1. Introduction
Road hazards can result in significant injuries and fatalities, making them a major public health and safety concern worldwide. The NHTSA estimated that there were 42,915 fatalities in vehicle crashes in 2021, which is over a 10% increase from 2020 [
1]. One of the major causes of road accidents in the U.S. is road hazards. Road hazards such as potholes, roadwork, vehicles that have been in an accident, and other unexpected obstacles lead to fatal incidents every year. Being aware of such road hazards can contribute to a decrease in accidents and an increase in safety, comfort, and fuel economy. Traditional techniques to monitor road surfaces include surveying techniques and profilometer measurements. Surveying is a traditional technique to monitor road surface conditions, wherein a technician walks down the road to assess road defects. Such a technique requires efforts by human inspection, is prone to human errors, has limited coverage, is time-consuming, and does not provide road defect data in real time. Another method is to use a profilometer to measure the road surface’s profile, roughness, and other characteristics by laser non-contact profilometers or physical sensor contact-based profilometers. The profilometer apparatus is costly and operated by qualified experts only.
Previously, researchers came up with different techniques for detecting road conditions smartly using different classification algorithms. Most of those attempts are based on signals from the motion of vehicles, such as speed and acceleration. For example, González et al. [
2] used acceleration measurements from vehicles to detect the road surface’s roughness and classify the road’s profile. They proposed a method for the estimation of power spectral density to detect road damage levels using transfer functions and the relationship between vehicle acceleration and the road’s surface. Chen et al. [
3] proposed a low-cost global positioning system (GPS) and a low-cost inertial measurement unit (IMU) sensor in a vehicle to analyze the power spectral density and classify the roughness of the road pavement. Lei et al. [
4] proposed an IMU-based distributed sensor network to estimate road and traffic conditions. The use of vision-based techniques is another prominent trend in the current works. Li et al. [
5] proposed a CNN-based network to detect different types of road conditions with information from a customized camera setup. Tsai et al. [
6] discussed the various segmentation algorithms used to classify types of pavement distress. Llopis-Castello et al. [
7] took into consideration the quantification of the type of distress experienced by a road, along with the identification and classification of the distress. Alipour et al. [
8] proposed a deep, fully convolutional crack detection model (CrackPix) by transforming the fully linked layers of common image classification architectures into convolutional filters for dense predictions.
Although these recently developed methods for monitoring road conditions are far more practical than the conventional approaches, they still depend on specialized data collection devices; this restricts the scope of their uses. In order to enhance driving comfort and safety in the transportation system, it would be advantageous to continuously monitor road conditions if an effective and economical approach could be created. The use of smartphones has skyrocketed in recent years. Smartphones also feature an increasing amount of processing power and a wide range of sensors, including an accelerometer, gyroscope, magnetometer, GPS, and camera. Smartphones are the best devices for creating a mobile in-vehicle sensor network because of these features. Researchers have examined the potential of utilizing smartphones to monitor road conditions. Sattar et al. [
9] studied how deep learning techniques, such as long short-term memory (LSTM) and convolutional neural networks (CNN), can be used to detect road features such as potholes or bumps from data collected from cyclists’ iPhones. Varona et al. [
10] employed deep learning techniques and data from smartphones to recognize various types of road surfaces and potholes. Chatterjee et al. [
11] examined what influences smartphone measurements in a moving vehicle the most and how that alters measurements of road roughness. Some cloud computing-based technologies have been used previously to monitor road conditions. Ramesh et al. [
12] developed a cloud-computing-based road condition monitoring technique using motion and vision data from smartphones. Ameddah et al. [
13] applied a similar cloud-based technique to detect road conditions with good precision in less time. Yuan et al. [
14] used a cloud-based system to alert the end users of road conditions. Pham et al. [
15] used a faster R-CNN for the vision-based detection of road damage. A few research works have shown that the usage of LSTM networks to predict time-series-based data has been effective. LSTM networks have been used in numerous studies to detect and predict patterns from time series data. For instance, Mahjoub et al. (2022) [
16] used LSTM networks to anticipate energy consumption. Kapoor et al. (2020) [
17] used an LSTM network to predict time-series-based complex patterns for the prediction of stock prices. Some research has suggested that LSTM models perform better than similar models, with a few using different machine learning models. Ma et al. (2022) [
18] compared LSTM and an autoregressive integrated moving average model (ARIMA) to predict quality control patterns based on 24 pre-recorded QC items. LSTM outperformed ARIMA model. Poh et al. (2019) [
19] compared LSTM and a hidden Markov model (HMM) to detect anomilies in daily activity sequences. Their results showed that LSTM outperforms the HMM.
However, despite the recent efforts focusing on road conditions, road hazards have not been well studied yet. Road hazards can be caused by bad road conditions, such as potholes, as well as some road events, such as roadwork, vehicles that have been involved in accidents, and other unexpected obstacles. In addition, sufficient acquisition of road hazard data is another challenge in conducting such a study, especially for deep-learning-based approaches, which usually require a large amount of data. Furthermore, the detection accuracy of an individual smartphone cannot always be 100% due to the sensing and vehicle position variations that occur when it passes through potential road hazards. Therefore, the objective and contribution of the current paper are to develop a technique to detect road hazards using smartphones that is data-abundant and cost-effective. The proposed method uses motion data from smartphones with a deep learning network based on LSTM to estimate potential road hazards. We propose to leverage both real-world vehicle data and simulated vehicle data to generate sufficient data with combined learning to address the issue of large data requests for deep learning. We also propose a cloud-based fusion approach to further improve the detection accuracy to address the issue of misdetections from an individual smartphone. The proposed approaches are validated and demonstrated through experimental results.
2. Materials and Methods
2.1. System Framework
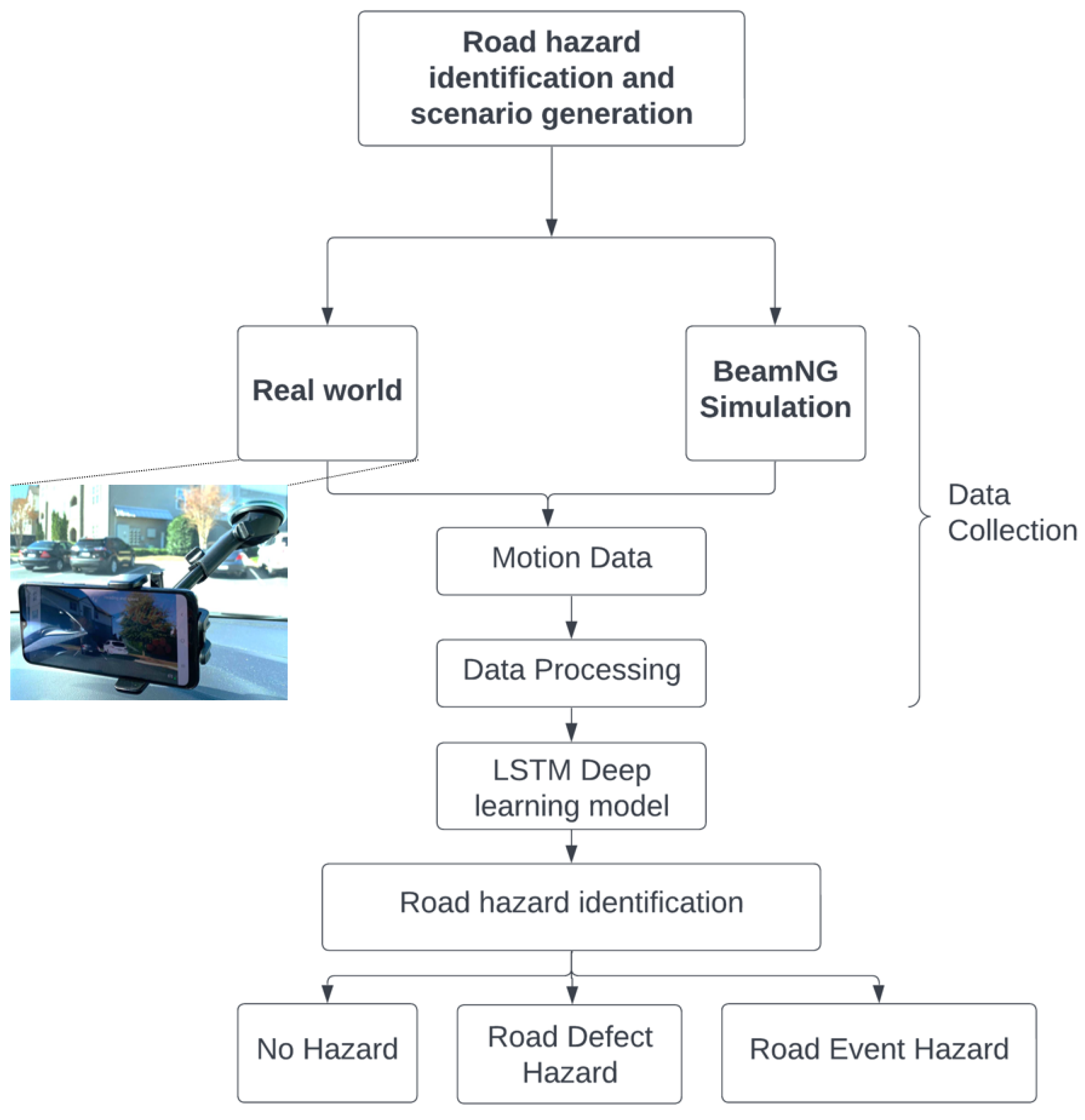
Smartphones, when mounted in a vehicle, can reflect the profile of a road when driven over it. Smartphone sensors, such as accelerometers, g-force sensors, gyroscopes, and magnetometers can record the motion of the vehicle, reflecting the road surface’s profile [
11]. Additionally, vehicle simulation platforms that employ soft-body physics, such as BeamNG Tech, have vehicle sensors such as g-force sensors and accelerometers. These sensors are used to generate a large number of road surface profiles. This paper uses these motion data to classify road hazards using a recurrent neural network (RNN) called long short-term memory (LSTM). This paper categorizes the road hazard conditions into three major situations, including “No Hazards”; “Road Defect Hazards”, which represents hazards caused by road defects, such as potholes and bumps vehicles could drive over; and “Road Event Hazards”, which represents hazards caused by road events such as roadwork, vehicles that have been involved in an accident, and other unexpected obstacles which vehicles have to avoid or dodge.
