1. Introduction
Automatic drum transcription (ADT) is one of the most important subtasks in automatic music transcription (AMT) because the drum part forms the rhythmic backbone of popular music. In this study, we deal with the three main instruments of the basic drum kit: bass drum (BD), snare drum (SD), and hi-hats (HH). Since these drums produce unpitched impulsive sounds, only the onset times are of interest in ADT. The standard approach to ADT is to estimate the activations (gains) or onset probabilities of each drum from a music spectrogram
at the frame level and then to determine the onset frames using an optimal path search algorithm based on some cost function [
1]. Although the ultimate goal of ADT is to estimate a human-readable symbolic drum score, few studies have attempted to estimate the onset times of drums quantized
at the tatum level. In this paper, the “tatum” is defined as a tick position on the sixteenth-note-level grid (four times finer than the “beat” on the quarter-note-level grid) and the tatum times are assumed to be estimated in advance [
2].
Nonnegative matrix factorization (NMF) and deep learning have been used for frame-level ADT [
3]. The time-frequency spectrogram of a percussive part, which can be separated from a music spectrogram [
4,
5], has a low-rank structure because it is composed of repeated drum sounds with varying gains. This has motivated the use of NMF or its convolutional variants for ADT [
6,
7,
8,
9,
10], where the basis spectra or spectrogram templates of drums are prepared and their frame-level activations are estimated in a semi-supervised manner. The NMF-based approach is a physically reasonable choice, but the supervised DNN-based approach has recently gained much attention because of its superior performance. Comprehensive experimental comparison of DNN- and NMF-based ADT methods have been reported in [
3]. Convolutional neural networks (CNNs), for example, have been used for extracting local time-frequency features from an input spectrogram [
11,
12,
13,
14,
15]. Recurrent neural networks (RNNs) are expected to learn the temporal dynamics inherent in music and have successfully been used, often in combination with CNNs, for estimating the smooth onset probabilities of drum sounds at the frame level [
16,
17,
18]. This approach, however, cannot learn musically meaningful drum patterns on the symbolic domain, and the tatum-level quantization of the estimated onset probabilities in an independent post-processing step often yields musically unnatural drum notes.
To solve this problem, Ishizuka et al. [
19] attempted to use the encoder–decoder architecture [
20,
21] for frame-to-tatum ADT. The model consisted of a CNN-based frame-level encoder for extracting the latent features from a drum-part spectrogram and an RNN-based tatum-level decoder for estimating the onset probabilities of drums from the latent features pooled at the tatum level. This was inspired by the end-to-end approach to automatic speech recognition (ASR), where the encoder acted as an acoustic model to extract the latent features from speech signals and the decoder acted as a language model to estimate the grammatically coherent word sequences [
22]. Unlike ASR models, the model used the temporal pooling and had no attention mechanism that connected the frame-level encoder to the tatum-level decoder, i.e., that aligned the frame-level acoustic features with the tatum-level drum notes, because the tatum times were given. Although the tatum-level decoder was capable of learning musically meaningful drum patterns and favored musically natural drum notes as its output, the performance of ADT was limited by the amount of paired data of music signals and drum scores.
Transfer learning [
23,
24,
25] is a way of using external non-paired drum scores for improving the generalization capability of the encoder–decoder model. For example, the encoder–decoder model could be trained in a regularized manner such that the output score was close to the ground-truth drum score and at the same time was preferred by a language model pretrained from an extensive collection of drum scores [
19]. More specifically, a repetition-aware bi-gram model and a gated recurrent unit (GRU) model were used as language models for evaluating the probability (musical naturalness) of a drum score. Assuming that drum patterns were repeated with an interval of four beats as was often the case with the 4/4 time signature, the bi-gram model predicted the onset activations at each tatum by referring to those at the tatum four beats ago. The GRU model worked better than the bi-gram model because it had no assumption about the time signature and could learn the sequential dependency of tatum-level onset activations. Although the grammatical knowledge learned by the GRU model was expected to be transferred into the RNN-based decoder, such RNN-based models still could not learn the repetitive structure of drum patterns on the global time scale.
