1. Introduction
Energy plays a crucial role in modern society, whether through the distribution of electricity, gas, or other forms of energy [
1]. With increasing digitization, energy networks are becoming more interconnected with information technology (IT) and operational technology (OT) [
2], enabling better monitoring and management of energy networks, thereby enhancing their efficiency and security [
3]. In the context of energy systems, digital twins (DTs) are increasingly being discussed as a way to optimize the functional parameters of the entire system [
4]. Energy networks are one of the key elements of the modern world, comprising extensive infrastructures that include generation sources, transmission and distribution grids, connections, and consumers [
5]. The purpose of electrical power networks is to ensure an efficient, reliable, and secure energy distribution throughout the society [
6]. The energy sector also engages in research and development in the field of data communication and network management to achieve optimal performance and security [
7]. Data communication networks are responsible for the transmission and control of data in energy systems, which includes various hardware and software components interconnected so as to allow data transfer between different devices [
5]. Currently, data networks for energy systems have become a key element in the modern energy sector, facilitating fast and reliable data transmission, monitoring, and control of energy systems [
8]. Hardware components may include sensors, actuators, control units, and others, while software components may encompass various applications for energy network management and control, database elements, historical servers, and other supporting services. Communication between these components is ensured through various protocols that enable fast and reliable data transmission and control signals. An overview schematic of an electrical network is shown in
Figure 1 [
9].
The diagram consists of seven basic components: (1) markets, (2) operational systems, (3) service providers, and an energy chain composed of four main parts: (4) power plants (generation sites), (5) transmission system, (6) distribution system, and (7) customers (consumption sites) [
9]. All parts except for service providers communicate with each other, forming an integrated system [
2]. Within the energy chain, data about the status of the network are transmitted, as well as the electrical energy itself [
10]. Operational systems are responsible for monitoring and controlling various aspects of the electrical network [
6]. They enable network operators to monitor the status of the network, control devices, perform diagnostics and analysis, and respond to various events and situations in the network [
11]. The last components are markets and service providers. Markets influence the price of energy and services in smart grids, while service providers are responsible for providing various energy services such as load management, electric vehicle charging, and optimization of energy consumption [
9].
A digital twin (DT) is a virtual model of a physical system or object that allows real-time analysis, monitoring, and simulation [
12]. This model uses data collected from the real environment to accurately reflect the current state and behavior of the system. In contrast, a digital twin network (DTN) extends the principles of DTs to an entire system or network composed of multiple interconnected components, such as electric energy systems (EES) [
13]. The main difference between DTs and DTNs lies in the scope and complexity of the modeling. DTs focus on individual objects, whereas DTNs encompass entire networks, emphasizing the interactions within a complex system.
DTs represent a significant advancement over traditional data collection and analysis methods, primarily because of their ability to provide accurate real-time models of physical systems. In terms of accuracy, DTs excel because they utilize complex and up-to-date data directly from operations, enabling more precise simulations and predictions. Traditional methods such as manual measurements and offline analyses often suffer from delays and limited ability to update models, which can lead to less accurate results [
14]. In terms of speed, DTs allow for instant analysis and response to changes in real time, which is crucial for many applications. In contrast, traditional methods can be time consuming, especially when they involve manual data collection and subsequent analysis [
12]. Regarding costs and efficiency, DTs may initially require higher investments in technology and data infrastructure [
15]. However, in the long term, they offer greater efficiency through process optimization, predictive maintenance, and reduced operational costs. While traditional methods may be cheaper to implement, their limited efficiency can lead to higher costs in the long run.
The application scenarios for DTs demonstrate their wide-ranging use across various industries, where they often outperform traditional methods. For example, in the energy sector DTs can enable precise monitoring and prediction of the performance of the energy system, which is critical to optimizing energy production and distribution. In the manufacturing and automotive industries, DTs can support predictive maintenance and process optimization, leading to increased productivity and reduced downtime. In these scenarios, traditional methods are limited by their inability to perform real-time analysis and often require manual intervention, reducing their effectiveness [
16]. However, there are scenarios in which traditional methods may continue to be advantageous. For example, in smaller applications or environments where real-time analysis is not necessary, traditional methods may be sufficient and more cost-effective. In certain cases where only a basic level of monitoring and analysis is required, the deployment of DTs could be unnecessarily complex and expensive.
The current state of DT technology shows that it has evolved rapidly in recent years and reached a high level of maturity, particularly in sectors such as energy, manufacturing, biomedicine, and transportation [
17]. In these areas, DTs provide sophisticated tools for simulation, analysis, and prediction, enabling them to surpass traditional methods in many aspects. However, DTs continue to face challenges such as high implementation costs, the need for extensive data infrastructure, and data security concerns. Moreover, while DTs offer significant advantages in accuracy and speed, their effective use requires advanced skills and knowledge, which can be a barrier for some organizations. Traditional methods of data collection and analysis, although less sophisticated, are well established, easy to implement, and do not demand such high levels of technology and expertise. Although they lack the advanced capabilities of DTs, their simplicity and low cost can make them an attractive option for many organizations, especially in less critical applications. In general, while DTs can be said to represent the future in many industries, their full potential will only be realized with further technological advancements and the broader adoption of these systems.
Creating DTNs for the management of EES brings about specific challenges and obstacles that must be overcome for effective implementation. These challenges stem from the complex and dynamic nature of EES, which encompasses a wide range of heterogeneous components and interactions. One of the main challenges is the availability and integration of data. Gathering and integrating extensive and heterogeneous data from various sources in real time is crucial for creating an accurate and up-to-date DTN. This challenge involves data collection, standardization, and linking data from different systems and devices. Another key challenge is modeling complex systems. EES involve intricate interactions among physical, control, and market components. Creating a realistic and precise DTN model capable of capturing these interactions and simulating the behavior of EES under various conditions is a demanding task. Finding sufficient computational power is also a significant challenge. Simulating complex DTN models in real time requires substantial computational power, which may be a hindrance to implementing DTNs in extensive EES contexts. Cybersecurity cannot be overlooked either, as DTNs contain sensitive information about EES. Ensuring the protection of DTNs against unauthorized access, manipulation, and cyberattacks is essential. Lastly, there are organizational and regulatory aspects to consider. Implementing DTN requires changes in organizational processes and regulatory frameworks for managing EES. This can pose a challenge in terms of coordination among various stakeholders and adapting existing procedures.
Contemporary research in the field of power engineering emphasizes the optimization of energy network management and operation through modern technologies. As part of this effort, digital models are utilized to provide a virtual representation of physical systems and allow detailed analysis and simulation of their behavior [
18]. These models further specialize in digital shadows and DTs, representing even more sophisticated forms of digital models capable of achieving higher levels of realism and accuracy. The direct application of DTs can be found in various segments of the energy system. For example, in the area of energy production, DTs can be used to monitor and optimize power plant performance by enabling the simulation of different operational scenarios, predicting equipment failures, and reducing downtime. In transmission systems, DTNs can help to manage the flow of electricity across the grid by simulating various load conditions, identifying potential bottlenecks, and optimizing the energy distribution in real-time. For distribution networks, DTNs allow operators to model grid behavior under different conditions, leading to better management of the distributed energy resource (DER), improved grid stability, and faster fault detection and resolution. By integrating these digital models into the energy system, operators can achieve greater efficiency, reliability, and resilience, ultimately contributing to more sustainable energy management. A key trend today is the increasing interconnection of systems in various domains, which could bring about revolutionary changes in the energy sector. The development of DT technologies promises to connect different systems in a way that enables more comprehensive and precise data collection and analysis. Such integrated approaches could significantly enhance predictive capabilities and response times between subsystems. For example, integrating a DTN of an energy systems with other critical infrastructure systems could provide major advantages during crises by allowing faster and more effective decision-making and coordination through real-time data from various sources. This interconnected approach could also improve the prediction of system behavior under nonstandard conditions and support preventive measures, leading to earlier detection of potential issues and more effective strategies for their resolution. Although it remains unclear how exactly these possibilities will unfold, the benefits of system interconnection promise substantial improvements in the management of complex and dynamic energy systems. As technologies continue to evolve, their ability to provide holistic insights and drive coordinated responses may become a key factor in successfully handling the growing complexity and demands of modern energy systems.
This article focuses on analyzing approaches to creating DTs and providing a detailed examination of various types of connection within these models, particularly with regard to their utilization in managing electrical power systems. Based on this analysis, key parameters of DTs are identified, including their architecture, integration mechanisms, and functionality, with an emphasis on the specifics of electro-energy applications. In addition, we analyze the main challenges and obstacles currently associated with the process of creating, implementing, and updating DTs in the context of electro-energy systems management. Based on these findings, recommendations are formulated for effective ways to address these issues and maximizing the utilization of DTs in practice within the electro-energy sector.
2. Related Works
Digital twins represent objects of intensive investigation within the scientific community, drawing the attention of numerous research teams worldwide [
19]. These digital replicas of physical entities serve as the basis for intelligent automation, enabling detailed analysis of specific entities and decision-making based on complex datasets [
20]. Current DTs are typically the result of individual and unique implementations, requiring extensive expertise and resources for deployment [
12].
The MIT team has focused on developing sophisticated algorithms for creating dynamic DTs using artificial intelligence (AI) methods [
20], with the aim of improving the accuracy of system simulations and predictions. They have been able to realize advanced algorithms that enable the creation of DTs capable of modeling and predicting the behavior of real systems with higher accuracy. These abstract mathematical models enable the formulation of a probabilistic graphical model for a DT. This model provides a systematic approach to data integration, analysis, model updating, control optimization, and uncertainty quantification. Furthermore, the methodology of reducing component-based models allows for scalable physics-based DTs and dynamic in-flight state monitoring. The combination of interpretable machine learning and physics-based models enables efficient and interpretable sensing strategies for DTs. However, it is necessary to consider certain limitations of this research. The computational complexity of physics-based models can be restrictive for real-time applications as well as for many queries. Classical model reduction techniques may not meet the scalability and expressiveness requirements of DTs. As a result, a number of scientific questions have been identified that require further investigation. These include questions regarding effective data integration for DTs, leveraging physics-based models for predictive DTs, designing data sensing strategies for DTs, and the relationship between interpretable machine learning and physics-based models in DT creation. Related works also include the exploration of methods for parameterizing DT models. This issue is crucial to effectively creating and updating DTs in practice, and presents a challenge in integrating the physical and data-driven aspects of models. Comparing the methodology of probabilistic graphical modeling with various approaches to model parameterization provides a comprehensive view of the possibilities and limitations in the creation of DTs. Our article aims to present an analysis of the challenges and obstacles associated with the parameterization of DT models. We focus on the integration of physical and data aspects of the models, identify key challenges, and present possible strategies and solutions. This review provides a foundational view of the research that allows us to delve deeper into the specific challenges and obstacles in the field of DT model parameterization.
In [
21], researchers from the University of Cambridge focused on presenting a system architecture for DTs designed specifically at both the building and city levels. They also introduced the development of a DT demonstrator for the West Cambridge area at the University of Cambridge in the UK, integrating diverse data sources and supporting efficient data query and analysis. Emphasis was placed on supporting decision-making processes in operations and maintenance management and on further connecting human relationships with buildings/cities. Their study unveiled a novel approach to DT in the architecture, engineering, and construction (AEC) sector, emphasizing the potential of DTs to improve operations and maintenance (O&M) management. A comprehensive system architecture was tailored to both building and city levels, with the aim of streamlined data integration, analysis, and decision-making processes. A significant outcome of the research was the development of a DT demonstrator for the University of Cambridge’s West Cambridge site in the UK. This demonstrator showcases the integration of heterogeneous data sources, efficient data querying, and decision support functionalities in O&M practices. However, the study highlights challenges in the current adoption of DTs within the AEC sector, particularly the limited focus on the O&M phase, which represents the longest time frame in the asset life cycle. Additionally, while the DT demonstrator shows promise, there may be implementation hurdles and scalability limitations that need to be addressed. Nonetheless, the insights gained from this research offer valuable guidance for practitioners, policymakers, and researchers. By providing a roadmap for the implementation of a DT and addressing specific challenges, the study aims to advance the use of DTs in the contexts of buildings and cities. Our goal is to build on the findings of the study and further investigate the entire process of developing a DT, not only at the building and city levels but also from a technical perspective. We focus on identifying the key challenges and obstacles associated with this development and seek new strategies and approaches for their resolution.
In the field of predictive analysis and forecasting within the DT context, a wide range of algorithms and methods can significantly enhance DTs’ effectiveness. One such approach is Bayesian dynamic modeling, which allows for probabilistic prediction of system conditions based on historical data and current measurements. A notable work that addresses the development of complex predictive models is the article by Y. Zhang et al. [
22]. This article introduced a dynamic Gaussian Process Regression (GPR) model designed for probabilistic prediction of pavement conditions, specifically focusing on the International Roughness Index (IRI). The proposed methodology aimed to improve performance prediction and optimize budget allocation for road maintenance through advanced statistical techniques. The study developed a dynamic GPR model incorporating a moving window strategy to tackle computational inefficiencies and adapt to the time-varying characteristics of pavement conditions. A genetic algorithm was employed to determine the optimal window size, effectively balancing computational efficiency and prediction accuracy. The feasibility of the model was demonstrated using data from the Long-Term Pavement Performance (LTPP) program. The dynamic GPR model showed superior performance compared to traditional GPR and Bayesian Linear Regression (BLR) models, with accuracy improved by up to 2.27 times. This model excels in capturing nonlinear and time-varying data patterns, leading to improved prediction accuracy and uncertainty quantification. Despite its advancements, the dynamic GPR model remains computationally intensive, which may limit its applicability in real-time scenarios. It is important to emphasize that while this study explored advanced predictive algorithms, its main contribution is in its comprehensive approach to the design, implementation, and practical analysis of the dynamic GPR model. The work provides valuable information on procedural methodologies and practical considerations for the prediction of pavement condition. In the context of our work, these insights can be applied to other domains, such as power engineering, where they could be utilized within DTN operations to analyze or even predict the behavior of specific system components. These applications could assist in identifying system weaknesses or forecasting future developments, thereby contributing to more efficient management and optimization of complex energy systems.