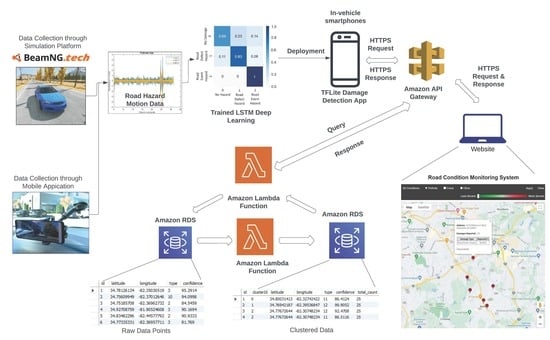
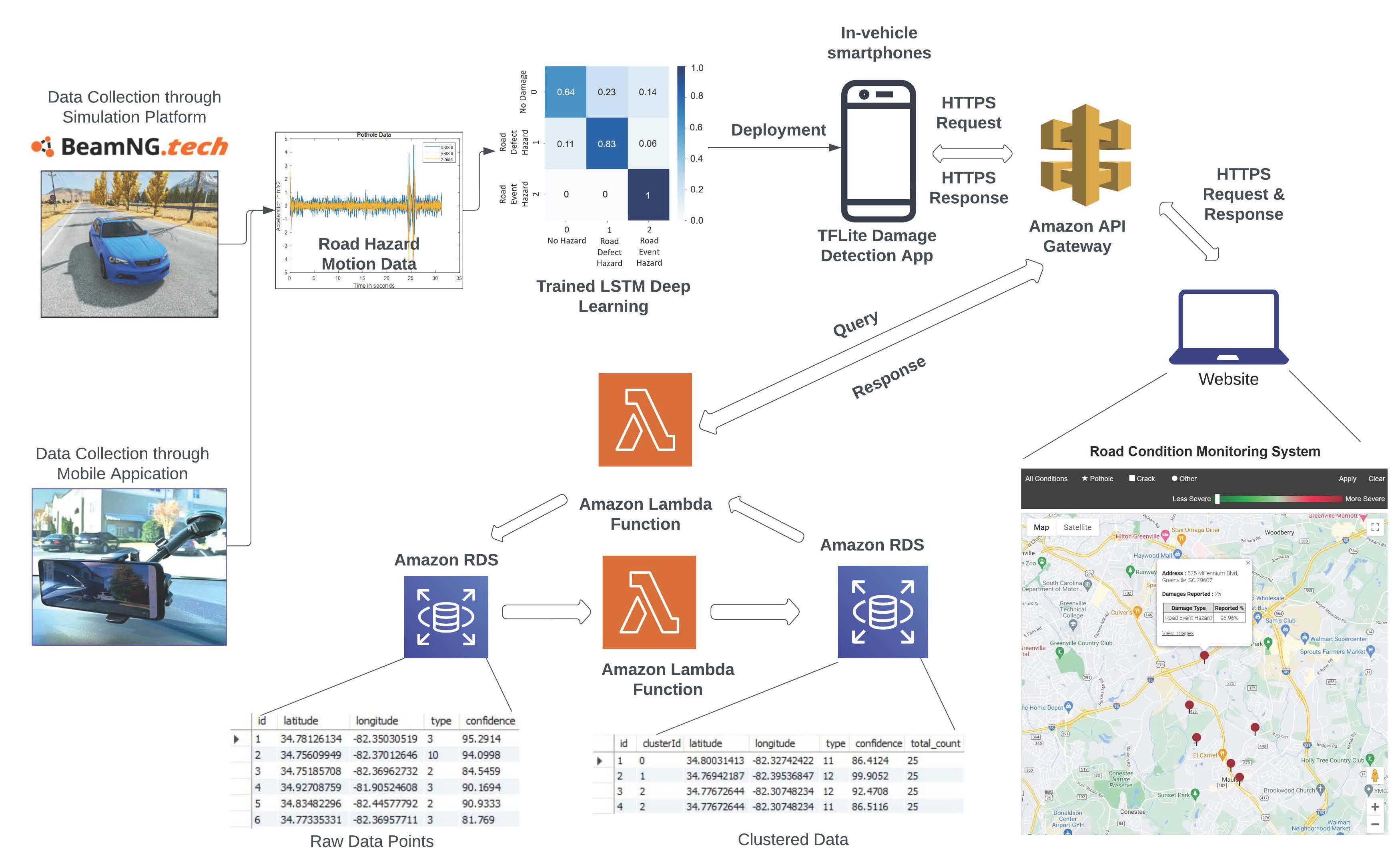
Figure 1 represents the framework of the system of the road hazard detection process.
2.2. Data Acquisition
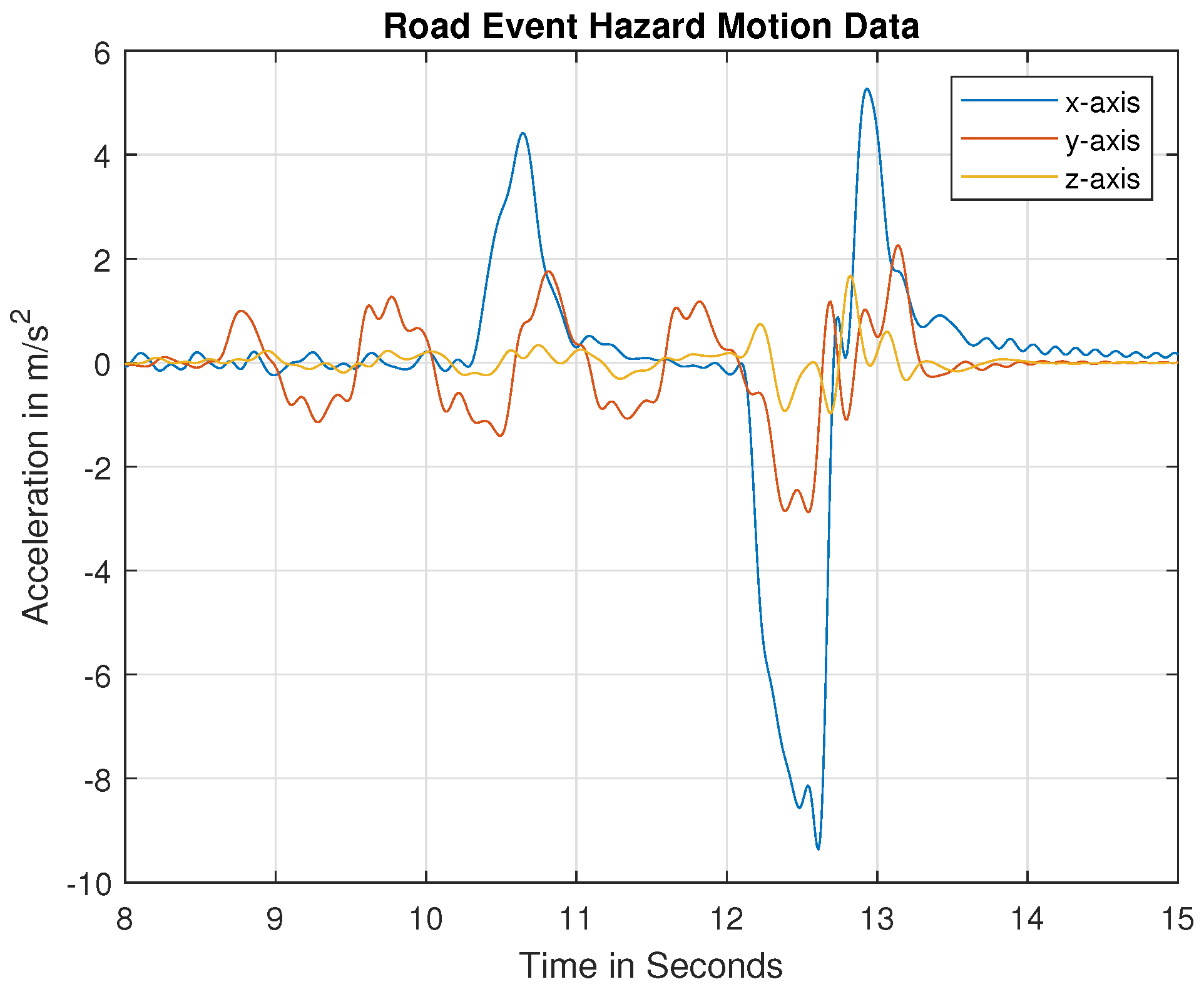
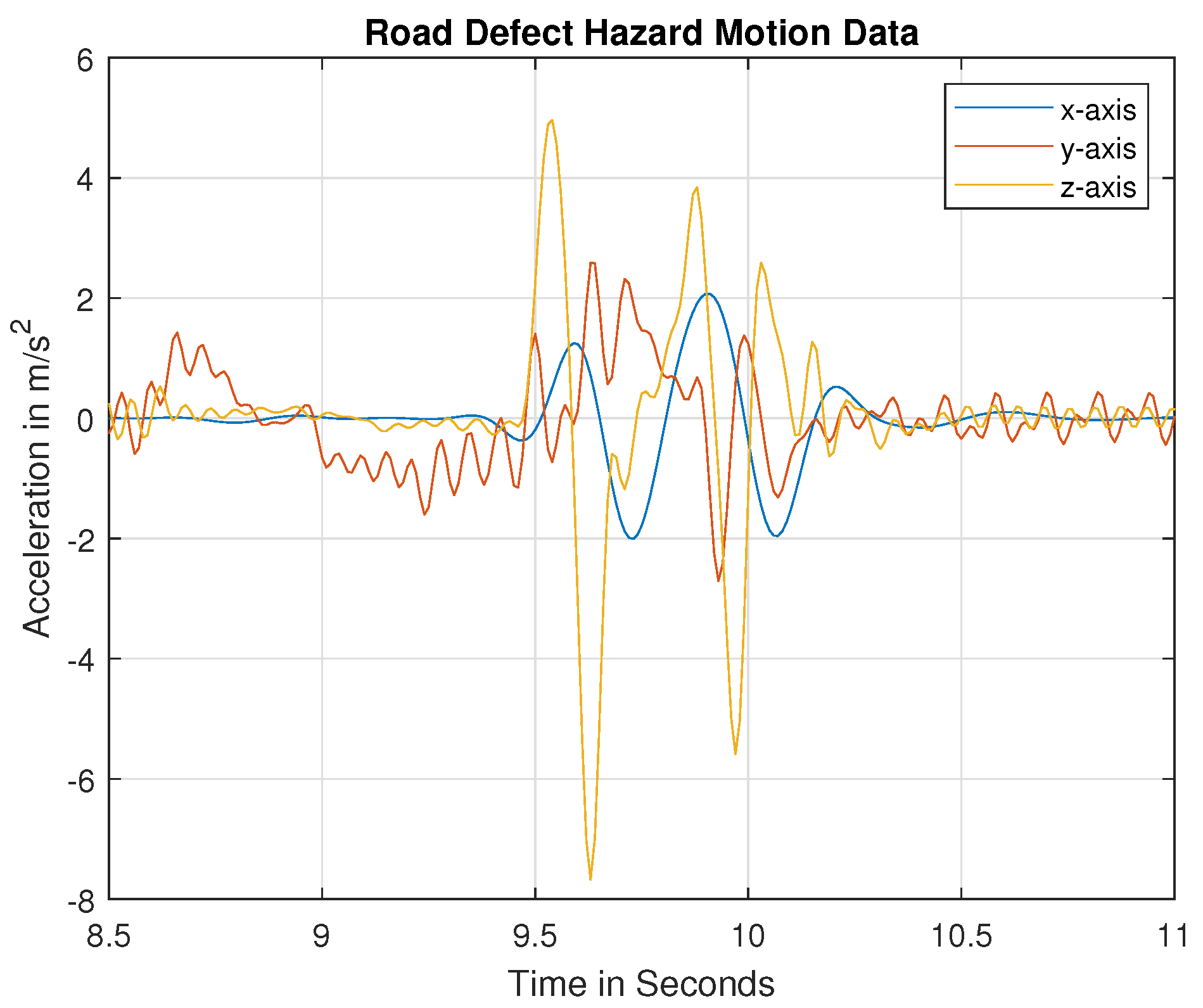
Generally, bumps or potholes represents a form of road damage to vehicles that occurs in the vertical direction, represented as vertical acceleration. During an obstacle avoidance course on the road, vehicles sway in a lateral direction to generate lateral acceleration with some torsional acceleration. Therefore, it is crucial to find the relationship between vertical vehicle acceleration, lateral acceleration, and the type of road damage. We collected historical data on the vertical, lateral, and torsional acceleration of vehicles over several sections of damaged roads to examine the type of road hazard in simulated and real-world scenarios. For real-world data, 3-axis acceleration data were measured from smartphones mounted on the dashboards or windshields of vehicles (see
Figure 1). The MATLAB application, which ran on an Android smartphone, was used to collect the motion data. For the BeamNG Tech simulation platform, the g-force/acceleration sensor was used to measure the motion data.
The motion data from the real-world environment were gathered on numerous roadways in various cities located in South Carolina, USA, including Clemson, Greenville, Spartanburg, and Columbia. Multiple cars were used to collect the data from the MATLAB phone application. The MATLAB Android/iOS application has a sensor suite option that allows data, such as acceleration, magnetic field, angular velocity, orientation, and GPS position, to be recorded from different sensors. For our research, motion data with a sampling rate of 100 hertz were considered to classify different road hazards. Data were collected at various speeds, placements, and road inclinations and for different types of damage on the roads. For road defect hazards, acceleration data from potholes and bumps with varying widths and depths/heights were recorded. For road event hazards, acceleration