1. Introduction
During the agricultural machinery service process, improper resource allocation, information circulation issues, and insufficient emergency response capabilities during peak periods are common challenges [
1]. Agricultural service organizations typically face a large number of dispersed fieldwork tasks, each with different times, locations, and requirements. These tasks have seasonal characteristics, especially during the peak agricultural production period, when the demand for agricultural machinery is high and the time windows are tight, leading to inflexible resource allocation among agricultural machinery stations, resulting in equipment idling or overuse. Additionally, the high dispersion of operation points increases the difficulty of scheduling. Without reasonable routing, unnecessary detours and excessive transfer distances can lead to higher operational costs. Furthermore, mismatches between arrival times and farmers’ preferred time windows may reduce service satisfaction, ultimately weakening the long-term cooperation between farmers and cooperatives. On the other hand, the transmission of work information usually relies on manual operations, and delayed updates lead to a mismatch between machinery supply and farmer demand, causing the service organization to be unable to provide targeted services based on farmer needs.
The task assignment work is generally solved using agricultural machinery scheduling methods. The agricultural machinery scheduling problem refers to the reasonable arrangement of tasks, sequence, and operation time of agricultural machinery under limited resources to ensure efficient and economical operations [
2].
In recent years, significant progress has been made in agricultural machinery scheduling models, with research focus gradually shifting from single-machine operation optimization to multi-machine coordination and further evolving towards complex multi-region, multi-depot scheduling problems. Early studies mainly focused on the optimization of single or a small number of machines, laying the theoretical and framework foundation for agricultural machinery scheduling models. Guan et al. [
3] proposed a framework to manage mechanical movement sequences and coordination deadlocks. This framework offers methodological support for complex scheduling problems. Edwards et al. [
4] constructed a multi-machine coordination scheduling framework from the perspective of operational readiness, enhancing efficiency in multi-location operations through task sequence, condition constraints, and location state linkage. Alaiso et al. [
5] proposed an integrated scheduling model for agricultural contracting work by systematically describing tasks, resource replenishment points, and machinery attributes, effectively solving agricultural contracting operation scheduling problems. These studies provided basic modeling ideas for agricultural machinery scheduling but still had limitations in dealing with large-scale, multi-entity coordination scheduling problems.
With the development of mechanization and intelligence, agricultural machinery scheduling problems are gradually moving towards multi-machine collaboration, task optimization, and dynamic adjustment. Mohamed et al. [
6] started from the perspective of agricultural machinery selection and scheduling, establishing a scheduling plan that minimizes the total cost of machinery. To address the uncertainty in scheduling, Aguayo et al. [
7] proposed a cyclic dynamic rescheduling strategy, adjusting field status and machinery location in real-time. Seyyedhasani et al. [
8] solved the real-time scheduling problem from the perspective of multi-point path planning. In terms of multi-machine collaboration, Cao et al. [
9] explored the task allocation mechanism for multiple agricultural machines; He et al. [
10] proposed a coordinated operation plan for harvesters and transporters for fragmented fields; Han et al. [
11] focused on the dynamic collaboration between harvesters and auxiliary transport vehicles, effectively reducing operation waiting time. Agricultural machinery service scheduling research mainly focuses on improving service efficiency and resource utilization. In terms of single-region service, He et al. [
12] developed an integer programming model to optimize the scheduling of agricultural machinery on fragmented fields. The model allows multiple harvesters to harvest the same field, improving efficiency and shortening the harvest cycle. Si et al. [
13] proposed a hierarchical game method to optimize the real-time scheduling of harvesters, enhancing the matching degree of farmer demand and machinery utilization. Hou et al. [
14] constructed a service quality evaluation model, considering factors such as time urgency, working conditions, field size, and distance, and adjusted the weight of time urgency dynamically to optimize the agricultural machinery rental plan. However, the single-region service model is often limited by resource capacity and geographical range when facing large-scale operation demands. Ding et al. [
15] addressed the underutilization of individual agricultural machinery resources and the lack of trust among all parties involved in scheduling, proposing a blockchain-based regional agricultural machinery resource scheduling system and agricultural machinery scheduling optimization model to reduce regional agricultural production costs and improve resource utilization. However, the single-region service model often faces limitations in terms of resource capacity and geographical range when facing large-scale operation demands.
To address these challenges, multi-regional cooperative scheduling has gradually become a research hotspot. Ma et al. [
16] proposed a multi-region coordination architecture to improve the allocation of agricultural machinery resources between regions using an improved knapsack model and hybrid algorithms to solve the resource imbalance problem between regions. Huang et al. [
17] proposed a multi-station, multi-machine collaborative real-time response dispatch system based on fuzzy membership degrees to optimize scheduling efficiency and improve farmer satisfaction. Cao et al. [
18] established a bi-objective optimization model for wheat harvesting scenarios across regions, providing decision support for multi-regional interconnection scheduling.
In terms of algorithms, with the increase in resource constraints and objectives in agricultural production, single-objective optimization solutions can no longer meet practical requirements, which has driven the development of multi-objective optimization algorithms. Multi-objective algorithms can consider multiple conflicting optimization objectives simultaneously, providing a set of non-dominated solutions for decision-makers to balance. Lu et al. [
19] used adaptive crossover strategies to enhance the convergence capability of NSGA-II. Guo et al. [
20] proposed a multi-objective genetic algorithm based on time window priority rules and tabu search strategies, significantly improving the efficiency and cost-effectiveness of cross-regional agricultural machinery coordination operations through time window priority-based initial population generation, sequential crossover operations, etc. Sethanan et al. [
21] designed a multi-objective particle swarm optimization algorithm that combines a three-layer social structure and seven movement strategies to balance local search and global exploration. Liu et al. [
22] developed an improved multi-objective immune algorithm that integrates non-dominated neighbor selection and tabu search, enhancing the algorithm’s performance in static partition optimization and dynamic cross-region cooperation.
