
Cybersecurity Threats and Their Mitigation Approaches Using Machine Learning—A Review



 ,
,  ,
,
Abstract
:1. Introduction
- To comprehend the applicability of data-driven decision making, a report on the existing idea of cybersecurity protection plans and associated approaches is presented first. To do this, several machine learning techniques used in cybersecurity have been discussed and numerous cybersecurity datasets, emphasizing their importance and applicability in this domain, have been presented.
- In addition, an examination of several related research challenges and future objectives in the field of cybersecurity machine learning approaches has been presented.
- Finally, the most common issues in applying machine learning algorithms on cybersecurity datasets have been explored within the scope of improvements to build a robust system.
2. Background
- Confidentiality is a property that prevents information from being shared with unauthorized entities, people or systems.
- Integrity is a property that protects data from being tampered with or destroyed without permission.
- Availability is used to ensure that authorized entities have timely and reliable access to information assets and systems.
2.1. Cyber-Attacks and Security Risks
- It blocks network key components.
- It installs additional harmful software for spying with malware itself.
- It gains access to personal data and transmits information.
- It disrupts certain components and makes the system inoperable for users.
- Unsecured public WiFi, where intruders insert themselves between a visitor’s device and the network.
- If an attacker’s malware successfully breaches the victim’s system, they can install software to gain the victim’s secure information.
2.2. Defense Strategies
2.3. Cybersecurity Framework
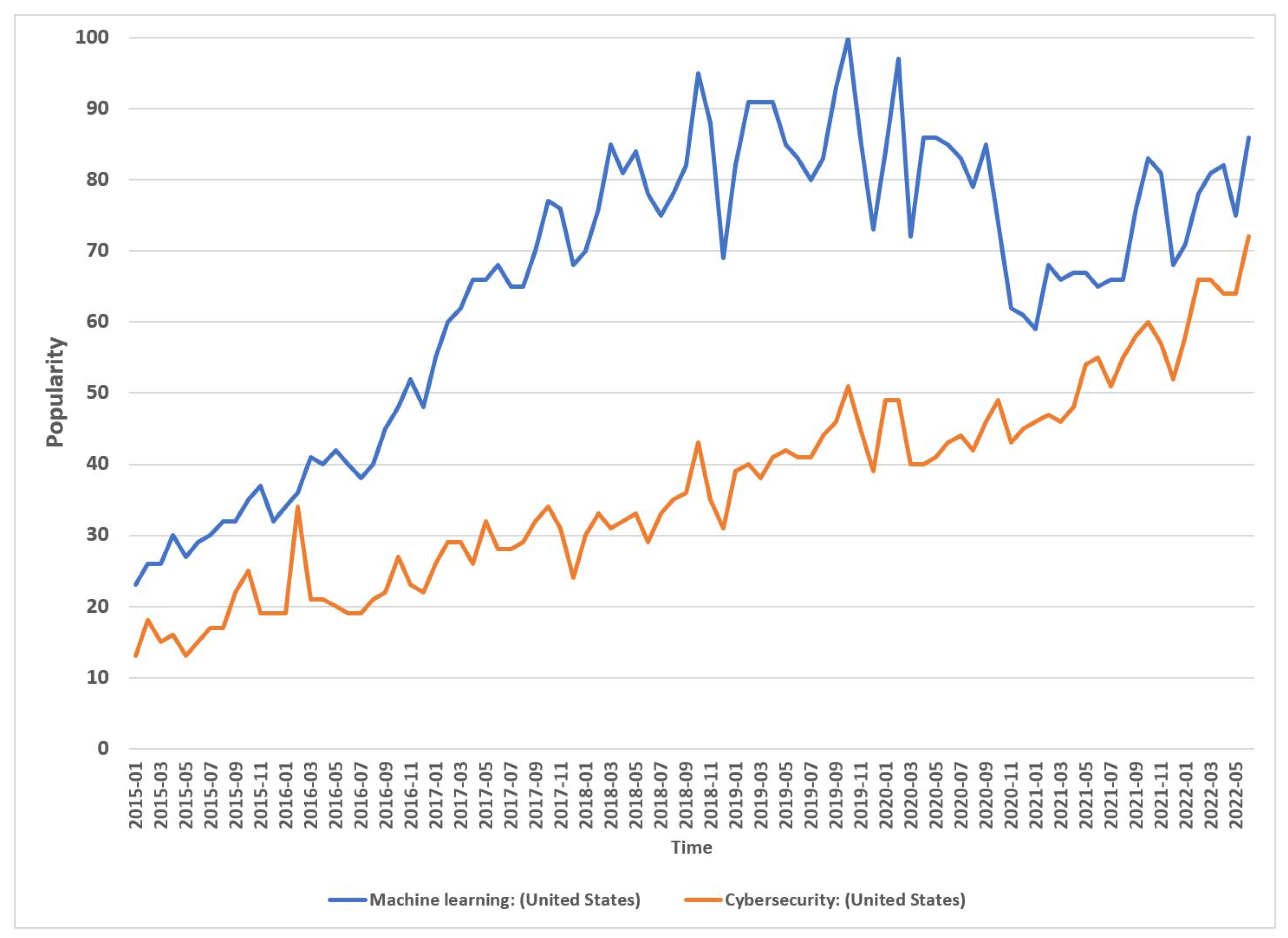
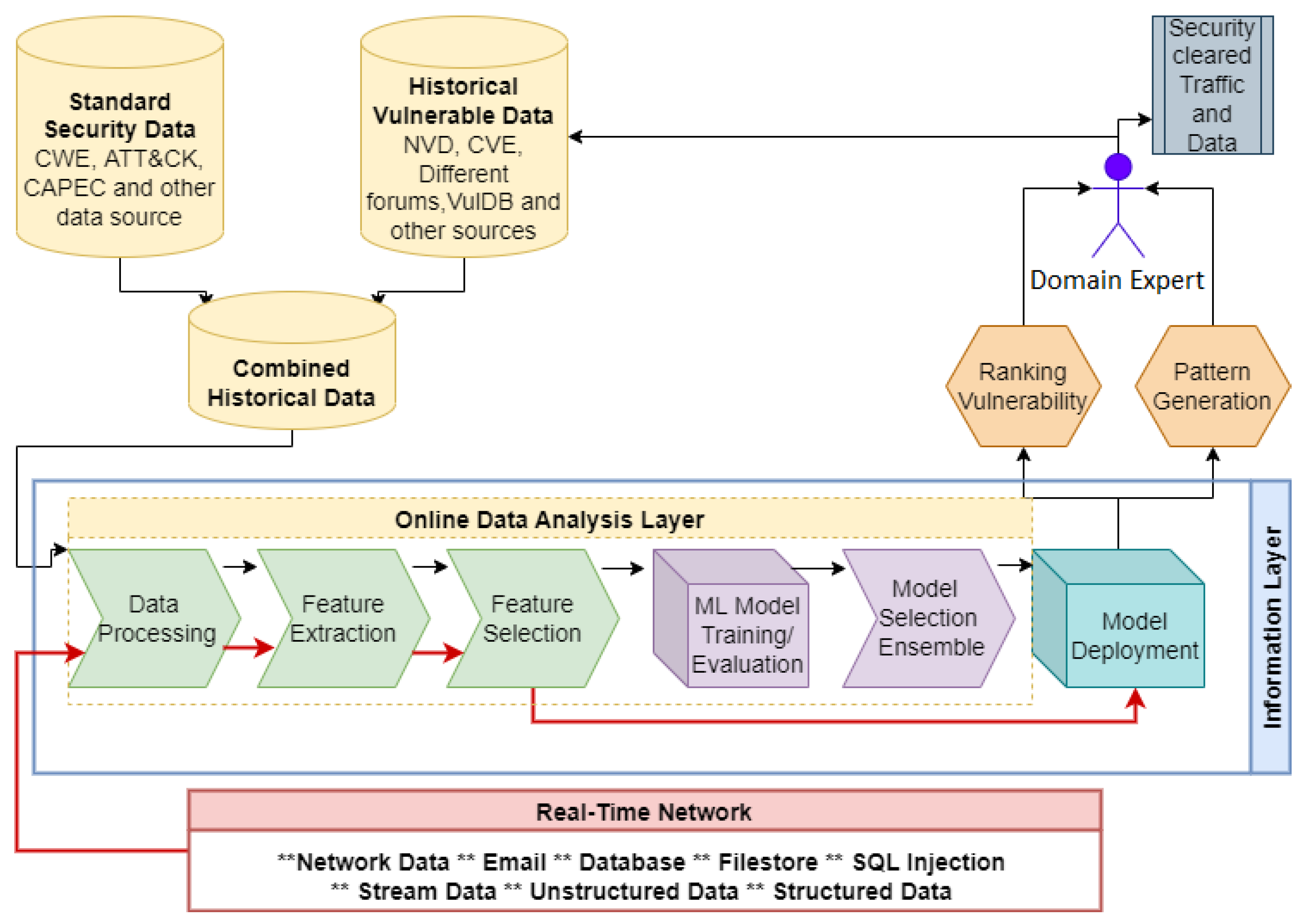
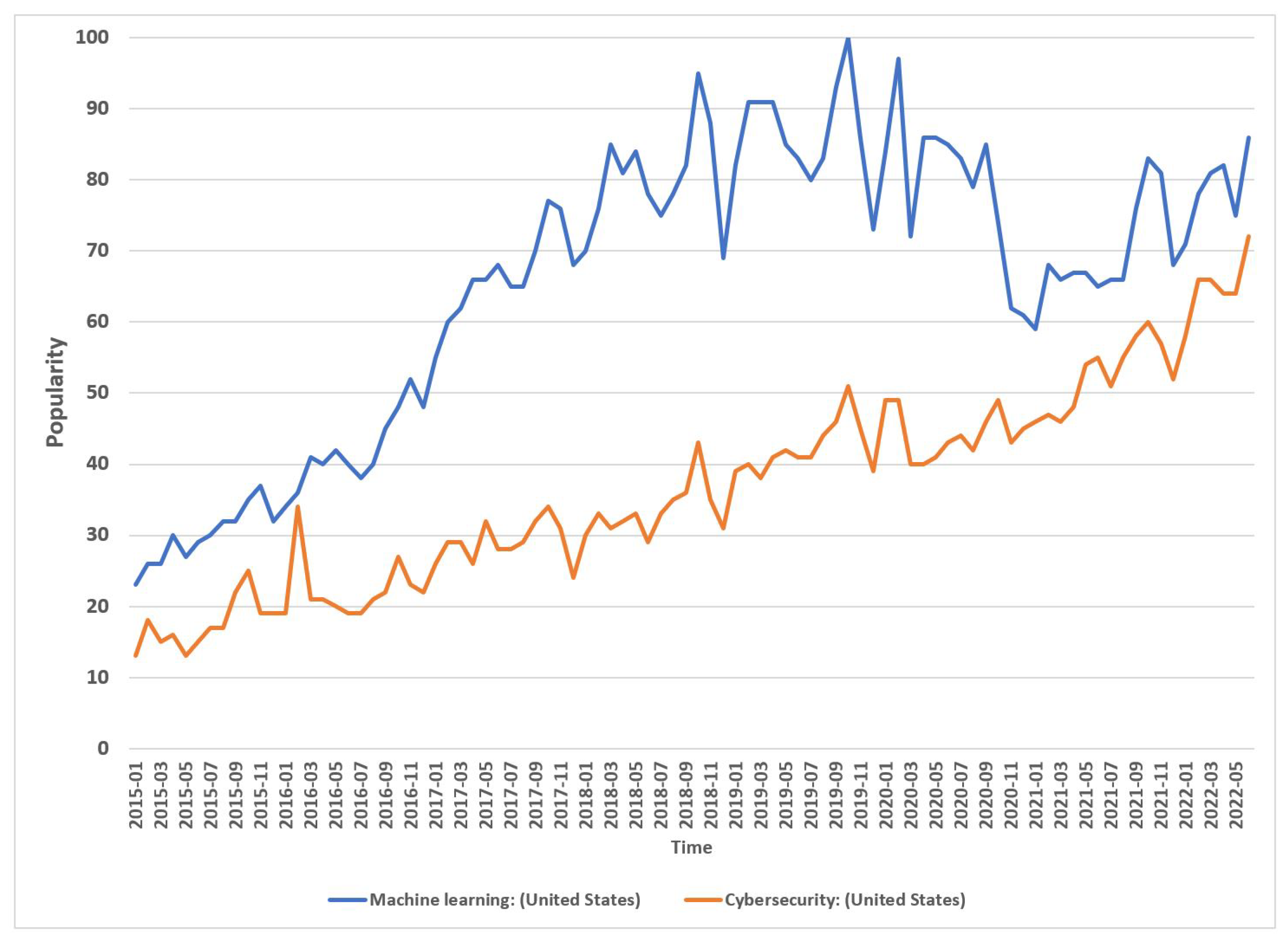
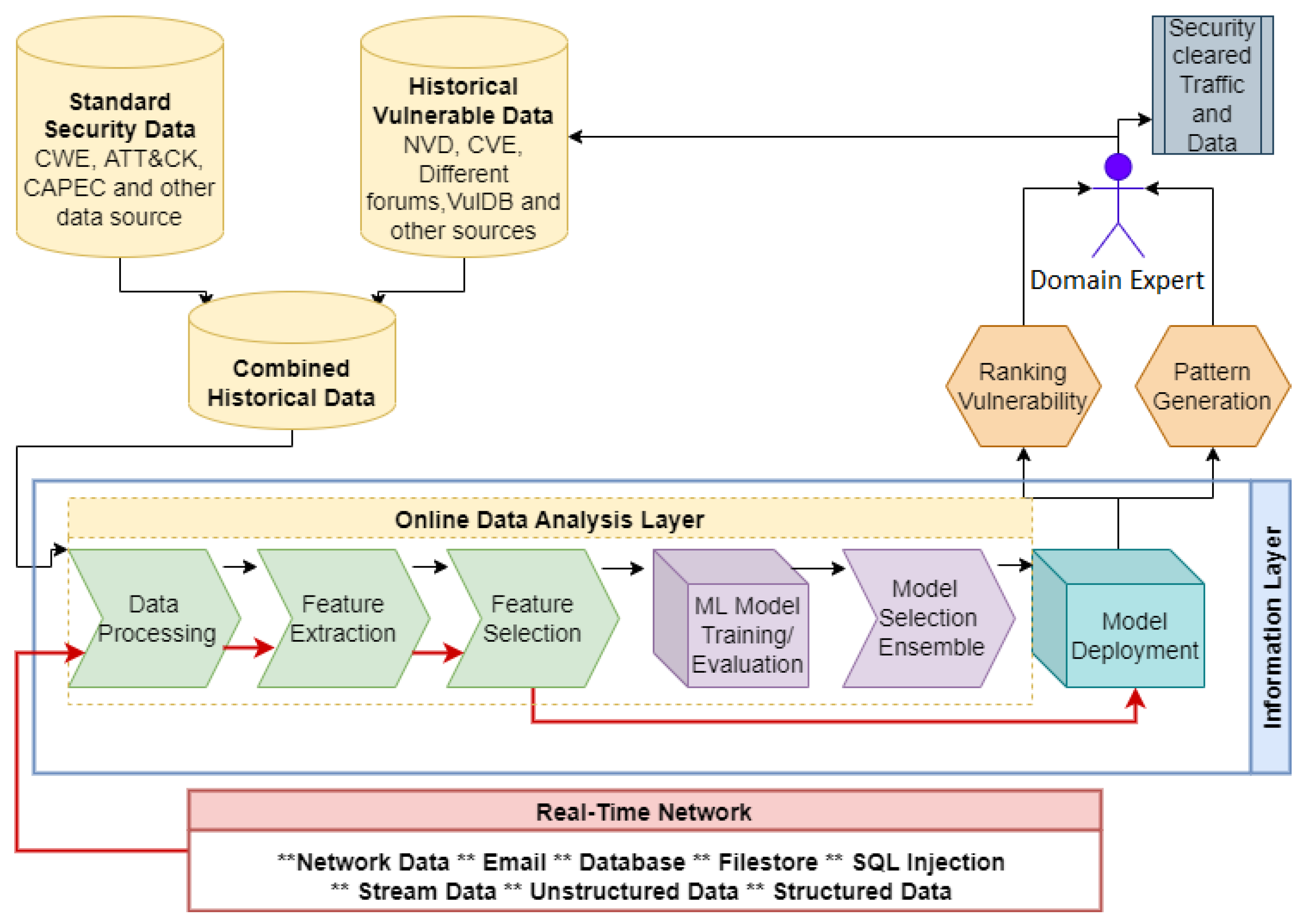
2.4. Cybersecurity Data
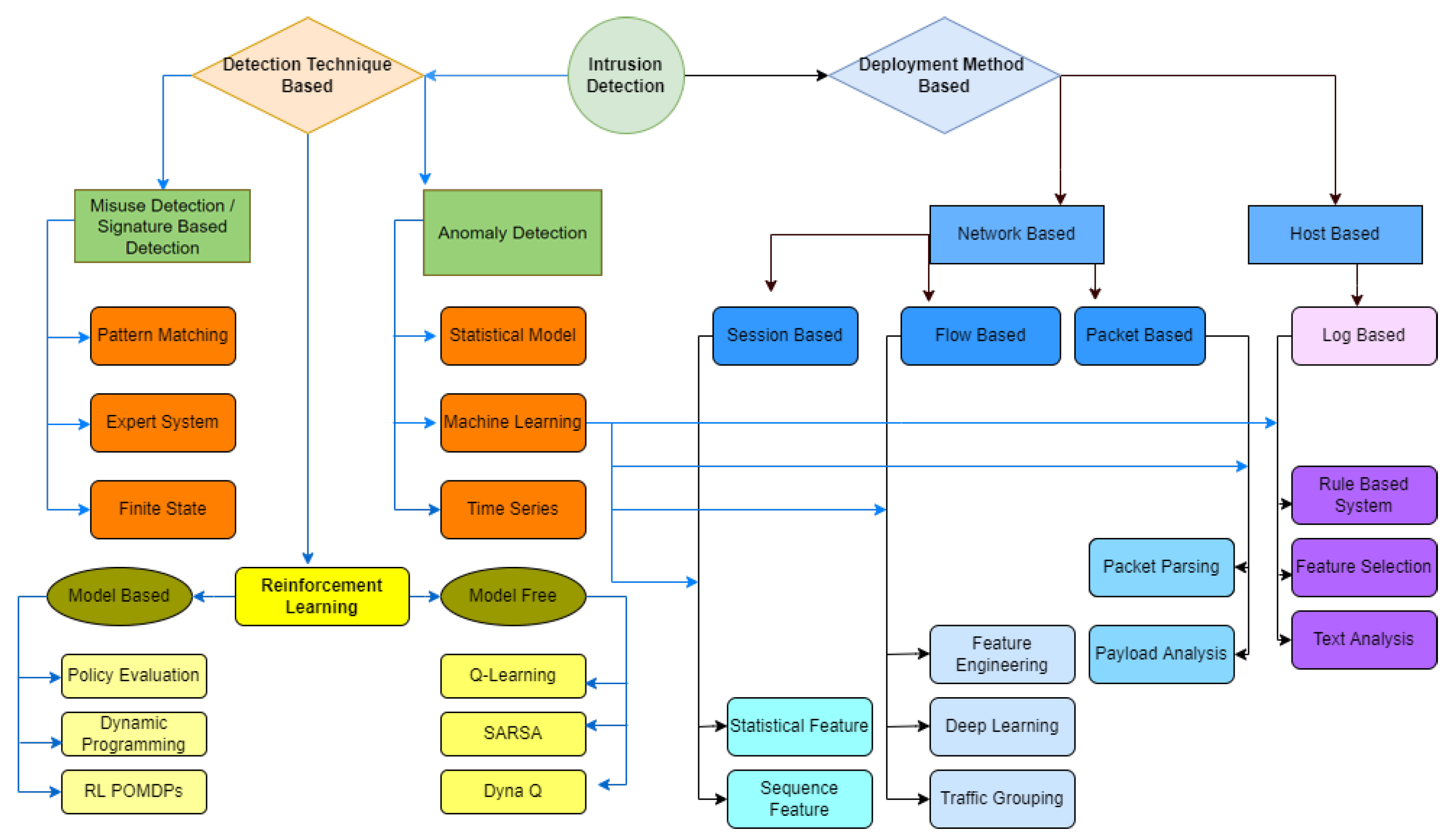
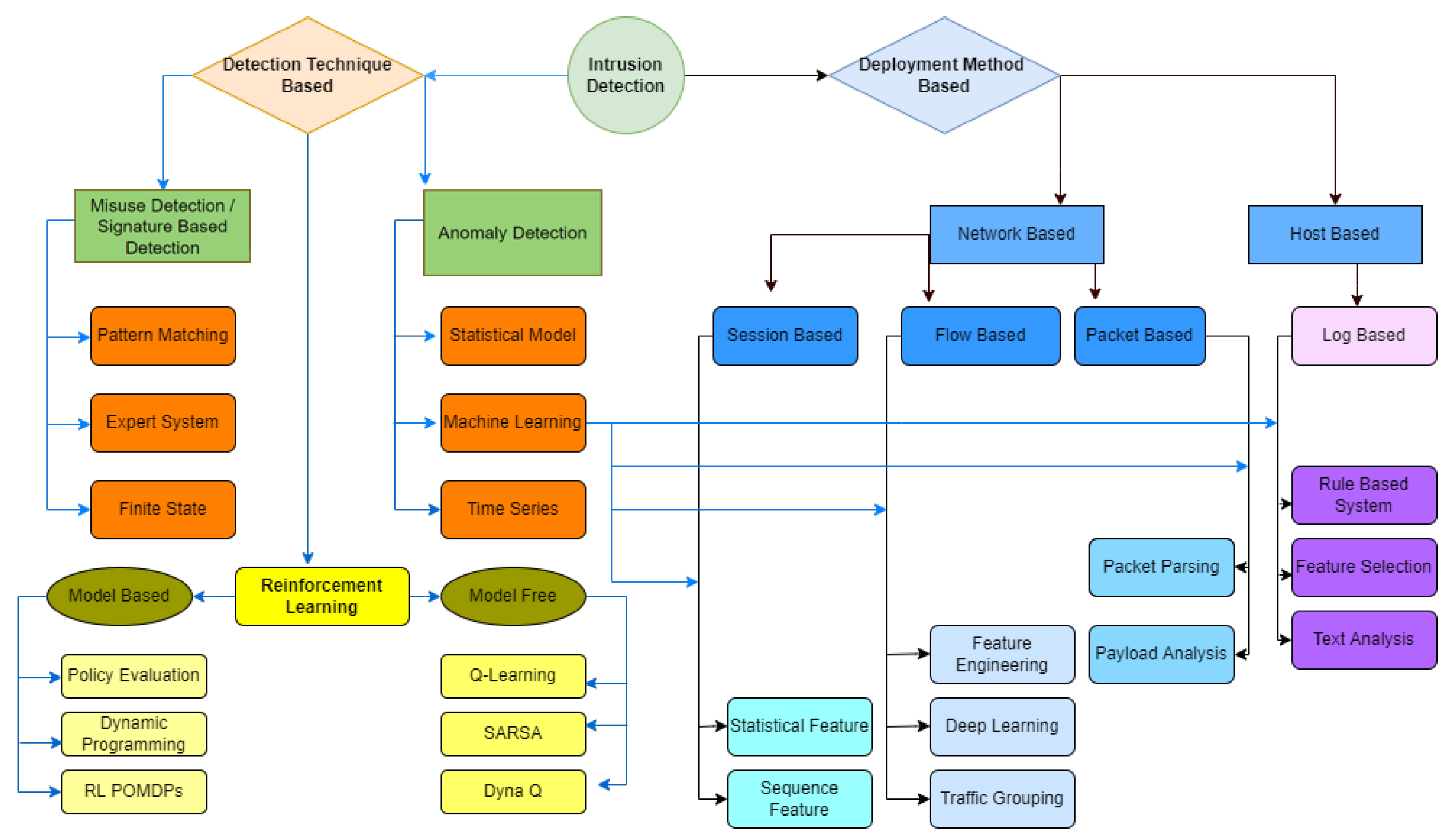
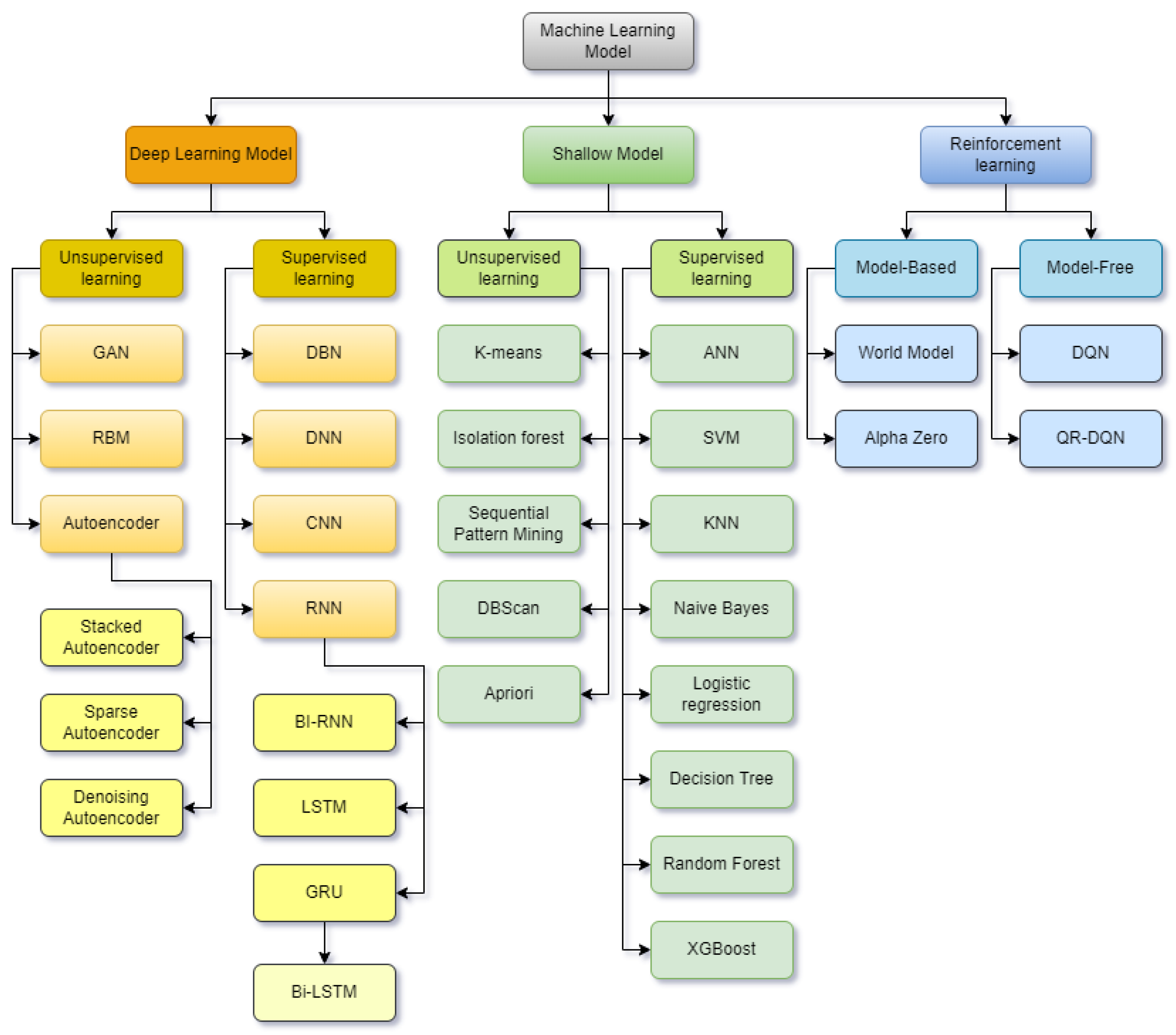
3. Machine Learning Techniques in Cybersecurity
3.1. Stages of a Cyber-Attack
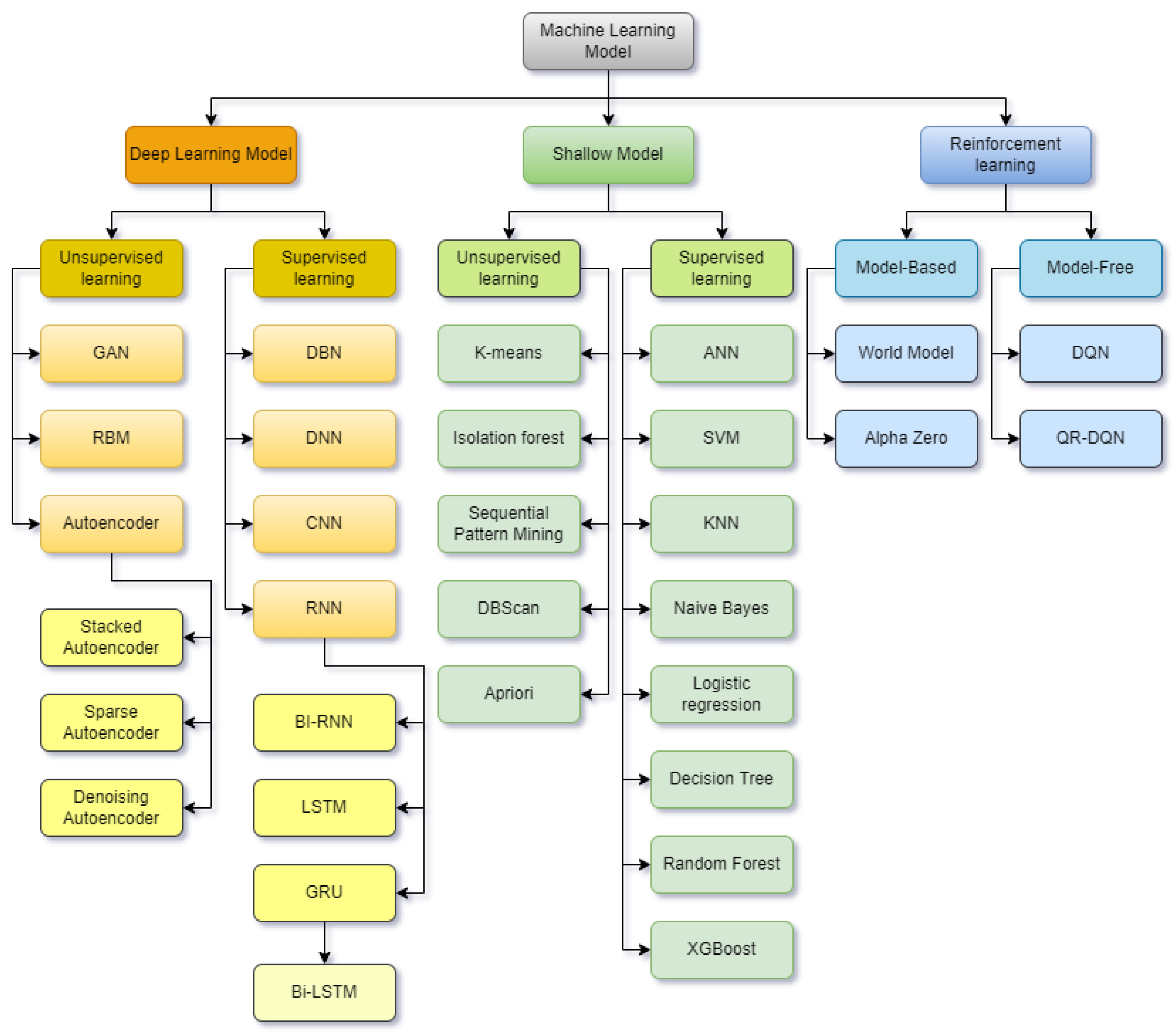
3.2. Supervised Learning
3.3. Unsupervised Learning
3.4. Artificial Neural Networks (ANN)
4. Future Improvements and Challenges for ML-Based Cybersecurity
4.1. Cybersecurity Dataset Availability
4.2. Cybersecurity Dataset Standard
4.3. Hybrid Learning
4.4. Feature Engineering in Cybersecurity
4.5. Data Leakage
4.6. Homomorphic Encryption
4.7. Quantum Computing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| LSTM | Long Short-Term Memory |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| GRU | Gated Recurrent Units |
| RF | Random Forest |
| NB | Naive Bayes |
| DoS | Denial of Service |
| DDoS | Distributed Denial of Service |
| SVM | Support Vector Machines |