data were collected considering obstacles of various sizes ahead of a vehicle. For this, the driver steered the vehicle to avoid hitting obstacles. These obstacles were generally vehicles involved in accidents, roadwork equipment, or any unexpected objects that the vehicle should avoid hitting. To recreate all common scenarios to enable machine models to detect hazards in real-time, as many diverse data labels as possible were collected with varying vehicle speeds and hazard sizes, different locations, and multiple smartphones.
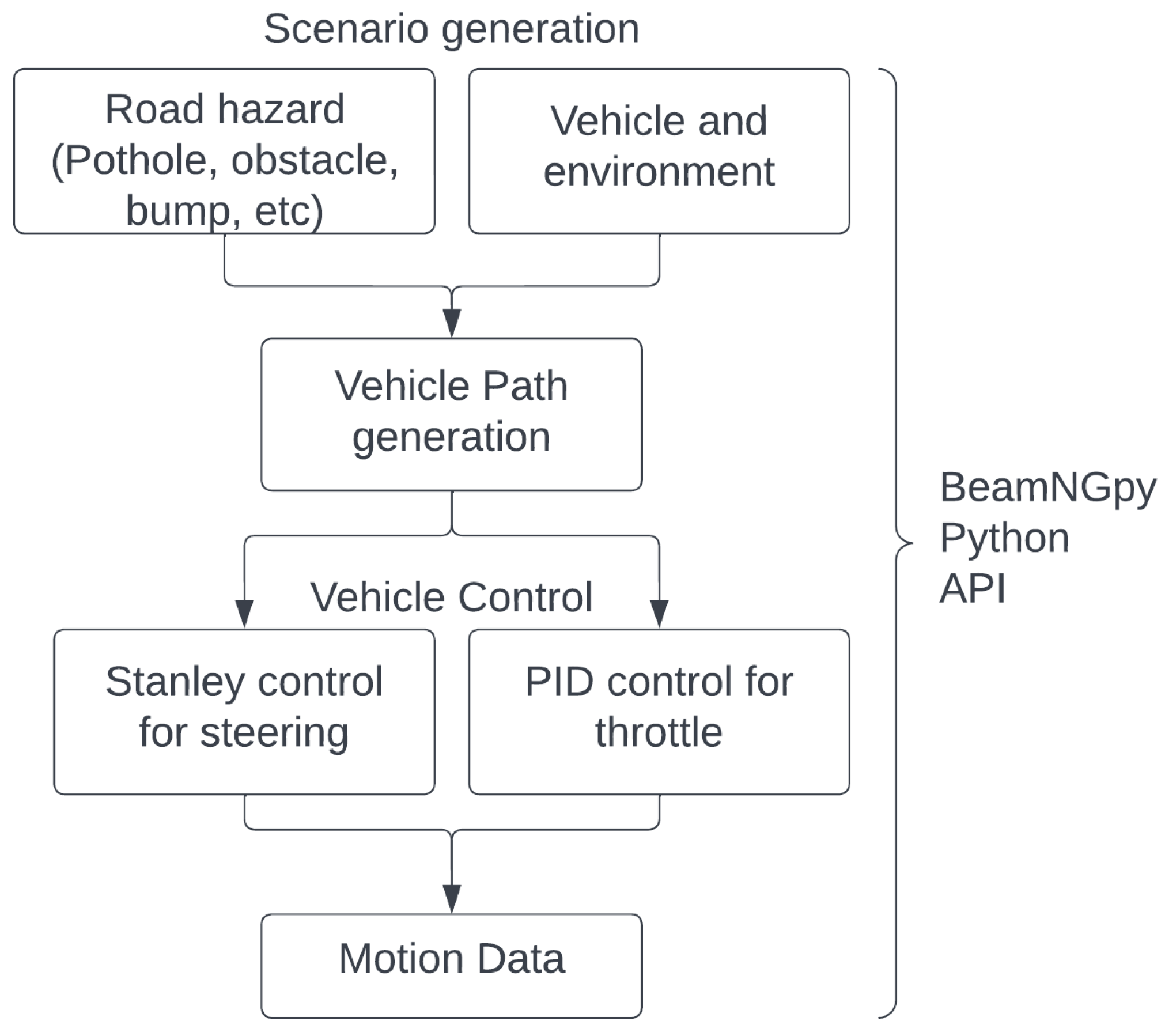
BeamNG is a high-fidelity soft-body vehicle simulation software that is authentic and provides realistic vehicle behavior [
20]. In this paper, BeamNG Tech software was used to generate the required road hazard data; the data generation framework can be seen in
Figure 2. A custom environment was built with varying road hazard dimensions and scenarios. Data were collected from multiple vehicles built into the software, such as the Ibishu Pessima, a mid-sized sedan, and the Mazda CX7, a large-size vehicle. The motion data were recorded by the g-force/acceleration sensor mounted on the simulation vehicle and accessed through BeamNGpy (Python-based API). Indentations were made in the asphalt road with a constant width of 0.5 m and the depth ranging from 0.1 m to 0.5 m (refer to
Figure 3). Multiple vehicles traveling at speeds ranging from 10 miles to 55 miles per hour went over these generated potholes to generate the motion data for potholes. For obstacle avoidance (dodge) road hazards, Stanley control was used to steer the simulated vehicle while tracking the pre-defined vehicle path. Scenarios were built to track the vehicle’s motion, avoiding different sizes of obstacles, with vehicle speeds ranging from 10 miles to 55 miles per hour. For both potholes and road hazards that must be dodged, a proportional, integral, and derivative (PID) control was used for throttle commands with smoothening to avoid jarring vehicle motion. The motion at a frequency of 100 hertz was collected in a text file and later used in the deep learning model.
