Highlights
What are the main findings?
- The Urbanite project developed a unified open-source simulation platform applied to four diverse European cities, effectively addressing specific mobility challenges in each city.
- The integration of simulation, advanced visualizations, decision support tools, and machine learning modules significantly enhances the decision-making process in urban planning.
What is the implication of the main finding?
- Policymakers can utilize these AI-driven tools to make more informed, data-supported decisions, improving urban mobility and sustainability
- The methodology can be adapted to other cities, demonstrating the scalability and flexibility of the Urbanite platform in various urban settings.
Abstract
To address the growing need for advanced tools that enable urban policymakers to conduct comprehensive cost-benefit analyses of traffic management changes, the Urbanite H2020 project has developed innovative artificial intelligence methods. Among them is a robust decision support system that assists policymakers in evaluating and selecting optimal urban mobility planning modifications by combining objective and subjective criteria. Utilising open-source microscopic traffic simulation tools, accurate digital models (or “digital twins”) of four pilot cities—Bilbao, Amsterdam, Helsinki, and Messina—were created, each addressing unique mobility challenges. These challenges include reducing private vehicle access in Bilbao’s city center, analysing the impact of increased bicycle traffic and population growth in Amsterdam, constructing a mobility-enhancing tunnel in Helsinki, and improving public transport connectivity in Messina. The research introduces five key innovations: the application of a consistent open-source simulation platform across diverse urban environments, addressing integration and consistency challenges; the pioneering use of Dexi for advanced decision support in smart cities; the implementation of advanced visualisations; and the integration of the machine learning tool, Orange, with a user-friendly GUI interface. These innovations collectively make complex data analysis accessible to non-technical users. By applying multi-label machine learning techniques, the decision-making process is accelerated by three orders of magnitude, significantly enhancing urban planning efficiency. The Urbanite project’s findings offer valuable insights into both anticipated and unexpected outcomes of mobility interventions, presenting a scalable, open-source AI-based framework for urban decision-makers worldwide.
1. Introduction
1.1. Motivation
The rapid pace of urbanisation poses complex challenges for contemporary urban centers. In response, the smart city concept [1,2,3,4] has emerged, harnessing digital technologies and innovative methodologies to transform urban management. These advancements enable cities to overcome traditional limitations, fostering greater sustainability, environmental stewardship, resilience, and livability. Central to this urban evolution is the “digital twin” concept [5,6], which utilises digital technologies to create dynamic, real-time representations of a city’s physical and social infrastructures. Digital twins provide urban planners and policymakers with critical insights, allowing them to anticipate challenges and develop effective solutions to improve the quality of urban life.
Artificial intelligence (AI) [7] plays a pivotal role in addressing smart city challenges, leveraging subfields such as machine learning (ML) and artificial general intelligence (AGI). AI models are invaluable for analysing complex urban data and identifying patterns that may elude human analysts. This analytical capability generates predictive insights into urban trends, assesses policies’ impact, and informs infrastructure optimisation recommendations. Additionally, incorporating AI is crucial for thoroughly evaluating the broad effects of changes within urban environments. Whether introducing new infrastructure, redesigning transportation systems, or adopting innovative policies, these changes must be carefully evaluated to ensure their effectiveness and alignment with the city’s goals and values [1,8]. These innovative AI-based approaches enhance traffic management efficiency and contribute to broader smart city development by enabling a more holistic approach to urban planning [9].
These technologies, including machine learning (ML)—a subset of AI that focuses on building systems capable of learning from and making decisions based on data—have become essential tools for evaluating and selecting the most effective urban mobility strategies [10,11]. By processing vast amounts of real-time data, these AI-driven systems provide dynamic, evidence-based recommendations that empower city planners to optimise traffic flow, reduce congestion, and enhance overall urban efficiency. Projects like Urbanite have been at the forefront of this transformation, incorporating AI technologies to support decision-making processes and ensure that urban traffic planning remains responsive and adaptive to the evolving needs of modern cities.
In addition to AI and ML, the development of Generative Pre-trained Transformers (GPTs) has introduced a new dimension to artificial intelligence. GPT models, a type of AI capable of generating human-like text, have demonstrated remarkable capabilities in natural language processing, excelling in tasks such as translation, summarising, and creative writing. The implications of these models extend beyond technical applications, prompting comprehensive analyses of AI consciousness and the potential of models like ChatGPT to pass the Turing Test [12].
These emerging technologies offer advanced solutions to smart-city challenges. For instance, constructing a new tunnel might reduce pollution, but it could also introduce other benefits or drawbacks. Decision-makers often face a multitude of options, each accompanied by its own set of advantages and disadvantages. This complexity arises from the need to consider a wide range of factors, including economic feasibility, environmental sustainability, social equity, and community well-being [3,4]. Effective solutions must address both objective criteria, such as cost-effectiveness and efficiency, and subjective considerations, including public opinion, cultural values, and stakeholder engagement [6]. Tackling urbanisation challenges requires a careful balance between quantitative data-driven analysis and qualitative insights that are socially inclusive, environmentally sustainable, and culturally relevant [13].
Urban traffic management has long employed various tools and methodologies to optimise traffic flow and minimise congestion. Traditional approaches include traffic signal control systems, adaptive traffic management systems (ATMSs), and real-time traffic information services. These systems typically rely on sensor networks, traffic cameras, and GPS data to monitor conditions and make real-time adjustments. For example, adaptive traffic signal systems can modify light timings based on current traffic patterns to improve flow efficiency. Additionally, predictive traffic modelling is widely used, allowing cities to anticipate congestion based on historical data and current trends.
While traditional methods have been somewhat effective, they often struggle to meet the increasingly complex demands of modern urban environments. Challenges such as unpredictable traffic patterns, the integration of new modes of transportation, and the need to evaluate potential city modifications, particularly when considering cultural and societal impacts, highlight the limitations of these conventional approaches. The Urbanite project addresses these gaps by enhancing existing traffic management tools through the integration of advanced AI-driven decision support systems and ML algorithms. These technologies enable more accurate predictions and adaptive responses to traffic conditions, facilitating more dynamic and flexible management strategies better suited to today’s cities’ evolving needs.
1.2. Contribution
This paper is grounded in the findings and methodologies developed through the Urbanite H2020 project, a three-year initiative involving numerous contributors (for more details, visit the Urbanite project website: https://urbanite-project.eu (accessed on 11 September 2024)). The project focuses on leveraging disruptive technologies to enhance urban decision-making processes.
The Urbanite project’s foundation lies in its open-source simulation tools incorporating real-time data to model various traffic scenarios. These tools are enhanced with AI and ML modules, offering decision-makers actionable insights to manage traffic proactively. Moreover, Urbanite’s approach is designed to engage local stakeholders in decision-making, ensuring that the solutions are technologically advanced, contextually relevant, and socially inclusive.
Through these innovations, Urbanite addresses the limitations of traditional traffic management systems. It sets a new standard for urban mobility solutions, contributing to the broader goals of sustainable and innovative city development based on subjective and objective evaluations. This paper introduces several innovations encapsulated in the five integrated modules of the Urbanite platform. Each of these modules represents a novel approach in a specific domain:
- A unified, upgraded, open-source simulator tested on four diverse cities: The implementation of a unified open-source simulator to model realistic urban environments in four major cities—Bilbao, Amsterdam, Helsinki, and Messina—represents a novel achievement in urban planning, to the best of our knowledge.
- An advanced decision support and recommendation module with the Dexi tool: This paper presents the first application of DEXi for several smart cities, demonstrating its capability to deliver prototype decision support tailored to the unique needs of four different urban environments.
- Advanced visualisations for comprehensive policy assessment: In addition to existing visualisation methods, we introduce advanced visualisations that support up to a five-dimensional presentation of various scenarios based on policy impacts, significantly enhancing the depth and clarity of policy assessment.
- An ML module with the Orange tool: The integration of simulation outputs with the Orange machine learning tool [14] enables city teams to harness advanced ML capabilities without the need for traditional programming, thereby making these powerful tools accessible to a broader audience.
- An advanced multi-label ML module: This module, besides enabling multi-label analysis, significantly accelerates the decision-making process, reducing the time required to simulate novel policies by three orders of magnitude, enabling policy evaluations to be performed in seconds instead of hours [15,16].
The Urbanite approach was evaluated on four cities: Bilbao, Amsterdam, Helsinki, and Messina, each with unique requirements identified by the Urbanite city team. The success of this software platform in these diverse scenarios suggests its potential applicability to other European cities. By encouraging collaboration, melding human insights with AI technologies, and integrating a simulation tool, city-specific subjective key performance indicators (KPIs), a recommendation engine, and ML techniques, this project aspires to enrich the evolution of European cities into intelligent, future-prepared urban centres.
The remainder of this paper is organised as follows. Section 2 reviews and analyses the related work. Section 3 provides an overall description of the proposed system. In this section, the architecture and each of the modules are described. Sample results of the data collected with the proposed system are presented in Section 4 and further discussed in Section 5. Section 6 concludes with a plan for future work.
2. Literature Review
Smart-city initiatives are part of a transformative era in urban development, integrating technology to foster intelligent, efficient, and sustainable urban ecosystems. Urbanite, a pioneering project at the forefront of these initiatives, focuses on revolutionising mobility policy and decision-making processes in European cities through disruptive technologies.
Smart cities signify a shift in urban development, using technology for intelligent, efficient, and sustainable ecosystems. These initiatives address challenges like traffic congestion and sustainability and enhance urban life. The concept’s evolution, seen in projects like Songdo and the Barcelona Smart City, integrates digital technologies for comprehensive urban-living improvements [17,18]. Key concepts include the Internet of Things (IoT) and sensor networks for real-time data on traffic, air quality, and energy consumption [19], decision support systems and data analytics for informed choices [20,21], urban-mobility solutions for sustainable transport, simulation tools for policy impact assessments, and digital twins for real-time city optimisation [22,23,24,25]. Sustainability, citizen engagement, cybersecurity, open-data initiatives, collaboration, and resilience planning are integral to creating technologically advanced, environmentally conscious, and citizen-responsive cities.
In single-city smart-city projects, various initiatives showcase the multifaceted applications of technology for urban development. Singapore’s Smart Nation Initiative [26] employs extensive IoT solutions and predictive analytics for efficient traffic management and informed decision-making. Barcelona’s Smart City Project [18] prioritises sustainable transportation and data-driven decision-making by implementing IoT sensors and data analytics. Songdo, South Korea’s International Business District, stands as a greenfield smart city, integrating advanced technologies such as intelligent transportation systems and digital twins for urban planning [17]. Dubai’s Smart Dubai project [27] focuses on a comprehensive transformation, utilising blockchain and AI for secure transactions and decision support. In Copenhagen, the Connecting project [28] emphasises data-driven urban planning, integrating information from diverse sources to inform decisions about smart traffic management and sustainable transportation. Toronto’s Sidewalk Labs [29] introduced innovative urban solutions using advanced sensors, data analytics, and simulation tools. The transformative potential of machine learning combined with wireless sensor networks in sustainable urban development was comprehensively reviewed in [30], highlighting their significance in smart-city initiatives. Amsterdam’s Smart City [31] initiative promotes sustainable urban development, using IoT applications for traffic optimisation and electric mobility.
In multi-city, smart-city projects, the European Innovation Partnership on Smart Cities and Communities (EIP-SCC) [32] is a collaborative platform fostering smart-city initiatives across Europe. As a specialised solution, Urbanite excels in the smart-city landscape by providing tailored mobility-policy management, advanced decision support systems, and efficient simulation tools for urban planning. Its focus on innovation in ML further enhances decision-making efficiency. Aligned with the broader goals of the EIP-SCC, Urbanite contributes to collaborative efforts in advancing smart-city solutions, offering a specialised and innovative approach within the evolving landscape of urban development.
Recent studies underscore the importance of data-driven approaches in promoting urban sustainability within smart cities. The need for smart-city policies that foster stakeholder collaboration, as emphasised in [33], aligns with Urbanite’s aim to accelerate European city transformation through knowledge exchange. The role of big data analytics in decision-making, highlighted in [34], resonates with Urbanite’s utilisation of advanced decision support systems. The exploration of digital solutions for urban efficiency in [35] also aligns with Urbanite’s focus on enhancing urban life quality. Furthermore, refs. [36,37] discuss leveraging artificial intelligence for decision-making and innovation, which mirrors Urbanite’s innovative approach. The sustainability evaluation frameworks proposed in [38] complement Urbanite’s commitment to sustainability. Additionally, ref. [39] highlights the multi-dimensional nature of urban competitiveness, emphasising the importance of integrating socio-cultural, environmental, and security aspects in urban planning to enhance the overall competitiveness of cities.
A comprehensive overview of the smart-city literature in the Scopus database is provided in [40]. The following hits were obtained when posting a specific query: “smart city” (4282 in 2021, 3537 in 2022, 3306 in 2023), “artificial intelligence” (33,735 in 2021, 35,689 in 2022, 43,409 in 2023), and both combined (282 in 2021, 230 in 2022, 246 in 2023). These figures reveal a substantial increase of about one-third of the hits for the “artificial intelligence” keyword over the same period. This trend underscores AI’s growing prominence as a central field of research and development in the smart-city field, especially as the European Union faces intense competition from China, some Asian countries such as Singapore, and the United States in this area.
Urbanite stands out by integrating disruptive technologies like UAVs [41] and AI and ML into a unified platform for smart-city development. Unlike other studies focusing on specific aspects, Urbanite offers a holistic solution for urban mobility challenges. Its tailored approach addresses the unique needs of European cities, ensuring contextual relevance. Urbanite’s advanced decision support systems and simulation tools, utilising technologies like Dexi and Orange ML, enable informed decision-making and policy simulation. Moreover, Urbanite implements real-world solutions, validating its effectiveness in pilot cities and bridging the research–application gap. Its emphasis on stakeholder collaboration ensures inclusivity and reflects diverse perspectives, making it a leading initiative in smart-city development. The references are schematically presented in Table 1.

Table 1.
Key References in smart-city development and technologies.
Urbanite’s innovation lies in its use of ML, simulation tools, and decision support systems. This technology-driven approach not only enhances urban planning but also addresses the dynamic complexities of modern cities. The project’s emphasis on mobility policy management aligns with the critical challenges that cities face today.
3. Methodology
3.1. General Schema
The proposed framework, illustrated in Figure 1, begins with collecting essential city-related data, encompassing people’s movements and the city’s infrastructure. Decision-makers then outline a range of potential scenarios to address specific urban challenges. These scenarios are simulated and predefined using a microscopic traffic simulator, and subjective KPIs are computed to assess the changes relative to the baseline scenario.
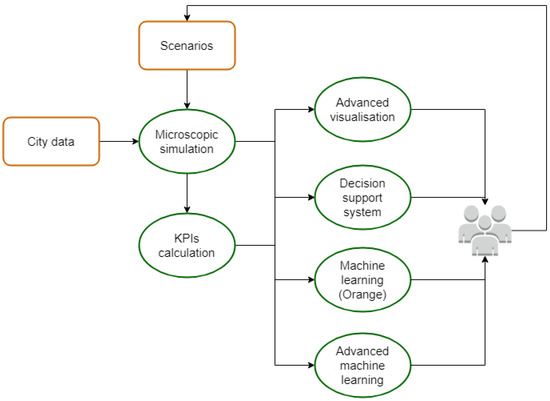
Figure 1.
General Urbanite schema.
Key performance indicators (KPIs) are essential metrics used to assess the effectiveness and progress of urban mobility strategies within the Urbanite project. These indicators offer a quantitative foundation for evaluating diverse dimensions of urban development, such as traffic flow, environmental impact, and public satisfaction. The percentage ranges provided are designed for flexibility, enabling each participating city to adapt the KPIs to its unique context and specific objectives. These values are derived from a synthesis of historical data, simulations, and expert insights, ensuring that they are both feasible and grounded in reality. While the Urbanite 1.0 software system employs these KPIs as decision-making inputs, it is important to recognise that they are not universally applicable. Rather, they are customised to reflect the specific conditions and priorities of each city, encompassing both objective measures (e.g., traffic flow) and subjective factors (e.g., citizen satisfaction). This generalised framework serves as a foundation, with more detailed KPIs being developed on a case-by-case basis to account for the distinct constraints and opportunities within each urban environment. This tailored approach ensures that the KPIs remain relevant and actionable, thereby enhancing the project’s overall impact on urban mobility and sustainability.
Subsequently, the calculated KPIs are inputs for four distinct modules, each contributing to a comprehensive analysis. These modules include advanced visualisations for user-friendly representations, a decision support system, an ML module that uses the Orange tool for pattern recognition and predicting non-simulated scenarios, and an advanced ML module that proposes policies based on user-defined preferences.
The Orange tool, tailored for use by non-programmers, enables the seamless implementation of one of the ML modules. The advanced ML module, leveraging KPIs as input features and a mobility policy as the target, refines its algorithm through data learning. This process allows the module to predict optimal mobility policies that align with user-specified preferences. In essence, this architecture integrates data collection, scenario simulation, and analysis into a unified and accessible solution for addressing urban challenges. The following subsections provide a detailed discussion of each of these modules.
