1. Introduction
With the advancement of edge intelligence and data privacy regulations such as GDPR and HIPAA, achieving cross-device collaborative learning while preserving data locality has become a key challenge in building intelligent systems [
1,
2]. Federated learning (FL), with its distributed modeling paradigm of “keeping data local”, has attracted significant attention in recent years [
3,
4]. By performing local training on edge devices and uploading only model parameters, FL effectively reduces the risk of data leakage and improves deployability in sensitive scenarios such as smart terminals, healthcare, and financial risk control, as illustrated in
Figure 1.
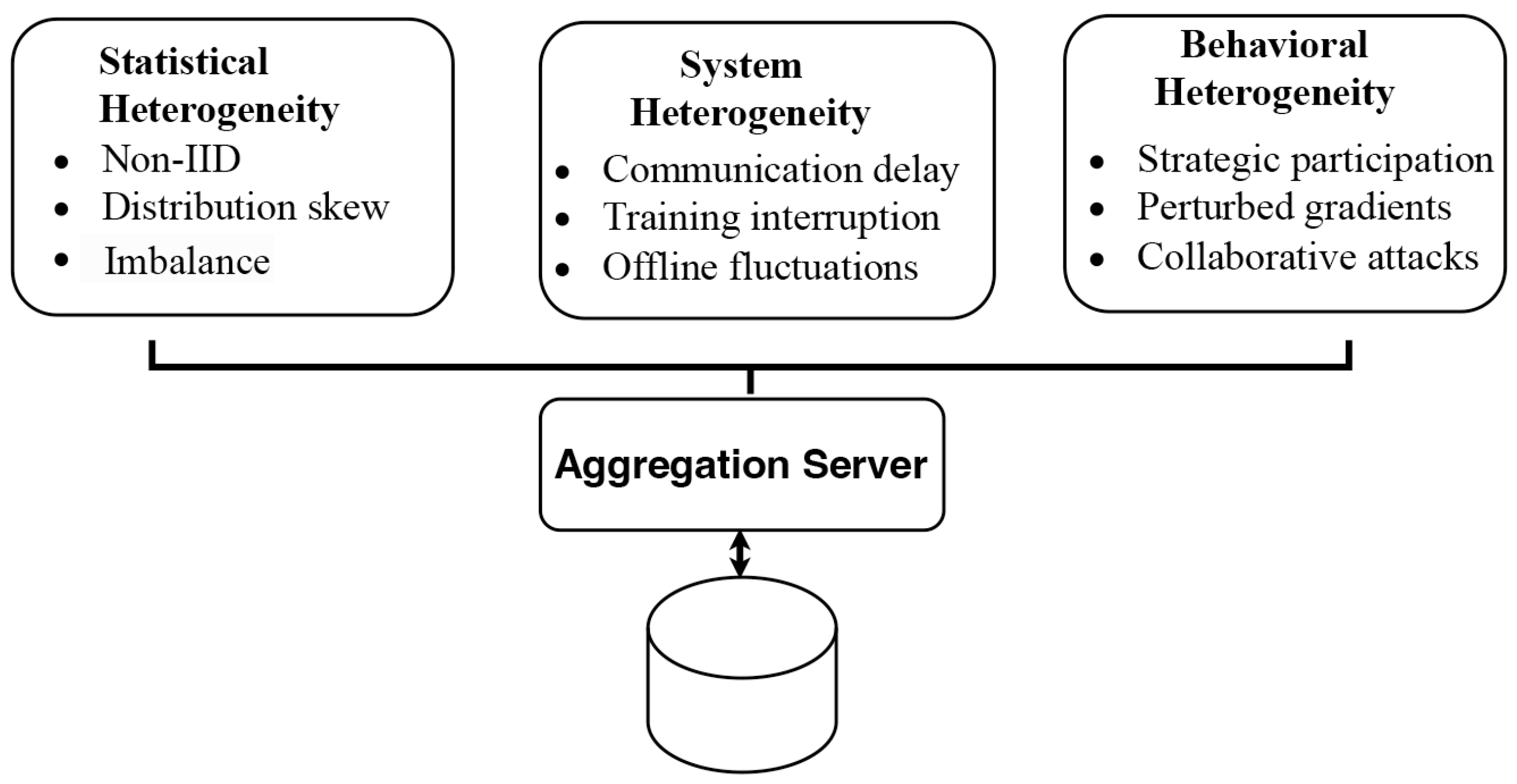
Nevertheless, the deployment of FL in real-world environments still faces critical challenges, particularly due to heterogeneity in statistical properties, system performance, and client behavior [
5,
6], as shown in
Figure 2. First, data collected by different clients often come from distinct users, environments, or tasks, leading to highly non-independent and imbalanced distributions, which severely hinder global model convergence and generalization [
7,
8]. Second, due to the heterogeneous resource capacities of edge devices, issues such as communication delays, interrupted training, and intermittent connectivity commonly arise, widening performance gaps at the system level. More critically, client behaviors in open environments are uncontrollable and may include strategic participation, perturbed gradient uploads, or even collusive poisoning attacks, potentially destabilizing FL training or crashing the global model [
9,
10].
To address these issues, extensive research has been conducted in robust aggregation, security mechanisms, trust management, and incentive design [
11,
12]. Robust aggregation algorithms such as the Krum [
13] and the Trimmed Mean [
14] effectively eliminate outlier updates and enhance system resilience, but most adopt rigid filtering strategies and lack tolerance for weak or high-variance clients. In terms of trust mechanisms, approaches such as FedTrust [
15] and TrustFL [
16] assess client credibility based on model similarity or behavioral patterns, yet are often decoupled from incentive schemes. Existing incentive mechanisms typically design reward allocation based on static indicators (e.g., data volume, training time), which struggle to detect opportunistic behaviors masked as honesty, and may result in incentive abuse under adversarial strategies [
17,
18].
It is particularly noteworthy that most existing works treat trust modeling, robust aggregation, and incentive mechanisms as separate submodules, lacking a systematic integrated modeling approach. Trust scores fail to feed back into resource allocation, and aggregation strategies do not respond adaptively to incentive feedback, leading to persistent internal incentive bias, behavior distortion, and training uncontrollability. Furthermore, due to the inherently dynamic nature of client behaviors, one-shot scoring or static thresholds fail to capture long-term trends and fluctuations, often resulting in misjudgments and misallocated rewards that compromise fairness and stability.
