1. Introduction
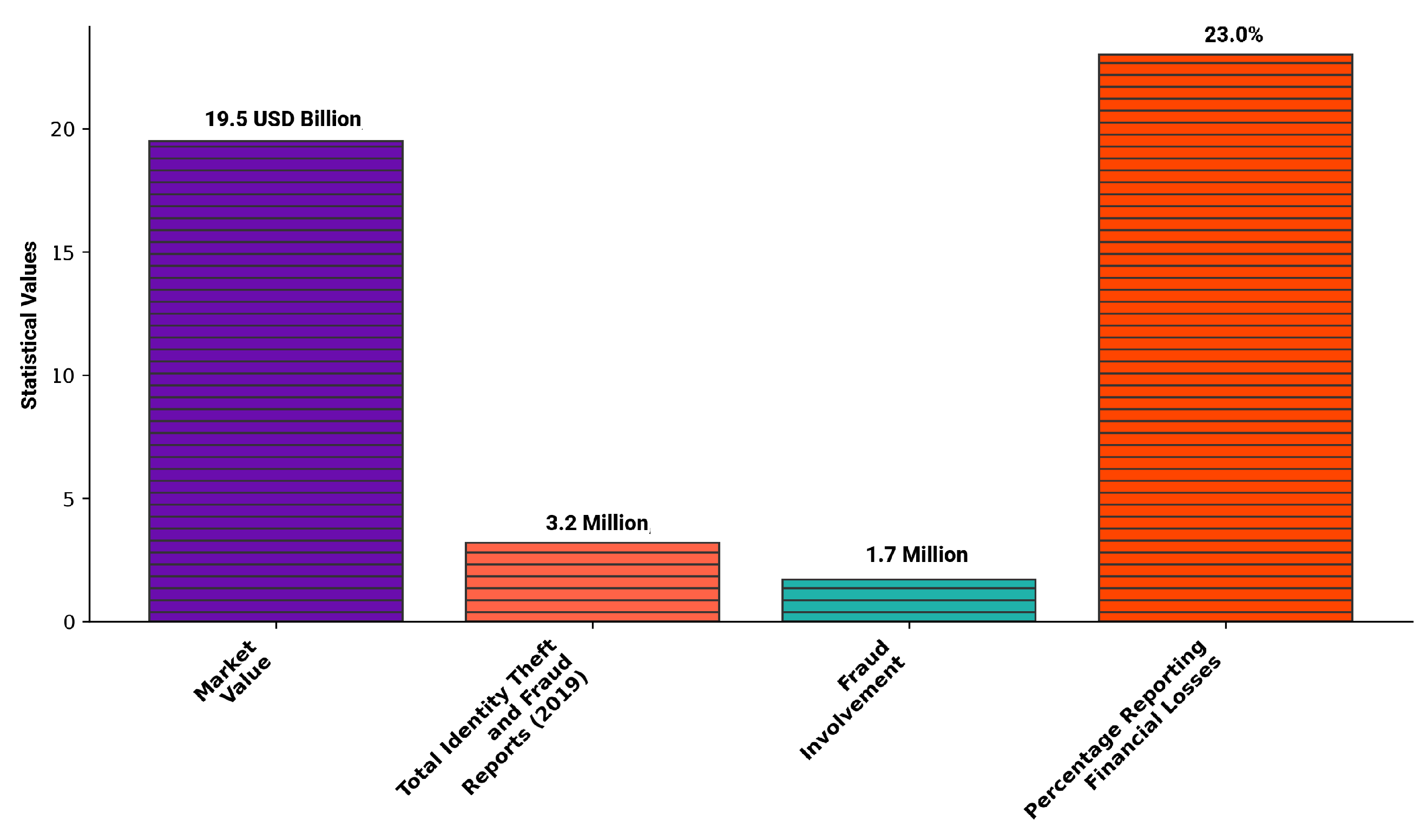
Recent studies estimate that the fraud detection and prevention market is valued at USD 19.5 billion. According to the Consumer Sentinel Network in the USA, among the 3.2 million identity theft and fraud reports in 2019, 1.7 million involved fraud [
1]. Of these cases, 23% reported financial losses, highlighting the significant impact on both institutions and individuals. Rapid detection of fraudulent activities is crucial and should occur as soon as streams containing relevant financial data are received. This urgency results in extensive datasets within financial institutions, which are often complex due to the diverse features recorded in transactions [
2].
Figure 1 shows the statistical number discussed above in a better manner.
Financial institutions are tasked with the critical challenge of quickly and accurately identifying and isolating fraudulent transactions while maintaining a smooth customer experience. “Quickly” emphasizes the need for a detection model that minimizes delays, protecting both customers and institutions from potential issues. Meanwhile, “accurately” highlights the importance of precise fraud detection, as false positives can lead to unnecessary resource allocation [
3]. Traditionally, fraud detection methods, such as manual review or rule-based models, have shown limited effectiveness. Manual detection is slow, requiring a long time to conclude, while rule-based approaches involve complex rules that must be applied and assessed before a transaction can be labeled as suspicious [
4]. Both methods demand significant effort to establish criteria for identifying fraudulent transactions and struggle to detect new, unknown, and sophisticated fraud patterns. For this reason, financial institutions spend a lot of money searching for powerful techniques to prevent fraudulent transactions with higher accuracy by employing artificial intelligence. AI-driven fraud detection systems provide unmatched speed, efficiency, and adaptability [
5]. Machine learning models (ML), such as Logistic Regression, Decision Tree, Random Forest, Gradient Boosting, XGBoost, LightGBM, K-Nearest Neighbors, Naive Bayes, AdaBoost, and Bagging Classifier, offer a range of solutions for detecting fraudulent transactions [
6]. These models are effective at handling various data patterns and can be used individually or combined to enhance fraud detection capabilities [
7]. Likewise, deep learning techniques (DL), including Long Short-Term Memory networks, Artificial Neural Networks, and Recurrent Neural Networks, further strengthen these solutions by analyzing large datasets and uncovering intricate patterns [
8]. The integration of these ML and DL models into hybrid algorithms provides a comprehensive approach to fraud detection. Hybrid models leverage diverse techniques to improve detection accuracy, reduce false positives, and adapt to evolving fraud tactics [
9]. They also optimize computational resources for scalability, ensuring efficient performance even with large-scale data. As financial fraud becomes increasingly sophisticated, the application of advanced ML and DL models helps institutions stay ahead of threats, manage risks effectively, comply with regulations, and protect against financial losses [
10].