3.2. Simulation
The Urbanite simulation module is characterised by its ability to model four distinct cities simultaneously, each of which contends with unique demands and urban challenges. The simulation in this study serves two primary purposes: first, to construct an accurate model of the current traffic dynamics within each city, and second, to evaluate various scenarios based on this foundational representation. Microscopic traffic simulations are integral to achieving these goals, as they provide a detailed, data-driven framework for understanding complex urban traffic patterns.
The simultaneous modelling of four cities faces many challenges, mainly due to the inherent complexities and idiosyncrasies associated with each urban environment. These complexities are driven by various factors, including the diverse formats of the data provided by each city, variations in data characteristics, and the overarching concerns surrounding data privacy. The modelling process relies on the MATSim (Multi-Agent Transport Simulation) tool [42], which was deemed the most appropriate choice for our purposes when compared to other leading simulation methods such as SUMO (Simulation of Urban Mobility) [24] and PTV Vissim [43]. Several simulation software packages were considered for selection, the most appropriate are listed in Table 2. The required features for the tools include ease of integration and extensibility, the ability to support multi-modal simulations—encompassing at least car, bicycle, and public transport modes—and the capability to perform microscopic simulations. Most modern traffic simulation tools fulfil these criteria; however, MATSim was ultimately chosen for its superior extensibility and ease of integration.
Table 2.
Comparison of selected traffic simulation tools. Only open-source software packages were evaluated as outlined in the project proposal, while commercial tools were considered the industry standard and used as a benchmark for feature completeness.
SUMO, a widely adopted microscopic traffic simulation tool, excels at replicating expansive transportation networks with intricate detail. It adeptly captures the characteristics of individual vehicles, their interactions, and the dynamics of urban traffic. SUMO factors in lane changes, traffic lights, and road infrastructure, resulting in highly realistic urban traffic simulations.
In contrast, PTV Vissim specialises in public transport simulations, offering comprehensive modelling of various public transport system components, including schedules, routes, and passenger behaviour. PTV Vissim enables analysts to assess public transport performance and identify opportunities for improving efficiency, reliability, and passenger satisfaction.
MATSim is an activity-based, multi-agent simulation framework specifically designed to model complex transportation systems. The agents within MATSim simulate the intricate behaviours and interactions of individual travellers across a comprehensive network. At its core, the framework replicates the daily activities of each traveller, including commuting patterns, transportation mode choices, and route selection. This detailed simulation approach offers a granular understanding of transportation dynamics and their significant implications for urban mobility. To execute the simulation, various input files related to population demand, such as city maps and traffic data (as depicted in Figure 2), must be provided. MATSim was selected for its flexibility and seamless integration into larger software systems.
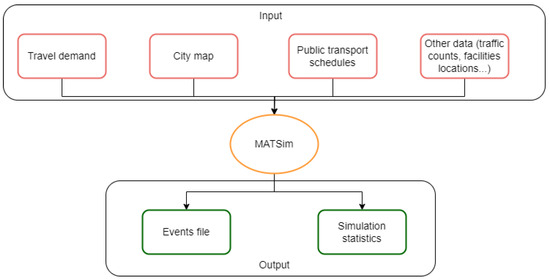
Figure 2.
MATSim input/output data.
The simulation begins with an initial demand, which is processed within the Mobsim module, followed by an assessment in the scoring module. This evaluation is based on criteria such as journey time, cost, environmental impact, and user preferences. The simulation is highly adaptive, running through multiple iterations to continuously optimize system performance. This flexibility allows the simulation to swiftly respond to changing conditions and policy interventions, which are managed by the re-planning module. The cyclical and adaptive nature of this process is illustrated in Figure 3.
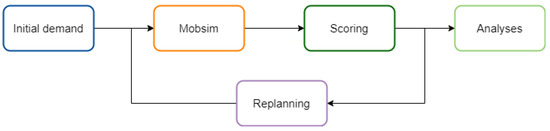
Figure 3.
MATSim cycle.
To successfully implement MATSim across the four cities, several adjustments to the input data were necessary, including the development of realistic agents and their corresponding demands. For example, a student might follow a typical route to a faculty in the morning under normal conditions but would opt for an alternative route in the event of a traffic jam. Agents and their demands form a plan, which is developed within a general framework unique to the Urbanite project. It incorporates city-specific data on people’s movements, categorised by attributes such as age, on a particular day, like a typical Monday. A flowchart illustrating the Urbanite simulation model is provided in Figure 4.
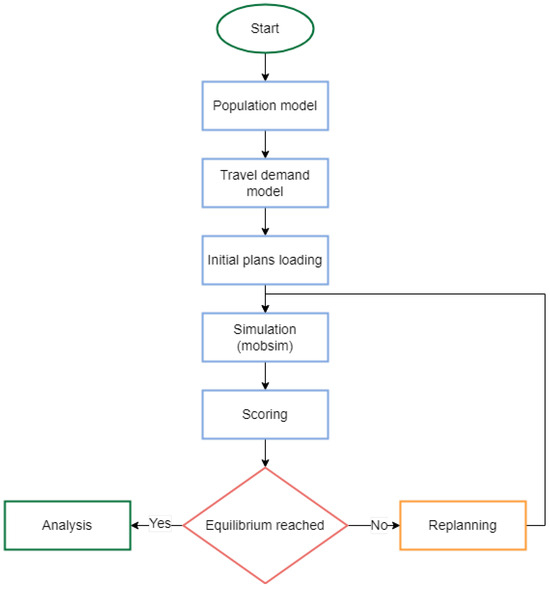
Figure 4.
Flowchart of Urbanite simulation model.
3.3. Calculation of the KPIs
In this subsection, we examine the algorithms used to determine the objective and subjective KPI metrics that capture the essence of a traffic simulation. The KPI algorithms calculate the values of specific metrics based on the traffic simulation results, defined in collaboration with the city’s decision-makers. The KPIs enable a unified evaluation framework across all four pilot cities, further elaborated in the DSS (Decision Support System) section. Additionally, the calculated KPIs define the preference space, allowing for the evaluation and comparison of different mobility policies.
Several KPIs were developed in collaboration with each pilot city, as listed and explained in Table 3. These KPIs provide an expert method for assessing quality of life within a consistent framework. This framework facilitates automatic integration with the decision support and recommendation system.
Table 3.
Descriptions of key performance indicators and their relevance to various aspects of urban mobility and sustainability.
KPI calculations are based on analysing the simulation results, which involves filtering out relevant events and mapping and aggregating the data appropriately. Section Results details how specific KPIs are calculated for each city.
3.4. Advanced Visualisations
In multi-criteria decision analyses, advanced visualisations are critical in presenting the complex interplay between various factors and criteria, thereby supporting a comprehensive understanding of their impact. Furthermore, visual tools are essential for comparing diverse policy options, providing stakeholders with clear insights into each proposal’s relative strengths and weaknesses, and enabling understanding of complex relations. Innovative and advanced visualisation techniques are well suited to address these needs, enabling a detailed evaluation of multiple KPIs within the context of mobility policy decisions.
The novel method developed in the Urbanite project enables the incorporation of additional dimensions through the use of attributes such as colour, time, and multi-figure overlays, allowing for visualisations of up to 9 dimensions (9D). However, based on experiments conducted in the Urbanite project, an up to 5-dimensional (5D) visualisation scheme was adopted as it strikes an optimal balance between complexity and user comprehensibility. This approach enables decision-makers to compare multiple scenarios simultaneously, with each dimension representing a specific KPI or attribute. While the system is still capable of supporting 9D visualisations, 5D was determined to be the practical limit for most users, as higher-dimensional representations tend to overwhelm the cognitive capacity of an average human user. Even 5D visualisations pose challenges for many, although they offer a highly effective tool for advanced users capable of grasping complex, interacting variables in a single viewpoint. In contrast, 3D and 4D visualisations are generally accepted as more intuitive and easier to interpret.
By employing these novel visualisation techniques, decision-makers are better equipped to interpret and analyse the intricate relationships between KPIs. These techniques allow users to visualise and understand the complex interplay and cause–effect relationships between different variables, significantly improving both the speed and quality of comprehending the changes introduced. This enhanced understanding enables decision-makers to engage in more informed, strategic, and timely decision-making processes.
3.5. Decision Support System
This decision support system was implemented for all four cities in the Urbanite project. Due to the varying requirements and goals of each city, four distinct decision models were developed. Each model was tailored using the essential KPIs relevant to the specific city. In this context, KPIs are referred to as attributes, and the decision model was structured as a multi-attribute model.
The Dexi tool was employed for the decision support system (DSS) [44]. DEXi utilises qualitative (symbolic) attributes, which are expressed as discrete scales composed of words rather than numerical values. Depending on the complexity of the decision model, it may be necessary to group several attributes under a parent attribute. This grouping is crucial, as the model requires the definition of a rule set that encompasses all possible combinations of scale values. Without such grouping, the model could face a combinatorial explosion if the number of attributes without a parent attribute is large and/or their scales involve multiple values.
The flowchart of the Urbanite DSS model is illustrated in Figure 5. Following the simulation of various scenarios and the computation of the KPIs, the next step involves preparing the data for DEXi. The DSS (DEXi) compares a baseline simulation, where no modifications have been made, with a scenario simulation, where a modification has been made to its parameters and/or city network. The KPIs of both simulations are compared, and a relative number is calculated to represent the percentage change between the two. This percentage is assigned to the range it falls into from the following options:
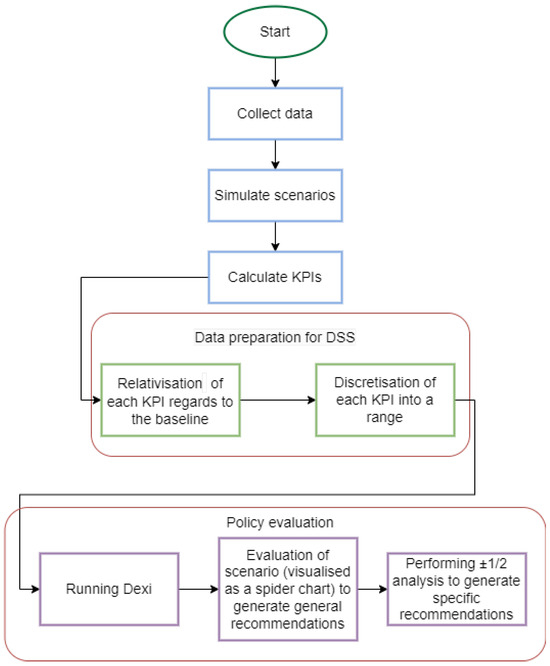
Figure 5.
Flowchart of the Urbanite DSS model illustrates the decision support system process, including the comparison of baseline and scenario simulations, KPI computation, and the application of multi-attribute modelling using DEXi.
- <−15% indicates a large decrease;
- <−5% indicates a small decrease;
- >−5% & <5% indicates no or negligible change;
- >5% indicates a small increase;
- >15% indicates a large increase.
The ranges were determined after conducting numerous simulations and performing a statistical analysis of the resulting KPI values, followed by the manual selection of sensible, rounded numbers. These ranges are applied to attributes that are not classified as parent attributes. In contrast, parent attributes are assigned one of three possible values: Better, Same, or Worse. These values provide a subjective score, indicating whether the KPI from the scenario simulation is better, the same, or worse compared to the KPI from the baseline simulation.
When the DSS evaluates a simulation against a baseline, the results obtained are the subjective values for each KPI and the top-level attribute, the Mobility Policy Quality. This attribute serves as a comprehensive score, providing a general recommendation about whether the scenario is better, equal to, or worse than the baseline. It encapsulates an overarching assessment of the simulation’s performance compared to the established baseline.
A comprehensive ±1 and ±2 analysis was ultimately performed on the top-ranked policies for the final evaluation. This analytical approach generates specific recommendations aimed at improving the overall quality of mobility policies. These recommendations are classified into the ±1 suggestion and the ±2 suggestion. The ±1 recommendation provides insights for incremental improvements in specific areas, such as air quality or public transportation, leading to a gradual enhancement of the policy. In contrast, the ±2 recommendation suggests more substantial adjustments, potentially addressing multiple dimensions simultaneously, to achieve a broader improvement in the scenario’s overall quality.
The ±1 and ±2 analyses operate by iteratively adjusting the input values of DEXi’s child-level attributes, increasing or decreasing them by 1 or 2 units. This adjustment shifts the range in which a particular KPI falls. The process is applied to each child-level KPI, and the entire DEXi evaluation is rerun to generate updated results. These new results are then compared with the original outcomes. If a change is detected, it indicates that an improvement has occurred in the parent-level KPIs.
This analysis provides the city team with valuable hints on how to influence the overall policy evaluation (i.e., improve the analysed city modification), identifying which KPIs should be prioritised for enhancement. For example, the analysis might reveal that implementing public campaigns to shift behaviour from individual car use to public transport could significantly improve the overall quality of life in the city when a new bus lane is introduced. Conversely, neglecting such measures may lead to stagnation or even a decline in key metrics. By targeting the right KPIs for improvement, the city team can make informed decisions that lead to broader benefits across multiple aspects of urban life.
3.6. Machine Learning with Orange
In this subsection, we introduce the Urbanite ML module, designed to enable decision-makers to assess the quality of proposed policies by harnessing ML advantages without programming. For example, the impact of closing a specific part of a city on traffic can be assessed based on prior simulations, eliminating the need for conducting new simulations each time a policy change is proposed.
Traditionally, a comprehensive microscopic traffic simulation is required to evaluate the effects of each policy change. For attributes with a wide range of possible values, this typically involves splitting the attribute into several discrete values and running simulations for each scenario. Since each simulation can take approximately one hour on a fast PC, this process becomes time-consuming. However, by applying ML techniques to learn from the outcomes of a reasonable number of previously simulated scenarios, this time-intensive process can be bypassed. The Urbanite ML module predicts policy impacts and provides rapid and efficient evaluations without the need for repeated resource-heavy simulations.
This particular module aims to evaluate the objective and subjective preferences attributed to these policies. It adopts an innovative approach that relies on a single simulation run as a training example, allowing the ML model to learn from the simulation results. Once trained, the ML model enables further analysis, such as visualising or evaluating new scenarios. The simulation’s input and output parameters serve as features, while the KPIs represent the target variables. For each ML task, only one target variable can be chosen, such as emissions.
This approach offers two significant advantages: First, the analysis and visualisation can be performed using an ML tool without requiring any programming. Second, scenario parameters (e.g., policy changes) can be adjusted within the ML module, eliminating the need for running new simulations, thus providing the city’s decision-makers with faster and more efficient means to identify the optimal solution.
The primary goal is to enhance the simulation tool with ML services, e.g., visualisation, discovery of new relations, etc. This will save valuable time, energy, and resources when evaluating the quality of the mobility policies. The second goal is to obtain additional services from the ML modules, such as transparency.
To make this process accessible to a broader audience, including city officials and decision-makers, the user-friendly Orange tool is employed [45]. Unlike many other ML tools, Orange is designed for non-programmers. Simulation results are connected to the Orange input via an API, enabling a seamless flow of data. Through a diagrammatic interface in Orange, which serves as a visual programming environment, users can select the ML method and the desired type of reporting or visualisation. The process, illustrated in Figure 6, begins with collecting the necessary data for the simulation. A series of potential scenarios is then defined, followed by the execution of the simulation. Upon completion, a set of predefined KPIs are calculated to create the dataset, where each instance represents a vector of simulation input/output data and corresponding KPIs. These data are subsequently imported into the Orange tool, where various analyses can be performed using different widgets. Multiple ML models can be applied, and these models can ultimately be tested on unseen examples to ensure accuracy and predictive performance.
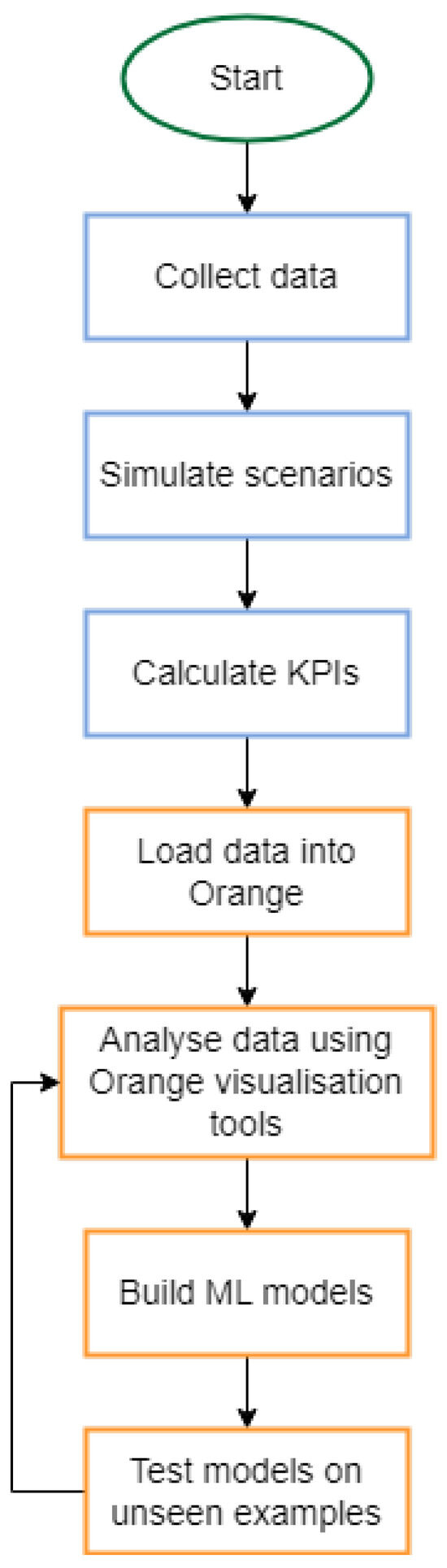
Figure 6.
