Detection of Malicious Office Open Documents (OOXML) Using Large Language Models: A Static Analysis Approach



Abstract
1. Introduction
1.1. What Is a Malicious Document
1.2. Underlying Structure of Office Documents
1.3. Threat Assessment of Microsoft Office Documents
1.4. Common Attack Vectors for Malicious Office Documents
1.4.1. Entry Points— Social Attacks to Lure a Victim to Accept a Malicious Document
1.4.2. Malicious Techniques in Office Documents
- Create a malicious word template (.dotm) and host it
- Create a benign word document from a template, convert it to a ZIP-file and unzip it
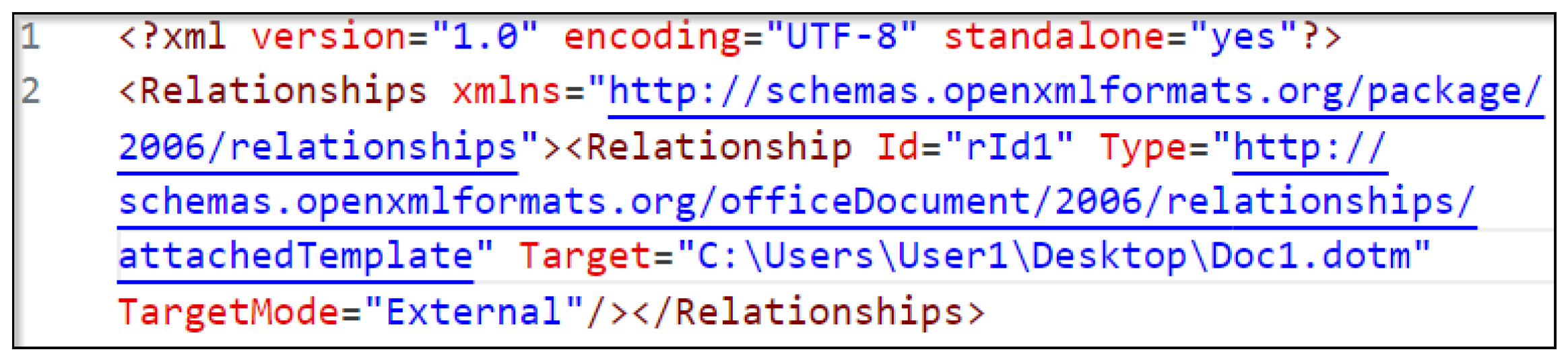
- Edit the /word/_rels/settings.xml.rels file; the attribute Target should point to the hosted .dotm template, as shown in Figure 3
- Zip up the files again, without compressing it, and change the file extension back to the original one
1.5. Summary of Contributions and Structure of the Paper
- We propose LLM-Sentinel, a novel methodology for detecting malicious Microsoft Office documents using LLMs.
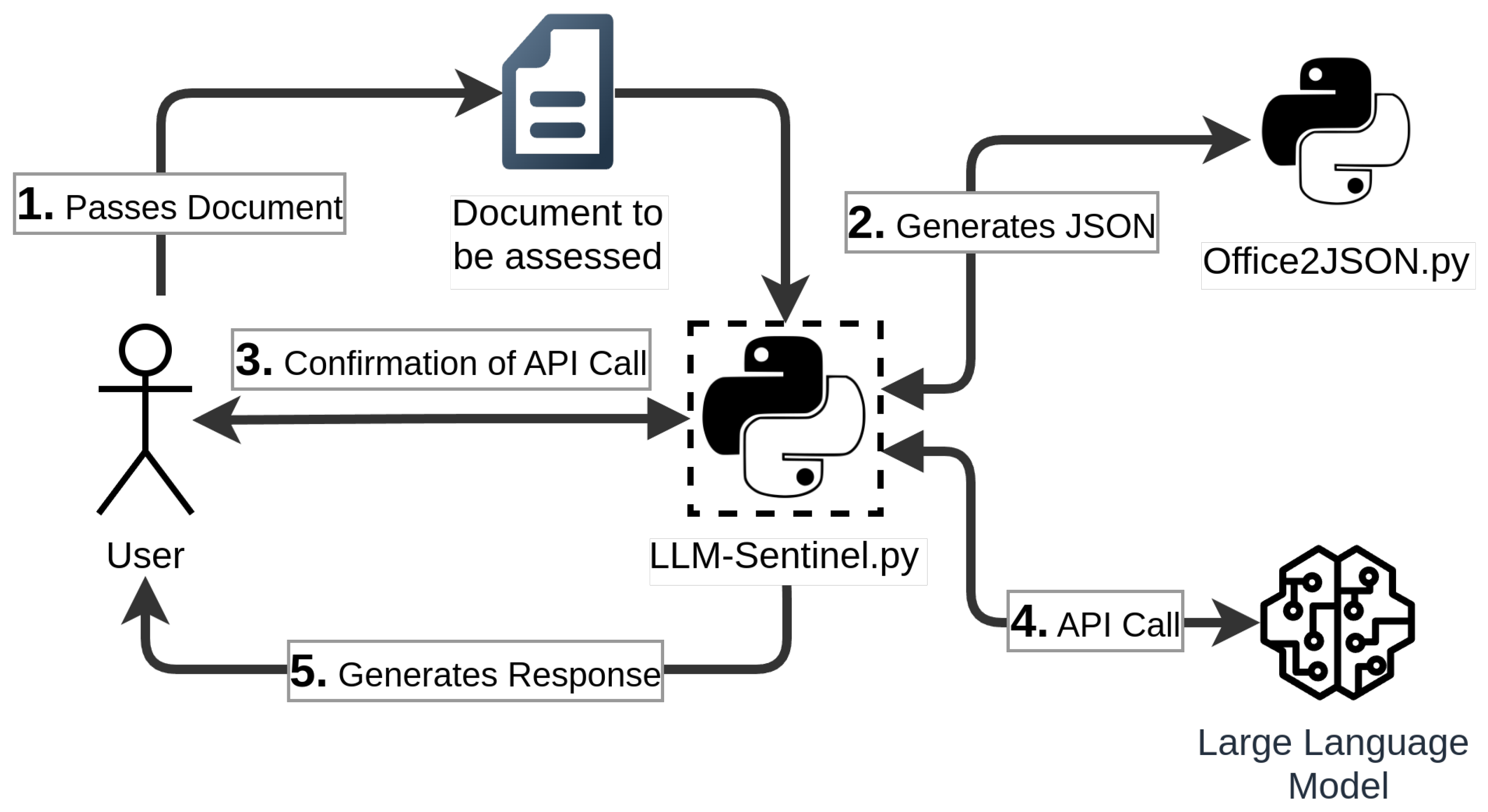
- We introduce a data extraction pipeline based on Office2JSON, which transforms OOXML content into structured textual input suitable for LLM analysis.
