1. Introduction
Nowadays, technology contributes more and more to aid its users in carrying out challenging tasks by creating innovative applications. Especially in the healthcare sector, assistive technologies provide benefits of convenience and accessibility, collecting patients’ healthcare data, helping doctors to provide better diagnoses, and helping caregivers to control patients’ conditions even remotely via mobile devices. Health apps must adhere to the same level of privacy as the doctor–patient confidentiality regulation in medical visits. Users must rely on trust when it comes to the handling of personal information in apps and the services they connect to, ensuring a high level of usability for a seamless experience. This trust is based on the belief that app services are operated ethically, adhering to privacy regulations and security best practices [
1]. According to [
2], even popular applications fail to provide basic protection for users’ privacy due to either inappropriate implementations or poor design choices. Data that is used in healthcare applications contains information such as their name, age, sex, and many other critical forms of identity information, in addition to the healthcare records that characterize the user’s physical condition. Consequently, if this data was to be disclosed to a malicious entity, it would place the patient at significant risk regarding their security and privacy.
Health applications are exposed to a multitude of vulnerabilities across various processes, ranging from user access control to communication between different stakeholders, and data processes throughout their lifecycle. Consequently, these reasons necessitate the adoption of Privacy-Enhancing Technologies (PETs) in health applications. PETs refers to a group of different techniques for enhancing both privacy and security [
3]. Key characteristics and examples of PETs include data anonymization and pseudonymization, homomorphic encryption, privacy-preserving authentication mechanisms, Federated Learning, differential privacy, and blockchain technology. Despite advancements in PETs, many developments are still at the proof-of-concept stage, explaining why their adoption is not widespread, underscoring the need for further exploration of the barriers preventing their integration into the healthcare sector [
3,
4,
5].Therefore, widespread adoption of PETs remains a challenge that must be addressed to ensure the future of secure digital healthcare solutions.
In this work, we present a general framework regarding safeguarding health applications from security and privacy risks and develop it for a specific use case, particularly in our case, the concept of using apps to manage Attention Deficit Hyperactivity Disorder (ADHD) in children. Mental health apps deal with highly sensitive data, in contrast to other general health apps, e.g., for fitness and wellness [
6]. Especially when these apps are dedicated to children, it is crucial to prioritize security and privacy features. Our ultimate goal is to provide a trustworthy and privacy-preserving solution to different actors involved in the gamified ADHD application, particularly children, parents, medical staff, and educators. We develop a highly efficient, scalable, and user-centric identity management framework that integrates advanced Privacy-Enhancing Technologies (PETs) with a Federated Learning (FL) architecture. This combined approach enables AI-driven predictions while strengthening data privacy, supporting patient autonomy, and overcoming the inherent limitations of centralized healthcare systems. In contrast to traditional models that rely on centralized models prone to single points of failure, our solution embraces a decentralized paradigm. By incorporating a blockchain-based identity management system, we ensure secure, tamper-resistant credential issuance and verification, fostering trust, resilience, and compliance with modern privacy regulations. This work makes several key contributions. We propose a decentralized identity management architecture that overcomes single-point-of-failure risks in existing systems while integrating Privacy-Attribute-Based Credentials (p-ABCs) to support fine-grained, consent-driven, and unlinkable identity disclosures essential for multi-stakeholder access control in health applications. The system incorporates a Federated Learning pipeline adapted to low-trust, shared-device scenarios such as children using tablets in clinics, ensuring both predictive performance and privacy compliance. We address a critical gap in mental health technology by offering a decentralized, privacy-preserving digital service model that enables seamless access to e-health services across organizational boundaries while maintaining strict privacy guarantees. We validate the approach through real-world implementation, including user feedback from parents and clinicians, and empirical performance evaluation under privacy constraints. Finally, we conduct a user-centered design process based on questionnaires and clinician interviews to understand user needs and inform system development. The architecture embodies privacy-by-design principles and ensures GDPR compliance, contributing to scalable, ethical, and patient-centered digital health ecosystems that balance data utility with privacy protection.
The rest of the paper is organized as follows.
Section 2 presents the methodology used to identify stakeholder needs through questionnaires and clinician interviews.
Section 3 reviews related work on privacy-enhancing technologies and Federated Learning in healthcare. Next,
Section 4 introduces the AURORA MINDS framework, outlining its architecture, identity management system, and core design considerations.
Section 5 describes the system architecture, key components, and implementation details, including identity enrollment and Federated Learning modules.
Section 6 illustrates a real-world use case of identity management enrollment and machine learning model training for ADHD risk prediction.
Section 7 presents performance and evaluation results for both identity operations and Federated Learning models.
Section 8 discusses the cross-domain applicability of the framework.
Section 9 provides an analysis of end-user perceptions based on a focused survey.
Section 10 outlines system limitations and areas for future improvement. Finally,
Section 11 concludes the paper with a summary of key contributions and impacts.
2. Methodology
This study presents a comprehensive and multi-dimensional methodology to adopt security and privacy-preserving technologies in the healthcare sector and analyze their impact. Our primary objective is to collect a range of perspectives from various stakeholders, including parents and clinicians. By doing so, we aim to create an environment that caters to the needs of all parties involved, ultimately leading to a user-centric approach. Our methodology is outlined in the following subsections.
2.1. Questionnaire for Evaluating User Needs
A very significant part of our user co-creation methodology was a comprehensive questionnaire aimed at gathering detailed insights from parents of children diagnosed or suspected of having ADHD. The survey was designed to capture both quantitative and qualitative data, allowing us to assess parental perceptions, expectations, and experiences with existing ADHD monitoring tools, particularly in terms of privacy, usability, and utility. The questionnaire was distributed online and consisted of 15 questions, including 10 Likert scale items, 3 open-ended questions, and 2 ranking questions. The responses were collected over a three-week period, ensuring a diverse set of perspectives.
The questionnaire was developed in collaboration with clinicians and experts in human–computer interaction to ensure relevance and clarity. Likert scale questions addressed topics such as the following:
Privacy Concerns: Parents were asked to rate their level of comfort with sharing sensitive data, with 0 indicating “Not at all comfortable” and 10 indicating “Extremely comfortable”.
Usability of Existing Tools: Participants evaluated how user-friendly they found current ADHD management applications.
Trust in Digital Solutions: This section explored parental trust in digital tools, specifically focusing on data security and compliance with privacy laws like GDPR.
Open-ended questions encouraged parents to elaborate on challenges they faced, features they valued in existing tools, and what improvements they desired. Ranking questions, on the other hand, required parents to prioritize functionalities they deemed most important, such as real-time behavioral monitoring, intuitive dashboards, or multi-user access for educators and clinicians.
A total of 25 participants completed the questionnaire, recruited through collaborations with local speech therapists. The sample included the following:
Parents of newly diagnosed children (40%),
Parents managing ADHD for more than three years (30%),
Parents exploring the possibility of an ADHD diagnosis for their children (30%).
The participants represented a diverse range of educational and technological backgrounds, ensuring the findings were not biased towards a specific demographic.
The results highlighted significant parental concerns about privacy. The average comfort level for sharing data was rated at 3.8 out of 10. Parents expressed fears of potential misuse of their child’s sensitive information. Interestingly, 70% of respondents reported that a lack of clarity on data storage and usage policies had deterred them from using existing ADHD applications. When asked to rate the usability of currently available tools, the average score was 4.2 out of 10. Parents frequently cited overly complex interfaces and poor guidance during setup as barriers to sustained use. In ranking functionalities, parents placed the highest importance on visual progress dashboards (80%), followed by the ability to customize data-sharing permissions (70%). Gamified exercises for children were also highly valued, with 65% of parents noting that engaging activities would improve their child’s participation.
Open-ended responses revealed a consensus on the need for a user-centric design. Parents called for features like the following:
Simplified Navigation: Several participants highlighted the need for intuitive layouts that minimize cognitive load.
Clear Privacy Policies: Parents wanted transparent communication about how data would be stored, processed, and accessed.
Customizable Features: Options to tailor the application to individual child profiles were deemed essential.
The insights gathered through the questionnaire directly influenced the development of AURORA MINDS, specifically:
Enhanced Privacy Features: The integration of Privacy-Attribute-Based Credentials (p-ABCs) ensures that parents can customize data-sharing permissions and have full control over their child’s information.
User-Centric Design: Based on feedback about usability challenges, the application was built with an intuitive interface and included a guided onboarding process.
Interactive Dashboards: Responding to the demand for visual progress tracking, the app features interactive dashboards that display behavioral trends over time, making it easier for parents to monitor their child’s development.
2.2. Interviews with Clinicians
Interviews with clinicians were a vital part of our methodology, offering insights into the clinical requirements, diagnostic challenges, and practical needs of healthcare providers working with children with ADHD. These semi-structured interviews were designed to delve deeper into the experiences and expectations of medical staff, focusing on their interaction with current diagnostic tools and their perspectives on integrating innovative, privacy-preserving technologies like those proposed in AURORA MINDS.
The interviews were conducted over a four-week period, involving three medical professionals, including one pediatrician specializing in neurodevelopmental disorders and two speech therapists with expertise in behavioral assessments. Each interview lasted between 60 and 90 min and followed a structured guide that covered the following themes:
Current Diagnostic Tools: Strengths and limitations of existing solutions.
Challenges in ADHD Management: Practical issues in diagnosis, monitoring, and patient engagement.
Privacy Concerns: Specific worries about data handling and compliance with regulations like GDPR.
Expectations for New Technologies: Features and functionalities desired in a next-generation application.
All three participants highlighted significant limitations in current diagnostic tools. While existing systems like checklists and standardized questionnaires provide a baseline for diagnosis, they lack dynamic and contextual insights into a child’s behavior. Additionally, medical staff pointed out that current tools are often poorly integrated into their workflows, creating inefficiencies.
Privacy emerged as a major concern among clinicians. While recognizing the value of digital tools, medical staff expressed apprehension about data breaches and unauthorized access to sensitive patient information. The clinicians also emphasized the need for compliance with data protection regulations, particularly GDPR. They highlighted the importance of transparency in data handling and the ability of parents to exercise control over their children’s information. Lastly, the concept of Federated Learning received positive feedback. Clinicians appreciated the idea of collaboratively improving diagnostic models without compromising the privacy of patient data.
2.3. Design Principles
Recognizing the aforementioned needs of the entities involved, AURORA MINDS sets itself apart from existing solutions through several distinctive features:
User-Centric Design: AURORA MINDS is dedicated to prioritizing the needs of end-users. By incorporating a gamified experience, the application effortlessly integrates into the daily activities of children, fostering their educational and personal growth. Simultaneously, it empowers caregivers, i.e., parents, educators, and clinicians, to effectively track the development of children’s communication skills.
AI-Empowerment: AURORA MINDS harnesses the power of artificial intelligence to provide tailored and precise predictions about ADHD development. This AI-driven approach ensures that each user receives personalized insights, enhancing the effectiveness of the diagnostic process.
Full Data Control: In line with strict data governance standards and European regulations, AURORA MINDS guarantees that users have full control over their data. This is achieved through the integration of identity management, which allows users to selectively grant access to their information to trusted entities. Furthermore, the application includes consent management mechanisms designed to safeguard user permissions, reinforcing our commitment to user autonomy and data security.