For the multi-region agricultural machinery scheduling problem, a two-stage optimization method decomposes the problem into two sub-problems: area division and path planning, effectively reducing the complexity. Chen [
23] addressed the multi-agricultural machinery scheduling problem with fuzzy time windows by first using clustering to transform it into a single cooperative scheduling problem and then optimizing the scheduling using an improved genetic algorithm. Huang et al. [
24] combine Voronoi diagrams with particle swarm optimization to optimize the scheduling plans of multiple regions. Sheng et al. [
25] propose a two-stage method based on K-Means and multi-objective evolutionary algorithms for emergency agricultural machinery operations under natural disaster conditions, effectively enhancing the executability of the operation path. Yu et al. [
26] propose a two-stage emergency allocation algorithm for agricultural machinery, combining field division with intra-field machinery allocation, and optimize the operation scheduling of agricultural machinery in each area using an improved genetic algorithm to reduce grain loss.
Current research indicates that decoupling order allocation and path optimization into two subproblems and solving them step-by-step is an effective method. However, in the actual agricultural operation process, due to the seasonal characteristics of agricultural production, there is often a sudden increase in the demand for agricultural machinery during specific periods. Additionally, the demand is geographically dispersed, which requires efficient collaboration between multiple machinery stations. Existing order allocation methods based on spatial distance often only consider spatial factors when allocating tasks, neglecting important factors such as timeliness. This leads to deficiencies in scenarios with dense task demands, especially in ensuring the rationality of service times. Moreover, most current scheduling algorithms focus on single-objective optimization or use weighted methods to