Class imbalance is a critical challenge in machine learning problems because it poses significant issues for most machine learning algorithms. By default, these algorithms optimize overall accuracy, which can cause models to ignore the minority class, prioritizing correct predictions for the majority while failing to detect rare but critical instances. For example, in fraud detection, fraudulent transactions may represent less than 1% of all data, allowing a model to achieve 99% accuracy by naively labeling every transaction as legitimate [
11]. However, accurately identifying rare fraudulent transactions is critical for financial institutions to prevent losses. The imbalance makes it difficult for classifiers to effectively learn from the limited examples of fraudulent transactions [
12]. Traditional methods designed for balanced datasets often focus on overall accuracy, which can result in poor performance in detecting the minority class. To tackle this issue, several techniques have been developed [
13]. Data-level methods, such as oversampling and undersampling, aim to adjust the dataset to mitigate the imbalance. Oversampling increases the number of fraudulent transaction samples by duplicating them, while undersampling reduces the number of legitimate transactions, potentially at the cost of losing valuable information [
4]. Advanced methods like the Synthetic Minority Oversampling Technique (SMOTE) generate synthetic examples of fraudulent transactions [
14], and its variants—like the Adaptive Synthetic Sampling Approach (ADASYN) [
15], Borderline-SMOTE, Majority Weighted Minority Oversampling Technique (MWMOTE), and Weighted Kernel-Based SMOTE—generate synthetic samples to better balance the dataset [
16], helping to balance the dataset without risking overfitting. These approaches are essential for improving detection rates and effectively managing class imbalance in fraud detection systems.
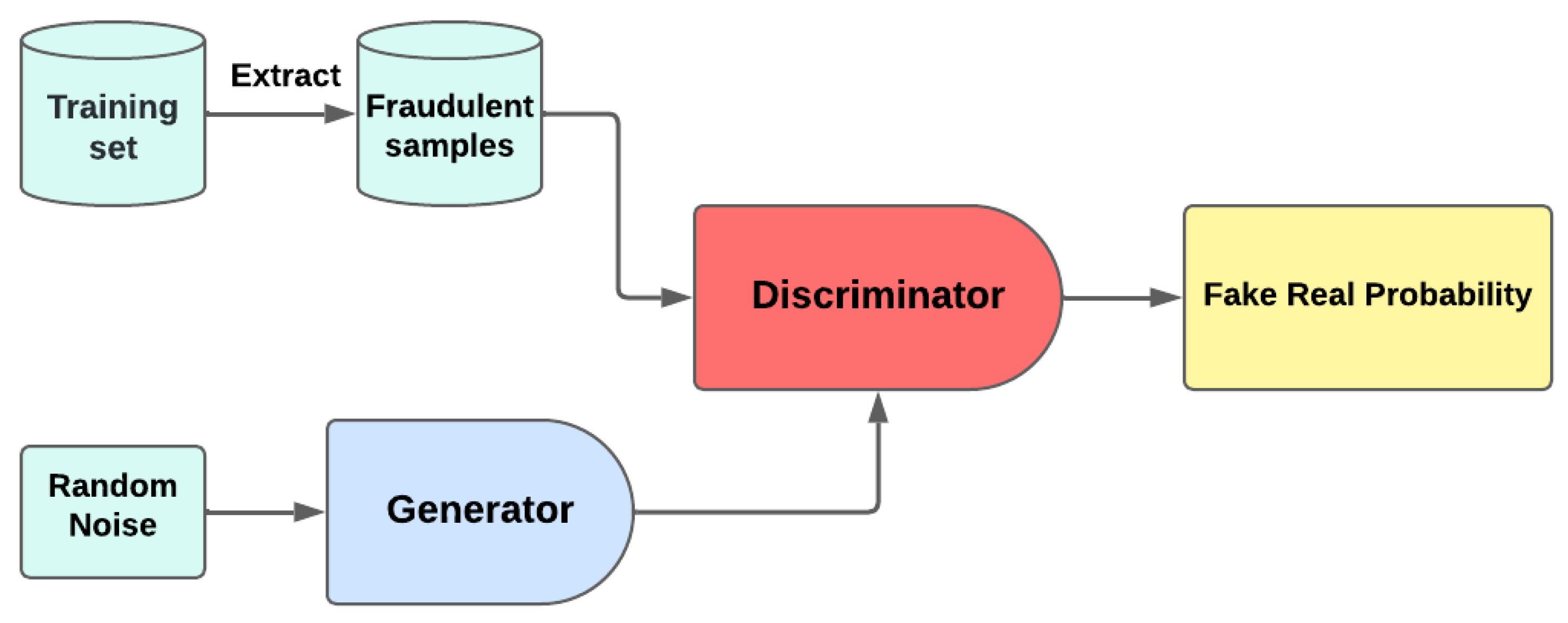
Generative modeling has recently garnered significant attention due to its effectiveness in handling diverse types of data and simulating sample behaviors [
17]. Its applicability extends to various domains, including image generation and noise reduction [
18]. This paper aims to leverage the capabilities of generative modeling to address the challenge of imbalanced credit card fraud detection. Specifically, we propose several models: an Autoencoder, a Variational Autoencoder (VAE), a Generative Adversarial Network (GAN), and a hybrid architecture that combines a GAN with an Autoencoder. These techniques are used for data augmentation by exploiting their ability to mimic synthetic datasets. The choice of these models is justified by their proven effectiveness in generating synthetic images and tabular datasets across various fields.
To evaluate the proposed solutions, we conducted extensive experiments using a real-world credit card dataset. We utilized various standard evaluation metrics and introduced a new metric, the Balanced Fraud Detection Score (BFDS), which combines these metrics for more accurate results and to identify the best-performing methods. Our contributions can be summarized as follows:
Proposal of Machine Learning and deep learning Models: Several advanced machine learning and deep learning models are proposed for detecting fraudulent transactions.
Generative Models for Handling Imbalanced Learning: To address the issue of class imbalance, we propose multiple generative models to create synthetic fraudulent samples based on historical datasets, including Autoencoders, Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and a hybrid model combining GANs with Autoencoders. These models aim to balance the dataset and improve the detection of rare fraudulent transactions.
Introduction of a New Evaluation Metric: We introduce a novel metric called the Balanced Fraud Detection Score (BFDS) that combines accuracy, precision, sensitivity, G-mean, and specificity to provide a comprehensive assessment of model performance.
Empirical Validation and Comparison: Extensive experiments are conducted using a real-world credit card dataset. The results demonstrate the effectiveness of our generative modeling solutions in classifying transactions and highlight their superior performance compared to traditional methods like SMOTE and ADSYN based on the BFDS metric.
These efforts aim to advance the field of fraud detection by providing innovative solutions to class imbalance and enhancing the performance of detection systems.
Our work is organized as follows:
Section 2 reviews the related work,
Section 3 provides background information on the proposed model,
Section 4 discusses the methodology and the materials used,
Section 5 presents the experimental evaluation of our approach, and
Section 6 concludes the paper and outlines our future research plans
2. Related Work
In the literature, numerous solutions have been proposed for maximizing the detection of fraudulent transactions using a variety of approaches centered on machine learning (ML) and deep learning (DL) models. To enhance these models, several strategies have been developed, including the use of statistical processes, mathematical theories, and optimization techniques such as metaheuristic algorithms [
19,
20] and Bayesian optimization [
21]. Additionally, various methods have been proposed to handle imbalanced learning. In the rest of this section, we provide a critical review of some significant works that aim to detect fraudulent transactions effectively and with higher accuracy.
