4.1.1. Dataset and Settings
For the validation of our approach, we generated synthetic datasets to contain a known ‘amount’ of evidence of discrimination. To this end, we defined a simple decisional process regarding the hiring of candidates on the basis of their personal characteristics.
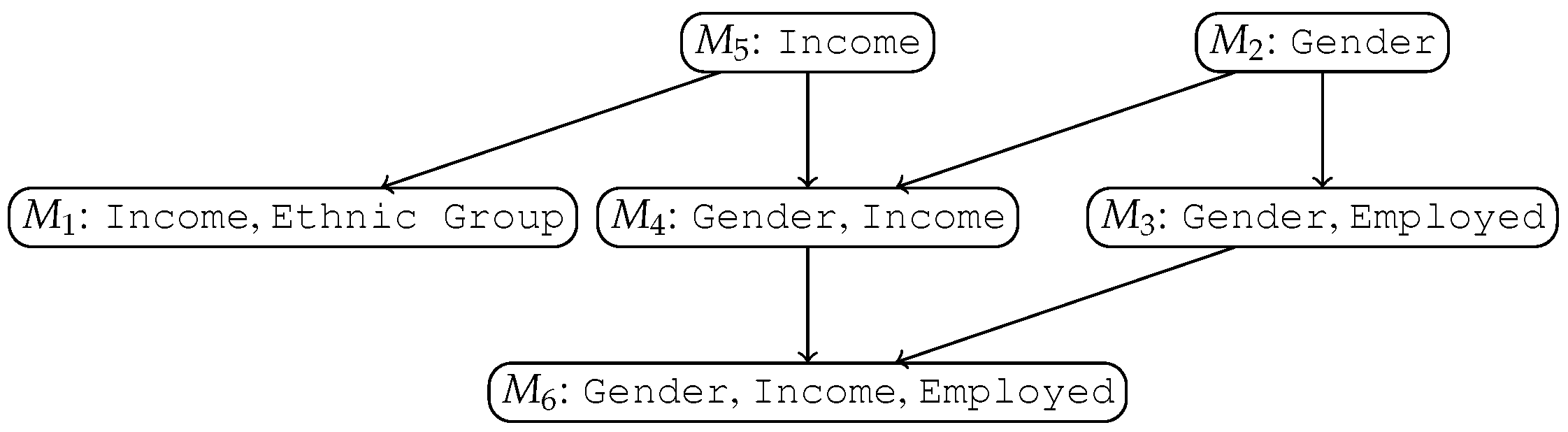
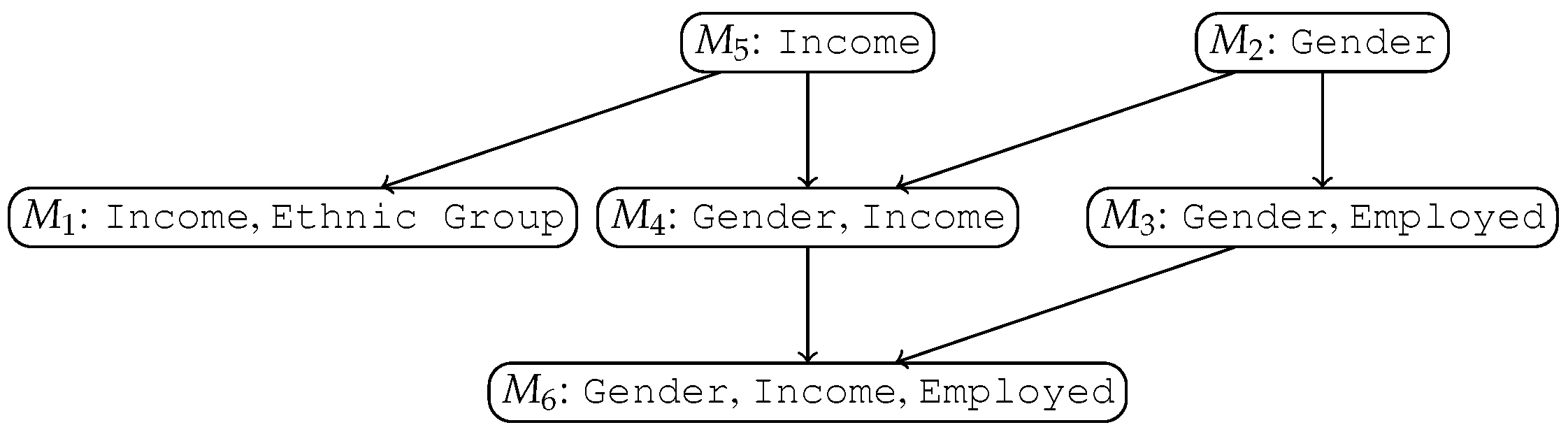
Table 4 shows the variables characterizing the hiring process along with their domain. We consider the variable
Age as a ‘discriminatory variable’, whereas the others are considered ‘context variables’. We generate the synthetic data in two steps. First, we created the discriminated groups as groups of subjects sharing the same value of
Age as well as a (randomly chosen) subset of context values; the values of the other context variables were randomly assigned from the respective domains. Discriminated subjects have a probability of 80% of being assigned to class “N”. Second, we generated all ‘non-discriminated’ subjects simply by randomly selecting a value for each context variable and for the
Age variable. Non-discriminated subjects have a 50% probability of being assigned to either the “N” or “Y” class.
In total, we generated 12 datasets by varying the number of discriminated groups (i.e., 1, 2 and 3) and the complexity of the dataset to test our methodology in different situations. The complexity of a dataset is defined over two dimensions: (1) presence/absence of noise, intended as subjects that do not belong to any of the generated context groups but in which one or more context variables assume a value used in one of the discriminated groups; and (2) the presence/absence of overlapping, meaning that subjects in two or more discriminated groups share at least a context variable and its value. Combining these two dimensions, we obtain four types of datasets: (i) without noise and overlapping, which represents the simplest situation; (ii) without noise but with overlapping; (iii) with noise but without overlapping; (iv) with noise and overlapping, which represents the most difficult situation to deal with, since spurious correlations can easily arise (note that the presence of overlapping only has an impact when more than one discriminated group exists). For every dataset, we generated a total of 10,000 subjects; among them, every discriminated group covered 25% of the dataset. We chose 25% to strike a balance between absolute minority (<50%) and small groups. For every dataset, we tested several configurations of support, which varied between 1% and 10% with a step of 1%, and confidence, which varied between 50% and 95% with a step of 5%. Note that when generating the regression models, we did not consider potential interactions among the variables in the experiments; namely, we used only factors of the first order when computing the regression models. While this choice can lead to lose some interesting correlation, it provides us with a good approximation of the relations characterizing the decisional process, and prevents the generation of noisy recommendations. Directionality is given by the sign of the corresponding coefficients.
4.1.2. Evaluation Metrics
To validate the approach, we compare the recommendations returned by our methodology and those returned by rule mining alone against the ‘ground truth’ used to generate the synthetic datasets. More precisely, we compute the fraction of correct models returned by our methodology as the ratio of the number of models involving significant regressors that indicate (at least some) true discriminatory factors among the variables over the total number of models returned by the approach. To compare this outcome with the one obtained using rule mining, we compute the ratio of the number of rules indicating (at least some) true discriminatory factors over the total number of mined rules.
To this end, we first derive for each model the set of significant regressors along with their coefficients. Then, we compare each regressor with the set of variables describing the discriminated groups. This comparison can return five different outcomes: (a) Exact, indicating that the set of significant regressors of the model involve all and only the variables characterizing one of the discriminated groups; (b) Too general, indicating that the set of explanatory variables in the regressors is a strict subset of the set of variables characterizing one of the discriminated groups; (c) Too specific, indicating that the set of explanatory variables in a regressor is a strict superset of the set of variables characterizing one of the discriminated groups; (d) Partial, indicating that the set of explanatory variables in the regressor overlaps with the set of variables characterizing one of the discriminated groups (but it is not a superset); (e) Off target, indicating that there are no significant regressors involving any variable characterizing a discriminated group. The output of rule mining is classified in the same way, by comparing the set of variables reported in a rule against the set of variables describing the discriminated groups. For a fair comparison, we only considered the variables involved in the antecedent of the rules; indeed, we are interested in determining whether a group shows signs of discrimination, rather than specifying whether it is a positive or negative discrimination.