transform multi-objective problems into single-objective problems, which, although simple, introduces subjectivity in weight setting and limits their practical application. Multi-objective optimization algorithms can handle multiple competing objectives simultaneously, providing a set of trade-off solutions for decision-makers, but there are still deficiencies in maintaining solution diversity and convergence, and research on multi-objective optimization algorithms is relatively scarce. Therefore, how to improve the rationality of task allocation based on timeliness and design multi-objective optimization algorithms that can obtain high-quality non-dominated solution sets is the key issue that this paper needs to address.
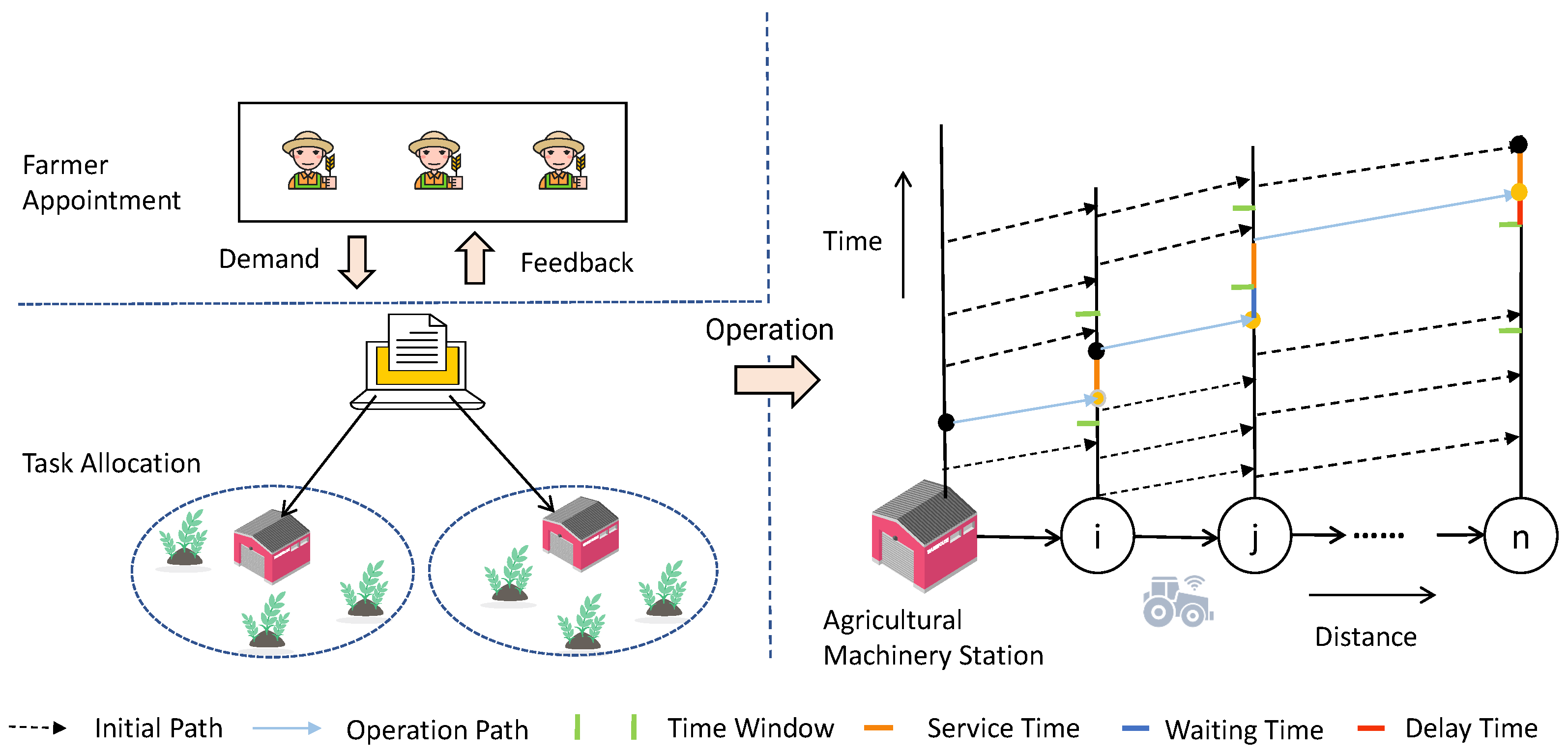
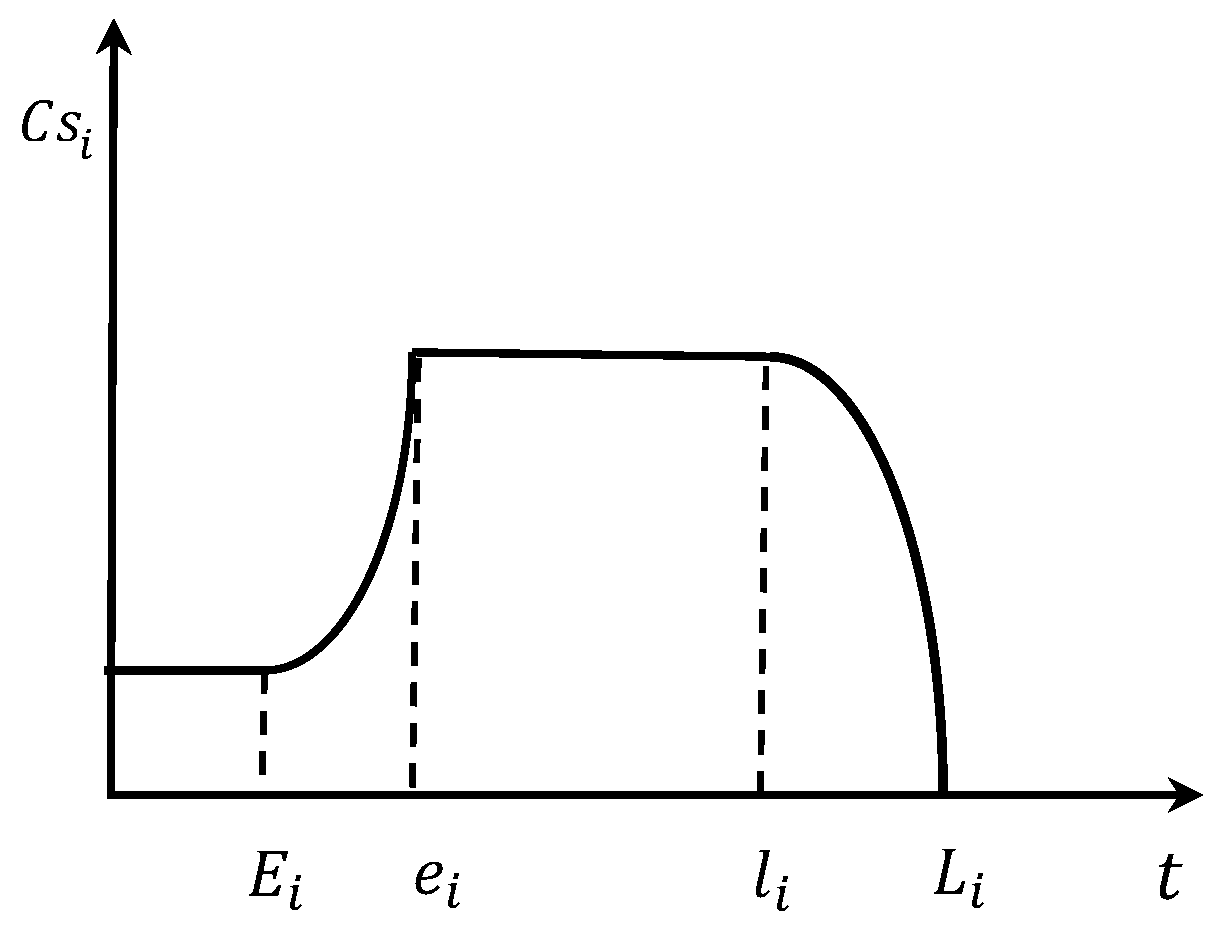
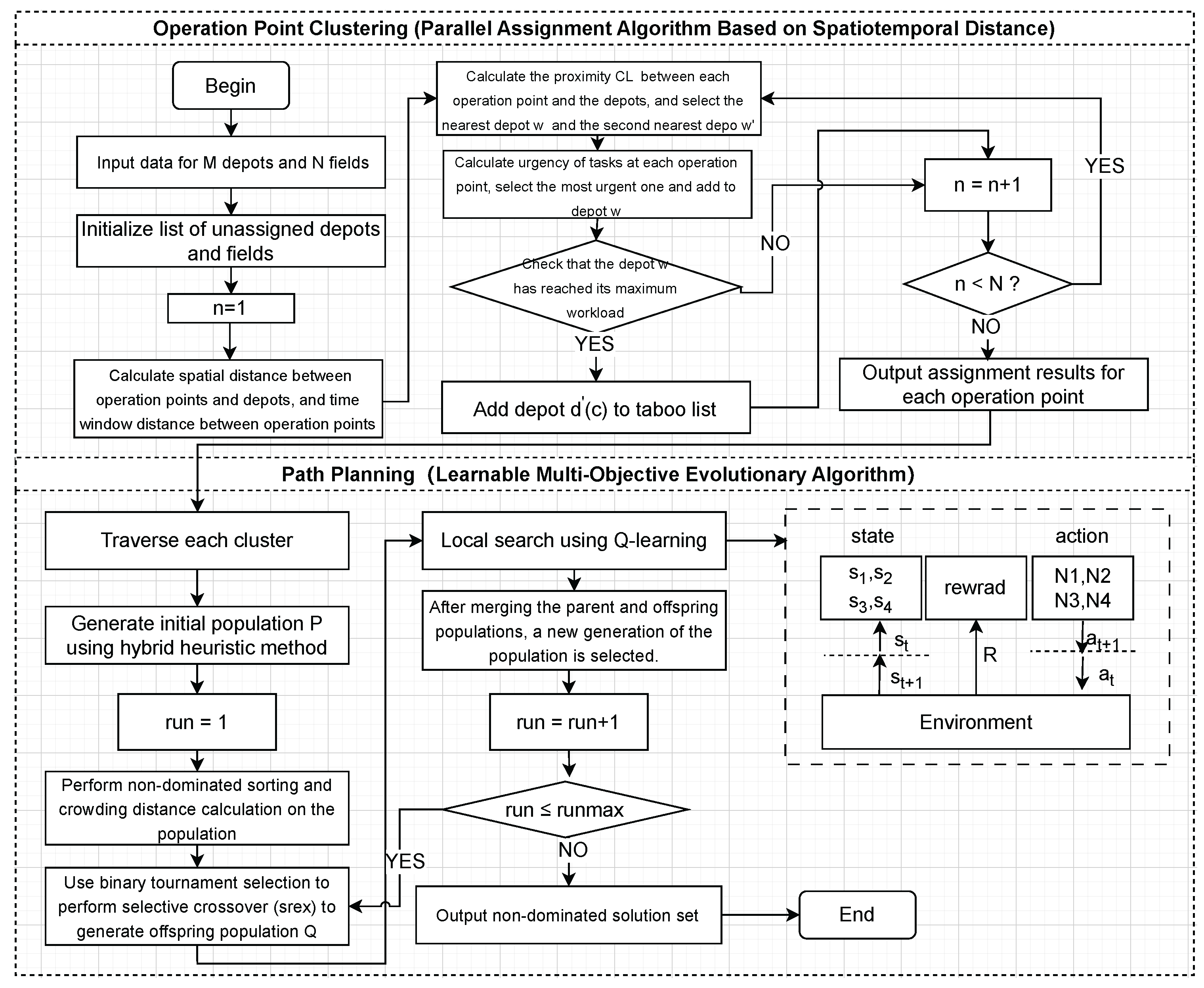
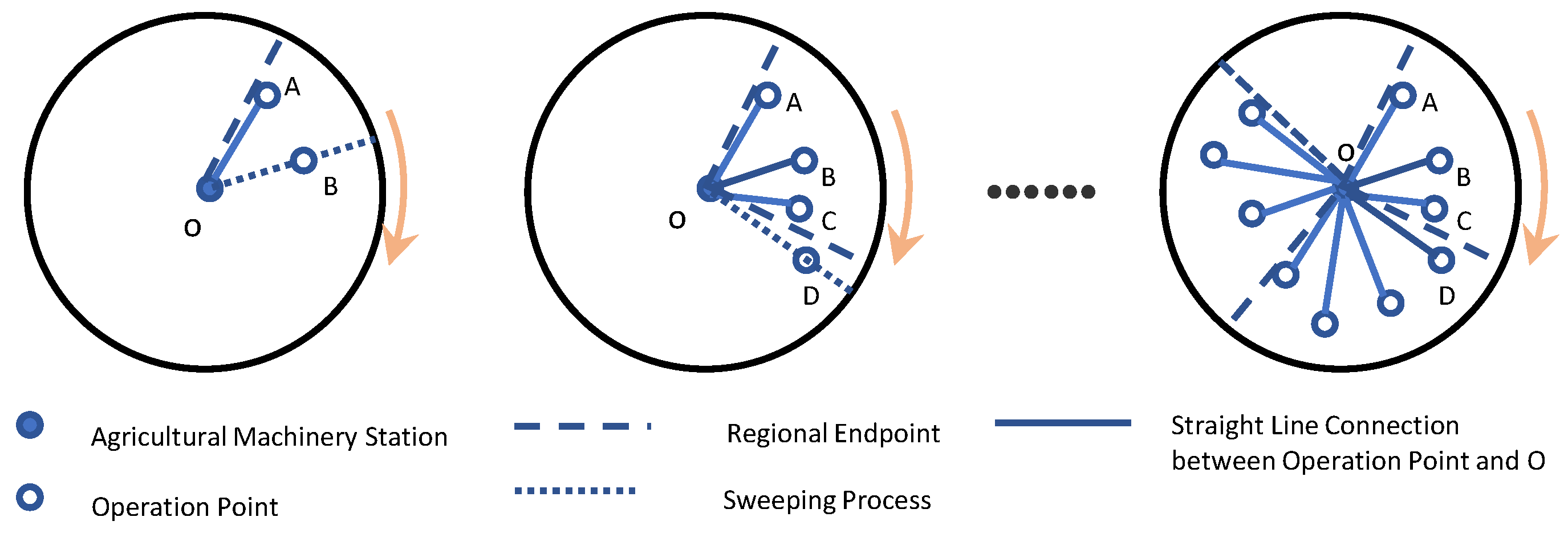
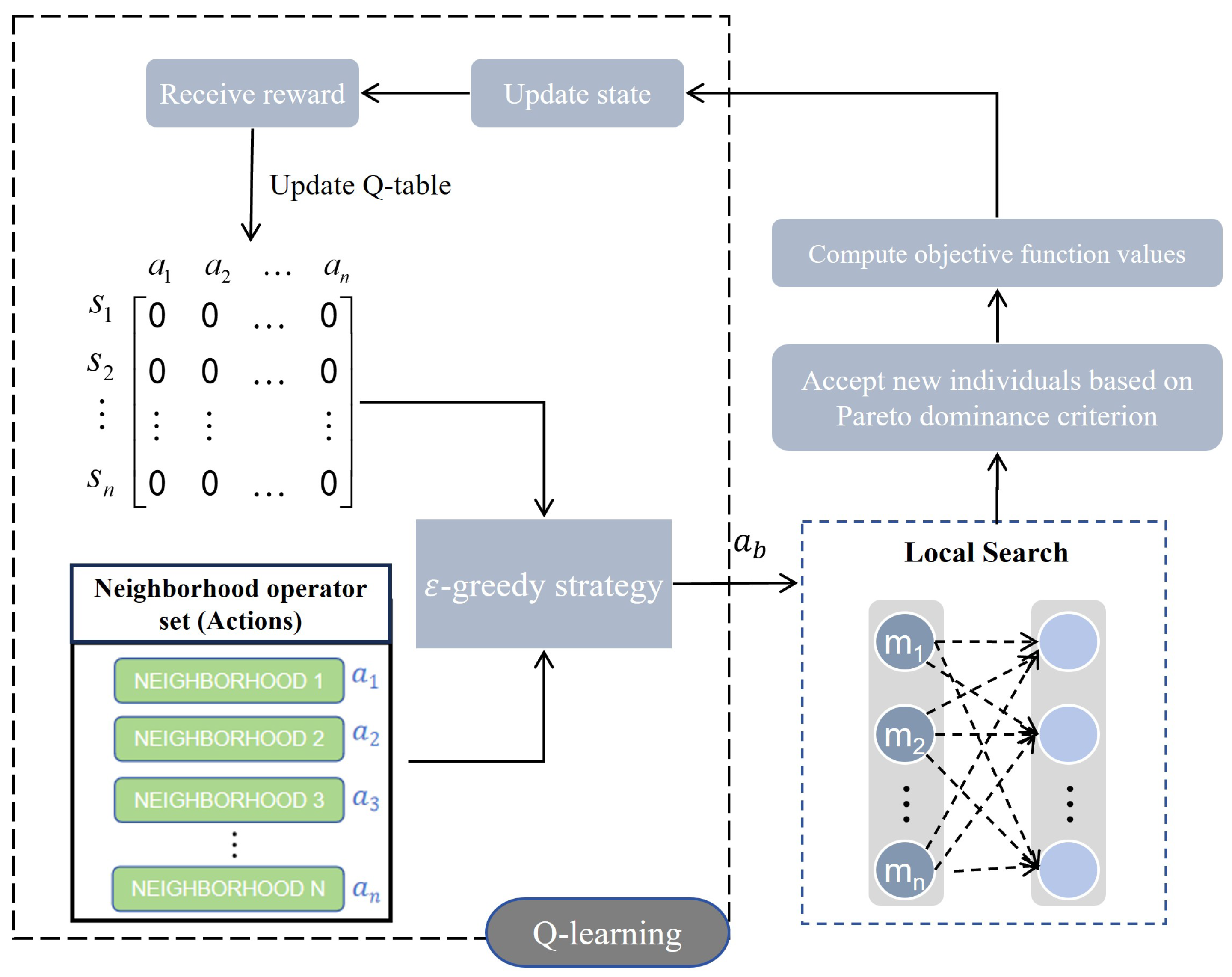
