
On the Synergy between Nonconvex Extensions of the Tensor Nuclear Norm for Tensor Recovery


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We propose a general constrained optimization problem and an efficient solver for analyzing the relationship between the weightings of singular values and the schatten-p extension for tensors.
- We show that the weighting and the schatten-p extension are synergetic and that the effective value of p is dependent on how the weights are determined.
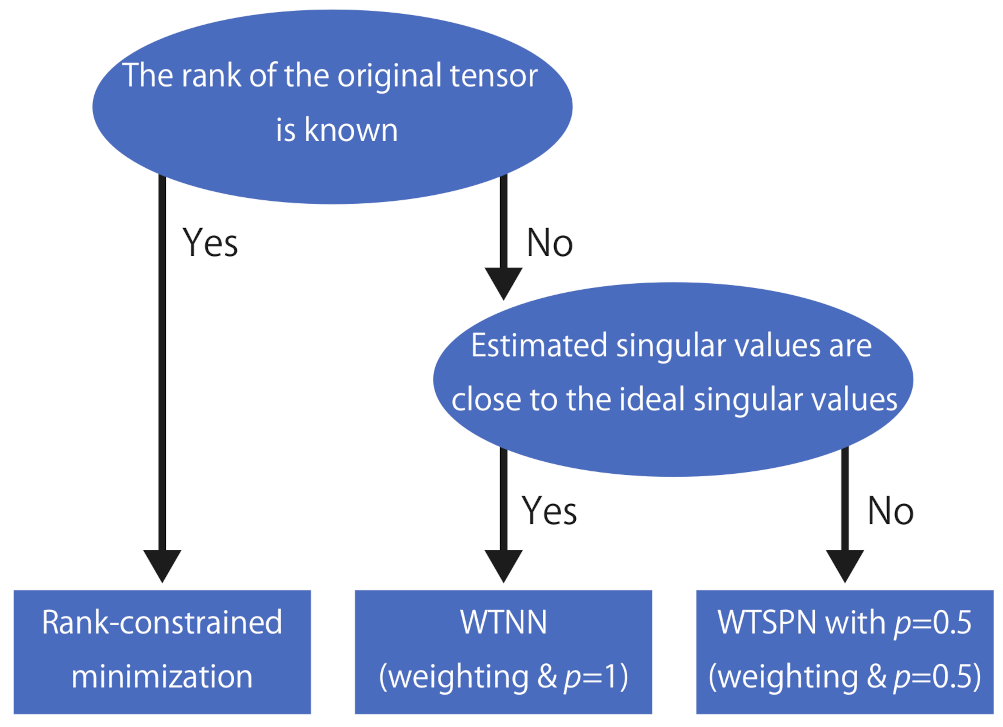
- We show that the rank constrained minimization problem is not able to outperform the advanced methods unless the true rank of the original tensor is known. The performance is sensitive to the rank values used as the constraints.
2. Low-Rank Tensor Completion
3. Proposed Method
| Algorithm 1 Proposed algorithm |
| Input:, , , , p, |
| 1: Initialize , , , , |
| 2: while A stopping criterion is not satisfied do |
| 3: |
| 4: for to N do |
| 5: |
| 6: |
| 7: end for |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: end while |
| Output: |
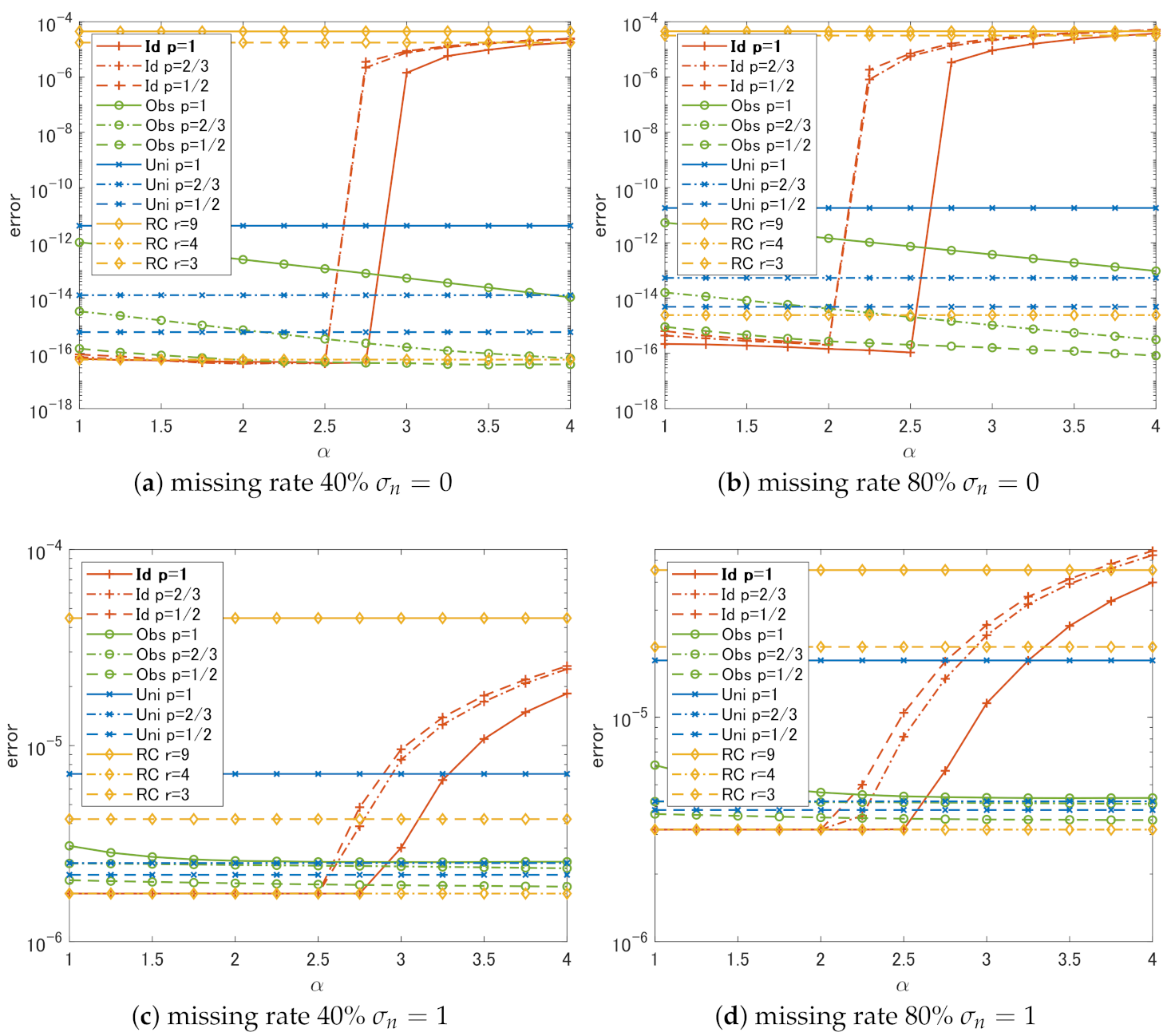
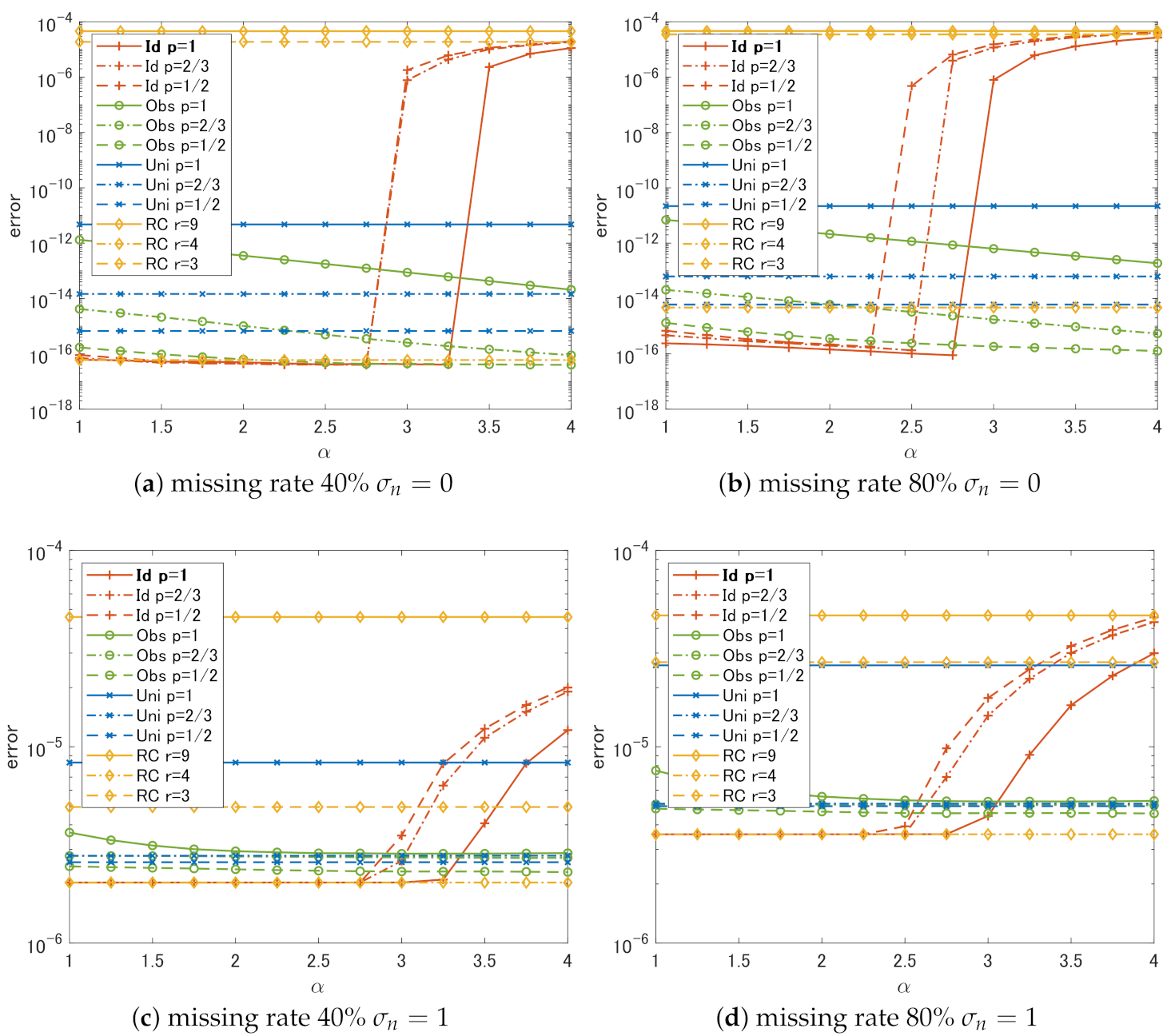
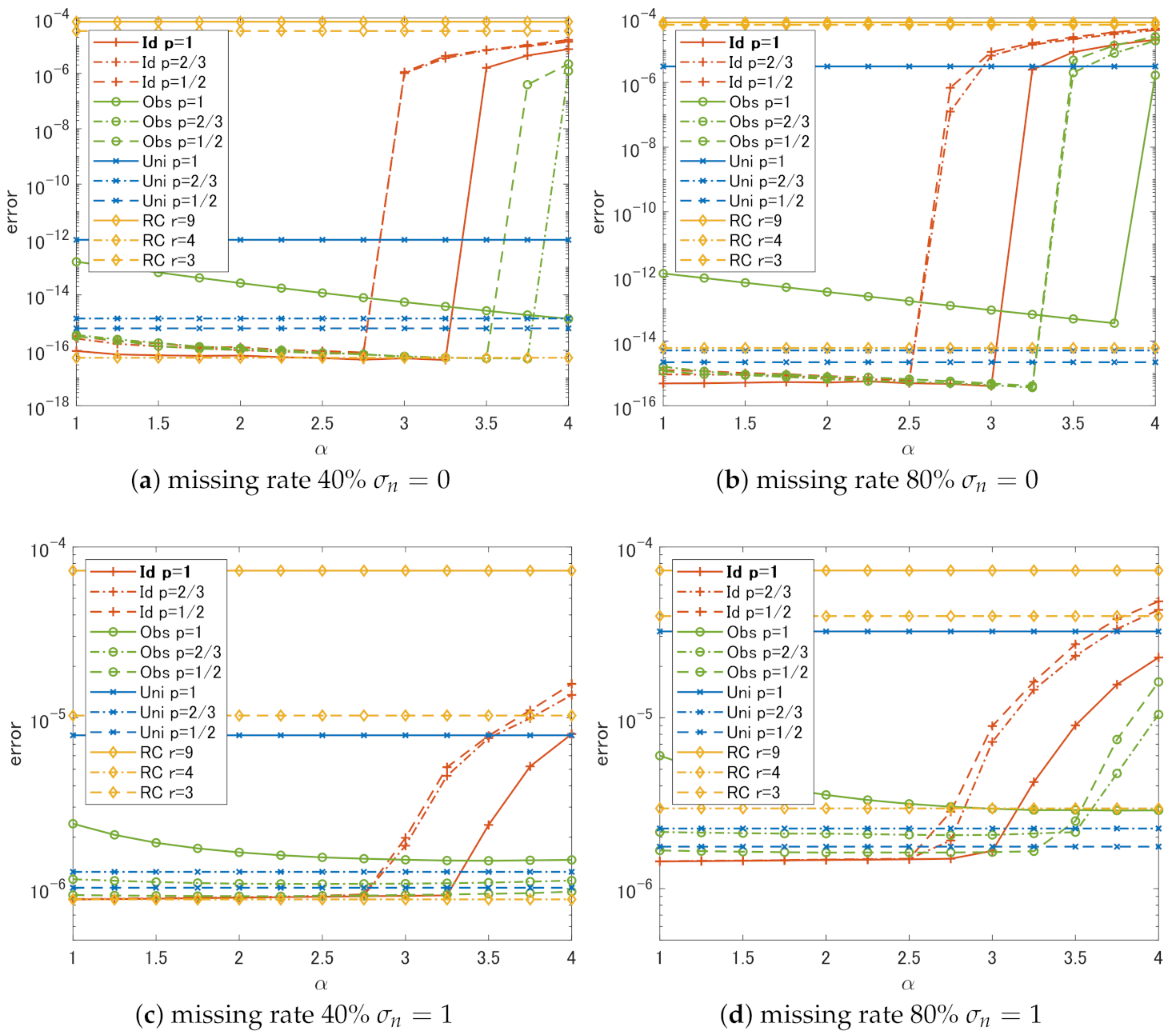
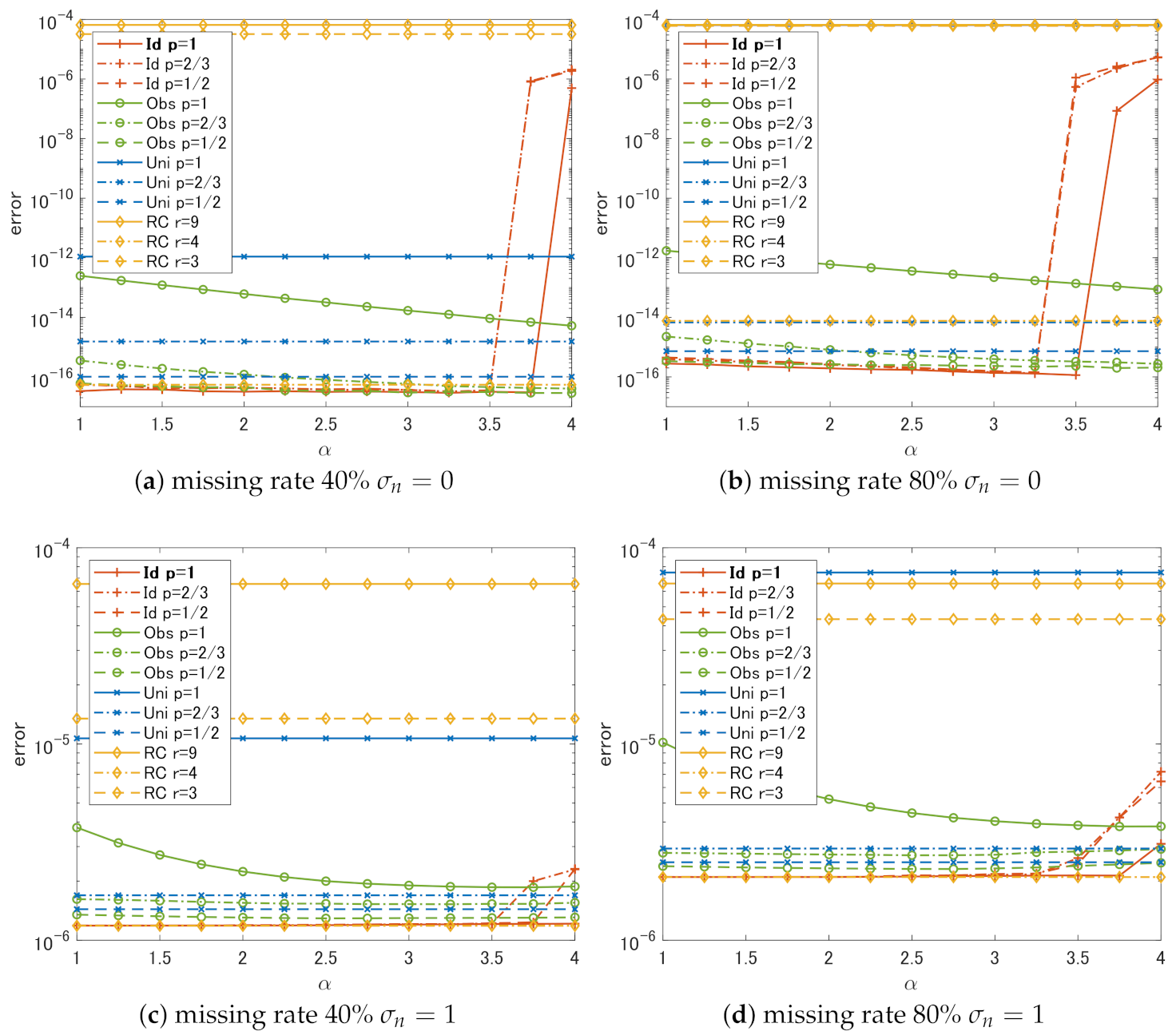
4. Experimental Comparison
4.1. Setting
- Are the effects of the weighting and p-squared on singular values synergistic? Or does one encompass the other?