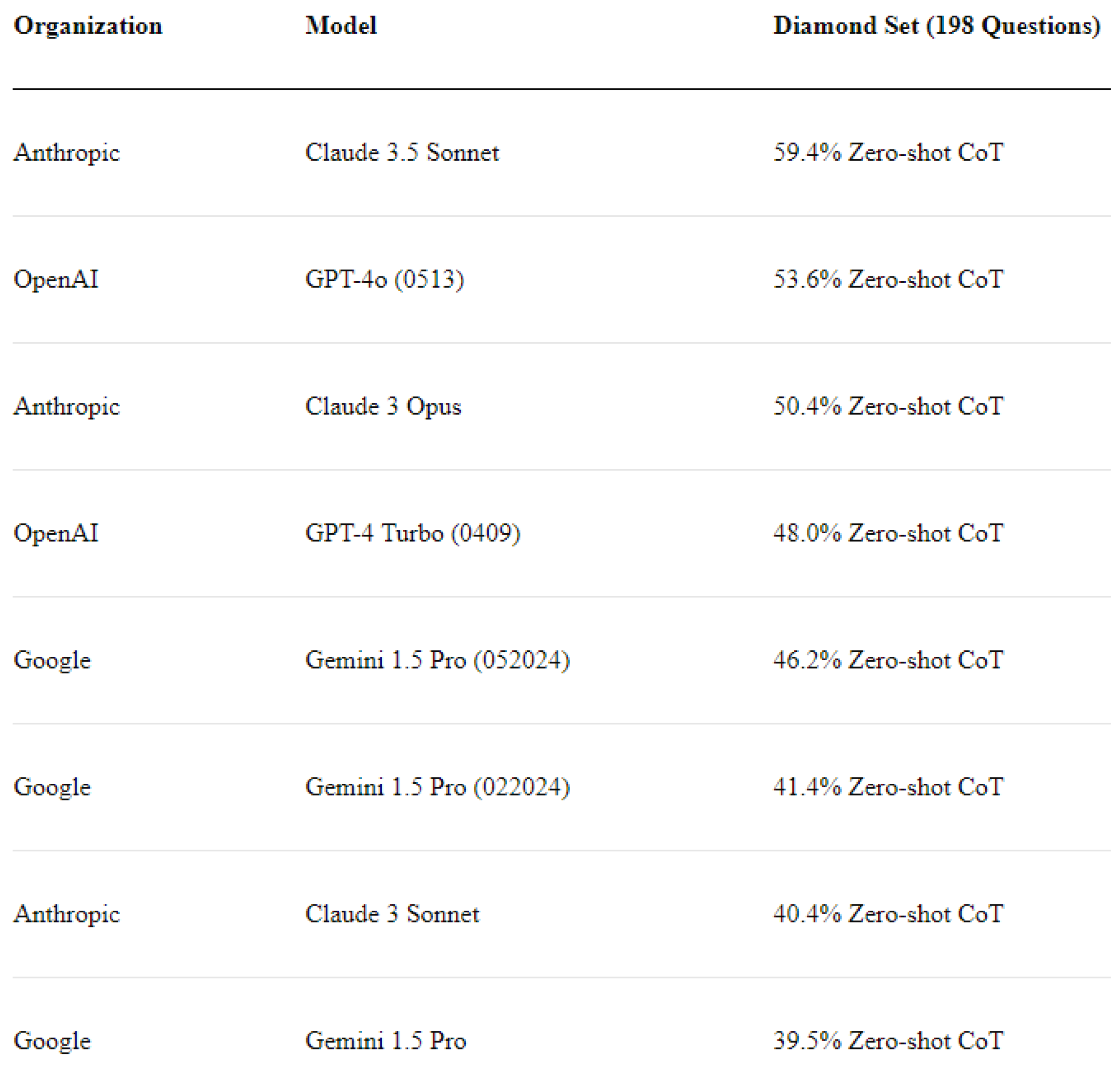
- We demonstrate that Claude 3.5 Sonnet is capable of identifying fine-grained malicious indicators within several hundred pages of raw document data, achieving an average F1-score of 0.929.
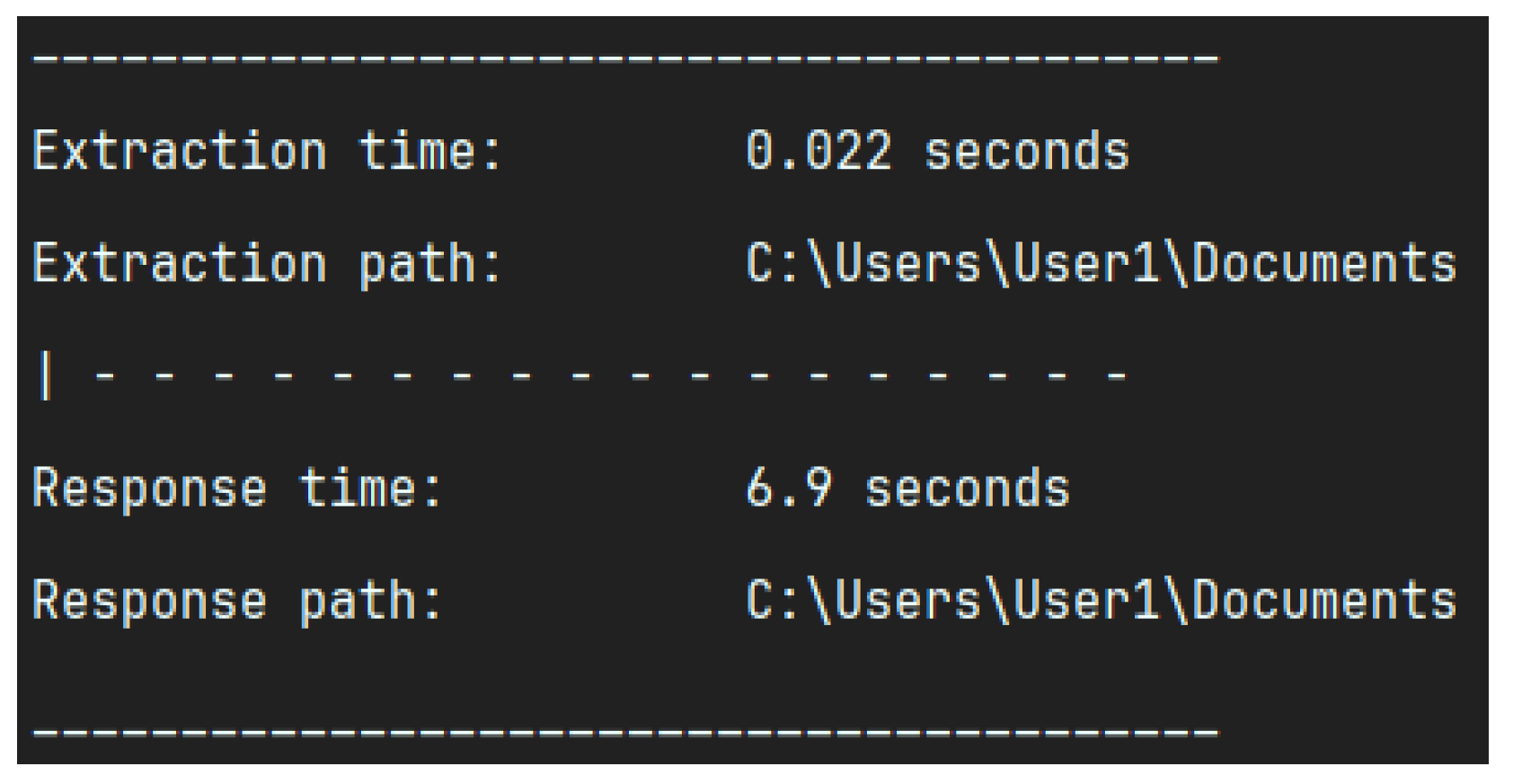
- We provide a detailed cost-performance evaluation, showing an average analysis time of 5–9 s and a mean cost of USD 0.19 per analysis.