To tackle the above challenges, this paper proposes a unified Trust-Aware Incentive Mechanism(TAIM) that integrates client trust modeling, incentive feedback, and robust aggregation. Guided by the principle of “trust drives participation, incentive motivates resource investment, aggregation ensures robustness”, TAIM achieves deep coupling between strategic and optimization layers to enhance system robustness, fairness, and sustainable participation. The main contributions are as follows:
We design a dynamic trust modeling framework that integrates participation frequency, gradient consistency, and contribution effectiveness, capturing client behavioral trajectories and quantifying their stability and reliability;
A trust-driven incentive mechanism based on Stackelberg game theory is developed to derive the optimal resource allocation under equilibrium, guiding the rational strategy convergence of clients;
A confidence-aware smoothing aggregation algorithm is proposed, incorporating a soft filtering function to suppress and recover low-trust updates, effectively balancing robustness and diversity;
Extensive experiments under multiple non-IID datasets and adversarial scenarios validate the robustness, fairness, and convergence performance of the proposed method, along with comparative analysis against existing baselines.
The remainder of this paper is organized as follows:
Section 2 reviews related works and key methodologies.
Section 3 defines the modeling of client behavior in federated systems and formulates the problem.
Section 4 elaborates on the trust modeling, algorithm design, and theoretical analysis of TAIM.
Section 5 presents the experimental validation and comparative evaluation.
Section 6 discusses limitations and future research directions.
2. Related Work
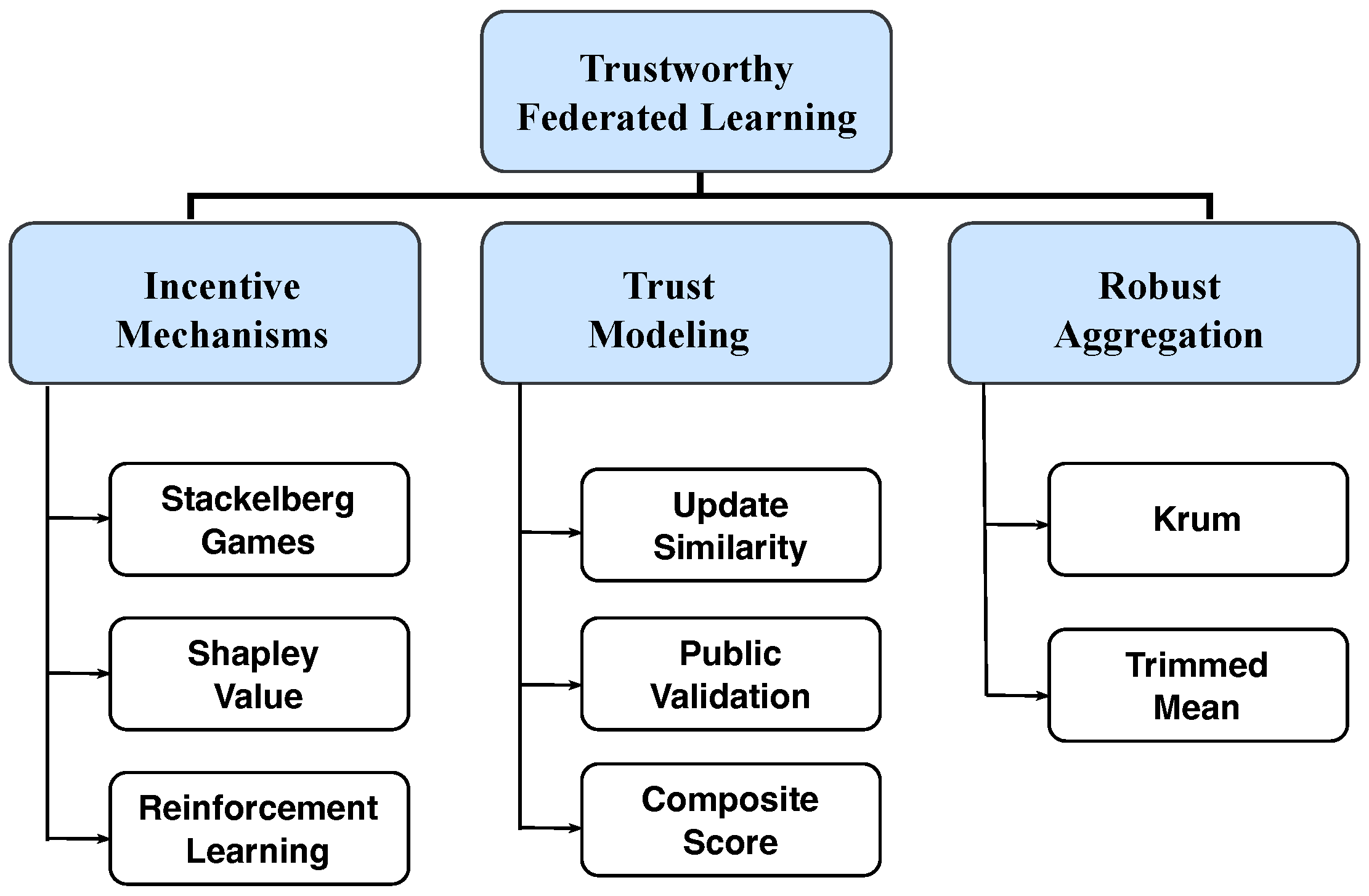
To build a trustworthy federated learning system tailored for heterogeneous edge environments, researchers have extensively explored three major directions in recent years: client incentive mechanisms, trust modeling, and robust aggregation algorithms. As illustrated in
Figure 3, this section systematically reviews these research directions, identifies the key limitations in current approaches, and highlights the novelty and distinctiveness of this work.
2.1. Incentive Mechanism Design in Federated Learning
In practical deployments, federated learning involves numerous clients with varying resource capabilities. Due to privacy concerns and resource consumption, clients are often reluctant to participate consistently and contribute high-quality updates [
19,
20]. Therefore, designing effective incentive mechanisms to enhance participation and contribution has become a key research challenge [
21,
22]. A comprehensive survey by Zhou [
23] categorizes these mechanisms, highlighting the prominence of game theory, auction theory, and contract theory in addressing the challenge of motivating self-interested clients.