An example of a flowchart of the machine learning process using the Orange tool. This diagram illustrates the step-by-step tasks, including data import, model training, and visualization, connected through an interactive pipeline for seamless analysis.
An example of an Orange program is illustrated in Figure 7. In this Orange workflow, widgets represent distinct tasks such as data import, model training, and visualisation. Each widget is responsible for a specific function, such as selecting relevant data columns, training machine learning models, or visualising the output, like a decision tree. The connections between widgets visually depict the flow of data from one step to the next, ensuring that the outputs from one widget serve as the inputs for another. This structure creates a seamless, interactive analysis pipeline, enabling users to explore various models and scenarios efficiently and without the need for programming.
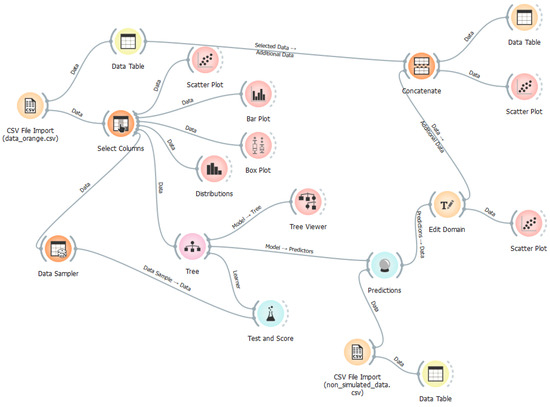
Figure 7.
An example of a flowchart of the machine learning process using the Orange tool. This diagram illustrates the step-by-step tasks, including data import, model training, and visualization, connected through an interactive pipeline for seamless analysis.
3.7. Multi-Output Machine Learning for Suggesting Mobility Policies
When aiming to enhance decision-making processes in European cities as part of the Urbanite project, advanced ML techniques have the potential to play a pivotal role. Specifically, multi-output or multi-label ML can be leveraged to generate more effective recommendations for mobility policies, leading to improvements in urban areas beyond what is achieved by integrating simulation outputs with tools like Orange. While in previous cases, only one class was chosen from available options, addressing complex challenges in smart-city decision-making requires the application of multi-output learning. This approach enables the simultaneous prediction of multiple variables and their interdependencies.
The advanced ML module employed in Urbanite integrates sophisticated tools to tackle these complex problems. Its key innovation lies in the application of multi-output ML models that are directly connected to simulation results. This allows for the simultaneous prediction of multiple outcomes based on a diverse set of input variables, offering a more comprehensive analysis of policy impacts. Since the primary objective of the ML module is to assist decision-makers in defining potential city scenarios and utility functions, the ML model must identify complex policy solutions that best align with the given constraints and preferences. For example, this advanced ML module might significantly enhance both the depth of analysis and the speed of policy testing, with performance improvements potentially reaching several orders of magnitude.
The complexity of the problem arises from the need to predict multiple target variables that are both discrete and continuous. For example, the policy we aim to predict involves the start times, the duration of the closure, and the specific area of the city centre to be closed. This creates two distinct types of machine learning tasks: classification, which handles the categorical nature of the closure area, and regression, which deals with predicting continuous variables such as start times and closure duration. In addressing this multi-output problem, this study tested various machine learning algorithms across both classification and regression tasks. For multi-label classification, a logistic regression (LR) base classifier was implemented. This method efficiently generates distinct predictions for each label, allowing simultaneous predictions for multiple binary targets. On the regression side, transformation techniques were applied to a variety of algorithms, including a linear support vector machine (LSVM), a gradient boosting regressor (GBR), an elastic net (EN), stochastic gradient descent (SGD), support vector regression (SVR), Bayesian ridge (BR), linear regression (LNR), k-nearest neighbors (KNN), a decision tree (DT), and random forest (RF) regressors. These algorithms were selected for their ability to handle multi-output regression and for their interpretability, making them suitable for providing actionable insights. Table 4 and Table 5 summarise the algorithms involved in the transformation process, as well as the adapted algorithms capable of supporting multi-output regression.
Table 4.
Transformed algorithms for multi-output regression.
Table 5.
Adapted algorithms for multi-output regression.
The primary task can be defined as follows. Let D be the training dataset containing N examples, where . Each instance is associated with a feature vector and a subset of where is the set of q possible labels. The task is to create a classifier H that will accurately predict an unlabelled instance E described with the feature vector x and an undefined subset of labels Y, i.e., .
Figure 8 presents the flowchart of the Urbanite Advanced ML approach. Unlike the Orange tool, this approach demands actual coding. The resulting program is not fully universal, meaning another application might require modifications. However, the program is open-source, and only the modifications need to be coded.
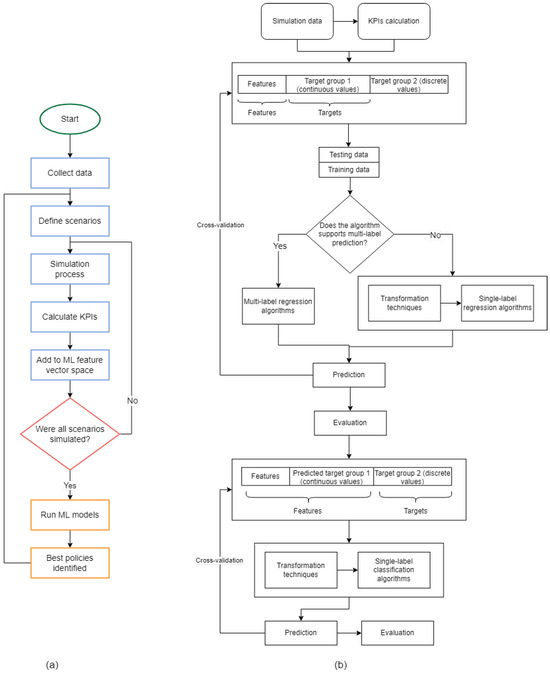
Figure 8.
Flowchart illustrating the advanced machine learning process (a); workflow of the machine learning model (b), detailing the sequential steps from data input to model training, evaluation, and output analysis.
Multi-label algorithms require distinct evaluation methods compared to single-label algorithms. In single-label tasks, instances are classified as either correct or incorrect, whereas in multi-label tasks, they can be partially correct. This introduces the concept of a soft match, where a prediction is not entirely correct but closely aligns with the actual result, allowing for partial credit. For evaluation, both micro-averaging and macro-averaging can be used to calculate the average difference between the true and predicted values. Micro-averaging aggregates results by summing the true positives, false positives, and false negatives across all labels, providing a more holistic view of performance. Macro-averaging, on the other hand, calculates the average of a specific metric for each label, treating all labels equally. In both cases, the performance of the proposed method was evaluated using K-fold cross-validation, with the results compared to those of other methods using the same technique. The soft match concept was particularly important for evaluating partial correctness in multi-label predictions, ensuring that predictions closely matching the true values were appropriately rewarded.
The precision and recall are computed to determine the effectiveness of a classification model.
To determine the effectiveness of the regression model, the following metrics were computed: the mean squared error (MSE), the mean absolute error (MAE), the coefficient of determination (R2), and the root mean squared error (RMSE).
The MAE (Equation (5)) measures the average absolute difference between the predicted and true values. It quantifies the average magnitude of the errors:
The MSE measures the average squared difference between the predicted and true values (Equation (6)). Also, it emphasises larger errors due to the squared term. The negative sign indicates that the lower values of the MSE correspond to a better model performance. By negating the MSE, we align it with the convention where smaller values indicate better accuracy.
The R2 is a statistical measure representing the proportion of the variance in the dependent variable that can be explained by the independent variables (Equation (7)). It indicates the goodness of fit for the regression model.
The RMSE is a variant of the MSE that measures the square root of the average squared difference between the predicted and true values (Equation (8)). It is used to quantify the typical magnitude of the errors in the predictions:
In Equations (5)–(8) above, represents the predicted value for the ith instance, represents the true value for the ith instance, N represents the total number of instances, and represents the mean of the true values.
The overall performance of the models is calculated as the mean value of the evaluation metrics for each target variable :
Overall, the Urbanite project’s multi-output module explains complex relationships between factors like traffic patterns and travel behaviour. It provides insights and recommendations to city planners, aiding their informed decisions. This study is the first to address policy testing in a real city using multi-output ML. Additionally, the ML module speeds up the simulations by several orders of magnitude, transforming time-demanding simulations into nearly interactive ML modules.
3.8. Data
This subsection outlines the data sources utilised within the Urbanite framework. The baseline scenarios were meticulously developed using publicly available data that accurately represent the current state of each city, supplemented with additional data provided by city teams. Most of the data were collected from city teams and pre-existing databases, forming a robust foundation for the simulations. Detailed city maps were sourced from OpenStreetMap. To model travel plans, a synthetic population was generated using data from the European Union Statistics on Income and Living Conditions (EUSILC). This synthetic population was further refined using marginal distributions specific to each pilot city to ensure accuracy. Where available, origin–destination matrices were used to represent the flow of travellers between locations. Emissions were calculated using the Handbook of Emission Factors, applied to the simulation outputs to estimate environmental impact. A summary of the data used for the simulations is provided in Table 6.
Table 6.
Key data sources used for the Urbanite simulations, including city maps, synthetic population data, origin–destination matrices, and emission factors.
4. Results
The following subsections present the outcomes from various modules, focusing specifically on Bilbao. Given the complexity of the system and the space limitations of this paper, it is not possible to provide detailed results for all four cities. As such, Bilbao is used as a representative case to demonstrate the system’s functionality and performance.
4.1. Simulating Diverse Scenarios
Gathering the data for four cities involves addressing privacy considerations and data availability, as each city has its unique requirements and specifications. A consistent methodology was applied across all pilot cities, beginning with the modelling of a baseline scenario to capture the current traffic conditions. This was followed by the implementation of changes to simulate a new mobility policy for comparison with the baseline. For each city, at least two simulations were conducted: one for the baseline scenario and another reflecting the proposed mobility policy. For the modified scenario, from one to hundreds of variations were executed to explore different outcomes. In the case of Bilbao, adjustments were made to the second scenario to meet the requirements of the ML modules. The specific scenarios for each city are outlined as follows:
- Bilbao: Closure of Moyua Square in the city centre to private vehicles. Modifications to this scenario include the closure of various surrounding areas for different times and durations and changing the number of cyclists nearby.
- Messina: Introduction of a new bus line in the city centre.
- Amsterdam: Construction of a new district—Amsterdam Nord.
- Helsinki: Construction of a new tunnel to connect the harbour area to the highway.
4.2. KPIs
Amsterdam is focused on bicycle mobility, bicycle safety, and bicycle congestion. The following KPIs were developed:
- Bicycle infrastructure: the extent and quality of the infrastructure available to support cycling. A score is given to each road segment based on how appropriate the road is for cyclists. Bicycle-only roads, bicycle lanes, and living streets are scored high, while motorways, main roads, and paths with stairways are scored low.
- Bicycle intensity: the number of cyclists on each road segment.
- Bicycle safety: estimation for the mixed-use of roads by bicycles and motor vehicles, and their interactions. Road segments with cyclists are given a high score, while road segments where cyclists and motor vehicles share the road are scored low.
- Bicycle congestion: the length of all the congested road segments combined. Any traffic situation where cyclists are moving slowly due to the road being at or near capacity is considered congestion.
Bilbao is focused on the quality of life in the inner city while considering multimodal transport, including public transport, cyclists, and private cars. The following KPIs were developed:
- Air pollution, including , , and PM10: calculated using the Handbook of Emission Factors (HBEFA). The emission estimation takes into account the simulated traffic situations (slow moving, congested traffic vs. free-flowing conditions, etc.), vehicle fleet composition, including type of engine and EURO-standard support, and even whether the vehicle’s engine is cold or hot.
- Noise pollution: estimated on a grid over a section of the city, based on the simulated traffic situation and the geometry of the buildings in the city.
- Daily city bicycle journeys:
- Pedestrian journey time: average length of a pedestrian journey in minutes. All journeys are considered, but only long pedestrian journeys over 60 min are visualised and reported.
Helsinki is focused on the traffic caused by the arrival of ferries to the West Harbour. The harbour is located on a peninsula, connected to the mainland with a single road causing congestion and lowering the quality of life in the area. The following KPIs were developed:
- Air pollution, including , , and PM10: as described above.
- Noise pollution: as described above.
- Congestion and bottlenecks: the length of all congested road segments combined. Any traffic situation where vehicles are moving slowly due to the road being at or near capacity is considered congestion.
- Harbour area traffic flow: the traffic flow on the main road connecting the harbour with the mainland.
Messina is focused on the public transport in the city. The following KPIs were developed:
- Average speed of public transport: the average speed is calculated for each vehicle, and a weighted average is calculated by considering the total length of the vehicles’ journeys.
- Public transport usage: the number of people using public transport.
- Shares of cars, bicycle, and public transport journeys: the daily shares of journeys made, by transport mode.
4.3. Advanced Visualisations
Advanced visualisations were applied across all four cities to enable a comprehensive comparison of multiple scenarios. These Urbanite visualisations allow for the selection of up to five dimensions with the y-axis representing the time per hour over a 24 h day, and the x-axis and z-axis representing two key performance indicators (KPIs). Additionally, colour is employed to depict another KPI, facilitating a detailed comparison. An illustrative example from Bilbao is presented in Figure 9, where four dimensions are showcased for clarity. In this 4D visualisation, the x-axis represents the different scenarios, the y-axis indicates the time of day, and the z-axis reflects local pollution levels. The colour gradient represents the local concentration, ranging from dark blue (indicating low pollution) to yellow (indicating high pollution). For example, the term “Bilbao Moyua LTZ” denotes a complete closure of the square for the entire day, with the scenario names indicating specific closure times. The z-axis shows the cumulative local pollution across five scenarios. Notably, closing the square from 4 p.m. to 8 p.m. results in higher cumulative levels compared to the baseline scenario, likely due to increased congestion during peak afternoon hours. In contrast, closing the square from 8 a.m. to 12 p.m. results in no significant difference in cumulative , while a closure from 10 a.m. to 1 p.m. leads to increased pollution levels.
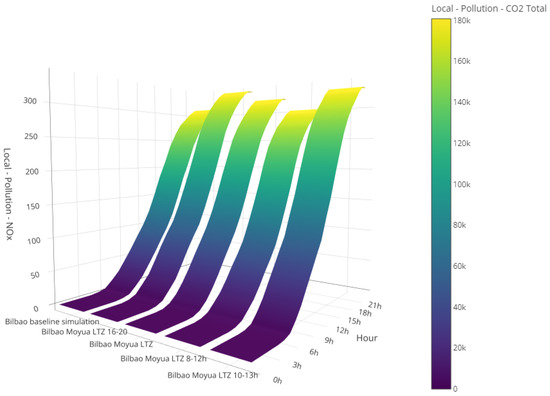
Figure 9.
Comparison of different scenarios using advanced visualisations.
4.4. DSS
The results from the DSS are presented as two major components of the Urbanite platform: the spider chart and the recommendation system. The spider chart visualizes the relative change between the selected simulation and the baseline. A value of three in the spider chart indicates no significant change in the relevant attribute, while higher or lower values signify improvement or deterioration, depending on how the attribute is defined in the decision model. Additionally, the recommendation system offers tailored suggestions based on the simulation results, helping decision-makers identify the most effective mobility policies. This system leverages the multi-output machine learning models to recommend specific actions or adjustments that could improve various KPIs. Together, these two components provide comprehensive insights into the performance of different scenarios, enabling a more informed and data-driven decision-making process.