| ICT | Information and Communication Technology |
| MITM | Man-in-the-Middle attack |
| IDS | Intrusion Detection System |
| FAR | False Acceptance Rate |
| RBF | Radial Basis Function |
References
- Li, S.; Da Xu, L.; Zhao, S. The internet of things: A survey. Inf. Syst. Front. 2015, 17, 243–259. [Google Scholar] [CrossRef]
- Sun, N.; Zhang, J.; Rimba, P.; Gao, S.; Zhang, L.Y.; Xiang, Y. Data-driven cybersecurity incident prediction: A survey. IEEE Commun. Surv. Tutor. 2018, 21, 1744–1772. [Google Scholar] [CrossRef]
- McIntosh, T.; Jang-Jaccard, J.; Watters, P.; Susnjak, T. The inadequacy of entropy-based ransomware detection. In Proceedings of the International Conference on Neural Information Processing, Sydney, Australia, 12–15 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 181–189. [Google Scholar]
- Alazab, M.; Venkatraman, S.; Watters, P.; Alazab, M. Zero-day malware detection based on supervised learning algorithms of API call signatures. In Proceedings of the Ninth Australasian Data Mining Conference (AusDM’11), Ballarat, Australia, 1–2 December 2011. [Google Scholar]
- Shaw, A. Data breach: From notification to prevention using PCI DSS. Colum. JL Soc. Probs. 2009, 43, 517. [Google Scholar]
- Gupta, B.B.; Tewari, A.; Jain, A.K.; Agrawal, D.P. Fighting against phishing attacks: State of the art and future challenges. Neural Comput. Appl. 2017, 28, 3629–3654. [Google Scholar] [CrossRef]
- Geer, D.; Jardine, E.; Leverett, E. On market concentration and cybersecurity risk. J. Cyber Policy 2020, 5, 9–29. [Google Scholar] [CrossRef]
- Buecker, A.; Borrett, M.; Lorenz, C.; Powers, C. Introducing the IBM Security Framework and IBM Security Blueprint to Realize Business-Driven Security; International Technical Support Organization: Riyadh, Saudi Arabia, 2010. [Google Scholar]
- Fischer, E.A. Cybersecurity Issues and Challenges: In Brief; Library of Congress: Washington, DC, USA, 2014. [Google Scholar]
- Chernenko, E.; Demidov, O.; Lukyanov, F. Increasing International Cooperation in Cybersecurity and Adapting Cyber Norms; Council on Foreign Relations: New York, NY, USA, 2018. [Google Scholar]
- Papastergiou, S.; Mouratidis, H.; Kalogeraki, E.M. Cyber security incident handling, warning and response system for the european critical information infrastructures (cybersane). In Proceedings of the International Conference on Engineering Applications of Neural Networks, Crete, Greece, 24–26 May 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 476–487. [Google Scholar]
- O’Connell, M.E. Cyber security without cyber war. J. Confl. Secur. Law 2012, 17, 187–209. [Google Scholar] [CrossRef]
- Tolle, K.M.; Tansley, D.S.W.; Hey, A.J. The fourth paradigm: Data-intensive scientific discovery [point of view]. Proc. IEEE 2011, 99, 1334–1337. [Google Scholar] [CrossRef] [Green Version]
