1. Introduction
The top resolutions in track fitting, discussed in [
1,
2,
3], require special types of probability density functions (PDFs) for their realizations. The maximum likelihood, used to obtain the top resolutions, implies the handling of products of the observation PDFs (likelihood), one PDF for each observation of the fit. Such PDFs must have analytical expressions, appositely tuned on the statistical properties of the used signals. In our case, signals were released by minimum ionizing particles (MIPs) in silicon micro-strip detectors. In fact, a careful observation of the simulated data evidences the impossibility to reproduce the scatter-plots with a single variance (homoscedasticity). The homoscedasticity of the observations implies immense simplification of the fitting problem: the variances of the observations disappear from the equations for the least-squares. Those equations can be applied to any type of fitting problem. The homoscedasticity is a fundamental assumption of mathematical statistics, as repeatedly recalled in [
4]. The failure of this key point of mathematical statistics imposes a completely different strategy. The properties of the observations (hits) must be carefully studied to extract the essential information to achieve the fit optimality [
5]. The scatter-plots, which provided a hint to these studies, were those of [
6], showing samples of center of gravity (COG) of MIP signals as a function of the MIP impact points, (
).
To explore the relevance of additional pieces of information, those simulations were used to produce seven very rough approximations of the PDFs as functions of
for a fixed interval of COG values. Those rough PDFs were used in a maximum likelihood search of fitted parameters of MIP straight tracks. The evident improvement of the parameter distributions convinced us about the importance of the additional pieces of information. A feature was particularly convincing: the unexpected richness of exact values, absent in the standard fits (homoscedastic least squares). This feature was clearly evident as narrow peaks in all our simulations. However, to effectively use those hints, the rough PDFs need to be replaced with accurate forms such as those derived in the following and used in [
1,
2,
3]. In addition, we demonstrated in Refs. [
5,
7] that the usual fitting methods are non-optimal just for the neglect of the variance differences of the hits. Those studies proved that the variances of the fitted parameters, given by the standard fits, are always greater than the variances obtained by weighted fits with the hit variances as weights. The demonstrations are perfectly consistent with our early empirical results.
The aim of this study is to complete the previously employed methods giving the derivations and the explicit expressions of the PDFs essential to obtain our previous results. The implied PDFs are those calculated for the center of gravity (COG) algorithm. The COG algorithm is an easy and efficient positioning algorithm that is widely used in particle physics and in many other technological problems. The generic COG definition is
, where
are the signals of a cluster inserted in the COG and
denote their positions. The different selections of the signals, inserted in the COG expression, generate positioning algorithms with different analytical and statistical properties. Our special attention is directed to the two strip COG (COG
2) for its minimal noise and usefulness for tracks at orthogonal incidence (direction with the worst resolution). The COG
2 is computed with the signals of the leading strip (seed) and the maximum of the two contiguous strips. The corresponding PDF has a typical gap, the explanation of this feature and examples are reported in [
8]. It is just this typical feature that renders very complicated the calculation and very long the equation of the PDF for the COG
2. Nevertheless, the COG
2 PDF is extensively used in the simulations of [
2,
3] with very large improvements for the resolutions of the track parameters (up to a factor three for the most favorable cases). Although our attention is focalized on COG
2, other COG PDFs are calculated as well, and few of them are frequently used in our approaches. However, the COG PDFs are only a part of the probabilities for track fitting, the other part is the insertion of the functional dependence on
. Completed with the particle impact point (
), the PDF can take into account the signal-to-noise ratio of each strip and correct the COG systematic errors. The insertion of the
functional dependence requires the exploration and filtering of special types of random processes and the availability of large sets of homogeneous data [
2]. Further details about the handling of these types of random processes will be discussed elsewhere.
As a non-trivial by product, the analytical expression of the COG
2 PDF also allows us to discuss an approximate demonstration for the lucky model [
1]. The same equation also consents to an extension of the lucky model to trackers formed with non-identical detectors (a declared limitation for the lucky model in [
1]).
In
Section 2, the necessity to go beyond the standard (homoscedastic) least squares method is illustrated and the simplest forms of COG PDFs are reported. In the following, the least squares method, which uses the equations for homoscedastic systems, is called “standard least squares.”
