver distraction detection based on multiscale features extractions and channel attention mechanism. Sensors 2023, 23, 3835. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Wang, Z. ViT-DD: Multi-Task Vision Transformer for Semi-Supervised Driver Distraction Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium Workshops (IV Workshops), Anchorage, AK, USA, 4 June 2023. [Google Scholar]
- Peng, K.; Roitberg, A.; Yang, K.; Zhang, J.; Stiefelhagen, R. TransDARC: Transformer-based driver activity recognition with latent space feature calibration. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 278–285. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two pure transformers can make one strong gan, and that can scale up. Adv. Neural Inf. Process. Syst. 2021, 34, 14745–14758. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Abouelnaga, Y.; Eraqi, H.M.; Moustafa, M.N. Real-time distracted driver posture classification. arXiv 2017, arXiv:1706.09498. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Qin, B.; Qian, J.; Xin, Y.; Liu, B.; Dong, Y. Distracted driver detection based on a CNN with decreasing filter size. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6922–6933. [Google Scholar] [CrossRef]
- Mittal, H.; Verma, B. CAT-CapsNet: A Convolutional and Attention Based Capsule Network to Detect the Driver’s Distraction. IEEE Trans. Intell. Transp. Syst. 2023, 24, 9561–9570. [Google Scholar] [CrossRef]
- Xiao, W.; Liu, H.; Ma, Z.; Chen, W. Attention-based deep neural network for driver behavior recognition. Futur. Gener. Comput. Syst. 2022, 132, 152–161. [Google Scholar] [CrossRef]
- Yang, W.; Tan, C.; Chen, Y.; Xia, H.; Tang, X.; Cao, Y.; Zhou, W.; Lin, L.; Dai, G. BiRSwinT: Bilinear full-scale residual swin-transformer for fine-grained driver behavior recognition. J. Frankl. Inst. 2023, 360, 1166–1183. [Google Scholar] [CrossRef]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Duan, C.; Gong, Y.; Liao, J.; Zhang, M.; Cao, L. FRNet: DCNN for Real-Time Distracted Driving Detection toward Embedded Deployment. IEEE Trans. Intell. Transp. Syst. 2023, 24, 9835–9848. [Google Scholar] [CrossRef]
- Zhang, B. Apply and Compare Different Classical Image Classification Method: Detect Distracted Driver; Computer Science Department, Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Majdi, M.S.; Ram, S.; Gill, J.T.; Rodríguez, J.J. Drive-net: Convolutional network for driver distraction detection. In Proceedings of the 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Las Vegas, NV, USA, 8–10 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Huang, C.; Wang, X.; Cao, J.; Wang, S.; Zhang, Y. HCF: A hybrid CNN framework for behavior detection of distracted drivers. IEEE Access 2020, 8, 109335–109349. [Google Scholar] [CrossRef]
- Janet, B.; Reddy, U.S. Real time detection of driver distraction using CNN. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 185–191. [Google Scholar]




| Exps | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Aver Acc ↑ | STD ↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SC-Exp | 94.26 | 94.87 | 94.96 | 95.27 | 95.13 | 94.91 | 94.79 | 94.95 | 94.89 | 94.78 | 94.881 | 0.264 |
| Shift-Exp | 95.21 | 95.17 | 95.45 | 94.96 | 95.39 | 95.27 | 95.63 | 95.46 | 95.32 | 95.43 | 95.329 | 0.187 |
| Our method | 95.33 | 95.62 | 95.78 | 95.81 | 95.63 | 95.21 | 95.97 | 95.75 | 95.63 | 95.58 | 95.631 | 0.224 |
| Paired T-test | Shift-Exp vs. SC-Exp | Our method vs. Shift-Exp |
| p-value | (0.000367) | † (0.00429) |
| Experiments | Accuracy (%) |
|---|---|
| ADNet [46] | 90.22 |
| BiRSwinT [47] | 92.25 |
| NasNet Mobile [48] | 94.69 |
| FRNet [49] | 94.74 |
| MobileVGG [12] | 95.25 |
| D-HCNN [44] | 95.59 |
| ST-HDFL (ours) | 95.66 |
| Experiments | Accuracy (%) |
|---|---|
| VGG16 + VGG-GAP [50] | 92.60 |
| Drive-Net [51] | 95.00 |
| HCF [52] | 96.74 |
| Vanilla CNN [53] | 97.05 |
| D-HCNN [44] | 99.86 |
| CAT-CapsNet [45] | 99.88 |
| ST-HDFL (ours) | 99.73 |
| Methods | AlexNet | VGG16 | MobileNet | ResNet 50 | Swin Transformer |
|---|---|---|---|---|---|
| Time cost | 0.52 ms | 1.13 ms | 2.55 ms | 2.85 ms | 4.81 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Yang, L.; Lv, C. Highly Discriminative Driver Distraction Detection Method Based on Swin Transformer. Vehicles 2024, 6, 140-156. https://doi.org/10.3390/vehicles6010006
Zhang Z, Yang L, Lv C. Highly Discriminative Driver Distraction Detection Method Based on Swin Transformer. Vehicles. 2024; 6(1):140-156. https://doi.org/10.3390/vehicles6010006
Chicago/Turabian StyleZhang, Ziyang, Lie Yang, and Chen Lv. 2024. "Highly Discriminative Driver Distraction Detection Method Based on Swin Transformer" Vehicles 6, no. 1: 140-156. https://doi.org/10.3390/vehicles6010006
APA StyleZhang, Z., Yang, L., & Lv, C. (2024). Highly Discriminative Driver Distraction Detection Method Based on Swin Transformer. Vehicles, 6(1), 140-156. https://doi.org/10.3390/vehicles6010006