Researchers from the University of Malaga investigated DTs by focusing on the identification of potential threats [
23]. Their study examined the complexities of DT technology, highlighting the convergence of technologies such as cyber–physical systems, the Industrial Internet of Things (IoT), edge computing, virtualization infrastructures, AI, and big data. Importantly, this integration introduces significant security challenges that have yet to be fully addressed. Motivated by this gap, the authors conducted a comprehensive survey of potential threats associated with DTs, emphasizing the importance of layering in conceptualizing DTs. Threats were classified according to functionality layers and their corresponding technologies, shedding light on the intricate security landscape of DT deployments. Recognizing the criticality of DTs, particularly in critical infrastructures, they analyzed operational requirements and introduced new ones tailored to emerging scenarios. The requirements were hierarchically organized to facilitate their implementation in various contexts. To comprehensively address security threats, vulnerabilities across the four layers of functionality of DTs were analyzed, thereby providing information on the complex security challenges faced by DT deployments. By identifying threats and assessing their impact, the study emphasized the need to address security concerns in DT deployments, particularly in critical infrastructure scenarios. Recommendations and approaches were provided to enhance the security posture of DTs. Importantly, further research is necessary in order to fully address the multiplicity of threats in diverse operational environments and ensure robust security.
The above studies represent comprehensive analyses of the DT concept, focusing on their implementation and utilization in various industries. However, some aspects remain inadequately explored in the specific field of electrical power systems management. Similarly, despite extensive research, additional problems and challenges associated with new technologies such as AI remain insufficiently addressed and accounted for.
3. Digital Conversion
Digital models serve as the fundamental building blocks in the realm of digital technologies and innovative concepts employed in various industries and technological sectors. These models represent physical objects, systems, and processes in digital environments, enabling the simulation, analysis, and optimization of their behavior and properties [
24]. Digital models can be static or dynamic, and can encompass various levels of detail and complexity depending on the specific purpose of their utilization [
25]. Another type of DT is the so-called digital shadow, a digital representation that reflects the real-time state of a physical object to allow the monitoring of its operational indicators and behavior without the need for direct physical interaction [
26]. Digital shadows are often used in industrial and technological sectors to monitor and control the operation of equipment and systems, contributing to improved efficiency, safety, and reliability of work processes [
27]. As mentioned above, DTs represent an innovative concept in creating virtual models of real physical systems or devices [
28]. This concept goes beyond simple digital modeling, as it includes data, processes, and the current state of the real object, making it possible to simulate, monitor, and analyze its behavior [
29]. DTs have found applications in industries such as energy, manufacturing, healthcare, and transportation [
12]. They offer numerous benefits, including predictive maintenance, performance optimization, and a platform for innovation [
30]. In addition, they provide a secure environment for simulation and training, which can significantly improve the efficiency of the work process [
31]. However, the implementation of DTs is not without challenges, including high financial costs and the need for comprehensive protection of sensitive data [
13].
DT creators face complex tasks associated with developing accurate models and managing complex systems. Although the financial investments and time requirements can be significant, the potential benefits in terms of increased efficiency, predictive control, and innovation make DTs a key tool for optimizing modern control systems, including in the field of power engineering [
32]. An overview of DT models is shown in
Figure 2 [
13]. Part (a) of the figure illustrates the actual connections of the physical system, including real communication links (physical–physical, PP). In contrast, part (b) of the figure contains the logical representation of the DT, including its virtual (virtual–virtual, VV) and physical–virtual (virtual–physical, VP) links. While these connections may not physically exist, they can be interconnected, allowing for the simulation of interactions between different systems (for example, the heat transmitted between them) that affect their functional parameters.
3.1. Types of Connections
Distinguishing between different types of connection when creating DTs is a fundamental element of the architecture of these models. Precise and differentiated representation of the connections between the components is crucial for accurate and efficient simulation of the system’s behavior [
13]. Identifying physical connections is critical, involving precise modeling of mechanical, electrical, and other physical links that directly influence the physical aspects of simulated objects [
9]. On the other hand, digital connections involve the transfer of information between different parts of the DT. Properly defined, digital communication includes parameters such as bandwidth, latency, and protocols [
33]. Time synchronization of connections is essential for simulations that require a real-time framework. Maintaining synchronization between the virtual model and the real world is crucial to obtaining accurate results [
34]. Virtual connections represent abstract relationships that may not have a physical basis but are crucial for simulation. These include logical connections, hierarchical structures, and dependency relationships [
33]. Detailed and precise specification of these connections is essential for creating DTs that accurately represent the structure and behavior of real systems [
35]. This differentiated resolution of connections is key to the successful use of DTs in the monitoring, analysis, and optimization of real systems [
28]. Communication plays a crucial role in the implementation of DTs. The flow of data within DTs can be either unidirectional, where information flows only from the real object to the digital space, or bidirectional, allowing for mutual interaction between the real and digital worlds [
13]. Furthermore, communication within DTs can be divided into three basic types based on physical aspects, including the transfer of data between the physical object and its DT. These aspects play a key role in establishing connections between the real world and its digital representation, allowing for effective monitoring, control, and optimization of systems and processes through DTs [
36].
3.1.1. Physical–Physical
Communication between physical devices enables interaction and information sharing among physical objects. These objects can be connected using wireless and wired devices (sensors, actuators, controllers, WiFi access points, and base stations) that support PP communication.
3.1.2. Virtual–Physical
Communication between physical and virtual devices involves transferring information between the physical object and the DT using various communication technologies, such as Ethernet, LoRa, or 5G/6G mobile communication. The physical object becomes a terminal connected to the DT access network and the base station. The critical parameters of PV communication include latency, transmission reliability, data transmission security, and bandwidth.
3.1.3. Virtual–Virtual
Communication between virtual devices occurs within the virtual space of the DT, and mirrors the behavior of communication in the real physical system. The characteristics of VV communication mainly depend on the computational power of the DT servers which model the data behavior. The main benefits of VV communication include modeling data transmission, overcoming time constraints in the real world, and enabling simulation of long periods of communication with low time costs.
Communication between physical objects (PP) enables direct interaction and information sharing among devices in the real world, facilitating fast and reliable data exchange. However, reliance on physical infrastructure may limit the flexibility and scalability of this communication. In contrast, connections between physical and virtual objects (VP) allow for integration between physical devices and the DT, thereby enhancing monitoring and control capabilities. Higher bandwidth and security requirements may pose challenges, especially in environments with high device density. Communication between virtual objects (VV) within the DT enables simulation of system behavior for testing various scenarios without the need for real-world experiments. This flexibility and the ability to simulate long periods are crucial for system development and optimization; however, higher computational power requirements may be a limit, particularly for complex simulations.
In general, different types of connections each have their advantages and disadvantages in the context of DTs. While physical–physical communication offers fast and reliable data exchange, connections between physical and virtual objects allow simulation of system behavior and better integration with the DT. Finally, virtual–virtual communication enables flexible modeling and testing of various scenarios without physical limitations, albeit at the cost of higher computational power requirements.
3.2. Model Creation Approach
The creation of DTs is currently a predominantly manual process that can be complemented using existing data sources from the system [
2]. Compared to the automated approach, the manual method allows for more detailed and accurate modeling, but requires domain expertise in the respective field [
33]. The accuracy of the model is heavily dependent on the quality of the data; therefore, it is advisable to include various configurations of routing, topology, traffic planning, and loads that represent the behavior of the modeled network [
28]. Furthermore, in order to create different scenarios, a dataset with various events that negatively impact data communication must be ensured, for example, link and interface failures, incorrect configurations, and scenarios with high congestion [
15]. Another important aspect to consider is the issue of data acquisition. Essentially, the dataset can be obtained from real networks (real network events) or non-production network infrastructures (predefined network events) [
32]. The training dataset can be created in a real (production) network of the system operator or in a dedicated testing (nonproduction) environment (e.g., a testing model). However, generating training sets for non-standard states in production networks is impractical. Importantly, the dataset should include faults, incorrect configurations, and unpredictable behavior scenarios [
30].
Creating a training dataset on a production network is unacceptable, as it can lead to service disruptions; within the testing model, the network can be configured with various traffic profiles, faults, incorrect configurations, and errors, and a wide range of configurations can be set without disrupting user services [
33]. The main problem with a dataset created using testing models is that while the DT has been trained in a specific network case, upon deployment it must operate in a customer network that is still unknown [
28].
There are several approaches to creating DTs, each offering a specific perspective on modeling real-world objects [
29]. One key approach is the method of
Geometric Representation, which focuses on the precise mapping of physical objects to a virtual space [
1]. In architecture and urbanism, this method is used for detailed visualization and analysis of structural and spatial arrangements. Geometric Representation (GR) is widely utilized due to its ability to produce highly accurate and detailed models. CAD software such as AutoCAD and SolidWorks, along with BIM tools such as Revit, are essential in this process. These tools facilitate the precise mapping of shapes, dimensions, and spatial positions of objects. Techniques such as 3D scanning, laser scanning, and photogrammetry are commonly used to capture the necessary data. The advantages of this approach are numerous. The high accuracy of the models ensures that the virtual representations closely match their real-world counterparts. This level of detail is invaluable for visualization purposes, allowing stakeholders to meticulously analyze structures and spatial arrangements. Furthermore, the ability to conduct simulations and analyses on these virtual models provides insights that can significantly improve decision-making processes in design and urban planning. However, the method does come with certain drawbacks. The computational demands are substantial, requiring significant processing power and storage capabilities. In addition, the costs associated with the necessary hardware and software can be quite high. Moreover, there is a steep learning curve involved, as proper modeling requires specialized knowledge and expertise. Despite these challenges, the benefits of Geometric Representation make it a powerful tool in the realm of DTs, offering unparalleled precision and analytical capabilities.
Another significant approach is the method of
Physical Modeling, which utilizes mathematical models to simulate the behavior of objects based on physical principles [
33]. This approach finds particular application in engineering fields for the design and optimization of technical systems, where the accuracy of modeling physical phenomena is crucial. Physical modeling plays a pivotal role in the realm of DT creation for SCADA (Supervisory Control and Data Acquisition) systems. Tools such as MATLAB, Simulink, and ANSYS are extensively used to develop these DTs. These platforms enable engineers to accurately simulate and analyze the physical and operational characteristics of energy systems and control processes. The key parameters monitored during these simulations include the physical properties of the materials along with their thermal, mechanical, and dynamic behavior. By accurately modeling these parameters, DTs can provide real-time insight into the performance and potential issues of energy and control systems, thereby improving operational efficiency and reliability. Commonly employed methods in physical modeling for DTs include Finite Element Analysis (FEA) and Computational Fluid Dynamics (CFD). FEA allows for detailed structural analysis by breaking down complex geometries into smaller and more manageable finite elements, which is crucial for assessing the integrity of physical components in SCADA systems. CFD focuses on simulating fluid flow and heat transfer, providing critical data for systems where fluid dynamics and thermal management are essential. One of the primary advantages of physical modeling in this context is the ability to perform precise simulations of physical phenomena. This precision is invaluable for optimizing technical systems to ensure that they perform as intended under various conditions. DTs powered by these simulations can predict system behavior, anticipate failures, and facilitate preventive maintenance, improving the reliability and efficiency of energy and control SCADA systems. However, physical modeling comes with certain disadvantages. It is computationally intensive, often requiring significant processing power and time to perform complex simulations. In addition, it requires a deep understanding of physical principles and modeling techniques, which requires specialized knowledge and expertise. Overall, while the method of physical modeling offers detailed and accurate simulations that are crucial for creating effective DTs for energy and control SCADA systems, it also poses challenges in terms of computational resources and the need for specialized skills. These simulations enable the optimization and proactive management of critical infrastructure, ensuring higher levels of operational excellence and safety.
The method of
Data Collection and Analysis is often used in various industrial sectors [
29]. This approach involves utilizing existing operational data from the real environment. Sensors and monitoring devices capture information, which is then analyzed to create DTs. This method is valuable for monitoring equipment performance and optimizing processes. Key tools such as Siemens WinCC, Wonderware InTouch, and National Instruments Data Logger enable efficient data collection and processing. These tools are essential for monitoring operational data such as temperature, pressure, vibrations, and other parameters. They allow for detailed monitoring of equipment performance and the conditions under which they operate. Several methods canb e utilized to analyze these data. Real-time monitoring allows for immediate tracking of operational states and detection of potential anomalies in real time. Big data analysis and the utilization of machine learning can then enable deeper and more complex data analysis, facilitating the identification of long-term trends and the performance of predictive analytics. Despite the many advantages these methods bring, there are also disadvantages. Large volumes of data require robust infrastructure for processing and storage, which can be costly and technically demanding. In addition, there is a dependence on the quality and reliability of the sensors, which are crucial for the accuracy and reliability of the analysis.
Machine learning plays a significant role in the emerging field of AI [
37]. Algorithms based on this method process and interpret large amounts of data, extracting knowledge from operational information and enabling the prediction of future system behavior. This method finds particular application in predictive maintenance and adaptive control. Tools such as TensorFlow, PyTorch, and Scikit-learn are utilized for the implementation of these algorithms. These tools enable the processing and interpretation of large amounts of data, which is essential to extracting knowledge from operational information and predicting future system behavior. Various parameters are monitored when employing machine learning methods, such as historical data and system behavior patterns. Thanks to methods such as supervised learning, unsupervised learning, and reinforcement learning, these parameters can be analyzed and used for automatic learning and adaptation to new situations. The primary advantages of using machine learning methods include their ability to predict future system behavior and engage in automatic learning, allowing for adaptation to varying conditions; in particular, these methods find applications in predictive maintenance and adaptive control. However, the need for large training datasets, the complexity of the models and algorithms, and higher computational demands are among the disadvantages that need to be considered when implementing these methods.
In the context of DTs, it is important to evaluate various approaches and tools that enable their creation and management. The
Process Simulator method provides a unique opportunity to create DTs through simulations of system behavior [
35]. This approach allows for the testing of different scenarios and the optimization of systems without the risks associated with real-world experiments. It is particularly useful in designing new systems and processes. In addition to
Process Simulator, there are several other tools that can be used to create DTs, such as AnyLogic, Arena, and Simio. Each of these tools has its own specific advantages and is suitable for particular applications in the field of DTs. When monitoring DTs, it is important to consider certain parameters. Among the typically monitored parameters are operational scenarios, process flows, and performance metrics. These parameters allow for a thorough evaluation of system behavior and its effectiveness. Methods such as Discrete Event Simulation (DES) and Agent-Based Modeling (ABM) are often used to create simulations of DTs. These methods enable for detailed modeling of the behavior of the system and interactions between different elements. Although creating DTs through simulations can provide many advantages, there are also notable disadvantages. These include dependence on the quality of the created model, which can affect the simulation results. In addition, there may be differences between simulations and the real world which can lead to incorrect decisions. Creating and calibrating simulations can be challenging, and may require specific knowledge and skills.