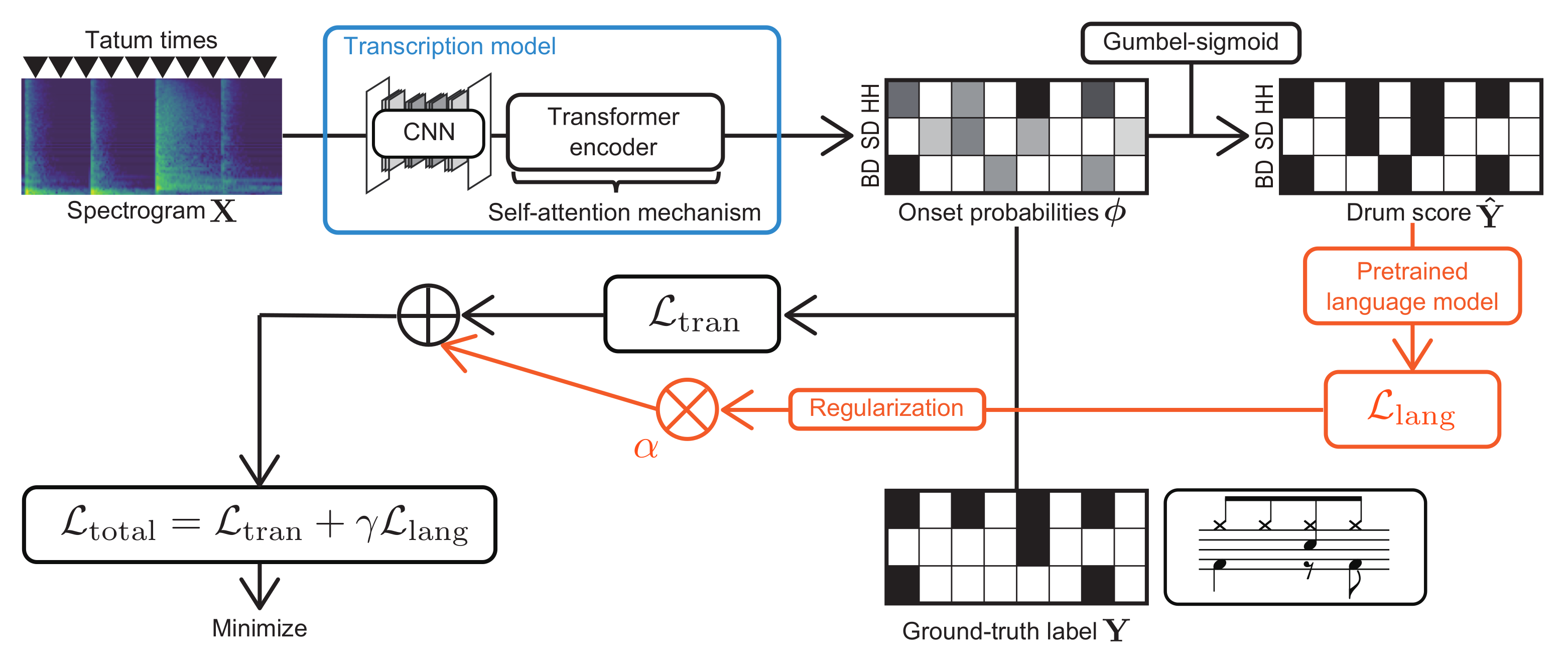
To overcome this limitation, in this paper, we propose a global structure-aware frame-to-tatum ADT method based on an encoder–decoder model with a self-attention mechanism and transfer learning (
Figure 1), inspired by the success in sequence-to-sequence tasks such as machine translation and ASR. More specifically, our model involves a tatum-level decoder with a self-attention mechanism, where the architecture of the decoder is similar to that of the encoder of the transformer [
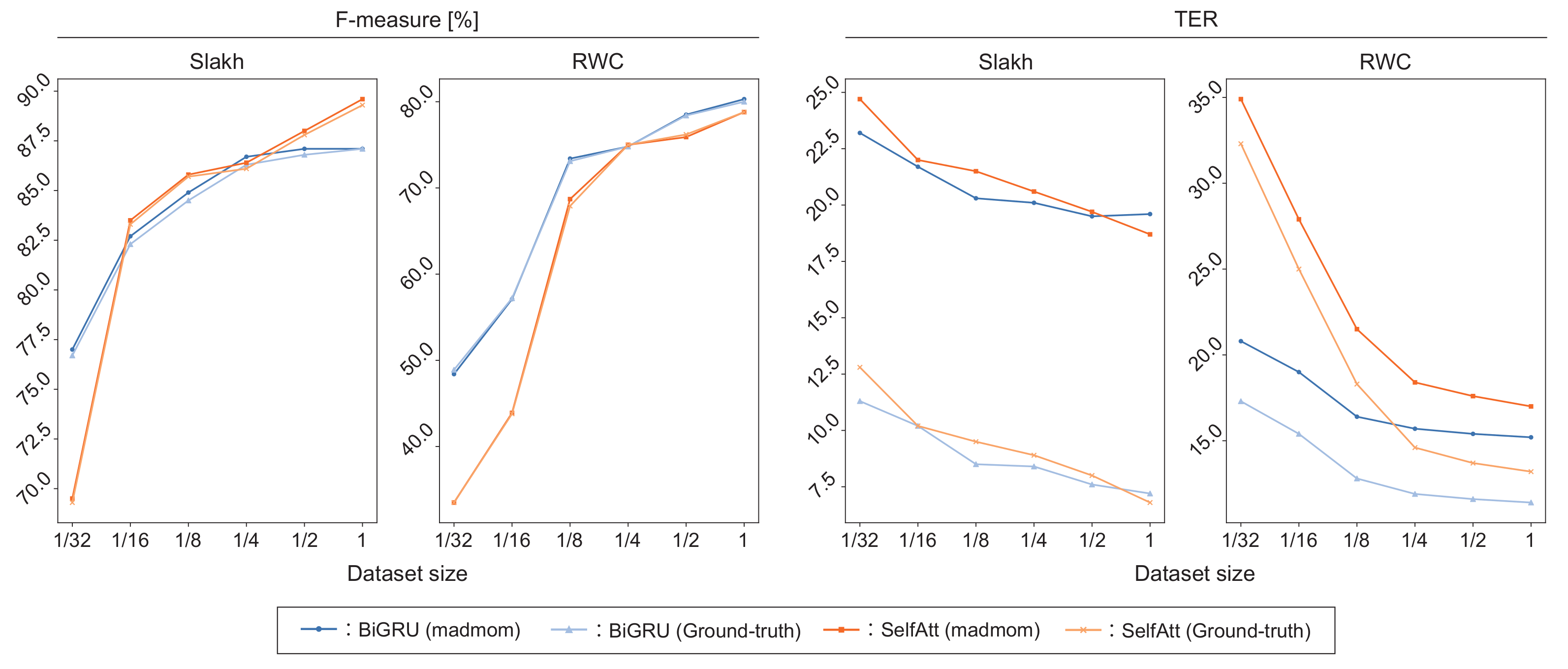
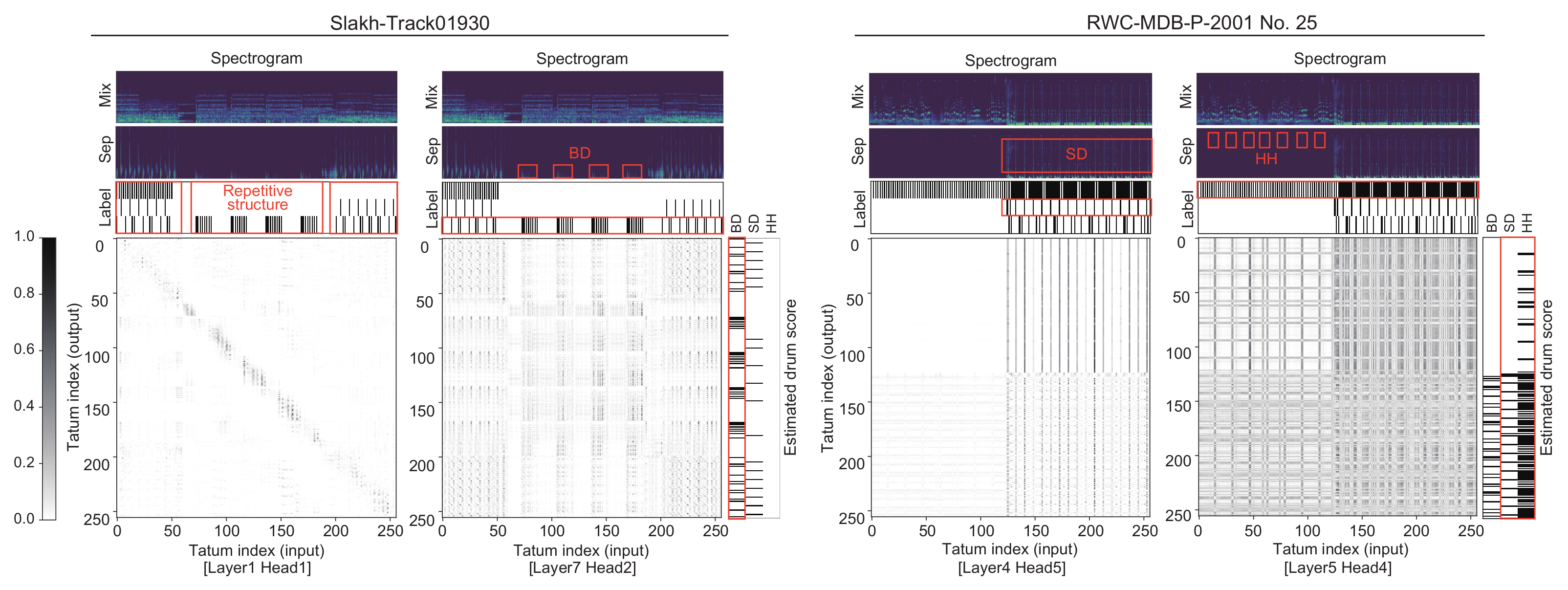
26] because the input and output dimensions of the decoder are the same. To consider the temporal regularity of tatums for the self-attention computation, we propose a new type of positional encoding synchronized with the tatum times. Our model is trained in a regularized manner such that