
Estimating Explanatory Extensions of Dichotomous and Polytomous Rasch Models: The eirm Package in R




Abstract
:1. Theoretical Background
1.1. Types of Explanatory IRT Models
1.2. Software Programs to Estimate Explanatory IRT Models
2. eirm
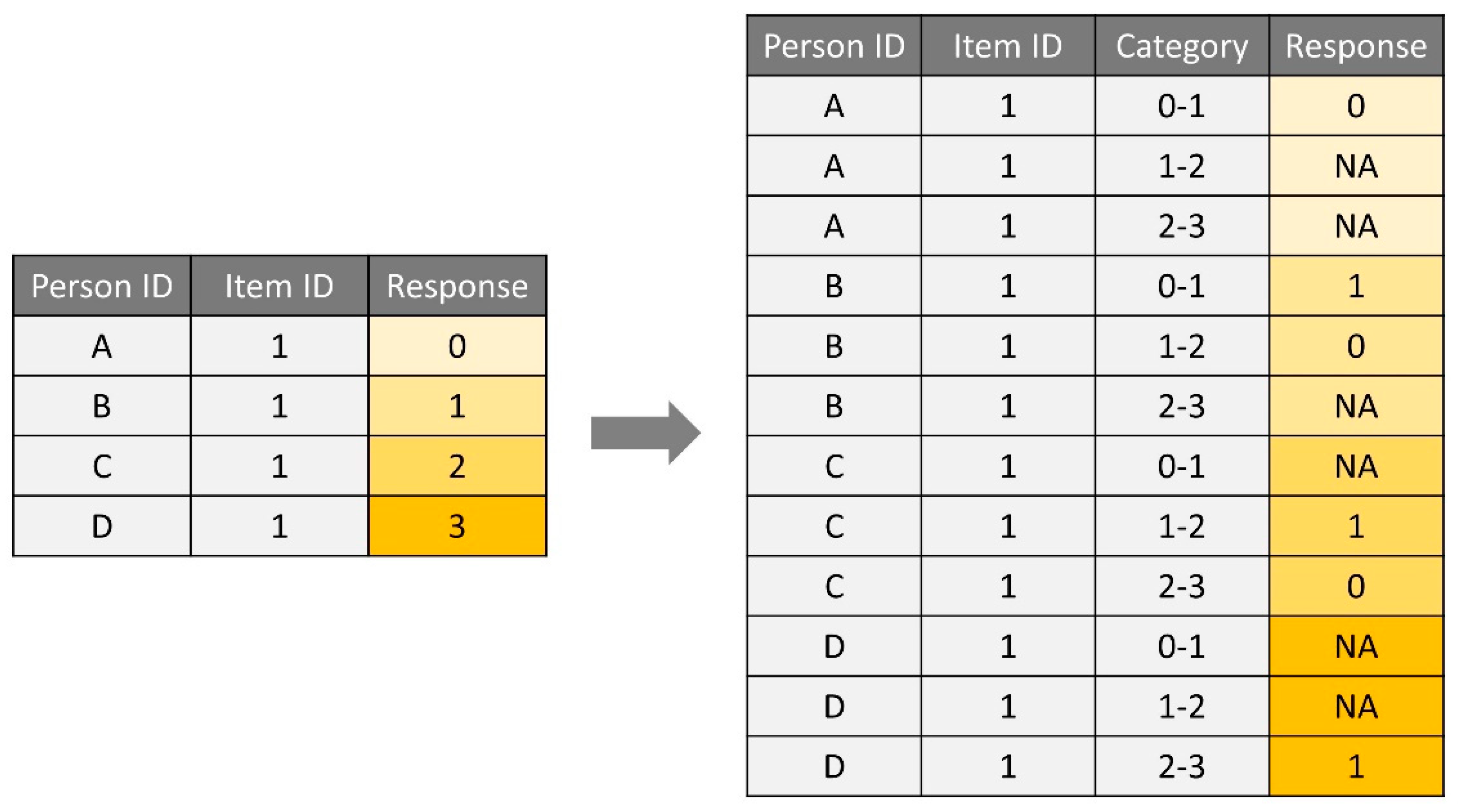
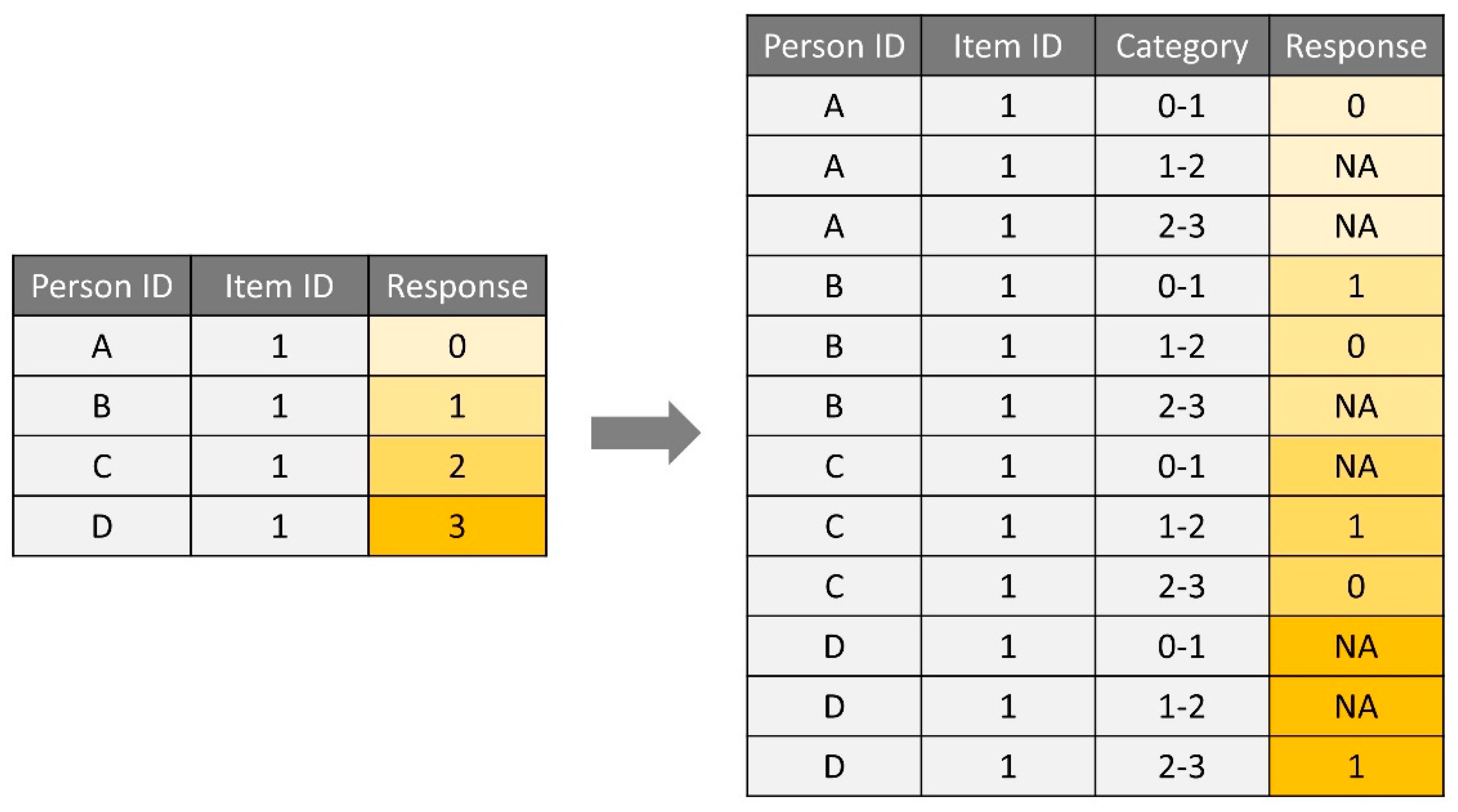
2.1. Data Preparation
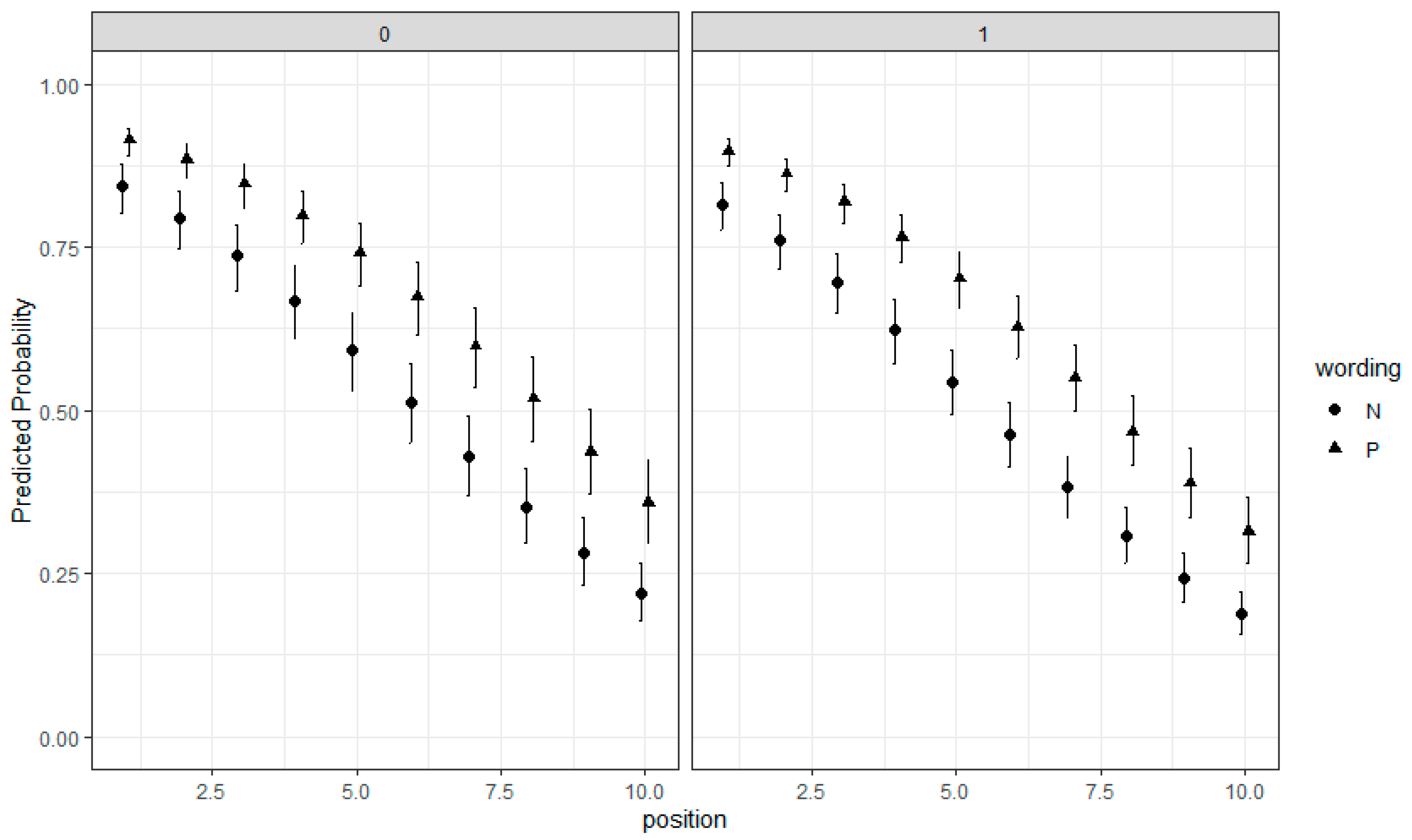
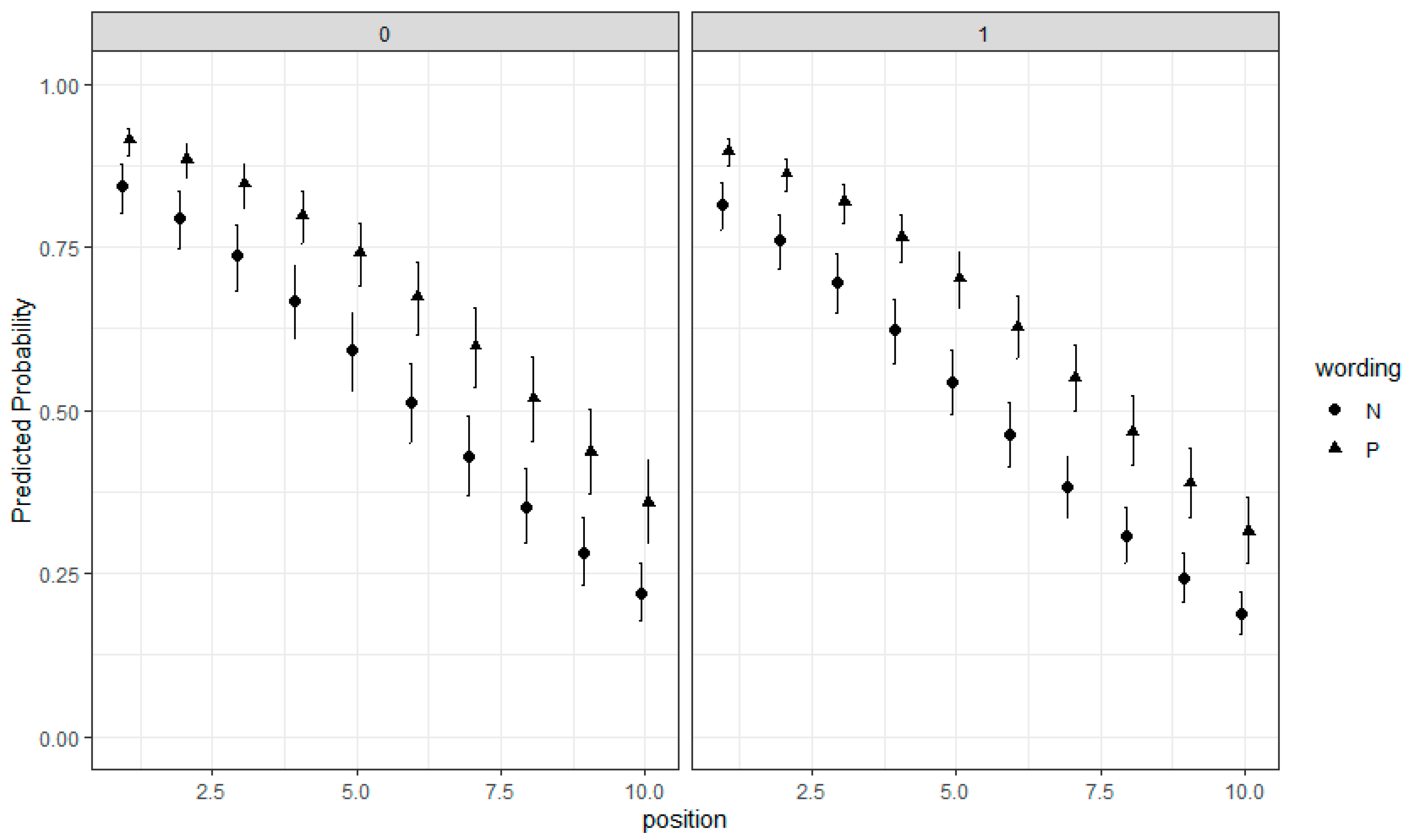
2.2. EIRM for Dichotomous Responses
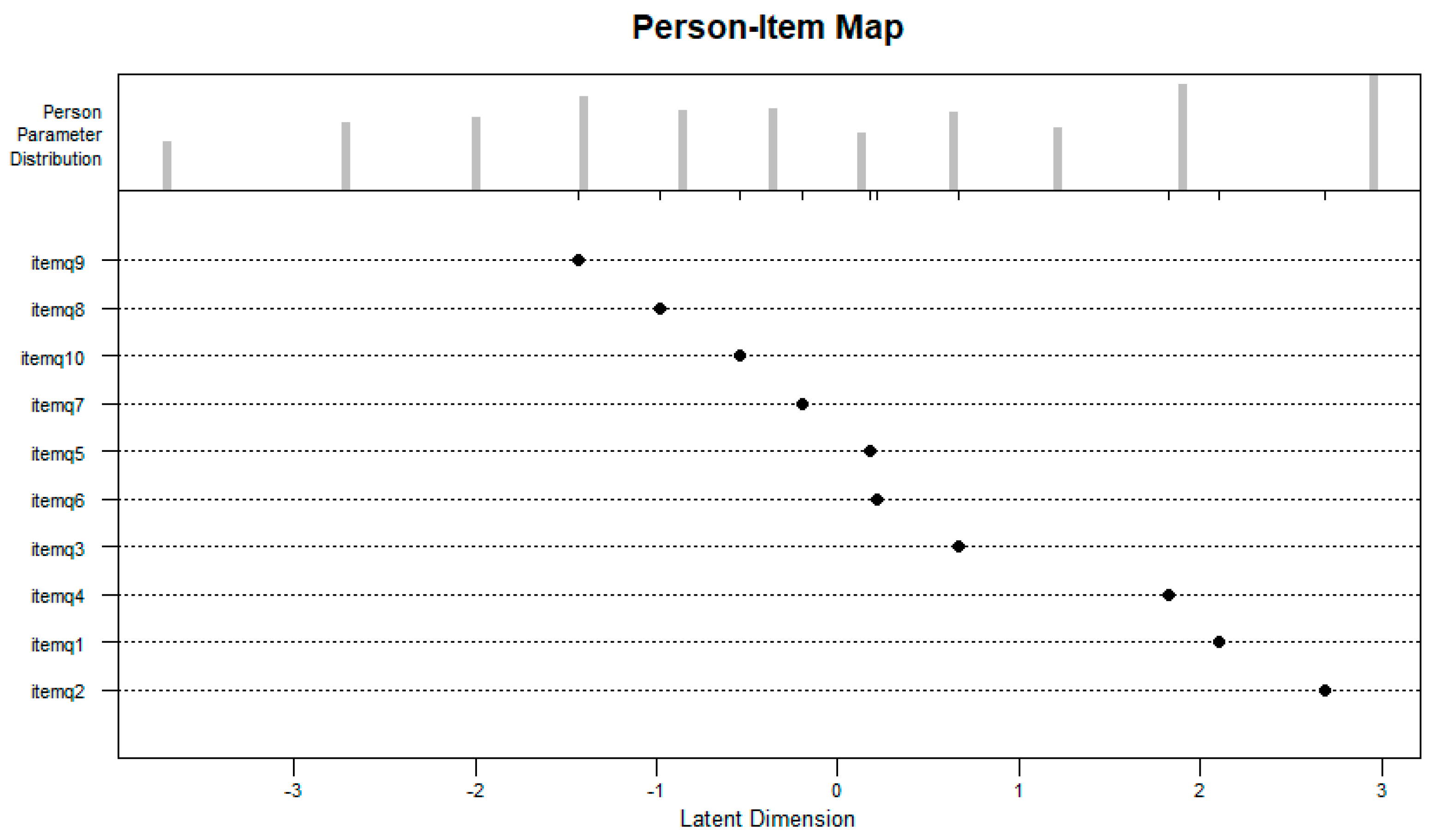
2.3. EIRM for Polytomous Responses
3. Discussion
Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wilson, M.; De Boeck, P.; Carstensen, C.H. Explanatory item response models: A brief introduction. In Assessment of Competencies in Educational Contexts; Hartig, J., Klieme, E., Leutner, D., Eds.; Hogrefe & Huber Publishers: Göttingen, Germany, 2008; pp. 91–120. [Google Scholar]