In a recent study on imbalanced classification [
22], a novel approach called the clustering-based noisy-sample-removed undersampling scheme (NUS) is introduced to address the challenges faced in applications like credit card fraud detection (CCFD) and defective part identification. The study highlights the difficulties classifiers encounter due to noisy samples in both majority and minority classes. The NUS technique begins by clustering majority-class samples and then utilizes the Euclidean distance from cluster centers to define hyperspheres, identifying and excluding noisy samples. This method is applied to both majority and minority classes to enhance the classifier’s performance. The effectiveness of NUS is validated by integrating it with basic classifiers such as Random Forest (RF), Decision Tree (DT), and Logistic Regression (LR) and comparing it with seven other undersampling, oversampling, and noisy-sample-removed methods. The experiments, conducted on 13 public datasets and three real e-commerce transaction datasets, demonstrate that NUS significantly improves the performance of existing classifiers. In another paper [
23], the researchers highlight the significant impact of fraud on businesses and individuals globally, where millions of US dollars are lost annually. With the surge in online transactions, credit cards have become a prevalent payment method, but they have also increased opportunities for fraudulent activities. Furthermore, the paper addresses the critical issue of data imbalance in machine learning models used for fraud detection, as fraudulent transactions constitute only a small percentage of the total data. This imbalance can severely hinder the performance of classifiers. To tackle this, the study explores various data augmentation techniques and introduces a novel model called K-means Convolutional Generative Adversarial Network (K-CGAN), which is specifically designed for credit card fraud detection. Additionally, they evaluate the effectiveness of different augmentation techniques, including B-SMOTE, K-CGAN, and SMOTE, using major classification techniques. The findings indicate that K-CGAN achieves the highest precision, recall, F1 score, and accuracy, outperforming other methods and significantly enhancing the detection of fraudulent transactions.
In [
24], they focused on the importance of accurately classifying fraudulent transactions to protect customers. Using machine learning methodologies, the study tested various models, finding XGBoost to perform well with a precision score of 0.91 and an accuracy score of 0.99. To address the dataset’s imbalance, several sampling techniques were applied, with Random Oversampling emerging as the most effective, achieving a precision and accuracy score of 0.99 with XGBoost. The study emphasizes the significance of data-balancing methods in improving the performance of fraud detection models. Otherwise, Ibomoiye et al. [
25] tackle the challenges of credit card fraud detection by addressing the issues posed by dynamic shopping patterns and class imbalance. They propose a robust deep learning approach, utilizing Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) neural networks as base learners in a stacking ensemble framework, with a Multilayer Perceptron (MLP) serving as the meta-learner. To manage the class imbalance problem, the study employs the SMOTE-ENN method. As a result, they achieve a sensitivity of 1.000 and a specificity of 0.997, outperforming other commonly used machine learning classifiers and methods. This research underscores the potential of combining advanced deep learning techniques with data balancing strategies to improve credit card fraud detection systems. In addition, ref. [
26] proposes a two-stage framework that uses a deep Autoencoder for representation learning, followed by supervised deep learning techniques for fraud detection. This approach significantly improves the performance of deep learning classifiers compared to those trained on original data and other methods like PCA. The findings highlight the effectiveness of this advanced method in enhancing fraud detection systems.
Likewise, the authors in [
27] proposed a framework called HNN-CUHIT that combines a hybrid neural network with a clustering-based undersampling technique, leveraging identity and transaction features. They evaluated their solution on a real dataset from a city bank during the SARS-CoV-2 pandemic in 2020. As a result, the proposed solution outperforms traditional models such as Logistic Regression, Random Forest, and CNN, particularly in handling imbalanced class distributions by achieving the best F1 score in fraud detection, highlighting its superior performance in identifying fraudulent transactions. This innovative approach offers a valuable contribution to improving fraud detection in the financial sector. Furthermore, the study [
28] proposes federated learning frameworks, such as TensorFlow Federated and PyTorch. Their solution aims to enhance detection across banks without sharing sensitive data. They compare individual and hybrid resampling techniques, which prove that Random Forest classifiers outperform other models, achieving the best performance metrics. The PyTorch framework yields higher prediction accuracy for federated learning models, though with increased computational time, highlighting its effectiveness in handling skewed datasets. In addition, the study [
29] tackles the challenge of acquiring labeled datasets, particularly in highly class-imbalanced domains like credit card fraud detection. It introduces a novel methodology using Autoencoders to synthesize class labels for such data. This approach minimizes the need for expert input by leveraging an error metric from the Autoencoder to create new binary class labels. These labels are then used to train supervised classifiers for fraud detection. Conducted experiments demonstrate that the synthesized labels are of high quality, significantly improving classifier performance as measured by the area under the precision–recall curve. The study also shows that increasing the proportion of positive-labeled instances enhances classifier performance, effectively addressing class imbalance concerns. In [
30], the authors focus on developing a real-time fraud detection framework that can adapt to the constantly changing fraud characteristics, handle the class imbalance, and complete separation issues inherent in fraud data. The proposed solution includes a novel approach to managing non-stationary changes in transaction patterns and a robust fuzzy logistic regression model to tackle class imbalance and separation problems. This methodology improves model training efficiency and maintains high specificity and sensitivity, even with small sample sizes. The framework achieves an accuracy greater than 0.99 in identifying fraudulent and non-fraudulent transactions, outperforming other machine learning and fraud detection methods. The enhanced classification performance ensures better precision in detecting fraudulent transactions, reduces false positives, and minimizes financial losses while increasing customer satisfaction. Otherwise, Asma Cherif et al. [
31] propose a new solution based on Graph Neural Networks (GNNs) for credit card fraud detection. They focus on selecting relevant features and designing a model to capture the relationships between entities like merchants and customers. Their novel encoder–decoder-based GNN model, enhanced with a graph converter and batch normalization, showed promising results on a large-scale dataset, outperforming other models in precision, recall, and F1 score.
In this paper, we aim to improve the detection of fraudulent transactions by addressing the imbalance issue through advanced generative modeling techniques. Unlike traditional methods, which often struggle with the sparse and imbalanced nature of fraudulent transaction data, our approach utilizes Variational Autoencoders (VAEs), Autoencoders, Generative Adversarial Networks (GANs), and a hybrid GAN-Autoencoder model. These models are adept at generating synthetic fraudulent samples, thereby enriching the dataset and enhancing the model’s ability to detect fraud. The efficacy of our approach is underscored by its demonstrated success in generating realistic synthetic data, as evidenced by its performance in related fields such as image and text generation. This innovative use of deep learning architectures ensures a more robust and accurate detection system, which is capable of adapting to the evolving patterns of fraudulent behavior. However, our approach has certain limitations. First, the quality of synthetic samples heavily depends on the proper tuning of hyperparameters, which can be computationally intensive. Second, the generated synthetic data may not fully capture rare or highly complex fraudulent patterns, potentially limiting the model’s generalization to unseen cases.
Table 1 provides a detailed description of the cited works.