- Is simple rank-constrained minimization insufficient?
4.2. Results and Discussion
- In the case of Id, if we choose , the choice of p does not have much effect on the performance. The slowest degradation of performance due to the change in is obtained at .
- Regardless of p, the performance of Id and Obs is the same or better than that of Uni in all cases.
- In all cases, RC shows the worst performance unless we can choose the correct rank r.
- It is sufficient to use if weights that are close to the ideal weights can be estimated in some way.
- It is better to set a small p-value if the weights estimated from the degraded singular values are not reliable.
- Simple methods using rank constraints are very sensitive to the choice of ranks used for the constraints and cannot outperform complex methods like the proposed algorithm unless one can correctly estimate the original ranks.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Algorithm for Rank-Constrained Minimization
| Algorithm A1 Algorithm for rank-constrained minimization |
| Input:, , |
| 1: Initialize , , , , |
| 2: while A stopping criterion is not satisfied do |
| 3: |
| 4: for to N do |
| 5: |
| 6: |
| 7: end for |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: end while |
| Output: |
References
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef]
- Roughan, M.; Zhang, Y.; Willinger, W.; Qiu, L. Spatio-temporal compressive sensing and internet traffic matrices (extended version). IEEE/ACM Trans. Netw. 2012, 20, 662–676. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef]
- Liu, X.Y.; Aeron, S.; Aggarwal, V.; Wang, X.; Wu, M.Y. Tensor completion via adaptive sampling of tensor fibers: Application to efficient indoor RF fingerprinting. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2529–2533. [Google Scholar] [CrossRef]
- Ng, M.K.P.; Yuan, Q.; Yan, L.; Sun, J. An ddaptive weighted tensor completion method for the recovery of remote sensing images with missing data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3367–3381. [Google Scholar] [CrossRef]
- Sun, W.; Chen, Y.; Thus, H.C. Tensor completion using kronecker rank-1 tensor train with application to visual data inpainting. IEEE Access 2018, 6, 47804–47814. [Google Scholar] [CrossRef]
- Xie, Q.; Zhao, Q.; Meng, D.; Xu, Z. Kronecker-basis-representation based tensor sparsity and its applications to tensor recovery. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1888–1902. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, J.; Yan, Y.; Zhao, L.; Jiang, R. Joint weighted tensor schatten p-norm and tensor lp-norm minimization for image denoising. IEEE Access 2019, 7, 20273–20280. [Google Scholar] [CrossRef]