Privacy Enhancement: Complying with European standards on digital identity and data privacy, AURORA MINDS implements cutting-edge measures to enhance data privacy. Central to this strategy is Federated Learning, an innovative distributed machine learning method that permits the collaborative development of a machine learning model among users without necessitating the direct sharing of private information. In this way, AURORA MINDS not only stands out for its commitment to privacy and data control but also its unique, engaging approach to ADHD diagnosis, making it a pioneer in the field.
Cloud Infrastructure: We leverage a cloud-based environment to ensure that the platform can dynamically scale resources according to usage demand. The cloud services architecture, using platforms like AWS or Microsoft Azure, provides a flexible and cost-effective solution to manage increasing data volumes and user traffic as AURORA MINDS grows.
3. Related Work
Security and privacy in healthcare applications are highly sensitive because of personal information and health details that necessitate secure access, minimal information disclosure, and high accuracy. However, in [
2], the authors conducted a year-long analysis of popular mobile health applications, revealing major shortcomings, including data protection violations, lack of encryption, insecure data transmission, and improper programming practices, risking user privacy by exposing health conditions, personal details, and location data to third parties. Also, works like [
1,
6] have found significant gaps in user data protection. Key findings indicated that a substantial percentage of healthcare applications may collect and share user data with third parties, highlighting the urgent need for clearer communication and improved regulations in the health application market to protect users.
Although there are numerous digital applications that offer healthcare e-services and personalized healthcare experiences, there is a notable lack of effort to ensure compliance with GDPR, which prioritizes user privacy and data protection. The research in [
7] indicates that significant data privacy issues persist, such as unnecessary permissions, insecure cryptographic implementations, and the leakage of personal data and credentials in logs and web requests. Furthermore, the risk of user profiling remains high, as many applications fail to implement robust mechanisms to prevent linkability, detectability, and identifiability. One potential solution to these challenges could involve the use of PETs, as they provide a range of features for protecting users’ personal information and sensitive data from unauthorized access and tracking [
8].
Furthermore, to enhance personalized experiences in healthcare applications, machine learning algorithms are increasingly used to analyze user data and deliver tailored outcomes. However, these techniques also raise significant privacy concerns [
9]. They can expose sensitive patterns in the data, which may be exploited by malicious actors to cause financial or social harm, or by corporations to infer personally identifiable or confidential health information for commercial purposes [
9,
10]. To address these risks while still preserving personalization, Federated Learning (FL) has emerged as a promising solution. FL enables collaborative model training across distributed devices or institutions without transferring raw data, thereby minimizing exposure and enhancing data security [
11].
Despite extensive research on privacy in healthcare, a critical gap persists: no unified system has been implemented that holistically addresses the operational needs of healthcare organizations while reconciling patient and clinician requirements with modern privacy-preserving technologies. Existing solutions often fail to integrate essential components such as traditional e-services (e.g., secure authentication) with privacy-centric features like anonymous access, or they neglect the unique challenges of FL when applied to sensitive health data collected from smart devices—particularly in mental health contexts, where robust privacy protections are urgently needed but rarely deployed. Our work advances the state of the art by presenting a fully implemented system that bridges these gaps. The system combines conventional e-health services with privacy-enhancing functionalities, including anonymous access and FL-based model training, while rigorously evaluating the trade-offs between model accuracy, security, and privacy preservation. By demonstrating practical performance through real-world implementation and compliance with GDPR and privacy-by-design principles, we provide a scalable solution that aligns with both clinical workflows and patient expectations, setting a new benchmark for deployable privacy-preserving healthcare systems.
3.1. Adoption of PETs in Healthcare
The integration of PETs in healthcare applications seems promising, as these primitives are designed to prevent data leaks while striking a balance between privacy and usability [
12]. However, their practical applicability faces several challenges. Challenges include inconsistent standards, lack of real-world validation, and trade-offs between privacy and data utility. Moreover, no single PET offers a complete solution; effective implementation requires context, specific combinations and expert judgment [
12]. The work in [
13] examined the development of existing PETs in various fields and whether they comply with legal principles and privacy standards and reduce the threats to privacy in IoT-related environments. The authors conclude that PETs remain in the early stages of technological readiness, with effectiveness varying across different threat types. Their computational complexity impacts usability, while adoption is influenced by cost and user-friendliness. Additionally, legal compliance requires adherence to regulations like GDPR, and integration challenges persist, particularly with existing systems. Notably, even in the recent work in [
14], it is determined that the maturity of these technologies still lags, except the technology of Federated Learning specifically for healthcare settings, overcoming the problem of health data leakage.
The analysis of [
15], specifically for the healthcare sector, indicates that Privacy-Attribute-Based Credentials (p-ABCs) are suitable tools for every smart health scenario. By utilizing p-ABCs, individuals can selectively disclose specific details about their identity, enhancing their privacy and security. Moreover, the design of these credentials ensures that different uses of the same credential cannot be linked together, safeguarding user privacy, even in the event of collusion among multiple malicious entities, and supporting distributed issuance (dp-ABC) [
16]. P-ABCs were also utilized for privacy-preserving authentication in solutions like uProve [
17], Identity Mixer [
18], and elPASSO [
19]. Solutions like uProve and Identity Mixer have been developed to offer privacy advantages over conventional SSO systems, while projects such as ABC4Trust [
20] and ARIES [
21] use p-ABCs to improve user privacy and data control. Identity systems like Sovrin, uPort, and Jolocom face several drawbacks related to their identity management systems.
However, the aforementioned solutions rely on a single identity provider, making them vulnerable to single-point-of-failure attacks and third-party control, and threatening privacy since user behavior is exposed to the identity provider. Blockchain-based electronic health records systems, such as [
22,
23,
24,
25], while they were assumed to rely on a decentralized IdM, they rely on a centralized IdM of healthcare institutions [
26]. Therefore, the implementation of a decentralized IdM, which enables users to control their digital identities independently from service providers [
27], or identity providers is crucial in the healthcare sector.
Table 1 outlines key differences among various identity management systems, comparing them in terms of privacy, user autonomy, and technical architecture.
Moreover, the adoption of blockchain technology in the healthcare sector is steadily increasing. Further, it is often combined with privacy-preserving techniques, like cryptography and machine learning, to reduce risks such as linkability, traceability, and identity exposure [
28]. However, according to the recent systematic review in [
28], although these methods enhance privacy, they primarily offer pseudonymization rather than full anonymization, and they are often hindered by high computational overhead and limited scalability, posing challenges for large-scale deployment in healthcare systems. In our solution, the blockchain’s role is primarily to support verifiable credential issuance and revocation, ensuring integrity without exposing sensitive user data. True anonymization is achieved through the integration of Privacy-Attribute-Based Credentials (p-ABCs), which allow users to reveal only the minimum necessary information (e.g., age) while keeping all other identity attributes concealed.
Emerging blockchain-based identity management solutions, such as Sovrin [
29], uPort [
30], Jolocom [
31], and Shocard [
32], support user-controlled identities, aligning with Self Sovereign Identity (SSI) principles. However, these approaches have limited applicability to the healthcare domain, as they lack proper identity verification, making them unsuitable for healthcare, where validating patient and provider identities is crucial [
29,
33]. Moreover, they do not address challenges related to healthcare applications [
26]. These systems do not store credentials on a blockchain but rather with agents or cloud providers. This reliance on third parties can introduce vulnerabilities if these entities are compromised. Moreover, only Sovrin and uPort support issuer-initiated revocations, limiting user control over credential management. Furthermore, identifying the controller for Decentralized Identifiers (DIDs) on public blockchains can be complex, leading to uncertainties in GDPR applicability. While public blockchains lack clear controllers, permissioned blockchains like Sovrin may have designated entities that set permissions, complicating compliance.
Table 1.
Differences in privacy, user autonomy, and technical structures across identity management systems.
Table 1.
Differences in privacy, user autonomy, and technical structures across identity management systems.
| Identity System | P-ABCs | User Control and Sovereignty | Security Model | Centralized/Decentralized | Drawbacks |
|---|
| Identity Mixer [18] | Utilizes zero-knowledge proofs for credential verification and privacy. | Limited selective disclosure; reliance on trusted devices for full security. | Zero-knowledge proof and blind signature. | Centralized | Complexity in usability, heavy cryptographic setup, SPoF. |
| U-Prove [17] | Designed for attribute-based credentials with partial data disclosure. | Provides user-side control over attributes but lacks a distributed IdP system. | Signature-based system. | Centralized | High implementation complexity, limited adoption, SPoF. |
| ABC4Trust [20] | Privacy via p-ABC and data minimization; supports selective disclosure. | User-controlled attributes with potential for federated identity. | Combines zero-knowledge proofs and anonymous credentials. | Centralized | SPoF, usability challenges. |
| ARIES [21] | Built on a decentralized blockchain supporting privacy-preserving credentials. | Strong user sovereignty with decentralized issuance; however, IdPs may pose privacy risks. | Blockchain-based; trust is managed through verifiable credentials. | Decentralized | The level of privacy heavily relies on the segregation of components and the trustworthiness of their implementations, SPoF, complex authorization processes, PKI, tracking issues. |
| Sovrin [29] | Blockchain-based self-sovereign ID, emphasizing decentralized trust;
builds a platform for intermediaries between users and its network, and an interface for other identity systems is also supported. | Users can choose ID to use and attributes to reveal; potential to use a web of trust to protect users from deception. | Anonymous credentials based on zero-knowledge proofs guarantee the principle of “least amount of identifying information” disclosure; only authorized parties and agencies can access the attributes; supports omnidirectional identifiers. | Decentralized | Public blockchain visibility can impact sensitive data privacy, SPoF,
not clear about the usability and user understanding of privacy in Sovrin. |
| Jolocom [31] | DID-based with verifiable credentials; designed for secure, self-owned IDs. | Credentials are under the entire control of the user; allows for the generation of child DIDs that can hide that credentials concern the same person. | Does not store the credentials on a blockchain. The credentials are stored with an agent, a cloud provider, or under direct control of the data subject. | Decentralized | SPoF, credential management risks privacy leakage. |
| ShoCard [32] | Blockchain-based, focused on secure identity sharing and validation. | Users control the creation and disclosure of ShoCardIDs; only parties invited by ShoCardIDs’ owner can access the attributes, and all attributes will be validated by ShoCard servers. | Only parties invited by ShoCardIDs’ owner can access the attributes, and the ShoCard servers can also access the attributes without invitation; supports unidirectional sharing of identifiers between parties; parties can parse existing trusted credentials after integrations with ShoCard centralized servers. | Centralized | Tied to mobile device security, limiting accessibility; SPoF.