3.3. Key Parameters of Digital Models
Distinguishing and specifying the key parameters and properties of DTs is the cornerstone of successful creation and utilization of these models. Understanding and emphasizing these aspects is not only a technical concern but also a crucial factor for effective and reliable simulations of real systems [
19]. In this context, it is important to distinguish and analyze individual parameters and properties for several reasons. The first and most fundamental reason is to achieve the highest accuracy and fidelity of the results of the digital model compared to the real world [
34]. Precise modeling of the interactions and behaviors of systems requires careful specification of connections and properties, which ultimately contributes to the creation of reliable simulation environments. Furthermore, considering time synchronization and integration with real systems is essential in order to utilize models in real time [
4]. Synchronization is key to achieving accurate and dynamic simulations, especially in situations where quick response to events is necessary. Distinguishing and defining connections and interactions within these models is necessary to capturing complex relationships between components and systems [
13]. Abstract relationships and hierarchies not only have technical significance but also contribute to an overall understanding of the behavior of modeled systems. Overall, a clear specification of key parameters and properties enables the creation of models that not only efficiently simulate the real world but also provide detailed and useful insight into system behavior. This differentiated analysis is therefore essential for the successful deployment of DTs in the monitoring, analysis, and optimization of real systems across various industries. The following parameters identified during our analysis serve to identify the fundamental characteristics of reviewed the models.
3.3.1. Sector
This parameter identifies the specific sector in which a model or DT is used (e.g., energy, economics, or healthcare). Determining the particular sector provides context for understanding how the model is utilized in the real world. This knowledge is crucial for several reasons, one of which is understanding the context and goals associated with the use of a DT in a given sector. Each sector faces its own specific challenges and opportunities, which inform a better understanding of the purpose of DT and its intended use. For example, a DT in the aviation industry may focus on flight simulations and performance optimization, while one in medicine may be used to model physiological processes and disease diagnosis. Another factor is the need to identify relevant technologies and approaches specific to the sector. Industries often rely on unique technologies and methods for developing DTs, allowing for better selection of suitable technologies and tools for specific applications. For example, tools for CAD simulation and modeling are commonly used in the manufacturing sector, while in the energy sector tools for modeling complex systems are preferred. Finally, it is essential to assess the potential impact of the DT on the given sector. Each industry has specific needs and characteristics, making it necessary to consider how DTs can affect efficiency, innovation, and overall value in particular contexts. Knowledge of the sector enables better evaluation of these potential impacts and allows for adaptation of the DT implementation strategy according to specific needs.
3.3.2. Purpose
This parameter delineates the primary objectives of the model, encompassing various functions such as simulation, phenomenon prediction, security aspect testing, dataset generation, or educational purposes. Categorizing these diverse functionalities can provide a deeper understanding of the model’s operational characteristics and the underlying logic governing its construction. This comprehensive understanding provides a structured framework for discerning the model’s focal points and the value that it adds to its respective domain.
3.3.3. Model Type
Another key parameter is the identification of the type of model. This aspect is crucial in determining the nature of the model under study. Within our analysis, four basic types have been defined: DT, physical model (P), emulated model (E), and simulated or purely virtual model (SV), along with their combinations. A DT represents a virtual replication of a physical system, including its behavior, properties, and interactions with the surrounding environment. A physical model consists of real physical components directly interconnected and influencing each other. An emulated model is a simulation of a real system at the software level, where its functions and behavior are modeled. A simulated or purely virtual model is a full software representation of the system, simulating its behavior and interactions without direct connection to physical components. Each of these types of models has specific characteristics and potential uses that need to be analyzed for specific applications within the management of power systems.
3.3.4. Purdue Model Level (PL)
In evaluating the identified models, we have emphasized their integration into the various levels of the Purdue model hierarchy. This analysis allowed us to determine on which level the models operate within industrial processes. Each model receives a value from 0 to 5, representing its level of focus. Certain models focus on multiple levels, meaning that they can be classified into multiple layers of the hierarchy simultaneously.
3.3.5. Flexibility and Scalability (F&S)
The flexibility and scalability parameter gauges the model’s capacity to react to environmental changes and its adaptability regarding the scale and intricacy of the problem at hand. This evaluation criterion aids in assessing the model’s adeptness at accommodating novel conditions and scenarios as well as its proficiency in handling diverse levels of workload or data complexity. This parameter serves as a crucial indicator of the robustness and suitability of the model for dynamic real-world applications.
3.3.6. Data Source (DS)
The parameter identifies the source from which the model acquires its input data. This includes logical or random internal processes that are simulated as well as direct data collection from physical devices. This parameter helps in understanding how the model acquires its input data and how to assess data quality and reliability. Identification of the data source is crucial for assessing the model’s ability to process data in real time and its overall credibility. Three basic types of sources have been established:
Simulated devices: The model utilizes simulation techniques to create internal processes and events that generate input data; these processes can be logically defined or generated based on random events or algorithms.
Physical devices: The model obtains data directly from real physical devices using sensors, detectors, or other data collection technologies.
Combination of both approaches: The model may combine internal processes with direct data collection from physical devices or simulate data when physical devices are unavailable, providing flexibility and robustness in data processing.
3.3.7. Independence of External Data Sources (IDS)
This parameter describes whether the model is independence of the data from physical devices where such devices are present in the model. Its purpose is to determine whether the presence and proper functioning of physical devices are necessary for the model’s operation and whether data from these devices are essential for its reliability and usability. This dependency on data from physical devices is crucial for assessing the effectiveness and applicability of the model for other purposes.
3.3.8. Physical Energy Devices (PED)
This parameter evaluates whether the model is capable of working with physical devices. Including physical devices in the model allows for a more faithful simulation of operational conditions and the environment in which the model is to be used. These devices include equipment such as ABB REF615, Siemens SICAM S8000, and various phasors or relays. This provides a better basis for integrating the model into the processes of controlling electrical power systems and enhances its ability to respond to actual operational conditions. This analysis allows us to identify whether the model includes sensors, detectors, or other devices commonly used in practice. In this way, it is possible to assess the model’s ability to work effectively with existing infrastructure and equipment in electrical power systems. Including physical devices in the model also enables better calibration and validation of the model using real data and measurements, thereby increasing its reliability and credibility. Flexibility and scalability may vary depending on the specific model and its purpose. A model with high flexibility and scalability can operate effectively under various conditions and with different types of data. Conversely, a model with low flexibility and scalability may be limited in its response to changes in the environment, or may have difficulty adjusting to new conditions. Assessing the flexibility and scalability of the model is important for evaluating its ability to adapt to dynamic conditions in the real world. Models with high flexibility and scalability are often preferred because they provide greater robustness and universality in various situations. On the other hand, models with lower flexibility and scalability may be suitable for specific purposes or environments with tightly defined conditions.
3.3.9. Industrial Control System Protocols (ICS)
This parameter identifies the communication protocols utilized by the discovered model, such as DNP3, IEC 60870, IEC 61850, Modbus, OPC UA, or S7. Taking into account the supported protocols is crucial for determining the model’s ability to communicate effectively with other systems in the given environment, especially with actively utilized energy devices. Analyzing the supported protocols is essential for a detailed examination of data transmission, which should be an indispensable part of the model. This analysis enables a deeper understanding of various communication types within the discovered models and can contribute to higher-quality data generation, such as for dataset creation purposes.
3.3.10. Central Control Element (CCE)
This parameter evaluates the presence of a central control element in the model, allowing for control and monitoring of the model’s operation, such as SCADA software. The presence of this element is crucial both for human oversight and for creating credible process simulations, such as those within energy networks, to train new employees. The central control element allows operators to monitor system performance and behavior in real time, identify and resolve problems efficiently, and optimize operational parameters. In addition, it supports historical data analysis, which is essential for strategic decision making and maintenance planning.
3.3.11. Data Validation and Verification (V&V)
Another monitored parameter is the validation and verification of the data, which determines whether the data from the model are validated and verified. This parameter is important for assessing the reliability and accuracy of the model’s outputs and ensuring their quality and credibility. Data validation is performed by comparing the model’s outputs with real or reference data, while data verification focuses on checking the integrity of data and ensuring their quality before use in the model. Thorough data validation and verification are crucial to ensuring the reliability and accuracy of the model, especially during simulation or prediction of phenomena.
3.3.12. Artificial Intelligence (AI)
This parameter focuses on the presence of AI utilization in the analyzed model. The objective is to determine whether AI is implemented in the model, which has become a trend in current research. The presence of AI can bring about improvements in various areas, such as data validation or simulation of a particular phenomenon. This use of AI can support more efficient operation of the model and enhance its performance.
3.3.13. Energy Requirements (ER)
This parameter evaluates the energy consumption of the model and provides information about the efficient use of energy and ecological sustainability. It is divided into three states depending on the model’s energy requirements: high, medium, or low. Its assessment is important for practical usage, as high energy consumption can make model operation economically disadvantageous even if it offers benefits such as accurate predictions.
3.4. Comparison
The process of finding suitable models for our analysis was based on the analysis of several key parameters. First, we considered the publication date, focusing on models published since 2020 to ensure that they are sufficiently current and relevant for our analysis. Next, we focused on electro-energetic models to guarantee their relevance to our investigation. In our search for existing solutions, we included models that are not explicitly defined solely as DTs, such as physically-based models (P), emulated models (E), and virtually simulated models (VS). This enhances the relevance of the identifying methods and approaches and ensured that they can contribute to understanding and utilizing not only DTs but also other model types. Furthermore, we evaluated the complexity of the model description in terms of the level of detail and the scope of the studied systems, taking into account the availability of data required for the validation and calibration of the models to ensure a thorough analysis. To search for relevant studies, we used indexed databases such as Web of Science and Scopus, which provided us with a broad and up-to-date range of literature. These parameters provided us with the basis for identifying suitable models for our analysis and ensured that our results were relevant, current, and adequately supported. The identified models and their corresponding properties are depicted in
Table 1.
3.4.1. Analysis of Existing Solutions
This article provides a detailed analysis of existing DTs with the aim of not only providing an overview of the current state of the technology but also demonstrating the specific advantages and benefits that DTs can provide in the context of the management of electric power grids. This analysis is crucial from a technical point of view as well as from a strategic point of view, as it offers insight into specific applications, challenges, and potential of DTs in the field of electrical power engineering. During this exploration, the focus is on technological aspects as well as comprehensive economic and operational considerations. The results of this analysis serve as a starting point for the design and implementation of DTs in the context of the management of electric power grids. In addition, emphasis has been placed on identifying key features and functions of existing solutions that are critical for the successful implementation of DTs in power grid management. In this context, technological innovations, economic perspectives, and practical applications are examined.
3.4.2. Purposefulness and Design
The majority of existing models primarily focus on simulation and security aspects, with only limited interest in other functionalities such as data processing and anomaly detection. Data processing plays a crucial role in real operations, as it enables quick responses to events and situations. Simulations are useful for analyzing future developments and uncovering potential weaknesses in the system. Our model also emphasizes the educational aspect, allowing students to better understand security issues and develop their professional skills. Another significant challenge associated with the creation of these models is the detection of cyber-related vulnerabilities. Virtual models often fail to provide a simulation of all processes in real operations, which can lead to a failure to detect some errors and vulnerabilities and in turn to actual security incidents. Emulated–physical models, which combine virtual and physical elements, allow for vulnerability testing on real devices, but only to a limited extent and with limited flexibility; moreover, their adaptation and modification can be difficult due to complex compatibility issues between individual components. In contrast, virtual models offer greater opportunities for modification and rapid adaptation, though often at the expense of realism and simulation accuracy.
3.4.3. Complexity and Modifiability
Among the relevant models, we performed an analysis of their coverage of the levels of the Purdue model. The results are shown in
Figure 3. The largest number of models covered up to three layers of the Purdue model. In contrast, none of the models implemented all levels. Expanding the range of levels of the Purdue model increases the complexity of the model, which can limit its flexibility.
In terms of the flexibility and scalability of the models, it is evident from
Figure 4 that the emulated models (E) and the combination of the emulated and virtual–simulated models (E+VS) are easily adjustable and modifiable, making them suitable for various testing purposes. However, their outcomes may not always correspond to reality due to the deterministic nature of these models, whereas the unexpected influences that exist in a real-world setting provide an advantage to DTs, physical models (P), and physical–emulated models (P+E).
3.4.4. Communication Data
While DTs primarily use data from physical devices for their operations, some models, such as those mentioned in [
40,
41], also integrate simulated sources. This integration is particularly useful for the prediction and simulation of various operational scenarios, and can enhance the functional capabilities of the DT. On the other hand, emulated models primarily rely on generating simulated data, often using tools such as RTDS (Real-Time Data Simulator) or HIL (Hardware-In-the-Loop). These models create a virtual environment that simulates the behavior of physical devices. Their simple structure allows for easy modification and adaptation to different scenarios and requirements.
Figure 5 shows the distribution of the individual models and their dependence on data from external sources.
Most models that accept data from physical devices are directly dependent on these data. However, the optimal approach is a combination of real and simulated data, which allows the model to better predict and simulate various events and phenomena.
The presence of physical energy devices (PED) was also examined, especially in terms of usability for managing power systems. As can be seen in
Figure 6, physical–emulated models (P+E) dominate this area, often containing various power devices and also implementing Industrial Control Systems (ICS) protocols. The implementation of these protocols was somewhat of an exception within the DT context.
3.4.5. Data Control
In most existing DT models, with the exception of emulated approaches, little emphasis is placed on data validation and verification, which represents a critical aspect for their effective functioning. This absence is particularly problematic because the accuracy and reliability of the data are crucial to the successful utilization of DTs in practice. Thus, a significant portion of current models often lack robust procedures for verifying the quality and reliability of data, which can jeopardize their ability to accurately simulate and predict the behavior of real systems. Furthermore, even though AI offers many effective tools for improving the quality of data processes, its utilization in DTs is often inadequate. AI could play a key role in automating data validation and management, thereby significantly improving the reliability and control over data flows in these models. The integration of AI could greatly increase the level of data control and management in DTs, contributing to their effective deployment in practice and maximizing their utility.
Figure 7 shows a comparison of the use of AI and data verification and validation among the relevant models.