Section 3 and
Section 4 are devoted to the complete COG
2 PDF and the PDF for the three strip COG. Applications of these results are reported in
Section 5, with proofs and extensions of the lucky model.
Section 6 contains the conclusions.
Appendix A gives a derivation of a partial COG
2 PDF from the cumulative probability distribution and
Appendix B reports on a better approximation of the COG
2 PDF. These results are obtained with the extended use of MATHEMATICA [
9] and verified in many realistic cases with MATLAB [
10] simulations.
2. Definition of the Problem
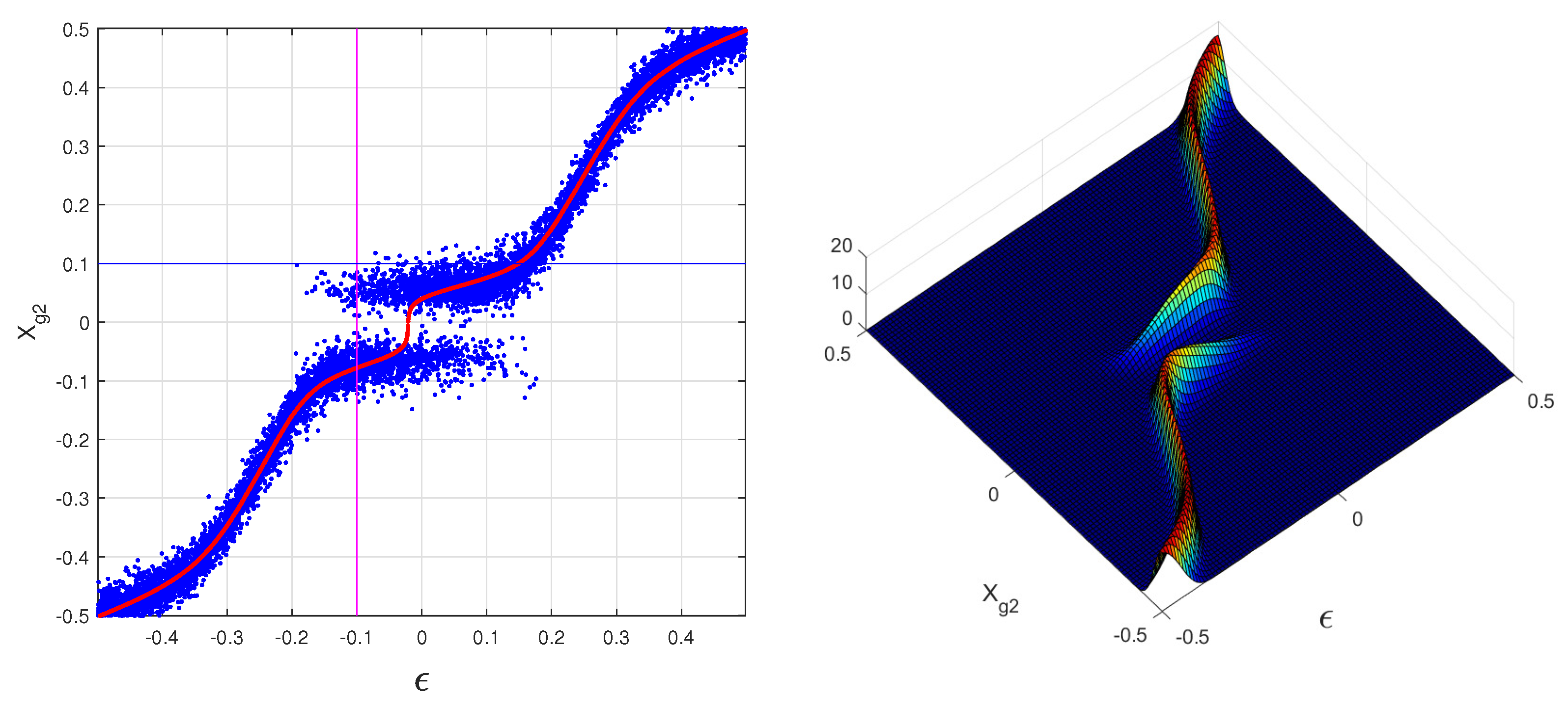
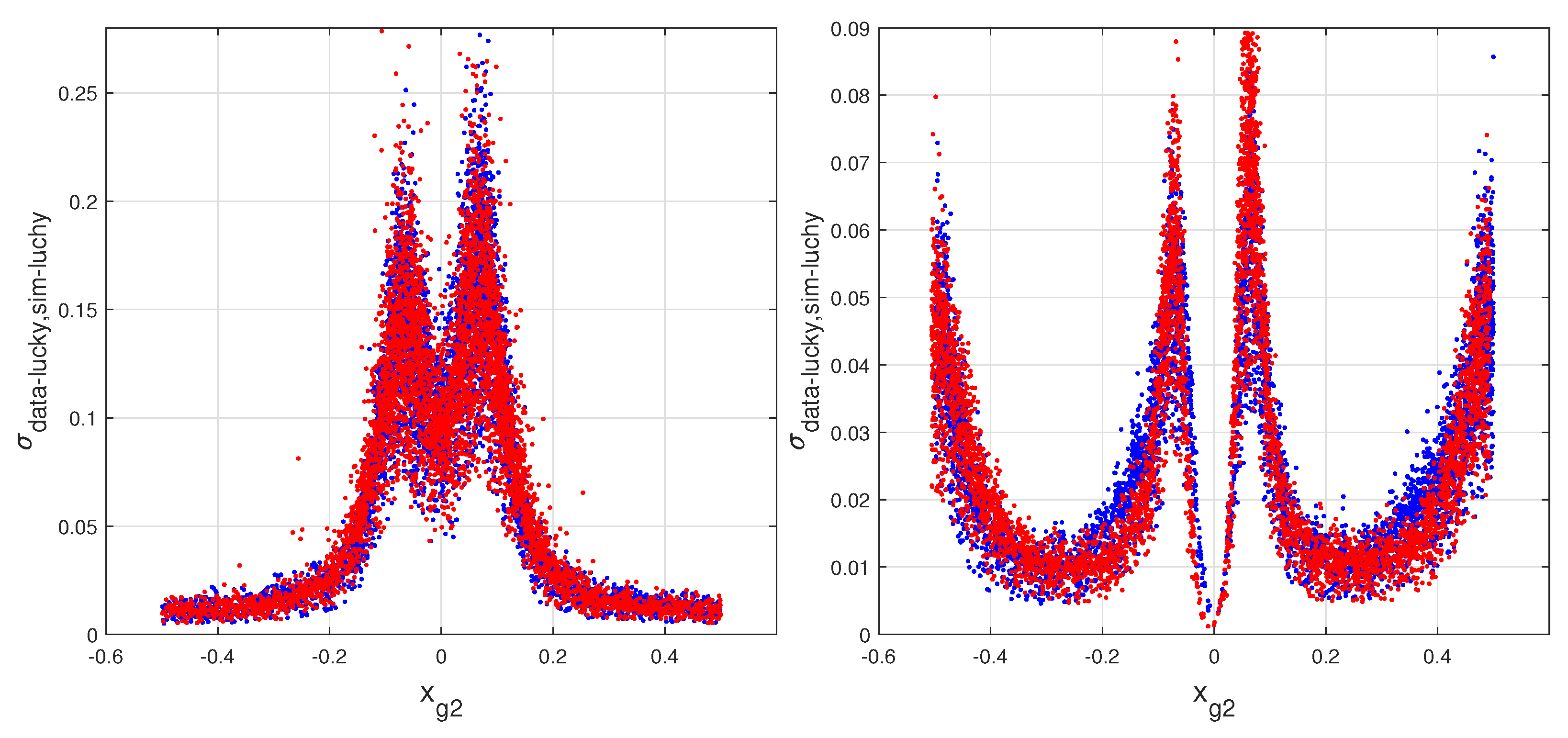
