1. Background
Although many applications of item response theory are in the context of parametric models such as the Rasch, two, and three-parameter logistic models [
1], there is also a recognized need for models that allow for more flexible relationships between the latent trait and an item category response [
2]. Models and techniques that allow for more flexible item response functions are variously known as non-parametric [
2], quasi-parametric [
3], or semi-parametric [
4] models, and include methods such as Mokken scale analysis [
5], kernel smoothing [
6], and polynomial splines [
4]. Historically, flexible item response models have been used to analyze data sets with small sample sizes, to check the assumptions of parametric item response models, and as an alternative to poorly fitting parametric models [
2]. In recent years, flexible item response models have increasingly been used in confirmatory contexts. For example, flexible item response models have recently been applied to computerized adaptive testing [
7,
8], the creation of item banks for measuring health outcomes [
9], and the development of optimal scoring procedures [
10].
A compelling recent addition to the family of semi-parametric item response models is the filtered monotonic polynomial (FMP) model [
3,
11]. The general form of the FMP model [
12] used in this paper is a generalization of Muraki’s generalized partial credit model [
13] (GPCM) that replaces a linear function of the latent trait
with a polynomial expansion of
. As clarified below, constraints are placed on the item parameters so that this polynomial function is a monotonically increasing function of
. For item
i with
ordered response categories and person
j, the item response function (IRF) of the general FMP model gives the probability of a response in category
c,
, as
where
, and
is a vector of item parameters in a polynomial coefficient parameterization.
In Equations (
1) and (
2), the
parameter is an item-specific non-negative integer that controls the maximum degree of the polynomial function of
. Specifically, the highest-order polynomial equals
, and so
, 1, and 2 imply linear, cubic, and fifth-degree polynomial functions of
. Note that this formulation forces an
odd value for the highest-order polynomial of
, which is a necessary (but not sufficient) condition for the polynomial to be a monotonic function of
.
A key feature of the FMP model is that it reduces to familiar parametric item response models when
is set to be a linear function of
(i.e., when
). Specifically, if
, Equation (
1) reduces to the GPCM, and if both
and
(i.e., scored item responses are dichotomous), then Equation (
1) reduces to the two-parameter logistic (2PL) model. Another key feature of this model not shared by many flexible item response models is that its model parameters are portable [
3], meaning that the FMP model can be used to construct item banks, conduct adaptive testing, and score examinees not included in the original sample. To better acquaint the reader with the relationship between the FMP model with
and other item response models used in popular IRT software packages, several examples of finding FMP parameters from the output of the R packages
ltm [
14],
mirt [
15], and
TAM [
16] are included in
Appendix A.
The FMP model requires that
be a
monotonically increasing function of
. To enforce monotonicity, we may use a transformation of the polynomial coefficient parameters
. In general, consider the polynomial function
Equation (
3) is a strictly monotonically increasing function of
if and only if the first derivative of
,
is positive at all values of
. One way to enforce positivity is through the following reparameterization of Equation (
4) [
3,
12,
17]:
In this parameterization, no boundary constraints are required for
,
, or
,
. Because
parameters do not affect the monotonicity of
, no transformation of these parameters is necessary, but we use the symbol
to use notation consistently across the different parameterizations. Therefore,
for
,
, and the
parameters are functions of
,
, and
calculated using matrix operations described elsewhere [
3,
11,
12,
18,
19]. Thus, the FMP model is equivalently represented by the polynomial coefficient parameters
and the Greek-letter parameters
. In both parameterizations, an item with
response categories and item complexity
is described by
item parameters. To better acquaint the reader with the Greek-letter and polynomial coefficient parameterizations,
Appendix B includes formulas to calculate the polynomial coefficients from the Greek-letter parameters up to
.
2. Specifying the FMP Model in flexmet
The
R package
flexmet provides broad functionality for specifying, fitting, and transforming the FMP model, and many of its features (relative to version 1.1) are illustrated in the remainder of this paper. The IRF for the FMP model is specified using the polynomial coefficient parameters
as described in the previous section. However, the Greek-letter parameterization is also needed when fitting and generating FMP items to ensure monotonicity. The
flexmet package includes the
greek2b and
b2greek functions to navigate between the two different parameterizations. To illustrate these functions, consider a six-item test. Three items (items 1, 2, and 3) are defined for binary item responses, and three items are defined for four-category responses (items 4, 5, and 6). Additionally, items 1 and 4 have
, items 2 and 5 have
, and items 3 and 6 have
. The parameters used for this illustration (both the Greek-letter and polynomial coefficient parameterizations) are printed in
Table 1.