5. Results and Discussion
To evaluate our proposed solution, we conducted extensive experiments using a variety of machine learning algorithms and deep learning models. The machine learning algorithms included Logistic Regression (LR), Decision Tree (DT), Random Forest (RF), Gradient Boosting (GB), XGBoost (XGB), LightGBM (LGBM), K-Nearest Neighbors (KNN), Naive Bayes (NB), AdaBoost (AB), and Bagging Classifier (BC). For deep learning, we utilized Artificial Neural Networks (ANNs), Long Short-Term Memory (LSTM) networks, and Recurrent Neural Networks (RNNs). Although LSTM and RNN models are typically used for sequential data with temporal dependencies, we employed these models to capture complex patterns and non-linear interactions within the features. Fraud detection often involves intricate relationships between variables that may not be fully captured by conventional models. By leveraging LSTM and RNN architectures, we aimed to enhance the model’s ability to identify subtle patterns indicative of fraudulent behavior, even in the absence of explicit temporal information. Additionally, our main objective is to offer a performance analysis comparing traditional machine learning models with deep learning models in detecting fraudulent transactions. These experiments aimed to assess the performance and effectiveness of our solution across various techniques and models.
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 show the results obtained using different resampling techniques. From these figures, we observe that the outcomes are promising, demonstrating the efficiency of our proposed methods.
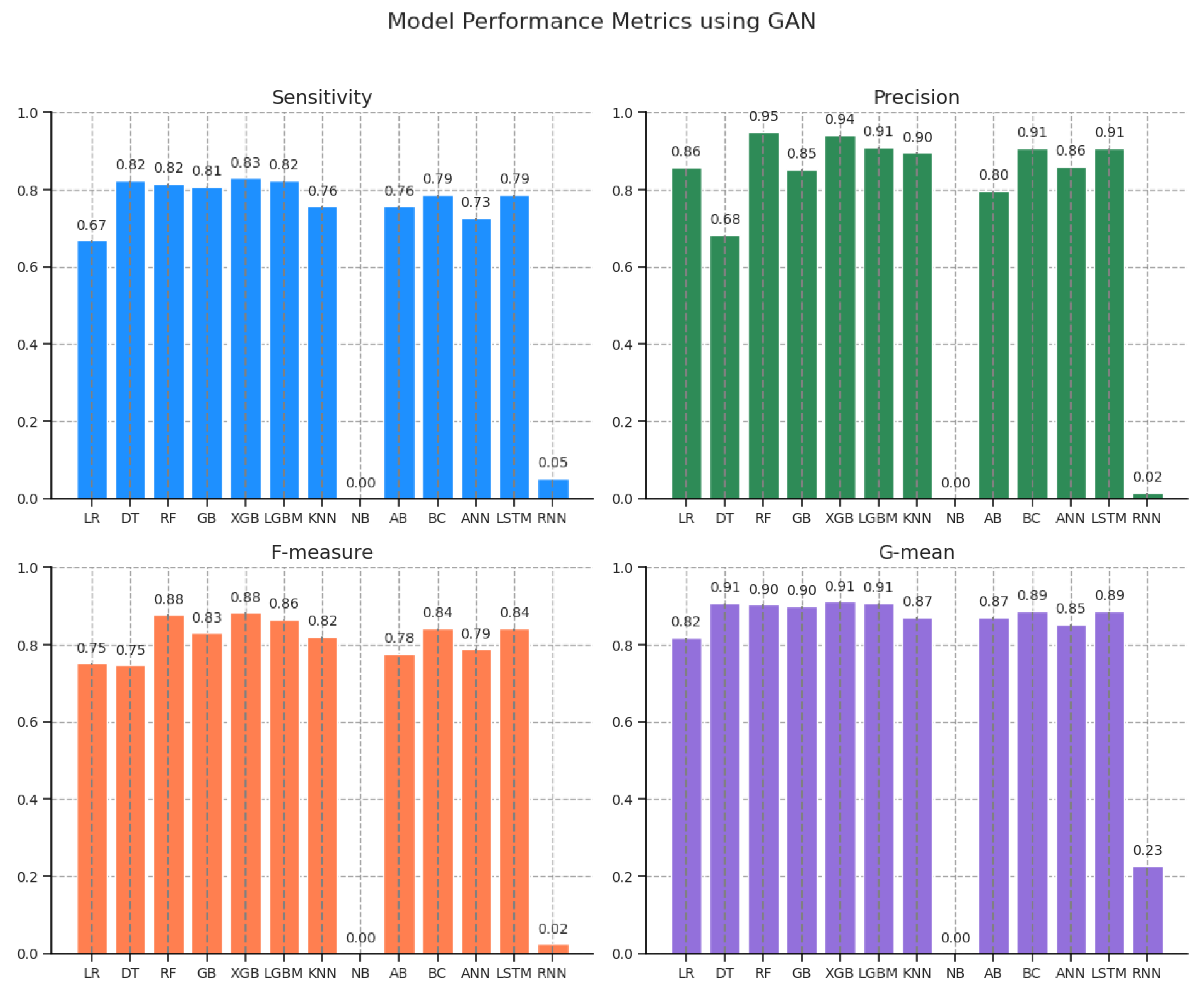
Table 4 presents the performance metrics of various machine learning models using Generative Adversarial Networks for data augmentation. Among the evaluated models, XGB achieved the highest sensitivity (0.830882) and demonstrated strong performance across other metrics, including precision (0.941667), F-measure (0.882813), and G-mean (0.911490). RF also performed competitively with an F-measure of 0.877470 and a G-mean of 0.903393, indicating a balanced trade-off between sensitivity and specificity. LR and DT showed moderate sensitivity (0.669118 and 0.823529, respectively), with DT having a higher G-mean (0.907209) compared to LR (0.817924). Notably, the NB model performed poorly, with a sensitivity of 0.000000 and corresponding F-measure and G-mean values of 0.000000, suggesting its ineffectiveness in the given context. Additionally, advanced neural network models such as LSTM and ANN demonstrated robust performance, with LSTM matching the performance of BC in all metrics. Overall, tree-based ensemble methods (RF, XGB, and LGBM) consistently outperformed other models, reflecting their ability to capture complex data patterns effectively.
Figure 7 provides a clear visualization of the performance metrics of various models using GAN to address class imbalance. From these plots, it is evident that XGB and RF outperform other models, achieving the highest sensitivity, precision, F-measure, and G-mean. LGBM and GB exhibit strong performance, though it is slightly lower than XGB and RF. DT performs well in sensitivity but lags in precision, which affects its overall F-measure. Simpler models like LR and KNN show moderate results, with AB performing similarly. NB and RNN struggle to adapt to GAN-generated data, performing poorly across all metrics.
Table 5 displays the performance metrics of various machine learning models using Autoencoder–Generative Adversarial Networks (AE-GANs). Among the models, XGB achieved the best overall performance, with the highest sensitivity (0.808824), precision (0.964912), F-measure (0.880000), and a G-mean of 0.899325, indicating its superior ability to balance false positives and false negatives. LGBM also performed well, with a sensitivity of 0.816176 and an F-measure of 0.850575, reflecting its effectiveness in handling complex patterns. RF and GB achieved similar performance levels, with F-measure values of 0.844622 and 0.850394, respectively, demonstrating the robustness of ensemble-based methods. In contrast, NB again performed poorly, with sensitivity, precision, and F-measure values of 0.000000, indicating its inability to capture meaningful patterns in the AE-GAN-enhanced dataset. Neural network models such as LSTM and ANN showed moderate performance, with LSTM achieving a higher sensitivity (0.801471) and F-measure (0.822642) compared to ANN. The RNN model exhibited the weakest performance among deep learning methods, with a low sensitivity (0.308824) and an F-measure of 0.181425. Overall, tree-based ensemble methods, particularly XGB and LGBM, consistently outperformed other models, highlighting their adaptability and effectiveness when paired with AE-GAN-generated data.
