A Curb-Detection Network with a Tri-Plane BEV Encoder Module for Autonomous Delivery Vehicles


Abstract
1. Introduction
2. Related Work
3. Methodology
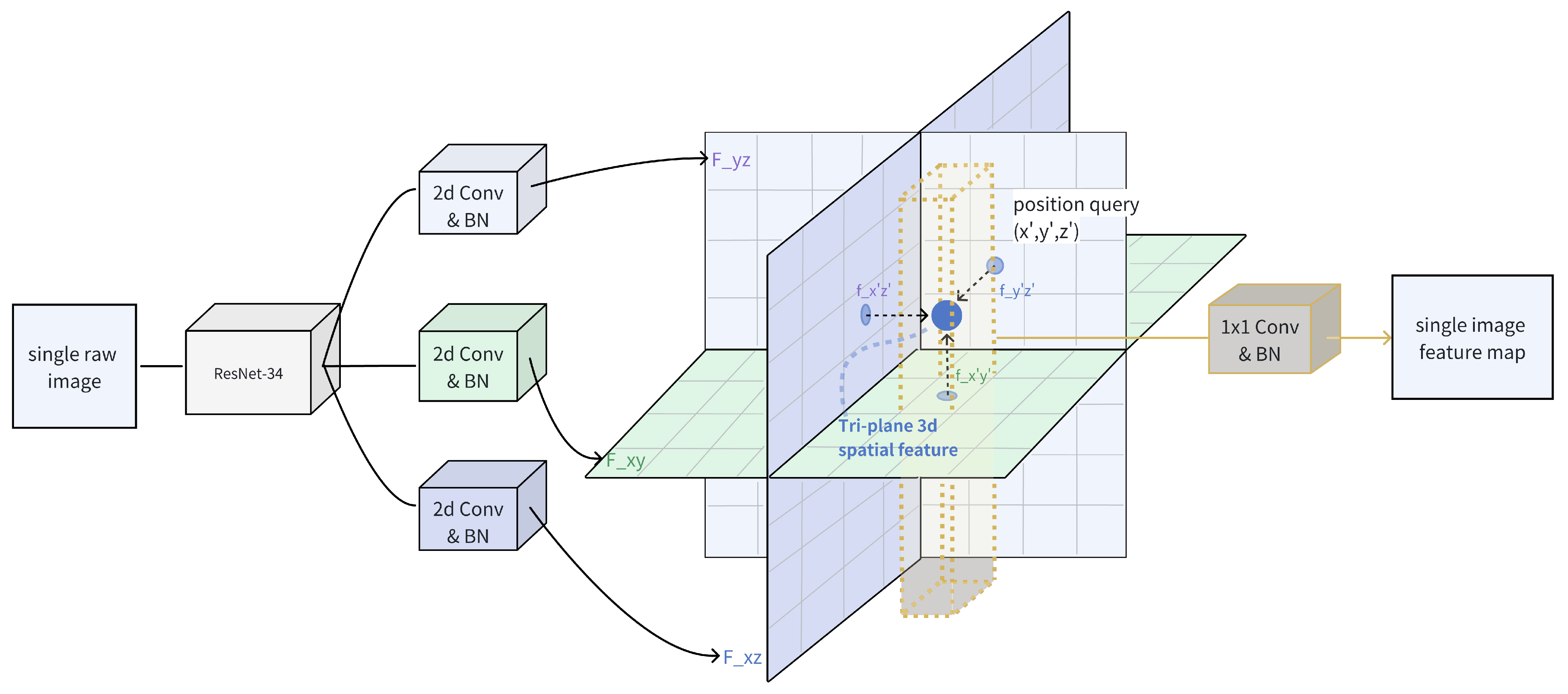
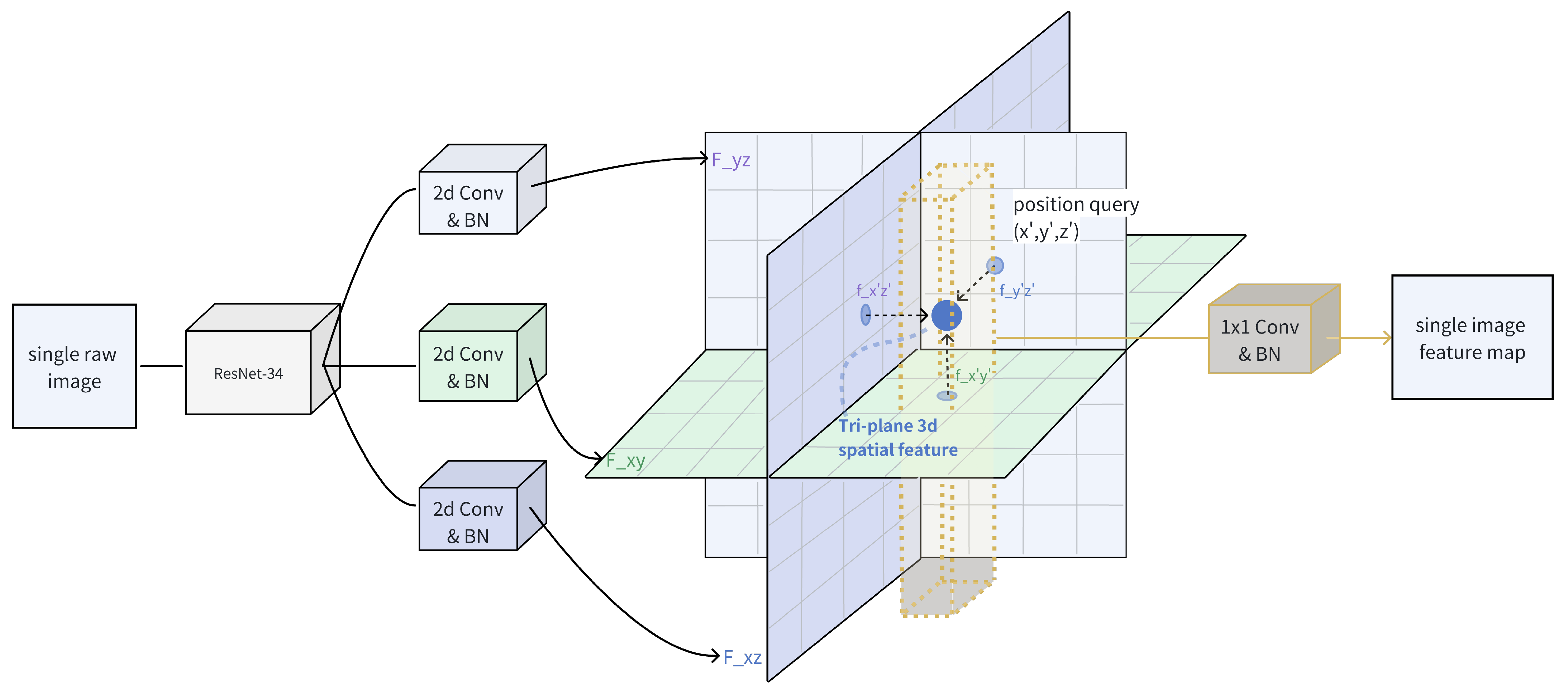
3.1. Modified Tri-Plane BEV-Encoder
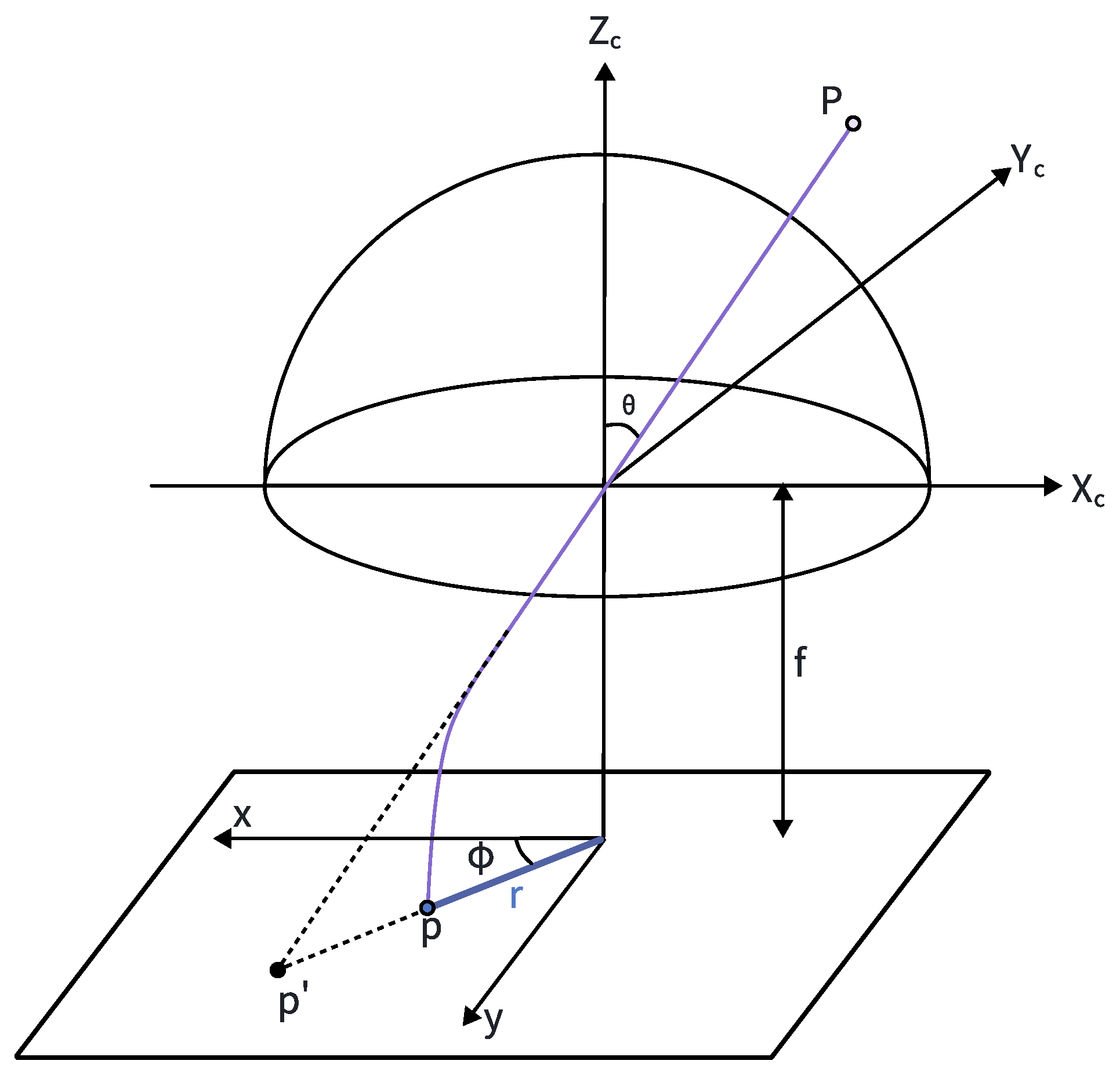
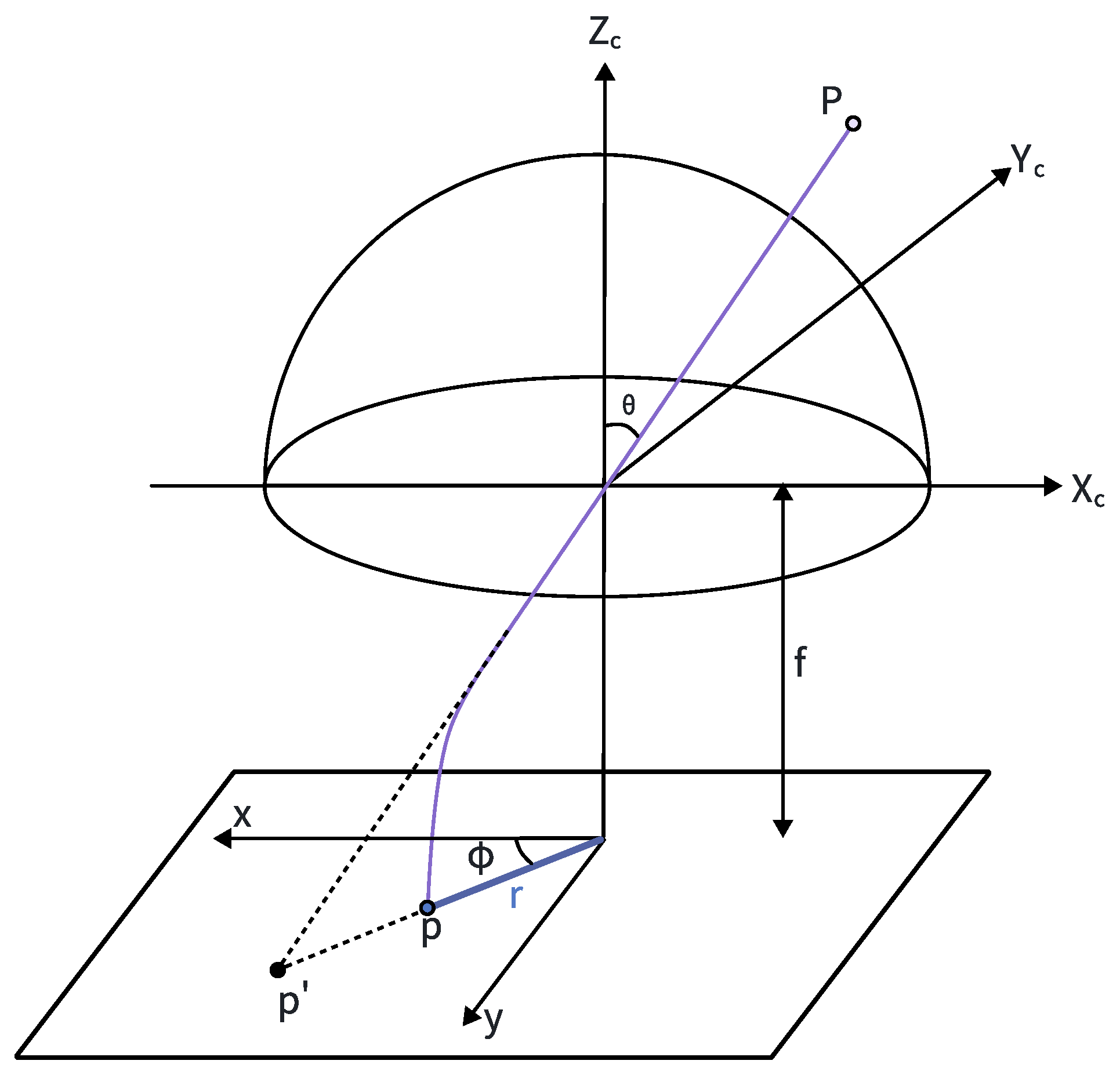
3.2. A Fisheye-Camera Rectification Module
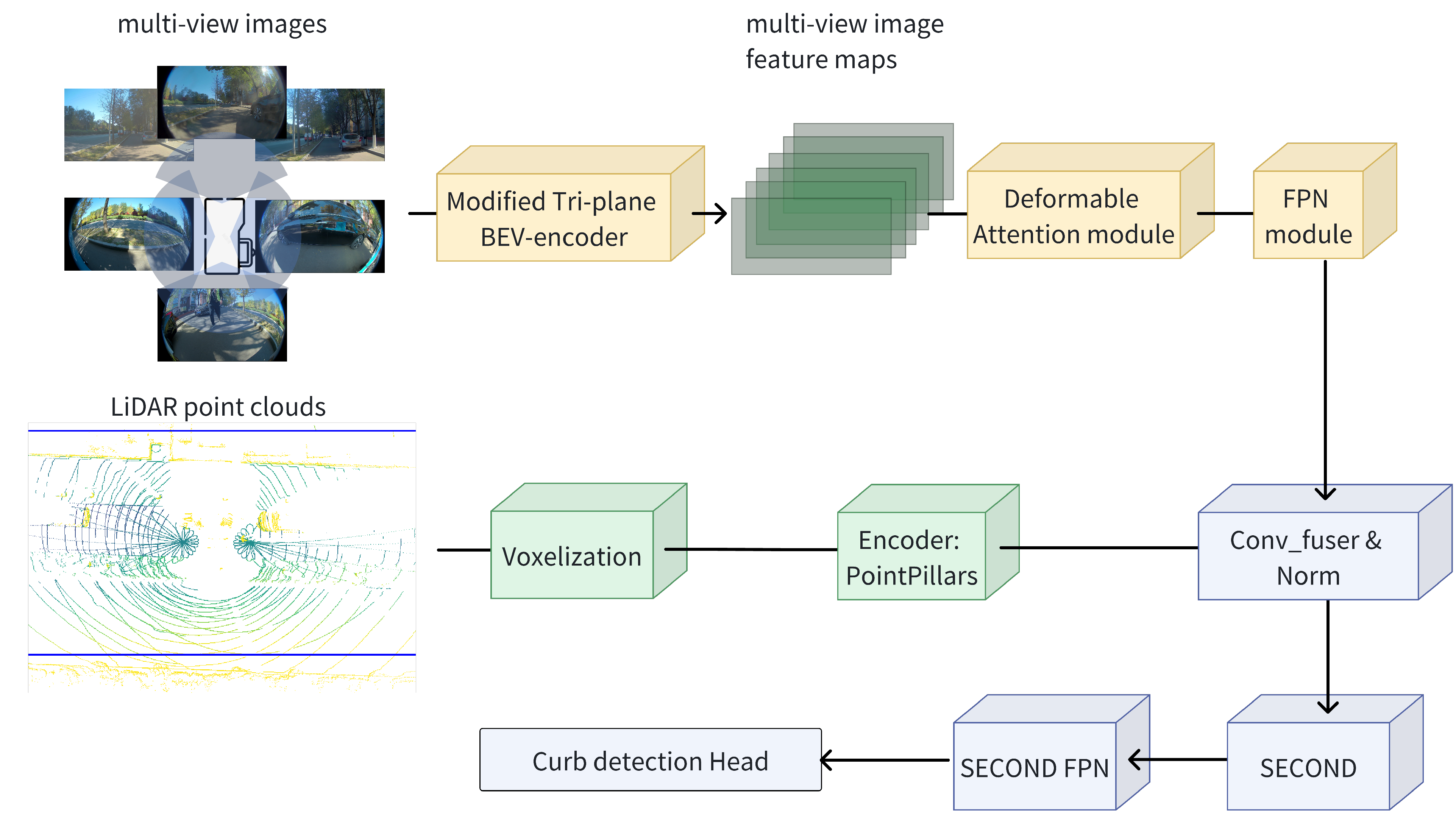
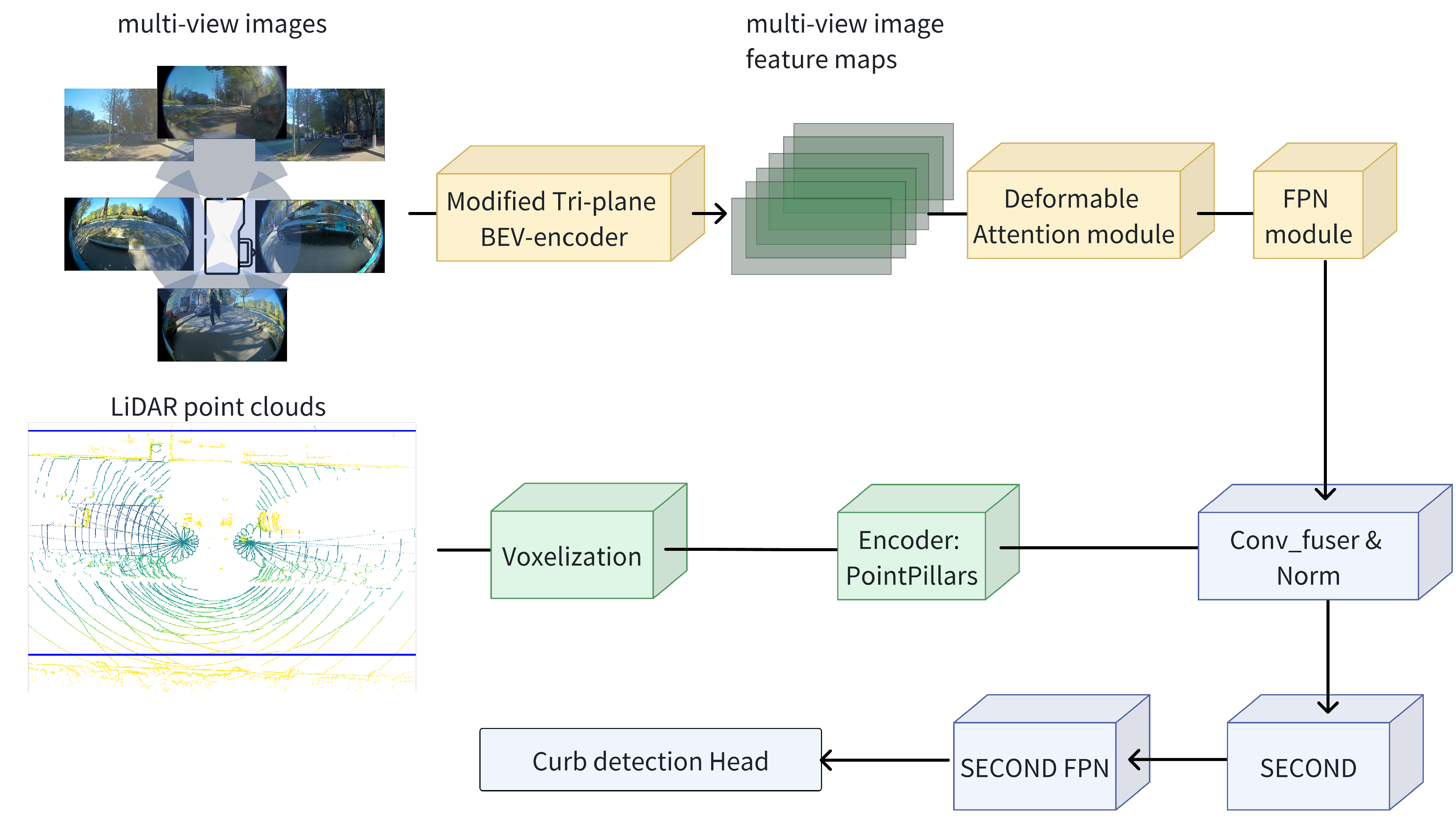
3.3. A Curb-Detection Algorithm Using LiDAR–Camera Fusion with a Tri-Plane BEV-Encoder