- Yokota, T.; Hontani, H. Simultaneous tensor completion and denoising by noise inequality constrained convex optimization. IEEE Access 2019, 7, 15669–15682. [Google Scholar] [CrossRef]
- Wang, A.; Song, X.; Wu, X.; Lai, Z.; Jin, Z. Robust low-tubal-rank tensor completion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3432–3436. [Google Scholar] [CrossRef]
- Hosono, K.; Ono, S.; Miyata, T. Weighted tensor nuclear norm minimization for color image restoration. IEEE Access 2019, 7, 88768–88776. [Google Scholar] [CrossRef]
- Gao, S.; Fan, Q. Robust schatten-p norm based approach for tensor completion. J. Sci. Comput. 2020, 82, 11. [Google Scholar] [CrossRef]
- Harshman, R.A. Foundations of the PARAFAC procedure: Models and conditions for an “explanatory” multi-modal factor analysis. UCLA Work. Phon. 1970, 16, 1–84. [Google Scholar]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Hastad, J. Tensor rank is NP-complete. J. Algorithms 1990, 11, 644–654. [Google Scholar] [CrossRef]
- Fazel, M. Matrix Rank Minimization with Applications. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2002. [Google Scholar]
- Chen, K.; Dong, H.; Chan, K.S. Reduced rank regression via adaptive nuclear norm penalization. Biometrika 2013, 100, 901–920. [Google Scholar] [CrossRef]
- Xie, Y.; Gu, S.; Liu, Y.; Zuo, W.; Zhang, W.; Zhang, L. Weighted schatten p-norm minimization for image denoising and background subtraction. IEEE Trans. Image Process. 2016, 25, 4842–4857. [Google Scholar] [CrossRef]