Early studies primarily focused on resource-driven incentive models. For example, Zhang et al. [
24] proposed a Stackelberg game-based incentive model that rewards clients based on the quality of uploaded models rather than data volume or training time. While such methods can improve system efficiency to some extent, they often ignore heterogeneity in model quality and participation behavior, leading to excessive rewards for strategically behaving clients who appear to contribute.
To enhance fairness and robustness, some works introduced game theory and marginal contribution analysis. Huang et al. [
25] and Xia et al. [
26] designed demand-based reward allocation strategies using Shapley value estimation to evaluate each client’s marginal improvement to the global model. Different game-theoretic approaches have also been explored; for instance, Pang et al. [
27] designed an incentive auction for heterogeneous client selection, focusing on creating a market-based environment for efficient resource allocation. While effective, auction mechanisms differ from our approach by emphasizing competitive bidding rather than long-term trust cultivation. However, computing Shapley values is computationally intensive and lacks robustness in adversarial or non-ideal environments.
Recognizing the limitations of static or purely contribution-based metrics, recent works have shifted towards evaluating client behavior over time. For example, Al-Saedi et al. [
28] proposed a method to predict client contributions by evaluating past behaviors, aiming to proactively select more reliable participants. This predictive approach complements our reactive trust-scoring mechanism, which assesses credibility after each round to dynamically adjust rewards and aggregation weights. Moreover, some research has explored reinforcement learning for dynamic incentive strategy generation. For instance, Ma et al. [
29] introduced a deep reinforcement learning algorithm for incentive-based demand response which continuously optimizes interaction strategies using client states and feedback signals under incomplete information. Although such approaches improve adaptability, they often rely on global reward signals and struggle to capture individual trustworthiness or defend against strategic manipulation. The growing complexity and diversity of these mechanisms also underscore the need for standardized evaluation frameworks, as addressed by platforms like FLWB [
30], which facilitate reproducible performance comparisons of FL algorithms.
In summary, current incentive mechanisms lack effective modeling and utilization of client behavioral credibility, resulting in misallocated or abused rewards. This study incorporates trust scores into the game-theoretic incentive function to construct a behavior-driven resource allocation mechanism, aiming to enhance system security and participation stability.
2.2. Trust Modeling and Robust Aggregation in Federated Learning
Security threats in federated learning primarily stem from clients uploading malicious or low-quality updates that degrade global model performance. To mitigate this, trust modeling and robust aggregation have become central research topics.
In trust modeling, various methods have been proposed to evaluate client credibility from different perspectives. FedTrust [
31] calculates trust scores based on similarity among uploaded models and adjusts aggregation weights accordingly. TrustFL [
32] dynamically adjusts client weights based on performance fluctuations on a public validation set and consistency of feature representations. Lyubchyk et al. [
33] constructed a composite trust scoring system using multi-dimensional indicators to reflect long-term behavioral stability and reliability.
At the same time, robust aggregation algorithms provide effective defenses against poisoning attacks. Methods such as the Krum [
34] and the Trimmed Mean [
35] eliminate outlier gradients or select consistent subsets of updates to enhance robustness. However, most rely on static thresholds or distance-based filtering, which struggle to adapt to dynamic client behaviors and often overlook the strategic interactions among participants.
Recently, some works have attempted to couple trust mechanisms with robust aggregation. Perry et al. [
36] introduced update correlation analysis for dynamic detection of collusive poisoning, and Abri et al. [
37] modeled the trust learning process as a Markov decision process to recognize potential attack states. However, these approaches still neglect client responses to incentive feedback. Without a proper incentive regulation mechanism, the effectiveness of trust scoring and aggregation strategies can be compromised.
This work proposes a soft trust filtering mechanism that introduces a smoothing suppression function during aggregation to avoid penalizing edge clients with behavioral fluctuations. Moreover, the trust evaluation is coupled with the incentive allocation function to form a “high trust–high incentive–high participation” positive feedback loop, thereby enhancing adaptive defense and strategy stability.
2.3. Federated Modeling Mechanisms for Heterogeneous Edge Environments
In real-world scenarios, federated systems are commonly deployed across heterogeneous edge environments, facing non-ideal conditions such as device heterogeneity, resource imbalance, communication disruptions, and dynamic client availability. These factors significantly amplify challenges in fairness and robustness [
38,
39,
40].
To address system-level heterogeneity, FedProx [
41] introduces a regularization term into the local training objective to limit model divergence and improve global convergence. FedNova [
42] normalizes updates to unify contribution scales across clients, while FedCS [
43] proposes a bandwidth-aware client selection strategy to optimize training efficiency under communication constraints. Other works have focused on the timeliness of information, proposing Age of Information (AoI)-aware client selection or update weighting schemes to prioritize fresher updates from clients with better connectivity, thereby mitigating the negative impact of stragglers and stale models [
22]. While these approaches have achieved progress in system optimization, they largely ignore the dynamics of client participation and strategic evolution, making them less effective in open edge environments with frequent malicious behaviors.
In particular, under the presence of strategic participants, clients may evade detection and manipulate rewards through mimicry attacks, intermittent poisoning, or frequent switching, ultimately undermining long-term stability [
44,
45]. Therefore, “behavioral trustworthiness” must be considered a core constraint in federated learning systems to enable multi-objective optimization under trustworthy guidance.
This work integrates edge heterogeneity modeling, dynamic trust evaluation, and incentive–response mechanisms to construct a trust-driven game-theoretic regulation framework at the strategic level. A soft suppression strategy is incorporated during aggregation, enabling robustness, incentive compatibility, and resource adaptation. This provides a systematic modeling paradigm for building secure and controllable federated learning systems at the edge.