- Benioff, M. Data, data everywhere: A special report on managing information (pp. 21–55). The Economist, 27 February 2010. [Google Scholar]
- Cost of Cyber Attacks vs. Cost of Cybersecurity in 2021|Sumo Logic. Available online: https://www.sumologic.com/blog/cost-of-cyber-attacks-vs-cost-of-cyber-security-in-2021/ (accessed on 10 May 2022).
- Anwar, S.; Mohamad Zain, J.; Zolkipli, M.F.; Inayat, Z.; Khan, S.; Anthony, B.; Chang, V. From intrusion detection to an intrusion response system: Fundamentals, requirements, and future directions. Algorithms 2017, 10, 39. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, S.; Mirvaziri, H.; Ghazizadeh-Ahsaee, M.; Karimipour, H. Cyber intrusion detection by combined feature selection algorithm. J. Inf. Secur. Appl. 2019, 44, 80–88. [Google Scholar] [CrossRef]
- Tapiador, J.E.; Orfila, A.; Ribagorda, A.; Ramos, B. Key-recovery attacks on KIDS, a keyed anomaly detection system. IEEE Trans. Dependable Secur. Comput. 2013, 12, 312–325. [Google Scholar] [CrossRef]
- Saxe, J.; Sanders, H. Malware Data Science: Attack Detection and Attribution; No Starch Press: San Francisco, CA, USA, 2018. [Google Scholar]
- Rainie, L.; Anderson, J.; Connolly, J. Cyber Attacks Likely to Increase; Pew Research Center: Washington, DC, USA, 2014. [Google Scholar]
- Fischer, E.A. Creating a National Framework for Cybersecurity: An Analysis of Issues and Options; Library of Congress Washington DC Congressional Research Service: Washington, DC, USA, 2005. [Google Scholar]
- Craigen, D.; Diakun-Thibault, N.; Purse, R. Technology Innovation Management Review Defining Cybersecurity; Technology Innovation Management Review: Ottawa, ON, Canada, 2014. [Google Scholar]
- Goodman, S.E.; Lin, H.S. Toward a Safer and More Secure Cyberspace; National Academies of Sciences, Engineering, and Medicine: Washington, DC, USA, 2007; pp. 1–328. [Google Scholar] [CrossRef]
- Jang-Jaccard, J.; Nepal, S. A survey of emerging threats in cybersecurity. J. Comput. Syst. Sci. 2014, 80, 973–993. [Google Scholar] [CrossRef]
- Joye, M.; Neven, G. Identity-Based Cryptography; IOS Press: Amsterdam, The Netherlands, 2009; Volume 2. [Google Scholar]
- Gisin, N.; Ribordy, G.; Tittel, W.; Zbinden, H. Quantum cryptography. Rev. Mod. Phys. 2002, 74, 145. [Google Scholar] [CrossRef] [Green Version]
- Zou, C.C.; Towsley, D.; Gong, W. A Firewall Network System for Worm Defense in Enterprise Networks; Technical Report TR-04-CSE-01; University of Massachusetts: Amherst, MA, USA, 2004. [Google Scholar]
- Corey, V.; Peterman, C.; Shearin, S.; Greenberg, M.S.; Van Bokkelen, J. Network forensics analysis. IEEE Internet Comput. 2002, 6, 60–66. [Google Scholar] [CrossRef]
- Hu, V.C.; Ferraiolo, D.; Kuhn, D.R. Assessment of Access Control Systems; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2006. [Google Scholar]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Brahmi, I.; Brahmi, H.; Yahia, S.B. A multi-agents intrusion detection system using ontology and clustering techniques. In Proceedings of the IFIP International Conference on Computer Science and Its Applications, Saida, Algeria, 20–21 May 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 381–393. [Google Scholar]