Mobile applications are provided, but usability and user understanding of privacy are not clear;
high transaction time, delaying authentication process. |
| uPort [30] | Creation and disclosure of uPortIDs (verifiable credentials) are fully controlled by users, and users can prove their ownership;
leverages Ethereum to give users full control over their digital identities. | There is no need to disclose personal attributes when attaining a uPort identifier;
everyone can access the attributes in the registry; potential for encrypted data to be leaked. | Supports unidirectional sharing of identifiers between parties;
allows for customization of types, although using a specific data format will be preferred. | Decentralized | Mobile application is provided, but usability and user understanding of privacy are not clear;
potential for leakage of attributes in the registry. |
| AURORA MINDS | Blockchain-based IdP with p-ABCs and selective disclosure. | High control over attribute sharing; aims for no central authority reliance;
identity proof and feature proof. | Distributed IdPs with zero-knowledge proofs; mitigates single point of failure and unlinkability across Relying Parties. | Decentralized | The organization itself is responsible for developing and managing the infrastructure, such as distributing cryptographic material and deploying vIdP;
heavyweight. |
We believe that blockchain technology can be effectively utilized for identity management purposes, such as authentication and access control, while not being used for storing healthcare information. There are works in the literature that use blockchain for storing and managing healthcare data [
34]. Additionally, e-health organizations often support a range of diverse and transparent e-services, which requires the integration of various systems [
35]. These factors, along with technical limitations, such as block size restrictions [
36], the immutable and public nature of blockchain [
37], and the lack of technical expertise and resources within many healthcare institutions, make blockchain integration a challenging task. As a result, our solution avoids the direct storage of health records on the blockchain. Instead, our system ensures that sensitive data remains off-chain and securely protected using cryptographic techniques such as zero-knowledge proofs (ZKPs) and homomorphic encryption. These technologies enable controlled data sharing while safeguarding the privacy of sensitive health information.
In addition to these challenges, the adoption of smart contracts, which is a core component of blockchain technology, faces several significant barriers [
38,
39]. Smart contracts can manage different permissions for different stakeholders to access critical data [
40]; however, they operate in a transparent and publicly accessible environment. Thus, potential publicly available metadata could be associated with a user’s profile, compromising privacy and leading to de-anonymization [
41,
42]. Moreover, achieving interoperability between blockchain systems in healthcare is an ongoing challenge, with various ecosystems struggling to communicate seamlessly [
37,
43].
Based on the above discussion, our work using blockchain for improving data security, privacy, and patient control over personal information continues to drive innovation in the sector.
However, the literature presents various e-healthcare applications and services that have introduced patient-centric blockchain systems. Works like ours aim to investigate the trust gap from the perspectives of both patients and healthcare professionals, contributing to a deeper understanding of the challenges that must be addressed in order to fully benefit from this relatively recent technology [
35]. To address these challenges, we have developed an alternative solution for a blockchain-based identity management system. At the core of this architecture lies the Virtual Identity Provider (vIdP), which transforms the traditional model by decentralizing the identity provider into a network of interconnected entities. Unlike centralized systems that depend on a single authority, this distributed framework mitigates the risk of a single point of failure, significantly enhancing both system resilience and security. AURORA MINDS does not explicitly adopt any specific blockchain network or smart contract language. While the current implementation is managed in a single organizational domain for convenience purposes, the architecture is designed for deployment by multiple parties, where each vIdP could be operated by a separate healthcare entity (e.g., clinics).
Our architecture is designed for healthcare e-services, fostering a trustworthy environment through cryptographic operations such as blind signatures and zero-knowledge proofs. These mechanisms ensure robust anonymization by guaranteeing unlinkability and untraceability. While establishing trust with a centralized entity is straightforward, this approach necessitates preinstalled protocols and introduces the risk of a single point of failure. In contrast, our decentralized solution enhances both system resilience and security.
We argue that in healthcare applications, users must retain control over their stored data, sharing only cryptographic proofs rather than raw personal information. Furthermore, our model supports selective disclosure, allowing users to control their credentials and reveal only specific attributes when necessary. For instance, a patient could disclose their age for age-restricted prescriptions while keeping other sensitive data anonymized. Unlike centralized databases, which are prime targets for identity theft, this approach significantly reduces the attack surface. In this dynamic environment, patients can access various e-services through distributed vIdPS. For example, a patient might prove their age and healthcare insurance ID to obtain medication while only verifying their valid membership status when booking an online doctor’s appointment. We contend that blockchain technology is particularly well-suited for supporting such distributed vIdPs, as it ensures transparency, immutability, and resistance to single points of failure. This becomes especially critical in scenarios where a patient’s vIdP issues verifiable credentials that are interoperable across different e-service healthcare providers or systems adopting the same framework. To demonstrate our approach, we examine two distinct e-services: one for accessing medical games (e.g., therapeutic applications) and another for managing patient profiles and test results. By leveraging a distributed vIdP, users can securely share proofs with multiple e-services without relying on a central authority. We envision our methodology being adopted by hospitals and healthcare institutions that manage diverse e-services. Access control in such settings should be supported by a distributed ledger rather than a centralized server, mitigating challenges related to connectivity, availability, security, and privacy.
3.2. Federated Learning in Healthcare
Federated Learning (FL) is widely utilized in the medical field, where large volumes of data are collected with the aim of training models and producing meaningful outcomes, like in our work. FL [
44] is a machine learning paradigm that enables collaborative model training across decentralized data sources, particularly useful in fields like healthcare, where data privacy and security are paramount. In healthcare, FL empowers institutions to use large-scale data across multiple hospitals or devices, enhancing predictive accuracy and enabling personalized treatment without requiring data centralization. This approach has led to advancements in diagnostic accuracy, patient monitoring, and privacy preservation, making FL a compelling solution in sensitive domains.
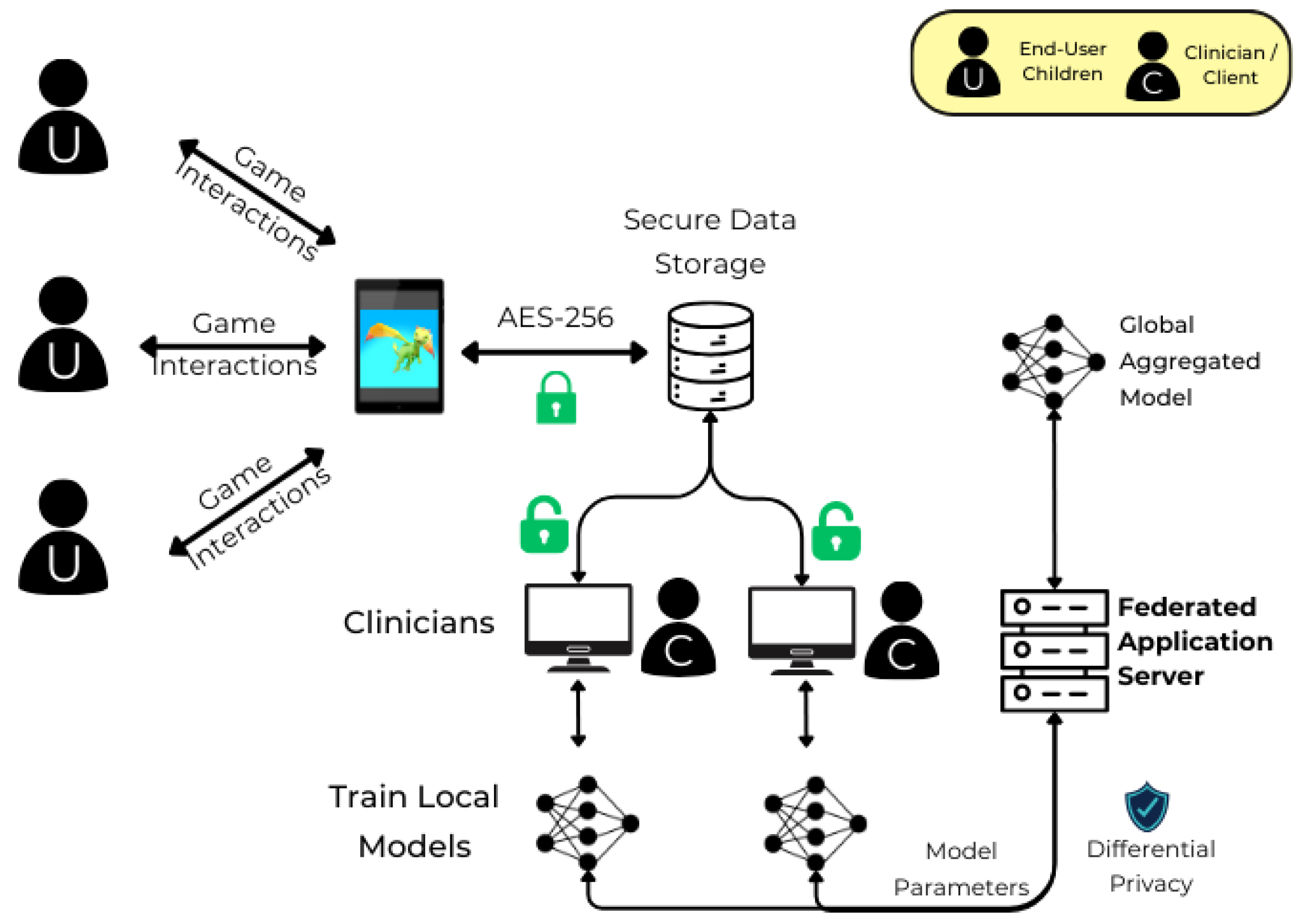
To address the privacy challenges associated with machine learning model training, we adopted FL. FL enables privacy preservation by transferring only learnable model parameters rather than raw data, thus eliminating the need to share sensitive patient information. In our case, model training is performed locally on clinic tablets, and only the parameters are securely transferred, ensuring data confidentiality throughout the process.
Furthermore, there is no research work that has specifically investigated the use of FL techniques in the mental health domain, in which ADHD is dedicated. Therefore, the authors in [
7] aimed to bridge this gap by providing an in-depth background on using FL and its state-of-the-art techniques applied in the mental health field. Consequently, in our application, we leveraged FL to ensure data privacy in the highly sensitive environment of children’s cognitive health monitoring.
Recent studies highlight FL’s potential and innovations in healthcare. One prominent application is anomaly detection for early-stage diagnosis of Autism Spectrum Disorder (ASD). This study employs a semi-supervised FL approach using AutoEncoder-based machine learning models and data from a specially designed serious game. This setup allows for early ASD detection while preserving user privacy through fully homomorphic encryption during model aggregation, reducing the risk of inference attacks. The results suggest that FL can accurately predict ASD risk while addressing the privacy needs of sensitive data, demonstrating the flexibility of FL for neurodevelopmental disorder screening [
45].
In another study, FL is applied to breast cancer diagnosis by integrating Explainable AI (XAI) to enhance trust and interpretability. By training models on distributed datasets and computing SHAP values locally, researchers preserved privacy without sacrificing diagnostic accuracy. The model achieved high performance metrics, including a 97.59% accuracy on the Wisconsin Diagnostic Breast Cancer Dataset, using artificial neural networks. This study illustrates FL’s ability to maintain privacy, enable interpretability, and support critical medical decisions in cancer diagnostics [
46].
FL has also proven effective in IoT-based healthcare systems, where homomorphic encryption enhances security by protecting local models against inference attacks, allowing robust medical image analysis and diagnostic tasks. This has been particularly useful in scenarios where dataset quality varies across nodes, enabling more equitable contributions to global models and reducing computational overhead [
47].
Furthermore, FL frameworks are increasingly adopted in remote health-monitoring systems, providing solutions for privacy-preserving patient tracking and chronic disease management. Studies show that using FL to train models with isolated datasets improves diagnostic accuracy, making it a suitable solution for distributed healthcare applications [
48].