the model output (drum score) is preferred by a masked language model (MLM) with a self-attention mechanism that evaluates the pseudo-probability of the drum notes at each tatum based on both the forward and backward contexts. We experimentally validate the effectiveness of the self-attention mechanism used in the decoder and/or the language model and that of the tatum-synchronous positional encoding. We also investigate the computational efficiency of the proposed ADT method and compare it with that of the conventional RNN-based ADT method.
In
Section 2 of this paper, we introduce related work on ADT and language modeling.
Section 3 describes the proposed method, and
Section 4 reports the experimental results. We conclude in
Section 5 with a brief summary and mention of future work.
3. Proposed Method
Our goal is to estimate a drum score from the mel spectrogram of a target musical piece , where M is the number of drum instruments (BD, SD, and HH, i.e., M = 3), N is the number of tatums, F is the number of frequency bins, and T is the number of time frames. We assume that all onset times are located on the tatum-level grid, and the tatum times , where and , are estimated in advance.
In
Section 3.1, we explain the configuration of the encoder–decoder-based transcription model.
Section 3.2 describes the masked language model as a bidirectional language model with the bi-gram- and GRU-based language models as unidirectional language models. The regularization method is explained in
Section 3.3.
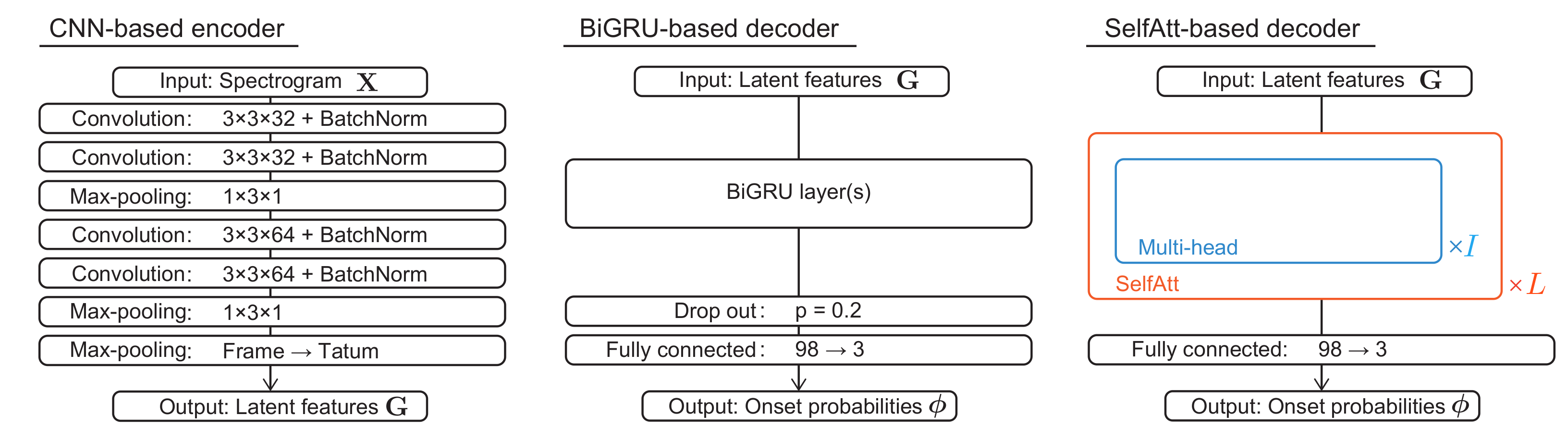
3.1. Transcription Models
The transcription model is used for estimating the tatum-level onset probabilities , where represents the probability that drum m has an onset at tatum n. The drum score is obtained by binarizing with a threshold .