- Semantic Segmentation Branch: a binary classification semantic segmentation branch for predicting whether each BEV grid cell belongs to the lane line;
- Instance Segmentation Branch: used to distinguish between different lane lines instances;
- Position Offset Branch: predicts the minimum distance of lane line instances from the center of the BEV grid cells, serving as the position offset loss for curb detection in order to enhance detection accuracy. The output channel number is 2, corresponding to the offset in the x and y directions.
4. Experiments
4.1. Dataset Setup
4.2. Fisheye Camera Rectification
4.3. Comparison with Existing Image-to-BEV Feature Projection Method
4.4. Evaluation Metrics
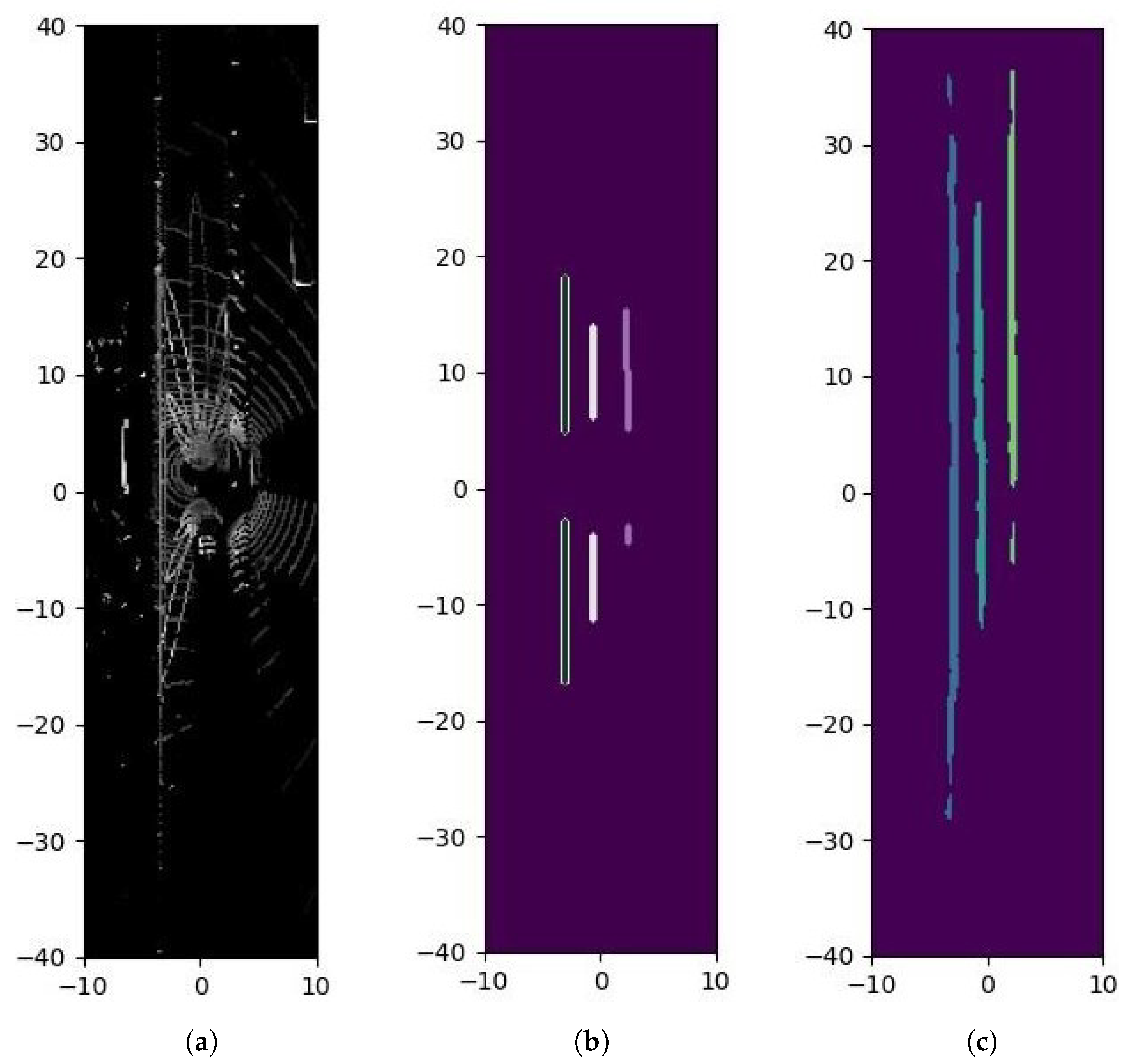
4.4.1. Instance Matching for Detected and Ground Truth Curbs
4.4.2. Calculation of Matching Information for Each Curb Instance
4.4.3. Aggregation and Statistical Metrics
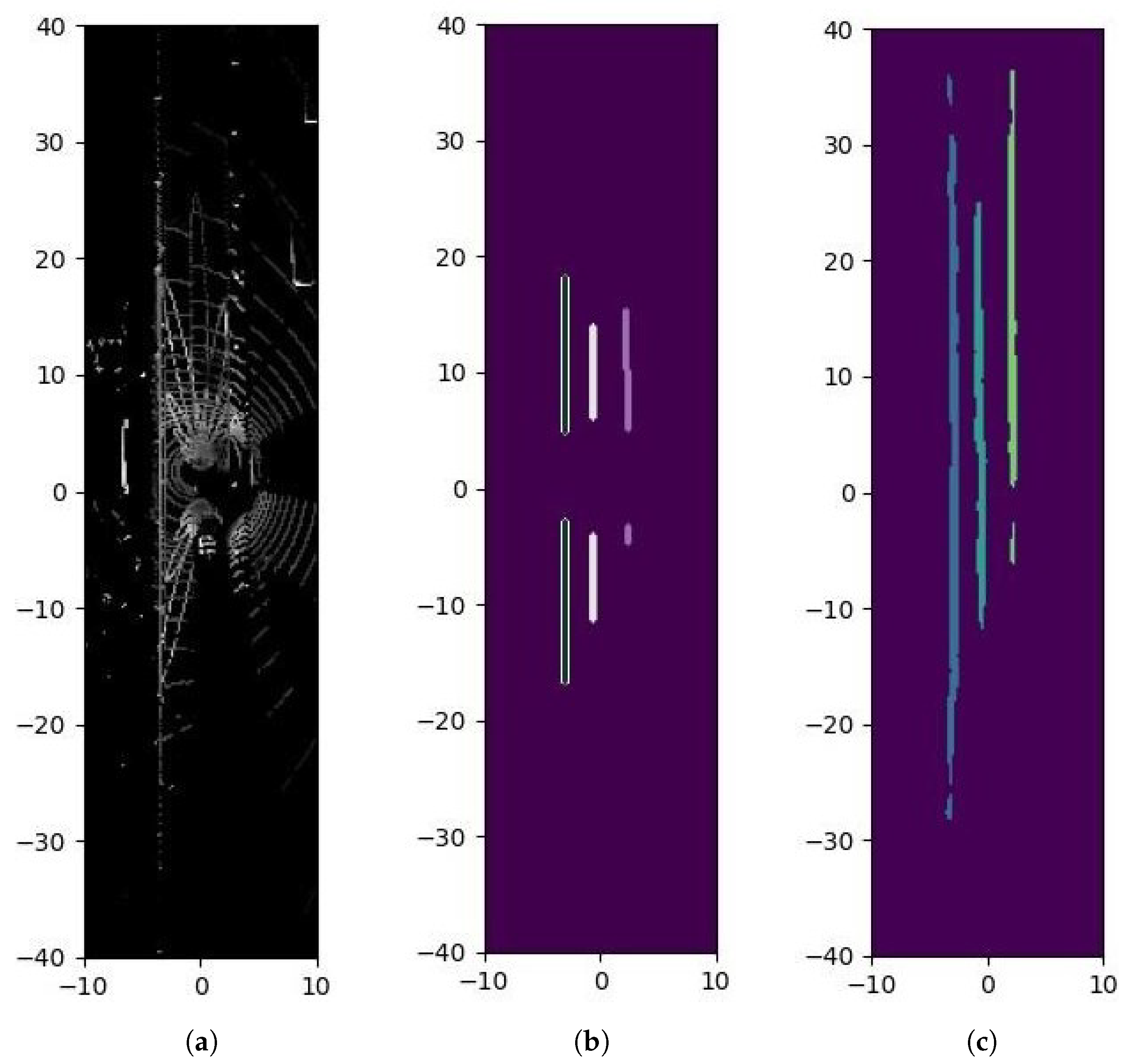
5. Results and Discussion
5.1. Methodology and Criteria for Data Presentation Selection
5.2. Comparative Experimental Analysis of Algorithm Modules
- The modified tri-plane BEV-encoder module, compared to the M2BEV’s image-to-BEV feature projection module, demonstrated superior average precision and recall rates in the urban-area road experiments conducted for autonomous delivery vehicles in this article under conditions both with and without the fisheye rectification preprocessing step for fisheye camera images;
- The presence of a fisheye camera distortion correction preprocessing step showed relatively minor performance differentiation when neither of the above-mentioned spatial transformation modules were utilized. However, when employing the M2BEV’s image-to-BEV feature projection module, considering both the average accuracy and recall, the fisheye camera distortion correction preprocessing did not result in a notable improvement in performance. In contrast, with the implementation of the tri-plane encoder module, this preprocessing step led to a certain degree of performance enhancement.