Figure 8 visualizes the performance metrics of various models using AE-GAN to address class imbalance in fraud detection. XGB achieved the highest accuracy at 99.96%, with Naive Bayes (NB) showing perfect specificity but zero sensitivity, limiting its usefulness. Sensitivity was highest in XGB, LGBM, and LSTM, at around 80–81%. XGB also achieved the highest precision and F-measure, demonstrating its strong fraud detection ability. G-mean scores were highest in XGB and LGBM, reflecting their balanced performance. The RNN model showed lower performance across all metrics, particularly in sensitivity and precision, indicating its limited effectiveness.
Table 6 presents the performance metrics of various machine learning models using Autoencoder (AE) for feature extraction. XGB achieved the best overall performance, with the highest sensitivity (0.816176), precision (0.973684), and F-measure (0.888000), along with a G-mean of 0.903409, indicating its effectiveness in maintaining a balance between sensitivity and specificity. LGBM also performed competitively, with a sensitivity of 0.801471 and an F-measure of 0.868526, demonstrating its robustness in handling the AE-transformed data. RF followed closely with a sensitivity of 0.786765 and an F-measure of 0.856000, further confirming the strength of ensemble-based approaches. Conversely, the NB model again performed poorly, yielding sensitivity, precision, and F-measure values of 0.000000, making it unsuitable for this dataset. Neural network models displayed mixed results, with LSTM achieving better performance (F-measure of 0.809160) than ANN (0.718182), while the RNN model exhibited the weakest performance across all metrics (sensitivity of 0.029412 and F-measure of 0.000765), indicating challenges in learning from AE-transformed data. DT and Bagging Classifier (BC) showed moderate performance, with G-means of 0.878411 and 0.870199, respectively. Overall, tree-based ensemble models, especially XGB and LGBM, outperformed other models, highlighting their superior ability to extract meaningful patterns from AE-enhanced datasets.
Figure 9 visualizes the performance metrics of various models using AE to address class imbalance in fraud detection. XGB achieved the highest accuracy at 99.97%, with NB showing perfect specificity but zero sensitivity, limiting its usefulness. Sensitivity was highest in XGB and LGBM, with values of 81.6% and 80.1%, respectively. XGB also achieved the highest precision (97.37%) and F-measure, reflecting its strong fraud detection ability. G-mean scores were highest in XGB and LGBM, indicating their robustness in fraud detection. The RNN model performed poorly across all metrics, particularly in sensitivity, precision, and G-mean, highlighting its limited effectiveness in fraud detection.
Table 7 shows the performance metrics of various machine learning models using Variational Autoencoder (VAE) for data augmentation. RF and XGB demonstrated the best overall performance, both achieving a sensitivity of 0.801471 and comparable F-measure values of 0.851562 and 0.844961, respectively. RF slightly outperformed XGB in terms of precision (0.908333 vs. 0.893443), suggesting it is more effective at minimizing false positives. LGBM also performed well, with a sensitivity of 0.808824 and a G-mean of 0.899130, indicating a balanced ability to detect positive instances while maintaining high specificity. Among neural network models, ANN achieved the highest sensitivity (0.838235) and F-measure (0.832117), showing its strength in handling the complex data generated by VAE. In contrast, the NB model performed the worst, with a sensitivity of 0.022059 and an F-measure of 0.000466, making it ineffective for this dataset. Logistic Regression (LR) also struggled, with a low F-measure of 0.039565 despite a relatively high G-mean (0.913741). While DT and BC delivered moderate performance, boosting-based models like GB and AB underperformed in terms of sensitivity (0.669118 and 0.551471, respectively). Overall, ensemble methods—particularly RF, XGB, and LGBM—consistently achieved superior performance, while NB and simpler models like LR were less effective in learning from VAE-augmented data.
Figure 10 shows the performance of various models using Variational Autoencoder (VAE) for fraud detection. XGB and RF excel with high accuracy, specificity, and balanced sensitivity, precision, and F-measure. LGBM also performs well, achieving high specificity and good sensitivity (80.88%) with a strong G-mean. LR and DT show good specificity but struggle with precision and F-measure, limiting their fraud detection ability. NB underperforms with low sensitivity and precision. The LSTM model demonstrates a good balance, with a high G-mean (87.02%), while the RNN model has low sensitivity and precision. XGB and RF are the top performers.
Table 8 presents the performance metrics of various machine learning models using the Synthetic Minority Oversampling Technique (SMOTE) to address class imbalance. Among the models, Random Forest (RF) achieved the best overall performance, with a sensitivity of 0.867647, a precision of 0.855072, and an F-measure of 0.861314, highlighting its strong ability to detect minority class samples while maintaining high accuracy. XGB and ANN models also performed competitively, with XGB achieving a sensitivity of 0.860294 and an F-measure of 0.790541, while ANN recorded a sensitivity of 0.875000 and an F-measure of 0.777778, showcasing their robustness in learning from the oversampled data. LGBM achieved a similar sensitivity (0.867647) but had a lower precision (0.504274), resulting in a lower F-measure (0.637838), indicating a trade-off between detecting positive samples and minimizing false positives. In contrast, simpler models like LR and NB struggled with low precision (0.052764 and 0.055274, respectively) and F-measures (0.099842 and 0.104031, respectively), despite having relatively high sensitivity (0.926471 for LR and 0.882353 for NB), reflecting their difficulty in handling the increased complexity of the SMOTE data. DT and BC displayed moderate performance, with sensitivities of 0.750000 and 0.808824, respectively, and F-measures of 0.481132 and 0.698413. Notably, GB and AB underperformed in precision (0.109075 and 0.053700) and F-measure (0.195008 and 0.101559), reflecting their challenges in balancing false positives and false negatives. Overall, ensemble models—particularly RF, XGB, and ANN—outperformed other approaches, demonstrating their effectiveness in handling class imbalance when combined with SMOTE. Simpler models like LR, NB, and boosting methods exhibited lower precision and F-measure, making them less suitable for datasets with imbalanced classes.
The bar plots in
Figure 11, representing the model performance metrics with SMOTE, showcase the accuracy, specificity, sensitivity, precision, F-measure, and G-mean of different classifiers. Random Forest (RF) stands out with consistently high values across all metrics, particularly in accuracy and specificity, emphasizing its effectiveness in detecting both fraudulent and non-fraudulent transactions. XGB and ANN also display solid performances, particularly in accuracy, specificity, and sensitivity, making them reliable choices for fraud detection. On the other hand, models like Naive Bayes (NB), AdaBoost (AB), and Logistic Regression (LR) show significant discrepancies, with low precision and F-measure, indicating challenges in identifying fraudulent transactions accurately. Likewise, K-Nearest Neighbors (KNN) and Gradient Boosting (GB) show a balance in their metrics, particularly in sensitivity, though their precision and F-measure could be improved. Overall, the plot indicates that RF, XGB, and ANN are the top performers, while models like Naive Bayes and AdaBoost need further optimization for better fraud detection.
