1. Introduction
The SKT (Syndrom-Kurz-Test) Short Cognitive Performance Test by Erzigkeit [
1] is a diagnostic instrument for the early detection of cognitive deterioration and the assessment of the cognitive decline severity. The SKT is well-established in Germany, and manuals for its use are available in numerous languages, including English [
2]. The SKT measures memory performance and attention in terms of processing speed; for a short description of the SKT, see also [
3].
The goal of this paper was to examine whether the modern regression-based continuous norming technique (i.e., [
4]) with the SKT is also applicable to English-speaking populations. For this reason, we compared the test results and the standardization based on a German-speaking sample with those based on English-speaking samples.
The raw scores of the SKT subtests can be converted into norm values which are summed into a total summary score and two subscores for memory and attention. The summary score is used to assess the severity of cognitive impairments. Numerous studies have empirically confirmed the two-factor structure of the SKT with the two dimensions of attention in the sense of processing speed and memory [
5,
6]. Stemmler and colleagues [
7] also tested the SKT using item-response theory and found that a two-dimensional graded response model provided the best fit. This structure forms the basis for a meaningful interpretation of the two subscores.
In 2015, the German version of the SKT was subjected to a new standardization to update the old norming and to be more sensitive to early cognitive decline; the old norming turned out to be too lenient in the early stages of cognitive decline, producing too many false negatives [
8]. Instead of using norming tables, a regression-based continuous norming approach was used to compare the obtained test scores of a subject with those of a norming sample [
9]. A test score was predicted for each test person while taking into account individual characteristics of that person (i.e., age, gender, and intelligence); then the actually observed test score was compared to the predicted score. This Continuous Norming approach was proposed by Zachary and Gorsuch [
4]. Here, multivariate regression equations are calculated, which include all predictor variables significantly related to the test performance. Based on the data of the total norming sample, the population parameters can be estimated [
4].
In the new German norming of the SKT, linear regression equations with the predictors age, intelligence, and gender were created for all SKT subtests. These equations were used to predict the expected test performance of a person which is then compared to the observed test performance. To compare the observed performance with the predicted performance, the estimated value is subtracted from the observed value, and the difference is divided by
, the standard error for a new observation as suggested by Crawford and Howell [
10]. The result is a t-distribution with
n−2 degrees of freedom [
9,
11]. A positive difference between observed and predicted values indicates that the person performed better than predicted. In this case, 0 deviation points or norm values are assigned. If there is a substantial negative difference, comparable to the percentile rank (PR) between PR 25 and PR 16 of the t-distribution, then the norm value 1 is assigned. If the negative difference is even larger, comparable to the percentile rank of 16 or below, then the test person receives 2 deviation points or norm values in the respective subtest (cf. [
12]). The norm values or deviation points can then be summed up to a total summary score, which ranges from 0 to 18 points. A cross-validation study by Hessler and colleagues [
13] showed that the newly normed SKT was able to detect cognitive decline at early stages. Since the new regression-based norming for German-speaking countries has proven successful in recent years, the goal of this paper is to evaluate whether this SKT standardization can be applied to English-speaking samples.
3. Procedure
To identify relevant predictors for the continuous norming and the respective multiple regression equations, correlation analyses were performed for each subtest. Those variables that were significantly related to the test performance in a subtest were included as predictors in the respective regression model. The model with the best fit was determined using the coefficient of determination