The greek2b function outputs the vector associated with the inputted xi, omega, and (optionally) alpha and tau values. For example, the vector for item 1 can be found as follows.
As another example, let us find the vector for item 6. In this case, the greek2b function requires the user also to specify the alpha and tau arguments, as well as multiple xi parameters corresponding to the different response categories. Note that the xi parameters should be given in order from , and the alpha and tau vectors should also be ordered and .
![Psych 03 00031 i002]()
It is also possible to represent FMP item parameters with different k values and different numbers of items in the same matrix. To do this, the NA symbol may be used to represent higher-order values for items with . In addition, specifying and will set the corresponding polynomial coefficients (i.e., and ) to be equal to 0. For example, to find the matrix of polynomial–coefficient item parameters for the example six-item test, we can bind together calls to greek2b that have xi, alpha, and tau arguments of the same length for each item.
![Psych 03 00031 i003]()
Following from Equation (
1), these item parameters can be used to find the probability of responding in each response category as a function of the latent trait
; that is, the IRF. The
irf_fmp function calculates item response probabilities for the FMP model given a scalar or vector of latent trait value(s)
theta and a matrix or vector of item parameters
bmat in the polynomial coefficient parameterization. It may also be necessary to specify the
maxncat function, which gives the maximum number of response categories represented in the matrix (such that the first
maxncat-1 columns are interpreted as
parameters). The default value of
maxncat = 2, so this argument should be specified if
bmat includes at least one polytomous item. Calls to
irf_fmp will result in a three-dimensional array with
values in the first dimension, items in the second dimension, and response categories in the third dimension. For example,
![Psych 03 00031 i004]()
In the above output (and elsewhere in this tutorial), informative dimension labels have been added to ease readability. This output shows, for example, that the probabilities of responding in categories 0, 1, 2, and 3 to item 6 for a person with equal 0.4118, 0.3800, 0.1849, and 0.0233. Notice that the output also includes some NA values. This is because items 1, 2, and 3 have only 2 response categories, and therefore these subjects can only respond in categories 0 and 1 and categories 2 and 3 are NA.
For dichotomous items, it is common to only find the probability of responding in the higher response category (because the sum of response category probabilities must sum to 1 for each , probabilities for category 0 are 1 minus those for category 1). In flexmet, specific category response probabilities can be found by adding the returncat argument. This is illustrated below for item 1:
![Psych 03 00031 i005]()
Notice that the maxncat argument is set equal to 4 in this example, even though the item is dichotomous. This is because the item parameters are taken from the first row of bmat, and bmat includes columns corresponding to four-category items. In other words, maxncat should be set to one greater than than the number of bmat columns (or one greater than the number of bmat entries, if bmat is a vector) that correspond to parameters, even if no item with maxncat categories is included in the call to bmat. Note that the returncat argument represents the value of the category to output, where categories are labeled starting at 0. Therefore, returning category “1” for dichotomous item 1 returns the probability of a positive item response to item 1. By default, if maxncat = 2, only probabilities for category “1” are returned, and if maxncat > 2, all response category probabilities are returned.
Calls to
irf_fmp also can be used to plot IRFs.
Figure 1 displays the IRFs for the six example items, and tge code to produce a version of this figure is included in
Appendix C. In this figure, response probabilities for category 1 (a positive response) are shown for the 3 dichotomous items, and all response category probabilities are shown for the 3 polytomous items.
3. Fitting the FMP Model in flexmet
The
flexmet package includes functionality for specifying, fitting, and manipulating the general FMP model. Notably,
flexmet is not the only
R package available for fitting the FMP model. For example, the
mirt package [
15] includes functionality to estimate FMP item parameters using marginal maximum likelihood estimation. However, if any items have
, the
mirt package currently (version 1.34 of
mirt is current at the time of writing) requires the user to estimate either 2PL or GPCM parameters rather than FMP parameters. Because
mirt parameterizes the 2PL and GPCM differently than the Greek-letter FMP parameterization, this may make the
mirt package less than ideal for tests with a variety of
values and for advanced applications of the FMP model (such as scale transformations, as described in a later section). Therefore, the
flexmet package includes several ways to estimate FMP model parameters, including built-in methods for fixed-effects and random-effects estimation, as well as a wrapper that uses the
mirt package to estimate parameters and return parameter estimates in a standardized format. As illustrated below,
flexmet facilitates item parameter estimation for items with any combination of
values and numbers of response categories, with or without the use of Bayesian priors.