- Gu, S.; Xie, Q.; Meng, D.; Zuo, W.; Feng, X.; Zhang, L. Weighted nuclear norm minimization and its applications to low level vision. Int. J. Comput. Vis. 2017, 121, 183–208. [Google Scholar] [CrossRef]
- Zha, Z.; Zhang, X.; Wu, Y.; Wang, Q.; Liu, X.; Tang, L.; Yuan, X. Non-convex weighted ℓp nuclear norm based ADMM framework for image restoration. Neurocomputing 2018, 311, 209–224. [Google Scholar] [CrossRef]
- Gabay, D.; Mercier, B. A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 1976, 2, 17–40. [Google Scholar] [CrossRef]
- Chartrand, R.; Wohlberg, B. A nonconvex ADMM algorithm for group sparsity with sparse groups. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6009–6013. [Google Scholar] [CrossRef]
- Sun, D.L.; Févotte, C. Alternating direction method of multipliers for non-negative matrix factorization with the beta-divergence. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6201–6205. [Google Scholar] [CrossRef]
- Ono, S. L0 gradient projection. IEEE Trans. Image Process. 2017, 26, 1554–1564. [Google Scholar] [CrossRef]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A. An augmented lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2011, 20, 681–695. [Google Scholar] [CrossRef] [PubMed]