Another application emphasizes FL’s ability to tackle data heterogeneity in diagnostic imaging, particularly in mammography. By training models across multiple healthcare facilities, researchers have achieved similar diagnostic performance to centralized methods while addressing data privacy, showing FL’s adaptability in clinical imaging and diagnostics [
49].
In addition, FL integrated with blockchain has demonstrated promising results in distributed healthcare environments by maintaining data integrity and securing model updates on a decentralized ledger. Blockchain-backed FL frameworks in healthcare offer solutions to trust and transparency challenges, thus fostering collaboration among institutions while ensuring robust model training [
50].
In the literature, there are a lot of methods for secure aggregation, like Secure Multi-party Computation (SMPC), Differential Privacy (DP), and Homomorphic Encryption (HE). Despite these security measures, ongoing advancements are necessary to establish a secure aggregation FL-based system [
51]. For example, while homomorphic encryption allows computations on encrypted data without exposing raw inputs, it often incurs significant computational overhead and degrades model accuracy, especially in deep learning settings [
52,
53]. Similarly, SMPC and DP may reduce model utility or introduce noise that hampers prediction performance [
54]. However, while cryptographic techniques safeguard data confidentiality, they do not always ensure anonymity or prevent linkability, critical in healthcare scenarios where re-identification could occur from aggregate patterns. Therefore, our Federated Learning setup utilizes differential privacy during the federated aggregation process to enhance privacy and protect the system against model inversion attacks and AES encryption to ensure that there is a security copy of the sensitive data collected during the gamified experience. Although DP may impact model performance due to injected noise, we tried to maintain a balance between data protection and predictive accuracy, since in our case, preventing re-identification attacks is paramount.
Moreover, recent research has explored privacy-preserving Federated Learning in Internet of Things (IoT) environments. For example, FedSuper [
55], a Federated Learning framework designed for IoT networks, incorporates adaptive trust management and secure, decentralized model training. FedSuper highlights how Federated Learning can be hardened against adversarial threats and made robust in dynamic, heterogeneous environments. FedSuper enhances Byzantine resilience by giving the server a trusted validation mechanism (shadow dataset), enabling it to detect and discard malicious updates before aggregation. While the framework focuses on low-level sensor applications, its core principles, such as decentralized trust and privacy-preserving aggregation, are highly relevant to mobile health ecosystems. However, FedSuper does not address critical aspects of healthcare deployments, such as user-level identity, informed consent, or legal compliance.
In general, approaches that develop FL focus on data processes rather than securing the access points. In our research, we address this gap by implementing robust access control measures that adhere to various user policies. Different stakeholders, such as children, parents, or medical workers, need to access critical personal data. This personal information is highly sensitive, as it contains personal health details that necessitate secure access and minimal communication delays [
56]. Strict regulations like GDPR have been established to govern the interpretation and utilization of this data. These regulations present numerous challenges for advanced data processing techniques, such as Machine Learning (ML) and Deep Learning (DL), which require a substantial amount of training data. Therefore, utilizing conventional ML techniques in the development of smart healthcare systems requires the sharing and communication of data with centralized servers or the cloud, which can lead systems to security breaches. This can further lead to unauthorized access to sensitive medical records during data transmission, or third parties may exploit vulnerabilities to access data from cloud servers without the consent of the data owners [
56,
57].
3.3. Innovation
To better contextualize the contribution of our work within the existing technological landscape,
Table 2 provides a comparative overview of the limitations found in current approaches and the corresponding innovations introduced by our system. This comparison highlights how AURORA MINDS addresses critical challenges in privacy, identity management, and healthcare applicability that are not fully resolved by existing PETs, blockchain-based IdM solutions, or Federated Learning frameworks.
In a nutshell, there is a proliferation of digital applications and frameworks designed for diagnosing ADHD. These applications may not always adhere to established diagnostic criteria, leading to the potential for misdiagnosis or overdiagnosis. These applications aim to simplify and streamline the diagnostic process. However, the key question is whether these tools are indeed making the process more efficient and accurate and how they contribute to the broader issue of user privacy. The criteria for diagnosing ADHD in a privacy-friendly manner are comprehensive and require a nuanced understanding of the individual’s behavior across different contexts, something that may be challenging. AURORA MINDS not only stands out for its commitment to privacy and data control but also its engaging approach to ADHD diagnosis, making it a pioneer in the field.
Table 3 illustrates how AURORA MINDS distinguishes itself from existing applications.
4. Proposed Approach
4.1. AURORA MINDS’ Approach
In order to deliver a holistic secure solution for healthcare applications, we identify two main modules, the identity management module and the data pipeline for sharing, training, and modeling.
For the identity management module, our approach proposes a blockchain-based system moving from a centralized to a distributed identity provider model. This approach is based on the following research works [
64,
65]. Multiple entities share the task of managing identities on behalf of a public-facing organization. Specifically, we distribute the role of the identity provider between several entities, called virtual Identity Providers (vIdPs). These virtual entities run on distinct physical machines, at different physical locations, with different system admins and operating systems, and include three main modules to enable authentication, credential issuance, and token management. The distributed issuance can be accomplished in two ways: using tokens or attribute-based credentials (ABCs). This approach eliminates the vulnerabilities of centralized identity management systems, like single-point-of-failure attacks and third-party control; enhances security and privacy; and empowers users with control over their own identities through decentralized identifiers and verifiable credentials.
For the data pipeline module, in healthcare applications, data generated from user interactions is used for training models, with the results applied for clinical purposes. Thus, to ensure data privacy, it must be carefully aggregated, transmitted, and trained. In our approach, Federated Learning addresses potential privacy risks by keeping raw data on the client’s device. However, new challenges arise when data is stored locally on devices, as it can be lost if a device is changed or misplaced and can be worsened in scenarios where multiple users share a single device. Therefore, we propose to secure data with encryption mechanisms, like Differential Privacy. This approach ensures data availability, allowing users to grant access to authorized individuals while maintaining both security and accessibility.
4.2. Design Methodology
AURORA MINDS’ solution is designed to provide a user-centric, reliable, and privacy-focused healthcare application. The design methodology outlined in this section is derived from a comprehensive analysis of both qualitative and quantitative data collected through the questionnaires and interviews (
Section 2). Parents and clinicians placed a strong emphasis on key aspects such as privacy, data control, and usability. This analysis also considers domain-specific regulatory requirements, such as the General Data Protection Regulation (GDPR). Additionally, legal compliance requirements have directly influenced our decisions to incorporate features such as selective disclosure, data minimization, and secure consent management. These insights have significantly shaped our design approach.
Furthermore, the technical requirements for scalability, interoperability, and cryptographic robustness have been informed by the implementation goals and constraints identified during the system’s development and deployment phases, as detailed in
Section 5 and
Section 6. Based on these diverse parameters, we aimed to create a robust and user-centric system that meets both regulatory standards and user expectations.
4.2.1. Data Privacy
The process, transmission, and storage of healthcare data and user private information should comply with relevant standards, cryptography requirements, and authentication protocols. To maximize the level of data accuracy and privacy, we have to identify the data flow in the health app ecosystem and the exchange between involved actors. The first step involves the device hosting a health application, collecting personal data, and transmitting it to a company or a service provider. Next, the following step is the transmitted data, which is utilized for training and prediction and is stored in the company’s database.
To strengthen resilience within the AURORA MINDS platform, we prioritized robust encryption protocols to secure all data exchanges, ensuring data integrity and protection even under challenging conditions. Specifically, we implemented AES-256 encryption, a quantum-resistant protocol, to protect data during transmission and storage. AES-256 not only provides an advanced level of security against potential threats but also safeguards sensitive information against future quantum computing vulnerabilities, ensuring long-term data resilience. Additionally, the platform includes secure backup mechanisms for critical data, allowing rapid restoration in case of interruptions. By integrating these encryption protocols within our platform, we ensure that decentralized data exchanges remain secure, resilient, and consistent, even in variable network conditions. This approach enhances the platform’s overall reliability, supporting both usability and scalability in diverse operational settings.
Moreover, AURORA MINDS achieves 92% accuracy in assessing the trustworthiness of user data, leveraging Federated Learning models to infer patterns without compromising privacy. This ensures that trust labels are assigned with high precision, minimizing false positives and negatives in trust evaluation.
4.2.2. Confidentiality
User data should be hardened against cracking attempts. To ensure robust privacy protection, our solution employs probabilistic metrics and entropy-based measures to assess and maintain user anonymity. By leveraging these techniques, we achieve an anonymity set size of over 500 for protected health information (PHI), making it significantly more difficult for malicious actors to re-identify individuals. This approach enhances privacy by ensuring that data points remain indistinguishable within a large pool of similar records.
Furthermore, to ensure both trustworthiness and privacy, our solution integrates advanced cryptographic techniques, including zero-knowledge proofs, homomorphic encryption, and attribute-based credentials (ABCs). These mechanisms provide strong security guarantees by enabling verifiable trust assessments without exposing sensitive data. Moreover, zero-knowledge proofs allow one party to prove the validity of information without revealing the actual data, while homomorphic encryption ensures computations can be performed on encrypted data without decryption, preserving privacy throughout the process. Additionally, ABCs enhance access control by granting permission based on verified attributes rather than personal identifiers. These security measures work together to maintain data integrity, confidentiality, and user anonymity, strengthening the system’s ability to resist unauthorized access and privacy breaches.
4.2.3. Reliability
Our solution utilizes Federated Learning, enabling decentralized data processing across user devices, achieving high reliability and quality of service without central data storage. Additionally, it decentralizes the role of Identity Providers (IdPs) by distributing via virtual IdPs the authentication and digital signatures across multiple entities. Therefore, for an attacker, it would be possible to compromise the integrity of the system only by compromising all the participants in the system. This innovative approach removes single points of failure, significantly improving security, reliability, and overall system resilience.
4.2.4. Scalability
AURORA MINDS ensures scalability by utilizing cloud-based Federated Learning and distributed virtual Identity Providers (vIDPs), allowing seamless expansion to additional devices and regions. Moreover, cloud platforms like AWS or Microsoft Azure help to handle growing amounts of data and users flexibly and cost-effectively.
4.2.5. Interoperability and Standardization
Interoperability and standardization are crucial design considerations to ensure seamless integration with diverse technologies and systems. Developers must assess and evaluate the compatibility of various technologies, ensuring that the solution can adapt to different environments and platforms. To achieve this, our solution adheres to the following methodologies and standards:
Syntactic Interoperability: AURORA MINDS utilizes JSON-LD (JavaScript Object Notation for Linked Data) for structured data exchange, ensuring compatibility across systems that use linked data principles. This approach facilitates the integration of data from various sources while maintaining consistency and adaptability. The system also employs OAuth 2.0 and JWTs (JSON Web Tokens) for secure and efficient token-based authentication, ensuring that users can securely interact with the system across different platforms. These widely adopted standards streamline the integration of external applications while ensuring robust data protection.