The peculiar non-uniformity (heteroscedasticity) of the point distributions in the scatter plots of COG simulations are easily observed, (as in [
2,
6] and in the figures shown in this study). In [
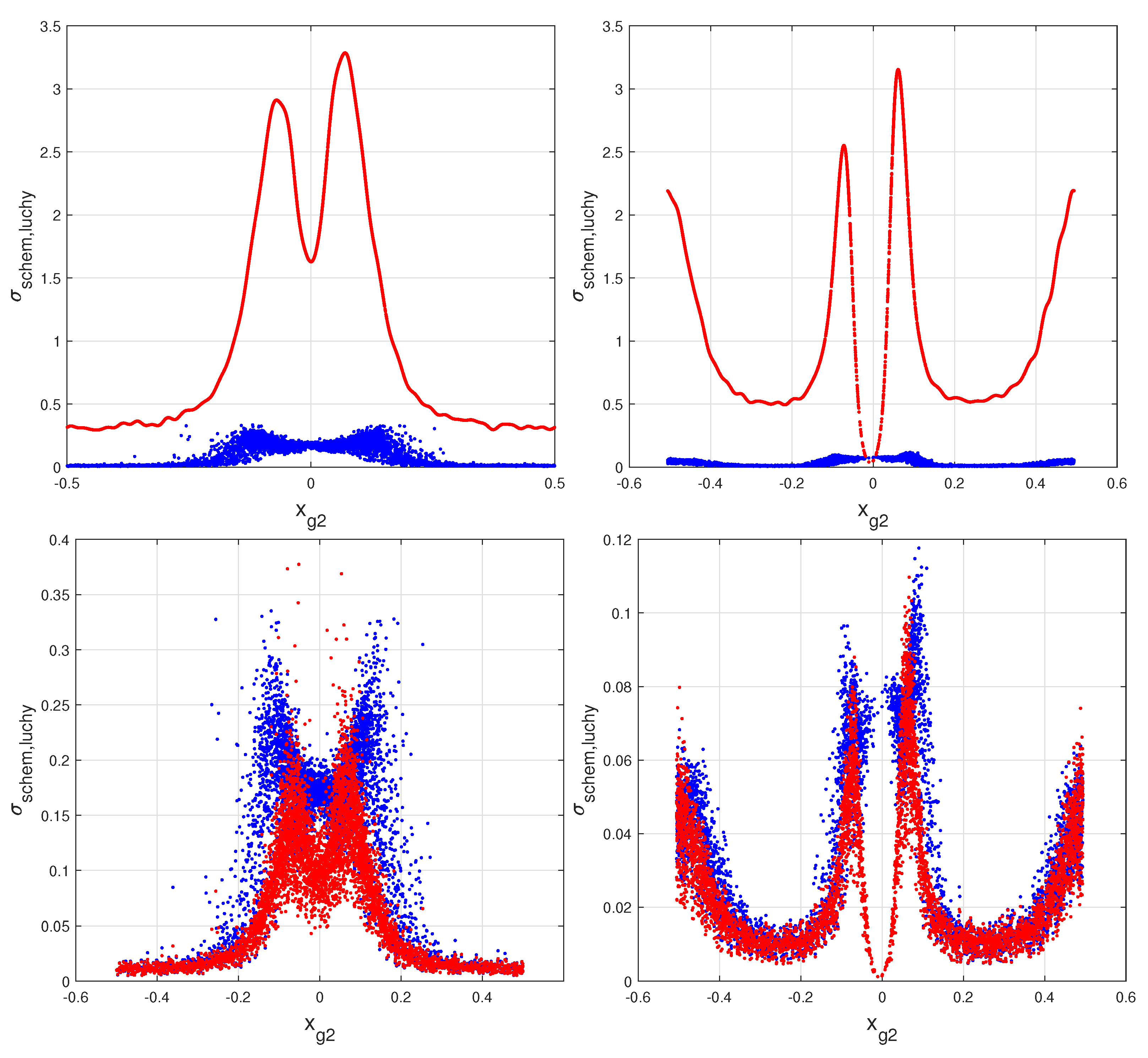
2], this heteroscedasticity is demonstrated with the definition of an effective variance for each hit and with the distributions of the samples of these values. The plots of those distributions substantially differ from a horizontal line, the obvious result for an identical variance for all hits (homoscedasticity). Therefore, the hypothesis of homoscedasticity for the positioning errors must be ruled out in favor of more realistic assumptions. In fact, the variance reduction, introduced by the distinction of good or excellent hits (heteroscedasticity) on a track containing two or more hits of such types, is easily grasped. This is the reason for the evident richness of the exact values of the heteroscedastic fits, absent in the standard least squares. The distributions of the hit effective standard deviations also show trends surprisingly similar to the COG histograms. This similarity consents the definition of a sub-optimal model (the lucky model [
1]) for the hit variances that introduce good improvements in the fitting results, without the complications of the full calculation.