- We evaluate the resilience of the proposed method against obfuscation techniques, including prompt injection and encrypted file payloads.
- We discuss regulatory implications and future directions, including the use of self-hosted LLMs and multi-format applicability.
2. Background and Literature Review
2.1. Methods for Static Malware Analysis
2.2. Methods for Dynamic Malware Analysis
2.3. Limitations of Traditional Detection Methods
2.4. Large Language Models in a Nutshell
- Expert-Level Difficulty: extremely challenging questions, with domain experts achieving an accuracy of 65%
- Google-Proof Nature: not being able to use shallow web search for answering the question
- Performance of AI Systems: using specific questions to test the accuracy of AI systems
2.5. Scientific Literature on Maldoc Detection Using LLMs
2.6. Conclusions on Related Work and Research Gap Identification
3. Preparation Step: Data Collection from the Office Document for Malware Analysis
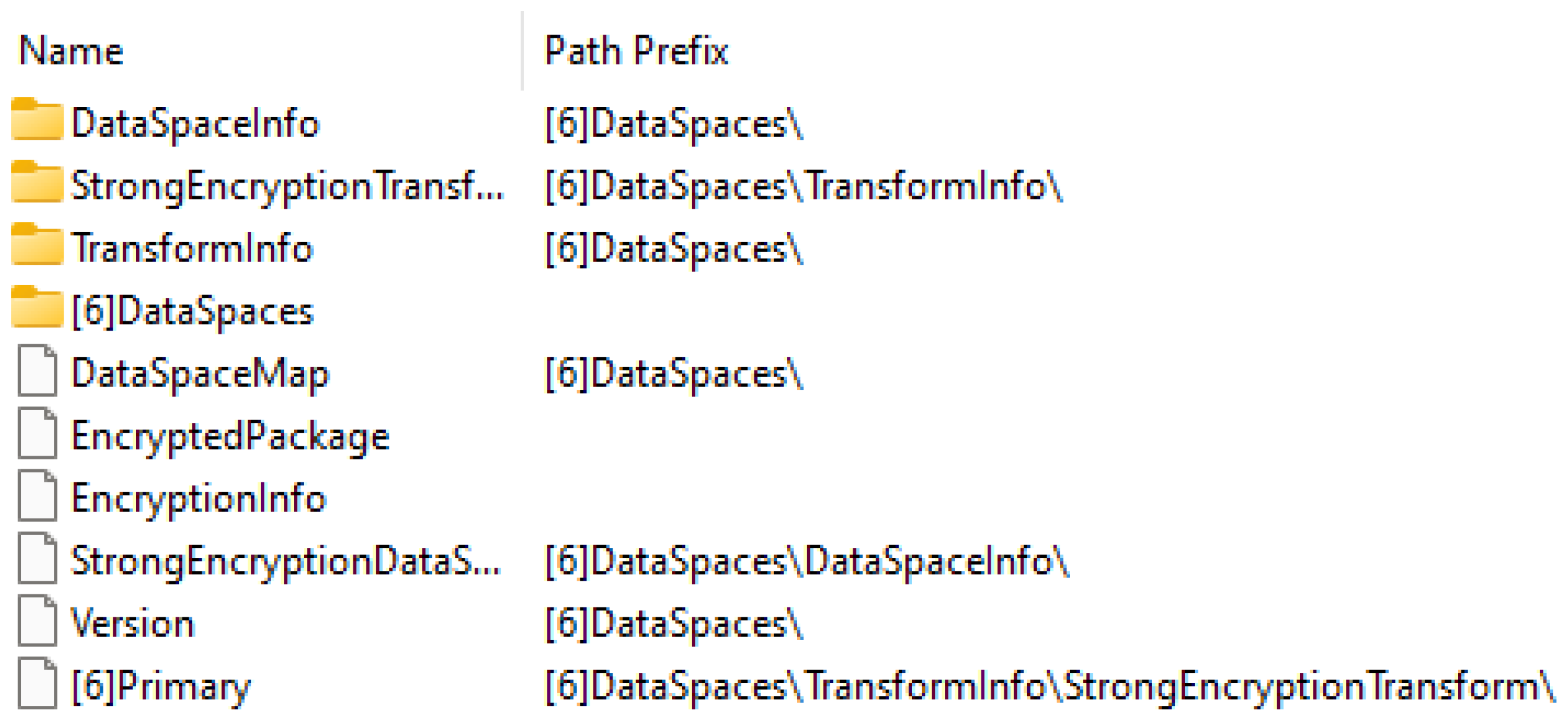
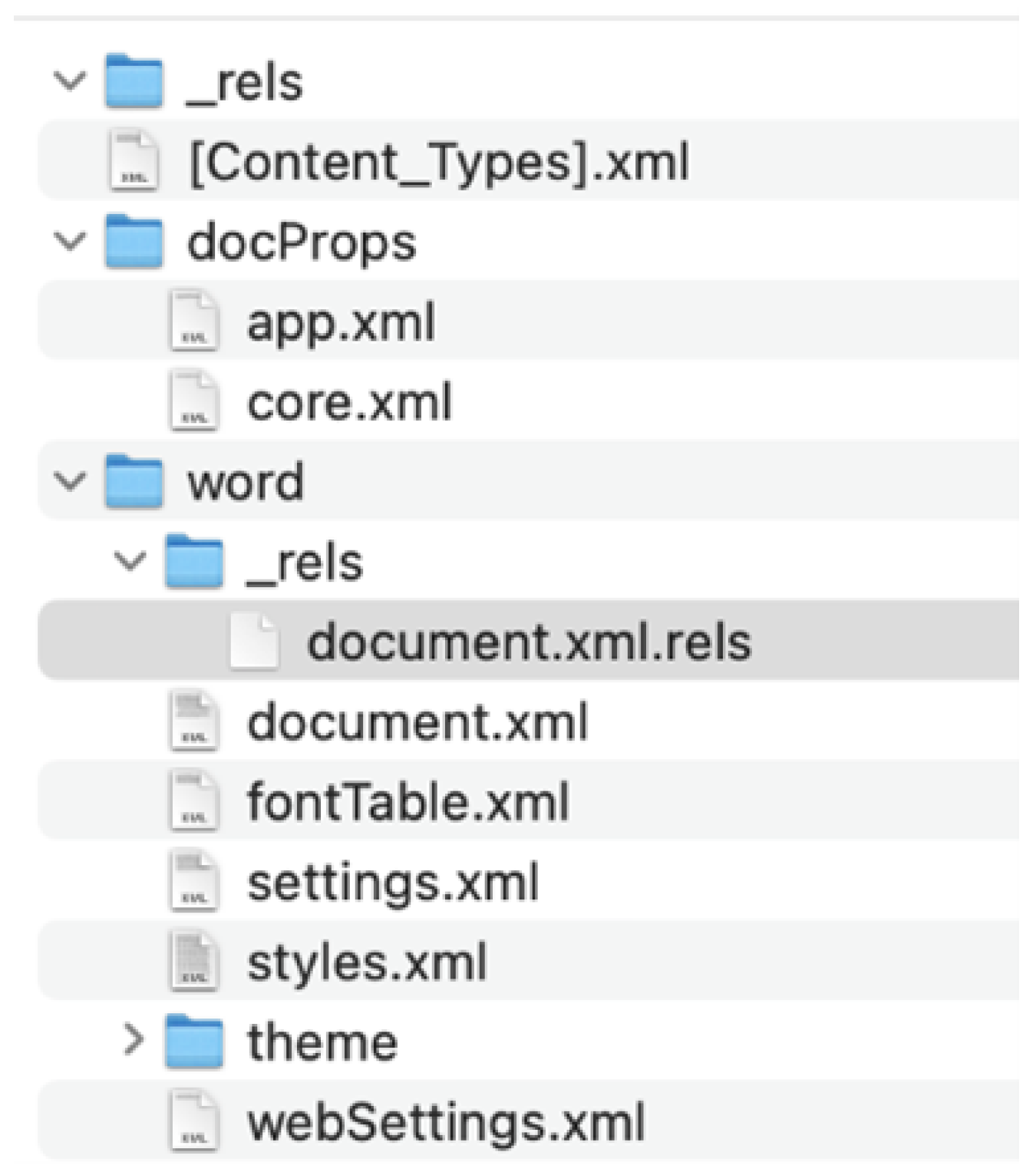
3.1. Contents of OOXML
- [Content_Types].xml: Contains a list of all content types of the package
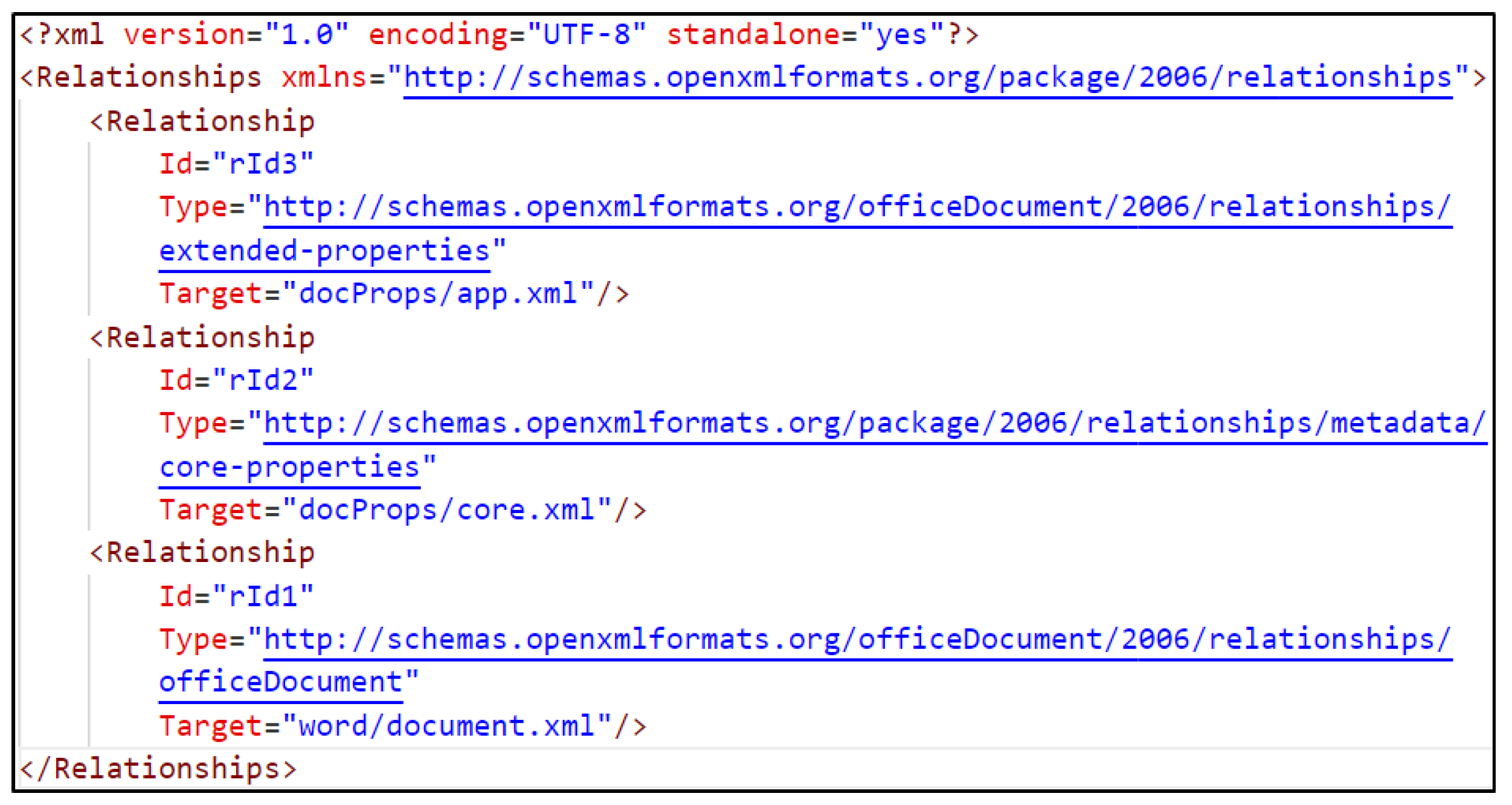
- *.rels: Acts like a manifest file, containing relationships between the parts of the file. Each relationship has an ID, a Type, and a Target, as seen in Figure 11.