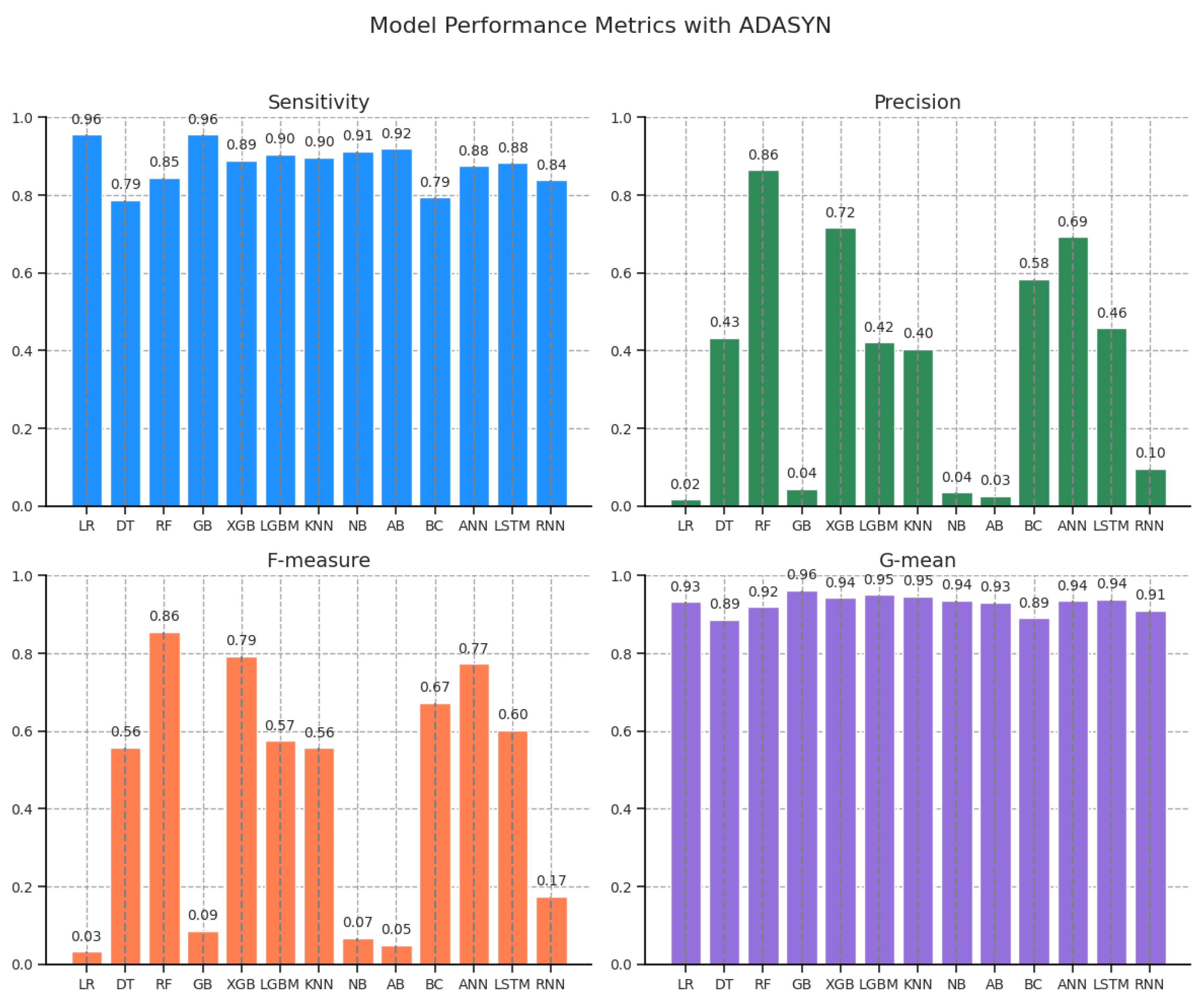
Table 9 presents the performance metrics of various machine learning models using the Adaptive Synthetic (ADASYN) sampling technique to address class imbalance. Among the models, Random Forest (RF) achieved the highest overall performance, with a sensitivity of 0.845588, a precision of 0.864662, and an F-measure of 0.855019, indicating a strong ability to accurately classify both the majority and minority classes. XGB also performed well, with a sensitivity of 0.889706 and an F-measure of 0.793443, reflecting its effectiveness in handling the ADASYN-augmented dataset. LGBM followed closely, achieving a sensitivity of 0.904412 and a G-mean of 0.950063, though its lower precision (0.421233) resulted in a lower F-measure (0.574766). Neural network models exhibited competitive performance, with the Artificial Neural Network (ANN) achieving a sensitivity of 0.875000 and an F-measure of 0.772727, while the LSTM model showed a sensitivity of 0.882353 and an F-measure of 0.603015. In contrast, RNN performed less effectively, with a lower sensitivity (0.838235) and an F-measure (0.173780), indicating its struggles in capturing the patterns of the ADASYN-enhanced data. Simpler models such as Logistic Regression (LR) and Naive Bayes (NB) underperformed despite having high sensitivity (0.955882 for LR and 0.911765 for NB), with low precision (0.016447 and 0.035048, respectively) and corresponding low F-measures (0.032338 and 0.067501). GB and AB also showed weak performance in precision (0.044720 and 0.025422) and F-measure (0.085442 and 0.049476), highlighting their difficulty in effectively handling the oversampled data. Overall, ensemble-based models—particularly RF, XGB, and ANN—demonstrated the best performance under ADASYN, achieving a strong balance between sensitivity and precision. In contrast, simpler models like LR, NB, and boosting algorithms struggled to maintain high precision, limiting their effectiveness in this context.
The bar plots
Figure 12 highlight the performance of various classifiers with ADASYN in fraud detection. RF is the top performer, excelling in accuracy, specificity, sensitivity, and F-measure. XGB and ANN also show strong results, particularly in sensitivity and F-measure. LR struggles with precision and F-measure, while GB and AB underperform in these metrics. NB has moderate performance but is weaker in fraud detection. KNN, LGBM, and RNN show consistent sensitivity but need improvement in precision and F-measure. Overall, RF and XGB lead in performance, while LR and AB require further optimization.
To assess the effectiveness of the proposed methods, we employed a Wilcoxon Rank-Sum test at a 95% confidence level. This non-parametric test is used to determine whether there are significant differences between two independent samples. After resampling the dataset, the resampled datasets were used to train six different classifiers. The classifiers’ performances were evaluated using various metrics. To compare the resampling techniques, the average performance metrics were calculated. The null hypothesis and alternative hypothesis for the Wilcoxon Rank-Sum test in this case can be formulated as follows:
Null Hypothesis : There is no significant difference between the performance metrics of the two oversampling methods when applied to the resampled datasets.