The corrections of the hit properties, due to the differences of the detector technologies along the lines of Ref. [
11], are small steps in the right direction but absolutely insufficient. Experimental indications about the differences of the hit resolutions are reported in [
12]. However, the Landau distribution of the charge released by a MIP is another well known experimental fact, adding further differences to the hit properties and definitively suppressing the homoscedasticity. Instead, the maximum likelihood method involves all the available information contained in the data, and it is able to obtain drastic improvements of the track parameters also in presence of outliers [
2]. This ability to handle outliers is a consequence of the tails of PDFs. As previously discussed, another important feature is introduced by the different quality of hit PDFs. Two goods (or excellent) hits suffice for a good (or excellent) straight track fit as in [
2], or three of them for momentum reconstruction in a known homogeneous magnetic field as in [
3]. The probability of good (or excellent) hits grows proportionally to the number
N of hits (detecting layers) per track [
1,
5,
7]. Therefore, the pool of the track parameters is enriched at this rate (≈linear in
N) for a range of
N-values of interest for tracker physics. Instead, the standard least squares, not accounting for the hit differences, grows as
. This is a very slow growth compared with the linear one, implying a waste of tracker resolution and an increase of tracker complexity.
In spite of the proofs of the maximum likelihood as the best fitting method, intrinsic difficulties limit its use. For very complex trackers, the full machinery of the maximum likelihood could be beyond reasonable computing resources. Although the schematic model [
2] substitutes the maximum likelihood method with a weighted least squares, the computing of the effective hit variances also requires large processing time. The lucky model of Ref. [
1] and its advanced version can be an easy substitute. Evidently, each departing step from the maximum likelihood adds a loss of resolution. It must be remembered that the schematic model, the lucky model, and its advanced form are ineffective with the outliers.
The required analytical expressions of the PDFs have the general functional forms
, where,
is a generic COG with
n-strips. The conditional probabilities,
and
, are connected with the marginal probabilities,
and
[
13]:
The constant probability of the impact point
is assured by
and it is consistent with the assumption of uniformity and normalization on a strip.
The Kolmogorov axioms [
13] attribute to the cumulative probability distribution a fundamental role to calculate the PDF. The cumulative probability distribution for a continuous case is given by integrations on the appropriate portion of the plane, or the space, as required by the geometry of the problem. Differentiating the cumulative probability distribution produces the PDF. This method becomes extremely long with complicated algorithms. However, our first approach was modeled on the ratio of two random variables of [
13], and we used the cumulative distributions for all the considered PDFs, from the simplest to the most complex one. This very long set of integrals is quite tedious, to be reported in a paper. This is the principal reason for the delay of this report. Here, a different approach is utilized, very direct and flexible, with the use of Dirac
-functions and Heaviside
-functions, operating directly on the PDFs of the strip noise; an assay was given in [
3]. This method is a variance of the Fermi “golden rule 1” that is used for the cross-section calculations (or diffusion probabilities), and it recovers the results of our geometric approaches. However, Gauss [
14] gives similar generic expressions as obtained after the
-integration, but we found that old fundamental paper only recently. To underline the consistency with the geometric approach, the first part of the COG
2 PDF is obtained with the cumulative probability distribution in
Appendix B.