- settings.xml.rels: File keeping information about referenced Office templates
- docProps: Folder that contains core.xml and app.xml
- core.xml: Information about metadata, like author, title, keywords, and creation date
- customXML: Section that can store custom XML documents, containing properties, user-defined tags, or entire other documents
- Word: Section stores the main content of the document, like text, formatting, styles, and objects
3.2. Data Extraction—Office2JSON
- Clone the repository to a machine.
- pip install -r requirements.txt
- Open a terminal session in that directory.
- python Office2JSON *PathToOfficeFile*
3.3. Sample Collection
4. LLM-Sentinel: An Approach for LLM-Based Office File Assessment
4.1. Overview on the Solution Architecture
4.2. Data Processing and API Calls
4.3. Increased Efficiency with Prompt Engineering
4.4. Verbose Output
4.5. Risk of Prompt Injection
- <json_content>
- {{JSON_CONTENT}}
- </json_content>
4.6. Encrypted Documents
4.7. Limitations
4.7.1. Technical Limitations
4.7.2. Implementation-Based Limitations
- Clone both GitHub repositories (Office2JSON and LLM-Sentinel) to the machine.
- Install requirements.txt.
- Add two new environment variables:
- -
- PYTHONPATH, with the /src/ directory of Office2JSON.py.
- -
- ANTHROPIC_API_KEY, with the created Anthropic API key.