- De Boeck, P.; Wilson, M. Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach; Springer: New York, NY, USA, 2004. [Google Scholar]
- Briggs, D.C. Using explanatory item response models to analyze group differences in science achievement. Appl. Meas. Educ. 2008, 21, 89–118. [Google Scholar] [CrossRef]
- American Educational Research Association; American Psychological Association; National Council on Measurement in Education. Standards for Educational and Psychological Testing; American Educational Research Association: Washington, DC, USA, 2014. [Google Scholar]
- Fahrmeir, L.; Tutz, G. Models for multicategorical responses: Multivariate extensions of generalized linear models. In Multivariate Statistical Modelling Based on Generalized Linear Models; Springer: New York, NY, USA, 2001; pp. 69–137. [Google Scholar]
- McCulloch, C.E.; Searle, S.R. Generalized, Linear, and Mixed Models; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Rasch, G. Studies in Mathematical Psychology: 1. Probabilistic Models for Some Intelligence and Attainment Tests; Nielsen and Lydiche: Oxford, UK, 1960. [Google Scholar]
- Rasch, G. Probabilistic Models for Some Intelligence and Attainment Tests; University of Chicago Press: Chicago, IL, USA, 1980. [Google Scholar]
- Masters, G.N. A Rasch model for partial credit scoring. Psychometrika 1982, 47, 149–174. [Google Scholar] [CrossRef]
- Andrich, D. A rating formulation for ordered response categories. Psychometrika 1978, 43, 561–573. [Google Scholar] [CrossRef]
- Fischer, G.H. The linear logistic test model as an instrument in educational research. Acta Psychol. 1973, 37, 359–374. [Google Scholar] [CrossRef]
- Hohensinn, C.; Kubinger, K.D.; Reif, M.; Holocher-Ertl, S.; Khorramdel, L.; Frebort, M. Examining item-position effects in large-scale assessment using the Linear Logistic Test Model. Psychol. Sci. Q. 2008, 50, 391–402. [Google Scholar]