In summary, this paper designs a two-stage scheduling framework starting from order allocation and path planning. To address the limitations of existing order allocation methods that only consider spatial factors, a parallel assignment algorithm based on spatiotemporal characteristics is proposed. This algorithm constructs a temporal distance function to describe the feasibility of continuous operations and evaluates the spatiotemporal proximity of operation points and stations for clustering allocation. Additionally, for the path planning problem, a learnable multi-objective evolutionary algorithm (LMOEA) based on the NSGA-II framework is designed. The algorithm improves the distribution of initial solutions through a hybrid initialization strategy and enhances the diversity of the population with a dynamic crowding distance mechanism. In terms of local search strategy selection, existing methods often use random selection, ignoring the knowledge generated during the evolutionary process. Therefore, we introduce a Q-learning agent to enable the algorithm to learn from the evolutionary process and guide the selection of search strategies, thereby improving the search efficiency of the algorithm.
Our specific work schedule is as follows:
First, we constructed a mathematical model for agricultural machinery operation service scheduling in
Section 2.1. In
Section 2.1.1, by analyzing the characteristics and influencing factors of the scheduling problem in detail, we clarified the definitions of various parameters and variables in the model and constructed a service satisfaction function based on fuzzy time windows. In
Section 2.1.2, we established a multi-objective optimization model aimed at minimizing operational costs and maximizing service satisfaction, and detailed various constraints. Based on this, we introduced a two-stage algorithm framework in
Section 2.2 and provided detailed descriptions of each stage in
Section 2.3 and
Section 2.4.
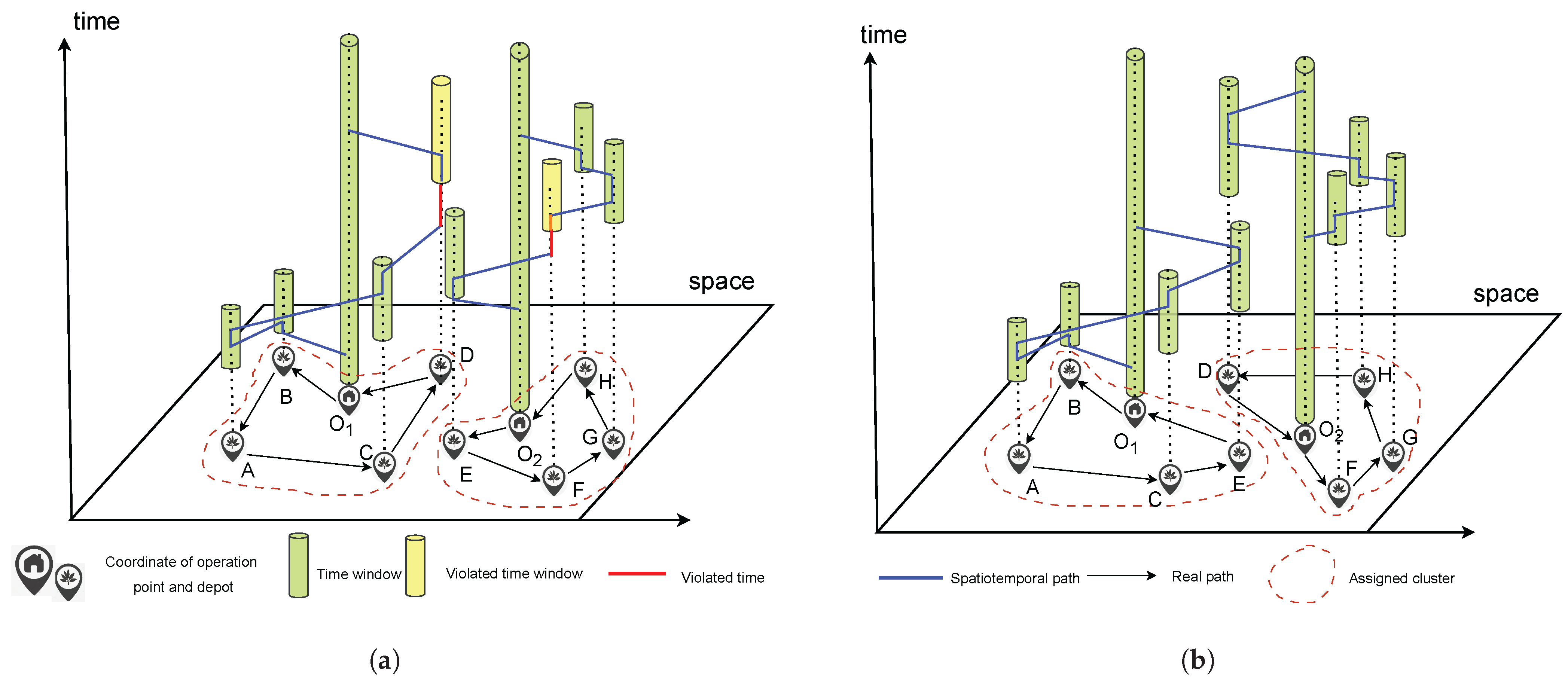