In Figure 10, the spider chart illustrates the changes after a simulated scenario was introduced for the city of Bilbao. It includes the relevant KPIs, representing attributes in the decision model. Parent attributes, providing a broader context for lower-level attributes, are also displayed. A key observation from the scenario “Bilbao Moyua LTZ (Limited Traffic Zone) 16–20 (from 4 p.m. to 8 p.m.)” is that emissions, such as local and , were reduced, contributing to an overall improvement in the mobility policy. These reductions are visualised in the spider chart, where values for environmental KPIs show improvement compared to the baseline scenario. This improvement is largely due to the restricted traffic flow during peak hours, which reduced pollution in the affected area. However, as is often the case with such analyses, some KPIs show deterioration. For example, the “Entry capacity to centre” attribute worsened, indicating reduced accessibility to the city centre during the closure period. This reduction in capacity is likely due to the limited traffic zone restrictions, which, while improving environmental quality, also restrict the flow of vehicles, affecting convenience for residents and visitors. In contrast, some KPIs, such as “Public transport usage”, remain the same, suggesting that the closure did not significantly impact public transport ridership within the specified time frame.
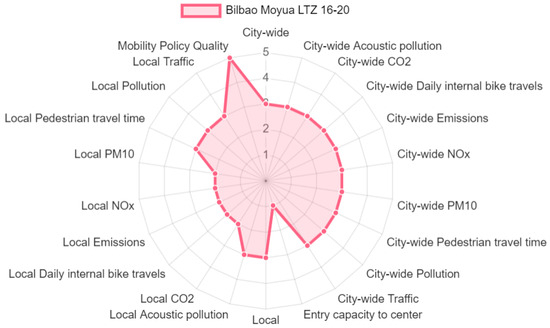
Figure 10.
Spider chart for a scenario simulation for the city of Bilbao illustrating the relative performance of key KPIs for the “Bilbao Moyua LTZ (Limited Traffic Zone) 16–20” scenario, comparing changes in emissions, entry capacity, and other attributes against the baseline.
This balance between improvements in environmental factors and potential trade-offs in accessibility highlights the complexity of urban mobility policy decisions, where enhancing one attribute can lead to a decline in others, requiring careful consideration by decision-makers.
In the recommendation component of the Urbanite system, the DSS is also used to provide textual information to the user on whether a selected scenario simulation is better, the same, or worse than the baseline. Below are textual recommendations generated by the recommendation engine:
- In order to change the KPI of Mobility Policy Quality by 10%, PM should be improved by 10%.
- In order to change the KPI of Local Emissions by 10%, PM should be improved by 10%.
- In order to change the KPI of Entry capacity to centre by 20%, PM should be improved by 10%.
- In order to change the KPI of Mobility Policy Quality by 10%, Entry capacity to centre should be improved by 20%.
These recommendations provide actionable insights for decision-makers aiming to optimise specific KPIs within the urban mobility context. The results from the DSS are available for Bilbao on the web platform created during the Urbanite project. (For more details, visit the Urbanite Bilbao project website: https://bilbao.urbanite.esilab.org/pages/home, (accessed on 11 September 2024).)
4.5. Machine Learning with Orange
For a practical demonstration, the analysis in Bilbao focuses on the potential effects of closing Moyua Square in the city centre and increasing the number of cyclists on the levels of air pollution, with a specific focus on estimating the emissions. Multiple ML algorithms were tested, and the findings suggest that closing the city centre square and promoting cycling has a positive impact on reducing emissions.
To generate the dataset for Orange, 14 simulations were conducted in Bilbao, examining the consequences of closing Moyua Square in the city centre to private vehicles. Two scenarios were implemented: the baseline reflecting the current network state and a modified scenario with the closure of Moyua square. Variations in the latter included adjustments in the number of cyclists (ranging from 1500 to 19,000) and inhabitants (ranging from 2000 to 20,000). These variations illustrated the potential outcomes if the applied policy and the number of cyclists changed.
Figure 11 illustrates the results of the implemented policy, explicitly showcasing the correlation between the number of cyclists and the emissions. The x-axis indicates cyclists near the square, while the y-axis represents those in the centre. Different colours signify varying levels of emissions, with the orange circle indicating the baseline scenario. The findings suggest that closing the main square to private vehicles and reducing the number in proximity leads to a decrease in emissions.
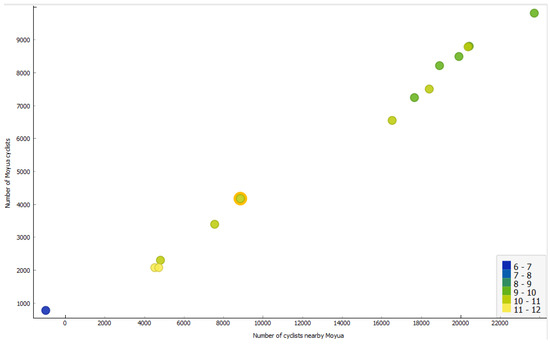
Figure 11.
Displaying the relationship between the number of cyclists and emissions.
Several inferences can be drawn from Figure 11, including the observation that the number of cyclists inside and outside the square is strongly correlated—the more cyclists enter, the more cyclists leave. This expected relationship is captured by the simulator. Additionally, the figure confirms the anticipated result that closing the main square to private vehicles (such as cars and motorbikes) leads to a significant drop in emissions. Furthermore, the presence of more cyclists in the square, which is closed to private vehicles, correlates with fewer cars and thus reduced emissions.
However, the relation is not purely linear since there is some traffic remaining, e.g., public transport vehicles and their . The left-down simulation in Figure 11 indicates a large amount of emissions; however, it turned out that there was an error in the input data. This underscores the importance of verifying simulation outputs and highlights how transparent visualisations and human verification play a crucial role in identifying and addressing such issues.
After constructing the ML model (decision tree) using the data mentioned earlier, it becomes possible to forecast outcomes for new instances not simulated previously. In Figure 12, the outcomes of predicting emissions for novel data points, without prior simulation, are presented. The new data points are scaled up, and it can be inferred that the colour, representing the level of , aligns consistently with the other instances.
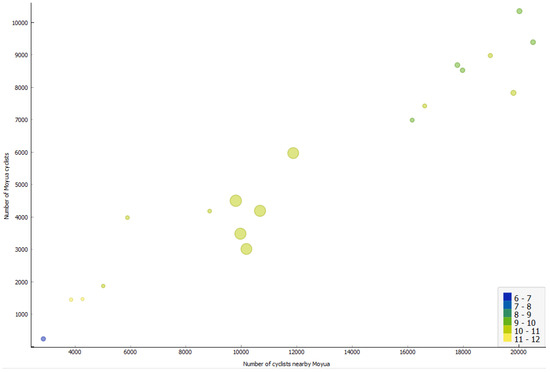
Figure 12.
New Additional data points generated by the ML model, showcasing predicted outcomes for unseen instances of emissions. These predictions align with previously simulated scenarios, demonstrating the ML model’s capability to extend analysis beyond the original simulation results.
After constructing an ML model, potentially in the form of a decision tree using the previously mentioned data, it becomes possible to predict outcomes for unseen examples—instances that were not part of the initial simulations. In Figure 12, the outcomes of predicting emissions for these new data points, which were not simulated previously, are displayed. The new instances are scaled up for clarity, and it can be observed that the colour representing the level of rather consistently aligns with the other previously simulated examples. This demonstrates the effectiveness of ML knowledge models in forecasting results for novel scenarios, enabling faster and more efficient policy evaluation without the need for additional simulations.
4.6. Advanced Machine Learning
The advanced ML model underwent testing in Bilbao’s Moyua area, while trying to find the best policies for closing specific districts to private vehicles and determining the ideal timing for these closures based on data from simulated and learned scenarios. The scenarios specified the start time and the duration of the closures, resulting in 1452 possible combinations. Due to time and resource constraints, Latin hypercube sampling was employed to choose a subset of scenarios for the simulation. The KPIs related to pollutants (, , and PM) were measured across different geographical levels, providing insights into the effectiveness of the pollution-mitigation measures. The analysis considered the impact of specific measures, such as closing streets in the city centre, on pollution levels and congestion. Different transportation modes’ contributions to pollution were examined, helping to formulate effective mobility policies. The analysis also factored in congestion, modelling it by incorporating travel times to develop policies addressing both congestion and pollution for a sustainable urban environment. The target variables in the analysis represented a mobility policy influenced by input features, including KPIs, with continuous values for the start time and the duration and closed areas encoded in a binary format with nine attributes.
The advanced ML model was tested in Bilbao’s Moyua area to identify the optimal policies for closing specific districts to private vehicles and determining the best timings for these closures based on data from both simulated and learned scenarios. The scenarios included variables such as the start time and duration of closures, resulting in 1452 potential combinations. Due to time and resource constraints, Latin hypercube sampling was employed to select a reasonable subset of scenarios for simulation. KPIs related to pollutants, such as , , and particulate matter (PM), were measured across different geographic levels, providing insights into the effectiveness of pollution-mitigation strategies. The analysis assessed the impact of specific interventions, such as closing streets in the city centre, on pollution levels and traffic congestion. The contributions of different transportation modes to overall pollution were also examined, aiding in the development of more effective mobility policies. In addition to pollution levels, the analysis factored in congestion by incorporating travel time data to develop policies that address both congestion and pollution, fostering a more sustainable urban environment. The target variables in the analysis represented a mobility policy influenced by various input features, including continuous values for start time and duration, and closed areas encoded as binary attributes across nine variables.
The process initiates with a regression task aimed at predicting the start time and duration. The predicted values are then appended to the feature space, serving as features for the subsequent classification step. In this latter stage, the area of closure is predicted, and modelled as nine binary classes, using logistic regression. Each task is evaluated independently to ensure a comprehensive assessment.
In the first part of the analysis, a thorough evaluation was conducted by testing 10 diverse regression algorithms: linear regression, k-nearest neighbors (KNN), decision tree, random forest, linear support vector machine (LSVM), gradient boosting, elastic net, stochastic gradient descent (SGD), support vector regression (SVR), and Bayesian ridge. The first four algorithms—linear regression, KNN, decision tree, and random forest—natively support multi-label regression through algorithmic adaptation, while the remaining models are trained using problem-transformation techniques to handle multiple outputs.
The application of k-fold cross-validation is commonly used for evaluating the performances of ML models. The results for are presented in Figure 13, which displays the distribution of scores across each fold using a boxplot. Linear regression emerges as the most effective algorithm, with a mean mean absolute error (MAE) of 1.514 and a standard deviation of 0.230. This indicates that linear regression provides accurate predictions for the start time and duration of the Moyua square closure for private vehicles, with an average error of approximately one and a half hours.
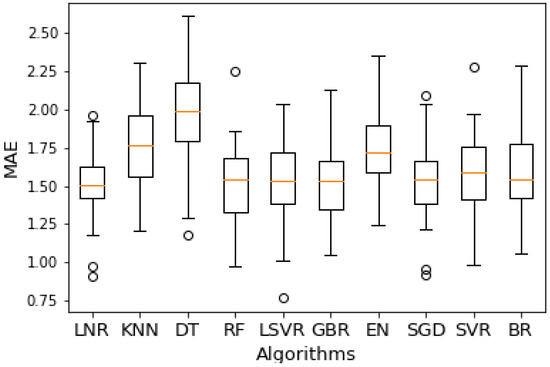
Figure 13.
Comparison of methods for the regression task, presenting the mean absolute error (MAE) and standard deviations for each of the 10 regression algorithms tested, highlighting the performance differences across methods in predicting the start time and duration of Moyua square closures. Linear regression demonstrates the lowest MAE, with other models displaying varying degrees of prediction accuracy.
The next challenge involves constructing a model to predict the area of closure, using the previously predicted start time and duration as input features. To address this, a problem-transformation method is essential for handling the multi-label classification task. Logistic regression, applied individually to predict each area, is identified as a suitable approach.
The overall performance of the ML model is illustrated in Figure 14. The model achieved a 90-percent recall score (true positive rate) and 77-percent accuracy when exact matches between features and labels were considered (depicted in orange). In addition to this, two alternative approaches were explored to provide a more comprehensive assessment of the model’s effectiveness.
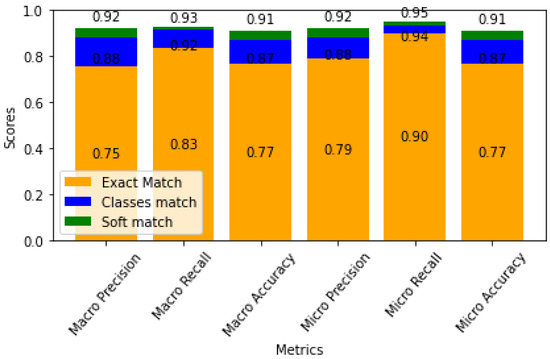
Figure 14.
Accuracy of different evaluation approaches for the classification task, including exact matching, Euclidean distance-based classification, and feature vector alignment, with results displayed in orange, blue, and green.
The limitation of exact matching lies in the potential misclassification of instances due to a single erroneous prediction for an area. This overlooks the opportunity for improved outcomes through a combination of predicted closures, leading to reduced emissions and shorter journey times. To address this, an alternative approach incorporated the Euclidean distance between the predicted and actual values. The introduction of a defined threshold allowed a distinction between accurate and inaccurate classifications for each instance. The bar plot, highlighting the results in blue, revealed an accuracy enhancement, increasing from 77 to 87 percent. This modification suggests that a solution that is close enough is likely to be acceptable, even if it is not an exact match. Fine-tuning through actual simulations might be necessary in such cases.
The limitation of exact matching is that a single erroneous prediction in one dimension, such as a closure area, can result in the misclassification of an entire instance. This strict approach overlooks the potential for improved outcomes through a combination of predicted closures, which could lead to reduced emissions and shorter journey times. To address this, an alternative approach was introduced that incorporates the Euclidean distance between the predicted and actual values. By defining a threshold, this method distinguishes between accurate and inaccurate classifications for each instance, even when the predictions are not an exact match.
The bar plot in Figure 14, with results displayed in blue, shows a notable accuracy improvement, increasing from 77 percent to 87 percent. This adjustment suggests that a “close enough” solution is often acceptable, even if it does not perfectly match the actual values in every dimension, but provides an acceptable overall result. However, fine-tuning through additional simulations may still be necessary in such cases to ensure optimal outcomes and further refine the predictions.
Additionally, a third approach was introduced to explore the feature vectors associated with similar policy outcomes, closures, and durations using Euclidean distance measurements. In the case of the predicted class vector being closely aligned with any of these selected feature vector classes, the prediction was considered accurate. This semantic approach, represented in green on the bar plot in the figure, achieved a 91-percent accuracy without requiring parameter tuning. The implication is that similar or even better outcomes can be achieved through policies aligned with decision-makers’ objectives, eliminating the need for manual or automatic parameter scaling.
4.7. Summary List of Modules
A list of several Urbanite modules is presented in Table 7.
Table 7.
Tools and technologies employed in the Urbanite project, including simulation platforms, machine learning models, and visualization techniques, highlighting their roles in data analysis, policy evaluation, and decision support.
5. Discussion and Implications
The Urbanite H2020 project introduces several innovative AI-based modules, providing a unified framework that empowers decision-makers to tackle complex urban mobility challenges efficiently. By addressing a wide range of urban challenges, from reducing pollution to enhancing infrastructure, the Urbanite system demonstrated its adaptability and efficacy in tackling real-world mobility issues. Moreover, Urbanite’s focus on fostering collaboration and knowledge sharing promotes a culture of innovation and continuous learning in smart-city development. Through establishing partnerships and disseminating best practices, Urbanite plays a pivotal role in a collective endeavour to enhance urban sustainability and resilience. The project’s collaborative spirit, bridging diverse geographic and professional groups, is vital for addressing the multifaceted challenges of urbanisation and championing inclusive, participatory approaches to urban development.
Regarding particular modules, the simulations are adaptable to any city with minimal adjustments, such as incorporating a city map and travel data through enhancements to the open-source simulation platform. The system was successfully tested across four pilot cities; however, due to space limitations, only the results from Bilbao are presented in detail. Discussions with the city teams confirmed the system’s efficacy and its potential to address real-world challenges. Furthermore, in leveraging the Orange tool, simulation outputs are seamlessly linked to machine learning methodologies, enabling effortless pattern identification without the need for direct programming. Additionally, the advanced multi-ML approach drastically reduces the time required to test a policy, cutting it down to mere seconds. Computing outcomes using machine learning was approximately three orders of magnitude faster than running full simulations, while still achieving 90-percent accuracy. Final verification was required only after identifying the most promising solutions, reducing the need to run hundreds of simulations to just a few, streamlining the process significantly.
In addition, the comprehensive decision support tool provides both subjective and objective analyses of the benefits and drawbacks of proposed urban modifications, ensuring a well-rounded evaluation process. In summary, both the project team and EU reviewers acknowledged the innovations introduced by the project as functionally significant, even at the stage of a functional prototype.
The advanced visualisation module enables the display of complex results, allowing the representation of up to five dimensions within a single graphical display. It visualises simulation results hourly over 24 h for various scenarios, with specific dimensions dedicated to KPIs. This module is primarily used in two scenarios, focusing on selected KPIs. Initially, 3–5 KPIs are chosen to detect disparities, though no variance is often observed across several KPI perspectives. Subsequent analyses typically concentrate on the KPIs exhibiting notable differences.