3.5. Our BUT Physical–Emulated Model
We focused on creating a physically-emulated model with high versatility and modularity. This model, specializing in the electrical system of the Czech Republic, covers the entire spectrum, from production (power plants) to end consumption (end users). It includes almost all levels of the Purdue model, from physical devices (PLCs, electricity meters) through the control center (SCADA) to the application layer (user and educational scenarios). The model integrates a wide range of ICS protocols (IEC 60870-5-104, SV, MMS, DLMS) and includes a supervisory SCADA center realized using the OpenMUC framework. The modular design allows for easy modification and implementation of new physical or virtual devices. The model is designed to function without physical devices, allowing for simulation and prediction.
The model is divided into two main parts: physical and virtual. The physical part includes a cluster of 50 Raspberry Pi 3B+ units (RPis) running the Raspbian OS. Of these, 47 serve as the main terminal units (MTU) of a power plant or substation in the Czech Republic’s transmission system, each connected to a display showing critical values. The remaining three RPis emulate a substation according to the IEC 61850 standard. Other physical components include real devices (Merging Unit, Intelligent Electronic Device, Remote Terminal Unit from ABB and Siemens), a signal emulator (for simulating electrical inputs), a management station (for managing the model)m and network infrastructure (connecting all components).
The virtual part of the model consists of a server cluster with virtualization tools. Virtualize OpenMUC software, represents the SCADA system and simulates virtual devices. This allows a greater number of devices to be connected to a single physical interface. The whole model represents a larger system designed for research and educational purposes, including tools such as Cyber Arena [
60], which provides educational and training scenarios focused on the electric transmission and distribution network. The primary goal of the model is to create a testing and analytical environment that also serves as a platform for educational scenarios.
We are currently working on implementing a system for analyzing, validating, and controlling simulated and emulated data of virtual devices compared to real device data, such as the PQ monitor (e.g., Mega44PAN). In addition, we are integrating AI tools for analyzing device behavior, including state identification and prediction. The model is still in development, with the ultimate aim of transforming it into a fully fledged DT.
3.6. Commercially Available Solutions
In the field of energy systems, a growing array of commercially available DT solutions offer advanced capabilities that can help to optimize performance and efficiency. Solutions developed by leading technology firms leverage state-of-the-art digital modeling and analytics to enhance various aspects of energy management. Given the proprietary nature of these technologies, detailed information about the methodologies and implementation specifics of these DTs is often closely protected. Consequently, this overview has been constructed on the basis of the information provided on the official websites of the respective companies.
The following
Table 2 presents a selection of notable DT solutions tailored for applications within the electrical power sector. It includes key details such as the name of the company, the specific DT solution offered, its core functionalities, potential application scenarios, and the advantages, disadvantages, and limitations of each solution. This summary aims to provide a comprehensive view of available technologies and their practical implications for the energy industry.
Siemens Energy is a global leader in energy technologies, providing products and services for energy generation, transmission, and distribution. The company has faced challenges with integrating DTs into various existing systems and ensuring data security. Siemens has responded by developing modular platforms that facilitate the integration of DTs with different devices and systems as well as implementing advanced security protocols to protect sensitive data. Siemens Energy offers the Siemens Xcelerator platform, which integrates DTs with various processes and devices within a single module, thereby simplifying management and improving interoperability.
General Electric (GE) is an American multinational corporation with a strong focus on technological innovations in the energy, aviation, and other industrial sectors. GE has encountered difficulties in creating accurate DTs for complex systems such as turbines as well as in keeping these models up to date. The company is introducing advanced simulation tools and automated systems to update its DTs. GE offers the GE Digital Twin Platform, which includes simulation and analytical tools for precise modeling and real-time monitoring.
Schneider Electric is a French multinational company that specializes in energy management and automation. Schneider faced challenges involving the interoperability of DTs with various devices and systems as well as with processing large volumes of data. The company uses standardized protocols and cloud solutions for efficient data processing and analysis. Schneider Electric offers EcoStruxure, an open and interoperable platform that incorporates DTs and cloud services to optimize energy management and automation.
ABB is a Swiss multinational company focused on electrification, automation, and digitalization in the industry. ABB has faced challenges around the high costs of implementing DTs and the performance demands of these technologies. The company has invested in cost optimization and computing power through high-performance servers and optimized algorithms. ABB offers Ability Digital Twin, which provides advanced analytical tools and real-time monitoring to optimize device and system performance.
Honeywell is a multinational American corporation with a broad portfolio that includes technologies for building management, manufacturing, and aviation. Honeywell has faced challenges with integrating DTs into legacy systems and the need for employee training. The company has developed compatible integration solutions and provided training and support. Honeywell offers Honeywell Forge, a DT platform that includes integrated solutions for real-time monitoring and operational optimization.
Emerson is an American company that provides technological solutions in automation, regulation, and energy. Emerson has faced challenges in maintaining data quality as well as in predictive maintenance. The company is introducing advanced analytical tools to ensure data quality and improved algorithms for predictive maintenance. Emerson offers Emerson’s Plantweb Digital Ecosystem, which includes DTs for optimization and predictive maintenance.
Rockwell Automation is an American company that specializes in industrial automation and IT. Rockwell has faced challenges with adapting to new technologies and integrating with existing systems, along with related security challenges. The company has developed adaptive architectures and implemented robust security measures. Rockwell offers FactoryTalk® InnovationSuite, a platform for DTs and analytics that improves integration and security.
DNV GL is a Norwegian company that provides expert services in classification and certification with an emphasis on safety, environment, and sustainability. DNV GL has faced challenges with the accuracy of simulations and the availability of data for DTs. The company has invested in improved simulation tools and methodologies. DNV GL offers Synergi Life, a DT platform that includes advanced simulation tools and analytical methodologies to ensure accuracy and efficiency.
4. Open Challenges
Within the field of creating DTs and multifunctional physical or physically-emulated models, several outstanding challenges require careful approaches and innovative solutions. While digital replication of physical systems has tremendous potential for optimization and simulation, there are several key challenges that need to be overcome.
4.1. Technological Advancement
Technological advancement poses a challenge for DT development due to the field’s sensitivity to current technological trends [
15]. With rapid progress in areas such as AI, the IoT, and cybersecurity, constant updating and innovation are necessary. Older models may become outdated and inflexible to new technological trends, requiring flexibility and the ability to adapt quickly to new developments. This dynamic requires the ability to not only create effective models but also to keep them up-to-date and compatible with the constantly changing technological environment.
One approach is continuous research and development (R&D) involving constant innovation and updates to DTs according to current technological trends. While this approach maintains the relevance and effectiveness of DT in a rapidly changing environment, it requires high investments in research and development, and it may prove difficult to keep up with the pace of technological progress. Another possible solution is a modular approach to DT development allowing for easy updating and exchange of DT components without complete reworking. This approach provides flexibility and scalability in integrating new technologies, but may cause module management and integration complexity, requiring careful planning. Another option is to collaborate and partner with technology companies through cooperation with external partners to access the latest technologies and knowledge. This approach may reduce costs and enable the sharing of resources and knowledge, but may also lead to dependence on external partners and incur the risk of not meeting requirements. Investment in research into AI and IoT solutions represents another possible solution. Such investment supports technologies that are crucial for DTs, and promotes innovation and efficiency improvement; however, it has a long return on investment and carries the risk of failure in some research directions.
We are continuously adding new devices to our model, including updates to standards and protocols, making it a suitable and up-to-date platform for analysis and testing. Due to its modular construction, it is easy to replace parts of the model with new software and hardware versions, ensuring its relevance over time.
4.2. Integration and Interoperability
Interoperability between different DTs is one of the main challenges in the efficient operation of complex systems [
61]. DTs, which are still in the early stages of development, have often been designed as isolated systems focused on specific tasks or individual devices. However, this approach causes problems when these twins need to be integrated into broader interconnected ecosystems. As a result, difficulties are encountered in their ability to communicate and share data, which significantly limits their capacity to effectively contribute to optimization and management at the system level.
Interoperability is particularly crucial in areas such as energy, where DT can play an increasingly important role in the management of entire ecosystems and infrastructures. In the context of the power sector, DTs that monitor the production, distribution, and consumption of energy may face significant challenges if they cannot efficiently communicate and share information. This can lead to suboptimal resource utilization, inefficient load management, and delayed response to outages, ultimately reducing the overall efficiency of the system and limiting opportunities to improve its reliability and sustainability. To address these challenges, it is essential to focus on several key areas that can significantly enhance the interoperability of DTs.
4.2.1. Data Formats
Different DTs may use varying data formats, which can significantly complicate their integration. Therefore, it would be beneficial to develop and standardize universal data formats specifically for DTs [
62]. However, the different industries in which DTs can be applied have varying needs and requirements, which can be very complicated for the actual development of a new format. Another approach is to leverage existing formats that are already widely used. For example, formats such as JSON or XML are widely used, but need to be adapted to the specific requirements of different industrial applications. This could include extending these formats with elements specific to the energy sector, such as metrics to monitor energy consumption or parameters to manage production and distribution.
4.2.2. Communication Protocols
For efficient and reliable real-time data exchange between devices and the DT itself, it is crucial to use standardized communication protocols [
63]. This is important because standardized protocols ensure consistent and reliable communication, reducing the risk of errors and delays caused by incompatible systems. To ensure interoperability between DTs, industrial standards such as MQTT, OPC UA, and DDS can be utilized. These protocols enable flexible and secure communication between devices and systems and support various types of data transmission, from small packets of information to complex data flows. It is also important to ensure that these protocols can be adapted to the specific needs of different sectors, including energy, where low latency and high communication reliability are critical.
4.2.3. Semantic Interoperability
In addition to technical aspects, it is essential to ensure that data are consistently interpreted between different systems. Semantic interoperability means that data have the same meaning regardless of which system uses them. This is crucial for accurate data analysis and interpretation, allowing DTs to collaborate effectively [
64]. Moreover, consistent semantic logic can significantly improve processing speed by eliminating the need for an intermediary that converts data into a unified semantic framework, thereby reducing unnecessary data processing. This could involve creating shared ontologies or reference models that define the meaning and context of data in specific applications, such as energy flow management or monitoring the condition of equipment.
These measures and strategies are key to overcoming the challenges associated with the interoperability of DTs. In our model, we strive for the broadest possible integration of systems and technologies, including the connection of physical, emulated, and simulated devices. This approach allows us to test and optimize interoperability under various conditions, thereby enhancing the reliability and efficiency of our solutions. We believe that by doing so we can contribute to the development of open and interoperable systems capable of autonomously managing energy flows, predicting outages, and optimizing resource utilization in real time, leading to a more sustainable and efficient energy mix.
4.3. Hyperconnectivity
Hyperconnectivity refers to a state in which individual elements are interconnected in multiple ways [
36]. In a DT, the connections between PV and PP play a crucial role; however, they can be influenced by events such as power outages, software changes, and deployment errors. The requirements for network connectivity vary depending on the scenario. In the case of construction and operation (for example, drilling or floating mining platforms), DTs can use real-time data analysis to improve asset integrity assessment and operational efficiency and to reduce the probability of downtime.
One approach is to implement redundancy and failover mechanisms within the network infrastructure. This involves duplicating critical components or pathways to provide backup options in case of failures. For example, redundant communication links, servers, or data centers can be deployed to ensure continuous connectivity and operation. Although this improves system reliability and availability by minimizing the impact of network failures, it can increase deployment and maintenance costs due to implementation complexity and resource inefficiencies. Dynamic network configuration is another strategy to adapt to changing network conditions and optimize performance. By adjusting network settings and priorities in real time, the system can efficiently allocate resources and prioritize critical connections. Dynamic routing protocols, Quality of Service (QoS) adjustments, and traffic shaping mechanisms are examples of such configurations. However, this approach requires sophisticated algorithms and continuous monitoring to manage network configurations effectively, and dynamic changes may introduce overhead and latency.
Edge computing and distributed processing offer a decentralized approach to data processing, reducing dependence on centralized infrastructure and minimizing data transfer over the network [
65]. By distributing processing tasks closer to the data source or endpoint devices, edge computing reduces latency and bandwidth requirements while enhancing data privacy and security. However, implementing edge computing requires investment in infrastructure and expertise, and coordination among distributed components may introduce complexity and overhead. Fault-tolerant protocols and communication standards provide another avenue to improve the reliability and resilience of the system against network disruptions. These protocols and standards are designed to tolerate failures and ensure reliable communication. By adopting such protocols, DT systems can improve interoperability and compatibility with existing networking technologies. However, this may require updates or modifications to existing systems and protocols, and balancing fault tolerance with performance involves careful consideration of tradeoffs.
Finally, predictive maintenance and proactive monitoring use data analytics and machine learning techniques to predict and prevent potential network problems before they occur. By continuously monitoring network performance metrics and analyzing data, proactive measures can be taken to address anomalies and prevent disruptions. Although this approach improves system reliability and availability, it requires access to comprehensive network telemetry data and robust analytics capabilities. In addition, false positives or inaccurate predictions can lead to unnecessary interventions or overlooked issues.
We will address the challenge of hyperconnectivity with the full transition of our model to a DT. Our approach involves creating a cluster system with isolated parts that communicate internally, which minimizes the creation of redundant and potentially vulnerable connections.
4.4. Operation in Large-Scale Scenarios
For the internal network of the DT, efficient management of operations in large networks is crucial, while scalability must be considered as well [
32]. In meeting these challenges, the performance and computational demands of the DT should scale at a rate similar to the network size. The training process must be optimized for the ability to scale well with networks, as larger scenarios are more complex and require more computational time for model training. When using DTs in broader systems, it is necessary to ensure that performance remains consistent and that training does not exceed acceptable limits in order to preserve the advantages over traditional simulations.
One possible solution is to utilize distributed computing, where tasks are divided among multiple computing nodes to parallelize computation and process large scenarios. This method offers high scalability and fault tolerance, but can be complex and requires expertise. Another option is to leverage cloud computing, which allows for offloading computational tasks and storage requirements to scalable and flexible cloud resources. This provides access to powerful computing resources without significant upfront investments, but comes with the risk of high costs and concerns about data protection. Optimized algorithms present another option. Algorithms optimized for scalability can be developed and implemented, reducing the computational complexity of DT operations. Such algorithms can significantly reduce computational overhead, but require time for development and tuning and may involve certain trade-offs. Edge computing, where computation and data processing are performed closer to the data source, can be utilized to reduce latency and bandwidth requirements. This method is suitable for real-time applications, but may be limited by the available resources on edge devices and the management of a distributed network. Finally, hybrid approaches that combine different techniques, such as a combination of cloud and edge computing, can be considered to leverage the benefits of both approaches. These approaches offer flexibility and redundancy but require complex management and cost optimization. Each solution has its advantages and disadvantages, and the choice depends on the specific requirements of the application, the available resources, and the organizational preferences.