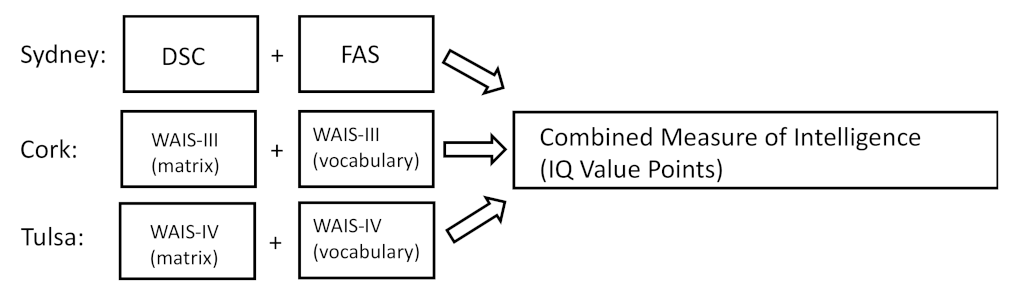
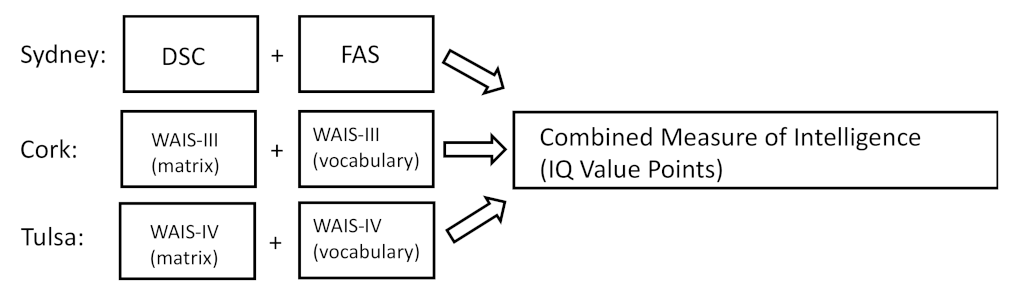
R2. Non-significant predictors were excluded from the model unless they were present in the model in a higher order (as an interaction or squared). For the predictor intelligence, the mean scores of the two test values were transformed into the Wechsler value points. We used two measures of cognitive ability, one assessing fluid intelligence (e.g., DSC and WAIS matrix reasoning) and one assessing crystalized intelligence (e.g., FAS and WAIS vocabulary). In Sydney, the FAS and DSC were applied, and two Wechsler subtests were used in Cork and Tulsa (matrix and vocabulary), although with different versions of the WAIS (e.g., either III or IV). Always the mean of the two intelligence measures was calculated and aggregated to one variable of ‘intelligence’ (see
Figure 1). To avoid multicollinearity, the continuous variables age and intelligence were mean-centered. Subsequently, the interactions of age and gender, age and intelligence, and gender and intelligence were calculated.
The statistical requirements for all multiple regression analyses were fulfilled. If homoscedasticity or normal distribution requirements were not met, the criterion variable was transformed accordingly. For each SKT subtest, a multiple linear regression was calculated. The criterion was the test performance in the respective SKT subtest. In subtests I and III to VII, the test performance was represented by the required processing time measured in seconds; in subtests II, VIII, and IX, test performance was measured by the number of objects not remembered. The following variables were included as predictors: age in years, gender, and intelligence, as well as all interactions between these variables. In addition, age squared was included as a predictor to determine the acceleration of cognitive decline in very old age.
All statistical calculations were performed using SPSS version 26. The PROCESS macro for SPSS version 3.4 was used for the calculation and graphical preparation of interactions [
21].
4. Results
The range of the total intelligence level extends from 3 to 18.5 Wechsler value points, which covers both extreme areas of the scale well. The average value is 10.76 value points (SD = 9.92), which corresponds to an average intelligence of about 100 to 105 IQ points. In the German normative sample, the measured intelligence was 10.67 on average.
Table 2 lists mean values, medians, standard deviations, and value ranges of the observed test performances in the nine SKT subtests for the English-speaking as well as for the German-speaking samples. The average processing time of the attention tests was between 10.3 and 29.8 seconds (s) in the English-speaking sample and between 7.7 and 23.4 s in the German-speaking sample. The subtest Naming Numerals was completed the fastest by the test subjects (subtest III) in both samples. Half of the English-speaking subjects needed no more than 9 s (
M = 10.3;
SD = 4.8) in comparison to 7 s (
M = 7.7;
SD = 2.5) in the German-speaking sample. The Reversal Naming test (subtest VII) took the longest to complete, averaging 29.8 seconds (
SD = 9.7; median = 27) in the English-speaking sample and 23.4 s (
SD = 6.7; median = 22) in the German-speaking sample. A comparison of the mean values with the medians indicated that the distributions for both data sets were highly skewed to the right. The median was always below the mean in all attention tests, also indicating a skewed distribution. In the Immediate Recall (subtest II) and Delayed Recall (subtest VIII) memory tests, the average number of objects not remembered by test subjects was 5.8 (
SD = 2.2) for the English-speaking subjects and 5.6 (
SD = 1.5) in the comparison sample. The median number of objects not remembered in these two tests was six for both samples. In the task Recognition Memory (subtest IX), the number of not-remembered objects was 1.5 (
SD = 1.9), on average, in the English-speaking sample and 0.8 (
SD = 1.2), on average, in the German-speaking sample. This task proved to be very easy for the cognitively unimpaired study participants. All descriptive values indicate a high similarity between the two samples despite some random fluctuations.