3. System Model and Problem Formulation
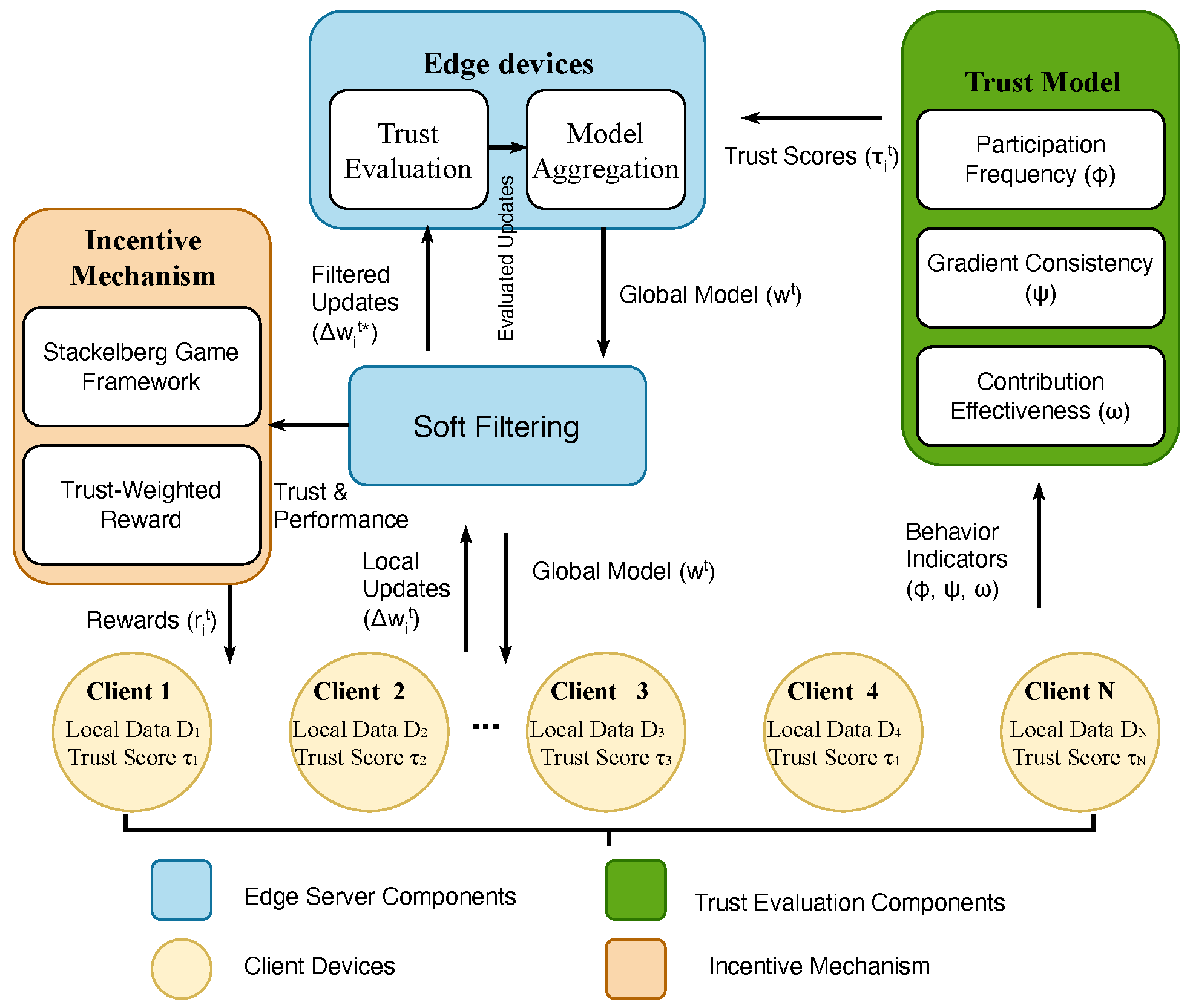
In this section, we first formalize the basic structure of federated learning. We then construct a system modeling framework tailored for heterogeneity in edge computing environments by introducing dynamic trust modeling and incentive allocation mechanisms. Finally, we define a unified optimization objective. The overall system architecture is illustrated in
Figure 4, and the notations used throughout the paper are summarized in
Table 1.
3.1. Federated Learning Task Modeling
We consider a cross-device federated learning scenario consisting of a central server and a set of edge clients , where each client owns a local dataset that is typically highly non-IID. The goal of the system is to collaboratively train a robust and high-performing global model without sharing raw data.
During each communication round t, the server selects a subset of clients to participate in training. Each selected client performs the following steps:
- (1)
Downloads the current global model ;
- (2)
Trains locally using its own dataset and computes a model update ;
- (3)
Uploads to the server for aggregation.
The server aggregates the received updates via weighted averaging to produce a new global model , which is then broadcast to all clients, completing one round of training.
3.2. Heterogeneity and Behavior Modeling
Due to the inherent heterogeneity of edge devices, we model client states from three aspects:
Statistical heterogeneity: Differences in data distributions between and such as label imbalance and sample shift.
System heterogeneity: Variations in computational capabilities and communication latency across clients.
Behavioral heterogeneity: Behavioral anomalies such as unstable participation, gradient manipulation, or strategic uploads.
To capture dynamic behavioral characteristics, we introduce a Trust-Aware Incentive Mechanism to enable behavior perception and adaptive regulation during training.
3.3. Dynamic Trust Score Modeling
Each client
is assigned a trust score
in round
t, representing the overall reliability of its recent behavior. The score is updated via the following exponential decay rule:
where
is the memory decay coefficient, and
is the instantaneous score defined as a weighted sum of behavioral indicators where
Specifically, is the participation frequency, or the proportion of active rounds within the past T rounds; is the gradient consistency, or the cosine similarity between the local update and the global average direction; and is the contribution effectiveness, or the improvement of the validation error brought by the update.
The trust score serves not only as a behavioral descriptor but also as a control variable in both aggregation and incentive allocation.
3.4. Incentive Mechanism and Optimization Objective
Let
denote the incentive allocated by the server to client
in round
t, subject to the following budget constraint:
Each client responds by investing local resources
to complete the training. The client’s utility function is defined as follows:
where the first term represents the trust-weighted share of incentives, and the second term captures the cost of resource consumption.
The server’s objective is to design and aggregation weights to ensure model quality while promoting high-trust participation and suppressing malicious updates.