The encoder of the transcription model is implemented with a CNN. The mel spectrogram
is converted to latent features
, where
is the feature dimension. The frame-level latent features
are then summarized into tatum-level latent features
through a max-pooling layer referring to the tatum times
as follows:
where
and
are introduced for the brief expression.
The decoder of the transcription model is implemented with a bidirectional GRU (BiGRU) or a self-attention mechanism (SelfAtt) followed by a fully connected layer. The intermediate features
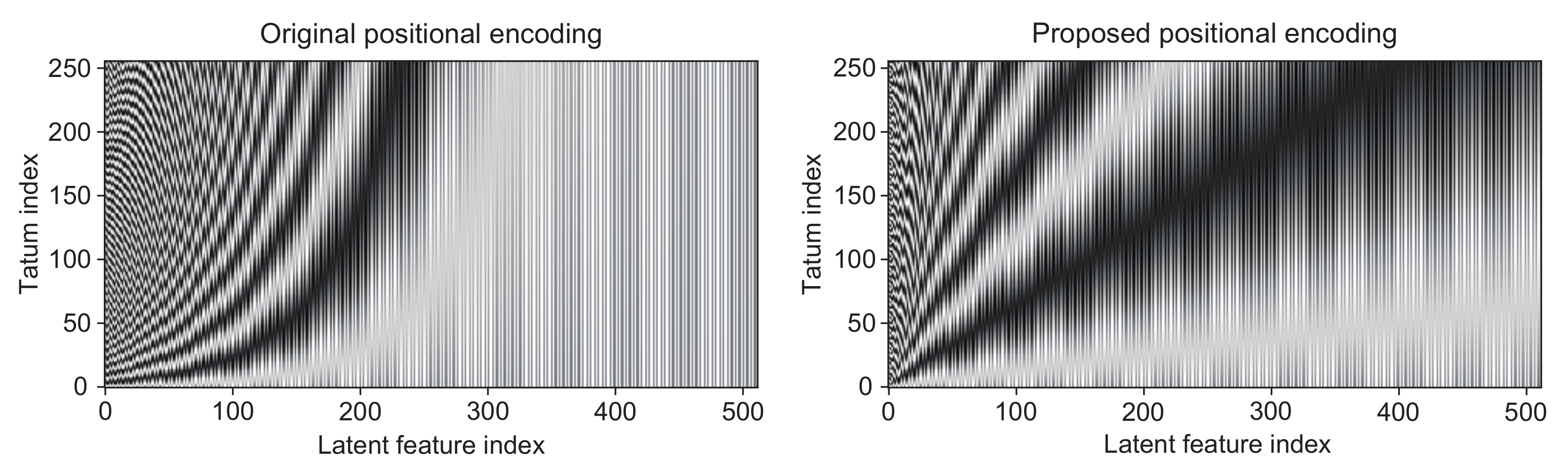
are directly converted to the onset probabilities at the tatum level. In the self-attention-based decoder, the onset probabilities are estimated without recursive computation. To learn the sequential dependency and global structure of drum scores, the positional encoding
are fed into the latent features
to obtain extended latent features
. The standard positional encodings proposed in [
26] are given by
In this paper, we propose tatum-synchronous positional encodings (denoted SyncPE):
where
represents the floor function. As shown in
Figure 2, the nonlinear stripes patterns appear in the encodings proposed in [
26] because the period of the trigonometric functions increases exponentially with respect to the latent feature indices, whereas the proposed tatum-synchronous encodings exhibit the linear stripes patterns.