- Johnson, L. Computer Incident Response and Forensics Team Management: Conducting a Successful Incident Response; Newnes: Oxford, UK, 2013. [Google Scholar]
- Qu, X.; Yang, L.; Guo, K.; Ma, L.; Sun, M.; Ke, M.; Li, M. A survey on the development of self-organizing maps for unsupervised intrusion detection. Mob. Netw. Appl. 2019, 26, 808–829. [Google Scholar] [CrossRef]
- Radivilova, T.; Kirichenko, L.; Alghawli, A.S.; Ilkov, A.; Tawalbeh, M.; Zinchenko, P. The complex method of intrusion detection based on anomaly detection and misuse detection. In Proceedings of the 2020 IEEE 11th International Conference on Dependable Systems, Services and Technologies (DESSERT), Kyiv, Ukraine, 14–18 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 133–137. [Google Scholar]
- Mosqueira-Rey, E.; Alonso-Betanzos, A.; Río, B.B.d.; Pineiro, J.L. A misuse detection agent for intrusion detection in a multi-agent architecture. In Proceedings of the KES International Symposium on Agent and Multi-Agent Systems: Technologies and Applications, Wroclaw, Poland, 31 May–1 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 466–475. [Google Scholar]
- Liao, H.J.; Lin, C.H.R.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Alazab, A.; Hobbs, M.; Abawajy, J.; Alazab, M. Using feature selection for intrusion detection system. In Proceedings of the 2012 International Symposium on Communications and Information Technologies (ISCIT), Sydney, Australia, 9–12 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 296–301. [Google Scholar]
- Viegas, E.; Santin, A.O.; Franca, A.; Jasinski, R.; Pedroni, V.A.; Oliveira, L.S. Towards an energy-efficient anomaly-based intrusion detection engine for embedded systems. IEEE Trans. Comput. 2016, 66, 163–177. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Dutt, I.; Borah, S.; Maitra, I.K.; Bhowmik, K.; Maity, A.; Das, S. Real-time hybrid intrusion detection system using machine learning techniques. In Advances in Communication, Devices and Networking; Springer: Berlin/Heidelberg, Germany, 2018; pp. 885–894. [Google Scholar]
- Ghanem, M.C.; Chen, T.M. Reinforcement learning for efficient network penetration testing. Information 2019, 11, 6. [Google Scholar] [CrossRef] [Green Version]
- Alghamdi, M.I. Survey on Applications of Deep Learning and Machine Learning Techniques for Cyber Security. Int. J. Interact. Mob. Technol. 2020, 14, 210–224. [Google Scholar] [CrossRef]
- Text—S.1353—113th Congress (2013–2014): Cybersecurity Enhancement Act of 2014|Congress.gov|Library of Congress. Available online: https://www.congress.gov/bill/113th-congress/senate-bill/1353/text (accessed on 10 May 2022).