Alternative Hypothesis : There is a significant difference between the performance metrics of the two oversampling methods when applied to the resampled datasets.
The results of the statistical significance tests are presented in
Table 10,
Table 11,
Table 12 and
Table 13, which show the
p-values for comparisons of sensitivity, precision, F-measure, and G-mean, respectively. These tables display the
p-values obtained from the Wilcoxon test for comparisons between pairs of resampling techniques for sensitivity, precision, F-measure, and G-mean metrics.
Table 10 presents the
p-values from the Wilcoxon Rank-Sum test for sensitivity comparisons among various oversampling techniques. The results indicate that VAE significantly improves sensitivity compared to GAN, AE-GAN, and AE, with
p-values of 0.6848, 0.9593, and 0.2549, respectively, suggesting its effectiveness. Similarly, ADASYN demonstrates notable improvements over GAN, AE-GAN, and AE, with
p-values of 0.0012, 0.0022, and 0.0002, respectively, confirming its strong performance. However, the difference between VAE and ADASYN is not statistically significant, as indicated by a
p-value of 0.0022. SMOTE also exhibits better sensitivity than GAN and AE, with
p-values of 0.0034 and 0.0004, respectively, but does not significantly outperform VAE or ADASYN, as seen in its
p-values of 0.0017 and 0.1542. In contrast, GAN and AE-GAN show relatively higher
p-values compared to VAE and ADASYN, indicating less substantial improvements in sensitivity. Overall, these findings highlight the superior effectiveness of VAE and ADASYN in enhancing sensitivity, while GAN and AE-GAN are comparatively less impactful.
Table 11 presents the
p-values obtained from the Wilcoxon Rank-Sum test for precision comparisons among different oversampling techniques. The results indicate that VAE significantly outperforms GAN, AE-GAN, and AE in terms of precision, with
p-values of 0.0061, 0.0076, and 0.0229, respectively, highlighting its effectiveness in improving precision. Similarly, ADASYN demonstrates notable improvements over GAN, AE-GAN, and AE, with
p-values of 0.0012, 0.0007, and 0.0017, respectively, confirming its strong performance. However, there is no significant difference between VAE and ADASYN, as indicated by a
p-value of 0.0134, suggesting comparable performance between these two techniques. SMOTE also shows better precision than GAN and AE, with
p-values of 0.4801 and 0.0012, respectively, but does not significantly differ from VAE or ADASYN, as seen in its
p-values of 0.0134 and 0.4801. In contrast, GAN and AE-GAN exhibit higher
p-values compared to VAE and ADASYN, indicating less substantial improvements in precision. Overall, these findings underscore the superior precision performance of VAE and ADASYN, while GAN and AE-GAN perform relatively worse in this metric.
Table 12 presents the
p-values from the Wilcoxon Rank-Sum test for F-measure comparisons across different oversampling techniques. The results show that VAE significantly enhances the F-measure compared to GAN, AE-GAN, and AE, with
p-values of 0.0327, 0.0186, and 0.0843, respectively, reinforcing its effectiveness. ADASYN also demonstrates a significant improvement over GAN, AE-GAN, and AE, with
p-values of 0.0061, 0.0080, and 0.0170, respectively, further validating its strong performance. Additionally, AE-GAN outperforms AE with a
p-value of 0.0262. However, the comparison between VAE and ADASYN does not indicate a significant difference, as shown by a
p-value of 0.0573, suggesting comparable performance in improving F-measure. Conversely, SMOTE does not show a significant advantage over VAE or ADASYN, with
p-values of 0.0942 and 0.4327, respectively, positioning it as less effective in enhancing the F-measure. Nonetheless, SMOTE performs better than GAN and AE-GAN, with
p-values of 0.0061 and 0.0061, respectively. Overall, these findings confirm VAE and ADASYN as the most effective techniques for optimizing the F-measure, while GAN and AE-GAN show comparatively lower performance.
Table 13 presents the
p-values from the Wilcoxon Rank-Sum test for G-mean comparisons between different oversampling techniques. The results indicate that VAE significantly enhances the G-mean compared to GAN, AE-GAN, and AE, with
p-values of 0.8925, 0.9374, and 0.2393, respectively, reinforcing VAE’s effectiveness in improving the G-mean metric. Similarly, ADASYN demonstrates a substantial improvement over GAN, AE-GAN, and AE, with
p-values of 0.0012, 0.0004, and 0.0002, respectively, highlighting its superior performance. However, there is no significant difference between VAE and ADASYN, as indicated by a
p-value of 0.0002, suggesting comparable G-mean performance between these two techniques. On the other hand, SMOTE does not show a significant improvement over VAE or ADASYN, with
p-values of 0.0012 and 0.9374, respectively, indicating its relatively lower effectiveness in optimizing the G-mean. Overall, the findings confirm that VAE and ADASYN are the most effective techniques for enhancing the G-mean, whereas GAN, AE-GAN, and AE exhibit comparatively weaker performance in this regard.
Table 14 presents the Balanced F-Measure (BFDS) scores for various models across different oversampling techniques, highlighting their effectiveness in handling class imbalance. Among the oversampling techniques evaluated, AE-GAN consistently provides the highest BFDS scores for most models, indicating its superior ability to enhance classifier performance in detecting fraudulent transactions. Specifically, RF, with a BFDS of 0.697, and XGB, with a BFDS of 0.691, achieve the highest scores, showcasing their robustness and precision. These models, combined with AE-GAN, demonstrate the best performance, effectively balancing sensitivity and precision. In comparison, traditional oversampling techniques like SMOTE and ADASYN perform slightly lower, with RF scoring 0.685 and 0.671, respectively, under these methods. While these techniques are still effective, AE-GAN’s innovative approach seems to offer a more nuanced enhancement, particularly for ensemble methods like RF and XGB. Deep learning models, such as ANN, also benefit significantly from AE-GAN, achieving a BFDS of 0.692, indicating strong potential for these models in fraud detection tasks. Conversely, simpler models like NB and RNN exhibit poor performance across all oversampling techniques, with notably low BFDS scores, underscoring their limited utility in this context. Overall, the combination of AE-GAN with advanced ensemble methods like RF and XGB emerges as the most effective strategy for fraudulent transaction detection. This combination not only maximizes the BFDS but also ensures a balanced approach to handling class imbalance, making it a superior choice for optimizing model performance in this challenging domain.
The Wilcoxon test
p-values for BFDS comparison across various oversampling techniques are presented in
Table 15. This table provides a comprehensive statistical analysis of performance differences among the tested methods. The results indicate that VAE exhibits significant improvements over multiple techniques, particularly compared to GAN (
p-value = 0.0024), AE-GAN (
p-value = 0.0002), and AE (
p-value = 0.0075). Similarly, ADASYN demonstrates statistically significant differences when compared to GAN (
p-value = 0.0061), AE-GAN (
p-value = 0.0104), and AE (
p-value = 0.0134). These findings highlight the superior performance of VAE and ADASYN in enhancing BFDS metrics. Conversely, AE-GAN and AE do not exhibit significant differences from each other (
p-value = 0.0572), indicating their comparable performance. Moreover, SMOTE does not show statistically significant improvements over most techniques, as reflected in its relatively high
p-values, particularly against VAE (
p-value = 0.0409) and ADASYN (
p-value = 0.0803). Overall, these results reinforce the effectiveness of VAE and ADASYN in improving BFDS performance compared to traditional oversampling techniques. In contrast, methods like AE-GAN, AE, and SMOTE exhibit more comparable performance levels, with fewer statistically significant differences.