The implemented scenarios reflect real system conditions, enabling detailed analysis and simulations at various levels (e.g., within the L1 Purdue model concerning device data communication). This capability provides deeper insight into the behavior of the system under different operational conditions and offers various perspectives within defined scenarios.
4.5. Data Collection and Storage
Data collection and processing often present a challenging and financially demanding process [
12]. For efficient data utilization, it is crucial to ensure comprehensibility and usability. However, in real networks, data often come from various sources and have various formats, requiring aggregation and conversion to a unified representation. To collect data, it is necessary to use common telemetry systems that gather relevant network-related data. One limitation of data collection is high storage space requirements, especially for networks with large flows. Therefore, methods to reduce data size and network compression techniques are being developed and investigated.
For efficient data collection and storage in network environments, there are several possible approaches; one is centralized data collection and storage, in which data are gathered and stored in a central repository. This approach offers simple implementation and management, and allows easy access to data for analysis and processing; however, it carries the risk of a single point of failure, and has higher demands on the scalability and performance of the central system. An alternative is distributed data collection and storage, where data is collected and stored in a distributed way among various network nodes. This approach provides data redundancy and higher fault tolerance, and enables efficient utilization of distributed resources; on the other hand, it requires complex implementation and management as well as the need for data synchronization among nodes. Another solution is data compression, which aims to reduce data volume and improve the efficiency of transmission and storage. This approach allows for reduced storage requirements and faster data transmission, but may lead to possible loss of information or quality during compression as well as increased computational resource overhead. The last proposed solution is data aggregation, which involves summarizing data into relevant aggregates, thereby reducing the volume of data, and facilitating analysis. This approach offers reduced data volume and simplified analysis, but may result in potential loss of details or specific information as well as potential bias in analysis results due to aggregation. Each of these approaches has its own advantages and disadvantages, and the suitability of their use depends on the specific needs and constraints of the network environment.
The communication data monitored by our model are not voluminous, thereby avoiding overloading our logging (historian) server. Furthermore, data are stored only for a specified period, helping to continually free up capacity. Although all information about monitored processes and devices may be retained when necessary, routine storage is unnecessary and undesirable in the normal operation of the model.
4.6. Data Processing
Processing data from physical devices on a central server is a key step for effective use of the data in the DT. This process allows for reducing the dimensionality of the data, and enables more efficient analysis and interpretation. However, data processing at the central level faces several challenges that can affect the quality and reliability of results [
13]. To ensure effective processing and visualization of data at the central level, it is crucial to implement advanced algorithms and techniques to handle large volumes of data and visualization tools that can manage variability and uncertainty in the data.
4.6.1. Data Uncertainty
One of the main challenges is the uncertainty of the data, which can manifest in various ways [
66]. In a DT environment, the distribution of data from physical devices varies depending on the environment and types of physical objects, which can cause variability in the quality and characteristics of the data. The data transfer rate can be temporarily variable, and is influenced by factors such as the number and type of physical objects as well as the specifications of the network environment. This variability can affect the stability and consistency of the data transmitted to the central repository. To address these issues, various advanced models and algorithms can be utilized. For example, the
Bayesian Dynamic Linear Model (DLM) uses Bayesian methods to estimate dynamic changes in data over time. This model can adjust predictions for changes in transfer rates or data variability, providing robust estimates even in the presence of variability. Another useful tool is the
Kalman filter, an algorithm that focuses on estimating the state of a system from imperfect or noisy measurements. This filter is effective in predicting and correcting data deviations caused by transfer variability. For situations where data are highly uncertain or exhibit high variability, the
particle filter is suitable. This algorithm, an extension of the Kalman filter, can handle nonlinear and nonstationary data, and is effective in estimating hidden states of the system even under complex conditions.
4.6.2. Data Quality
Another challenge is the quality of physical data, which can be affected by objective factors such as missing data or variations in the accuracy of the measurement instruments [
67]. These factors can have a significant impact on data processing and modeling, leading to less accurate or incomplete results. Measurement errors and insufficient data can undermine the integrity of models and analyses; thus, it is essential to use robust methods for data cleaning and validation before processing. One useful method for improving data quality is
Bayesian Dynamic Regression (BDR), which combines dynamic modeling and Bayesian inference. This algorithm allows for estimating missing data and correcting inconsistencies. Through the Bayesian approach, missing values can be reconstructed and uncertainty in estimates evaluated, thus increasing the model accuracy. Another valuable tool is the
Expectation Maximization (EM) algorithm, which is useful to estimate hidden parameters in models with missing data. The EM algorithm uses an iterative optimization process to find the best possible estimates for missing values, helping to improve the quality of the model.
Robust Regression (RR) is another approach that focuses on improving the resilience of the model to errors and outliers in the data. Methods such as
Huber Regression (HR) help to increase model accuracy even when the data contain errors, contributing to more robust analysis and more reliable results.
4.6.3. Visualization
With the increasing volume of data generated by physical devices, data visualization is becoming increasingly important [
68]. Effective visualization allows for quick identification of anomalies and system issues, and facilitates understanding of complex data patterns and trends. In large networks that generate large amounts of data, advanced visualization techniques may involve specialized knowledge and powerful computational resources. These techniques enable better data interpretation and effective presentation of information in a clear and understandable form. An example of advanced visualization techniques is
t-Distributed Stochastic Neighbor Embedding (t-SNE), a dimensionality reduction method that converts high-dimensional data into two or three dimensions. This technique is highly effective for visualizing complex patterns and relationships in the data, allowing for an easier understanding of hidden structures in large datasets. Another important method is
Principal Component Analysis (PCA), which serves to identify the principal components that contribute the most to the variability in the data. PCA helps to simplify the visualization of large datasets by focusing on key features, making analysis and interpretation easier.
Heatmaps represent another useful visualization technique. These visualizations display data in a matrix with color gradients, enabling effective representation of patterns in dense or complex data such as correlation matrices or event frequencies. Heatmaps facilitate the understanding of the distribution and intensity of the data, which is especially valuable for analyzing and monitoring systems that generate large volumes of data.
In our model, we focus primarily on methods for efficient communication data processing, reducing computational load, and ensuring rapid system response. Currently, we perform centralized data processing, which can lead to high computational server load and longer response times. In the future, we plan to integrate edge computing technologies, particularly edge devices themselves, which will allow data to be processed locally closer to the data sources. Our goal is to analyze different approaches to both effective data processing and detection of errors and anomalies, including data visualization and presentation to end users. We are currently focusing on creating communication data heatmaps, which will allow us to effectively display patterns and trends in complex data.
4.7. Edge Computing
Data processing is a key challenge in the field of DTs, mainly due to the large amount of data generated by various sensors and systems. The traditional approach of sending data to central cloud storage for analysis creates issues with delay and latency, which jeopardizes the ability of systems to respond in real-time. This problem is critical, especially in industries such as energy where quick response is essential. The ability to process data in real time is crucial, as immediate responses to changes directly affect the efficiency and reliability of systems [
65]. In the energy sector, delays can lead to suboptimal energy flow management, inefficient resource use, and potential power outages. Fast and reliable data processing is essential to monitoring and controlling distributed energy resources [
69] such as solar panels or wind turbines. Inefficient solutions could lead to missed opportunities to improve the resilience and stability of energy grids, with significant economic and environmental consequences.
One key approach to improving real-time data processing is the deployment of edge computing, which allows data processing directly at the source [
65]. This significantly reduces latency and increases decision-making speeds. For example, in the energy sector, edge computing ensures quick localization of issues and immediate response to outages without the need to wait for instructions from a central control system. This approach is also essential for predictive maintenance, where continuous monitoring of equipment conditions enables timely maintenance and minimizes unplanned downtime [
70]. The deployment of edge computing presents technological challenges such as limited computational power and energy efficiency of devices, which can restrict the ability to process complex algorithms and large volumes of data [
71]. In order to fully exploit the potential of edge computing it is crucial to focus on enhancing the computational power of edge devices and developing energy-efficient microprocessors. This reduces the need to transfer data to central storage, thereby speeding up processing, and minimizing latency. At the same time, optimizing energy consumption is important, including innovations in battery technologies and energy management to extend the life of these systems and ensure long-term sustainability. Developing more powerful and efficient edge devices will improve the effectiveness and capabilities of DTs, leading to better stability and reliability of energy grids while bringing significant benefits to system operators using DTs, increasing the resilience of these systems to outages, and supporting more efficient use of renewable energy resources.
Within our model, we recognize the importance of edge computing and plan to integrate it into our infrastructure. Although our system is not yet very extensive, we plan to expand our infrastructure with smart devices such as smart meters and RTUs (Remote Terminal Units). This integration will enable us to analyze more effective methods for monitoring and managing energy and information flows. We are also developing simulated devices to test various logical configurations, which will help us to optimize the balance between computational power, energy consumption, and data transfer volumes. Our goal is to create practically usable and economically viable solutions that contribute to the development of robust and sustainable systems for efficient real-time energy management.
4.8. High Modeling Accuracy
Conventional DT modeling utilizes general-purpose programming languages (such as Java, Python, C++), simulation languages (such as Simulink, AnyLogic, Arena), or specialized simulation software (such as AutoMod, NS-3) to describe the corresponding model. Machine learning-based models play a pivotal role in the system’s operation process; however, it is challenging to update them in real time with data that would enable achieving high reliability in predicting the behavior of physical objects [
28]. Conventional modeling is time-consuming and does not provide the level of detail required to achieve the desired complexity and accuracy. Most modeling methods have drawbacks such as limited flexibility, complex configuration, and susceptibility to errors. Therefore, further development in modeling and simulation technologies is necessary to create a reliable DT.
There are various approaches that can help to achieve high modeling accuracy within DTs. One possible solution is to use advanced modeling techniques such as AI methods, including neural networks or genetic algorithms. These techniques are capable of analyzing large amounts of data and uncovering complex patterns and relationships among them, allowing for the creation of more accurate and robust DT models. This approach has advantages in terms of high accuracy, flexibility, and the ability to automatically update models based on new data; however, it requires a large amount of training data and can be difficult to interpret. Another possible approach is the integration of physical models with real data from the monitoring of the system. In this way, the power of physical models, which describe the behavior of the system based on knowledge of physical laws, is combined with information obtained from real operations. This approach allows for leveraging the accuracy and interpretability of physical models while improving the accuracy and reliability of models using real data. However, it requires complex creation of physical models and may be difficult to update them according to changes in the system. A third possible approach is the combination of expert knowledge about the system with real data. This approach utilizes the knowledge of experts in the system or individuals with years of experience operating and maintaining the system. These insights are then integrated with real data to create more accurate and reliable models. This approach allows for the use of expert knowledge to improve model accuracy, and may be more easily interpretable; however, it can depend on the availability of experts, and has limited flexibility when models need to be updated without expert involvement.
Due to the hybrid nature of our model, which is neither purely physical nor purely emulated, it has the flexibility and precision to allow adjustment of individual model components as needed. This flexibility allows us to model specific scenarios and conduct detailed analyses without significant impacts on other parts of the system.
4.9. Continuous Model Updating
The aim of modeling physical objects in the DT environment is to create a comprehensive and accurate replica of the system [
13]. This can be continuously updated on the basis of data from physical devices, allowing for its representation, diagnostics, and predictions about the physical space. The principles of most physical objects are not entirely clear, and the creation of faithful models is challenging. The challenge lies in the continuous updating of the DT based on principles, data, diagnostics, or predictions, as precise data and sufficient computational power are required. In the energy domain, DTs must function effectively in various unknown network scenarios [
32]. The process of training a DT model is time-consuming and cannot be repeated after network changes such as connectivity outages. Energy networks often experience rapid changes, making it impossible to perform repeated model training. Given the scale of modern energy networks, it is challenging to replicate them in a testbed or simulate them to ensure an adequate dataset for DT model training. The ability to generalize the model allows for training it in smaller networks and subsequently deploying it into larger real-world networks without performance loss.
One approach is to utilize incremental learning algorithms that allow the DT model to be updated gradually as new data become available, avoiding the need to retrain from scratch. This approach enables continuous refinement of the DT model without significant computational overhead. However, it requires careful selection and tuning of algorithms to achieve a balance between model accuracy and computational efficiency. In addition, incremental updates may introduce biases or errors if not managed properly. Another approach is the implementation of online learning techniques combined with adaptive control mechanisms, which enables the DT model to be updated in real time based on the incoming data streams. This allows the DT model to rapidly adapt to changing network conditions and supports real-time decision making. However, it requires robust data processing and analysis for efficient handling of data streams and increases complexity with the sophistication of adaptive control mechanisms. Another option is to leverage transfer learning techniques, which allow the DT model to be trained on smaller, more manageable datasets or simpler network scenarios and then transfer the learned knowledge to larger and more complex networks. This reduces the need for extensive data collection and model training in large-scale networks and facilitates the rapid deployment of DT models in diverse network scenarios. However, the performance of generalization may vary depending on the similarity between training and deployment environments, and careful consideration of domain adaptation techniques is required for effective knowledge transfer. The final approach considered here is the combination of physics-based modeling with data-driven approaches to create hybrid DT models that utilize both domain knowledge and real-world data for continuous updates. This approach harnesses the strengths of both modeling paradigms, and provides flexibility to incorporate new insights and data while maintaining model fidelity. However, integrating different modeling paradigms can introduce complexity and increase computational overhead, which requires careful validation and calibration to ensure consistency between model components. Each of these approaches offers specific advantages and disadvantages, and the choice depends on factors such as data availability, computational resources, and the specific requirements of the energy network application. Evaluating these options in light of specific conditions and constraints can help in selecting the most suitable solution for continuous model updating in DTs for energy networks.
Due to the modular and flexible design of our model, regular updates can be performed with minimal impact on the existing structure. This capability is crucial to keeping the model up-to-date with the latest technological advancements and changes in the configurations of the electric transmission system.