We only consider exact and too general recommendations to be useful recommendations, since they include the true discriminated group, and therefore provide the analyst with a first, non-misleading indication of possible discriminatory relations. In contrast, the other categories of output are undesirable since, even if some do return part of the actual discriminatory group, the whole discriminated group cannot be identified as it is not included in the recommendation. Therefore, we compute the fraction of useful recommendations as the number of Exact and Too general models (rules) over all returned models (rules).
In addition to comparing the returned models against the ground truth, we also compare rule mining and regression analysis in terms of the number of output rules and regressors, respectively. The goal is to assess the capability of our approach to reduce the outcome complexity, thus making the analysis more accessible for a human analyst.
4.1.3. Results
Models vs. rules.Table 5 reports descriptive statistics of the results over all experiment runs.
The first set of rows reports the statistics for association rule mining, whereas the second set reports the statistics for our approach. We first observe that the number of rules is significantly larger than both the number of total models (i.e., the models derived from the set of rules) and that of selected models (i.e., the models returned in output by our approach). Furthermore, the number of the selected models is, on average, four times smaller than the overall number of models. The average experimental run produces approximately 12.87 rules, with a maximum of 139. The relatively high standard deviation (with respect to the mean) indicates that the number of rules in output can vary by large amounts across experimental setups. In contrast, the number of total (selected) models per experimental setup is, on average, more than two (twelve) times smaller, similarly to what can be observed for the maximum. The low standard deviation indicates a relatively stable output across experiments, especially for the selected models. Overall, this indicates that the model selection procedure appears to be removing a large number of rules but says little about the correctness of this process.
A first indication of the correctness of this process can be derived by evaluating of the number of exact, too general, too specific, partial, and off target rules/models in output of our method. Considering the obtained rules, we observed that association rule mining never returns off target recommendations. Moreover, it is able to identify, on average, at least one correct recommendation, either in terms of exact or too general recommendations. However, comparing these numbers with the overall average number of rules returned, these recommendations are likely to be hidden in a multitude of misleading recommendations. In fact, the results show that rule mining tends to return a much higher number of undesirable recommendations; on average, we obtain 3.52 too specific and 6.58 partial recommendations.
On the other hand, we observe that our approach returns a higher number of max exact recommendations. This is because a regressor (matching the ground truth) can be significant in multiple models. In general, we observe a similar distribution in the first and second quartile, even though the mean and median values show in general a lower overall capability of our approach to identify relevant groups under most circumstances (the median of Exact is 0). However, this minimal loss in detection is compensated by a large reduction in false positives to investigate. Moving to higher quartiles, we observe that our approach never returns partial or off target results, and generates much less too specific and too general recommendations. Overall, the results suggest that our approach is able to generate a more accurate output. However, this clearly depends on the number of discriminated groups, and results may vary significantly depending on the noise and overlap introduced in the synthetic datasets.
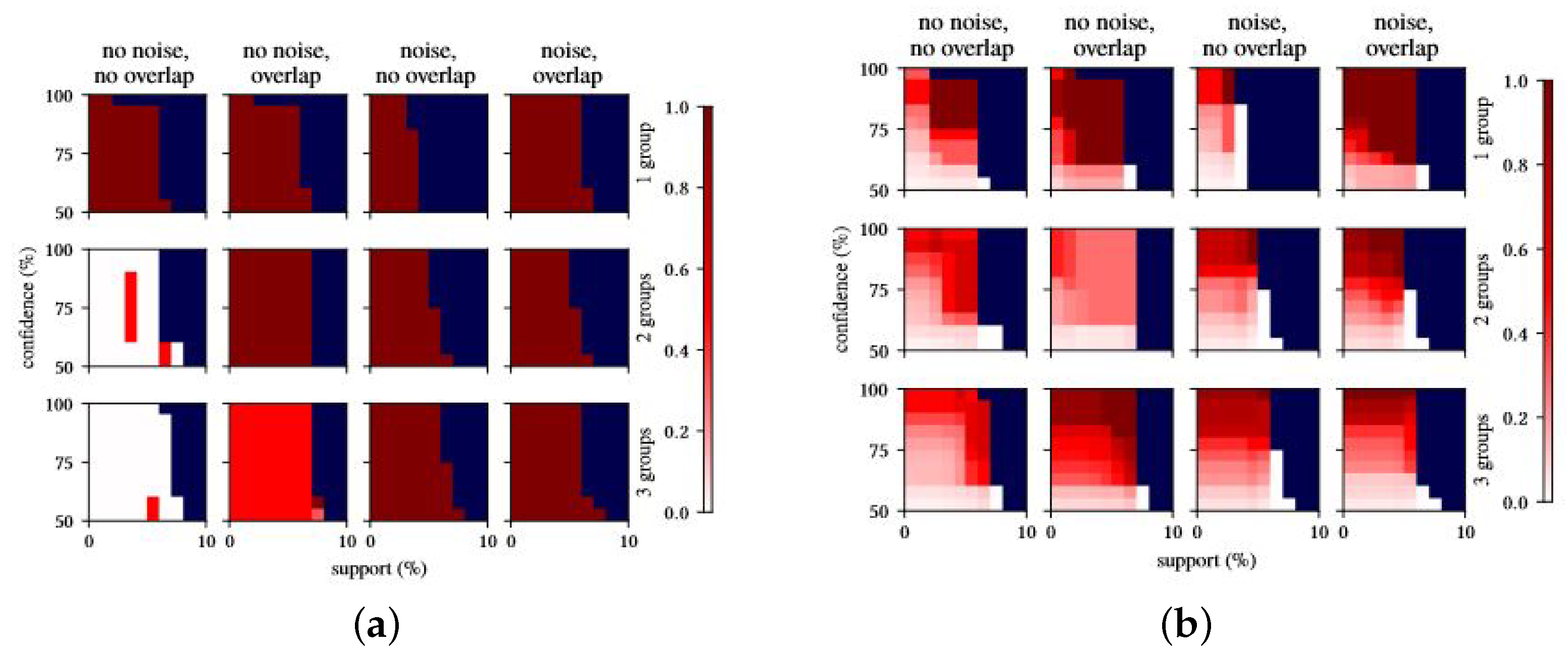
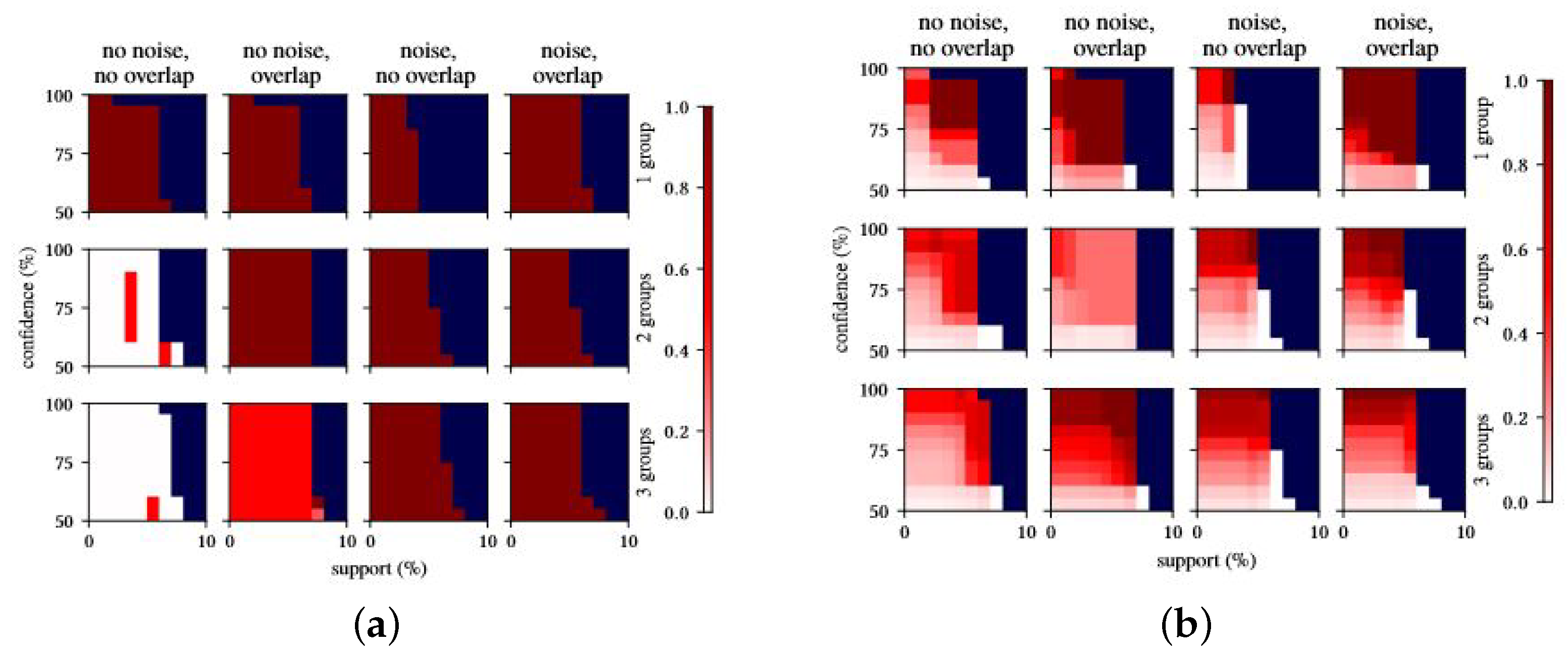
Figure 3 shows the density of ‘useful’ recommendations provided by rules mining and our approach, respectively, across our experimental conditions.