The ML modules operate on two levels: they identify patterns within the simulated data and construct an ML model that mirrors the simulator. One particular ML module, developed using Orange, with which no coding experience is needed, can predict specific KPIs, such as emissions, eliminating the need for comprehensive simulations. For example, it can estimate the impact of closing Moyua Square, providing accurate predictions for scenarios not previously encountered, as shown in Figure 12.
The advanced ML module further enhances the decision-making process by recommending mobility policies that align with predefined user preferences, reducing reliance on the traditional, time-consuming cycle of simulations and expert analysis. This approach effectively creates a rapid ML model of the simulator, significantly accelerating the policy development process. In the context of Bilbao, the module suggests closures of streets in the city centre and surrounding areas, guided by the improvement of user-specified KPIs. This innovation enables the quick evaluation of mobility policies in just seconds, a substantial improvement compared to the hours previously required for full simulations. While the ML-based model does not replicate the original simulator’s results exactly, it achieves over 90% accuracy, as demonstrated in Figure 14. Consequently, employing the ML simulator module for testing various mobility policies enables the fast verification of mobility policies, with the final adjustments verified through the original simulator.
However, while Urbanite’s comprehensive approach and innovative application of AI and ML technologies represent a significant advancement in smart-city planning, the project’s complexity and magnitude introduce considerable challenges. The project’s status as a detailed and complex research prototype is a primary concern. Although it illustrates the feasibility of fully operational software, a significant rewriting may be required for its practical, real-world implementation. This need for potential re-engineering highlights the divide between prototype creation and the development of deployable, user-friendly solutions. Another problem is updating a submodel or system support every few months. The current prototype’s size and complexity render it somewhat inaccessible for community groups unfamiliar with the system’s intricacies.
The practical application of the Urbanite system introduces additional complexities. In reality, it is usually not feasible to undertake infrastructural modifications in urban settings, such as the construction of tunnels or the development of new districts, within this project’s scope. Furthermore, the necessity for comprehensive data gathering to ensure accurate simulations and predictions underscores the requirement for multiple simulations, underlining a resource-demanding facet of the project that may impede its scalability and adaptability in varied urban landscapes.
From a social standpoint, Urbanite’s open-source framework offers a transparent and accessible platform for exploring AI-driven mobility solutions, democratizing smart city planning and encouraging the broader adoption of innovative technologies. This framework allows any community to assess potential urban mobility improvements. Moreover, Urbanite’s approach can be extended to other sectors, such as energy and water management, providing data-driven insights to optimize resource use and promote sustainability across urban services.
Regarding the five major contributions declared in the Introduction, the following can be summarily derived:
- A unified, upgraded, open-source simulator tested on four diverse cities: Tested across four cities, this platform addresses the challenge of standardising simulations for diverse urban settings. It enhances reliability and consistency in comparing urban policies, though the need for substantial execution time remains a challenge.
- An advanced decision support and recommendation module with the Dexi tool: The integration of the DEXi tool enables context-aware decision support, providing detailed recommendations based on subjective preferences. However, training is required for users to fully leverage its potential.
- Advanced visualisations for comprehensive policy assessment: Visualisation tools simplify the exploration of complex data, though most users can handle only up to 3D or 4D representations. Presenting higher-dimensional data remains a challenge.
- An ML module with the Orange tool: This module democratises machine learning for urban planning, making data-driven decision-making accessible to non-experts. However, users still require a few hours of training to maximise the system’s capabilities.
- The advanced multi-label ML module: The module introduces significant speed improvements, allowing rapid scenario testing. However, its complexity requires users to develop expertise in interpreting results and applying insights effectively.
6. Conclusions