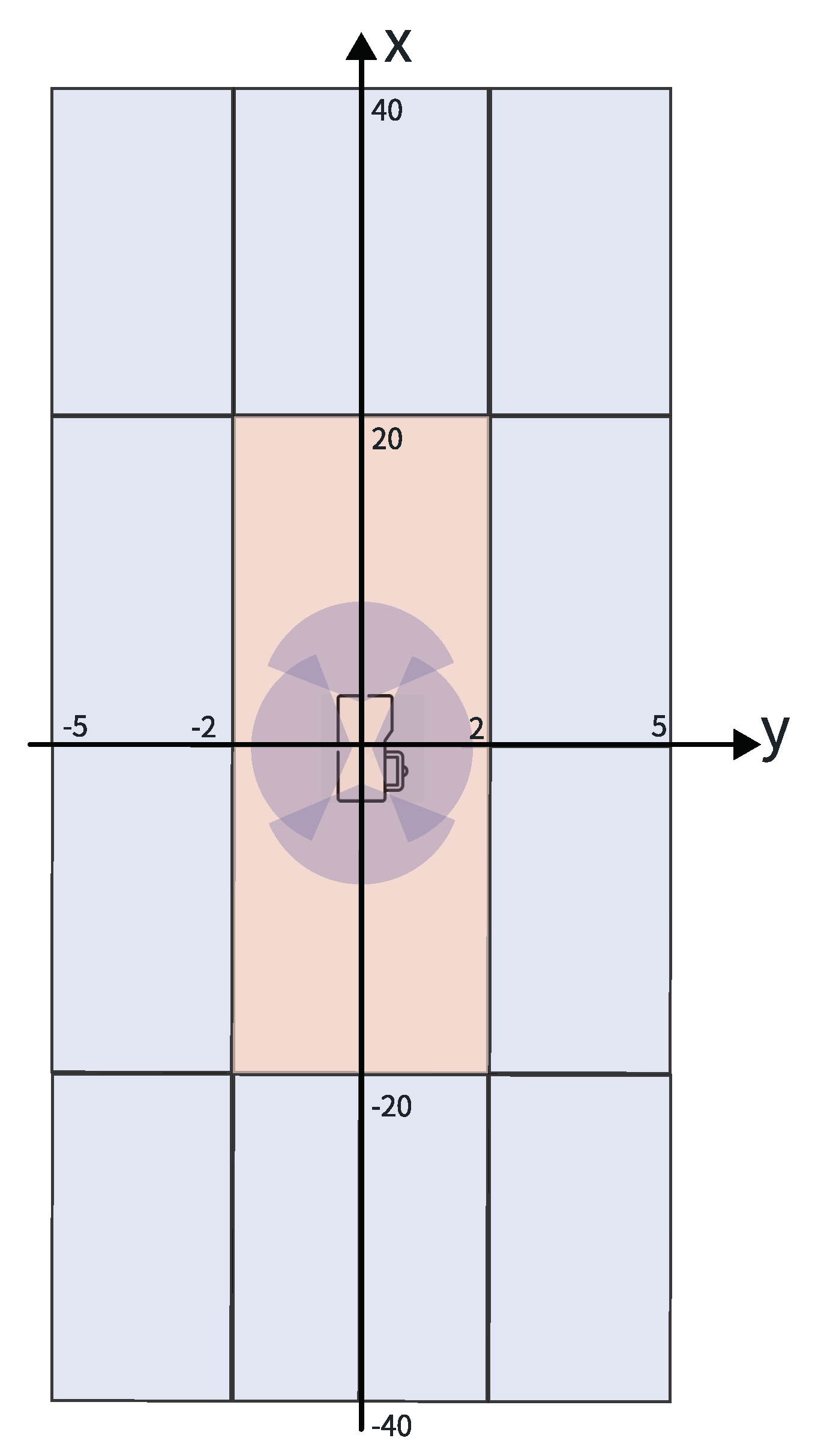
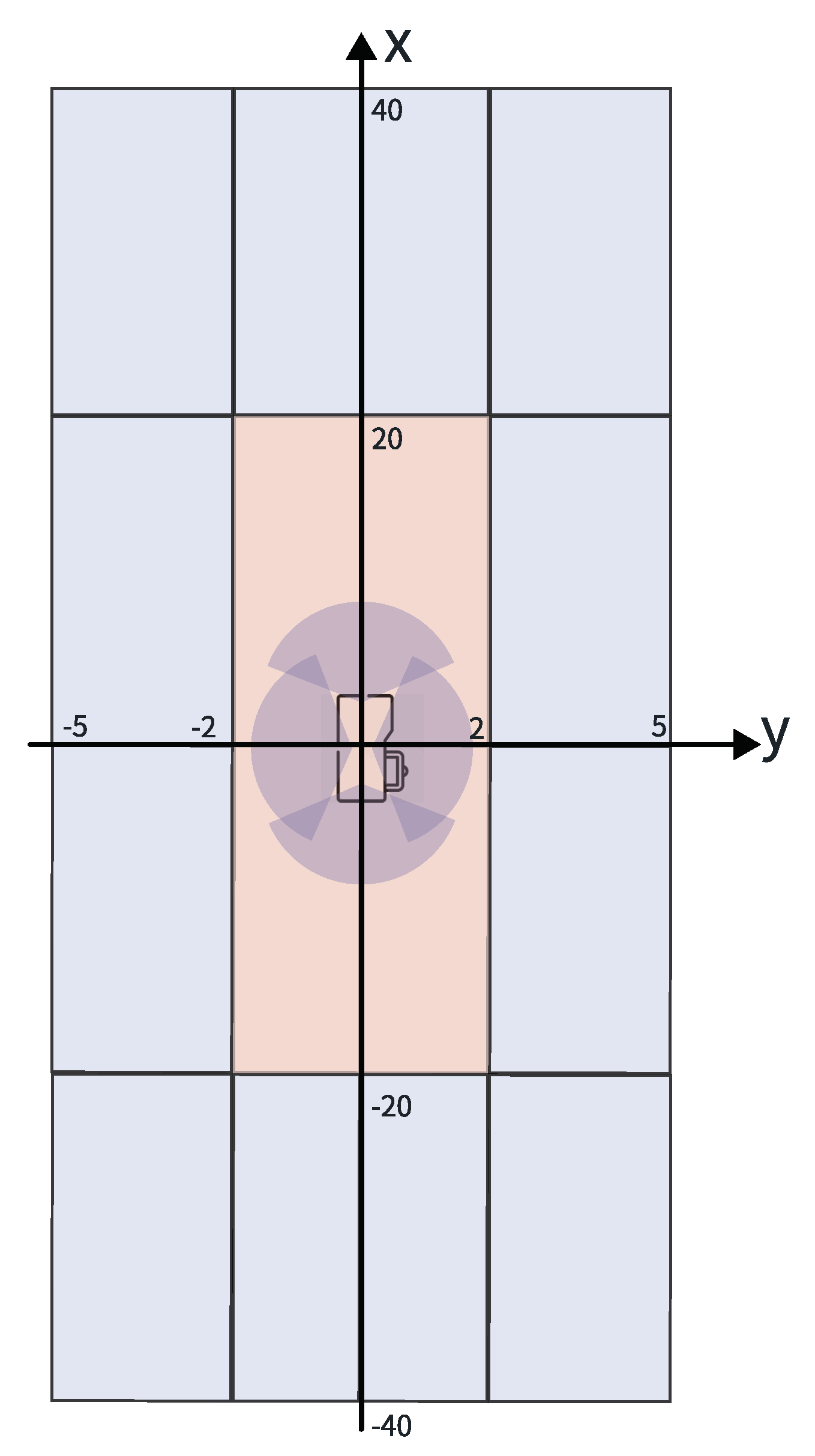
5.3. Performance Analysis of ROI Partitioning in Algorithms
6. Conclusions
6.1. The Effectiveness of the Modified Tri-Plane Encoder
- The tri-plane BEV-encoder module, adapted and introduced from the domain of 3D image reconstruction, has shown potential for application in tasks such as curb detection. This is evidenced by its comparative analysis with an existing similar method, despite the well-acknowledged inherent randomness associated with deep learning-based approaches.