Early applications of the FMP model treated the latent trait as a fixed effect to estimate item parameters [
3,
11]. In this fixed-effects approach, initial estimates of the
parameters are treated as known quantities when calculating maximum likelihood estimates of the Greek-letter parameters for an individual item. These fixed
values are called
surrogates [
3,
11] and are calculated as the first principal components scores of the full data matrix. In the following code chunk, 1000 true
values are simulated from a standard normal distribution. Then, the
sim_data function in
flexmet is used in conjunction with the six-item
bmat matrix defined earlier to randomly generate item response data. Finally,
surrogates are calculated by passing the simulated data to
flexmet’s
get_surrogates function.
![Psych 03 00031 i006]()
The tsur object now includes 1000 surrogate values calculated from the simulated data. To estimate item parameters for a single item using fixed-effects estimation with surrogates, we can use the fmp_1 function in flexmet. As illustrated below, this function requires the user to specify the data vector, the desired k value, and a vector of surrogates tsur. Below, this is illustrated for k values of 0, 1, and 2.
The best choice of
k for a given item is typically unknown, and so authors have suggested comparing the item-level Akaike Information Criteria (AIC) value to select the optimal
k value [
3,
12]. We can perform this comparison by extracting the
AIC list element from each call to
fmp_1.
![Psych 03 00031 i008]()
In this example,
k = 1 leads to the lowest AIC value. Incidentally,
is also the data-generating
k value for this item (item 2), though this will not always be the case. Note that it is not always desirable to seek the “correct”
value, but instead it may be preferable to approximate the population curve as closely as possible without overfitting the data. One measure of the similarity of item response functions is the root integrated mean squared error (RIMSE; [
6,
12]), which is defined here as
where
and
represent the two item response functions to compare (not necessarily from the FMP model), and
indicates a
distribution to integrate over. Smaller values of RIMSE indicate greater similarity between the two curves. In
flexmet, the
rimse function can calculate the RIMSE for any combination of
-vectors that represent the same number of response categories (though not illustrated here,
rimse can also be used with non-FMP item response functions). In
flexmet,
is standard normal by default but can be modified using the
int argument, which expects a matrix with two columns. The first column should include a sequence of quadrature points, and the second column should include the densities of each quadrature point, scaled so that the densities sum to 1. The
int_mat function in
flexmet facilitates the creation of this matrix. The
int_mat function takes a distribution function
distr (such as
dnorm or
dunif), a named list
args of the parameters of that distribution, the lower and upper bounds of the quadrature points,
lb and
ub, and the number of quadrature points,
npts. An example of modifying these arguments of the
int_mat function is included later in this paper (
Section 4.2).
The first two arguments to rimse should be two vectors of -parameters, in either order. In the code below, the true -parameters for item 2 are listed first. Note that because columns 2 and 3 of bmat represent category intercept parameters for polytomous items (and include NA values for item 2), we omit these from the -vector when calling rimse. The estimated -parameters are listed second and are found in the bmat list element of each call to fmp_1. If items are polytomous, the ncat argument should also be specified to indicate the number of response categories. Because the default value of ncat = 2, it is not necessary to include this argument for dichotomous items.
Comparing the RIMSE of the estimated curves versus the data-generating curves for 3 values of k, we see that k = 0 leads to the highest error in estimation, followed by k = 2, and k = 1 most closely traces the population item response function.
It is also possible to estimate fixed-effects item parameters for multiple items in one command using the fmp function with the em = FALSE argument. This method will automatically calculate surrogates based on the provided data matrix. In the fmp function, it is possible to specify different k values for different items. Namely, if a scalar is specified for the k argument, the same k value will be used for all items. Otherwise, a vector of k values should be specified, one per item.
In the example below, the fixed-effects FMP model is fit several times. First, all items are fit with , , and . Based on these results, a model with differing k values is specified based on the optimal k value, as indicated by comparing item-level AIC values.
The user may notice that the model with k = 2 produces an error that the (item parameter) information matrix cannot be inverted. This is a common problem with high k values. If this error occurs, standard errors are not available for the estimated item parameters; however, the item parameter estimates themselves may be used without concern.