4. Trust-Driven Incentive and Aggregation Mechanism
In this section, we systematically present the proposed Trust-Aware Incentive Mechanism (TAIM) and robust aggregation algorithm. The core objective is to achieve a triple control logic in federated learning: incentives should follow trust orientation, aggregation should enhance robustness, and client behaviors should form a positive-feedback convergence driven by incentives. Compared to traditional methods that decouple trust, incentive, and aggregation, our design achieves unified modeling of the three components and introduces corresponding game-theoretic solution strategies and weight adjustment mechanisms.
4.1. Trust-Aware Incentive Allocation Modeling
Incentive mechanism design is critical for motivating clients and ensuring behavioral quality in federated learning systems. Based on trust modeling, we use the trust score and the client’s contribution as the main factors in reward allocation, avoiding the manipulation that arises from using static metrics such as data volume or training epochs.
Specifically, the raw contribution
is defined as the normalized
norm of the uploaded update as follows:
The incentive reward function is then defined as follows:
This function satisfies the incentive compatibility and prioritizes high-trust, high-contribution clients under the budget constraint .
To prevent manipulation through pseudo-contributions (e.g., uploading high-norm but low-benefit updates), we introduce a validation-based actual gain function
as follows:
The corrected contribution is computed as and is used in both incentive and aggregation processes.
4.2. Stackelberg Game-Based Solution Strategy
To model the strategic interaction between the server and clients, we adopt a Stackelberg game formulation. The server, as the leader, decides the total budget and reward strategy ; the clients, as followers, choose their resource investment to maximize utility.
Each client’s utility function is defined as follows:
where the first term denotes the trust-weighted incentive share, and the second term captures the cost of local resource usage.
The quadratic cost function
is widely adopted in economics and resource allocation models [
46], as it ensures convexity and reflects diminishing returns—i.e., increasing cost per unit as resource consumption rises. This formulation facilitates closed-form analysis and captures the realistic non-linearity of energy or training time costs on edge devices.
It is worth noting that each client’s best response depends on the global term
, which is generally unknown in decentralized settings. We address this by assuming that the server provides an aggregated signal during each communication round. This approximation is consistent with many Stackelberg-based FL mechanisms [
47], where clients respond based on coarse-grained information rather than full observability. In future work, distributed best-response estimation or local belief updates could be explored to eliminate this assumption.
This convex utility yields the following closed-form best-response function via the first-order derivative:
The server’s utility function is defined as the net benefit of the improved model accuracy minus the incentive cost, calculated as follows:
where
represents the loss reduction after aggregation and
is a balancing coefficient controlling budget sensitivity. The server’s objective is to choose
and
such that
is maximized under budget constraints while also encouraging high-trust participation from clients.
Using backward induction, the server can derive the optimal reward strategy and establish a closed-loop linkage between incentive allocation and client behavior adaptation.
4.3. Trust-Guided Soft Aggregation Mechanism
Traditional robust aggregation methods often adopt rigid techniques such as outlier removal or hard thresholds, which may harm diversity and inclusiveness. To address this, we propose a trust-guided non-linear soft suppression strategy to attenuate the impact of low-trust updates via a continuous weighting function.
We define a sigmoid-based suppression function as follows:
where
controls the suppression threshold and
k controls the steepness. The final aggregation weight is determined by the trust score and corrected contribution as follows:
The global model update becomes the following:
This aggregation scheme suppresses the influence of malicious updates while allowing low-trust clients to be re-evaluated and regain weight, enhancing long-term fairness and convergence.
To ensure practical deployability, the sigmoid-based suppression function is implemented using precomputed lookup tables or approximate activation functions to avoid runtime overhead. Similarly, trust score updates are server-side vector operations with minimal cost. These design choices ensure that the trust-aware mechanism does not introduce significant delays compared to standard aggregation.
4.4. Robustness Enhancement and Anomaly Detection Mechanisms
To defend against attackers mimicking trustworthy patterns or frequently switching strategies, we introduce the following two robustness enhancement modules:
- (1)
The Deviation Penalty Mechanism: Here, the relative deviation of the updates is defined as follows:
If
, the trust score is penalized as follows:
- (2)
Sliding Window-Based Trust Correction: A sliding window tracks the fluctuation of client trust scores. If a client exhibits drastic, non-monotonic variations, we slow down the growth of its aggregation weight to prevent short-term strategic speculation from receiving high incentives.
These mechanisms improve the behavioral sensitivity and anomaly adaptability of the trust model, forming a layered defense framework for the system.
4.5. Integrated Federated Training Procedure
By combining trust modeling, game-theoretic incentive allocation, and soft aggregation, the TAIM training process is summarized as follows (see Algorithm 1).
| Algorithm 1 TAIM: Trust-Aware Incentive and Robust Aggregation Algorithm |
- Require:
Initial model , total rounds T, initialize - 1:
for each round to T do - 2:
Server selects client set and broadcasts - 3:
for each client do - 4:
Train on to obtain - 5:
Upload ; server computes , - 6:
Update trust , correct contribution - 7:
Compute reward , assign aggregation weight - 8:
end for - 9:
Aggregate: - 10:
end for - 11:
return
|
This training process maintains the deployability of the standard FedAvg framework while constructing a complete trust–incentive–aggregation feedback loop. It offers enhanced security and strategy adaptiveness, making it particularly suitable for heterogeneous, dynamic, and untrusted open edge environments.
For complexity analysis, the computational overhead introduced by TAIM is manageable and does not alter the overall complexity of the federated learning process. Let
be the number of selected clients per round and
d be the dimensionality of the model parameters. The primary computations in TAIM include the following: (1) Trust score update: Calculating gradient consistency (cosine similarity) for each client against the average update requires
operations. Other components are
per client. (2) Incentive allocation: This step involves normalization and summations over
clients, resulting in an overhead of
. (3) Soft aggregation: Computing the aggregation weights also requires
operations. The final weighted aggregation of the model updates remains
. Therefore, the total complexity per round is dominated by model-related vector operations, remaining at
. The additional trust and incentive calculations introduce a constant factor increase in server-side computation but do not scale with model complexity in a prohibitive way, making TAIM practical for large-scale deployments, as supported by the empirical overhead analysis in
Section 5.5.