In conclusion, the Urbanite H2020 project introduces a groundbreaking framework aimed at tackling the intricate challenges brought about by urbanisation and city expansion. By harnessing the power of disruptive technologies such as AI and ML, the project delivers a holistic strategy for decision-makers grappling with urban mobility dilemmas. The initiative is distinguished by five innovative components: an open-source simulator, sophisticated decision support and recommendation modules, state-of-the-art visualisations for policy evaluation, and two ML modules.
Urbanite’s approach revolutionises traditional urban planning, which has historically relied on expert knowledge, limiting exploring potential solutions due to the impracticality of exhaustive testing. While software simulators have helped mitigate this challenge, Urbanite takes it further by standardising and informing the decision-making process, offering valuable insights into diverse scenarios. This framework marks a significant advancement over prior studies focusing on individual cities or domains. Rigorous testing on four European cities—Bilbao, Messina, Amsterdam, and Helsinki—demonstrated Urbanite’s ability to address a range of challenges, from pollution reduction to public transport and cyclist safety improvements. The system provided critical insights into the effects of proposed changes and offered recommendations based on both objective and subjective criteria.
Two key observations emerged from the analyses. First, urban planning changes do not always produce outcomes that surpass the baseline scenario, often yielding complex results. For example, reducing emissions in city centres may inadvertently increase congestion in peripheral areas. This highlights the importance of evaluating the broader impact of each KPI on the overall urban quality of life. Second, the complexity of the Urbanite system requires proper user training to fully harness its capabilities. While most users can easily interpret three-dimensional (3D) and four-dimensional (4D) visualisations, five-dimensional (5D) representations prove challenging. However, with sufficient practice, approximately one-third of users become proficient in understanding 5D visualisations, making comprehensive training essential for maximising the system’s potential.
Despite its strengths, the Urbanite project does face certain limitations. One of the primary challenges lies in the sheer size and complexity of the software system, which consists of approximately a million lines of code and tens of modules. This vast codebase makes maintenance, debugging, and updates particularly difficult, creating potential barriers to its scalability and user adoption. The complexity of the system may also limit its accessibility for non-expert users or smaller municipalities without dedicated technical teams, reducing its broader appeal. Secondly, the Urbanite system remains a research prototype rather than a fully verified and tested application ready for large-scale deployment. While its proof of concept has been demonstrated in multiple pilot cities, the system has not undergone the rigorous validation required for real-world implementation at scale. This means there could be undiscovered issues, especially in scenarios that were not thoroughly tested during the development phase. As a prototype, it also lacks the fine-tuning and user-friendliness that a production-level system would require for seamless integration into existing city infrastructures.
A key area for further development is extending the framework to encompass a wider range of European cities, allowing for a broader evaluation of potential solutions across different urban contexts. Additionally, the framework could be expanded to address other city sectors, such as water consumption or public lighting, further enhancing its utility. There is also an opportunity to apply only specific modules like the ML modules in more cities, increasing the versatility and overall impact of the Urbanite framework. To ensure broader adoption, it will be crucial to provide user-friendly interfaces and comprehensive manuals, making the system more accessible and practical for a wide range of users.
In summary, Urbanite’s ongoing research and development efforts signal continued progress in smart city planning. Through leveraging AI-based methodologies and the insights gained from the four pilot cities, Urbanite is poised for further innovation. The project not only addresses today’s urban challenges but also envisions a future where technology drives sustainable growth and improves urban living. Urbanite’s use of AI in urban development emphasises the importance of considering social, economic, and environmental factors, laying the groundwork for more resilient and sustainable cities. Although the goal of providing EU citizens with an open-source platform for independent mobility modifications has not yet been fully realised, this functional prototype demonstrates the concept’s viability and sets the stage for future advancements.
Author Contributions
M.G. provided most of the conceptualization, supervision, and methodology for the Jozef Stefan Institute (JSI) part of the Urbanite system, and therefore, also for the general approach in this paper. M.S. (Miljana Shulajkovska), M.S. (Maj Smerkol) and G.N., provided most of the programming, integration, writing reports, project administration, and similar. All authors have read and agreed to the published version of the manuscript.
Funding