Based on the above results, we see that the lowest AIC value is observed for 0, 0, 2, 2, 0, and 1 for the 6 items. We may then choose to fit a new fixed-effects FMP model with these varying k values, as illustrated below.
In the item parameter matrix printed above, notice how items with different k values and numbers of response categories are represented. Specifically, NA’s are used as placeholders for items 1–3 that include less than the maximum number of response categories. In contrast, if is less than the maximum value represented in the parameter matrix (as is the case for items 1, 2, 5, and 6), then the higher-order parameters are set to 0.
In addition to fixed-effects estimation,
flexmet also provides functionality for random-effects estimation using marginal maximum likelihood estimation via the expectation-maximization (EM) algorithm [
20]. The
flexmet package includes both an inbuilt algorithm for estimating item parameters (using the
fmp function with option
em = TRUE) and a wrapper to the
mirt [
15] package (using the
fmp function with option
em = "mirt"). The
mirt algorithm is currently faster and more reliable than the inbuilt algorithm, and so this option is used for illustration. Note that the
mirt package must be installed in order to use this option. Using the same pattern of
k values found with the fixed-effects model, we find the following results:
![Psych 03 00031 i012]()
At a glance, comparing the bmat outputs of fe_mixed and re_mixed indicates that while some parameter estimates are similar across the two estimation methods, others are quite different. Notably, for highly parameterized models such as the FMP model, very different sets of parameters can trace similar curves. For this reason, it is useful to plot curves or to apply overall summary measures such as the RIMSE when comparing estimated curves to the true curve or to each other. These RIMSE values are calculated for fe_mixed and re_mixed after illustrating one final estimation method.
Another useful estimation option available for both the
fmp_1 and
fmp functions is the use of Bayesian priors. Particularly, for higher values of
k, the FMP model may become computationally unstable, which can be somewhat alleviated through the use of priors [
12]. Because the Greek-letter parameterization of the FMP is used for parameter estimation, priors are placed on the Greek-letter parameters rather than on the more readily interpretable
parameters. When choosing priors, it may be helpful to note that
and that
. In addition, higher-order
parameters will equal zero if the corresponding
and
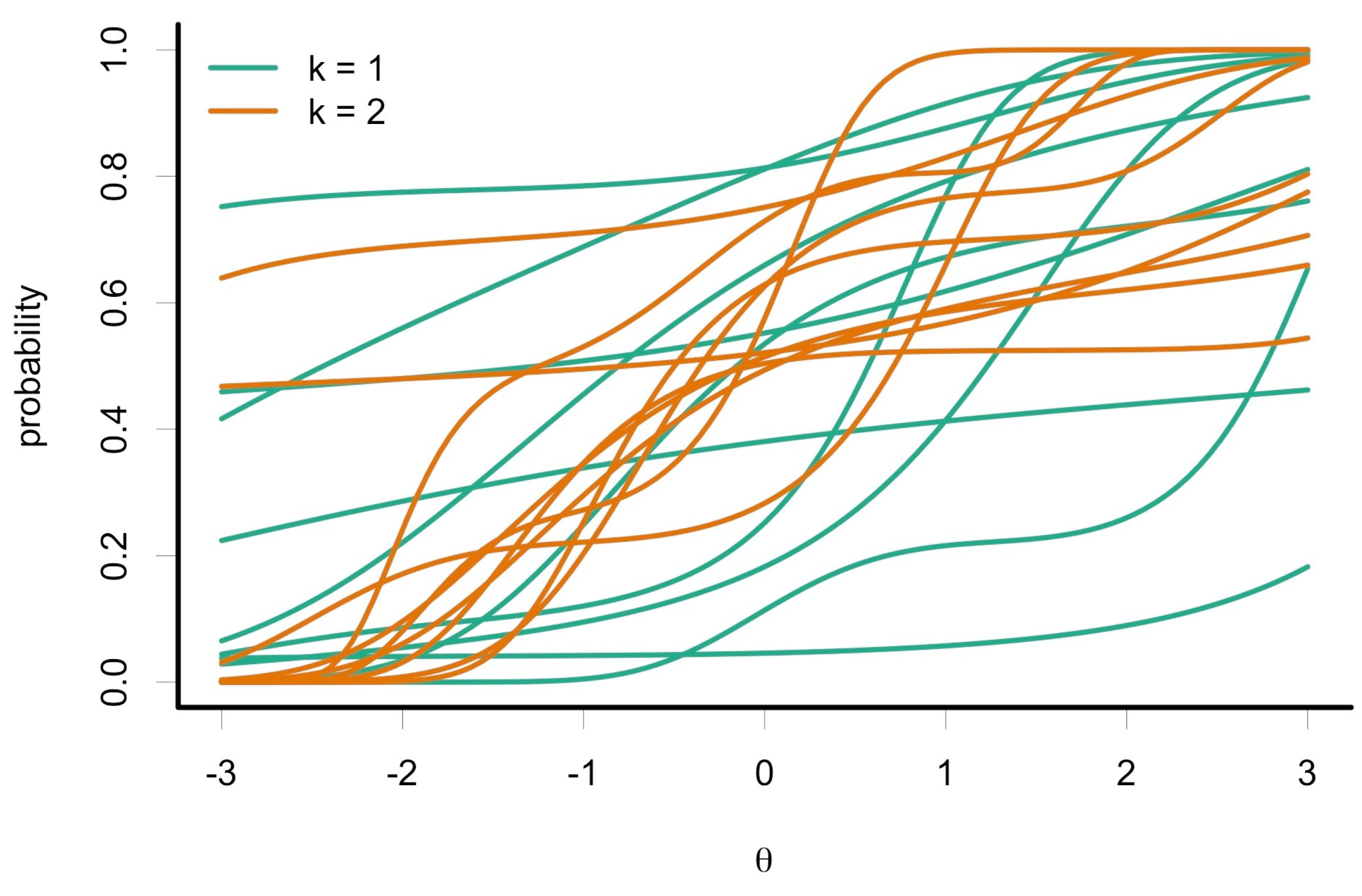
. Prior predictive simulation may help the user to select appropriate priors. For example, the following code produces a prior predictive simulation of 20 item response curves generated from the following distributions:
,
−
,
, and
. The plot produced by this code is shown in