5. Experimental Evaluation
To validate the effectiveness and robustness of the proposed TAIM in realistic federated learning environments, this section conducts a comprehensive empirical study across multiple representative datasets, attack types, and baseline methods. The evaluation focuses on the following research questions: (1) Can TAIM improve global model accuracy and convergence efficiency under heterogeneous client participation? (2) Is TAIM more robust against various attack types and capable of identifying adversarial behaviors? (3) Is the overhead of TAIM acceptable under realistic constraints such as limited resources and client uncertainty?
To ensure reproducibility, we describe the experimental setup, attack modeling, evaluation metrics, baseline methods, and result analysis in the following sections.
5.1. Experimental Setup and Datasets
We select three representative federated learning tasks covering image, text, and handwritten character classification under heterogeneous settings. This selection is motivated by the need to validate TAIM’s effectiveness across diverse data modalities and types of heterogeneity that mirror real-world challenges. Specifically, the FEMNIST task, provided by the LEAF benchmark, involves handwritten character recognition with a highly non-IID user-based split that naturally models the statistical heterogeneity found in real-world user data. CIFAR-10 is a classical image classification dataset with 10 classes. We generate non-IID partitions using a Dirichlet distribution with to systematically control and evaluate the impact of statistical heterogeneity. Sent140 is a Twitter sentiment analysis task where each client reflects individual language styles, making it an ideal testbed for modeling the behavioral heterogeneity that TAIM is designed to manage. For all experiments, datasets are split into training, validation, and test sets with a ratio of 80:10:10, respectively, unless otherwise specified. This split ensures consistent evaluation across all baseline and proposed methods.
Model Configuration and Training Details
We adopt a CNN for CIFAR-10, a two-layer CNN for FEMNIST, and LSTM for Sent140 as local models. In each round, 10% of clients are randomly selected. Local training runs for five epochs using SGD with a learning rate of 0.01 and momentum 0.9. Trust parameters are set as , , , . The sigmoid suppression function uses , .
5.2. Attack Modeling and Client Behavior Settings
To simulate realistic threats in federated environments, we inject a varying proportion of malicious clients per round and implement four types of adversarial behaviors: a Label Flip attack, which flips a portion of labels (e.g., class 1 to class 9) to mislead convergence; a Gaussian Noise attack, which adds Gaussian noise (mean 0, std 5) to gradients; an On–Off attack, which alternates between honest and malicious behavior to evade trust accumulation; and a Mimic attack, which imitates the gradients of high-trust clients to evade detection while disturbing aggregation.
The client composition is as follows: 10–30% are malicious clients with evenly distributed attack types; 20% are resource-constrained clients with reduced upload frequency; the rest are benign clients.