Section 2.3 introduced our intelligent allocation of operation demands through an improved parallel assignment algorithm in the first stage, which not only considered traditional spatial distance factors but also introduced a time distance function to evaluate the temporal compatibility between operation points. In
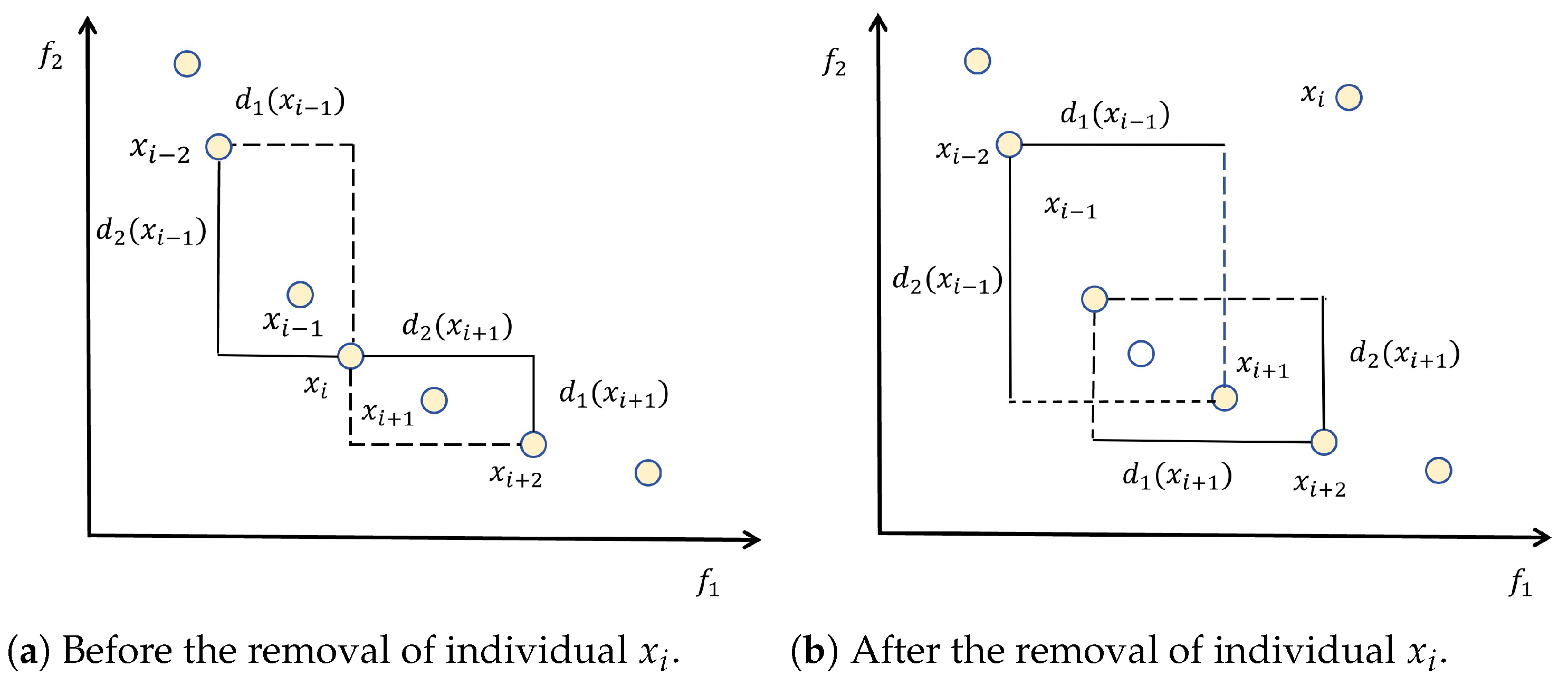
Section 2.4, we designed LMOEA in the second stage. LMOEA is based on the NSGA-II algorithm, with improvements in three aspects: initialization (
Section 2.4.1), crowding distance calculation (
Section 2.4.2), and local search (
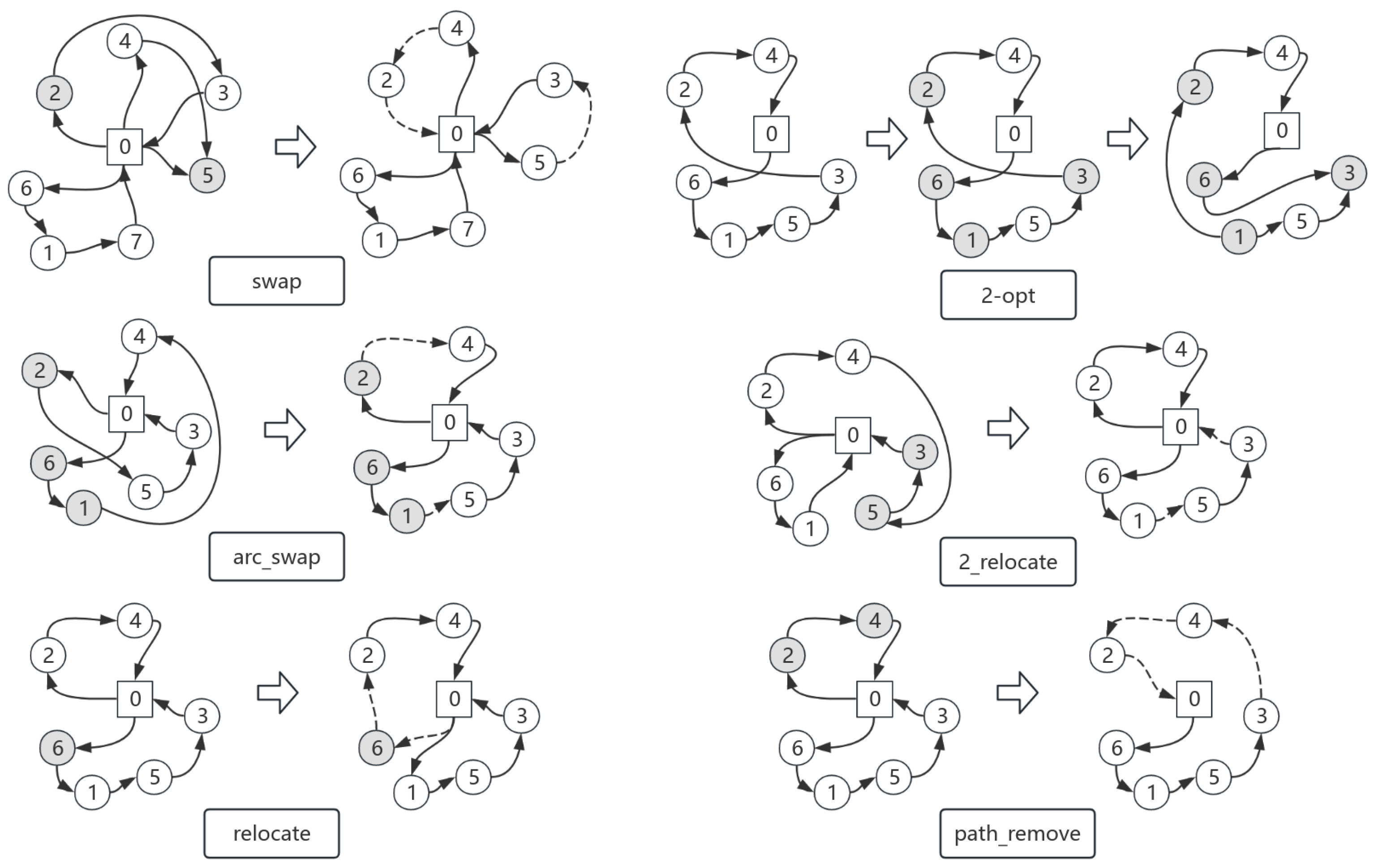
Section 2.4.3).
In
Section 3.1 and
Section 3.2 of the experiments, we defined the instances (datasets) and multi-objective algorithm evaluation criteria, respectively. In
Section 3.3, we determined the main hyperparameters of the algorithm through parameter sensitivity experiments of LMOEA.
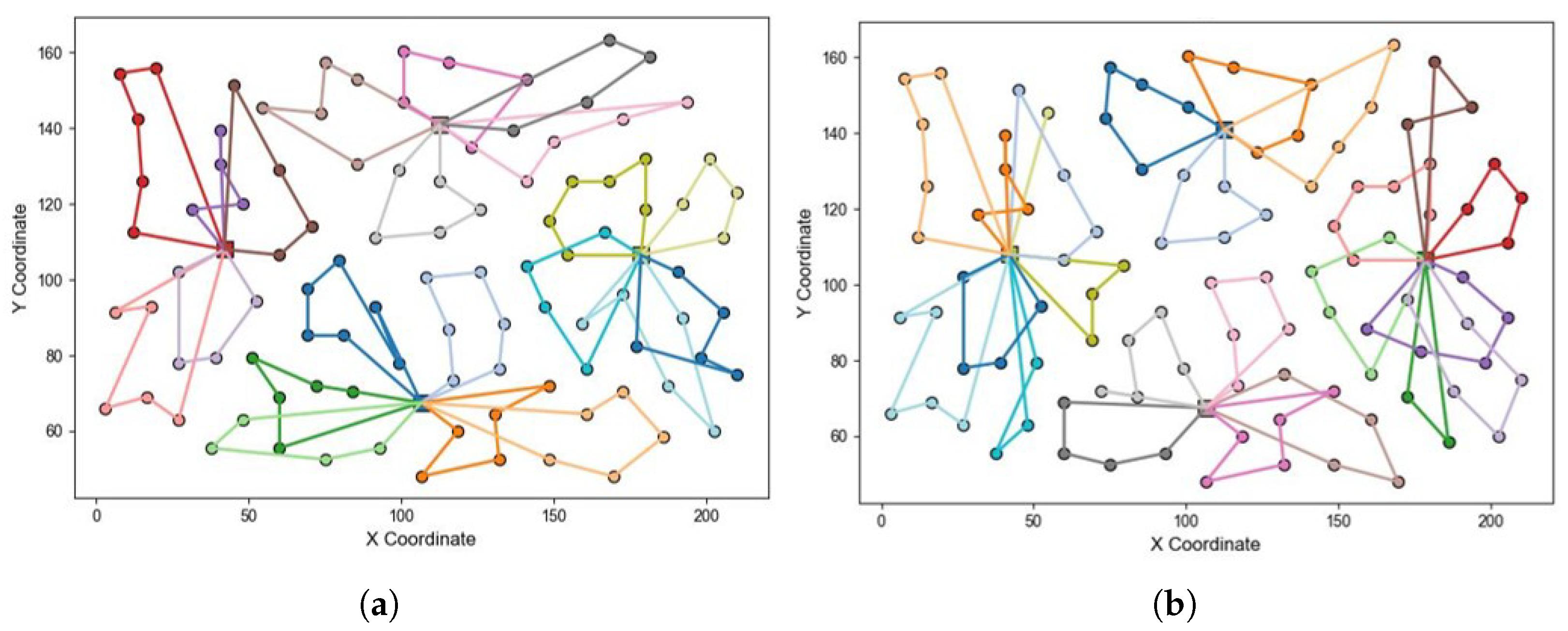
Section 3.4 was designed to verify that the job allocation method based on spatiotemporal clustering in the first stage of
Section 2.3 is superior to the job allocation method based on spatial clustering.