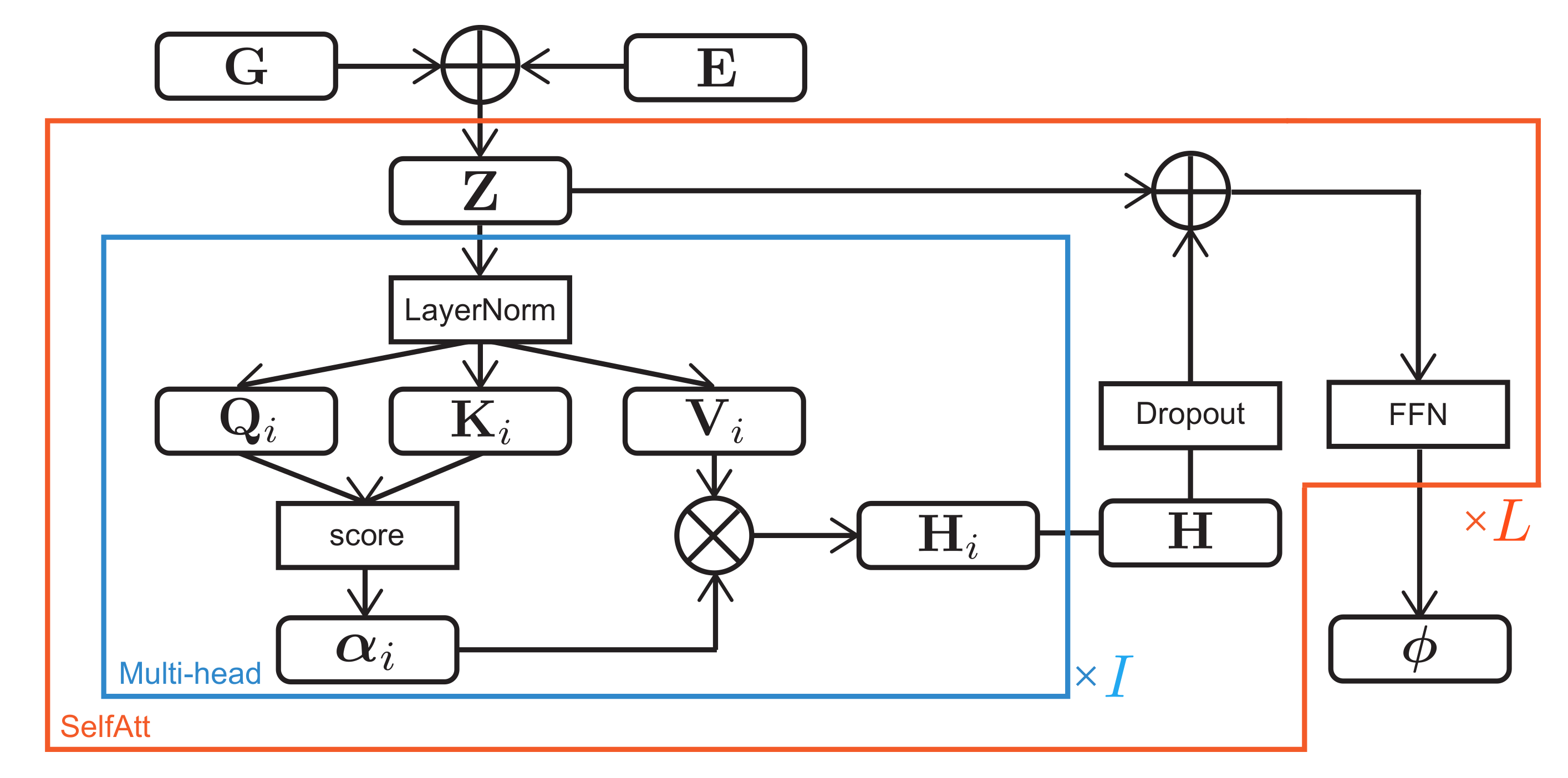
As shown in
Figure 3, the extended features
are converted to the onset probabilities
through a stack of
L self-attention mechanisms with
I heads [
26] and the layer normalization (Pre-Norm) [
57] proposed for the simple and stable training of the transformer models [
58,
59]. For each head
i (
), let
,
, and
be query, key, and value matrices given by
where
is the feature dimension of each head (
in this paper as in [
26]);
,
, and
are query, key, and value vectors, respectively;
,
, and
are weight matrices; and
,
, and
are bias vectors. Let
be a self-attention matrix consisting of the degrees of self-relevance of the extended latent features
, which is given by
where
represents the matrix or vector transpose, and
n and
represent the feature indices of
and
, respectively. Let
be a feature matrix obtained by concatenating all the heads, where
.