- Cybersecurity, C.I. Framework for Improving Critical Infrastructure Cybersecurity. 2018; p. 4162018. Available online: https://nvlpubs.nist.gov/nistpubs/CSWP/NIST.CSWP (accessed on 10 May 2022).
- Hu, V. Machine Learning for Access Control Policy Verification; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2021. [Google Scholar]
- Rizk, A.; Elragal, A. Data science: Developing theoretical contributions in information systems via text analytics. J. Big Data 2020, 7, 1–26. [Google Scholar] [CrossRef]
- IMPACT. Available online: https://www.impactcybertrust.org/ (accessed on 10 May 2022).
- Stanford Large Network Dataset Collection. Available online: https://snap.stanford.edu/data/index.html (accessed on 10 May 2022).
- Traffic Data from Kyoto University’s Honeypots. Available online: http://www.takakura.com/Kyoto_data/ (accessed on 10 May 2022).
- KDD Cup 1999 Data. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 10 May 2022).
- NSL-KDD|Datasets|Research|Canadian Institute for Cybersecurity|UNB. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 10 May 2022).
- 1998 DARPA Intrusion Detection Evaluation Dataset|MIT Lincoln Laboratory. Available online: https://www.ll.mit.edu/r-d/datasets/1998-darpa-intrusion-detection-evaluation-dataset (accessed on 10 May 2022).
- The UNSW-NB15 Dataset|UNSW Research. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 10 May 2022).
- ADFA IDS Datasets|UNSW Research. Available online: https://research.unsw.edu.au/projects/adfa-ids-datasets (accessed on 10 May 2022).
- MAWI Working Group Traffic Archive. Available online: https://mawi.wide.ad.jp/mawi/ (accessed on 10 May 2022).
- Insider Threat Test Dataset. Available online: https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=508099 (accessed on 10 May 2022).
- The Bot-IoT Dataset|UNSW Research. Available online: https://research.unsw.edu.au/projects/bot-iot-dataset (accessed on 10 May 2022).
- Cucchiarelli, A.; Morbidoni, C.; Spalazzi, L.; Baldi, M. Algorithmically generated malicious domain names detection based on n-grams features. Expert Syst. Appl. 2021, 170, 114551. [Google Scholar] [CrossRef]
- García, S.; Grill, M.; Stiborek, J.; Zunino, A. An empirical comparison of botnet detection methods. Comput. Secur. 2014, 45, 100–123. [Google Scholar] [CrossRef]
- CAIDA Data—Completed Datasets—CAIDA. Available online: https://www.caida.org/catalog/datasets/completed-datasets/ (accessed on 10 May 2022).
- Sharafaldin, I.; Lashkari, A.; Hakak, S.; Ghorbani, A.A. Developing realistic distributed denial of service (DDoS) attack dataset and taxonomy. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019. [Google Scholar] [CrossRef]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A. Toward Developing a Systematic Approach to Generate Benchmark Datasets for Intrusion Detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Yang, L.; Ciptadi, A.; Laziuk, I.; Ahmadzadeh, A.; Wang, G. BODMAS: An open dataset for learning based temporal analysis of PE malware. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), Virtual, 27 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 78–84. [Google Scholar]
- Keila, P.S.; Skillicorn, D.B. Structure in the Enron Email Dataset. Comput. Math. Organ. Theory 2005, 11, 183–199. [Google Scholar] [CrossRef]
- Arp, D.; Spreitzenbarth, M.; Hübner, M.; Gascon, H.; Rieck, K. Drebin: Effective and Explainable Detection of Android Malware in Your Pocket. In Proceedings of the NDSS’14, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Sangster, B.; O’connor, T.J.; Cook, T.; Fanelli, R.; Dean, E.; Adams, W.J.; Morrell, C.; Conti, G. Toward Instrumenting Network Warfare Competitions to Generate Labeled Datasets; United States Military Academy: New York, NY, USA, 2009. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data mining concepts and techniques third edition. Morgan Kaufmann Ser. Data Manag. Syst. 2011, 5, 83–124. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Practical machine learning tools and techniques. Morgan Kaufmann 2005, 2, 578. [Google Scholar]
- Dua, S.; Du, X. Data Mining and Machine Learning in Cybersecurity; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD-94, Oregon, Portland, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Inokuchi, A.; Washio, T.; Motoda, H. An apriori-based algorithm for mining frequent substructures from graph data. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Lyon, France, 13–16 September 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 13–23. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Dabney, W.; Rowland, M.; Bellemare, M.; Munos, R. Distributional reinforcement learning with quantile regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Force, J.T. Risk management framework for information systems and organizations. NIST Spec. Publ. 2018, 800, 37. [Google Scholar]
- Breier, J.; Baldwin, A.; Balinsky, H.; Liu, Y. Risk Management Framework for Machine Learning Security. arXiv 2020, arXiv:2012.04884. [Google Scholar]
- Buchanan, B.; Bansemer, J.; Cary, D.; Lucas, J.; Musser, M. Automating Cyber Attacks: Hype and Reality; Center for Security and Emerging Technology: Washington, DC, USA, 2020. [Google Scholar] [CrossRef]
- Thomas, T.; Vijayaraghavan, A.P.; Emmanuel, S. Machine Learning Approaches in Cyber Security Analytics; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Sakthivel, R.K.; Nagasubramanian, G.; Al-Turjman, F.; Sankayya, M. Core-level cybersecurity assurance using cloud-based adaptive machine learning techniques for manufacturing industry. Trans. Emerg. Telecommun. Technol. 2020, 33, e3947. [Google Scholar] [CrossRef]
- Dasgupta, P.; Collins, J. A survey of game theoretic approaches for adversarial machine learning in cybersecurity tasks. AI Mag. 2019, 40, 31–43. [Google Scholar] [CrossRef] [Green Version]
- De Lucia, M.J.; Cotton, C. Adversarial machine learning for cyber security. J. Inf. Syst. Appl. Res. 2019, 12, 26. [Google Scholar]
- Xi, B. Adversarial machine learning for cybersecurity and computer vision: Current developments and challenges. Wiley Interdiscip. Rev. Comput. Stat. 2020, 12, e1511. [Google Scholar] [CrossRef]
- Sarker, I.H.; Kayes, A.; Watters, P. Effectiveness analysis of machine learning classification models for predicting personalized context-aware smartphone usage. J. Big Data 2019, 6, 1–28. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating continuous distributions in Bayesian classifiers. arXiv 2013, arXiv:1302.4964. [Google Scholar]
- Keerthi, S.S.; Shevade, S.K.; Bhattacharyya, C.; Murthy, K.R.K. Improvements to Platt’s SMO algorithm for SVM classifier design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Salzberg, S.L. C4. 5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef] [Green Version]
- Sarker, I.H.; Colman, A.; Han, J.; Khan, A.I.; Abushark, Y.B.; Salah, K. Behavdt: A behavioral decision tree learning to build user-centric context-aware predictive model. Mob. Netw. Appl. 2020, 25, 1151–1161. [Google Scholar] [CrossRef] [Green Version]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. ICML 1996, 96, 148–156. [Google Scholar]
- Le Cessie, S.; Van Houwelingen, J.C. Ridge estimators in logistic regression. J. R. Stat. Soc. Ser. Appl. Stat. 1992, 41, 191–201. [Google Scholar] [CrossRef]
- Panda, M.; Patra, M.R. Network intrusion detection using naive bayes. Int. J. Comput. Sci. Netw. Secur. 2007, 7, 258–263. [Google Scholar]
- Amor, N.B.; Benferhat, S.; Elouedi, Z. Naive bayes vs decision trees in intrusion detection systems. In Proceedings of the 2004 ACM Symposium on Applied Computing, Nicosia, Cyprus, 14–17 March 2004; pp. 420–424. [Google Scholar]
- Carl, L. Using machine learning technliques to identify botnet traffic. In Proceedings of the 2006 31st IEEE Conference on Local Computer Networks, Tampa, FL, USA, 14–16 November 2006; IEEE: Piscataway, NJ, USA, 2006. [Google Scholar]
- Kokila, R.; Selvi, S.T.; Govindarajan, K. DDoS detection and analysis in SDN-based environment using support vector machine classifier. In Proceedings of the 2014 Sixth International Conference on Advanced Computing (ICoAC), Chennai, India, 17–19 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 205–210. [Google Scholar]
- Amiri, F.; Yousefi, M.R.; Lucas, C.; Shakery, A.; Yazdani, N. Mutual information-based feature selection for intrusion detection systems. J. Netw. Comput. Appl. 2011, 34, 1184–1199. [Google Scholar] [CrossRef]
- Hu, W.; Liao, Y.; Vemuri, V.R. Robust Support Vector Machines for Anomaly Detection in Computer Security. In Proceedings of the ICMLA, Los Angeles, CA, USA, 23–24 June 2003; pp. 168–174. [Google Scholar]
- Vuong, T.P.; Loukas, G.; Gan, D.; Bezemskij, A. Decision tree-based detection of denial of service and command injection attacks on robotic vehicles. In Proceedings of the 2015 IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 16–19 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Moon, D.; Im, H.; Kim, I.; Park, J.H. DTB-IDS: An intrusion detection system based on decision tree using behavior analysis for preventing APT attacks. J. Supercomput. 2017, 73, 2881–2895. [Google Scholar] [CrossRef]