4.10. Predictability and Interpretation
When evaluating neural networks (NN), it is often difficult to obtain a reliable uncertainty interval for predicted values [
37]. This challenge is particularly important because NNs can have overconfidence in their predictions, leading to distrust and reluctance to make decisions based on NNs in real-world settings. To address this problem, network operators are seeking robust and reliable methods to address network challenges. Developing methods to assess the credibility of NN predictions has become a crucial step towards the successful deployment of NNs in practice. In this context, researchers are exploring the replacement of NN weights with distributions, which represents an innovative approach to improving the interpretation and credibility of models. NNs as an option for training DTs are often perceived as black boxes, which hinders their practical use in real network scenarios. Currently, there is growing interest in better understanding and interpreting machine learning models, especially NNs. The development of NN-based tools aims to provide a usable and understandable means of interpretation for experts outside the field of machine learning. This would enable network operators to effectively utilize the knowledge gained from NN models to identify potential problems or propose optimization solutions.
In addressing the challenge of predictability and interpretation in neural networks, several approaches can be considered. One avenue involves implementing uncertainty quantification methods, such as Bayesian neural networks or Monte Carlo dropout, to provide probabilistic estimates of predictions. Although this offers better decision-making in uncertain scenarios, it can be computationally expensive and requires additional training. Another strategy is sensitivity analysis, which systematically perturbs input data to understand the impact of features on model predictions. Although it offers insights into influential features, it may not fully capture complex interactions and can be subjective. Layer-wise relevance propagation (LRP) techniques attribute relevance to input features or neurons, aiding in explaining the decision-making process. However, these interpretations may not always align with intuition and can be computationally intensive. Visual techniques such as saliency maps and Grad-CAM provide intuitive visualizations of model decision making, particularly in CNNs. Although helpful for interpretation and debugging, they are limited to specific network types and may lack precision. Model distillation offers a transparent alternative by training simpler interpretable models to mimic neural network behavior. Although it sacrifices some accuracy, it provides insight into decision-making. However, selecting the right interpretable model and training procedure is crucial.
The need for sophisticated prediction and interpretation of the data is currently limited in our model. We have not yet integrated AI into key system functions. Currently, our focus is primarily on optimizing data processing processes, which are a significant part of our operational environment.
4.11. Security and Data Privacy
As DTs represents complex systems consisting of various networks, it is challenging to ensure complete privacy and security [
13]. One of the problems is the sharing of information within the DT network. It may have bidirectional connections with the physical system, which can raise security issues. An attacker who may not have access to sensitive information through the physical device could obtain it by manipulating the DT network. For example, critical infrastructure DTs require the collection of various sensitive infrastructure-related information that may not be publicly known. There are also challenges related to securing computationally intensive tasks and data analysis when processed using cloud servers, for example, which may not be fully protected from attackers. Therefore, it is not entirely possible to ensure that sensitive data leakage does not occur.
To address security and data privacy challenges in DT, several specific approaches can be considered. One is the implementation of encrypted communication protocols within the DT network, which can ensure that data transmitted between components remain confidential and secure, for example by using techniques such as Transport Layer Security (TLS) or Virtual Private Networks (VPNs). Another important measure is the implementation of robust access control mechanisms. This includes user authentication, role-based access control (RBAC), and privilege escalation policies, which help to restrict unauthorized access to sensitive data in the DTN. To ensure secure data storage and processing, techniques such as encryption-at-rest and secure multi-party computation can be utilized. This protects data integrity and confidentiality even in the event of physical storage compromise. Currently, it is essential to implement continuous monitoring and intrusion detection systems, which allow for timely detection and response to security threats in the DTN. This involves monitoring network traffic, anomaly detection, and automated response mechanisms to reduce the likelihood and impact of security incidents.
In the field of security and data protection for DTs, various technologies and approaches can contribute to better protection and reliability of systems [
72]. For example,
Zero-Trust Security Models represent a contemporary approach that requires continuous authentication and verification of every element and access within the system. This model differs from traditional approaches that rely on location-based trust within the network, instead assuming that no element is implicitly trustworthy. This approach can significantly improve the security of DTs and protect critical infrastructure in the energy sector. However, implementing Zero Trust can be costly and complex, requiring ongoing updates and monitoring. Another example is
blockchain technology [
73], which offers a decentralized and immutable record of all interactions within the DTN. This approach increases transparency and trust by maintaining unalterable records of all transactions and interactions. Although blockchain technology can provide an additional layer of security, it is not without its challenges. The best approach to secure DTs often involves a combination of multiple measures tailored to the specific needs and constraints of the environment.
Our infrastructure is designed to operate within an isolated network with restricted access, ensuring a high level of security. Because we work only with data and structures similar to those in real deployment, and not with actual data, the risk of sensitive information leakage is minimized. For external deployments (production networks), we would employ peer-to-peer connections such as IPsec to effectively protect transmitted information. In addition, we store data on our own secure servers to prevent data leakage.
4.12. Costs
Another obstacle or challenge to consider is the cost associated with creating DTs. Building a comprehensive DT relies on a large amount of data as well as physical devices and other technologies [
15]. It is necessary to consider the costs of data collection based on the complete deployment of sensors. In addition, it is essential to take into account the consumption of hardware, communication, computational, and storage resources.
The first approach is to optimize data collection. This approach focuses on efficiently gathering data using modern sensors and technologies, thereby minimizing the costs associated with their processing and storage. This can improve data quality and relevance, subsequently increasing efficiency and reducing analysis costs. However, investments in new sensors and infrastructure can be costly, requiring additional resources for management and maintenance. The second option is more efficient utilization of hardware and communication resources. This approach aims to minimize the costs of hardware and communication resources through their effective utilization and optimization. This can lead to lower equipment and operations costs as well as reduced data transmission costs. However, investments in technology modernization can be expensive, and may require additional resources for management and maintenance. The third approach involves leveraging cloud services and computational resources. This approach utilizes cloud services to minimize the cost of physical servers and infrastructure while enabling the scalability of computational resources as needed. This can result in reduced infrastructure investments and scalability options. However, the pricing policies of cloud services providers can be unpredictable, and reliance on external providers may increase risk. A final approach is to optimize computational processes and storage. This approach aims to efficiently utilize computational resources and storage through advanced algorithms and technologies. This can lead to reduced operational and maintenance costs and increased system performance. However, investments in sophisticated systems can be expensive and require additional resources for management and optimization.
Our model does not include a physical topology. This means that all infrastructure above the L3 Purdue model level is realized in virtual form. This architecture offers the advantage of cost reduction, as physical devices in a real environment are not required. The primary costs of the model consist of virtual resources and the central server that ensures the operation and management of the entire system.
4.13. Future Research Directions
In the rapidly evolving field of DTs, exploring future research directions is essential in order to stay ahead of emerging challenges and opportunities. As technology continues to advance, new possibilities arise that can fundamentally expand the capabilities and applications of DTs. A thorough investigation into key areas such as new sensor technologies, big data analytics, AI, and more is critical to accelerating the implementation of DTs and maximizing their potential. This research will not only improve existing technologies, it will also open new pathways for innovations that can significantly enhance the capabilities of DTs.
4.13.1. New Sensor Technologies
New sensor technologies play a key role in the functioning of DTs, as sensors provide essential data for real-time monitoring of the physical world [
74]. The precision and reliability of these sensors directly impact the quality of the simulations and the subsequent decisions enabled by the DTs [
75]. Historically, sensor technology has evolved rapidly; however, many sensors still face limitations such as insufficient resolution, limited accuracy, or short lifespan. These shortcomings can negatively affect the quality of the data underlying DTs. In recent years, sensors have become more powerful and capable of performing complex calculations on-site (edge computing), which introduces new possibilities. This not only increases the speed of response and measurement accuracy but also reduces the load on the network and transmission capacity, which can significantly enhance the efficiency and performance of DTs. Thus, innovations in sensor technology could lead to higher data accuracy, longer lifetime, and the ability to operate in challenging conditions as well as to more efficient data processing [
76]. However, developing new sensors is costly and time-consuming. Miniaturization, resistance to extreme conditions, and ensuring energy efficiency are key technical challenges that need to be addressed. In the energy sector, improved sensors could lead to advances in network management, renewable resource monitoring, and predictive maintenance of critical systems. As the collection of large amounts of data through sensors also raises concerns about privacy and data security, it is essential to ensure that these data are not misused.
4.13.2. Big Data Analytics
Big data analytics is essential for the effective functioning of DTs, as it enables processing and interpretation of the vast amounts of data generated by DTs. Although big data analysis methods are evolving rapidly, they still face challenges related to processing speed, high computational demands, and the need for advanced algorithms [
77]. For example, machine learning algorithms such as k-means clustering or decision trees are often used to identify patterns in the data. However, these algorithms can suffer from scalability issues, especially with large datasets, leading to longer processing times and higher computational resource consumption. Another example is the MapReduce algorithm, which is effective for processing distributed data but may have shortcomings regarding latency and efficiency in real-time scenarios when handling large volumes of data in dynamic environments. Innovations in analytical tools could enable faster and more accurate decision-making, better predictions, and overall optimization of operations [
78]. Key challenges include algorithm complexity, the need for substantial computational resources, and the standardization of data analysis methodologies. In the energy sector, big data analytics can contribute to optimizing load distribution, predicting system failures, and improving the efficiency of distribution networks. However, processing such large volumes of data can involve sensitive information, necessitating robust protection measures.
4.13.3. Artificial Intelligence Applications
AI has the potential to significantly enhance the capabilities of DTs, particularly in areas such as advanced predictions, optimization, and autonomous decision making [
79]. AI technologies can transform the way DTs model and respond to dynamic conditions within energy systems, thereby contributing to their increased efficiency and reliability [
80]. However, implementing AI in complex systems such as energy networks remains a challenge due to the need for extensive data sets and high computational power. One key area where AI can make substantial improvements is in simulating user behavior and energy consumption. DTs must accurately reflect consumption patterns and user behaviors in order to provide useful predictions and optimizations [
81]. While historical attempts to model energy consumption have produced various models, current simulations often suffer from a lack of accuracy and flexibility. AI can contribute to the development of better models and algorithms that enable realistic modeling of dynamic behavior and consumption patterns. Innovations in AI can lead to improved predictive maintenance and operational optimization, but may also face challenges such as high computational demand, the need for extensive datasets, and the complexity of integrating AI into existing systems. In the energy sector, AI can help to optimize the distribution of loads, predict failures, and improve the efficiency of distribution networks. However, as with simulating user behavior, AI also raises ethical questions about the transparency of decision-making processes, accountability for AI-made decisions, and the risks associated with reliance on autonomous systems.
4.13.4. Renewable Energy Sources
Integrating DTs with renewable energy sources can play a crucial role in the efficient management and optimization of these resources [
82]. DTs can model and simulate the behavior of renewable energy systems such as solar panels and wind turbines, providing valuable insights into their performance. However, integrating renewable sources comes with challenges, including managing variability and improving prediction accuracy [
83]. Current technologies often struggle with precise modeling and forecasting, which can hinder effective integration. Innovations in this area could lead to better predictive models and optimization tools, enhancing the efficiency of the utilization of renewable resources. Key challenges include improving simulation accuracy, integrating diverse energy sources, and ensuring compatibility with existing systems. In the energy sector, better integration of renewable sources can lead to increased efficiency and sustainability of energy systems. Furthermore, ethical considerations are important to ensure that models and simulations do not have unforeseen negative impacts on ecosystems and local communities.
4.13.5. Augmented and Virtual Reality
Augmented Reality (AR) and Virtual Reality (VR) can significantly enhance visualization and interaction with DTs [
84]. These technologies allow users to view and manipulate DTs in an immersive environment, improving the understanding and management of complex systems [
85]. Historically, AR and VR technologies were more experimental, but have become more accessible and advanced in recent years. Innovations in this area could provide better visualization and training tools to facilitate system analysis and maintenance. The main challenges include the high costs of hardware and software, the need for substantial computational power, and integration with existing systems. In the energy sector, AR and VR can improve training, maintenance, and analysis of complex systems and equipment. However, there are security concerns, including ensuring that visualizations do not lead to misunderstandings or errors in interpreting critical data.
4.13.6. Blockchain Technology
Combining DT with blockchain technology could unlock new possibilities for data security and transparency [
86]. Blockchains can ensure the immutability and auditability of data, which is crucial to the credibility of DTs. Although this combination is still in its early stages, initial applications demonstrate the potential to improve data security and traceability [
73]. Innovations in this area could lead to improved security and transparency, with blockchains providing a means to verify data integrity and track data provenance. Challenges include the technical complexity of integrating blockchains into existing systems, high implementation costs, and the need for standardized protocols. In the energy sector, this combination could improve supply chain traceability, data security, and transaction transparency. Ethical and security considerations include managing access rights to the blockchain and protecting privacy when recording sensitive information.
4.13.7. Protection Against Cyberattacks
With the growing trend of cyberattacks, the resilience of DTs against these threats is becoming increasingly important [
87]. DTs are vulnerable to cyberattacks, which can impact their precision and reliability and potentially lead to severe consequences such as loss of data or damage to the system [
88]. Historical incidents show that similar systems have already been targeted, with serious outcomes. Organizations such as the NIST are working to develop advanced security standards and measures to protect DTs and other technologies from these threats. However, it is likely impossible to cover all emerging threats comprehensively, underscoring the importance of regular system updates and ongoing security testing.
5. Final Recommendation
5.1. Focus Areas of Existing Digital Twin Models
Our analysis of existing DT models indicates that these models mainly focus on simulation and security aspects, with limited interest in other functionalities such as data processing and anomaly detection. Data processing has proven to be crucial for real-world deployment, as it enables rapid notification of events and situations. Simulations are useful for analyzing future developments and identifying potential weaknesses in the system. Furthermore, our model emphasizes the educational aspect, allowing students to better understand the security issues in DTs and develop their professional skills.
5.2. Challenges in Detecting Cyber Vulnerabilities
Another significant challenge associated with the creation of DTs is the detection of cyber-related vulnerabilities. Virtual models often fail to provide simulations of all processes in real operations, which can lead to failure to detect some errors and vulnerabilities, in turn resulting in actual security incidents. In contrast, physically emulated models combine virtual and physical elements, enabling vulnerability testing on real devices, though with more limited flexibility. A significant drawback of these models is their static nature and inability to adapt quickly to new situations.