Results are arranged in a matrix, where each box represents a set of experiments with varying confidence and support levels (on the y and x axis, respectively, values are reported as percentages); the four columns correspond to the four combinations of noise and overlap, whereas the three rows correspond to the number of discriminated groups in the dataset. Recall that overlap does not impact the results when a single discriminated group is considered. The difference in the recommendations obtained for this dataset are mostly due to randomness in the data generation process. We reported them anyway for the sake of completeness. Within each box, each square corresponds to a combination of support and confidence thresholds. Squares are colored on the basis of the density of useful recommendations for the given combination of support and confidence. A darker color indicates a higher density (and vice versa). Blue cells represent support–confidence combinations from which no significant rules/regressors were obtained (resulting in a denominator of zero), and white cells represent support–confidence combinations for which no exact or too general recommendations were obtained.
We observe that, across almost all experimental setups, our approach produces a much higher density of relevant recommendations compared to rule mining alone. This confirms the observations made from
Table 5; namely, rule mining tends to return a high number of recommendations, in which useful recommendations are hidden among the others. Our approach, instead, provides almost only useful recommendations in almost all performed experiments, with the exception of the experiments involving two and three discriminated groups with no noise and no overlap (first column of the second and third sets of experiments). While this might seem counter intuitive, delving into the corresponding dataset, we find that the over-imposed constraints for data generation turned out to produce unrealistic relations that significantly reduce the discriminating effects of the chosen variables. For more than one discriminated group, and in the absence of noise and overlap, the variable values used for the discriminated groups only occur for subjects fitting the related context. For example, in the experiments with two discriminated groups, we have discriminating context groups, “
SpeakLanguage =
Y” and “
PreviousRole =
Employee”. Because of the generation constraints, there are no subjects assuming both these values. This creates the rather unrealistic situation whereby the value of one variable precludes another variable to assume some values. Our approach (correctly) detects a strong correlation among context variables
SpeakLanguage and
PreviousRole. This leads to the generation of