Regarding the vehicle frame axes, the X-axis represents the lateral acceleration, the Y-axis represents the torsional acceleration, and the Z-axis represents the vertical acceleration of the vehicle for road event hazards or road defect hazards.
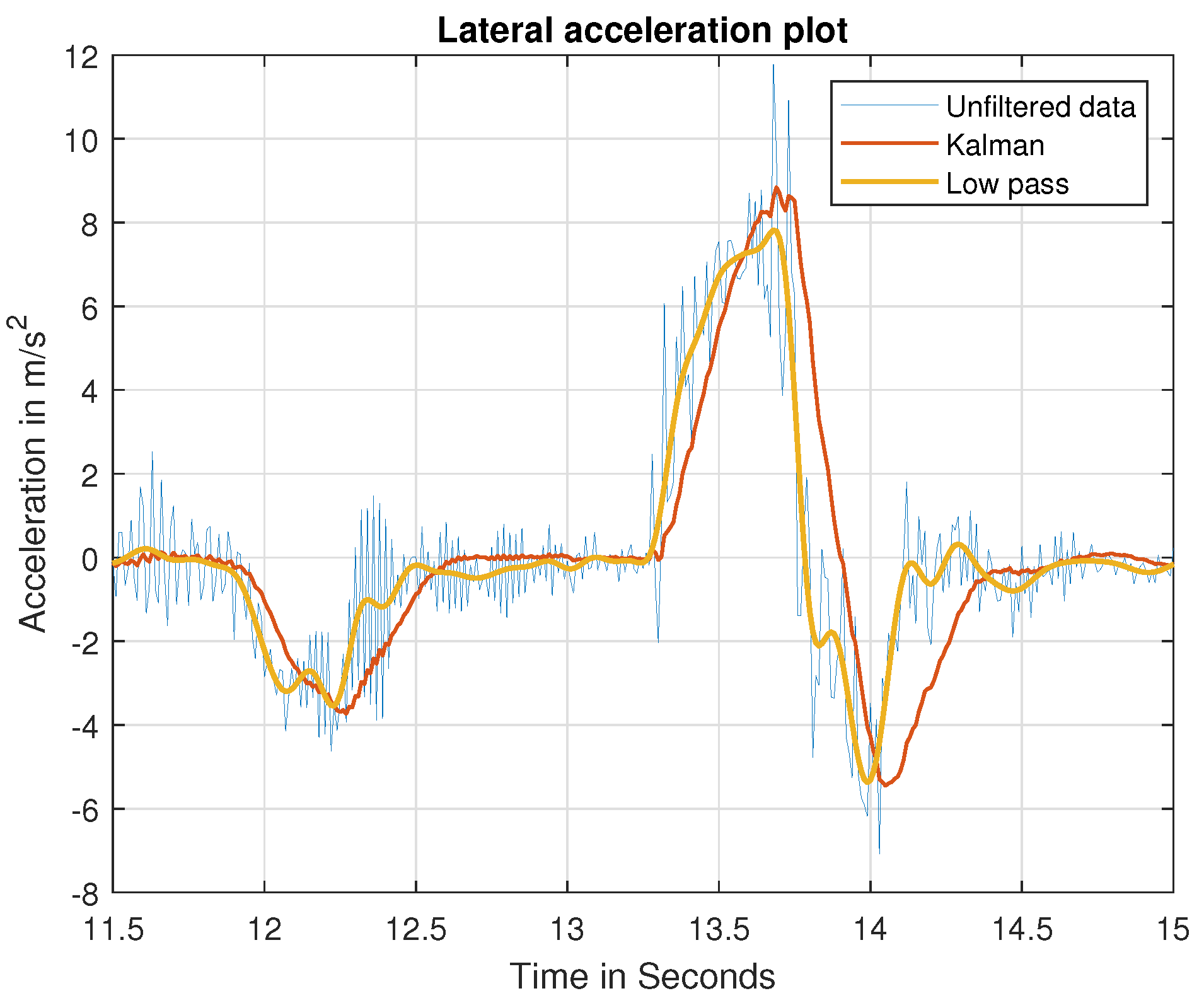
2.3. Data Processing
The accelerometer sensors in the smartphone and BeamNG provide motion data over time but have noise associated with them. To accurately identify the type of road hazard, data should be free of noise and must be filtered. Two different filtering techniques were explored in this research to eliminate the high-frequency noise, namely Kalman filtering and low-pass filtering. For Kalman filtering, different measurement noise covariance and dynamic noise covariance matrixes were tuned to eliminate the high-frequency noise [
21]. For low-pass filtering, the band-pass frequency and sampling rate were tuned to eliminate the high-frequency noise [
22].
2.4. Deep-Learning-Based Road Hazard Detection Model
As an essential tool, long short-term memory (LSTM) networks have an impressive performance when detecting the patterns in time series data because of their capacity to retain information over long periods of time. The LSTM network was chosen because it features feedback connections in contrast to traditional feed-forward neural networks. Both individual data points and complete data sequences, such as time series motion data, can be processed according to Ramesh et al. [
12] and Sepp Hochreiter et al. [
23]. Since a single motion data point cannot identify specific road surface conditions, this specialization is crucial for our strategy. Time-series data obtained from acceleration sensors generate certain patterns of different road hazards. An LSTM network is very suited to predict these road hazards based on time-series acceleration inputs.
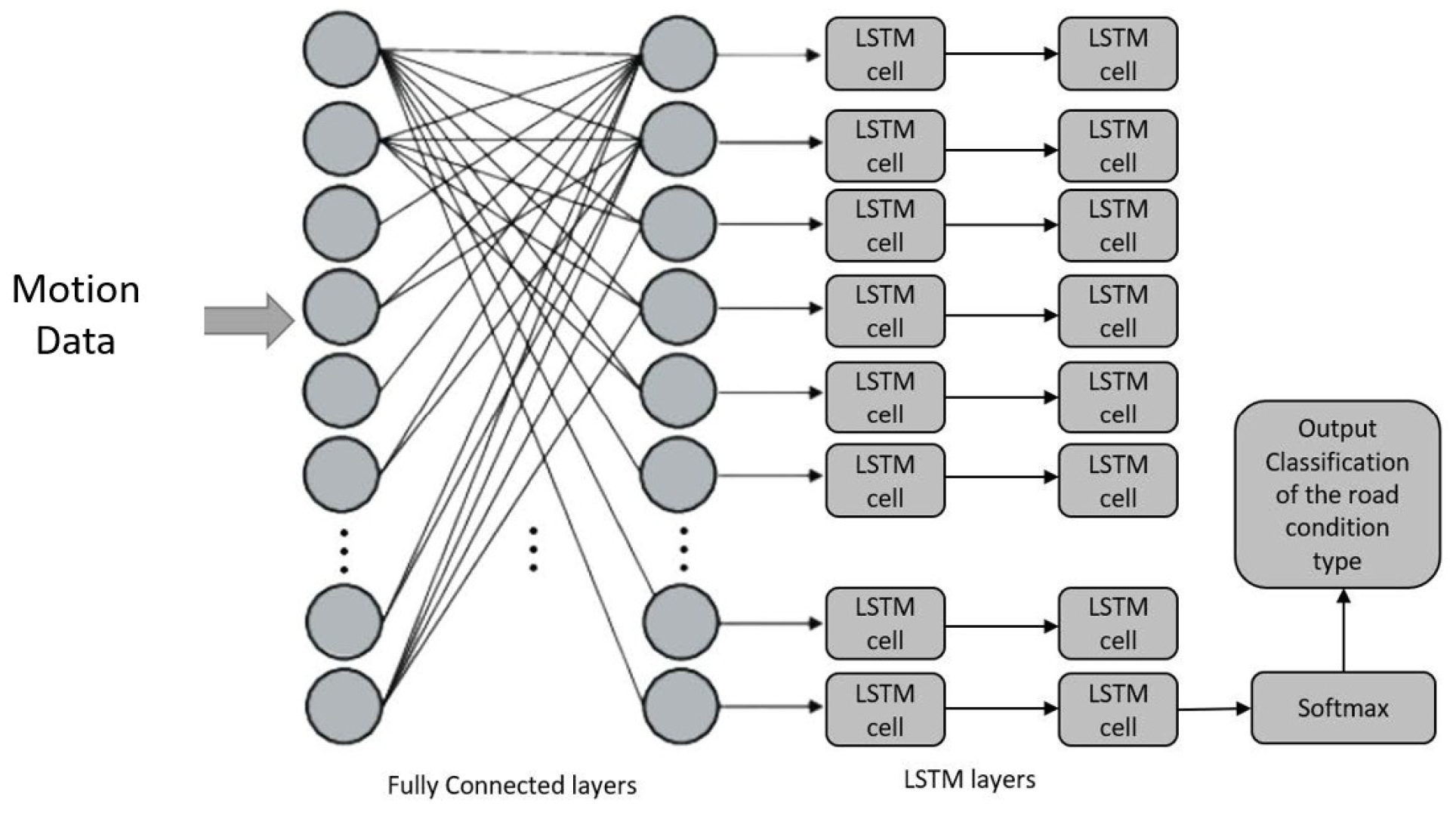
For this paper, motion data obtained from both the simulation and the real world are the inputs to the LSTM network. The suggested solution makes use of a stacking architecture made up of two completely connected layers, followed by two LSTM layers. The proposed architecture is depicted in
Figure 4; 80 hidden units are the input size for the first completely connected layer, followed by another hidden layer. This is followed by two LSTM layers that each have 64 units layered on top of one another. The final cell’s output is extracted, and the softmax function is applied. This is the likelihood that each class will exist, according to the model. As in
Figure 4, an LSTM unit is composed of a cell, an input gate, an output gate, and a forget gate. The cell remembers values across arbitrary time intervals, and the three gates regulate the flow of information into and out of the cell. The first gate, referred to as the forget gate, chooses which portion should be deleted from the cell state data. The input gate (second gate) chooses the data that will be included in the cell state. Last but not least, the output gate produces output data based on cell status, providing a classification of the road hazard and corresponding probabilities.