5.3. Importance of Data Processing
Proper data processing is crucial, especially for experimental models and DTs, which often combine real and simulated data to better predict and simulate various events and phenomena. However, in real-world applications of DTs, it is more appropriate to use algorithms that can quickly estimate missing values without disrupting system operations rather than relying on simulated sources. For faster and more efficient data processing, it is essential to develop edge devices that enable local data processing in order to minimize load on the communication link with the central system. To fully harness the potential of edge computing, it is important to focus on increasing the computational power of these devices and developing energy-efficient microprocessors. This approach not only speeds up processing and reduces latency, but also ensures long-term sustainability through innovations in battery technology and energy management. The development of more powerful and efficient edge devices will not only enhance the stability and reliability of energy networks but will also provide significant benefits to system operators that use DTs, including greater resilience against outages and more efficient use of renewable energy sources.
5.4. Integration of Artificial Intelligence
The integration of AI is a crucial aspect in the development of DTs and models, significantly enhancing the reliability and control of data flows. AI plays a key role in automatically validating and managing data, contributing to the effective deployment and maximizing the utility of these models in practice. Developing DTs requires the consideration of various key aspects, with AI integration being one of the most impactful factors to ensuring their success and effectiveness.
5.5. Ensuring Security and Data Protection
Another important factor is security and data protection. Implementing security measures such as encryption and access control is crucial to ensuring the integrity and privacy of sensitive information. Security risks such as information sharing within the DT or external attacks require careful attention and solutions. Security measures should also include protection against potential attacks on data flows, which could jeopardize the stability and reliability of digital models.
5.6. Continuous Updating and Maintenance for Real-Time Relevance
Continuous updating of models is key to maintaining their ongoing ability to dynamically respond to changes in the environment as well as their real-time relevance. This includes monitoring and collecting new data to update models and adapt to new conditions. High model accuracy and reliability are necessary in order to achieve desired levels of performance and user satisfaction. Detailed and accurate modeling along with quality data processing are crucial to achieving these goals. Data flow management, data collection, and storage are important for the success of both DTs and models, and effective data flow management and interpretation are essential for the successful use of these technologies. Interconnected processes such as these allow models to be updated according to current needs while ensuring that data are properly captured and interpreted for optimal results.
5.7. Monitoring and Adaptation to Technological Advancements
To ensure the continued effectiveness and relevance of DTs, ongoing monitoring and adaptation to technological advancements are crucial. With rapid progress in AI and cybersecurity, it is essential to keep DTs up to date and aligned with the latest technological trends. This proactive approach is key to successfully deploying and utilizing these technologies in practical applications.
6. Conclusions
Digital twins represent an innovative concept that offers the possibility of creating virtual models of real-world systems or processes. In the field of electric power system management, DTs promise a revolutionary approach to monitoring, optimizing, and managing energy networks. With their ability to accurately model and simulate operational conditions, DTs enable prediction and response to changes in the environment, optimization of operations, and increased efficiency. Their applications include monitoring equipment condition, optimization of performance, fault prediction, and rapid anomaly detection.