too specific recommendations for most of the support–confidence thresholds, with some exceptions mostly due to the randomness of data. We observe a similar though not as strong effect on the experiments with overlap and no noise. The constraint on the noise led to obtain some correlations between some context group values which in turn led to generate some misleading recommendations. Nevertheless, the overall density values remain high. We point out that the presence of such correlations is a by-product of the data generation constraints and is unlikely to represent a realistic situation under real-life conditions. Therefore, we do not expect this behavior to affect the reliability of the recommendations provided by the approach in real-life contexts.
It is worth noting that, while we observe performance to significantly vary for rule mining depending on the support/confidence thresholds, our approach proved to be more stable, keeping a constant level of density in almost all cases. This is in line with previous observations that rule mining is sensitive to parameterization, and that choosing the correct parameter configuration largely depends on unknown structures in the data. By contrast, our approach performs well across the board. This effectively removes the need for fine-tuning the support and confidence thresholds for rule selection, with regression model selection doing the larger part of the heavy lifting required to cherry-pick relevant rules and discarding imprecise ones.
Regressors vs. rules. The previous paragraph discussed the results obtained at the regression models level. Here we focus on the obtained regressors.
Table 6 shows descriptive statistics about rules and regressors obtained for the tested datasets.
The table shows some interesting trends. First, we observe much more variation in the number of rules than in the number of regressors (sd = 23.74 and 1.93, respectively), and that extreme values far away from the median are more likely to appear in the former than in the latter distribution. This confirms that the outcome of our approach is much more stable than the rule mining outcome. Furthermore, it is straightforward to see that, on average, the number of regressors is significantly lower than the number of rules. This is particularly evident from the mean value, equal to 12.87 for the rules, while the mean number of regressors is 2.11, with a six-fold reduction. An even stronger reduction can be observed considering the maximum values (139 for the rules, 6 for the regressors).
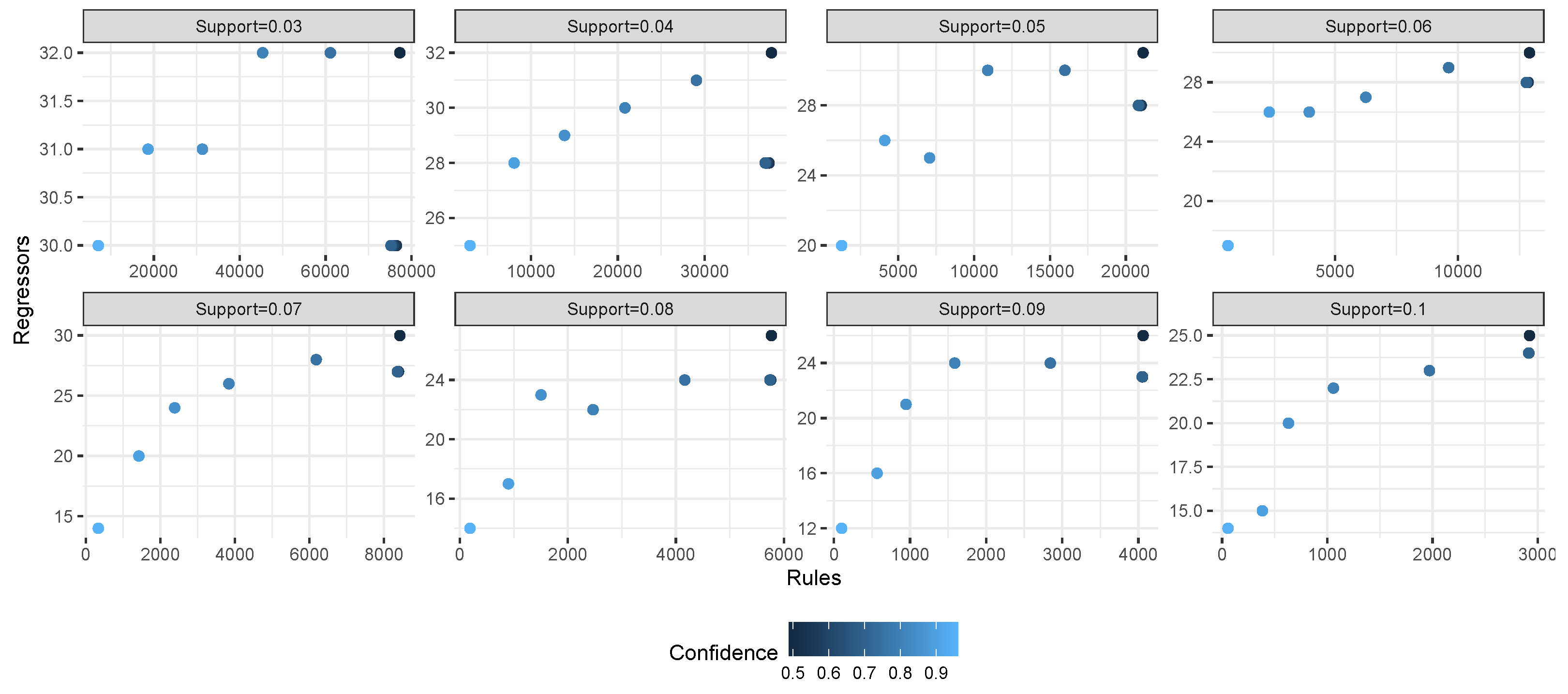
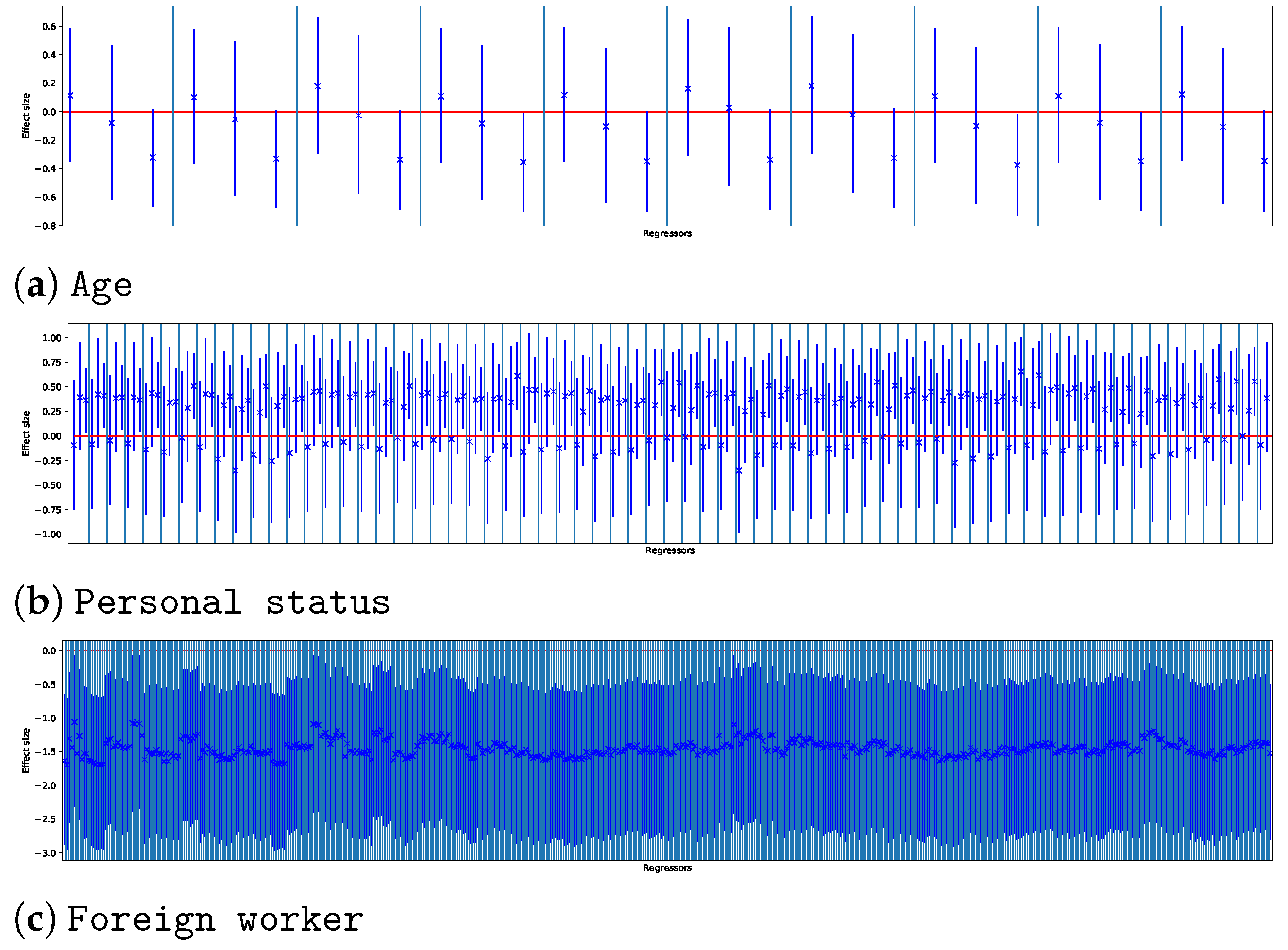
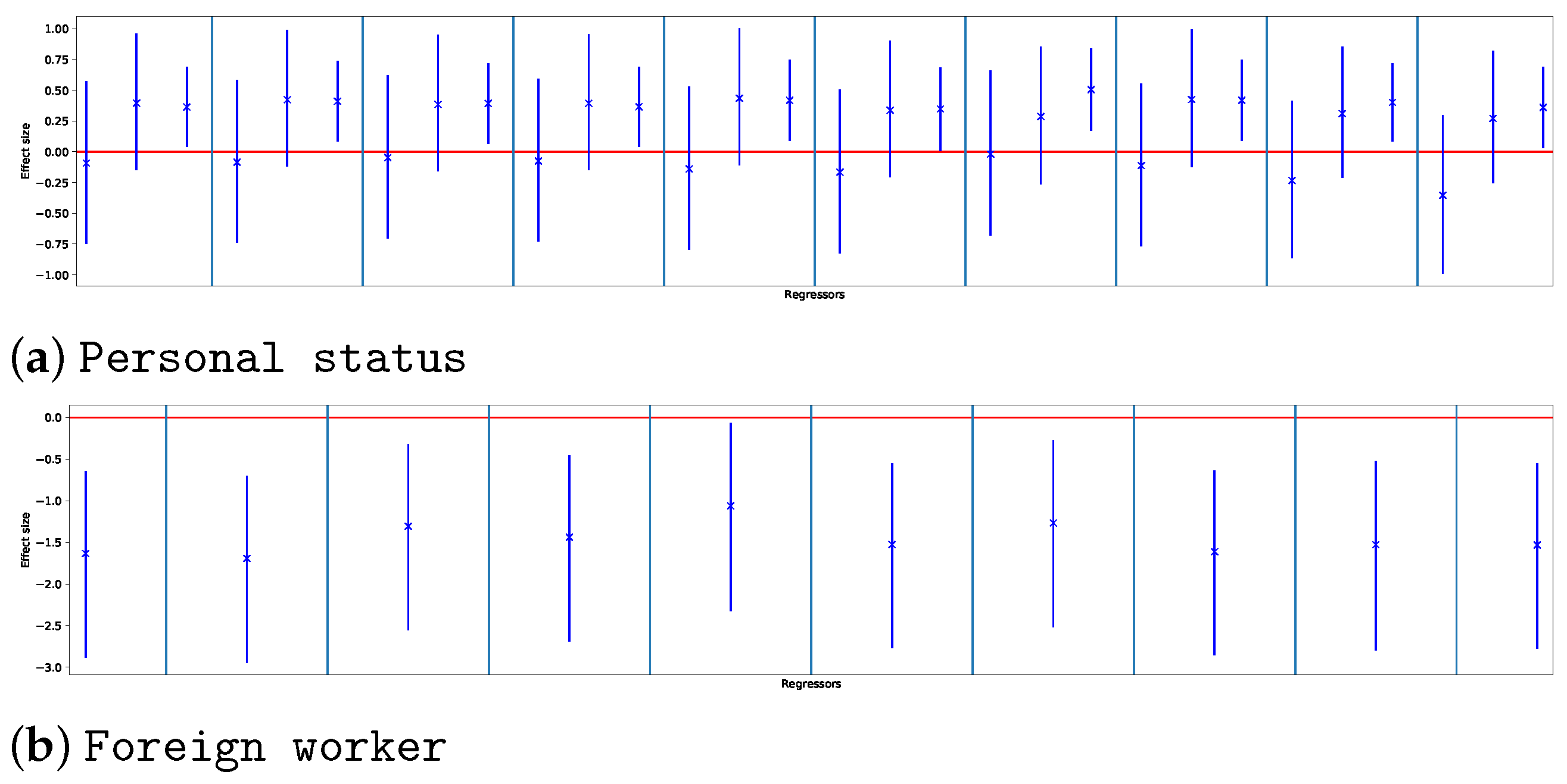
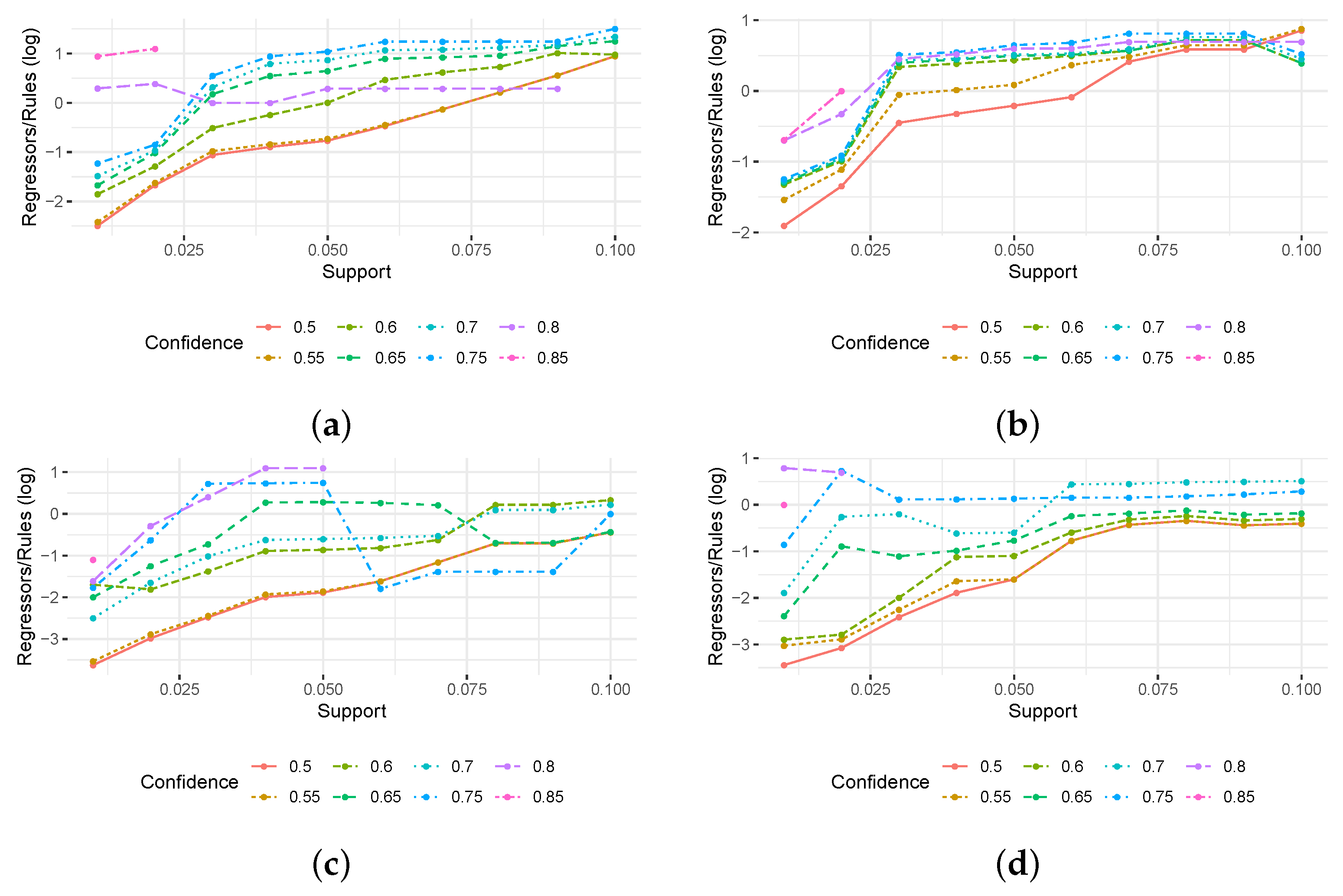
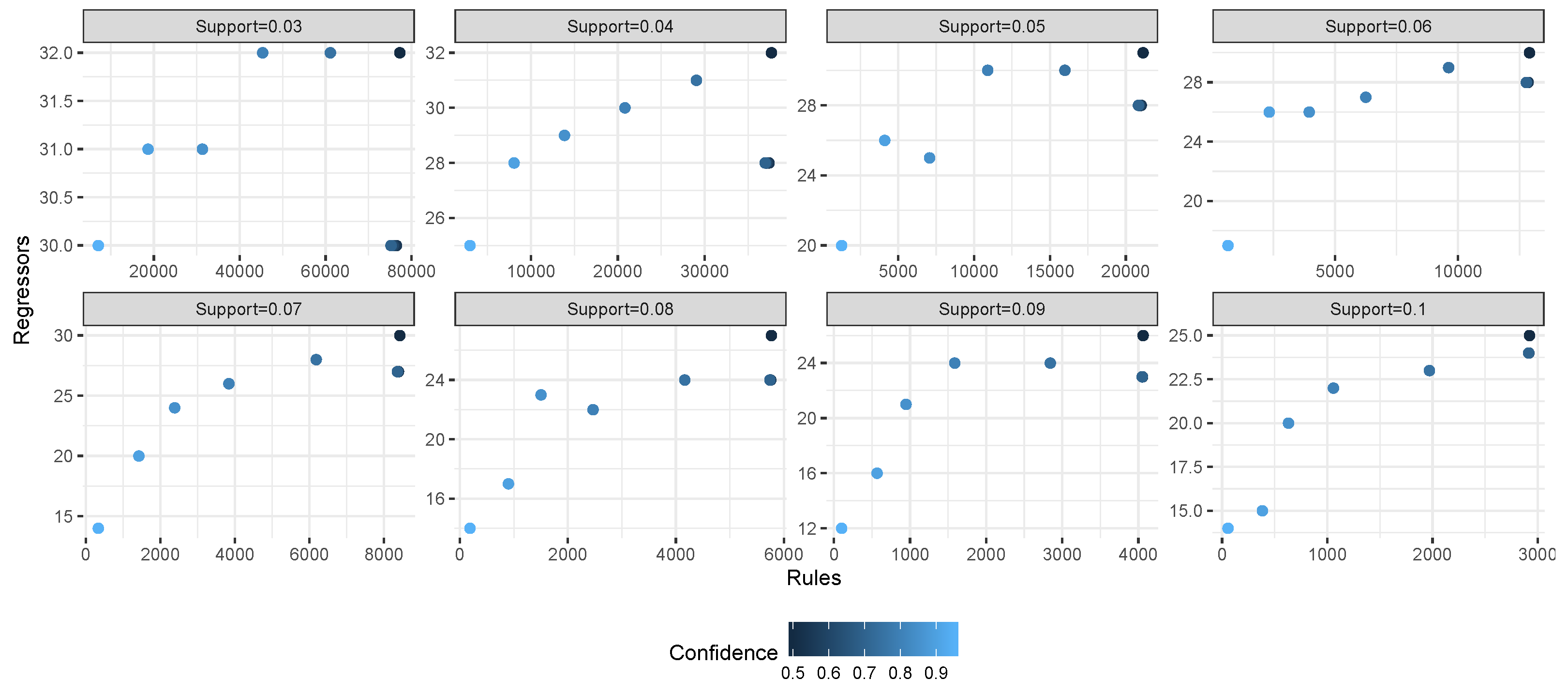
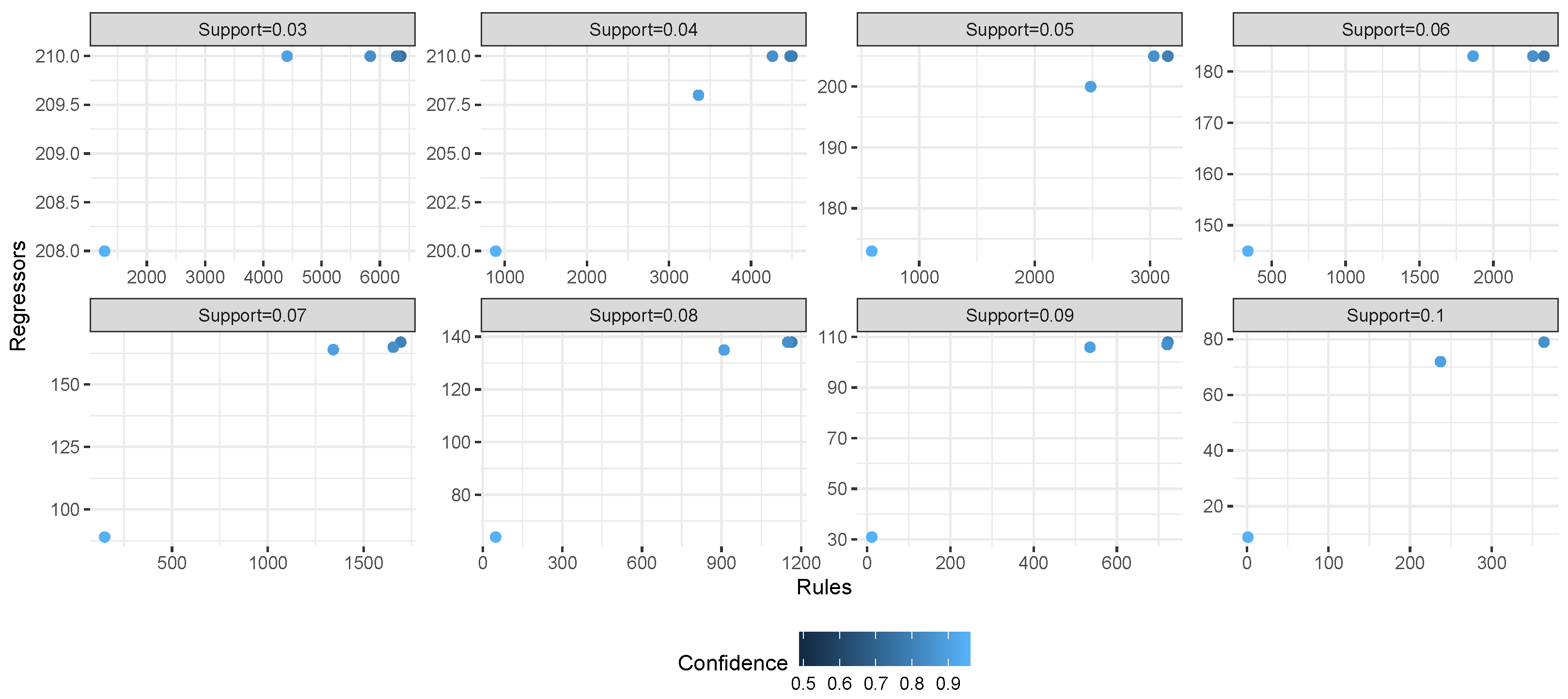
Figure 4 reports the relation between regressors and rules across the experiments for each dataset. Each grid corresponds to a single experimental setting (i.e., to one combination of support and confidence threshold); the
