Perceptions on Smart Gas Meters in Smart Cities for Reducing the Carbon Footprint




Abstract
1. Introduction
2. Background
2.1. Smart Meters for Low Carbon
2.2. Data Privacy
3. Investigation Methodology
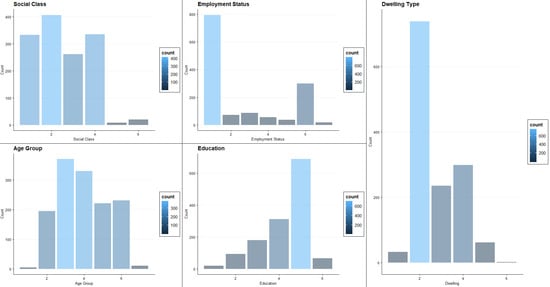
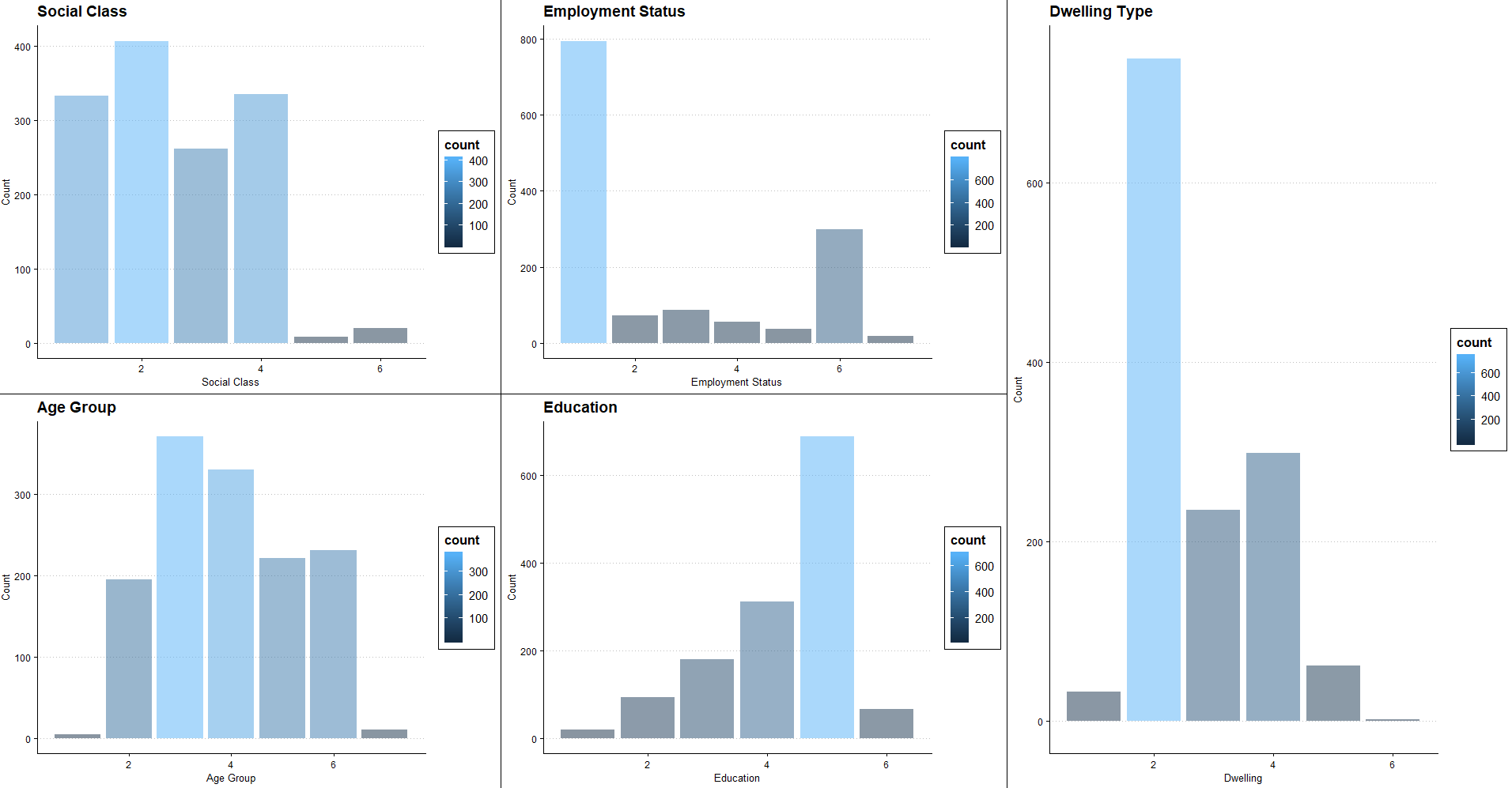
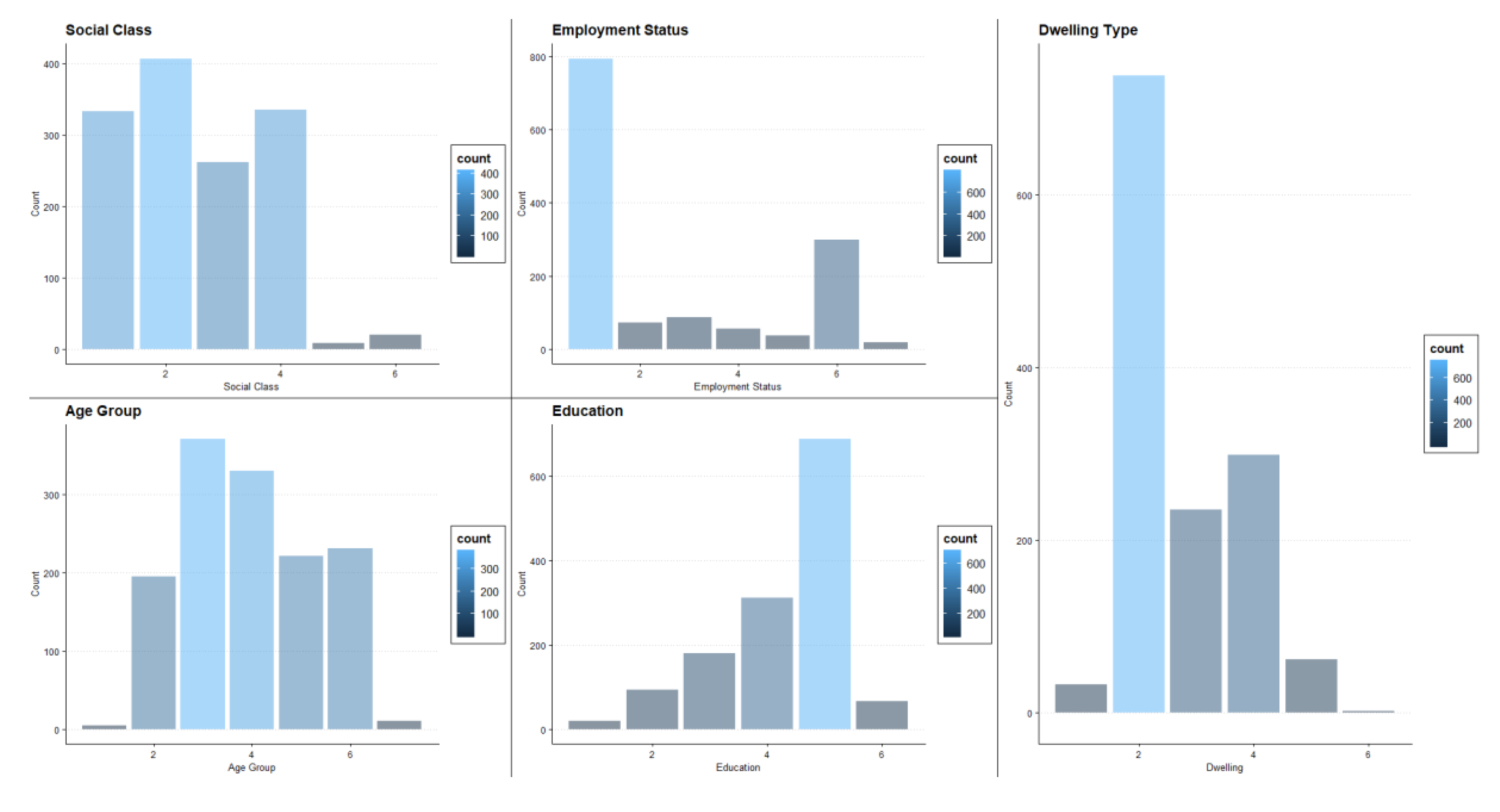
3.1. Data Overview
3.2. Multiple Regression and Predictor Variables
4. Results
4.1. Hypothesis 1 Evaluation—Reducing the Bill
4.2. Hypothesis 2 Evaluation—Enviromental Impact
4.3. Hypothesis 3 Evaluation—Behaviour Change
4.4. Hypothesis 4 Evaluation —Save Energy
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Browne, N. Regarding Smart Cities in China, the North and Emerging Economies—One Size Does Not Fit All. Smart Cities 2020, 3, 186–201. [Google Scholar] [CrossRef]
- Caballero, V.; Vernet, D.; Zaballos, A. A Heuristic to Create Prosumer Community Groups in the Social Internet of Energy. Sensors 2020, 20, 3704. [Google Scholar] [CrossRef]
- Lin, C.; Yu, Y.; Wu, D.; Gong, B. Traffic Flow Catastrophe Border Identification for Urban High-Density Area Based on Cusp Catastrophe Theory: A Case Study under Sudden Fire Disaster. Appl. Sci. 2020, 10, 3197. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, J.; Tadikamalla, P.R.; Zhou, L. The Mechanism of Social Organization Participation in Natural Hazards Emergency Relief: A Case Study Based on the Social Network Analysis. Environ. Res. Public Health 2019, 16, 4110. [Google Scholar] [CrossRef]
- Jose, T.; Ohde, J.W.; Hays, T.; Burke, M.V.; Warner, D.O. Design and Pilot Implementation of an Electronic Health Record-Based System to Automatically Refer Cancer Patients to Tobacco Use Treatment. Environ. Res. Public Health 2020, 17, 4054. [Google Scholar] [CrossRef]
- Cirillo, F.; Wu, F.-J.; Solmaz, G.; Kovacs, E. Embracing the Future Internet of Things. Sensors 2019, 19, 351. [Google Scholar] [CrossRef]
- Leyerer, M.; Sonneberg, M.-O.; Heumann, M.; Breitner, M.H. Shortening the Last Mile in Urban Areas: Optimizing a Smart Logistics Concept for E-Grocery Operations. Smart Cities 2020, 3, 585–603. [Google Scholar] [CrossRef]
- Kim, J.; Moon, H.; Jung, H. Drone-Based Parcel Delivery Using the Rooftops of City Buildings: Model and Solution. Appl. Sci. 2020, 10, 4362. [Google Scholar] [CrossRef]
- GOV.UK. UK Becomes First Major Economy to Pass Net Zero Emissions Law, June 2019. Available online: https://www.gov.uk/government/news/uk-becomes-first-major-economy-to-pass-net-zero-emissions-law (accessed on 2 August 2020).