The random signals of our interest are modeled on the charges released on the strips by the hitting MIPs. The signals are corrupted by additive random noises produced by the rest of the acquisition system. The data are at their final elaboration procedure (calibration, pedestal, common noise suppression, etc.) and are ready to be used in a positioning algorithm of any type. The stream of primary charges, released by a MIP, diffuses in the detector toward a cluster of strips. The charges, collected by a strip, are correlated with those, collected by the cluster. The distributions of the charges in the cluster depend, among other parameters such as particle direction and total released charges, on the MIP impact point. Hence, the dependence of must be contained in the strip signal . The signals are considered as parameters, and the PDF will be expressed in the form , where is the set of strips inserted in . The variable is abandoned for a simpler ! x. The strip size is always taken to be one, and this is the length scale of the system (all the implied lengths are divided by the strip widths). The parameters, , can be expressed in any dimensional units consistent with those of the noise (we use directly the ADC (analog-to-digital converter) counts.) The variable x turns out to be a pure number as the PDFs.
Each strip has its own random additive noise uncorrelated with that of any other strip. In strips without MIP signals, the strip noise is well reproduced with a Gaussian PDF. Thus, the PDFs for the signal plus noise of the strip
i become:
The Gaussian mean values are the (noiseless) charges, collected by the strips, and are positive numbers (we assume to have signals from real particles). The parameters are the standard deviations of the additive zero-average Gaussian noise.
2.1. Probability for the Ratio
The first explored PDF is the distribution of the random values of
x with
. This expression has the structure of a COG with the origin of the reference system in the center of the strip 2 (
random variable) and another signal on the right strip 1 (
random variable). This form of COG is the right part of the full COG
2 algorithm. Due to its limitation to only two random variable
, it is a first step toward more complex PDFs. The derivation of the PDF for
with the cumulative distribution is illustrated in
Appendix B However, this PDF can be rapidly obtained with this method:
Integrating the
-function with
:
the expression for
is easily obtained:
The heavy tails of a Cauchy–Agnesi-like distribution are evident; Equation (
5) shows
behavior for
, and the factor
goes to
. In this limit, the integral is convergent and different from zero. Identically for
. The singularity for
is apparent because one integrand goes to zero for
and can be removed with the coordinate transformation
. However, it is useful to save the
factor to remember the divergence of the variance for
. The Gaussian integral is analytic for any
x and
and has the following form:
The expression of the
shows some aspects that will be found often in the following. One can easily recognize, in Equation (
6), part of the PDF reported in [
3]. Equation (
6) has a maximum for
. The maximum is the noiseless COG for this combination of variables and tends to eliminate the COG systematic error [
8]. Around the maximum,
looks similar to a Gaussian. However, the exponential differs from a Gaussian for large
x. The modulating term of the exponential is connected to the signal to noise ratio of the two strips. The positivity of the PDF is granted by the term
, which, for a not too small
A, converges rapidly to
. Around zero,
is a continuous differentiable function and differs from
essentially for the cusp at
of
. The range of the differences with respect to
are of the order of
(or some weighted average with
). This range is expected to be negligible, if the hit-detection algorithm works well and discards almost all the fake hits (with
). Thus, very often we will substitute
with
.
The last term will be indicated as “Cauchy-like” term; it is very similar, but not identical, to a Cauchy-Agnesi PDF. This term survives also for and could be a probability of fake hits. It assures the strict positivity of the PDF. For , the Cauchy-like term is heavily suppressed by the negative exponents, quadratic in the strip signal-to-noise ratio.
The validity of this PDF is limited to one side of the COG2 algorithm. The track reconstruction requires a rigid connection to the local reference system, which is naturally locked in the seed-strip center. Therefore, it is important to conserve a difference from the left strip, the central strip, and the right strip. The track impact point, , can also be located outside the seed strip.
Another PDF, which composes the complete COG
2 PDF, contains the random variable
, the signal collected by strip 3 positioned to the left of strip 2. This PDF will be indicated as
. As for
, the strip 2 is the seed of the strip cluster. As always, the origin of the reference system is the center of strip 2. Now,
x is given by the combination of random variables
. The function
is obtained from Equation (
6) with the substitution
,
and
. We report here
; often in the following, terms of this type will be indicated with the substitutions needed for their construction:
The small
x approximation is now:
The approximation of
as a Dirac
-function in the integration of Equation (
5) does not reproduce the Cauchy-like term. The factor
is retained, being contained in the argument of the
-function. Its role is essential to obtain the maximum of
in the expected position
of its noiseless COG.