x axis shows the number of extracted rules, while the
y axis shows the number of extracted regressors. Different symbols and colors are used to represent the complexity of the dataset. A common trend for all datasets is that the number of rules exceeds the number of regressors for at least one order of magnitude at low support/confidence thresholds. Even when increasing the support/confidence thresholds, for most of the tested configurations, the number of rules was at least twice the number of regressors.
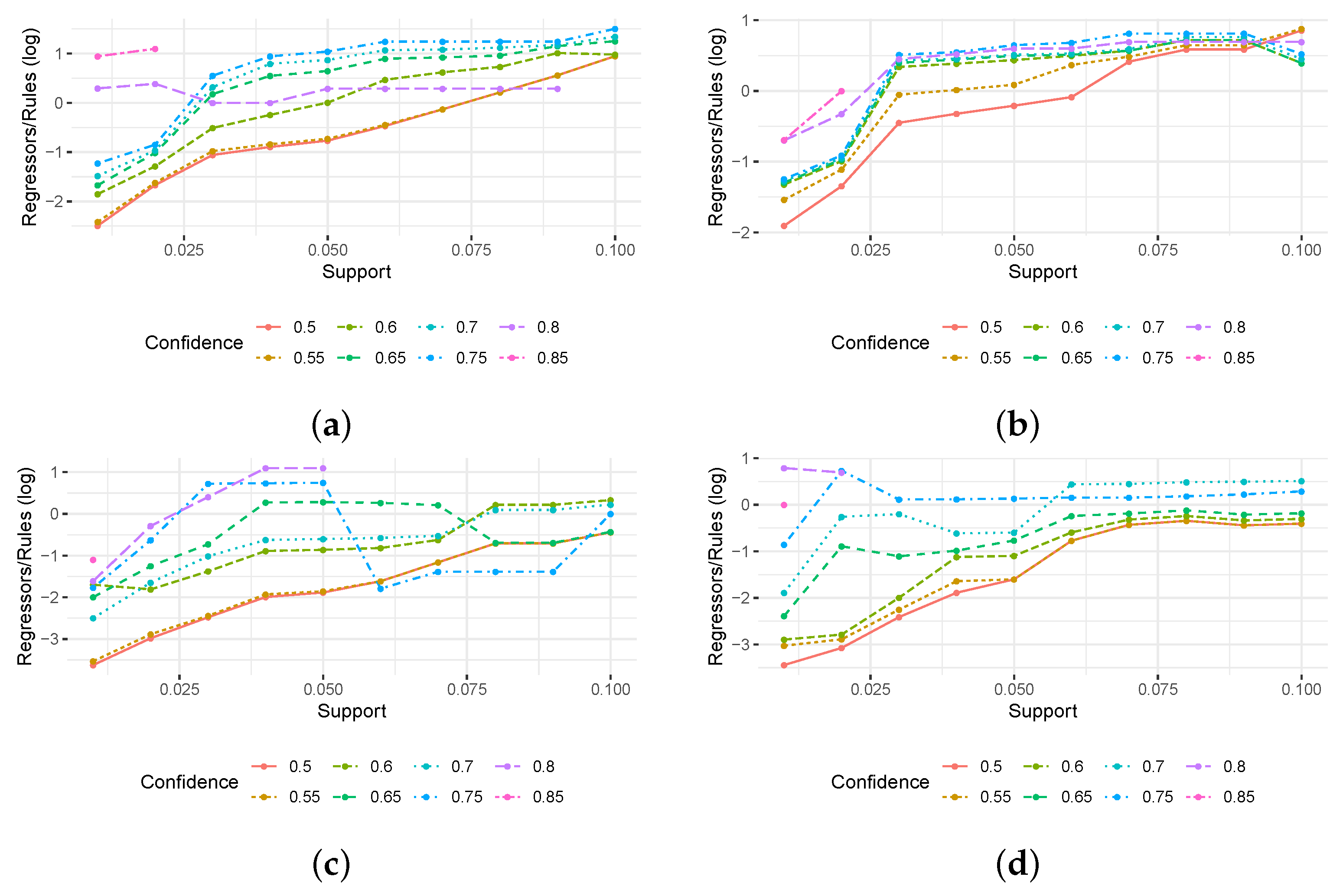
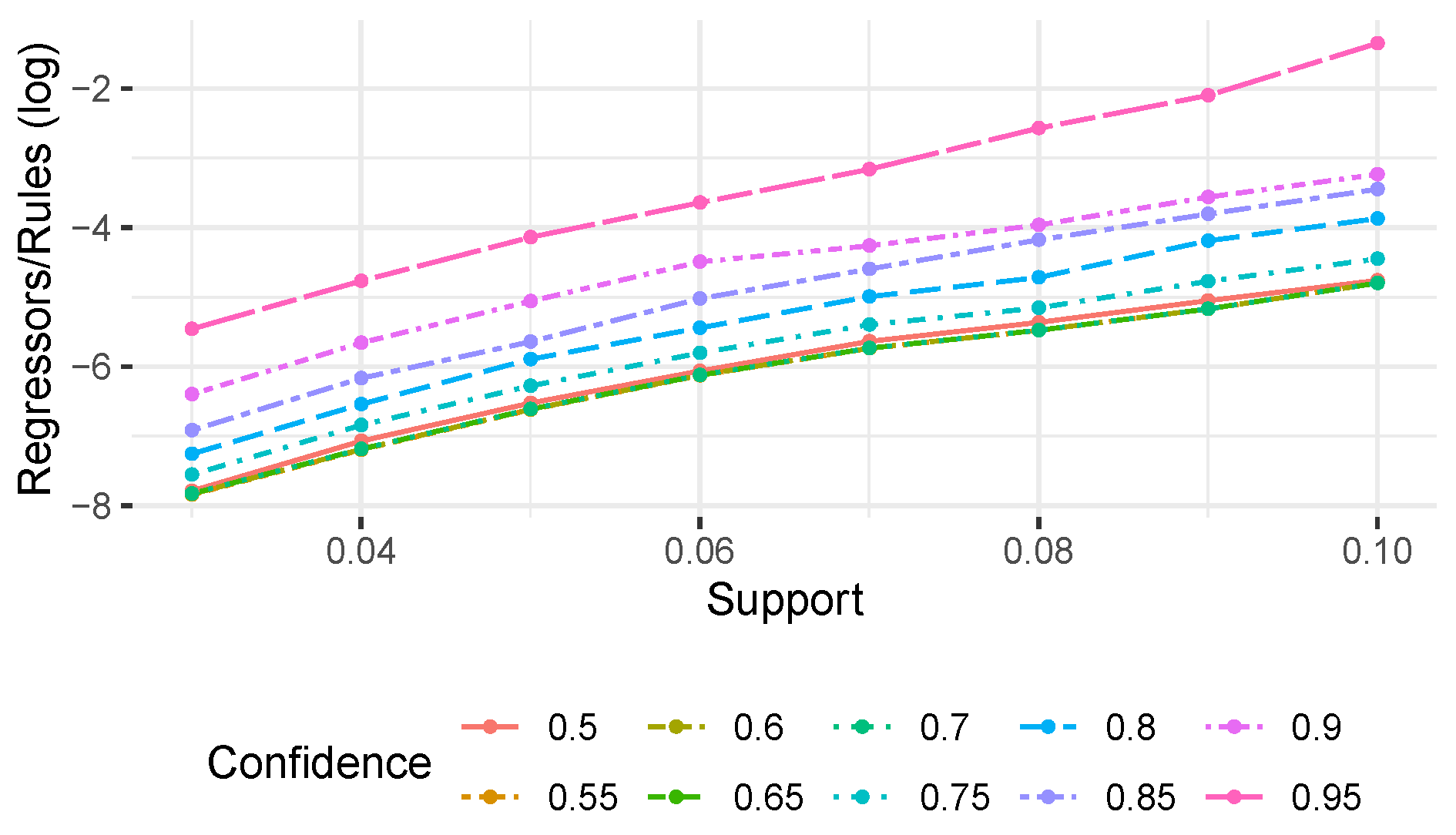
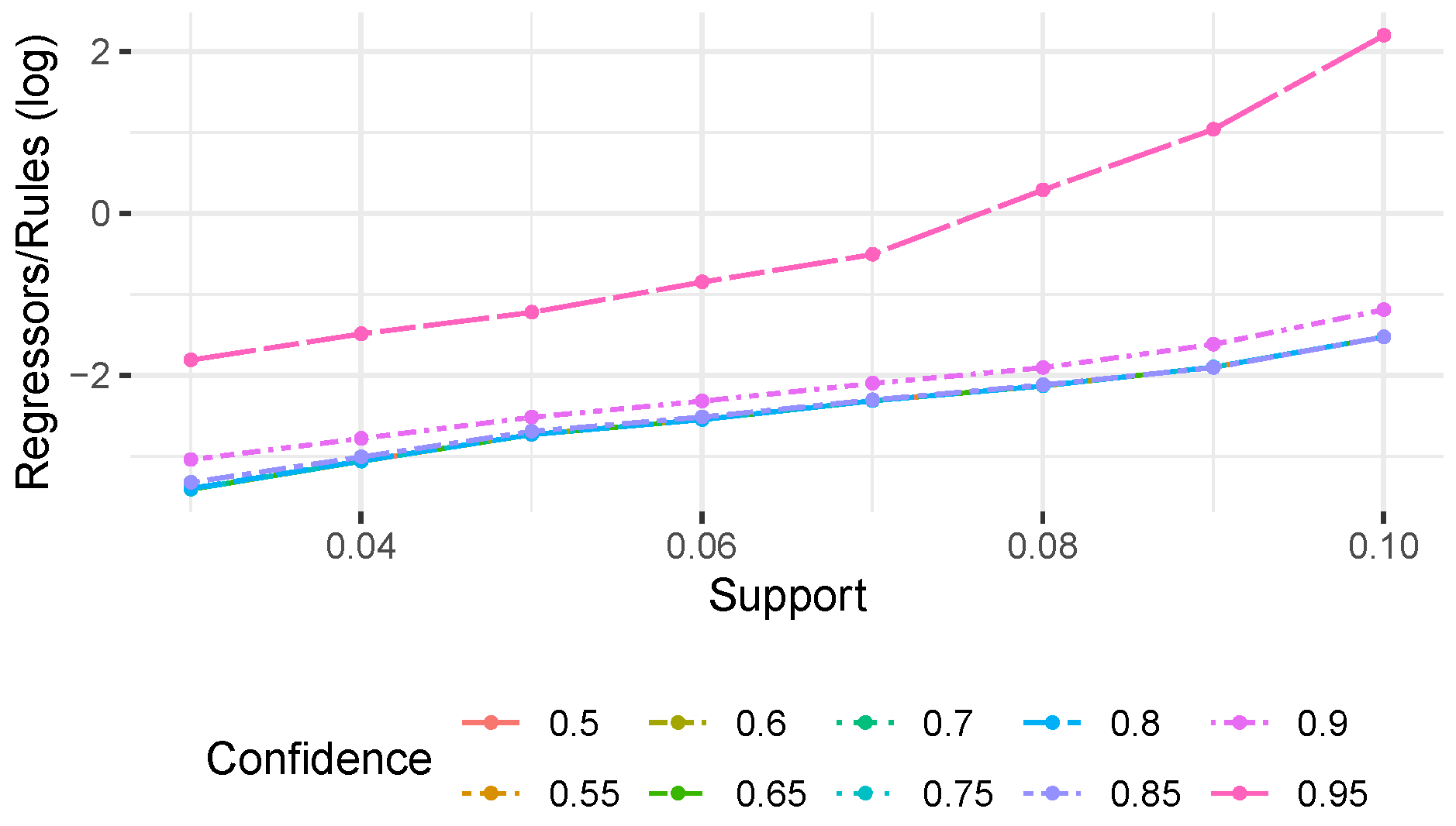
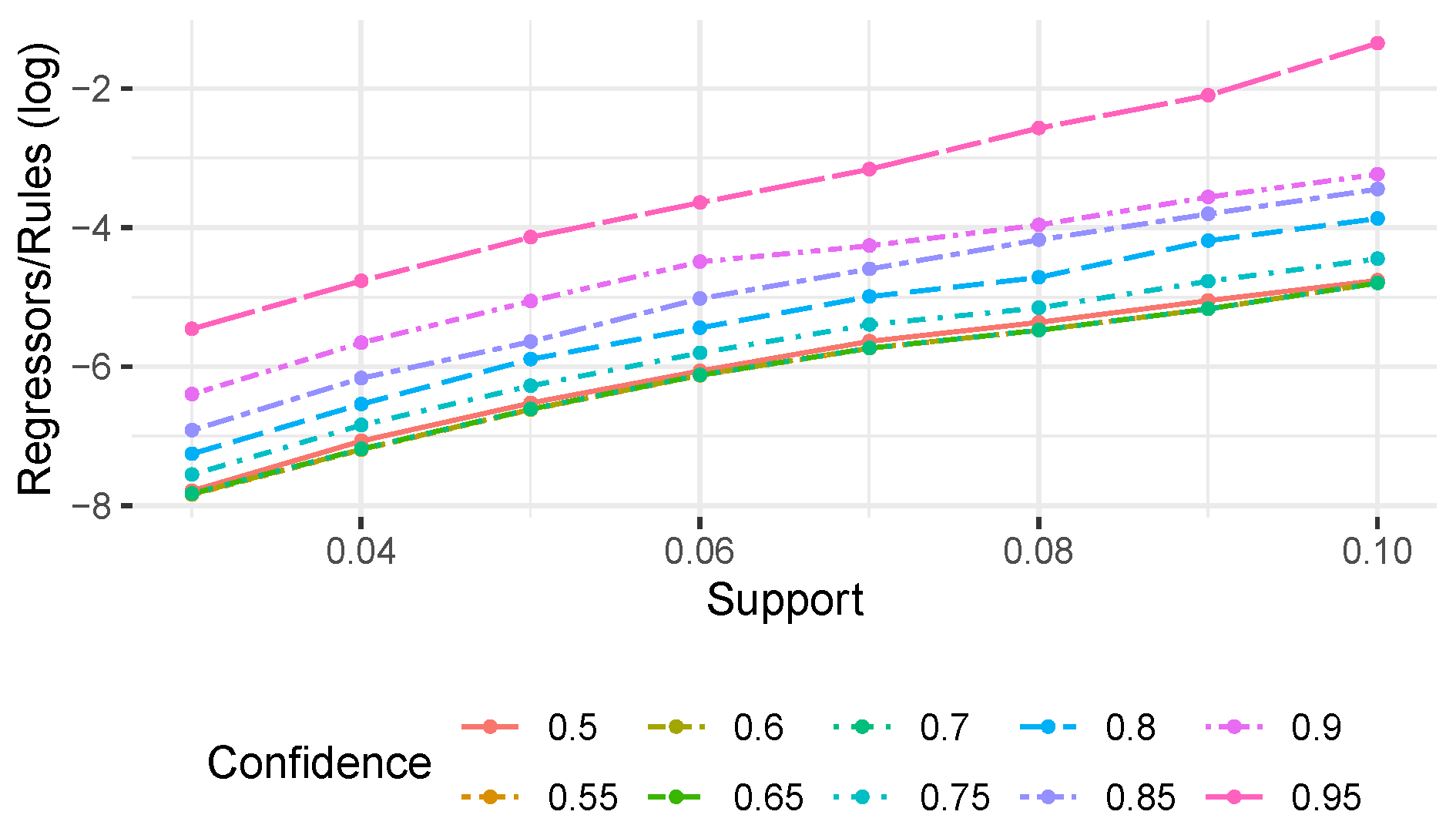
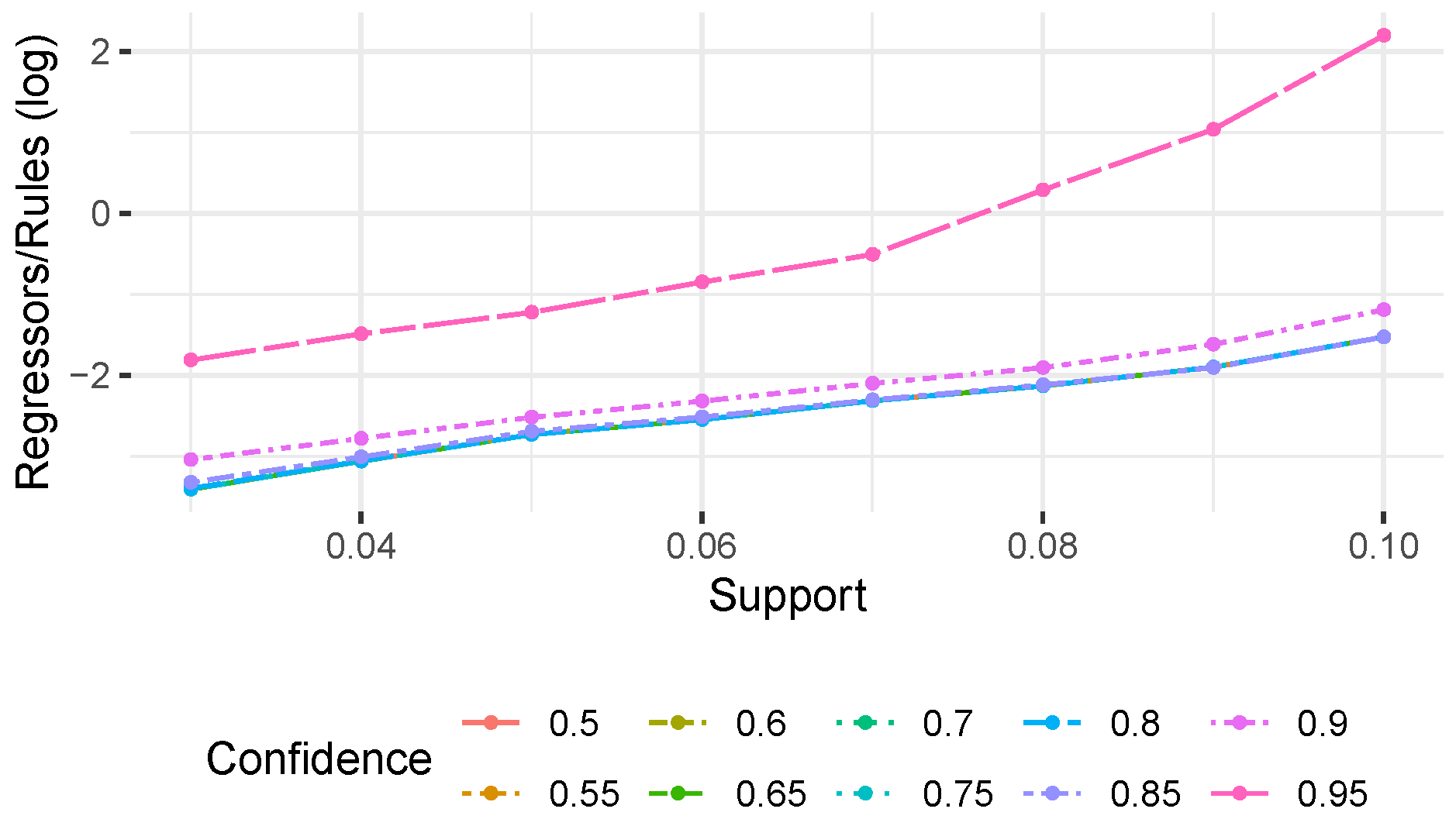
To visualize the order of magnitude in the difference between regressors and rules,
Figure 5 reports (on a log scale) the ratio between regressors and rules for each experimental setting (without considering configurations where no rules were found). We observe that the datasets involving noise are also the ones in which we observe a stronger difference between the number of rules/regressors. In both datasets, we obtained at most the same numbers of regressors and rules, while in most of the configurations, the number of regressors is significantly lower (up to a three-fold reduction compared to the number of rules). For the datasets without noise, instead, while we still obtain overall less