- The rectification of fisheye camera images contributes to an improvement in the performance of the aforementioned spatial transformation module.
6.2. The Effectiveness of the Proposed Multi-Modal Edge Detection Network
6.3. Highlight of Contributions
- The spatial transformation of features, particularly the conversion of image features to Bird’s Eye View (BEV) space, remains a focal issue in the field of autonomous driving detection. We observed that the tri-plane encoder within the EG3D network from the domain of 3D image reconstruction achieves a balance between parameter quantity and the volume of spatial representation information. Consequently, this feature space transformation module was fine-tuned and integrated into a multi-modal network.
- This paper introduces a multi-modal curb detection network that supports LiDAR, pinhole telephoto cameras, and fisheye cameras. In addition to the camera branch featured in the above-mentioned module, the network’s LiDAR branch employs one of the industry’s most widely used models from the PointPillar series; meanwhile, the task head for curb detection takes a weighted sum of a semantic segmentation loss in BEV space, a longitudinal and lateral detection offset loss in the BEV plane, and a clustering loss for different curb instances.
- We utilized a logistics vehicle equipped with LiDAR, pinhole telephoto, and fisheye cameras to collect 24,350 frames of real-world data on urban roads for training and testing the proposed model. This data also served to validate the effectiveness of the tri-plane encoder module and assess the impact of fisheye camera image distortion removal preprocessing on the network relative to a baseline comparison.
- Based on the results analyzed, the introduced tri-plane encoder module exhibits considerable performance in curb detection tasks. Furthermore, the proposed multi-modal curb detection network meets the fundamental application requirements for this scenario.
6.4. Limitations and Future Directions of the Study
- A fisheye camera correction model of limited precision was employed, without comparison to more refined correction models or novel correction modules based on GAN networks, etc.
- The study did not subdivide specific curb scenarios and hard case for detection, which would have allowed for targeted optimization in scenarios where the detection algorithm under performs.
- The introduced tri-plane encoder module requires further investigation into these aspects:
- Its placement relative to other components of the network, such as being positioned before the FPN module or integrated within it;
- The optimization of voxel resolution settings in relation to the ego-vehicle’s ROI size.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Siegemund, J.; Pfeiffer, D.; Franke, U.; Farstner, W. Curb reconstruction using Conditional Random Fields. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), La Jolla, CA, USA, 21–24 June 2010; pp. 203–210. [Google Scholar]
- Panev, S.; Vicente, F.; De la Torre, F.; Prinet, V. Road Curb Detection and Localization with Monocular Forward-View Vehicle Camera. IEEE Trans. Intell. Transp. Syst. 2018, 20, 3568–3584. [Google Scholar] [CrossRef]
- Mi, X.; Yang, B.; Dong, Z.; Chen, C.; Gu, J. Automated 3D Road Boundary Extraction and Vectorization Using MLS Point Clouds. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5287–5297. [Google Scholar] [CrossRef]
- Rato, D.; Santos, V. LIDAR based detection of road boundaries using the density of accumulated point clouds and their gradients. Robot. Auton. Syst. 2021, 138, 103714. [Google Scholar] [CrossRef]
- Deac, S.E.C.; Giosan, I.; Nedevschi, S. Curb detection in urban traffic scenarios using LiDARs point cloud and semantically segmented color images. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3433–3440. [Google Scholar]
- Ma, L.; Li, Y.; Li, J.; Marcato Junior, J.; Nunes Gonçalves, W.; Chapman, M. BoundaryNet: Extraction and Completion of Road Boundaries with Deep Learning Using Mobile Laser Scanning Point Clouds and Satellite Imagery. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5638–5654. [Google Scholar] [CrossRef]
- Schneider, D.; Schwalbe, E.; Maas, H.G. Validation of geometric models for fisheye lenses. ISPRS J. Photogramm. Remote Sens. 2009, 64, 259–266. [Google Scholar] [CrossRef]
- Liao, K.; Lin, C.; Zhao, Y.; Gabbouj, M. DR-GAN: Automatic radial distortion rectification using conditional GAN in real-time. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 725–733. [Google Scholar] [CrossRef]
- Liao, K.; Lin, C.; Zhao, Y.; Xu, M. Model-free distortion rectification framework bridged by distortion distribution map. IEEE Trans. Image Process. 2020, 29, 3707–3718. [Google Scholar] [CrossRef]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 194–210. [Google Scholar]
- Chen, S.; Cheng, T.; Wang, X.; Meng, W.; Zhang, Q.; Liu, W. Efficient and robust 2d-to-bev representation learning via geometry-guided kernel transformer. arXiv 2022, arXiv:2206.04584. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Conference on Robot Learning; PMLR: Baltimore, MD, USA, 2022; pp. 180–191. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training generative adversarial networks with limited data. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; Volume 33, pp. 12104–12114. [Google Scholar]
- Oechsle, M.; Peng, S.; Geiger, A. UNISURF: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Lombardi, S.; Simon, T.; Saragih, J.; Schwartz, G.; Lehrmann, A.; Sheikh, Y. Neural volumes: Learning dynamic renderable volumes from images. ACM Trans. Graph. 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Reiser, C.; Peng, S.; Liao, Y.; Geiger, A. KiloNeRF: Speeding up neural radiance fields with thousands of tiny MLPs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- DeVries, T.; Bautista, M.A.; Srivastava, N.; Taylor, G.W.; Susskind, J.M. Unconstrained scene generation with locally conditioned radiance fields. arXiv 2021, arXiv:2104.00670. [Google Scholar]
- Chan, E.R.; Lin, C.Z.; Chan, M.A.; Nagano, K.; Pan, B.; De Mello, S.; Gallo, O.; Guibas, L.J.; Tremblay, J.; Khamis, S.; et al. Efficient geometry-aware 3D generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16123–16133. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Kannala, J.; Brandt, S.S. A generic camera model and calibration method for conventional, wide-angle, and fish-eye lenses. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1335–1340. [Google Scholar] [CrossRef]
- OpenCV Documentation. Available online: https://docs.opencv.org/3.4/db/d58/group__calib3d__fisheye.html (accessed on 4 March 2024).