- In the console, navigate to LLM-Sentinel.py and execute it with:python .\LLM-Sentinel.py path_to_ooxml_doc
5. Evaluation
5.1. Data Composition
5.2. Metrics and Scoring
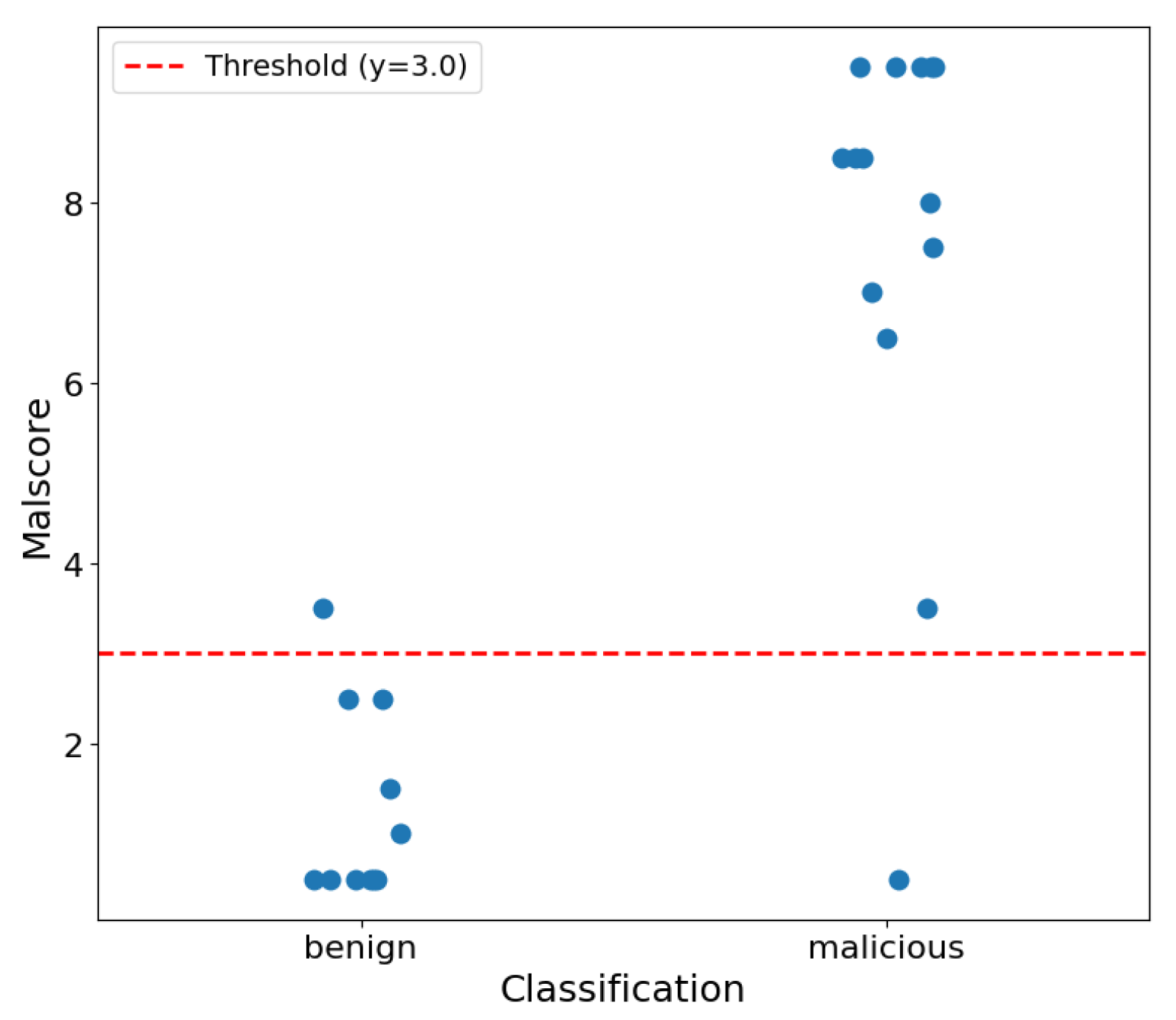
5.2.1. Confusion Matrix
- True positive (TP), top-left: correctly classified as malicious
- True negative (TN), bottom-right: correctly classified as benign
- False positive (FP), bottom-left: falsely classified as malicious
- False negative (FN), top-right: falsely classified as benign
5.2.2. Accuracy
5.2.3. Precision
5.2.4. Recall
5.2.5. F1-Score
5.3. Comparison with Existing Detection Methods
5.4. Costs
- Input:
- Output:
5.5. Performance for the Data Extraction Using Office2JSON in Terms of Time
6. Prospects and Discussion
6.1. Use Cases
6.2. AI Act of the European Union
6.3. Future Work
6.3.1. Expand Document Scope
6.3.2. Integrations
6.3.3. Self-Hosted LLMs
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Sample Verbose Static Analysis Report
| Listing A1. XML Analysis Report. |
  |
Appendix B. Default Prompt
| Listing A2. AI Assistant Prompt for OOXML Document Assessment. |
 |
Appendix C. Verbose Prompt
| Listing A3. Prompt for Full Static Analysis of Malicious OOXML Document. |
  |
References
- Microsoft Office Statistics: Latest Data & Summary. 2024. Available online: https://wifitalents.com/statistic/microsoft-office/#sources (accessed on 20 June 2024).
- Macros from the Internet Are Blocked by Default in Office. 2024. Available online: https://learn.microsoft.com/en-us/deployoffice/security/internet-macros-blocked (accessed on 20 June 2024).
- The Beginner’s Guide to—OOXML Malware Reverse Engineering Part 1. 2024. Available online: https://bufferzonesecurity.com/the-beginners-guide-to-ooxml-malware-reverse-engineering-part-1/ (accessed on 16 June 2024).
- How to Analyze Malicious Microsoft Office Files. 2025. Available online: https://intezer.com/blog/malware-analysis/analyze-malicious-microsoft-office-files/ (accessed on 2 April 2025).