- Kruegel, C.; Toth, T. Using decision trees to improve signature-based intrusion detection. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Pittsburgh, PA, USA, 8–10 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 173–191. [Google Scholar]
- Zhang, J.; Zulkernine, M.; Haque, A. Random-forests-based network intrusion detection systems. IEEE Trans. Syst. Man Cybern. Part Appl. Rev. 2008, 38, 649–659. [Google Scholar] [CrossRef]
- Watters, P.A.; McCombie, S.; Layton, R.; Pieprzyk, J. Characterising and predicting cyber attacks using the Cyber Attacker Model Profile (CAMP). J. Money Laund. Control 2012, 15, 430–441. [Google Scholar] [CrossRef]
- Kaddoura, S.; Alfandi, O.; Dahmani, N. A spam email detection mechanism for english language text emails using deep learning approach. In Proceedings of the 2020 IEEE 29th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Virtual, 10–13 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 193–198. [Google Scholar]
- Li, Z.; Zhang, A.; Lei, J.; Wang, L. Real-time correlation of network security alerts. In Proceedings of the IEEE International Conference on e-Business Engineering (ICEBE’07), Hong Kong, China, 24–26 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 73–80. [Google Scholar]
- Blowers, M.; Williams, J. Machine learning applied to cyber operations. In Network Science and Cybersecurity; Springer: Berlin/Heidelberg, Germany, 2014; pp. 155–175. [Google Scholar]
- Sequeira, K.; Zaki, M. Admit: Anomaly-based data mining for intrusions. In Proceedings of the eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 386–395. [Google Scholar]
- Zhengbing, H.; Zhitang, L.; Junqi, W. A novel network intrusion detection system (nids) based on signatures search of data mining. In Proceedings of the First International Workshop on Knowledge Discovery and Data Mining (WKDD 2008), Adelaide, Australia, 23–24 January 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 10–16. [Google Scholar]
- Zaman, M.; Lung, C.H. Evaluation of machine learning techniques for network intrusion detection. In Proceedings of the NOMS 2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Ravipati, R.D.; Abualkibash, M. Intrusion detection system classification using different machine learning algorithms on KDD-99 and NSL-KDD datasets—A review paper. Int. J. Comput. Sci. Inf. Technol. 2019, 11, 65–80. [Google Scholar] [CrossRef] [Green Version]
- Abrar, I.; Ayub, Z.; Masoodi, F.; Bamhdi, A.M. A machine learning approach for intrusion detection system on NSL-KDD dataset. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 919–924. [Google Scholar]
- Gao, X.; Shan, C.; Hu, C.; Niu, Z.; Liu, Z. An adaptive ensemble machine learning model for intrusion detection. IEEE Access 2019, 7, 82512–82521. [Google Scholar] [CrossRef]
- Rupa Devi, T.; Badugu, S. A review on network intrusion detection system using machine learning. In Advances in Decision Sciences, Image Processing, Security and Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 598–607. [Google Scholar]
- Kocher, G.; Kumar, G. Performance analysis of machine learning classifiers for intrusion detection using unsw-nb15 dataset. Comput. Sci. Inf. Technol. 2020, 31–40. [Google Scholar]
- Kasongo, S.M.; Sun, Y. Performance analysis of intrusion detection systems using a feature selection method on the UNSW-NB15 dataset. J. Big Data 2020, 7, 1–20. [Google Scholar] [CrossRef]
- Rana, M.S.; Gudla, C.; Sung, A.H. Evaluating machine learning models for Android malware detection: A comparison study. In Proceedings of the 2018 VII International Conference on Network, Communication and Computing, Taipei, Taiwan, 14–16 December 2018; pp. 17–21. [Google Scholar]
- Li, C.; Mills, K.; Niu, D.; Zhu, R.; Zhang, H.; Kinawi, H. Android malware detection based on factorization machine. IEEE Access 2019, 7, 184008–184019. [Google Scholar] [CrossRef]
- Raghuraman, C.; Suresh, S.; Shivshankar, S.; Chapaneri, R. Static and dynamic malware analysis using machine learning. In Proceedings of the First International Conference on Sustainable Technologies for Computational Intelligence, Jaipur, India, 29–30 March 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 793–806. [Google Scholar]
- Singh, M. User-Centered Spam Detection Using Linear and Non-Linear Machine Learning Models; University of Victoria: Victoria, BC, Canada, 2019. [Google Scholar]
- Islam, M.K.; Al Amin, M.; Islam, M.R.; Mahbub, M.N.I.; Showrov, M.I.H.; Kaushal, C. Spam-Detection with Comparative Analysis and Spamming Words Extractions. In Proceedings of the 2021 9th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; IEEE: Piscataway, NJ, USA, 2021; pp. 1–9. [Google Scholar]
- Şahin, D.Ö.; Demirci, S. Spam Filtering with KNN: Investigation of the Effect of k Value on Classification Performance. In Proceedings of the 2020 28th Signal Processing and Communications Applications Conference (SIU), Gaziantep, Turkey, 5–7 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Sarker, I.H. Context-aware rule learning from smartphone data: Survey, challenges and future directions. J. Big Data 2019, 6, 1–25. [Google Scholar] [CrossRef] [Green Version]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965; Volume 1, pp. 281–297. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–35. [Google Scholar]
- Sneath, P.H. The application of computers to taxonomy. Microbiology 1957, 17, 201–226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sorensen, T.A. A method of establishing groups of equal amplitude in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish commons. Biol. Skar. 1948, 5, 1–34. [Google Scholar]
- Kim, G.; Lee, S.; Kim, S. A novel hybrid intrusion detection method integrating anomaly detection with misuse detection. Expert Syst. Appl. 2014, 41, 1690–1700. [Google Scholar] [CrossRef]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 26–28 May 1993; pp. 207–216. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. ACM Sigmod Rec. 2000, 29, 1–12. [Google Scholar] [CrossRef]
- Flach, P.A.; Lachiche, N. Confirmation-guided discovery of first-order rules with Tertius. Mach. Learn. 2001, 42, 61–95. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference Very Large Data Bases, VLDB, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Houtsma, M.; Swami, A. Set-oriented mining for association rules in relational databases. In Proceedings of the Eleventh International Conference on Data Engineering, Taipei, Taiwan, 6–10 March 1995; IEEE: Piscataway, NJ, USA, 1995; pp. 25–33. [Google Scholar]
- Liu, B.; Hsu, W.; Ma, Y. Integrating classification and association rule mining. Knowl. Discov. Data Min. Inf. 1998, 98, 80–86. [Google Scholar]
- Das, A.; Ng, W.K.; Woon, Y.K. Rapid association rule mining. In Proceedings of the Tenth International Conference on Information and Knowledge Management, Atlanta, GA, USA, 5–10 October 2001; pp. 474–481. [Google Scholar]
- Zaki, M.J. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef] [Green Version]
- Cannady, J. Artificial neural networks for misuse detection. In Proceedings of the 1998 National Information Systems Security Conference (NISSC’98), Arlington, VA, USA, 5–8 October 1998; pp. 443–456. [Google Scholar]
- Lippmann, R.P.; Cunningham, R.K. Improving intrusion detection performance using keyword selection and neural networks. Comput. Netw. 2000, 34, 597–603. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Qu, Y.; Chao, F.; Shum, H.P.; Ho, E.S.; Yang, L. Machine learning algorithms for network intrusion detection. In AI in Cybersecurity; Springer: Berlin/Heidelberg, Germany, 2019; pp. 151–179. [Google Scholar]
- Wang, G.; Hao, J.; Ma, J.; Huang, L. A new approach to intrusion detection using Artificial Neural Networks and fuzzy clustering. Expert Syst. Appl. 2010, 37, 6225–6232. [Google Scholar] [CrossRef]
- Kayacik, H.G.; Zincir-Heywood, A.N.; Heywood, M.I. A hierarchical SOM-based intrusion detection system. Eng. Appl. Artif. Intell. 2007, 20, 439–451. [Google Scholar] [CrossRef]
- Ding, Y.; Chen, S.; Xu, J. Application of deep belief networks for opcode based malware detection. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3901–3908. [Google Scholar]
- Gao, N.; Gao, L.; Gao, Q.; Wang, H. An intrusion detection model based on deep belief networks. In Proceedings of the 2014 Second International Conference on Advanced Cloud and Big Data, Huangshan, China, 20–22 November 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 247–252. [Google Scholar]
- Tan, Q.S.; Huang, W.; Li, Q. An intrusion detection method based on DBN in ad hoc networks. In Proceedings of the International Conference on Wireless Communication and Sensor Network (WCSN 2015), Changsha, China, 12–13 December 2015; World Scientific: Singapore, 2016; pp. 477–485. [Google Scholar]
- Zhu, D.; Jin, H.; Yang, Y.; Wu, D.; Chen, W. DeepFlow: Deep learning-based malware detection by mining Android application for abnormal usage of sensitive data. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 438–443. [Google Scholar]