2.5. Heterogeneous Training Methods
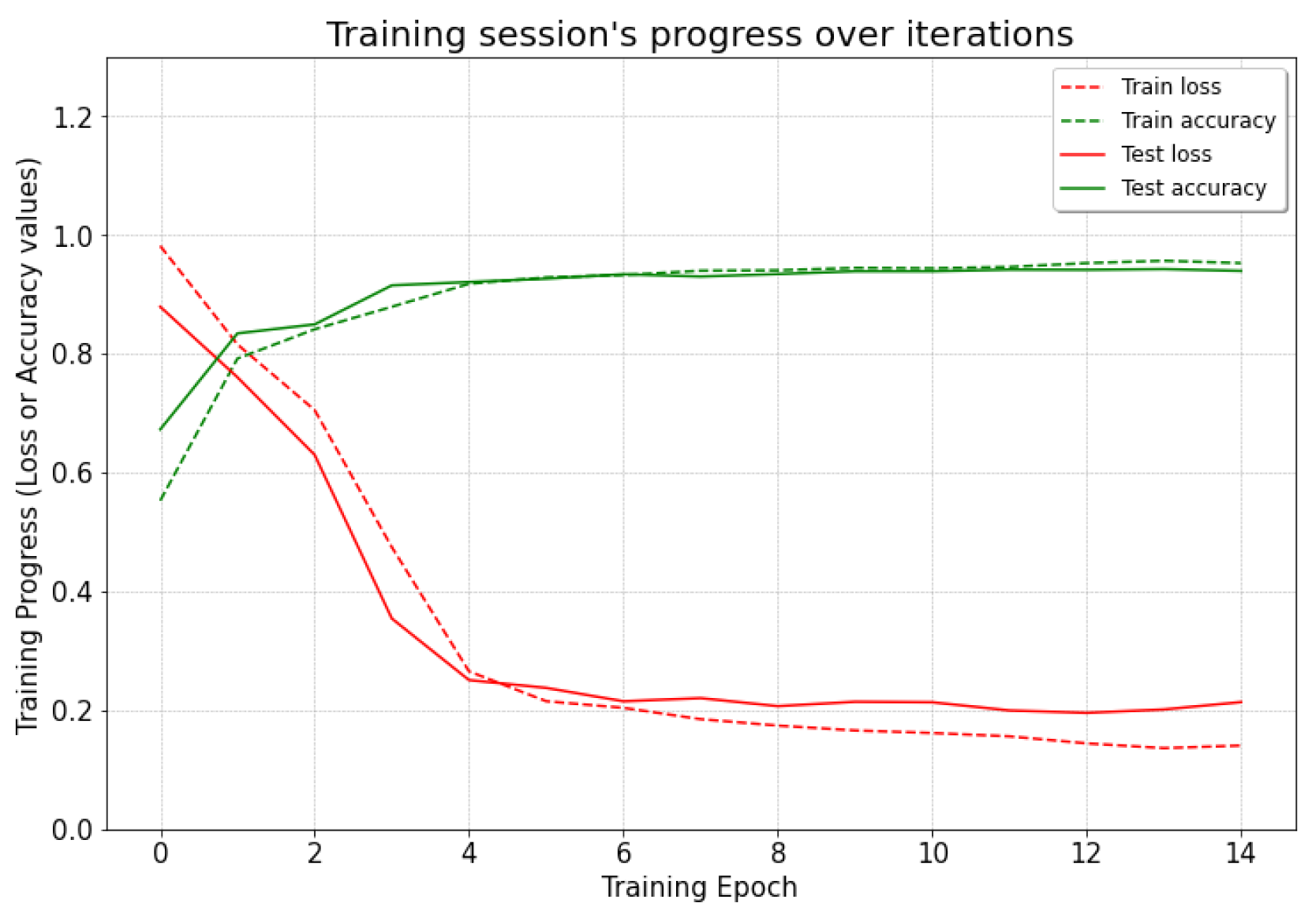
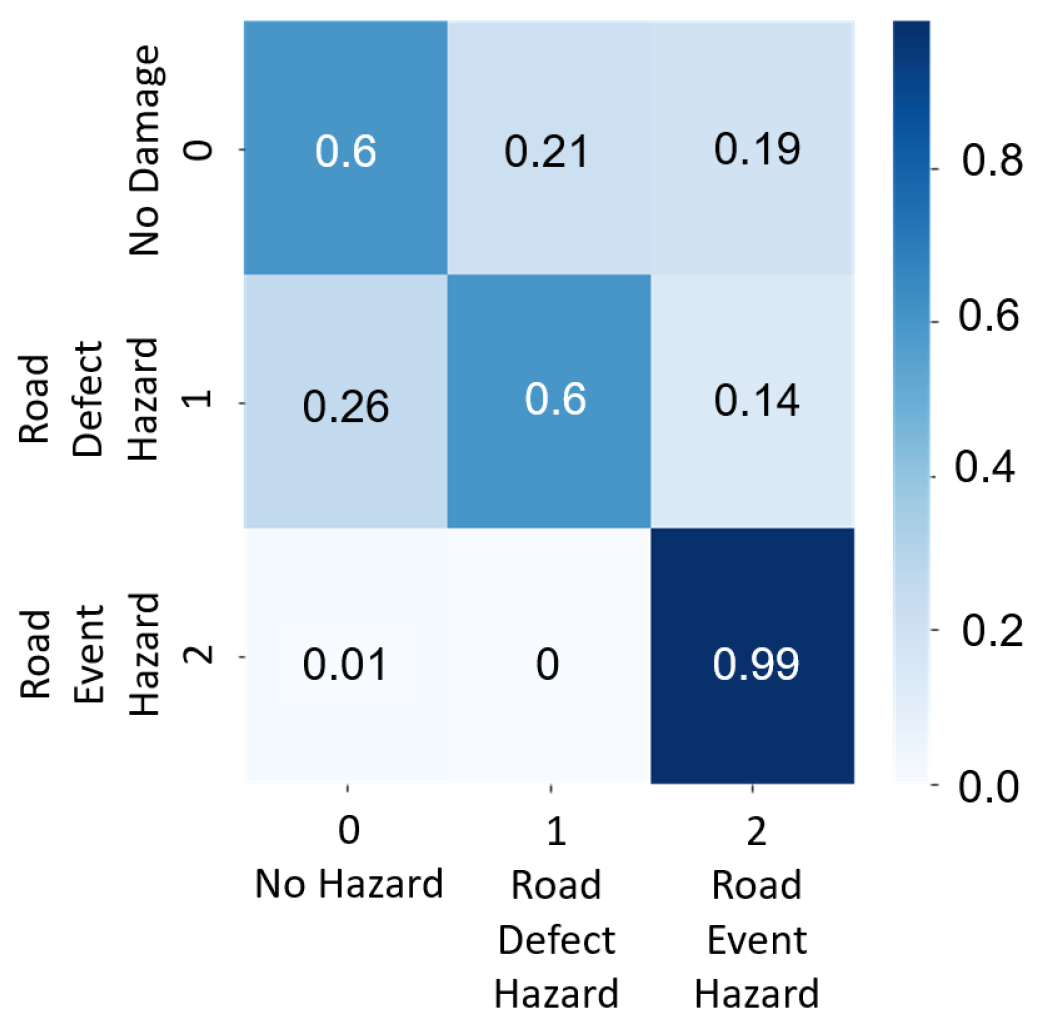
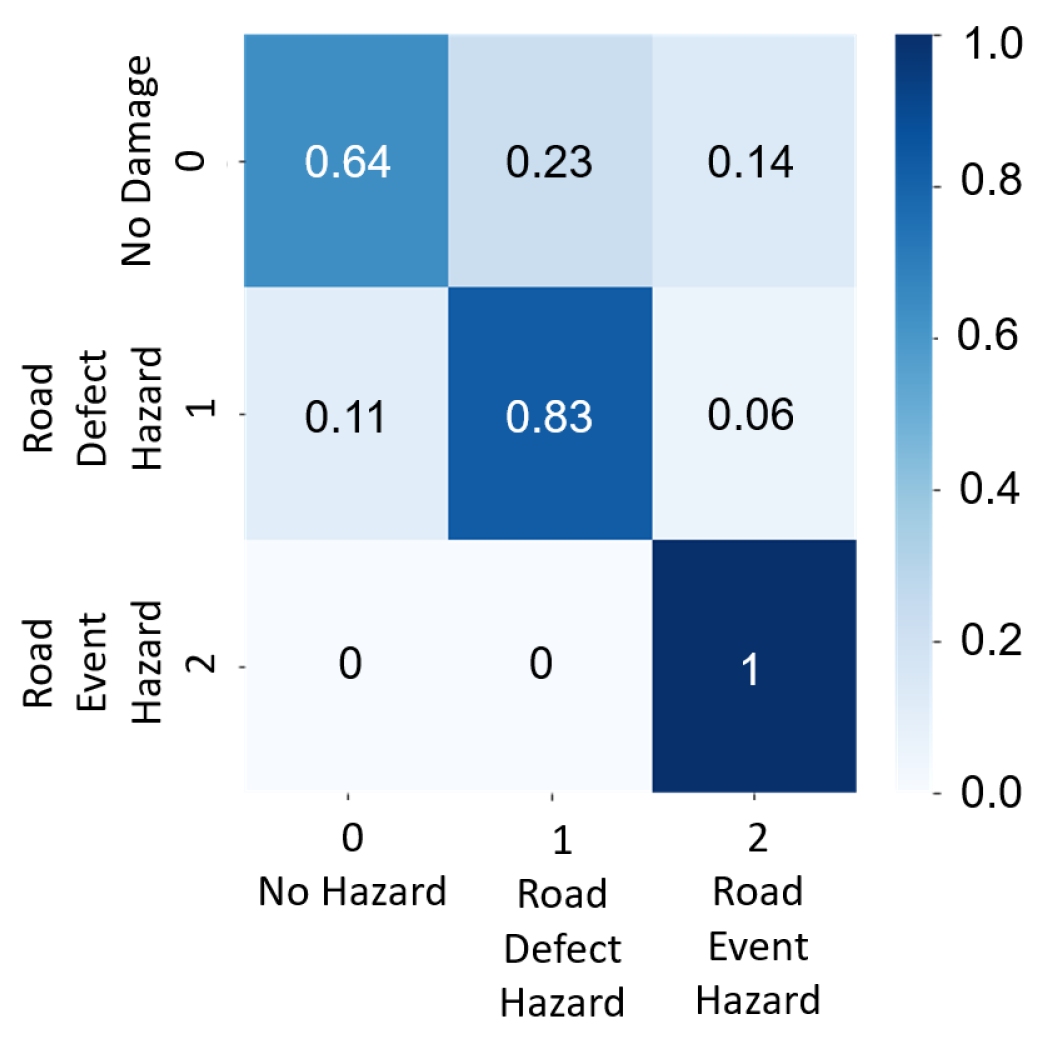
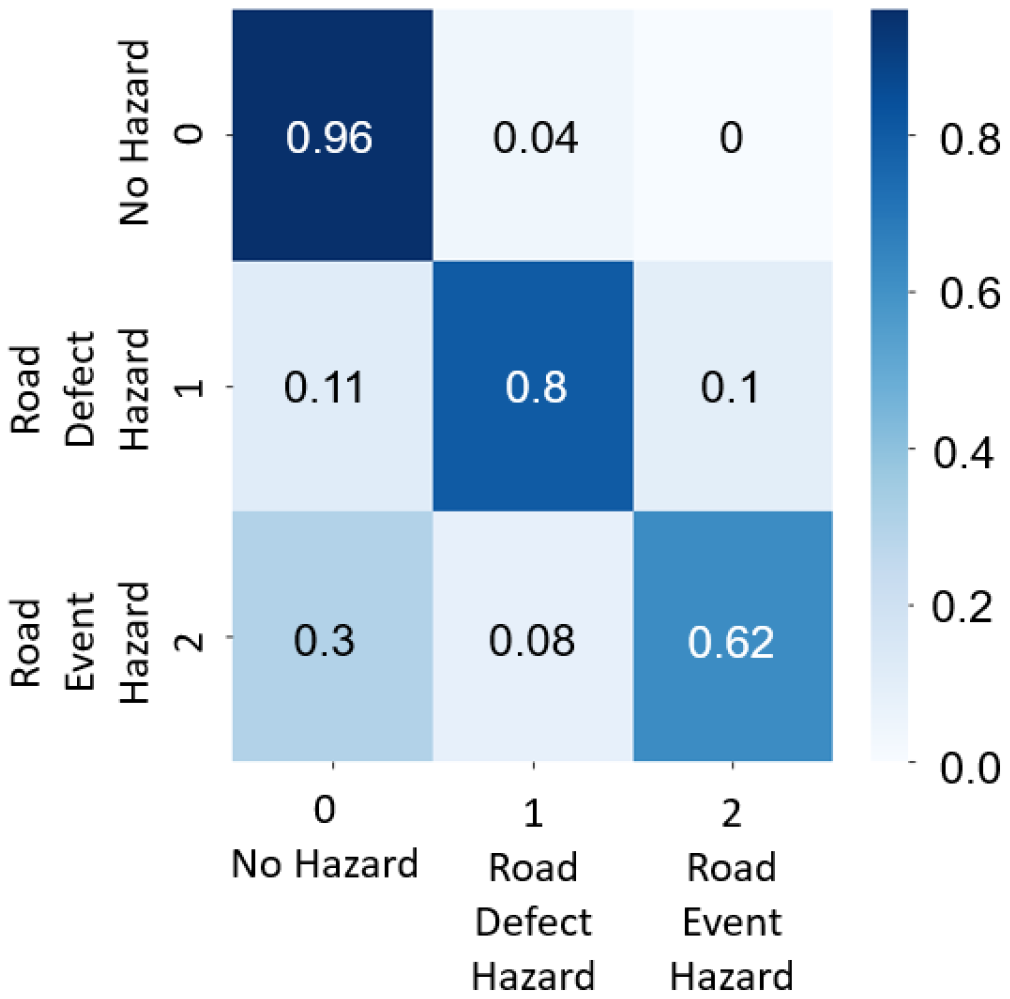
Simulations do not represent the real world exactly. The LSTM model was tested on three heterogeneous training methods to validate the accuracy of simulation and real-world data for road hazard detection. The test–train data split was performed on a random basis. The three types of tests were as follows.
2.5.1. Test 1 (Simulation Only)