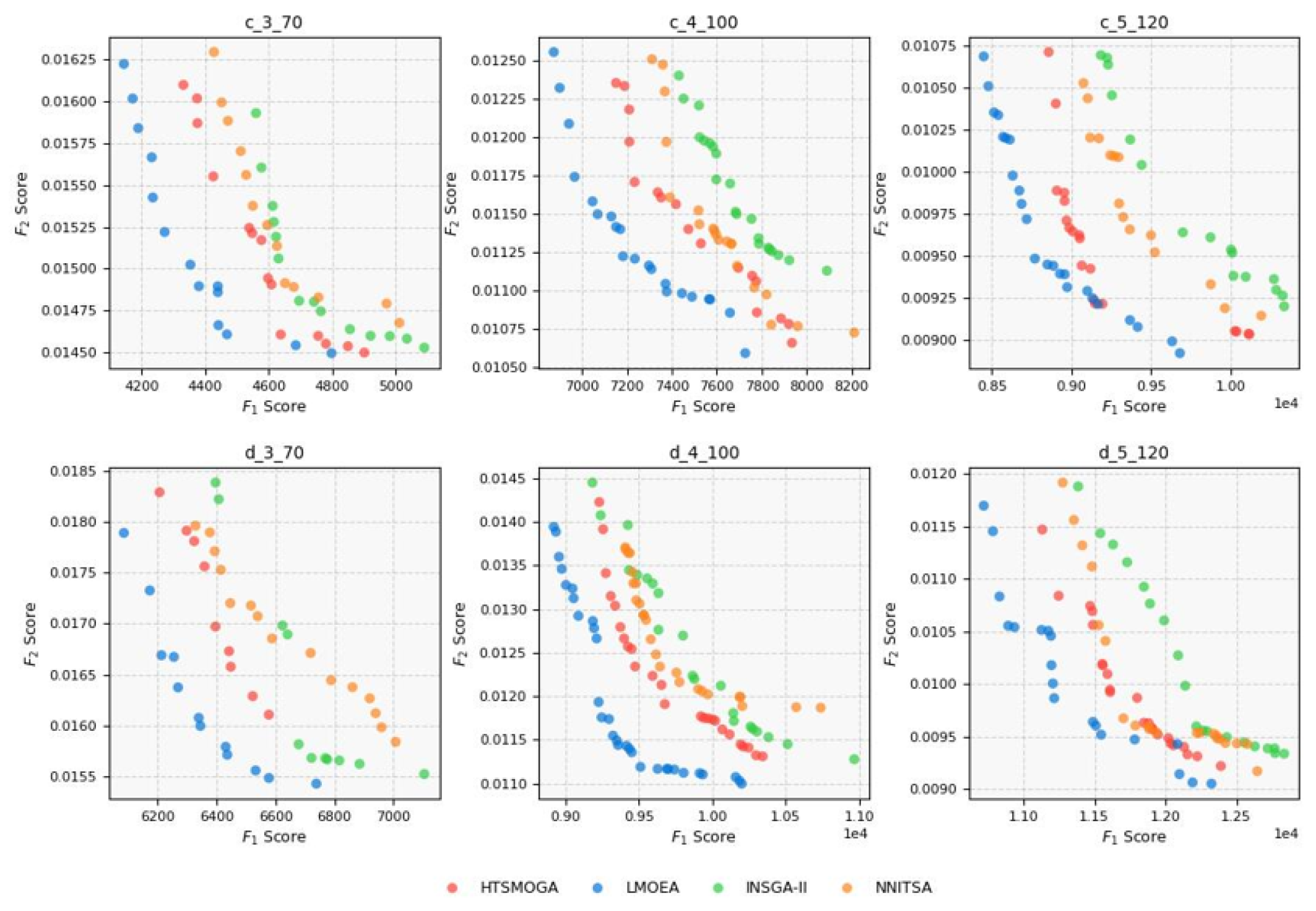
Section 3.5 and
Section 3.6 were designed to verify that the multi-objective evaluation criteria of LMOEA in the second stage of
Section 2.4 are superior to INSGA-II, HTSMOGA, and NNITSA.
Section 3.7 is an ablation study corresponding to the improvements of LMOEA in
Section 2.4.1,
Section 2.4.2,
Section 2.4.3.
4. Conclusions
In real-world operations, agricultural machinery cooperatives face several challenges: (1) the demand for services is often highly concentrated in both time and space, requiring the completion of numerous scattered field tasks within narrow time windows; (2) agricultural machinery resources are unevenly distributed, making it necessary to coordinate equipment deployment across multiple service stations; and (3) farmers’ expectations for service quality are rising, requiring scheduling solutions that balance operational efficiency with service satisfaction.
To address these challenges, we first formulated a mathematical model for agricultural machinery operation scheduling. By thoroughly analyzing the problem characteristics and influencing factors, we defined key parameters and variables and introduced a service satisfaction function based on fuzzy time windows. A multi-objective optimization model was then established to minimize operational costs and maximize service satisfaction, subject to various practical constraints. To solve the proposed model, we designed a two-stage solution framework. In the first stage, an improved parallel assignment algorithm was developed to allocate field tasks to service stations by jointly considering spatial and temporal proximity. Comparative experiments with traditional methods demonstrated superior performance across multiple instances. In the second stage, a learnable multi-objective evolutionary algorithm (LMOEA) based on the NSGA-II framework was proposed, featuring enhancements in initialization, crowding distance computation, and local search. Experimental results confirmed that LMOEA outperforms baseline algorithms (INSGA-II, HTSMOGA, NNITSA) in terms of both solution quality and diversity for multi-depot, multi-objective scheduling problems.
Looking forward, the proposed scheduling approach has significant practical implications for agricultural cooperatives. Future research will aim to further extend the model in three directions: (1) integrating heterogeneous multi-task scheduling scenarios involving different types of agricultural machinery and task requirements; (2) incorporating uncertain conditions such as equipment failures or dynamic demand changes to improve robustness under real-world constraints; and (3) enhancing scalability to accommodate ultra-large-scale scheduling problems involving hundreds of operation points. These enhancements will contribute to improving the intelligence, flexibility, and reliability of agricultural machinery scheduling systems, supporting the modernization of agricultural service organizations.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}