regressors than rules, this reduction is quite strong only for low support/confidence thresholds, and becomes less and less evident while increasing the thresholds. For the first dataset, the number of regressors exceeds, even though just slightly, the number of rules in few configurations. This is consistent with the characteristics of the used datasets; indeed, the datasets with no noise are also the ones more favorable to rule mining which, with high support/confidence thresholds, is able to return a limited number of rules. Nevertheless, overall these results show that the use of regression analysis reduces up to three times the number of generated bias candidates.
Summarizing, the results show that our approach is able to significantly reduce the number of recommendations provided by rule mining without losing knowledge on the potential bias in the data. The approach also returned consistent results across varying support and confidence thresholds, thus showing to be robust with respect to parametrization. Interestingly, the cases where the approach showed more difficulties are the ones where the data generation procedure created very strong and undesired correlations among variables between which no correlation was intended. We discuss the limitations of the proposed method, such as spurious correlations, in
Section 5.




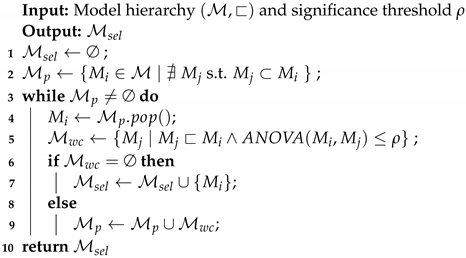

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}