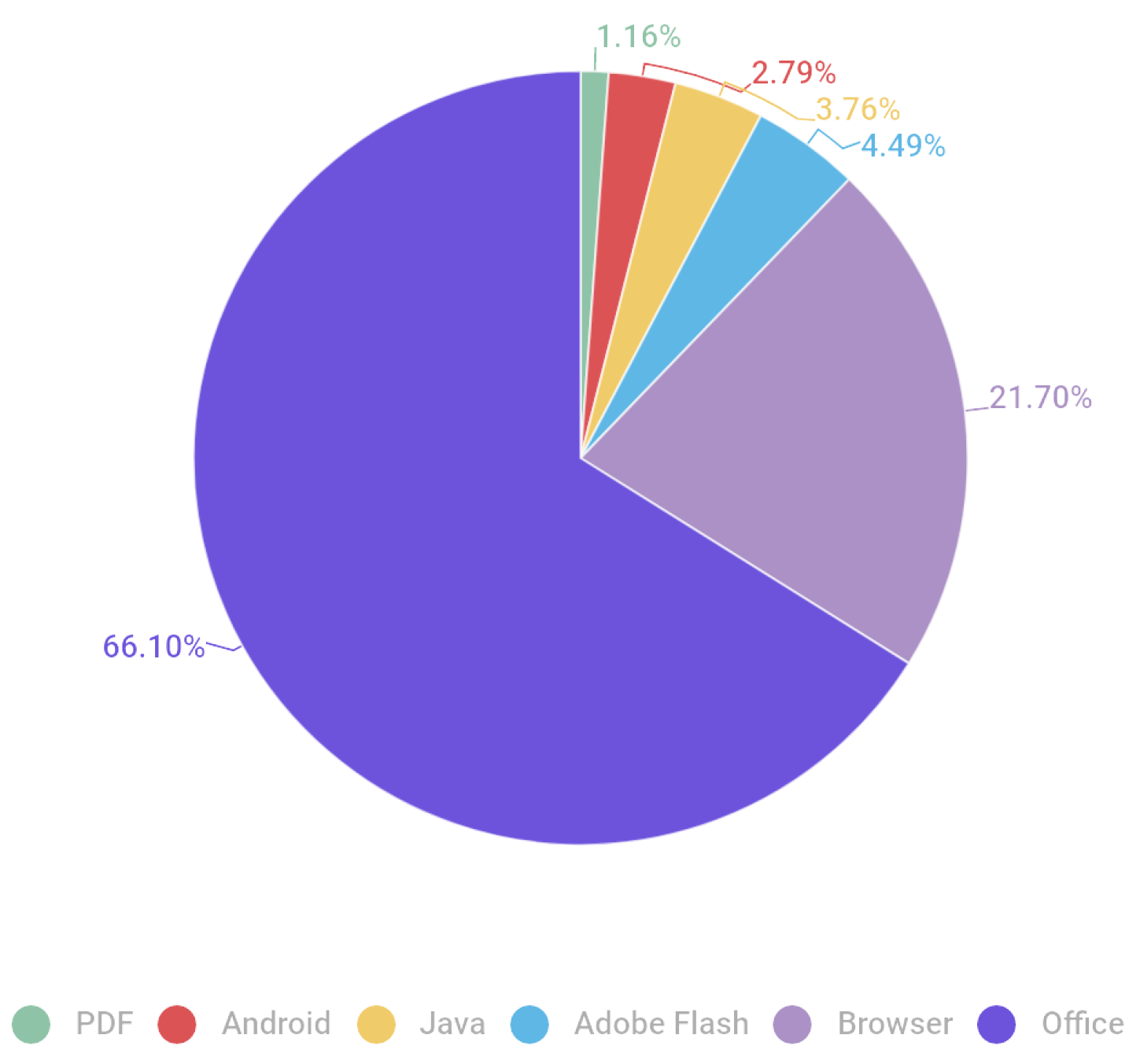
- A Distribution of Exploits Used in Attacks by Type of Application Attacked, May 2020. 2024. Available online: https://securelist.com/kaspersky-security-bulletin-2020-2021-eu-statistics/102335/#vulnerable-applications-used-by-cybercriminals (accessed on 17 June 2024).
- Microsoft 365 MSO 2306 Build 16.0.16529.20100 Remote Code Execution. 2025. Available online: https://packetstormsecurity.com/files/173361/Microsoft-365-MSO-2306-Build-16.0.16529.20100-Remote-Code-Execution.html (accessed on 3 April 2025).
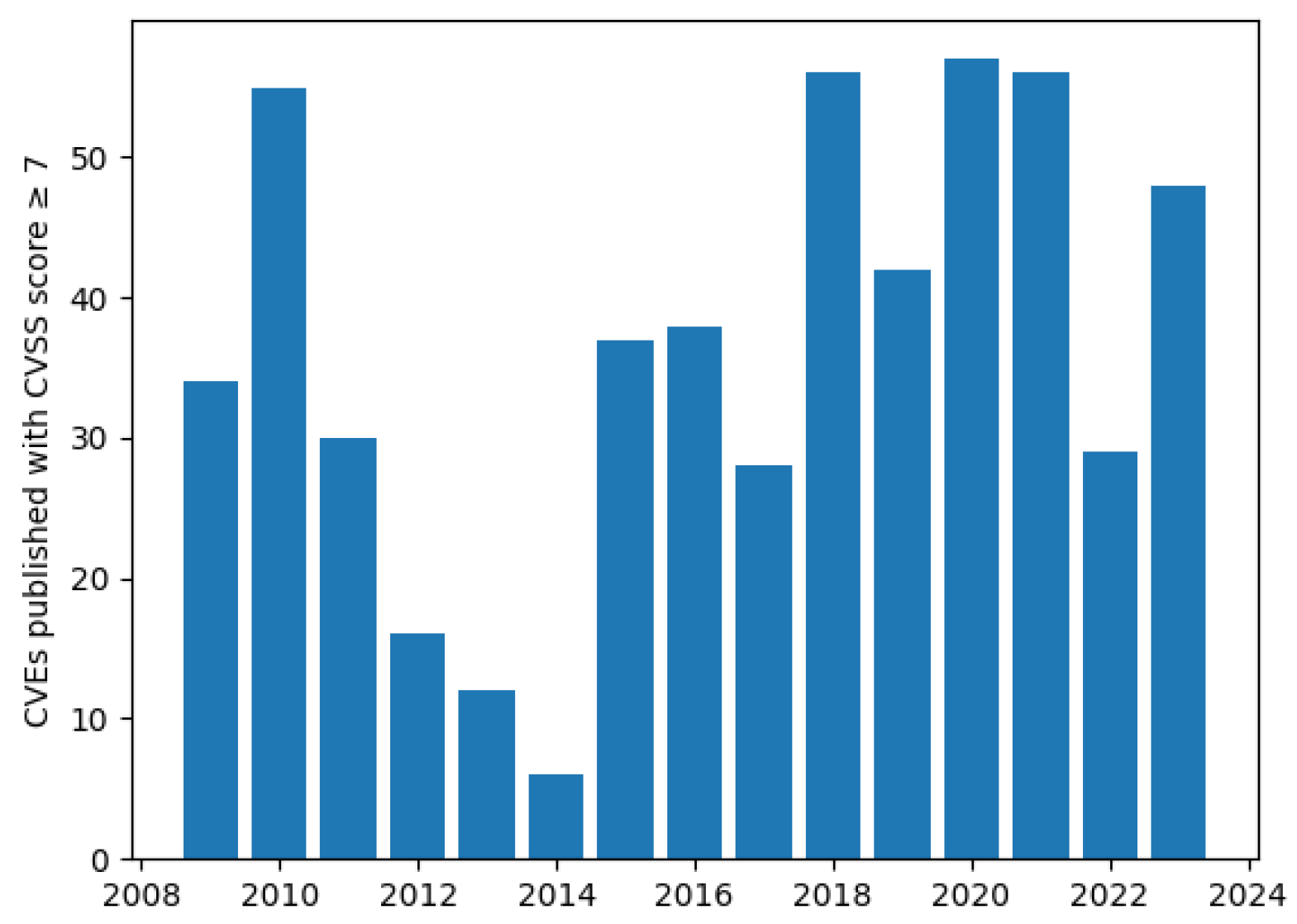
- Microsoft Office Security Vulnerabilities, CVEs CVSS Score >= 7. 2025. Available online: https://www.cvedetails.com/vulnerability-list/vendor_id-26/product_id-320/Microsoft-Office.html?page=1&cvssscoremin=7 (accessed on 3 April 2025).