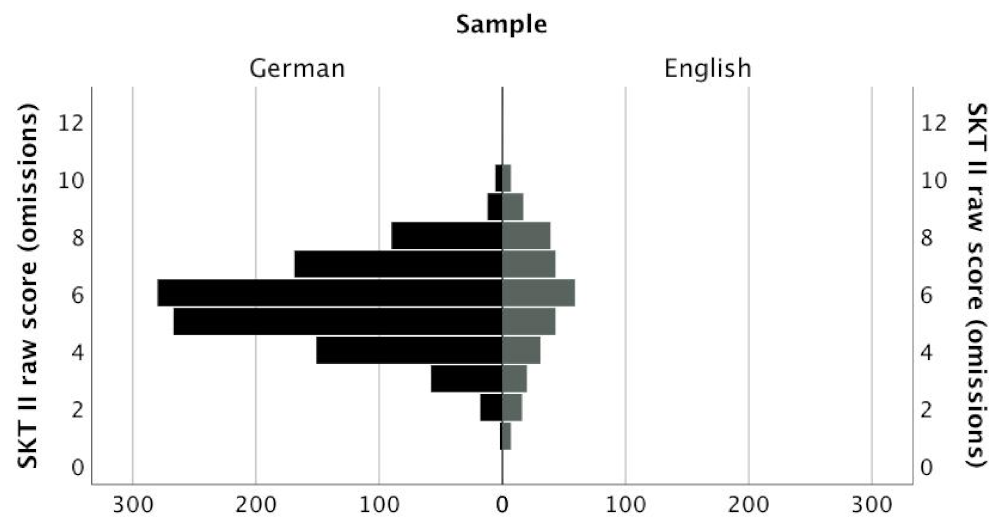
The raw value distributions of a selected SKT subtest (i.e., subtest II) for the German-speaking and English-speaking samples is shown in
Figure 2. Despite different sample sizes (and therefore different heights of the histograms), the distributions of the two samples show a remarkable similarity.
The examination of the distributions showed that the regression residuals were normally distributed only for the SKT subtests II and VIII in both datasets. The regression residuals of the remaining seven subtests showed right-skewed distributions, most extremely in subtest IX (Recognition Memory). To meet the normal distribution requirement for regression residuals, the right-skewed subtests I, III, IV, V, VI, and VII were transformed as indicated in
Table 3. For subtests IV and VI, a square-root transformation instead of a logarithmic transformation was applied; a logarithmic transformation was preferred over the square-root transformation if the data were more extremely skewed. For subtests I, V, and VII, a transformation using the reciprocal (1:x) was conducted; here, a logarithmic and a square-root transformation was applied in the German-speaking sample. It should be noted that a reciprocal transformation inverts the two poles of the distribution. Thus, after the transformation, low values represent a longer processing time, while high values represent a shorter processing time [
22]. Subtests III, IV, and VI could be normalized by a decadic logarithm (LG10). Due to the extreme skewness of the distribution of subtest IX, it was not possible to achieve a normal distribution of residuals by any transformation.
Table 3 presents the predictors included in the respective regression models for subtests I to VIII in both samples. Age and intelligence were the most important predictors (included in all eight models of the English-speaking sample and seven models of the German-speaking sample). In three models, age squared was a significant predictor. In contrast to the English-speaking sample, age squared was not included in any of the German models; here, the interaction between intelligence and age showed significance in the regression model for subtest II (Immediate Recall). Only two regression models contained gender as a predictor for the English-speaking subjects. Gender turned out to be significant in six German regression equations. The interaction of gender and age made a significant contribution to the prediction of the score in subtest V in both datasets. All regression models achieved statistical significance. Column
R2 in
Table 3 lists the amount of variance explained by the respective models. It varied between 5.0% and 26.3% in the English-speaking sample and between 5.4% and 27.2% in the German-speaking sample, depending on the complexity and requirements of the cognitive task. The models of subtests I (Naming Objects) and III (Naming Numerals) had the lowest explained variance with 9.8% and 5.0% (German-speaking sample: 5.4% and 5.4%), respectively. The models of subtests V (Replacing Blocks) and VII (Reversal Naming) explained the most variance with 26.3% (about 27% in the German-speaking dataset) each, followed by subtest IV (Arranging Blocks) with 26.1% (German-speaking sample: 27.1%). In sum, the explained variance in the models was comparable in both samples. Only in subtest II did the model for the English-speaking sample (21.9%) explain considerably more variance than that of the German-speaking sample (13.4%).