The boxplot in
Figure 13 illustrates the distribution of Balanced F-Measure (BFDS) scores across various oversampling techniques used with different classifiers. AE-GAN stands out with the highest median BFDS scores, indicating its superior ability to enhance classifier performance consistently. The narrow interquartile range (IQR) and minimal outliers for AE-GAN suggest stable and reliable results across different models. In contrast, traditional oversampling techniques like SMOTE and ADASYN exhibit moderate median BFDS scores with greater variability, showing that while effective, they do not consistently match the performance enhancement provided by AE-GAN. Other techniques, such as GAN, AE, and VAE, generally display lower median BFDS scores and wider IQRs, reflecting less effective performance improvements. Notably, classifiers like NB and RNN consistently show the lowest BFDS scores across all oversampling techniques, with high variability indicating persistent challenges in achieving balanced performance. Overall, AE-GAN emerges as the most effective technique for optimizing BFDS scores, offering a more reliable and enhanced performance across a range of classifiers compared to other methods.
Figure 14 provides a visual comparison of Balanced F-Measure (BFDS) scores for various machine learning models across different oversampling techniques. AE-GAN stands out with the highest BFDS scores, indicating its effectiveness in enhancing classifier performance across most models. The bars representing AE-GAN are notably higher, reflecting its superior ability to balance sensitivity and precision. In contrast, traditional oversampling techniques such as SMOTE and ADASYN show moderate BFDS scores, with bars that are shorter than those for AE-GAN, suggesting less consistent performance improvement. Techniques like GAN, AE, and VAE also exhibit lower BFDS scores, as evidenced by their shorter bars, indicating that they provide less significant gains in balancing performance. The bars for NB and RNN are the shortest across all techniques, highlighting their lower BFDS scores and challenges in achieving balanced performance. Overall, the bar plot underscores AE-GAN as the most effective oversampling technique for optimizing BFDS scores, offering superior performance across various classifiers compared to other methods.
Figure 15 shows the Balanced F-Measure (BFDS) scores for various machine learning models across different oversampling techniques, with the x-axis representing the models and the y-axis depicting the BFDS scores. Notably, the orange line, which represents the AE-GAN technique, stands out with consistently high BFDS scores across most models. This line illustrates AE-GAN’s superior performance in improving the balance between sensitivity and precision compared to other techniques. In contrast, lines for other oversampling methods, such as SMOTE and ADASYN, generally display lower BFDS scores, with the lines often positioned beneath the orange AE-GAN line. This indicates that while these techniques are effective, they do not achieve the same level of enhancement in model performance. Techniques like GAN, AE, and VAE show even lower BFDS scores, as their lines remain further below the AE-GAN line, reflecting their reduced effectiveness. The lines for NB and RNN also trail at the lower end, highlighting their difficulties in achieving balanced performance. Overall, the orange AE-GAN line underscores its role as the most effective oversampling technique for maximizing BFDS scores, surpassing other methods in enhancing model performance.
Table 16 shows the obtained performance metrics for each model, highlighting the best sensitivity, precision, F-measure, and G-mean values along with the corresponding oversampling techniques. The analysis reveals that different oversampling techniques have a notable impact on model performance. For instance, the AB model achieves the highest sensitivity (0.933824) and G-mean (0.953585) using the SMOTE technique, indicating a strong capability in detecting positive instances and maintaining a balanced performance. In contrast, the ANN model exhibits superior precision (0.940476) with the AE technique, demonstrating its effectiveness in reducing false positives, and performs well in F-measure (0.832117) with VAE. The BC model, utilizing AE-GAN, excels in precision (0.913793), showcasing its proficiency in correctly classifying positive instances. The DT model achieves the highest G-mean (0.907209) with GAN, reflecting balanced performance but with lower sensitivity and precision. Techniques such as SMOTE and ADASYN generally improve sensitivity and G-mean across several models, highlighting their efficacy in managing class imbalance. Conversely, AE and VAE techniques improve precision, as demonstrated by ANN and XGB. Notably, the NB model shows a significant trade-off with high sensitivity (0.911765) but low precision (0.055274) using SMOTE. These results emphasize the importance of selecting appropriate oversampling techniques to balance the trade-offs between sensitivity, precision, and overall model performance.
Figure 16 presents the best metric scores in terms of sensitivity, precision, F-measure, and G-mean across various models, along with the associated oversampling techniques. SMOTE is the most frequently appearing method, demonstrating its broad effectiveness, particularly excelling in G-mean and sensitivity for models such as RF, KNN, and AB. GAN also shows significant utility, notably enhancing precision and F-measure in models like DT and RF, highlighting its strength in balancing sensitivity and precision. ADASYN is employed in several instances, achieving impressive results in sensitivity and G-mean for models including LR, GB, and LSTM. AE-GAN appears less frequently but is notable for improving F-measure in models like GB and LSTM. AE and VAE are the least appearing techniques, with AE showing strong performance in F-measure for XGB and VAE excelling in precision for DT. This figure underscores the effectiveness of various oversampling techniques, with SMOTE and ADASYN standing out for their broad applicability and GAN and AE-GAN providing targeted improvements in specific metrics.
The results in
Table 17 demonstrate the performance of various oversampling techniques across different models, evaluated using BFDS. The findings show that AE-GAN consistently outperforms or remains competitive with traditional methods like SMOTE and ADSYN, particularly for complex models. For LR, AE-GAN achieves the highest BFDS (0.453), closely followed by AE (0.452) and GAN (0.451). This indicates that generative approaches are more effective than conventional methods in addressing class imbalance for linear models. In DT and GB, ADSYN achieves the best performance (0.586 and 0.674, respectively), suggesting that simpler oversampling techniques can still be effective for these models. However, for more advanced models like RF and XGB, AE-GAN leads with BFDS values of 0.697 and 0.691, respectively, highlighting its ability to generate high-quality synthetic data that enhance fraud detection. For AB and BC, GAN achieves the highest BFDS (0.620 and 0.678, respectively), while AE-GAN remains competitive, reinforcing the strength of generative models in ensemble learning. In ANN, LSTM, and RNN, GAN achieves the best results for ANN (0.694), while AE-GAN consistently ranks in the top three for all neural models. This suggests that the hybrid AE-GAN model effectively improves class balance while maintaining strong performance across diverse architectures. For NB, SMOTE achieves the best BFDS (0.091), while generative models (AE-GAN and GAN) perform similarly (0.070). This indicates that simple generative methods may not be optimal for probabilistic models. Overall, AE-GAN ranks first or closely behind the best-performing method across 11 out of 13 models, demonstrating its ability to handle class imbalance effectively. Future work will focus on optimizing AE-GAN using Bayesian optimization and distributed metaheuristic algorithms to further enhance performance and scalability.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}