Semantic Interoperability: Our solution focuses on privacy and secure data handling, leveraging Decentralized Identifiers (DIDs) and Verifiable Credentials (VCs) to provide secure, privacy-preserving data exchanges. Although our solution does not explicitly rely on specific healthcare ontologies like Healthcare Level Seven (HL7) in its core architecture, the modular design of the p-ABCs (privacy-enhancing Attribute-Based Credentials) seamlessly integrates with these ontologies. This ensures that data exchanged between systems is meaningful, standardized, and understandable, particularly in health data exchange scenarios.
AURORA MINDS incorporates several interoperable data formats and communication protocols in its implementation to ensure security and privacy while enabling seamless integration with existing identity management systems. The interoperability standards employed in our solution are the following:
OAuth 2.0 for secure authorization and access control.
JSON Web Tokens (JWTs) for securely transmitting claims between parties.
OpenID Connect and SAML for authentication and identity management.
RESTful APIs for standardized communication between systems.
Distributed Password Authentication and Digital Signatures to ensure data integrity and authenticity.
4.2.6. Legal and Ethical Compliance
AURORA MINDS ensures full legal and ethical compliance with data protection regulations, including the General Data Protection Regulation (GDPR). All users are informed about the processing of their data through clear and transparent privacy notices, outlining how their data will be processed and the purposes for which it is collected. Consent is obtained before any data is collected, with users given the option to withdraw consent at any time, ensuring that data collection is legally justified. The processing of personal data is limited strictly to the purposes of ADHD diagnosis, adhering to the principle of purpose limitation. Users are notified of retention periods, with personal data stored for a maximum of two years before being anonymized or deleted, in line with the data retention policy. Additionally, data accuracy is maintained through regular checks and updates to ensure compliance with GDPR’s requirement for data to be kept accurate and up to date.
Strong technical measures, such as encryption of personal data in transfer and at rest, secure access controls, and regular security audits, are implemented to protect data confidentiality and integrity. All data processors are bound by agreements that include confidentiality clauses and adherence to GDPR standards. The system ensures that users have rights such as access, correction, and deletion, with requests being processed within 30 days. Personal data is not transferred to third countries unless adequate protection measures are in place. A record of processing activities is meticulously maintained, ensuring accountability and compliance with relevant legal and ethical standards. Furthermore, necessary approvals and ethical reviews from competent authorities have been obtained to ensure full regulatory compliance in data processing.
4.2.7. Selective Disclosure
Users should have full control over which parts of the sensitive data they are willing to reveal to whom. This is achieved through the utilization of p-ABCs that enable selective disclosure.
4.2.8. Anonymity
The user’s identity must not be leaked to any other party in the system, neither through the presentation itself nor through metadata, except if the user consented to reveal it. AURORA MINDS maintains user anonymity through advanced cryptographic methods including zero-knowledge proofs, homomorphic encryption, and attribute-based credentials, ensuring no personally identifiable information is revealed during authentication or data processing. All sensitive data remains encrypted and indistinguishable within large anonymity sets, with no identity-revealing metadata shared unless explicitly consented to by the user.
4.2.9. Controlled Linkability
User metadata, such as usage or access patterns, can constitute sensitive information. A privacy-preserving identity management solution should allow users to control which activities are linkable and which remain provably unlinkable. In our solution, this is achieved through minimal information disclosure, the use of privacy-preserving techniques, and by ensuring unlinkability when the Identity Provider (IdP) interacts with third-party services.
4.2.10. Authenticity and Key Material Verification
To ensure trust and secure access control, the service provider (or relying party) must receive formally provable guarantees that the attributes revealed by the user have not been altered. Acting as a verifier, the relying party checks the signed access form to confirm the user’s authorization to access specific resources or services. This process relies on the user’s agreement with the access policy and explicit consent to disclose the necessary attributes or proofs.
Equally important is the authenticity of the cryptographic key material used in credential issuance. In real-world deployments, it must be guaranteed that keys belong to legitimate issuers to prevent adversaries from issuing credentials under unauthorized or uncertified keys. In our system, user credentials are constructed through trusted processes—either physical (e.g., visiting a government authority) or digital (e.g., leveraging existing government-issued eIDs)—to ensure the binding of keys to verified identities.
4.2.11. Minimizing User-Side Hardware Dependencies
To enhance accessibility and usability, our solution is designed to minimize reliance on specialized user-side hardware. Users can manage their digital identities without requiring trusted devices or hardware tokens, ensuring broader adoption and usability across diverse environments. This approach reduces barriers to entry while maintaining strong security guarantees through software-based cryptographic protections and secure authentication protocols.
4.3. Threat Model
To clarify the security posture of our system,
Table 4 summarizes the defined threat model by categorizing potential attacker types, their capabilities, targeted assets, and the privacy-preserving or cryptographic mechanisms employed to mitigate each threat.
5. System Description
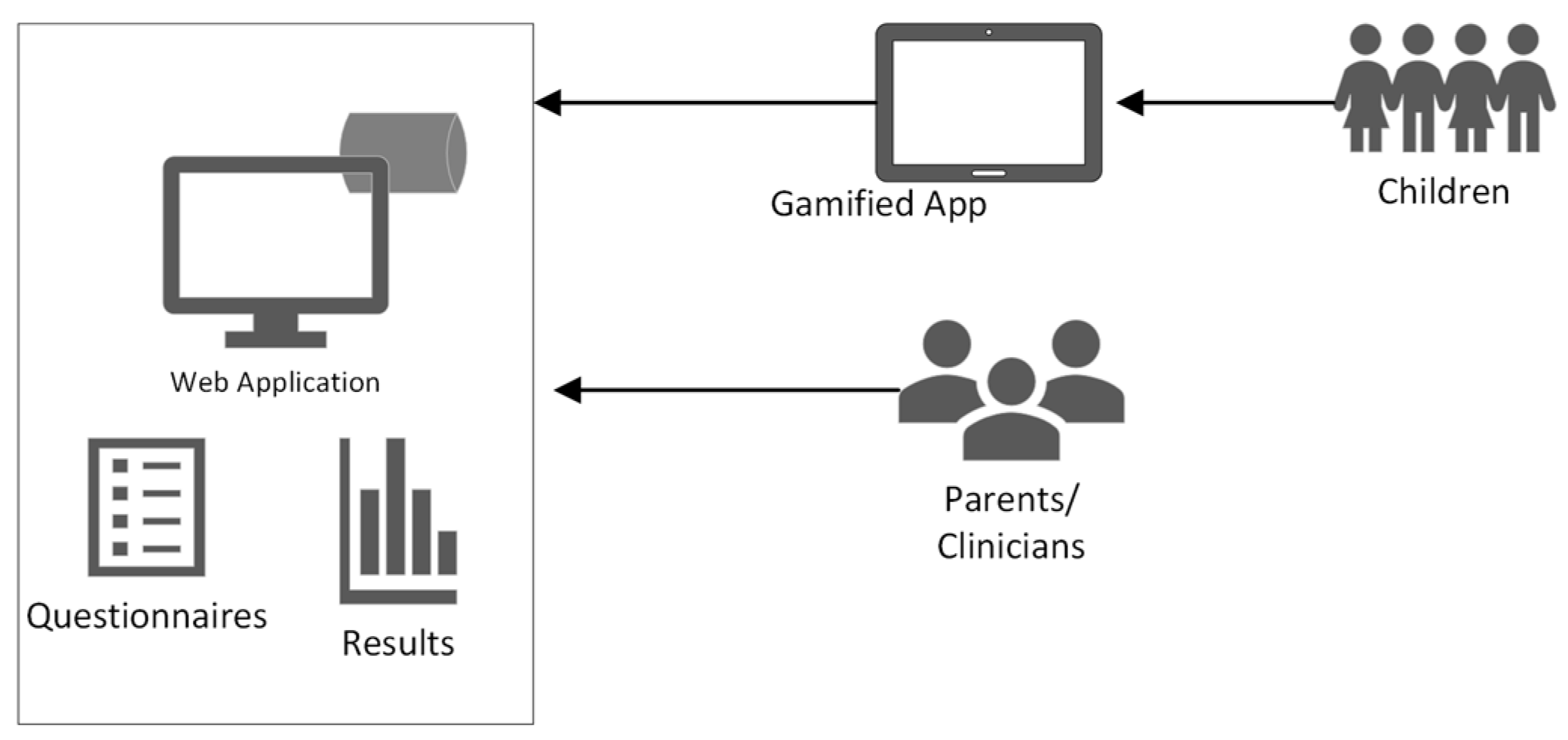
In our system, each participating entity has a unique role, which necessitates corresponding access rights. The following participants are identified:
Children: the primary end-users who engage with the application, generating valuable data for monitoring communication development.
Parents: serving as legal guardians for the children, providing information and medical records, and overseeing access to data by third parties to ensure informed consent.
Clinicians: external actors responsible for monitoring children’s progress. They require access to specific data related to the child’s development but not direct access to all personal information due to confidentiality reasons.
An overview of our system’s architecture is depicted in
Figure 1.
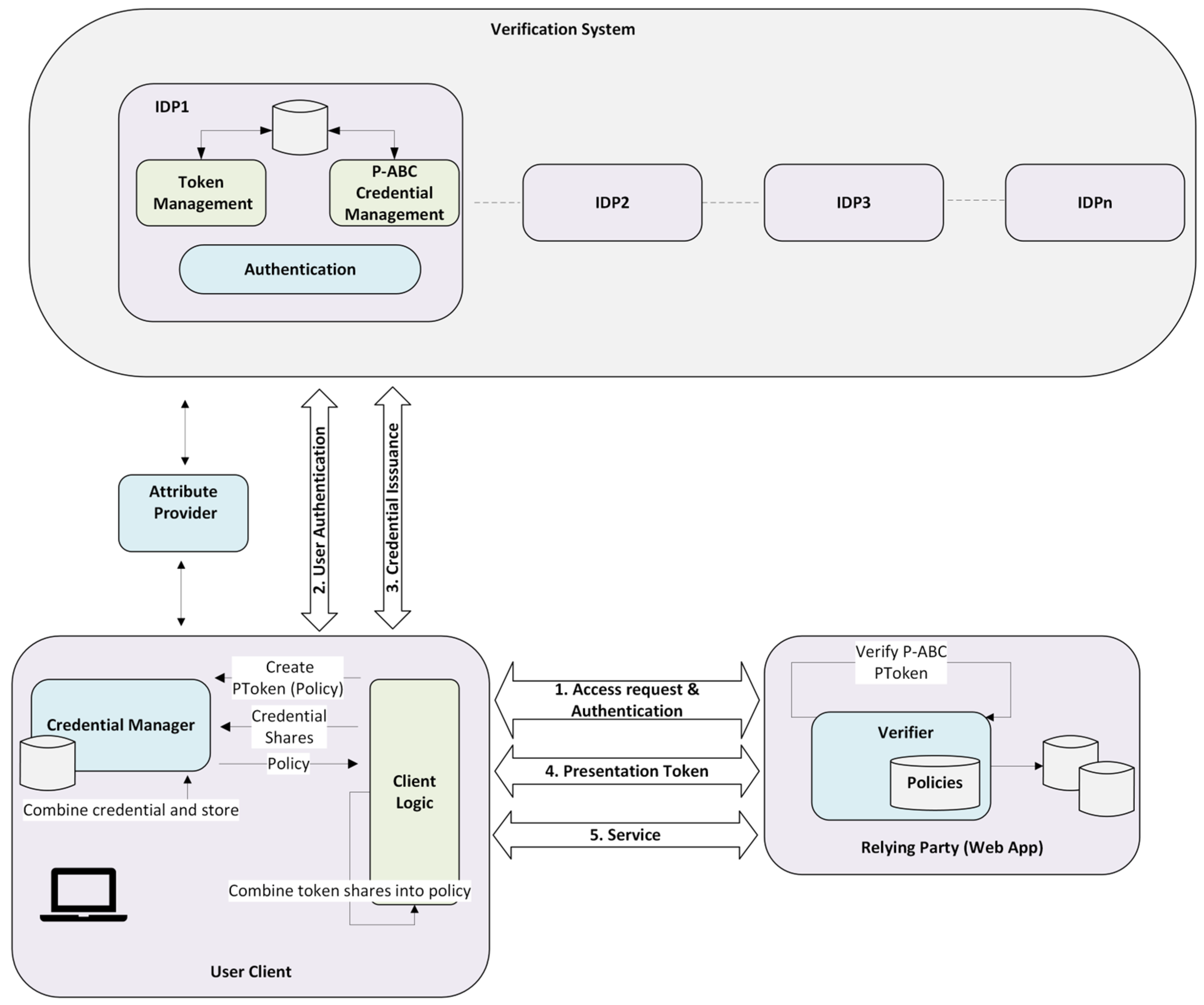
5.1. Architecture
Our advanced cryptographic techniques allow moving from a centralized to a distributed identity provider model. The proposed system architecture offers a secure, privacy-preserving, and modular identity management solution. It divides the operation into two distinct phases: user authentication and the issuance of access authorization, either as a one-time token or a reusable privacy-preserving credential. The system operates by distributing tasks across multiple independent servers through advanced cryptographic techniques. This approach effectively minimizes reliance on individual components and user devices, enhancing overall security. However, it is essential for both the client app and relying party web app to establish trusted communication in order to facilitate this process. To accommodate different application scenarios, the architecture supports two modes of operation: one that generates distributed tokens for immediate use and another that issues credentials allowing users to derive access proofs offline. This flexible design is compatible with widely adopted standards like OAuth and SAML, making it suitable for modern, scalable, and user-centric identity systems.