- Fernández, C.G.; Peek, D. Smart and Sustainable? Positioning Adaptation to Climate Change in the European Smart City. Smart Cities 2020, 3, 511–526. [Google Scholar] [CrossRef]
- Fredericks, D.; Fan, Z.; Woolley, S.; Quincey, E.D.; Streeton, M. A Decade On, How Has the Visibility of Energy Changed? Energy Feedback Perceptions from UK Focus Groups. Energies 2020, 13, 2566. [Google Scholar] [CrossRef]
- Hock, D.; Kappes, M.; Ghita, B. Entropy-Based Metrics for Occupancy Detection. Entropy Inf. Theory Probab. Stat. 2020, 22, 731. [Google Scholar]
- Sinitsyna, K.; Petrochenkov, A.; Krause, B. Identification of Electric Power Consumption Patterns in Relation to Standard Load Profiles. In IEEE International Conference on Computational Science and Engineering (CSE), and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), 1–3 August 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Haben, S.; Singleton, C.; Grindrod, P. Analysis and Clustering of Residential Customers Energy Behavioral Demand Using Smart Meter Data. IEEE Trans. Smart Grid 2016, 7, 136–144. [Google Scholar] [CrossRef]
- Cotton, J. The Data Impact, 03 April 2014. Available online: https://www.ibi.com/blog/james-cotton/16610 (accessed on 8 June 2020).