In this case, the road hazard data for training the LSTM model were only simulated data, and the testing data were also only simulated data. A total of 2008 simulated data labels were split into 1236 for training and 772 for testing.
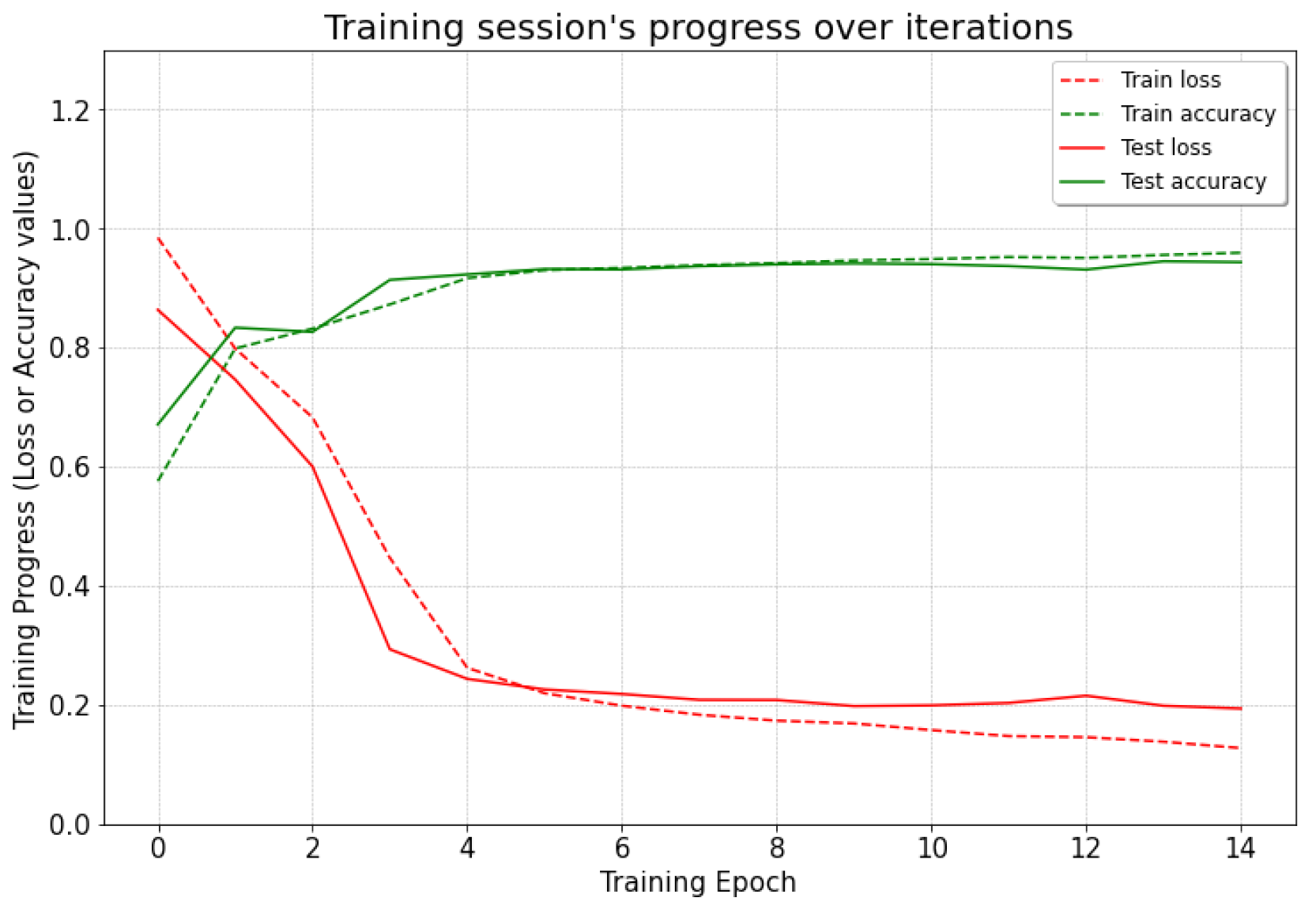
2.5.2. Test 2 (Simulation and Real, Separate)
In this case, the road hazard data for training the LSTM model were only simulated data, and the testing data were only real-world data. This test was performed to check the accuracy and correlation of simulated and real-world tests. A total of 2758 data labels were split into 2008 simulation-only data for training and 750 real-world data for testing.