The Federated Learning architecture adopted in our system is designed to uphold data privacy while enabling collaborative model training. It introduces a decentralized machine learning paradigm where data remains local, and only model updates are shared. To address the critical issue of data availability, especially relevant in settings with shared devices, we augment the architecture with encrypted data storage mechanisms.
A critical challenge lies in selecting the appropriate technology and evaluating its suitability for existing e-services. Key considerations include (1) the effort required to establish a trusted connection between users and healthcare providers; (2) whether blockchain-based solutions can enhance the efficiency of privacy-preserving technologies; and (3) if AI models trained via Federated Learning, while preserving privacy, can still maintain diagnostic accuracy for patients.
Our proposed model addresses these challenges by integrating the following:
Blockchain-based virtual Identity Providers (v-IDPs) to enable decentralized and tamper-proof identity management;
Privacy-Attribute-Based Credentials (p-ABCs) to ensure anonymity and selective disclosure, grounded in established mathematical models introduces in [
66,
67], and
Federated Learning for secure, distributed analysis of smart device data;
Relying Parties (e.g., hospitals, pharmacies, insurers) interact with this framework through cryptographic protocols enforced by the distributed ledger, specifically:
Authentication and Authorization: Relying parties verify user credentials via zero-knowledge proofs (ZKPs) and smart contracts, eliminating the need for direct data exposure.
Immutable Audit Trails: All transactions (e.g., access requests, credential issuance) are recorded on-chain, providing transparency while preserving privacy through pseudonymization.
Interoperability: The blockchain acts as a universal trust layer, allowing relying parties to independently validate proofs (e.g., age, insurance status) without centralized coordination.
By combining these components, our system not only mitigates the drawbacks of siloed architectures (e.g., single points of failure, privacy breaches) but also demonstrates how decentralized technologies can improve the security, efficiency, and user control of healthcare e-services.
5.2. Main Building Blocks
In the proposed system architecture, three main roles are introduced: the user client, the virtual Identity Provider (vIdP), and the Relying Party (RP).
User Client: The user client module serves to transmit the username and password to the IdP to initiate the distributed authentication process. It oversees distributed token and p-ABC mechanisms through two modules: the client logic module, which handles token recomposition and presentation while delegating credential management to the credential manager module, the second one, which manages p-ABC credentials, reassembles and stores them, and generates access tokens according to access policies for use with relying party services.
Virtual Identity Provider (vIdP): The virtual identity provider of AURORA MINDS serves as the cornerstone of its blockchain-based architecture. This innovative approach transforms traditional federated identity management by decentralizing the identity provider into multiple interconnected entities, known as virtual identity providers. This design effectively eliminates the single point of failure that often plagues conventional systems. Furthermore, it enhances user privacy by preventing any single identity provider from tracking users through their interactions with various service providers. This decentralized framework not only increases security but also fosters a more user-centric identity management experience. By protecting user identities before data is shared or processed, AURORA MINDS reduces the risk of privacy breaches.
Each of these vIdPs enables authentication, credential issuance, and token management. The process of authentication handles distributed password verification by interacting with authentication modules across vIdPs. The issuance manages distributed issuance via tokens or p-ABC credentials, specifically:
- i.
P-ABC Credential Management: Each vIdP generates a credential share. When combined, these shares form a complete, reusable credential for accessing protected services.
- ii.
Token Management: Similar to credentials, vIdPs generate token shares that, when combined, create a one-time use presentation token tied to an access policy.
Relying Party (Web application): The relying party is the service provider that requests some kind of authentication from the user to grant him access to the service and deposits its trust in the AURORA MINDS vIdP for this authentication. Its main purpose is to ensure that the user has permission to use the service or resources. The user must agree to the terms of the access policy and consent to the disclosure of the required attributes or proofs (out-of-band of the Verification System). The Relying Party assumes also the role of the verifier, confirming the signed access form presented by the user and their compliance with the access policy, using methods like OAuth, SAML, or p-ABC tokens.
The overall architecture is depicted in
Figure 2.
5.3. System Pre-Conditions
To implement our web application, we utilized a series of programs and tools to ensure the efficiency and stability of our project. Specifically, to support cross-platform deployment and system portability, the AURORA MINDS framework was implemented using containerized microservices with Docker Engine v26.0.0 and developed in Java 1.8.0_312 using Maven 3.8.7 managing project dependencies. Front-end services were built with Node.js. The implementation details, the source code, and environment configuration are publicly available on GitHub for transparency and reproducibility. All performance evaluations of the AURORA MINDS system were conducted on a Lenovo ThinkSystem SR950 8S server. The evaluation environment consisted of a virtual machine running Ubuntu 22.04.3 LTS, allocated 16 GB of RAM, and orchestrated via Docker v26.0.0 for containerized deployment. For the Federated Learning modules and data processing pipelines, Python 3.10 was employed. These specific versions were selected based on their maturity, performance characteristics, and compatibility with the modular, microservice-based architecture of AURORA MINDS. This environment was chosen to emulate typical enterprise-grade infrastructure used in institutional or clinical settings.
The various components of the platform, including the virtual Identity Providers (vIdPs), web-facing service provider (Relying Party), client application, and Federated Learning aggregator, were containerized to ensure modularity and portability. Containers were launched with specific resource constraints to reflect realistic operational conditions, in particular:
Each container was limited to 2 GB of memory using the memory = 2 g flag.
CPU usage per container was capped at 1.5 cores using the cpus = 1.5 option.
Docker bridge networking mode (network = bridge) was used to simulate isolated communication between services.
Persistent volumes (e.g., -v aurora_data:/app/data) were mounted to manage secure and persistent storage of user credentials and encrypted datasets.
All containers were orchestrated using a Docker Compose v2.24.0. configuration, which defined the setup of multi-service communication, startup dependencies, and environment variables for each component.
The base images used included OpenJDK 8 for Java-based identity management modules and Node.js v14.21.3 for server-side scripts and web services, ensuring compatibility and minimal resource overhead.
This setup provided a controlled and secure environment for benchmarking latency, registration time, and Federated Learning performance, enabling an accurate evaluation of AURORA MINDS in conditions comparable to production deployment.
6. Use Case: Privacy Identity Management Enrollment
This section presents the use case, describing all the steps and interactions needed for a user to join a privacy-preserving identity management system. Next, we specify the functionalities that are inherent to our privacy-preserving application.
6.1. Registration
During this phase, the user creates a new account with the virtual Identity Provider (vIdP). Enrollment involves providing a username, password, and optionally a set of user attributes. As a second authentication factor, an authenticator or code-generation app is used, which generates a One-Time Password (OTP) based on a user-specific seed and timestamp. This registration process is interactive and takes place between the user and all the identity providers that collectively form the vIdP. The registration process is outlined in the following steps:
Administrator Login: The system administrator logs into the AURORA MINDS platform using their credentials (username and password).
User Role Selection: Once authenticated, the administrator chooses the type of user to be registered (i.e., clinician, parent, or children).
Clinician Registration: The administrator fills in the clinician’s details, sets a username, and generates an OTP.
Instead of relying on a single shared seed, each partial Identity Provider (IdP) in the virtual IdP (vIdP) system maintains its unique seed. Consequently, the user’s One-Time Password (OTP) is generated as a combination of individual OTPs derived from each partial IdP’s seed. To verify the authenticity of the OTP, the partial IdPs can exchange their respective portions of the OTP corresponding to the same timestamp, allowing them to collaboratively validate the result. Additionally, user attributes—such as roles or certifications—are obtained from a trusted external Attribute Provider. The vIdP verifies the validity of these attributes before storing or associating them with the user account.
At the end of the registration protocol, the user receives a confirmation message indicating the successful completion of the account creation. From this moment, the user has an account in the Verification System vIdP.
6.2. Authentication and p-ABC Management
The authentication process begins when the user submits their username and password to the vIdP. Once successfully authenticated, a p-ABC is issued to the user by the Verification System. This credential can be securely stored on the user’s device and used to access services that enforce specific access policies. The next steps are the following:
- 4.
User login: When accessing the application for the first time, the user begins the login process through the AURORA MINDS system.
If the user has already been registered by the administrator (as described in Steps 1–3), the user is directed to the Verification System page to log in using their assigned username and OTP.
If the user has not yet been registered, they must initiate the enrollment process through the designated registration portal, where they will provide the necessary information to receive their login credentials. Once registration is completed, they will be able to authenticate and access the application securely.
6.3. Credential Issuance
In this phase, the user typically is authenticated by the issuer, and the two parties negotiate the specific attributes to be certified for the user (e.g., name, birth date, etc.). At the end of the interaction, the user receives a digital certificate (a p-ABC credential) attesting to these attributes.
- 5.
The user can then access their credential storage, where the certified attributes are displayed. At this point, the user has the option to review the stored information and manage what personal data they wish to disclose during future interactions with service providers.
- 6.
Before sharing any information, the user is prompted to confirm which attributes are to be revealed. A confirmation message is shown, allowing the user to review and authorize the disclosure. Once confirmed, a notification confirms the successful verification of the user’s attributes.