In this article, we analyze key open questions and challenges related to the deployment of DTs, including edge computing, AI, interoperability, and security. Although DTs offers significant potential for efficient power system management, it is necessary to address technical and organizational issues, including ways to ensure data security and integrity. We have also identified important directions for future research that will have a significant impact on the capabilities and properties of DTs, including new sensor technologies, big data analysis techniques, and protection against cyberattacks. Progress in these areas is crucial for more efficient and secure utilization of DTs in real-world operations.
Combining the insights gleaned from existing DT models with the challenges they face can provide a roadmap for addressing open questions. Ensuring security and data protection through encryption, access control, and vigilant monitoring is a foundational pillar. Implementing encrypted communication protocols, robust access control mechanisms, and techniques such as encryption-at-rest and intrusion detection systems can help to safeguard data integrity and confidentiality. In addition, continuous updating and maintenance are vital for maintaining real-time relevance, and require the integration of AI in order to automate validation and data management processes. Techniques such as machine learning for anomaly detection and predictive maintenance can ensure that the models are accurate and up-to-date. Proper data processing, whether from physical devices or simulated sources, emerges as a critical aspect for accurate modeling and predictive capabilities. The use of edge computing, closely related to hardware modernization such as smart meters, can significantly ease data processing and enhance overall modeling efficiency. The current trend in the energy sector is the modernization of edge devices, which is creating new opportunities for the practical deployment of various DTs. Employing a combination of real and simulated data can enhance the predictive power and adaptability of models to various scenarios. Monitoring new technological advancements and adapting to them, especially in the contexts of AI and cybersecurity, is necessary in order to ensure the continued effectiveness of DTs and their compatibility with evolving standards. To address the challenges associated with data integration, it is crucial to clearly define which systems the DT will communicate with as well as to establish a unified communication framework. This approach minimizes interoperability issues and facilitates the smooth integration of diverse data sources. Regular evaluation of emerging technologies and best practices in AI and cybersecurity can provide updates and enhancements to DT systems. By focusing on these key areas and implementing specific solutions tailored to each challenge, stakeholders can navigate the complexities of DT development with confidence, maximizing their utility while mitigating potential risks.


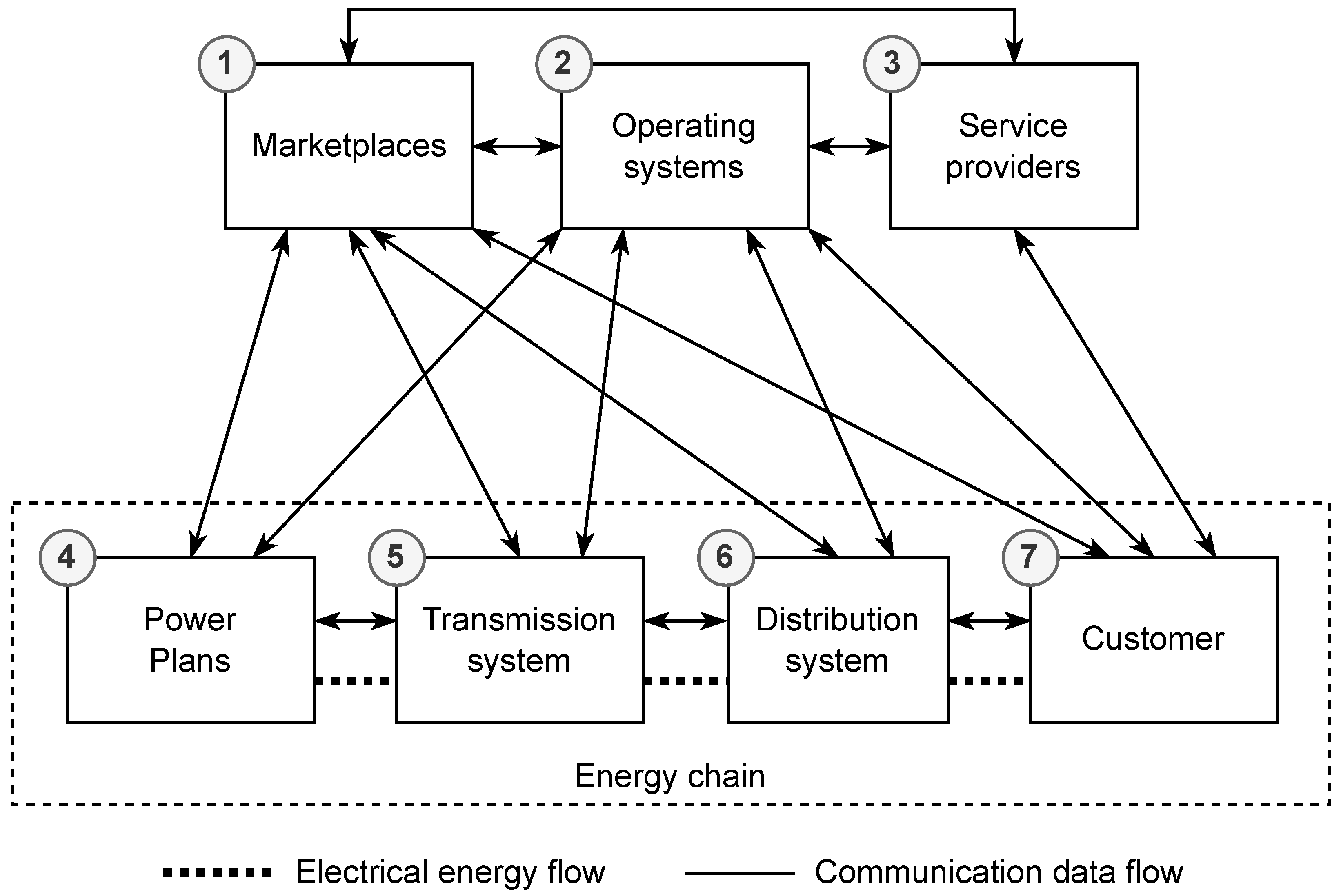
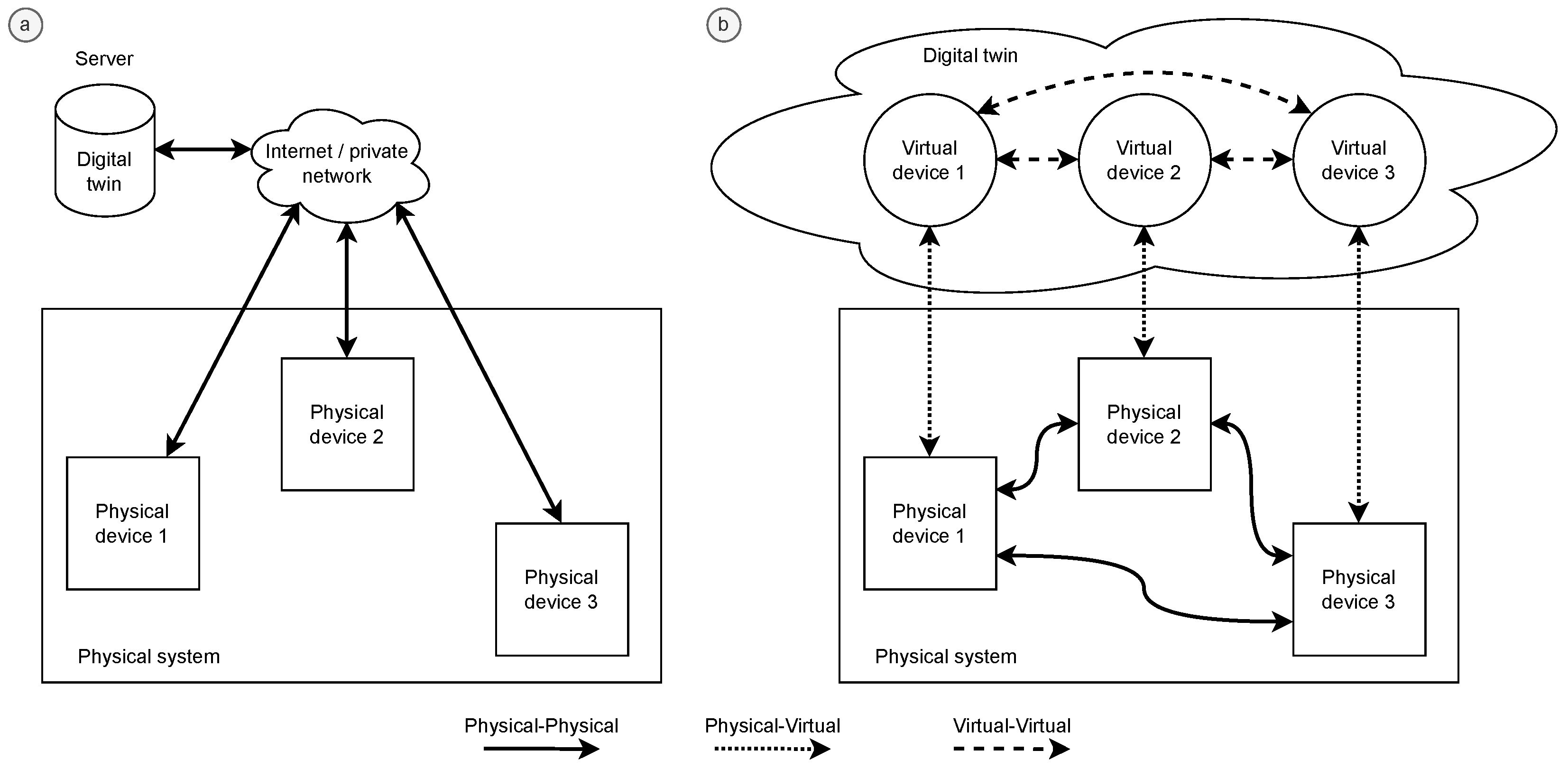
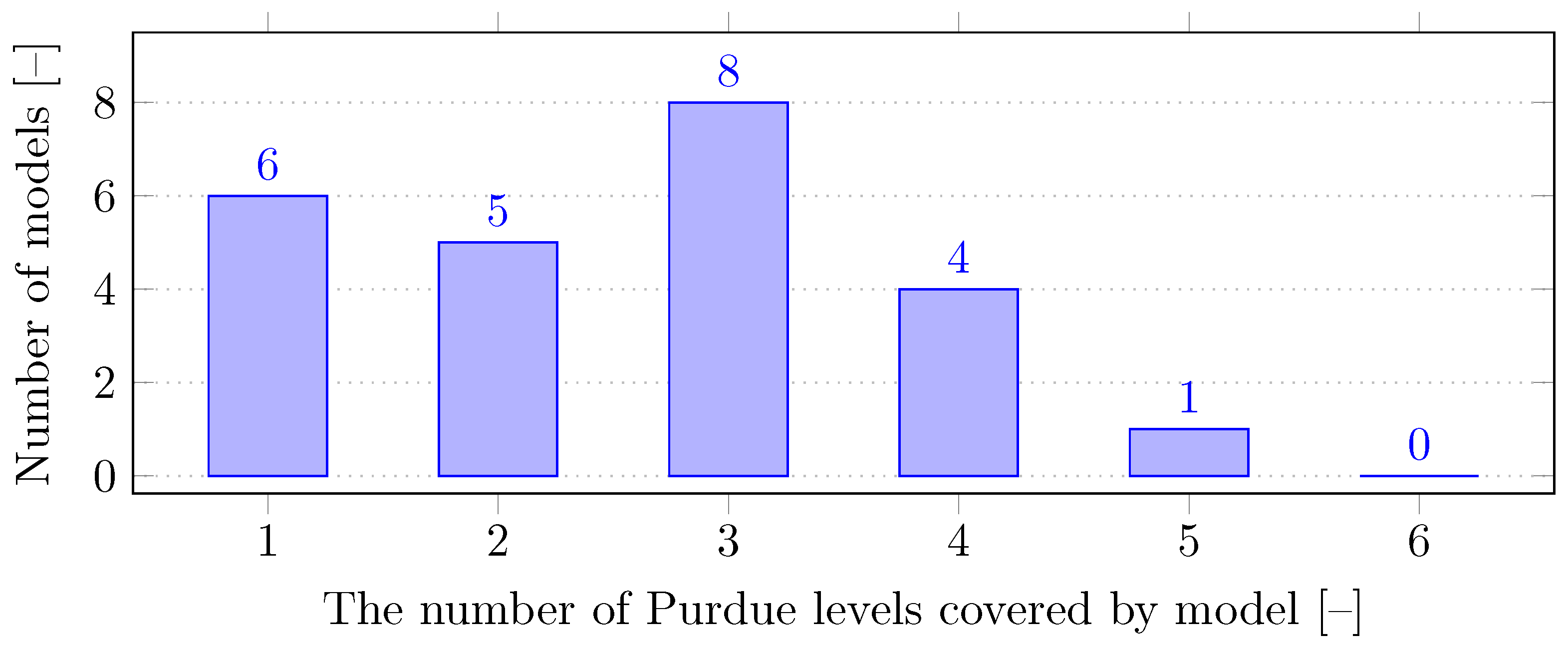
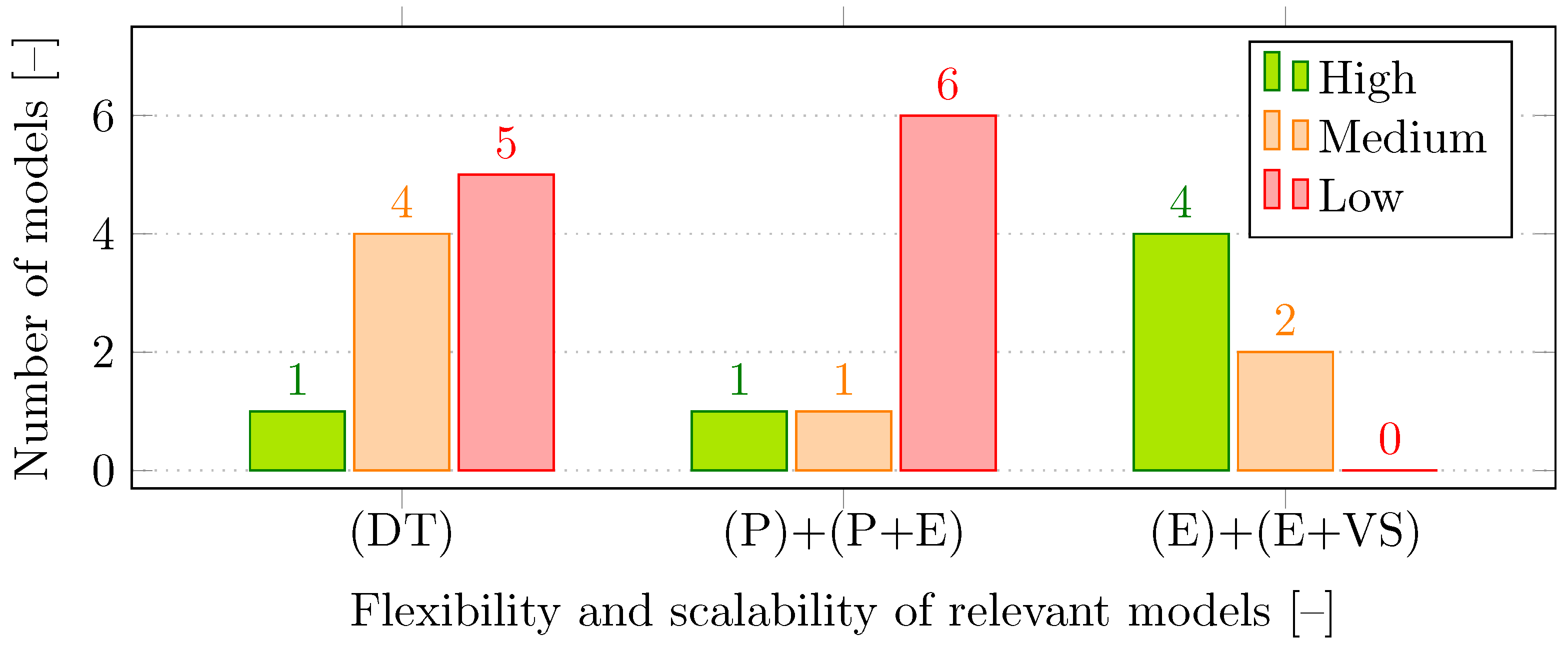
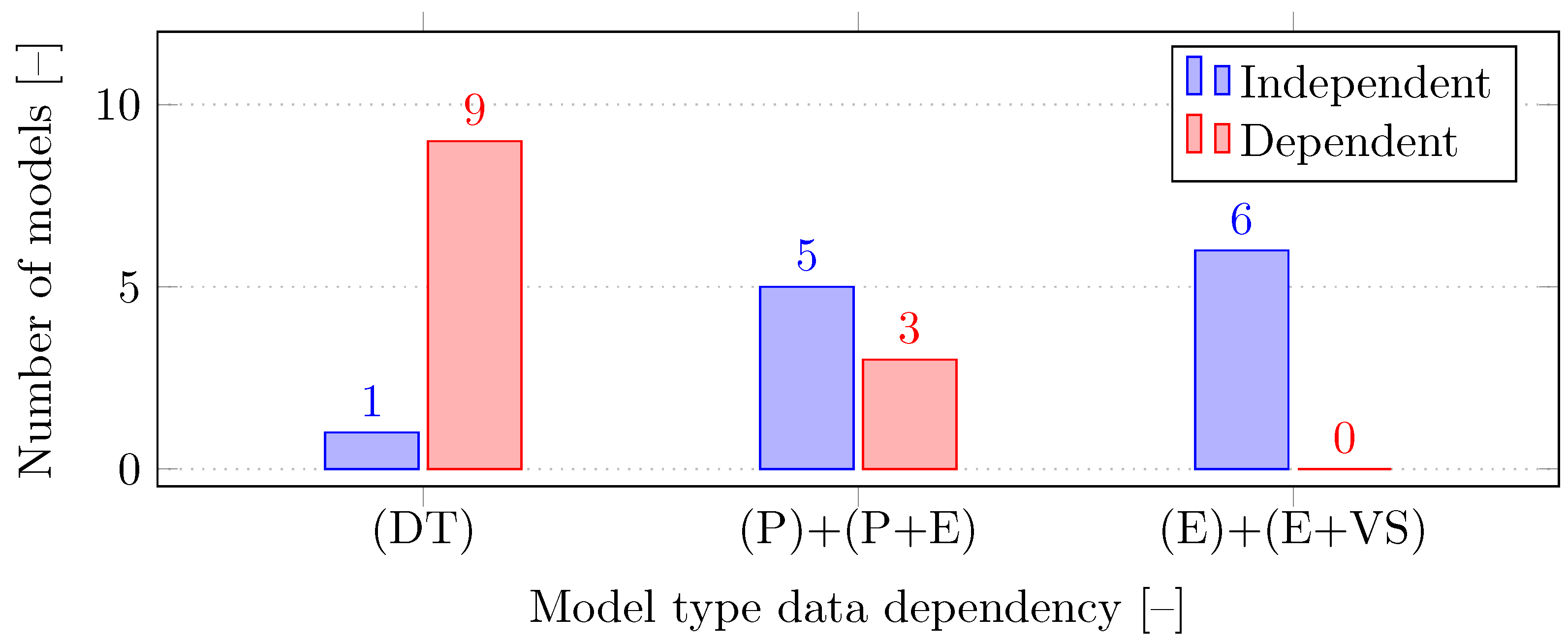
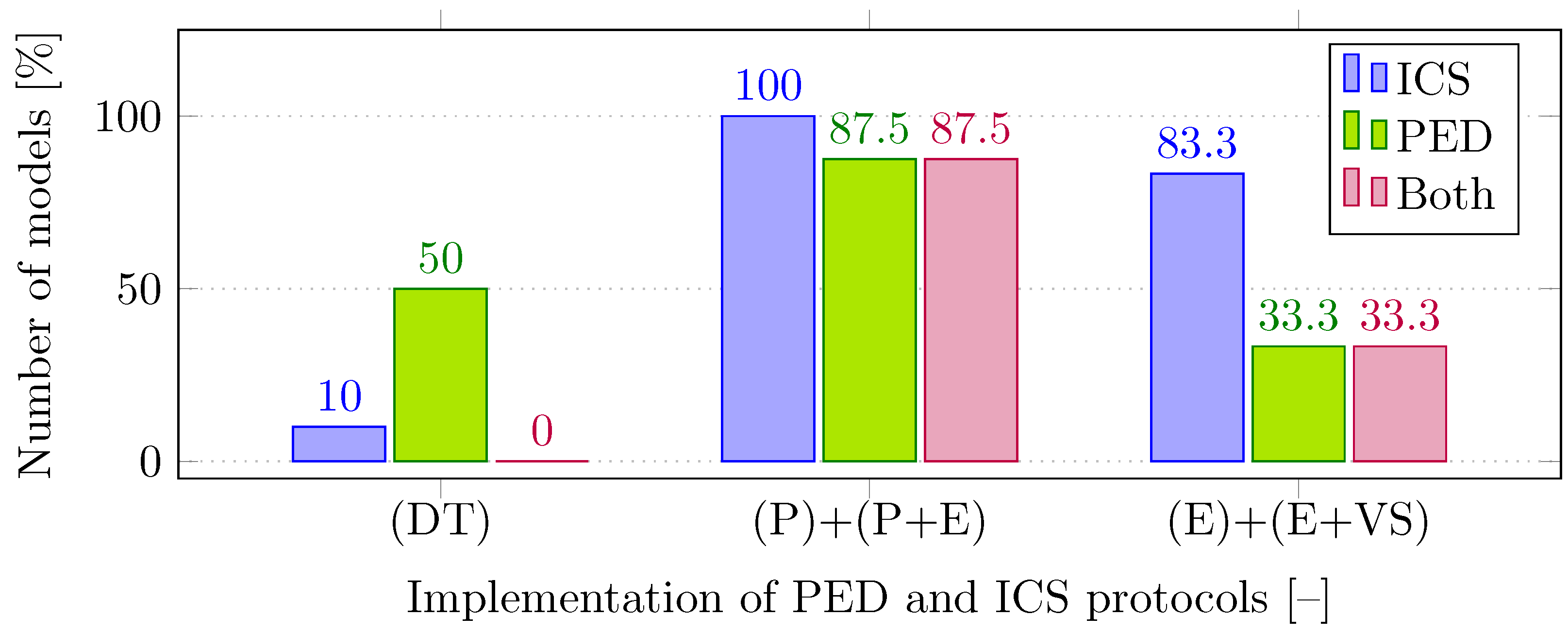
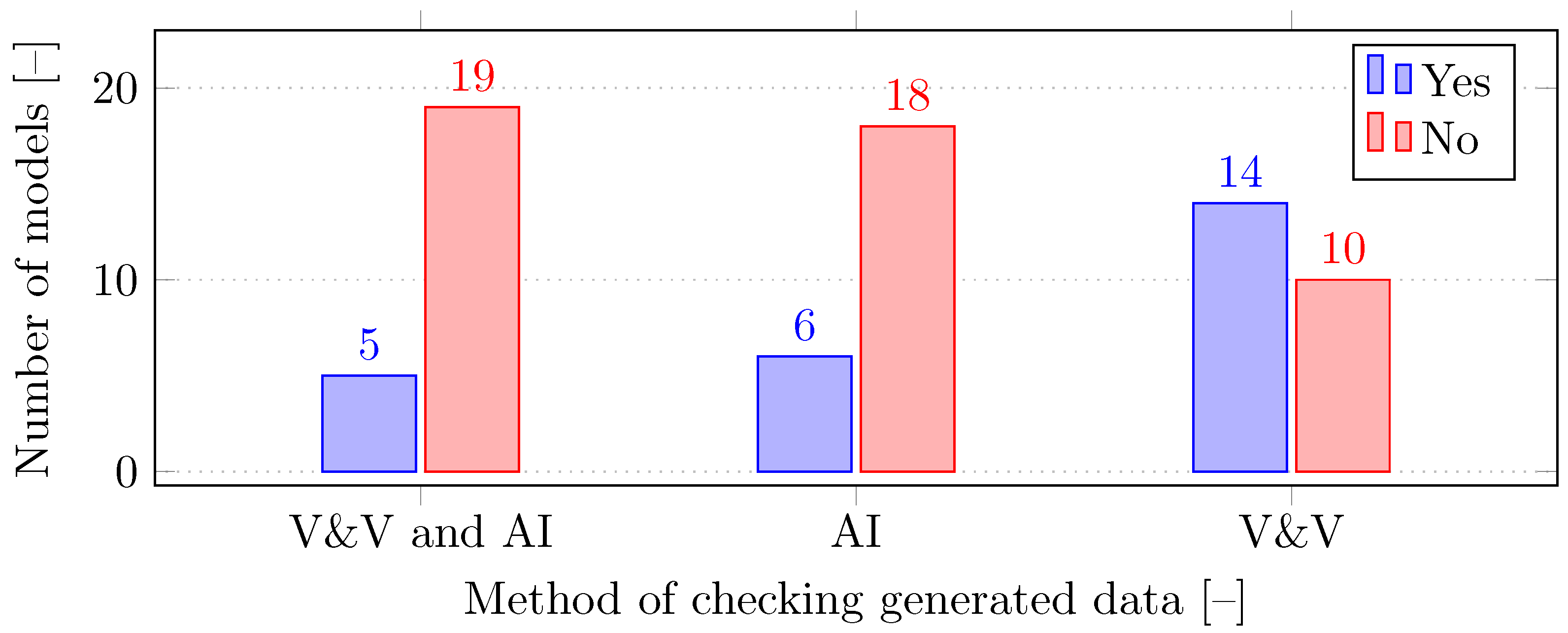

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

























 = Still in progress;
= Still in progress;  = Yes;
= Yes; 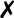 = No;
= No;  = Level in the Purdue model;
= Level in the Purdue model;  = Virtual or simulated model; BUT = Our model created at the Institute of Telecommunications at Brno University of Technology.
= Virtual or simulated model; BUT = Our model created at the Institute of Telecommunications at Brno University of Technology.