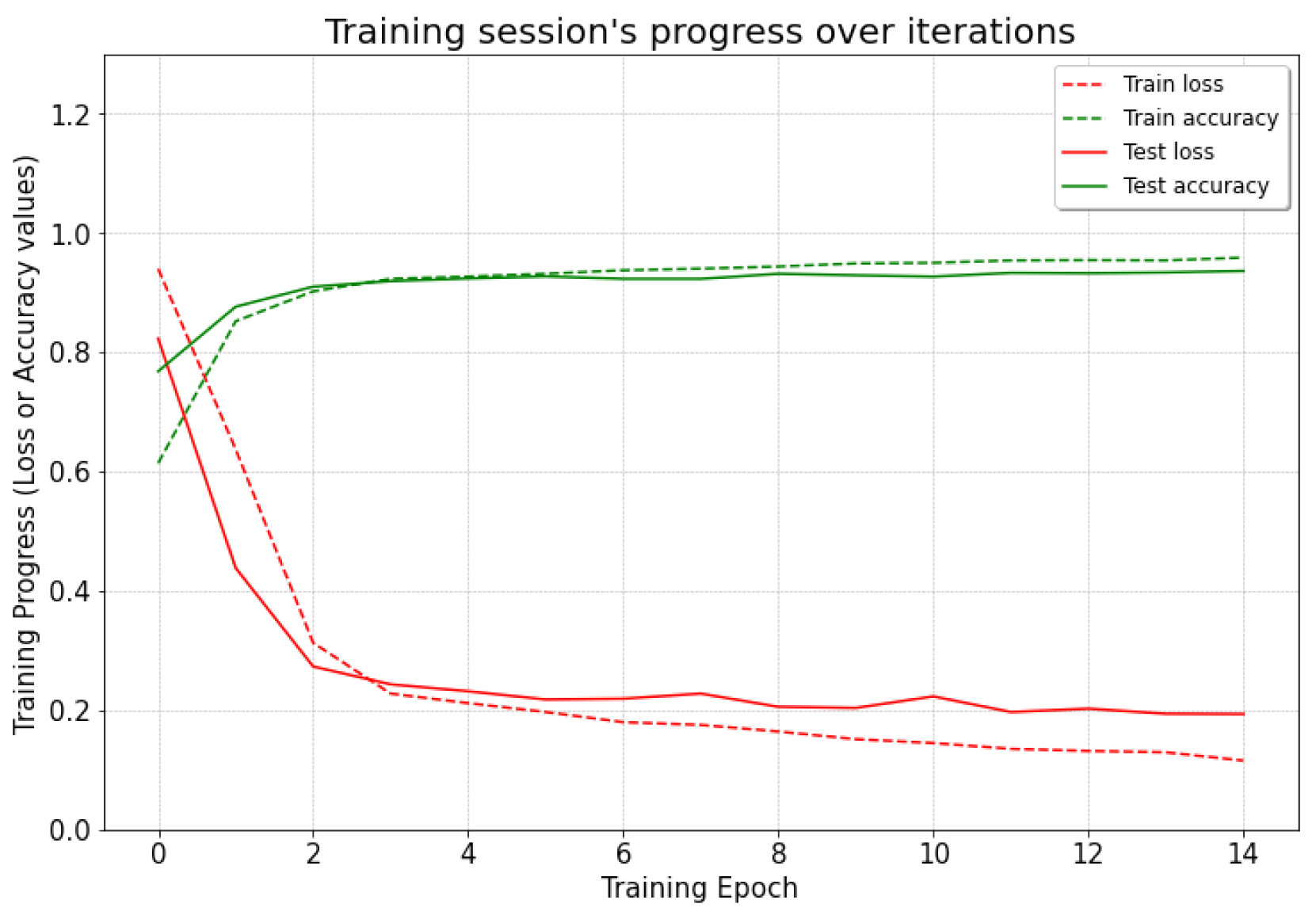
2.5.3. Test 3 (Simulation and Real Mixed)
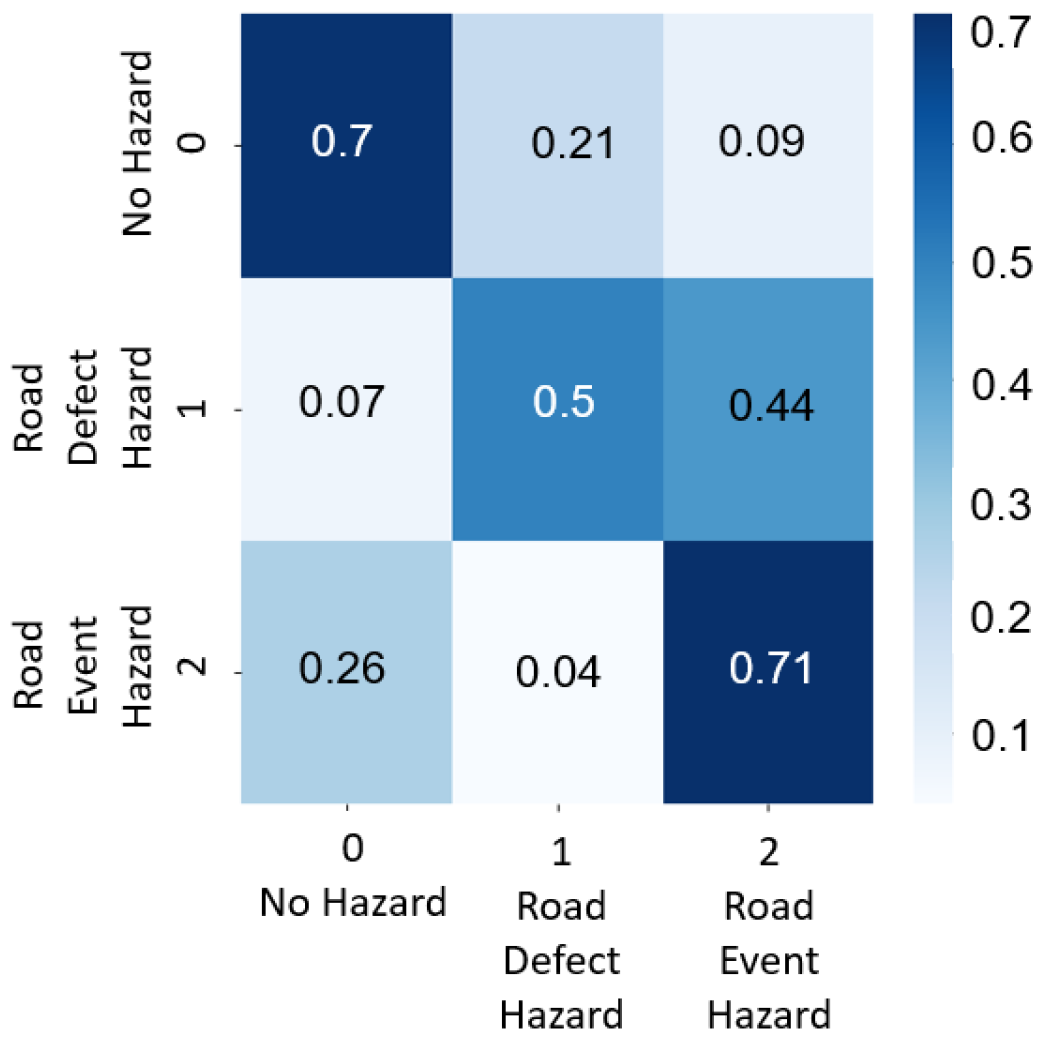
In this case, the road hazard data for training the LSTM model were a mix of simulation data and real-world data, whereas the testing data were only real-world data. A total of 2758 data labels were split into 2211 mixed data for training and 547 real-world data for testing.