- Chierchia, G.; Pustelnik, N.; Pesquet, J.C.; Pesquet-Popescu, B. Epigraphical projection and proximal tools for solving constrained convex optimization problems. Signal Image Video Process. 2015, 9, 1737–1749. [Google Scholar] [CrossRef]
- Ono, S.; Yamada, I. Signal recovery with certain involved convex data-fidelity constraints. IEEE Trans. Signal Process. 2015, 63, 6149–6163. [Google Scholar] [CrossRef]
- Cao, W.; Sun, J.; Xu, Z. Fast image deconvolution using closed-form thresholding formulas of Lq (q = 1/2, 2/3) regularization. J. Vis. Commun. Image Represent. 2013, 24, 31–41. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hosono, K.; Ono, S.; Miyata, T. On the Synergy between Nonconvex Extensions of the Tensor Nuclear Norm for Tensor Recovery. Signals 2021, 2, 108-121. https://doi.org/10.3390/signals2010010
Hosono K, Ono S, Miyata T. On the Synergy between Nonconvex Extensions of the Tensor Nuclear Norm for Tensor Recovery. Signals. 2021; 2(1):108-121. https://doi.org/10.3390/signals2010010
Chicago/Turabian StyleHosono, Kaito, Shunsuke Ono, and Takamichi Miyata. 2021. "On the Synergy between Nonconvex Extensions of the Tensor Nuclear Norm for Tensor Recovery" Signals 2, no. 1: 108-121. https://doi.org/10.3390/signals2010010
APA StyleHosono, K., Ono, S., & Miyata, T. (2021). On the Synergy between Nonconvex Extensions of the Tensor Nuclear Norm for Tensor Recovery. Signals, 2(1), 108-121. https://doi.org/10.3390/signals2010010