- Alrawashdeh, K.; Goldsmith, S. Optimizing Deep Learning Based Intrusion Detection Systems Defense Against White-Box and Backdoor Adversarial Attacks Through a Genetic Algorithm. In Proceedings of the 2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Choudhary, S.; Kesswani, N. Analysis of KDD-Cup’99, NSL-KDD and UNSW-NB15 datasets using deep learning in IoT. Procedia Comput. Sci. 2020, 167, 1561–1573. [Google Scholar] [CrossRef]
- Sai, N.R.; Kumar, G.S.C.; Safali, M.A.; Chandana, B.S. Detection System for the Network Data Security with a profound Deep learning approach. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 8–10 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1026–1031. [Google Scholar]
- Ahsan, M.; Nygard, K.E. Convolutional Neural Networks with LSTM for Intrusion Detection. CATA 2020, 69, 69–79. [Google Scholar]
- Gurung, S.; Ghose, M.K.; Subedi, A. Deep learning approach on network intrusion detection system using NSL-KDD dataset. Int. J. Comput. Netw. Inf. Secur. 2019, 11, 8–14. [Google Scholar] [CrossRef]
- Ding, Y.; Zhai, Y. Intrusion detection system for NSL-KDD dataset using convolutional neural networks. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Shenzhen, China, 12–14 December 2018; pp. 81–85. [Google Scholar]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep learning methods on network intrusion detection using NSL-KDD dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Jameel, A.S.M.M.; Mohamed, A.P.; Zhang, X.; El Gamal, A. Deep learning for frame error prediction using a DARPA spectrum collaboration challenge (SC2) dataset. IEEE Netw. Lett. 2021, 3, 133–137. [Google Scholar] [CrossRef]
- Nilă, C.; Patriciu, V.; Bica, I. Machine Learning Datasets for Cyber Security Applications. Secur. Future 2019, 3, 109–112. [Google Scholar]
- Zhiqiang, L.; Mohi-Ud-Din, G.; Bing, L.; Jianchao, L.; Ye, Z.; Zhijun, L. Modeling network intrusion detection system using feed-forward neural network using unsw-nb15 dataset. In Proceedings of the 2019 IEEE 7th International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–14 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 299–303. [Google Scholar]
- Ahsan, M.; Gomes, R.; Chowdhury, M.; Nygard, K.E. Enhancing Machine Learning Prediction in Cybersecurity Using Dynamic Feature Selector. J. Cybersecur. Priv. 2021, 1, 199–218. [Google Scholar] [CrossRef]
- Al, S.; Dener, M. STL-HDL: A new hybrid network intrusion detection system for imbalanced dataset on big data environment. Comput. Secur. 2021, 110, 102435. [Google Scholar] [CrossRef]
- Millar, S.; McLaughlin, N.; del Rincon, J.M.; Miller, P. Multi-view deep learning for zero-day Android malware detection. J. Inf. Secur. Appl. 2021, 58, 102718. [Google Scholar] [CrossRef]
- Naway, A.; Li, Y. A review on the use of deep learning in android malware detection. arXiv 2018, arXiv:1812.10360. [Google Scholar]
- Pei, X.; Yu, L.; Tian, S. AMalNet: A deep learning framework based on graph convolutional networks for malware detection. Comput. Secur. 2020, 93, 101792. [Google Scholar] [CrossRef]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box generation of adversarial text sequences to evade deep learning classifiers. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 50–56. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Sarker, I.H.; Colman, A.; Han, J. Recencyminer: Mining recency-based personalized behavior from contextual smartphone data. J. Big Data 2019, 6, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Massaoudi, M.; Refaat, S.S.; Abu-Rub, H. Intrusion Detection Method Based on SMOTE Transformation for Smart Grid Cybersecurity. In Proceedings of the 2022 3rd International Conference on Smart Grid and Renewable Energy (SGRE), Doha, Qatar, 20–22 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Ahsan, M.; Gomes, R.; Denton, A. Smote implementation on phishing data to enhance cybersecurity. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 0531–0536. [Google Scholar]
- Tsai, C.W.; Lai, C.F.; Chao, H.C.; Vasilakos, A.V. Big data analytics: A survey. J. Big Data 2015, 2, 1–32. [Google Scholar]
- Sarker, I.H.; Abushark, Y.B.; Khan, A.I. Contextpca: Predicting context-aware smartphone apps usage based on machine learning techniques. Symmetry 2020, 12, 499. [Google Scholar] [CrossRef] [Green Version]
- Qiao, L.B.; Zhang, B.F.; Lai, Z.Q.; Su, J.S. Mining of attack models in ids alerts from network backbone by a two-stage clustering method. In Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops & Phd Forum, Shanghai, China, 21–25 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1263–1269. [Google Scholar]
- Wall, M.E.; Rechtsteiner, A.; Rocha, L.M. Singular value decomposition and principal component analysis. In A Practical Approach to Microarray Data Analysis; Springer: Berlin/Heidelberg, Germany, 2003; pp. 91–109. [Google Scholar]
- Zhao, S.; Leftwich, K.; Owens, M.; Magrone, F.; Schonemann, J.; Anderson, B.; Medhi, D. I-can-mama: Integrated campus network monitoring and management. In Proceedings of the 2014 IEEE Network Operations and Management Symposium (NOMS), Krakow, Poland, 5–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–7. [Google Scholar]
- Kaufman, S.; Rosset, S.; Perlich, C.; Stitelman, O. Leakage in data mining: Formulation, detection, and avoidance. ACM Trans. Knowl. Discov. Data TKDD 2012, 6, 1–21. [Google Scholar] [CrossRef]
- Nisbet, R.; Elder, J.; Miner, G.D. Handbook of Statistical Analysis and Data Mining Applications; Academic Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Rosset, S.; Perlich, C.; Świrszcz, G.; Melville, P.; Liu, Y. Medical data mining: Insights from winning two competitions. Data Min. Knowl. Discov. 2010, 20, 439–468. [Google Scholar] [CrossRef]
- Kohavi, R.; Brodley, C.E.; Frasca, B.; Mason, L.; Zheng, Z. KDD-Cup 2000 organizers’ report: Peeling the onion. ACM Sigkdd Explor. Newsl. 2000, 2, 86–93. [Google Scholar] [CrossRef]
- Gupta, I.; Mittal, S.; Tiwari, A.; Agarwal, P.; Singh, A.K. TIDF-DLPM: Term and Inverse Document Frequency based Data Leakage Prevention Model. arXiv 2022, arXiv:2203.05367. [Google Scholar]
- Stuart, M. Understanding robust and exploratory data analysis. J. R. Stat. Soc. Ser. D 1984, 33, 320–321. [Google Scholar] [CrossRef]
- Pulido-Gaytan, L.B.; Tchernykh, A.; Cortés-Mendoza, J.M.; Babenko, M.; Radchenko, G. A Survey on Privacy-Preserving Machine Learning with Fully Homomorphic Encryption. In Proceedings of the Latin American High Performance Computing Conference, Cuenca, Ecuador, 2–4 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 115–129. [Google Scholar]
- Kjamilji, A.; Savaş, E.; Levi, A. Efficient secure building blocks with application to privacy preserving machine learning algorithms. IEEE Access 2021, 9, 8324–8353. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Takabi, H.; Hesamifard, E.; Ghasemi, M. Privacy preserving multi-party machine learning with homomorphic encryption. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Fang, H.; Qian, Q. Privacy preserving machine learning with homomorphic encryption and federated learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Yang, Y.; Xiao, X.; Cai, X.; Zhang, W. A secure and high visual-quality framework for medical images by contrast-enhancement reversible data hiding and homomorphic encryption. IEEE Access 2019, 7, 96900–96911. [Google Scholar] [CrossRef]
- Salim, M.M.; Kim, I.; Doniyor, U.; Lee, C.; Park, J.H. Homomorphic Encryption Based Privacy-Preservation for IoMT. Appl. Sci. 2021, 11, 8757. [Google Scholar] [CrossRef]
- Bakshi, M.; Last, M. Cryptornn-privacy-preserving recurrent neural networks using homomorphic encryption. In International Symposium on Cyber Security Cryptography and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 245–253. [Google Scholar]
- Guan, Z.; Bian, L.; Shang, T.; Liu, J. When machine learning meets security issues: A survey. In Proceedings of the 2018 IEEE International Conference on Intelligence and Safety for Robotics (ISR), Shenyang, China, 24–27 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 158–165. [Google Scholar]
- Li, X.; Chen, D.; Li, C.; Wang, L. Secure data aggregation with fully homomorphic encryption in large-scale wireless sensor networks. Sensors 2015, 15, 15952–15973. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Latif, S.; Dola, F.F.; Afsar, M.; Esha, I.J.; Nandi, D. Investigation of Machine Learning Algorithms for Network Intrusion Detection. Int. J. Inf. Eng. Electron. Bus. 2022, 14, 1–22. [Google Scholar]
- Mavroeidis, V.; Vishi, K.; Zych, M.D.; Jøsang, A. The impact of quantum computing on present cryptography. arXiv 2018, arXiv:1804.00200. [Google Scholar] [CrossRef] [Green Version]
- Shor, P.W. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 124–134. [Google Scholar]
- Bone, S.; Castro, M. A Brief History of Quantum Computing; Imperial College in London: London, UK, 1997; Available online: http://www.doc.ic.ac.uk/~{}nd/surprise_97/journal/vol4/spb3 (accessed on 10 May 2022).