The final multiple regression equations for the SKT subtests I to VIII are shown in
Table 4 for both datasets. Each equation contains all predictors relevant for the prediction of the respective test result with the corresponding unstandardized regression coefficients and the intercepts. By inserting the person-specific variable characteristics, a predicted score can be calculated for each subtest, to which the observed test score can be subsequently compared. For the non-transformed subtests II and VIII, the number of objects not remembered is predicted. The predicted score of all other subtests cannot be interpreted directly because of the transformations made. Therefore, the observed scores must also be transformed accordingly for the comparison of the predicted and actually observed scores.
For subtest IX, the multiple regression calculation was not possible due to the extremely right-skewed distribution of residuals in both datasets. Instead, an area transformation of the raw values was performed (Tabachnick and Fidell [
20]). The predictors age, gender, and intelligence could not be taken into account. The results of the area transformation are presented in the form of a conversion table. This enables a direct transformation of the raw scores; in this case the number of objects not recalled, into percentiles. Two-thirds of both norming samples recognized eleven or twelve objects. Only a small number of participants (less than 10%) did not remember four or more objects.
5. Discussion
The goal of this paper was to evaluate the application of the German-based cognitive SKT test on three different English-speaking populations using a regression-based norming technique [
9]. Although the SKT was designed to be a culture fair German test, we were able to test convenience samples from three uniquely different English-speaking populations: the United States, Australia, and Ireland. The results showed a remarkable concordance for the use of the SKT in both German and three English-speaking populations. We were able to provide a comprehensive picture of how the newly normed German test would fare to demonstrate the utility of the SKT in the English-speaking populations.
One difference between the German- and English-language norming was that age squared proved to be a significant predictor in three regression equations in the latter, whereas age squared was not included in any German-language model. A possible reason for this discrepancy is the different age distributions of the two samples. The group of people aged 85 years and older was underrepresented in the German-speaking sample (6.8%) compared to the English-speaking sample (17.9%). A larger sample size of the oldest age group increases the probability that a significant acceleration of cognitive impairment can be observed with increased age.
Overall, however, there are clear similarities in the regression models of the German- and English-speaking samples; the SKT is validly and reliably applicable to English-speaking populations. Since the German regression-based norming has so far proven to be useful in practice and particularly sensitive in the area of mild cognitive impairment (cf. [
11]), it can be assumed that these favorable characteristics will also be evident for the English-language norming. The use for the new English-language sample of the methodological approach developed in the German norming thus appears justified.
On the other hand, the above-mentioned differences between the samples underline the need for a fine-tuning of the standardization and the need to calculate extra regression equations for the English-speaking world. A simple translation of the German manual and the complete adoption of the German standards would have led to a significant loss of validity of the SKT in English-speaking populations. The modern regression-based norming of the SKT now offers the advantage of continuous norming. More predictors and the interactions between different predictors can now be considered. In addition, a new evaluation program (i.e., EXCEL sheet) for computers makes it easier to convert the raw values into standard values and to assess the severity of cognitive impairment.
Another limitation was that we did not use the MMSE in Tulsa. We used two subtests of the WAIS-III (matrices and vocabulary test) to measure the current level of intelligence and regression equations based on age, gender, and intelligence to predict the MMSE. Intelligence was the only significant predictor. Testing and controlling for the influence of age and intelligence as important predictors for cognitive performance in older adults is another reason to plea for more regression-based norming in the area of gerontology.
Unfortunately, different testing centers used different measures of intelligence. We preferred any valid measure of intelligence over an estimate of intelligence, such as an estimate based on years of education. The different measures were made comparable through a transformation into the Wechsler norm values. To account somewhat for the different intelligence tests used, two measures of intelligence were always used: one for fluid intelligence and one for crystallized intelligence.
More limitations can be seen in the much smaller English sample size in comparison to the German one (n = 285 versus n = 1051). It would have been more appropriate if other countries would have participated, such as Great Britain, Canada, or India, in order to obtain a more representative sample of the English-speaking world. However, the SKT consists of almost culturally free test stimuli (e.g., painted objects, Arabic numerals, and other symbols) and one can assume that the assessment of the cognitive functioning of older adults in the remaining English-speaking countries would be equivalently valid while using the regression-based norming approach which controls for age, gender, intelligence, and all possible interactions.
Nevertheless, it is desirable to review the new English language norms in the near future based on further national samples. Cross-validations on clinical samples should be carried out to investigate whether the English regression-based norming of the SKT is suitable as a reliable assessment of cognitive disorders, especially in the area of MCI, and how well the results of the SKT correspond to the clinical diagnoses of experts (cf. [
23]).
Future work should aim at creating a regression-based norming of the SKT for other languages, too. We are in the process of validating the SKT in China [
24]. In addition, for the new regression-based norming, the sewing test in practice is still missing.






{kind=link}
{kind=link}