- Plenz, M.; Dong, C.; Grumm, F.; Meyer, M.F.; Schumann, M.; McCulloch, M. Framework Integrating Lossy Compression and Perturbation for the Case of Smart Meter Privacy. Electronics 2020, 9, 465. [Google Scholar] [CrossRef]
- Mehmood, G.; Khan, M.Z.; Waheed, A.; Zareei, M.; Mohamed, E.M. Trust-Based Energy-Efficient and Reliable Communication Scheme (Trust-Based ERCS) for Remote Patient Monitoring in Wireless Body Area Networks. IEEE Access 2020, 8, 131397–131413. [Google Scholar] [CrossRef]
- Department for Business, Energy and Industrial Strategy. Delivering a Smart System: Consultation on a Smart Meter Policy Framework Post 2020; Department for Business, Energy and Industrial Strategy: London, UK, 2019. [Google Scholar]
- Alkawsi, G.A.; Ali, N.; Baashar, Y. An Empirical Study of the Acceptance of IoT-Based Smart Meter in Malaysia: The Effect of Electricity-Saving Knowledge and Environmental Awarenes. IEEE Access 2020, 8, 42794–42804. [Google Scholar] [CrossRef]
- Luciani, C.; Casellato, F.; Alvisi, S.; Franchini, M. Green Smart Technology for Water (GST4Water): Water Loss Identification at User Level by Using Smart Metering Systems. Water 2019, 11, 405. [Google Scholar] [CrossRef]
- Irish Social Science Data Archive. Commission for Energy Regulation Smart Metering Project—Gas Customer Behaviour Trial, 2009–2010; SN: 0013-00; Irish Social Science Data Archive: Dublin, Ireland, 2012; Available online: www.ucd.ie/issda/CER-gas (accessed on 9 October 2020).
- Verdejo, H.; Becker, C. The Erratic Implementation of Measuring, Monitoring and Control System (MMCS) in Chile: The crisis on smart meters. Elsevier Energy Rep. 2020, 6, 2140–2145. [Google Scholar] [CrossRef]
- Smart Energy GB, The Missing Piece in Climate Conversations. Available online: https://www.smartenergygb.org/en/smart-living/the-missing-piece-in-the-climate-conversation (accessed on 10 August 2020).
- Van den Broek, K.L.; Walker, I. Exploring the perceptions of drivers of energy behaviour. Elsevier Energy Policy 2019, 129, 1297–1305. [Google Scholar] [CrossRef]
- Fahim, M.; Sillitti, A. Analyzing Load Profiles of Energy Consumption to Infer Household Characteristics Using Smart Meters. Energies 2019, 12, 773. [Google Scholar] [CrossRef]
- Zhang, X.-Y.; Kuenzel, S.; Córdoba-Pachón, J.-R.; Watkins, C. Privacy-Functionality Trade-Off: A Privacy-Preserving Multi-Channel Smart Metering System. Energies 2020, 13, 3221. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, J. EPPRD: An Efficient Privacy-Preserving Power Requirement and Distribution Aggregation Scheme for a Smart Grid. Sensors 2017, 17, 1814. [Google Scholar] [CrossRef]
- Pham, C.; Månsson, D. A Study on Realistic Energy Storage Systems for the Privacy of Smart Meter Readings of Residential Users. IEEE Access 2019, 7, 150262–150270. [Google Scholar] [CrossRef]
- Nabil, M.; Ismail, M.; Mahmoud, M.M.E.A.; Alasmary, W.; Serpedin, E. PPETD: Privacy-Preserving Electricity Theft Detection Scheme with Load Monitoring and Billing for AMI Networks. IEEE Access 2019, 7, 96334–96348. [Google Scholar] [CrossRef]
- Tellbach, D.; Li, Y.-F. Cyber-Attacks on Smart Meters in Household Nanogrid: Modeling, Simulation and Analysis. Energies 2018, 11, 316. [Google Scholar] [CrossRef]
- Wang, Y.; Luo, F.; Dong, Z.; Tong, Z.; Qiao, Y. Distributed meter data aggregation framework based on Blockchain and homomorphic encryption. IET Cyber Phys. Syst. Theory Appl. 2019, 3, 30–37. [Google Scholar] [CrossRef]
- Afzal, M.; Huang, Q.; Amin, W.; Umer, K.; Raza, A.; Naeem, M. Blockchain Enabled Distributed Demand Side Management in Community Energy System with Smart Homes. IEEE Access 2020, 8, 37428–37439. [Google Scholar] [CrossRef]
- Gao, J. GridMonitoring: Secured Sovereign Blockchain Based Monitoring on Smart Grid. IEEE Access 2018, 6, 9917–9925. [Google Scholar] [CrossRef]
- Giaconi, G.; Gunduz, D.; Poor, H.V. Privacy-Aware Smart Metering: Progress and Challenges. IEEE Signal Process. Mag. 2018, 35, 59–78. [Google Scholar] [CrossRef]
- Social Grade|National Readership Survey. 2016. Available online: http://www.nrs.co.uk/nrs-print/lifestyle-and-classification-data/social-grade/ (accessed on 13 August 2020).