2.6. Cloud-Based Fusion
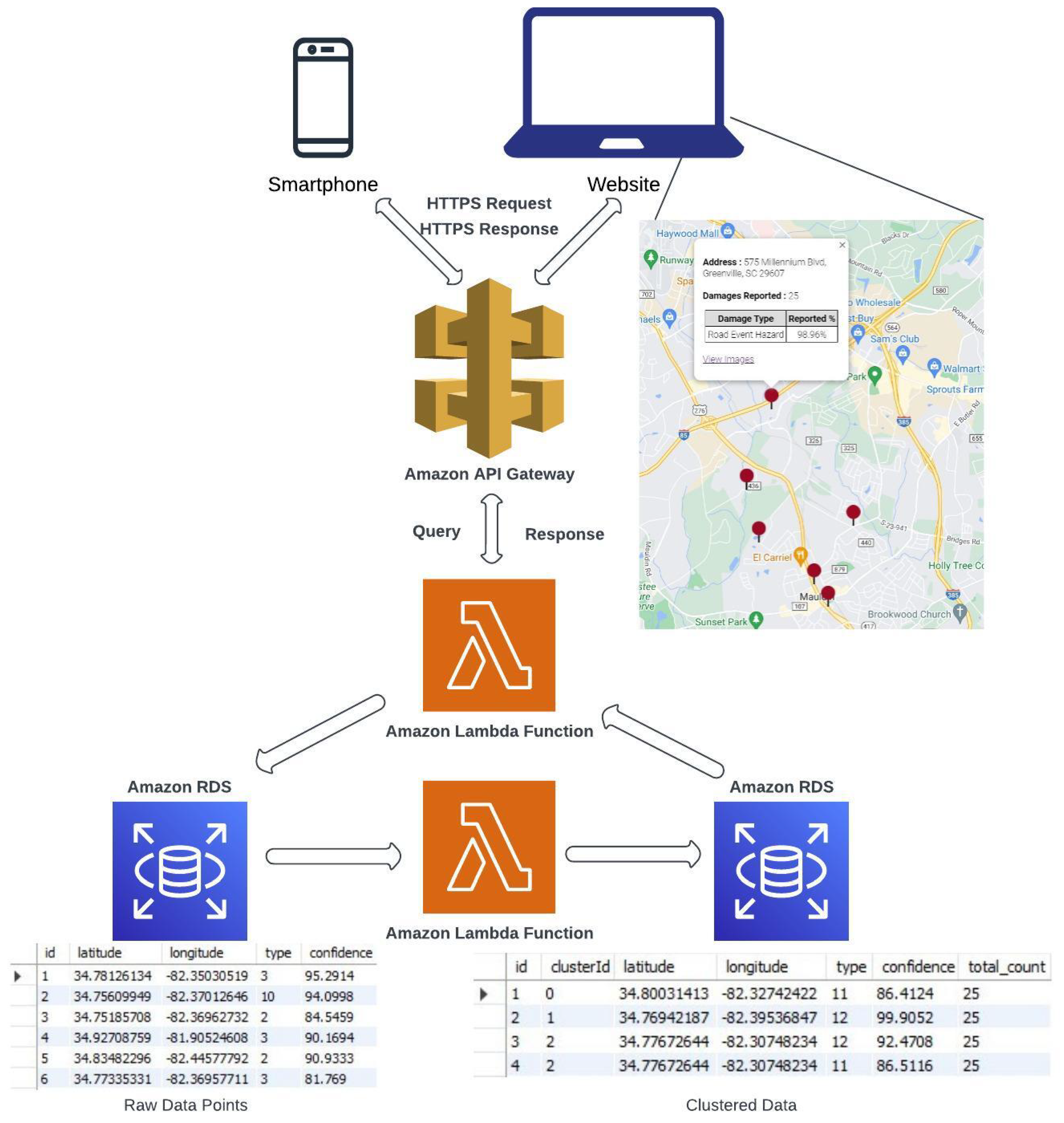
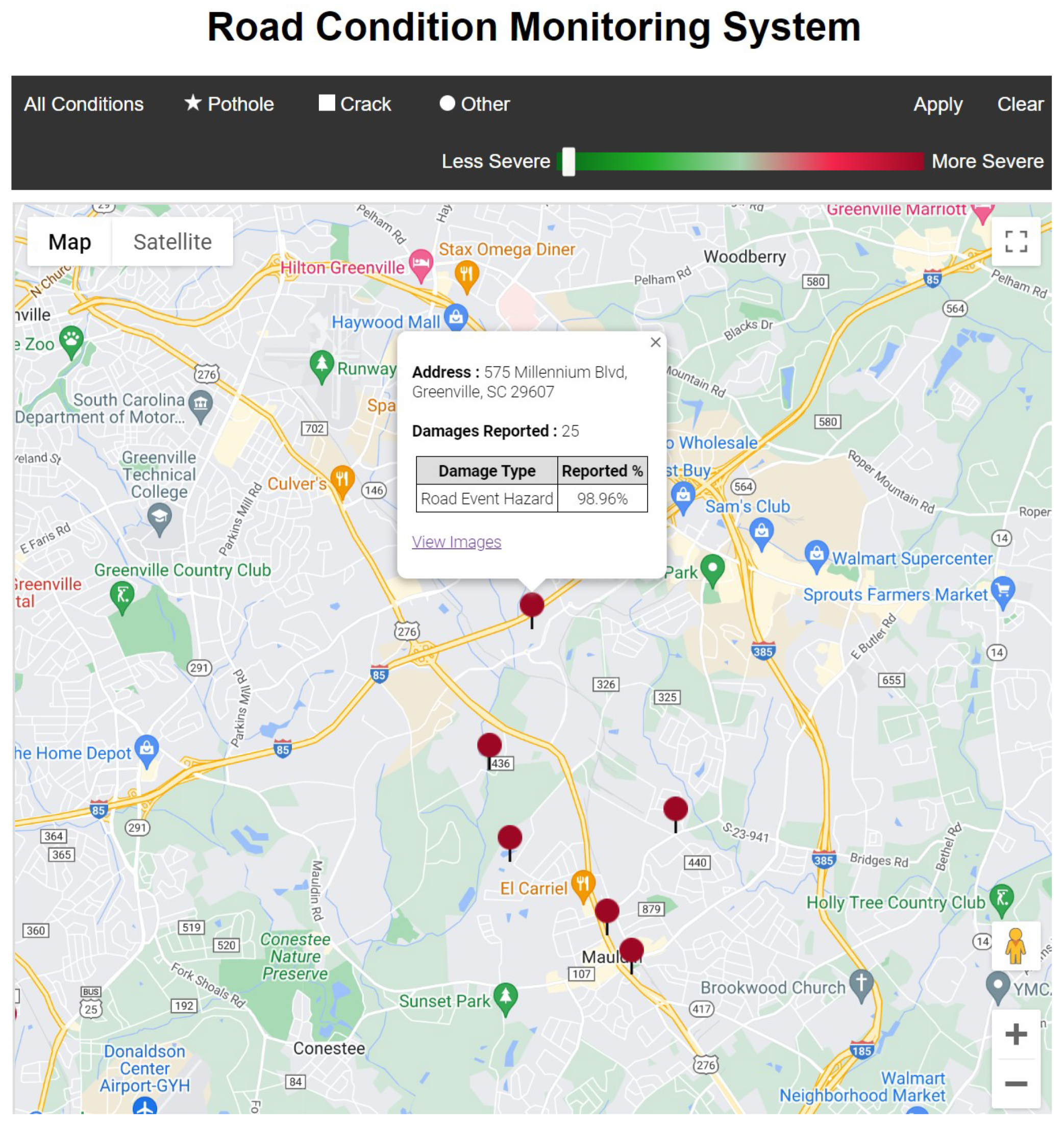
The motion-based road hazard data labels recorded by multiple vehicles at multiple locations were used to generate more reliable and accurate detection. For cloud-based fusion, the type of hazard, GPS locations of road hazard detection, and confidence were utilized. The recorded hazards were stored in a database through a relational database service (RDS) of the Amazon Web Services (AWS) cloud. The RDS contained the type of hazard, GPS coordinates, and confidence ratings. For multiple readings of road hazards detected by different vehicles at the same location, clustering was required to report the damages and was achieved by cloud-based fusion. The AWS lambda function posted the data from the AWS API gateway to the relational database. Raw road hazard detection data were populated and clustered to provide optimized results. Furthermore, the road hazard data were posted to the website through the AWS lambda and the API gateway functions.
Figure 5 gives an overview of the optimized clustering and cloud-based fusion approach. Due to various types of noise and environmental factors, road hazard detection at the same location will have slightly varying GPS coordinates. To consolidate these detections, k-means clustering, an unsupervised, non-deterministic, and iterative algorithm, was implemented. This clustering method has been proven effective in obtaining accurate results and has been used in many practical applications [
24]. The k-means clustering algorithm showed effective results in [
25,
26] by converging to the local minimum. At first, k centers are randomly chosen by the algorithm, and each data point is assigned to the nearest k center calculated by the Euclidean distance. The first k clusters are created as a result. The algorithm recalculates new centers by averaging the data labels given to the initial centers after allocating data labels to k centers. Then, newly created centers are further recalculated and reassigned up until the criterion function is minimized or the algorithm loops a predetermined number of times.
This paper considers only latitudes and longitudes from the data labels collected. Algorithm 1 represents the outline of k-means clustering. The initial value of k is considered to be 1; consequently, k-means clustering is performed on the dataset. The value of k increases until the average within-cluster sum of squares (WCSS) of the previous k and current k is less than or equal to 0.001, thus obtaining a final and optimum number of k clusters. WCSS is the average squared distance from every point inside a cluster to the centroid of the cluster. Each cluster represents the data labels that are nearest to one another and have a high probability of being close or at the exact location. Each cluster is allotted with a centroid latitude and longitude value of that cluster, type of hazard, average confidence of all the data labels in that cluster for each hazard type, the total count of the data labels in a cluster, and a cluster ID containing the top three hazard types based on decreasing average confidences, as shown in
Figure 5. A web UI displays the cluster information on a map with its address, hazard type, total damages reported, and respective confidence.
| Algorithm 1 Clustering Algorithm |
- 1:
for k in range(k_initial,k_maximum+1) do - 2:
kmeans = k_clusters.fit(locations) - 3:
centroids = kmeans.random_centers - 4:
predict = kmeans.centroids - 5:
for i in range(number of locations) do - 6:
centroids = kmeans.random_centers - 7:
WCSS = WCSS + (locations(i) − current_center(i)) - 8:
if WCSS < 0.001 & k > 1 then - 9:
return WCSS, centroid, k, predict - 10:
end if - 11:
end for - 12:
end for - 13:
return WCSS, centroid, k, predict
|
2.7. Threshold-Based Road Hazard Detection Model
Regarding the types of road hazards, various acceleration inputs are generated by the smartphone in the vehicle. These types of road hazards can be recognized by different patterns or by setting a logic-based threshold value. For instance, if the vehicle hits a pothole or a bump, passengers experience a spike in vertical acceleration. If a vehicle tries to avoid obstacles by going sideways, passengers experience lateral acceleration. Threshold values are applied to 3-axis acceleration data to find sudden accelerations in the sensor data that can be identified as road hazards. The acceleration data are analyzed, and thresholds are determined in an iterative optimization manner to obtain the most effective method of detecting road hazards.
4. Conclusions
This paper emphasises the problem of road surface monitoring for various detected road hazards. The method uses vehicle motion data from a simulation platform and the real world collected from smartphones. A deep-learning-based LSTM technique was trained for this task. A soft-body-physics-based simulation platform was explored to provide realistic vehicle behavior. The performance of the proposed method was proven in the simulation platform and real-world experiments. Cloud-based fusion techniques provided more accurate results, allowing the road hazards to be monitored with more reliability. The following areas of the work, however, could still use improvement. We can add more information to the dataset currently used for training the deep learning models. This work involves only motion-based data. In the future, vision-based and motion-based road hazard detection will be combined to provide better results. The current work does not provide information on the severity of the road hazards. In our future work, we will provide metrics to include the severity index for various road hazards. Moreover, we will classify road hazards based on sub-types of hazards, such as potholes, cracks, unpaved roads, bumps, etc. The current work involves gathering the data and testing it on the deep learning model. In our future work, we will further deploy a road hazard warning system on the smartphone application to the commuters traveling on the road in close proximity based on GPS-recorded road hazard data.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}