This work is part of a project that has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 870338. The authors also acknowledge the financial support from the Slovenian Research and Innovation Agency (research core funding No. P2-0209.
Data Availability Statement
Data associated with this study have been deposited at https://repo.ijs.si/urbanite/ml-mobility-proposal/-/tree/master (accessed on 11 September 2024).
Acknowledgments
This work is part of a project that has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 870338. The authors also acknowledge financial support from the Slovenian Research Agency (research core funding No. P2-0209). Several people played an important role in the related project, including Sergio Campos, Dino Alessi, Tatiana Bartolomé, Sonia Bilbao, Mario Colosi, Giuseppe Ciulla, Erik Dovgan, Maria Fazio, María José López, Maria Llambrich, Francesco Martella, Isabel Matranga, Ignacio Olabarrieta, Massimo Villari, Arianna Villari, Marit Hoefsloot, Jure Grabnar, Jorge Garcia, Eduardo Green, Maitena Ilardia, Torben Jastrow, Julia Jansen, Giovanni Parrino, Heli Ponto, Nathalie van Loon, Thomas van Dijk, Keye Wester, Zdenko Vuk, and Iñaki Etxaniz.
Conflicts of Interest
There are no conflicts of interest. Some project members were considered for coauthorship; however, it was determined that the key contributions were made by the authors listed in the paper. Individuals who contributed less significantly to the study are acknowledged in the acknowledgments section.
References
- Dameri, R.P. Searching for smart city definition: A comprehensive proposal. Int. J. Comput. Technol. 2013, 11, 2544–2551. [Google Scholar] [CrossRef]
- Law, K.H.; Lynch, J.P. Smart city: Technologies and challenges. IT Prof. 2019, 21, 46–51. [Google Scholar] [CrossRef]
- Anthopoulos, L.G. Understanding the smart city domain: A literature review. In Transforming City Governments for Successful Smart Cities; Springer: Berlin/Heidelberg, Germany, 2015; pp. 9–21. [Google Scholar]
- Bibri, S.E.; Krogstie, J. Smart sustainable cities of the future: An extensive interdisciplinary literature review. Sustain. Cities Soc. 2017, 31, 183–212. [Google Scholar] [CrossRef]
- Roda-Sanchez, L.; Cirillo, F.; Solmaz, G.; Jacobs, T.; Garrido-Hidalgo, C.; Olivares, T.; Kovacs, E. Building a Smart Campus Digital Twin: System, Analytics and Lessons Learned from a Real-World Project. IEEE Internet Things J. 2024, 11, 4614–4627. [Google Scholar] [CrossRef]
- White, G.; Zink, A.; Codecá, L.; Clarke, S. A digital twin smart city for citizen feedback. Cities 2021, 110, 103064. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence a Modern Approach; Pearson: London, UK, 2010. [Google Scholar]
- Washburn, D.; Sindhu, U.; Balaouras, S.; Dines, R.A.; Hayes, N.; Nelson, L.E. Helping CIOs understand “smart city” initiatives. Growth 2009, 17, 1–17. [Google Scholar]
- Batty, M. Artificial Intelligence and Smart Cities. Environ. Plan. B Urban Anal. City Sci. 2018, 45, 3–6. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Gams, M.; Kramar, S. Evaluating ChatGPT’s Consciousness and Its Capability to Pass the Turing Test: A Comprehensive Analysis. J. Comput. 2024, 12, 219–237. [Google Scholar] [CrossRef]
- Farsi, M.; Daneshkhah, A.; Hosseinian-Far, A.; Jahankhani, H. Digital Twin Technologies and Smart Cities; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Naik, A.; Samant, L. Correlation review of classification algorithm using data mining tool: WEKA, Rapidminer, Tanagra, Orange and Knime. Procedia Comput. Sci. 2016, 85, 662–668. [Google Scholar] [CrossRef]
- Shulajkovska, M.; Smerkol, M.; Dovgan, E.; Gams, M. A machine-learning approach to a mobility policy proposal. Heliyon 2023, 9, e20393. [Google Scholar] [CrossRef]
- Shulajkovska, M.; Noveski, G.; Smerkol, M.; Grabnar, J.; Dovgan, E.; Gams, M. EU smart cities: Towards a new framework of urban digital transformation. Informatica 2023, 47. [Google Scholar] [CrossRef]
- Kshetri, N.; Alcantara, L.L.; Park, Y. Development of a smart city and its adoption and acceptance: The case of new songdo. Commun. Strateg. 2014, 96, 113–128. [Google Scholar]
- Bakici, T.; Almirall, E.; Wareham, J. A smart city initiative: The case of Barcelona. J. Knowl. Econ. 2013, 4, 135–148. [Google Scholar] [CrossRef]
- Syed, A.S.; Sierra-Sosa, D.; Kumar, A.; Elmaghraby, A. IoT in smart cities: A survey of technologies, practices and challenges. Smart Cities 2021, 4, 429–475. [Google Scholar] [CrossRef]
- Bartolozzi, M.; Bellini, P.; Nesi, P.; Pantaleo, G.; Santi, L. A smart decision support system for smart city. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 117–122. [Google Scholar]
- Bonczek, R.H.; Holsapple, C.W.; Whinston, A.B. Foundations of Decision Support Systems; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Barceló, J.; Codina, E.; Casas, J.; Ferrer, J.L.; García, D. Microscopic traffic simulation: A tool for the design, analysis and evaluation of intelligent transport systems. J. Intell. Robot. Syst. 2005, 41, 173–203. [Google Scholar] [CrossRef]
- Fellendorf, M.; Vortisch, P. Microscopic traffic flow simulator VISSIM. In Fundamentals of Traffic Simulation; Springer: Berlin/Heidelberg, Germany, 2010; pp. 63–93. [Google Scholar]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; Wießner, E. Microscopic traffic simulation using sumo. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2575–2582. [Google Scholar]