- The Last Six Months Shows a 341% Increase in Malicious Emails. 2025. Available online: https://www.securitymagazine.com/articles/100687-the-last-six-months-shows-a-341-increase-in-malicious-emails (accessed on 15 April 2025).
- 139,445—Pentesting SMB. 2025. Available online: https://book.hacktricks.xyz/network-services-pentesting/pentesting-smb (accessed on 19 April 2025).
- HTTP Spoofing. 2025. Available online: https://www.invicti.com/learn/mitm-https-spoofing-idn-homograph-attack/ (accessed on 9 April 2025).
- Malicious Shapes In Office—Part 1. 2025. Available online: https://medium.com/@laughing_mantis/malicious-shapes-in-office-part-1-8a4efca74358 (accessed on 15 April 2025).
- Malicious Shapes In Office—Part 2. 2025. Available online: https://medium.com/@laughing_mantis/malicious-shapes-in-office-part-2-910375cd05f3 (accessed on 15 April 2025).
- Heß, J. Office2JSON. 2024. Available online: https://github.com/RuntimeException420/Office2JSON (accessed on 18 June 2024).
- MalwareBazaar Database. 2024. Available online: https://bazaar.abuse.ch/browse/ (accessed on 18 June 2024).
- VirusTotal—Search. 2025. Available online: https://www.virustotal.com/gui/home/search (accessed on 10 April 2025).
- HashMyFiles by NirSoft. 2025. Available online: https://www.nirsoft.net/utils/hash_my_files.html (accessed on 16 April 2025).
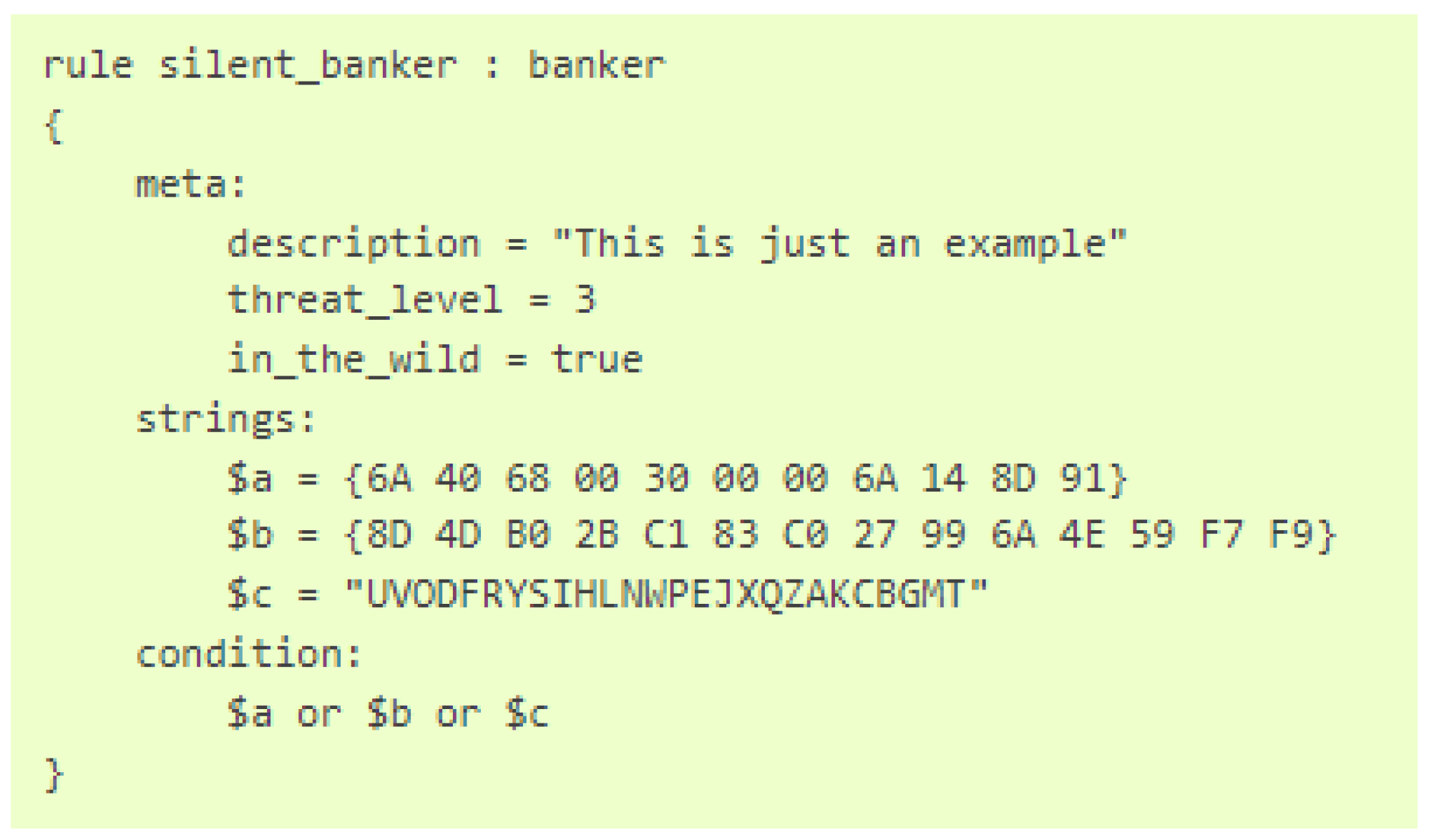
- YARA’s Documentation. 2025. Available online: https://yara.readthedocs.io/en/v4.4.0/index.html (accessed on 16 April 2025).
- PeStudio Overview: Setup, Tutorial and Tips. 2025. Available online: https://www.varonis.com/blog/pestudio (accessed on 16 April 2025).
- Decalage2/Oletools. 2024. Available online: https://github.com/decalage2/oletools (accessed on 19 June 2024).
- REMnux: A Linux Toolkit for Malware Analysis. 2025. Available online: https://remnux.org/#home (accessed on 16 April 2025).
- LetsDefend: Dynamic Malware Analysis Part 1. 2025. Available online: https://infosecwriteups.com/letsdefend-dynamic-malware-analysis-part-1-1ce35ff5b59f (accessed on 16 April 2025).
- What Is Endpoint Detection and Response? 2025. Available online: https://www.trellix.com/security-awareness/endpoint/what-is-endpoint-detection-and-response/ (accessed on 16 April 2025).
- What Are Metamorphic and Polymorphic Malware? 2024. Available online: https://www.techtarget.com/searchsecurity/definition/metamorphic-and-polymorphic-malware (accessed on 28 June 2024).
- Naidu, V.; Narayanan, A. A Syntactic Approach for Detecting Viral Polymorphic Malware Variants. In Proceedings of the Intelligence and Security Informatics, Auckland, New Zealand, 19 April 2016; Volume 9650. [Google Scholar] [CrossRef]
- Protect a Document with a Password. 2025. Available online: https://support.microsoft.com/en-us/office/protect-a-document-with-a-password-05084cc3-300d-4c1a-8416-38d3e37d6826 (accessed on 16 April 2025).