The extended latent features and the extracted features
with Dropout (
) [
60] are then fed into a feed forward network (FFN) with a rectified linear unit (ReLU) as follows:
where
and
are weight matrices,
and
are bias vectors, and
is the dimension of the output. Equation (
4) to Equation (
9) are repeated
L times with different parameters. The onset probabilities
are finally calculated as follows:
where
is a sigmoid function,
is a weight matrix, and
is a bias vector.
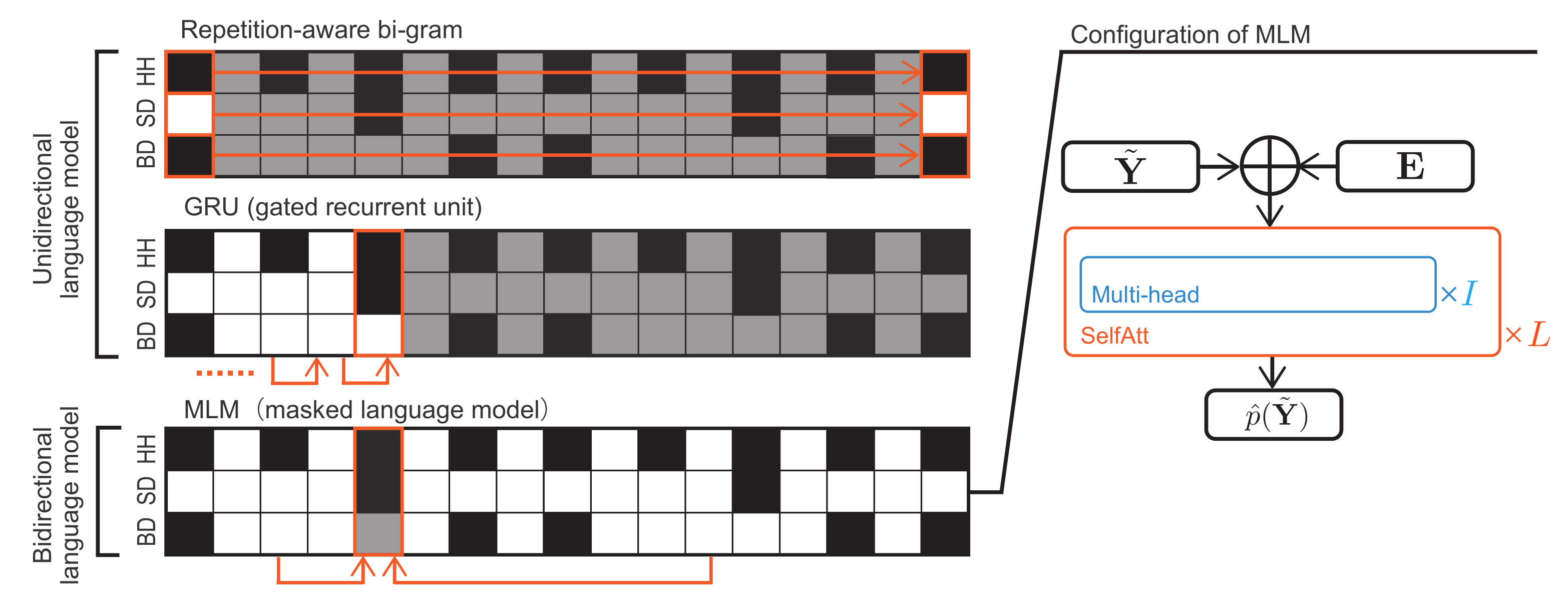
3.2. Language Models
The language model is used for estimating the generative probability (musical naturalness) of an arbitrary existing drum score
. For brevity, we assume that only one drum score is used as training data. In practice, a sufficient amount of drum scores are used. In this study, we use unidirectional language models such as the repetition-aware bi-gram model and GRU-based model proposed in [
19] and a masked language model (MLM), a bidirectional language model proposed for pretraining in BERT [
46] (
Figure 4).