- Hohensinn, C.; Kubinger, K.D. Applying item response theory methods to examine the impact of different response formats. Educ. Psychol. Meas. 2011, 71, 732–746. [Google Scholar] [CrossRef]
- Adams, R.J.; Wilson, M.; Wu, M. Multilevel item response models: An approach to errors in variables regression. J. Educ. Behav. Stat. 1997, 22, 47–76. [Google Scholar] [CrossRef]
- Kim, J.; Wilson, M. Polytomous item explanatory item response theory models. Educ. Psychol. Meas. 2020, 80, 726–755. [Google Scholar] [CrossRef]
- Stanke, L.; Bulut, O. Explanatory item response models for polytomous item responses. Int. J. Assess. Tool Educ. 2019, 6, 259–278. [Google Scholar] [CrossRef]
- French, B.F.; Finch, W.H. Hierarchical logistic regression: Accounting for multilevel data in DIF detection. J. Educ. Meas. 2010, 47, 299–317. [Google Scholar] [CrossRef]
- Kan, A.; Bulut, O. Examining the relationship between gender DIF and language complexity in mathematics assessments. Int. J. Test. 2014, 14, 245–264. [Google Scholar] [CrossRef]
- Bulut, O.; Palma, J.; Rodriguez, M.C.; Stanke, L. Evaluating measurement invariance in the measurement of development assets in Latino English language groups across development stages. Sage Open 2015, 5, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Cho, S.J.; Athay, M.; Preacher, K.J. Measuring change for a multidimensional test using a generalized explanatory longitudinal item response model. Brit. J. Math Stat. Psy. 2013, 66, 353–381. [Google Scholar] [CrossRef]
- Qian, M.; Wang, X. Illustration of multilevel explanatory IRT model DIF testing with the creative thinking scale. J. Creat. Think. 2020, 54, 1021–1027. [Google Scholar] [CrossRef]
- Sulis, I.; Tolan, M.D. Introduction to multilevel item response theory analysis: Descriptive and explanatory models. J. Early Adolesc. 2017, 37, 85–128. [Google Scholar] [CrossRef]
- De Boeck, P.; Partchev, I. IRTrees: Tree-based item response models of the GLMM family. J. Stat. Softw. 2012, 48, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Plieninger, H. Developing and applying IR-tree models: Guidelines, caveats, and an extension to multiple groups. Organ. Res. Methods 2021, 24, 654–670. [Google Scholar] [CrossRef] [Green Version]
- Rabe-Hesketh, S.; Skrondal, A.; Pickles, A. GLLAMM Manual, UC Berkeley Division of Biostatistics Working Paper Series, Paper No. 160; University of California, Berkeley: Berkeley, CA, USA, 2004; Available online: http://biostat.jhsph.edu/~fdominic/teaching/bio656/software/gllamm.manual.pdf (accessed on 12 July 2021).