- Asghar, M.R.; Dan, G.; Miorandi, D.; Chlamtac, I. Smart Meter Data Privacy: A Survey. IEEE Commun. Surv. Tutor. 2017, 19, 99. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Dwelling | Education | Employment Status | Social Class | Age |
|---|---|---|---|---|---|
| 1 | Apartment | No formal education | An employee | AB | 18–25 |
| 2 | Semi-detached house | Primary | Self-employed (with employees) | C1 | 26–35 |
| 3 | Detached house | Secondary to Intermediate Cert Junior Cert level | Self-employed (no employees) | C2 | 36–45 |
| 4 | Terraced house | Secondary to Leaving Cert level | Unemployed (actively seeking work) | DE | 46–55 |
| 5 | Bungalow | Third level | Unemployed (not actively seeking work) | Farmer | 56–65 |
| 6 | Refused | Refused | Retired | Refused | 65+ |
| 7 | / | / | Carer Worker | / | Refused |
| Estimate Std. | Error | t Value | Pr(>|t|) | |
|---|---|---|---|---|
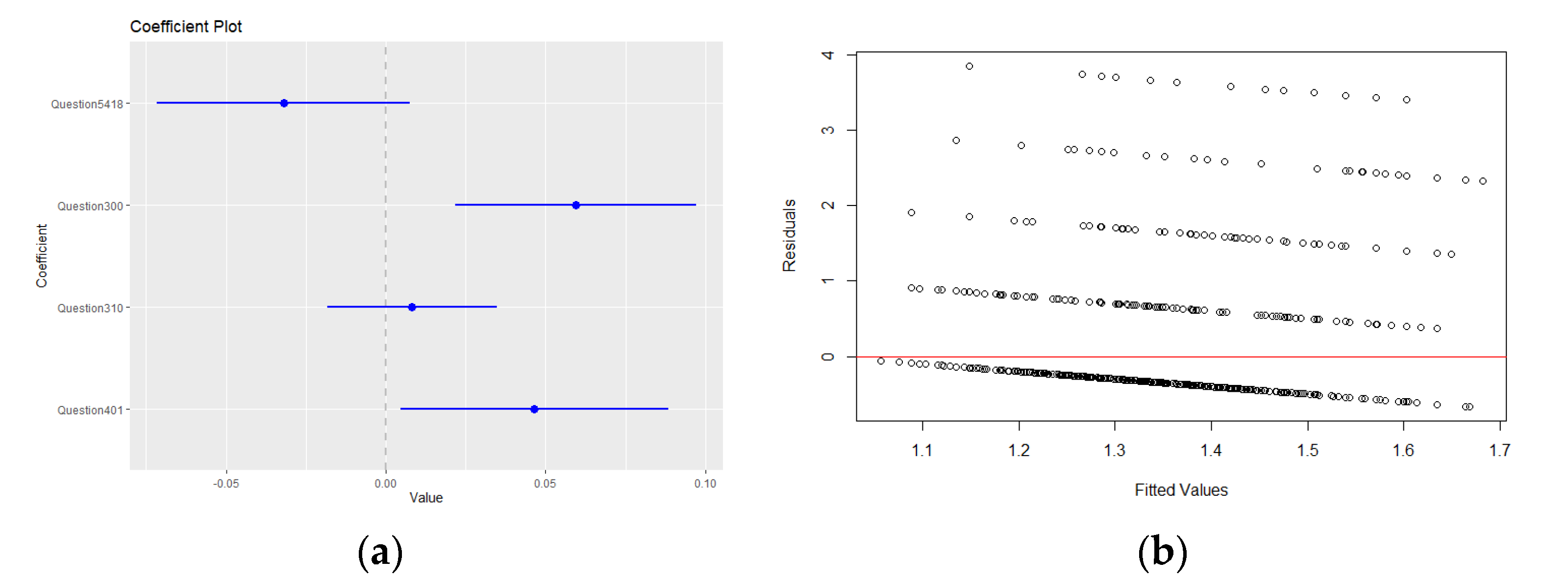
| (Intercept) | 1.074785 | 0.130390 | 8.243 | 3.92 × 10−16 |
| Question401 | 0.046504 | 0.020976 | 2.217 | 0.0268 |
| Question310 | 0.008176 | 0.013244 | 0.617 | 0.5371 |
| Question300 | 0.059517 | 0.018823 | 3.162 | 0.0016 |
| Question5418 | −0.031983 | 0.019811 | −1.614 | 0.1067 |
| Estimate Std. | Error | t Value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 1.395896 | 0.155932 | 8.952 | 2 × 10−16 |
| Question401 | 0.028856 | 0.025085 | 1.150 | 0.2502 |
| Question310 | −0.004334 | 0.015838 | −0.274 | 0.7844 |
| Question300 | 0.037998 | 0.022510 | 1.688 | 0.0916 |
| Question5418 | −0.025360 | 0.023692 | −1.070 | 0.2846 |
| Likert Scale | Frequency | Percentage | Cumulative Percentage |
|---|---|---|---|
| 1 | 613 | 44.908 | 44.91 |