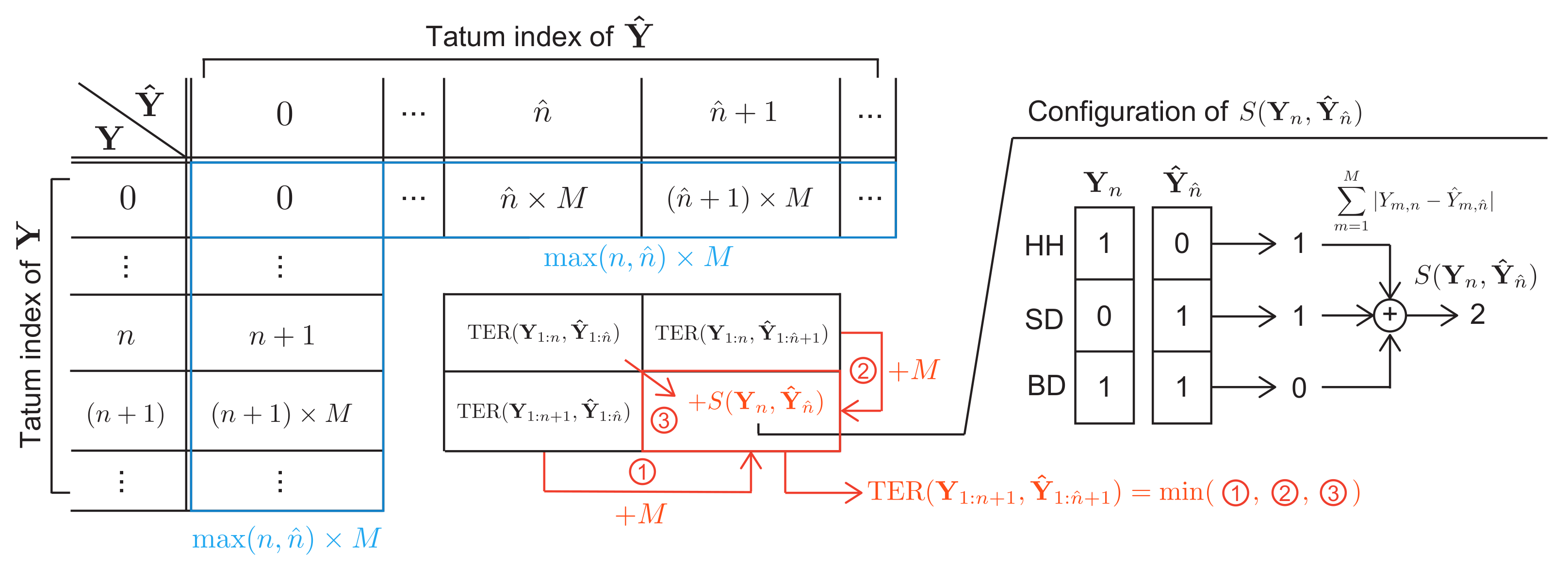
The unidirectional language model is trained beforehand in an unsupervised manner such that the following negative log-likelihood
is minimized:
where “
” represents a set of indices from
i to
j, and “:” represents all possible indices. In the repetition-aware bi-gram model (top figure in
Figure 4), assuming that target musical pieces have the 4/4 time signature, the repetitive structure of a drum score is formulated as follows:
where
represents the transition probability from
A to
B. Note that this model assumes the independence of the
M drums. In the GRU model (middle figure in
Figure 4),
is directly calculated using an RNN.
The MLM is capable of learning the global structure of drum scores (bottom figure in
Figure 4). In the training phase, drum activations at randomly selected 15% of tatums in
are masked and the MLM is trained such that those activations are predicted as accurately as possible. The loss function
to be minimized is given by
3.3. Regularized Training
To consider the musical naturalness of the estimated score
obtained by binarizing
, we use the language model-based regularized training method [
19] that minimizes
where
is a ground-truth score,
is a weighting factor, the symbol * denotes “uni“ or “bi“, and
is the modified negative log-likelihood given by
where
is a weighting factor compensating for the imbalance between the numbers of onset and non-onset tatums.
To use backpropagation for optimizing the transcription model, the binary score
should be obtained from the soft representation
in a differentiable manner instead of simply binarizing
with a threshold. We thus use a differentiable sampler called the Gumbel-sigmoid trick [
61], as follows:
where
and
is a temperature (
= 0.2 in this paper). Note that the pretrained language model is used as a fixed regularizer in the training phase and is not used in the prediction phase.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}