- Tan, T.K.; Serena, L.W.S.; Hogan, D. Rasch Model and Beyond with PROC GLIMMIX: A Better Choice. Center for Research in Pedagogy and Practice, Paper No. 348-2011; Center for Research in Pedagogy and Practice, Nanyang Technological University: Singapore, 2011; Available online: http://support.sas.com/resources/papers/proceedings11/348-2011.pdf (accessed on 12 July 2021).
- Hoffman, L. Example 6: Explanatory IRT Models as Crossed Random Effects Models in SAS GLIMMIX and STATA MELOGIT Using Laplace Maximum Likelihood Estimation. Available online: https://www.lesahoffman.com/PSQF7375_Clustered/PSQF7375_Clustered_Example6_Explanatory_Crossed_MLM.pdf (accessed on 12 July 2021).
- Wu, M.L.; Adams, R.J.; Wilson, M.R. ConQuest: Multi-aspect Test Software [Computer Program]; Australian Council for Educational Research: Melbourne, Australia, 1997. [Google Scholar]
- Muthen, L.K.; Muthen, B.O. Mplus User’s Guide; Muthen & Muthen: Los Angeles, CA, USA, 1998–2019. [Google Scholar]
- De Boeck, P.; Bakker, M.; Zwitser, R.; Nivard, M.; Hofman, A.; Tuerlinckx, F.; Partchev, I. The estimation of item response models with the lmer function from the lme4 package in R. J. Stat. Softw. 2011, 39, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. arXiv 2014, arXiv:1406.5823. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Petscher, Y.; Compton, D.L.; Steacy, L.; Kinnon, H. Past perspectives and new opportunities for the explanatory item response model. Ann. Dyslexia. 2020, 70, 160–179. [Google Scholar] [CrossRef]
- Bulut, O. eirm: Explanatory Item Response Modeling for Dichotomous and Polytomous Item Responses. R Package Version 0.4. 2021. Available online: https://CRAN.R-project.org/package=eirm (accessed on 12 July 2021).
- Jeon, M.; Rockwood, N. PLmixed. R Package Version 0.1.5. 2020. Available online: https://cran.r-project.org/web/packages/PLmixed/index.html (accessed on 12 July 2021).