- Balmer, M.; Rieser, M.; Meister, K.; Charypar, D.; Lefebvre, N.; Nagel, K. MATSim-T: Architecture and simulation times. In Multi-Agent Systems for Traffic and Transportation Engineering; IGI Global: Hershey, PA, USA, 2009; pp. 57–78. [Google Scholar]
- Chang, F.; Das, D. Smart nation Singapore: Developing policies for a citizen-oriented smart city initiative. In Developing National Urban Policies: Ways Forward to Green and Smart Cities; Springer: Berlin/Heidelberg, Germany, 2020; pp. 425–440. [Google Scholar]
- Breslow, H. The smart city and the containment of informality: The case of Dubai. Urban Stud. 2021, 58, 471–486. [Google Scholar] [CrossRef]
- Ghasemi, A. Sustainability and Data Collection in the Smart City—A Case Study of the Wi-Fi and Bluetooth Tracking Project in Copenhagen; Lund University: Lund, Sweden, 2015. [Google Scholar]
- Flynn, A.; Valverde, M. Where the Sidewalk ends: The governance of waterfront Toronto’s sidewalk labs deal. Windsor Yearb. Access Justice 2019, 36, 263–283. [Google Scholar] [CrossRef]
- Priyadarshi, R.; Ranjan, R.; Vishwakarma, A.K.; Kumar, R.R. A Comprehensive Overview of Transformative Potential of Machine Learning and Wireless Sensor Networks in Sustainable Urban Development. In Proceedings of the 2024 International Conference on Intelligent Systems for Cybersecurity (ISCS), Gurugram, India, 3–4 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Capra, C.F. The Smart City and its citizens: Governance and citizen participation in Amsterdam Smart City. Int. J. Plan. Res. (IJEPR) 2016, 5, 20–38. [Google Scholar] [CrossRef]
- Macrorie, R.; Marvin, S.; Smith, A.; While, A. A common management framework for European smart cities? The case of the European innovation partnership for smart cities and communities six nations forum. J. Urban Technol. 2023, 30, 63–80. [Google Scholar] [CrossRef]
- Anthony Jnr, B. Exploring data driven initiatives for smart city development: Empirical evidence from techno-stakeholders’ perspective. Urban Res. Pract. 2022, 15, 529–560. [Google Scholar] [CrossRef]
- Shahat Osman, A.M.; Elragal, A. Smart cities and big data analytics: A data-driven decision-making use case. Smart Cities 2021, 4, 286–313. [Google Scholar] [CrossRef]
- Ahvenniemi, H.; Huovila, A. How do cities promote urban sustainability and smartness? An evaluation of the city strategies of six largest Finnish cities. Environ. Dev. Sustain. 2021, 23, 4174–4200. [Google Scholar] [CrossRef]
- Bokolo, A.J. Data driven approaches for smart city planning and design: A case scenario on urban data management. Digit. Policy Regul. Gov. 2023, 25, 351–367. [Google Scholar] [CrossRef]
- Ortega-Fernández, A.; Martín-Rojas, R.; García-Morales, V.J. Artificial intelligence in the urban environment: Smart cities as models for developing innovation and sustainability. Sustainability 2020, 12, 7860. [Google Scholar] [CrossRef]
- Benites, A.J.; Simoes, A.F. Assessing the urban sustainable development strategy: An application of a smart city services sustainability taxonomy. Ecol. Indic. 2021, 127, 107734. [Google Scholar] [CrossRef]
- Komasi, H.; Zolfani, S.; Nemati, A. Evaluation of the social-cultural competitiveness of cities based on sustainable development approach. Decis. Mak. Appl. Manag. Eng. 2023, 6, 583–602. [Google Scholar] [CrossRef]
- Wolniak, R. Artificial Intelligence and Smart Cities: A Scopus-Based Literature Review. J. Urban Technol. 2024, 31, 45–67. [Google Scholar]
- Garau Guzman, J.; Baeza, V. Enhancing Urban Mobility through Traffic Management with UAVs and VLC Technologies. Drones 2023, 8, 7. [Google Scholar] [CrossRef]
- W Axhausen, K.; Horni, A.; Nagel, K. The Multi-Agent Transport Simulation MATSim; Ubiquity Press: London, UK, 2016. [Google Scholar]
- Kučera, T.; Chocholáč, J. Design of the city logistics simulation model using PTV VISSIM software. Transp. Res. Procedia 2021, 53, 258–265. [Google Scholar] [CrossRef]
- Berčič, T.; Bohanec, M.; Ažman Momirski, L. Integrating Multi-Criteria Decision Models in Smart Urban Planning: A Case Study of Architectural and Urban Design Competitions. Smart Cities 2024, 7, 786–805. [Google Scholar] [CrossRef]
- Zupan, B.; Demsar, J.; Kattan, M.W.; Ohori, M.; Graefen, M.; Bohanec, M.; Beck, J.R. Orange and decisions-at-hand: Bridging predictive data mining and decision support. In Proceedings of the ECML/PKDD Workshop on Integrating Aspects of Data Mining, Decision Support and Meta-Learning, Freiburg, Germany, 3–5 September 2001; pp. 151–162. [Google Scholar]
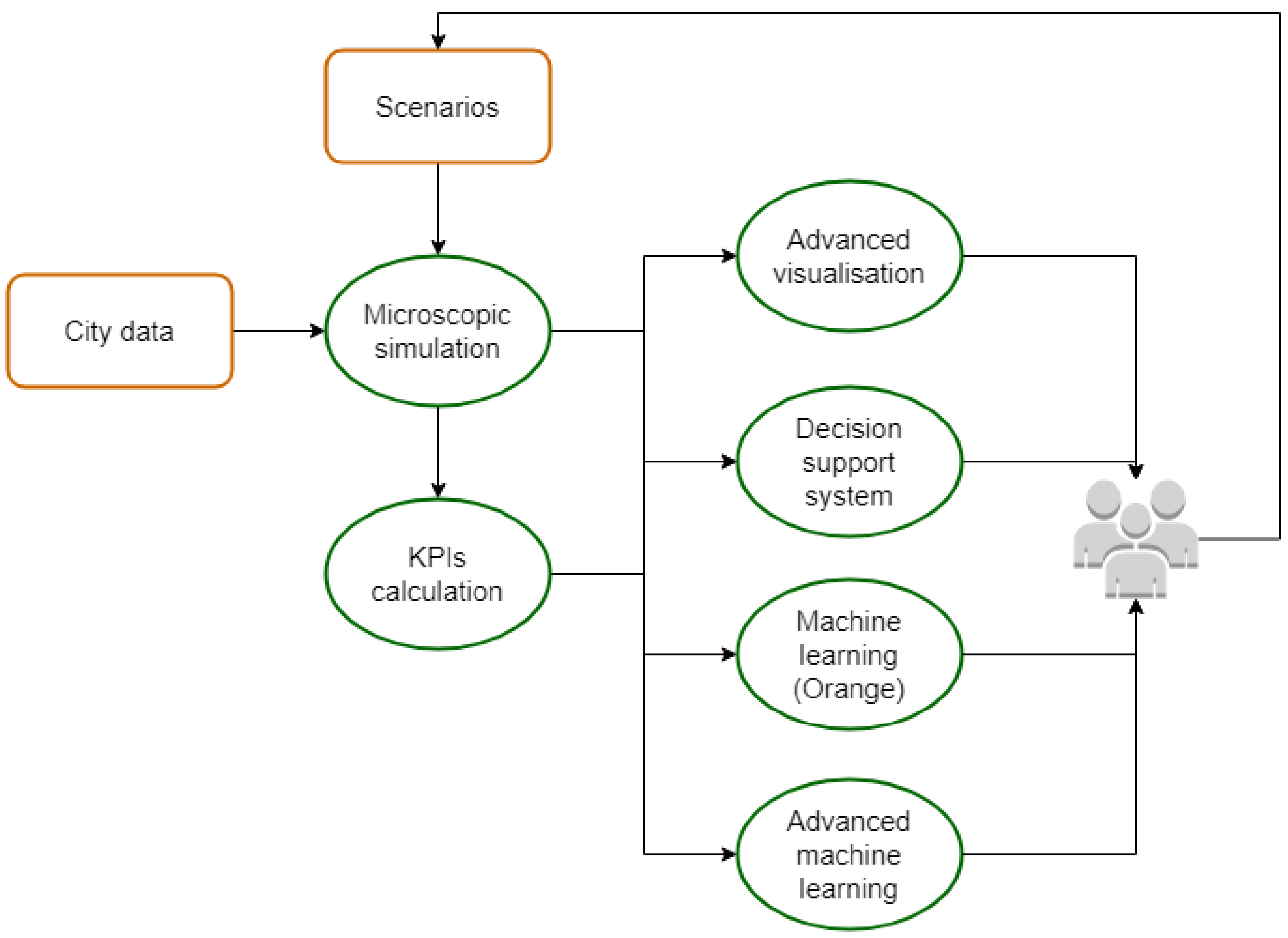
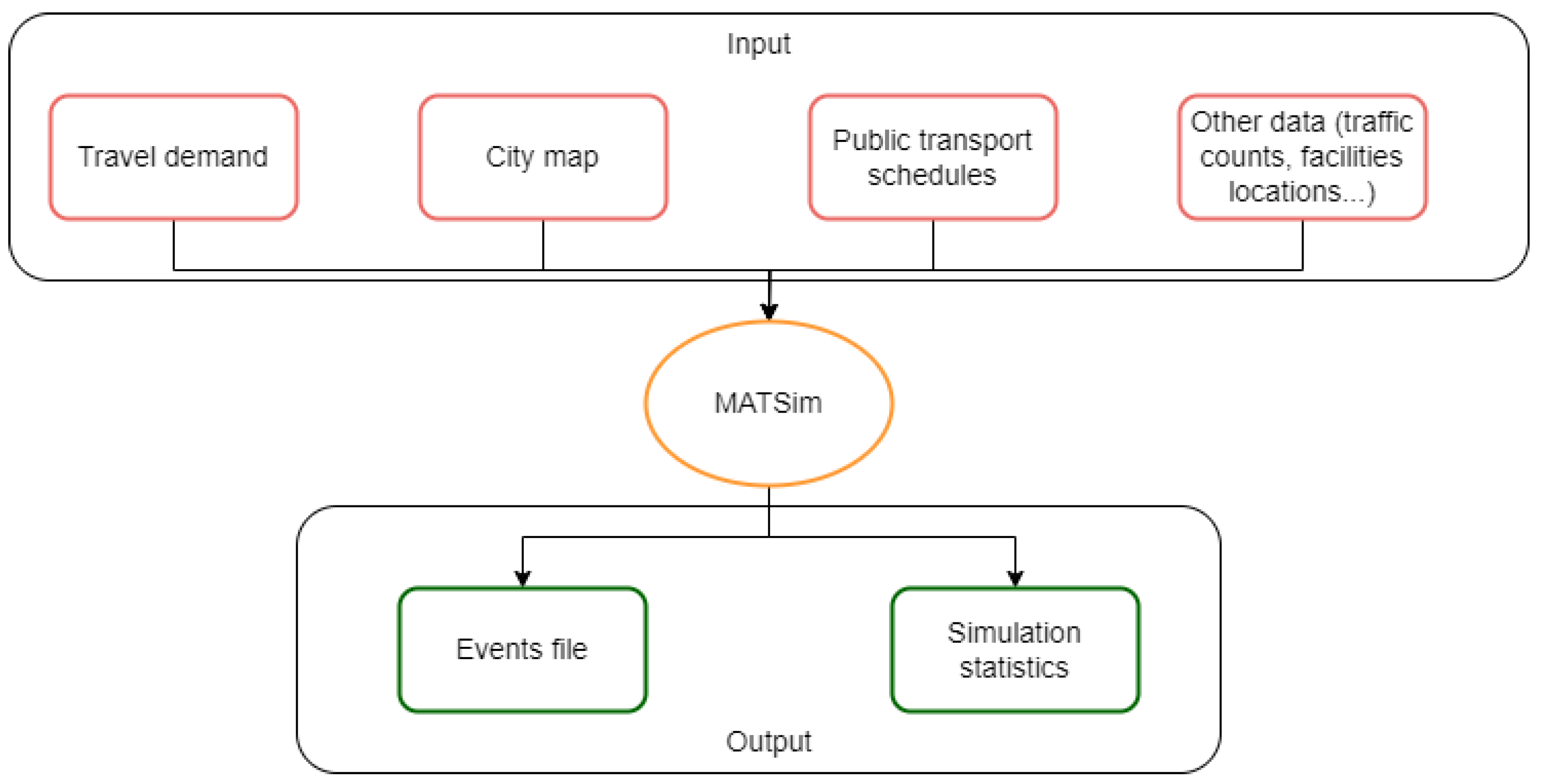
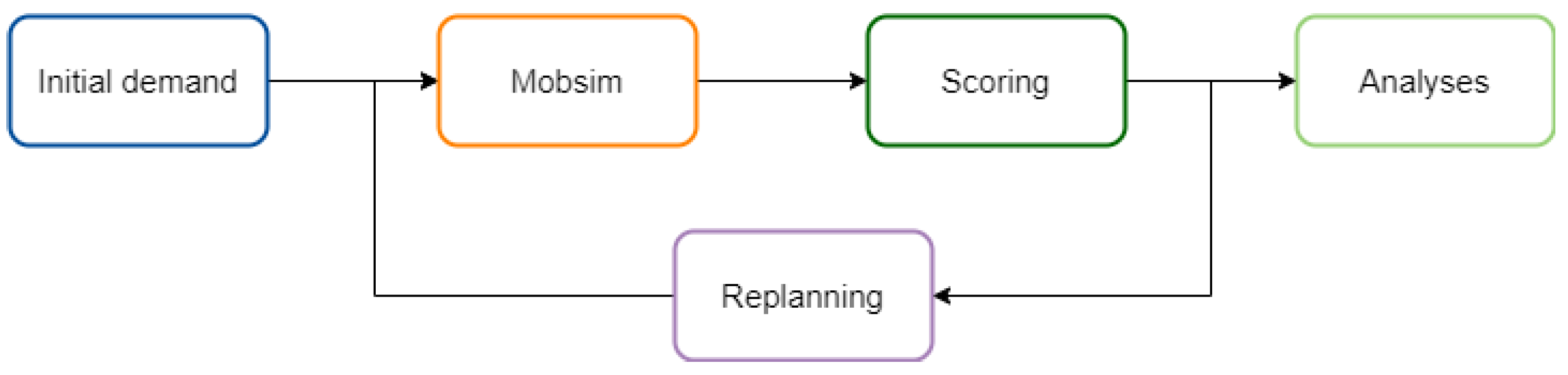
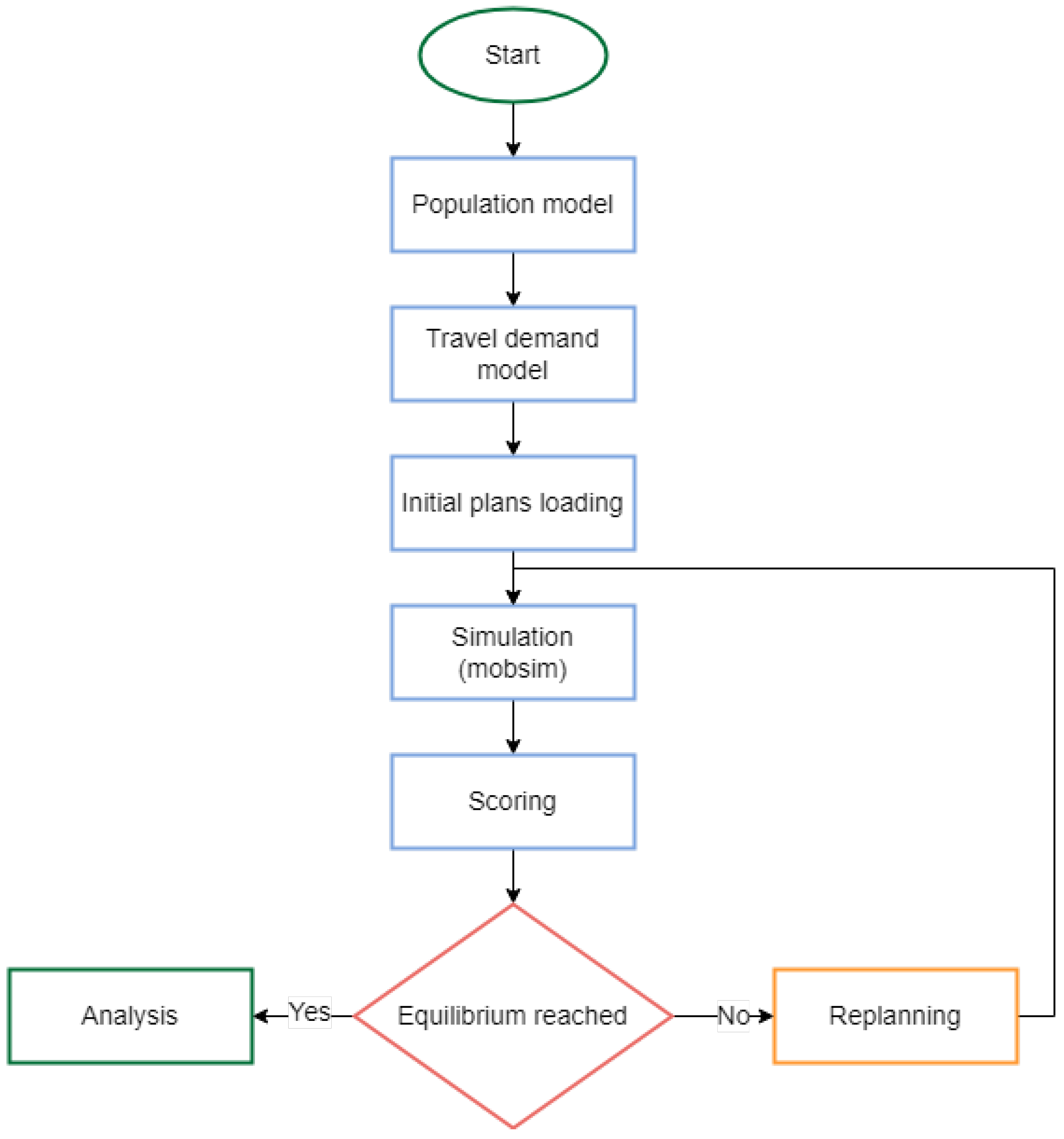
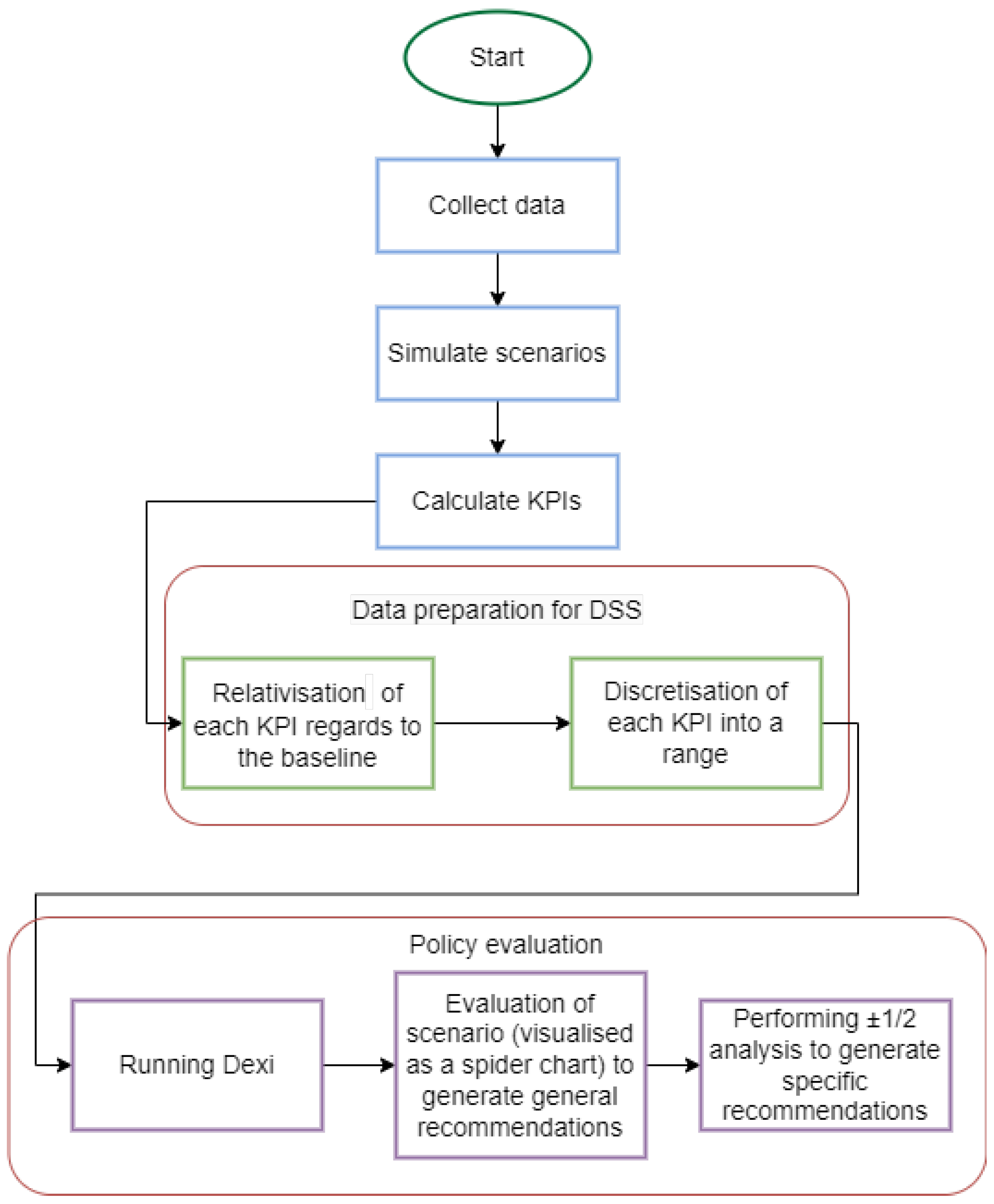
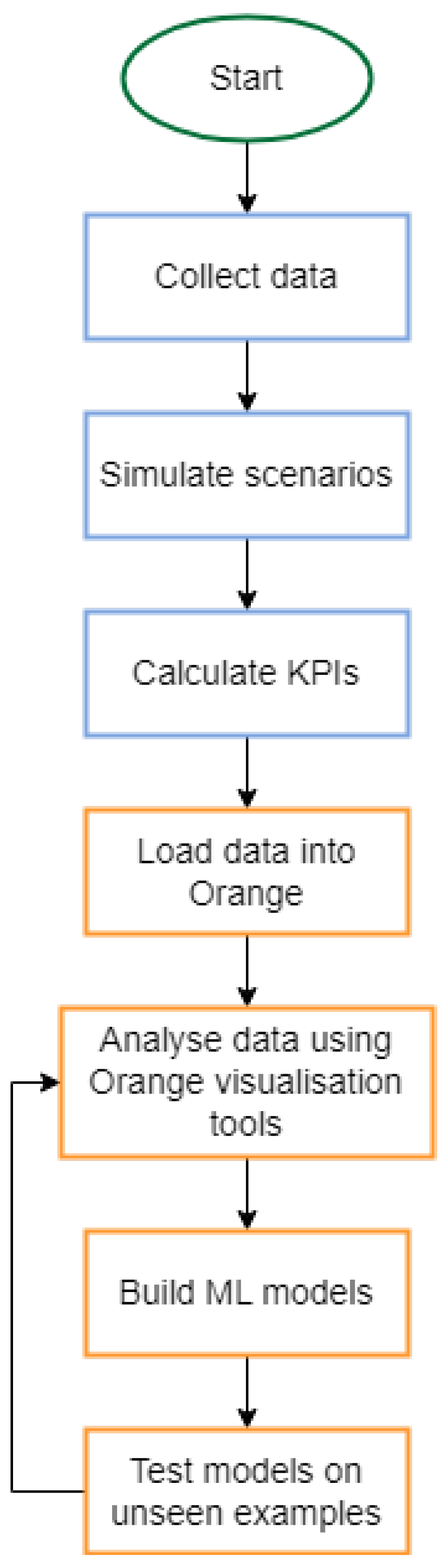
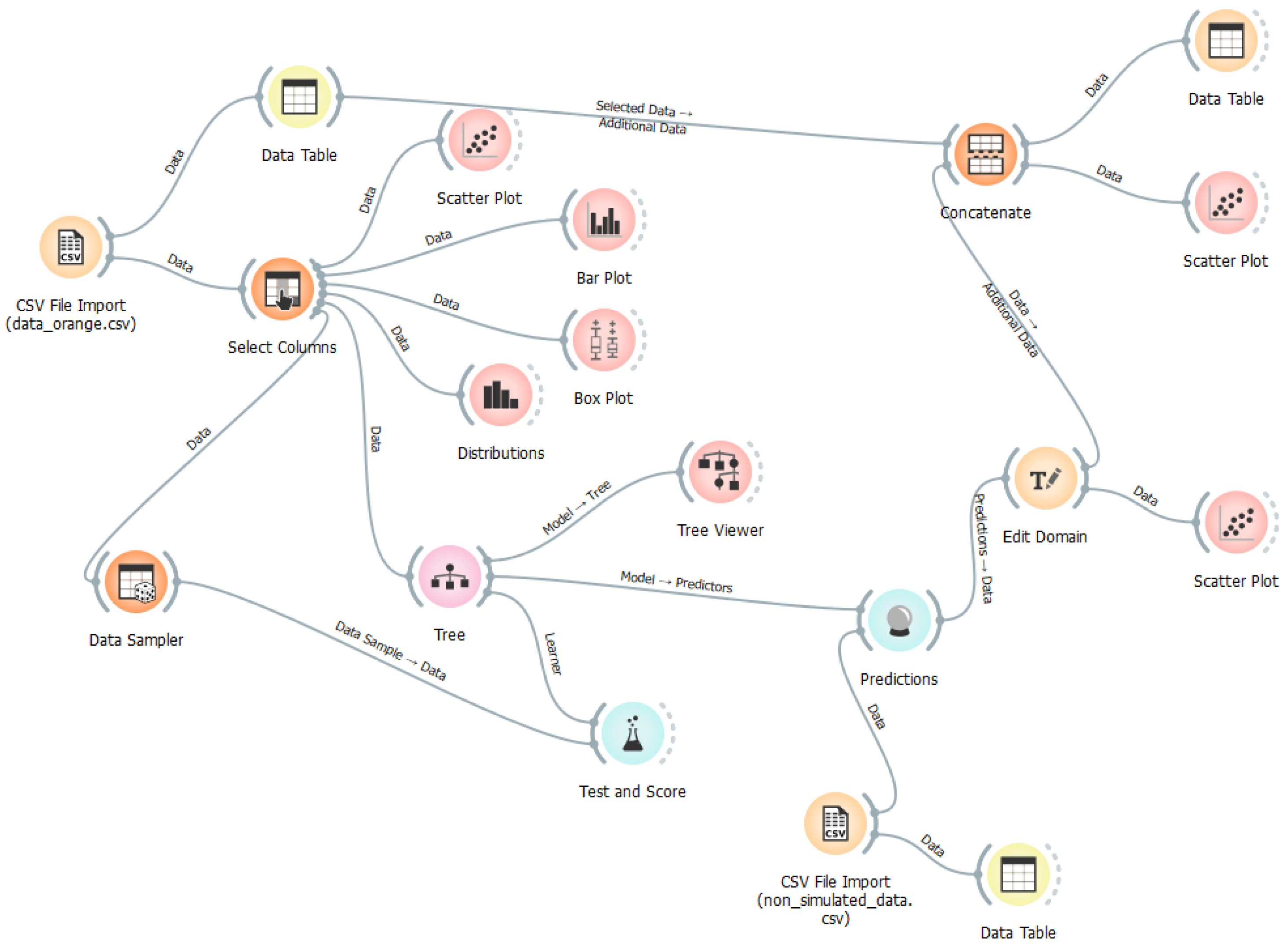
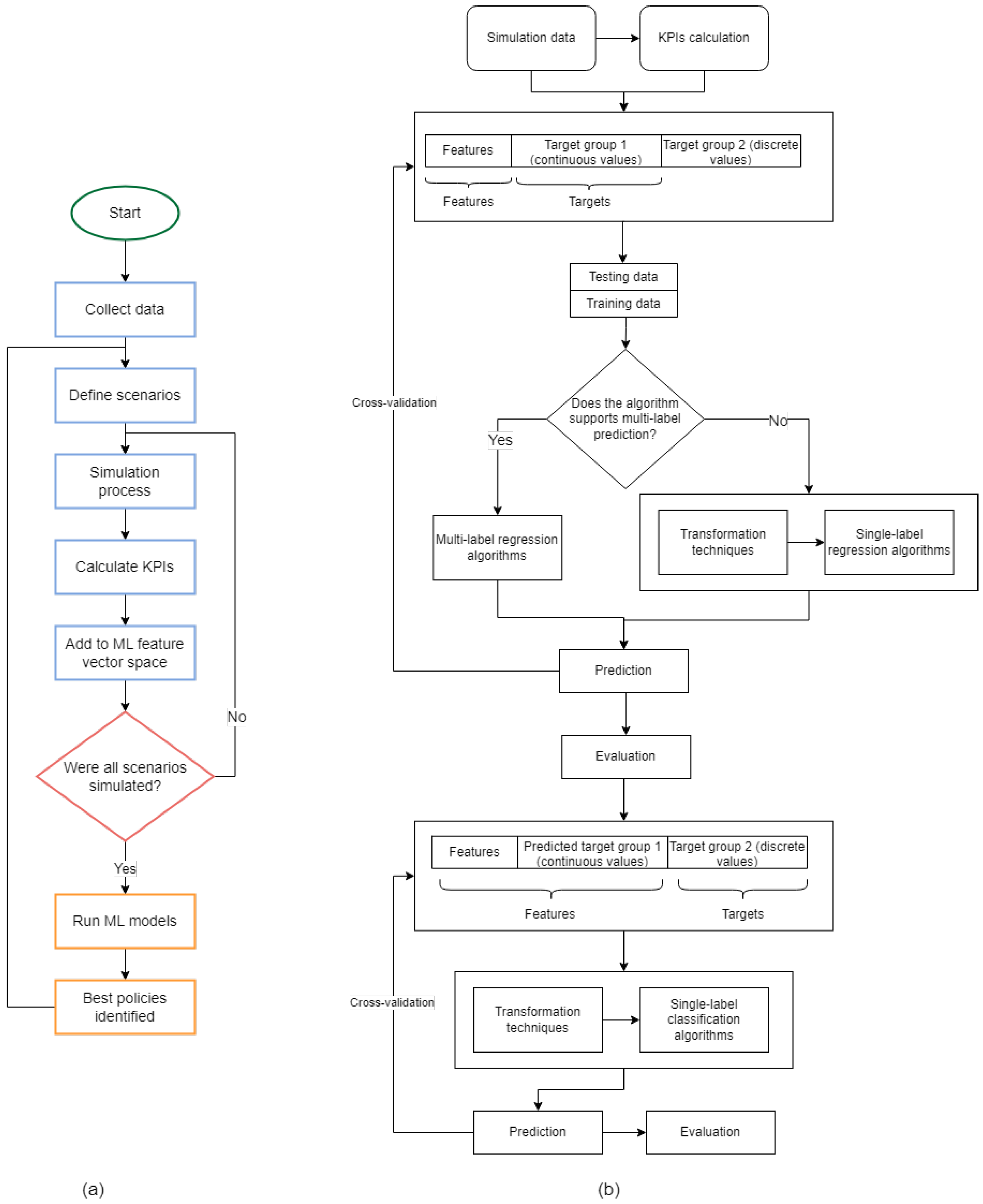
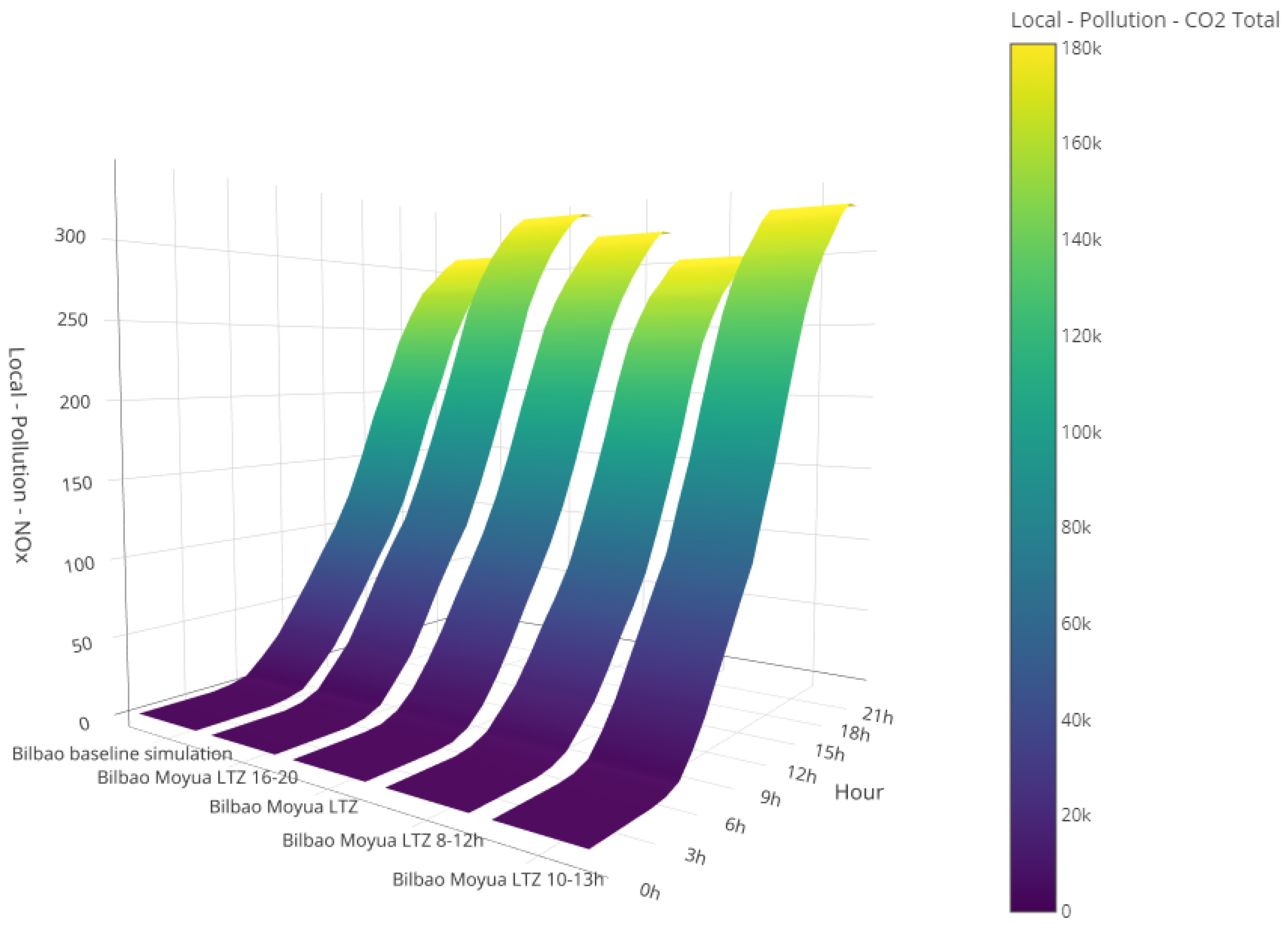
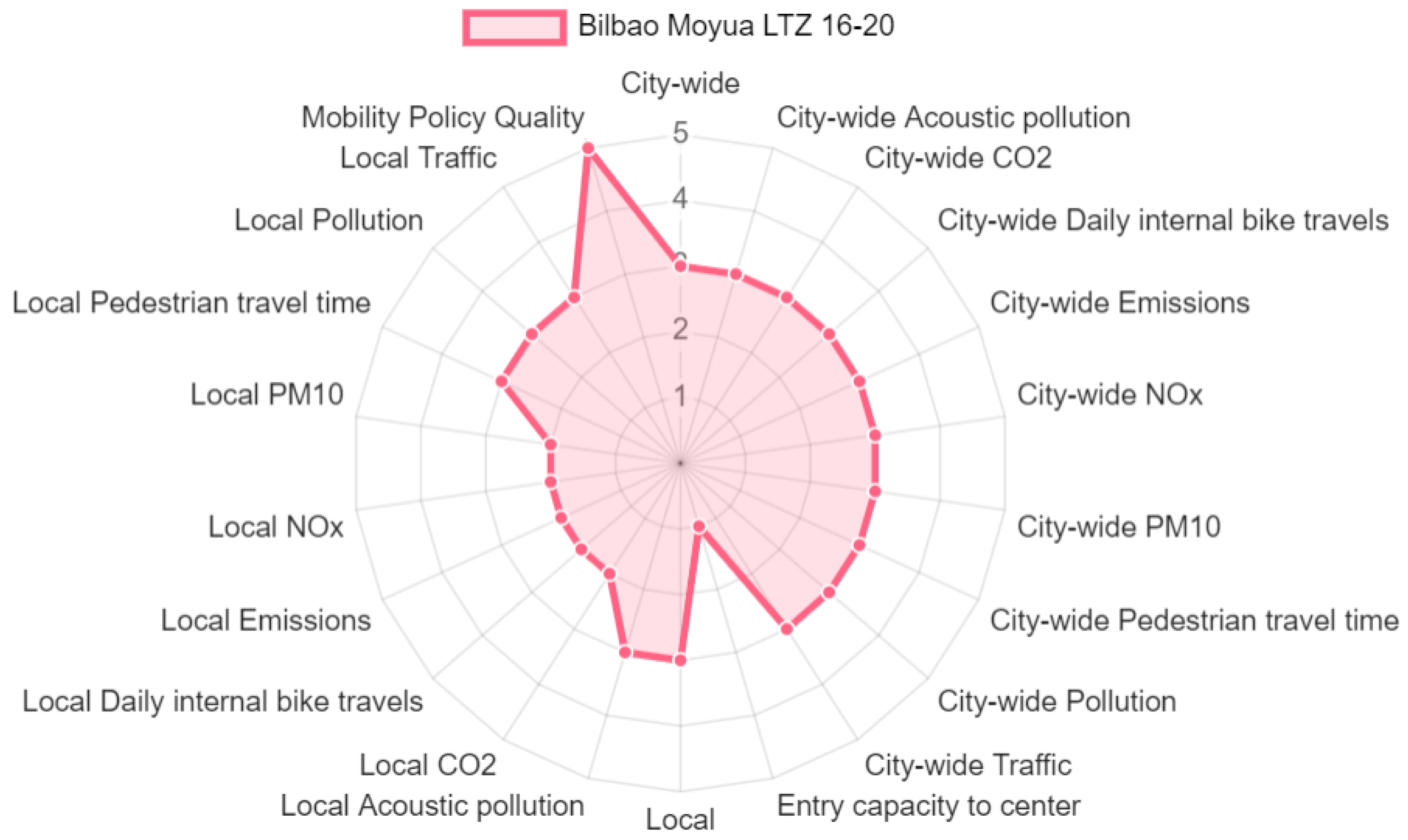
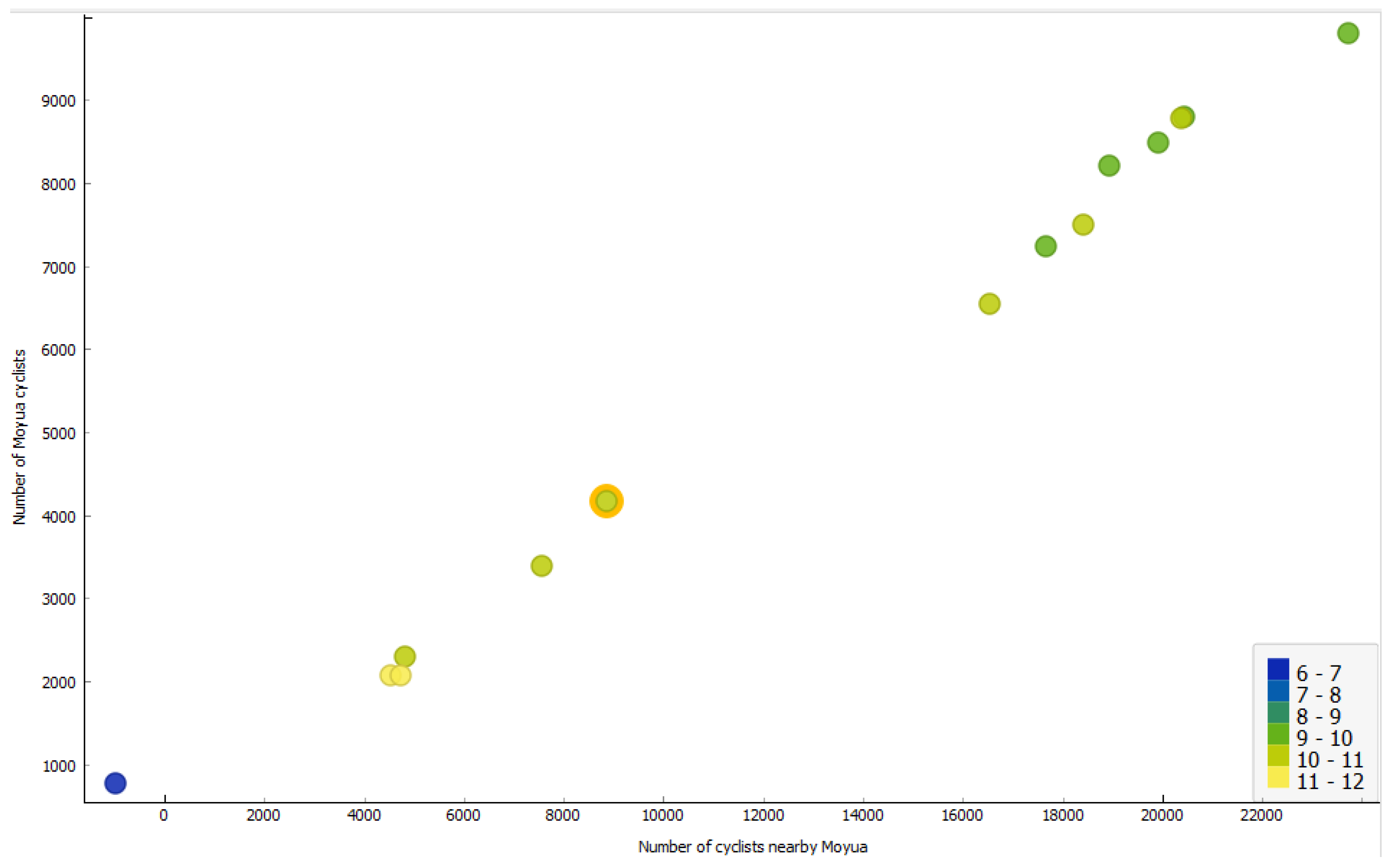
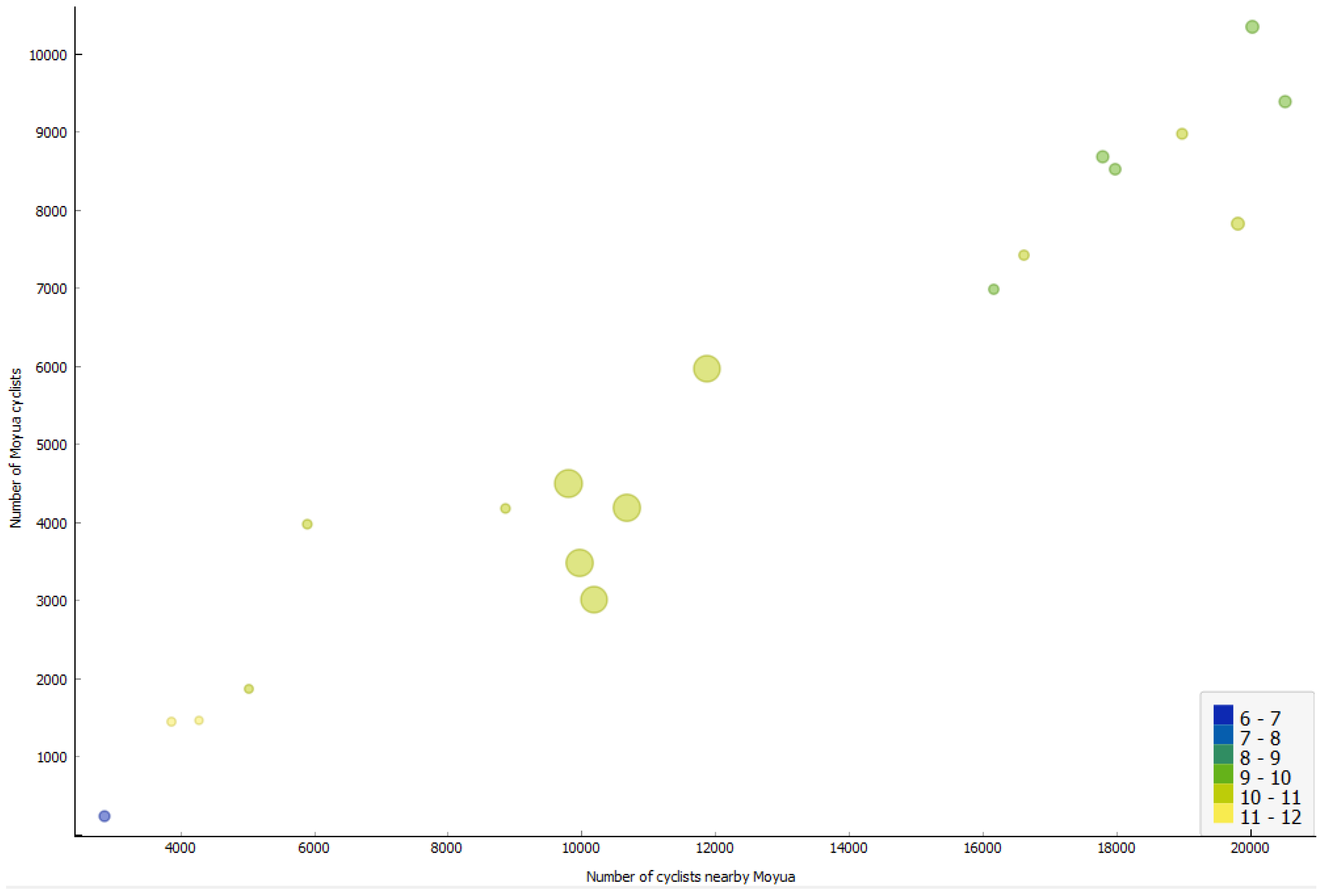
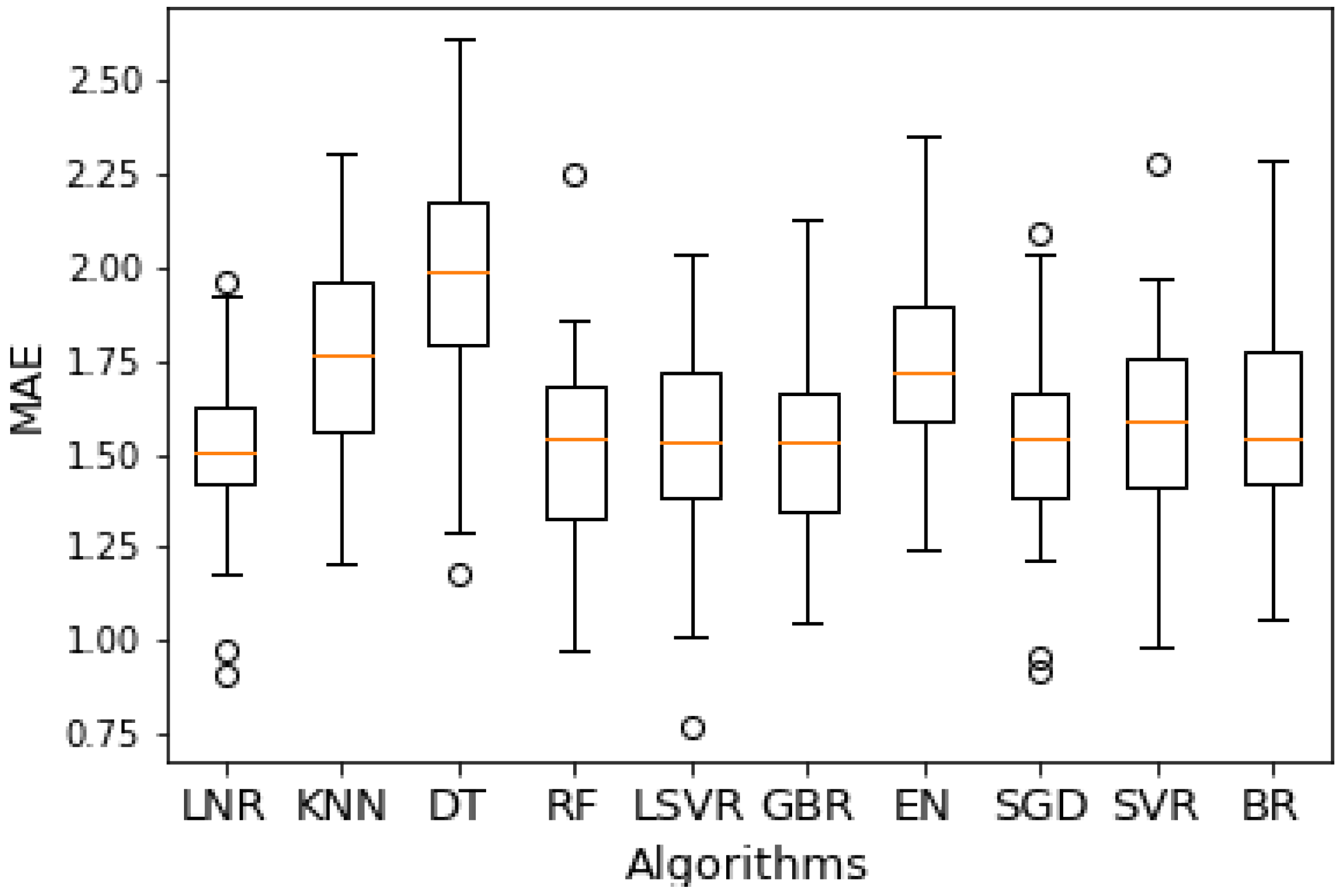
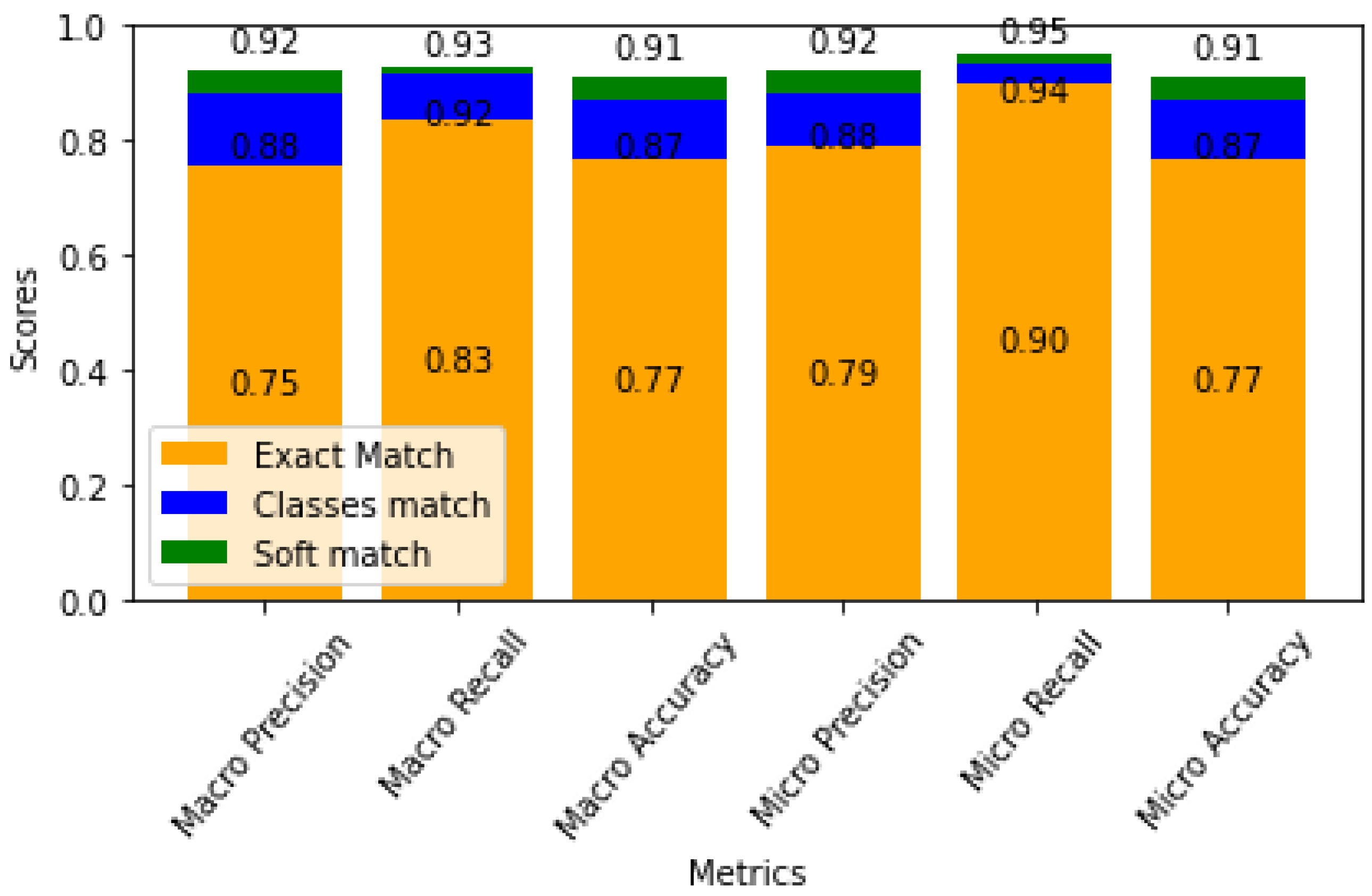
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).