- Pleshakova, E.; Osipov, A.; Gataullin, S.; Gataullin, T.; Vasilakos, A. Next gen cybersecurity paradigm towards artificial general intelligence: Russian market challenges and future global technological trends. J. Comput. Virol. Hacking Tech. 2024, 20, 429–440. [Google Scholar] [CrossRef]
- Minaee, S.; Mikolov, T.; Nikzad, N.; Chenaghlu, M.; Socher, R.; Amatriain, X.; Gao, J. Large Language Models—A Survey. arXiv 2024, arXiv:2402.06196. [Google Scholar] [CrossRef]
- GPQA: A Graduate-Level Google-Proof Q&A Benchmark. 2025. Available online: https://klu.ai/glossary/gpqa-eval (accessed on 14 April 2025).
- LLM Leaderboard. 2025. Available online: https://klu.ai/llm-leaderboard (accessed on 14 April 2025).
- Sanchez, P.M.S.; Celdran, A.H.; Bovet, G.; Perez, G.M. Transfer Learning in Pre-Trained Large Language Models for Malware Detection Based on System Calls. arXiv 2024, arXiv:2405.09318. [Google Scholar] [CrossRef]
- Singh, P. Detection of Malicious OOXML Documents Using Domain Specific Features. Ph.D. Thesis, Indian Institute of Information Technology and Management Gwalior, Gwalior, India, 2017. [Google Scholar]
- Zahan, N.; Burckhardt, P.; Lysenko, M.; Aboukhadijeh, F.; Williams, L. Shifting the Lens: Detecting Malicious npm Packages using Large Language Models. arXiv 2025, arXiv:2403.12196. [Google Scholar] [CrossRef]
- Patsakis, C.; Casino, F.; Lykousas, N. Assessing LLMs in Malicious Code Deobfuscation of Real-world Malware Campaigns. arXiv 2025, arXiv:2404.19715. [Google Scholar] [CrossRef]
- Müller, J.; Ising, F.; Mainka, C.; Mladenov, V.; Schinzel, S.; Schwenk, J. Office Document Security and Privacy. In Proceedings of the 14th USENIX Workshop on Offensive Technologies (WOOT 20), Boston, MA, USA, 10–11 August 2020. [Google Scholar]
- Nath, H.V.; Mehtre, B. Static Malware Analysis Using Machine Learning Methods. In Proceedings of the International Conference on Security in Computer Networks and Distributed Systems (SNDS-2014), Trivandrum, India, 13–14 March 2014. [Google Scholar] [CrossRef]
- Khan, B.; Arshad, M. Comparative Analysis of Machine Learning Models for PDF Malware Detection: Evaluating Different Training and Testing Criteria. J. Cyber Secur. 2023, 5, 1–11. [Google Scholar] [CrossRef]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of Machine Learning Techniques for Malware Analysis. arXiv 2017, arXiv:1710.08189. [Google Scholar] [CrossRef]
- Shalaginov, A.; Banin, S.; Dehghantanha, A.; Franke, K. Machine Learning Aided Static Malware Analysis: A Survey and Tutorial. arXiv 2025, arXiv:1808.01201. [Google Scholar] [CrossRef]
- PEP 8—Style Guide for Python Code. 2025. Available online: https://peps.python.org/pep-0008/ (accessed on 10 April 2025).
- Mandiant/Flare-vm. 2025. Available online: https://github.com/mandiant/flare-vm (accessed on 17 April 2025).
- Heß, J. LLM-Sentinel. 2025. Available online: https://github.com/RuntimeException420/LLM-Sentinel (accessed on 10 April 2025).
- Generate Better Prompts in the Developer Console. 2025. Available online: https://www.anthropic.com/news/prompt-generator (accessed on 10 April 2025).
- Using the API—Client SDKs. 2025. Available online: https://docs.anthropic.com/en/api/client-sdks#python (accessed on 11 April 2025).
- Prompt Engineering Overview. 2025. Available online: https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview (accessed on 10 April 2025).
- A Guide to Prompt Engineering: Enhancing the Performance of Large Language Models (LLMs). 2025. Available online: https://roboticsbiz.com/a-guide-to-prompt-engineering-enhancing-the-performance-of-large-language-models-llms/ (accessed on 20 May 2025).
- Zhan, Q.; Liang, Z.; Ying, Z.; Kang, D. INJECAGENT: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. arXiv 2024, arXiv:2403.02691. [Google Scholar] [CrossRef]
- Learn About Claude—Models. 2025. Available online: https://docs.anthropic.com/en/docs/about-claude/models (accessed on 10 April 2025).
- Introducing the Next Generation of Claude. 2025. Available online: https://www.anthropic.com/news/claude-3-family (accessed on 10 April 2025).
- Naik, N.; Jenkins, P.; Savage, N.; Yang, L.; Boongeon, T.; Iam-On, N.; Naik, K.; Song, J. Embedded YARA rules: Strengthening YARA Rules Utilising Fuzzy Hashing and Fuzzy Rules for Malware Analysis. 2020. Available online: https://link.springer.com/article/10.1007/s40747-020-00233-5 (accessed on 27 May 2025).
- Anthropic—Pricing. 2025. Available online: https://www.anthropic.com/pricing#anthropic-api (accessed on 5 April 2025).
- Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying Down Harmonised Rules on Artificial Intelligence and Amending Regulations. 2025. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689 (accessed on 14 April 2025).
- Commercial Terms of Service. 2025. Available online: https://www.anthropic.com/legal/commercial-terms (accessed on 14 April 2025).
- Introducing Llama 3.1: Our Most Capable Models to Date. 2025. Available online: https://ai.meta.com/blog/meta-llama-3-1/ (accessed on 6 April 2025).
- Gemma Open Models. 2025. Available online: https://ai.google.dev/gemma (accessed on 6 April 2025).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Malicious | Benign | |
|---|---|---|
| .docm | 3 | 1 |
| .docx | 4 | 3 |
| .dotm | 0 | 1 |
| .dotx | 0 | 1 |
| .pptx | 1 | |
| .xlsm | 3 | |
| .xlsx | 3 | 3 |
| Predicted | |||
|---|---|---|---|
| Malicious | Benign | ||
| Actual | Malicious | 13 | 1 |
| Benign | 1 | 10 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heß , J.; Graffi, K. Detection of Malicious Office Open Documents (OOXML) Using Large Language Models: A Static Analysis Approach. J. Cybersecur. Priv. 2025, 5, 32. https://doi.org/10.3390/jcp5020032
Heß J, Graffi K. Detection of Malicious Office Open Documents (OOXML) Using Large Language Models: A Static Analysis Approach. Journal of Cybersecurity and Privacy. 2025; 5(2):32. https://doi.org/10.3390/jcp5020032
Chicago/Turabian StyleHeß , Jonas, and Kalman Graffi. 2025. "Detection of Malicious Office Open Documents (OOXML) Using Large Language Models: A Static Analysis Approach" Journal of Cybersecurity and Privacy 5, no. 2: 32. https://doi.org/10.3390/jcp5020032
APA StyleHeß , J., & Graffi, K. (2025). Detection of Malicious Office Open Documents (OOXML) Using Large Language Models: A Static Analysis Approach. Journal of Cybersecurity and Privacy, 5(2), 32. https://doi.org/10.3390/jcp5020032