- Rosenberg, M. Rosenberg self-esteem scale (RSE). Accept. Commit. Ther. Meas. Package 1965, 61, 18. [Google Scholar]
- Rosenberg, M. Society and Adolescent Self-Image; Princeton University Press: Princeton, NJ, USA, 1965. [Google Scholar]
- De Boeck, P. Random item IRT models. Psychometrika 2008, 73, 533–559. [Google Scholar] [CrossRef]
- Wickham, H. Reshaping data with the reshape package. J. Stat. Softw. 2007, 21, 1–20. [Google Scholar] [CrossRef]
- Mair, P.; Hatzinger, R. Extended Rasch modeling: The eRm package for the application of IRT models in R. J. Stat. Softw. 2007, 20, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Lüdecke, D. ggeffects: Tidy data frames of marginal effects from regression models. J. Open Source Softw. 2018, 3, 772. [Google Scholar] [CrossRef] [Green Version]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Andrich, D. An extension of the Rasch model for ratings providing both location and dispersion parameters. Psychometrika 1982, 47, 105–113. [Google Scholar] [CrossRef]
- Yau, D.T.; Wong, M.C.; Lam, K.F.; McGrath, C. Longitudinal measurement invariance and explanatory IRT models for adolescents’ oral health-related quality of life. Health Qual. Life Out. 2018, 16, 60. [Google Scholar] [CrossRef] [Green Version]
- Albano, A.D.; Rodriguez, M.C. Examining differential math performance by gender and opportunity to learn. Educ. Psychol. Meas. 2013, 73, 836–856. [Google Scholar] [CrossRef] [Green Version]
- Albano, A.D. Multilevel modeling of item position effects. J. Educ. Meas. 2013, 50, 408–426. [Google Scholar] [CrossRef]
- Stanke, L.; Bulut, O.; Rodriguez, M.C.; Palma, J. Investigating Linear and Nonlinear Item Parameter Drift with Explanatory IRT Models. Presented at the National Council on Measurement in Education, Washington, DC, USA, 7–8 April 2016. [Google Scholar]
- Chalmers, R.P. mirt: A multidimensional item response theory package for the R environment. J. Stat. Softw. 2012, 48, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Dorie, V.; Bates, D.; Maechler, M.; Bolker, B.; Walker, S. Blme: Bayesian Linear Mixed-Effects Models. R Package Version 1.0-5. Available online: https://CRAN.R-project.org/package=blme (accessed on 23 July 2021).
- Bürkner, P.-C.; Gabry, J.; Weber, S.; Johnson, A.; Modrak, M. Brms: Bayesian Regression Models Using ‘Stan’. R Package Version 2.15.0. Available online: https://CRAN.R-project.org/package=brms (accessed on 23 July 2021).
- Robitzsch, A.; Kiefer, T.; Wu, M. TAM: Test. Analysis Modules. R Package Version 3.7-16. Available online: https://CRAN.R-project.org/package=TAM (accessed on 12 July 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wide Format | Long Format | |||||
|---|---|---|---|---|---|---|
| Person | q1 | q2 | q3 | Person | Item | Response |
| 1 | 2 | 2 | 3 | 1 | q1 | 2 |
| 2 | 2 | 2 | 0 | 1 | q2 | 2 |
| 3 | 1 | 1 | 0 | 1 | q3 | 3 |
| 4 | 2 | 2 | 2 | 1 | q4 | 3 |
| 5 | 2 | 2 | 2 | 1 | q5 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bulut, O.; Gorgun, G.; Yildirim-Erbasli, S.N. Estimating Explanatory Extensions of Dichotomous and Polytomous Rasch Models: The eirm Package in R. Psych 2021, 3, 308-321. https://doi.org/10.3390/psych3030023
Bulut O, Gorgun G, Yildirim-Erbasli SN. Estimating Explanatory Extensions of Dichotomous and Polytomous Rasch Models: The eirm Package in R. Psych. 2021; 3(3):308-321. https://doi.org/10.3390/psych3030023
Chicago/Turabian StyleBulut, Okan, Guher Gorgun, and Seyma Nur Yildirim-Erbasli. 2021. "Estimating Explanatory Extensions of Dichotomous and Polytomous Rasch Models: The eirm Package in R" Psych 3, no. 3: 308-321. https://doi.org/10.3390/psych3030023
APA StyleBulut, O., Gorgun, G., & Yildirim-Erbasli, S. N. (2021). Estimating Explanatory Extensions of Dichotomous and Polytomous Rasch Models: The eirm Package in R. Psych, 3(3), 308-321. https://doi.org/10.3390/psych3030023