- OpenCV Documentation. Available online: https://docs.opencv.org/3.4/da/d54/group__imgproc__transform.html#gab75ef31ce5cdfb5c44b6da5f3b908ea4 (accessed on 4 March 2024).
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Xie, E.; Yu, Z.; Zhou, D.; Philion, J.; Anandkumar, A.; Fidler, S.; Luo, P.; Alvarez, J.M. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation. arXiv 2022, arXiv:2204.05088. [Google Scholar]
- Huang, B.; Li, Y.; Xie, E.; Liang, F.; Wang, L.; Shen, M.; Liu, F.; Wang, T.; Luo, P.; Shao, J. Fast-BEV: Towards Real-time On-vehicle Bird’s-Eye View Perception. arXiv 2023, arXiv:2301.07870. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment Setting | Precision | Recall | ||
|---|---|---|---|---|
| Tri-Plane Encoder | M2BEV’s Image-to-BEV Feature Projection | Fisheye Rectification | ||
| ✓ | 62.2% | 66.0% | ||
| ✓ | ✓ | 65.7% | 64.6% | |
| ✓ | 64.8% | 66.6% | ||
| ✓ | ✓ | 66.6% | 67.3% | |
| 60.0% | 62.9% | |||
| ✓ | 60.1% | 62.6% |
| y_Range (m) | x_Range (m) | With Tri-Plane Encoder & without Fisheye Rectification | With Tri-Plane Encoder & with Fisheye Rectification | Without Tri-Plane Encoder & without Fisheye Rectification | Without Tri-Plane Encoder & with Fisheye Rectification |
|---|---|---|---|---|---|
| 2~5 | −40~−20 | 78.7% | 80.6% | 77.8% | 77.8% |
| −20~0 | 83.3% | 79.7% | 82.3% | 82.6% | |
| 0~20 | 71.2% | 77.2% | 72.5% | 72.6% | |
| 20~40 | 75.6% | 69.7% | 76.4% | 76.2% | |
| 0~2 | −40~−20 | 52.7% | 48.2% | 65.7% | 61.2% |
| −20~0 | 81.3% | 78.5% | 77.5% | 75.3% | |
| 0~20 | 58.6% | 78.1% | 49.9% | 51.6% | |
| 20~40 | 45.2% | 75.0% | 38.7% | 41.7% | |
| −2~0 | −40~−20 | 58.9% | 53.8% | 63.8% | 63.5% |
| −20~0 | 93.4% | 93.2% | 87.4% | 86.1% | |
| 0~20 | 96.3% | 96.1% | 90.2% | 89.6% | |
| 20~40 | 71.8% | 50.2% | 70.9% | 70.6% | |
| −5~−2 | −40~−20 | 80.8% | 64.3% | 81.3% | 80.3% |
| −20~0 | 57.7% | 53.8% | 52.0% | 52.2% | |
| 0~20 | 48.4% | 56.2% | 44.8% | 45.3% | |
| 20~40 | 59.3% | 59.2% | 60.9% | 60.7% |
| y_Range (m) | x_Range (m) | With Tri-Plane Encoder & without Fisheye Rectification | With Tri-Plane Encoder & with Fisheye Rectification | Without Tri-Plane Encoder & without Fisheye Rectification | Without Tri-Plane Encoder & with Fisheye Rectification |
|---|---|---|---|---|---|
| 2~5 | −40~−20 | 34.7% | 43.0% | 36.6% | 37.4% |
| −20~0 | 88.8% | 91.4% | 89.8% | 89.9% | |
| 0~20 | 88.9% | 93.4% | 89.6% | 89.3% | |
| 20~40 | 69.0% | 75.5% | 68.1% | 68.1% | |
| 0~2 | −40~−20 | 21.9% | 44.2% | 21.4% | 21.2% |
| −20~0 | 45.2% | 65.6% | 35.8% | 37.3% | |
| 0~20 | 64.7% | 76.7% | 42.4% | 45.1% | |
| 20~40 | 32.2% | 54.5% | 26.3% | 26.9% | |
| −2~0 | −40~−20 | 39.8% | 45.0% | 36.3% | 37.7% |
| −20~0 | 64.5% | 67.3% | 57.6% | 57.2% | |
| 0~20 | 81.4% | 81.6% | 76.3% | 75.7% | |
| 20~40 | 43.9% | 42.8% | 44.0% | 45.0% | |
| −5~−2 | −40~−20 | 82.6% | 83.3% | 82.3% | 84.2% |
| −20~0 | 82.6% | 88.0% | 81.0% | 80.8% | |
| 0~20 | 74.7% | 88.5% | 73.1% | 73.3% | |
| 20~40 | 65.6% | 68.4% | 62.6% | 62.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wang, J.; Zhu, X.; Ma, Z. A Curb-Detection Network with a Tri-Plane BEV Encoder Module for Autonomous Delivery Vehicles. Vehicles 2024, 6, 539-552. https://doi.org/10.3390/vehicles6010024
Zhang L, Wang J, Zhu X, Ma Z. A Curb-Detection Network with a Tri-Plane BEV Encoder Module for Autonomous Delivery Vehicles. Vehicles. 2024; 6(1):539-552. https://doi.org/10.3390/vehicles6010024
Chicago/Turabian StyleZhang, Lu, Jinzhu Wang, Xichan Zhu, and Zhixiong Ma. 2024. "A Curb-Detection Network with a Tri-Plane BEV Encoder Module for Autonomous Delivery Vehicles" Vehicles 6, no. 1: 539-552. https://doi.org/10.3390/vehicles6010024
APA StyleZhang, L., Wang, J., Zhu, X., & Ma, Z. (2024). A Curb-Detection Network with a Tri-Plane BEV Encoder Module for Autonomous Delivery Vehicles. Vehicles, 6(1), 539-552. https://doi.org/10.3390/vehicles6010024