| 2 | 328 | 24.029 | 68.94 |
| 3 | 216 | 15.824 | 84.76 |
| 4 | 91 | 6.667 | 91.43 |
| 5 | 117 | 8.571 | 100.00 |
| Estimate Std. | Error | t Value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 1.76912 | 0.22537 | 7.850 | 8.39 × 10−15 |
| Question401 | −0.01575 | 0.03626 | −0.435 | 0.66398 |
| Question310 | 0.06026 | 0.02289 | 2.632 | 0.00858 |
| Question300 | 0.07340 | 0.03253 | 2.256 | 0.02422 |
| Question5418 | −0.01784 | 0.03424 | −0.521 | 0.60255 |
| Estimate Std. | Error | t Value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 1.31163 | 0.14910 | 8.797 | <2 × 10−16 |
| Question401 | 0.01416 | 0.02399 | 0.590 | 0.5551 |
| Question310 | 0.01807 | 0.01514 | 1.193 | 0.2329 |
| Question300 | 0.04118 | 0.02152 | 1.913 | 0.0559 |
| Question5418 | −0.02655 | 0.02265 | −1.172 | 0.2414 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hurst, W.; Tekinerdogan, B.; Kotze, B. Perceptions on Smart Gas Meters in Smart Cities for Reducing the Carbon Footprint. Smart Cities 2020, 3, 1173-1186. https://doi.org/10.3390/smartcities3040058
Hurst W, Tekinerdogan B, Kotze B. Perceptions on Smart Gas Meters in Smart Cities for Reducing the Carbon Footprint. Smart Cities. 2020; 3(4):1173-1186. https://doi.org/10.3390/smartcities3040058
Chicago/Turabian StyleHurst, William, Bedir Tekinerdogan, and Ben Kotze. 2020. "Perceptions on Smart Gas Meters in Smart Cities for Reducing the Carbon Footprint" Smart Cities 3, no. 4: 1173-1186. https://doi.org/10.3390/smartcities3040058
APA StyleHurst, W., Tekinerdogan, B., & Kotze, B. (2020). Perceptions on Smart Gas Meters in Smart Cities for Reducing the Carbon Footprint. Smart Cities, 3(4), 1173-1186. https://doi.org/10.3390/smartcities3040058