2.2. Probability Distribution for
Another type of COG
2 algorithm is of frequent use, for example, in [
15]. The main difference of this combination of random variables, from previous expressions, is a translation with respect to the standard reference system (centered in the middle of the strip 2). Now, the reference system is centered on the right border of the strip 2. This COG
2 algorithm has the following form:
Although this is another direct transformation of Equation (
6), we report its general form and the case of Gaussian PDF for completeness:
In the form of
, we directly use the substitution of
with
. In any case,
is easily obtained from Equation (
6):
With a similar transformation, the PDF for
can be obtained; here, the reference system is centered on the left border of strip 2 with strip 3. A discussion of the variance of
y for small errors is given in [
16], although the variance is an ill defined parameter due to the Cauchy–Agnesi-like tails of the PDF. In this case, the results depend on the assumptions introduced.
These PDFs have simple analytical forms; they are defined in reference systems that depend on the signal in the second strip. Their use in maximum likelihood search, could imply heavy complications in the exploration of the likelihood surface. In fact, to allow for the maximum to be outside the two strips of the PDF, another function must be introduced with a different reference system.
2.3. Probability Distribution for
As a final use of Equation (
5), we apply it to obtain the PDF for the ratio of random variables
. Now it reads:
The integral expression of
becomes:
and transforming Equation (
6) in
w, as indicated, the
for Gaussian PDFs becomes:
Now, the maximum of the first term is moved to be around
. For
, the last term, the only non-zero, coincides with that reported in [
13].
4. Simplified form of the Three Strip COG
To test the accuracy of the functions
, the reconstruction of the two-strip and three-strip COG (COG
2 and COG
3) histograms were extensively used in [
2]. For this task, the COG
3 PDF was also essential. To simplify, we leave out of this discussion the complications of the full form of the COG
3 PDF and their gaps at the strip borders as discussed in [
8], limiting the demonstration to the easiest COG
3 form. This incomplete PDF is useful in all the cases when the border gaps are very small (near orthogonal incidence):
Again, the normalization of
is easily verified. The substitution of variables,
,
, and
, simplifies the Dirac
-function integration. The Jacobian of the substitution equals
. Integrating over
the Dirac
-function, the remaining double integral has the following form:
The integration in
is a convolution of Gaussian PDFs and provides another Gaussian. Due to the
, the integral on
z produces the term of the form
that, as above, we approximate as
. The introduction of the auxiliary constants
and
further simplifies the form of
. The Cauchy term, indicated with
, is the first one discussed and it is:
The term
for
, as it is often, has a very simple form:
This term also survives for
and becomes an exact Cauchy–Agnesi PDF. The main term
is:
the approximation of
as
has no observable differences in our realistic simulations. Anyway, the
-function is:
The upper part of the fraction in the
-argument in Equation (
25) coincides with the corresponding term in the absolute value of Equation (
24). The numerator of the
-argument represents rather peculiar recurrent form (in the main term (
24)); the
of each strip is multiplied by the noiseless COG
3, referred to in the position of that strip and identically for the running
x. A similar feature can also be seen in the COG
2 PDF.
A complete form for the COG
3 algorithm must account for the gap at the strip borders. This happens when the signal distribution is larger than two strips, and the values of
are suppressed in the COG
3 creating gaps at the strip borders. The suppression increases rapidly as the (average) signal distribution grows beyond the two-strip size. Near to the strip borders, the noise can increase the signal collected by the nearby strip (as the strip 1), becoming the seed of another three-strip cluster. In this case, the COG
3 algorithm must operate with the signal triplet
, where
is the signal of the strip to the right of the strip 1. Thus, the algorithm becomes:
The two sides of Equation (
26) are defined in the identical reference system centered on strip 2. A similar expression is required for the gap at the other border of the strip 2. The details of these extensions of the COG
3 algorithm are reported in [
19] (and references therein.) These are the instruments to move toward large angles of incidence. However, the selection of the COG algorithm depends on the sizes and shapes of the average signal distributions. Such parameters must be extracted from the data with the equations from [
2].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}