6.4. Presentation
A user can prove possession of a credential certifying certain personal attributes to a service provider (i.e., relying party) by engaging in a presentation protocol. In this protocol, the two parties agree on which attributes the user needs to reveal, e.g., based on a policy of the service provider. At the end of the interaction, the service provider receives these attributes with high authenticity guarantees, while the user is guaranteed that no other information was revealed to the service provider.
- 7.
Once the user has received their credentials, they can proceed to log in using the option to authenticate with those credentials. At this stage, the system checks the stored data to ensure validity.
- 8.
The user can now utilize the application to demonstrate the required attributes or conditions associated with their credential, allowing the service to verify them.
- 9.
Finally, the user is redirected to the credential management page, where they follow the same process of step 6 to manage or review their stored credentials and associated attributes.
6.5. Machine Learning
A significant part of our application is using machine learning on each child’s game scores in order to predict a risk indicator that showcases the probability of demonstrating a communication disorder. The machine learning approach followed to address this task is presented in this section.
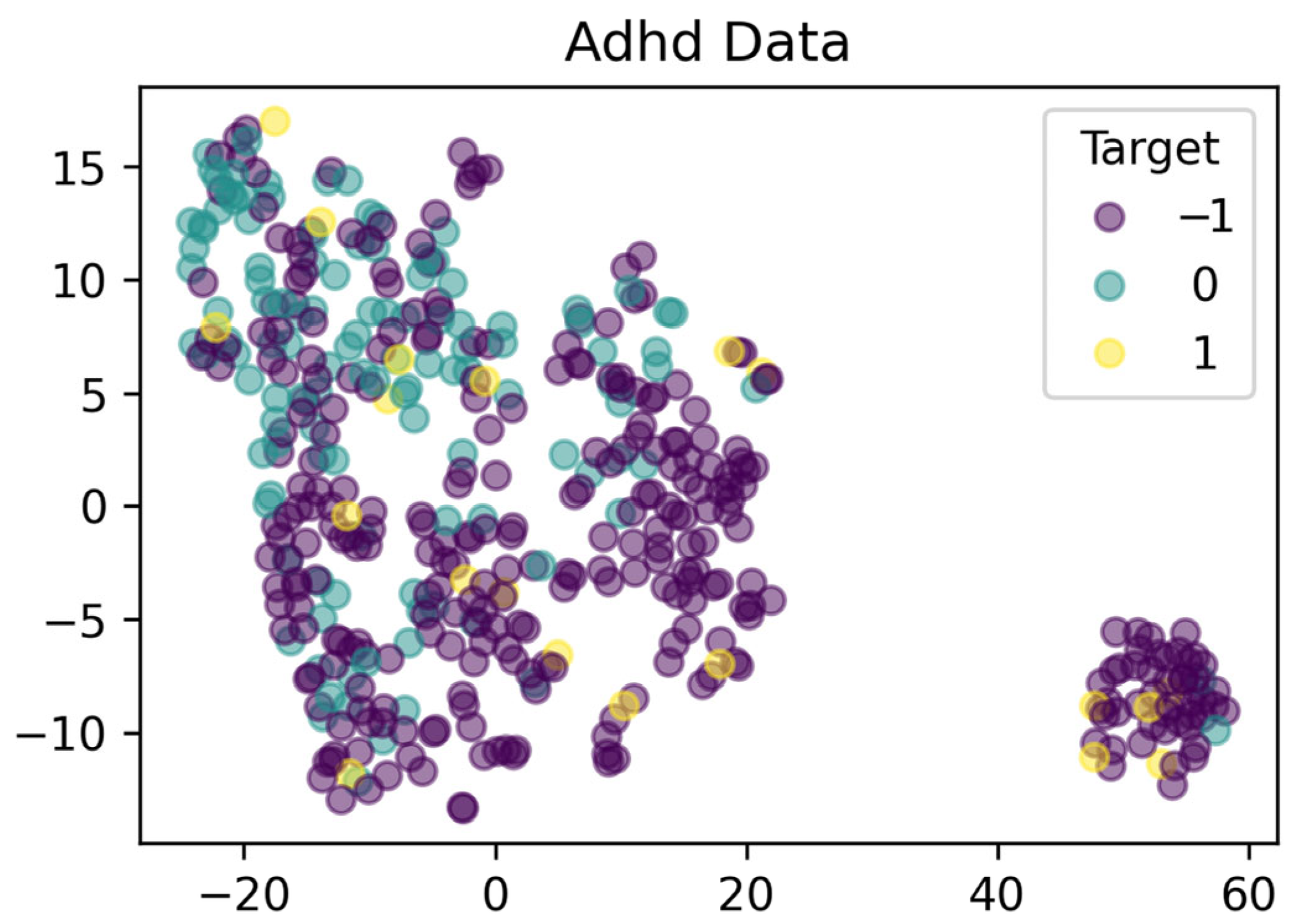
The game scores dataset we obtained from the mobile app specifically focuses on addressing ADHD deficiencies in children. The dataset contains data from 451 cases. Each entry in the dataset includes the following details:
case_id: An anonymized identifier used to distinguish cases.
client_id: Identifies the client to which the case belongs, useful for dataset splitting in federated settings.
A series of scores measuring specific communication skills: These scores, such as Verbalization, Voicing, Syntax, etc., are derived from the child’s performance in specialized gamified exercises and have been computed with the assistance of expert clinicians.
target: Can be −1 (no clinician’s diagnosis available for the case), 0 (no diagnosed deficiency in the case), 1 (indicates a positive diagnosis of communication deficiency by a clinician).
The machine learning task associated with this dataset involves predicting the probability of a case being diagnosed with a specific communication deficiency. We have five clinicians with 451 total cases. The dataset train–test split was performed based on our proposed solution architecture that handles this problem as an anomaly detection task using a semi-supervised learning approach. Our methodology involves training ML models on “normal” cases labeled as 0 (no diagnosed deficiency) and some selected unlabeled cases (−1) that are presumed to be normal. During training, the model is evaluated on all possible labels, i.e., negative, unknown, and positive cases. To this end, we utilized AutoEncoder-based architecture, a type of neural network that tries to reconstruct the original input. The goal throughout the project was to train the model on “normal” data and learn a hidden representation of the normal distribution. When the network encounters data that significantly differs from the training samples (in the project’s context, cases with disability), we expect that it will result in a higher reconstruction error since the associated patterns differ from what the model learned as normal. During inference, when the model encounters samples that are hard to reconstruct accurately, it will result in a high reconstruction error, indicating a potential disability.
In the
Figure 3 and
Figure 4, there is a TSNE visualization for the whole dataset, as well as the visualization for each respective clinician participating in the process. The TSNE visualizations suggest that the cases are not easily distinguishable in the reduced feature space. In both instances, a significant overlap between the different labels is observed. In addition, the clusters do not show a clear separation, which implies that there is not a straightforward linear boundary that separates a negative and a positive deficiency diagnosis.
As already mentioned, the model that we are going to utilize in our application is an AutoEncoder. An AutoEncoder is a type of machine learning model that learns to compress data into a reduced hidden representation and then reconstructs the original data as accurately as possible from this compressed form. It consists of an encoder that transforms the input into a latent space and a decoder that reconstructs the input from this representation. This characteristic makes AutoEncoders particularly suitable for our task, where the model is trained in normal cases. The model learns a hidden representation of these normal cases, and we expect a low reconstruction error for negative diagnoses, enabling the detection of positive instances by highlighting them with a higher reconstruction error. In our project, the encoder consists of two linear layers, each with 64 units, and a dropout layer between them for regularization. The decoder has the exact opposite architecture of the encoder, and in the last layer, it applies a sigmoid function to generate an output between 0 and 1.
6.5.1. Evaluation Metrics
Evaluating anomaly detection algorithms is a challenging task due to the absence of ground-truth-labeled data. Nevertheless, there are some commonly accepted classification-based metrics to estimate the model’s predictive performance. In this project, we use three ranking-based metrics to assess our model’s ability to separate between negative and positive deficiency diagnoses, along with two metrics that do not require labeled data.
Area Under the Receiver Operating Characteristics Curve (AUC-ROC): This metric takes into account the entire outlier ranking and is used to measure how well the anomaly detection system is capable of separating the classes of normal and anomalous instances. A high ROC AUC score indicates that, in the overall ranking, outliers are more likely to be ranked ahead of inliers, but it does not necessarily mean that the top rankings are dominated by outliers.
Average Precision (AP): Average precision is a way to summarize the precision–recall curve within a single value representing the average precision across the recall levels. In the context of anomaly detection, higher AP scores represent higher-quality predictions.
Similarity-based Internal Relative Evaluation of Outlier Solutions (SIREOS): This metric is a recent advancement in the domain of evaluating unsupervised algorithms in the absence of ground truth labels. SIREOS uses a similarity measure to discover how distinct the detected outliers (in the project’s score, positive deficiency diagnoses) are, relative to the rest of the data points. This metric is proposed to overcome the computational demands of IREOS while showing comparable or even superior quality to similar unsupervised metrics. In the context of anomaly detection, lower SIREOS values indicate high-quality model predictive performance.
6.5.2. Secure Federated Aggregation
In this section, we present the developed components for performing Federated Learning (FL) in our application. The FL framework comprises two main subcomponents: the aggregation server and the client application. The aggregation server, developed by our team, is responsible for model aggregation. The client application can be any endpoint in any application, but for demonstration purposes, we have developed a demo client app.
During the development process and based on feedback from end-users and developers, we identified a significant challenge related to data availability in Federated Learning. The issue arises because data is stored locally in the devices’ local storage. Consequently, if a user changes or loses their device, their data will be lost forever without any possibility of retrieval. Furthermore, in our case, children did not have their own devices (tablets) but used a shared clinician’s tablet. This shared usage exacerbates the data availability problem. To mitigate this deployment threat, we designed our system to store the data on a central server while protecting it using AES-256 cryptography. This approach ensures that users can grant access to their data to authorized users, maintaining both availability and security.
The Federated Learning architecture involves several key actors and processes.
Figure 5 illustrates the overall flow of our FL component.
The main actors/components of the FL approach are the following:
Shared Device: This is the endpoint where data is generated and initially processed. In our demonstration, this is a shared tablet used by children under clinician supervision.
Secure Data Storage: This database collects encrypted user data and stores it to address the data availability problem.
Web Clients: The clinicians can access the data of the children they monitor (if their parents have granted permission) and train a local machine learning model.
Aggregation Server: The central server that receives model updates from web clients, aggregates these updates, and improves the global model.
The main activities that are essential for performing the federated aggregation process are as follows:
Data Generation and Secure Storage: Children generate data through their interaction with the game, and the generated data (game scores) is encrypted and sent to secure storage.
Model Update Process: Each clinician accesses the data that they have been granted permission to train a local model on and periodically sends the model updates (not the raw data) to the aggregation server.
Aggregation Process: The aggregation server collects the model updates from multiple client devices, aggregates these updates to form a new global model, and sends the updated global model back to the client devices.
The flow begins with client devices training their local models using the data available to them. Once the local training is completed, the clients send the model updates to the aggregation server. The aggregation server then aggregates these updates to refine the global model. This updated global model is subsequently sent back to the clients, who use it as the new starting point for further local training. This iterative process continues, enhancing the model’s accuracy without compromising data privacy.