5.3. Evaluation Metrics
We evaluate all methods from four perspectives: accuracy, robustness, fairness, and detection ability. Final Accuracy (Acc) refers to the test accuracy achieved by the global model after convergence. Robustness Drop (RD) measures the performance degradation caused by adversarial clients. The Gini coefficient is used to quantify inequality in the reward distribution among clients. Recall and False-Positive Rate (FPR) are computed based on the identification of malicious clients. In addition, we report the total Training Time and Communication Volume to assess the system-level overhead and scalability.
To quantify the fairness of incentive distribution, the Gini coefficient
G is calculated as follows:
where
is the cumulative reward received by client
i, and
n is the total number of clients. A lower Gini value indicates a more balanced and equitable incentive distribution.
This metric enables the assessment of whether TAIM’s trust-guided reward allocation contributes to reducing reward centralization and maintaining fairness among heterogeneous clients.
5.4. Baseline Methods
We compare TAIM against several mainstream FL strategies: FedAvg (standard averaging) [
48], FedProx (adds a proximal term to mitigate heterogeneity) [
49], FedTrust (trust-weighted aggregation) [
50], and Krum (robust aggregation against outliers) [
51]. These baselines serve as the foundation for our comprehensive comparison and analysis.
5.5. Overall Performance Comparison
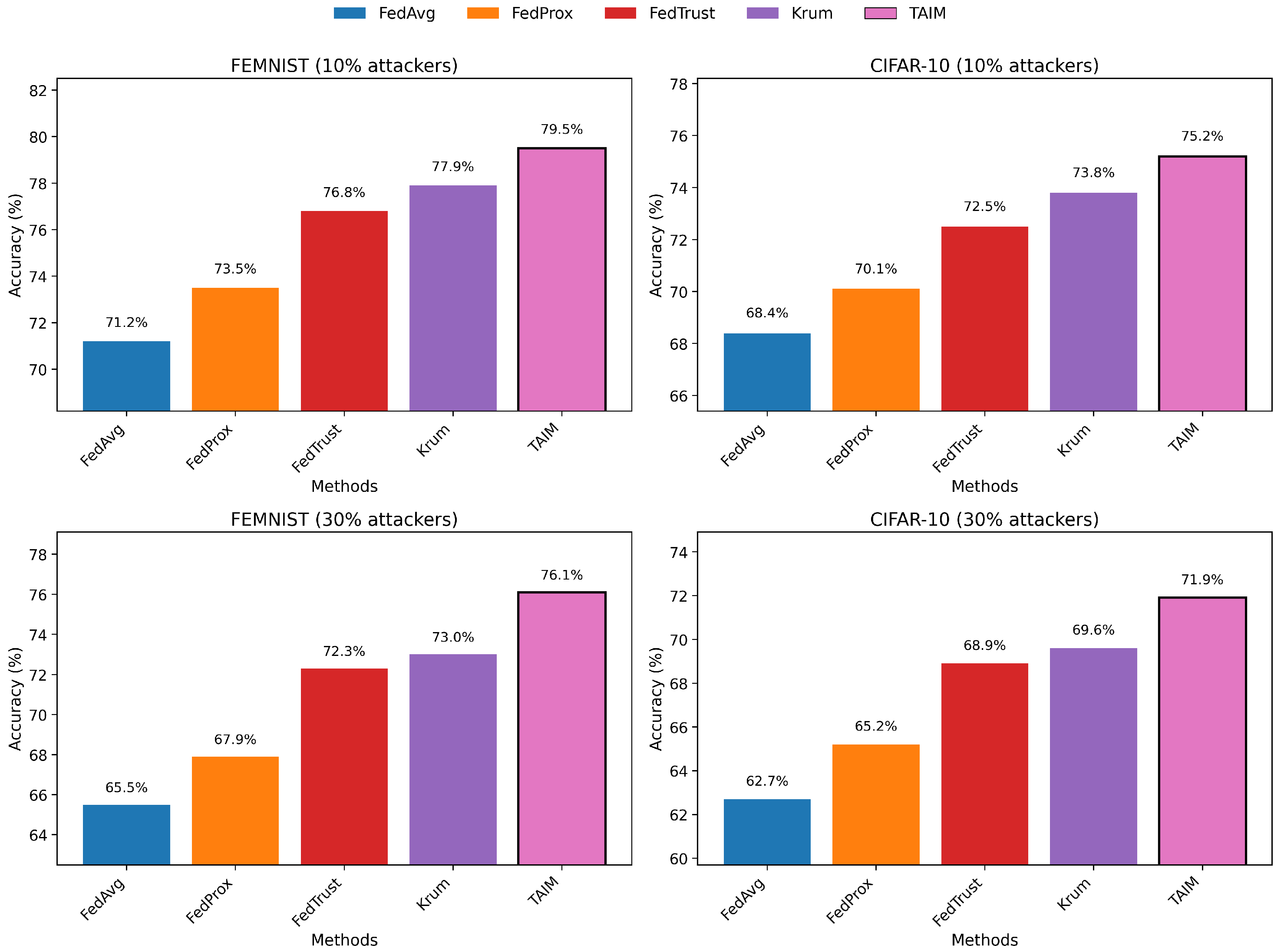
Figure 5 shows the final test accuracy under 10% and 30% attack ratios on FEMNIST and CIFAR-10. As the attack ratio increases, most methods experience a significant drop in accuracy. TAIM consistently achieves the best performance: 79.5% and 76.1% on FEMNIST; 75.2% and 71.9% on CIFAR-10. Compared to FedAvg and FedProx, TAIM shows up to 9.2% higher accuracy under heavy attacks, demonstrating its effectiveness in suppressing adversarial disturbances through trust modeling and incentive mechanisms.
Figure 6 shows model robustness under On–Off and Mimic attacks. Traditional methods like FedAvg and FedProx exhibit severe performance fluctuation, and even robust methods like FedTrust and Krum are affected by Mimic attacks. In contrast, TAIM maintains stable accuracy with minimal drop, outperforming Krum by 2.5% under Mimic attacks. This indicates that the multi-dimensional trust model in TAIM effectively filters disguised adversaries.
Table 2 quantifies the detection performance. Traditional methods cannot detect malicious clients (denoted by “—”). FedTrust and Krum achieve 82.4% and 85.7% recall, with 9.6% and 12.1% FPR, respectively. TAIM outperforms them with 91.3% recall and only 5.8% FPR, owing to its use of participation, gradient consistency, and contribution effectiveness in trust modeling.
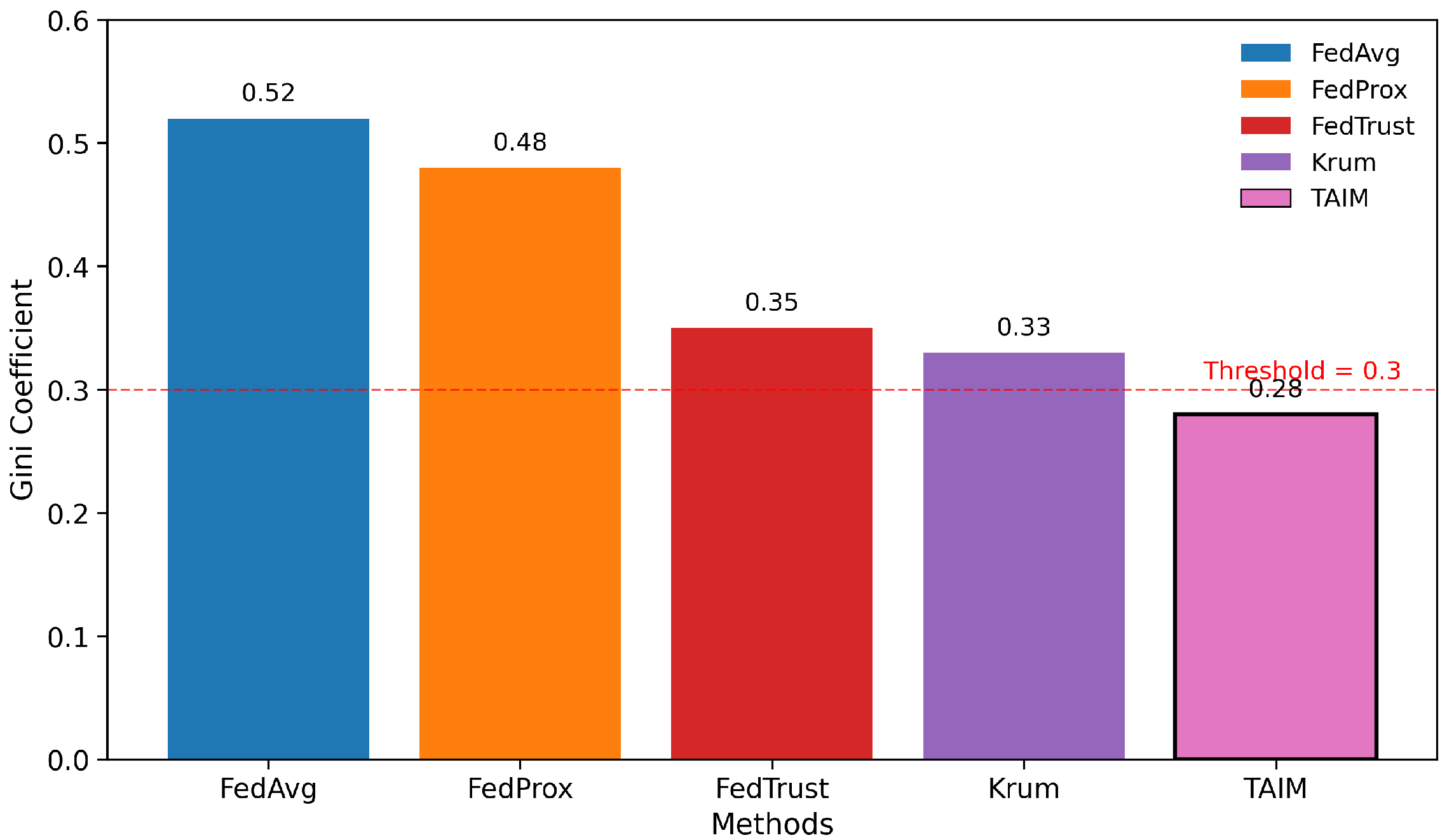
Figure 7 presents the Gini coefficient during training, reflecting the incentive fairness. FedTrust and FedProx exhibit rising Gini values, indicating reward centralization. TAIM maintains a Gini coefficient < 0.3 throughout thanks to its balanced trust design that considers both participation and quality.