- Grover, L.K. A fast quantum mechanical algorithm for database search. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, Philadelphia, PA, USA, 22–24 May 1996; pp. 212–219. [Google Scholar]
- Cerf, N.J.; Levy, M.; Van Assche, G. Quantum distribution of Gaussian keys using squeezed states. Phys. Rev. A 2001, 63, 052311. [Google Scholar] [CrossRef] [Green Version]
- Ding, J.; Yang, B.Y. Multivariate public key cryptography. In Post-Quantum Cryptography; Springer: Berlin/Heidelberg, Germany, 2009; pp. 193–241. [Google Scholar]
- Hassija, V.; Chamola, V.; Goyal, A.; Kanhere, S.S.; Guizani, N. Forthcoming applications of quantum computing: Peeking into the future. IET Quantum Commun. 2020, 1, 35–41. [Google Scholar] [CrossRef]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. The quest for a quantum neural network. Quantum Inf. Process. 2014, 13, 2567–2586. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defense Technology | Categories of Defense Technologies Used Against Malware | Description of Defense Categories |
|---|---|---|
| Cryptography is a way to change data in such a way that only the intended receiver has the information to extract information from the changed form (encrypted data). It is the most used method to secure data. | Identity-based cryptography [25] | This is a public key generated using identification-based information, e.g., email address. The generation is processed by a trusted certifying authority. This is an active research area, to overcome the inconveniences of this cryptography against malware attacks. |
| Quantum cryptography [26] | In this cryptography, for the two parties, sender and receiver, the transmission generates cryptographic keys to encrypt data, following the laws of quantum mechanics. Hence, this encryption is not hackable. | |
| Perimeter defense/defense in depth is securing an organization’s network from outside intrusion | Firewall is the prevalent perimeter defense technology that controls network traffic (input data and outgoing data). It decides whether the data will go through or not based on a set of preset rules [27]. Despite the sophistication of firewalls, they can fail when a compromised but previously trusted system sends any request, and the attacking machine uses a trusted system’s identity. | 1. Network-layer firewall or packet filtering works at the network layer controlling data flow but has the drawback of having static rules that are not able to block undesirable data. Hence, it cannot block malware payload. 2. Application-layer firewall controls the flow of input, output and system calls by an application. This firewall makes the tempering of internal components by malware difficult. 3. Proxy servers work as a mediator between outside connections and internal components of a system and hence can hinder the tampering of these components by malware. |
| Network forensics [28] is the process of eavesdropping on the internet, Ethernet or TCP/IP to learn the attack pattern. There are numerous network forensics tools. | 1. eMailTrackerPro investigates the header of an email to look for an IP address, to find the sender. 2. Web browser traffic forensic tool, SmartWhoIs, can provide all available information about an IP address. 3. WebHistorian analyzes a website’s URL. 4. Index.datanalyzer analyzes the browsing history, cache and cookies. 5. In the wireless LAN interface and network interface, packet intercepts can be caught using AirPcap and WinPcap, respectively. 6. Honeypots are mock resources that trap the attacker and gather information. | |
| Access control [29] differentiates between users and controls resource access of the user based on the user’s preset rights. It provides authentication, authorization and accountability. | 1. Two broad divisions of access control, used in malware defense, are capability-based access control and the access control list-based approach. 2. Three access control models are Discretionary Access Control (DAC), Mandatory Access Control (MAC), Role-Based Access Control (RBAC). |
| Dataset | Description |
|---|---|
| IMPACT [47] | Mostly known as the Protected Repository for the Defense of Infrastructures Against Cyber Threats (PREDICT), a community that produces security-relevant network operation data and research. Repository provides regularly updated network operations data of cyber defense technology development. |
| SNAP [48] | Not specific to security, but there are several relevant graph datasets. |
| KYOTO [49] | Traffic data from Kyoto University’s Honeypots. |
| KDD’99 Cup [50] | Contains 41 features that could be used to evaluate ML models. Threats are categorized into four major target labels, such as remote-to-local (R2L), denial of service (DoS), probing and user-to-remote (U2R). |
| NSL-KDD [51] | Updated variant of KDD’99 Cup dataset. Records that are redundant have been removed. It also addresses issues associated with class imbalance. |
| DARPA [52] | LLDOS 1.0 and LLDOS 2.0.2 attack scenario data from the Authenticated Intrusion Detection System (IDS). MIT Lincoln Laboratory collects data traffic and threats from the DARPA dataset in order to evaluate network intrusion detection systems (NIDS). |
| UNSW- NB15 [53] | It has 49 independent features spread over nine different threat types, including DoS, which were gathered from the University of New South Wales (UNSW) cybersecurity Lab in 2015. UNSW-NB15 can be used for evaluation of ML-based anomaly detection systems in cyber applications. |
| ADFA IDS [54] | This is an intrusion dataset with different versions, named ADFA-LD and ADFA-WD, that is issued by the Australian Defense Academy (ADFA). This dataset is designed to evaluate host-based IDS. |
| MAWI [55] | A cybersecurity dataset regulated by Japanese network research institutions and academic institutions that is commonly used to detect and assess DDoS threats using machine learning techniques. |
| CERT [56] | The purpose of creating user activity logs was to validate insider-threat detection algorithms in this dataset. Based on machine learning, it can be used to track and evaluate user behavior. |
| Bot-IoT [57] | This is a dataset that includes authentic and simulated Internet of Things (IoT) network traffic, as well as various assaults for network forensic analytics in the IoT space. Bot-IoT is primarily used in forensics to assess reliability using multiple statistics and machine learning techniques. |
| DGA [58] | The Alexa Top Sites dataset reliably hosts domain names that are benign. Malicious domain names are collected from OSINT and DGArchive. These datasets find perfect application in DGA botnet detection or domain classification using automated ML models. |
| CTU-13 [59] | This is a labeled malware dataset including background traffic, botnet and normal user activities, which was captured at CTU University, Czech Republic. CTU-13 is used for data-driven malware analysis using machine learning techniques and to evaluate the standard malware detection system. |
| CAIDA [60] | The CAIDA’07 and CAIDA’08 datasets contain DDoS attack traffic and normal standard traffic history. They are primarily used to assess machine learning-based DDoS attack detection models and to spot internet DOS activities. |
| CIC- DDoS2019 [61] | The Canadian Institute for Cybersecurity has compiled a database of historical DDoS assaults. CIC-DDoS is an excellent network traffic behavioral analytics tool for detecting DDoS attacks using machine learning approaches. |
| ISCX’12 [62] | This dataset contains 19 features and 19.11% of the network traffic belongs to DDoS attacks. ISCX’12 was documented at the Canadian Institute for Cybersecurity and is well known for its use in the evaluation of the effectiveness of machine learning-based network intrusion detection modeling. |
| Malware [63] | This is a collection of malicious files from several malware-based datasets such as the Genome Project, VirusTotal, Virus Share, Comodo, Contagio, Microsoft and DREBIN. These datasets are commonly used for data-driven malware analysis and evaluation of existing malware detection systems utilizing machine learning techniques. |
| EnronSpam [64] | Email-based datasets are difficult to collect because of privacy concerns. This dataset is a collection of emails with spam and ham classification. |
| DREBIN [65] | Researchers have created these datasets from the Drebin project, which is publicly available, in order to encourage and improve research on Android malware. There are 5560 programs in this collection, spanning 179 different malware categories. The samples were collected between August 2010 and October 2012, and the MobileSandbox initiative made them freely available to cybersecurity practitioners. |
| CDX 2009 Network USMA [66] | This dataset highlights the correlation found between IP addresses associated with the PCAP files to hosts that are found on the internal USMA network. Not all network modifications are reflected in this dataset. |
| Algorithm | Objective | Dataset | Accuracy | Reference |
|---|---|---|---|---|
| Naive Bayes | Can be used to analyze continuous and discrete values. Features are evaluated in a mutually exclusive fashion, making it relatively fast, thereby finding applicability in real-time decision making. | KWeka package, KDD 1999 | 90–99% | [103] |
| KDD 1999 | 97% | [93] | ||
| TCP data collected from the Dartmouth University campus’ wireless network | 93% | [94] | ||
| Support Vector Machines | Effective in high-dimensional spaces. Relatively memory-efficient. Numerical and categorical features. | DARPA | 95.11% | [95] |
| KDD-99 | 93–99% | [96] | ||
| DARPA 1998 | 75–100% | [97] | ||
| Decision Tree | Requires little data preparation. Can be used to analyze continuous and discrete data. Can be generalized using dynamic tree-cut parameters. | TCP data collected from the Dartmouth University campus’ wireless network | 97% | [94] |
| 3000 behavior events collection | 84.7% | [99] | ||
| KDD dataset | 94.7% | [101] | ||
| Sequential Pattern Mining | Frequent sequential patterns for a frequency support measure. | DARPA 1999 and 2000 | 93% | [104] |
| DBSCAN | Identify outliers, separate clusters of high density from clusters of low density. | KDD-99 | 98% | [105] |
| ADMIT | Not reliant on a lot of labeled data. Uses a dynamic clustering technique Modified form of K-means clustering. | Data collected from UNIX users from Purdue University | 80% | [106] |
| A priori algorithm | The resulting rules are intuitive. Does not require labeled data as it is fully unsupervised. | Nine different-sized custom databases | 70–100% | [107] |
| Radial Basis Function (RBF) | Real-time network anomaly detection. | KYOTO | 95.6% | [108] |
| Random forest | Multi-class classification of network traffic threats. | KDD’99 Cup | 99.0% | [109] |
| Extra-tree classifier (ETC) | Multi-class classification of DoS, probe, R2L and U2R. | KDD’99 Cup | 99.51% | [110,111] |
| Radial Basis Function (RBF) | Comparative classification between lazy, eager learning and deep learning. | DARPA | 97.41% | [108,112] |
| Random forest | Comparative classification between lazy, eager learning and deep learning. | UNSWNB15 | 95.43% | [113,114] |
| Random forest | Android malware detection. | DREBIN | 94.33% | [115,116,117] |
| XGBoost | Classification of spam and ham from emails. | ENRON Spam | 98.67% | [118,119,120] |
| Algorithm | Objective | Dataset | Accuracy | Reference |
|---|---|---|---|---|
| ANN | Abilities to learn, classify and process information; faster self-organization. | RealSecure network monitor | 96.5% | [135] |
| DeepFlow | Custom-developed to distinguish malware. It uses the static taint analysis tool FlowDroid. Identifies sensitive data flows in Android apps. | Features extracted from 11,000 benign and malicious apps from Google Play Store | 95.05% | [143] |
| DBNs | Discovers layers of features and uses feed-forward neural network to optimize discrimination. | Custom dataset | 96% | [140] |
| KDD’99 Cup | 93.49% | [141] | ||
| Network feature sample | 97.60% | [142] | ||
| Deep Belief Network (DBN) | Real-time network anomaly detection. | KYOTO | 98% | [144] |
| Gated Recurrent Unit (GRU) | Multi-class classification of network traffic threats. | KDD’99 Cup | 98.64% | [145,146] |
| CNN-LSTM | Multi-class classification of DoS, probe, R2L and U2R. | KDD’99 Cup | 99.70% | [147,148,149,150] |
| Deep Feed Forward (DFF) | Comparative classification between lazy, eager learning and deep learning. | DARPA | 99.63% | [151,152] |
| Temporal convolutional networks (TCN) | Comparative classification between lazy, eager learning and deep learning. | UNSWNB15 | 99.6% | [153,154,155] |
| CNN | Android malware detection. | DREBIN | 99.29% | [156,157,158] |
| Bi-LSTM | Classification of spam and ham from emails. | ENRON Spam | 98.84% | [103,159] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahsan, M.; Nygard, K.E.; Gomes, R.; Chowdhury, M.M.; Rifat, N.; Connolly, J.F. Cybersecurity Threats and Their Mitigation Approaches Using Machine Learning—A Review. J. Cybersecur. Priv. 2022, 2, 527-555. https://doi.org/10.3390/jcp2030027
Ahsan M, Nygard KE, Gomes R, Chowdhury MM, Rifat N, Connolly JF. Cybersecurity Threats and Their Mitigation Approaches Using Machine Learning—A Review. Journal of Cybersecurity and Privacy. 2022; 2(3):527-555. https://doi.org/10.3390/jcp2030027
Chicago/Turabian StyleAhsan, Mostofa, Kendall E. Nygard, Rahul Gomes, Md Minhaz Chowdhury, Nafiz Rifat, and Jayden F Connolly. 2022. "Cybersecurity Threats and Their Mitigation Approaches Using Machine Learning—A Review" Journal of Cybersecurity and Privacy 2, no. 3: 527-555. https://doi.org/10.3390/jcp2030027
APA StyleAhsan, M., Nygard, K. E., Gomes, R., Chowdhury, M. M., Rifat, N., & Connolly, J. F. (2022). Cybersecurity Threats and Their Mitigation Approaches Using Machine Learning—A Review. Journal of Cybersecurity and Privacy, 2(3), 527-555. https://doi.org/10.3390/jcp2030027