7. Results
Firstly, we present the performance results of the identity management system that demonstrate that the system maintains low latency across all key operations, indicating strong suitability for real-world deployment.
The initial phase of establishing a local server for the virtual Identity Provider (vIdP) entails integrating multiple partial IdP servers, which collectively require approximately 20 min to configure. These servers work together to securely manage user identities by establishing the essential keys needed for the identity management process.
Likewise, setting up a web-facing service provider and client application for AURORA MINDS demands 9.35 min to finalize. This process includes a testing phase to verify the effectiveness of all installed security parameters.
Once the Administrator logs into the system and selects the appropriate role for each user, the users will receive an OTP to complete the registration process. Then, the users log into the client app, enter the OTP, and are redirected to the Verification System page. Upon successful registration, a confirmation message is received within 0.22 s.
Next, after the users have received their credentials, they can log into the AURORA MINDS client app and perform the following actions. By utilizing the saved credentials in local storage, they can quickly access/log in to the user client app within 0.30 s. After successful registration, they can securely store their credentials through the AURORA MINDS dashboard in 13 s.
Furthermore, when a user wishes to verify their possessed credentials, they can utilize the credential storage to select the attributes they want to reveal through p-ABC technology. The user also provides their consent and receives a message confirming that the verification process is completed within 0.39 s. The execution times of identity management operations are presented in
Table 5 below.
Secondly, we present the results of the machine learning models under three different settings, i.e., individual learning, in which clients perform only local training without collaboration; centralized learning, in which all the data is used to train a common global model; and Federated Learning, during which each client trains its model, but they also collaborate by aggregating their model parameters to create a global model with better performance.
The results of
Table 6 illustrate the trade-offs and advantages of each learning paradigm. Individual learning excels in local discrimination (AUC-ROC: 0.8) but lacks robustness and generalization due to isolated training, as reflected in its low SIREOS (0.05) and moderate AP (0.74). Centralized learning leverages a unified dataset to achieve a high robustness score (SIREOS: 0.0513) and balanced precision–recall performance (AP: 0.7498), but it comes at the expense of data privacy and potential overfitting to heterogeneous data.
Federated Learning stands out by striking a balance between privacy, performance, and generalization. Achieving an AUC-ROC (0.7925) comparable to centralized learning, it preserves data locality, ensuring compliance with privacy regulations such as GDPR. While its robustness (SIREOS: 0.050) slightly trails centralized learning, Federated Learning provides sufficient stability across clients and enhances the generalization capacity of the global model. This makes it a viable and scalable approach for privacy-sensitive applications, such as healthcare, where the trade-off between privacy and model performance is paramount.
These findings confirm Federated Learning’s potential to enable collaborative intelligence without sacrificing individual data privacy, making it an innovative solution in secure machine learning systems.
8. Generalization and Cross-Domain Applicability
The architecture and methodologies implemented in our solution are incredibly versatile and show great promise for widespread adoption across a variety of domains in e-services that must adhere to EU legislation and GDPR compliance. Due to the multi-dimensional nature of our development, it can be utilized as either a standalone solution or as individual solutions.
Our identity management system could be utilized in cases that require strong authentication and a high level of assurance. For example, it could be used in educational institutions to securely manage student and staff identities, enforce role-based access control, and protect sensitive academic or personal information. Τhe p-ABC credential can be used multiple times to generate unlinkable privacy-preserving crypto-tokens, allowing the user to interact with the relying party offline. This is particularly useful for scenarios like IoT or face-to-face interactions, where short-range wireless communication (such as Bluetooth or NFC) is used, enabling privacy-preserving interactions even in real-time environments. Additionally, the selective disclosure feature proves advantageous in scenarios where users wish to share only necessary information. It is imperative that users are informed and provide consent when their data is disclosed. Our client app and dashboard have incorporated these legislative restrictions to ensure compliance with GDPR regulations, which are applicable to a wide range of e-services. This can be applied in scenarios such as obtaining a driver’s license or purchasing alcohol, where users are required to disclose either their license or simply their age.
Moreover, our identity management system could be well suited for IoT environments, as its architectural design and lightweight cryptographic mechanisms can effectively support device-to-device interactions, even in offline scenarios involving resource-constrained IoT devices.
Our FL procedure could also be applied in various domains where data privacy and decentralization are critical, such as healthcare, education, finance, and IoT. Its privacy-preserving design and secure aggregation make it ideal for scenarios involving sensitive, distributed data, ranging from hospital diagnostics to personalized education and collaborative cybersecurity.
Of course, our approach can be deployed as a standalone solution across a range of domains that require secure access management, distributed data analysis, and personalization. It is applicable in healthcare and educational environments where protection of sensitive information is critical, in finance for privacy-compliant identity verification, in smart cities and IoT networks for secure device authentication and collaborative learning, and in government services for anonymous verifiable citizen interactions.
In summary, the challenges addressed in our use case—privacy-sensitive data, multi-role access, regulatory compliance, and decentralized operation—are not exclusive to pediatric mental health. They are representative of broader societal needs, making our solution adaptable and valuable for a wide spectrum of real-world applications.
9. Survey on End-User Perception
To better assess the anticipated user acceptance of the AURORA MINDS platform, a focused survey was conducted, with 40 participants recruited through the consortium’s existing communication channels. The respondents did not directly interact with the platform but were instead presented with a detailed overview describing the platform’s goals, privacy architecture, and key features. This approach aimed to capture early impressions regarding usability, data protection, transparency, diagnostic reliability, and overall value. Participants evaluated each item on a 10-point Likert scale, ranging from 0 (not at all) to 10 (extremely), reflecting their subjective perceptions based on the descriptive information provided. The results are illustrated in
Table 7.
The survey responses highlight the current landscape of digital health app adoption among caregivers and clinicians. The average score of 5.6 for current usage of ADHD apps reveals a moderate familiarity with digital tools for behavioral management. While a segment of the population is accustomed to using such applications, another segment remains less engaged, possibly due to concerns about complexity, cost, or trustworthiness. These findings reinforce the need for AURORA MINDS to prioritize user onboarding strategies and to provide clear, accessible pathways for first-time users. Moreover, the notably low average score (4.2) on comfort with sharing personal information reaffirms that privacy concerns remain a barrier to wider adoption. This strengthens the platform’s rationale for integrating Privacy-Enhancing Technologies and Federated Learning from the outset.
The survey also underscores a strong user preference for features that offer transparency, insight, and control. Participants rated the importance of tracking their child’s behavioral patterns (Q3) and receiving transparent explanations about data handling (Q4) among the highest in the survey, with average scores of 8.9 and 9.1, respectively. These results demonstrate that parents and clinicians are not only interested in diagnostic tools but also in applications that provide actionable insights and offer full transparency about how sensitive data is managed. In this respect, the platform’s modular design—especially the use of Privacy-ABCs for managing data access—is well aligned with stakeholder expectations. High satisfaction with the described privacy and security protocols (Q5) and strong confidence in data accuracy (Q6) further validate the design philosophy of AURORA MINDS, suggesting that the project’s foundational choices resonate positively with its intended users.
Finally, indicators of long-term platform viability and community-driven dissemination were encouraging. The likelihood of recommending the platform to others (Q7) and the likelihood of sustained use over time (Q8) received solid average scores of 7.6 and 7.4, respectively. These figures point to a promising trajectory for user retention and organic growth, provided that the platform continues to evolve in line with user needs. Together, the results suggest that AURORA MINDS is perceived not only as a secure and transparent solution but also as a potentially essential tool for managing ADHD more effectively. Moving forward, user engagement strategies should focus on addressing initial privacy hesitations, reinforcing trust through visual communication and demos, and extending pilot testing to include real-world interactions that further validate the platform’s usability and clinical relevance.
10. Challenges, Limitations, and Future Work
During the setup of each relying party, key exchanges take place. While using a general verifier app could be an effective solution, finding an online method to authenticate trusted key exchanges is challenging. To address this, we implemented a desktop application as a trusted approach. Ideally, this process could be streamlined by installing a web browser add-on. However, there is a risk that the verification process could be bypassed, allowing unauthorized entities to display their content. Therefore, integrating additional partners, such as hospitals or external healthcare providers, requires installation and technical setup, which may hinder scalability and adoption. In addition, since no specific blockchain network or smart contract platform is inherently adopted, the organization itself is responsible for developing and managing the infrastructure, such as distributing cryptographic material and deploying virtual Identity Providers. This could be particularly demanding in the absence of dedicated technical staff, and the complex initial setup combined with the high cost of institutional integration further amplify the challenge.
Moreover, while user consent mechanisms exist, they need further refinement to ensure seamless and explicit user approval for all data-sharing scenarios. For example, when a clinician updates a medical report, the system should promptly notify the parent to ensure they remain informed.
Additionally, the implementation of differential privacy was a critical aspect of ensuring the confidentiality of sensitive medical data. While it effectively protected user information by introducing calibrated noise to the model updates, this approach introduced a trade-off between privacy and accuracy. By carefully tuning the privacy parameters, we were able to maintain a balance that preserved data privacy while ensuring the model’s utility for clinical applications.
Another key challenge identified by our collaboration with clinicians was the data availability problem, particularly in scenarios where children lost access to their devices or data became inaccessible due to hardware failure. This situation can have a negative impact on a participant’s overall monitoring procedure, thus making the system difficult to use. To address this, we implemented AES-256 encryption for secure backup and storage of critical data, ensuring it could be safely recovered and restored without compromising privacy.
Despite these advancements, certain limitations remain open for future exploration. For instance, our current implementation relies on the FedAvg aggregator for Federated Learning, which has limitations in handling highly heterogeneous data. Incorporating more sophisticated aggregation methods, such as FedProx or adaptive aggregators, is a key area for future work to better address client variability. Additionally, while the system has demonstrated its effectiveness in pilot studies, further testing with larger datasets is needed to fully validate its scalability and robustness in diverse real-world environments. These open areas represent significant opportunities to refine and expand the system’s capabilities in privacy-preserving healthcare applications.
Enhanced personalization will make the platform more inclusive and adaptable to diverse user needs, while expanded diagnostic capabilities promise broader utility across a range of mental and developmental health conditions. Incorporating sensor data and fostering interoperability with existing digital health platforms will further enrich the platform’s functionality, enabling comprehensive, multi-modal assessments and seamless integration into healthcare ecosystems.
11. Conclusions
The AURORA MINDS solution represents a significant leap forward in the application of privacy-preserving technologies to digital health. The technologies of Privacy-Attribute-Based Credentials (p-ABCs) and Federated Learning address the dual imperatives of data security and usability in sensitive healthcare contexts. While these individual methodologies have been extensively explored, our innovative approach integrates these technologies into a cohesive system, marking a significant advancement in healthcare. Moreover, by reducing obstacles to medical diagnosis and improving secure data management, the platform showcases the transformative power of privacy-focused digital health solutions
Additionally, the influence of our proposed solution goes beyond technological progress, offering socio-economic advantages such as enhanced access to diagnostic tools and potential cost savings for long-term healthcare management. Through these advancements, our work positions itself as a cornerstone in the future of secure, accessible, and innovative digital healthcare, paving the way for widespread adoption and long-term impact.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}