Table 3 compares system overhead. Despite additional trust computation and soft aggregation, TAIM’s cost remains comparable: only 0.5 MB more in communication and 0.16 s server aggregation time. Compared with Krum, which involves costly distance calculations, TAIM is equally efficient while providing higher robustness and fairness.
Despite integrating additional trust computation and soft aggregation mechanisms, TAIM remains computationally efficient. This is because (1) trust score updates rely on lightweight operations such as exponential smoothing and cosine similarity, which are low-cost and executed server-side; (2) the soft aggregation function is implemented via a fast sigmoid approximation or lookup table, avoiding expensive distance or sorting operations as in Krum; (3) TAIM does not require additional communication rounds or model retraining, and its trust parameters are updated in line with the standard training flow. Therefore, the overall additional overhead is marginal.
To eliminate the confounding effects caused by differences in model architecture across datasets, we conduct a control experiment with a unified lightweight CNN (two convolutional layers and two fully connected layers, 0.5 M parameters) on both FEMNIST and CIFAR-10. For Sent140, since the data are inherently sequential, we retain the same LSTM-based model for all methods to ensure consistency and fairness in comparison. The corresponding results are presented in
Table 4.
These results show that TAIM consistently outperforms other methods across all three datasets even under unified or consistent model settings. This confirms that the observed performance gains are attributable to the trust-aware mechanism rather than model architecture differences, thereby strengthening the validity and generalizability of our conclusions.
5.6. Ablation Study and Parameter Sensitivity
Table 5 shows the ablation results of the trust components. Removing participation frequency
drops the accuracy to 70.5%; removing gradient consistency
further lowers it to 67.9%; excluding contribution effectiveness
gives 69.4%. This confirms the complementary roles of all three components in accurate trust assessment.
Figure 8 illustrates the sensitivity of the TAIM model to hyperparameter configurations, specifically analyzing the sigmoid suppression steepness parameter
k and the trust component weights
.
The left subfigure shows how the steepness parameter k in the sigmoid suppression function affects the final model accuracy. When k is set to a small value (e.g., 2.5), the model accuracy drops to 70.8% because the resulting trust scores are overly smooth, which fails to distinguish high- and low-trust clients effectively. As k increases, the accuracy gradually improves, reaching a peak of 75.2% at , then slightly decreases but remains relatively high (e.g., 74.6% at ). This suggests that moderately enhancing the steepness helps amplify trust-based differentiation in aggregation, while excessively steep functions may overfit trust estimates and impair generalization. Overall, the system demonstrates robustness to a wide range of k values. The right subfigure examines the influence of different trust component weight configurations. The result shows that, with an equal weight setting (equal: 0.33, 0.33, 0.33), the model achieves 73.8% accuracy, indicating that each trust dimension independently contributes to performance. However, when one dimension is overly emphasized—such as participation frequency ()—the accuracy significantly drops to 72.1%. In contrast, emphasizing gradient consistency (consist. heavy: 0.2, 0.6, 0.2) leads to a better result of 74.3%, highlighting the importance of gradient-level behaviors in robust modeling. TAIM’s default setting (0.3, 0.4, 0.3) achieves the highest accuracy of 75.2%, confirming the effectiveness of the proposed joint modeling strategy in balancing trust dimensions.
6. Conclusions and Future Work
In this paper, we propose a unified framework called TAIM (Trust-Aware Incentive Mechanism) to address key challenges in federated learning in edge computing environments, including client heterogeneity, incentive imbalance, and adversarial robustness. TAIM integrates dynamic multi-dimensional trust modeling and incentive game theory, jointly modeling participation reliability, gradient consistency, and contribution effectiveness. Based on these trust scores, a Stackelberg game-based incentive allocation strategy and a trust-guided soft aggregation algorithm are designed.
TAIM achieves a balance between incentive rationality, fairness, and system robustness. Experimental results show that TAIM consistently outperforms baseline methods across various non-IID data and adversarial settings. It improves model accuracy (up to +6.1%), reduces robustness degradation (kept within 3%), and maintains low False-Positive Rates and stable fairness. Moreover, the proposed soft filtering strategy enhances system security while preserving client diversity, enabling long-term trust evolution and reputation recovery.
Despite the progress made, several limitations remain to be addressed in future work:
First, the current trust evaluation process relies on centralized server control, posing potential risks of data linkage leakage and single-point failure. Future research may explore decentralized technologies such as blockchain and secure multi-party computation (SMC) to enhance privacy and system resilience.
Second, the client response function in the Stackelberg game is simplified, assuming fully rational and immediate reactions. It does not account for constrained strategy spaces or delayed behavior. Future extensions may incorporate game learning methods (e.g., Q-learning Stackelberg) or evolutionary game theory to better capture real-world client dynamics.
Third, this work primarily focuses on single-task, unimodal scenarios. The applicability of TAIM to multi-modal federated learning (e.g., joint modeling of vision and language) remains unexplored. Future studies should investigate trust modeling across modalities to support collaborative heterogeneous tasks.
Lastly, the current trust mechanism is not integrated with differential privacy (DP), raising potential privacy leakage concerns. Future work may investigate how to ensure trust computation effectiveness and robustness under DP budget constraints.
In summary, TAIM provides an effective trust-driven solution for building future-ready federated learning systems characterized by openness, dynamism, and strategic participation. Ongoing efforts will focus on enhancing the generality, security, and distributed capability of the mechanism to enable wide deployment of trustworthy federated intelligence.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}