Figure 2. This choice of priors appears to allow for a variety of shapes and locations of the FMP curves, and so we continue to illustrate Bayesian estimation with these priors.
![Psych 03 00031 i013]()
Priors can be added to models fit using flexmet by specifying the prior argument to the fmp or fmp_1 function. As of version 1.1 of flexmet, only normally distributed priors are available, and the same priors are applied to all model parameters of a given class (i.e., for all items in the data set and for all instances of that parameter type within an item). To specify priors, a list with named elements xi, omega, alpha, and tau should be passed to the prior argument. For example, to specify a standard normal prior for all s, we may write prior = list(xi = c("norm", 0, 1)). The code below illustrates Bayesian estimation with the em = "mirt" option.
![Psych 03 00031 i014]()
Finally, we may compare the accuracy of each of the three illustrated estimation methods using the rimse function. The code below does this for each of the six simulated items. For each item, random-effects estimation tends to lead to somewhat more accurate curves than fixed-effects estimation, and the use of priors improves parameter estimation accuracy in some, but not all, cases.
![Psych 03 00031 i015]()
Several other estimation options are available with the fmp and fmp_1 functions that are not illustrated here. A vector of starting values may be specified with the start_vals argument, where parameters should be listed in the same order as the estimated parameters given in the parmat list element of the fitted model object. For fixed-effects estimation, the method argument indicates the optimization algorithm (passed to the optim function in R’s stats package). For random-effects estimation, the max_em option indicates the maximum number of EM cycles (default 500), and the n_quad function indicates the number of quadrature points (default 49). Additional named arguments may be passed to the optim function (if em = TRUE) or the mirt function (if em = "mirt").
Finally,
flexmet includes the
th_est_ml and
th_est_eap functions for maximum likelihood (ML) and
expected a posteriori (EAP, [
21]) person parameter estimation. Both of these functions require a data matrix
dat and a matrix of
-parameters
bmat. If at least one item is polytomous, the
maxncat argument should also be specified. By default, the
th_est_eap function uses a standard normal prior with 33 quadrature points, and this may be modified using the
int argument in conjunction with
int_mat. A call to either trait estimation function will result in a matrix with two columns: one for the
parameter estimates and one for the standard errors (for ML) or posterior standard deviations (for EAP). The code below illustrates this procedure for the example data and the
re_priors estimated item parameters.

























































{kind=link}
{kind=link}
{kind=link}
{kind=link}